多模态大语言模型arxiv论文略读(109)

Math-PUMA: Progressive Upward Multimodal Alignment to Enhance Mathematical Reasoning
➡️ 论文标题:Math-PUMA: Progressive Upward Multimodal Alignment to Enhance Mathematical Reasoning
➡️ 论文作者:Wenwen Zhuang, Xin Huang, Xiantao Zhang, Jin Zeng
➡️ 研究机构: University of Chinese Academy of Sciences、Beijing Institute of Technology、Beihang University
➡️ 问题背景:多模态大语言模型(Multimodal Large Language Models, MLLMs)在解决基于文本的数学问题方面表现出色,但在处理涉及图像的数学问题时面临挑战。这些模型主要在自然场景图像上进行训练,导致在处理数学图表时性能下降。人类在解决问题时,无论信息以何种模态呈现,难度通常相似,且视觉辅助通常能增强解决问题的能力。然而,MLLMs在处理视觉信息时的能力显著下降,尤其是在从文本到视觉的过渡中。
➡️ 研究动机:为了解决MLLMs在处理数学图表时的不足,研究团队提出了Math-PUMA,一种基于渐进式向上多模态对齐(Progressive Upward Multimodal Alignment, PUMA)的方法,旨在通过三个阶段的训练过程增强MLLMs的数学推理能力。该方法通过构建大规模的数据集和多模态对齐技术,有效缩小了不同模态问题之间的性能差距。
➡️ 方法简介:Math-PUMA方法包括三个阶段:1) 首先,通过大量基于文本的数学问题数据集训练语言模型,增强其数学推理能力;2) 然后,构建包含不同模态信息的数据对,通过计算KL散度实现视觉和文本模态的对齐,逐步提升模型处理多模态数学问题的能力;3) 最后,利用高质量的多模态数据进行指令调优,进一步增强模型的多模态数学推理能力。
➡️ 实验设计:研究团队在三个广泛使用的多模态数学问题解决基准上进行了实验,包括MATHVERSE、MATHVISTA和WE-MATH。实验结果表明,经过Math-PUMA训练的MLLMs在多个基准上显著优于大多数开源模型,特别是在处理不同模态的问题时,性能差距明显缩小。
Med-PMC: Medical Personalized Multi-modal Consultation with a Proactive Ask-First-Observe-Next Paradigm
➡️ 论文标题:Med-PMC: Medical Personalized Multi-modal Consultation with a Proactive Ask-First-Observe-Next Paradigm
➡️ 论文作者:Hongcheng Liu, Yusheng Liao, Siqv Ou, Yuhao Wang, Heyang Liu, Yanfeng Wang, Yu Wang
➡️ 研究机构: Shanghai Jiao Tong University, Shanghai AI Lab
➡️ 问题背景:尽管多模态大语言模型(MLLMs)在医疗领域展现出处理多模态信息的能力,但其在临床场景中的应用仍处于探索阶段。现有的医疗多模态基准测试主要集中在医疗视觉问答(VQA)和报告生成上,未能全面评估MLLMs在复杂临床多模态任务中的表现。此外,这些模型在处理个性化患者模拟器时,未能有效收集多模态信息,并在决策任务中表现出潜在的偏见。
➡️ 研究动机:为了更全面地评估MLLMs在实际临床场景中的性能,研究团队提出了一个新颖的医疗个性化多模态咨询(Med-PMC)范式。Med-PMC通过构建模拟临床环境,要求MLLMs与患者模拟器进行多轮互动,以完成多模态信息收集和决策任务。研究旨在通过这一范式,揭示MLLMs在处理复杂和动态临床互动中的能力,为未来医疗MLLMs的发展提供指导。
➡️ 方法简介:研究团队设计了一个模拟临床环境,其中MLLMs需要与个性化患者模拟器进行多轮互动,以收集患者的多模态症状信息,并最终提供可能的诊断结果和治疗建议。患者模拟器由状态跟踪器、响应生成器和个性化演员三个主要组件构成,能够模拟真实临床场景中的患者多样性,确保模拟的可靠性和真实性。
➡️ 实验设计:研究在30个真实的医疗案例上进行了实验,这些案例主要来自普通外科。实验评估了12种不同类型的MLLMs在信息收集和最终决策两个方面的表现。评估指标包括信息收集的召回率和决策的准确性,采用自动评估和基于大语言模型的评估方法进行验证。实验结果表明,即使是最先进的医疗MLLMs在处理多模态医疗信息时仍存在显著不足,为未来的研究指明了方向。
ECG-Chat: A Large ECG-Language Model for Cardiac Disease Diagnosis
➡️ 论文标题:ECG-Chat: A Large ECG-Language Model for Cardiac Disease Diagnosis
➡️ 论文作者:Yubao Zhao, Tian Zhang, Xu Wang, Puyu Han, Tong Chen, Linlin Huang, Youzhu Jin, Jiaju Kang
➡️ 研究机构: 北京师范大学、中国地质大学、法国高等电力学院、山东建筑大学、南方科技大学、英国利物浦大学、吉林大学珠海学院、北京工业大学
➡️ 问题背景:多模态大语言模型(MLLMs)在医疗辅助领域展现了巨大潜力,允许患者使用生理信号数据进行对话。然而,现有的MLLMs在心脏病诊断方面表现不佳,尤其是在ECG数据分析和长文本医疗报告生成的整合上,主要原因是ECG数据分析的复杂性和文本与ECG信号模态之间的差距。此外,模型在长文本生成中往往表现出严重的稳定性不足,缺乏与用户查询紧密相关的精确知识。
➡️ 研究动机:为了解决上述问题,研究团队提出了ECG-Chat,这是第一个专注于ECG医疗报告生成的多任务MLLM,提供基于心脏病学知识的多模态对话能力。研究旨在通过对比学习方法整合ECG波形数据与文本报告,实现ECG特征与报告内容的细粒度对齐,从而提高模型在信号数据表示上的性能。此外,研究还构建了一个19K的ECG诊断数据集和25K的多轮对话数据集,用于训练和微调ECG-Chat,以提供专业的诊断和对话能力。
➡️ 方法简介:研究团队提出了一种系统的方法,通过对比学习方法将ECG波形数据与文本报告结合,实现ECG特征与报告内容的细粒度对齐。此外,研究团队还构建了一个新的数据生成管道,使用现有数据集和GPT-4创建了一个ECG指令调优数据集(ECG-Instruct),包含19K的诊断数据和25K的对话数据。基于这些数据集,研究团队微调了Vicuna-13B,创建了一个ECG领域的语言模型ECG-Chat,支持报告生成、ECG问题回答等多种功能。
➡️ 实验设计:研究团队在多个任务上测试了模型的性能,包括ECG报告检索、ECG分类和ECG报告生成,并建立了ECG报告生成任务的基准。实验结果表明,ECG-Chat在分类、检索、多模态对话和医疗报告生成任务上均取得了最佳性能。此外,研究团队还提出了一种诊断驱动的提示(DDP)方法,有效提高了模型的准确性,并使用自动化LaTeX生成管道生成了详细的ECG报告。
Reefknot: A Comprehensive Benchmark for Relation Hallucination Evaluation, Analysis and Mitigation in Multimodal Large Language Models
➡️ 论文标题:Reefknot: A Comprehensive Benchmark for Relation Hallucination Evaluation, Analysis and Mitigation in Multimodal Large Language Models
➡️ 论文作者:Kening Zheng, Junkai Chen, Yibo Yan, Xin Zou, Xuming Hu
➡️ 研究机构: Hong Kong University of Science and Technology (Guangzhou), Hong Kong University of Science and Technology
➡️ 问题背景:多模态大语言模型(Multimodal Large Language Models, MLLMs)在多种任务中展现了强大的能力,但它们在生成过程中容易产生幻觉(hallucinations),尤其是关系幻觉(relation hallucinations)。现有的研究和基准测试主要集中在对象级和属性级幻觉上,而忽视了更复杂的关系幻觉,这些幻觉需要更高级的推理能力。此外,现有的关系幻觉基准测试缺乏详细的评估和有效的缓解策略,且数据集往往存在系统性偏差。
➡️ 研究动机:为了应对上述研究空白,研究团队提出了Reefknot,这是一个全面的基准测试,旨在评估和缓解多模态大语言模型中的关系幻觉。Reefknot包含超过20,000个真实世界的样本,通过系统地定义关系幻觉并构建基于场景图数据集的关系语料库,研究团队揭示了当前MLLMs在处理关系幻觉方面的显著局限性。此外,研究团队提出了一种基于置信度的缓解策略,该策略在三个数据集上平均减少了9.75%的幻觉率。
➡️ 方法简介:研究团队构建了Reefknot基准测试,该基准测试包括感知和认知两个类别的关系幻觉,以及三种评估任务(Yes/No、多项选择题和视觉问答)。Reefknot的数据集基于Visual Genome场景图数据集中的语义三元组构建,确保了数据的真实性和多样性。研究团队还提出了一种名为“Detect-Then-Calibrate”的方法,通过分析模型在生成过程中的置信度变化来检测和缓解幻觉。
➡️ 实验设计:研究团队在Reefknot基准测试上评估了多个主流的MLLMs,包括LLaVA、MiniGPT4-v2、Qwen-vl等。实验设计了不同的任务类型(如Yes/No、多项选择题和视觉问答),以全面评估模型在处理关系幻觉方面的表现。实验结果表明,MLLMs在感知关系幻觉方面比认知关系幻觉更容易出现问题。此外,研究团队通过分析模型在不同层的置信度变化,揭示了关系幻觉生成的机制,并提出了基于置信度的缓解策略。
FFAA: Multimodal Large Language Model based Explainable Open-World Face Forgery Analysis Assistant
➡️ 论文标题:FFAA: Multimodal Large Language Model based Explainable Open-World Face Forgery Analysis Assistant
➡️ 论文作者:Zhengchao Huang, Bin Xia, Zicheng Lin, Zhun Mou, Wenming Yang, Jiaya Jia
➡️ 研究机构: Tsinghua University、The Chinese University of Hong Kong、HKUST
➡️ 问题背景:随着深度伪造技术的快速发展,面部伪造对公共信息安全构成了严重威胁。现有的面部伪造分析数据集缺乏对伪造技术、面部特征和环境因素的详细描述,导致模型在复杂条件下的伪造检测能力有限。此外,现有的方法难以提供用户友好且可解释的结果,阻碍了对模型决策过程的理解。
➡️ 研究动机:为了应对上述挑战,研究团队引入了一种新的开放世界面部伪造分析视觉问答任务(OW-FFA-VQA)及其相应的基准测试。通过构建包含多样化的真伪面部图像及其描述和伪造推理的FFA-VQA数据集,研究团队旨在提高模型的泛化能力和鲁棒性,同时提供用户友好且可解释的结果。
➡️ 方法简介:研究团队提出了FFAA(Face Forgery Analysis Assistant),该系统由一个微调的多模态大语言模型(MLLM)和多答案智能决策系统(MIDS)组成。通过在FFA-VQA数据集上微调MLLM,并结合假设性提示,FFAA能够有效缓解模糊分类边界的影响,增强模型的鲁棒性。
➡️ 实验设计:研究团队在多个公开数据集上进行了实验,包括OW-FFA-Bench。实验设计了多种因素的变化,如图像质量、面部属性和环境因素,以全面评估模型在复杂条件下的表现。实验结果表明,FFAA不仅提供了用户友好且可解释的结果,还在准确性和鲁棒性方面显著优于现有方法。
相关文章:
多模态大语言模型arxiv论文略读(109)
Math-PUMA: Progressive Upward Multimodal Alignment to Enhance Mathematical Reasoning ➡️ 论文标题:Math-PUMA: Progressive Upward Multimodal Alignment to Enhance Mathematical Reasoning ➡️ 论文作者:Wenwen Zhuang, Xin Huang, Xiantao Z…...
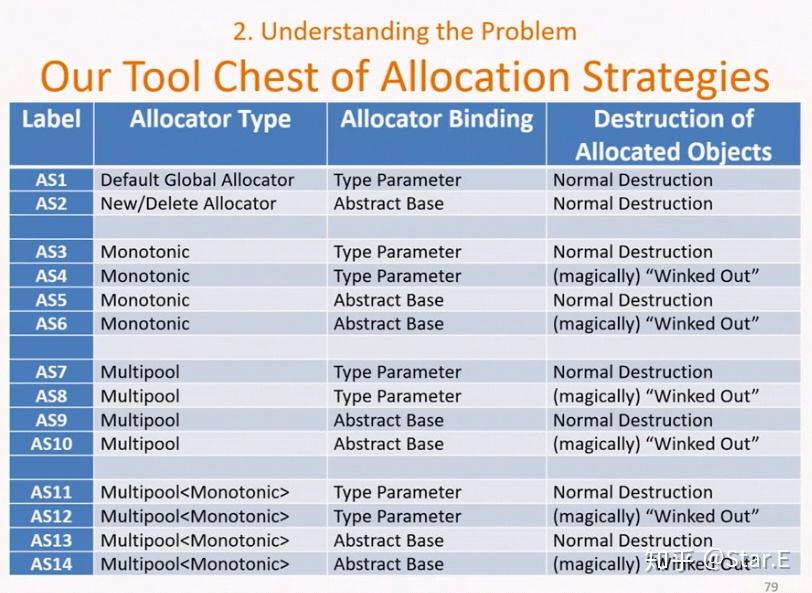
性能优化笔记
性能优化转载 https://www.cnblogs.com/tengzijian/p/17858112.html 性能优化的一般策略及方法 简言之,非必要,不优化。先保证良好的设计,编写易于理解和修改的整洁代码。如果现有的代码很糟糕,先清理重构,然后再考…...

bat批量去掉本文件夹中的文件扩展名
本文本夹内 批量去掉本文件夹中的文件扩展名 假如你有一些文件,你想去掉他们的扩展名 有没有方便的办法呢 今天我们就分享一种办法。 下面,就来看看吧。 首先我们新建一个记事本,把名字改为,批量去掉本文件夹中的文件扩展名.txt 然…...

基于ROS2,撰写python脚本,根据给定的舵-桨动力学模型实现动力学更新
提问 #! /usr/bin/env python3from control_planner import usvParam as P from control_planner.courseController import courseLimitationimport tf_transformations # ROS2没有自带tf.transformations, 需装第三方库 import rclpy from rclpy.node import Node from pid_…...
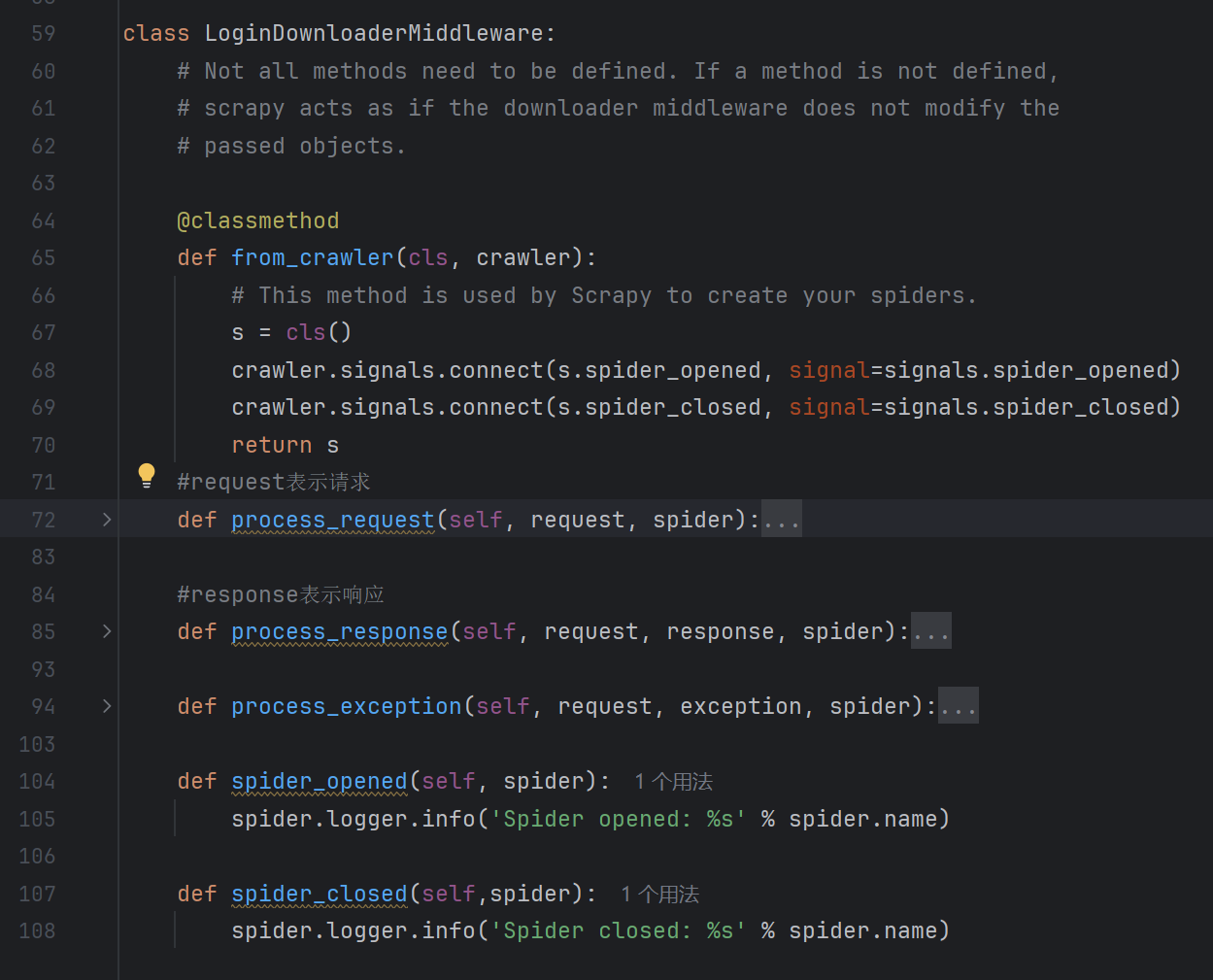
Scrapy爬虫教程(新手)
1. Scrapy的核心组成 引擎(engine):scrapy的核心,所有模块的衔接,数据流程梳理。 调度器(scheduler):本质可以看成一个集合和队列,里面存放着一堆即将要发送的请求&#…...

数据可视化大屏案例落地实战指南:捷码平台7天交付方法论
分享大纲: 1、落地前置:数据可视化必备的规划要素 2、数据可视化双路径开发 3、验证案例:数据可视化落地成效 在当下数字化转型浪潮中,数据可视化建设已成为关键环节。数据可视化大屏的落地,成为企业数据可视化建设的难…...

第五篇:Go 并发模型全解析——Channel、Goroutine
第五篇:Go 并发模型全解析——Channel、Goroutine 一、序章:Java 的并发往事 在 Java 世界中,说到“并发”,你可能立马想到以下名词:Thread、Runnable、ExecutorService、synchronized、volatile。再复杂点,ReentrantLock、CountDownLatch、BlockingQueue 纷纷登场,仿…...

锁的艺术:深入浅出讲解乐观锁与悲观锁
在多线程和分布式系统中,数据一致性是一个核心问题。锁机制作为解决并发冲突的重要手段,被广泛应用于各种场景。乐观锁和悲观锁是两种常见的锁策略,它们在设计理念、实现方式和适用场景上各有特点。本文将深入探讨乐观锁和悲观锁的原理、实现…...
)
在网页加载时自动运行js的方法(2025最新)
在网页加载时自动运行JavaScript方法有多种实现方式,以下是常见的几种方法: 1. 使用 DOMContentLoaded 事件 当初始HTML文档完全加载和解析后触发(无需等待图片等资源加载): document.addEventListener(DOMC…...

在Windows下编译出llama_cpp_python的DLL后,在虚拟环境中使用方法
定位编译生成的文件 在VS2022编译完成后,在构建目录(如build/Release或build/Debug)中寻找以下关键文件: ggml.dll、ggml_base.dll、ggml_cpu.dll、ggml_cuda.dll、llama.dll(核心动态链接库) llama_cp…...

CSS radial-gradient函数详解
目录 基本语法 关键参数详解 1. 渐变形状(Shape) 2. 渐变大小(Size) 3. 中心点位置(Position) 4. 颜色断点(Color Stops) 常见应用场景 1. 基本圆形渐变 2. 椭圆渐变 3. 模…...
)
n8n 自动化平台 Docker 部署教程(附 PostgreSQL 与更新指南)
n8n 自动化平台 Docker 部署教程(附 PostgreSQL 与更新指南) n8n 是一个强大的可视化工作流自动化工具,支持无代码或低代码地集成各种服务。本文将手把手教你如何通过 Docker 快速部署 n8n,并介绍如何使用 PostgreSQL、设置时区以…...
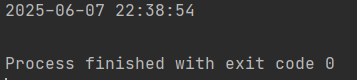
关于datetime获取时间的问题
import datetime print(datetime.now())如果用上述代码,会报错: 以下才是正确代码: from datetime import datetime print(datetime.now()) 结果: 如果想格式化时间,使用代码: from datetime import da…...

前端面试五之vue2基础
1.属性绑定v-bind(:) v-bind 是 Vue 2 中用于动态绑定属性的核心指令,它支持多种语法和用法,能够灵活地绑定 DOM 属性、组件 prop,甚至动态属性名。通过 v-bind,可以实现数据与视图之间的高效同…...

使用python实现奔跑的线条效果
效果,展示(视频效果展示): 奔跑的线条 from turtle import * import time t1Turtle() t2Turtle() t3Turtle() t1.hideturtle() t2.hideturtle() t3.hideturtle() t1.pencolor("red") t2.pencolor("green") t3…...

Oracle 审计参数:AUDIT_TRAIL 和 AUDIT_SYS_OPERATIONS
Oracle 审计参数:AUDIT_TRAIL 和 AUDIT_SYS_OPERATIONS 一 AUDIT_TRAIL 参数 1.1 参数功能 AUDIT_TRAIL 是 Oracle 数据库中最核心的审计控制参数,决定审计记录的存储位置和记录方式。 1.2 参数取值及含义 取值说明适用场景NONE禁用数据库审计测试环…...

Android LinearLayout、FrameLayout、RelativeLayout、ConstraintLayout大混战
一、为什么布局性能如此重要? 在Android应用中,布局渲染耗时直接决定了界面的流畅度。根据Google官方数据,超过60%的卡顿问题源于布局性能不佳。本文将彻底解析三大传统布局的性能奥秘,并提供可直接落地的优化方案。 二、三大布局…...
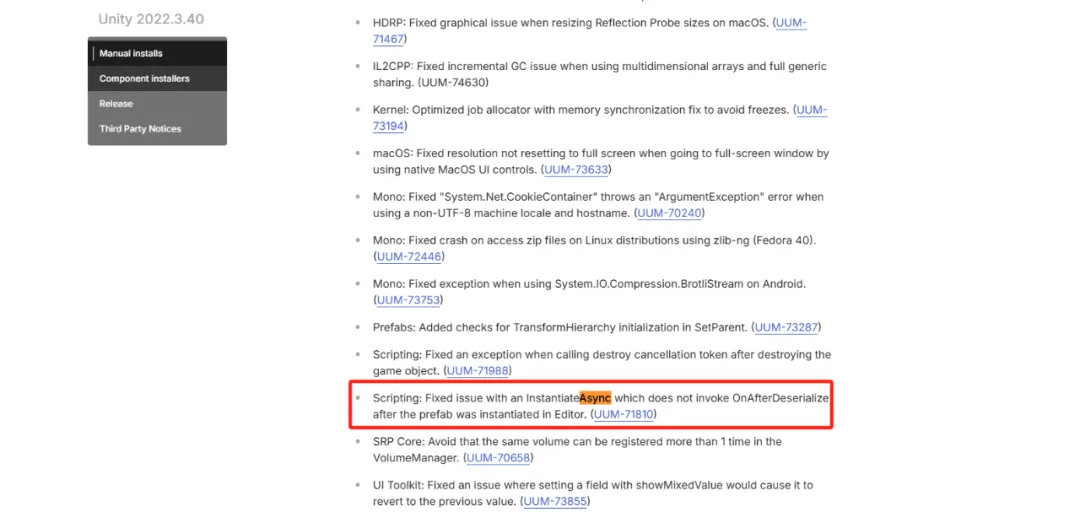
Unity版本使用情况统计(更新至2025年5月)
UWA发布|本期UWA发布的内容是Unity版本使用统计(第十六期),统计周期为2024年11月至2025年5月,数据来源于UWA网站(www.uwa4d.com)性能诊断提测的项目。希望给Unity开发者提供相关的行业趋势作为参…...

GPUCUDA 发展编年史:从 3D 渲染到 AI 大模型时代(上)
目录 文章目录 目录1960s~1999:GPU 的诞生:光栅化(Rasterization)3D 渲染算法的硬件化实现之路 学术界算法研究历程工业界产品研发历程光栅化技术原理光栅化技术的软件实现:OpenGL 3D 渲染管线设计 1. 顶点处理&…...
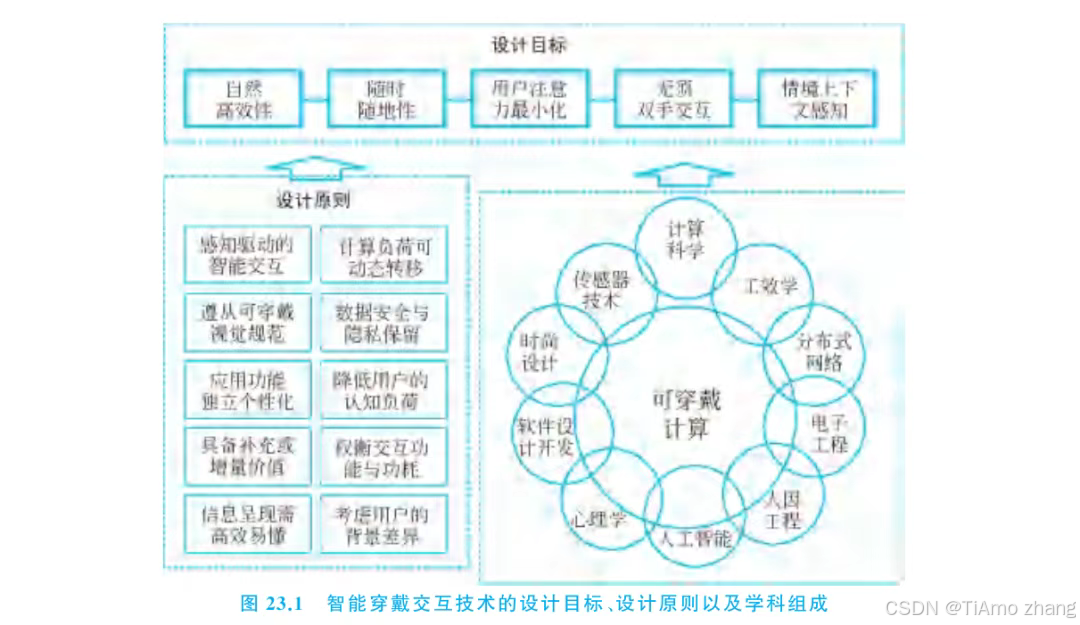
人机融合智能 | 可穿戴计算设备的多模态交互
可穿戴计算设备可以对人体以及周围环境进行连续感知和计算,为用户提供随时随地的智能交互服务。本章主要介绍人机智能交互领域中可穿戴计算设备的多模态交互,阐述以人为中心的智能穿戴交互设计目标和原则,为可穿戴技术和智能穿戴交互技术的设计提供指导,进而简述支持智能穿戴交…...
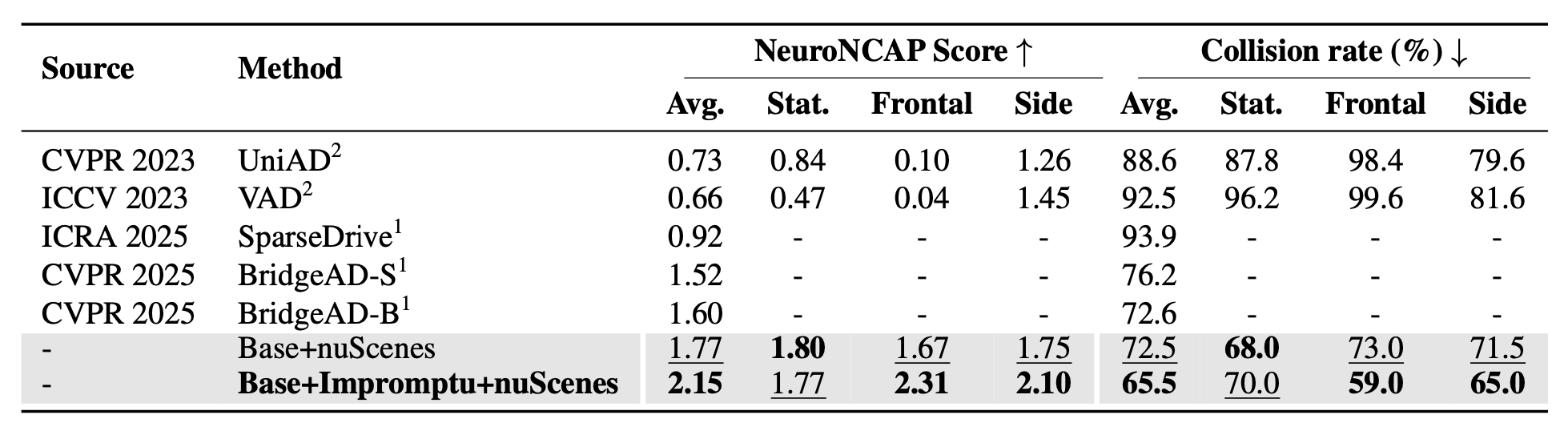
Impromptu VLA:用于驾驶视觉-语言-动作模型的开放权重和开放数据
25年5月来自清华和博世的论文“Impromptu VLA: Open Weights and Open Data for Driving Vision-Language-Action Models”。 用于自动驾驶的“视觉-语言-动作” (VLA) 模型前景光明,但在非结构化极端场景下却表现不佳,这主要是由于缺乏有针对性的基准测…...

AI智能体,为美业后端供应链注入“智慧因子”(4/6)
摘要:本文深入剖析美业后端供应链现状,其产品具有多样性、更新换代快等特点,原料供应和生产环节也面临诸多挑战。AI 智能体的登场为美业后端供应链带来变革,包括精准需求预测、智能化库存管理、优化生产计划排程、升级供应商管理等…...
跨平台资源下载工具:res-downloader 的使用体验
一款基于 Go Wails 的跨平台资源下载工具,简洁易用,支持多种资源嗅探与下载。res-downloader 一款开源免费的下载软件(开源无毒、放心使用)!支持Win10、Win11、Mac系统.支持视频、音频、图片、m3u8等网络资源下载.支持视频号、小程序、抖音、…...

ps蒙版介绍
一、蒙版的类型 Photoshop中有多种蒙版类型,每种适用于不同的场景: 图层蒙版(Layer Mask) 作用:控制图层的可见性,黑色隐藏、白色显示、灰色半透明。特点:可随时编辑,适合精细调整。…...
数据湖是什么?数据湖和数据仓库的区别是什么?
目录 一、数据湖是什么 (一)数据湖的定义 (二)数据湖的特点 二、数据仓库是什么 (一)数据仓库的定义 (二)数据仓库的特点 三、数据湖和数据仓库的区别 (一&#…...

用Ai学习wxWidgets笔记——在 VS Code 中使用 CMake 搭建 wxWidgets 开发工程
声明:本文整理筛选Ai工具生成的内容辅助写作,仅供参考 >> 在 VS Code 中使用 CMake 搭建 wxWidgets 开发工程 下面是一步步指导如何在 VS Code 中配置 wxWidgets 开发环境,包括跨平台设置(Windows 和 Linux)。…...

【深度学习新浪潮】如何入门三维重建?
入门三维重建算法技术需要结合数学基础、计算机视觉理论、编程实践和项目经验,以下是系统的学习路径和建议: 一、基础知识储备 1. 数学基础 线性代数:矩阵运算、向量空间、特征分解(用于相机矩阵、变换矩阵推导)。几何基础:三维几何(点、线、面的表示)、射影几何(单…...

Android实现点击Notification通知栏,跳转指定activity页面
效果 1、点击通知栏通知,假如app正在运行,则直接跳转到指定activity显示具体内容,在指定activity中按返回键返回其上一级页面。 2、点击通知栏通知,假如app已经退出,先从SplashActivity进入,显示app启动界…...
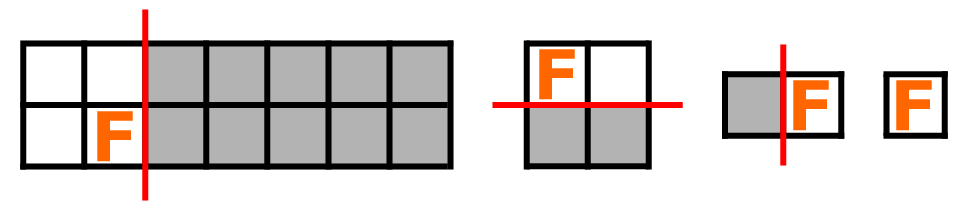
Codeforces Round 1025 (Div. 2) B. Slice to Survive
Codeforces Round 1025 (Div. 2) B. Slice to Survive 题目 Duelists Mouf and Fouad enter the arena, which is an n m n \times m nm grid! Fouad’s monster starts at cell ( a , b ) (a, b) (a,b), where rows are numbered 1 1 1 to n n n and columns 1 1 1 t…...
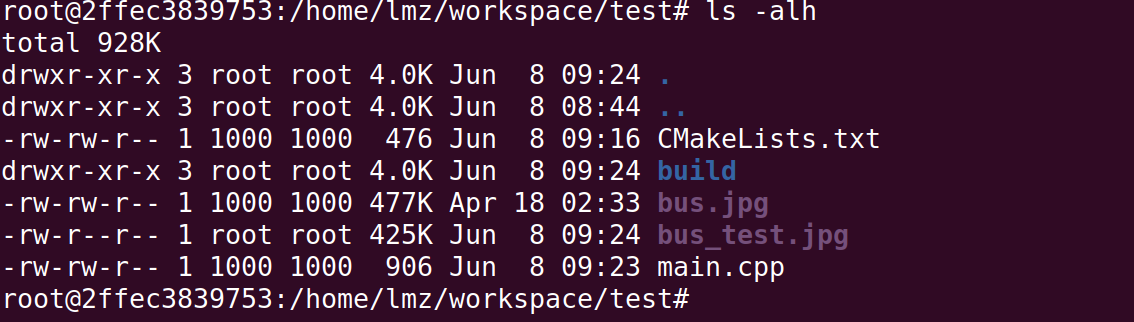
ubuntu中使用docker
上一篇我已经下载了一个ubuntu:20.04的镜像; 1. 查看所有镜像 sudo docker images 2. 基于本地存在的ubuntu:20.04镜像创建一个容器,容器的名为cppubuntu-1。创建的时候就会启动容器。 sudo docker run -itd --name cppubuntu-1 ubuntu:20.04 结果出…...