DAY 45 Tensorboard使用介绍
- tensorboard的发展历史和原理
- tensorboard的常见操作
- tensorboard在cifar上的实战:MLP和CNN模型
作业:对resnet18在cifar10上采用微调策略下,用tensorboard监控训练过程。
PS:
- tensorboard和torch版本存在一定的不兼容性,如果报错请新建环境尝试。启动tensorboard的时候需要先在cmd中进入对应的环境,conda activate xxx,再用cd命令进入环境(如果本来就是正确的则无需操作)。
- tensorboard的代码还有有一定的记忆量,实际上深度学习的经典代码都是类似于八股文,看多了就习惯了,难度远远小于考研数学等需要思考的内容
- 实际上对目前的ai而言,你只需要先完成最简单的demo,然后让他给你加上tensorboard需要打印的部分即可。---核心是弄懂tensorboard可以打印什么信息,以及如何看可视化后的结果,把ai当成记忆大师用到的时候通过它来调取对应的代码即可。
(一)tensorboard的发展历史和原理
①发展历史
tensorboard是一种交互和可视化工具,他可以很方便的很多可视化的功能,尤其是他可以在运行过程中实时渲染,方便我们根据图来动态调整训练策略,避免训练完了才知道好不好的弊端。
TensorBoard 是 TensorFlow 生态中的官方可视化工具(也可无缝集成 PyTorch),用于实时监控训练过程、可视化模型结构、分析数据分布、对比实验结果等。它通过网页端交互界面,将枯燥的训练日志转化为直观的图表和图像,帮助开发者快速定位问题、优化模型。简单来说,TensorBoard 是 TensorFlow 自带的一个「可视化工具」,就像给机器学习模型训练过程装了一个「监控屏幕」。你可以用它直观看到训练过程中的数据变化(比如损失值、准确率)、模型结构、数据分布等,不用盯着一堆枯燥的数字看,对新手非常友好。
TensorBoard 的发展历程如下:
-
2015 年随着 TensorFlow 框架一起发布,最初是为了满足深度学习研究者可视化复杂模型训练过程的需求。2016-2018 年新增了更多可视化功能,图像 / 音频可视化:可以直接看训练数据里的图片、听音频(比如在图像分类任务中,查看输入的图片是否正确)。
直方图:展示数据分布(比如权重参数的分布是否合理)。
多运行对比:同时对比多个训练任务的结果(比如不同学习率的效果对比)。 -
2019 年后与 PyTorch 兼容,变得更通用了。功能进一步丰富,比如支持3D 可视化、模型参数调试等。
目前这个工具还在不断发展,比如一些额外功能在tensorboardX上存在,但是我们目前只需要要用到最经典的几个功能即可
- 保存模型结构图
- 保存训练集和验证集的loss变化曲线,不需要手动打印了
- 保存每一个层结构权重分布
- 保存预测图片的预测信息
②原理
TensorBoard 的核心原理就是在训练过程中,把训练过程中的数据(比如损失、准确率、图片等)先记录到日志文件里,再通过工具把这些日志文件可视化成图表,这样就不用自己手动打印数据或者用其他工具画图。
所以核心就是2个步骤:
- 数据怎么存?—— 先写日志文件
训练模型时,TensorBoard 会让程序把训练数据(比如损失值、准确率)和模型结构等信息,写入一个特殊的日志文件(.tfevents 文件)
- 数据怎么看?—— 用网页展示日志
写完日志后,TensorBoard 会启动一个本地网页服务,自动读取日志文件里的数据,用图表、图像、文本等形式展示出来。如果只用 print(损失值) 或者自己用 matplotlib 画图,不仅麻烦,还得手动保存数据、写代码,尤其训练几天几夜时,根本没法实时盯着看。而 TensorBoard 能自动把这些数据 “存下来 + 画出来”,还能生成网页版的可视化界面,随时刷新查看!
③核心代码操作
-
日志目录自动管理
自动避免日志目录重复。若 runs/cifar10_mlp_experiment 已存在,会生成 runs/cifar10_mlp_experiment_1、_2 等新目录,确保每次训练的日志独立存储。方便对比不同训练任务的结果(如不同超参数实验)
-
记录标量数据(Scalar)
在 tensorboard的SCALARS 选项卡中查看曲线,支持多 run 对比。
-
可视化模型结构(Graph)
TensorBoard 界面:在 GRAPHS 选项卡中查看模型层次结构(卷积层、全连接层等)。
-
可视化图像(Image)
展示原始图像、数据增强效果、错误预测样本等。
-
记录权重和梯度直方图(Histogram)
在 HISTOGRAMS 选项卡中查看不同层的参数分布随训练的变化。监控模型参数(如权重 weights)和梯度(grads)的分布变化,诊断训练问题(如梯度消失 / 爆炸)。
#日志目录自动管理
log_dir = 'runs/cifar10_mlp_experiment'
if os.path.exists(log_dir):i = 1while os.path.exists(f"{log_dir}_{i}"):i += 1log_dir = f"{log_dir}_{i}"
writer = SummaryWriter(log_dir) #关键入口,用于写入数据到日志目录#记录标量数据
# 记录每个 Batch 的损失和准确率
writer.add_scalar('Train/Batch_Loss', batch_loss, global_step)
writer.add_scalar('Train/Batch_Accuracy', batch_acc, global_step)# 记录每个 Epoch 的训练指标
writer.add_scalar('Train/Epoch_Loss', epoch_train_loss, epoch)
writer.add_scalar('Train/Epoch_Accuracy', epoch_train_acc, epoch)#可视化模型结构
dataiter = iter(train_loader)
images, labels = next(dataiter)
images = images.to(device)
writer.add_graph(model, images) # 通过真实输入样本生成模型计算图#可视化图像
# 可视化原始训练图像
img_grid = torchvision.utils.make_grid(images[:8].cpu()) # 将多张图像拼接成网格状(方便可视化),将前8张图像拼接成一个网格
writer.add_image('原始训练图像', img_grid)# 可视化错误预测样本(训练结束后)
wrong_img_grid = torchvision.utils.make_grid(wrong_images[:display_count])
writer.add_image('错误预测样本', wrong_img_grid)#记录权重和梯度直方图(Histogram)
if (batch_idx + 1) % 500 == 0:for name, param in model.named_parameters():writer.add_histogram(f'weights/{name}', param, global_step) # 权重分布if param.grad is not None:writer.add_histogram(f'grads/{name}', param.grad, global_step) # 梯度分布
(二)tensorboard在cifar上的实战:MLP和CNN模型
-
cifar-10 MLP实战
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
import numpy as np
import matplotlib.pyplot as plt
import os# 设置随机种子以确保结果可复现
torch.manual_seed(42)
np.random.seed(42)# 1. 数据预处理
transform = transforms.Compose([transforms.ToTensor(), # 转换为张量transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)) # 标准化处理
])# 2. 加载CIFAR-10数据集
train_dataset = datasets.CIFAR10(root='./data',train=True,download=True,transform=transform
)test_dataset = datasets.CIFAR10(root='./data',train=False,transform=transform
)# 3. 创建数据加载器
batch_size = 64
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)# CIFAR-10的类别名称
classes = ('plane', 'car', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck')# 4. 定义MLP模型(适应CIFAR-10的输入尺寸)
class MLP(nn.Module):def __init__(self):super(MLP, self).__init__()self.flatten = nn.Flatten() # 将3x32x32的图像展平为3072维向量self.layer1 = nn.Linear(3072, 512) # 第一层:3072个输入,512个神经元self.relu1 = nn.ReLU()self.dropout1 = nn.Dropout(0.2) # 添加Dropout防止过拟合self.layer2 = nn.Linear(512, 256) # 第二层:512个输入,256个神经元self.relu2 = nn.ReLU()self.dropout2 = nn.Dropout(0.2)self.layer3 = nn.Linear(256, 10) # 输出层:10个类别def forward(self, x):# 第一步:将输入图像展平为一维向量x = self.flatten(x) # 输入尺寸: [batch_size, 3, 32, 32] → [batch_size, 3072]# 第一层全连接 + 激活 + Dropoutx = self.layer1(x) # 线性变换: [batch_size, 3072] → [batch_size, 512]x = self.relu1(x) # 应用ReLU激活函数x = self.dropout1(x) # 训练时随机丢弃部分神经元输出# 第二层全连接 + 激活 + Dropoutx = self.layer2(x) # 线性变换: [batch_size, 512] → [batch_size, 256]x = self.relu2(x) # 应用ReLU激活函数x = self.dropout2(x) # 训练时随机丢弃部分神经元输出# 第三层(输出层)全连接x = self.layer3(x) # 线性变换: [batch_size, 256] → [batch_size, 10]return x # 返回未经过Softmax的logits# 检查GPU是否可用
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")# 初始化模型
model = MLP()
model = model.to(device) # 将模型移至GPU(如果可用)criterion = nn.CrossEntropyLoss() # 交叉熵损失函数
optimizer = optim.Adam(model.parameters(), lr=0.001) # Adam优化器# 创建TensorBoard的SummaryWriter,指定日志保存目录
log_dir = 'runs/cifar10_mlp_experiment'
# 如果目录已存在,添加后缀避免覆盖
if os.path.exists(log_dir):i = 1while os.path.exists(f"{log_dir}_{i}"):i += 1log_dir = f"{log_dir}_{i}"
writer = SummaryWriter(log_dir)# 5. 训练模型(使用TensorBoard记录各种信息)
def train(model, train_loader, test_loader, criterion, optimizer, device, epochs, writer):model.train() # 设置为训练模式# 记录训练开始时间,用于计算训练速度global_step = 0# 可视化模型结构dataiter = iter(train_loader)images, labels = next(dataiter)images = images.to(device)writer.add_graph(model, images) # 添加模型图# 可视化原始图像样本img_grid = torchvision.utils.make_grid(images[:8].cpu())writer.add_image('原始训练图像', img_grid)for epoch in range(epochs):running_loss = 0.0correct = 0total = 0for batch_idx, (data, target) in enumerate(train_loader):data, target = data.to(device), target.to(device) # 移至GPUoptimizer.zero_grad() # 梯度清零output = model(data) # 前向传播loss = criterion(output, target) # 计算损失loss.backward() # 反向传播optimizer.step() # 更新参数# 统计准确率和损失running_loss += loss.item()_, predicted = output.max(1)total += target.size(0)correct += predicted.eq(target).sum().item()# 每100个批次记录一次信息到TensorBoardif (batch_idx + 1) % 100 == 0:batch_loss = loss.item()batch_acc = 100. * correct / total# 记录标量数据(损失、准确率)writer.add_scalar('Train/Batch_Loss', batch_loss, global_step)writer.add_scalar('Train/Batch_Accuracy', batch_acc, global_step)# 记录学习率writer.add_scalar('Train/Learning_Rate', optimizer.param_groups[0]['lr'], global_step)# 每500个批次记录一次直方图(权重和梯度)if (batch_idx + 1) % 500 == 0:for name, param in model.named_parameters():writer.add_histogram(f'weights/{name}', param, global_step)if param.grad is not None:writer.add_histogram(f'grads/{name}', param.grad, global_step)print(f'Epoch: {epoch+1}/{epochs} | Batch: {batch_idx+1}/{len(train_loader)} 'f'| 单Batch损失: {batch_loss:.4f} | 累计平均损失: {running_loss/(batch_idx+1):.4f}')global_step += 1# 计算当前epoch的平均训练损失和准确率epoch_train_loss = running_loss / len(train_loader)epoch_train_acc = 100. * correct / total# 记录每个epoch的训练损失和准确率writer.add_scalar('Train/Epoch_Loss', epoch_train_loss, epoch)writer.add_scalar('Train/Epoch_Accuracy', epoch_train_acc, epoch)# 测试阶段model.eval() # 设置为评估模式test_loss = 0correct_test = 0total_test = 0# 用于存储预测错误的样本wrong_images = []wrong_labels = []wrong_preds = []with torch.no_grad():for data, target in test_loader:data, target = data.to(device), target.to(device)output = model(data)test_loss += criterion(output, target).item()_, predicted = output.max(1)total_test += target.size(0)correct_test += predicted.eq(target).sum().item()# 收集预测错误的样本wrong_mask = (predicted != target).cpu()if wrong_mask.sum() > 0:wrong_batch_images = data[wrong_mask].cpu()wrong_batch_labels = target[wrong_mask].cpu()wrong_batch_preds = predicted[wrong_mask].cpu()wrong_images.extend(wrong_batch_images)wrong_labels.extend(wrong_batch_labels)wrong_preds.extend(wrong_batch_preds)epoch_test_loss = test_loss / len(test_loader)epoch_test_acc = 100. * correct_test / total_test# 记录每个epoch的测试损失和准确率writer.add_scalar('Test/Loss', epoch_test_loss, epoch)writer.add_scalar('Test/Accuracy', epoch_test_acc, epoch)# 计算并记录训练速度(每秒处理的样本数)# 这里简化处理,假设每个epoch的时间相同samples_per_epoch = len(train_loader.dataset)# 实际应用中应该使用time.time()来计算真实时间print(f'Epoch {epoch+1}/{epochs} 完成 | 训练准确率: {epoch_train_acc:.2f}% | 测试准确率: {epoch_test_acc:.2f}%')# 可视化预测错误的样本(只在最后一个epoch进行)if epoch == epochs - 1 and len(wrong_images) > 0:# 最多显示8个错误样本display_count = min(8, len(wrong_images))wrong_img_grid = torchvision.utils.make_grid(wrong_images[:display_count])# 创建错误预测的标签文本wrong_text = []for i in range(display_count):true_label = classes[wrong_labels[i]]pred_label = classes[wrong_preds[i]]wrong_text.append(f'True: {true_label}, Pred: {pred_label}')writer.add_image('错误预测样本', wrong_img_grid)writer.add_text('错误预测标签', '\n'.join(wrong_text), epoch)# 关闭TensorBoard写入器writer.close()return epoch_test_acc # 返回最终测试准确率# 6. 执行训练和测试
epochs = 20 # 训练轮次
print("开始训练模型...")
print(f"TensorBoard日志保存在: {log_dir}")
print("训练完成后,使用命令 `tensorboard --logdir=runs` 启动TensorBoard查看可视化结果")final_accuracy = train(model, train_loader, test_loader, criterion, optimizer, device, epochs, writer)
print(f"训练完成!最终测试准确率: {final_accuracy:.2f}%")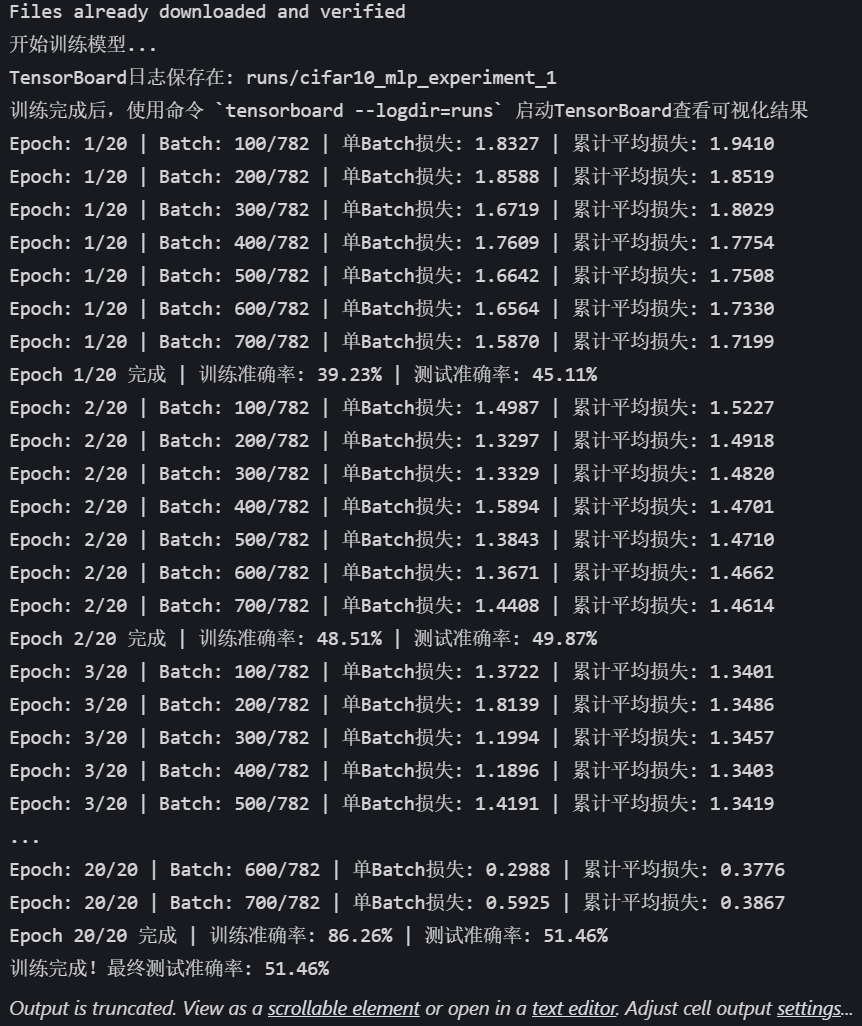
TensorBoard日志保存在: runs/cifar10_mlp_experiment_1
可以在命令行中进入目前的环境,然后通过tensorboard --logdir=xxxx(目录)即可调出本地链接,点进去就是目前的训练信息,可以不断F5刷新来查看变化。
在TensorBoard界面中,你可以看到:
-
SCALARS 选项卡:展示损失曲线、准确率变化、学习率等标量数据----Scalar意思是标量,指只有大小、没有方向的量。
-
IMAGES 选项卡:展示原始训练图像和错误预测的样本
-
GRAPHS 选项卡:展示模型的计算图结构
-
HISTOGRAMS 选项卡:展示模型参数和梯度的分布直方图
-
CNN实战
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
import matplotlib.pyplot as plt
import numpy as np
import os
import torchvision # 记得导入 torchvision,之前代码里用到了其功能但没导入# 设置中文字体支持
plt.rcParams["font.family"] = ["SimHei"]
plt.rcParams['axes.unicode_minus'] = False # 解决负号显示问题# 检查GPU是否可用
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"使用设备: {device}")# 1. 数据预处理
train_transform = transforms.Compose([transforms.RandomCrop(32, padding=4),transforms.RandomHorizontalFlip(),transforms.ColorJitter(brightness=0.2, contrast=0.2, saturation=0.2, hue=0.1),transforms.RandomRotation(15),transforms.ToTensor(),transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010))
])test_transform = transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010))
])# 2. 加载CIFAR-10数据集
train_dataset = datasets.CIFAR10(root='./data',train=True,download=True,transform=train_transform
)test_dataset = datasets.CIFAR10(root='./data',train=False,transform=test_transform
)# 3. 创建数据加载器
batch_size = 64
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)# 4. 定义CNN模型的定义(替代原MLP)
class CNN(nn.Module):def __init__(self):super(CNN, self).__init__() # 继承父类初始化# ---------------------- 第一个卷积块 ----------------------# 卷积层1:输入3通道(RGB),输出32个特征图,卷积核3x3,边缘填充1像素self.conv1 = nn.Conv2d(in_channels=3, # 输入通道数(图像的RGB通道)out_channels=32, # 输出通道数(生成32个新特征图)kernel_size=3, # 卷积核尺寸(3x3像素)padding=1 # 边缘填充1像素,保持输出尺寸与输入相同)# 批量归一化层:对32个输出通道进行归一化,加速训练self.bn1 = nn.BatchNorm2d(num_features=32)# ReLU激活函数:引入非线性,公式:max(0, x)self.relu1 = nn.ReLU()# 最大池化层:窗口2x2,步长2,特征图尺寸减半(32x32→16x16)self.pool1 = nn.MaxPool2d(kernel_size=2, stride=2) # stride默认等于kernel_size# ---------------------- 第二个卷积块 ----------------------# 卷积层2:输入32通道(来自conv1的输出),输出64通道self.conv2 = nn.Conv2d(in_channels=32, # 输入通道数(前一层的输出通道数)out_channels=64, # 输出通道数(特征图数量翻倍)kernel_size=3, # 卷积核尺寸不变padding=1 # 保持尺寸:16x16→16x16(卷积后)→8x8(池化后))self.bn2 = nn.BatchNorm2d(num_features=64)self.relu2 = nn.ReLU()self.pool2 = nn.MaxPool2d(kernel_size=2) # 尺寸减半:16x16→8x8# ---------------------- 第三个卷积块 ----------------------# 卷积层3:输入64通道,输出128通道self.conv3 = nn.Conv2d(in_channels=64, # 输入通道数(前一层的输出通道数)out_channels=128, # 输出通道数(特征图数量再次翻倍)kernel_size=3,padding=1 # 保持尺寸:8x8→8x8(卷积后)→4x4(池化后))self.bn3 = nn.BatchNorm2d(num_features=128)self.relu3 = nn.ReLU() # 复用激活函数对象(节省内存)self.pool3 = nn.MaxPool2d(kernel_size=2) # 尺寸减半:8x8→4x4# ---------------------- 全连接层(分类器) ----------------------# 计算展平后的特征维度:128通道 × 4x4尺寸 = 128×16=2048维self.fc1 = nn.Linear(in_features=128 * 4 * 4, # 输入维度(卷积层输出的特征数)out_features=512 # 输出维度(隐藏层神经元数))# Dropout层:训练时随机丢弃50%神经元,防止过拟合self.dropout = nn.Dropout(p=0.5)# 输出层:将512维特征映射到10个类别(CIFAR-10的类别数)self.fc2 = nn.Linear(in_features=512, out_features=10)def forward(self, x):# 输入尺寸:[batch_size, 3, 32, 32](batch_size=批量大小,3=通道数,32x32=图像尺寸)# ---------- 卷积块1处理 ----------x = self.conv1(x) # 卷积后尺寸:[batch_size, 32, 32, 32](padding=1保持尺寸)x = self.bn1(x) # 批量归一化,不改变尺寸x = self.relu1(x) # 激活函数,不改变尺寸x = self.pool1(x) # 池化后尺寸:[batch_size, 32, 16, 16](32→16是因为池化窗口2x2)# ---------- 卷积块2处理 ----------x = self.conv2(x) # 卷积后尺寸:[batch_size, 64, 16, 16](padding=1保持尺寸)x = self.bn2(x)x = self.relu2(x)x = self.pool2(x) # 池化后尺寸:[batch_size, 64, 8, 8]# ---------- 卷积块3处理 ----------x = self.conv3(x) # 卷积后尺寸:[batch_size, 128, 8, 8](padding=1保持尺寸)x = self.bn3(x)x = self.relu3(x)x = self.pool3(x) # 池化后尺寸:[batch_size, 128, 4, 4]# ---------- 展平与全连接层 ----------# 将多维特征图展平为一维向量:[batch_size, 128*4*4] = [batch_size, 2048]x = x.view(-1, 128 * 4 * 4) # -1自动计算批量维度,保持批量大小不变x = self.fc1(x) # 全连接层:2048→512,尺寸变为[batch_size, 512]x = self.relu3(x) # 激活函数(复用relu3,与卷积块3共用)x = self.dropout(x) # Dropout随机丢弃神经元,不改变尺寸x = self.fc2(x) # 全连接层:512→10,尺寸变为[batch_size, 10](未激活,直接输出logits)return x # 输出未经过Softmax的logits,适用于交叉熵损失函数# 初始化模型
model = CNN()
model = model.to(device) # 将模型移至GPU(如果可用)criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
scheduler = optim.lr_scheduler.ReduceLROnPlateau(optimizer, # 指定要控制的优化器(这里是Adam)mode='min', # 监测的指标是"最小化"(如损失函数)patience=3, # 如果连续3个epoch指标没有改善,才降低LRfactor=0.5, # 降低LR的比例(新LR = 旧LR × 0.5)verbose=True # 打印学习率调整信息
)# ======================== TensorBoard 核心配置 ========================
# 创建 TensorBoard 日志目录(自动避免重复)
log_dir = "runs/cifar10_cnn_exp"
if os.path.exists(log_dir):version = 1while os.path.exists(f"{log_dir}_v{version}"):version += 1log_dir = f"{log_dir}_v{version}"
writer = SummaryWriter(log_dir) # 初始化 SummaryWriter# 5. 训练模型(整合 TensorBoard 记录)
def train(model, train_loader, test_loader, criterion, optimizer, scheduler, device, epochs, writer):model.train()all_iter_losses = [] iter_indices = [] global_step = 0 # 全局步骤,用于 TensorBoard 标量记录# (可选)记录模型结构:用一个真实样本走一遍前向传播,让 TensorBoard 解析计算图dataiter = iter(train_loader)images, labels = next(dataiter)images = images.to(device)writer.add_graph(model, images) # 写入模型结构到 TensorBoard# (可选)记录原始训练图像:可视化数据增强前/后效果img_grid = torchvision.utils.make_grid(images[:8].cpu()) # 取前8张writer.add_image('原始训练图像(增强前)', img_grid, global_step=0)for epoch in range(epochs):running_loss = 0.0correct = 0total = 0for batch_idx, (data, target) in enumerate(train_loader):data, target = data.to(device), target.to(device)optimizer.zero_grad()output = model(data)loss = criterion(output, target)loss.backward()optimizer.step()# 记录迭代级损失iter_loss = loss.item()all_iter_losses.append(iter_loss)iter_indices.append(global_step + 1) # 用 global_step 对齐# 统计准确率running_loss += iter_loss_, predicted = output.max(1)total += target.size(0)correct += predicted.eq(target).sum().item()# ======================== TensorBoard 标量记录 ========================# 记录每个 batch 的损失、准确率batch_acc = 100. * correct / totalwriter.add_scalar('Train/Batch Loss', iter_loss, global_step)writer.add_scalar('Train/Batch Accuracy', batch_acc, global_step)# 记录学习率(可选)writer.add_scalar('Train/Learning Rate', optimizer.param_groups[0]['lr'], global_step)# 每 200 个 batch 记录一次参数直方图(可选,耗时稍高)if (batch_idx + 1) % 200 == 0:for name, param in model.named_parameters():writer.add_histogram(f'Weights/{name}', param, global_step)if param.grad is not None:writer.add_histogram(f'Gradients/{name}', param.grad, global_step)# 每 100 个 batch 打印控制台日志(同原代码)if (batch_idx + 1) % 100 == 0:print(f'Epoch: {epoch+1}/{epochs} | Batch: {batch_idx+1}/{len(train_loader)} 'f'| 单Batch损失: {iter_loss:.4f} | 累计平均损失: {running_loss/(batch_idx+1):.4f}')global_step += 1 # 全局步骤递增# 计算 epoch 级训练指标epoch_train_loss = running_loss / len(train_loader)epoch_train_acc = 100. * correct / total# ======================== TensorBoard epoch 标量记录 ========================writer.add_scalar('Train/Epoch Loss', epoch_train_loss, epoch)writer.add_scalar('Train/Epoch Accuracy', epoch_train_acc, epoch)# 测试阶段model.eval()test_loss = 0correct_test = 0total_test = 0wrong_images = [] # 存储错误预测样本(用于可视化)wrong_labels = []wrong_preds = []with torch.no_grad():for data, target in test_loader:data, target = data.to(device), target.to(device)output = model(data)test_loss += criterion(output, target).item()_, predicted = output.max(1)total_test += target.size(0)correct_test += predicted.eq(target).sum().item()# 收集错误预测样本(用于可视化)wrong_mask = (predicted != target)if wrong_mask.sum() > 0:wrong_batch_images = data[wrong_mask][:8].cpu() # 最多存8张wrong_batch_labels = target[wrong_mask][:8].cpu()wrong_batch_preds = predicted[wrong_mask][:8].cpu()wrong_images.extend(wrong_batch_images)wrong_labels.extend(wrong_batch_labels)wrong_preds.extend(wrong_batch_preds)# 计算 epoch 级测试指标epoch_test_loss = test_loss / len(test_loader)epoch_test_acc = 100. * correct_test / total_test# ======================== TensorBoard 测试集记录 ========================writer.add_scalar('Test/Epoch Loss', epoch_test_loss, epoch)writer.add_scalar('Test/Epoch Accuracy', epoch_test_acc, epoch)# (可选)可视化错误预测样本if wrong_images:wrong_img_grid = torchvision.utils.make_grid(wrong_images)writer.add_image('错误预测样本', wrong_img_grid, epoch)# 写入错误标签文本(可选)wrong_text = [f"真实: {classes[wl]}, 预测: {classes[wp]}" for wl, wp in zip(wrong_labels, wrong_preds)]writer.add_text('错误预测标签', '\n'.join(wrong_text), epoch)# 更新学习率调度器scheduler.step(epoch_test_loss)print(f'Epoch {epoch+1}/{epochs} 完成 | 训练准确率: {epoch_train_acc:.2f}% | 测试准确率: {epoch_test_acc:.2f}%')# 关闭 TensorBoard 写入器writer.close()# 绘制迭代级损失曲线(同原代码)plot_iter_losses(all_iter_losses, iter_indices)return epoch_test_acc# 6. 绘制迭代级损失曲线(同原代码,略)
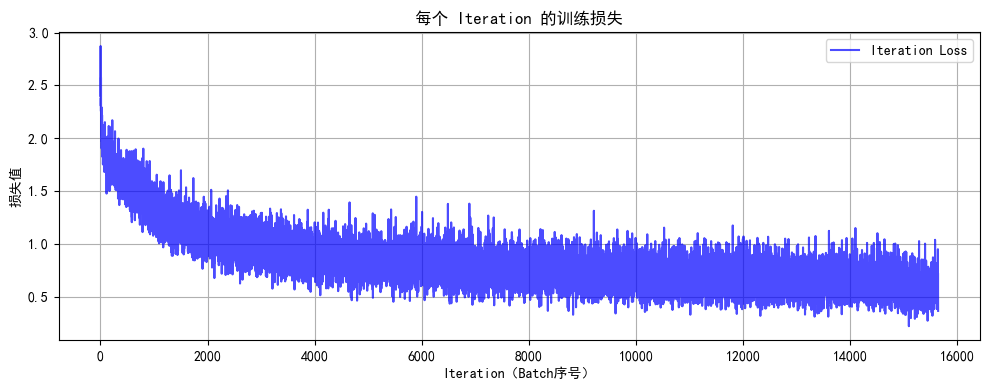
def plot_iter_losses(losses, indices):plt.figure(figsize=(10, 4))plt.plot(indices, losses, 'b-', alpha=0.7, label='Iteration Loss')plt.xlabel('Iteration(Batch序号)')plt.ylabel('损失值')plt.title('每个 Iteration 的训练损失')plt.legend()plt.grid(True)plt.tight_layout()plt.show()# (可选)CIFAR-10 类别名
classes = ('plane', 'car', 'bird', 'cat','deer', 'dog', 'frog', 'horse', 'ship', 'truck')# 7. 执行训练(传入 TensorBoard writer)
epochs = 20
print("开始使用CNN训练模型...")
print(f"TensorBoard 日志目录: {log_dir}")
print("训练后执行: tensorboard --logdir=runs 查看可视化")final_accuracy = train(model, train_loader, test_loader, criterion, optimizer, scheduler, device, epochs, writer)
print(f"训练完成!最终测试准确率: {final_accuracy:.2f}%")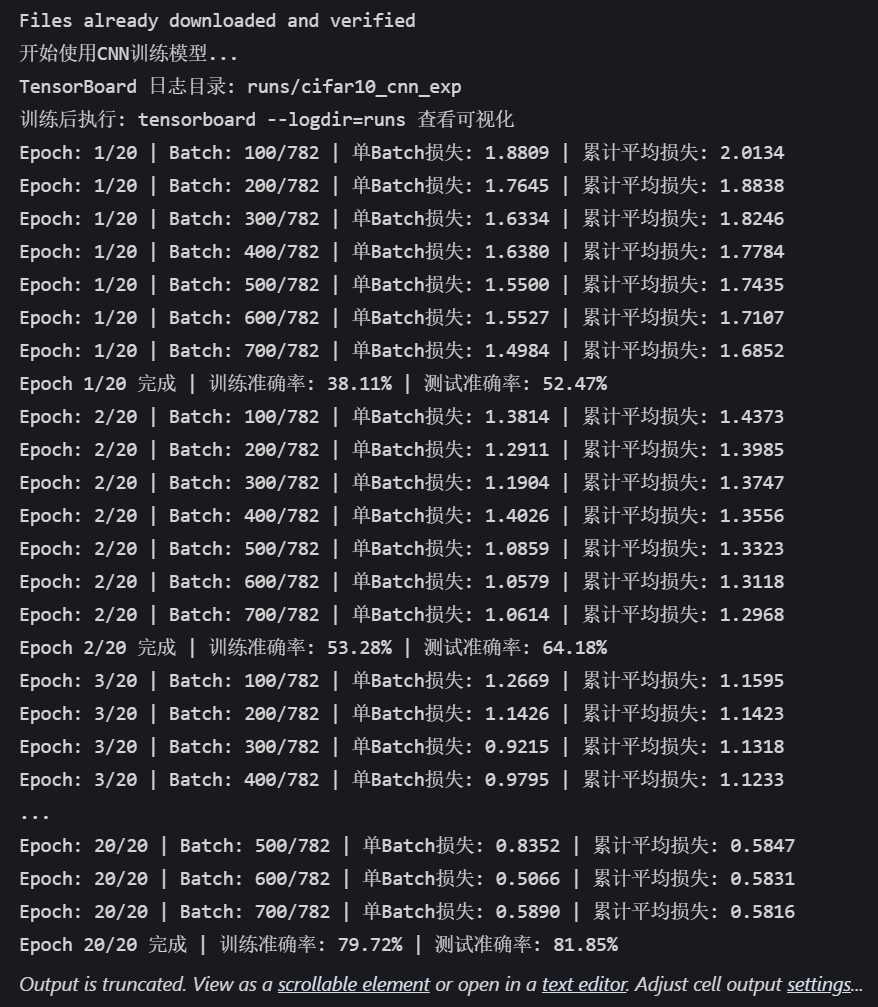
相关文章:
DAY 45 Tensorboard使用介绍
知识点回顾: tensorboard的发展历史和原理tensorboard的常见操作tensorboard在cifar上的实战:MLP和CNN模型 作业:对resnet18在cifar10上采用微调策略下,用tensorboard监控训练过程。 PS: tensorboard和torch版本存在一定的不兼容…...

LeetCode刷题 -- 542. 01矩阵 基于 DFS 更新优化的多源最短路径实现
LeetCode刷题 – 542. 01矩阵 基于 DFS 更新优化的多源最短路径实现 题目描述简述 给定一个 m x n 的二进制矩阵 mat,其中: 每个元素为 0 或 1返回一个同样大小的矩阵 ans,其中 ans[i][j] 表示 mat[i][j] 到最近 0 的最短曼哈顿距离 算法思…...
TM中,return new TransactionManagerImpl(raf, fc);为什么返回是new了一个新的实例
这是一个典型的 构造器注入 封装资源的用法 🧩 代码片段 return new TransactionManagerImpl(raf, fc);✅ 简单解释: 这行代码的意思是: 使用已经打开的 RandomAccessFile 和 FileChannel,创建并返回一个新的 TransactionManag…...

将 tensorflow keras 训练数据集转换为 Yolo 训练数据集
以 https://www.kaggle.com/datasets/vipoooool/new-plant-diseases-dataset 为例 1. 图像分类数据集文件结构 (例如用于 yolov11n-cls.pt 训练) import os import csv import random from PIL import Image from sklearn.model_selection import train_test_split import s…...
MySQL学习笔记(6):分组查询,正则表达式)
(新手友好)MySQL学习笔记(6):分组查询,正则表达式
目录 分组查询 创建分组 过滤分组 分组查询练习 正则表达式 匹配单个实例 匹配多个实例 正则表达式练习 练习答案 分组查询练习答案 正则表达式练习答案 分组查询 创建分组 group by 子句:根据一个或多个字段对结果集进行分组,在分组的字段上…...

台式机电脑CPU天梯图2025年6月份更新:CPU选购指南及推荐
组装电脑选硬件的过程中,CPU的选择无疑是最关键的,因为它是最核心的硬件,关乎着一台电脑的性能好坏。对于小白来说,CPU天梯图方便直接判断两款CPU性能高低,准确的说,是多核性能。下面给大家分享一下台式机电脑CPU天梯图2025年6月版,来看看吧。 桌面CPU性能排行榜2025 台…...

【hadoop】Flink安装部署
一、单机模式 步骤: 1、使用XFTP将Flink安装包flink-1.13.5-bin-scala_2.11.tgz发送到master机器的主目录。 2、解压安装包: tar -zxvf ~/flink-1.13.5-bin-scala_2.11.tgz 3、修改文件夹的名字,将其改为flume,或者创建软连接…...
将单体架构项目拆分成微服务时的两种工程结构
一.独立Project 1.示意图 此时我们创建一个文件夹,在这个文件夹中,创建N个Project,每一个Project对应一个微服务,组成我们的最终的项目。 2.特点 适合那种超大型项目,比如淘宝,但管理负担比较重。 二.Mave…...

Unity3D 开发中的创新技术:解锁 3D 开发的新境界
在 3D 开发的广袤天地里,Unity3D 一直是众多开发者的得力伙伴。可如今,普通的开发方式似乎难以满足日益增长的创意与效率需求。你是否好奇,凭什么别家团队能用 Unity3D 打造出令人拍案叫绝的 3D 作品,自己却总感觉差了那么一点火候…...
UOS 20 Pro为国际版WPS设置中文菜单
UOS 20 Pro为国际版WPS设置中文菜单 查看UOS操作系统系统安装国际版wps并汉化方法1:下载zh_CN.tar.gz语言包方法2:手动从国内版wps12的包中提取中文菜单解压国内版wps的包 复制中文语言包到wps国际版目录下安装Windows字体 安装开源office 查看UOS操作系统系统 # 查…...

树莓派系统中设置固定 IP
在基于 Ubuntu 的树莓派系统中,设置固定 IP 地址主要有以下几种方法: 方法一:使用 Netplan 配置(Ubuntu 18.04 及以上版本默认使用 Netplan) 查看网络接口名称 在终端输入ip link或ip a命令,查看当前所使…...
单例模式与锁(死锁)
目录 线程安全的单例模式 什么是单例模式 单例模式的特点 饿汉实现方式和懒汉实现方式 饿汉⽅式实现单例模式 懒汉⽅式实现单例模式 懒汉⽅式实现单例模式(线程安全版本) 单例式线程池 ThreadPool.hpp threadpool.cc 运行结果 线程安全和重⼊问题 常⻅锁概念 死…...

LLM基础2_语言模型如何文本编码
基于GitHub项目:https://github.com/datawhalechina/llms-from-scratch-cn 字节对编码(BPE) 上一篇博文说到 为什么GPT模型不需要[PAD]和[UNK]? GPT使用更先进的字节对编码(BPE),总能将词语拆分成已知子词 为什么需要BPE? 简…...

理解世界如淦泽,穿透黑幕需老谋
理解世界如淦泽,穿透黑幕需老谋 卡西莫多 2025年06月07日 安徽 极少主动跟别人提及恩师的名字,生怕自己比孙猴子不成器但又比它更能惹事的德行,使得老师跟着被拖累而脸上无光。不过老师没有象菩提祖师训诫孙猴子那样不能说出师傅的名字&a…...

如何确定微服务的粒度与边界
确定微服务的粒度与边界 在完成初步服务拆分之后,架构师往往会遇到另一个难题:该拆到多细?哪些功能可以归并为一个服务,哪些又必须单独部署?这就是“服务粒度与边界”的问题。本节将围绕实际架构经验,介绍…...
第三讲 Linux进程概念
1. 冯诺依曼体系结构 我们买了笔记本电脑, 里面是有很多硬件组成的, 比如硬盘, 显示器, 内存, 主板... 这些硬件不是随便放在一起就行的, 而是按照一定的结构进行组装起来的, 而具体的组装结构, 一般就是冯诺依曼体系结构 1.1. 计算机的一般工作逻辑 我们都知道, 计算机的逻…...

stm32-c8t6实现语音识别(LD3320)
目录 LD3320介绍: 功能引脚 主要特色功能 通信协议 端口信息 开发流程 stm32c8t6代码 LD3320驱动代码: LD3320介绍: 内置单声道mono 16-bit A/D 模数转换内置双声道stereo 16-bit D/A 数模转换内置 20mW 双声道耳机放大器输出内置 5…...

Vue作用域插槽
下面,我们来系统的梳理关于 **Vue 作用域插槽 ** 的基本知识点: 一、作用域插槽核心概念 1.1 什么是作用域插槽? 作用域插槽是 Vue 中一种反向数据流机制,允许子组件将数据传递给父组件中的插槽内容。这种模式解决了传统插槽中父组件无法访问子组件内部状态的限制。 1.2…...

「数据分析 - NumPy 函数与方法全集」【数据分析全栈攻略:爬虫+处理+可视化+报告】
- 第 104 篇 - Date: 2025 - 06 - 05 Author: 郑龙浩/仟墨 NumPy 函数与方法全集 文章目录 NumPy 函数与方法全集1. 数组创建与初始化基础创建序列生成特殊数组 2. 数组操作形状操作合并与分割 3. 数学运算基础运算统计运算 4. 随机数生成基础随机分布函数 5. 文件IO文件读写 …...
爬虫学习记录day1
什么是逆向? 数据加密 参数加密 表单加密扣js改写Python举例子 4.1 元素:被渲染的数据资源 动态数据 静态数据 如果数据是加密的情况则无法直接得到数据 4.2 控制台:输出界面 4.3 源代码页面 4.4 网络:抓包功能,获取浏…...
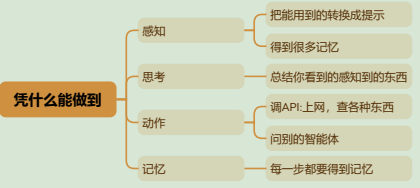
agent基础概念
agent是什么 我个人认为agent并没有一个所谓完美的定义,它是一个比较活的概念,就像是你眼中的一个机器人你希望它做什么事,和我眼中的机器人它解决事情的流程,其实是可以完全不同的,没有必要非得搞一个统一的概念或流程来概况它。但我们依然可以概况几个通用的词来描述它…...

MS8312A 车规 精密、低噪、CMOS、轨到轨输入输出运算放大器,用于传感器、条形扫描器
MS8312A 车规 精密、低噪、CMOS、轨到轨输入输出运算放大器,用于传感器、条形扫描器 简述 MS8312A 是双通道的轨到轨输入输出单电源供电运放。它们具有低的失调电压、低的输入电压电流噪声和宽的信号带宽。 低失调、低噪、低输入偏置电流和宽带宽的特性结合使得 …...

计算机二级Python考试的核心知识点总结
以下是计算机二级Python考试的核心知识点总结,结合高频考点和易错点分类整理: 1. **数据类型与运算** ▷ 不可变类型:int, float, str, tuple(重点区分list与tuple) ▷ 运算符优先级:** > * /…...
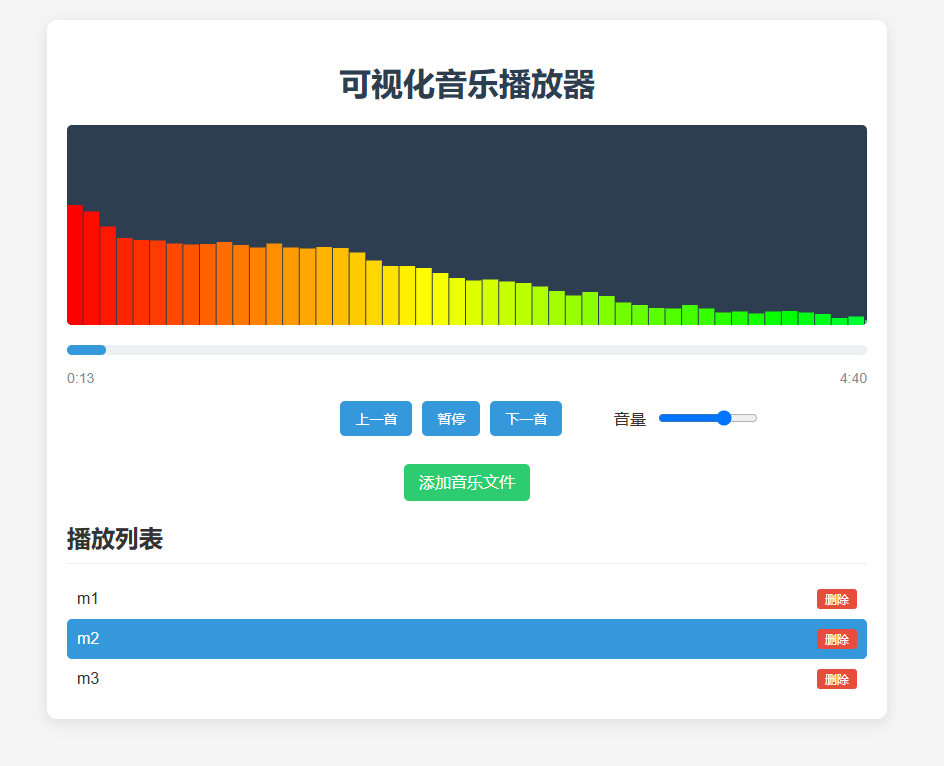
让音乐“看得见”:使用 HTML + JavaScript 实现酷炫的音频可视化播放器
在这个数字时代,音乐不仅是听觉的享受,更可以成为视觉的盛宴!本文用 HTML + JavaScript 实现了一个音频可视化播放器,它不仅能播放本地音乐、控制进度和音量,还能通过 Canvas 绘制炫酷的音频频谱图,让你“听见色彩,看见旋律”。 效果演示 核心功能 本项目主要包含以下…...
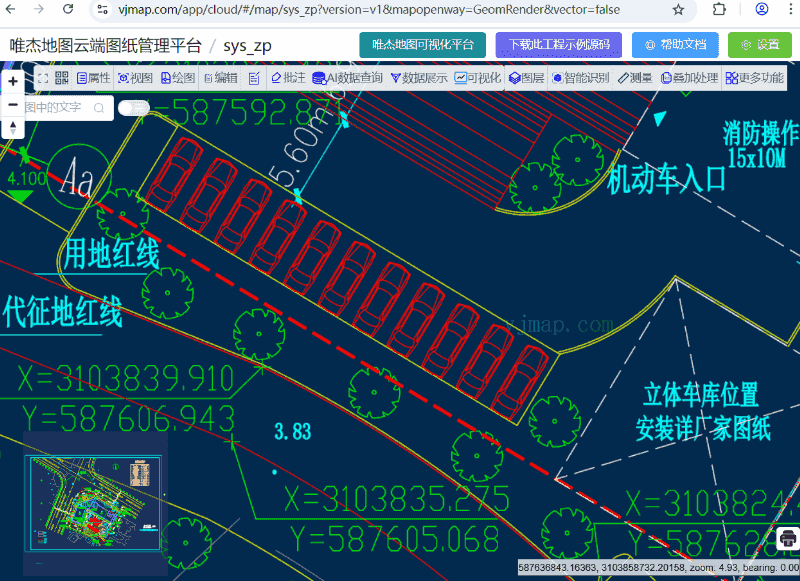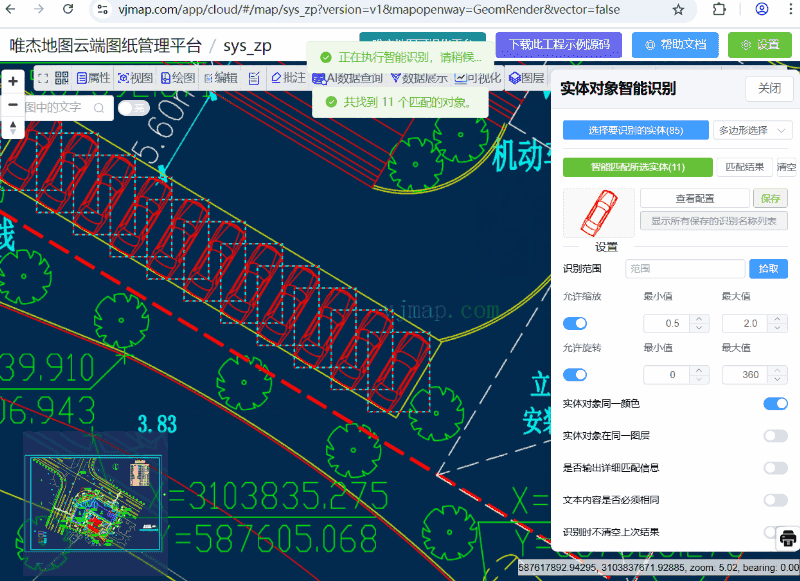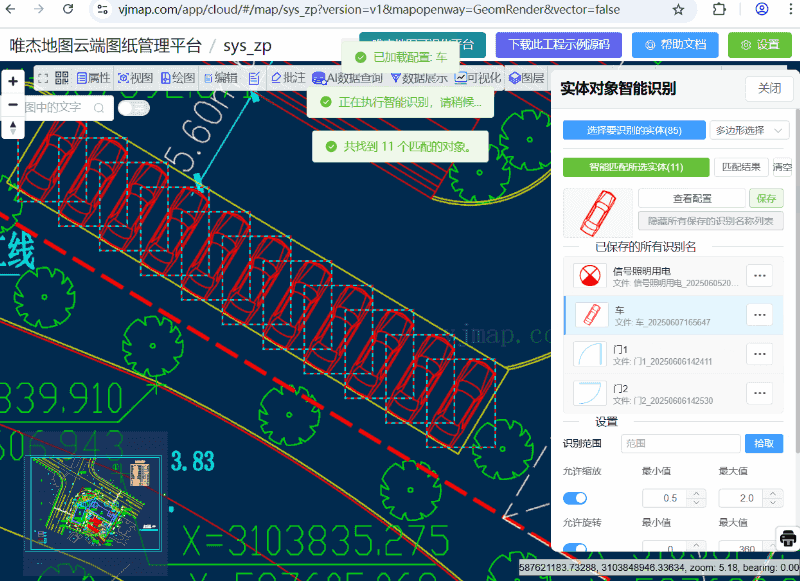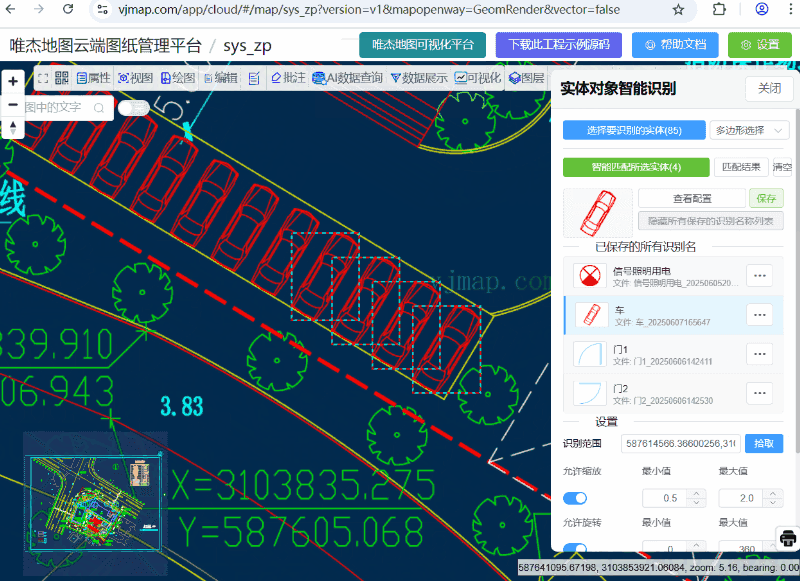
CAD实体对象智能识别
CAD实体对象智能识别 概述 实体对象智能识别能够在CAD图纸中智能识别和匹配相似的实体对象。该系统采用模式匹配算法,支持几何变换(缩放、旋转),并提供了丰富的配置选项和可视化界面。 系统提供两种主要的识别方式:…...
)
MySQL中的部分问题(2)
索引失效 运算或函数影响列的使用 当查询条件中对索引列用了函数或运算,索引会失效。 例:假设有索引:index idx_name (name) select * from users where upper(name) ALICE; -- 索引失效因为upper(name)会对列内容进行函数处理…...

【从前端到后端导入excel文件实现批量导入-笔记模仿芋道源码的《系统管理-用户管理-导入-批量导入》】
批量导入预约数据-笔记 前端场馆列表后端 前端 场馆列表 该列表进入出现的是这样的,这儿是列表操作 <el-table-column label"操作" align"center" width"220px"><template #default"scope"><el-buttonlinktype"…...
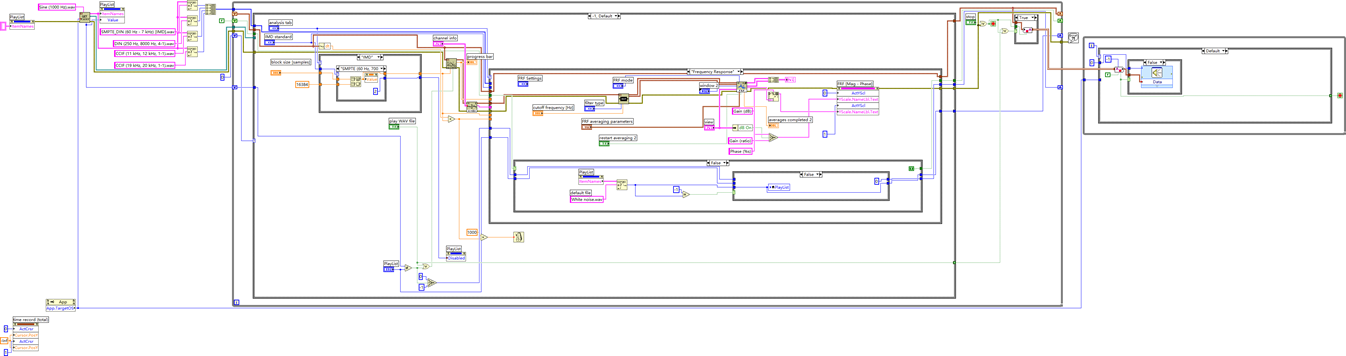
LabVIEW音频测试分析
LabVIEW通过读取指定WAV 文件,实现对音频信号的播放、多维度测量分析功能,为音频设备研发、声学研究及质量检测提供专业工具支持。 主要功能 文件读取与播放:支持持续读取示例数据文件夹内的 WAV 文件,可实时播放音频以监听被测信…...

MySQL 8.0 绿色版安装和配置过程
MySQL作为云计算时代,被广泛使用的一款数据库,他的安装方式有很多种,有yum安装、rpm安装、二进制文件安装,当然也有本文提到的绿色版安装,因绿色版与系统无关,且可快速复制生成,具有较强的优势。…...
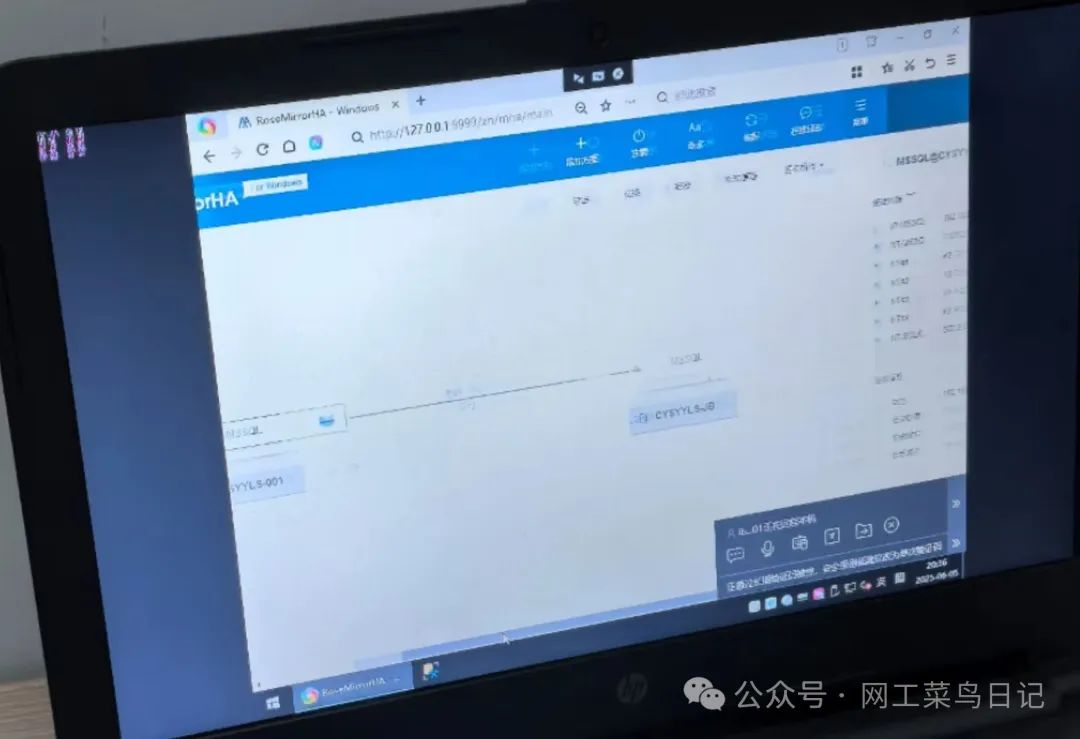
RoseMirrorHA 双机热备全解析
在数字化时代,企业核心业务系统一旦瘫痪,每分钟可能造成数万甚至数十万的损失。想象一下,如果银行的交易系统突然中断,或者医院的挂号系统无法访问,会引发怎样的连锁反应?为了守护这些关键业务,…...