LLM基础2_语言模型如何文本编码
基于GitHub项目:https://github.com/datawhalechina/llms-from-scratch-cn
字节对编码(BPE)
上一篇博文说到
为什么GPT模型不需要[PAD]和[UNK]?
GPT使用更先进的字节对编码(BPE),总能将词语拆分成已知子词
为什么需要BPE?
-
简单分词器的问题:遇到新词就卡住(如"Hello")
-
BPE的解决方案:把陌生词拆成已知的小零件
BPE如何工作?
就像拼乐高:
-
基础零件:先准备256个基础字符(a-z, A-Z, 标点等)
-
拼装训练:统计哪些字符组合常出现
-
创建新零件:把高频组合变成新"积木块"
# 使用GPT-2的BPE分词器
import tiktoken
tokenizer = tiktoken.get_encoding("gpt2")text = "Akwirw ier" # 模型没见过的词
integers = tokenizer.encode(text) # [33901, 86, 343, 86, 220, 959]# 查看每个部分的含义
for i in integers:print(f"{i} -> {tokenizer.decode([i])}")
# 33901 -> Ak
# 86 -> w
# 343 -> ir
# 86 -> w
# 220 -> (空格)
# 959 -> ier举例:
| 陌生词 | BPE分解 | 计算机理解 |
|---|---|---|
| Akwirw | Ak + w + ir + w | "Ak"是已知前缀,"w"是字母,"ir"是常见组合 |
| someunknownPlace | some + unknown + Place | 拆成三个已知部分 |
滑动窗口 - 文本的"记忆训练法"
语言模型的核心任务:根据上文预测下一个词。比如:“白日依山_",语言模型会根据上文推测出下文可能是“尽”,“水”……等,最终经过对比,选取最可能的词填上,得到“白日依山尽”。
#用滑动窗口创建训练数据
文本:"I had a cat" → 分词后:[40, 367, 2885, 1464]# 滑动窗口(窗口大小=4)
输入(x) 目标(y) 训练内容
[40] → [367] 看到"I"预测"had"
[40, 367] → [2885] 看到"I had"预测"a"
[40,367,2885]→[1464] 看到"I had a"预测"cat"使用举例:
from torch.utils.data import Dataset
from transformers import GPT2Tokenizerclass GPTDatasetV1(Dataset):def __init__(self, txt, max_length=256, stride=128): #stride控制相邻片段间的重叠长度self.tokenizer = GPT2Tokenizer.from_pretrained('gpt2') #使用GPT-2原生分词器self.tokenizer.pad_token = self.tokenizer.eos_token #用结束符代替填充符# 分词得到ID序列,自动添加特殊标记(默认添加<|endoftext|>),但不会添加BOS(开始符)token_ids = self.tokenizer.encode(txt)# 用滑动窗口创建多个训练片段self.examples = []for i in range(0, len(token_ids) - max_length, stride):input_ids = token_ids[i:i + max_length]target_ids = token_ids[i + 1:i + max_length + 1]self.examples.append((input_ids, target_ids))# 假设 token_ids = [1,2,3,4,5], max_length=3, stride=2# 窗口1:i=0 → input=[1,2,3], target=[2,3,4]# 窗口2:i=2 → input=[3,4,5], target=[4,5]def __len__(self):return len(self.examples)def __getitem__(self, idx):input_ids, target_ids = self.examples[idx]return input_ids, target_ids
当i + max_length +1超过数组长度时,target_ids会自动截断(可能产生短序列)
优化方向建议:
- 动态填充:使用
attention_mask区分真实token与填充 - 缓存机制:对大型文本文件进行分块处理
- 长度统计:添加样本长度分布分析功能
- 批处理优化:结合
collate_fn处理变长序列
参数选择指南:
- 短文本(<1k tokens):
max_length=64-128,stride=32-64 - 长文本(>10k tokens):
max_length=512-1024,stride=256-512
# 示例使用方式
text = "Self-explanatory knowledge, human intelligence, personal knowledge..." # 你的长文本数据
dataset = GPTDatasetV1(text)# 获取第一个样本
input_seq, target_seq = dataset[0]词元嵌入
之前的ID只是编号,没有含义。嵌入层给每个词从多个维度作向量表示
# 创建嵌入层(词汇表大小=6,向量维度=3)
embedding = torch.nn.Embedding(6, 3)# 查看权重矩阵
print(embedding.weight)
"""
tensor([[ 0.3374, -0.1778, -0.1690], # ID=0的向量[ 0.9178, 1.5810, 1.3010], # ID=1的向量... # 以此类推], requires_grad=True) # 可学习!
"""嵌入层的本质:
相当于高效版的"独热编码+矩阵乘法":
独热编码:[0,0,0,0,1] → 矩阵乘法 → [0.1, -0.5, 0.8]
嵌入层:直接取矩阵的第5行 → [0.1, -0.5, 0.8]流程总结:原始文本->BPE分词->ID序列->滑动窗口->训练样本->嵌入层->词向量
单词位置编码
为什么需要位置编码?
简单词嵌入的局限:
-
词嵌入只表示词语含义,不包含位置信息
-
模型会把所有词语当作无序集合处理
比如"猫追老鼠"和"老鼠追猫",虽然词语相同但意思完全相反!
位置编码的解决方案
就像给教室座位编号:每个词语有"含义身份证"(词嵌入)->再加个"座位号"(位置编码)
词嵌入层实现
import torch
import torch.nn as nn# 定义词嵌入层
token_embedding = nn.Embedding(num_embeddings=50257, embedding_dim=256)#num_embeddings参数表示嵌入字典的大小
#embedding_dim参数控制输出向量的维度位置嵌入层实现
# 定义位置嵌入层(假设序列最大长度为4)
pos_embedding = nn.Embedding(num_embeddings=4, embedding_dim=256)生成位置编码向量
# 生成位置编号0-3的序列
position_ids = torch.arange(4) # tensor([0, 1, 2, 3])# 获取位置向量(形状为[4, 256])
position_vectors = pos_embedding(position_ids)组合词嵌入与位置嵌入
# 假设输入的token_ids形状为[batch_size, seq_len]
token_vectors = token_embedding(token_ids)
final_embeddings = token_vectors + position_vectors.unsqueeze(0)#广播机制:
position_vectors扩展为(batch_size, seq_len, embedding_dim),与token_vectors维度对齐
假设参数:
batch_size = 4 #4个样本
seq_len = 16 #每个样本有16个tokens
embedding_dim = 512 #词嵌入为512维向量操作流程:
Token IDs形状 : (4, 16)
↓ 经过嵌入层
Token向量形状 : (4, 16, 512)
Position向量原始形状 : (16, 512)
↓ unsqueeze(0)
Position向量调整后 : (1, 16, 512)
↓ 广播相加
Final嵌入形状 : (4, 16, 512)- 位置嵌入通常需要扩展到与词嵌入相同的维度
- 在Transformer架构中,位置嵌入可以是可学习的(如本例)或使用固定公式计算
为什么用加法而不是拼接?
维度一致:保持向量维度不变(256维)
计算高效:加法比拼接更省资源
信息融合:位置和语义自然融合
相关文章:

LLM基础2_语言模型如何文本编码
基于GitHub项目:https://github.com/datawhalechina/llms-from-scratch-cn 字节对编码(BPE) 上一篇博文说到 为什么GPT模型不需要[PAD]和[UNK]? GPT使用更先进的字节对编码(BPE),总能将词语拆分成已知子词 为什么需要BPE? 简…...

理解世界如淦泽,穿透黑幕需老谋
理解世界如淦泽,穿透黑幕需老谋 卡西莫多 2025年06月07日 安徽 极少主动跟别人提及恩师的名字,生怕自己比孙猴子不成器但又比它更能惹事的德行,使得老师跟着被拖累而脸上无光。不过老师没有象菩提祖师训诫孙猴子那样不能说出师傅的名字&a…...

如何确定微服务的粒度与边界
确定微服务的粒度与边界 在完成初步服务拆分之后,架构师往往会遇到另一个难题:该拆到多细?哪些功能可以归并为一个服务,哪些又必须单独部署?这就是“服务粒度与边界”的问题。本节将围绕实际架构经验,介绍…...
第三讲 Linux进程概念
1. 冯诺依曼体系结构 我们买了笔记本电脑, 里面是有很多硬件组成的, 比如硬盘, 显示器, 内存, 主板... 这些硬件不是随便放在一起就行的, 而是按照一定的结构进行组装起来的, 而具体的组装结构, 一般就是冯诺依曼体系结构 1.1. 计算机的一般工作逻辑 我们都知道, 计算机的逻…...

stm32-c8t6实现语音识别(LD3320)
目录 LD3320介绍: 功能引脚 主要特色功能 通信协议 端口信息 开发流程 stm32c8t6代码 LD3320驱动代码: LD3320介绍: 内置单声道mono 16-bit A/D 模数转换内置双声道stereo 16-bit D/A 数模转换内置 20mW 双声道耳机放大器输出内置 5…...

Vue作用域插槽
下面,我们来系统的梳理关于 **Vue 作用域插槽 ** 的基本知识点: 一、作用域插槽核心概念 1.1 什么是作用域插槽? 作用域插槽是 Vue 中一种反向数据流机制,允许子组件将数据传递给父组件中的插槽内容。这种模式解决了传统插槽中父组件无法访问子组件内部状态的限制。 1.2…...

「数据分析 - NumPy 函数与方法全集」【数据分析全栈攻略:爬虫+处理+可视化+报告】
- 第 104 篇 - Date: 2025 - 06 - 05 Author: 郑龙浩/仟墨 NumPy 函数与方法全集 文章目录 NumPy 函数与方法全集1. 数组创建与初始化基础创建序列生成特殊数组 2. 数组操作形状操作合并与分割 3. 数学运算基础运算统计运算 4. 随机数生成基础随机分布函数 5. 文件IO文件读写 …...
爬虫学习记录day1
什么是逆向? 数据加密 参数加密 表单加密扣js改写Python举例子 4.1 元素:被渲染的数据资源 动态数据 静态数据 如果数据是加密的情况则无法直接得到数据 4.2 控制台:输出界面 4.3 源代码页面 4.4 网络:抓包功能,获取浏…...
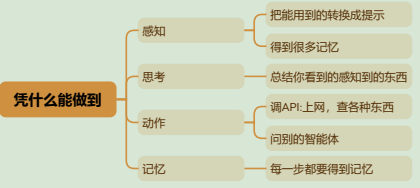
agent基础概念
agent是什么 我个人认为agent并没有一个所谓完美的定义,它是一个比较活的概念,就像是你眼中的一个机器人你希望它做什么事,和我眼中的机器人它解决事情的流程,其实是可以完全不同的,没有必要非得搞一个统一的概念或流程来概况它。但我们依然可以概况几个通用的词来描述它…...

MS8312A 车规 精密、低噪、CMOS、轨到轨输入输出运算放大器,用于传感器、条形扫描器
MS8312A 车规 精密、低噪、CMOS、轨到轨输入输出运算放大器,用于传感器、条形扫描器 简述 MS8312A 是双通道的轨到轨输入输出单电源供电运放。它们具有低的失调电压、低的输入电压电流噪声和宽的信号带宽。 低失调、低噪、低输入偏置电流和宽带宽的特性结合使得 …...

计算机二级Python考试的核心知识点总结
以下是计算机二级Python考试的核心知识点总结,结合高频考点和易错点分类整理: 1. **数据类型与运算** ▷ 不可变类型:int, float, str, tuple(重点区分list与tuple) ▷ 运算符优先级:** > * /…...
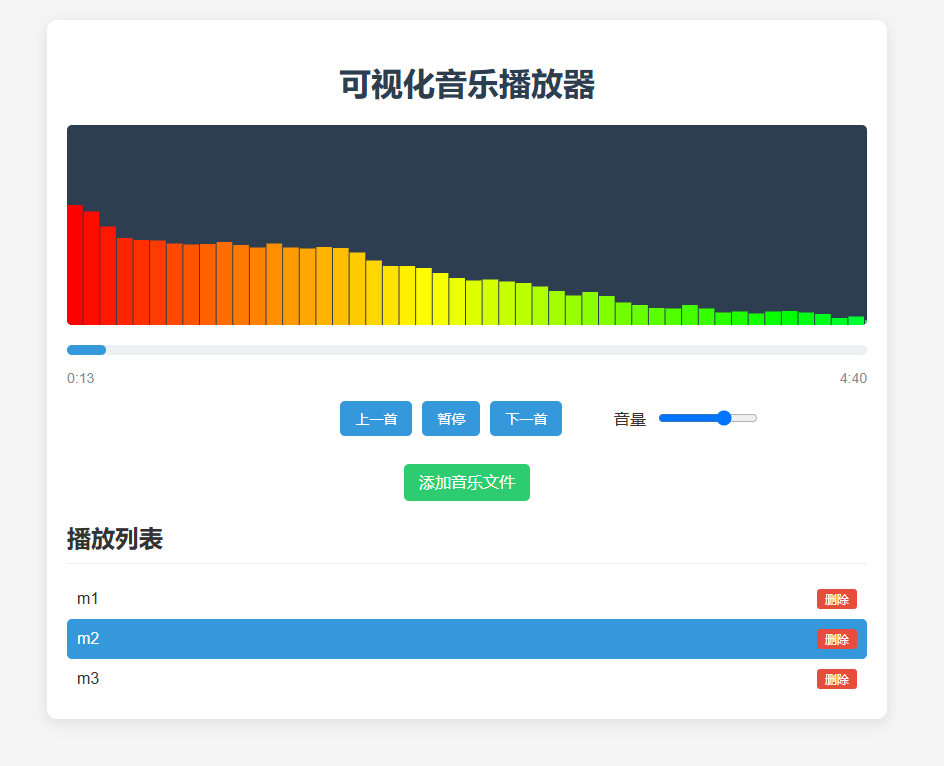
让音乐“看得见”:使用 HTML + JavaScript 实现酷炫的音频可视化播放器
在这个数字时代,音乐不仅是听觉的享受,更可以成为视觉的盛宴!本文用 HTML + JavaScript 实现了一个音频可视化播放器,它不仅能播放本地音乐、控制进度和音量,还能通过 Canvas 绘制炫酷的音频频谱图,让你“听见色彩,看见旋律”。 效果演示 核心功能 本项目主要包含以下…...
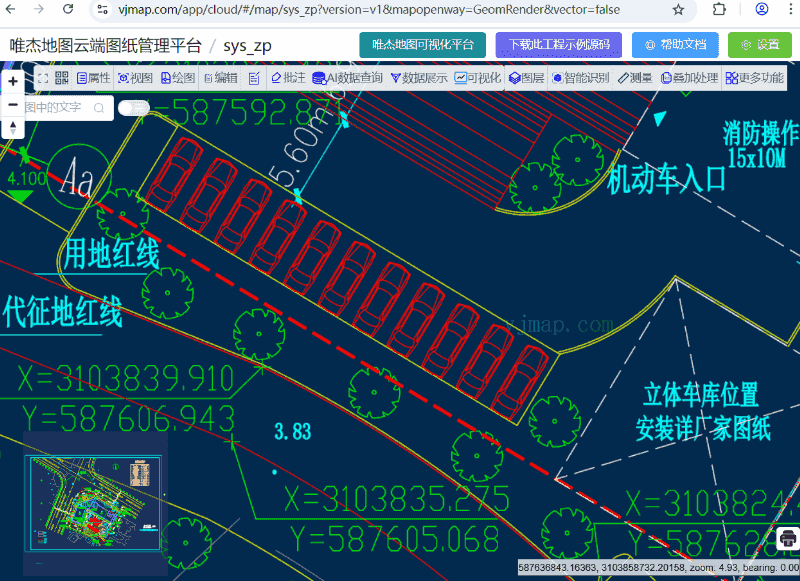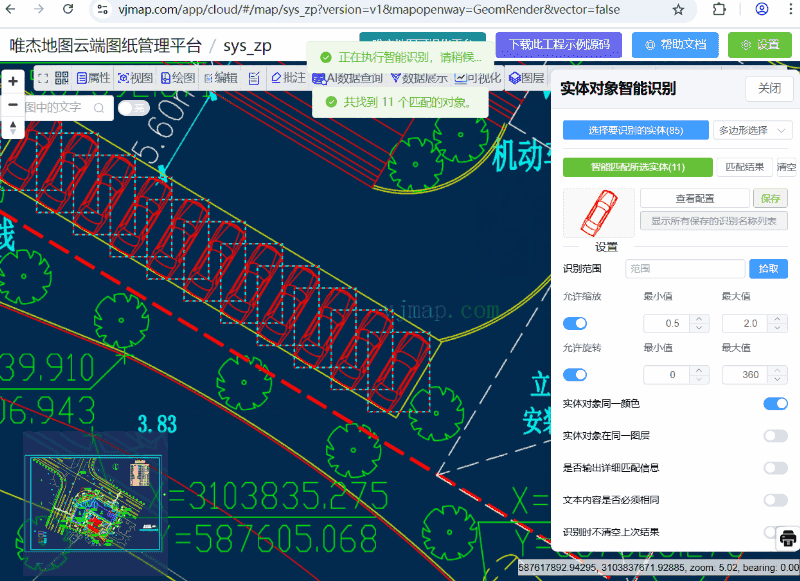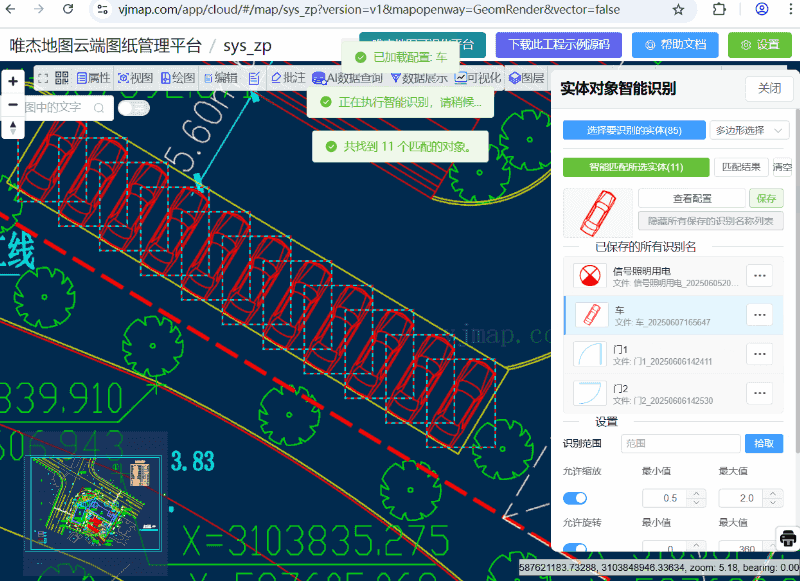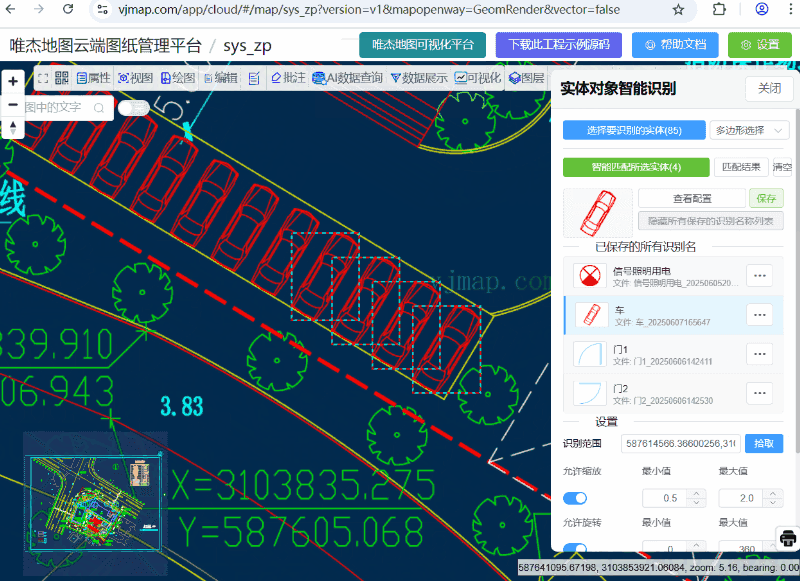
CAD实体对象智能识别
CAD实体对象智能识别 概述 实体对象智能识别能够在CAD图纸中智能识别和匹配相似的实体对象。该系统采用模式匹配算法,支持几何变换(缩放、旋转),并提供了丰富的配置选项和可视化界面。 系统提供两种主要的识别方式:…...
)
MySQL中的部分问题(2)
索引失效 运算或函数影响列的使用 当查询条件中对索引列用了函数或运算,索引会失效。 例:假设有索引:index idx_name (name) select * from users where upper(name) ALICE; -- 索引失效因为upper(name)会对列内容进行函数处理…...

【从前端到后端导入excel文件实现批量导入-笔记模仿芋道源码的《系统管理-用户管理-导入-批量导入》】
批量导入预约数据-笔记 前端场馆列表后端 前端 场馆列表 该列表进入出现的是这样的,这儿是列表操作 <el-table-column label"操作" align"center" width"220px"><template #default"scope"><el-buttonlinktype"…...
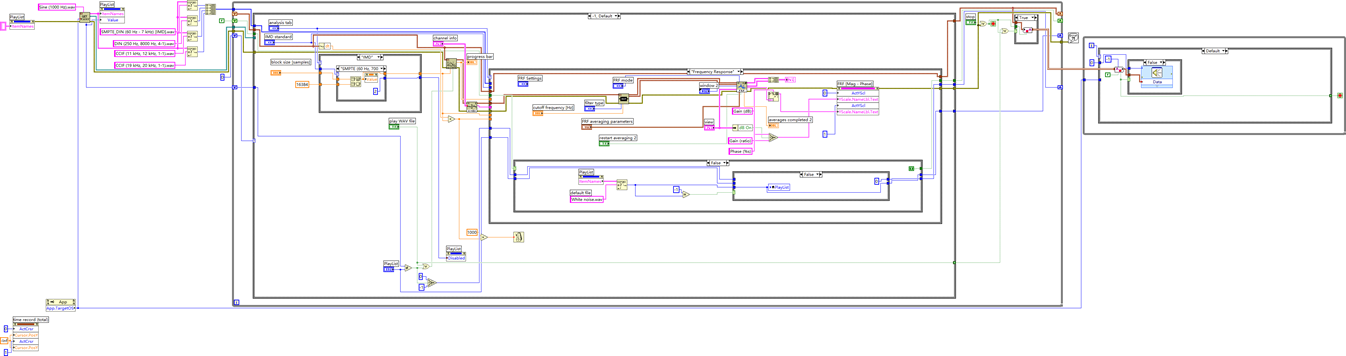
LabVIEW音频测试分析
LabVIEW通过读取指定WAV 文件,实现对音频信号的播放、多维度测量分析功能,为音频设备研发、声学研究及质量检测提供专业工具支持。 主要功能 文件读取与播放:支持持续读取示例数据文件夹内的 WAV 文件,可实时播放音频以监听被测信…...

MySQL 8.0 绿色版安装和配置过程
MySQL作为云计算时代,被广泛使用的一款数据库,他的安装方式有很多种,有yum安装、rpm安装、二进制文件安装,当然也有本文提到的绿色版安装,因绿色版与系统无关,且可快速复制生成,具有较强的优势。…...
RoseMirrorHA 双机热备全解析
在数字化时代,企业核心业务系统一旦瘫痪,每分钟可能造成数万甚至数十万的损失。想象一下,如果银行的交易系统突然中断,或者医院的挂号系统无法访问,会引发怎样的连锁反应?为了守护这些关键业务,…...

day 18进行聚类,进而推断出每个簇的实际含义
浙大疏锦行 对聚类的结果根据具体的特征进行解释,进而推断出每个簇的实际含义 两种思路: 你最开始聚类的时候,就选择了你想最后用来确定簇含义的特征, 最开始用全部特征来聚类,把其余特征作为 x,聚类得到…...

pandas 字符串存储技术演进:从 object 到 PyArrow 的十年历程
文章目录 1. 引言2. 阶段1:原始时代(pandas 1.0前)3. 阶段2:Python-backed StringDtype(pandas 1.0 - 1.3)4. 阶段3:PyArrow初次尝试(pandas 1.3 - 2.1)5. 阶段4…...

LLMs 系列科普文(6)
截止到目前,我们从模型预训练阶段的数据准备讲起,谈到了 Tokenizer、模型的结构、模型的训练,基础模型、预训练阶段、后训练阶段等,这里存在大量的术语或名词,也有一些奇奇怪怪或者说是看起来乱七八糟的内容。这期间跳…...

exp1_code
#include <iostream> using namespace std; // 链栈节点结构 struct StackNode { int data; StackNode* next; StackNode(int val) : data(val), next(nullptr) {} }; // 顺序栈实现 class SeqStack { private: int* data; int top; int capac…...
serv00 ssh登录保活脚本-邮件通知版
适用于自己有服务器情况,ssh定时登录到serv00,并在登录成功后发送邮件通知 msmtp 和 mutt安装 需要安装msmtp 和 mutt这两个邮件客户端并配置,参考如下文章前几步是讲配置这俩客户端的,很简单,不再赘述 用Shell脚本实…...

意识上传伦理前夜:我们是否在创造数字奴隶?
当韩国财阀将“数字永生”标价1亿美元准入权时,联合国预警的“神经种姓制度”正从科幻步入现实。某脑机接口公司用户协议中“上传意识衍生算法归公司所有”的隐藏条款,恰似德里达预言的当代印证:“当意识沦为可交易数据流,主体性便…...

【AIGC】RAGAS评估原理及实践
【AIGC】RAGAS评估原理及实践 (1)准备评估数据集(2)开始评估2.1 加载数据集2.2 评估忠实性2.3 评估答案相关性2.4 上下文精度2.5 上下文召回率2.6 计算上下文实体召回率 RAGas(RAG Assessment)RAG 评估的缩写ÿ…...
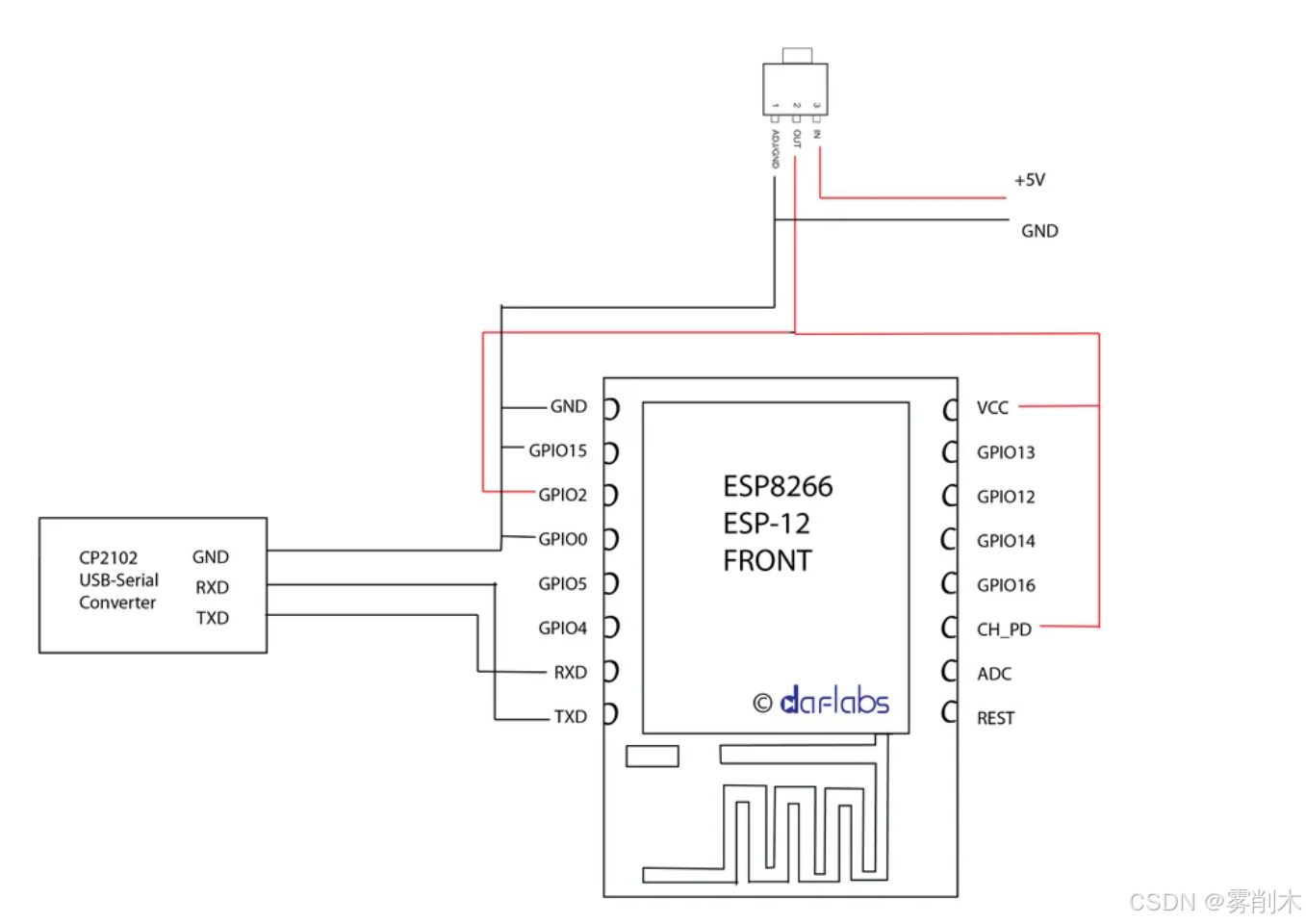
ESP12E/F 参数对比
模式GPIO0GPIO2GPIO15描述正常启动高高低从闪存运行固件闪光模式低高低启用固件刷写 PinNameFunction1RSTReset (Active Low)2ADC (A0)Analog Input (0–1V)3EN (CH_PD)Chip Enable (Pull High for Normal Operation)4GPIO16Wake from Deep Sleep, General Purpose I/O5GPIO14S…...

第二十八章 字符串与数字
第二十八章 字符串与数字 计算机程序完全就是和数据打交道。很多编程问题需要使用字符串和数字这种更小的数据来解决。 参数扩展 第七章,已经接触过参数扩展,但未进行详细说明,大多数参数扩展并不用于命令行,而是出现在脚本文件中。 如果没有什么特殊原因,把参数扩展放…...
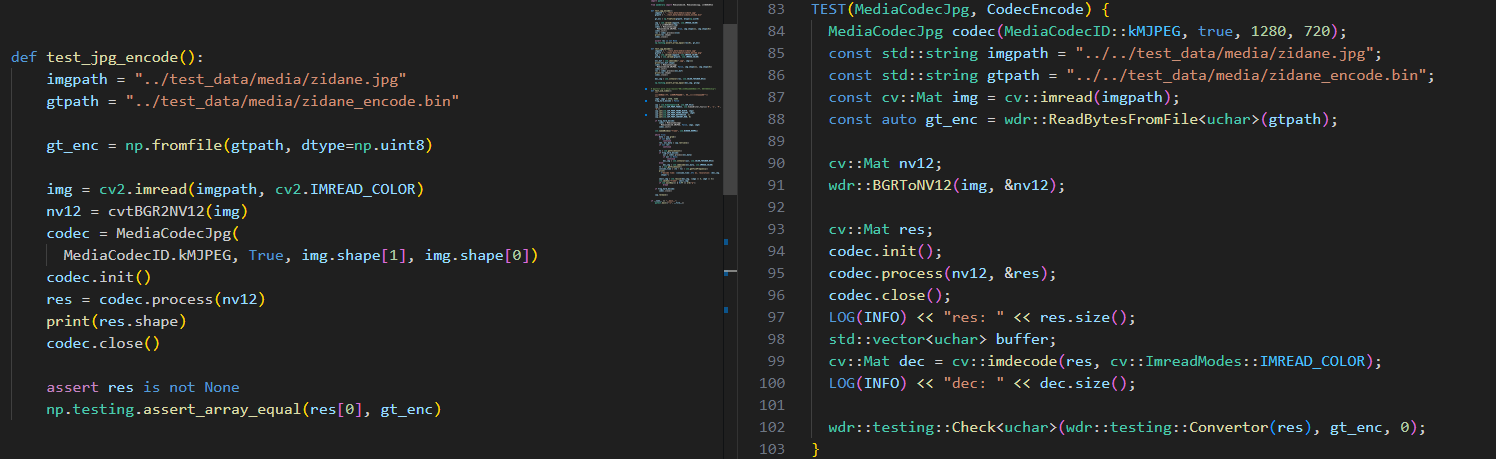
[RDK X5] MJPG编解码开发实战:从官方API到OpenWanderary库的C++/Python实现
业余时间一直在基于RDK X5搞一些小研究,需要基于高分辨率图像检测目标。实际落地时,在图像采集上遇到了个大坑。首先,考虑到可行性,我挑选了一个性价比最高的百元内摄像头,已确定可以在X5上使用,接下来就开…...

java复习 05
我的天啊一天又要过去了,没事的还有时间!!! 不要焦虑不要焦虑,事实证明只要我认真地投入进去一切都还是来得及的,代码多实操多复盘,别叽叽喳喳胡思乱想多多思考,有迷茫前害怕后的功…...

aardio 简单网页自动化
WebView自动化,以前每次重复做网页登录、搜索这些操作时都觉得好麻烦,现在终于能让程序替我干活了,赶紧记录下这个超实用的技能! 一、初次接触WebView WebView自动化就像给程序装了个"网页浏览器",第一步得…...