第三讲 Linux进程概念
1. 冯诺依曼体系结构
我们买了笔记本电脑, 里面是有很多硬件组成的, 比如硬盘, 显示器, 内存, 主板... 这些硬件不是随便放在一起就行的, 而是按照一定的结构进行组装起来的, 而具体的组装结构, 一般就是冯诺依曼体系结构
1.1. 计算机的一般工作逻辑
我们都知道, 计算机的逻辑大概就是计算机拿到数据, (计算机怎么拿到数据的? 可以是我们输入给计算机的, 也可以是计算机自己去硬盘或者网络中读取的...), 经过计算机运算, 再给我们反馈出来(可以通过屏幕显示内容, 也可以通过扬声器, 甚至是震动马达...), 就是拿数据->运算->反馈
所以, 按照这个逻辑, 我们计算机的基本架构应该是下面这样的:

但是, 实际上现在大部分计算机并不是按照上面图示进行架构的, 而是加入了内存的硬件. 加入了内存再加上输入输出CPU等硬件组成计算机. 一般我们把这种计算机组成方式称为冯诺依曼体系结构.
冯诺依曼体系结构是一种计算机的组成方式, 是由冯诺依曼博士(早期计算机创立者之一)命名的, 因为该体系对计算机的发展起到举足轻重的作用, 因而为了纪念它由他的名字命名.
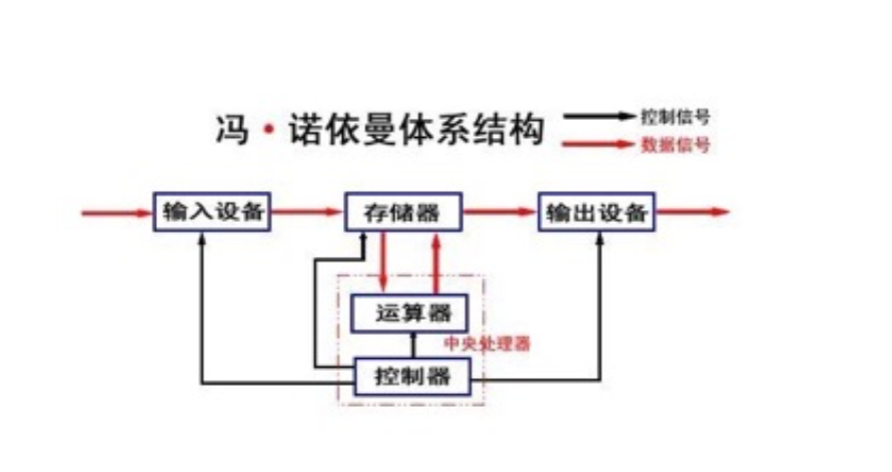
上面图片就是一个简单的冯诺依曼体系结构图. 那我们先来认识一下各个硬件部分.
1.2. 计算机各个硬件部分
- 输入设备: 对输入计算机硬件设备的统称, 一般包括鼠标, 键盘, 开关键, 麦克风, 摄像头, 网卡, 硬盘...
- 输出设备: 对输出计算机硬件设备的统称, 一般包括显示器, 扬声器, 硬盘, 网卡...
- 中央处理器: 简称CPU, Central Processing Unit, 由运算器和控制器组成, 负责对输入到计算机的数据进行处理.
- 存储器: 这是个专业名词的说法, 实际上就是我们平常称呼的内存. 是一个效率中等,存储容量中等的硬件设备, 对于它底层的硬盘来说, 存储器是一个巨大的缓存, 对于它顶层的CPU来说, 内存也是一个效率可观的"硬盘".
1.3. 各个单元之间的链接与传输拷贝
计算机的各个硬件部分不是孤立存在的, 相反, 各个部分必须紧密链接协调工作才能完成计算机从输入到输入一系列工作, 在这期间离开了谁也不行.
计算机各个硬件部分是靠线路进行链接的, 为了更加规范化和效率化, 计算机各个硬件单元是由主板进行链接的.

硬件单元里的数据通过这个主板的东西进行传输, 而数据的传输, 虽然形象理解起来好像水一般从输入设备流到CPU再流到输出设备的, 但实际上数据的传输是靠的拷贝完成的.
几乎所有硬件设备都有存储能力, 那意思是我们键盘上输入的数据是先暂时存储到键盘里, 然后键盘再把数据给到内存, 然后内存再把数据给到CPU, CPU再把数据返回给内存, 最后把这些数据给到显示器.
1.4. 数据在计算机中的流动: 本质是拷贝,拷贝的效率决定了计算机的整机效率
也就是说, 数据再计算机中的流动, 从键盘到内存, 从内存到CPU... 靠的是拷贝, 而非真正像水一般肆意流淌...
数据传输(拷贝)需要时间, 计算也需要时间, 实际上计算机所耗费的时间主要就是这俩而已.
但是因为相比于数据传输, CPU的计算速度太快了, 也就导致了计算机的耗费时间主要集中在数据传输上. 因此加快数据传输的效率是计算机提高效率的关键.
1.5. 存储的一般原则
往往输入设备和输出设备的数据流通速度很慢,而CPU的流通速度快,也就是说计算机的效率取决于输入和输出设备的流通速度(遵循木桶原理)。为了提高计算机效率,采用了冯诺依曼结构,在中间加上了内存的概念。
内存的加入, 使得原先输入-CPU-输出的模式效率显著提高, 之前效率比较低的原因在于输入设备的数据传输能力比较差, 而CPU的数据传输能力很强, 因此大部分时间都是CPU在等着输入设备给到CPU数据, 但是通过加入内存, 融合预先缓存的技术, 可以让CPU不再像以前一样等太久...
如下图,越往上数据传输越快,但是造价越高。
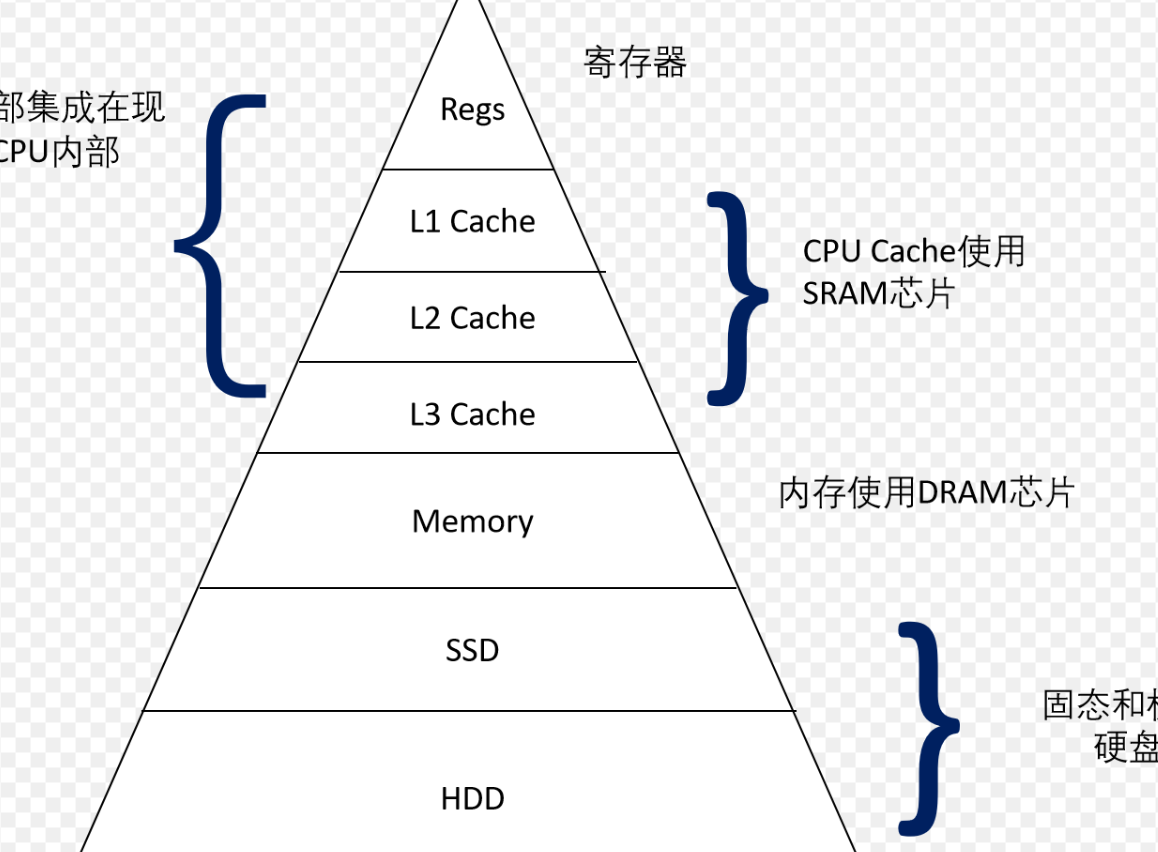
我们简单总结一下上面的内容:
在数据层面, 冯诺依曼结构体系使得CPU不直接与输入和输出设备关联, 而是与内存进行关联, 也就是说系统要先把数据拷贝到内存中,再经过CPU计算返回内存, 再经过内存给到输出设备...
1.6. 冯诺依曼体系结构的历史意义
冯诺依曼体系结构的意义:在保证计算机造价比较低的情况下,大大提高电脑性能。
这也就解释了为什么电脑设计为什么是冯诺依曼体系结构而不是下图:
程序为什么运行都要先加载到内存中呢?
因为冯诺依曼体系结构,CPU拿数据只从内存中读取,而程序是在磁盘中存放的,因而要运行程序,先要把对应的程序及其数据加载到内存当中进行读取和计算。
实际上, 即使是使用下面这个体系组装计算机也没有什么问题, 只要把存储设备都换成寄存器级别的存储单元就好了, 而且效率比我们现在电脑的效率会更好, 只不过造价会很高, 也会导致没几个人买得起电脑.

总结一下, 冯诺依曼是一种计算机体系, 这种体系并不是让计算机效率最大化, 而是一种价格与效率的折中方案, 保证了在比较低的价格仍然让计算机获得比较高的效率的这么一种方案, 也正因为如此, 计算机才的得以迅速普及发展, 使得人类进入了信息时代...
1.7. 代码需要先加载到内存中才能运行???
问题: 在学习C语言的时候, 我们就曾留下过一个疑问, 就是为什么代码需要先加载到内存中才能运行???
一句话: 冯诺依曼体系规定这么做, 可以不这么做吗? 可以, 两条路, 接受效率小一个量级的电脑, 或者接收昂贵的价格.
下面我们进行详细理解, 我们写的代码是什么? 是数据! 数据写完了要放在硬盘中保存吧, 因为你放在内存里一断电就没了, 而且容量比较小. 既然代码在硬盘里, 想要把代码跑起来, 按照冯诺依曼结构体系来说, 就得先把代码这个数据加载到内存, 然后CPU进行执行, CPU执行的时候我们就说代码就"跑"起来了呗.
1.8. 尝试在硬件的角度理解数据流动
下面忽略具体细节, 忽略网络部分, 做了理想化处理.

对于这个场景, 首先我打开qq的过程就是从硬盘上把qq的代码读取过来, 加载到内存当中, 在内存中的qq通过cpu的参与计算来运行. 对于我和朋友的"qq"加载过程均是如此.
之后, 我从键盘上输入信息, 该数据拷贝到内存当中, 经cpu参与, 加载到qq中, 之后cpu经过加密把加密后的信息返回给内存, 该数据再从内存中把该数据给到网卡, 网卡经过网络传输给到对方的网卡, 对方的网卡内的数据流动到内存当中, 再经过对方cpu的解密, 返回到内存中, 输出到显示屏上, 对方就看到了你发过去的信息.
2. 操作系统
2.1. 概念
我们都知道, 电脑在使用之前必须开机, 开机这个过程就是去把操作系统这个软件加载到内存当中..., 基本就是计算机加载的第一个软件...
操作系统是一款软件,用来对软硬件资源管理的软件。具体的管理例子: 下载一款软件, 卸载软件...接U盘..., 启动各种各样的软件加载到内存具体加载到哪...
广义上的操作系统:外壳周边程序 + 操作系统内核
狭义上的操作系统:操作系统内核
理解:
操作系统内核的任务一般是合理调度协调各种资源的分配, 文件的,硬件的软件的分配... 而外壳周边程序比较典型的就是图形化界面, 还有windows自带的各种软件...其实是为用户提供使用操作系统的方式...
对于广义和狭义的理解, 举个例子来说, 我们常用的安卓手机, 底层的操作系统内核就是对硬件包括摄像头屏幕扬声器各种处理为用户提供服务, 还给软件分配各种资源, 做一些协调管理...这个东西我们称之为操作系统内核, 安卓手机的操作系统内核是Linux内核, 不过各种手机厂商, 比如小米, OPPO, 荣耀...再给他外面套了一个可视化界面的壳子, 方便人机交互, 提升对用户的服务质量, 小米套了壳子之后就叫做小米系统, 荣耀套了荣耀的壳子之后叫做荣耀系统...即使是华为自己开发的鸿蒙操作系统底层也是大量借鉴了Linux操作系统内核的...然后外面再套个自己的壳子, 叫做华为系统(鸿蒙)...
2.2. 操作系统结构层级(承上启下)
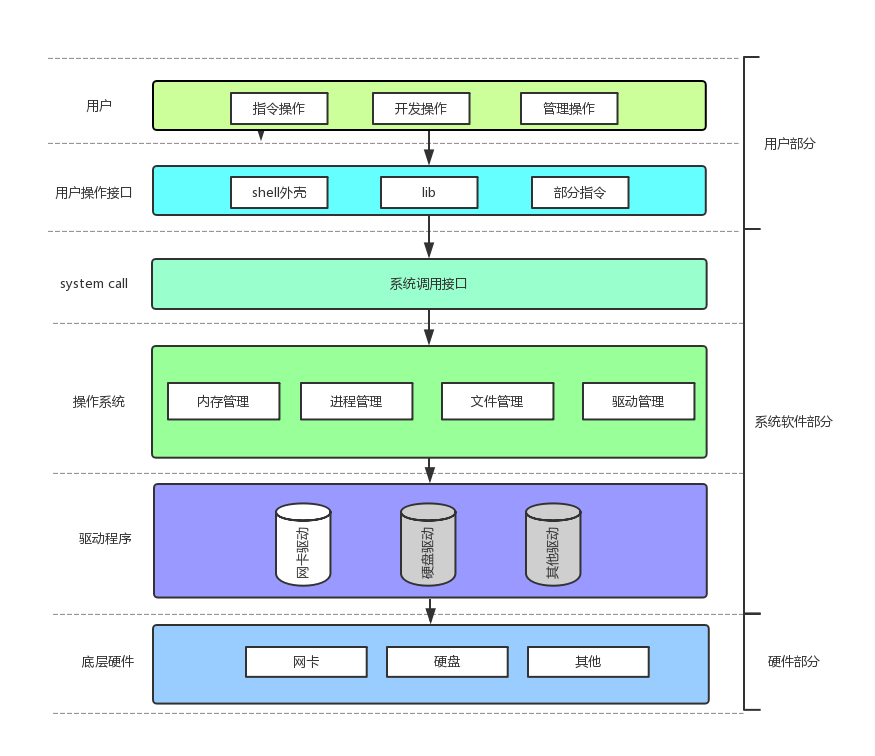
我们先一点点看上面这个图, 我们看到操作系统在整个图的中间区域, 操作系统上面是偏向于用户层面的东西, 下层是更偏向于硬件的一些东西. 先来简单写一下操作系统的四大功能.
操作系统向上更好的服务用户, 对下去对软硬件合理协调管理.
操作系统: 一般有四个核心功能(其他功能也有很多, 这里不一一列举), 即: 内存管理, 进程管理, 文件管理以及驱动管理.
操作系统对下的驱动管理, 协调硬件设备,
操作系统对接硬件以及相关问题: 驱动管理, 字面意思就是对计算机驱动层进行管理的, 前面说过计算机底层的硬件包括鼠标显示屏CPU等等一系列硬件是由冯诺依曼体系结构进行架构的, 然而想要在软件层面上使用这些硬件却不是一件容易的事情, 因为每一种硬件的差别都很大, 鼠标有鼠标的使用逻辑, 显示屏有显示屏的显示规则... 而且往往随着硬件设备的升级对应对硬件使用的操作系统也要升级(因为要对接), 还有个很大的问题: 就是硬件的改动直接影响到操作系统, 也就意味着硬件改变, 操作系统也有改变, 显然这是非常影响各种发展的.
操作系统与硬件的对接解决: 为了解决这一问题, 操作系统的下一层设立驱动层, 驱动层也是软件, 是针对于各种不同的硬件的, 每个硬件都有自己专属的通道对接到操作系统, 这样带来的好处无非就是硬件的改变不用修改操作系统, 只需要修改硬件对应的驱动即可. 因此每种硬件的生产厂商都会提供自己硬件的驱动程序来适配操作系统.
驱动程序存在的意义:应对不同的硬件性质而设计出来的针对不同硬件性质而存在的方便操作系统与硬件进行交互的软件。
同时, 操作系统承担了对上服务好用户的工作.
说完了操作系统的驱动管理, 操作系统之上还有系统调用接口, 图形化界面(shell), 设立这些就是为了更好的满足客户需求, 更方便快捷的与用户交互.
为什么要有操作系统?
计算机是一个工具, 是服务于人的工具, 操作系统正是对下充当着协调各种软件资源硬件资源进行工作, 对上提供图形化界面, shell指令方便用户使用, 降低用户使用的成本这样的存在, 从而为用户提供高效, 稳定, 安全的计算机使用环境.
总之, 操作系统承担了承上启下的作用, 面向人和底层的硬件, 以人为本, 高效, 稳定, 安全的服务用户.
我们进一步去理解, 操作系统怎么对下面的硬件进行"管理"呢?
操作系统对硬件的管理参照了现实中管理者对被关联者的管理方式, 只需要对下进行决策即可(大部分情况如此), 具体一点说, 校长不需要直接与学生接触, 只需要拿到校长关心的学生相关学习数据只需要操作这些数据即可, 即"先描述, 再组织". 描述只需要把我关心的属性信息拿到即可, 组织即是通过数据结构这种方式组织起来即可(方便操作).
同样的, 操作系统对硬件的管理也是同样的道理, 操作系统通过建立一系列的数据, 表示各个硬件的属性, 然后操作系统再通过数据结构组织起来, 这样操作系统只需要操作这些数据即可. 操作完数据之后再通过驱动层对硬件做修改即可...
然后, 操作系统上面的层, system call的意义是什么?
很简单, 操作系统需要对上提供服务, 面向用户, 为了操作系统内部安全稳定高效的考量, 不允许用户直接访问操作系统的内部核心数据, 但又得给用户提供相应的服务, 因此操作系统之上又由操作系统提供了一系列相关接口给用户使用, 这样下来既可以给用户提供服务, 也保证了操作系统内部的安全稳定和高效性.
system call层再之上的用户操作接口层是什么的?
system call说白了是操作系统提供给一些大概了解电脑系统的人(比如系统工程师)使用的, 这样仅仅面向专业人士, 不能向大众提供服务, 为了简化操作系统的使用, 电脑设计者再往上封装了一层, 提供了shell外壳, lib库等, 给那些不是很了解电脑的人来提供服务.
其中, 在Linux中, ldd命令可以查看一个程序用到了哪些lib库
开发的跨平台性?
实际上, 我们现在作为学生开发者还是处于使用lib, shell指令的层级, 我们的CPP/C就为我们提供了自洽的语法, lib标准库, 编译器. 我们日常所进行的开发工作, 都是用的lib库调用. 不同的操作系统, 就会提供不同的system call, 如果开发直接使用system call, 就会因为操作系统的不同而导致代码不具有跨平台性, 因此我们会使用CPP/C等可跨平台的代码进行开发. 这其实就回答了是否具备跨平台性的问题.
图形化界面
程序员作为电脑用户, 利用一些高级语言开发出的图形化界面还在上图的用户上面, 进一步封装, 满足日常发微信, 打游戏等日常需求... 图中的用户特指程序员群体.
系统调用和库函数概念
在开发角度,操作系统对外会表现为一个整体,但是会暴露自己的部分接口,供上层开发使用,这部分由操作系统提供的接口,叫做系统调用。系统调用在使用上,功能比较基础,对用户的要求相对也比较高,所以,有心的开发者可以对部分系统调用进行适度封装,从而形成库,有了库,就很有利于更上层用户或者开发者进行二次开发。
3. 进程
3.1. 进程的概念
课本概念:程序的一个执行实例,正在执行的程序等
内核观点:担当分配系统资源(CPU时间,内存)的实体。
实际上,
进程 = PCB + 对应程序的代码和数据
操作系统为了管理进程, 描述进程所以引入了一个PCB的概念.
3.1.1. 描述进程- PCB
3.1.1.1. 操作系统对进程的描述
我们知道, 管理都需要先描述再进行组织, 我们操作系统也需要对进程进行管理. 首先操作系统就是一个软件, 再开机的时候, 操作系统首先被拷贝进内存, 之后, 每当我们开始一个新的进程, 操作系统都会把对应的代码程序加载进内存, 之后在操作系统中创建一个PCB对这个程序的代码程序进行管理.
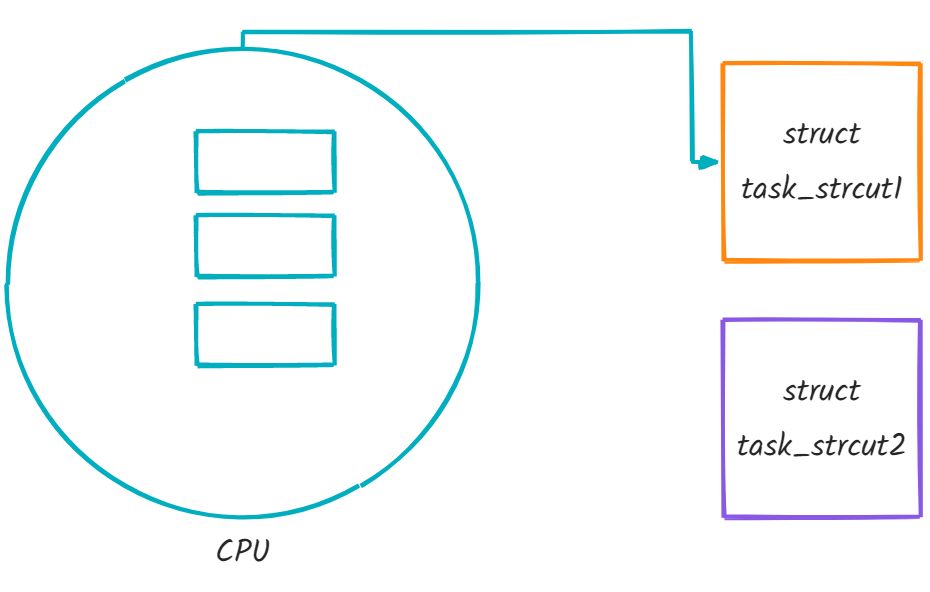
也就是说, 操作系统不是对进程进行直接管理, 而是拿着进程的信息进行管理. 换言之, 调度进程, 就是让进程控制块task_struct排队.
PCB的意义:操作系统对程序的管理,操作系统先对该进程描述为PCB结构体(Linux下的PCB为task_struct),然后管理这个结构体就行了。
3.1.1.2. task_struct-PCB的一种
其中, Linux下的PCB叫做task_struct.
3.1.1.3. 进程的动态运行
进程的动态运行:我们操作系统通过数据结构将PCB组织起来,这样方便对不同的PCB进行管理。
进程task_struct将来在操作系统的不同的队列中, 进程就可以访问不同区域的资源了.
3.1.1.4. task_ struct内容分类
- 标示符: 描述本进程的唯一标示符,用来区别其他进程。
- 状态: 任务状态,退出代码,退出信号等。
- 优先级: 相对于其他进程的优先级。
- 程序计数器: 程序中即将被执行的下一条指令的地址。
- 内存指针: 包括程序代码和进程相关数据的指针,还有和其他进程共享的内存块的指针
- 上下文数据: 进程执行时处理器的寄存器中的数据[休学例子,要加图CPU,寄存器]。
- I/O状态信息: 包括显示的I/O请求,分配给进程的I/O设备和被进程使用的文件列表。
- 记账信息: 可能包括处理器时间总和,使用的时钟数总和,时间限制,记账号等。
- 其他信息
既然上面说到了task_struct属性内容, 下面我们来具体的了解一下关于进程属性的相关知识.
3.2. 进程的启动
./xxx,本质就是让系统创建进程并运行。- 每个进程都有自己的唯一标识符:PID
- 可以用函数
getpid()进行查看 ctrl + c / kill -9 pid用来杀掉进程
3.2.1. ./xxx是把程序加载到内存并生成进程
./xxx,本质就是让系统创建进程并运行。
3.2.2. PID
task_strcut有哪些属性呢? 我们来看一下...


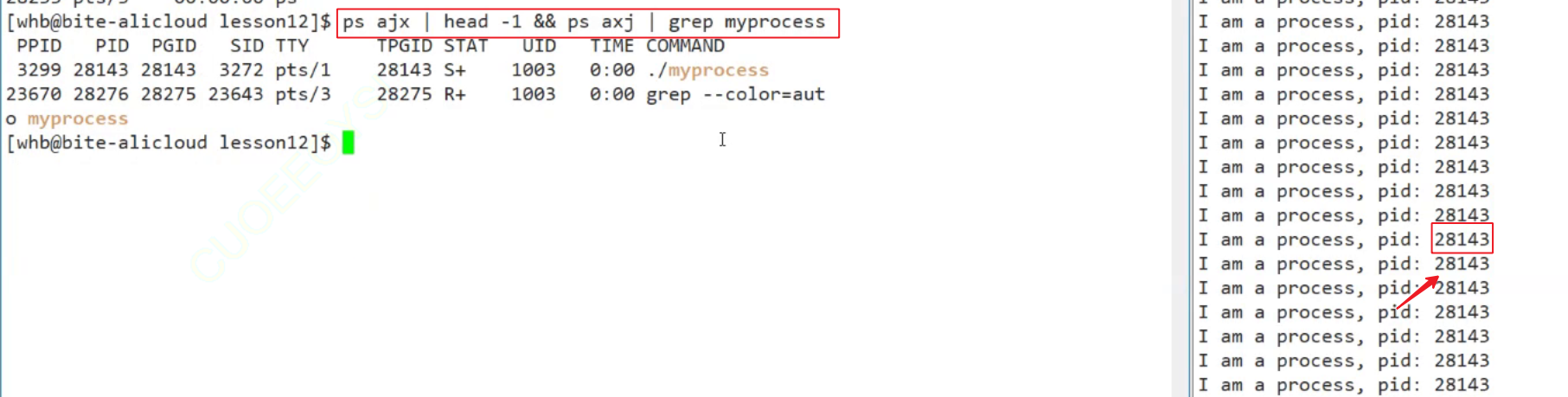
上面这段指令的意思是, 查找所有进程并且过滤出关键字包含"myprocess"的进程
查到有两个进程, 一个是myprocess本身这个进程, 另一个是启动的grep进程, 因为其中包含了myprocess过滤关键字而被查到了.
打印标头并打印相关的属性, 可以用&&进行指令集联

上面这段指令的意思是, 前半部分ps ajx | head -1就是查找指令打印标头, ps axj | grep myprocess意思是查找指令并过滤出包含关键字"myprocess"的进程, 这样可以实现一个把标头和属性信息打印在一起的效果.
3.2.3. PID, 怎么用代码的方式获取?
前面我们知道, 可以用ps axj | head -1 && ps axj | grep myprocess来查看进程的相关信息, 其中包含pid信息.
但如何在代码层面查看pid, 即不使用指令查看一个进程的pid???
我们不能直接去查看操作系统内的信息, 我们必须得用操作系统给我们提供的系统调用接口才可以, 操作系统给我们提供了一个叫getpid()的接口来查看自己进程的pid
#include <stdio.h>
#include <sys/types.h>
#include <unistd.h>
int main()
{
int ret = fork();
printf("hello proc : %d!, ret: %d\n", getpid(), ret);
sleep(1);
return 0;
}
3.2.4. 杀掉进程
ctrl + c 是在用户层面终止掉程序.
kill -9 pid 就是在操作系统层面杀掉对应的进程.
3.3. 进程的创建
3.3.1. 进程创建的代码方式
用fork()函数.
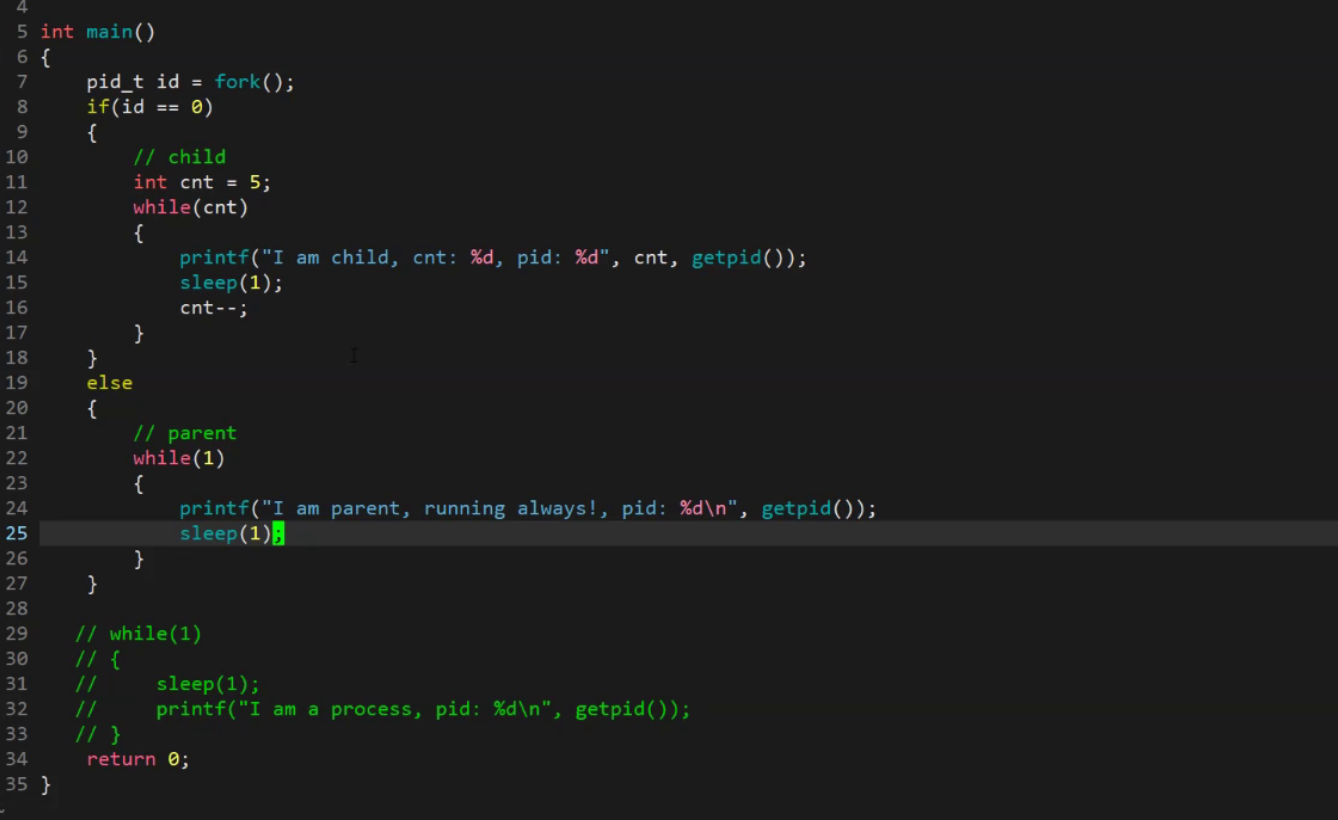
创建上面代码并运行之后, 我们可以发现有两个进程, 一个是父进程, 另一个是子进程.
而创建一个进程, 就是操作系统里多一个struct task_struct以及自己对应的代码和数据. 对于父进程, 他的代码和数据就是我们写的代码和数据, 而对于子进程, 默认情况下如果自己没有代码会继承父进程代码创建子进程以后的部分.
3.3.2. 我们为什么要创建子进程? 如何让子进程执行跟父进程不一样的代码?
我们创建子进程, 其实大部分情况都是为了执行跟父进程不一样的代码,从而提高效率的. 但是上面我们知道fork()默认创建出来的子进程会继承父进程的代码并执行, 这就没有意义了.
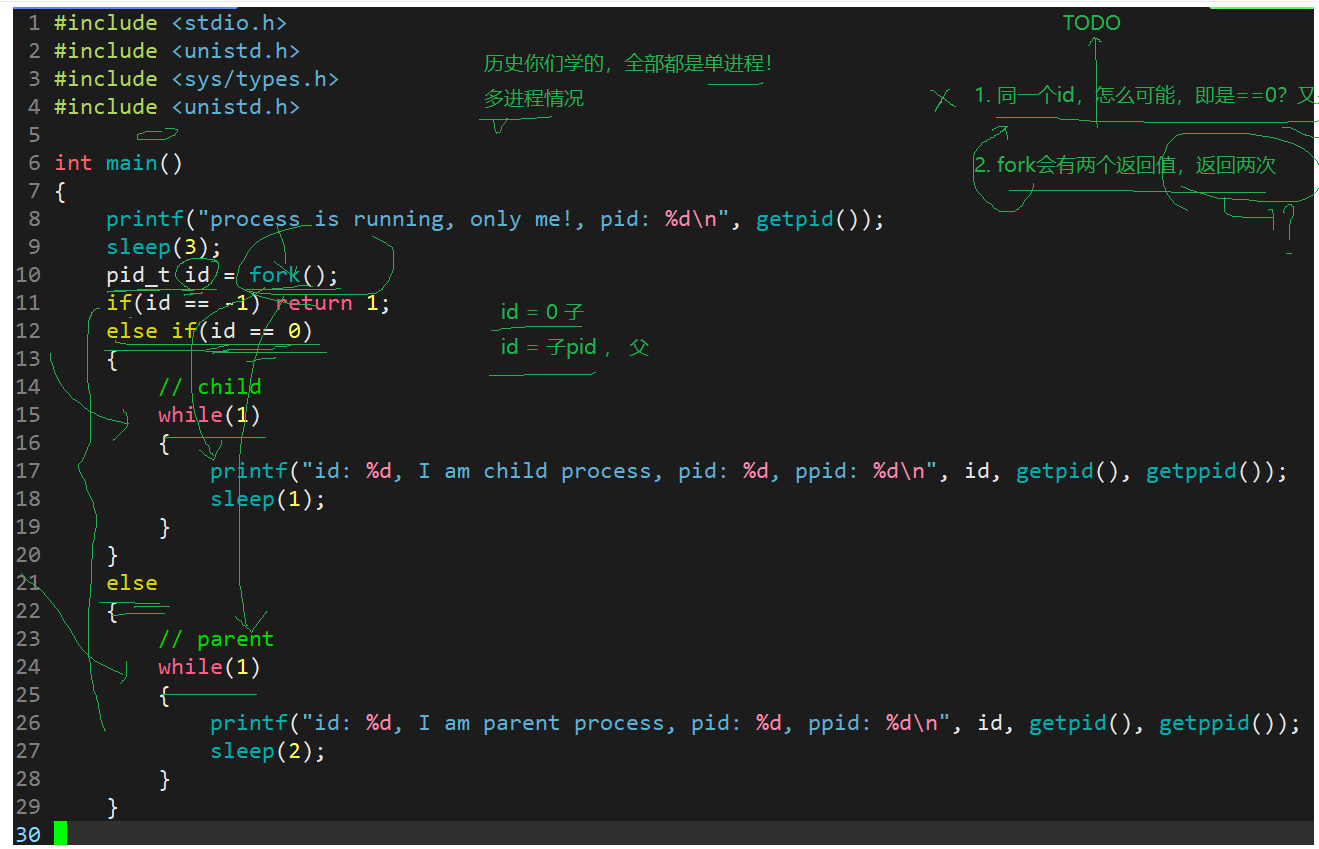
对于上面这个代码, 我们会有两个疑问:
- fork的返回值会返回两次, 如果创建成功, 返回给父进程的是子进程pid, 返回给子进程的是0; 如果失败就给父进程返回-1. 为什么会返回两次啊?
- 对于同一个id, 怎么可能同时做到id == 0,并且id > 0???(比较复杂) 说白了这个地方就是一个写时拷贝, 具体可以参见下面进程地址空间里面的写时拷贝来进行理解.
理解: 对于第一个疑问, 为啥fork()可以返回两次的问题, 其实很简单, fork也是一个函数, 所以大概是下面这种形式:
pid_t fork(void)
{//...return id;
}我们知道, fork创建出子进程之后代码共享, 所以在return之前其实子进程就已经做好了, 所以说对于return id;这个语句其实对于父子进程是共享的, 自然也就会返回两次了.
对于第二个疑问, 同一个变量为啥既是等于0又是大于0呢? 很简单, 对于每一个进程 = task_struct + 代码和数据, 对于代码是只读的, 因此可以共享, 但是数据应该是相互独立的, 再加上虚拟地址空间和父子写时拷贝技术的实现, 也就知道虽然他们两个id的名字是一样的, 但实际上里面的内容并不相同.
我们可以写下面代码一下创建多个子进程程序:
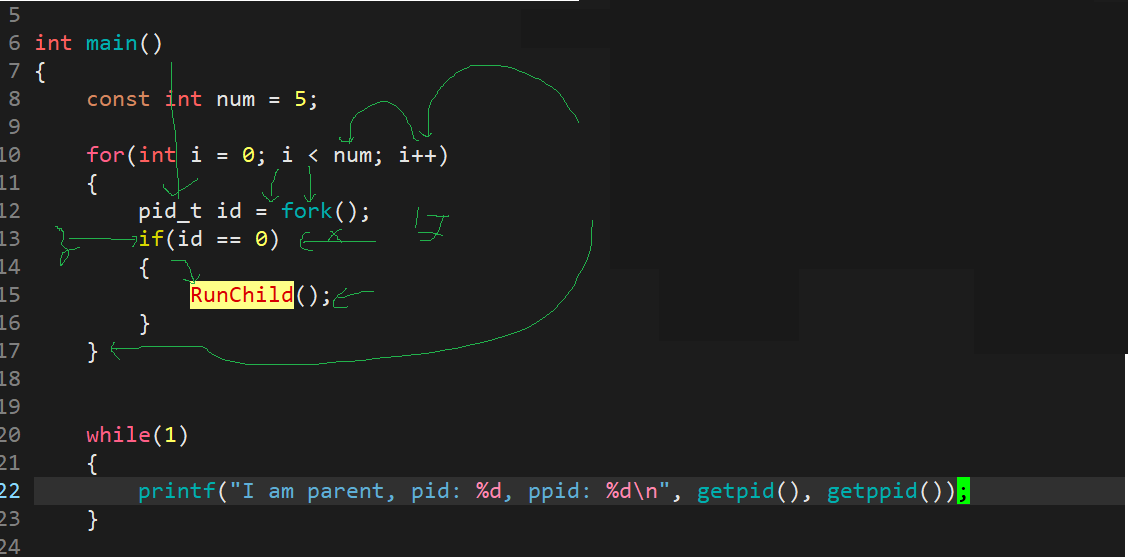
3.4. 进程在文件中查看
进程的信息可以通过/proc 系统文件夹查看

其中, 每个进程PCB下面记录下面信息.

cwd, 记录的是当前可执行文件的前缀路径, 即current work dir
exe, 记录的是当前进程对应的可执行文件的路径.
为了验证这一点, 我们下面来进行实验测试. 下面是我自己写的一个测试代码:
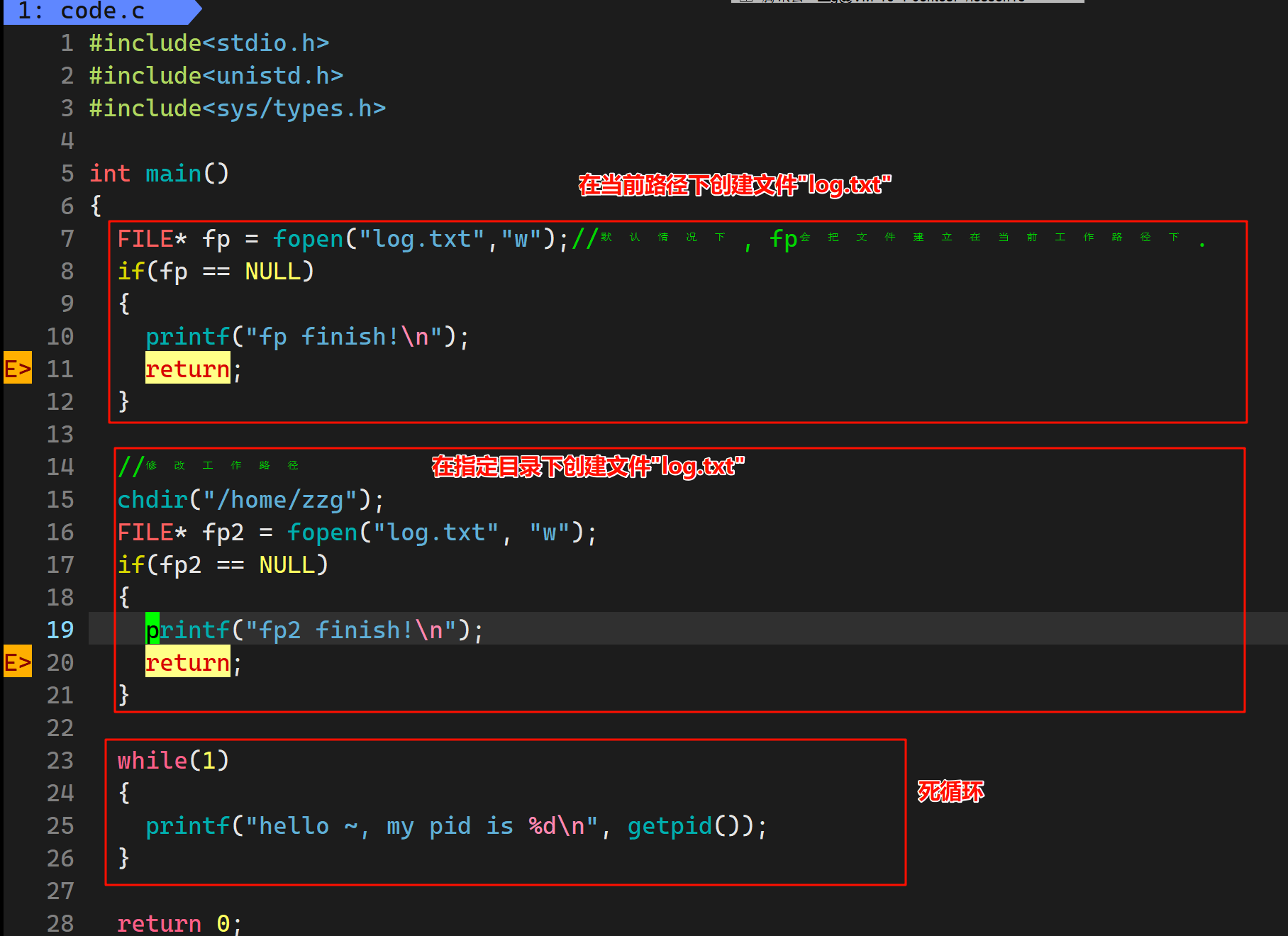
我们fopen("log.txt", "w")系统会默认给我们补充上具体工作路径, 即"log.txt"会被拼接为"/home/zzg/lesson15/log.txt"
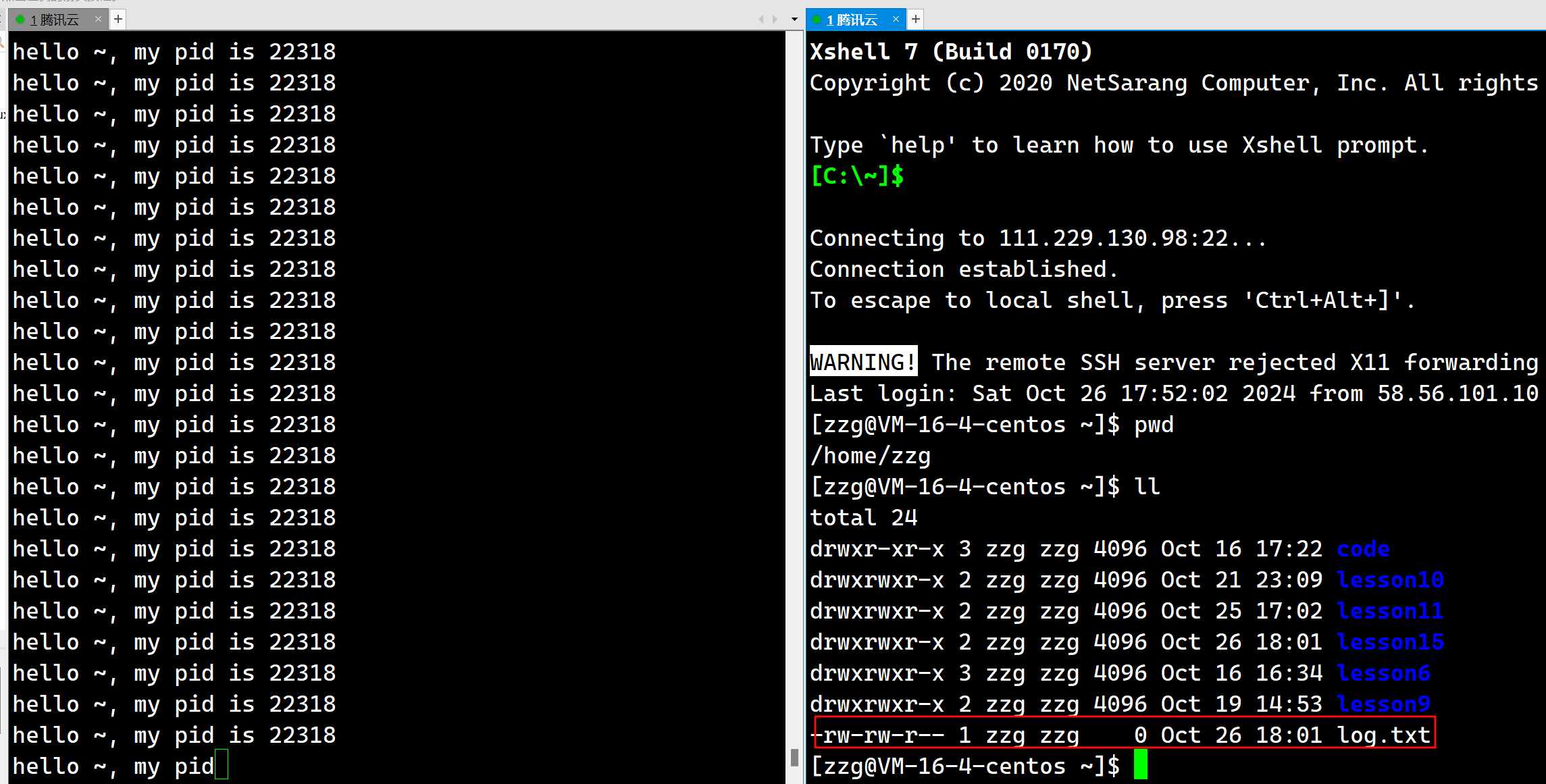
我们发现已经给我们建立出来了文件log.txt, 之后我们再来看一下进程的具体信息. 上面我们说过查看某个进程需要到指定目录/proc中查看, 对于上面这个进程, 就是/proc/22318, 我们看一下:
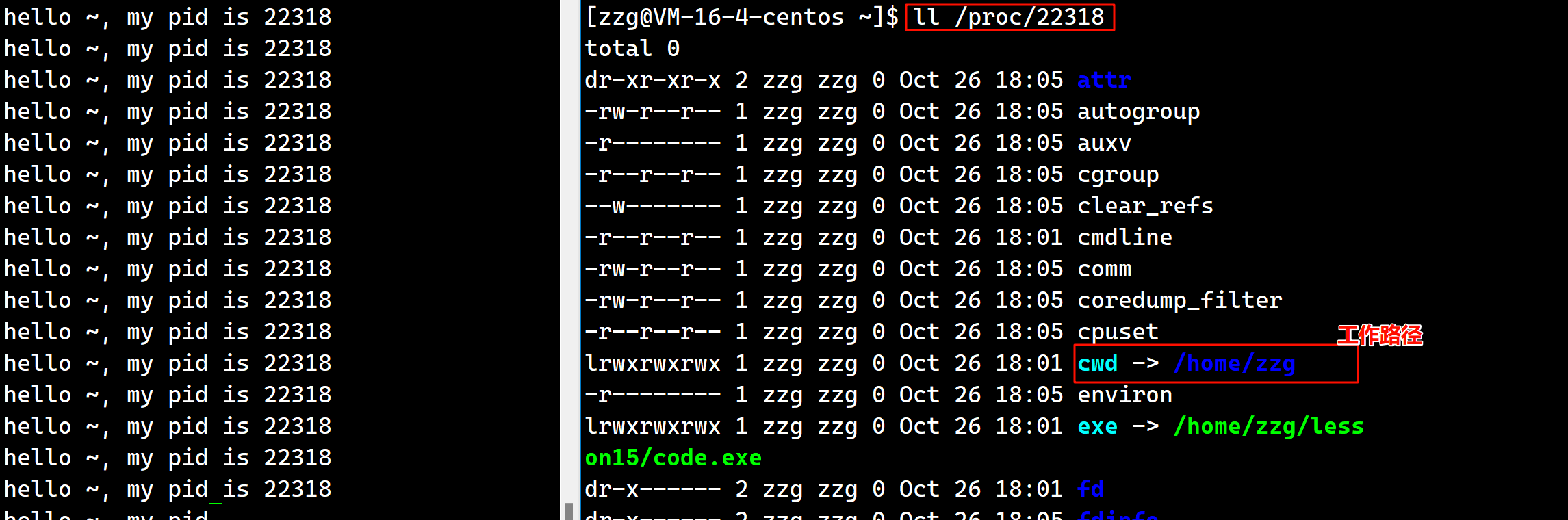
cwd就是一个当前工作路径的前缀, 而exe记录则是当前工作的全部.
进程状态
实际上进程状态就是进程中的一个变量表示而已, 比如我们有一个进程, 我们的操作系统会抽象出一个结构体来表示进程,
#define RUN 1
#define SLEEP 2
#define STOP 3struct struct_task proc1
{//...int status; // 表示进程状态
}为了更好的描述状态, linux规定状态如下:
/*
* The task state array is a strange "bitmap" of
* reasons to sleep. Thus "running" is zero, and
* you can test for combinations of others with
* simple bit tests.
*/
static const char * const task_state_array[] = {
"R (running)", /* 0 */
"S (sleeping)", /* 1 */
"D (disk sleep)", /* 2 */
"T (stopped)", /* 4 */
"t (tracing stop)", /* 8 */
"X (dead)", /* 16 */
"Z (zombie)", /* 32 */
};为了验证相关的状态, 我们写下下面的代码来进行验证:
S(sleeping) 状态: 程序休眠. 什么是休眠状态呢?
从下面例子中我们可以知道, 休眠就是进程在等待资源就绪. 可中断睡眠: 可以用命令终止进程, ctrl + c
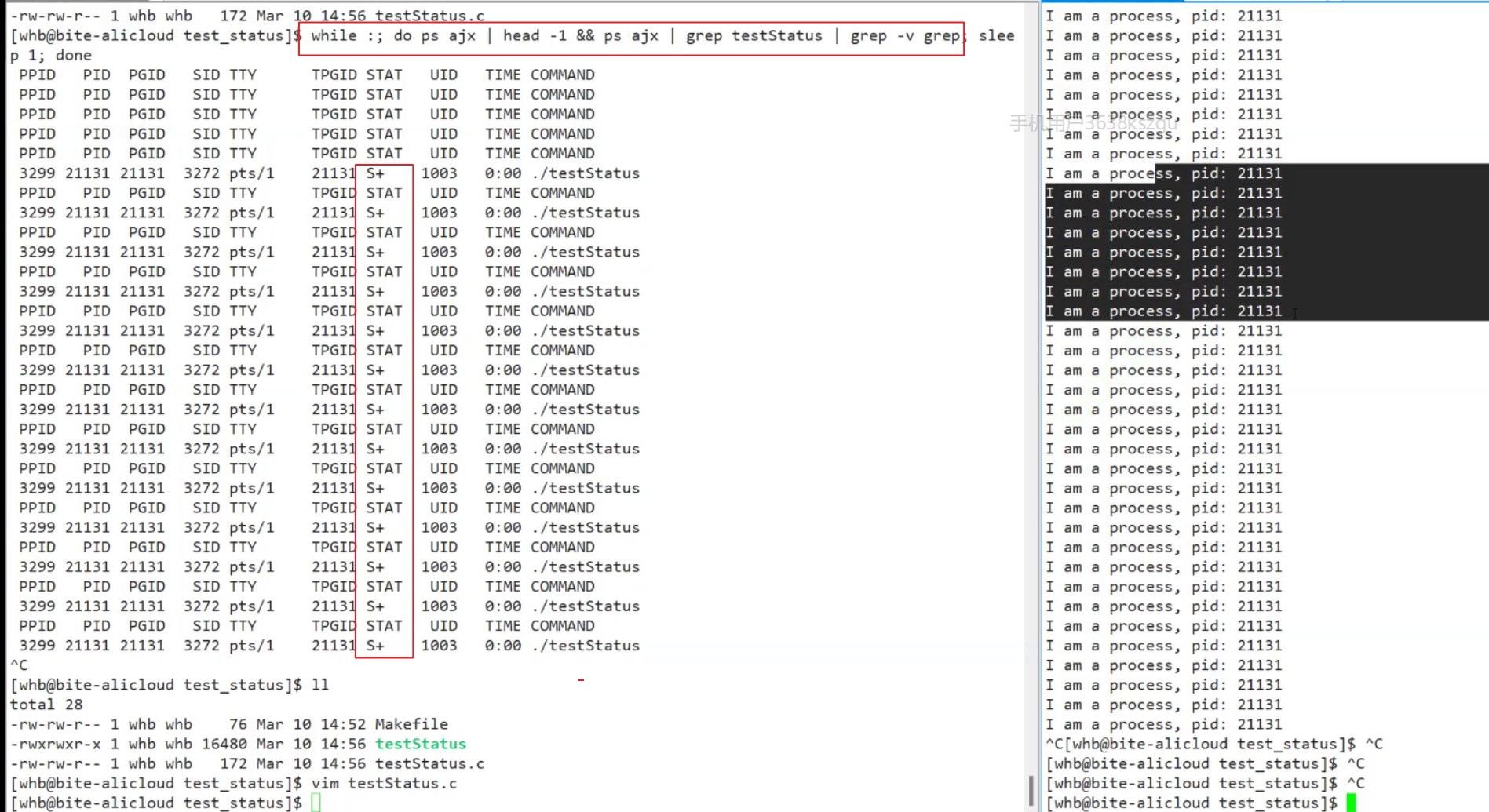
在启动程序时候, 后面带取地址&号, 表示后台运行, 其表示符号为S, 而不是上面的S+. +表示是不是在后台运行.
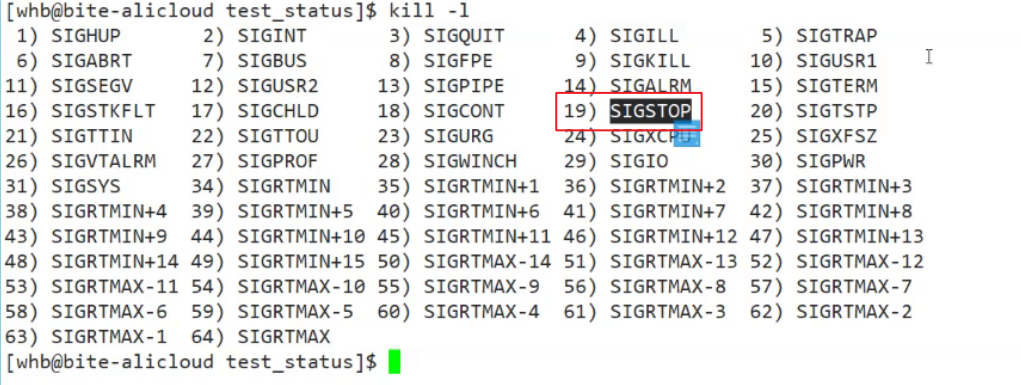
程序的停止与唤醒: 下面是关于kill的信号. -19可以让程序进入停止状态. -18可以重新唤醒进程.
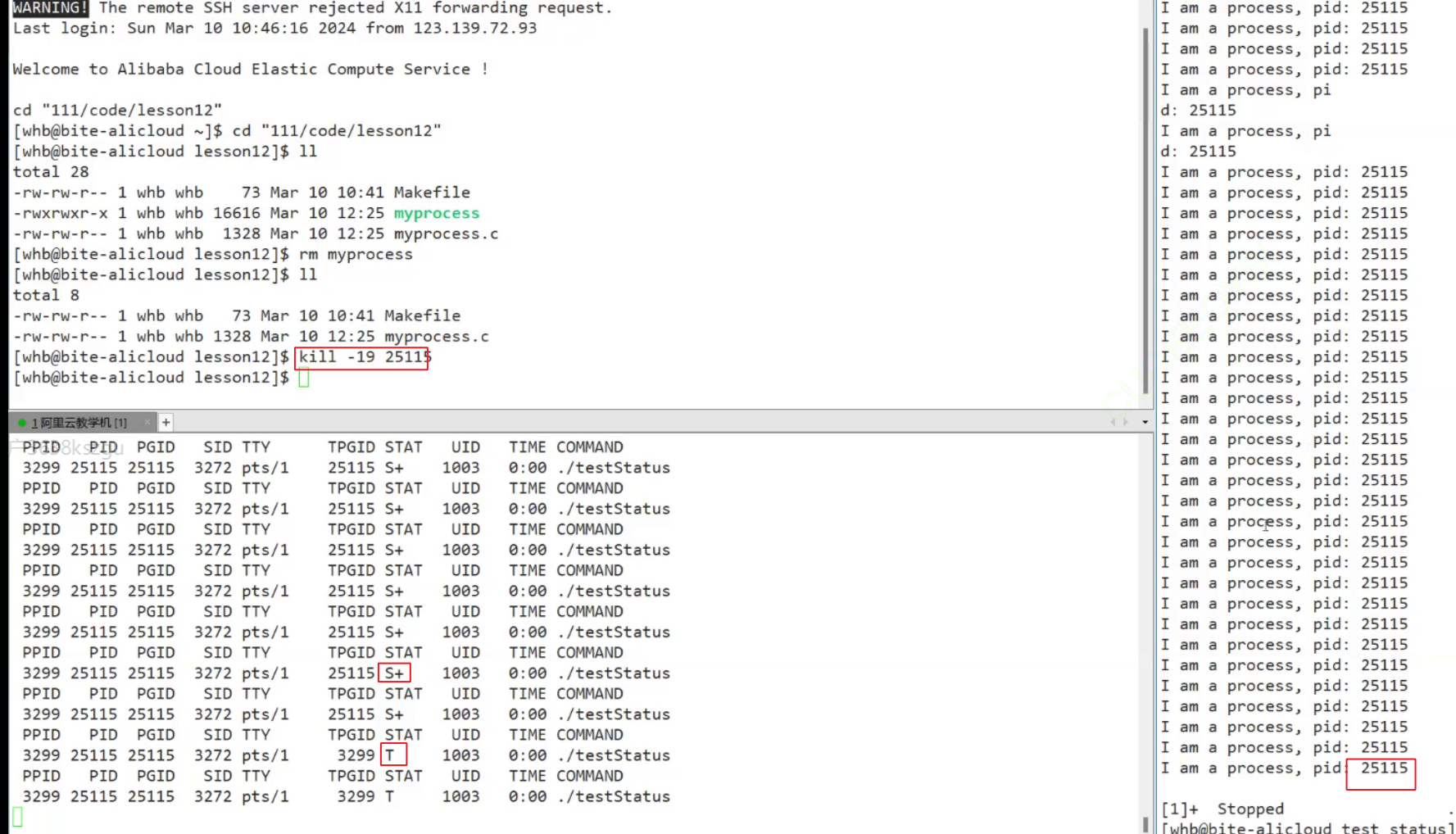
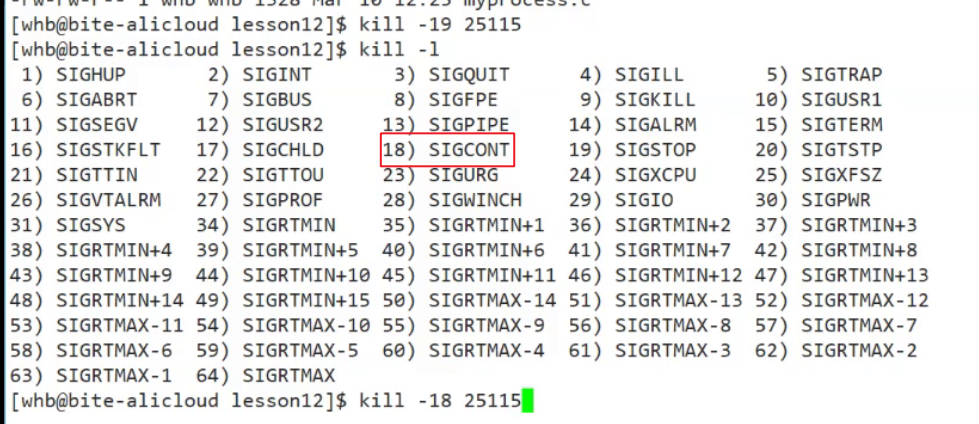
而我们平时调试, 就是让进程进入t暂停状态.
t状态表示进程正在被跟踪并因为某个信号而暂停,等待调试器或其他跟踪程序的处理。T状态表示进程已经被停止,不再执行,等待外部信号(如SIGCONT)来重新启动。
D状态: 磁盘休眠状态. 一种特殊的深度睡眠状态.
为了防止在极端内存不足情况下被Linux内核杀掉进程, 所以我们把正在进程IO流数据传输, 等待硬盘读写结果的进程状态设置为D状态, 该状态不可被杀, 不可中断. 对于该状态, 由于操作系统没有权限杀掉该进程, 所以kill命令不起用. 结束该进程的方式有两种, 等进程自己醒来运行结束, 或者重启甚至断电.
对于做应用开发的人员用的比较少, 对做数据存储的人很重要. 不过一般很少见, 因为出现D状态证明系统快不行了(一般磁盘刷新很快).
僵尸进程(Z)/孤儿进程:
一个进程完成了自己的任务, 会进入僵尸状态等待父进程回收其全部资源.
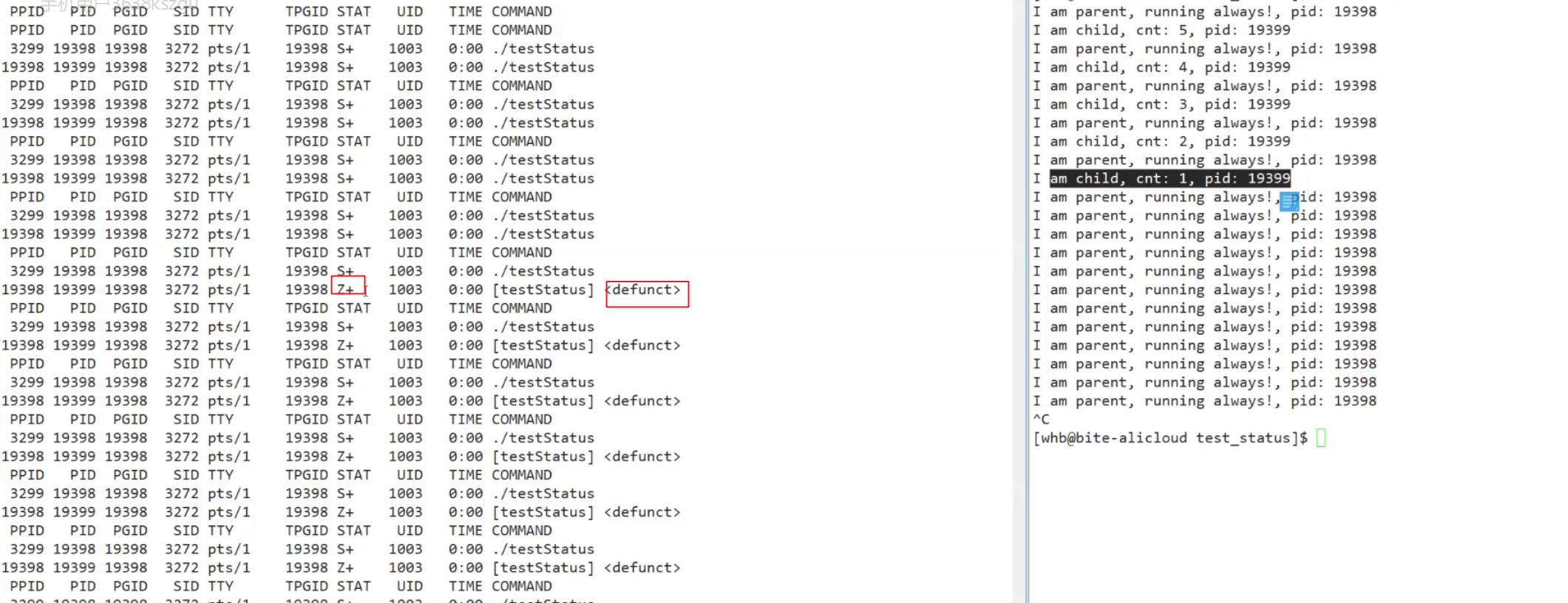
已经运行完毕, 生成自己的对应退出信息维护在task_struct中, 等待父进程读取. 如果没有父进程来读取, 子进程的僵尸进程一直存在. 进程 = task_struct + 数据/代码. 无论父进程是否读取子进程的退出信息, 子进程运行完成自己的代码和数据会自己释放掉. 进入Z状态, 如果被父进程读取了, 该进程会进入X进程, 之后迅速会被OS回收内存, 彻底消失.
产生问题: 僵尸进程一直不释放, 会发生内存泄露问题.
单进程编程很少见僵尸进程(至今没见过)? 单进程编程一般是直接在命令行中启动的进程, 其父进程一般是bash进程(bash进程就是我们与操作系统进行交互的进程, 即shell进程).
在Linux中,当一个进程结束时,其数据和代码以及task_struct资源的释放过程涉及多个方面。以下是对这一过程的详细解释:
进程自身资源释放
- 当一个进程执行完毕或调用exit()函数时,它会开始释放自己所占用的资源。这包括内存、文件描述符、网络连接等。
- 进程通过系统调用sys_exit()进入do_exit()函数,该函数负责处理进程终止时的各种任务。
task_struct和内核栈的保留
- 在进程释放大部分资源后,其task_struct数据结构(包含进程的各种信息,如进程ID、父进程ID、进程状态等)和内核栈会被保留一段时间。
- 此时,进程的状态被设置为僵死态(zombie state),等待其父进程来回收。
父进程回收资源
- 父进程通过调用wait4()等系统调用来查询其子进程是否已经终止。
- 一旦父进程确认子进程已经终止(即子进程进入僵死态),它就会调用wait4()等函数来回收子进程的task_struct和内核栈等资源。
- 这样,子进程就完全从系统中消失了,不会留下任何痕迹。
操作系统层面的角色
- 操作系统在整个过程中扮演着监督者和协调者的角色。
- 它提供了系统调用接口(如sys_exit()和sys_wait4()),并确保了这些调用的正确执行。
- 操作系统还负责维护进程的状态信息,确保进程能够正确地终止和回收资源。
综上所述,在Linux中,当一个进程结束时,其数据和代码是由进程自己释放的,而task_struct资源则是由其父进程通过系统调用回收的。操作系统在整个过程中提供了必要的支持和监督。因此,针对这个问题的答案是:这个进程的task_struct资源是由父进程释放掉的,而不是由操作系统直接释放。
什么是孤儿进程呢? 子进程还没有运行完毕被父进程和操作系统回收资源, 父进程先结束了. 子进程结束退出时, 由操作系统1号进程读取退出信息, 并回收其资源.
进程的阻塞, 运行和挂起:
上下文关系: 进程的阻塞, 运行和挂起状态是<<操作系统>>学科当中的专用术语, 而操作系统学科是针对各种操作系统的一个大致的基本逻辑框架理论, 而我们上面所说的S, D, X, Z状态都是Linux这款具体的操作系统下的具体实现状态.
运行: 一个进程的task_struct在操作系统所维护的运行队列中. 正在排队等待CPU运行计算. 这个"运行"指的不是正在被CPU运行计算, 而指的是准备好了, 随时可以被CPU计算的状态.
Linux系统下的进程运行理解: 一个进程一旦持有CPU, 该进程会一直运行到进程结束吗? 不会~ 假设是的话, 一直while(1);那么将会一直占用CPU, 这会导致其他程序类似于直接卡死. 我们现在CPU是基于时间片轮转调度进程. 让多个进程以切换的方式(切换速度很快)进行调度, 在一个时间段内同时得以推进代码, 叫做并发. 就是在极端时间内该进程没有进行完成, 没关系直接记录一下进行的位置, 然后扔到队列尾部(最简单的调度算法). 然而实际上Linux的调度算法并不是如此简单的(学校课本一般是这样说的).
任何时刻, 同时多个进程被真正的同时运行, 我们把该情况叫做并行(前提是至少得俩CPU及以上).
在Linux系统下,并行和并发是两个既相似又有所区别的概念,它们在多任务处理和计算中扮演着重要角色。以下是对这两个概念的简要说明:
并发(Concurrency)
- 定义:并发是指多个任务在时间上交替执行,给用户带来同时进行的感觉。但实际上,在同一时刻,CPU可能只在执行一个任务,通过上下文切换实现多个任务的协同运作。
- 实现方式:在Linux系统中,并发主要通过多进程、多线程机制以及POSIX线程库(pthread)等工具来实现。每个进程或线程都有自己的执行路径,但在单核CPU上,这些任务是通过时间片轮转的方式交替执行的。
- 特点:并发偏重于多个任务交替执行,虽然从外部观察者的角度来看,多个任务似乎是同时进行的,但实际上在微观层面上,这些任务是依次执行的。
并行(Parallelism)
- 定义:并行则是指在同一时间内,多个任务在多个处理器(或多核CPU)上真正同时执行。这意味着每个任务都有自己的处理器资源,可以同时进行计算和处理。
- 实现方式:在Linux环境中,并行计算的实现依赖于硬件层面的多核支持和操作系统级别的并行编程接口,如OpenMP、MPI(Message Passing Interface)等。这些接口使得开发者能够编写出能够在多核CPU上并行执行的程序。
- 特点:并行是真正意义上的同时执行,多个任务在同一时刻占用不同的处理器资源,从而实现了高效的计算和处理能力。
并发与并行的区别
- 执行方式:并发是多个任务在单个处理器上交替执行,而并行则是多个任务在多个处理器上同时执行。
- 资源需求:并发对硬件资源的要求相对较低,因为即使在没有多核CPU的情况下,也可以通过时间片轮转的方式实现多个任务的交替执行。而并行则需要多核CPU或分布式计算资源来支持多个任务的真正同时执行。
- 性能表现:在单核CPU上,并发的性能提升主要体现在任务切换的效率和资源利用率上。而在多核CPU上,并行则能够带来显著的性能提升,因为多个任务可以同时进行计算和处理。
综上所述,并发和并行是Linux系统下多任务处理和计算中的两个重要概念。它们各自具有不同的特点和实现方式,但在实际应用中往往相互补充,共同实现高效的多任务处理和计算能力。
阻塞状态(核心): -> S, D
我们的scanf函数, 如果我不对键盘做任何操作, 现在进程什么状态? 为啥? scanf在等待什么东西?
操作系统该如何对硬件进行管理呢?
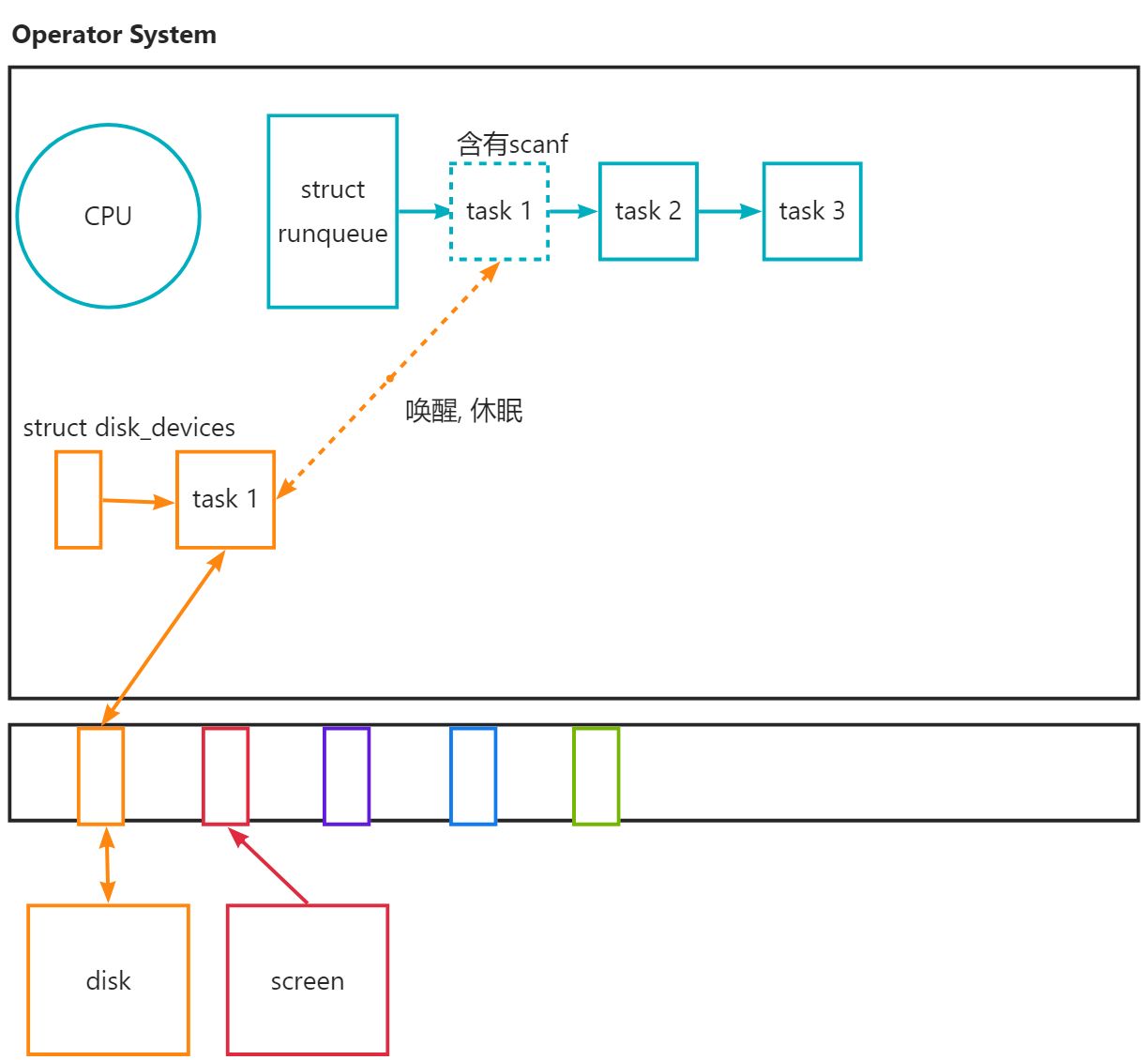
那如果我们写scanf, 操作系统内是个什么进行过程呢? 首先当你运行你写的程序时, 会生成对应的task_struct结构体, 用来描述我们这个程序, 即进程产生了. 该进程有着专属的pid用来标识身份. 假设pid=9876, 9876会被插入到CPU的执行等待队列中, 等待着被CPU调度, 当轮到9876的时候, 执行到scanf, 发现需要访问硬件设备, 所以操作系统就把9876这个结构体直接扔给disk_devices的等待队列中去排队, 此时该进程由于没有被CPU执行, 处于sleep状态, 拍到task1的时候, 键盘会等待用户输入内容, 用户确认好之后, 键盘拿到数据, 键盘这个硬件再通过驱动设备给到task1, task1再被操作系统重新放到CPU执行队列当中, ... 当进程在等待键盘给他数据的时候, 该进程处于阻塞状态, 即是没有被CPU执行的状态, 也可以简单理解为S或者D状态.
文心一言: 您的描述基本上是正确的,但有几个小地方可以进行澄清或者微调,以确保更加准确和清晰。以下是您的描述以及我的一些补充或修正:
- 进程创建和任务结构体:
-
- 当您运行程序时,确实会创建一个对应的
task_struct结构体来描述这个进程。这个结构体包含了进程的各种信息,如进程ID(PID)、状态、调度信息等。 - 假设 PID 为 9876,这个进程会被插入到 CPU 的执行等待队列中,等待被调度执行。
- 当您运行程序时,确实会创建一个对应的
- CPU 调度:
-
- 当 CPU 调度器选择 PID 为 9876 的进程执行时,如果执行到
scanf函数并需要访问硬件设备(如键盘),进程会请求相应的硬件资源。
- 当 CPU 调度器选择 PID 为 9876 的进程执行时,如果执行到
- 进程状态转换:
-
- 如果
scanf需要等待用户输入,操作系统会将该进程(PID 为 9876)的状态从运行状态(Runnable 或 Running)转换为阻塞状态(Blocked 或 Sleeping),并将其从 CPU 执行队列中移除,同时将其加入到键盘设备(或其他相关设备)的等待队列中。 - 此时,进程确实处于 "sleep" 状态,但这通常意味着它在等待某个事件(如用户输入)发生。
- 如果
- 硬件交互:
-
- 当用户通过键盘输入数据时,键盘硬件会捕获这些数据,并通过驱动程序将其传递给操作系统。
- 操作系统识别到这是 PID 为 9876 的进程所等待的数据后,会将该数据传递给进程,并将其从设备等待队列中移除,重新加入到 CPU 执行队列中。
- 进程重新执行:
-
- 一旦进程被重新调度到 CPU 上执行,它会继续从
scanf函数调用后的位置开始执行,处理用户输入的数据。
- 一旦进程被重新调度到 CPU 上执行,它会继续从
- 进程状态描述:
-
- 您提到的 "S 或 D 状态" 通常指的是进程的状态码。在 Linux 中,"S" 通常表示进程处于可中断的睡眠状态(Sleeping),而 "D" 表示进程处于不可中断的睡眠状态(Disk Sleep,通常是因为等待 I/O 操作)。在您的例子中,进程在等待键盘输入时,更可能是处于 "S" 状态。
综上所述,您的描述基本准确,但注意进程在等待 I/O 操作时的具体状态(如 "S" 或 "D")可能因操作系统和具体情况而异。此外,确保术语的准确性和一致性也有助于更好地理解和交流概念。
挂起状态:
挂起也是进程的一种状态之一, 往往和其他状态进行组合, 形成不同的各种类型的挂起状态.
挂起是种什么概念呢?
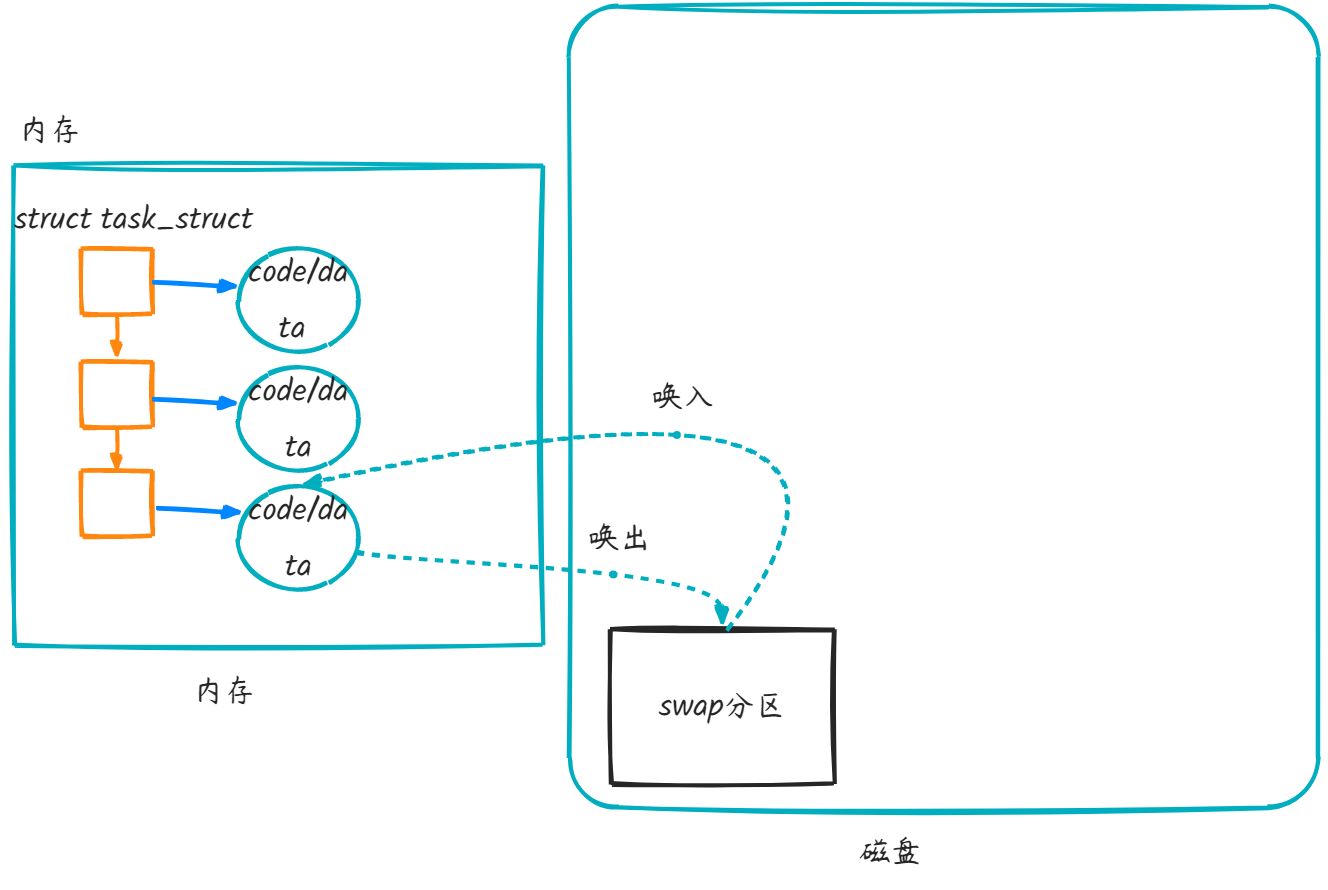
在某种情况下, 内存比较吃紧, OS可以把正在S的进程的code/data放到磁盘种的swap分区暂做保存(唤出), 当需要的时候再拿回来(唤入).
挂起状态的缺点是: 导致效率降低. 这玩意就类似于一种以效率换空间的一种方法.
您关于挂起的理解基本正确,以下是对挂起概念的详细解释和补充:
一、挂起的定义
挂起是指将某事物或活动暂时搁置或暂停执行的状态。在计算机科学中,挂起常用于线程或进程的管理中,以控制并发操作和资源的合理分配。具体来说,挂起是指暂时中止一个进程或线程的执行,将其放入一个等待状态,直到某个特定事件发生或满足一定条件后,再恢复被挂起的进程或线程的执行。
二、挂起的原因和场景
- 终端用户的请求:当终端用户在自己的程序运行期间发现有可疑问题时,希望暂停使自己的程序静止下来,以便研究其执行情况或对程序进行修改。
- 父进程的请求:有时父进程希望挂起自己的某个子进程,以便考察和修改子进程,或者协调各子进程间的活动。
- 负荷调节的需要:当实时系统中的工作负荷较重,已可能影响到对实时任务的控制时,可由系统把一些不重要的进程挂起,以保证系统能正常运行。
- 操作系统的需要:操作系统有时希望挂起某些进程,以便检查运行中的资源使用情况或进行记账。
- 内存资源紧张:当内存资源紧张时,操作系统可以将正在运行的进程的代码和数据暂时保存到磁盘的swap分区中(即唤出),以释放内存空间。当需要时,再将这些数据从磁盘中读回内存(即唤入),并恢复进程的执行。
三、挂起与暂停的区别
在虚拟机管理中,挂起(Suspend)和暂停(Pause)虽然都涉及到暂停虚拟机的执行,但二者存在区别:
- 挂起:挂起是一种持久化操作。挂起会将虚拟机的当前状态(包括内存和设备状态)保存到磁盘文件中。这样即使关闭虚拟机管理程序或重新启动宿主机,挂起的状态也能得以保留。
- 暂停:暂停只是临时停止虚拟机的执行,不会将状态保存到磁盘中。因此,如果关闭虚拟机管理程序或重新启动宿主机,暂停的状态将丢失。
四、挂起的实现方式
挂起的实现通常以管程或信号量为基础。管程是一种用于同步和互斥的抽象数据类型,通过提供进程或线程间进行通信和互斥的方法来支持并发程序设计。信号量是一种用于实现互斥和同步的同步原语,通过进程或线程间对信号量的操作来实现资源的互斥访问和同步。
在操作系统层面,可以使用系统调用来实现线程或进程的挂起与唤醒。在编程语言层面,通常提供了相应的库函数或关键字来实现线程或进程的挂起与唤醒。
综上所述,挂起是计算机科学中一个重要的概念,它涉及到进程或线程的管理、资源的合理分配以及并发操作的控制。通过挂起操作,可以有效地利用计算资源和提高系统的效率和响应速度。
fdisk, 是一种专门划分磁盘和写入文件系统的工具.
进程切换:
进程的切换, 最重要的一件事就是上下文数据的保存和恢复问题.
进程切换概念的理解: 当我们一个进程因为时间片到了, 或者各种原因需要去访问磁盘了...等等, 此时需要进行进程的切换, 因为该进程大概率是没有被进行完的, 所以需要将进行到哪了的相关信息保留好, 给到task_struct1里保存起来, 当task1下次来的时候恢复上下文数据继续执行.
为了更好的理解进程的切换概念, 我们进一步认识一下CPU中的寄存器, 寄存器本身是硬件, 本身具有存储能力, 每个进程都有属于自己的上下文, 当执行该进程的时候会把相关信息放到寄存器种, 因此一般寄存器里的信息对应不同的进程, 有很多套信息, 每套对应一个进程(通常情况下).
您的理解基本上是正确的,关于进程切换(也称为上下文切换)的概念,以下是更详细的解释和补充:
进程切换的基本概念
进程切换是多任务操作系统中的一项核心技术,它允许CPU在多个进程之间高效地切换,从而实现并发执行。当操作系统决定从一个进程切换到另一个进程时,它需要保存当前进程的状态(称为上下文),并恢复另一个进程的状态,以便后者可以继续执行。
上下文保存与恢复
- 上下文保存:当一个进程的时间片用完或因其他原因(如I/O操作、等待资源等)需要暂停执行时,操作系统会保存该进程的上下文。上下文包括CPU寄存器的内容(如程序计数器、堆栈指针等)、内存管理信息(如页表)、内核数据结构(如task_struct,在Linux中用于表示进程)等。这些信息被保存在进程的task_struct结构体中或其他适当的位置。
- 上下文恢复:当操作系统决定恢复一个进程的执行时,它会从该进程的task_struct中读取上下文信息,并恢复CPU寄存器和内存管理信息。这样,进程就可以从它被暂停的地方继续执行。
进程切换的时机
进程切换可以在多种情况下发生,包括但不限于:
- 时间片用完:在多任务操作系统中,每个进程都会被分配一个固定的时间片。当进程的时间片用完时,操作系统会选择一个新的进程来执行。
- I/O操作:当进程需要等待I/O操作完成时(如读取磁盘),操作系统可能会选择另一个进程来执行,以充分利用CPU资源。
- 资源等待:如果进程需要等待某些资源(如内存、锁等),它可能会被挂起,直到资源可用。在等待期间,操作系统可以执行其他进程。
- 中断和异常:某些中断和异常(如系统调用、定时器中断等)也可能触发进程切换。
进程切换的性能影响
虽然进程切换允许多个进程并发执行,但它也带来了额外的开销。这些开销包括保存和恢复上下文的时间、调度器选择新进程的时间以及可能引起的缓存失效等。因此,在设计操作系统时,需要仔细权衡进程切换的频率和开销,以确保系统的整体性能。
总的来说,您的理解是准确的,进程切换是一个复杂但重要的过程,它使得多任务操作系统能够高效地管理多个进程。
3.5. 进程的优先级
3.5.1. 什么是进程优先级
进程优先级: 指定某个进程获取某种资源(特指CPU)的先后顺序.
操作系统中进程的优先级, 是保存在task_struct结构体中间某一个字段的, 用整形来表示;, 一般数字越小, 优先级越高.
优先级与权限的概念辨析:
优先级: 已经有权限做了, 只不过需要确定顺序问题.
权限: 能不能做的问题.
3.5.2. 优先级的意义
问题就是, 进程的数量 > CPU资源, 因此需要优先级来确定先后顺序. 如果CPU数量够多, 也必定意味着能够启动更多的进程, 也依旧是进程 > CPU.
在Linux操作系统中,task_struct结构体是内核用来表示每个进程的主要数据结构。虽然进程在task_struct链表中有一定的顺序,但这个顺序并不直接决定CPU的执行顺序。实际上,CPU调度和进程执行顺序是由复杂的调度算法和机制来管理的,而不仅仅是基于链表中的顺序。
3.5.3. linux下的优先级
Linux的调度优先级遵循两个基本原则:
- 调度遵循基本的公平.
- PRI数字越小, 优先级越高.
公式: 新的优先级 = 优先级(80) + nice值, 即prio = default priority + nice.
查看进程状态:
ps -al解释:
在Linux系统下,ps 命令是一个非常有用的工具,用于显示当前系统中的进程状态。ps 命令可以接收多种选项和参数,以提供不同格式和详细程度的进程信息。
ps -al 命令结合了 -a 和 -l 两个选项:
-a(all):显示除了控制终端(controlling terminal)不是当前会话的领头进程(session leader)之外的所有进程。这通常意味着它会显示所有用户的所有进程,而不仅仅是与当前终端会话相关的进程。-l(long):以长格式显示进程信息。这提供了比默认输出更多的细节,包括进程的UID(用户ID)、PID(进程ID)、PPID(父进程ID)、C(CPU使用率估算值)、STIME(进程启动时间)、TTY(控制终端)、TIME(CPU使用时间累计)和CMD(启动进程的命令名/命令行)。
因此,ps -al 命令将显示系统中所有用户的所有进程(除了某些特定的领头进程),并以长格式展示这些进程的信息。
需要注意的是,ps 命令的输出可能会根据Linux发行版和ps命令的具体实现而有所不同。但是,通常你会看到类似于以下的输出(这里只展示了部分列以作说明):
F S UID PID PPID C PRI NI ADDR SZ WCHAN TTY TIME CMD
4 S root 1 0 0 80 0 - 4160 - ? 00:00:03 systemd
1 S root 2 0 0 80 0 - 0 kthrea ? 00:00:00 kthreadd
...在这个例子中:
F:标志列,显示进程的标志,比如是否是前台进程(foreground)或后台进程(background)。S:进程状态,比如S表示睡眠(sleeping),R表示运行(running)等。UID:进程所有者的用户ID。PID:进程ID。PPID:父进程ID。C:CPU使用率估算值(这是一个近似值,表示自上次更新以来进程使用的CPU时间百分比的一个快照)。PRI:进程的优先级(Priority)。NI:进程的“nice”值,这是一个可以手动调整的优先级偏移量。ADDR、SZ、WCHAN等列提供了关于进程内存使用、等待的通道(如果有的话)等额外信息。TTY:进程的控制终端。如果进程没有控制终端,则显示?。TIME:进程自启动以来使用的CPU时间累计。CMD:启动进程的命令名或命令行。
请注意,上面的输出示例可能并不完全匹配你实际看到的ps -al命令输出,因为不同的Linux发行版和ps版本可能会提供不同的列或格式。
修改进程的优先级:
top //查看任务进程管理器
r //进入调整进程优先级模式
//输入要修改进程的pid + 回车
//输入nice调整值 + 回车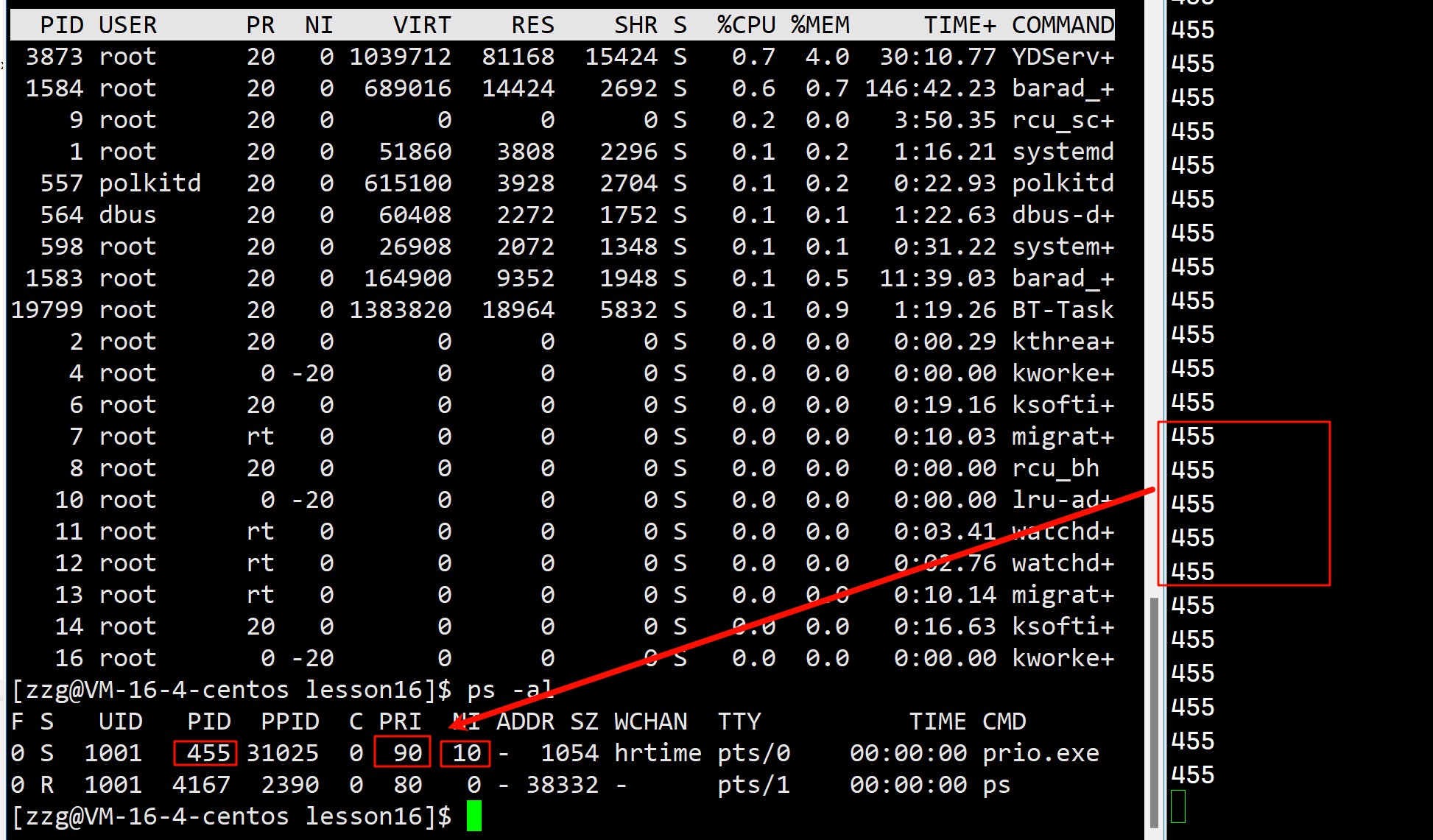
注意: nice值有调整范围: [-20, 19] 共计40个数字
3.6. 命令行参数和环境变量
3.6.1. 命令行参数
在我们之前学过main函数当中, 其实main后面可以带(int argc, char* argv[])参数, 前者用来统计argv指向的字符串个数, 后者是一个数组, 用来存放指向字符串的指针.
并且我们还知道, main的这些参数可以给他加上, 也可以不给他加上, main的这些参数究竟是一个什么东西呢? 我们来看一下:
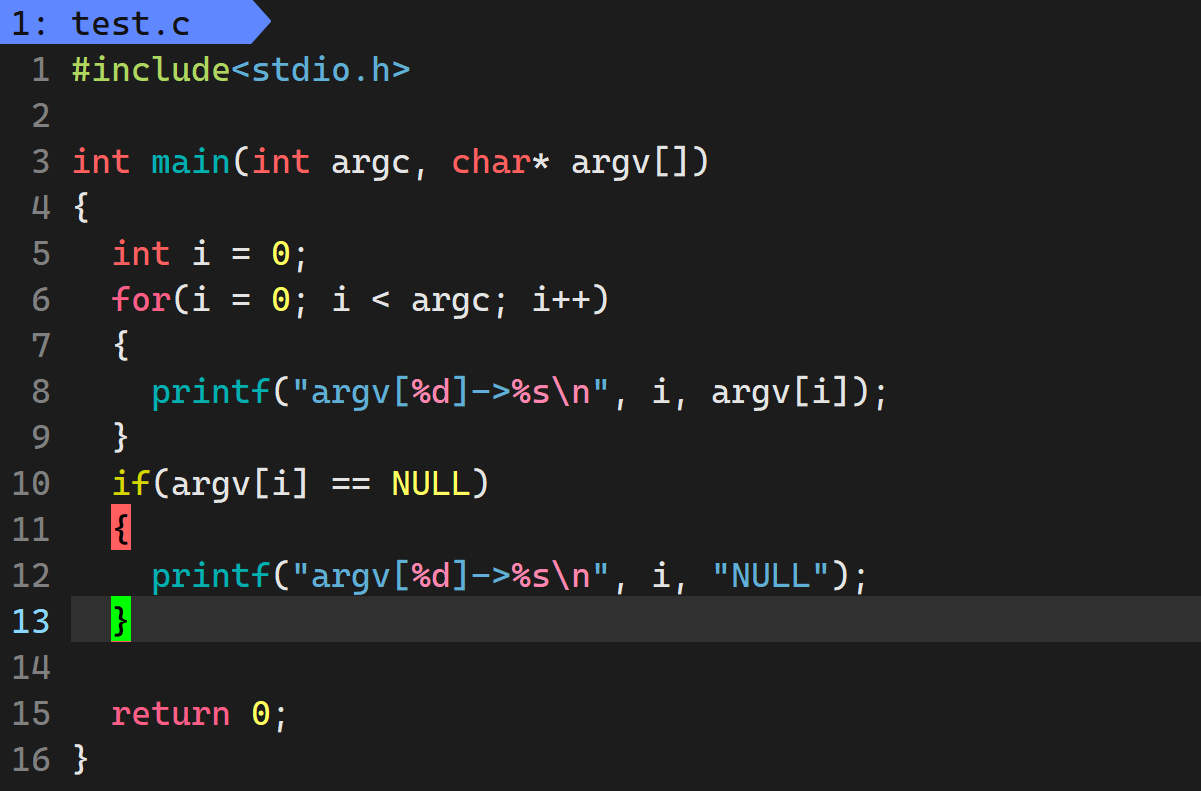

那这些玩意是做什么的呢? 就是当我们在命令行输入额外的选型时候, 命令行解释器会根据我们输入的内容进行解析成多个字符串, 开辟一块空间分别把选项存起来, 然后给到我们的main函数.
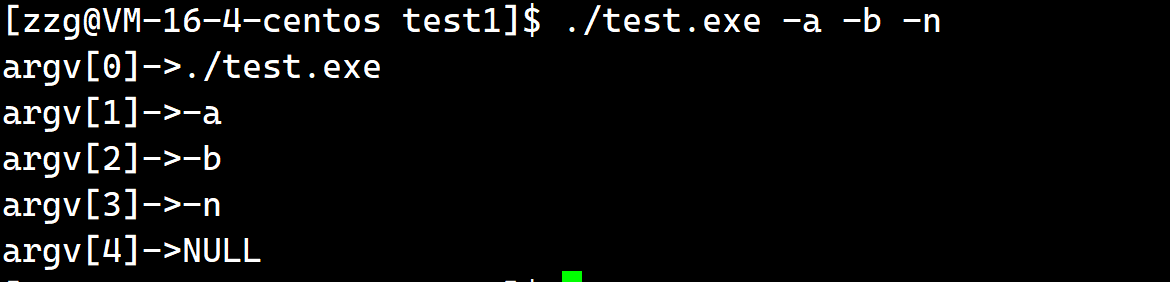
为什么要有命令行参数?
用来根据我们给的选型定制程序不同的子功能.
很简单, 因为我们想要同一个进程下实现多个子功能, 让用户具有选择性. 比如我们的ls命令, 我们可以选-l, 也可以选择-a来让ls命令完成不同的工作.
下面是一个例子, 大体程序就是这个思路:
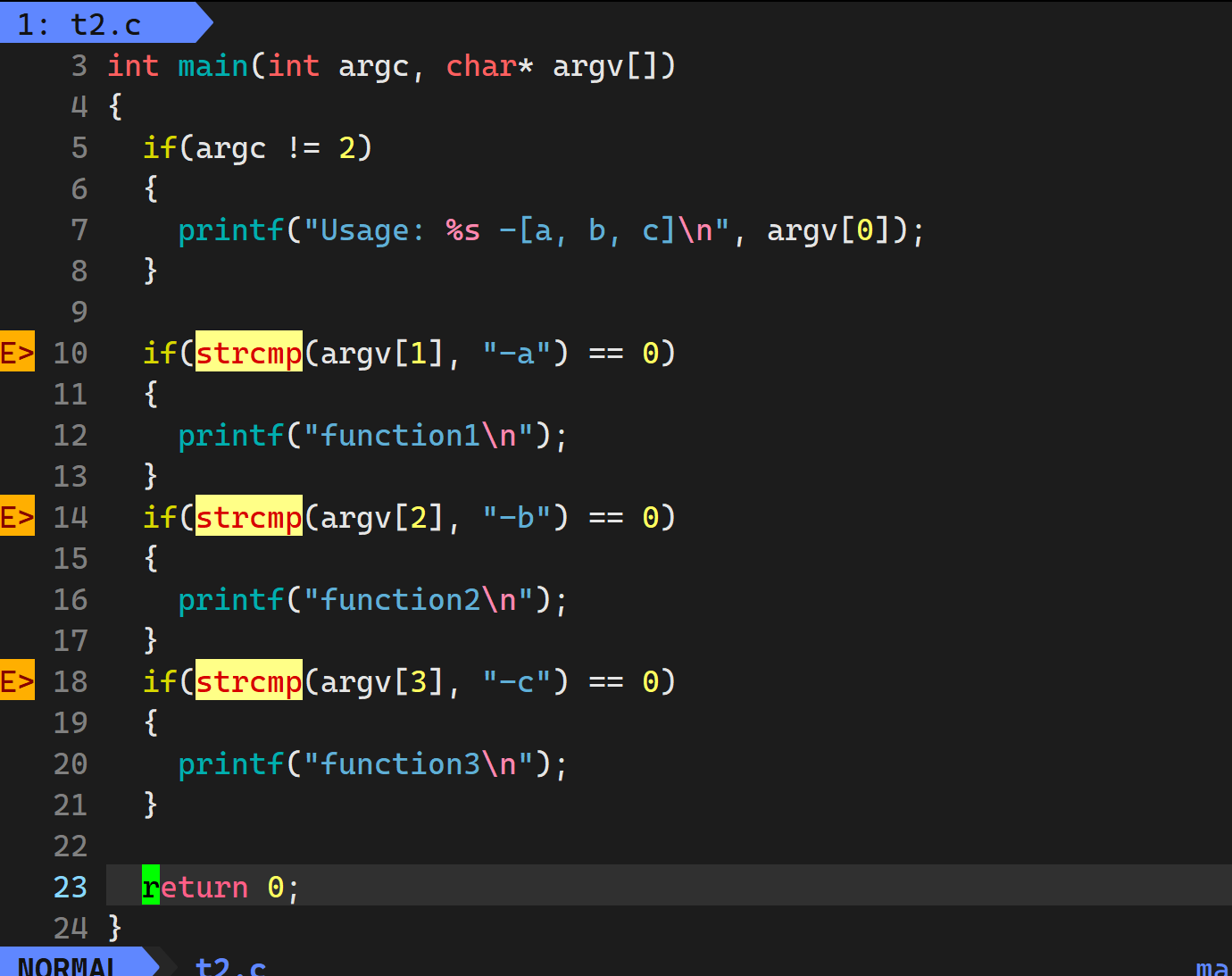
是谁将我们写的一整个字符串分割成成子字符串开辟数组给到我们的程序的呢?
bash, 我们写的字符串是一个整体, 给到我们的命令行解释器之后, 命令行解释器根据他自己的代码逻辑把我们的字符串分割成子字符串, 之后可能会开辟数组挨个往里面放, 再创建进程调用我们的main函数. 我们知道, 我们在命令行启动的进程是bash的子进程, 所以说main这个子进程可以看到bash创建的存储选项的数组.
3.6.2. 环境变量
3.6.2.1. 环境变量的初步认识
环境变量是个什么东西? 下面来进行介绍.
根据上文内容"命令行参数", 我们发现我们自己写的代码编译之后生成的二进制程序跟ls, pwd这种系统自带的命令有些不一样, 就是系统自带的命令可以在任何路径下执行, 但是我们自己写的却不行. 这是因为bash中配置的环境变量的问题.
环境变量是一些路径组成的文件, 然后这些文件在我们登录shell时候会被加载到bash中(因为bash是命令行解释器, 需要依赖全局的配置命令).
Linux中, 默认我们的环境变量是内存级的, 也就是说Linux的bash在运行的时候不是在内存中跑吗? 如果我们修改bash下读取并修改的例如PATH环境变量, 也只会修改内存级别的, 想要修改配置文件, 就需要到特定隐藏文件夹下去修改, 还需要root权限才可以.

如果想要修改内存级的环境变量, 只需要写PATH=$PATH:你自己程序所在的路径
注意: 如果写PATH=你自己程序所在的路径, 会直接覆盖原来路径, 想要跑之前的系统指令就得写全名了, 不然跑不了.
环境变量是默认在相关配置文件中的.

3.6.2.2. 环境变量的更多操作
除了上面介绍用到的环境变量PATH之外, 我们的环境变量还有PATH/HOME/HISTSIZE/PWD这些环境变量.
- PATH 指定命令的搜索路径
- HOME 指定用户的主工作目录(用户登录Linux系统是默认所处的位置, 家目录)
- HISTSIZE shell进程默认存储用户的历史命令
- PWD 在Linux系统中,PWD环境变量表示当前工作目录的绝对路径, 并且会随着工作目录的切换而实时更新.
- SHELL 当前Shell所在路径, 他的值通常是/bin/bash.
对于这些环境变量, 还会常常用到下面操作:
- env 查看相关的环境变量
- echo $EnvironmentName 打印环境变量下的内容
- export EnvironmentName=value 导入新的环境变量(默认是导入到内存级环境变量中去), 如果是本地变量, 就不需要后面赋值, 直接输入名字即可.
- unset EnvironmentName 卸载/删除环境变量
本地变量的概念:
然而, 除了上面导入环境变量之外, 我们bash中也有本地变量的东西. 本地变量不能被子进程继承.
hello=123456 //导入到bash中本地变量, 本地变量的名字是hello, 其值是123456
env | grep hello //这样是查不到hello变量的, 因为env是查询环境变量而不是本地变量的命令
echo $hello //用来打印变量的, 可以打印本地变量值, 其结果是1234563.6.2.3. 整体理解环境变量 + 代码结合
我们的环境变量默认也可以被子进程拿到, 比如我们可以写一个代码, 用C语言所维护的environment这个全局二级指针去访问.
那么下面我们就来梳理一下, 环境变量到bash, 然后被程序拿到的一个过程.
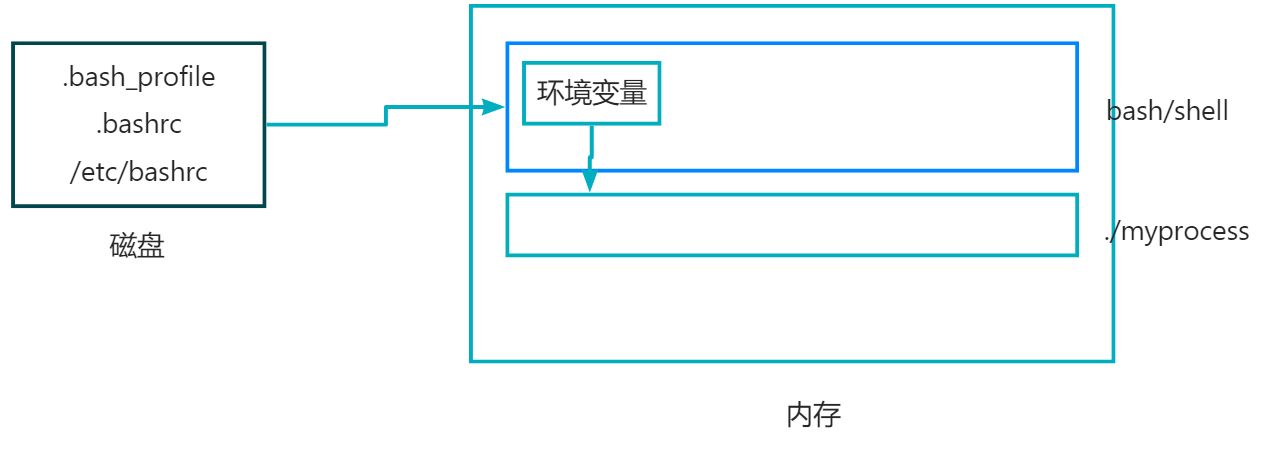
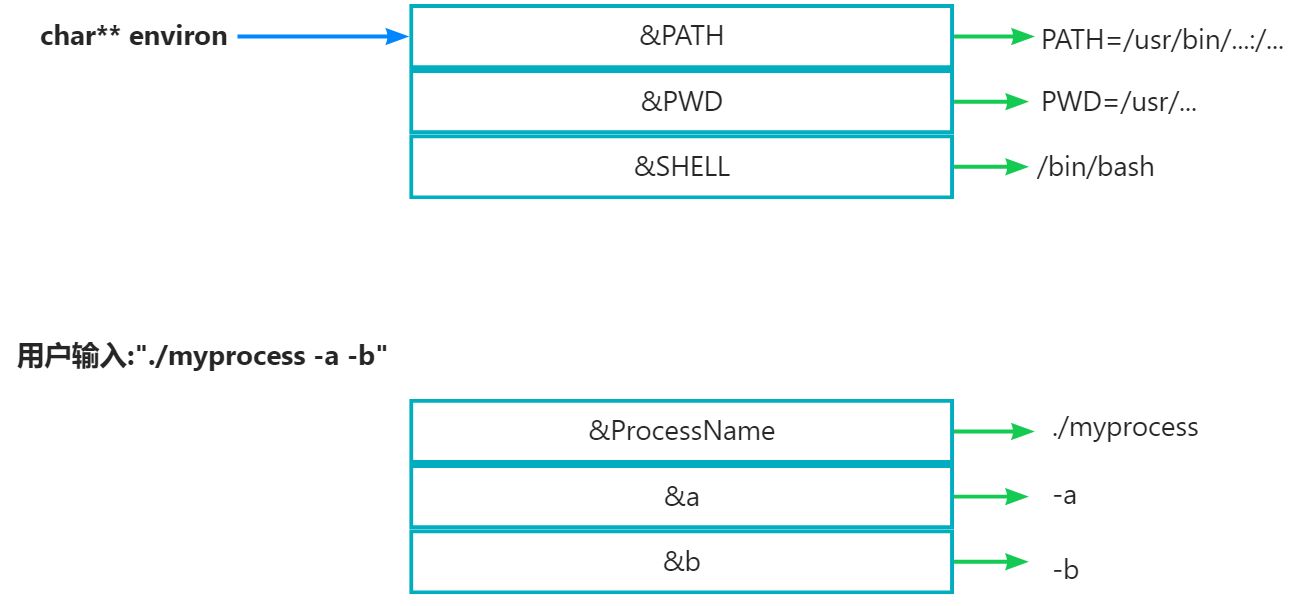
bash进程启动的时候, 默认会给我们子进程形成两张表, 一张是argv[]命令行参数表(数据来自用户输入的命令行), 另一张是env[]环境变量表(数据来自OS的配置文件). 然后bash通过各种方式交给我们子进程读取.
而所谓的导入环境变量, 就是添加给上面所画的表格当中.
获取环境变量的方式:
- extern char** environ
- 通过main中的参数
- getenv("EnvironmentName")
环境变量具有系统级的全局属性, 因为环境变量会因为bash创建子进程而继承下去.
内建命令: Linux中的命令分为少部分的内建命令和普通命令, 内建命令是由bash亲自执行, 而普通命令需要bash来创建子进程来进程. 比如echo, export就是内建命令, 这也就解释了我们导入环境变量能够被bash拿到了, 因为如果我们是再新创建一个子进程去导入环境变量, 对于他的父进程bash是不可见的.
3.7. 进程地址空间
3.7.1. 引入现象: 见相同地址却对应不同的值?
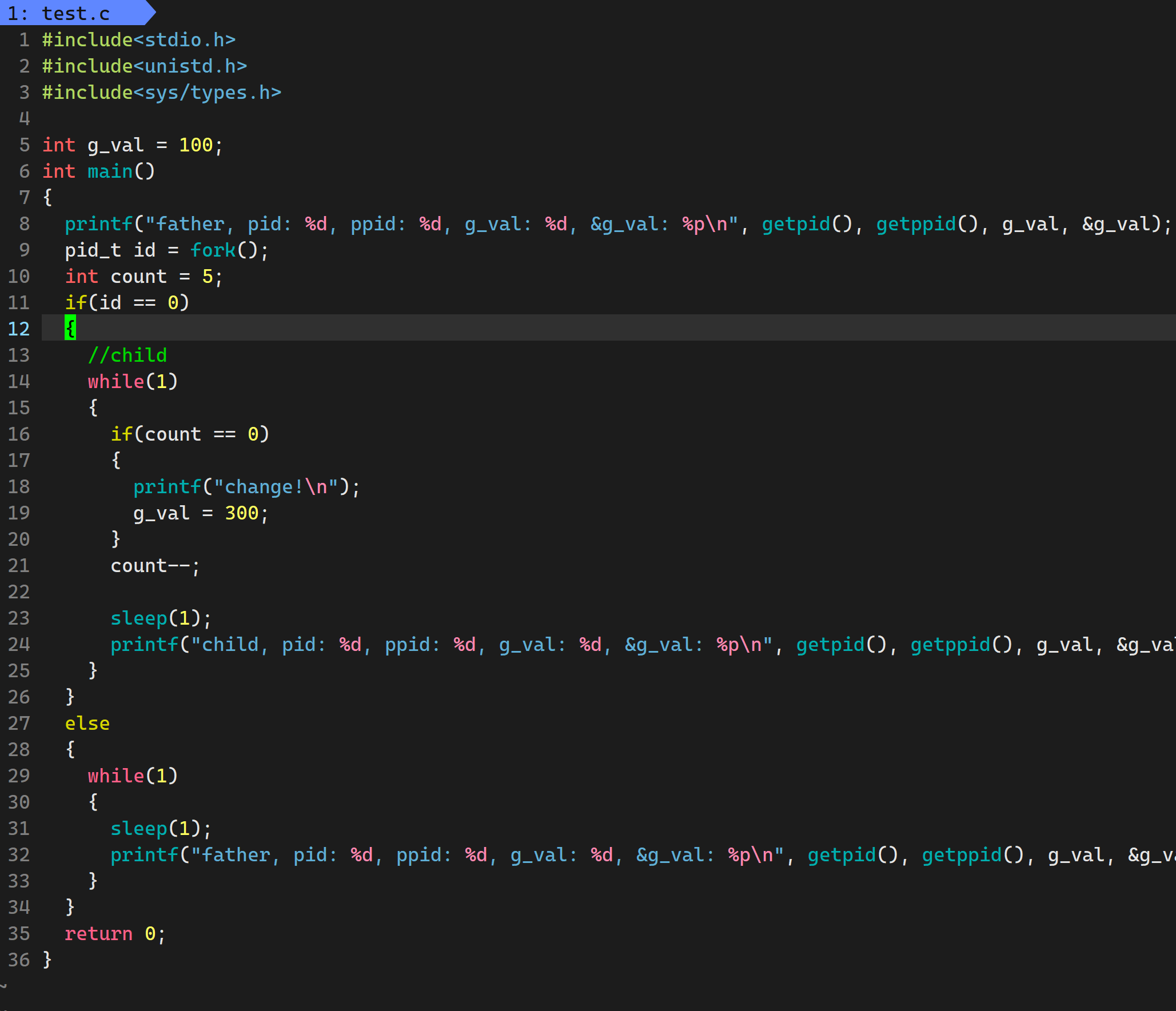
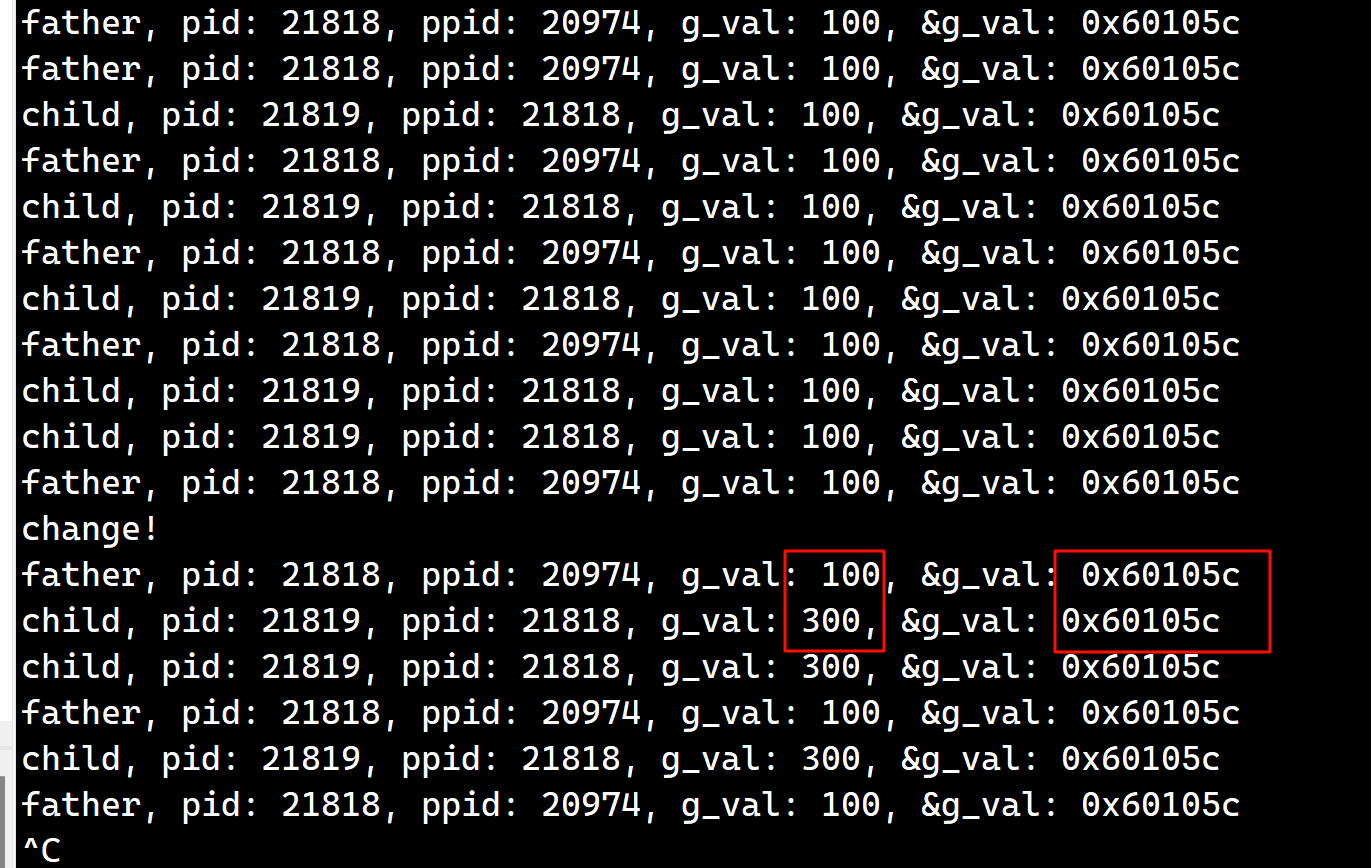
疑问: 我们知道, 进程 = 内核数据结构 + 代码(只读)和数据, 父子进程具有独立性. 那为啥有独立性他的地址一样但是值却不一样呢?
很显然, 这个后面的地址不是真正的物理地址, 而是虚拟地址. 下面就通过下面的图来解释这个问题:
3.7.2. 初步认识进程地址空间(画图解释)
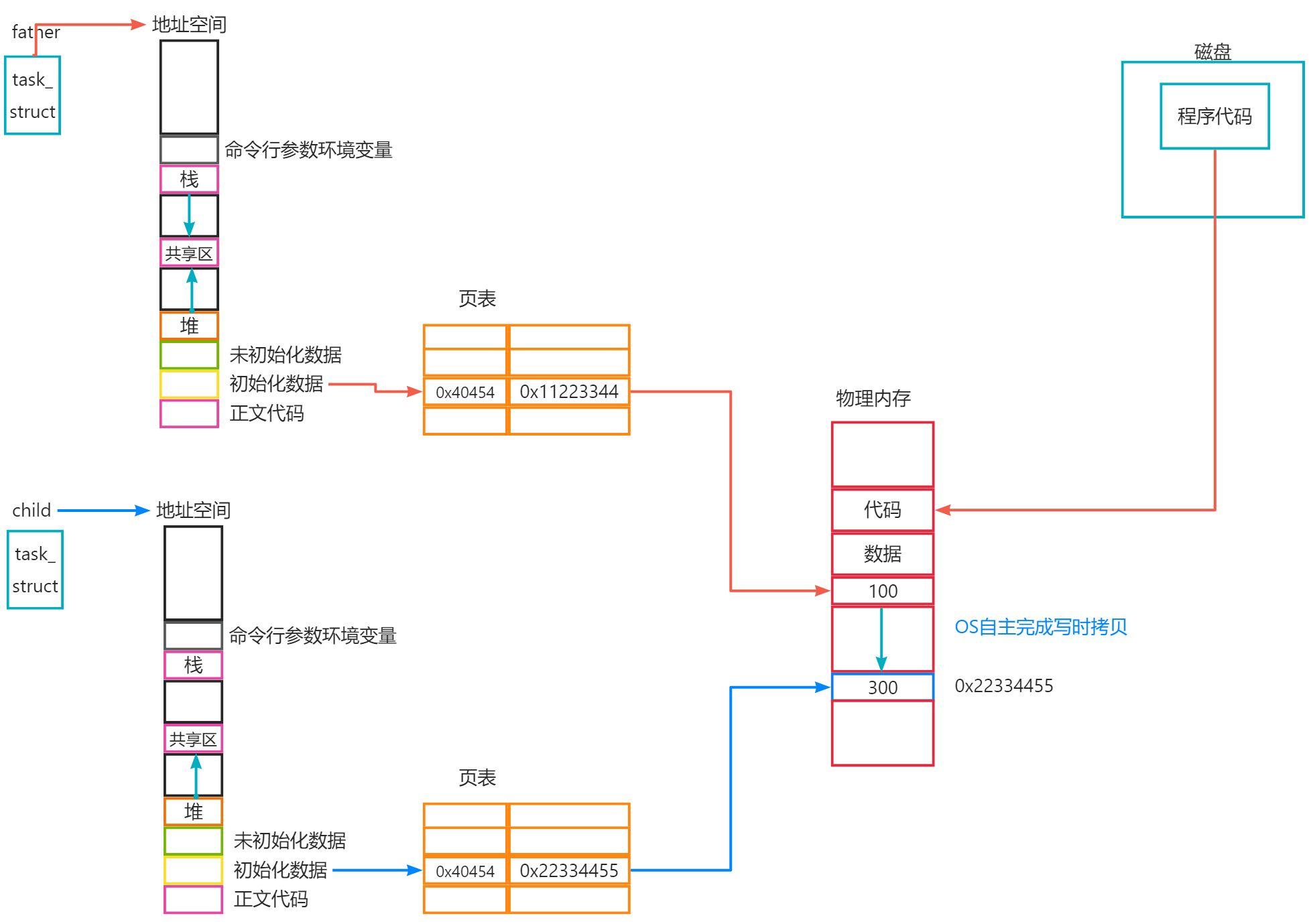
解读: 整体上图展现了两个进程关于写时拷贝的问题, 即首先我们写的一个包含fork函数的代码程序被加载到内存中, 此时操作系统内部会生成一个task_struct的结构体来堆这个进程进行管理, 这个task_struct会指向一个地址空间的东西, 然后地址空间存储的是一系列虚拟地址, 然后当需要访问某个变量的时候, 再通过页表查找对应的物理内存空间. 显然, 当只有father进程的时候, 虚拟地址0x40454会指向物理空间存储一百的地方, 即0x11223344的位置, 但是当fork函数产生了子进程, 子进程的虚拟地址空间也会产生地址空间和页表, 然后指向0x11223344, 但是当子进程对两个进程所共享的资源"100"进行修改的时候, 此时操作系统会在物理内存中把100这个空间数据拷贝到另一个物理内存空间中, 此时操作系统再把子进程所对应的页表修改一下, 让他指向新的物理内存0x22334455, 这个过程我们称之为写时拷贝. 之后, 子进程执行程序会把100改为300.
在上文中, 其实整个过程主要涉及到两个点, 一个是写时拷贝, 另一个是进程地址空间的概念, 下面进行详细解读.
3.7.3. 写时拷贝
写时拷贝的概念: 写时拷贝的概念是等到修改数据时,才真正分配内存空间进行拷贝,以优化程序性能。
写时拷贝的意义:
我们知道, 父进程的数据和代码是被子进程直接继承的, 并且我们又知道, 父子进程相对独立, 那为啥不在生成子进程的时候直接把对应的父进程数据"100"拷贝一份, 而是等到子进程进行修改的时候才进行拷贝啊? 明明在创建子进程的时候拷贝更加让进程之间具有独立性啊?
答: 提升内存使用率. 这是为了存储效率的考量, 并不是所有的数据都需要进行拷贝, 只需要对写的数据进行拷贝即可. 这样可以大大提高内存的使用率. 也就是说, 如果一上来不知道是不是要写就进行拷贝, 那么拷贝出来很多的一些数据都是没有意义的, 因此操作系统只有在一个进程对一个数据进行写入并且该数据是两个进程共享的时候进行写时拷贝.
你的笔记对于写时拷贝(Copy-On-Write, COW)问题的理解是正确的,下面我会对你的问题进行详细解释和补充,以确保内容更加完整和清晰。
问题解析
问题1: 我们知道,父进程的数据和代码是被子进程直接继承的,并且我们又知道,父子进程相对独立,那为啥不在生成子进程的时候直接把对应的父进程数据"100%"拷贝一份,而是等到子进程进行修改的时候才进行拷贝啊?明明在创建子进程的时候拷贝更加让进程之间具有独立性啊?
回答:
- 内存使用效率:
-
- 如果在创建子进程时立即对父进程的所有数据进行完整拷贝,这将导致大量的内存开销,特别是当父进程的数据量非常大时。在很多情况下,子进程可能并不需要修改这些数据,因此这种立即拷贝的方式会造成内存资源的浪费。
- 写时拷贝机制:
-
- 写时拷贝机制是为了解决上述内存浪费问题而设计的。它允许父子进程在创建时共享相同的物理内存页,直到其中一个进程尝试修改这些数据。当某个进程尝试写入时,操作系统会检测到这个写操作会破坏数据的共享状态,于是它会为该进程的数据创建一个新的内存页,并将旧的数据内容拷贝到这个新页中,然后允许该进程进行写入。而另一个进程仍然使用原来的内存页,保持数据的只读状态。
- 性能优化:
-
- 写时拷贝不仅提高了内存使用效率,还减少了不必要的I/O操作。因为只有在真正需要修改数据时才会进行拷贝,所以系统资源得到了更有效的利用。
- 进程独立性:
-
- 尽管父子进程在创建时共享内存,但它们的内存空间在逻辑上仍然是独立的。写时拷贝确保了当一个进程修改数据时,另一个进程不会受到影响,从而保持了进程的独立性。
总结
写时拷贝机制是一种高效的内存管理策略,它允许父子进程在创建时共享内存,直到某个进程尝试修改数据时才进行拷贝。这种方式不仅提高了内存使用效率,还减少了不必要的I/O操作,同时保持了进程的独立性。因此,写时拷贝在操作系统和虚拟化技术中得到了广泛应用。
你的笔记很好地捕捉到了写时拷贝的核心思想,即为了提升内存使用效率而设计的延迟拷贝策略。希望这个解释能进一步加深你对写时拷贝机制的理解。
写时拷贝的大致过程: 见进程地址空间意义.
3.7.4. 进程地址空间
3.7.4.1. 进程地址空间的概念
进程地址空间: 主要指的是每个进程所对应自己的虚拟地址空间的集合.
进程地址空间:
进程地址空间特指地址空间中的虚拟地址空间, 包括操作系统为每一个进程分配的独立的, 虚拟的内存区域, 这个区域包含了进程运行所需代码, 数据, 对, 栈空间等, 并且每个进程都有自己独立的地址空间, 以确保进程之间的内存相互隔离.
简单来说, 寄存你哼地址空间就类似于每个进程自己的"小世界", 在这个小世界当中, 进程可以自由访问自己的内存资源, 不会干扰到其他进程, 因为这个地址空间是虚拟的, 不对应实际的物理内存. 进程地址空间使得每个进程都认为自己拥有整个计算机的内存空间,而实际上,物理内存是被多个进程共享的。进程地址空间通过页表等机制与物理内存进行映射,以实现进程的内存访问和隔离。
地址空间:
地址空间包含虚拟地址空间和物理地址空间. 是指任何一个计算机实体(如外设、文件、服务器或网络计算机)所占用的内存大小的表示.
地址空间和进程地址空间的关系:
请注意, 虚拟地址空间和地址空间是两个东西, 两者是包含于的关系. 地址空间包含进程地址空间.
3.7.4.2. 进程地址空间的意义
进程地址空间,也即我们通常所说的虚拟地址空间,在计算机系统中扮演着至关重要的角色。以下是对其意义的详细阐述:
3.7.4.2.1. 内存隔离与保护:
虚拟地址空间为每个进程提供了一个独立的内存视图。这意味着,尽管多个进程可能同时运行在同一物理内存上,但它们的内存空间是相互隔离的。这种隔离机制有效地防止了进程间的非法内存访问,从而增强了系统的安全性和稳定性。
例如,一个进程崩溃时,它的内存空间被回收,但这不会影响其他进程的内存和数据。再比如, 对于不合理的非法请求, 可以在虚拟内存这一阶段进行拦截, 而不是到了真正的物理内存时候才进行拦截, 如果真的到了物理内存才进行拦截, 很容易造成进程间相互干扰(比如越界访问).
上面只是相对笼统的说了一例子, 我们下面来用一个具体的例子来说明地址空间意义内存隔离与保护的意义.
再比如, 我们C语言中常常写的一段代码: char* str = "hello world"; *str = "hello linux";我想不出意外, 一般情况下程序都会直接挂掉(程序崩溃).
下面来从进程地址空间这个角度来进行解释.
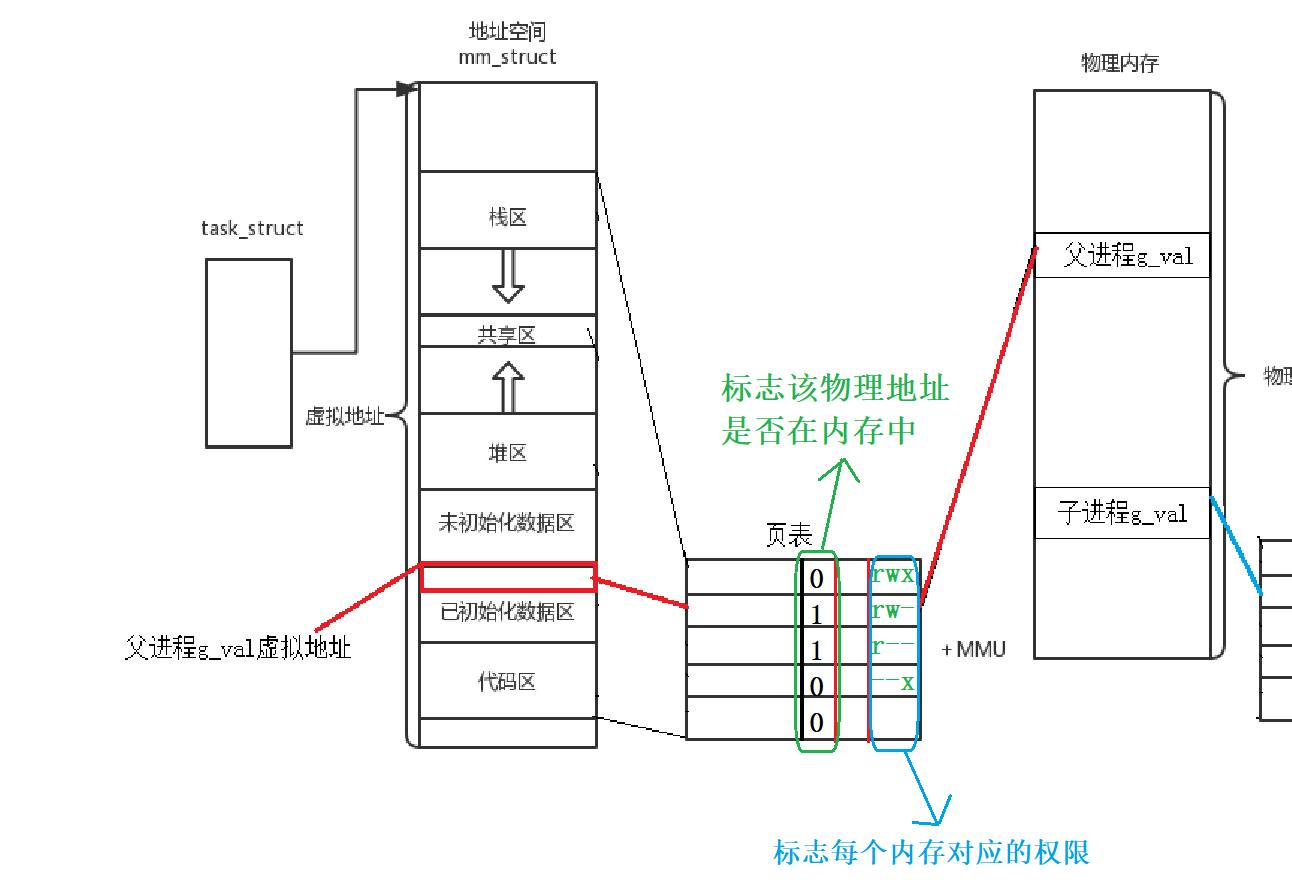
看上面图片, 当我们写下上面str的代码之后, 很显然str指向的是进程地址空间的已初始化数据区(字符串常量区), 当我们解引用的时候, CPU会根据task_strcut找到对应的虚拟地址空间, 之后来到页表, 页表的左边是虚拟地址, 右边是物理地址, 除此之外, 页表中还有标志该地址的权限, 因为字符串常量只有读权限, 而我们解引用是写权限, 这样因为权限冲突的问题操作系统会直接把这个进程挂掉, 因为他不满足权限, 我们用户层看到的就是程序崩溃. 实际上这是因为操作系统考量到物理内存的安全性而做的决策.
3.7.4.2.2. 内存管理简化和灵活化:
内存简化: 虚拟地址空间还为程序员提供了一种简化的内存管理模型。程序员可以不必担心物理内存的具体布局和分配情况,而只需关注虚拟地址空间中的内存布局和访问权限。这种模型降低了内存管理的复杂性,使得程序员能够更专注于程序的逻辑和功能实现。
内存简化举例: 内存简化是具体如何简化的呢? 为了理解内存简化, 我们举个例子.
假如说现在有一个进程, 这个进程的很多数据不是一下就申请的, 而是一步一步, 或者说分批进行申请的, 所以实际的物理内存肯定是相当杂乱的, 比如说下图:
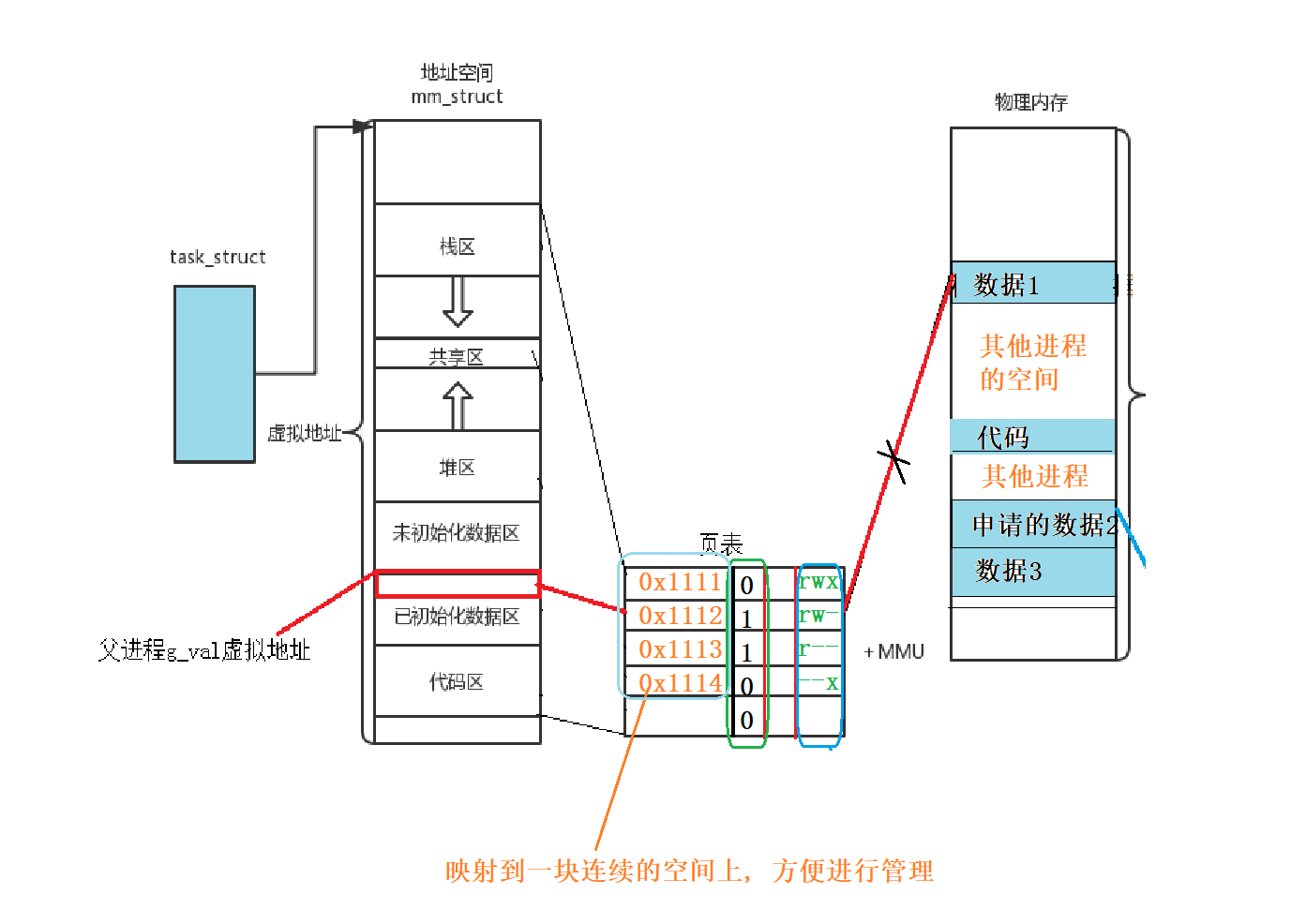
你看, 我们通过虚拟内存的形式, 把在实际内存当中的物理内存映射到一块区域, 是不是对于我们程序员来说, 也对于程序进行执行的时候是不是简单多了, 因为相对于分散的空间, 往往连续的内存空间更加方便管理, 对于程序员来说也更加简化.
内存管理灵活化: 通过虚拟地址空间,操作系统可以更灵活地管理内存。它可以根据进程的需求动态地分配和回收内存,而无需关心物理内存的实际布局。这种灵活性使得操作系统能够更有效地利用物理内存,提高内存资源的利用率。
内存管理举例: 什么意思呢? 相比上面只是笼统的说还是不是很理解, 因此下面再举一个具体的例子来进行理解: 我们的进程挂起就是一个内存管理灵活化的例子.
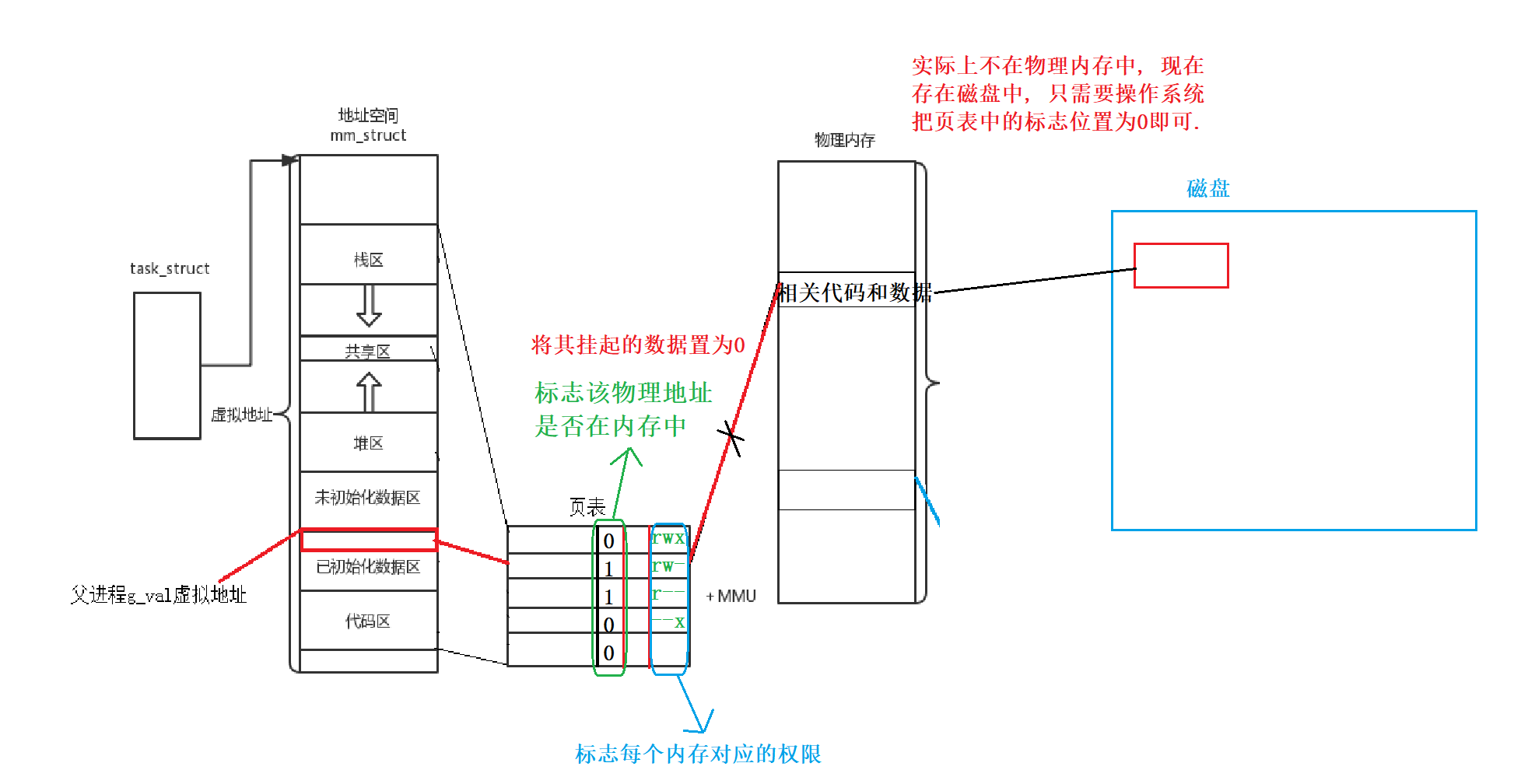
进程挂起: 是指将进程暂时从内存中移除或停止执行,以便让出资源给其他进程或进行其他操作。而进程挂起的具体实现就是通过地址空间结合页表实现的. 操作系统先停止该进程, 把一个进程对应的代码和数据放到磁盘中, 之后会在页表中把"挂起"的数据的虚拟地址的是否存在物理地址中的值置为"0", 表示该内容不在物理内存当中.
这个就是集成管理更加灵活的一个例子, 正因为有了"中间层"地址空间, 以及页表的存在才让进程挂起变得方便灵活起来.
3.7.4.2.3. 实现写时拷贝:
实现写时拷贝: 在进程创建(如通过fork系统调用)时,虚拟地址空间还支持写时拷贝机制。这意味着,在子进程创建之初,它与父进程共享相同的内存内容(但实际上是共享相同的页表项,指向相同的物理页面)。当子进程或父进程尝试修改这些共享内容时,操作系统才会为修改者创建一个新的物理页面,并更新其页表以指向这个新页面。这种机制减少了内存的使用,提高了系统的效率。
概括实现写时拷贝的过程: 那具体是如何实现写时拷贝的呢? 我们简单来说一下实现写时拷贝的过程:
假如说, 现在有下面代码:
int g_val = 100;int main()
{int count = 5;pid_t id = fork();if(id == 0){//childwhile(1){printf("%d\n", g_val); if(count == 0){g_val = 200;} sleep(1);}}else{//parentwhile(1){printf("%d\n", g_val); sleep(1);}}return 0;
}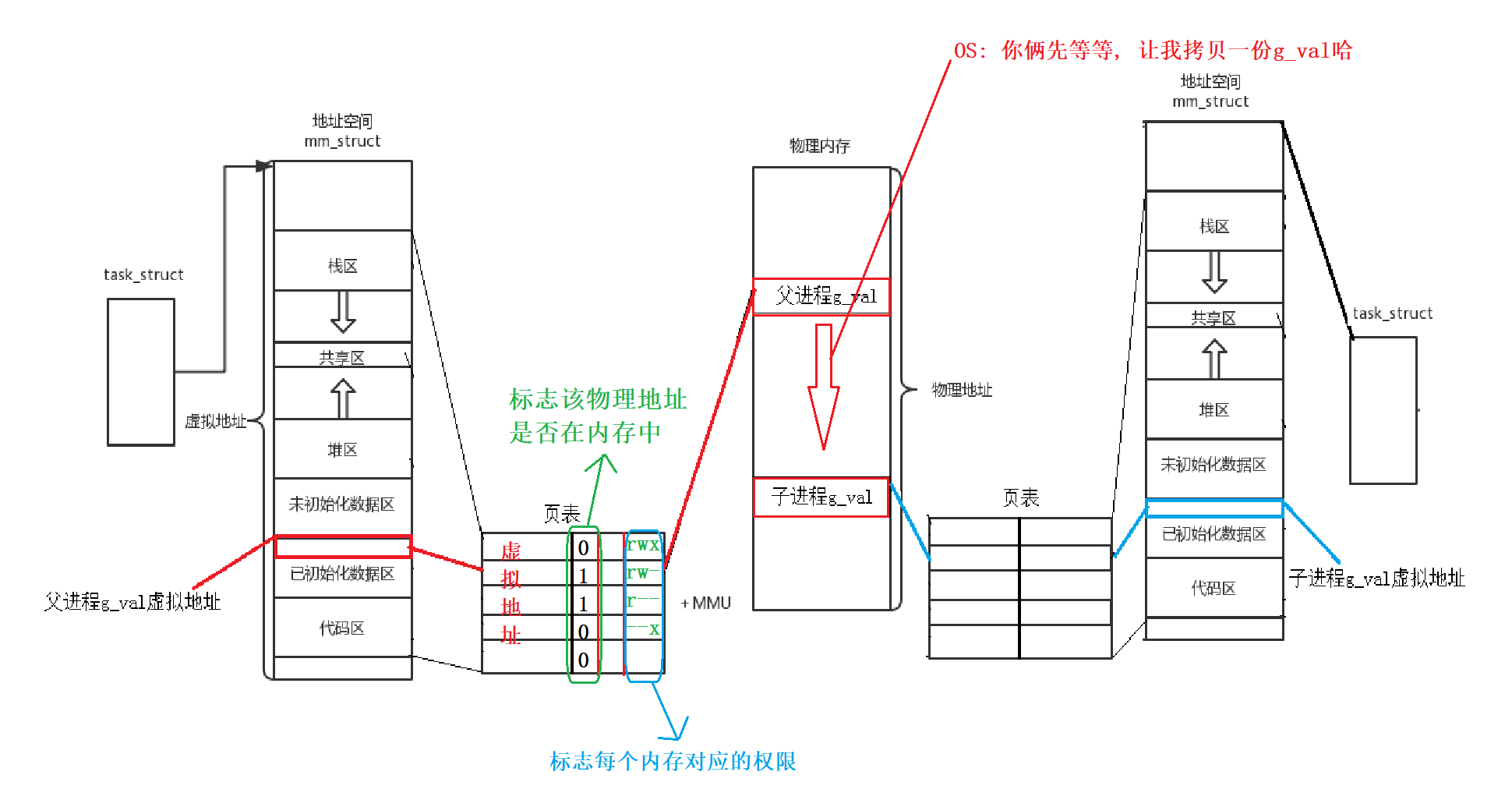
上面代码当大概在第五秒的时候, 会发生写时拷贝, 过程是这样的: 刚开始的时候, 操作系统会把两个进程对g_val的权限设置为只读, 当需要进行w的时候, 很明显发生了权限不一致, 此时操作系统判断是不是需要进行写时拷贝, 是不是发生异常需要终止进程, 是不是数据被挂起了??? 当认定为两个及两个以上程序访问该变量, 并且有个进程单独对其修改了, 此时操作系统暂停两个进程, 之后把g_val拷贝一份物理空间, 修改页表, 给到修改g_val的进程. 之后修改g_val的进程继续修改即可.
我们可以明白, 也正是有了虚拟地址空间和页表的存在, 才实现了写时拷贝, 也正因为有了写时拷贝, 才使得内存使用效率大大提高!
3.7.4.2.4. 支持多任务处理:
支持多任务处理: 虚拟地址空间使得操作系统能够同时运行多个进程,每个进程都有自己的地址空间。这样,即使多个进程在同时访问内存,它们也不会相互干扰。这种特性为多任务处理提供了有力的支持,使得计算机能够同时处理多个任务,提高了系统的并发性和吞吐量。
3.7.4.3. 进程地址空间初始化内容的由来
我们不妨来思考一下, 进程地址空间不能是操作系统申请一块空间丢给进程就拉到了吧? 对于每一个进程, 进程地址空间(也就是虚拟内存)肯定是不一样的, 所以说这些初始化内容是从哪里来的呢?
进程地址空间的初始化内容来源于二进制可执行文件:
实际上, 我们的程序经过平坦模式编译, 还在磁盘中的时候, 已经是二进制文件吧, 那对于这个二进制文件里面的变量名, 函数名全都变成了地址, 这个地址是虚拟地址, 所以我们操作系统在给每个进程创建进程地址空间的时候, 只需要把程序二进制文件中的地址按内容分到各个区域就好了. 一般二进制可执行文件中的地址放在磁盘中的时候我们叫逻辑地址, 而到了内存中, 改成"虚拟地址"这个称呼了.
之后, 操作系统再创建物理内存空间, 把对应物理地址填到每个进程的页表中即可.
3.8. Linux下进程的调度
我们说的是Linux内核版本2.6.11下的大O(1)调度算法, 这个调度算法时间复杂度可以几乎达到O(1)的水平. 我们所谈论的Linux操作系统是一种分时操作系统, 该系统的基本原则是对于每一个进程强调公平性, 而有些操作系统是实时操作系统, 强调实时概念.
下面是调度队列的结构图:
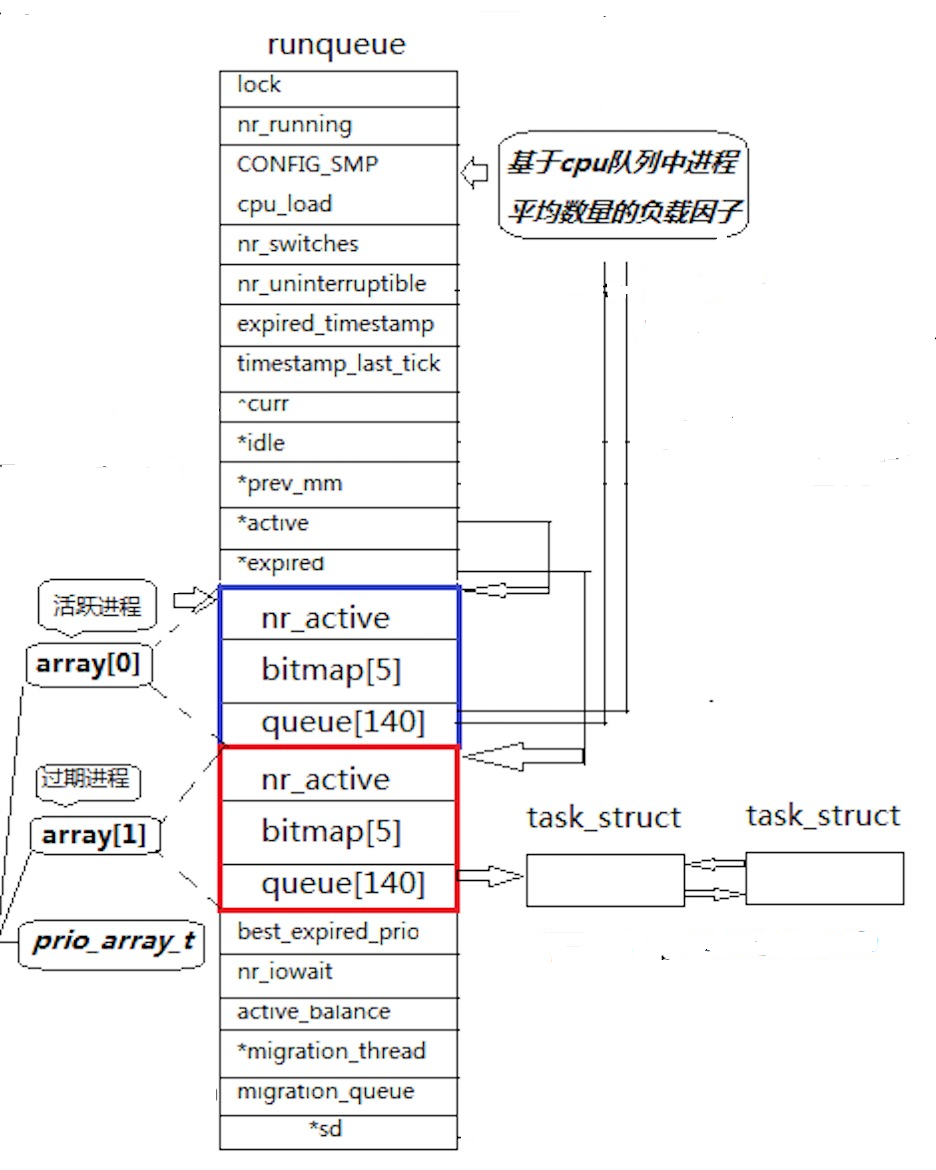
前面我们说过, Linux操作系统对于调度为了学习的考量我们只说Linux的调度队列只是一个简单的队列, CPU从这个队列的头到尾依次执行, 显然没有这么简单, 下面来说一下具体Linux内核是如何调度进程的?
Linux进程队列不是一个简单的队列, 而是一个复杂的结构体, 这个结构体中有一个数组, 叫array[2]; 显然这是一个数组, 数组中的第一个元素指向我们的活跃进程, 这个活跃进程包含nr_active, bitmap[5], 和queue[140]分别表示下面含义:
- nr_active: 当前活跃的任务或资源的数量
- queue[140]: 这是一个struct task_struct* queue[140], 里面的每个元素可以指向一个队列. 通常, 我们只用到后面100到139为下标的元素, 来对应优先级为60到99的进程. 如果是多个优先级为99的进程, 都会被链接到139下标的链表下.
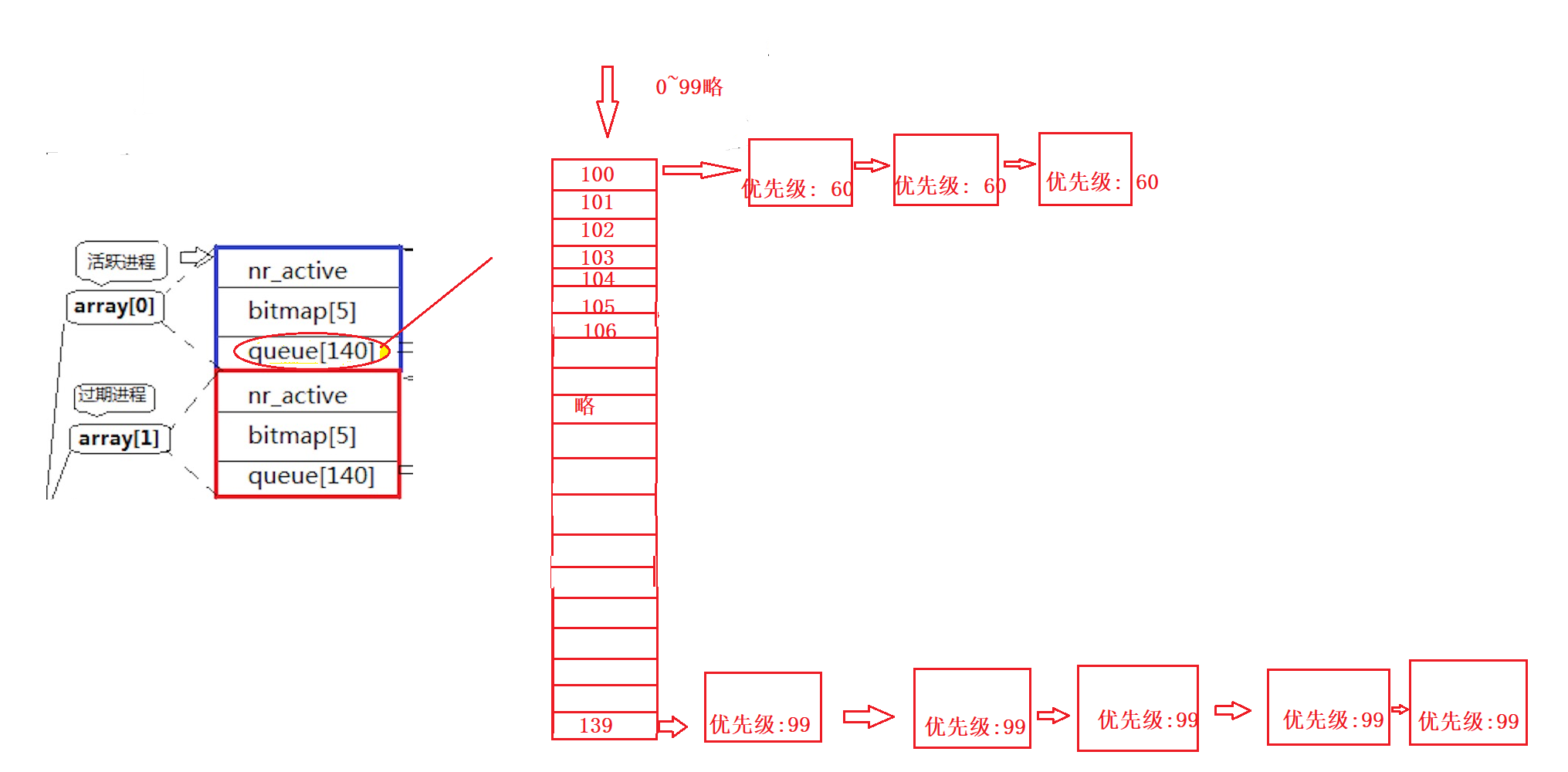
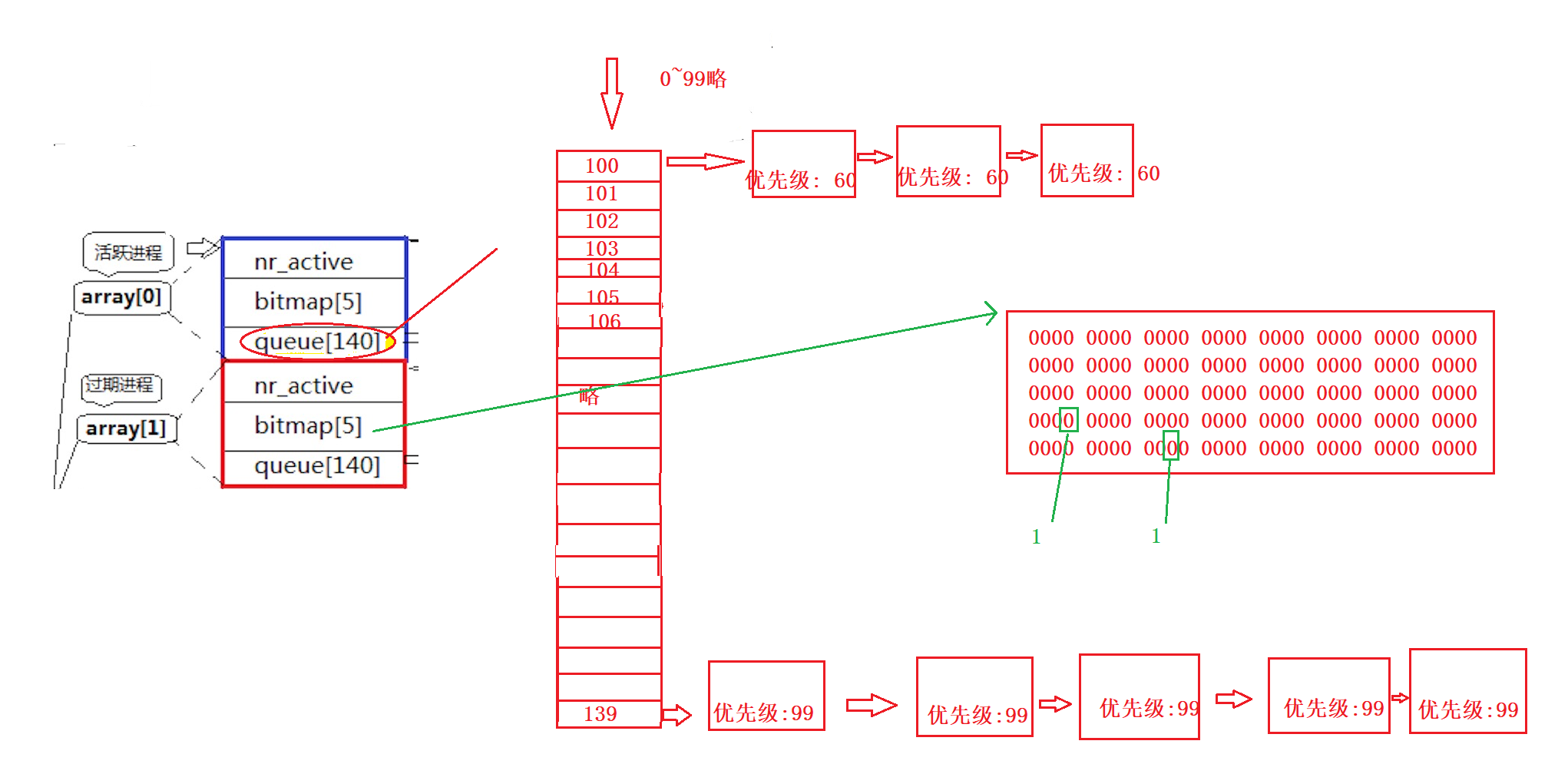
- bitmap[5]: 是一个位图, 即用5个long大小的数组来表示queue[140]中的一百四十个链表是否有内容, 如果有内容, 就把对应比特位设置为1, 如果没有就是0. 通过这种方式, 操作系统只需要查询5次(每次查32位)即可知道是否还有进程待执行, 不需要依次进行遍历.
除了array[0]这个结构体之外, 还有个结构体就是array[1], 这是一个过期结构体, 里面的结构与上卖弄介绍的活跃进程是一样的.
当array[0]内的进程是活跃进程时, 进程只出不进, 新建进程都在array[1]中, 当CPU把array[0]中的进程都执行完毕之后, 指向array[0]和array[1]的两个指针交换, array[0]变成过期进程, 进程只进不出, array变成活跃进程, 进程只出不进.
就是如此, 当array[1]被执行完之后, 活跃进程和过期进程的角色再次进行交换, 如此就完成了进程调度的轮转.
拓展: Linux的进程优先级 NI 和 PR
相关文章:
第三讲 Linux进程概念
1. 冯诺依曼体系结构 我们买了笔记本电脑, 里面是有很多硬件组成的, 比如硬盘, 显示器, 内存, 主板... 这些硬件不是随便放在一起就行的, 而是按照一定的结构进行组装起来的, 而具体的组装结构, 一般就是冯诺依曼体系结构 1.1. 计算机的一般工作逻辑 我们都知道, 计算机的逻…...

stm32-c8t6实现语音识别(LD3320)
目录 LD3320介绍: 功能引脚 主要特色功能 通信协议 端口信息 开发流程 stm32c8t6代码 LD3320驱动代码: LD3320介绍: 内置单声道mono 16-bit A/D 模数转换内置双声道stereo 16-bit D/A 数模转换内置 20mW 双声道耳机放大器输出内置 5…...

Vue作用域插槽
下面,我们来系统的梳理关于 **Vue 作用域插槽 ** 的基本知识点: 一、作用域插槽核心概念 1.1 什么是作用域插槽? 作用域插槽是 Vue 中一种反向数据流机制,允许子组件将数据传递给父组件中的插槽内容。这种模式解决了传统插槽中父组件无法访问子组件内部状态的限制。 1.2…...

「数据分析 - NumPy 函数与方法全集」【数据分析全栈攻略:爬虫+处理+可视化+报告】
- 第 104 篇 - Date: 2025 - 06 - 05 Author: 郑龙浩/仟墨 NumPy 函数与方法全集 文章目录 NumPy 函数与方法全集1. 数组创建与初始化基础创建序列生成特殊数组 2. 数组操作形状操作合并与分割 3. 数学运算基础运算统计运算 4. 随机数生成基础随机分布函数 5. 文件IO文件读写 …...
爬虫学习记录day1
什么是逆向? 数据加密 参数加密 表单加密扣js改写Python举例子 4.1 元素:被渲染的数据资源 动态数据 静态数据 如果数据是加密的情况则无法直接得到数据 4.2 控制台:输出界面 4.3 源代码页面 4.4 网络:抓包功能,获取浏…...
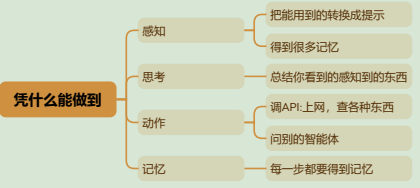
agent基础概念
agent是什么 我个人认为agent并没有一个所谓完美的定义,它是一个比较活的概念,就像是你眼中的一个机器人你希望它做什么事,和我眼中的机器人它解决事情的流程,其实是可以完全不同的,没有必要非得搞一个统一的概念或流程来概况它。但我们依然可以概况几个通用的词来描述它…...

MS8312A 车规 精密、低噪、CMOS、轨到轨输入输出运算放大器,用于传感器、条形扫描器
MS8312A 车规 精密、低噪、CMOS、轨到轨输入输出运算放大器,用于传感器、条形扫描器 简述 MS8312A 是双通道的轨到轨输入输出单电源供电运放。它们具有低的失调电压、低的输入电压电流噪声和宽的信号带宽。 低失调、低噪、低输入偏置电流和宽带宽的特性结合使得 …...

计算机二级Python考试的核心知识点总结
以下是计算机二级Python考试的核心知识点总结,结合高频考点和易错点分类整理: 1. **数据类型与运算** ▷ 不可变类型:int, float, str, tuple(重点区分list与tuple) ▷ 运算符优先级:** > * /…...
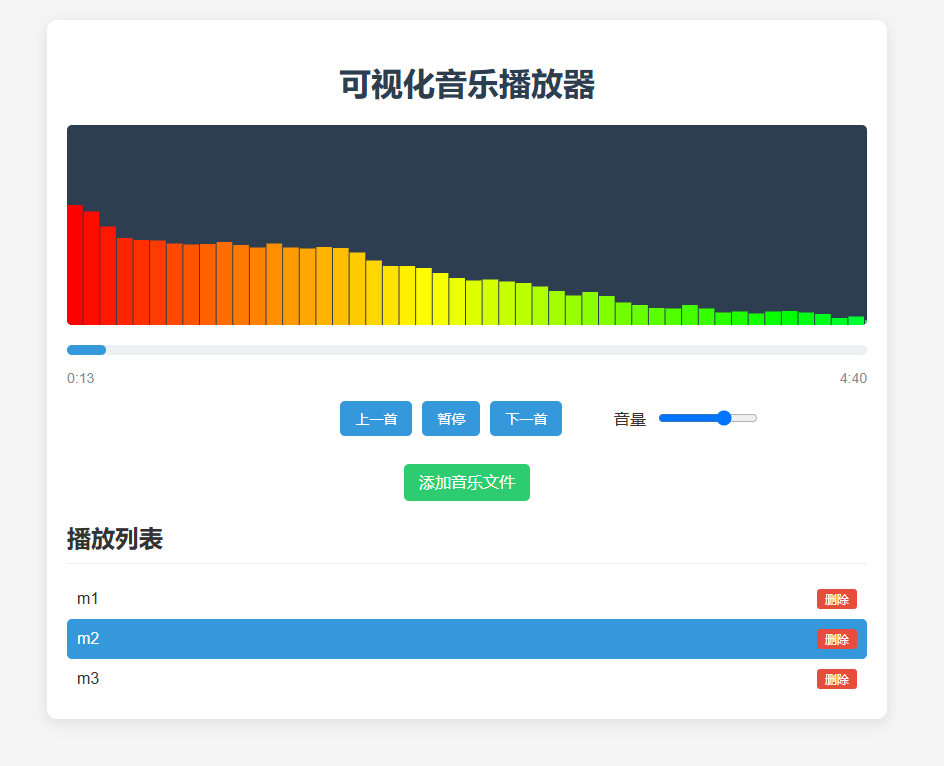
让音乐“看得见”:使用 HTML + JavaScript 实现酷炫的音频可视化播放器
在这个数字时代,音乐不仅是听觉的享受,更可以成为视觉的盛宴!本文用 HTML + JavaScript 实现了一个音频可视化播放器,它不仅能播放本地音乐、控制进度和音量,还能通过 Canvas 绘制炫酷的音频频谱图,让你“听见色彩,看见旋律”。 效果演示 核心功能 本项目主要包含以下…...
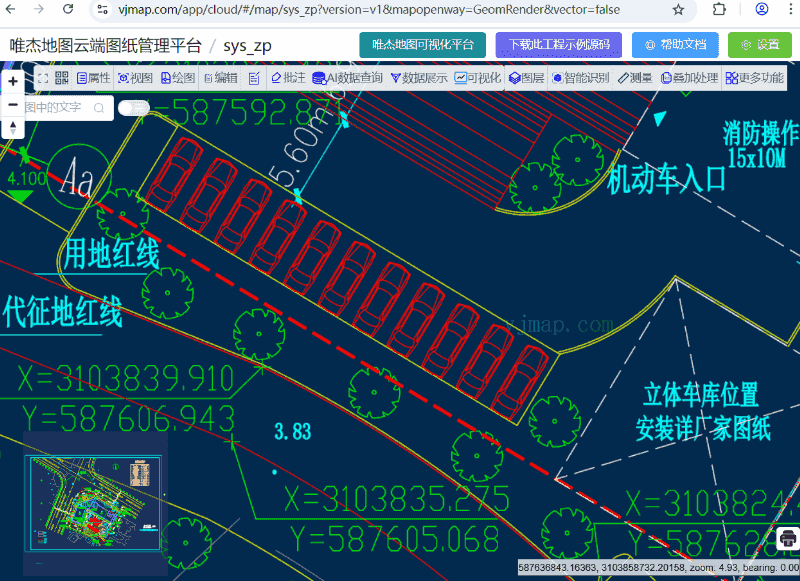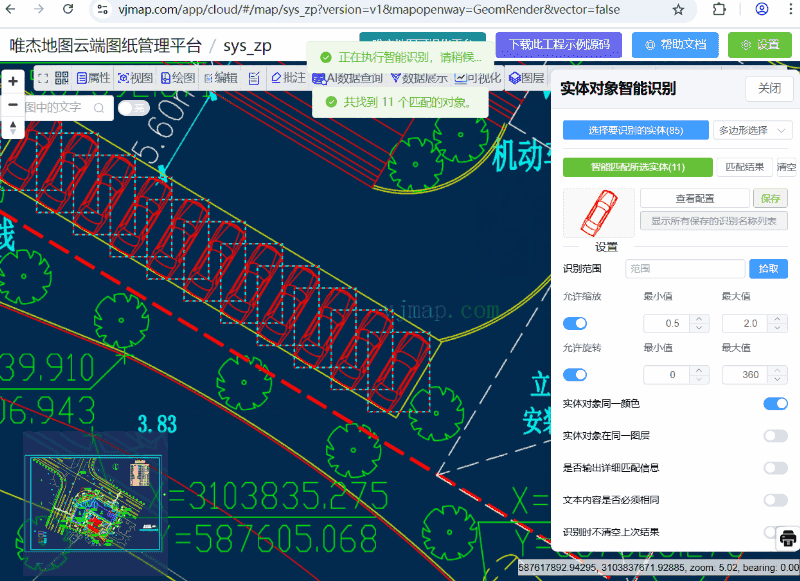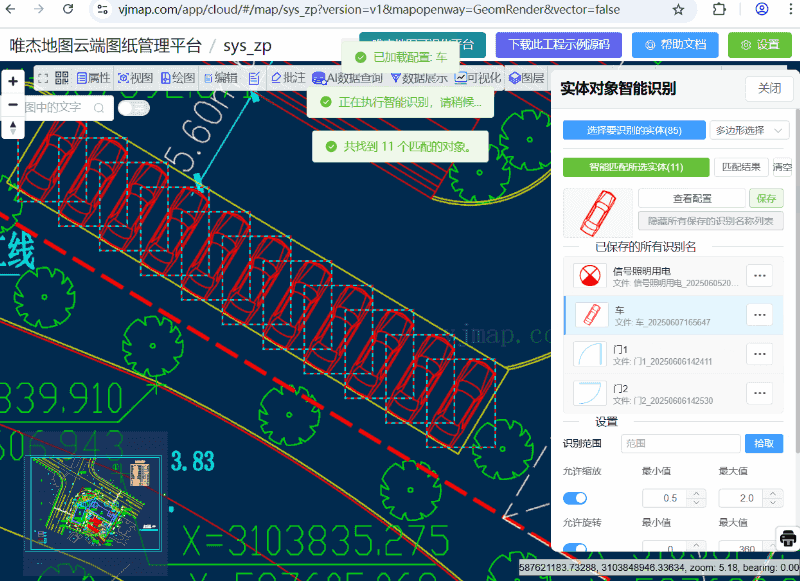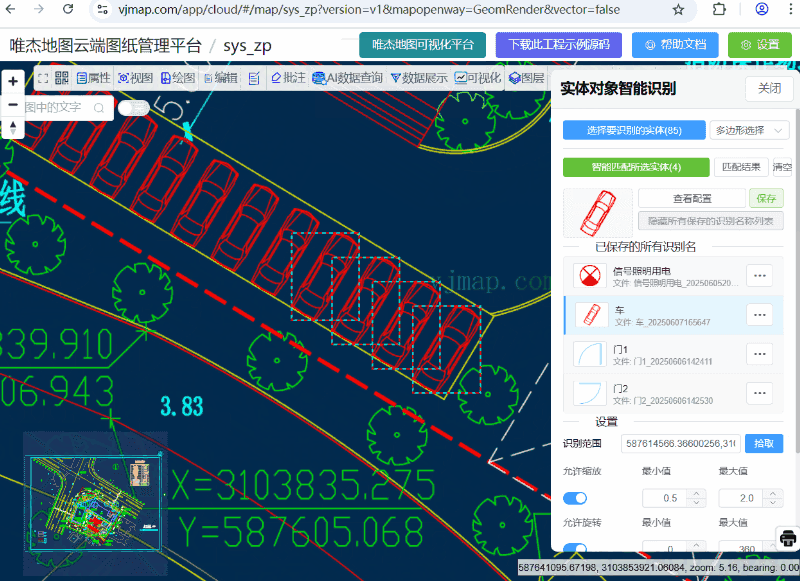
CAD实体对象智能识别
CAD实体对象智能识别 概述 实体对象智能识别能够在CAD图纸中智能识别和匹配相似的实体对象。该系统采用模式匹配算法,支持几何变换(缩放、旋转),并提供了丰富的配置选项和可视化界面。 系统提供两种主要的识别方式:…...
)
MySQL中的部分问题(2)
索引失效 运算或函数影响列的使用 当查询条件中对索引列用了函数或运算,索引会失效。 例:假设有索引:index idx_name (name) select * from users where upper(name) ALICE; -- 索引失效因为upper(name)会对列内容进行函数处理…...

【从前端到后端导入excel文件实现批量导入-笔记模仿芋道源码的《系统管理-用户管理-导入-批量导入》】
批量导入预约数据-笔记 前端场馆列表后端 前端 场馆列表 该列表进入出现的是这样的,这儿是列表操作 <el-table-column label"操作" align"center" width"220px"><template #default"scope"><el-buttonlinktype"…...
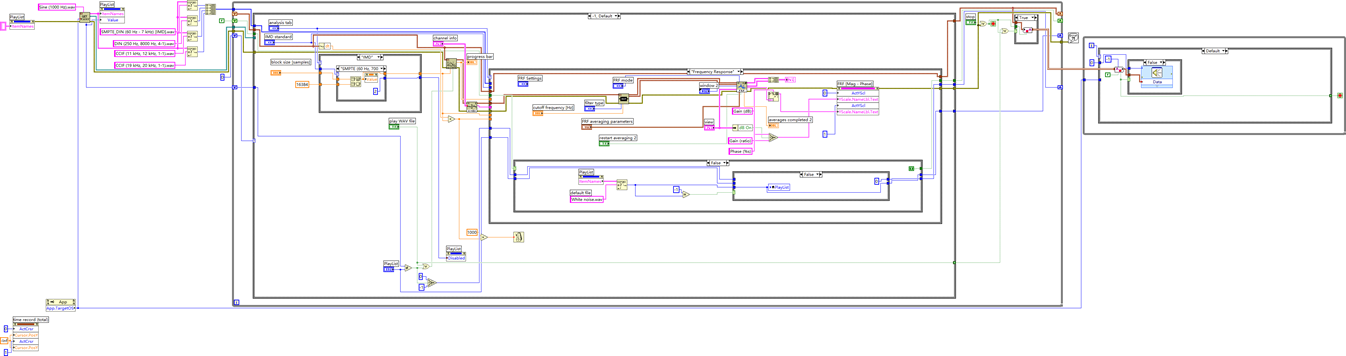
LabVIEW音频测试分析
LabVIEW通过读取指定WAV 文件,实现对音频信号的播放、多维度测量分析功能,为音频设备研发、声学研究及质量检测提供专业工具支持。 主要功能 文件读取与播放:支持持续读取示例数据文件夹内的 WAV 文件,可实时播放音频以监听被测信…...

MySQL 8.0 绿色版安装和配置过程
MySQL作为云计算时代,被广泛使用的一款数据库,他的安装方式有很多种,有yum安装、rpm安装、二进制文件安装,当然也有本文提到的绿色版安装,因绿色版与系统无关,且可快速复制生成,具有较强的优势。…...
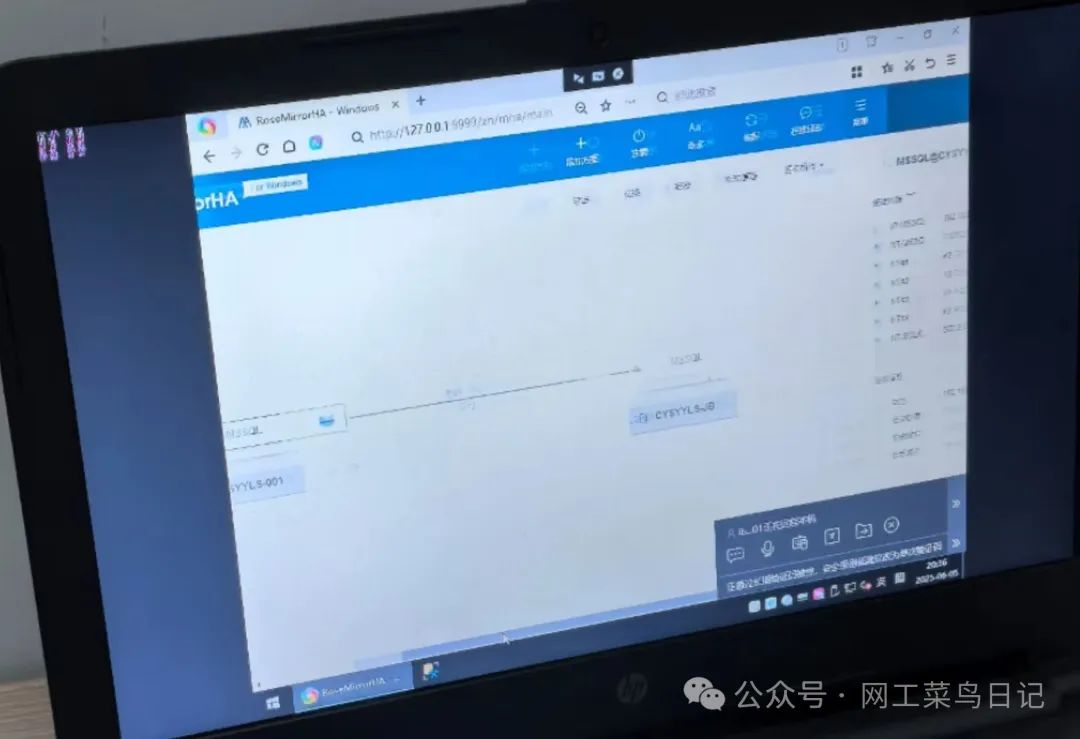
RoseMirrorHA 双机热备全解析
在数字化时代,企业核心业务系统一旦瘫痪,每分钟可能造成数万甚至数十万的损失。想象一下,如果银行的交易系统突然中断,或者医院的挂号系统无法访问,会引发怎样的连锁反应?为了守护这些关键业务,…...

day 18进行聚类,进而推断出每个簇的实际含义
浙大疏锦行 对聚类的结果根据具体的特征进行解释,进而推断出每个簇的实际含义 两种思路: 你最开始聚类的时候,就选择了你想最后用来确定簇含义的特征, 最开始用全部特征来聚类,把其余特征作为 x,聚类得到…...

pandas 字符串存储技术演进:从 object 到 PyArrow 的十年历程
文章目录 1. 引言2. 阶段1:原始时代(pandas 1.0前)3. 阶段2:Python-backed StringDtype(pandas 1.0 - 1.3)4. 阶段3:PyArrow初次尝试(pandas 1.3 - 2.1)5. 阶段4…...

LLMs 系列科普文(6)
截止到目前,我们从模型预训练阶段的数据准备讲起,谈到了 Tokenizer、模型的结构、模型的训练,基础模型、预训练阶段、后训练阶段等,这里存在大量的术语或名词,也有一些奇奇怪怪或者说是看起来乱七八糟的内容。这期间跳…...

exp1_code
#include <iostream> using namespace std; // 链栈节点结构 struct StackNode { int data; StackNode* next; StackNode(int val) : data(val), next(nullptr) {} }; // 顺序栈实现 class SeqStack { private: int* data; int top; int capac…...
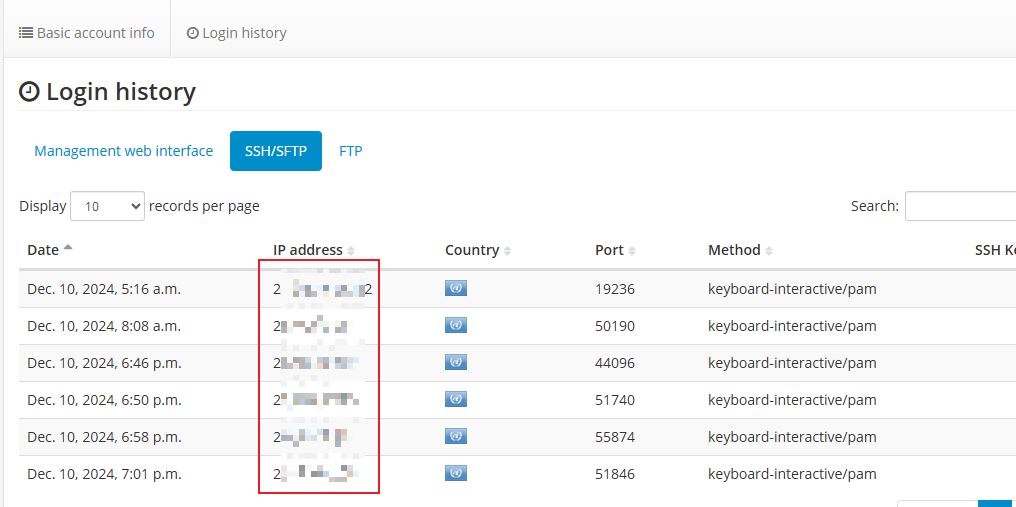
serv00 ssh登录保活脚本-邮件通知版
适用于自己有服务器情况,ssh定时登录到serv00,并在登录成功后发送邮件通知 msmtp 和 mutt安装 需要安装msmtp 和 mutt这两个邮件客户端并配置,参考如下文章前几步是讲配置这俩客户端的,很简单,不再赘述 用Shell脚本实…...

意识上传伦理前夜:我们是否在创造数字奴隶?
当韩国财阀将“数字永生”标价1亿美元准入权时,联合国预警的“神经种姓制度”正从科幻步入现实。某脑机接口公司用户协议中“上传意识衍生算法归公司所有”的隐藏条款,恰似德里达预言的当代印证:“当意识沦为可交易数据流,主体性便…...

【AIGC】RAGAS评估原理及实践
【AIGC】RAGAS评估原理及实践 (1)准备评估数据集(2)开始评估2.1 加载数据集2.2 评估忠实性2.3 评估答案相关性2.4 上下文精度2.5 上下文召回率2.6 计算上下文实体召回率 RAGas(RAG Assessment)RAG 评估的缩写ÿ…...
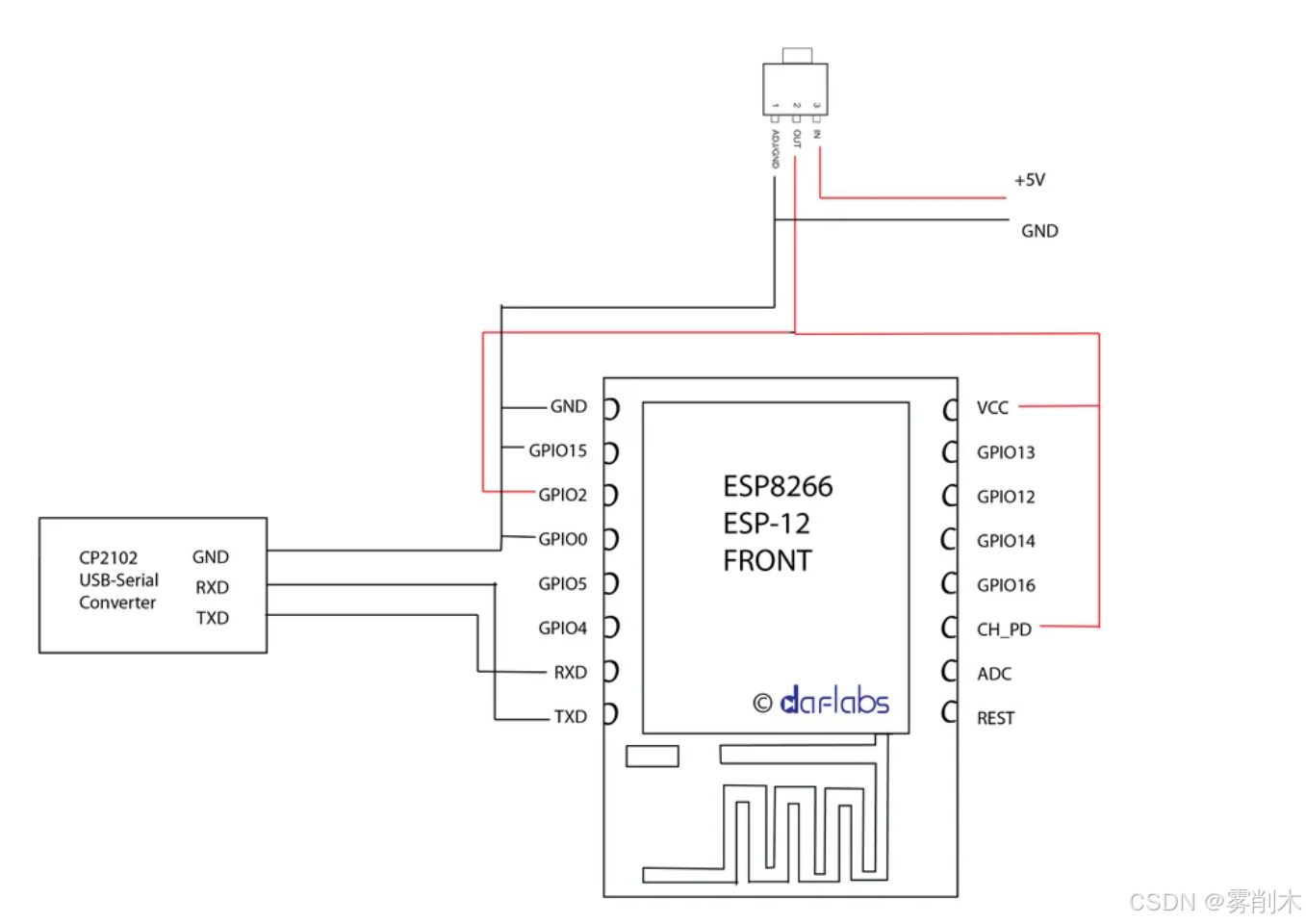
ESP12E/F 参数对比
模式GPIO0GPIO2GPIO15描述正常启动高高低从闪存运行固件闪光模式低高低启用固件刷写 PinNameFunction1RSTReset (Active Low)2ADC (A0)Analog Input (0–1V)3EN (CH_PD)Chip Enable (Pull High for Normal Operation)4GPIO16Wake from Deep Sleep, General Purpose I/O5GPIO14S…...

第二十八章 字符串与数字
第二十八章 字符串与数字 计算机程序完全就是和数据打交道。很多编程问题需要使用字符串和数字这种更小的数据来解决。 参数扩展 第七章,已经接触过参数扩展,但未进行详细说明,大多数参数扩展并不用于命令行,而是出现在脚本文件中。 如果没有什么特殊原因,把参数扩展放…...
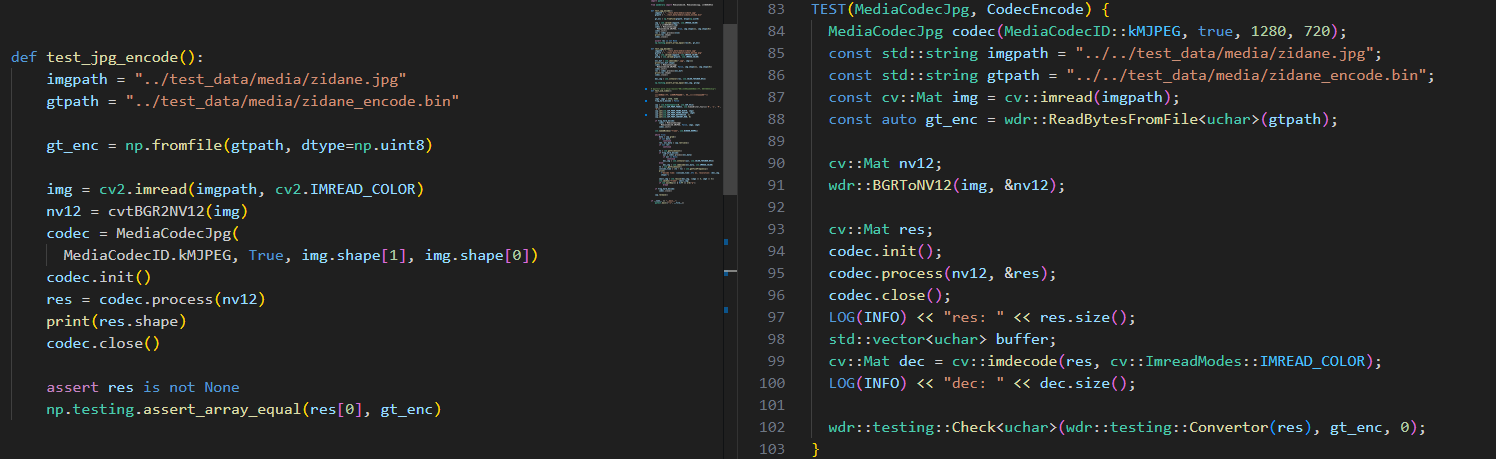
[RDK X5] MJPG编解码开发实战:从官方API到OpenWanderary库的C++/Python实现
业余时间一直在基于RDK X5搞一些小研究,需要基于高分辨率图像检测目标。实际落地时,在图像采集上遇到了个大坑。首先,考虑到可行性,我挑选了一个性价比最高的百元内摄像头,已确定可以在X5上使用,接下来就开…...

java复习 05
我的天啊一天又要过去了,没事的还有时间!!! 不要焦虑不要焦虑,事实证明只要我认真地投入进去一切都还是来得及的,代码多实操多复盘,别叽叽喳喳胡思乱想多多思考,有迷茫前害怕后的功…...

aardio 简单网页自动化
WebView自动化,以前每次重复做网页登录、搜索这些操作时都觉得好麻烦,现在终于能让程序替我干活了,赶紧记录下这个超实用的技能! 一、初次接触WebView WebView自动化就像给程序装了个"网页浏览器",第一步得…...

打卡第39天:Dataset 和 Dataloader类
知识点回顾: 1.Dataset类的__getitem__和__len__方法(本质是python的特殊方法) 2.Dataloader类 3.minist手写数据集的了解 作业:了解下cifar数据集,尝试获取其中一张图片 import torch import torch.nn as nn import…...

【评测】Qwen3-Embedding模型初体验
每一篇文章前后都增加返回目录 回到目录 【评测】Qwen3-Embedding模型初体验 模型的介绍页面 本机配置:八代i5-8265U,16G内存,无GPU核显运行,win10操作系统 ollama可以通过下面命令拉取模型: ollama pull modelscope…...

BeanFactory 和 FactoryBean 有何区别与联系?
导语: Spring 是后端面试中的“常青树”,而 BeanFactory 与 FactoryBean 的关系更是高频卡人点。很多候选人混淆两者概念,答非所问,轻则失分,重则直接被“pass”。本文将从面试官视角,深入剖析这一经典问题…...