将 tensorflow keras 训练数据集转换为 Yolo 训练数据集
以 https://www.kaggle.com/datasets/vipoooool/new-plant-diseases-dataset 为例
1. 图像分类数据集文件结构 (例如用于 yolov11n-cls.pt 训练)
import os
import csv
import random
from PIL import Image
from sklearn.model_selection import train_test_split
import shutil# ====================== 配置参数 ======================
# 从 Kaggle Hub 下载植物病害数据集
# https://www.kaggle.com/datasets/vipoooool/new-plant-diseases-dataset
import kagglehub
tf_download_path = kagglehub.dataset_download("vipoooool/new-plant-diseases-dataset")
print("Path to dataset files:", tf_download_path)
# 定义数据集路径
tf_dataset_path = f"{tf_download_path}/New Plant Diseases Dataset(Augmented)/New Plant Diseases Dataset(Augmented)"INPUT_DATA_DIR = tf_dataset_path # 输入数据集路径(解压后的根目录)
OUTPUT_YOLO_DIR = "./runs/traindata/yolo/yolo_plant_diseases_classify" # 输出YOLO数据集路径
if os.path.exists(OUTPUT_YOLO_DIR):shutil.rmtree(OUTPUT_YOLO_DIR)
os.makedirs(OUTPUT_YOLO_DIR, exist_ok=True)TRAIN_SIZE = 0.8 # 训练集比例
IMAGE_EXTENSIONS = [".JPG", ".jpg", ".jpeg", ".png"] # 支持的图像扩展名# ====================== 类别映射(需根据实际数据集调整) ======================
# 从原数据集的类别名称生成映射(示例:假设病害类别为文件夹名)
def get_class_mapping(data_dir):class_names = []for folder in os.listdir(data_dir):folder_path = os.path.join(data_dir, folder)if os.path.isdir(folder_path) and not folder.startswith("."):class_names.append(folder)class_names.sort() # 按字母序排序,确保类别编号固定return {cls: idx for idx, cls in enumerate(class_names)}# ====================== 划分数据集并保存 ======================
def save_dataset(annotations, class_map, output_dir, train_size=0.8):# 划分训练集和验证集random.shuffle(annotations)split_idx = int(len(annotations) * train_size)train_data = annotations[:split_idx]val_data = annotations[split_idx:]# 创建目录结构os.makedirs(os.path.join(output_dir, "train"), exist_ok=True)os.makedirs(os.path.join(output_dir, "val"), exist_ok=True)for cls in class_map.keys():os.makedirs(os.path.join(output_dir, "train", cls), exist_ok=True)os.makedirs(os.path.join(output_dir, "val", cls), exist_ok=True)# 保存训练集for data in train_data:img_path = data["image_path"]cls = data["class_name"]try:shutil.copy2(img_path, os.path.join(output_dir, "train", cls))print(f"图像 {img_path} 复制到训练集 {cls} 类成功")except Exception as e:print(f"图像 {img_path} 复制到训练集 {cls} 类失败,错误信息: {e}")# 保存验证集for data in val_data:img_path = data["image_path"]cls = data["class_name"]try:shutil.copy2(img_path, os.path.join(output_dir, "val", cls))print(f"图像 {img_path} 复制到验证集 {cls} 类成功")except Exception as e:print(f"图像 {img_path} 复制到验证集 {cls} 类失败,错误信息: {e}")# 生成类别名文件(classes.names)with open(os.path.join(output_dir, "classes.names"), "w") as f:for cls in class_map.keys():f.write(f"{cls}\n")# 生成数据集配置文件(dataset.yaml)yaml_path = os.path.join(output_dir, "dataset.yaml")with open(yaml_path, "w") as f:f.write(f"path: {output_dir}\n") # 数据集根路径f.write(f"train: train\n") # 训练集路径(相对于path)f.write(f"val: val\n") # 验证集路径# f.write(f"test: images/test\n") # 测试集路径(如果有)f.write(f"nc: {len(class_map)}\n") # 类别数# 修改 names 字段输出格式class_names = list(class_map.keys())f.write(f"names: {class_names}\n")return train_data, val_data# ====================== 主函数 ======================
if __name__ == "__main__":# 1. 检查输入路径是否存在if not os.path.exists(INPUT_DATA_DIR):raise FileNotFoundError(f"请先下载数据集并解压到路径:{INPUT_DATA_DIR}")# 2. 获取类别映射(假设图像按类别存放在子文件夹中)class_map = get_class_mapping(os.path.join(INPUT_DATA_DIR, "train")) # 假设训练集图像在train子文件夹中,每个子文件夹为一个类别# 3. 解析标注(仅按文件夹分类)annotations = []for cls, idx in class_map.items():cls_dir = os.path.join(INPUT_DATA_DIR, "train", cls) # 假设类别文件夹路径为train/类别名for img_file in os.listdir(cls_dir):if any(img_file.lower().endswith(ext) for ext in IMAGE_EXTENSIONS):img_path = os.path.join(cls_dir, img_file)annotations.append({"image_path": img_path,"class_name": cls})# 4. 保存为YOLO格式train_data, val_data = save_dataset(annotations, class_map, OUTPUT_YOLO_DIR, train_size=TRAIN_SIZE)print(f"✅ 转换完成!YOLO数据集已保存至:{OUTPUT_YOLO_DIR}")print(f"类别数:{len(class_map)},训练集样本数:{len(train_data)},验证集样本数:{len(val_data)}")train的时候,使用的文件夹
2. 目标检测数据集文件结构 (例如用于 yolo11n.pt 训练)
import os
import csv
import random
from PIL import Image
from sklearn.model_selection import train_test_split
import shutil# ====================== 配置参数 ======================
# 从 Kaggle Hub 下载植物病害数据集
# https://www.kaggle.com/datasets/vipoooool/new-plant-diseases-dataset
import kagglehub
tf_download_path = kagglehub.dataset_download("vipoooool/new-plant-diseases-dataset")
print("Path to dataset files:", tf_download_path)
# 定义数据集路径
tf_dataset_path = f"{tf_download_path}/New Plant Diseases Dataset(Augmented)/New Plant Diseases Dataset(Augmented)"INPUT_DATA_DIR = tf_dataset_path # 输入数据集路径(解压后的根目录)
OUTPUT_YOLO_DIR = "./traindata/yolo/yolo_plant_diseases" # 输出YOLO数据集路径
if os.path.exists(OUTPUT_YOLO_DIR):shutil.rmtree(OUTPUT_YOLO_DIR)
os.makedirs(OUTPUT_YOLO_DIR, exist_ok=True)TRAIN_SIZE = 0.8 # 训练集比例
IMAGE_EXTENSIONS = [".JPG", ".jpg", ".jpeg", ".png"] # 支持的图像扩展名# ====================== 类别映射(需根据实际数据集调整) ======================
# 从原数据集的类别名称生成映射(示例:假设病害类别为文件夹名)
def get_class_mapping(data_dir):class_names = []for folder in os.listdir(data_dir):folder_path = os.path.join(data_dir, folder)if os.path.isdir(folder_path) and not folder.startswith("."):class_names.append(folder)class_names.sort() # 按字母序排序,确保类别编号固定return {cls: idx for idx, cls in enumerate(class_names)}# ====================== 解析CSV标注(假设标注在CSV中) ======================
def parse_csv_annotations(csv_path, class_map, image_dir):annotations = []with open(csv_path, "r", encoding="utf-8") as f:reader = csv.DictReader(f)for row in reader:image_name = row["image_path"]class_name = row["disease_class"] # 需与CSV中的类别列名一致x_min = float(row["x_min"])y_min = float(row["y_min"])x_max = float(row["x_max"])y_max = float(row["y_max"])# 检查图像是否存在image_path = os.path.join(image_dir, image_name)if not os.path.exists(image_path):continue# 获取图像尺寸with Image.open(image_path) as img:img_width, img_height = img.size# 转换为YOLO坐标center_x = (x_min + x_max) / 2 / img_widthcenter_y = (y_min + y_max) / 2 / img_heightwidth = (x_max - x_min) / img_widthheight = (y_max - y_min) / img_heightannotations.append({"image_path": image_path,"class_id": class_map[class_name],"bbox": (center_x, center_y, width, height)})return annotations# ====================== 划分数据集并保存 ======================
def save_dataset(annotations, class_map, output_dir, train_size=0.8):# 划分训练集和验证集random.shuffle(annotations)split_idx = int(len(annotations) * train_size)train_data = annotations[:split_idx]val_data = annotations[split_idx:]# 创建目录结构os.makedirs(os.path.join(output_dir, "images/train"), exist_ok=True)os.makedirs(os.path.join(output_dir, "images/val"), exist_ok=True)os.makedirs(os.path.join(output_dir, "labels/train"), exist_ok=True)os.makedirs(os.path.join(output_dir, "labels/val"), exist_ok=True)# 保存训练集for data in train_data:img_path = data["image_path"]lbl_path = os.path.join(output_dir, "labels/train",os.path.splitext(os.path.basename(img_path))[0] + ".txt")# 复制图像try:shutil.copy2(img_path, os.path.join(output_dir, 'images/train'))print(f"图像 {img_path} 复制到训练集成功")except Exception as e:print(f"图像 {img_path} 复制到训练集失败,错误信息: {e}")# 保存标注with open(lbl_path, "w") as f:f.write(f"{data['class_id']} {' '.join(map(str, data['bbox']))}\n")# 保存验证集for data in val_data:img_path = data["image_path"]lbl_path = os.path.join(output_dir, "labels/val",os.path.splitext(os.path.basename(img_path))[0] + ".txt")# 复制图像try:shutil.copy2(img_path, os.path.join(output_dir, 'images/val'))print(f"图像 {img_path} 复制到验证集成功")except Exception as e:print(f"图像 {img_path} 复制到验证集失败,错误信息: {e}")# 保存标注with open(lbl_path, "w") as f:f.write(f"{data['class_id']} {' '.join(map(str, data['bbox']))}\n")# 生成类别名文件(classes.names)with open(os.path.join(output_dir, "classes.names"), "w") as f:for cls in class_map.keys():f.write(f"{cls}\n")# 生成数据集配置文件(dataset.yaml)yaml_path = os.path.join(output_dir, "dataset.yaml")with open(yaml_path, "w") as f:f.write(f"path: {output_dir}\n") # 数据集根路径f.write(f"train: images/train\n") # 训练集路径(相对于path)f.write(f"val: images/val\n") # 验证集路径# f.write(f"test: images/test\n") # 测试集路径(如果有)f.write(f"nc: {len(class_map)}\n") # 类别数f.write("names:\n")for idx, cls in enumerate(class_map.keys()):f.write(f" {idx}: {cls}\n")return train_data, val_data# ====================== 主函数 ======================
if __name__ == "__main__":# 1. 检查输入路径是否存在if not os.path.exists(INPUT_DATA_DIR):raise FileNotFoundError(f"请先下载数据集并解压到路径:{INPUT_DATA_DIR}")# 2. 获取类别映射(假设图像按类别存放在子文件夹中,无CSV标注时使用此方法)# 若有CSV标注,需手动指定CSV路径和列名,注释掉下方代码并取消注释parse_csv_annotations部分class_map = get_class_mapping(os.path.join(INPUT_DATA_DIR, "train")) # 假设训练集图像在train子文件夹中,每个子文件夹为一个类别# 3. 解析标注(根据实际情况选择CSV或文件夹分类)# 情况A:无标注,仅按文件夹分类(弱监督,边界框为图像全尺寸)annotations = []for cls, idx in class_map.items():cls_dir = os.path.join(INPUT_DATA_DIR, "train", cls) # 假设类别文件夹路径为train/类别名for img_file in os.listdir(cls_dir):if any(img_file.lower().endswith(ext) for ext in IMAGE_EXTENSIONS):img_path = os.path.join(cls_dir, img_file)with Image.open(img_path) as img:img_width, img_height = img.size# 边界框为全图(弱监督场景,仅用于分类任务,非检测)annotations.append({"image_path": img_path,"class_id": idx,"bbox": (0.5, 0.5, 1.0, 1.0) # 全图边界框})# # 情况B:有CSV标注(需取消注释以下代码并调整参数)# CSV_PATH = os.path.join(INPUT_DATA_DIR, "labels.csv") # CSV标注文件路径# IMAGE_DIR = os.path.join(INPUT_DATA_DIR, "images") # 图像根目录# class_map = {"Apple Scab": 0, "Black Rot": 1, ...} # 手动定义类别映射# annotations = parse_csv_annotations(CSV_PATH, class_map, IMAGE_DIR)# 4. 保存为YOLO格式train_data, val_data = save_dataset(annotations, class_map, OUTPUT_YOLO_DIR, train_size=TRAIN_SIZE)print(f"✅ 转换完成!YOLO数据集已保存至:{OUTPUT_YOLO_DIR}")print(f"类别数:{len(class_map)},训练集样本数:{len(train_data)},验证集样本数:{len(val_data)}")train的时候,使用的yaml文件路径
相关文章:

将 tensorflow keras 训练数据集转换为 Yolo 训练数据集
以 https://www.kaggle.com/datasets/vipoooool/new-plant-diseases-dataset 为例 1. 图像分类数据集文件结构 (例如用于 yolov11n-cls.pt 训练) import os import csv import random from PIL import Image from sklearn.model_selection import train_test_split import s…...
MySQL学习笔记(6):分组查询,正则表达式)
(新手友好)MySQL学习笔记(6):分组查询,正则表达式
目录 分组查询 创建分组 过滤分组 分组查询练习 正则表达式 匹配单个实例 匹配多个实例 正则表达式练习 练习答案 分组查询练习答案 正则表达式练习答案 分组查询 创建分组 group by 子句:根据一个或多个字段对结果集进行分组,在分组的字段上…...

台式机电脑CPU天梯图2025年6月份更新:CPU选购指南及推荐
组装电脑选硬件的过程中,CPU的选择无疑是最关键的,因为它是最核心的硬件,关乎着一台电脑的性能好坏。对于小白来说,CPU天梯图方便直接判断两款CPU性能高低,准确的说,是多核性能。下面给大家分享一下台式机电脑CPU天梯图2025年6月版,来看看吧。 桌面CPU性能排行榜2025 台…...

【hadoop】Flink安装部署
一、单机模式 步骤: 1、使用XFTP将Flink安装包flink-1.13.5-bin-scala_2.11.tgz发送到master机器的主目录。 2、解压安装包: tar -zxvf ~/flink-1.13.5-bin-scala_2.11.tgz 3、修改文件夹的名字,将其改为flume,或者创建软连接…...
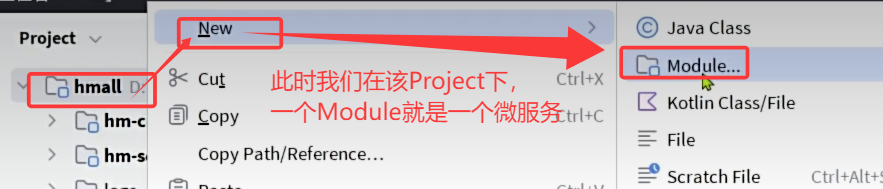
将单体架构项目拆分成微服务时的两种工程结构
一.独立Project 1.示意图 此时我们创建一个文件夹,在这个文件夹中,创建N个Project,每一个Project对应一个微服务,组成我们的最终的项目。 2.特点 适合那种超大型项目,比如淘宝,但管理负担比较重。 二.Mave…...

Unity3D 开发中的创新技术:解锁 3D 开发的新境界
在 3D 开发的广袤天地里,Unity3D 一直是众多开发者的得力伙伴。可如今,普通的开发方式似乎难以满足日益增长的创意与效率需求。你是否好奇,凭什么别家团队能用 Unity3D 打造出令人拍案叫绝的 3D 作品,自己却总感觉差了那么一点火候…...
UOS 20 Pro为国际版WPS设置中文菜单
UOS 20 Pro为国际版WPS设置中文菜单 查看UOS操作系统系统安装国际版wps并汉化方法1:下载zh_CN.tar.gz语言包方法2:手动从国内版wps12的包中提取中文菜单解压国内版wps的包 复制中文语言包到wps国际版目录下安装Windows字体 安装开源office 查看UOS操作系统系统 # 查…...

树莓派系统中设置固定 IP
在基于 Ubuntu 的树莓派系统中,设置固定 IP 地址主要有以下几种方法: 方法一:使用 Netplan 配置(Ubuntu 18.04 及以上版本默认使用 Netplan) 查看网络接口名称 在终端输入ip link或ip a命令,查看当前所使…...
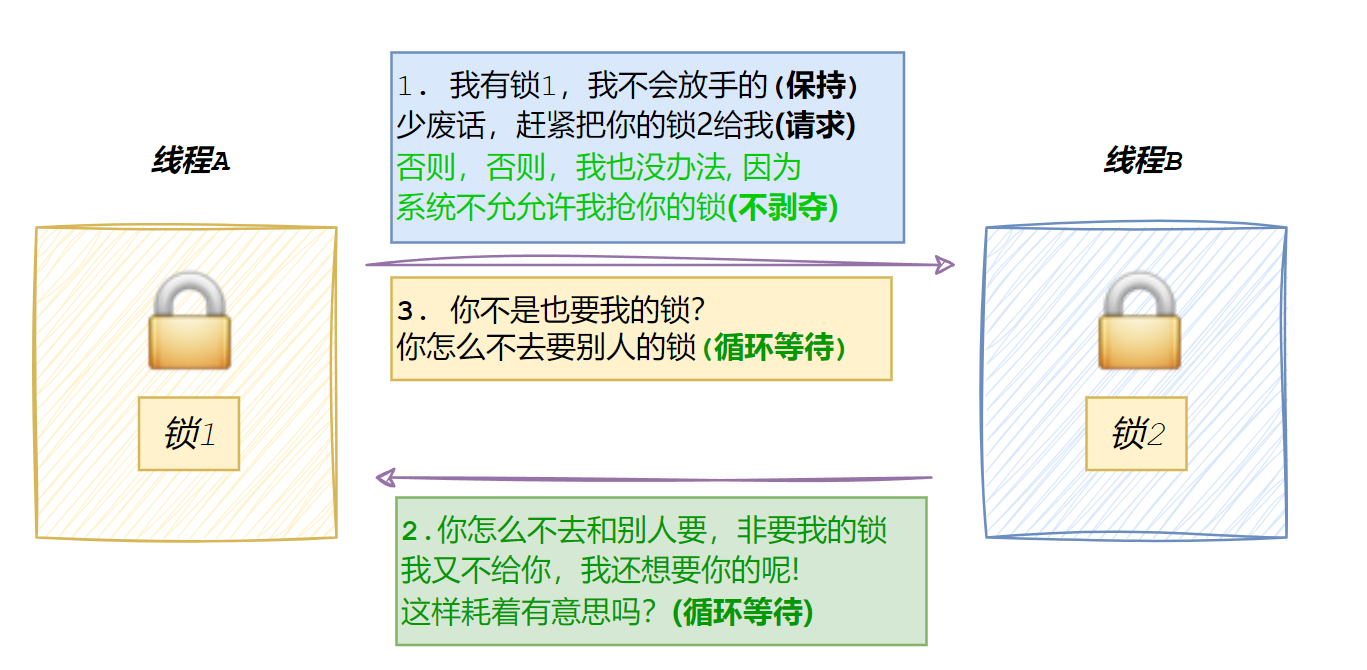
单例模式与锁(死锁)
目录 线程安全的单例模式 什么是单例模式 单例模式的特点 饿汉实现方式和懒汉实现方式 饿汉⽅式实现单例模式 懒汉⽅式实现单例模式 懒汉⽅式实现单例模式(线程安全版本) 单例式线程池 ThreadPool.hpp threadpool.cc 运行结果 线程安全和重⼊问题 常⻅锁概念 死…...

LLM基础2_语言模型如何文本编码
基于GitHub项目:https://github.com/datawhalechina/llms-from-scratch-cn 字节对编码(BPE) 上一篇博文说到 为什么GPT模型不需要[PAD]和[UNK]? GPT使用更先进的字节对编码(BPE),总能将词语拆分成已知子词 为什么需要BPE? 简…...

理解世界如淦泽,穿透黑幕需老谋
理解世界如淦泽,穿透黑幕需老谋 卡西莫多 2025年06月07日 安徽 极少主动跟别人提及恩师的名字,生怕自己比孙猴子不成器但又比它更能惹事的德行,使得老师跟着被拖累而脸上无光。不过老师没有象菩提祖师训诫孙猴子那样不能说出师傅的名字&a…...

如何确定微服务的粒度与边界
确定微服务的粒度与边界 在完成初步服务拆分之后,架构师往往会遇到另一个难题:该拆到多细?哪些功能可以归并为一个服务,哪些又必须单独部署?这就是“服务粒度与边界”的问题。本节将围绕实际架构经验,介绍…...
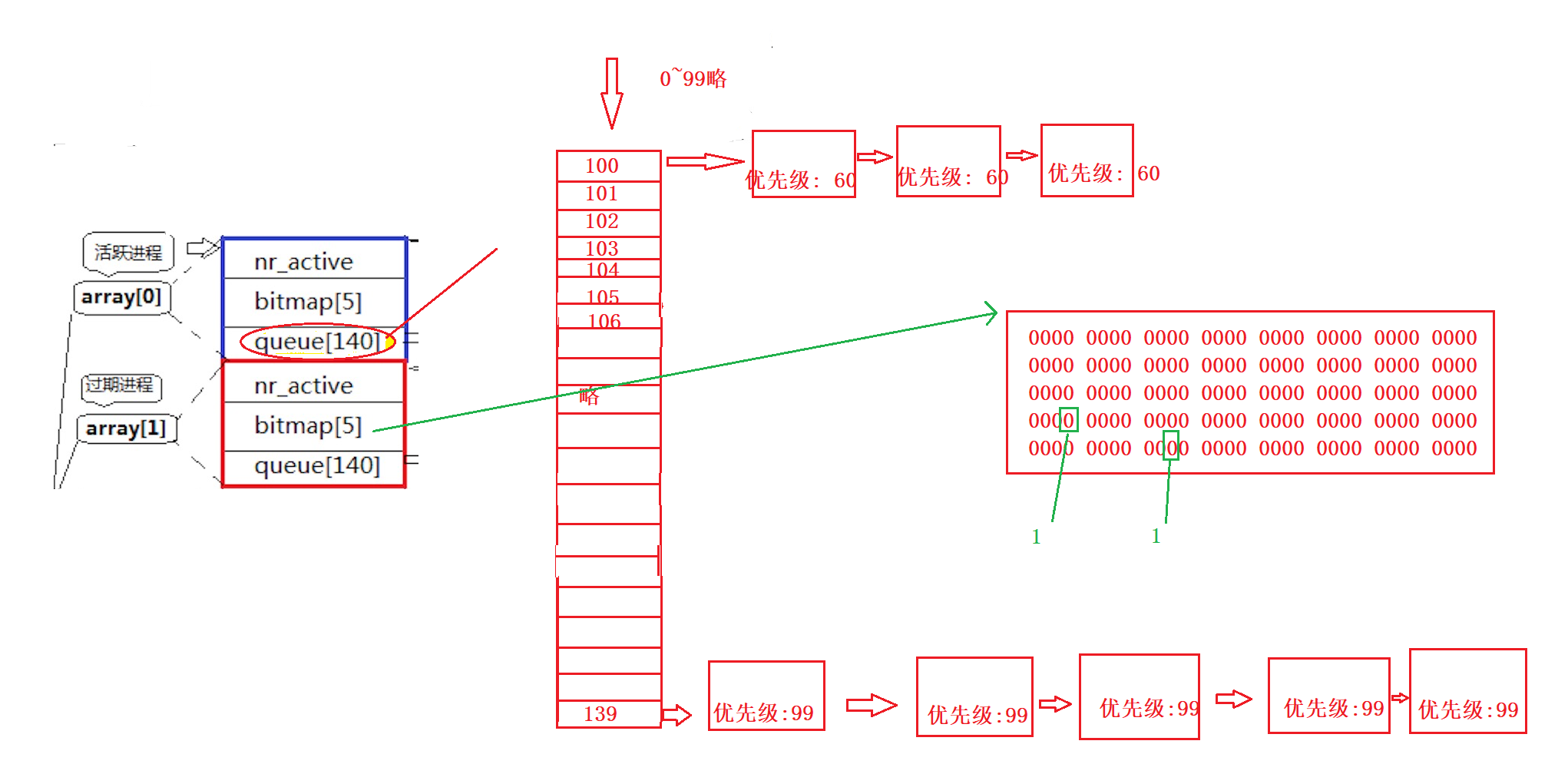
第三讲 Linux进程概念
1. 冯诺依曼体系结构 我们买了笔记本电脑, 里面是有很多硬件组成的, 比如硬盘, 显示器, 内存, 主板... 这些硬件不是随便放在一起就行的, 而是按照一定的结构进行组装起来的, 而具体的组装结构, 一般就是冯诺依曼体系结构 1.1. 计算机的一般工作逻辑 我们都知道, 计算机的逻…...

stm32-c8t6实现语音识别(LD3320)
目录 LD3320介绍: 功能引脚 主要特色功能 通信协议 端口信息 开发流程 stm32c8t6代码 LD3320驱动代码: LD3320介绍: 内置单声道mono 16-bit A/D 模数转换内置双声道stereo 16-bit D/A 数模转换内置 20mW 双声道耳机放大器输出内置 5…...

Vue作用域插槽
下面,我们来系统的梳理关于 **Vue 作用域插槽 ** 的基本知识点: 一、作用域插槽核心概念 1.1 什么是作用域插槽? 作用域插槽是 Vue 中一种反向数据流机制,允许子组件将数据传递给父组件中的插槽内容。这种模式解决了传统插槽中父组件无法访问子组件内部状态的限制。 1.2…...

「数据分析 - NumPy 函数与方法全集」【数据分析全栈攻略:爬虫+处理+可视化+报告】
- 第 104 篇 - Date: 2025 - 06 - 05 Author: 郑龙浩/仟墨 NumPy 函数与方法全集 文章目录 NumPy 函数与方法全集1. 数组创建与初始化基础创建序列生成特殊数组 2. 数组操作形状操作合并与分割 3. 数学运算基础运算统计运算 4. 随机数生成基础随机分布函数 5. 文件IO文件读写 …...
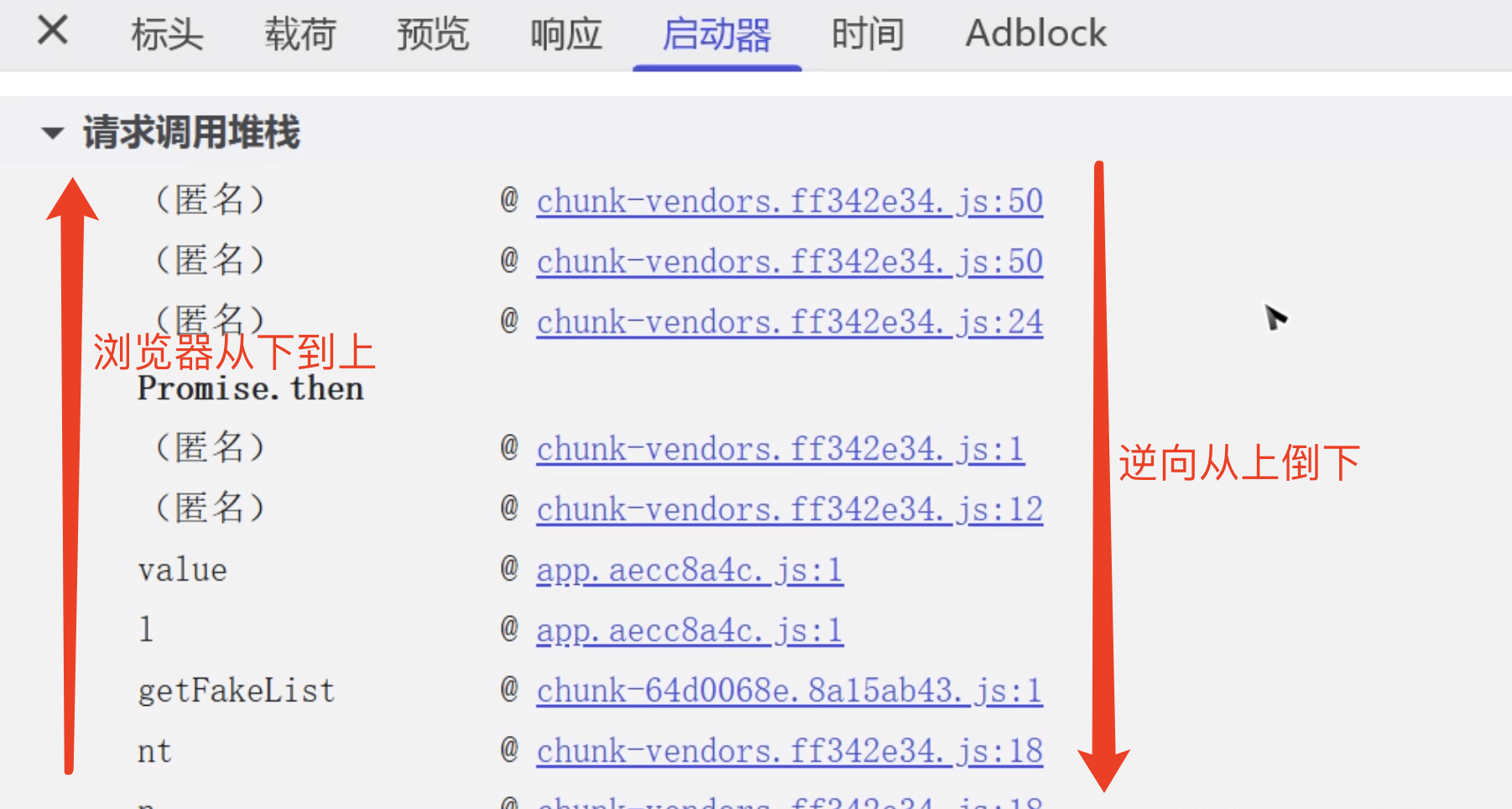
爬虫学习记录day1
什么是逆向? 数据加密 参数加密 表单加密扣js改写Python举例子 4.1 元素:被渲染的数据资源 动态数据 静态数据 如果数据是加密的情况则无法直接得到数据 4.2 控制台:输出界面 4.3 源代码页面 4.4 网络:抓包功能,获取浏…...
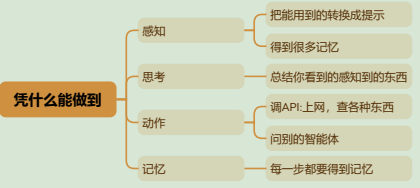
agent基础概念
agent是什么 我个人认为agent并没有一个所谓完美的定义,它是一个比较活的概念,就像是你眼中的一个机器人你希望它做什么事,和我眼中的机器人它解决事情的流程,其实是可以完全不同的,没有必要非得搞一个统一的概念或流程来概况它。但我们依然可以概况几个通用的词来描述它…...

MS8312A 车规 精密、低噪、CMOS、轨到轨输入输出运算放大器,用于传感器、条形扫描器
MS8312A 车规 精密、低噪、CMOS、轨到轨输入输出运算放大器,用于传感器、条形扫描器 简述 MS8312A 是双通道的轨到轨输入输出单电源供电运放。它们具有低的失调电压、低的输入电压电流噪声和宽的信号带宽。 低失调、低噪、低输入偏置电流和宽带宽的特性结合使得 …...

计算机二级Python考试的核心知识点总结
以下是计算机二级Python考试的核心知识点总结,结合高频考点和易错点分类整理: 1. **数据类型与运算** ▷ 不可变类型:int, float, str, tuple(重点区分list与tuple) ▷ 运算符优先级:** > * /…...
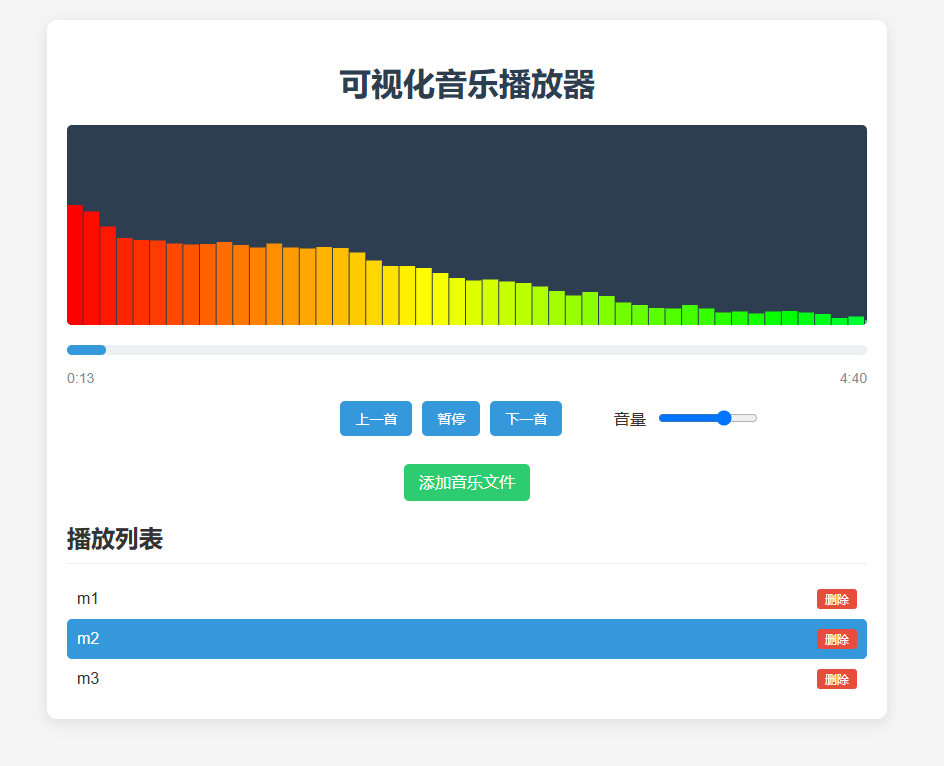
让音乐“看得见”:使用 HTML + JavaScript 实现酷炫的音频可视化播放器
在这个数字时代,音乐不仅是听觉的享受,更可以成为视觉的盛宴!本文用 HTML + JavaScript 实现了一个音频可视化播放器,它不仅能播放本地音乐、控制进度和音量,还能通过 Canvas 绘制炫酷的音频频谱图,让你“听见色彩,看见旋律”。 效果演示 核心功能 本项目主要包含以下…...
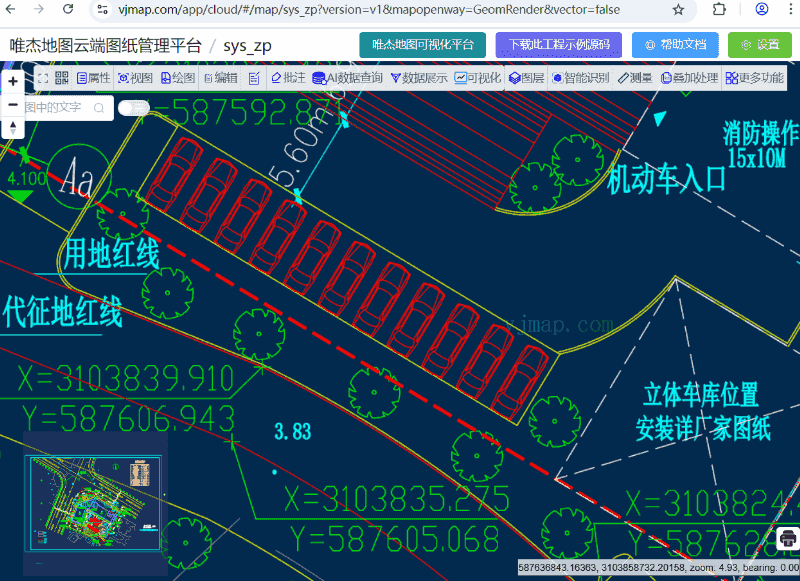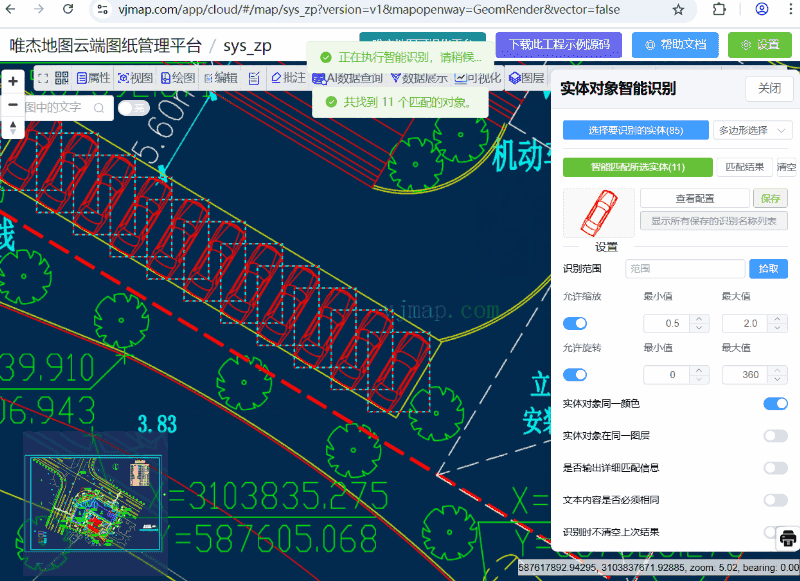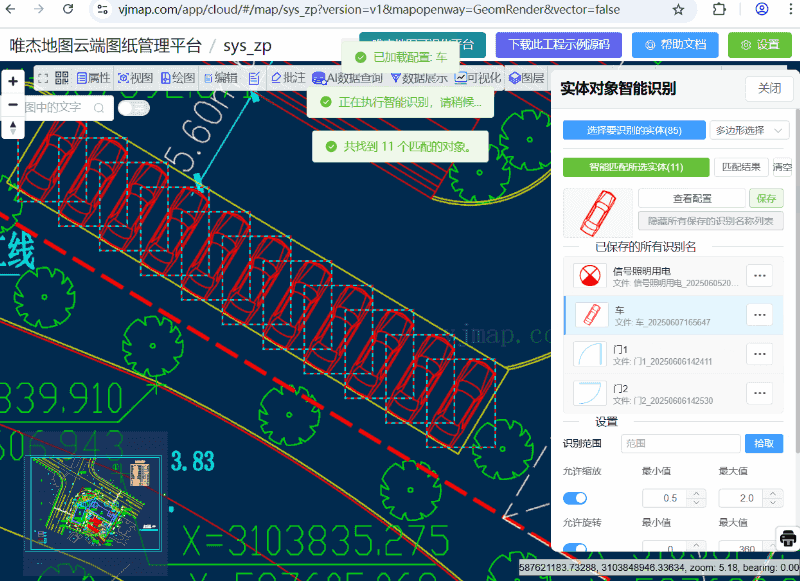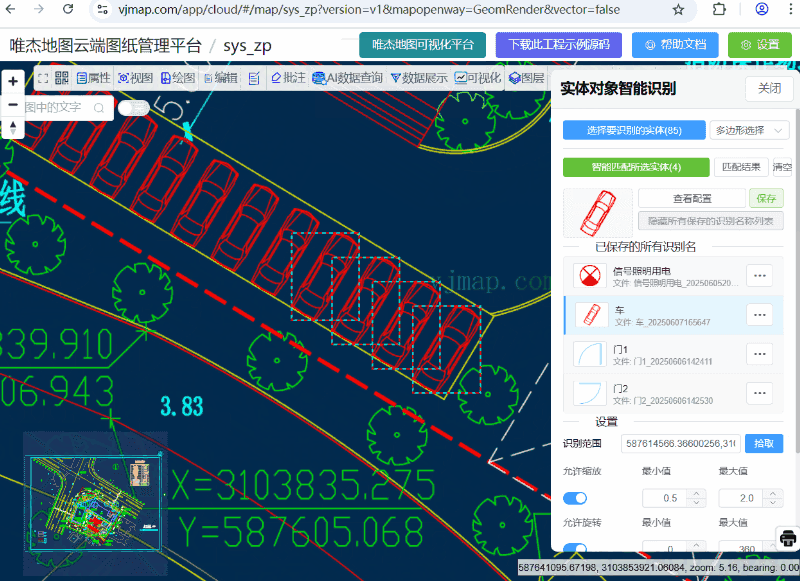
CAD实体对象智能识别
CAD实体对象智能识别 概述 实体对象智能识别能够在CAD图纸中智能识别和匹配相似的实体对象。该系统采用模式匹配算法,支持几何变换(缩放、旋转),并提供了丰富的配置选项和可视化界面。 系统提供两种主要的识别方式:…...
)
MySQL中的部分问题(2)
索引失效 运算或函数影响列的使用 当查询条件中对索引列用了函数或运算,索引会失效。 例:假设有索引:index idx_name (name) select * from users where upper(name) ALICE; -- 索引失效因为upper(name)会对列内容进行函数处理…...

【从前端到后端导入excel文件实现批量导入-笔记模仿芋道源码的《系统管理-用户管理-导入-批量导入》】
批量导入预约数据-笔记 前端场馆列表后端 前端 场馆列表 该列表进入出现的是这样的,这儿是列表操作 <el-table-column label"操作" align"center" width"220px"><template #default"scope"><el-buttonlinktype"…...
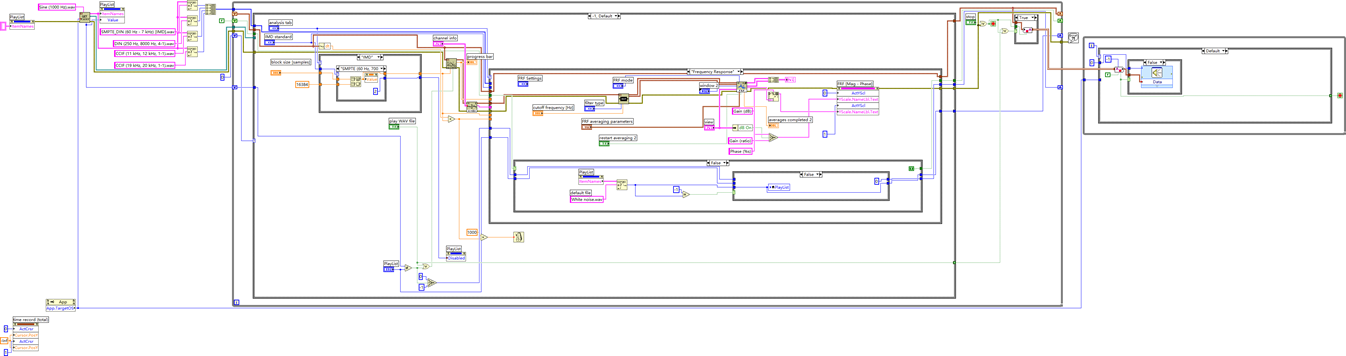
LabVIEW音频测试分析
LabVIEW通过读取指定WAV 文件,实现对音频信号的播放、多维度测量分析功能,为音频设备研发、声学研究及质量检测提供专业工具支持。 主要功能 文件读取与播放:支持持续读取示例数据文件夹内的 WAV 文件,可实时播放音频以监听被测信…...

MySQL 8.0 绿色版安装和配置过程
MySQL作为云计算时代,被广泛使用的一款数据库,他的安装方式有很多种,有yum安装、rpm安装、二进制文件安装,当然也有本文提到的绿色版安装,因绿色版与系统无关,且可快速复制生成,具有较强的优势。…...
RoseMirrorHA 双机热备全解析
在数字化时代,企业核心业务系统一旦瘫痪,每分钟可能造成数万甚至数十万的损失。想象一下,如果银行的交易系统突然中断,或者医院的挂号系统无法访问,会引发怎样的连锁反应?为了守护这些关键业务,…...

day 18进行聚类,进而推断出每个簇的实际含义
浙大疏锦行 对聚类的结果根据具体的特征进行解释,进而推断出每个簇的实际含义 两种思路: 你最开始聚类的时候,就选择了你想最后用来确定簇含义的特征, 最开始用全部特征来聚类,把其余特征作为 x,聚类得到…...

pandas 字符串存储技术演进:从 object 到 PyArrow 的十年历程
文章目录 1. 引言2. 阶段1:原始时代(pandas 1.0前)3. 阶段2:Python-backed StringDtype(pandas 1.0 - 1.3)4. 阶段3:PyArrow初次尝试(pandas 1.3 - 2.1)5. 阶段4…...

LLMs 系列科普文(6)
截止到目前,我们从模型预训练阶段的数据准备讲起,谈到了 Tokenizer、模型的结构、模型的训练,基础模型、预训练阶段、后训练阶段等,这里存在大量的术语或名词,也有一些奇奇怪怪或者说是看起来乱七八糟的内容。这期间跳…...