多模态大语言模型arxiv论文略读(110)

CoVLA: Comprehensive Vision-Language-Action Dataset for Autonomous Driving
➡️ 论文标题:CoVLA: Comprehensive Vision-Language-Action Dataset for Autonomous Driving
➡️ 论文作者:Hidehisa Arai, Keita Miwa, Kento Sasaki, Yu Yamaguchi, Kohei Watanabe, Shunsuke Aoki, Issei Yamamoto
➡️ 研究机构: Turing Inc.
➡️ 问题背景:自动驾驶技术面临的主要挑战之一是处理复杂和不可预测的驾驶环境,特别是那些罕见和复杂的驾驶场景。现有的多模态大语言模型(MLLMs)虽然在理解复杂环境和生成高级驾驶命令方面表现出潜力,但在端到端路径规划中的应用仍有限。主要的研究瓶颈是缺乏大规模的、结合视觉、语言和动作的标注数据集。
➡️ 研究动机:为了解决这一问题,研究团队提出了CoVLA(Comprehensive Vision-Language-Action)数据集,这是一个大规模的数据集,旨在克服现有数据集在规模和注释丰富性上的不足。CoVLA数据集通过自动化数据处理和字幕生成管道,创建了一个包含10,000个真实驾驶场景的丰富数据集,每个场景都有准确的驾驶路径和详细的自然语言描述。此外,研究团队还开发了CoVLA-Agent,一个基于VLA模型的路径规划模型,用于预测车辆的未来轨迹并生成驾驶场景的文本描述。
➡️ 方法简介:研究团队提出了一种系统的方法,通过自动化数据处理和字幕生成管道,从原始数据中生成场景描述和真实轨迹。具体方法包括:1) 使用Kalman滤波器结合GNSS和IMU数据估计车辆的行驶路径;2) 使用深度学习模型(如OpenLenda-s1)检测交通灯状态;3) 使用传感器融合技术检测和跟踪前车;4) 通过规则和预训练的视频语言模型(如VideoLLaMA 2)生成自然语言字幕。
➡️ 实验设计:研究团队在CoVLA数据集上训练了CoVLA-Agent模型,该模型在交通场景描述生成和轨迹预测两个任务上进行了训练。实验设置包括将数据集分为70%训练集、15%验证集和15%测试集。每个场景以2Hz的频率采样帧。实验结果表明,CoVLA-Agent模型在生成连贯的自然语言描述和预测轨迹方面表现出色,特别是在需要复杂和高级判断的场景中。
Video Emotion Open-vocabulary Recognition Based on Multimodal Large Language Model
➡️ 论文标题:Video Emotion Open-vocabulary Recognition Based on Multimodal Large Language Model
➡️ 论文作者:Mengying Ge, Dongkai Tang, Mingyang Li
➡️ 研究机构: BOSS ZhiPin (China)
➡️ 问题背景:多模态情感识别技术在人机交互领域占据重要地位,旨在通过整合视觉、听觉和文本语义等多模信息,准确捕捉和识别人们复杂的心理状态。然而,传统的数据集基于固定标签,导致模型往往只关注主要情绪,而忽视了复杂场景中的细微情感变化。
➡️ 研究动机:随着大规模语言模型(LLMs)技术的快速发展,许多开放性问题得到了前所未有的解决。然而,在多模态情感识别领域,这些技术的应用研究仍显不足。本报告探讨了使用多模态大规模语言模型(MLLMs)技术进行情感识别的解决方案,旨在提高模型在复杂情感计算中的性能。
➡️ 方法简介:研究团队提出了基于InternVL框架的情感识别训练方法,通过生成角色情感描述数据并进行LoRA微调,显著增强了模型解析角色表情的能力。此外,研究还探索了三模态开放词汇情感识别和多模型协同判断策略,以实现更全面和准确的情感判断。
➡️ 实验设计:实验在三个数据集上进行,包括MiniGPT-4和MER2024-OV。实验设计了不同的预处理方法(如面部对齐和全图输入),以及不同类型的模型融合策略,以全面评估模型在不同条件下的表现。实验结果表明,通过LoRA微调和多模型协同判断,模型的性能得到了显著提升。
EAGLE: Elevating Geometric Reasoning through LLM-empowered Visual Instruction Tuning
➡️ 论文标题:EAGLE: Elevating Geometric Reasoning through LLM-empowered Visual Instruction Tuning
➡️ 论文作者:Zhihao Li, Yao Du, Yang Liu, Yan Zhang, Yufang Liu, Mengdi Zhang, Xunliang Cai
➡️ 研究机构: Meituan, Beijing, China; Beihang University, Beijing, China; Tianjin University, Tianjin, China; East China Normal University, Shanghai, China
➡️ 问题背景:多模态大语言模型(MLLMs)在多种多模态任务中表现出色,但在解决数学几何问题时,由于需要卓越的视觉感知能力,这些模型的表现仍然受限。现有的MLLMs主要通过优化大语言模型(LLM)的骨干来获取几何推理能力,而很少强调视觉理解的改进,这导致了模型在几何问题解决中的表现不佳。
➡️ 研究动机:研究团队发现,现有的MLLMs在处理几何图形时存在严重的视觉感知不足和幻觉问题,这些问题严重限制了模型在几何问题解决中的表现。为了改善这一状况,研究团队提出了一种新的两阶段端到端视觉增强框架EAGLE,旨在通过LLM赋能的视觉指令调优来提升几何推理能力。
➡️ 方法简介:EAGLE框架包括两个阶段:初步视觉增强阶段和高级视觉增强阶段。在初步阶段,研究团队使用60K几何图像-标题对对视觉编码器进行微调,同时保持LLM骨干冻结,以赋予模型基本的几何知识。在高级阶段,通过引入LoRA模块来优化视觉编码器,并解冻LLM骨干,以促进更深入的几何理解。此外,研究团队在两个阶段中都优化了跨模态投影器,以促进自适应的视觉-语言对齐。
➡️ 实验设计:研究团队在两个流行的几何基准数据集GeoQA和MathVista上进行了广泛的实验。实验设计包括对不同训练策略的比较,以及对模型在几何问题解决任务中的表现的评估。实验结果表明,EAGLE在GeoQA基准上超越了现有的领先MLLMs,包括G-LLaVA 13B模型,仅用7B参数就实现了显著的性能提升。在MathVista的几何问题解决任务中,EAGLE也表现出色,超越了GPT-4V等模型。
EMO-LLaMA: Enhancing Facial Emotion Understanding with Instruction Tuning
➡️ 论文标题:EMO-LLaMA: Enhancing Facial Emotion Understanding with Instruction Tuning
➡️ 论文作者:Bohao Xing, Zitong Yu, Xin Liu, Kaishen Yuan, Qilang Ye, Weicheng Xie, Huanjing Yue, Jingyu Yang, Heikki Kälviäinen
➡️ 研究机构: Lappeenranta-Lahti University of Technology LUT、Great Bay University、Tianjin University、Shenzhen University
➡️ 问题背景:面部表情识别(Facial Expression Recognition, FER)是情感人工智能领域的重要研究课题。近年来,研究人员在这一领域取得了显著进展。然而,当前的FER方法在泛化能力、缺乏与自然语言对齐的语义信息、以及处理图像和视频的统一框架方面存在挑战,这限制了其在多模态情感理解和人机交互中的应用。多模态大语言模型(Multimodal Large Language Models, MLLMs)在这些方面显示出潜力,但直接应用预训练的MLLMs到FER任务中仍面临挑战,尤其是在情感理解方面与最先进的监督方法存在显著差距。
➡️ 研究动机:为了增强MLLMs在面部表情理解方面的能力,研究团队提出了一种新的MLLM——EMO-LLaMA,通过结合预训练的面部分析网络中的面部先验知识,提高模型对人类面部信息的提取能力。研究旨在通过改进FER任务,缩小MLLMs方法与传统分类范式之间的差距,并为未来的多模态、多线索情感理解任务奠定基础。
➡️ 方法简介:研究团队首先生成了五个FER数据集的指令数据,然后提出了EMO-LLaMA模型。该模型通过设计Face Info Mining模块提取全局和局部面部信息,并利用手工制作的提示引入年龄-性别-种族属性,考虑不同人群的情感差异。此外,研究团队还利用LoRA对预训练的MLLM进行微调,以适应FER任务。
➡️ 实验设计:研究在六个FER数据集上进行了实验,包括静态和动态FER任务。实验设计了不同的因素(如面部表情标签的多样性、面部图像的裁剪等),以及不同类型的评估指标(如准确率、UAR、WAR等),以全面评估EMO-LLaMA在不同条件下的表现。实验结果表明,EMO-LLaMA在多个FER数据集上达到了与现有SOTA方法相当或竞争性的性能,并展示了良好的泛化能力。
EE-MLLM: A Data-Efficient and Compute-Efficient Multimodal Large Language Model
➡️ 论文标题:EE-MLLM: A Data-Efficient and Compute-Efficient Multimodal Large Language Model
➡️ 论文作者:Feipeng Ma, Yizhou Zhou, Hebei Li, Zilong He, Siying Wu, Fengyun Rao, Yueyi Zhang, Xiaoyan Sun
➡️ 研究机构: 中国科学技术大学、腾讯微信、合肥综合性国家科学中心人工智能研究院
➡️ 问题背景:在多模态研究领域,许多研究利用大量的图像-文本对进行模态对齐学习,将大型语言模型(LLMs)转换为多模态LLMs,从而在各种视觉-语言任务中表现出色。现有的模态对齐方法主要分为自注意力机制和交叉注意力机制两大类。自注意力机制虽然数据效率高,但由于将视觉和文本标记直接连接作为LLM的输入,导致计算效率较低。而交叉注意力机制虽然计算效率高,但需要大量的预训练数据,导致数据效率较低。
➡️ 研究动机:为了克服自注意力机制和交叉注意力机制在数据效率和计算效率上的权衡,研究团队提出了一种数据高效且计算高效的多模态大型语言模型(EE-MLLM)。该模型通过引入复合注意力机制,既提高了数据效率,又提高了计算效率,旨在为多模态LLMs的进一步发展提供新的解决方案。
➡️ 方法简介:研究团队提出了一种复合注意力机制,该机制具有两个关键特性:1) 消除了视觉标记内部的自注意力计算,从而提高了计算效率;2) 重用了LLM每一层的权重,以促进视觉和语言之间的有效模态对齐,从而提高了数据效率。通过这种方式,EE-MLLM在不引入额外模块或可学习参数的情况下,实现了数据和计算的双重效率。
➡️ 实验设计:研究团队在多个基准数据集上评估了EE-MLLM的性能,包括通用基准如MMBench和SeedBench,以及细粒度任务如TextVQA和DocVQA。实验结果表明,EE-MLLM在这些基准上表现出色,同时在推理阶段的计算效率也显著提高。特别是在处理高分辨率图像输入时,EE-MLLM在保持性能的同时,显著降低了计算成本。例如,在980 × 980的输入图像上,EE-MLLM的FLOPs仅为自注意力机制方法的70%。此外,EE-MLLM在单个NVIDIA H800 GPU上的推理速度达到了77个标记/秒,比自注意力机制方法快1.9倍。
相关文章:
多模态大语言模型arxiv论文略读(110)
CoVLA: Comprehensive Vision-Language-Action Dataset for Autonomous Driving ➡️ 论文标题:CoVLA: Comprehensive Vision-Language-Action Dataset for Autonomous Driving ➡️ 论文作者:Hidehisa Arai, Keita Miwa, Kento Sasaki, Yu Yamaguchi, …...

React、Git、计网、发展趋势等内容——前端面试宝典(字节、小红书和美团)
React React Hook实现架构、.Hook不能在循环嵌套语句中使用 , 为什么,Fiber架构,面试向面试官介绍,详细解释 用户: React Hook实现架构、.Hook不能在循环嵌套语句中使用 , 为什么,Fiber架构,面试向面试官介绍&#x…...
Web APIS Day01
1.声明变量const优先 那为什么一开始前面就不能用const呢,接下来看几个例子: 下面这张为什么可以用const呢?因为复杂数据的引用地址没变,数组还是数组,只是添加了个元素,本质没变,所以可以用con…...
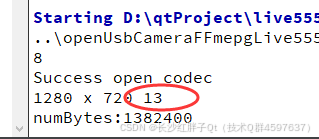
关于 ffmpeg设置摄像头报错“Could not set video options” 的解决方法
若该文为原创文章,转载请注明原文出处 本文章博客地址:https://hpzwl.blog.csdn.net/article/details/148515355 长沙红胖子Qt(长沙创微智科)博文大全:开发技术集合(包含Qt实用技术、树莓派、三维、OpenCV…...

Linux系统:进程间通信-匿名与命名管道
本节重点 匿名管道的概念与原理匿名管道的创建命名管道的概念与原理命名管道的创建两者的差异与联系命名管道实现EchoServer 一、管道 管道(Pipe)是一种进程间通信(IPC, Inter-Process Communication)机制,用于在不…...
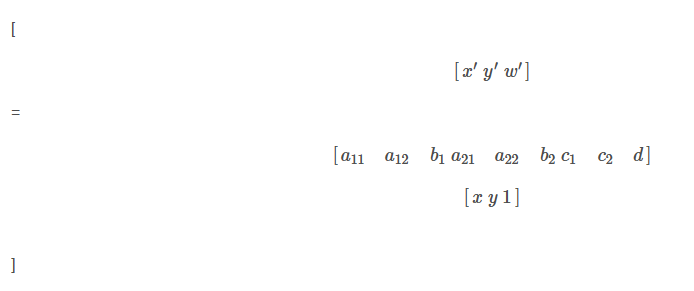
使用python进行图像处理—图像变换(6)
图像变换是指改变图像的几何形状或空间位置的操作。常见的几何变换包括平移、旋转、缩放、剪切(shear)以及更复杂的仿射变换和透视变换。这些变换在图像配准、图像校正、创建特效等场景中非常有用。 6.1仿射变换(Affine Transformation) 仿射变换是一种…...
使用homeassistant 插件将tasmota 接入到米家
我写一个一个 将本地tasmoat的的设备同通过ha集成到小爱同学的功能,利用了巴法接入小爱的功能,将本地mqtt转发给巴法以实现小爱控制的功能,前提条件。1需要tasmota 设备, 2.在本地搭建了mqtt服务可, 3.搭建了ha 4.在h…...

VUE3 ref 和 useTemplateRef
使用ref来绑定和获取 页面 <headerNav ref"headerNavRef"></headerNav><div click"showRef" ref"buttonRef">refbutton</div>使用ref方法const后面的命名需要跟页面的ref值一样 const buttonRef ref(buttonRef) cons…...
【笔记】结合 Conda任意创建和配置不同 Python 版本的双轨隔离的 Poetry 虚拟环境
如何结合 Conda 任意创建和配置不同 Python 版本的双轨隔离的Poetry 虚拟环境? 在 Python 开发中,为不同项目配置独立且适配的虚拟环境至关重要。结合 Conda 和 Poetry 工具,能高效创建不同 Python 版本的 Poetry 虚拟环境,接下来…...
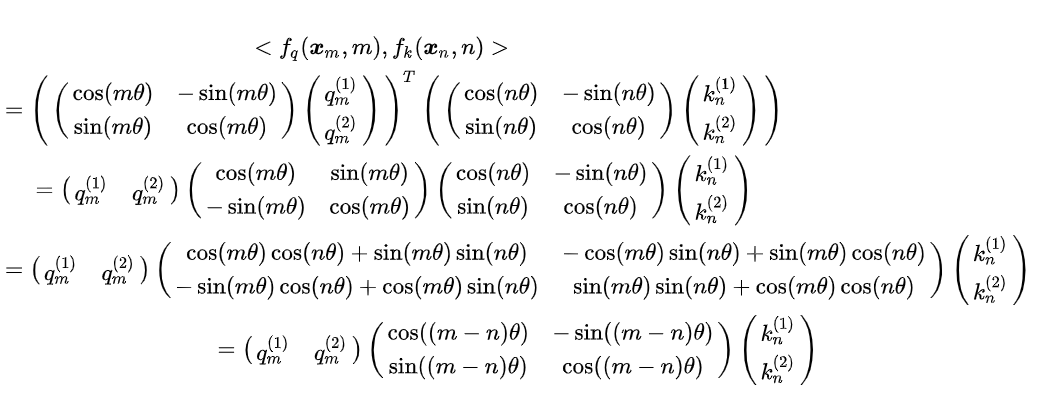
多模态学习路线(2)——DL基础系列
目录 前言 一、归一化 1. Layer Normalization (LN) 2. Batch Normalization (BN) 3. Instance Normalization (IN) 4. Group Normalization (GN) 5. Root Mean Square Normalization(RMSNorm) 二、激活函数 1. Sigmoid激活函数(二分类&…...

[10-1]I2C通信协议 江协科技学习笔记(17个知识点)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17...
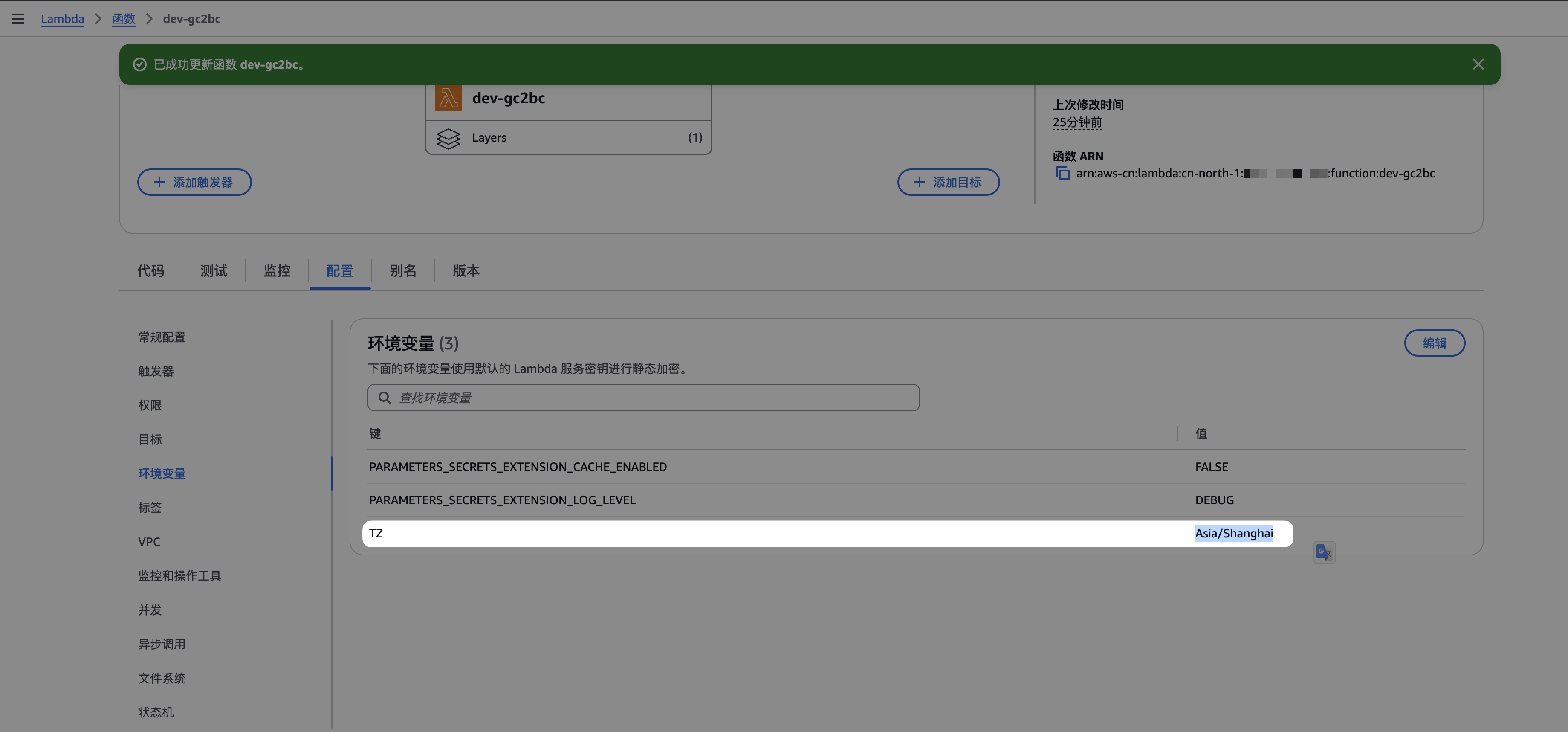
AWSLambda之设置时区
目标 希望Lambda运行的时区是东八区。 解决 只需要设置lambda的环境变量TZ为东八区时区即可,即Asia/Shanghai。 参考 使用 Lambda 环境变量...

RFID推动新能源汽车零部件生产系统管理应用案例
RFID推动新能源汽车零部件生产系统管理应用案例 一、项目背景 新能源汽车零部件场景 在新能源汽车零部件生产领域,电子冷却水泵等关键部件的装配溯源需求日益增长。传统 RFID 溯源方案采用 “网关 RFID 读写头” 模式,存在单点位单独头溯源、网关布线…...

[C++错误经验]case语句跳过变量初始化
标题:[C错误经验]case语句跳过变量初始化 水墨不写bug 文章目录 一、错误信息复现二、错误分析三、解决方法 一、错误信息复现 write.cc:80:14: error: jump to case label80 | case 2:| ^ write.cc:76:20: note: crosses initialization…...
Unity-ECS详解
今天我们来了解Unity最先进的技术——ECS架构(EntityComponentSystem)。 Unity官方下有源码,我们下载源码后来学习。 ECS 与OOP(Object-Oriented Programming)对应,ECS是一种完全不同的编程范式与数据架构…...
uni-app学习笔记二十七--设置底部菜单TabBar的样式
官方文档地址:uni.setTabBarItem(OBJECT) | uni-app官网 uni.setTabBarItem(OBJECT) 动态设置 tabBar 某一项的内容,通常写在项目的App.vue的onLaunch方法中,用于项目启动时立即执行 重要参数: indexnumber是tabBar 的哪一项&…...

7种分类数据编码技术详解:从原理到实战
在数据分析和机器学习领域,分类数据(Categorical Data)的处理是一个基础但至关重要的环节。分类数据指的是由有限数量的离散值组成的数据类型,如性别(男/女)、颜色(红/绿/蓝)或产品类…...
【字节拥抱开源】字节团队开源视频模型 ContentV: 有限算力下的视频生成模型高效训练
本项目提出了ContentV框架,通过三项关键创新高效加速基于DiT的视频生成模型训练: 极简架构设计,最大化复用预训练图像生成模型进行视频合成系统化的多阶段训练策略,利用流匹配技术提升效率经济高效的人类反馈强化学习框架&#x…...
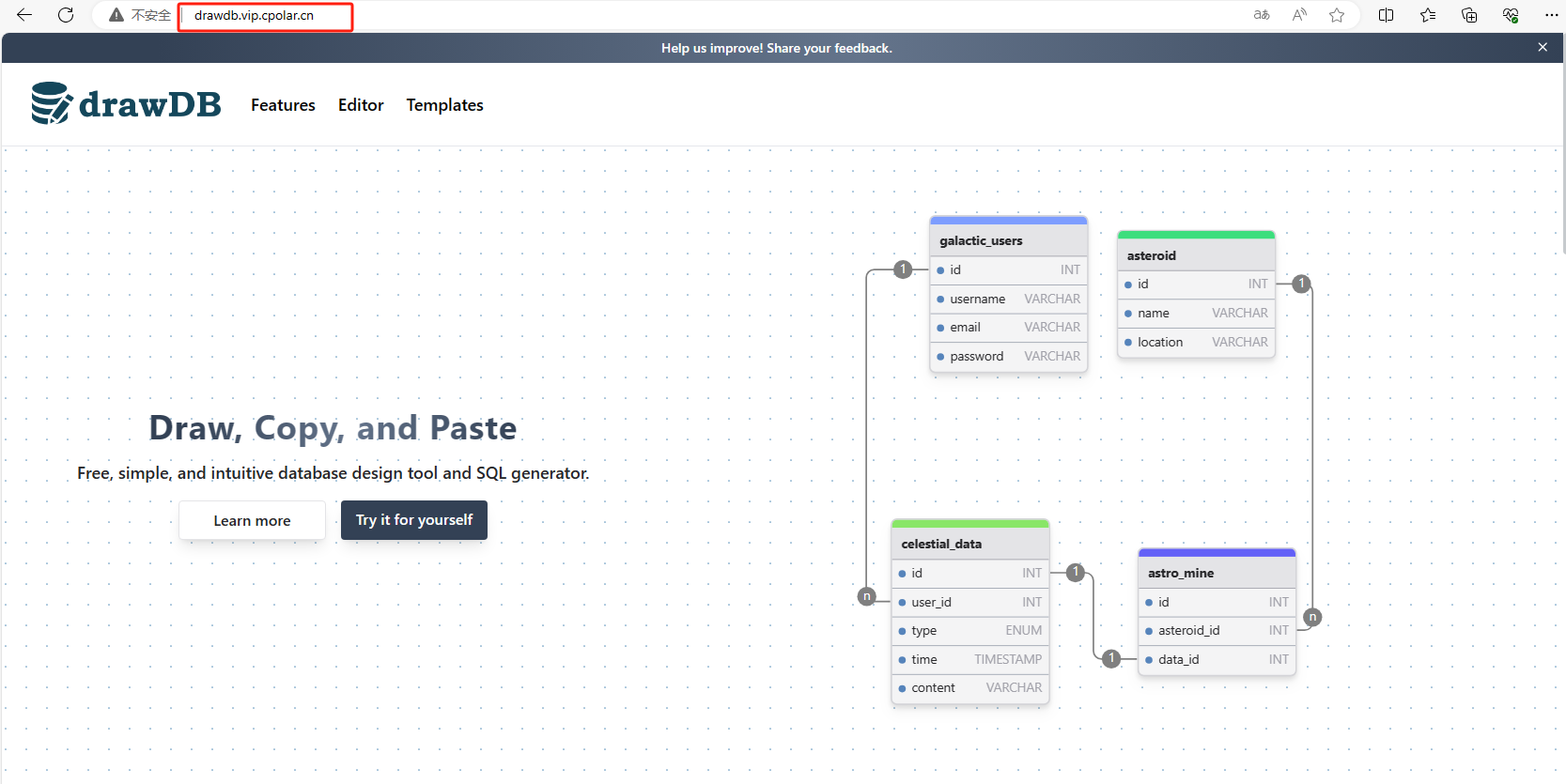
本地部署drawDB结合内网穿透技术实现数据库远程管控方案
文章目录 前言1. Windows本地部署DrawDB2. 安装Cpolar内网穿透3. 实现公网访问DrawDB4. 固定DrawDB公网地址 前言 在数字化浪潮席卷全球的背景下,数据治理能力正日益成为构建现代企业核心竞争力的关键因素。无论是全球500强企业的数据中枢系统,还是初创…...
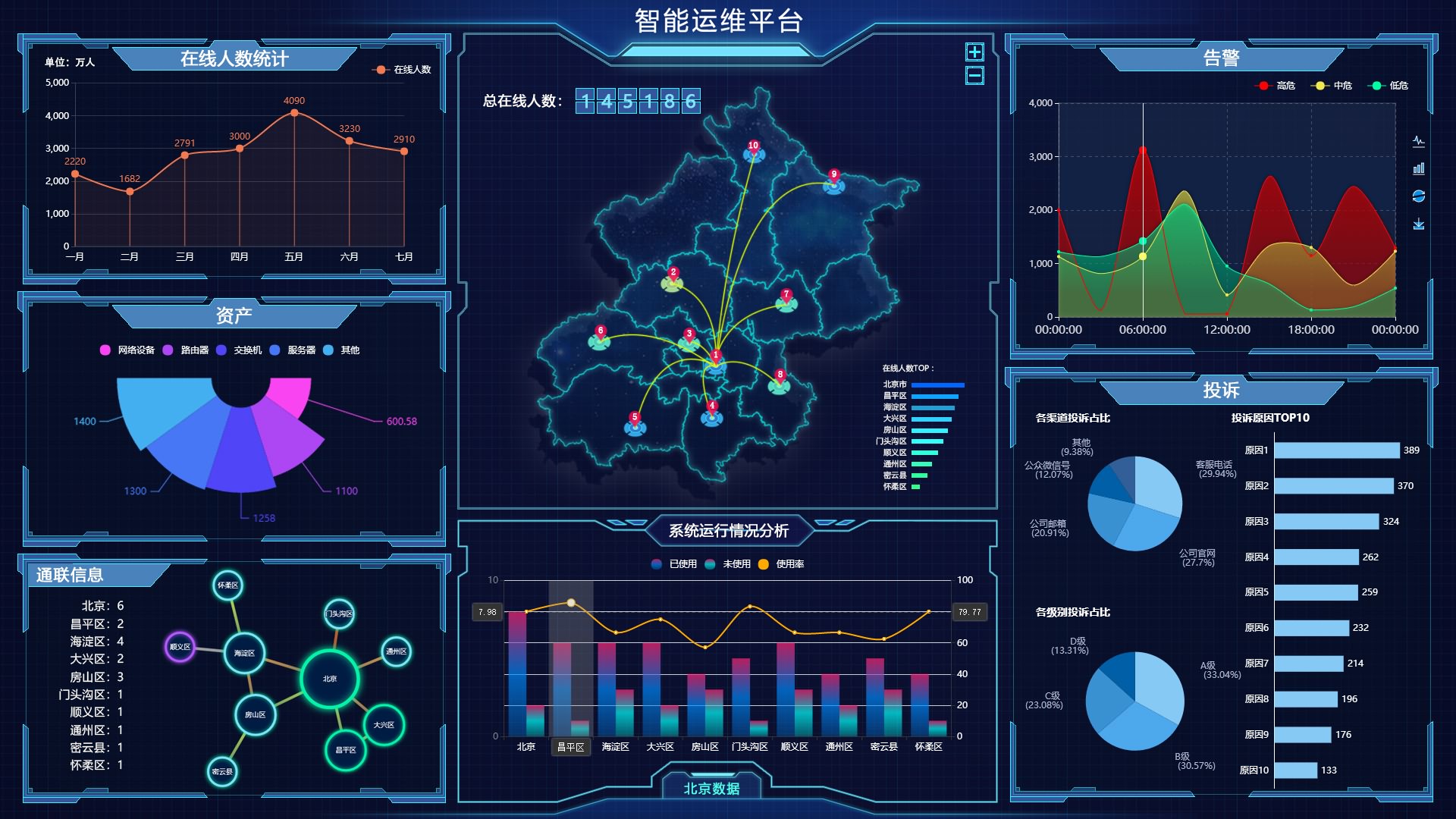
可视化预警系统:如何实现生产风险的实时监控?
在生产环境中,风险无处不在,而传统的监控方式往往只能事后补救,难以做到提前预警。但如今,可视化预警系统正在改变这一切!它能够实时收集和分析生产数据,通过直观的图表和警报,让管理者第一时间…...

多模态大语言模型arxiv论文略读(112)
Assessing Modality Bias in Video Question Answering Benchmarks with Multimodal Large Language Models ➡️ 论文标题:Assessing Modality Bias in Video Question Answering Benchmarks with Multimodal Large Language Models ➡️ 论文作者:Jea…...
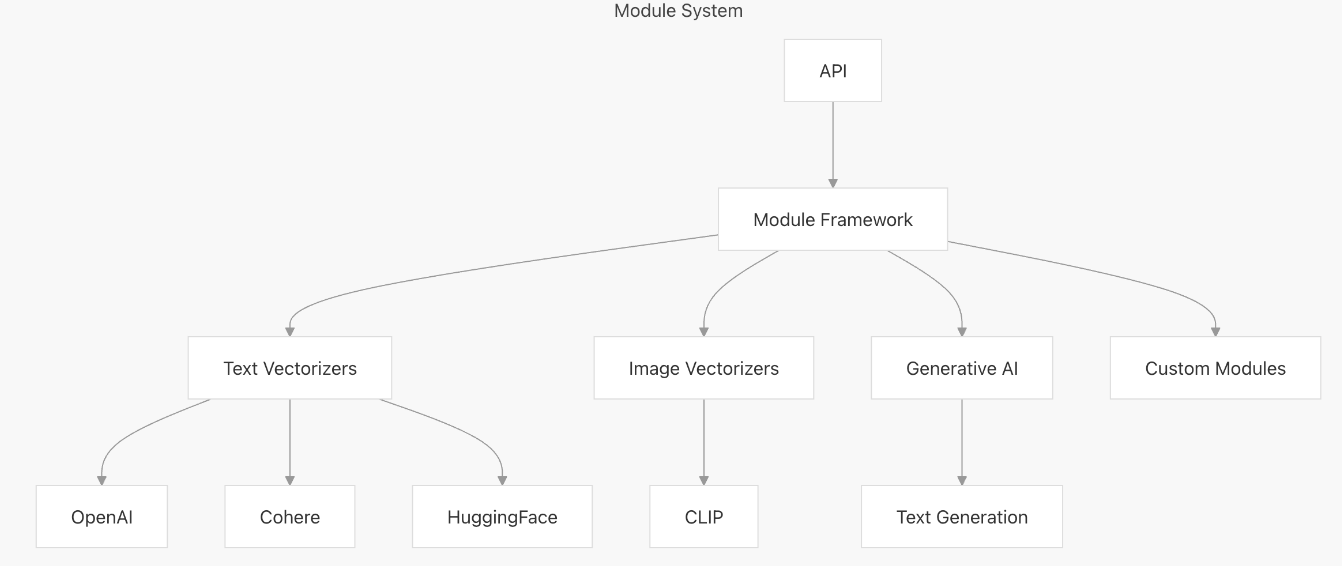
【向量库】Weaviate概述与架构解析
文章目录 一、什么是weaviate二、High-Level Architecture1. Core Components2. Storage Layer3. 组件交互流程 三、核心组件1. API Layer2. Schema Management3. Vector Indexing3.1. 查询原理3.2. 左侧:Search Process(搜索流程)3.3. 右侧&…...

PostgreSQL 对 IPv6 的支持情况
PostgreSQL 对 IPv6 的支持情况 PostgreSQL 全面支持 IPv6 网络协议,包括连接、存储和操作 IPv6 地址。以下是详细说明: 一、网络连接支持 1. 监听 IPv6 连接 在 postgresql.conf 中配置: listen_addresses 0.0.0.0,:: # 监听所有IPv4…...
)
python数据结构和算法(1)
数据结构和算法简介 数据结构:存储和组织数据的方式,决定了数据的存储方式和访问方式。 算法:解决问题的思维、步骤和方法。 程序 数据结构 算法 算法 算法的独立性 算法是独立存在的一种解决问题的方法和思想,对于算法而言&a…...

视觉slam--框架
视觉里程计的框架 传感器 VO--front end VO的缺点 后端--back end 后端对什么数据进行优化 利用什么数据进行优化的 后端是怎么进行优化的 回环检测 建图 建图是指构建地图的过程。 构建的地图是点云地图还是什么信息的地图? 建图并没有一个固定的形式和算法…...

统计按位或能得到最大值的子集数目
我们先来看题目描述: 给你一个整数数组 nums ,请你找出 nums 子集 按位或 可能得到的 最大值 ,并返回按位或能得到最大值的 不同非空子集的数目 。 如果数组 a 可以由数组 b 删除一些元素(或不删除)得到,…...

npm install 相关命令
npm install 相关命令 基本安装命令 # 安装 package.json 中列出的所有依赖 npm install npm i # 简写形式# 安装特定包 npm install <package-name># 安装特定版本 npm install <package-name><version>依赖类型选项 # 安装为生产依赖(默认&…...
)
Spring Boot 与 Kafka 的深度集成实践(二)
3. 生产者实现 3.1 生产者配置 在 Spring Boot 项目中,配置 Kafka 生产者主要是配置生产者工厂(ProducerFactory)和 KafkaTemplate 。生产者工厂负责创建 Kafka 生产者实例,而 KafkaTemplate 则是用于发送消息的核心组件&#x…...

【学习记录】使用 Kali Linux 与 Hashcat 进行 WiFi 安全分析:合法的安全测试指南
文章目录 📌 前言🧰 一、前期准备✅ 安装 Kali Linux✅ 获取支持监听模式的无线网卡 🛠 二、使用 Kali Linux 进行 WiFi 安全测试步骤 1:插入无线网卡并确认识别步骤 2:开启监听模式步骤 3:扫描附近的 WiFi…...
)
后端下载限速(redis记录实时并发,bucket4j动态限速)
✅ 使用 Redis 记录 所有用户的实时并发下载数✅ 使用 Bucket4j 实现 全局下载速率限制(动态)✅ 支持 动态调整限速策略✅ 下载接口安全、稳定、可监控 🧩 整体架构概览 模块功能Redis存储全局并发数和带宽令牌桶状态Bucket4j Redis分布式限…...