[NLP]LLM高效微调(PEFT)--LoRA
LoRA
背景
神经网络包含很多全连接层,其借助于矩阵乘法得以实现,然而,很多全连接层的权重矩阵都是满秩的。当针对特定任务进行微调后,模型中权重矩阵其实具有很低的本征秩(intrinsic rank),因此,论文的作者认为权重更新的那部分参数矩阵尽管随机投影到较小的子空间,仍然可以有效的学习,可以理解为针对特定的下游任务这些权重矩阵就不要求满秩。
技术原理
LoRA(论文:LoRA: LOW-RANK ADAPTATION OF LARGE LANGUAGE MODELS),该方法的核心思想就是通过低秩分解来模拟参数的改变量,从而以极小的参数量来实现大模型的间接训练。
在涉及到矩阵相乘的模块,在原始的PLM旁边增加一个新的通路,通过前后两个矩阵A,B相乘,第一个矩阵A负责降维,第二个矩阵B负责升维,中间层维度为r,从而来模拟所谓的本征秩(intrinsic rank)。
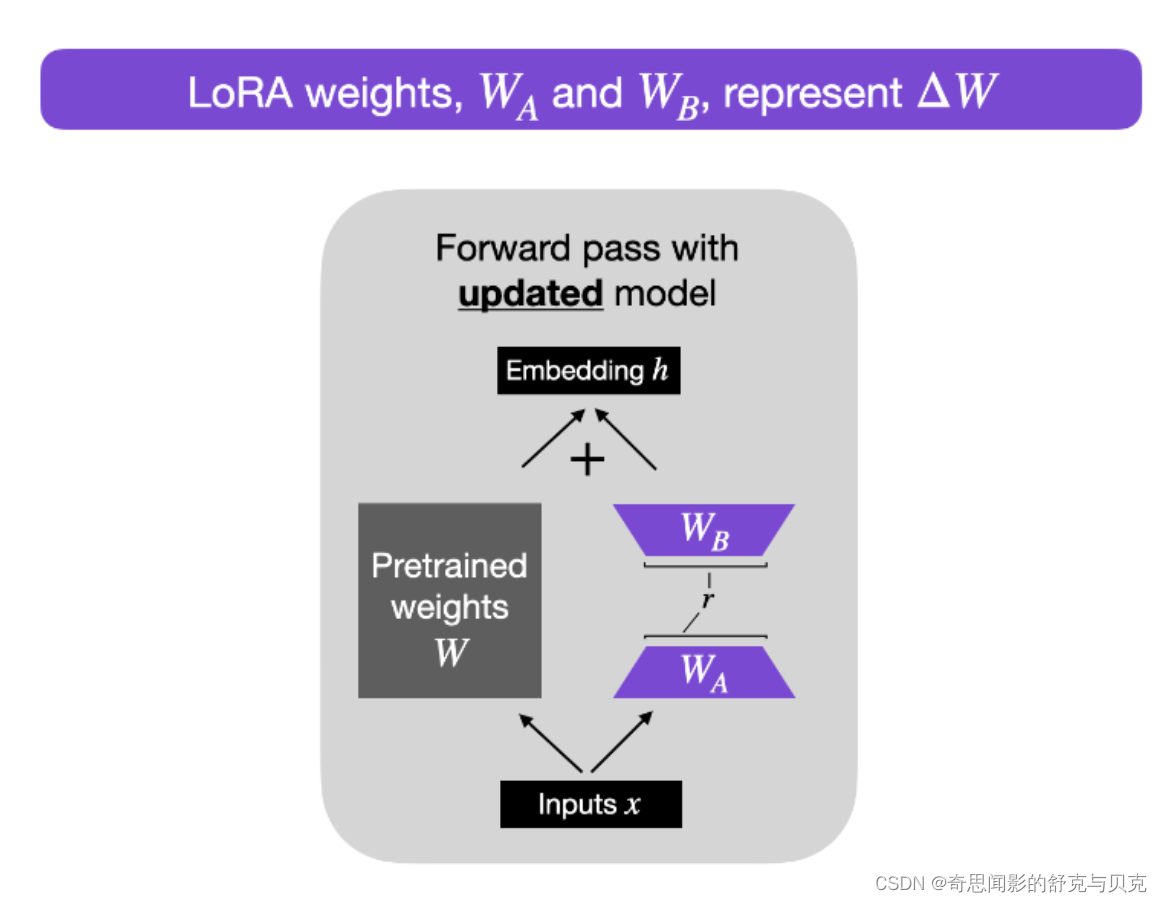
可训练层维度和预训练模型层维度一致为d,先将维度d通过全连接层降维至r,再从r通过全连接层映射回d维度,其中,r<<d,r是矩阵的秩,这样矩阵计算就从d x d变为d x r + r x d,参数量减少很多。
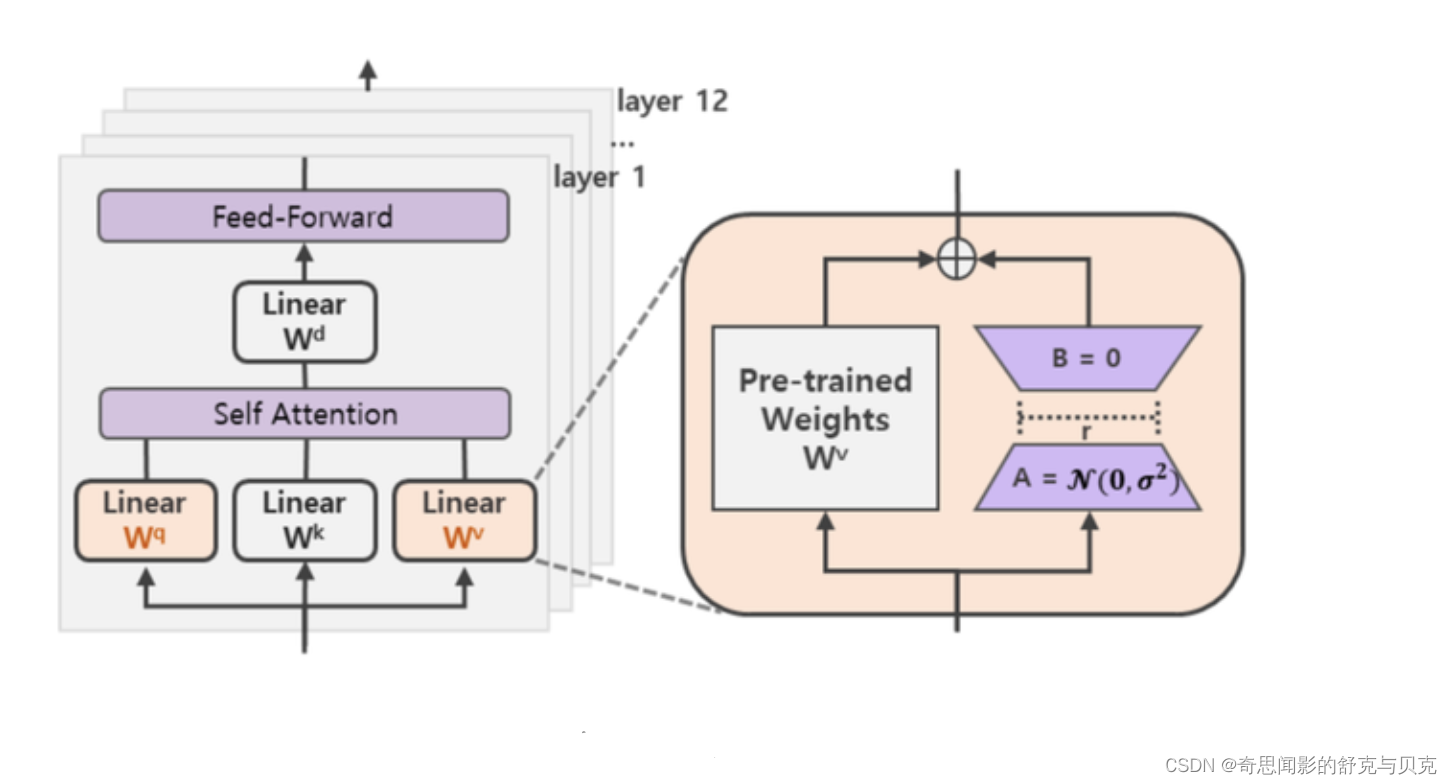
在下游任务训练时,固定模型的其他参数,只优化新增的两个矩阵的权重参数,将W跟新增的通路W1两部分的结果加起来作为最终的结果(两边通路的输入跟输出维度是一致的),即h=Wx+BAx。第一个矩阵的A的权重参数会通过高斯函数初始化,而第二个矩阵的B的权重参数则会初始化为零矩阵,这样能保证训练开始时新增的通路BA=0从而对模型结果没有影响。
在推理时,将左右两部分的结果加到一起即可,h=Wx+BAx=(W+BA)x,所以只要将训练完成的矩阵乘积BA跟原本的权重矩阵W加到一起作为新权重参数替换原本PLM的W即可,对于推理来说,不会增加额外的计算资源。
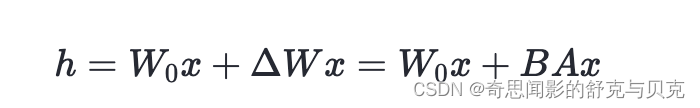
为什么更新ΔW只需要更新较少的参数呢?
现在,让我们解决房间里的大问题:如果我们引入新的权重矩阵,这个参数的效率如何?新矩阵WA和WB可以非常小。例如,假设A=100且B=500 ,则ΔW的大小为100 × 500 = 50,000。现在,如果我们将其分解为两个较小的矩阵,一个100×5维矩阵WA和一个5×500维矩阵WB。这两个矩阵总共只有5×100+5×500=3000个参数。
作者也在摘要中明确表示,他们采用lora方法微调,相比于GPT-3全量参数微调,可训练参数下降了10000倍,GPU显存需求下降了3倍,而lora微调后的效果,在特定任务上甚至可以媲美全量微调的模型。
为什么一直强调特定任务呢?因为lora基于的假设就是在特定任务上微调时,更新的参数矩阵具有较低的内在维度。可以把lora想象成一个特定能力的装备,而预训练模型是游戏角色本身。在预训练模型(游戏角色)的基础上,特定lora(装备)可以增强对于某一特定任务的表现,但是在其他不相关任务上该lora模块并不会起到作用。如果想同时在多个任务上有媲美全量参数微调模型的表现的话,就得需要针对不同的任务训练不同的ΔW模块(多个装备),最后整合在一起。但是,如果想模型(游戏角色)本身整体变强大,还是全量参数微调更合适。
至于是否适合作为通用指令微调的解决方案,有个问题我也没有搞懂,就是通用的指令样本是否真的有统一的低秩空间表征?这个表征又是什么含义?因为指令微调阶段的样本其实是混合的多任务指令样本,这种情况下lora是否合适,感觉需要更全面的评估.
## 初始化低秩矩阵A和B
self.lora_A.update(nn.ModuleDict({adapter_name: nn.Linear(self.in_features, r, bias=False)}))
self.lora_B.update(nn.ModuleDict({adapter_name: nn.Linear(r, self.out_features, bias=False)}))
self.scaling[adapter_name] = lora_alpha / r## 向前计算
result = F.linear(x, transpose(self.weight, self.fan_in_fan_out), bias=self.bias)
result += (self.lora_B[self.active_adapter](self.lora_A[self.active_adapter](self.lora_dropout[self.active_adapter](x)))* self.scaling[self.active_adapter]
)
此外,Transformer的权重矩阵包括Attention模块里用于计算query, key, value的Wq,Wk,Wv以及多头attention的Wo,以及MLP层的权重矩阵,LoRA只应用于Attention模块中的4种权重矩阵,而且通过消融实验发现同时调整 Wq 和 Wv 会产生最佳结果。
input_dim = 768 # e.g., the hidden size of the pre-trained model
output_dim = 768 # e.g., the output size of the layer
rank = 8 # The rank 'r' for the low-rank adaptationW = ... # from pretrained network with shape input_dim x output_dimW_A = nn.Parameter(torch.empty(input_dim, rank)) # LoRA weight A
W_B = nn.Parameter(torch.empty(rank, output_dim)) # LoRA weight B# Initialization of LoRA weights
nn.init.kaiming_uniform_(W_A, a=math.sqrt(5))
nn.init.zeros_(W_B)def regular_forward_matmul(x, W):h = x @ W
return hdef lora_forward_matmul(x, W, W_A, W_B):h = x @ W # regular matrix multiplicationh += x @ (W_A @ W_B)*alpha # use scaled LoRA weights
return h在上面的伪代码中,alpha是一个缩放因子,用于调整组合结果(原始模型输出加上低秩自适应)的大小。这平衡了预训练模型的知识和新的特定于任务的适应——默认情况下,alpha通常设置为 1。另请注意,虽然W A被初始化为小的随机权重,但W B被初始化为 0,因此
训练开始时ΔW = W AW B = 0 ,这意味着我们以原始权重开始训练。
实验还发现,保证权重矩阵的种类的数量比起增加隐藏层维度r更为重要,增加r并不一定能覆盖更加有意义的子空间。
Rank r 的设置
一个很直接的问题就是:在实践中,rank 应该设为多少比较合适呢?
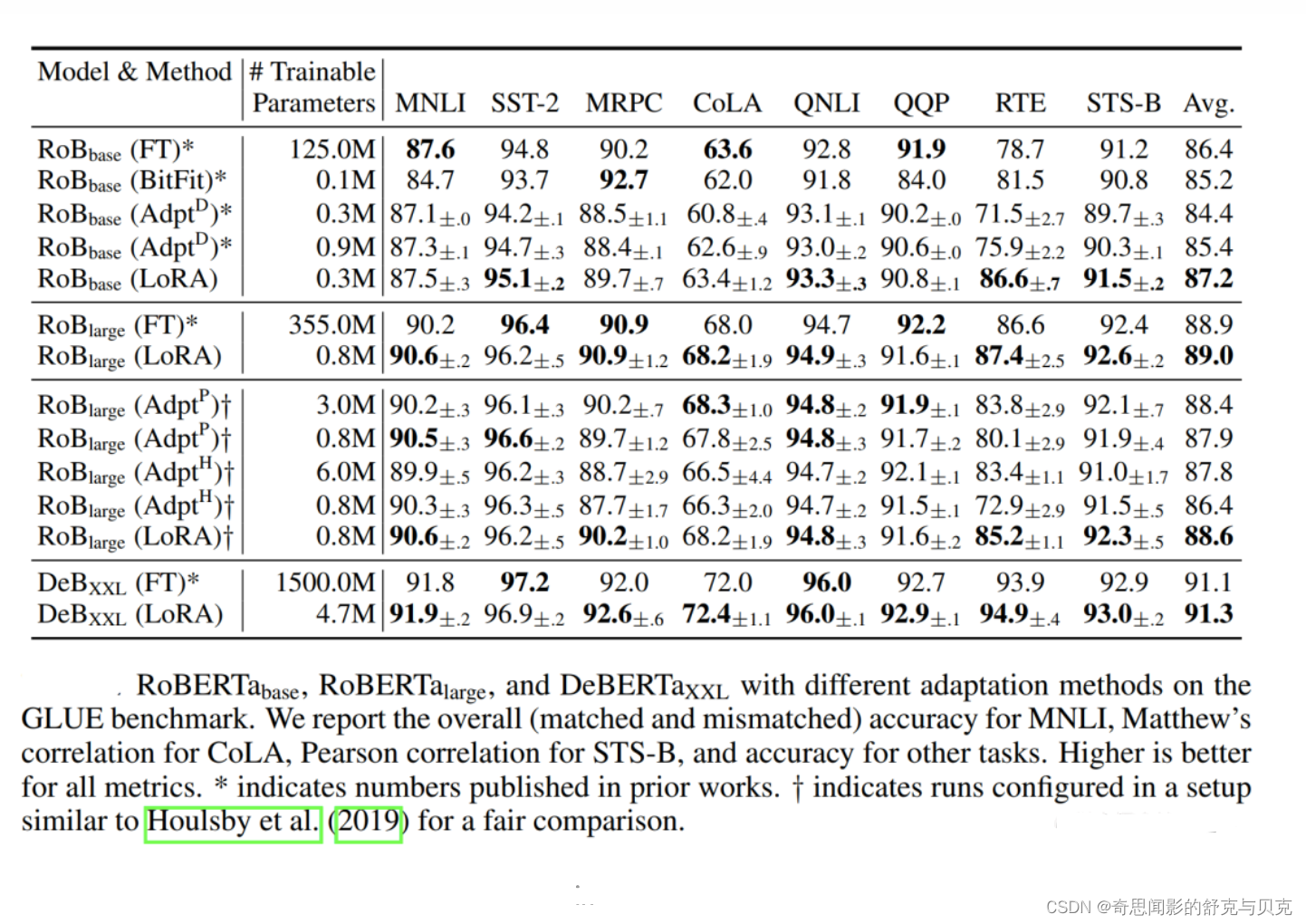
作者做了几组实验进行比较,结果发现 rank 可以很低,不超过8就很 OK 了,甚至是1也挺好..
关于秩的选择,通常情况下,rank为4,8,16即可。
通过实验也发现,在众多数据集上LoRA在只训练极少量参数的前提下,最终在性能上能和全量微调匹配,甚至在某些任务上优于全量微调。
减少推理开销
请注意,在实践中,如果我们在训练后保持原始权重W和矩阵W A和W B分开,如上所示,我们将在推理过程中产生小的效率损失,因为这引入了额外的计算步骤。相反,我们可以在训练后通过W' = W + WA WB更新权重,这类似于前面提到的W' = W + ΔW。
然而,将权重矩阵W A和W B分开可能具有实际优势。例如,假设我们希望将我们的预训练模型作为各种客户的基础模型,并且我们希望从基础模型开始为每个客户创建一个经过微调的 LLM。在这种情况下,我们不需要为每个客户存储完整的权重矩阵W',其中存储模型的所有权重W' = W + WA WB对于 LLM 来说可能非常大,因为 LLM 通常有数十亿到数万亿个权重参数。因此,我们可以保留原始模型W,只需要存储新的轻量级矩阵WA和WB。
为了用具体数字说明这一点,一个完整的 7B LLaMA 检查点需要 23GB 的存储容量,而如果我们选择r=8的等级,LoRA 权重可以小到 8MB 。
利用 LoRA可以如下优点:
- 在面对不同的下游任务时,仅需训练参数量很少的低秩矩阵,而预训练权重可以在这些任务之间共享;
- 省去了预训练权重的梯度和相关的 optimizer states,大大增加了训练效率并降低了硬件要求;
- 训练好的低秩矩阵可以合并(merge)到预训练权重中,多分支结构变为单分支,从而达到没有推理延时的效果;
- 与之前的一些参数高效的微调方法(如 Adapter, Prefix-Tuning 等)互不影响,并且可以相互结合
QLoRA和AdaLoRA
当红炸子鸡 LoRA,是当代微调 LLMs 的正确姿势? - 知乎 (zhihu.com)
相关文章:
[NLP]LLM高效微调(PEFT)--LoRA
LoRA 背景 神经网络包含很多全连接层,其借助于矩阵乘法得以实现,然而,很多全连接层的权重矩阵都是满秩的。当针对特定任务进行微调后,模型中权重矩阵其实具有很低的本征秩(intrinsic rank),因…...

vue3 vant上传图片
在 Vue 3 中使用 Vant 组件库进行图片上传,您可以使用 Vant 的 ImageUploader 组件。ImageUploader 是 Vant 提供的图片上传组件,可以方便地实现图片上传功能。 以下是一个简单的示例,演示如何在 Vue 3 中使用 Vant 的 ImageUploader 组件进行…...

深入理解linux内核--内存管理
RAM的某些部分永久分配给内核, 来存放内核代码及静态内核数据结构。 RAM的其余部分称为动态内存, 这不仅是进程所需的宝贵资源, 也是内核本身所需的宝贵资源。页框管理 Intel的Pentinum处理器可采用两种不同的页框大小: 4KB&…...
SpringBoot热部署的开启与关闭
1、 开启热部署 (1)导入依赖 <dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-devtools</artifactId> </dependency>(2)设置 此时就搞定了。。。 2、…...
)
k8s集群部署(使用kubeadm部署工具进行快速部署,相关对应版本为docker20.10.0+k8s1.23.0+flannel)
1. 安装要求 在开始之前,部署Kubernetes集群机器需要满足以下几个条件: 一台或多台机器,操作系统 CentOS7.x-86_x64硬件配置:2GB或更多RAM,2个CPU或更多CPU,硬盘20GB或更多可以访问外网,需要拉…...

20230729 git github gitee
1.gitee与gitHub概念? Gitee(码云)是开源中国社区推出的代码托管协作开发平台,支持Git和SVN,提供免费的私有仓库托管。Gitee专为开发者提供稳定、高效、安全的云端软件开发协作平台,无论是个人、团队、或是…...

php建造者模式
一,建造者模式,也叫做生成器模式,是创建设计模式的一种,它能将一个复杂的对象的创建过程分离开来,使你能够分步骤的创建对象。建造者模式也允许你使用相同的建造代码创造出不同类型和形式的对象。 建造者模式一般包括四…...

linux---》用户操作/su和sudo/普通权限/特殊权限/解压压缩/软件管理,rpm和yum/源码安装nginx
用户操作 ####创建用户####1 创建sa和sutdents组 groupadd sa groupadd students # 2 用户可以属于多个组,只能属于一个主组,附加组可以有多个 G useradd -u 5001 -g students -G sa -c "注释" -s /bin/bash lqz666 # 3 设置密码 passwd lqz6…...

tinkerCAD案例:20. Simple Button 简单按钮和骰子
文章目录 tinkerCAD案例:20. Simple Button 简单按钮Make a Trick Die tinkerCAD案例:20. Simple Button 简单按钮 Project Overview: 项目概况: This is a series of fun beginner level lessons to hone your awesome Tinkercad skills a…...

Java - 为什么要用BigDecimal?
🤔️为什么要用BigDecimal? 当然是因为使用Double计算,在某些对精度要求很高的场景下会出现问题💀不信你看⤵️ Test void test12() {// 丢失精度double result 0.2 0.1;System.out.println(result); // 输出结果为 0.300000000…...
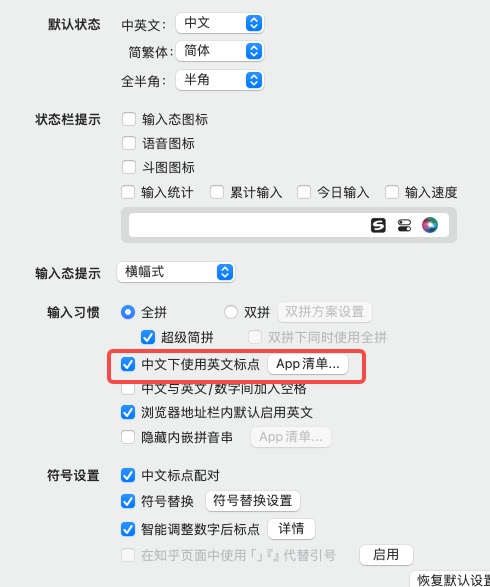
mac 删除自带的ABC输入法保留一个搜狗输入法,搜狗配置一下可以减少很多的敲击键盘和鼠标点击次数
0. 背景 对于开发者来说,经常被中英文切换输入法所困扰,我这边有一个方法,删除mac默认的ABC输入法 仅仅保留搜狗一个输入法,配置一下搜狗输入:哪些指定为英文输入,哪些指定为中文输入(符号也可…...

JiaYu说:如何做好IT类的技术面试?
IT类的技术面试 面试IT公司的小技巧IT技术面试常见的问题嵌入式技术面试嵌入式技术面试常见的问题嵌入式软件/硬件面试题 JiaYu归属嵌入式行业,所以这里只是以普通程序员的角度去分析技术面试的技巧 当然,也对嵌入式技术面试做了小总结,友友们…...

RL 实践(6)—— CartPole【REINFORCE with baseline A2C】
本文介绍 REINFORCE with baseline 和 A2C 这两个带 baseline 的策略梯度方法,并在 CartPole-V0 上验证它们和无 baseline 的原始方法 REINFORCE & Actor-Critic 的优势参考:《动手学强化学习》完整代码下载:7_[Gym] CartPole-V0 (REINFO…...
Python numpy库的应用、matplotlib绘图、opencv的应用
numpy import numpy as npl1 [1, 2, 3, 4, 5]# array():将列表同构成一个numpy的数组 l2 np.array(l1) print(type(l2)) print(l2) # ndim : 返回数组的轴数(维度数) # shape:返回数组的形状,用元组表示;元组的元素…...

SpringBoot 如何进行 统一异常处理
在Spring Boot中,可以通过自定义异常处理器来实现统一异常处理。异常处理器能够捕获应用程序中抛出的各种异常,并提供相应的错误处理和响应。 Spring Boot提供了ControllerAdvice注解,它可以将一个类标记为全局异常处理器。全局异常处理器能…...

数据库索引优化与查询优化——醍醐灌顶
索引优化与查询优化 哪些维度可以进行数据库调优 索引失效、没有充分利用到索引-一索引建立关联查询太多JOIN (设计缺陷或不得已的需求) --SQL优化服务器调优及各个参数设置 (缓冲、线程数等)–调整my.cnf数据过多–分库分表 关于数据库调优的知识点非常分散。不同的 DBMS&a…...
与知识蒸馏)
Student and Teacher network(学生—教师网络)与知识蒸馏
Student and Teacher network指一个较小且较简单的模型(学生)被训练来模仿一个较大且较复杂的模型(教师)的行为或预测。教师网络通常是一个经过训练在大型数据集上并在特定任务上表现良好的模型。而学生网络被设计成计算效率高且参…...

FPGA——PLD的区别以及各自的特点
目录 一、概述二、PLD的优点三、PLD的分类1、PROM(可编程只读存储器):2、PAL(可编程阵列逻辑)3、GAL(通用阵列逻辑)4、CPLD (复杂PLD)5、FPGA(现场可编程门阵…...
八、Kafka时间轮与常见问题
Kafka与时间轮 Kafka中存在大量的延时操作。 1、发送消息-超时重试机制 2、ACKS 用于指定分区中必须要有多少副本收到这条消息,生产者才认为写入成功(延时 等) Kafka并没有使用JDK自带的Timer或者DelayQueue来实现延迟的功能,而…...
Web端即时通讯技术(SEE,webSocket)
目录 背景简介个人见解被动推送轮询简介实现 长轮询(comet)简介实现 比较 主动推送长连接(SSE)简介实现GETPOST 效果 webSocket简介WebSocket的工作原理:WebSocket的主要优点:WebSocket的主要缺点: 实现用法一用法二 **效果** 比较…...

DeepSeek系统设计辅助:如何在48小时内完成可审计、可回滚、可压测的AI服务架构图?
更多请点击: https://intelliparadigm.com 第一章:DeepSeek系统设计辅助 DeepSeek系统设计辅助模块面向架构师与后端工程师,提供模型能力调用、接口契约生成、异步任务编排等核心支撑能力。该模块不替代人工设计决策,而是通过结构…...

高性能Windows流媒体服务器部署:5大核心技术与3种实战架构深度解析
高性能Windows流媒体服务器部署:5大核心技术与3种实战架构深度解析 【免费下载链接】srs-windows 项目地址: https://gitcode.com/gh_mirrors/sr/srs-windows 在Windows平台上构建专业级流媒体服务系统,需要综合考虑协议兼容性、性能优化和部署架…...

告别手写UI!用NXP GUI Guider拖拽设计LVGL界面,5分钟搞定音乐播放器Demo
嵌入式UI开发革命:5分钟用GUI Guider构建LVGL音乐播放器在嵌入式系统开发中,用户界面(UI)设计曾长期是工程师的痛点——既要考虑资源受限的硬件环境,又要实现流畅美观的交互体验。传统手动编写UI代码的方式不仅效率低下,调试过程更…...

别只拿PotPlayer看片了!挖掘它的采集录制功能,做Switch游戏存档大师
别把PotPlayer当普通播放器!解锁它的Switch游戏录制黑科技 你是否已经厌倦了在OBS、Bandicam等专业录制软件中反复调试参数的繁琐?是否想过那个每天用来看视频的PotPlayer,其实隐藏着令人惊喜的游戏录制能力?今天,我们…...
Transient、QuickEye、VerifyEye傻傻分不清?一文讲透Ansys里三种眼图仿真方法的适用场景与避坑指南
Transient、QuickEye、VerifyEye深度解析:Ansys眼图仿真技术选型实战指南 在高速数字系统设计中,眼图分析是评估信号完整性的黄金标准。面对Ansys工具链中三种截然不同的眼图生成方法,工程师常常陷入选择困境——是追求精确度的传统瞬态分析&…...

别被忽悠了!2026亲测靠谱的AI论文网站|避坑精选版
2026 年学术写作工具已高度分化,千笔AI与ThouPen为全流程首选,豆包、DeepSeek 为专项强手;避坑关键:拒绝假文献、严控 AIGC 率、优先国内适配、免费试用先行。 一、TOP3 全流程首选(亲测不踩雷) 1. 千笔AI&…...

FairyGUI Unity鼠标悬停与点击对象获取原理与实战
1. 这不是“加个OnMouseEnter就能用”的事:FairyGUI在Unity中处理鼠标交互的真实困境很多人第一次在Unity里集成FairyGUI,想实现“鼠标悬停显示提示”或“点击高亮当前按钮”,下意识就去翻Unity的MonoBehaviour文档,找OnMouseEnte…...

Qri高级功能:如何使用JSON Schema验证和描述数据集结构
Qri高级功能:如何使用JSON Schema验证和描述数据集结构 【免费下载链接】qri youre invited to a data party! 项目地址: https://gitcode.com/gh_mirrors/qr/qri Qri是一个强大的开源数据协作工具,它提供了丰富的功能来帮助用户管理、共享和验证…...
用Azure Kinect DK和Body Tracking SDK,5分钟实现一个实时人体骨骼点检测Demo(C++版)
5分钟实战:用Azure Kinect DK实现实时人体骨骼点追踪(C版) 当你第一次拿到Azure Kinect DK时,最令人兴奋的莫过于它强大的人体追踪能力。这款深度相机不仅能捕捉高清彩色图像,更能通过AI算法实时重建人体骨骼关节点。本…...

三步让小爱音箱秒变AI语音助手:MiGPT深度配置指南
三步让小爱音箱秒变AI语音助手:MiGPT深度配置指南 【免费下载链接】mi-gpt 🏠 将小爱音箱接入 ChatGPT 和豆包,改造成你的专属语音助手。 项目地址: https://gitcode.com/GitHub_Trending/mi/mi-gpt 还在为小爱音箱的"人工智障&q…...