【小白必看】Python爬虫实战之批量下载女神图片并保存到本地
文章目录
- 前言
- 运行结果
- 部分图片
- 1. 引入所需库
- 2. 发送请求获取网页内容
- 3. 解析网页内容并提取图片地址和名称
- 4. 下载并保存图片
- 完整代码
- 关键代码讲解
- 结束语

前言
爬取网络上的图片是一种常见的需求,它可以帮助我们批量下载大量图片并进行后续处理。本文将介绍如何使用 Python 编写一个简单的爬虫,从指定网页中获取女神图片,并保存到本地。
运行结果
部分图片


1. 引入所需库

首先需要导入两个库:requests 用于发送网络请求,lxml 用于解析和提取数据。
import requests
from lxml import etree
2. 发送请求获取网页内容

使用 requests.get() 方法发送一个 GET 请求到指定的 URL,并设置了请求头中的 User-Agent,以模拟浏览器发送请求。然后,我们将响应结果的编码设置为 GBK,通过 resp.encoding = 'gbk' 来告诉软件要用中文显示。最后,将获取到的网页内容打印出来。
url = 'http://www.netbian.com/mei/'
resp = requests.get(url, headers={'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.70 Safari/537.36'})
resp.encoding = 'gbk'
print(resp.text)
3. 解析网页内容并提取图片地址和名称

使用 etree.HTML() 方法将网页内容转换成 XPath 可解析的对象。然后,使用 XPath 表达式提取所有图片的 URL 和名称,并将结果存储在 img_urls 和 img_names 列表中。
xp = etree.HTML(resp.text)
img_urls = xp.xpath('//ul/li/a/img/@src')
img_names = xp.xpath('//ul/li/a/img/@alt')
4. 下载并保存图片

使用 zip() 函数将每个图片的 URL 和名称配对,并进行迭代。在迭代过程中,我们发送一个 GET 请求到图片的 URL,并将响应内容保存为图片文件。这里使用了 with open 语句来自动关闭文件。最后,我们将图片保存在 ./图片合成/img_f/ 目录下以图片名称命名。
for u, n in zip(img_urls, img_names):print(f'正在下载: 图片名:{n}')img_resp = requests.get(u, headers={'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.70 Safari/537.36'})with open(f'./图片合成/img_f/{n}.jpg', 'wb') as f:f.write(img_resp.content)
完整代码
# 地址
url = 'http://www.netbian.com/mei/'import requests
from lxml import etree# 发送请求获取网页内容
resp = requests.get(url,headers={'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.70 Safari/537.36'})
resp.encoding = 'gbk' # 告诉软件,要用中文给我显示
print(resp.text) # 打印文本结果# 使用lxml解析HTML内容
xp = etree.HTML(resp.text)# 提取图片URL和名称
img_urls = xp.xpath('//ul/li/a/img/@src')
img_names = xp.xpath('//ul/li/a/img/@alt')# 遍历图片URL和名称,并下载保存到本地
for u, n in zip(img_urls, img_names):print(f'正在下载:图片名:{n}')img_resp = requests.get(u, headers={'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.70 Safari/537.36'})with open(f'./图片合成/img_f/{n}.jpg', 'wb') as f:f.write(img_resp.content)关键代码讲解
# 地址
url = 'http://www.netbian.com/mei/'
这里定义了要爬取的网页地址。
import requests
from lxml import etree
导入所需的库:requests 用于发送网络请求,lxml 用于解析和提取数据。
resp = requests.get(url,headers={'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.70 Safari/537.36'})
resp.encoding = 'gbk' # 告诉软件,要用中文给我显示
print(resp.text) # 打印文本结果
通过发送 GET 请求获取指定网页的内容,并指定请求头中的
User-Agent为浏览器的标识,以模拟浏览器访问。使用resp.encoding设置编码为 GBK,以便正确显示中文字符。最后打印响应结果的文本内容。
xp = etree.HTML(resp.text)
使用 lxml 库的 etree.HTML 方法将网页内容转换为可解析的对象。
img_urls = xp.xpath('//ul/li/a/img/@src')
img_names = xp.xpath('//ul/li/a/img/@alt')
使用 XPath 表达式提取图片的 URL 和名称。xpath 函数返回一个列表,其中的元素是按照表达式提取的结果。
for u,n in zip(img_urls,img_names):print(f'正在下载: 图片名:{n}')img_resp = requests.get(u,headers={'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.70 Safari/537.36'})with open(f'./图片合成/img_f/{n}.jpg','wb') as f:f.write(img_resp.content)
通过迭代 img_urls 和 img_names 列表,使用 zip 函数将图片的 URL 和名称配对。在迭代的过程中,发送 GET 请求获取图片的响应内容。然后使用 with open 语句打开文件,并将图片内容写入文件中,保存到本地。这里使用了 wb 模式以二进制方式写入文件。
注意:在运行代码之前需要创建一个名为
图片合成/img_f的文件夹,用于保存下载的图片。
关键点讲解说明:
- 爬虫是一种自动化获取网页内容的技术,可以用于从指定网页上获取数据。
- 通过发送 HTTP 请求,可以获取网页的 HTML 内容。
- 使用
requests库可以方便地发送请求并获取响应。 - 使用 XPath 表达式可以方便地从 HTML 中提取所需的数据。
- 在爬虫过程中,需要模拟浏览器访问,以防止被网站阻止或误判为恶意行为。
- 下载文件时,可以使用
requests库的get方法获取文件的内容,并使用open函数将内容写入文件。
结束语
本文介绍了如何使用 Python 编写一个简单的爬虫,从指定网页中获取女神图片,并保存到本地。通过学习本文,你可以了解基本的网络请求和数据提取技巧,为你未来的爬虫项目打下基础。当使用爬虫进行图片下载时,请确保遵守相关法律法规和网站的使用规定,尊重他人的版权和隐私。同时,注意合理使用爬虫,避免给目标网站和服务器造成过大负担。谨慎、高效地开展爬虫工作,更好地应用于实际开发中。
相关文章:
【小白必看】Python爬虫实战之批量下载女神图片并保存到本地
文章目录 前言运行结果部分图片1. 引入所需库2. 发送请求获取网页内容3. 解析网页内容并提取图片地址和名称4. 下载并保存图片完整代码关键代码讲解 结束语 前言 爬取网络上的图片是一种常见的需求,它可以帮助我们批量下载大量图片并进行后续处理。本文将介绍如何使…...

道本科技||全面建立国有企业合规管理体系
为全面深化国有企业法治建设,不断加强合规管理,防控合规风险,保障企业稳健发展,近日,市国资委印发《常州市市属国有企业合规管理办法(试行)》(以下简称《办法》)…...

CentOS 8上安装和配置Redis
在本篇博客中,我们将演示如何在CentOS 8上安装和配置Redis。我们将首先安装Redis,然后配置Redis以设置密码并允许公开访问。 步骤 1:安装Redis 首先,更新软件包列表: sudo yum update安装Redis: sudo yum …...
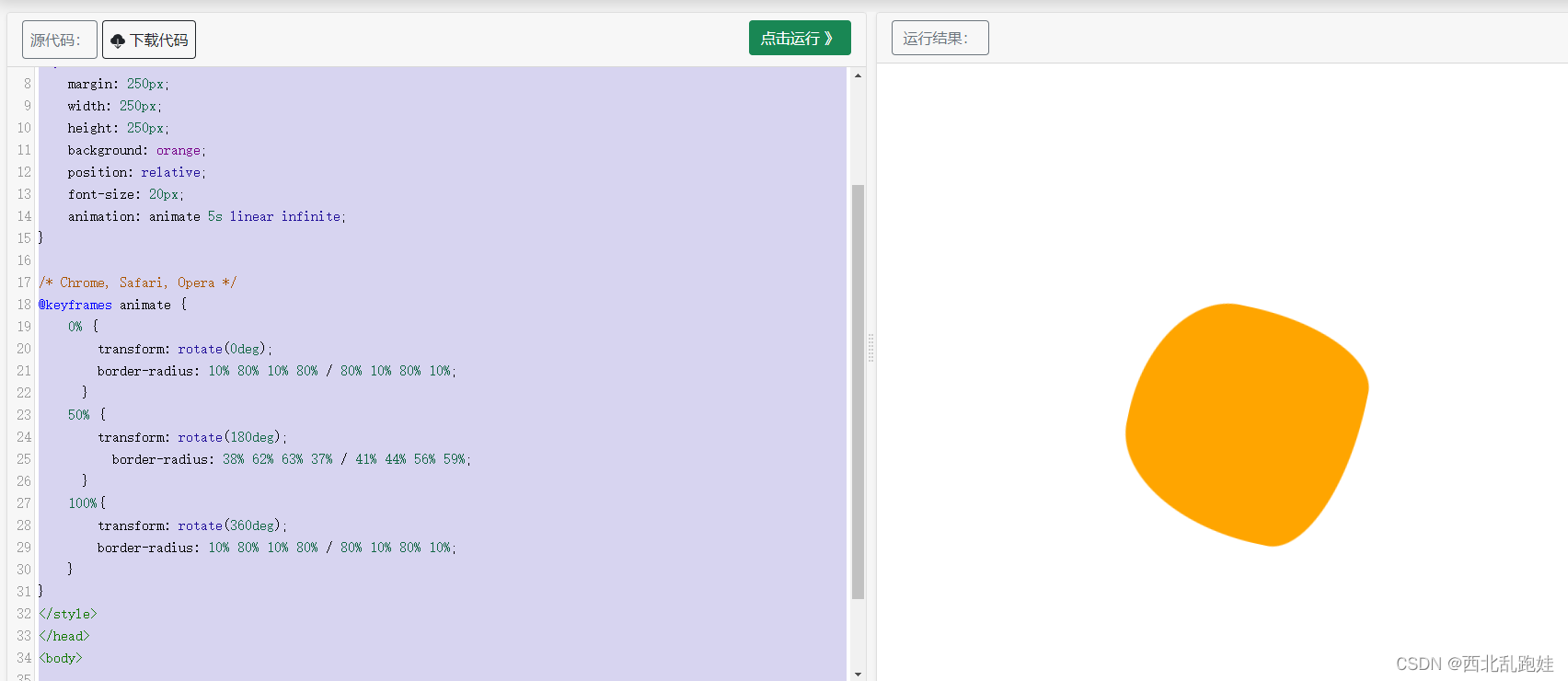
西北乱跑娃 -- CSS动态旋转果冻效果
<!DOCTYPE html> <html> <head> <meta charset"utf-8"> <title>旋转果冻</title> <style> #myDIV {margin: 250px;width: 250px;height: 250px;background: orange;position: relative;font-size: 20px;animation: anima…...

解决安装office出现1402错误和注册表编辑器无法设置安全性错误
写在前面 可能是由于之前的office没有卸载干净,看了很多文章,也有的说是使用了Windows Installer Clean Up卸载office的缘故,最后导致的结果是出现了再次安装office时出现了1402错误,而在解决1402错误的过程中,修改所…...
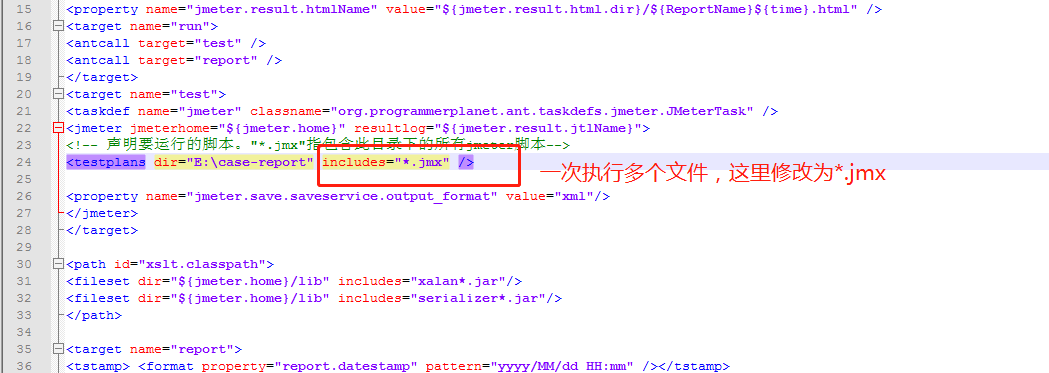
Jmeter接口自动化生成测试报告html格式
jmeter自带执行结果查看的插件,但是需要在jmeter工具中才能查看,如果要向领导提交测试结果,不够方便直观。 笔者刚做了这方面的尝试,总结出来分享给大家。 这里需要用到ant来执行测试用例并生成HTML格式测试报告。 一、ant下载安…...

移动IP的原理
目的 使得移动主机在各网络之间漫游时,仍然能保持其原来的IP地址不变 工作步骤 代理发现与注册 主机A:主机A移动到外地网络后,通过“代理发现协议”,与外地代理建立联系,并从外地代理获得一个转交地址,…...

uView 在 uni-app 中的使用
文章目录 一、uView是什么?1.uView 安装2.uView 在 uni-app 中的使用 一、uView是什么? 提示:正文内容: uView 官网: https://www.uviewui.com uView 是 uni-app 生态专用的 UI 框架 关于uView的取名来由,…...

netcat和netstat使用
Linux是一款受欢迎的开源操作系统,在Linux系统中要安装用于终端连接的nc(netcat)工具,可以帮助我们快速管理网络服务,在此文中,我们将介绍如何在Linux系统下安装nc工具的详细步骤。 一.安装nc工具 1.首先…...
mybatisPlus高级篇
文章目录 主键生成策略介绍AUTO策略INPUT策略ASSIGN_ID策略ASSIGN_UUID策略NONE策略 MybatisPlus分页分页插件自定义分页插件 ActiveRecord模式SimpleQuery工具类SimpleQuery介绍listmapGroup 主键生成策略介绍 主键:在数据库中,主键通常用于快速查找和…...
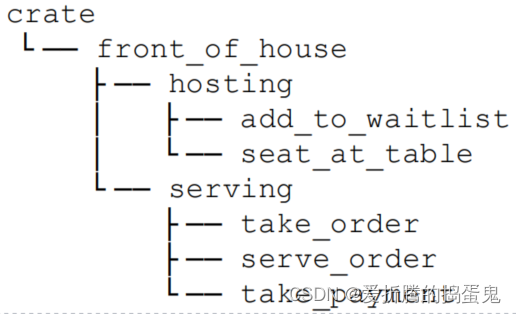
Rust之包、单元包及模块
包:一个用于构建、测试并分享单元包的Cargo功能;单元包:一个用于生成库或可执行文件的树形模块结构;模块及use关键字:被用于控制文件结构、作用域及路径的私有性;路径:一种用于命名条目的方法&a…...

内存函数讲解
💕"痛苦难以避免,而磨难可以选择。"-->村上春树💕 作者:Mylvzi 文章主要内容:数据在内存中的存储 内存函数就是管理内存数据的函数,包含于头文件<string.h>中 1.memcpy函数-->内存…...

C语言假期作业 DAY 01
题目 1.选择题 1、执行下面程序,正确的输出是( ) int x5,y7; void swap() { int z; zx; xy; yz; } int main() { int x3,y8; swap(); printf("%d,%d\n",x, y)…...
2023牛客暑期多校-J-Qu‘est-ce Que C‘est?(DP)
题意: 给定长度为n的数列,要求每个数都在的范围,且任意长度大于等于2的区间和都大于等于0,问方案数。。 思路: 首先要看出是dp题,用来表示遍历到第i位且后缀和最小为x的可行方案数(此时的后缀可以只有最…...
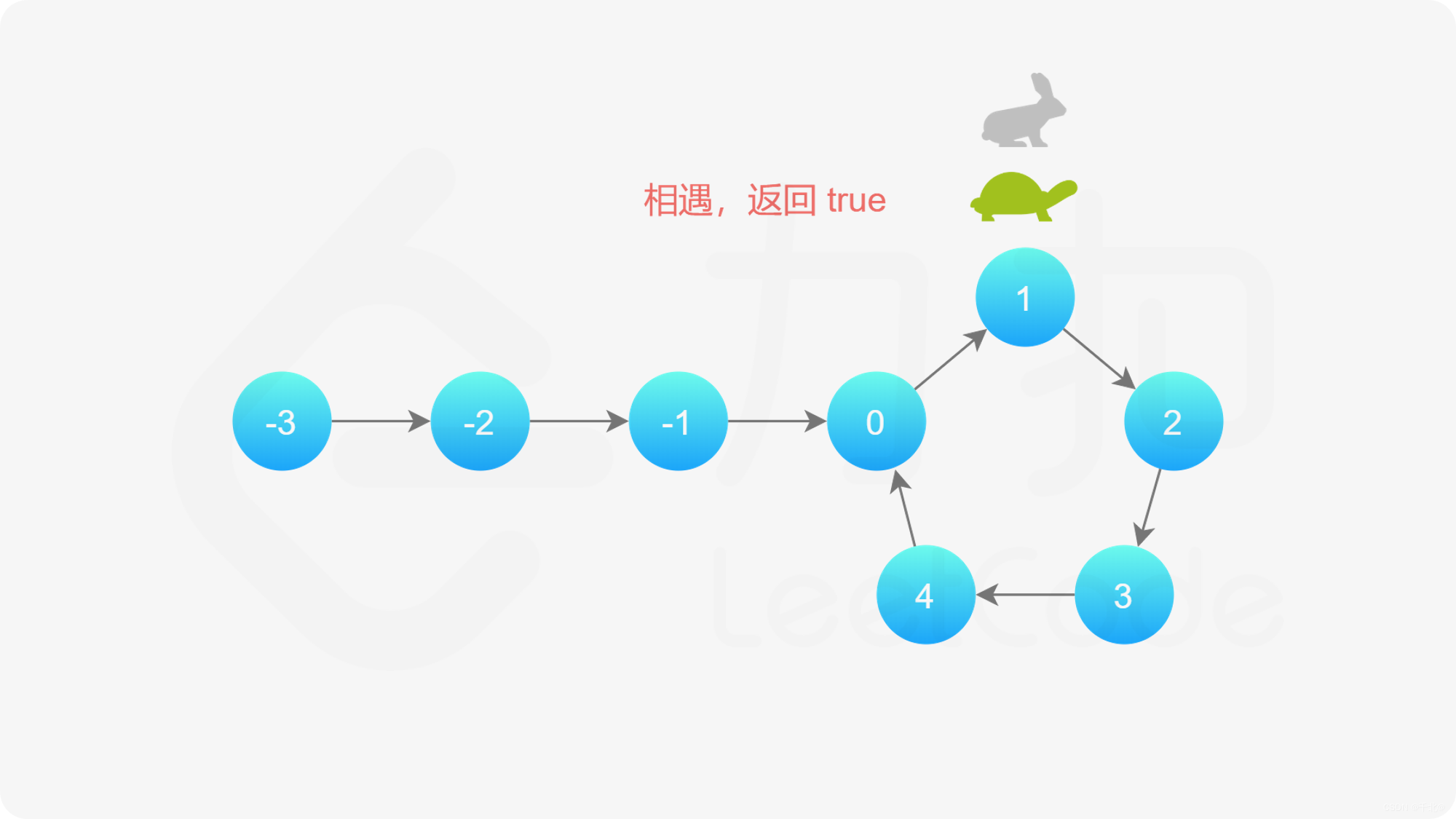
【141. 环形链表】
来源:力扣(LeetCode) 描述: 给你一个链表的头节点 head ,判断链表中是否有环。 如果链表中有某个节点,可以通过连续跟踪 next 指针再次到达,则链表中存在环。 为了表示给定链表中的环&#x…...
ORB特征笔记
简介 ORB Oriented FAST Rotated BRIEF 前面的Oriented FAST说明的是它的关键点的选取是一种改良过的FAST,在FAST的基础上加了方向信息;后面的Rotated BRIEF是指特征描述符使用BRIEF描述子(Binary Robust Independent Elementary Featur…...
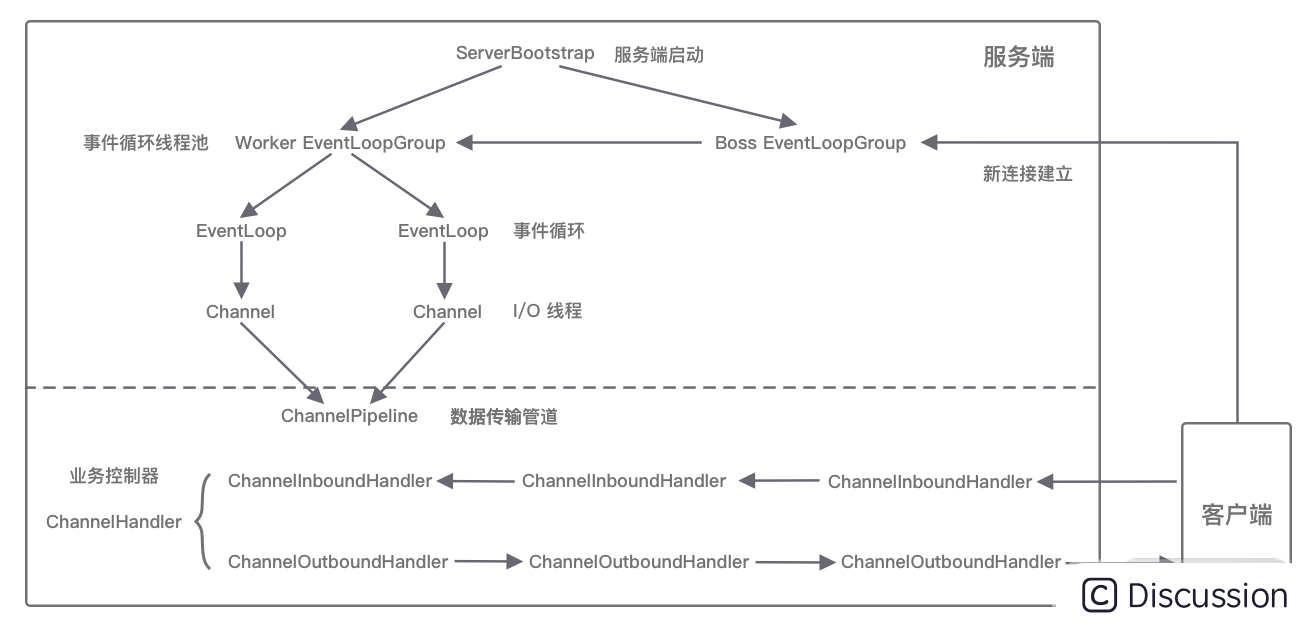
12.Netty源码之整体架构脉络
Netty 整体架构脉络 Netty 的逻辑处理架构为典型网络分层架构设计,共分为网络通信层、事件调度层、服务编排层,每一层各司其职。 网络通信层 网络通信层的职责是执行网络 I/O 的操作。它支持多种网络协议和 I/O 模型的连接操作。当网络数据读取到内核缓冲…...
【ArcGIS Pro二次开发】(54):三调名称转用地用海名称
三调地类和用地用海地类之间有点相似但并不一致。 在做规划时,拿到的三调,都需要将三调地类转换为用地用海地类,然后才能做后续的工作。 一般情况下,三调转用地用海存在【一对一,多对一和一对多】3种情况。 前2种情况…...

3D Tiles官方示例资源下载链接
本文列出Cesium官方提供的 3D Tiles 1.0和1.1规范的9个示例切块集(tileset)。 有关如何使用本地服务器托管这些示例的详细信息,请参阅 INSTRUCTIONS.md。 推荐:用 NSDT设计器 快速搭建可编程3D场景。 1、Metadata Granularities …...

【Java】分支结构习题
【Java】分支结构 文章目录 【Java】分支结构题1 :数字9 出现的次数题2 :计算1/1-1/21/3-1/41/5 …… 1/99 - 1/100 的值。题3 :猜数字题4 :牛客BC110 X图案题5 :输出一个整数的每一位题6 : 模拟三次密码输…...

无机布防火卷帘门报价透明,包工包料,一次说清所有费用
很多客户在选购无机布防火卷帘门时,最关心实际成交价格,也担心报价不清晰,后期产生各类额外支出。行业内产品定价参差不齐,选材做工不同,最终价位自然存在差距,挑选时不能只看表面低价。 👉 点击…...
)
从测速到配置:一套完整的cFosSpeed网络加速保姆级教程(适用于小白)
从零开始掌握cFosSpeed:网络加速全流程实战指南对于经常进行在线游戏、视频会议或大文件传输的用户来说,网络延迟和带宽利用率低下往往是影响体验的关键痛点。cFosSpeed作为一款专业的网络流量优化工具,能够显著改善这些问题,但许…...

量子计算中Loschmidt回声相位测量的创新方法
1. 量子计算中的Loschmidt回声相位测量方法概述Loschmidt回声是量子动力学中一个重要的概念,它描述了量子系统在时间反演演化后与初始状态的相似程度。在量子计算领域,精确测量Loschmidt回声的相位信息对于理解量子系统的非平衡态行为、计算能量本征值以…...

Visual Paradigm 17.0 团队协作新功能实测:手把手教你用项目模板和文件夹管理提效
Visual Paradigm 17.0 团队协作实战指南:从模板配置到文件夹管理的高效工作流在敏捷开发团队中,项目启动速度和资产管理的规范性往往直接影响整体效率。Visual Paradigm 17.0针对这一痛点推出的团队协作增强功能,特别是服务器端项目模板和文件…...

从多路复用到三维光阵:Arduino驱动8x8x8 LED立方体全解析
1. 项目概述:用Arduino点亮一个三维世界几年前,我第一次在创客展上看到一个8x8x8的LED立方体,那种由数百个光点构成的、在三维空间中流动的动画效果,瞬间就把我吸引住了。它不像普通的平面LED屏,而是真正有“深度”的光…...

如何在macOS上免费解锁QQ音乐加密文件:完整指南
如何在macOS上免费解锁QQ音乐加密文件:完整指南 【免费下载链接】QMCDecode QQ音乐QMC格式转换为普通格式(qmcflac转flac,qmc0,qmc3转mp3, mflac,mflac0等转flac),仅支持macOS,可自动识别到QQ音乐下载目录,默认转换结果…...

别只拿PotPlayer看片了!挖掘它的采集录制功能,做Switch游戏存档大师
别把PotPlayer当普通播放器!解锁它的Switch游戏录制黑科技 你是否已经厌倦了在OBS、Bandicam等专业录制软件中反复调试参数的繁琐?是否想过那个每天用来看视频的PotPlayer,其实隐藏着令人惊喜的游戏录制能力?今天,我们…...

6款高效降AI率工具 改写实力出众
写论文时反复检测出的AI痕迹总让你提心吊胆?别担心,这里整理了6款真正好用的论文降AI率工具,堪称应对AI生成特征的“得力助手”。它们能有效识别并消除AI生成的痕迹,改写能力出众,帮你快速降低查重率,顺利通…...

全链路压测实战:双十一级别的流量,我是这样扛住的
作为一名在质量保障领域摸爬滚打多年的测试工程师,我深知传统的单接口压测在如今分布式架构下的无力感。当业务流量达到双十一这种脉冲式、高并发的级别时,任何一个非核心链路上的“短板”都可能引发系统性的雪崩。全链路压测不再是选择题,而…...

告别浪费!SolidWorks企业级共享方案,实现降本增效全攻略
还在为 SolidWorks 高昂的硬件投入和混乱的图纸管理头疼?告别“一人一机”的浪费模式,企业级共享方案才是降本增效的正解。这套攻略基于“1 台高性能服务器 云飞云共享云桌面”架构,帮你把硬件成本砍掉 60%,把软件利用率翻倍。一…...