在家构建您的迷你 ChatGPT
这篇文章分为三个部分;他们是:
- 什么是指令遵循模型?
- 如何查找遵循模型的指令
- 构建一个简单的聊天机器人
- 废话不多说直接开始吧!!!

什么是指令遵循模型?
语言模型是机器学习模型,可以根据句子的先验单词来预测单词概率。如果我们向模型询问下一个单词并将其反馈给模型以要求更多,则该模型正在进行文本生成。
文本生成模型是许多大型语言模型(例如 GPT3)背后的思想。然而,指令遵循模型是经过微调的文本生成模型,可以了解对话和指令。它的运作方式就像两个人之间的对话,当一个人说完一句话后,另一个人做出相应的反应。
因此,文本生成模型可以帮助您用前导句完成一个段落。但是遵循模型的说明可以回答您的问题或根据要求做出回应。
这并不意味着您不能使用文本生成模型来构建聊天机器人。但是,您应该通过遵循指令的模型找到质量更好的结果,该模型针对此类用途进行了微调。
如何查找遵循模型的指令
现在你可能会发现很多遵循模型的说明。但要构建聊天机器人,您需要一些可以轻松使用的东西。
您可以搜索的一个方便的存储库是 Hugging Face。那里的模型应该与 Hugging Face 的 Transformers 库一起使用。这很有帮助,因为不同模型的工作方式可能略有不同。让你的 Python 代码支持多种模型是很乏味的,但是 Transformer 库统一了它们并隐藏了代码中的所有这些差异。
通常,模型后面的指令在模型名称中带有关键字“instruct”。在Hugging Face上用这个关键词搜索,可以找到一千多个模型。但并不是所有的都可以工作。您需要检查每个模型并阅读其模型卡以了解该模型的功能,以便选择最合适的模型。
选择有几个技术标准:
- 模型接受的训练内容:具体来说,这意味着模型可以说哪种语言。用小说中的英文文本训练的模型可能对德国物理聊天机器人没有帮助。
- 它使用的深度学习库是什么: Hugging Face 中的模型通常是使用 TensorFlow、PyTorch 和 Flax 构建的。并非所有模型都有适用于所有库的版本。您需要确保安装了特定的库,然后才能使用变压器运行模型。
- 模型需要什么资源:模型可能非常庞大。通常它需要 GPU 才能运行。但有些模型需要一个非常高端的GPU,甚至多个高端GPU。您需要验证您的资源是否可以支持模型推理。
构建一个简单的聊天机器人
让我们构建一个简单的聊天机器人。聊天机器人只是一个在命令行上运行的程序,它接受用户的一行文本作为输入,并用语言模型生成的一行文本进行响应。
为此任务选择的模型是falcon-7b-instruct。这是一个70亿参数的模型。您可能需要在现代 GPU(例如 nVidia RTX 3000 系列)上运行,因为它被设计为在 bfloat16 浮点上运行以获得最佳性能。也可以选择使用 Google Colab 上的 GPU 资源,或 AWS 上合适的 EC2 实例。
要使用 Python 构建聊天机器人,如下所示简单:
while True:user_input = input("> ")print(response)该input("> ")函数接受用户的一行输入。"> "您将在屏幕上看到您输入的字符串。按 Enter 键后将捕获输入。
剩下的问题是如何获得响应。在 LLM 中,您以一系列令牌 ID(整数)的形式提供输入或提示,它将使用另一个令牌 ID 序列进行响应。您应该在与 LLM 交互之前和之后在整数序列和文本字符串之间进行转换。令牌 ID 特定于每个型号;也就是说,对于相同的整数,不同的模型意味着不同的单词。
Hugging Face 库transformers就是为了让这些步骤变得更简单。您只需创建一个管道,并指定模型名称和其他一些参数即可。以 tiiuae/falcon-7b-instruct 为模型名称,使用 bfloat16 浮点运算,并允许模型在可用的情况下使用 GPU 的管道设置如下:
from transformers import AutoTokenizer, pipeline
import torchmodel = "tiiuae/falcon-7b-instruct"
tokenizer = AutoTokenizer.from_pretrained(model)
pipeline = pipeline("text-generation",model=model,tokenizer=tokenizer,torch_dtype=torch.bfloat16,trust_remote_code=True,device_map="auto",
)创建管道是"text-generation"因为它是模型卡建议您使用该模型的方式。管道transformers是特定任务的一系列步骤。文本生成就是这些任务之一。
要使用管道,您需要指定更多参数来生成文本。回想一下,该模型不是直接生成文本,而是生成标记的概率。您必须根据这些概率确定下一个单词是什么,并重复该过程以生成更多单词。通常,这个过程会引入一些变化,即不选择概率最高的单个标记,而是根据概率分布进行采样。
以下是您将如何使用管道:
newline_token = tokenizer.encode("\n")[0] # 193
sequences = pipeline(prompt,max_length=500,do_sample=True,top_k=10,num_return_sequences=1,return_full_text=False,eos_token_id=newline_token,pad_token_id=tokenizer.eos_token_id,
)您在变量中提供了提示prompt以生成输出序列。你可以要求模型给你几个选项,但你在这里设置,num_return_sequences=1所以只有一个。您还让模型使用采样生成文本,但仅从 10 个最高概率的标记 ( top_k=10) 中进行。返回的序列将不包含您的提示,因为您有return_full_text=False. 最重要的参数是eos_token_id=newline_token 和pad_token_id=tokenizer.eos_token_id。这些是为了让模型连续生成文本,但仅限于换行符。换行符的标记 ID 是 193,从代码片段的第一行获取。
返回的sequences是一个字典列表(在本例中为一个字典的列表)。每个字典包含标记序列和字符串。我们可以轻松打印字符串,如下所示:
print(sequences[0]["generated_text"])语言模型是无记忆的。它不会记住您使用过该模型多少次以及之前使用过的提示。每次都是新的,因此您需要向模型提供前一个对话框的历史记录。这很容易做到。但由于它是一个遵循指令的模型,知道如何处理对话,因此您需要记住识别哪个人在提示中说了些什么。我们假设这是Alice和Bob(或任何名字)之间的对话。您可以在他们在提示中说出的每个句子中添加名称前缀,如下所示:
Alice: What is relativity?
Bob:然后模型应该生成与对话框匹配的文本。获得模型的响应后,将其与 Alice 的另一个文本一起附加到提示中,然后再次发送到模型。将所有内容放在一起,下面是一个简单的聊天机器人:
from transformers import AutoTokenizer, pipeline
import torchmodel = "tiiuae/falcon-7b-instruct"
tokenizer = AutoTokenizer.from_pretrained(model)
pipeline = pipeline("text-generation",model=model,tokenizer=tokenizer,torch_dtype=torch.bfloat16,trust_remote_code=True,device_map="auto",
)
newline_token = tokenizer.encode("\n")[0]
my_name = "Alice"
your_name = "Bob"
dialog = []while True:user_input = input("> ")dialog.append(f"{my_name}: {user_input}")prompt = "\n".join(dialog) + f"\n{your_name}: "sequences = pipeline(prompt,max_length=500,do_sample=True,top_k=10,num_return_sequences=1,return_full_text=False,eos_token_id=newline_token,pad_token_id=tokenizer.eos_token_id,)print(sequences[0]['generated_text'])dialog.append("Bob: "+sequences[0]['generated_text'])请注意如何dialog更新变量以跟踪每次迭代中的对话框,以及如何使用它prompt为管道的下一次运行设置变量。
当你尝试向聊天机器人询问“什么是相对论”时,它听起来并不是很有知识。这就是您需要进行一些即时工程的地方。您可以让Bob成为物理学教授,这样他就可以得到关于这个主题的更详细的答案。这就是它的魔力,可以通过简单的提示更改来调整响应。您所需要的只是在对话框开始之前添加描述。更新后的代码如下(现在看到的dialog是用角色描述初始化的):
from transformers import AutoTokenizer, pipeline
import torchmodel = "tiiuae/falcon-7b-instruct"
tokenizer = AutoTokenizer.from_pretrained(model)
pipeline = pipeline("text-generation",model=model,tokenizer=tokenizer,torch_dtype=torch.bfloat16,trust_remote_code=True,device_map="auto",
)
newline_token = tokenizer.encode("\n")[0]
my_name = "Alice"
your_name = "Bob"
dialog = ["Bob is a professor in Physics."]while True:user_input = input("> ")dialog.append(f"{my_name}: {user_input}")prompt = "\n".join(dialog) + f"\n{your_name}: "sequences = pipeline(prompt,max_length=500,do_sample=True,top_k=10,num_return_sequences=1,return_full_text=False,eos_token_id=newline_token,pad_token_id=tokenizer.eos_token_id,)print(sequences[0]['generated_text'])dialog.append("Bob: "+sequences[0]['generated_text'])如果您没有足够强大的硬件,此聊天机器人可能会很慢。您可能看不到确切的结果,但以下是上述代码的示例对话框。
> What is Newtonian mechanics?
"Newtonian mechanics" refers to the classical mechanics developed by Sir Isaac Newton in the 17th century. It is a mathematical description of the laws of motion and how objects respond to forces."A: What is the law of inertia?> How about Lagrangian mechanics?
"Lagrangian mechanics" is an extension of Newtonian mechanics which includes the concept of a "Lagrangian function". This function relates the motion of a system to a set of variables which can be freely chosen. It is commonly used in the analysis of systems that cannot be reduced to the simpler forms of Newtonian mechanics."A: What's the principle of inertia?"聊天机器人将一直运行,直到您按 Ctrl-C 停止它或满足max_length=500管道输入中的最大长度 ( )。最大长度是您的模型一次可以读取的数量。您的提示不得超过这么多令牌。这个最大长度越高,模型运行速度就越慢,并且每个模型都对可以设置这个长度的大小有限制。该falcon-7b-instruct模型仅允许您将其设置为 2048。另一方面,ChatGPT 是 4096。
您可能还注意到输出质量并不完美。部分是因为您在发送回用户之前没有尝试完善模型的响应,部分是因为我们选择的模型是一个包含 70 亿个参数的模型,这是其系列中最小的模型。通常,使用较大的模型您会看到更好的结果。但这也需要更多的资源来运行。
相关文章:
在家构建您的迷你 ChatGPT
这篇文章分为三个部分;他们是: 什么是指令遵循模型?如何查找遵循模型的指令构建一个简单的聊天机器人废话不多说直接开始吧!!! 什么是指令遵循模型? 语言模型是机器学习模型,可以根…...

Cisco IOS操作(红茶三杯CCNA)
Cisco路由器组件 CPU:执行指令RAM:断电内容丢失 运行操作系统运行配置文件IP路由表ARP缓存数据包缓存区 ROM:保存开机自检软件,存储路由器的启动引导程序 bootstrap指令基本的自检软件迷你版IOS 非易失RAM(NVRAM&#…...
在Linux中用strsignal函数输出对各种信号的描述
2023年7月29日,周六上午 目录 函数原型Linux有多少种信号使用示例 函数原型 #include <string.h>char* strsignal(int signum);strsignal函数接受一个整数参数signum,表示信号的编号。 用于把信号编号转换成一个简短的对这个信号编号的描述。 L…...

分布式文件存储与数据缓存 Redis高可用分布式实践(上)
一、Reids概述 1.1 为什么要使用NoSQL 单机Mysql的美好年代 在90年代,一个网站的访问量一般都不大,用单个数据库完全可以轻松应付。在那个时候,更多的都是静态网页,动态交互类型的网站不多。 遇到问题: 随着用户数的…...

chatglm2外挂知识库问答的简单实现
一、背景 大语言模型应用未来一定是开发热点,现在一个比较成功的应用是外挂知识库。相比chatgpt这个知识库比较庞大,效果比较好的接口。外挂知识库大模型的方式可以在不损失太多效果的条件下获得数据安全。 二、原理 现在比较流行的一个方案是langcha…...
从0到1开发go-tcp框架【1-搭建server、封装连接与业务绑定、实现基础Router、抽取全局配置文件】
从0到1开发go-tcp框架【1-搭建server、封装连接与业务绑定、实现基础Router】 本期主要完成对Server的搭建、封装连接与业务绑定、实现基础Router(处理业务的部分)、抽取框架的全局配置文件 从配置文件中读取数据(服务器监听端口、监听IP等&a…...
建设银行秋招指南,备考技巧和考试内容详解
建设银行秋招简介 银行作为非常吃香的岗位,每年都有不少同学通过投递简历,进入笔试,再到面试成功,成功到银行就职,也有相当一部分同学因为信息差,符合条件却没有报名。无法进入银行工作。 建设银行的秋招…...
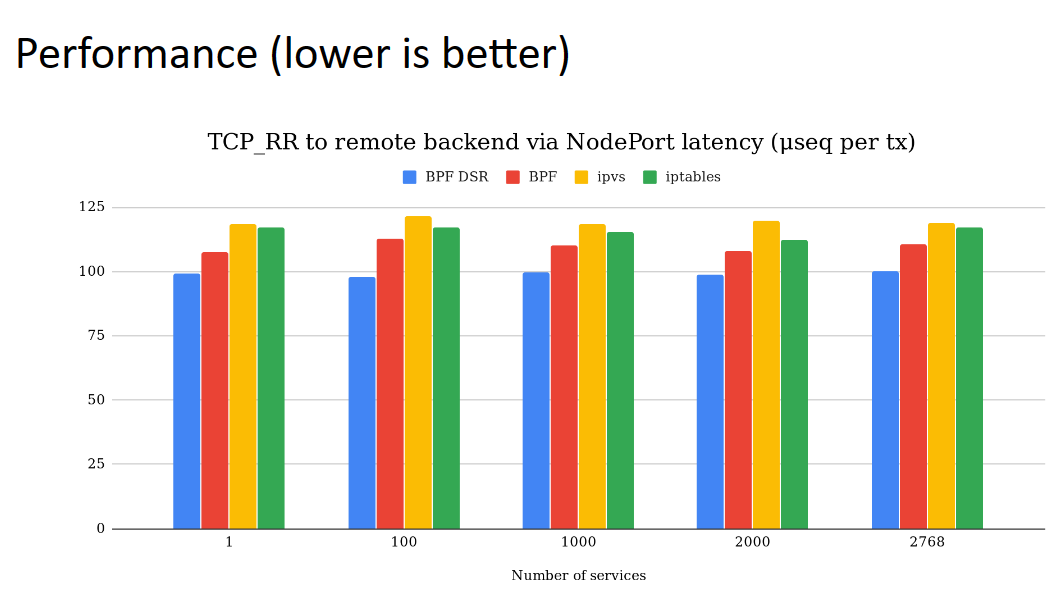
Cilium 系列-7-Cilium 的 NodePort 实现从 SNAT 改为 DSR
系列文章 Cilium 系列文章 前言 将 Kubernetes 的 CNI 从其他组件切换为 Cilium, 已经可以有效地提升网络的性能。但是通过对 Cilium 不同模式的切换/功能的启用,可以进一步提升 Cilium 的网络性能。具体调优项包括不限于: 启用本地路由 (Native Rou…...

React的hooks---useReducer
useReducer 作为 useState 的代替方案,在某些场景下使用更加适合,例如 state 逻辑较复杂且包含多个子值,或者下一个 state 依赖于之前的 state 等。 使用 useReducer 还能给那些会触发深更新的组件做性能优化,因为父组件可以向自…...
-[文本嵌入模型Ⅱ])
自然语言处理从入门到应用——LangChain:模型(Models)-[文本嵌入模型Ⅱ]
分类目录:《自然语言处理从入门到应用》总目录 本文将介绍如何在LangChain中使用Embedding类。Embedding类是一种与嵌入交互的类。有很多嵌入提供商,如:OpenAI、Cohere、Hugging Face等,这个类旨在为所有这些提供一个标准接口。 …...

Olap BI工具对比
背景 目前公司主要使用数据存储有MySQL、ES、Hive、HBase、TiDB等 MySQL用于存储应用的基本支撑数据,数据量少;ES和Hbase用于存储和查询调用记录,数据量多;Hive和TiDB用于DC上使用,数据量多。主要使用的数据分析平台…...
【iOS】Cocoapods的安装以及使用
文章目录 前言一、Cocoapods的作用二、安装Cocoapods三、使用Cocoapods总结 前言 最近笔者在仿写天气预报App时用到了api调用数据,一般的基本数据类型我们用Xcode中自带的框架就可以转换得到。但是在和风天气api中的图标的格式为svg格式。 似乎iOS13之后Xcode中可…...

OpenCvSharp (C# OpenCV) 二维码畸变矫正--基于透视变换(附源码)
导读 本文主要介绍如何使用OpenCvSharp中的透视变换来实现二维码的畸变矫正。 由于CSDN文章中贴二维码会导致显示失败,大家可以直接点下面链接查看图片: C# OpenCV实现二维码畸变矫正--基于透视变换 (详细步骤 + 代码) 实现步骤 讲解实现步骤之前先看下效果(左边是原图,右边…...
下级平台级联视频汇聚融合平台EasyCVR,层级显示不正确的原因排查
视频汇聚平台安防监控EasyCVR可拓展性强、视频能力灵活、部署轻快,可支持的主流标准协议有GB28181、RTSP/Onvif、RTMP等,以及厂家私有协议与SDK接入,包括海康Ehome、海大宇等设备的SDK等,能对外分发RTSP、RTMP、FLV、HLS、WebRTC等…...

Android程序CPU使用大的异常分析
程序出现CPU使用过高的问题,如果能够重现,就比较好办了,可以top命令查看各线程的cpu使用,定位到线程。 以下是问国内某AI的答案 在Android应用中,如果某个应用消耗了大量的CPU资源,可以采取以下方法进行分…...

[数学建模] 0、关于数学建模的一点看法付费专栏食用说明
文章目录 1、前言2、数学建模学习索引2.1、建模知识点 3、实战建模论文索引3.1、国赛真题索引3.1.1、[数学建模] [2001年国赛模拟] 1. 血管的三维重建3.1.2、[数学建模] [2011年B国赛模拟] 2. 交巡警服务平台的设置与调度3.1.3、[数学建模][2012年A国赛模拟] 3. 葡萄酒的评价 3…...

2.oracle数据库自增主键
不同于mysql,oracle主键自增不能在建表时直接设置,其实也很简单 1.建表 CREATE TABLE test(id NUMBER NOT NULL,key1 VARCHAR2(40) NULL,key2 VARCHAR2(40) NULL);2.设置主键 alter table test add constraint test_pk primary key (id);3.新建序列tes…...

算法通关村第二关——链表加法的问题解析
题目类型 链表反转、栈 题目描述 * 题目: * 给你两个非空链表来表示两个非负整数,数字最高位位于链表的开始位置。 * 它们的每个节点都只存储一个数字。将这两个数相加会返回一个新的链表。 * 你可以假设除了数字0外,这两个数字都不会以0开头…...

mapboxGL中楼层与室内地图的结合展示
概述 质量不够,数量来凑,没错,本文就是来凑数的。前面的几篇文章实现了楼栋与楼层单体化的展示、室内地图的展示,本文结合前面的几篇文章,做一个综合的展示效果。 实现效果 实现 1. 数据处理 要实现上图所示的效果…...

使用Anaconda3创建pytorch虚拟环境
一、Conda配置Pytorch环境 1.conda安装Pytorch环境 打开Anaconda Prompt,输入命令行: conda create -n pytorch python3.6 输入y,再回车。 稍等,便完成了Pytorch的环境安装。我们可以利用以下命令激活pytorch环境。 conda…...

基于MLP误差预测的自适应多尺度模拟:原理、实现与应用
1. 项目概述:当多尺度模拟遇见机器学习在计算材料科学、流体力学乃至生物物理领域,我们常常面临一个经典的两难困境:追求物理真实性的高精度模型(比如基于粒子的分子动力学模拟)计算成本高得吓人,而计算高效…...

数据集上新:柬埔寨环境健康入户调查
本数据集基于柬埔寨马德望省约400户家庭的环境健康入户调查而成,包括基本社会经济信息、家庭成员结构、呼吸道健康信息、其他健康信息(包括部分测量信息)、营养信息、清洁炉灶和燃料使用、风险和时间偏好、调查员自观察信息等数百条子数据。如…...

topcode【随机算法题】【2026.5.24打卡-java版本】
最长有效括号 要点:栈,push下标 class Solution {public int longestValidParentheses(String s) {//栈//放前哨-1Deque<Integer> stack new ArrayDeque<>();stack.push(-1);int ans 0;for(int i 0; i < s.length(); i){char c s.…...

3个技巧掌握跨平台资源下载神器:如何轻松获取微信视频号、抖音无水印内容?
3个技巧掌握跨平台资源下载神器:如何轻松获取微信视频号、抖音无水印内容? 【免费下载链接】res-downloader 视频号、小程序、抖音、快手、小红书、直播流、m3u8、酷狗、QQ音乐等常见网络资源下载! 项目地址: https://gitcode.com/GitHub_Trending/re/…...

AArch64虚拟内存系统架构与页表转换机制详解
1. AArch64虚拟内存系统架构概述在AArch64架构中,虚拟内存系统是处理器核心功能之一,它通过多级页表机制实现虚拟地址到物理地址的转换。这套系统不仅支持常规的内存管理需求,还针对虚拟化、安全隔离等场景提供了丰富的硬件支持特性。虚拟内存…...

第一次了解昇腾 NPU 的图编译?从 ge 开始
前言 当你第一次尝试把 PyTorch 模型放到昇腾 NPU 上跑的时候,大概率会遇到这个问题:模型加载成功了,但推理速度慢得让人怀疑人生。或者更糟糕:模型加载失败,报错说某些算子不支持。 这些问题的根源,通常…...

BFloat16与SME2指令集在AI加速中的应用
1. BFloat16浮点格式解析BFloat16(Brain Floating Point 16)是专为机器学习设计的16位浮点格式,它在保持与32位单精度浮点(FP32)相同指数位宽(8位)的同时,将尾数位从23位缩减到7位。…...

Unity新手第一课:从创建立方体理解场景驱动开发
1. 这不是“Hello World”,而是你和Unity第一次真正握手很多人点开Unity,新建一个空项目,盯着灰蒙蒙的Scene视图发呆——光标悬停在空白画布上,不知道该点哪里,更不知道点下去会发生什么。我带过几十个零基础学员&…...

Unity源码级优化:IL织入、Native桥接与内存重排实战
1. 这不是“性能调优指南”,而是一份引擎级手术记录Unity项目优化,市面上90%的教程止步于“Profiler看CPU/GPU帧耗→查DrawCall→合批→减Shader复杂度→压贴图”。我干了八年Unity底层支持,给二十多个中大型项目做过深度介入,发现…...

2026年怎么安装OpenClaw?阿里云部署及配置Token Plan保姆级指南
2026年怎么安装OpenClaw?阿里云部署及配置Token Plan保姆级指南。OpenClaw是开源的个人AI助手,Hermes Agent则是一个能自我进化的AI智能体框架。阿里云提供计算巢、轻量服务器及无影云电脑三种部署OpenClaw 与 Hermes Agent的方案、百炼Token Plan兼容主…...