18.Netty源码之ByteBuf 详解
highlight: arduino-light
ByteBuf 是 Netty 的数据容器,所有网络通信中字节流的传输都是通过 ByteBuf 完成的。
然而 JDK NIO 包中已经提供了类似的 ByteBuffer 类,为什么 Netty 还要去重复造轮子呢?本节课我会详细地讲解 ByteBuf。
JDK NIO的ByteBuffer
我们首先介绍下 JDK NIO 的 ByteBuffer,才能知道 ByteBuffer 有哪些缺陷和痛点。下图展示了 ByteBuffer 的内部结构:

从图中可知,ByteBuffer 包含以下四个基本属性:
- mark:为某个读取过的关键位置做标记,方便回退到该位置;
- position:当前读取的位置;
- limit:buffer 中有效的数据长度大小;
- capacity:初始化时的空间容量。
以上四个基本属性的关系是:mark <= position <= limit <= capacity。结合 ByteBuffer 的基本属性,不难理解它在使用上的一些缺陷。
第一,ByteBuffer 分配的长度是固定的,无法动态扩缩容,所以很难控制需要分配多大的容量。如果分配太大容量,容易造成内存浪费;如果分配太小,存放太大的数据会抛出 BufferOverflowException 异常。在使用 ByteBuffer 时,为了避免容量不足问题,你必须每次在存放数据的时候对容量大小做校验,如果超出 ByteBuffer 最大容量,那么需要重新开辟一个更大容量的 ByteBuffer,将已有的数据迁移过去。整个过程相对烦琐,对开发者而言是非常不友好的。
第二,ByteBuffer 只能通过 position 获取当前可操作的位置,因为读写共用的 position 指针,所以需要频繁调用 flip、rewind 方法切换读写状态,开发者必须很小心处理 ByteBuffer 的数据读写,稍不留意就会出错。
ByteBuffer 作为网络通信中高频使用的数据载体,显然不能够满足 Netty 的需求,Netty 重新实现了一个性能更高、易用性更强的 ByteBuf,相比于 ByteBuffer 它提供了很多非常酷的特性:
- 容量可以按需动态扩展,类似于 StringBuffer;
- 读写采用了不同的指针,读写模式可以随意切换,不需要调用 flip 方法;
- 通过内置的复合缓冲类型可以实现零拷贝;
- 支持引用计数;
- 支持缓存池。
这里我们只是对 ByteBuf 有一个简单的了解,接下来我们就一起看下 ByteBuf 是如何实现的吧。
痛点:
1.readIndex 和 writeIndex没有分开
2.需要调用flip和clear方法
3.api命名区分度低
Netty ByteBuf 内部结构
同样我们看下 ByteBuf 的内部结构,与 ByteBuffer 做一个对比。
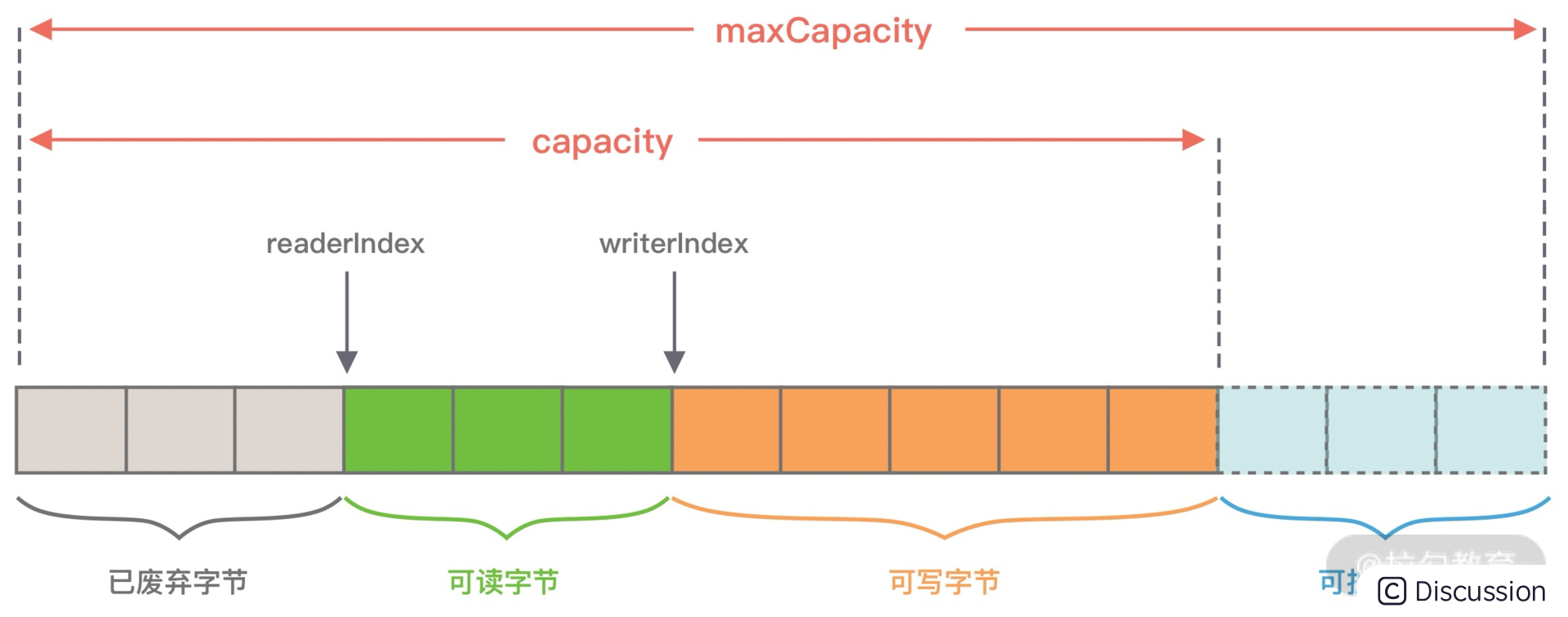
从图中可以看出,ByteBuf 包含三个指针:读指针 readerIndex、写指针 writeIndex、最大容量 maxCapacity,根据指针的位置又可以将 ByteBuf 内部结构可以分为四个部分:
第一部分是废弃字节,表示已经丢弃的无效字节数据。
第二部分是可读字节,表示 ByteBuf 中可以被读取的字节内容,可以通过 writeIndex - readerIndex 计算得出。从 ByteBuf 读取 N 个字节,readerIndex 就会自增 N,readerIndex 不会大于 writeIndex,当 readerIndex == writeIndex 时,表示 ByteBuf 已经不可读。
第三部分是可写字节,向 ByteBuf 中写入数据都会存储到可写字节区域。向 ByteBuf 写入 N 字节数据,writeIndex 就会自增 N,当 writeIndex 超过 capacity,表示 ByteBuf 容量不足,需要扩容。
第四部分是可扩容字节,表示 ByteBuf 最多还可以扩容多少字节,当 writeIndex 超过 capacity 时,会触发 ByteBuf 扩容,最多扩容到 maxCapacity 为止,超过 maxCapacity 再写入就会出错。
由此可见,Netty 重新设计的 ByteBuf 有效地区分了可读、可写以及可扩容数据,解决了 ByteBuffer 无法扩容以及读写模式切换烦琐的缺陷。
接下来,我们一起学习下 ByteBuf 的核心 API,你可以把它当作 ByteBuffer 的替代品单独使用。
引用计数
ByteBuf 是基于引用计数设计的,它实现了 ReferenceCounted 接口,ByteBuf 的生命周期是由引用计数所管理。
只要引用计数大于 0,表示 ByteBuf 还在被使用;
当 ByteBuf 不再被其他对象所引用时,引用计数为 0,那么代表该对象可以被释放。
当新创建一个 ByteBuf 对象时,它的初始引用计数为 1,当 ByteBuf 调用 release() 后,引用计数减 1。
所以不要误以为调用了 release() 就会保证 ByteBuf 对象一定会被回收。因为可能计数是2。
你可以结合以下的代码示例做验证:
md ByteBuf buffer = ctx.alloc().directBuffer(); assert buffer.refCnt() == 1; buffer.release(); assert buffer.refCnt() == 0;
引用计数对于 Netty 设计缓存池化有非常大的帮助,当引用计数为 0,该 ByteBuf 可以被放入到对象池中,避免每次使用 ByteBuf 都重复创建,对于实现高性能的内存管理有着很大的意义。
此外 Netty 可以利用引用计数的特点实现内存泄漏检测工具。
JVM 并不知道 Netty 的引用计数是如何实现的,当 ByteBuf 对象不可达时,一样会被 GC 回收掉,但是如果此时 ByteBuf 的引用计数不为 0,那么该对象就不会释放或者被放入对象池,从而发生了内存泄漏。
Netty 会对分配的 ByteBuf 进行抽样分析,检测 ByteBuf 是否已经不可达且引用计数大于 0,判定内存泄漏的位置并输出到日志中,你需要关注日志中 LEAK 关键字。
ByteBuf 分类
ByteBuf 有多种实现类,每种都有不同的特性,下图是 ByteBuf 的家族图谱,可以划分为三个不同的维度:Heap/Direct、Pooled/Unpooled和Unsafe/非 Unsafe,我逐一介绍这三个维度的不同特性。
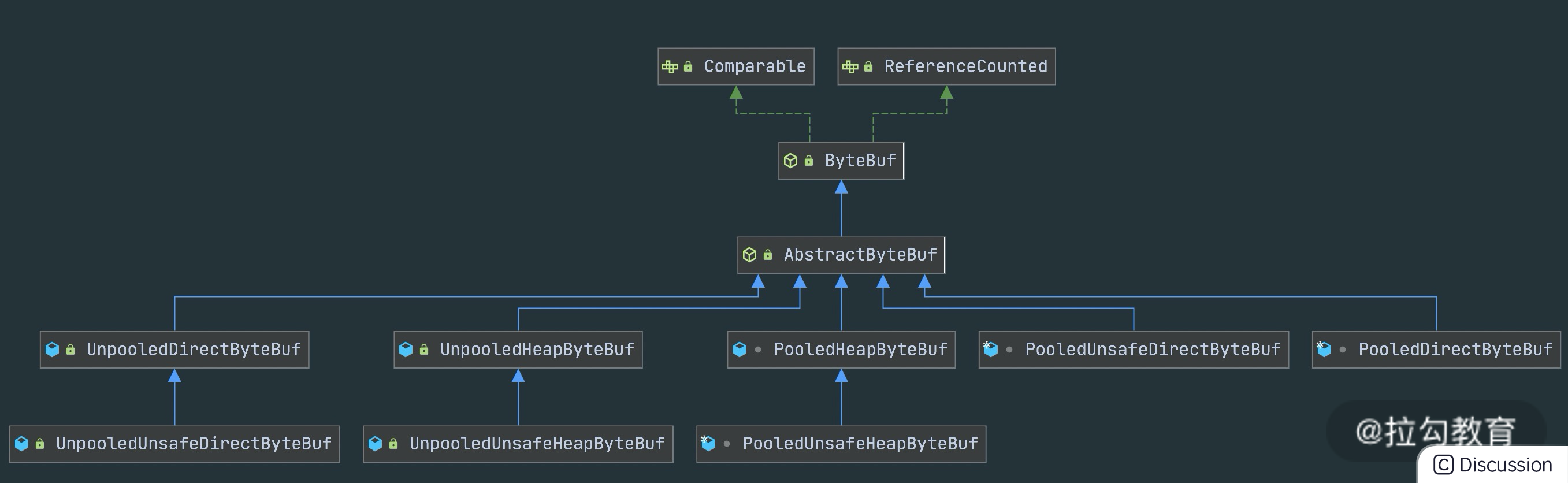
Heap/Direct
Heap/Direct 就是堆内和堆外内存。
Heap 指的是在 JVM 堆内分配,底层依赖的是字节数据;
Direct 则是堆外内存,不受 JVM 限制,分配方式依赖 JDK 底层的 ByteBuffer。
Pooled/Unpooled
Pooled/Unpooled 表示池化还是非池化内存。
Pooled 是从预先分配好的内存中取出,使用完可以放回 ByteBuf 内存池,等待下一次分配。
而 Unpooled 是直接调用系统 API 去申请内存,确保能够被 JVM GC 管理回收。
Unsafe/非 Unsafe
Unsafe/非 Unsafe 的区别在于操作方式是否安全。
Unsafe 表示每次调用 JDK 的 Unsafe 对象操作物理内存,依赖 offset + index 的方式操作数据。
非 Unsafe 则不需要依赖 JDK 的 Unsafe 对象,直接通过数组下标的方式操作数据。
ByteBuf 核心 API
我会分为指针操作、数据读写和内存管理三个方面介绍 ByteBuf 的核心 API。在开始讲解 API 的使用方法之前,先回顾下之前我们实现的自定义解码器,以便于加深对 ByteBuf API 的理解。
java public final void decode(ChannelHandlerContext ctx, ByteBuf in, List<Object> out) { // 判断 ByteBuf 可读取字节 if (in.readableBytes() < 14) { return; } in.markReaderIndex(); // 标记 ByteBuf 读指针位置 in.skipBytes(2); // 跳过魔数 in.skipBytes(1); // 跳过协议版本号 //获取序列化方式 byte serializeType = in.readByte(); in.skipBytes(1); // 跳过报文类型 in.skipBytes(1); // 跳过状态字段 in.skipBytes(4); // 跳过保留字段 //获取数据长度 int dataLength = in.readInt(); if (in.readableBytes() < dataLength) { in.resetReaderIndex(); // 重置 ByteBuf 读指针位置 return; } //根据数据长度构造 byte[] byte[] data = new byte[dataLength]; in.readBytes(data); //根据序列化方式 反序列化 SerializeService serializeService = getSerializeServiceByType(serializeType); //反序列化为对象 Object obj = serializeService.deserialize(data); if (obj != null) { out.add(obj); } }
指针操作 API
readerIndex()
readerIndex() 返回的是当前的读指针的 readerIndex 位置
writeIndex()
writeIndex() 返回的当前写指针 writeIndex 位置。
markReaderIndex()
markReaderIndex() 用于保存当前readerIndex 的位置。
resetReaderIndex()
resetReaderIndex() 则将当前 readerIndex 重置为之前markReaderIndex保存的位置。
markReaderIndex和resetReaderIndex这对 API 在实现协议解码时最为常用,例如在上述自定义解码器的源码中,在读取协议内容长度字段之前,先使用 markReaderIndex() 保存了 readerIndex 的位置,如果 ByteBuf 中可读字节数小于长度字段的值,则表示 ByteBuf 还没有一个完整的数据包,此时直接使用 resetReaderIndex() 重置readerIndex 的位置。
此外对应的写指针操作还有 markWriterIndex() 和 resetWriterIndex(),与读指针的操作类似,我就不再一一赘述了。
数据读写 API
isReadable()
isReadable() 用于判断 ByteBuf 是否可读,如果 writerIndex 大于 readerIndex,那么 ByteBuf 是可读的,否则是不可读状态。
readableBytes()
readableBytes() 可以获取 ByteBuf 当前可读取的字节数,可以通过 writerIndex - readerIndex 计算得到
readBytes(byte[] dst)
writeBytes(byte[] src)
readBytes() 和 writeBytes() 是两个最为常用的方法。
readBytes() 是将 ByteBuf 的数据读取相应的字节到字节数组dst 中,readBytes() 经常结合 readableBytes() 一起使用,
dst 字节数组的大小通常等于 readableBytes() 的大小。
java //收到的消息 ByteBuf bytebuf = (ByteBuf) msg; //构建字节数组 byte[] req = new byte[bytebuf.readableBytes()]; //将ByteBuf中的数据读取到字节数组中 bytebuf.readBytes(req); String body = new String(req, "UTF-8");
readByte()
writeByte(int value)
readByte() 是从 ByteBuf 中读取一个字节,相应的 readerIndex + 1;同理 writeByte 是向 ByteBuf 写入一个字节,相应的 writerIndex + 1。
类似的 Netty 提供了 8 种基础数据类型的读取和写入,例如 readChar()、readShort()、readInt()、readLong()、writeChar()、writeShort()、writeInt()、writeLong() 等,在这里就不详细展开了。
getByte(int index)
setByte(int index, int value)
readByte() 是从 ByteBuf 中读取一个字节,相应的 readerIndex + 1;
同理 writeByte 是向 ByteBuf 写入一个字节,相应的 writerIndex + 1。
与 readByte() 和 writeByte() 相对应的还有 getByte() 和 setByte(),get/set 系列方法也提供了 8 种基础类型的读写,那么这两个系列的方法有什么区别呢?
read/write 方法在读写时会改变readerIndex 和 writerIndex 指针,而 get/set 方法则不会改变指针位置。
release() & retain()
之前已经介绍了引用计数的基本概念,每调用一次 release() 引用计数减 1,每调用一次 retain() 引用计数加 1。
slice()
返回ByteBuf可读字节的一部分。 修改返回的ByteBuf或当前ByteBuf会影响彼此的内容, 同时它们维护单独的索引和标记,此方法不会修改当前ByteBuf的readerIndex或writerIndex *另请注意,此方法不会调用{@link #retain()},因此不会增加引用计数
slice() 等同于 slice(buffer.readerIndex(), buffer.readableBytes()),默认截取 readerIndex 到 writerIndex 之间的数据,最大容量 maxCapacity 为原始 ByteBuf 的可读取字节数,底层分配的内存、引用计数都与原始的 ByteBuf 共享。
duplicate()
duplicate() 与 slice() 不同的是,duplicate()截取的是整个原始 ByteBuf 信息,底层分配的内存、引用计数也是共享的。如果向 duplicate() 分配出来的 ByteBuf 写入数据,那么都会影响到原始的 ByteBuf 底层数据。
返回共享当前ByteBuf信息的新ByteBuf,他们使用独立的readIndex writeIndex markIndex *修改返回的ByteBuf或当前ByteBuf会影响彼此的内容,同时它们维护单独的索引和标记, *此方法不会修改当前ByteBuf的readerIndex或writerIndex, 另请注意,此方法不会调用{@link #retain()},因此不会增加引用计数
copy()
会从原始的 ByteBuf 中拷贝所有信息,所有数据都是独立的,向 copy() 分配的 ByteBuf 中写数据不会影响原始的 ByteBuf。
返回ByteBuf的可读字节的拷贝。修改返回的ByteBuf内容与当前ByteBuf完全不会相互影响。
此方法不会修改当前ByteBuf的readerIndex或writerIndex
到底为止,ByteBuf 的核心 API 我们基本已经介绍完了,ByteBuf 读写指针分离的小设计,确实带来了很多实用和便利的功能,在开发的过程中不必再去想着 flip、rewind 这种头疼的操作了。
内存管理 API
未池化堆内存
java ByteBuf heapByteBuf = Unpooled.buffer(10);
未池化直接内存
java ByteBuf directByteBuf = Unpooled.directBuffer(10);
池化堆内存
java PooledByteBufAllocator allocator = new PooledByteBufAllocator(false); ByteBuf pHeapByteBuf = allocator.buffer();
池化直接内存
java PooledByteBufAllocator allocator2 = new PooledByteBufAllocator(true);
ByteBuf 实战演练
学习完 ByteBuf 的内部构造以及核心 API 之后,我们下面通过一个简单的示例演示一下 ByteBuf 应该如何使用,代码如下所示。
java public class ByteBufTest { public static void main(String[] args) { // static final ByteBufAllocator DEFAULT_ALLOCATOR; // 根据allocType创建不同的分配器 如果没有值默认使用池化技术 // alloc = UnpooledByteBufAllocator.DEFAULT; // alloc = PooledByteBufAllocator.DEFAULT; // 初始是6 最大是10 ByteBuf buffer = ByteBufAllocator.DEFAULT.buffer(6, 10); printByteBufInfo("ByteBufAllocator.buffer(5, 10)", buffer); buffer.writeBytes(new byte[]{1, 2}); printByteBufInfo("write 2 Bytes", buffer); buffer.writeInt(100); printByteBufInfo("write Int 100", buffer); buffer.writeBytes(new byte[]{3, 4, 5}); printByteBufInfo("write 3 Bytes", buffer); byte[] read = new byte[buffer.readableBytes()]; buffer.readBytes(read); printByteBufInfo("readBytes(" + buffer.readableBytes() + ")", buffer); printByteBufInfo("BeforeGetAndSet", buffer); System.out.println("getInt(2): " + buffer.getInt(2)); buffer.setByte(1, 0); System.out.println("getByte(1): " + buffer.getByte(1)); printByteBufInfo("AfterGetAndSet", buffer); } private static void printByteBufInfo(String step, ByteBuf buffer) { System.out.println("------" + step + "-----"); System.out.println("readerIndex(): " + buffer.readerIndex()); System.out.println("writerIndex(): " + buffer.writerIndex()); System.out.println("isReadable(): " + buffer.isReadable()); System.out.println("isWritable(): " + buffer.isWritable()); System.out.println("readableBytes(): " + buffer.readableBytes()); System.out.println("writableBytes(): " + buffer.writableBytes()); System.out.println("maxWritableBytes(): " + buffer.maxWritableBytes()); System.out.println("capacity(): " + buffer.capacity()); System.out.println("maxCapacity(): " + buffer.maxCapacity()); } }
java ------ByteBufAllocator.buffer(5, 10)----- readerIndex(): 0 writerIndex(): 0 isReadable(): false isWritable(): true readableBytes(): 0 writableBytes(): 6 maxWritableBytes(): 10 capacity(): 6 maxCapacity(): 10 ------write 2 Bytes----- readerIndex(): 0 writerIndex(): 2 isReadable(): true isWritable(): true readableBytes(): 2 writableBytes(): 4 maxWritableBytes(): 8 capacity(): 6 maxCapacity(): 10 ------write Int 100----- readerIndex(): 0 writerIndex(): 6 isReadable(): true isWritable(): false readableBytes(): 6 writableBytes(): 0 maxWritableBytes(): 4 capacity(): 6 maxCapacity(): 10 ------write 3 Bytes----- readerIndex(): 0 writerIndex(): 9 isReadable(): true isWritable(): true readableBytes(): 9 writableBytes(): 1 maxWritableBytes(): 1 capacity(): 10 maxCapacity(): 10 ------readBytes(0)----- readerIndex(): 9 writerIndex(): 9 isReadable(): false isWritable(): true readableBytes(): 0 writableBytes(): 1 maxWritableBytes(): 1 capacity(): 10 maxCapacity(): 10 ------BeforeGetAndSet----- readerIndex(): 9 writerIndex(): 9 isReadable(): false isWritable(): true readableBytes(): 0 writableBytes(): 1 maxWritableBytes(): 1 capacity(): 10 maxCapacity(): 10 getInt(2): 100 getByte(1): 0 ------AfterGetAndSet----- readerIndex(): 9 writerIndex(): 9 isReadable(): false isWritable(): true readableBytes(): 0 writableBytes(): 1 maxWritableBytes(): 1 capacity(): 10 maxCapacity(): 10
结合代码示例,我们总结一下 ByteBuf API 使用时的注意点:
- write 系列方法会改变 writerIndex 位置,当 writerIndex 等于 capacity 的时候,Buffer 置为不可写状态;
- 向不可写 Buffer 写入数据时,Buffer 会尝试扩容,但是扩容后 capacity 最大不能超过 maxCapacity,如果写入的数据超过 maxCapacity,程序会直接抛出异常;
- read 系列方法会改变 readerIndex 位置,get/set 系列方法不会改变 readerIndex/writerIndex 位置。
总结
Netty 强大的数据容器 ByteBuf,它不仅解决了 JDK NIO 中 ByteBuffer 的缺陷,而且提供了易用性更强的接口。很多开发者已经使用 ByteBuf 代替 ByteBuffer,即便他没有在写一个网络应用,也会单独使用 ByteBuf。ByteBuf 作为 Netty 中最基础的数据结构。
相关文章:
18.Netty源码之ByteBuf 详解
highlight: arduino-light ByteBuf 是 Netty 的数据容器,所有网络通信中字节流的传输都是通过 ByteBuf 完成的。 然而 JDK NIO 包中已经提供了类似的 ByteBuffer 类,为什么 Netty 还要去重复造轮子呢?本节课我会详细地讲解 ByteBuf。 JDK NIO…...
#P0999. [NOIP2008普及组] 排座椅
题目描述 上课的时候总会有一些同学和前后左右的人交头接耳,这是令小学班主任十分头疼的一件事情。不过,班主任小雪发现了一些有趣的现象,当同学们的座次确定下来之后,只有有限的 DD 对同学上课时会交头接耳。 同学们在教室中坐…...

Sentinel 容灾中心的使用
Sentinel 容灾中心的使用 往期文章 Nacos环境搭建Nacos注册中心的使用Nacos配置中心的使用 熔断/限流结果 Jar 生产者 spring-cloud-alibaba:2021.0.4.0 spring-boot:2.6.8 spring-cloud-loadbalancer:3.1.3 sentinel:2021.0…...

深度学习中简易FC和CNN搭建
TensorFlow是由谷歌开发的PyTorch是由Facebook人工智能研究院(Facebook AI Research)开发的 Torch和cuda版本的对应,手动安装较好 全连接FC(Batch*Num) 搭建建议网络: from torch import nnclass Mnist_NN(nn.Module):def __i…...

【多模态】20、OVR-CNN | 使用 caption 来实现开放词汇目标检测
文章目录 一、背景二、方法2.1 学习 视觉-语义 空间2.2 学习开放词汇目标检测 三、效果 论文:Open-Vocabulary Object Detection Using Captions 代码:https://github.com/alirezazareian/ovr-cnn 出处:CVPR2021 Oral 一、背景 目标检测数…...
网络编程 IO多路复用 [select版] (TCP网络聊天室)
//head.h 头文件 //TcpGrpSer.c 服务器端 //TcpGrpUsr.c 客户端 select函数 功能:阻塞函数,让内核去监测集合中的文件描述符是否准备就绪,若准备就绪则解除阻塞。 原型: #include <sys/select.…...

数学建模学习(7):单目标和多目标规划
优化问题描述 优化 优化算法是指在满足一定条件下,在众多方案中或者参数中最优方案,或者参数值,以使得某个或者多个功能指标达到最优,或使得系统的某些性能指标达到最大值或者最小值 线性规划 线性规划是指目标函数和约束都是线性的情况 [x,fval]linprog(f,A,b,Aeq,Beq,LB,U…...

Element UI如何自定义样式
简介 Element UI是一套非常完善的前端组件库,但是如何个性化定制其中的组件样式呢?今天我们就来聊一聊这个 举例 就拿最常见的按钮el-button来举例,一般来说默认是蓝底白字。效果图如下 可是我们想个性化定制,让他成为粉底红字应…...

protobuf入门实践2
如何在proto中定义一个rpc服务? syntax "proto3"; //声明protobuf的版本package fixbug; //声明了代码所在的包 (对于C来说就是namespace)//下面的选项,表示生成service服务类和rpc方法描述, 默认是不生成的 option cc_generi…...

adb shell使用总结
文章目录 日志记录系统概览adb 使用方式 adb命令日志过滤按照告警等级进行过滤按照tag进行过滤根据告警等级和tag进行联合过滤屏蔽系统和其他App干扰,仅仅关注App自身日志 查看“当前页面”Activity文件传输截屏和录屏安装、卸载App启动activity其他 日志记录系统概…...
-Tag的含义、Tag类型与其他的转换)
UG NX二次开发(C++)-Tag的含义、Tag类型与其他的转换
文章目录 1、前言2、Tag号的含义3、tag_t转换为int3、TaggedObject与Tag转换3.1 TaggedObject定义3.2 TaggedObject获取Tag3.3 根据Tag获取TaggedObject4.Tag与double类型的转换1、前言 在UG NX中,每个对象对应一个tag号,C++中,其类型是tag_t,一般是5位或者6位的int数字,…...
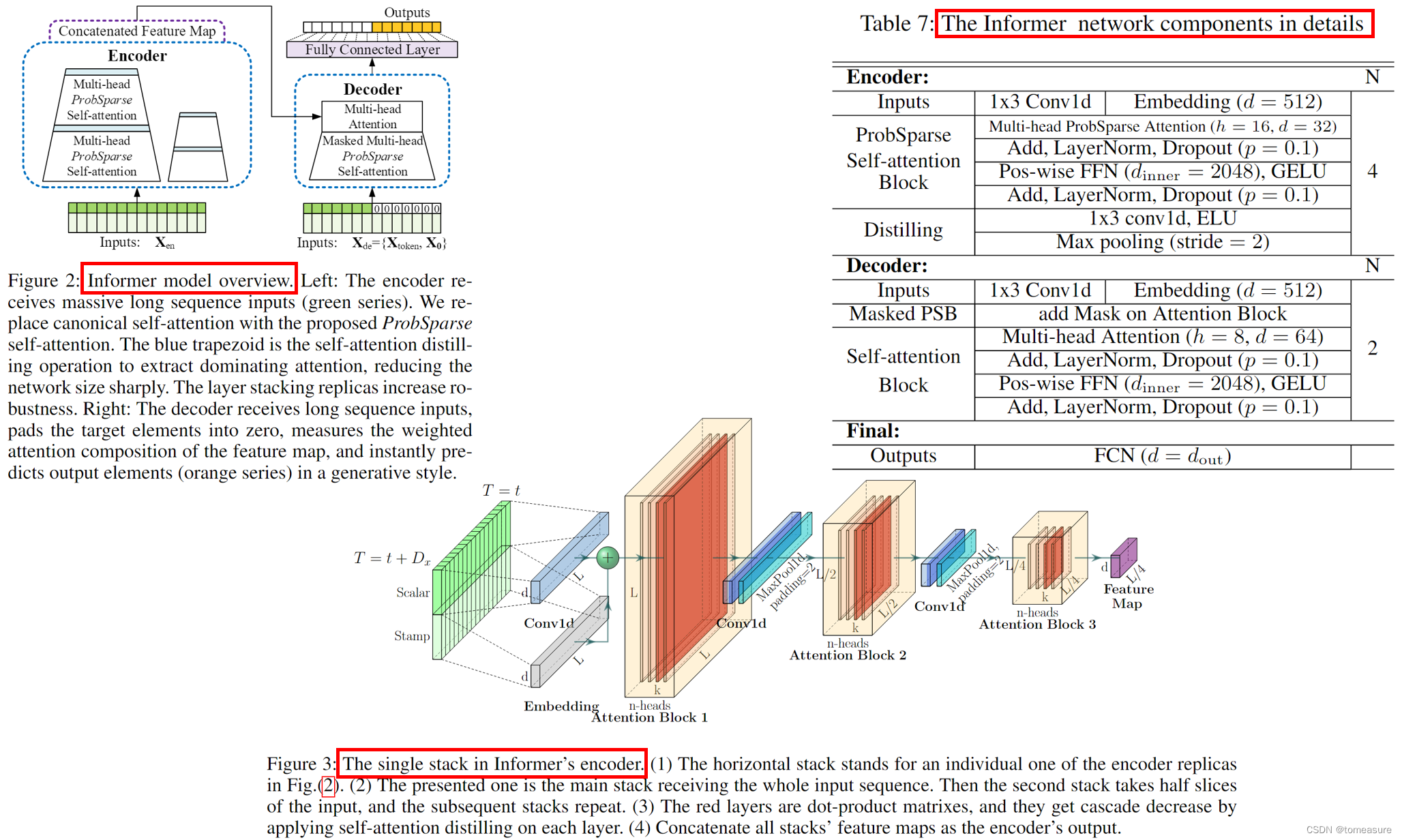
Informer 论文学习笔记
论文:《Informer: Beyond Efficient Transformer for Long Sequence Time-Series Forecasting》 代码:https://github.com/zhouhaoyi/Informer2020 地址:https://arxiv.org/abs/2012.07436v3 特点: 实现时间与空间复杂度为 O ( …...

c语言位段知识详解
本篇文章带来位段相关知识详细讲解! 如果您觉得文章不错,期待你的一键三连哦,你的鼓励是我创作的动力之源,让我们一起加油,一起奔跑,让我们顶峰相见!!! 目录 一.什么是…...
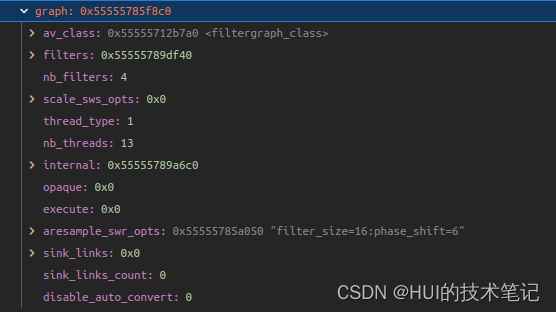
FFmpeg aresample_swr_opts的解析
ffmpeg option的解析 aresample_swr_opts是AVFilterGraph中的option。 static const AVOption filtergraph_options[] {{ "thread_type", "Allowed thread types", OFFSET(thread_type), AV_OPT_TYPE_FLAGS,{ .i64 AVFILTER_THREAD_SLICE }, 0, INT_MA…...

CAN学习笔记3:STM32 CAN控制器介绍
STM32 CAN控制器 1 概述 STM32 CAN控制器(bxCAN),支持CAN 2.0A 和 CAN 2.0B Active版本协议。CAN 2.0A 只能处理标准数据帧且扩展帧的内容会识别错误,而CAN 2.0B Active 可以处理标准数据帧和扩展数据帧。 2 bxCAN 特性 波特率…...

软工导论知识框架(二)结构化的需求分析
本章节涉及很多重要图表的制作,如ER图、数据流图、状态转换图、数据字典的书写等,对初学者来说比较生僻,本贴只介绍基础的轮廓,后面会有单独的帖子详解各图表如何绘制。 一.结构化的软件开发方法:结构化的分析、设计、…...

[SQL挖掘机] - 算术函数 - abs
介绍: 当谈到 SQL 中的 abs 函数时,它是一个用于计算数值的绝对值的函数。“abs” 代表 “absolute”(绝对),因此 abs 函数的作用是返回一个给定数值的非负值(即该数值的绝对值)。 abs 函数接受一个参数&a…...

vue拼接html点击事件不生效
vue使用ts,拼接html,点击事件不生效或者报 is not defined 点击事件要用onclick 不是click let data{name:测,id:123} let conHtml <div> "名称:" data.name "<br>" <p class"cursor blue&quo…...

【Spring】Spring之依赖注入源码解析
1 Spring注入方式 1.1 手动注入 xml中定义Bean,程序员手动给某个属性赋值。 set方式注入 <bean name"userService" class"com.firechou.service.UserService"><property name"orderService" ref"orderService"…...

【微软知识】微软相关技术知识分享
微软技术领域 一、微软操作系统: 微软的操作系统主要是 Windows 系列,包括 Windows 10、Windows Server 等。了解 Windows 操作系统的基本使用、配置和故障排除是非常重要的。微软操作系统(Microsoft System)是美国微软开发的Wi…...

Unity发行版DLL调试:破解IL2CPP元数据加密与mono.dll符号映射
1. 为什么发行版Unity游戏的DLL调试总卡在“找不到符号”这一步?你打包完一个Unity项目,导出为Windows独立发布版本,双击运行一切正常——但当你兴冲冲地用DnSpy打开GameAssembly.dll或Assembly-CSharp.dll,想设个断点看看登录逻辑…...

一键搞定B站视频下载:跨平台工具BilibiliDown完整使用指南
一键搞定B站视频下载:跨平台工具BilibiliDown完整使用指南 【免费下载链接】BilibiliDown (GUI-多平台支持) B站 哔哩哔哩 视频下载器。支持稍后再看、收藏夹、UP主视频批量下载|Bilibili Video Downloader 😳 项目地址: https://gitcode.com/gh_mirro…...

专业级EdgeRemover配置指南:5种高效部署方案深度解析
专业级EdgeRemover配置指南:5种高效部署方案深度解析 【免费下载链接】EdgeRemover A PowerShell script that correctly uninstalls or reinstalls Microsoft Edge on Windows 10 & 11. 项目地址: https://gitcode.com/gh_mirrors/ed/EdgeRemover EdgeR…...

taotoken的按token计费模式如何帮助个人开发者控制实验成本
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken的按Token计费模式如何帮助个人开发者控制实验成本 对于个人开发者、学生或独立研究者而言,在探索AI应用或进行…...

终极免费指南:如何用Wand-Enhancer深度解锁WeMod完整功能与远程控制
终极免费指南:如何用Wand-Enhancer深度解锁WeMod完整功能与远程控制 【免费下载链接】Wand-Enhancer Advanced UX and interoperability extension for Wand (WeMod) app 项目地址: https://gitcode.com/gh_mirrors/we/Wand-Enhancer Wand-Enhancer是一个开源…...

工业视觉光源颜色选型全攻略|白/红/蓝/绿光适用场景、原理与避坑细则
摘要:在工业AI视觉缺陷检测项目落地中,绝大多数工程师过度聚焦相机参数、镜头焦距、模型调参优化,却忽略了光源颜色选型这一核心前置条件。工业检测有一条公认铁律:成像决定上限,模型只负责兜底。相同工件、相同光源结…...

优化缺陷密度,核心是从“事后救火”转向“全程预防”
优化缺陷密度,核心是从“事后救火”转向“全程预防”,通过系统化的流程和工具,在生产代码中构建 “计划-执行-检查-改进”的持续优化闭环。📈 第一步:测量与评估,建立基线测量缺陷密度:按质量阶…...

Qwen-Image-2512+LoRA:构建Godot原生像素素材生成管线
1. 这不是“AI画图”,而是一次像素艺术工作流的底层重写你有没有试过在Godot 4.x里导入一张用Qwen-VL或Stable Diffusion生成的“像素风”图?放大一看——边缘糊成一团,颜色溢出格子,连88的精灵都对不齐网格。我去年帮一个独立游戏…...

智能网络资源嗅探器:5步掌握专业级内容下载技巧
智能网络资源嗅探器:5步掌握专业级内容下载技巧 【免费下载链接】res-downloader 视频号、小程序、抖音、快手、小红书、直播流、m3u8、酷狗、QQ音乐等常见网络资源下载! 项目地址: https://gitcode.com/GitHub_Trending/re/res-downloader 在数字内容创作时…...

开启Windows 11的安卓革命:WSA让电脑与手机完美融合
开启Windows 11的安卓革命:WSA让电脑与手机完美融合 【免费下载链接】WSA Developer-related issues and feature requests for Windows Subsystem for Android 项目地址: https://gitcode.com/gh_mirrors/ws/WSA 在数字生活多元化的今天,你是否曾…...