Elasticsearch入门笔记(一)
环境搭建
Elasticsearch是搜索引擎,是常见的搜索工具之一。
Kibana 是一个开源的分析和可视化平台,旨在与 Elasticsearch 合作。Kibana 提供搜索、查看和与存储在 Elasticsearch 索引中的数据进行交互的功能。开发者或运维人员可以轻松地执行高级数据分析,并在各种图表、表格和地图中可视化数据。
其它可视化还有elasticsearch-head(轻量级,有对应的Chrome插件),本文不会详细介绍。
Elasticsearch和Kibana的版本采用7.17.0,环境搭建采用Docker,docker-compose.yml文件如下:
version: "3.1"
# 服务配置
services:elasticsearch:container_name: elasticsearch-7.17.0image: elasticsearch:7.17.0environment:- "ES_JAVA_OPTS=-Xms1024m -Xmx1024m"- "http.host=0.0.0.0"- "node.name=elastic01"- "cluster.name=cluster_elasticsearch"- "discovery.type=single-node"ports:- "9200:9200"- "9300:9300"volumes:- ./es/plugins:/usr/share/elasticsearch/plugins- ./es/data:/usr/share/elasticsearch/datanetworks:- elastic_netkibana:container_name: kibana-7.17.0image: kibana:7.17.0ports:- "5601:5601"networks:- elastic_net# 网络配置
networks:elastic_net:driver: bridge
基础命令
- 查看ElasticSearch是否启动成功:
curl http://IP:9200
- 查看集群是否健康
curl http://IP:9200/_cat/health?v
- 查看ElasticSearch所有的index
curl http://IP:9200/_cat/indices
- 查看ElasticSearch所有indices或者某个index的文档数量
curl http://IP:9200/_cat/count?v
curl http://IP:9200/_cat/count/some_index_name?v
- 查看每个节点正在运行的插件信息
curl http://IP:9200/_cat/plugins?v&s=component&h=name,component,version,description
- 查看ik插件的分词结果
curl -H 'Content-Type: application/json' -XGET 'http://IP:9200/_analyze?pretty' -d '{"analyzer":"ik_max_word","text":"美国留给伊拉克的是个烂摊子吗"}'
index操作
- 查看某个index的mapping
curl http://IP:9200/some_index_name/_mapping
- 查看某个index的所有数据
curl http://IP:9200/some_index_name/_search
- 按ID进行查询
curl -X GET http://IP:9200/索引名称/文档类型/ID
- 检索某个index的全部数据
curl http://IP:9200/索引名称/_search?pretty
curl -X POST http://IP:9200/索引名称/_search?pretty -d "{\"query\": {\"match_all\": {} }}"
- 检索某个index的前几条数据(如果不指定size,则默认为10条)
curl -XPOST IP:9200/索引名称/_search?pretty -d "{\"query\": {\"match_all\": {} }, \"size\" : 2}"
- 检索某个index的中间几条数据(比如第11-20条数据)
curl -XPOST IP:9200/索引名称/_search?pretty -d "{\"query\": {\"match_all\": {} }, \"from\" : 10, \"size\" : 10}}"
- 检索某个index, 只返回context字段
curl -XPOST IP:9200/索引名称/_search?pretty -d "{\"query\": {\"match_all\": {} }, \"_source\": [\"context\"]}"
- 删除某个index
curl -XDELETE 'IP:9200/index_name'
ES搜索
- 如果有多个搜索关键字, Elastic 认为它们是or关系。
- 如果要执行多个关键词的and搜索,必须使用布尔查询。
$ curl 'localhost:9200/索引名称/文档类型/_search' -d '
{"query": {"bool": {"must": [{ "match": { "content": "软件" } },{ "match": { "content": "系统" } }]}}
}'
- 复杂搜索:
SQL语句:
select * from test_index where name='tom' or (hired =true and (personality ='good' and rude != true ))
DSL语句:
GET /test_index/_search
{"query": {"bool": {"must": { "match":{ "name": "tom" }},"should": [{ "match":{ "hired": true }},{ "bool": {"must":{ "match": { "personality": "good" }},"must_not": { "match": { "rude": true }}}}],"minimum_should_match": 1}}
}
ik分词器
ik分词器是Elasticsearch的中文分词器插件,对中文分词支持较好。ik版本要与Elasticsearch保持一致。
ik 7.17.0下载地址为:https://github.com/medcl/elasticsearch-analysis-ik/releases/tag/v7.17.0 ,下载后将其重名为ik,将其放至Elasticsearch的plugins文件夹下。
ik分词器的使用命令(Kibana环境):
POST _analyze
{"text": "戚发轫是哪里人","analyzer": "ik_smart"
}
输出结果为:
{"tokens" : [{"token" : "戚","start_offset" : 0,"end_offset" : 1,"type" : "CN_CHAR","position" : 0},{"token" : "发轫","start_offset" : 1,"end_offset" : 3,"type" : "CN_WORD","position" : 1},{"token" : "是","start_offset" : 3,"end_offset" : 4,"type" : "CN_CHAR","position" : 2},{"token" : "哪里人","start_offset" : 4,"end_offset" : 7,"type" : "CN_WORD","position" : 3}]
}
ik支持加载用户词典和停用词。ik 提供了配置文件 IKAnalyzer.cfg.xml(将其放在ik/config路径下),可以用来配置自己的扩展用户词典、停用词词典和远程扩展用户词典,都可以配置多个。
配置完扩展用户词典和远程扩展用户词典都需要重启ES,后续对用户词典进行更新的话,需要重启ES,远程扩展用户词典配置完后支持热更新,每60秒检查更新。两个扩展词典都是添加到ik的主词典中,对所有索引生效。
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties><comment>IK Analyzer 扩展配置</comment><!--用户可以在这里配置自己的扩展字典 --><entry key="ext_dict">custom/mydict.dic</entry><!--用户可以在这里配置自己的扩展停止词字典--><entry key="ext_stopwords">custom/ext_stopword.dic</entry><!--用户可以在这里配置远程扩展字典 --><!-- <entry key="remote_ext_dict">words_location</entry> --><!--用户可以在这里配置远程扩展停止词字典--><!-- <entry key="remote_ext_stopwords">words_location</entry> -->
</properties>
用户词典文件路径为:custom/mydict.dic,停用词词典路径为:custom/ext_stopword.dic,将它们放在ik/config/custom路径下。
用户词典文件中加入’戚发轫’,停用词词典加入’是’,对原来文本进行分词:
POST _analyze
{"text": "戚发轫是哪里人","analyzer": "ik_smart"
}
输出结果如下:
{"tokens" : [{"token" : "戚发轫","start_offset" : 0,"end_offset" : 3,"type" : "CN_WORD","position" : 0},{"token" : "哪里人","start_offset" : 4,"end_offset" : 7,"type" : "CN_WORD","position" : 1}]
}
如果’analyzer’选择ik_smart,则会将文本做最粗粒度的拆分;选择ik_max_word,则会将文本做最细粒度的拆分。测试如下:
POST _analyze
{"text": "戚发轫是哪里人","analyzer": "ik_max_word"
}
输出结果如下:
{"tokens" : [{"token" : "戚发轫","start_offset" : 0,"end_offset" : 3,"type" : "CN_WORD","position" : 0},{"token" : "发轫","start_offset" : 1,"end_offset" : 3,"type" : "CN_WORD","position" : 1},{"token" : "哪里人","start_offset" : 4,"end_offset" : 7,"type" : "CN_WORD","position" : 2},{"token" : "哪里","start_offset" : 4,"end_offset" : 6,"type" : "CN_WORD","position" : 3},{"token" : "里人","start_offset" : 5,"end_offset" : 7,"type" : "CN_WORD","position" : 4}]
}
总结
本文主要介绍了Elasticsearch一些基础命令和用法,是笔者的Elasticsearch学习笔记第一篇,后续将持续更新。
本文代码已放至Github,网址为:https://github.com/percent4/ES_Learning .
相关文章:
)
Elasticsearch入门笔记(一)
环境搭建 Elasticsearch是搜索引擎,是常见的搜索工具之一。 Kibana 是一个开源的分析和可视化平台,旨在与 Elasticsearch 合作。Kibana 提供搜索、查看和与存储在 Elasticsearch 索引中的数据进行交互的功能。开发者或运维人员可以轻松地执行高级数据分析…...
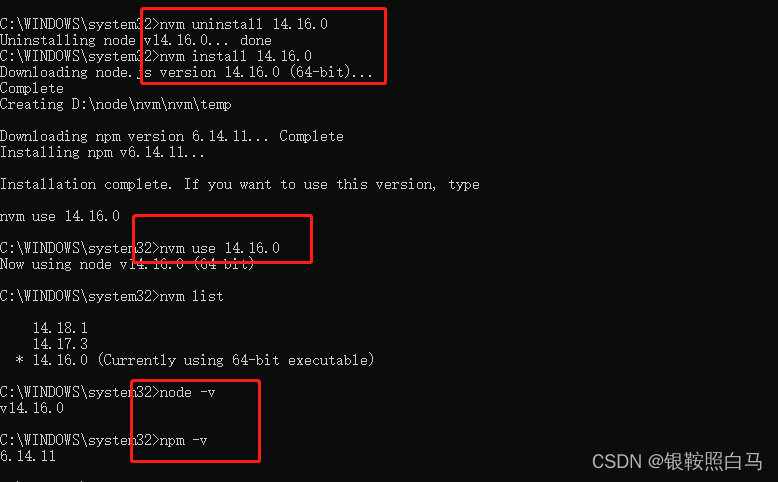
记一次安装nvm切换node.js版本实例详解
最后效果如下: 背景:由于我以前安装过node.js,后续想安装nvm将node.js管理起来。 问题:nvm-use命令行运行成功,但是nvm-list显示并没有成功。 原因:因为安装过node.js,所以原先的node.js不收n…...

生态共建丨YashanDB与构力科技完成兼容互认证
近日,深圳计算科学研究院崖山数据库系统YashanDB V22.2与北京构力科技有限公司BIMBase云平台完成兼容性互认证。经严格测试,双方产品完全兼容、运行稳定。 崖山数据库系统YashanDB是深算院自主研发设计的新型数据库系统,融入原创理论…...

React从入门到实战-react脚手架,消息订阅与发布
创建项目并启动 全局安装 npm install -g create-react-app切换到想创建项目的目录,使用命令:create-react-app 项目名称 [外链图片转存失败,源站可能有防盗链机制,建议将图片保存中…(iQ6hEUgAABpQAAAD1CAYAAABeIRZoAAAAAXNSR0IArs4c6QAAIABJREFUe…...
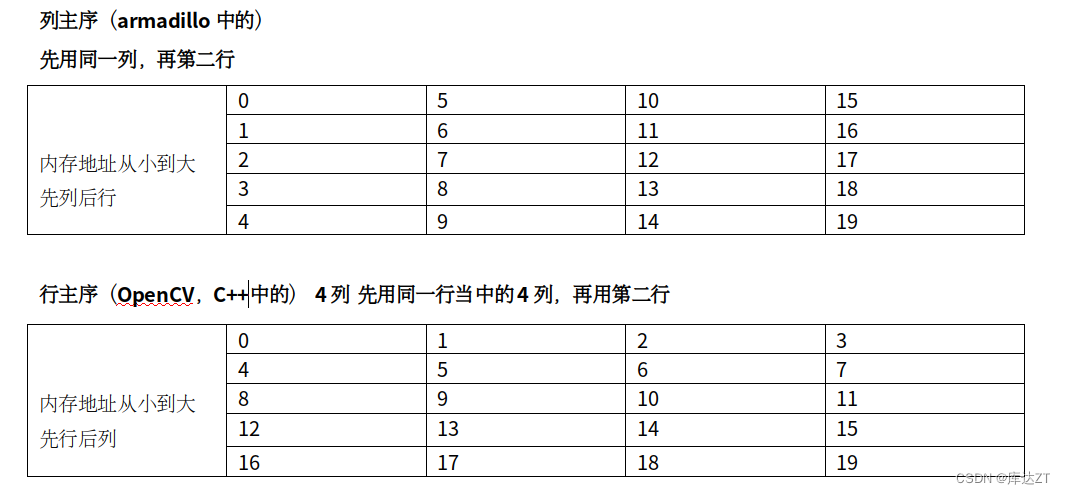
从零构建深度学习推理框架-1 简介和Tensor
源代码作者:https://github.com/zjhellofss 本文仅作为个人学习心得领悟 ,将原作品提炼,更加适合新手 什么是推理框架? 深度学习推理框架用于对已训练完成的神经网络进行预测,也就是说,能够将深度训练框…...

使用WGCLOUD监测安卓(Android)设备的运行状态
WGCLOUD是一款开源运维监控软件,除了能监控各种服务器、主机、进程应用、端口、接口、docker容器、日志、数据等资源 WGCLOUD还可以监测安卓设备,比如安卓手机、安卓设备等 我们只要下载对应的安卓客户端,部署运行即可,如下是下…...
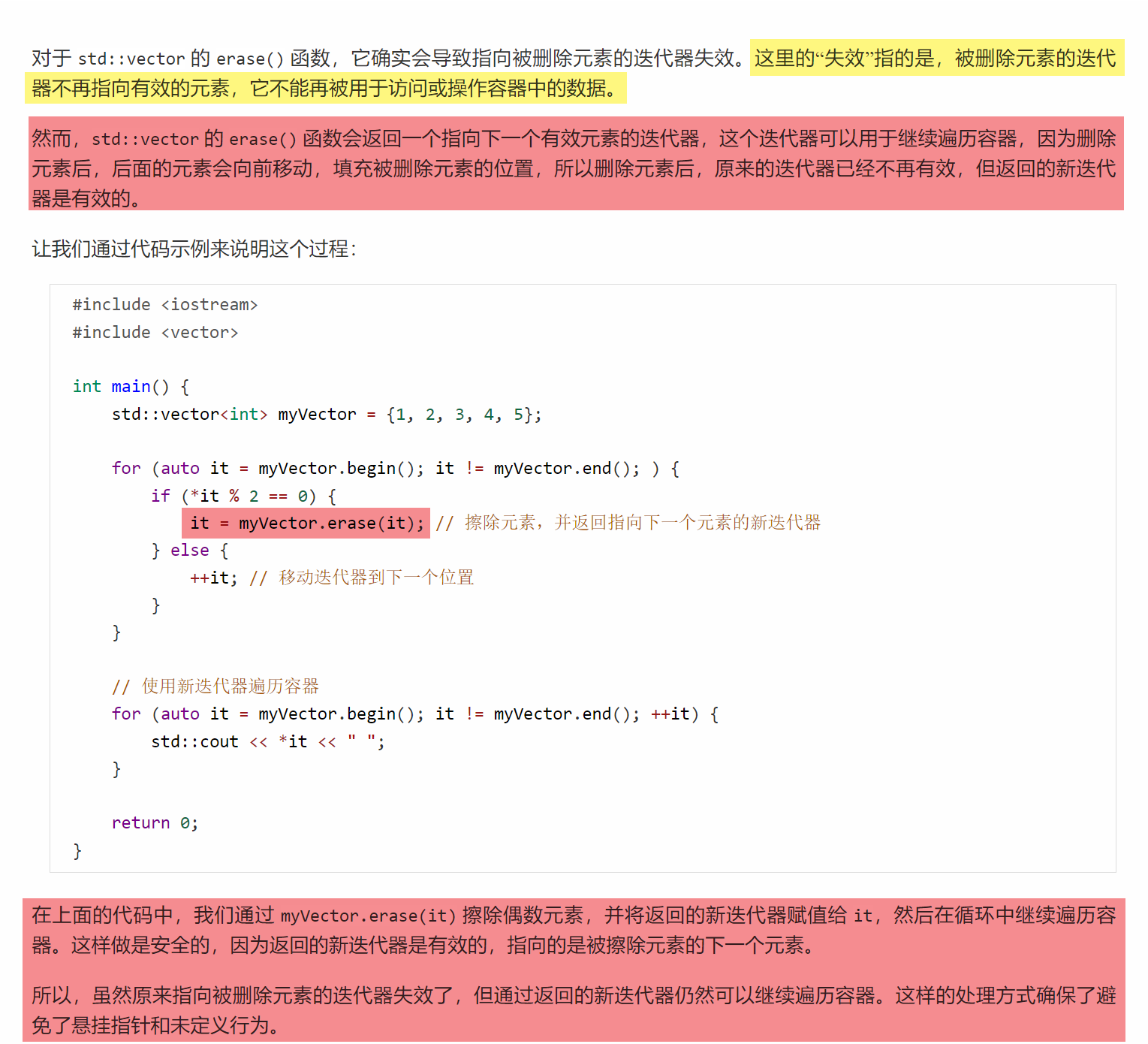
C++笔记之迭代器失效问题处理
C笔记之迭代器失效问题处理 code review! 参考博文:CSTL迭代器失效的几种情况总结 文章目录 C笔记之迭代器失效问题处理一.使用返回新迭代器的插入和删除操作二.对std::vector 来说,擦除(erase)元素会导致迭代器失效 一.使用返回…...

Tomcat的startup.bat文件出现闪退问题
对于双击Tomcat的startup.bat文件出现闪退问题,您提供的分析是正确的。主要原因是Tomcat需要Java Development Kit (JDK)的支持,而如果没有正确配置JAVA_HOME环境变量,Tomcat将无法找到JDK并启动,从而导致闪退。 以下是解决该问题…...

JAVA8-lambda表达式8:在设计模式-模板方法中的应用
传送门 JAVA8-lambda表达式1:什么是lambda表达式 JAVA8-lambda表达式2:常用的集合类api JAVA8-lambda表达式3:并行流,提升效率的利器? JAVA8-lambda表达式4:Optional用法 java8-lambda表达式5…...

React之组件间通信
React之组件间通信 组件通信: 简单讲就是组件之间的传值,包括state、函数等 1、父子组件通信 父组件给子组件传值 核心:1、自定义属性;2、props 父组件中: 自定义属性传值 import Header from /components/Headerconst Home ()…...
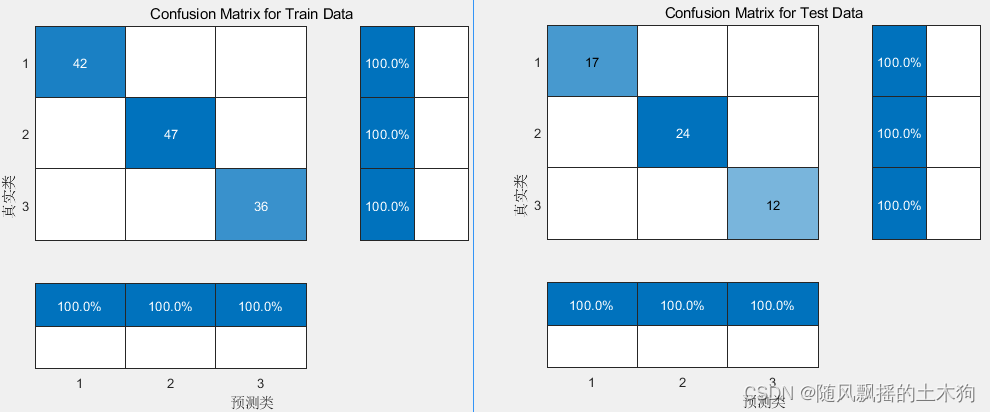
【MATLAB第58期】基于MATLAB的PCA-Kmeans、PCA-LVQ与BP神经网络分类预测模型对比
【MATLAB第58期】基于MATLAB的PCA-Kmeans、PCA-LVQ与BP神经网络分类预测模型对比 一、数据介绍 基于UCI葡萄酒数据集进行葡萄酒分类及产地预测 共包含178组样本数据,来源于三个葡萄酒产地,每组数据包含产地标签及13种化学元素含量,即已知类…...
CF1833 A-E
A题 题目链接:https://codeforces.com/problemset/problem/1833/A 基本思路:for循环遍历字符串s,依次截取字符串s的子串str,并保存到集合中,最后输出集合内元素的数目即可 AC代码: #include <iostrea…...

【深度学习】【Image Inpainting】Generative Image Inpainting with Contextual Attention
Generative Image Inpainting with Contextual Attention DeepFillv1 (CVPR’2018) 论文:https://arxiv.org/abs/1801.07892 论文代码:https://github.com/JiahuiYu/generative_inpainting 论文摘录 文章目录 效果一览摘要介绍论文贡献相关工作Image…...
二维深度卷积网络模型下的轴承故障诊断
1.数据集 使用凯斯西储大学轴承数据集,一共有4种负载下采集的数据,每种负载下有10种 故障状态:三种不同尺寸下的内圈故障、三种不同尺寸下的外圈故障、三种不同尺寸下的滚动体故障和一种正常状态 2.模型(二维CNN) 使…...

redis突然变慢问题定位
CPU 相关:使用复杂度过高命令、O(N)的这个N,数据的持久化,都与耗费过多的 CPU 资源有关 内存相关:bigkey 内存的申请和释放、数据过期、数据淘汰、碎片整理、内存大页、内存写时复制都与内存息息相关 磁盘…...
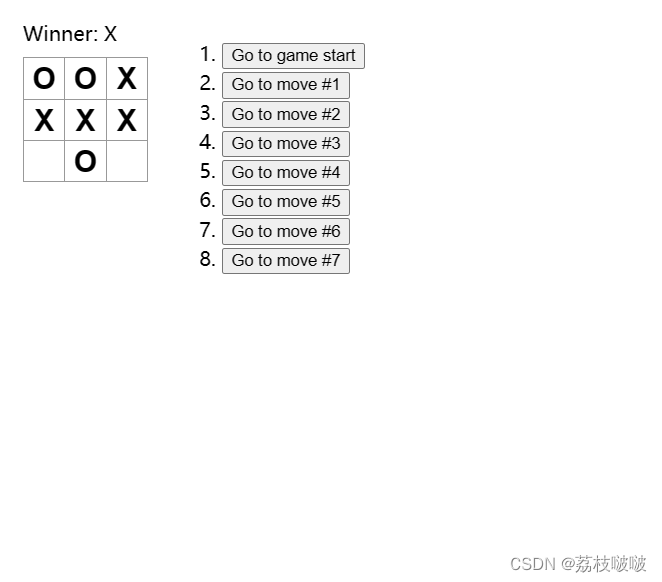
React井字棋游戏官方示例
在本篇技术博客中,我们将介绍一个React官方示例:井字棋游戏。我们将逐步讲解代码实现,包括游戏的组件结构、状态管理、胜者判定以及历史记录功能。让我们一起开始吧! 项目概览 在这个井字棋游戏中,我们有以下组件&am…...

七大经典比较排序算法
1. 插入排序 (⭐️⭐️) 🌟 思想: 直接插入排序是一种简单的插入排序法,思想是是把待排序的数据按照下标从小到大,依次插入到一个已经排好的序列中,直至全部插入,得到一个新的有序序列。例如:…...
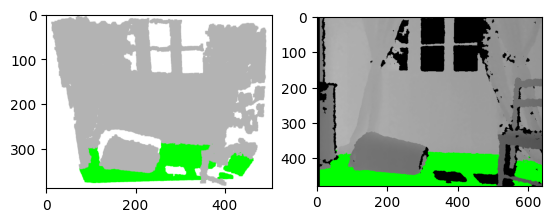
【点云处理教程】03使用 Python 实现地面检测
一、说明 这是我的“点云处理”教程的第3篇文章。“点云处理”教程对初学者友好,我们将在其中简单地介绍从数据准备到数据分割和分类的点云处理管道。 在上一教程中,我们在不使用 Open3D 库的情况下从深度数据计算点云。在本教程中,我们将首先…...
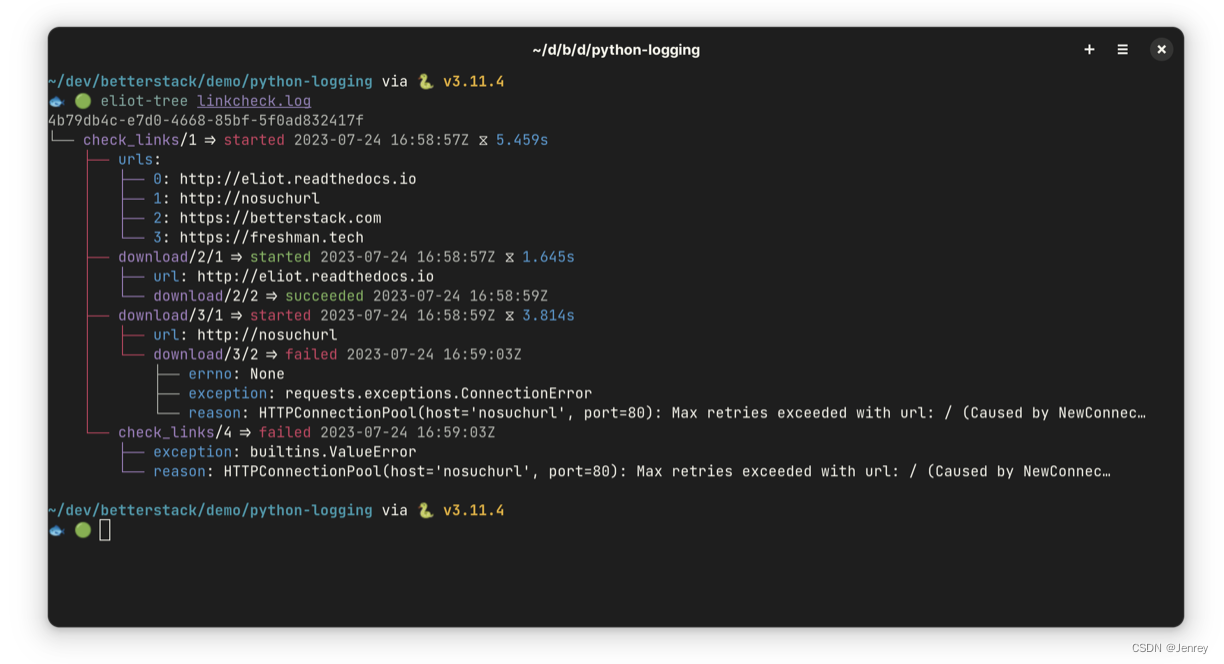
Python 日志记录:6大日志记录库的比较
Python 日志记录:6大日志记录库的比较 文章目录 Python 日志记录:6大日志记录库的比较前言一些日志框架建议1. logging - 内置的标准日志模块默认日志记录器自定义日志记录器生成结构化日志 2. Loguru - 最流行的Python第三方日志框架默认日志记录器自定…...

最近遇到一些问题的解决方案
最近遇到一些问题的解决方案 SpringBoot前后端分离参数传递方式总结Java8版本特性讲解idea使用git更新代码 : update project removeAll引发得java.lang.UnsupportedOperationException异常Java的split()函数用多个不同符号分割 Aspect注解切面demo 抽取公共组件,使…...

洛雪音乐音源:打破音乐平台壁垒的聚合解决方案
洛雪音乐音源:打破音乐平台壁垒的聚合解决方案 【免费下载链接】lxmusic- lxmusic(洛雪音乐)全网最新最全音源 项目地址: https://gitcode.com/gh_mirrors/lx/lxmusic- 你是否曾经为了听一首歌而在多个音乐平台之间来回切换?或者因为某个平台没有…...

CANN-昇腾NPU-多机多卡-怎么把16卡用出32卡的效果
16 张 Atlas 800I A2 的理论算力是 16 310 4960 TFLOPS(fp16)。但实际训练 Llama2-7B 只用到了 3200 TFLOPS——利用率 64%。这篇讲怎么把利用率从 64% 提到 85%,等效 16 卡用出 25 卡的效果。 利用率低的原因 理论算力: 16 310 4960 TFL…...

原来湖南2026年的灯光设计趋势竟然是这样的?
原来湖南2026年的灯光设计趋势竟然是这样的?随着科技的不断进步和人们生活水平的提高,灯光设计在家居和商业空间中的重要性日益凸显。湖南作为中部地区的经济大省,其灯光设计趋势也备受关注。本文将深入探讨2026年湖南灯光设计的主要趋势&…...

【收藏干货】2026 版 11 款主流 AI Agent 框架全方位对比!程序员小白入门大模型必备选型指南
本篇整合当下热度顶尖的 11 款 AI Agent 开发框架,囊括 LangChain、AutoGen、CrewAI 等主流工具,新版补充实战落地要点与行业最新应用方向。围绕各框架核心特性、优缺点、适配场景展开深度比对,依托大语言模型搭建智能自主系统,可…...

企业级应用通过Taotoken实现AI能力冗余与故障转移设计
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 企业级应用通过Taotoken实现AI能力冗余与故障转移设计 在构建依赖大模型API的企业级应用时,服务的连续性与稳定性是核心…...

抖音视频批量下载完整解决方案:从单视频到全自动归档管理
抖音视频批量下载完整解决方案:从单视频到全自动归档管理 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallback su…...

揭秘FPGA内部世界:PrjXRay开源工具完整指南
揭秘FPGA内部世界:PrjXRay开源工具完整指南 【免费下载链接】prjxray Documenting the Xilinx 7-series bit-stream format. 项目地址: https://gitcode.com/gh_mirrors/pr/prjxray 你是否曾好奇FPGA芯片内部的神秘世界?那些二进制位流背后究竟隐…...

TI C2000 系列 TMS320F280049 引导模式设置
1.GPIO配置引导模式注意:串口作为升级端口,默认GPIO是 GPIO28,GPIO29用其他的GPIO需要配置寄存器2.使用 C2Prog 工具更新程序注意:需要在 DSP 上电前配置好引导模式0.选择烧录文件1.选择SCI模式2.选择串口3.选择串口端口4.升级3.解决JTAG配置…...

电机正反转深度解析
电机正反转本质:通过改变内部磁场或电枢电流方向,实现顺时针/逆时针旋转,是设备控制核心功能! 📌核心原理(文字速记,新手好记): ① 三相异步电机(最常用):反转可通过任意…...

5个设计场景,Bebas Neue如何用大写字母征服现代视觉设计
5个设计场景,Bebas Neue如何用大写字母征服现代视觉设计 【免费下载链接】Bebas-Neue Bebas Neue font 项目地址: https://gitcode.com/gh_mirrors/be/Bebas-Neue 还在为设计项目寻找一款既简洁有力又能免费商用的字体吗?Bebas Neue这款由日本设计…...