【项目设计】MySQL 连接池的设计
目录
- 👉关键技术点👈
- 👉项目背景👈
- 👉连接池功能点介绍👈
- 👉MySQL Server 参数介绍👈
- 👉功能实现设计👈
- 👉开发平台选型👈
- 👉MySQL 数据库编程👈
- 👉连接池的编写👈
- 👉压力测试👈
- 👉项目常见问题👈
👉关键技术点👈
MySQL 数据库编程、单例模式、queue 队列容器、C++11 多线程编程、线程互斥、线程同步通信和 unique_lock、基于 CAS 的原子整形、智能指针 shared_ptr、lambda 表达式、生产者-消费者线程模型。
👉项目背景👈
为了提高 MySQL 数据库(基于 C/S 设计)的访问瓶颈,除了在服务器端增加缓存服务器缓存常用的数据之外(例如 redis),还可以增加连接池,来提高 MySQL Server 的访问效率,在高并发情况下,大量的 TCP 三次握手、MySQL Server 连接认证、MySQL Server 关闭连接回收资源和 TCP 四次挥手所耗费的性能时间也是很明显的,增加连接池就是为了减少这一部分的性能损耗。

在市场上比较流行的连接池包括阿里的 druid、c3p0 以及 apache dbcp 连接池,它们对于短时间内大量的数据库增删改查操作性能的提升是很明显的,但是它们有一个共同点就是,全部由 Java 实现的。
那么本项目就是为了在 C/C++ 项目中,提供 MySQL Server 的访问效率,实现基于 C++代 码的数据库连接
池模块。
👉连接池功能点介绍👈
连接池是一个数据库连接的管理工具,旨在优化数据库连接的开启、关闭和复用,从而提高数据库访问性能和系统的并发处理能力。连接池在应用程序启动时预先创建一定数量的数据库连接,并将它们放入一个池中。当应用程序需要连接数据库时,从连接池中获取一个空闲的连接,使用完毕后再将连接归还给连接池,以便其他请求可以复用这个连接。这样一来,就避免了频繁地开启和关闭数据库连接的开销。
连接池一般包含了数据库连接所用的 ip 地址、port 端口号、用户名和密码以及其它的性能参数,例如初始连接量,最大连接量,最大空闲时间、连接超时时间等,该项目是基于 C++ 语言实现的连接池,主要也是实现以上几个所有连接池都支持的通用基础功能。
初始连接量(initSize):表示连接池事先会和 MySQL Server 创建 initSize 个数的 connection 连接,当应用发起 MySQL 访问时,不用再创建和 MySQL Server 新的连接,直接从连接池中获取一个可用的连接就可以,使用完成后,并不去释放 connection,而是把当前 connection 再归还到连接池当中。
最大连接量(maxSize):当并发访问 MySQL Server 的请求增多时,初始连接量已经不够使用了,此时会根据新的请求数量去创建更多的连接给应用去使用,但是新创建的连接数量上限是 maxSize,不能无限制的创建连接,因为每一个连接都会占用一个 socket 资源,一般连接池和服务器程序是部署在一台主机上的,如果连接池占用过多的 socket 资源,那么服务器就不能接收太多的客户端请求了。当这些连接使用完成后,再次归还到连接池当中来维护。
最大允许空闲时间(maxIdleTime):当访问 MySQL 的并发请求多了以后,连接池里面的连接数量会动态增加,上限是 maxSize 个,当这些连接用完再次归还到连接池当中。如果在指定的 maxIdleTime 最大允许空闲时间里面,这些新增加的连接都没有被再次使用过,那么新增加的这些连接资源就要被回收掉,只需要保持初始连接量 initSize 个连接就可以了。连接资源回收掉后,系统的 socket 资源就会增多,可以接收更多的客户端请求。
连接超时时间(connectionTimeout):当 MySQL 的并发请求量过大,连接池中的连接数量已经到达 maxSize 了,而此时没有空闲的连接可供使用,那么此时应用从连接池获取连接无法成功,它通过阻塞的方式获取连接的时间如果超过 connectionTimeout 时间,那么获取连接失败,无法访问数据库。
该项目主要实现上述的连接池四大功能,其余连接池更多的扩展功能,可以自行实现。同时本项目实现的只是一个组件,并不涉及具体的业务,所以你可以根据自己的业务需求将该组件引入到你自己的项目中。
👉MySQL Server 参数介绍👈
show variables like 'max_connections';
该命令可以查看 MySQL Server 所支持的最大连接个数,超过 max_connections 数量的连接,MySQL
Server 会直接拒绝连接请求,所以在使用连接池增加连接数量的时候,MySQL Server 的 max_connections 参数也要适当的进行调整,以适配连接池的连接上限。
👉功能实现设计👈
- ConnectionPool.cpp 和 ConnectionPool.h:连接池代码实现。
- Connection.cpp 和 Connection.h:数据库操作代码、增删改查代码实现。

连接池主要包含了以下功能点:
- 连接池只需要一个实例,所以 ConnectionPool 以单例模式进行设计。
- 从 ConnectionPool 中可以获取和 MySQL 的连接Connection。
- 空闲连接 Connection 全部维护在一个线程安全的Connection 队列中,使用线程互斥锁保证队列的线
程安全。 - 如果 Connection 队列为空,还需要再获取连接,此时需要动态创建连接,上限数量是 maxSize。
- 队列中空闲连接时间超过 maxIdleTime 的就要被释放掉,只保留初始的 initSize 个连接就可以了,这个功能点肯定需要放在独立的线程中去做。
- 如果 Connection 队列为空,而此时连接的数量已达上限 maxSize,那么等待 connectionTimeout 时间如果还获取不到空闲的连接,那么获取连接失败,此处从 Connection 队列获取空闲连接,可以使用带超时时间的 mutex 互斥锁来实现连接超时时间。
- 用户获取的连接用 shared_ptr 智能指针来管理,用 lambda 表达式定制连接释放的功能(不真正释放
连接,而是把连接归还到连接池中)。 - 连接的生产和连接的消费采用生产者-消费者线程模型来设计,使用了线程间的同步通信机制条件变量和互斥锁。
👉开发平台选型👈
有关 MySQL 数据库编程、多线程编程、线程互斥和同步通信操作、智能指针、设计模式、容器等等这些技术在 C++ 语言层面都可以直接实现,因此该项目选择直接在 Windows 平台上进行开发,当然放在 Linux 平台下用 g++ 也可以直接编译运行。
👉MySQL 数据库编程👈
MySQL 的 Windows 安装教程见下方链接:
https://blog.csdn.net/m0_51510236/article/details/129190003


安装好后,development 开发包: mysql 头文件和 libmysql 库文件就都下载好了。
创建测试表
create database chat;use chat;create table user(
id int primary key auto_increment,name varchar(50),age int,sex enum('male', 'female'));mysql> desc user;
+-------+-----------------------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+-------+-----------------------+------+-----+---------+----------------+
| id | int(11) | NO | PRI | NULL | auto_increment |
| name | varchar(50) | YES | | NULL | |
| age | int(11) | YES | | NULL | |
| sex | enum('male','female') | YES | | NULL | |
+-------+-----------------------+------+-----+---------+----------------+
4 rows in set (0.01 sec)
这里的MySQL数据库编程直接采用oracle公司提供的MySQL C/C++客户端开发包,在VS上需要进行相
应的头文件和库文件的配置,如下:
- 右键项目 - C/C++ - 常规 - 附加包含目录,填写 mysql.h 头文件的路径
- 右键项目 - 链接器 - 常规 - 附加库目录,填写 libmysql.lib 的路径
- 右键项目 - 链接器 - 输入 - 附加依赖项,填写 libmysql.lib 库的名字
- 把 libmysql.dll 动态链接库(Linux下后缀名是.so库)放在工程目录下
日志功能:
// public.h
#pragma once#include <iostream>
using namespace std;/* 日志宏 */
#define LOG(str) \cout << __FILE__ << ":" << __LINE__ << " " << \__TIMESTAMP__ << " : " << str << endl;
MySQL 数据库 C++ 代码封装如下:
// Connection.h
#pragma once#include <string>
#include <mysql.h>using namespace std;/* 实现 MySQL 数据库的操作 */
class Connection
{
public:// 初始化数据库连接Connection();// 释放数据库连接资源~Connection();// 连接数据库bool connect(string ip,unsigned short port,string user,string password,string dbname);// 更新操作 insert、delete、updatebool update(string sql);// 查询操作 selectMYSQL_RES* query(string sql);private:MYSQL* _conn; // 表示和 MySQL Server 的一条连接
};
// Connection.cpp
#include "public.h"
#include "Connection.h"// 初始化数据库连接
Connection::Connection()
{_conn = mysql_init(nullptr);
}// 释放数据库连接资源
Connection::~Connection()
{if (_conn != nullptr) mysql_close(_conn);
}// 连接数据库: true 连接成功 false 连接失败
bool Connection::connect(string ip, unsigned short port,string user, string password, string dbname)
{MYSQL* p = mysql_real_connect(_conn, ip.c_str(), user.c_str(),password.c_str(), dbname.c_str(), port, nullptr, 0);if (p != nullptr){mysql_set_character_set(_conn, "utf8"); // 设置连接的编码return true;}elsereturn false;
}// 更新操作: insert、delete、update
bool Connection::update(string sql)
{// mysql_query: 1 表示失败 0 表示成功if (mysql_query(_conn, sql.c_str())){LOG("更新失败:" + sql);return false;}return true;
}// 查询操作: select
MYSQL_RES* Connection::query(string sql)
{if (mysql_query(_conn, sql.c_str())){LOG("查询失败:" + sql);return nullptr;}return mysql_use_result(_conn);
}
// main.cpp
#include <iostream>
#include "Connection.h"using namespace std;int main()
{Connection conn;char sql[1024] = { 0 };sprintf(sql, "insert into user (name, age, sex) values('%s', %d, '%s')","zhang san", 20, "male");bool ret = conn.connect("127.0.0.1", 3306, "root", "123456", "chat");conn.update(sql);return 0;
}
运行代码后,测看数据库。
mysql> select * from user;
+----+----------+------+------+
| id | name | age | sex |
+----+----------+------+------+
| 1 | zhangsan | 20 | male |
+----+----------+------+------+
1 row in set (0.00 sec)
👉连接池的编写👈
Connection.h
#pragma once#include <ctime>
#include <string>
#include <mysql.h>using namespace std;/* 实现 MySQL 数据库的操作 */
class Connection
{
public:// 初始化数据库连接Connection();// 释放数据库连接资源~Connection();// 连接数据库bool connect(string ip,unsigned short port,string user,string password,string dbname);// 更新操作 insert、delete、updatebool update(string sql);// 查询操作 selectMYSQL_RES* query(string sql);// 刷新一下连接的起始的空闲时间点void refreshAliveTime(){_aliveTime = clock(); // clock 函数返回值的单位为毫秒}// 获取连接已经空闲了多长时间clock_t getAliveTime() const{return clock() - _aliveTime;}private:MYSQL* _conn; // 表示和 MySQL Server 的一条连接clock_t _aliveTime; // 记录进入空闲状态后的起始存活时间
};
Connection.cpp
#include "public.h"
#include "Connection.h"// 初始化数据库连接
Connection::Connection()
{_conn = mysql_init(nullptr);
}// 释放数据库连接资源
Connection::~Connection()
{if (_conn != nullptr) mysql_close(_conn);
}// 连接数据库: true 连接成功 false 连接失败
bool Connection::connect(string ip, unsigned short port,string user, string password, string dbname)
{MYSQL* p = mysql_real_connect(_conn, ip.c_str(), user.c_str(),password.c_str(), dbname.c_str(), port, nullptr, 0);if (p != nullptr){mysql_set_character_set(_conn, "utf8"); // 设置连接的编码return true;}elsereturn false;
}// 更新操作: insert、delete、update
bool Connection::update(string sql)
{// mysql_query: 1 表示失败 0 表示成功if (mysql_query(_conn, sql.c_str())){LOG("更新失败:" + sql);return false;}return true;
}// 查询操作: select
MYSQL_RES* Connection::query(string sql)
{if (mysql_query(_conn, sql.c_str())){LOG("查询失败:" + sql);return nullptr;}return mysql_use_result(_conn);
}
CommonConnectionPool.h
#pragma once#include <string>
#include <queue>
#include <mutex>
#include <atomic>
#include <thread>
#include <memory>
#include <functional>
#include <condition_variable>
#include "Connection.h"using namespace std;/* 实现连接池功能模块 */
class ConnectionPool
{
public:// 获取连接池对象实例static ConnectionPool* getConnectionPool();// 给消费者线程提供接口, 从连接池中获取一个空闲的连接// 返回值是智能指针, 需要定制智能指针的删除器// 该删除器的功能就是当消费者线程用完连接后, // 连接自动放回连接池中shared_ptr<Connection> getConnection();private:// 构造函数私有化ConnectionPool(); // 加载配置文件bool loadConfigFile();// 生产连接, 由生产者线程调用void produceConnection();// 扫描空闲连接, 看其空闲时间是否超过 maxIdleTimevoid scannConnection();string _ip; // MySQL 的 IP 地址unsigned short _port; // MySQL 的端口号 3306string _username; // MySQL 登录用户名string _password; // MySQL 登录密码string _dbname; // 要连接的数据库int _initSize; // 连接池的初始连接量int _maxSize; // 连接池的最大连接量int _maxIdleTime; // 连接池的最大允许空闲时间int _connectionTimeout; // 连接池获取连接的超时时间queue<Connection*> _connectionQue; // 存储 MySQL 连接的队列mutex _queueMutex; // 保证连接队列线程安全的互斥锁atomic_int _connectionCnt; // 记录所创建的 Connection 连接的总数量condition_variable _cv; // 设置条件变量, 用于生产者线程和消费者线程之间的同步
};
配置文件 mysql.ini
# 数据库连接池的配置文件
ip=127.0.0.1
port=3306
username=root
password=123456
dbname=chat
initSize=10
maxSize=1024
# 最大允许空闲时间默认单位是秒
maxIdleTime=60
# 连接超时时间默认单位是毫秒
connectionTimeout=100
CommonConnectionPool.cpp
#include "public.h"
#include "CommonConnectionPool.h"// 线程安全的懒汉单例函数接口
ConnectionPool* ConnectionPool::getConnectionPool()
{static ConnectionPool pool; // 静态变量初始化, 编译器自动 lock 和 unlockreturn &pool;
}// 连接池的构造
ConnectionPool::ConnectionPool()
{// 加载配置文件失败if (!loadConfigFile()) return;// 创建初始数量的连接for (int i = 0; i < _initSize; ++i){Connection* p = new Connection();p->connect(_ip, _port, _username, _password, _dbname);// 此处没有多线程, 因此不存在线程安全问题p->refreshAliveTime(); // 刷新一下连接开始空闲的起始时间_connectionQue.push(p);++_connectionCnt;}// 启动一个新的线程, 作为生产连接的线程// 使用绑定器给生产者线程绑定类内方法thread producer(bind(&ConnectionPool::produceConnection, this));producer.detach();// 启动一个新的线程, 作为定时线程// 负责扫描多余的空闲连接, 对空闲时间超过 // maxIdleTime 的空闲连接, 进行回收thread scanner(bind(&ConnectionPool::scannConnection, this));scanner.detach();
}// 加载配置文件
bool ConnectionPool::loadConfigFile()
{FILE* pf = fopen("mysql.ini", "r");if (pf == nullptr){LOG("mysql.ini file not exists!");return false;}// 没有到文件末尾, feof 返回 0while (!feof(pf)){char line[1024] = { 0 };fgets(line, 1024, pf);string str = line;size_t index = str.find('=', 0);// password=123456\nif (index == string::npos) // 无效配置项{continue;}size_t endIndex = str.find('\n', index);string key = str.substr(0, index);string value = str.substr(index + 1, endIndex - index - 1);if (key == "ip") _ip = value;else if (key == "port") _port = stoi(value.c_str());else if (key == "username") _username = value;else if (key == "password") _password = value;else if (key == "dbname") _dbname = value;else if (key == "initSize") _initSize = stoi(value.c_str());else if (key == "maxSize") _maxSize = stoi(value.c_str());else if (key == "maxIdleTime") _maxIdleTime = stoi(value.c_str());else if (key == "connectionTimeout") _connectionTimeout = stoi(value.c_str());}return true;
}// 运行在独立的线程中, 专门负责生产新链接
void ConnectionPool::produceConnection()
{while (true){unique_lock<mutex> lock(_queueMutex);while (!_connectionQue.empty()){_cv.wait(lock); // 队列不为空, 生产者线程进入等待状态}// 连接数量没有到达上限, 继续创建新的连接if (_connectionCnt < _maxSize){Connection* p = new Connection();p->connect(_ip, _port, _username, _password, _dbname);p->refreshAliveTime(); // 刷新一下连接开始空闲的起始时间_connectionQue.push(p);++_connectionCnt;}// 通知消费者线程, 可以获取新连接了_cv.notify_all();}
}// 由服务器的应用线程调用, 获取连接
shared_ptr<Connection> ConnectionPool::getConnection()
{unique_lock<mutex> lock(_queueMutex);while (_connectionQue.empty()){// 不能使用 sleep 函数, sleep 是直接休眠// 线程向下执行的可能情况: 被唤醒和超时// 被唤醒的可能情况: 生产者生产了新连接或消费者归还了连接// 如果是被唤醒的话, 队列肯定不为空, 那么就会跳出 while 循环// 如果是超时的话, 再判断队列是否为空, 如果为空, 那么获取连接// 就失败了; 如果不为空, 那么也会跳出 while 循环if (cv_status::timeout == _cv.wait_for(lock, chrono::microseconds(_connectionTimeout))){if (_connectionQue.empty()){LOG("获取空闲连接超时了...获取连接失败!");return nullptr;}}}// 队列不为空// shared_ptr 智能指针析构时, 会把 Connection 资源直接 delete掉// 相当于调用 Connection 的析构函数, 将 MySQL 连接给关闭掉, 因此// 需要定制 shared_ptr 释放资源的方法// 定制删除器: 将消费者用完的 Connection 连接放回到队列中shared_ptr<Connection> sp(_connectionQue.front(), [&](Connection* pcon) {// 这里是在服务器应用线程中调用的, 因此一定要考虑队列的线程安全问题unique_lock<mutex> lock(_queueMutex);pcon->refreshAliveTime(); // 刷新一下连接开始空闲的起始时间_connectionQue.push(pcon);});_connectionQue.pop(); // 消费者获取了该连接, 因此需要 pop 掉if (_connectionQue.empty()){// 谁消费了队列中最后一个 Connection, 谁负责通知生产者进行生产_cv.notify_all(); }return sp;
}// 扫描空闲连接, 看其空闲时间是否超过 maxIdleTime
void ConnectionPool::scannConnection()
{while (true){// 通过 sleep 来模拟定时效果this_thread::sleep_for(chrono::seconds(_maxIdleTime));// 扫描整个队列, 释放多余的空闲连接unique_lock<mutex> lock(_queueMutex);while (_connectionCnt > _initSize){Connection* p = _connectionQue.front();if (p->getAliveTime() >= (_maxIdleTime * 1000)){_connectionQue.pop();--_connectionCnt;delete p; // 调用 ~Connection() 释放连接}else{break; // 队头连接都没有超过 _maxIdleTime, 其他连接肯定也没有}}}
}
👉压力测试👈
验证数据的插入操作所花费的时间,第一次测试使用普通的数据库访问操作,第二次测试使用带连接池的数据库访问操作,对比两次操作同样数据量所花费的时间,性能压力测试结果如下:

可以看到,在单线程场景下,使用连接池性能会得到很大的提升。而在多线程场景下,使用连接池性能提升不明显。原因可能是:多线程涉及互斥锁所带来的一系列开销,这个开销可能会抵消避免频繁建立连接所省去的开销。
压力测试代码
#include <iostream>
#include <vector>
#include "CommonConnectionPool.h"using namespace std;int main()
{// 四线程测试auto fun = []() {// 使用连接池ConnectionPool* cp = ConnectionPool::getConnectionPool();int times = 2500;for (int i = 0; i < times; ++i){char sql[1024] = { 0 };sprintf(sql, "insert into user (name, age, sex) values('%s', %d, '%s')","zhang san", 20, "male");shared_ptr<Connection> sp = cp->getConnection();sp->update(sql);}// 未使用连接池//int times = 2500;//for (int i = 0; i < times; ++i)//{// char sql[1024] = { 0 };// sprintf(sql, "insert into user (name, age, sex) values('%s', %d, '%s')",// "zhang san", 20, "male");// Connection conn;// conn.connect("127.0.0.1", 3306, "root", "123456", "chat");// conn.update(sql);//}};// 未使用连接池的情况需要先登录一下, 因为不能一个// 用户被多次同时登录, 如果不这样将无法完成测试Connection conn;conn.connect("127.0.0.1", 3306, "root", "123456", "chat");int num = 4;clock_t begin = clock();vector<thread> v;for (int i = 0; i < num; ++i) v.push_back(thread(fun));for (int i = 0; i < num; ++i) v[i].join();clock_t end = clock();cout << (end - begin) << "ms" << endl;return 0;// 单线程测试
#if 0size_t times = 10000;clock_t begin = clock();for (int i = 0; i < times; ++i){// 未使用连接池char sql[1024] = { 0 };sprintf(sql, "insert into user (name, age, sex) values('%s', %d, '%s')","zhang san", 20, "male");Connection conn;conn.connect("127.0.0.1", 3306, "root", "123456", "chat");conn.update(sql);// 使用连接池//char sql[1024] = { 0 };//sprintf(sql, "insert into user (name, age, sex) values('%s', %d, '%s')",// "zhang san", 20, "male");//shared_ptr<Connection> sp = cp->getConnection();//sp->update(sql);}clock_t end = clock();cout << (end - begin) << "ms" << endl;return 0;
#endif
}
压力测试注意事项:
- 每次进行压力测试前,需要将表中的数据都删除掉,避免这个因素对测试结果的影响。
- 电脑硬件资源的不同,对测试结果的影响是比较大的,只要控制变量来进行比较即可。
- 当 MYSQL 服务端收到大量的 SQL 请求,MYSQL 可能会处理不过来,然后会给客户端返回 MySQL server has gone away 的错误信息。
👉项目常见问题👈
在写数据库连接池项目的时候,经常出现的问题就是 MySQL API 调用出错,提示 insert、delete、update 等操作执行失败,或者 connect 连接 MySQL Server 失败等等,很多人不知道遇到这个问题该怎么办?
其实开源库提供的对外调用 API 还是很全面的,MySQL API 专门提供了两个函数,能够打印出错时的信息提示,如下:

例如,代码执行报错:

无论上面截图右侧输出信息上提示 insert 错误还是其它错误,都可以在代码上通过添加 mysql_error 函数打印错误提示,一般通过查看提示就知道是什么错误了,例如权限问题,但大部分都是细节错误,字段不对、类型不对、表名不对等等。

重新执行代码,这里出错的话,就会打印错误信息。
mysql_errno 返回的是一个 int 整型错误码,可以在网上搜索 MySQL 错误码 xxx,就可以看到错误是什么原因了。
相关文章:
【项目设计】MySQL 连接池的设计
目录 👉关键技术点👈👉项目背景👈👉连接池功能点介绍👈👉MySQL Server 参数介绍👈👉功能实现设计👈👉开发平台选型👈👉MyS…...

Ubuntu系统adb开发调试问题记录
Ubuntu系统adb开发调试问题记录 一、adb devices no permissions二、自定义adb server端口三、动态库目录四、USB抓包 一、adb devices no permissions lsusb -t 设备树直观地查看设备的Bus ID和Device Num,lsusb找到对应的PID和VID编辑udev规则 sudo vim /etc/ud…...

【宏定义】——检验条件是否成立,并返回指定的值
文章目录 功能说明实现示例解析扩展 功能说明 宏检验条件是否成立,并返回指定的值 #define TU_VERIFY(...) _GET_3RD_ARG(__VA_ARGS__, TU_VERIFY_2ARGS, TU_VERIFY_1ARGS, UNUSED)(__VA_ARGS__)TU_VERIFY(1) 检验为真,啥也不干TU_VERIFY(0) 校验为假&…...

UE5引擎源码小记 —反射信息注册过程
序 最近看了看反射相关的知识,用不说一点人话的方式来说,反射是程序在运行中能够动态获取修改或调用自身属性的东西。 一开始我是觉得反射用处好像不大,后续查了下一些反射的使用环境,发现我格局小了,我觉得用处不大的…...
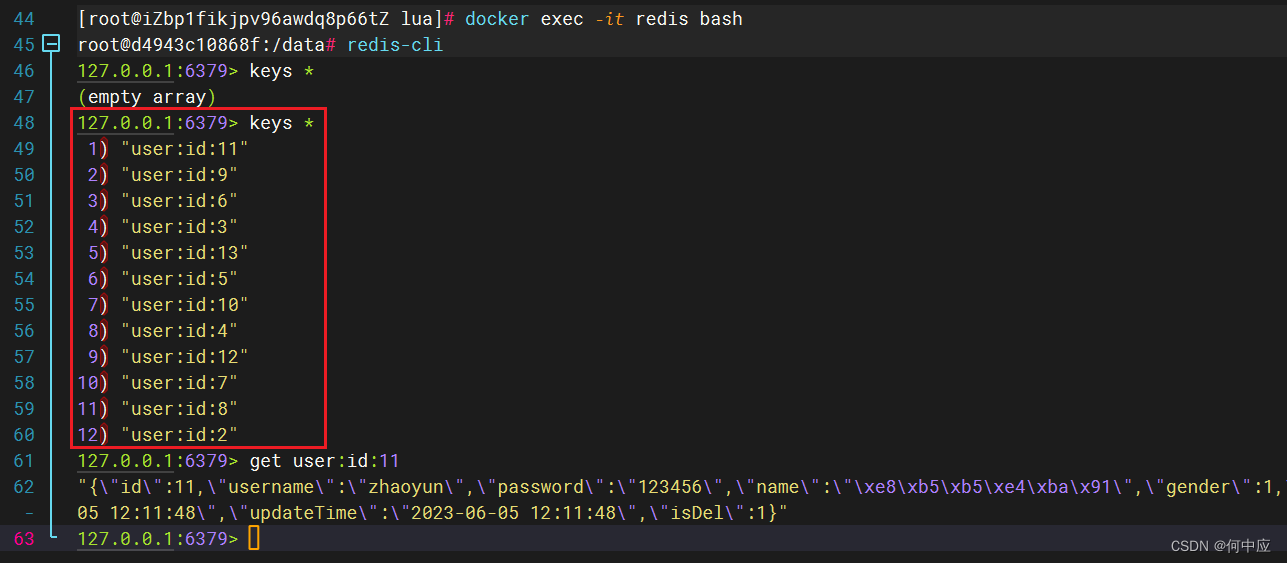
Redis缓存预热
说明:项目中使用到Redis,正常情况,我们会在用户首次查询数据的同时把该数据按照一定命名规则,存储到Redis中,称为冷启动(如下图),这种方式在一些情况下可能会给数据库带来较大的压力…...
Android 耗时分析(adb shell/Studio CPU Profiler/插桩Trace API)
1.adb logcat 查看冷启动时间和Activity显示时间: 过滤Displayed关键字,可看到Activity的显示时间 那上面display后面的是时间是指包含哪些过程的时间呢? 模拟在Application中沉睡1秒操作,冷启动情况下: 从上可知&…...

保护隐私与安全的防关联、多开浏览器
随着互联网的不断发展,我们越来越离不开浏览器这个工具,它为我们提供了便捷的网络浏览体验。然而,随着我们在互联网上的活动越来越多,我们的个人信息和隐私也日益暴露在网络风险之下。在这种背景下,为了保护个人隐私和…...

CloudStudio搭建Next框架博客_抛开电脑性能在云端编程(沉浸式体验)
文章目录 ⭐前言⭐进入cloud studio工作区指引💖 注册coding账号💖 选择cloud studio💖 cloud studio选择next.js💖 安装react的ui框架(tDesign)💖 安装axios💖 代理请求跨域&#x…...

【FPGA IP系列】FIFO深度计算详解
FIFO(First In First Out)是一种先进先出的存储结构,经常被用来在FPGA设计中进行数据缓存或者匹配传输速率。 FIFO的一个关键参数是其深度,也就是FIFO能够存储的数据条数,深度设计的合理,可以防止数据溢出,也可以节省…...

JavaScript中语句和表达式
在JavaScript编程中,Statements和Expressions都是代码的构建块,但它们有不同的特点和用途。 ● Statements(语句)是执行某些操作的完整命令;每个语句通常以分号结束。例如,if语句、for语句、switch语句、函…...

打卡力扣题目十
#左耳听风 ARST 打卡活动重启# 目录 一、题目 二、解决方法一 三、解决方法二 关于 ARTS 的释义 —— 每周完成一个 ARTS: ● Algorithm: 每周至少做一个 LeetCode 的算法题 ● Review: 阅读并点评至少一篇英文技术文章 ● Tips: 学习至少一个技术技巧 ● Shar…...

UniApp实现API接口封装与请求方法的设计与开发方法
UniApp实现API接口封装与请求方法的设计与开发方法 导语:UniApp是一个基于Vue.js的跨平台开发框架,可以同时开发iOS、Android和H5应用。在UniApp中,实现API接口封装与请求方法的设计与开发是一个十分重要的部分。本文将介绍如何使用UniApp实…...
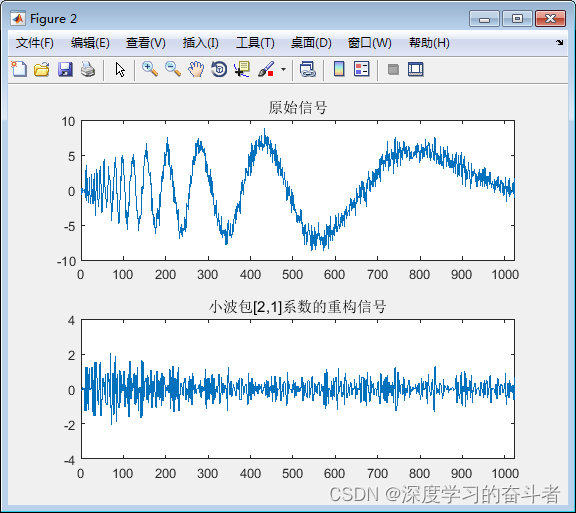
利用小波分解信号,再重构
function [ output_args ] example4_5( input_args ) %EXAMPLE4_5 Summary of this function goes here % Detailed explanation goes here clc; clear; load leleccum; s leleccum(1:3920); % 进行3层小波分解,小波基函数为db2 [c,l] wavedec(s,3,db2); %进行…...
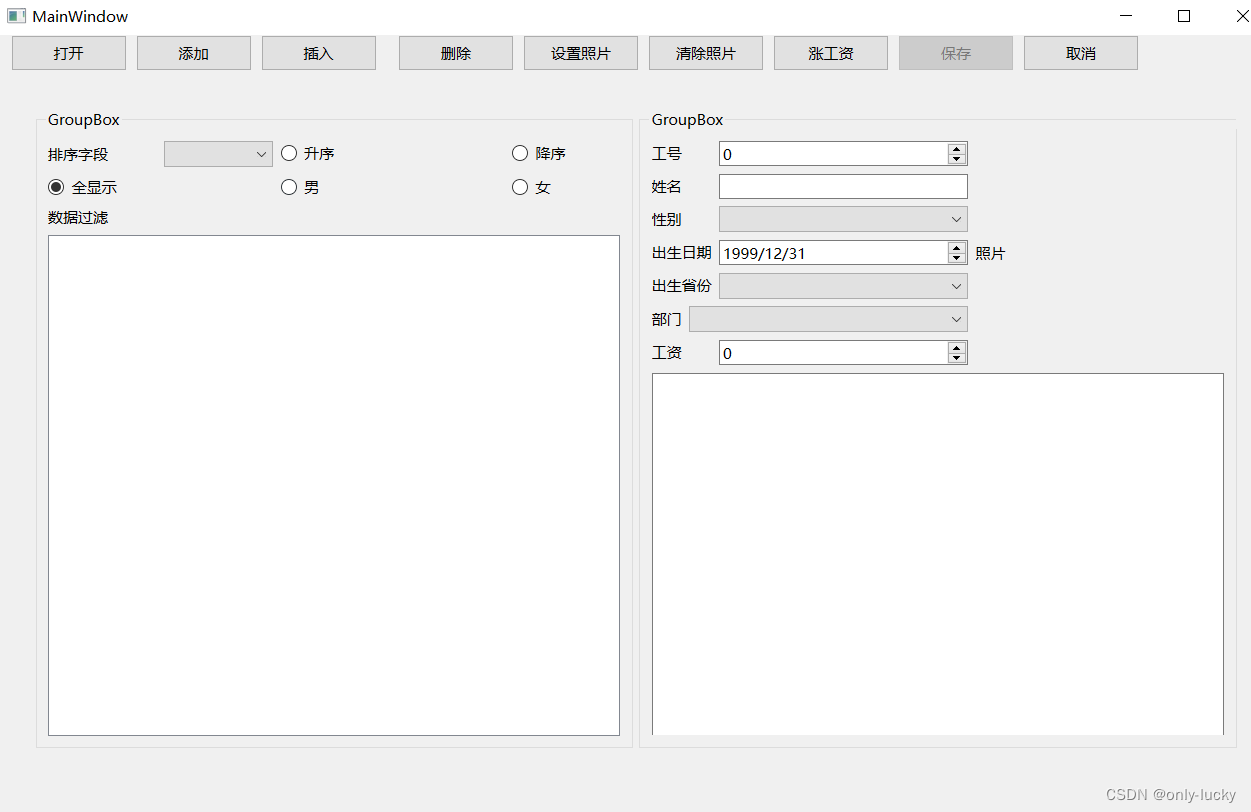
QT数据库编程
ui界面 mainwindow.cpp #include "mainwindow.h" #include "ui_mainwindow.h" #include <QButtonGroup> #include <QFileDialog> #include <QMessageBox> MainWindow::MainWindow(QWidget* parent): QMainWindow(parent), ui(new Ui::M…...

基于stm32单片机的直流电机速度控制——LZW
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 目录 一、实验目的二、实验方法三、实验设计1.实验器材2.电路连接3.软件设计(1)实验变量(2)功能模块a)电机接收信号…...

实际项目中使用mockjs模拟数据
项目中的痛点 自己模拟的数据对代码的侵入程度太高,接口完成后要删掉对应的代码,导致接口开发完后端同事开发完,前端自己得加班;接口联调的时间有可能会延期,接口完成的质量参差不齐;对于数据量过大的模拟…...
【家庭公网IPv6】
家庭公网IPv6 这里有两个网站: 1、 IPV6版、多地Tcping、禁Ping版、tcp协议、tcping、端口延迟测试,在本机搭建好服务器后,可以用这个测试外网是否可以访问本机; 2、 IP查询ipw.cn,这个可以查询本机的网络是否IPv6访问…...

【iOS】Frame与Bounds的区别详解
iOS的坐标系 iOS特有的坐标是,是在iOS坐标系的左上角为坐标原点,往右为X正方向,向下为Y正方向。 bounds和frame都是属于CGRect类型的结构体,系统的定义如下,包含一个CGPoint(起点)和一个CGSiz…...
SpringBoot百货超市商城系统 附带详细运行指导视频
文章目录 一、项目演示二、项目介绍三、运行截图四、主要代码 一、项目演示 项目演示地址: 视频地址 二、项目介绍 项目描述:这是一个基于SpringBoot框架开发的百货超市系统。首先,这是一个很适合SpringBoot初学者学习的项目,代…...
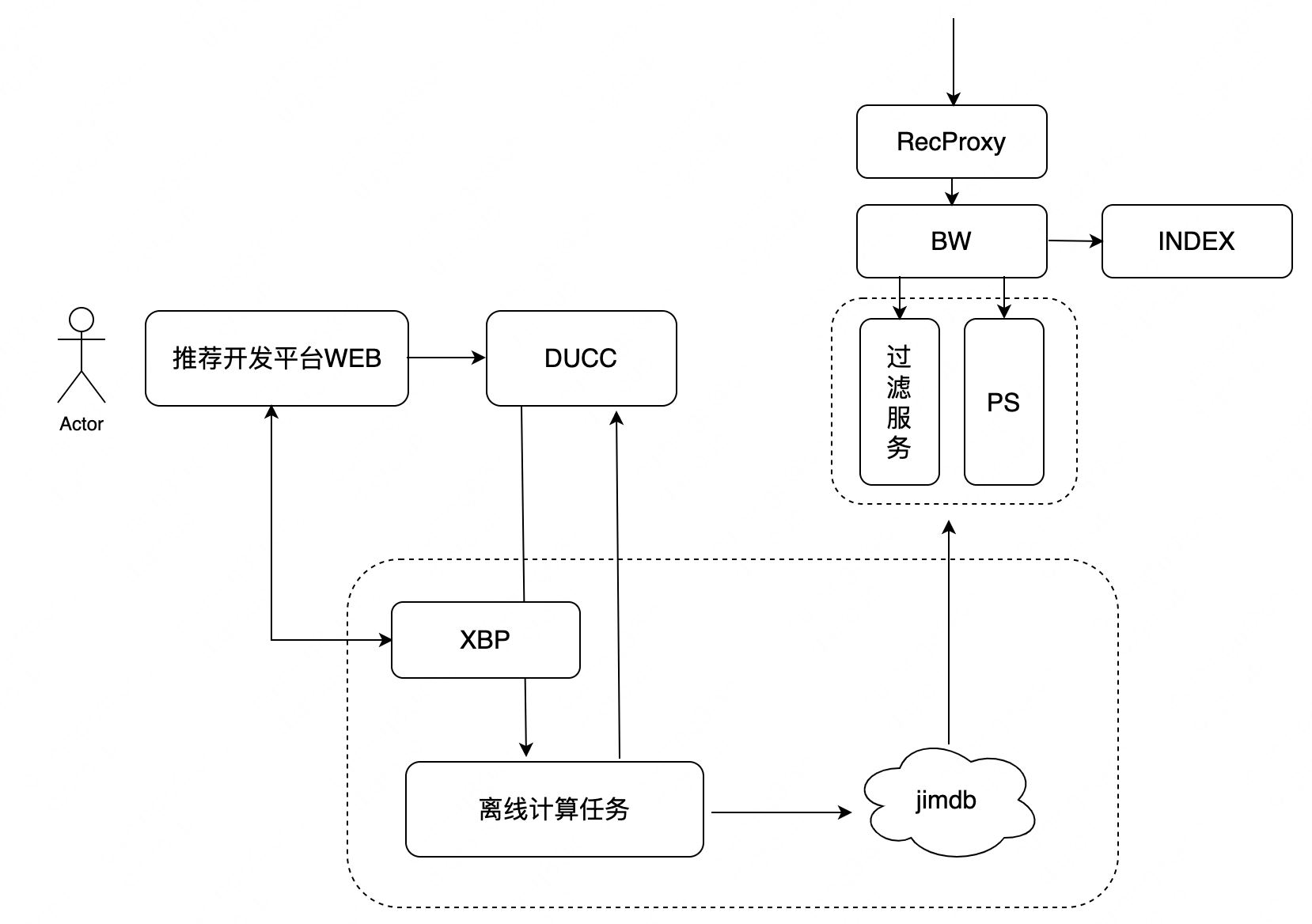
【实践篇】推荐算法PaaS化探索与实践 | 京东云技术团队
作者:京东零售 崔宁 1. 背景说明 目前,推荐算法部支持了主站、企业业务、全渠道等20业务线的900推荐场景,通过梳理大促运营、各垂直业务线推荐场景的共性需求,对现有推荐算法能力进行沉淀和积累,并通过算法PaaS化打造…...

VisualTFT自定义圆形进度条:Canvas绘图与嵌入式GUI开发实践
1. 项目概述与核心价值最近在做一个工业HMI的项目,客户要求在设备启动自检的界面上,用一个圆环形的进度条来展示自检进度,而不是传统的长条状进度条。他们觉得圆环看起来更“高级”,也更符合他们产品的整体UI风格。接到这个需求&a…...

Joy-Con Toolkit:深度解析开源手柄控制框架的技术实现与高级应用
Joy-Con Toolkit:深度解析开源手柄控制框架的技术实现与高级应用 【免费下载链接】jc_toolkit Joy-Con Toolkit 项目地址: https://gitcode.com/gh_mirrors/jc/jc_toolkit Joy-Con Toolkit是一款基于hidapi库开发的开源手柄控制框架,专为任天堂Jo…...

通过 curl 命令快速测试 Taotoken 各大模型接口连通性
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 通过 curl 命令快速测试 Taotoken 各大模型接口连通性 在接入大模型服务时,直接使用 curl 命令进行接口测试是一种高效…...

2026网盘怎么选:别只盯“不限速”,更该看同步稳定性与数据安全
很多人换网盘的导火索是“限速”,但真正拉开体验差距的,往往是:同步是否稳定、复杂网络下是否容易失败、多人协作有没有权限与版本控制、数据安全与合规是否站得住脚。下面这篇不再只比较“快不快”,而是用更贴近长期使用的维度&a…...

卡梅德生物技术快报|多肽库筛选:基于全质粒 PCR 的噬菌体文库构建与小分子表位淘选实战
正文摘要本文面向生物研发、实验技术、噬菌体展示方向开发者,系统讲解多肽库筛选完整流程:从问题分析、瓶颈定位、实验方案设计到质控与结果输出,提供可复现的技术方案与关键参数。内容基于真实学位论文研究,聚焦高库容、高多样性…...

意法半导体STM32F407VET6代理商
在当今快速发展的电子行业中,选择一家可靠且专业的微控制器(MCU)供应商至关重要。对于那些正在寻找意法半导体STM32F407VET6系列单片机解决方案的企业而言,深圳市粤科源兴科技有限公司凭借其优质的服务、合理的价格及充足的库存量…...

揭秘AI专著写作:如何利用AI工具一键生成20万字专著并降低查重率?
撰写学术专著的挑战与AI工具解决方案 撰写学术专著不仅考验研究者的学术能力,更是对心理承受力的一种考验。与团队协作完成论文不同,专著的撰写往往是一个人的战斗。研究者需要在选题、构建框架到内容撰写和修改的每个环节都独立面对。长时间的孤独创作…...

WeChatFerry微信机器人完整指南:构建企业级智能自动化助手
WeChatFerry微信机器人完整指南:构建企业级智能自动化助手 【免费下载链接】WeChatFerry 微信机器人,可接入DeepSeek、Gemini、ChatGPT、ChatGLM、讯飞星火、Tigerbot等大模型。微信 hook WeChat Robot Hook. 项目地址: https://gitcode.com/GitHub_Tr…...

QMCDecode:三步快速解密QQ音乐加密音频的免费工具
QMCDecode:三步快速解密QQ音乐加密音频的免费工具 【免费下载链接】QMCDecode QQ音乐QMC格式转换为普通格式(qmcflac转flac,qmc0,qmc3转mp3, mflac,mflac0等转flac),仅支持macOS,可自动识别到QQ音乐下载目录,默认转换结…...

3分钟掌握PlantUML Editor:用代码思维绘制专业UML图表的终极指南
3分钟掌握PlantUML Editor:用代码思维绘制专业UML图表的终极指南 【免费下载链接】plantuml-editor PlantUML online demo client 项目地址: https://gitcode.com/gh_mirrors/pl/plantuml-editor 还在为复杂的UML图表绘制而烦恼吗?传统的拖拽式绘…...