ViT-vision transformer
ViT-vision transformer
介绍
Transformer最早是在NLP领域提出的,受此启发,Google将其用于图像,并对分类流程作尽量少的修改。
起源:从机器翻译的角度来看,一个句子想要翻译好,必须考虑上下文的信息!
如:The animal didn’t cross the street because it was too tired将其翻译成中文,这里面就涉及了it这个词的翻译,具体it是指代animal还是street就需要根据上下文来确定,所以现在问题就变成,如何让机器学习上下文?
例如有两个特征,分别为性别和收入,二者做交互特征(简单的说即两个特征相乘),可以得到如:此数据为男人的状态下收入为多少的特征,则可以利用这个特征去分析性别对收入的影响,相对于同时考虑了性别和收入的关系。那么借鉴这个思想,相对于引入一个相乘的交互关系就可以去表示上下文信息了。而Attention在本质上用一句话概括就是:带权重的相乘求和。
在Attention中,假如我们要翻译it这个词,这时候it这个词称为query(Q)待查询。查询什么呢,查询句子中的其他单词包括自己(这里其他的单词包括自己称为(keys(K)),这里的查询操作相对于上文说的相乘,而在Attention中用的是点乘操作。如果还记得Attention的输入是Patch embedding的结果,即是一个个N维空间的向量,即Q和K代表的内容都为N维空间的向量,那么点乘即可以表示这两个向量的相似程度——Q*K = |Q||K|cosθ
Q和K相乘后可以得到一个代表词和词之间相似度的概念,这里记为S。如果我们对这个S取softmax,是不是相对于就得到了当前要查询的Q,到底对应哪个词的概率比较大的概率,这里记为P。
而Attention就是对P做权重加和的结果,而为什么还要对P做权重(这个权重也是可学习的)加和呢,其实我觉得这才是Attention的精髓,因为每个权重即代表了网络对于哪个概率对应下的内容更加注意,对于哪些内容不需要注意,使网络可以更加关注与需要注意的东西,其他无关的东西,通过这个权重,相对于舍弃了。而我们记这个权重为V。
思路:ViT算法中,首先将整幅图像拆分成若干个patch,然后把这些patch的线性嵌入序列作为Transformer的输入送入网络,然后使用监督学习的方式进行图像分类的训练。
具体流程:
- 将图像拆分成若干个patch
- 将patches通过一个线性映射层,得到若干个token embedding
- 将多个token embedding concat一个cls_token(可学习参数)
- 每个参数均加上position embedding位置编码,防止无法找到原来的位置
- 将token embedding、cls_token和position embedding一同传入encoder模块
- encoder模块(L个block)
- Layer Norm:标准归一化(便于收敛)
- MSA/MHA:多头子注意力机制
- 输入输出作残差链接
- Layer Norm:标准归一化(便于收敛)
- MLP:全连接层(Linear+…)
- encoder的输出通过MLP Head作分类任务
优点:模型简单且效果好,较好的扩展性,模型越大效果越好。
与CNN结构对比
- Transformer的平移不变性和局部感知性较差,在数据量不充分时,效果较差
- 但是对于大量的训练数据,Transformer的效果更佳
- 无需像CNN构造复杂的网络结构,CNN往往是不断加深网络,才能对刷新某任务的SOTA

模型结构
图像分块嵌入Patch Embedding
具体步骤:
-
将 H ∗ W ∗ C H * W * C H∗W∗C的图像,变成一个 N ∗ ( P 2 ∗ C ) N * (P^2*C) N∗(P2∗C)的序列,这个序列由一系列展平的图像块构成,即把图像切分成小块后再展平,其中, N = H W / P 2 N=HW/P^2 N=HW/P2个图像块,每个图像块的维度为 P 2 ∗ C P^2*C P2∗C, P P P表示图像块大小, C C C表示通道数量。
-
将每个图像块的维度由 P 2 ∗ C P^2*C P2∗C变换为 D D D,在此进行embedding,只需对每个 P 2 ∗ C P^2*C P2∗C图像块做一个线性变换,将维度压缩至 D D D。
-
将 ( N + 1 ) ∗ D (N+1)*D (N+1)∗D的序列作为encoder的输入。
为啥是N+1呢?因为要多加上一个维度才能关联到全局的信息,这个恰好是class token
class PatchEmbed(nn.Module):"""2D Image to Patch Embedding"""def __init__(self, img_size=224, patch_size=16, in_c=3, embed_dim=768, norm_layer=None):super().__init__()img_size = (img_size, img_size)patch_size = (patch_size, patch_size)self.img_size = img_sizeself.patch_size = patch_sizeself.grid_size = (img_size[0] // patch_size[0], img_size[1] // patch_size[1])self.num_patches = self.grid_size[0] * self.grid_size[1]self.proj = nn.Conv2d(in_c, embed_dim, kernel_size=patch_size, stride=patch_size)self.norm = norm_layer(embed_dim) if norm_layer else nn.Identity()def forward(self, x):B, C, H, W = x.shapeassert H == self.img_size[0] and W == self.img_size[1], \f"Input image size ({H}*{W}) doesn't match model ({self.img_size[0]}*{self.img_size[1]})."# flatten: [B, C, H, W] -> [B, C, HW]# transpose: [B, C, HW] -> [B, HW, C]x = self.proj(x).flatten(2).transpose(1, 2)x = self.norm(x)return x
多头自注意力机制Multi-head Self-attention
多头较于单头的优势是增强了网络的稳定性和鲁棒性
将 ( N + 1 ) ∗ D (N+1)*D (N+1)∗D的序列输入至encoder进行特征提取,其最重要的结构是多头自注意力机制,2 head的multi-head attention结构如下所示,具体步骤如下:
- 输入 a i a^i ai经过转移矩阵 W W W,得到 q i , k i , v i q^i,k^i,v^i qi,ki,vi,再分别切分成 q i , 1 , q i , 2 , k i , 1 , k i , 2 , v i , 1 , v i , 2 , q i , 1 . . . q^{i,1},q^{i,2},k^{i,1},k^{i,2},v^{i,1},v^{i,2},q^{i,1}... qi,1,qi,2,ki,1,ki,2,vi,1,vi,2,qi,1...
- 接着 q i , j 与 k i , j q^{i,j}与k^{i,j} qi,j与ki,j做attention,得到权重向量 α α α,将 α α α与 v i , j v^{i,j} vi,j进行加权求和,最终得到 b i , j b^{i,j} bi,j
- 将 b i , j b^{i,j} bi,j拼接起来,通过一个线性层进行处理,得到最终的结果。
具体说说其中的attention, q i , j , k i , j 与 v i , j q^{i,j},k^{i,j}与v^{i,j} qi,j,ki,j与vi,j计算 b i , j b^{i,j} bi,j的方法是缩放点积注意力 (Scaled Dot-Product Attention),加权内积得到 α α α:
α 1 , i = q 1 ∗ k i d α_{1,i}=\frac{q^1*k^i}{\sqrt{d}} α1,i=dq1∗ki
其中,d是q和k的维度大小,除以一个 d \sqrt{d} d可以达到归一化的效果。
接着,将 α 1 , i α_{1,i} α1,i取softmax操作,并与 v i , j v^{i,j} vi,j相乘得到最后结果。


class Attention(nn.Module):def __init__(self,dim, # 输入token的dimnum_heads=8,qkv_bias=False,qk_scale=None,attn_drop_ratio=0.,proj_drop_ratio=0.):super(Attention, self).__init__()self.num_heads = num_headshead_dim = dim // num_headsself.scale = qk_scale or head_dim ** -0.5self.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias)self.attn_drop = nn.Dropout(attn_drop_ratio)self.proj = nn.Linear(dim, dim)self.proj_drop = nn.Dropout(proj_drop_ratio)def forward(self, x):# [batch_size, num_patches + 1, total_embed_dim]B, N, C = x.shape# qkv(): -> [batch_size, num_patches + 1, 3 * total_embed_dim]# reshape: -> [batch_size, num_patches + 1, 3, num_heads, embed_dim_per_head]# permute: -> [3, batch_size, num_heads, num_patches + 1, embed_dim_per_head]qkv = self.qkv(x).reshape(B, N, 3, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)# [batch_size, num_heads, num_patches + 1, embed_dim_per_head]q, k, v = qkv[0], qkv[1], qkv[2] # make torchscript happy (cannot use tensor as tuple)# transpose: -> [batch_size, num_heads, embed_dim_per_head, num_patches + 1]# @: multiply -> [batch_size, num_heads, num_patches + 1, num_patches + 1]attn = (q @ k.transpose(-2, -1)) * self.scaleattn = attn.softmax(dim=-1)attn = self.attn_drop(attn)# @: multiply -> [batch_size, num_heads, num_patches + 1, embed_dim_per_head]# transpose: -> [batch_size, num_patches + 1, num_heads, embed_dim_per_head]# reshape: -> [batch_size, num_patches + 1, total_embed_dim]x = (attn @ v).transpose(1, 2).reshape(B, N, C)x = self.proj(x)x = self.proj_drop(x)return x
多层感知机Multilayer Perceptron
class Mlp(nn.Module):"""MLP as used in Vision Transformer, MLP-Mixer and related networks"""def __init__(self, in_features, hidden_features=None, out_features=None, act_layer=nn.GELU, drop=0.):super().__init__()out_features = out_features or in_featureshidden_features = hidden_features or in_featuresself.fc1 = nn.Linear(in_features, hidden_features)self.act = act_layer()self.fc2 = nn.Linear(hidden_features, out_features)self.drop = nn.Dropout(drop)def forward(self, x):x = self.fc1(x)x = self.act(x)x = self.drop(x)x = self.fc2(x)x = self.drop(x)return x
DropPath
一种特殊的 Dropout,用来替代传统的Dropout结构。作用是:若x为输入的张量,其通道为[B,C,H,W],那么drop_path的含义为在一个Batch_size中,随机有drop_prob的样本,不经过主干,而直接由分支进行恒等映射。
def drop_path(x, drop_prob: float = 0., training: bool = False):if drop_prob == 0. or not training:return xkeep_prob = 1 - drop_probshape = (x.shape[0],) + (1,) * (x.ndim - 1) # work with diff dim tensors, not just 2D ConvNetsrandom_tensor = keep_prob + torch.rand(shape, dtype=x.dtype, device=x.device)random_tensor.floor_() # binarizeoutput = x.div(keep_prob) * random_tensorreturn outputclass DropPath(nn.Module):"""Drop paths (Stochastic Depth) per sample (when applied in main path of residual blocks)."""def __init__(self, drop_prob=None):super(DropPath, self).__init__()self.drop_prob = drop_probdef forward(self, x):return drop_path(x, self.drop_prob, self.training)
Class Token
假设我们将原始图像切分成 3 × 3 = 9个小图像块,最终的输入序列长度却是10,也就是说我们这里人为的增加了一个向量进行输入,我们通常将人为增加的这个向量称为 Class Token。
若没有这个向量,也就是将 N = 9 个向量输入 Transformer 结构中进行编码,我们最终会得到9个编码向量,可对于图像分类任务而言,我们应该选择哪个输出向量进行后续分类呢?两个方案可以实现:
- ViT算法提出了一个可学习的嵌入向量 Class Token,将它与9个向量一起输入到 Transformer 结构中,输出10个编码向量,然后用这个 Class Token 进行分类预测即可。
- 取除了cls_token之外的所有token的均值作为类别特征表示,即编码中的x[:,self.num_tokens:].mean(dim=1)
Positional Encoding
在self-attention中,输入是一整排的tokens,我们很容易知道tokens的位置信息,但是模型是无法分辨的,因为self-attention的运算是无向的,因此才使用positional encoding把位置信息告诉模型。
按照 Transformer 结构中的位置编码习惯,这个工作也使用了位置编码。不同的是,ViT 中的位置编码没有采用原版 Transformer 中的 sin/cos 编码,而是直接设置为可学习的 Positional Encoding。
MLP Head
得到输出后,ViT中使用了 MLP Head对输出进行分类处理,这里的 MLP Head 由 LayerNorm 和两层全连接层组成,并且采用了 GELU 激活函数。
参考链接:
- https://blog.csdn.net/qq_42735631/article/details/126709656?ops_request_misc=&request_id=&biz_id=102&utm_term=vision%20transformer%E6%A8%A1%E5%9E%8B&utm_medium=distribute.pc_search_result.none-task-blog-2allsobaiduweb~default-0-126709656.nonecase&spm=1018.2226.3001.4187
- https://blog.csdn.net/aixiaomi123/article/details/128025584?ops_request_misc=&request_id=&biz_id=102&utm_term=vision%20transformer%E6%A8%A1%E5%9E%8B&utm_medium=distribute.pc_search_result.none-task-blog-2allsobaiduweb~default-1-128025584.nonecase&spm=1018.2226.3001.4187
- https://github.com/google-research/vision_transformer/tree/main
- https://blog.csdn.net/lzzzzzzm/article/details/122963640?ops_request_misc=&request_id=&biz_id=102&utm_term=vit%20transformer%E4%B8%AD%E7%9A%84%E5%A4%9A%E5%A4%B4%E8%87%AA%E6%B3%A8%E6%84%8F%E5%8A%9B%E6%9C%BA%E5%88%B6&utm_medium=distribute.pc_search_result.none-task-blog-2allsobaiduweb~default-1-122963640.nonecase&spm=1018.2226.3001.4187
02&utm_term=vit%20transformer%E4%B8%AD%E7%9A%84%E5%A4%9A%E5%A4%B4%E8%87%AA%E6%B3%A8%E6%84%8F%E5%8A%9B%E6%9C%BA%E5%88%B6&utm_medium=distribute.pc_search_result.none-task-blog-2allsobaiduweb~default-1-122963640.nonecase&spm=1018.2226.3001.4187- https://blog.csdn.net/weixin_41803874/article/details/125729668
相关文章:
ViT-vision transformer
ViT-vision transformer 介绍 Transformer最早是在NLP领域提出的,受此启发,Google将其用于图像,并对分类流程作尽量少的修改。 起源:从机器翻译的角度来看,一个句子想要翻译好,必须考虑上下文的信息&…...

Election of the King 2023牛客暑期多校训练营4-F
登录—专业IT笔试面试备考平台_牛客网 题目大意:有一个n个数的数组a,有n-1轮操作,每轮由每个数选择一个和它的差最大的数,如果相同就选值更大的,被最多数组选择的数字被删去,有相同的也去掉数值更大的那个…...
Nacos的搭建及服务调用
文章目录 一、搭建Nacos服务1、Nacos2、安装Nacos3、Docker安装Nacos 二、OpenFeign和Dubbo远程调用Nacos的服务1、搭建SpringCloudAlibaba的开发环境1.1 构建微服务聚合父工程1.2 创建子模块cloud-provider-payment80011.3 创建子模块cloud-consumer-order80 2、远程服务调用O…...
uniapp小程序自定义loding,通过状态管理配置全局使用
一、在项目中创建loding组件 在uniapp的components文件夹下创建loding组件,如图: 示例代码: <template><view class"loginLoading"><image src"../../static/loading.gif" class"loading-img&q…...

leetcode 45. 跳跃游戏 II
2023.7.30 class Solution { public:int jump(vector<int>& nums) {int step 0;int cover 0;int largest 0;if(nums.size() 1) return step;for(int i0; i<nums.size(); i){cover max(cover , inums[i]); //最大覆盖范围if(cover > nums.size()-1) retur…...

力扣热门100题之矩阵置0【中等】
题目描述 给定一个 m x n 的矩阵,如果一个元素为 0 ,则将其所在行和列的所有元素都设为 0 。请使用 原地 算法。 示例 1: 输入:matrix [[1,1,1],[1,0,1],[1,1,1]] 输出:[[1,0,1],[0,0,0],[1,0,1]] 示例 2ÿ…...
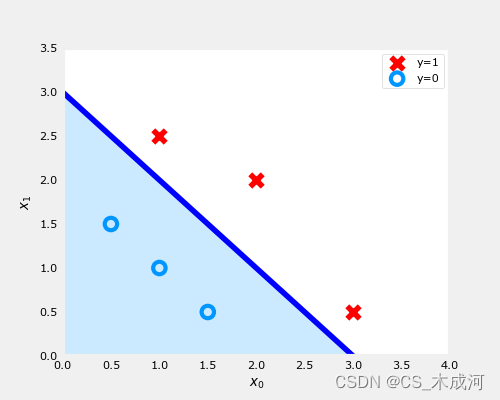
【机器学习】Classification using Logistic Regression
Classification using Logistic Regression 1. 分类问题2. 线性回归方法3. 逻辑函数(sigmod)4.逻辑回归5. 决策边界5.1 数据集5.2 数据绘图5.3 逻辑回归与决策边界的刷新5.4 绘制决策边界 导入所需的库 import numpy as np %matplotlib widget import m…...

全方位支持图文和音视频、100+增强功能,Facebook开源数据增强库AugLy
Facebook 近日开源了数据增强库 AugLy,包含四个子库,每个子库对应不同的模态,每个库遵循相同的接口。支持四种模态:文本、图像、音频和视频。 最近,Facebook 开源了一个新的 Python 库——AugLy,该库旨在帮…...
RxSwift 使用方式
背景 最近项目业务,所有模块已经支持Swift混编开发,正在逐步使用Swift 方式进行开发新业务,以及逐步替换老业务方式进行发展,所以使用一些较为成熟的Swift 的三方库,成为必要性,经过调研发现RxSwift 在使用…...

HTML5 Web Worker
HTML5 Web Worker是一种浏览器提供的JavaScript多线程解决方案,它允许在后台运行独立于页面主线程的脚本,从而避免阻塞页面的交互和渲染。Web Worker可以用于执行计算密集型任务、处理大量数据、实现并行计算等,从而提升前端应用的性能和响应…...

25.9 matlab里面的10中优化方法介绍—— 惩罚函数法求约束最优化问题(matlab程序)
1.简述 一、算法原理 1、问题引入 之前我们了解过的算法大部分都是无约束优化问题,其算法有:黄金分割法,牛顿法,拟牛顿法,共轭梯度法,单纯性法等。但在实际工程问题中,大多数优化问题都属于有约…...

django channels实战(websocket底层原理和案例)
1、websocket相关 1.1、轮询 1.2、长轮询 1.3、websocket 1.3.1、websocket原理 1.3.2、django框架 asgi.py在django项目同名app目录下 1.3.3、聊天室 django代码总结 小结 1.3.4、群聊(一) 前端代码 后端代码 1.3.5、群聊(二)…...
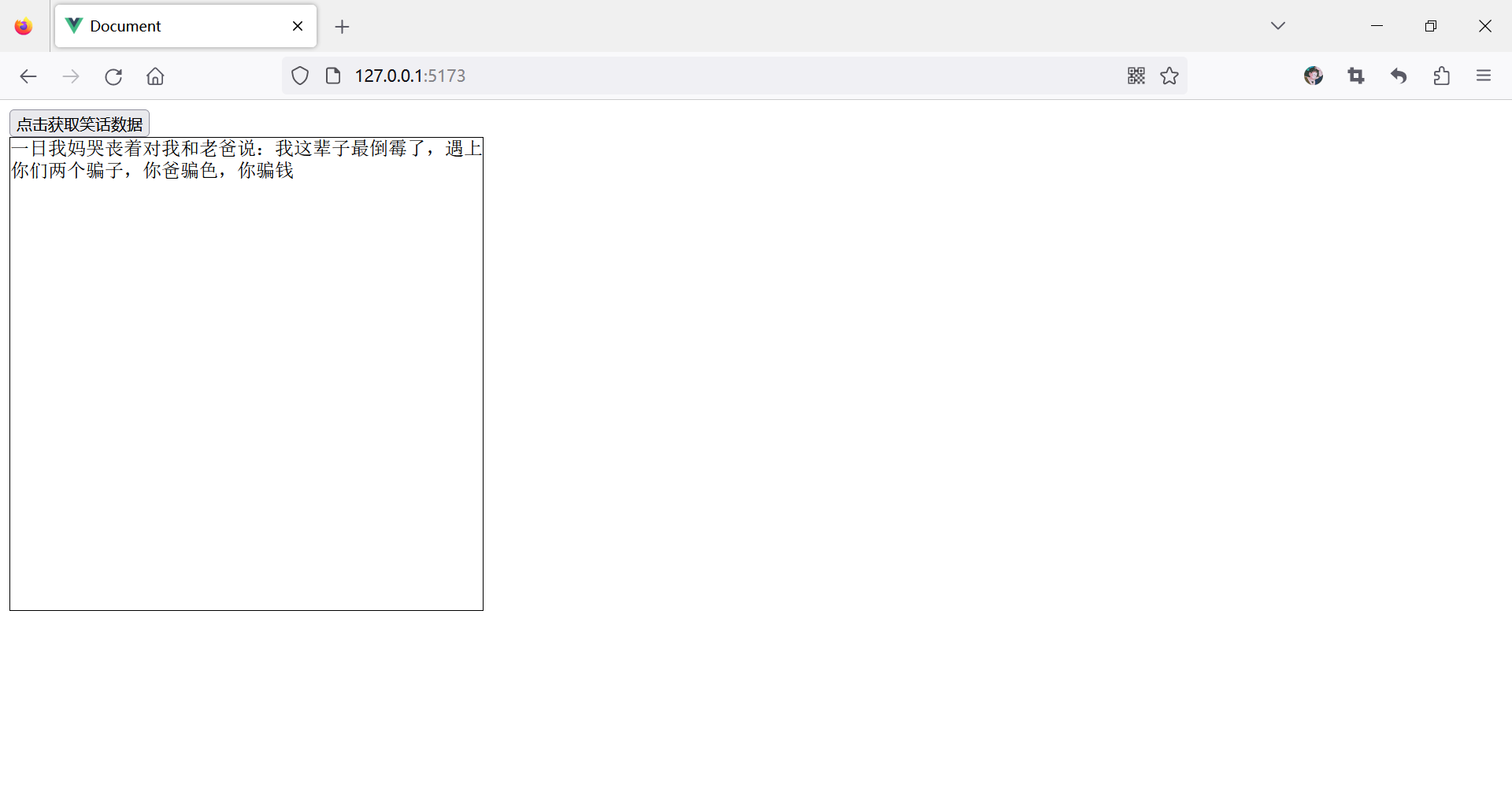
学习使用axios,绑定动态数据
目录 axios特性 案例一:通过axios获取笑话 案例二:调用城市天气api接口数据实现天气查询案例 axios特性 支持 Promise API 拦截请求和响应(可以在请求前及响应前做某些操作,例如,在请求前想要在这个请求头中加一些…...
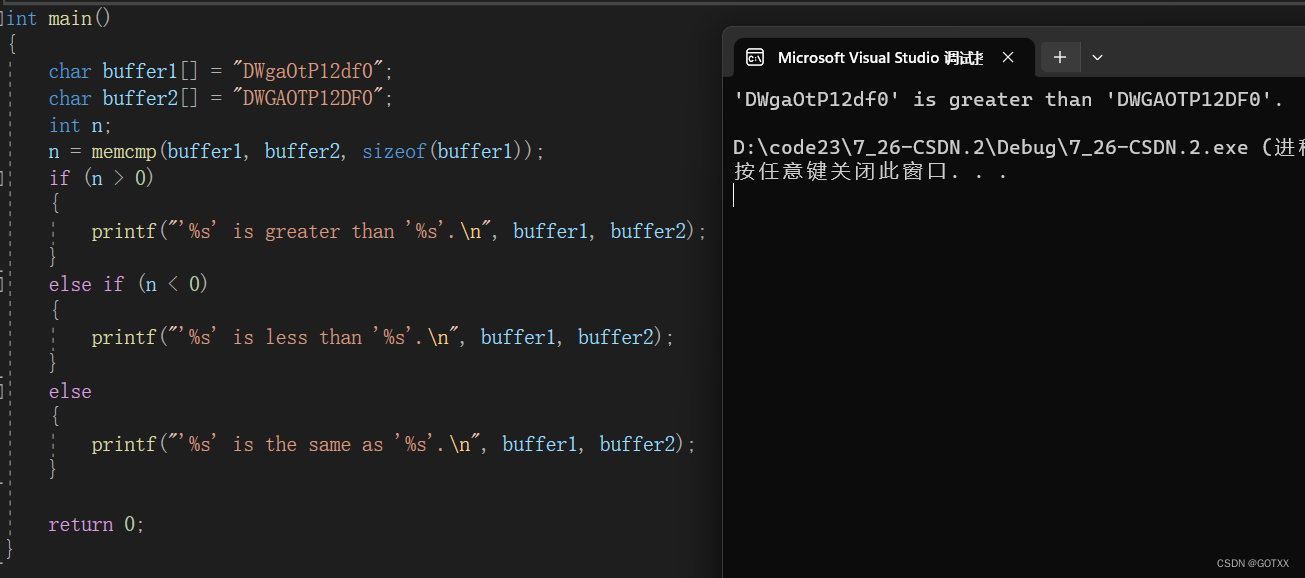
c语言内存函数的深度解析
本章对 memcpy,memmove,memcmp 三个函数进行详解和模拟实现; 本章重点:3个常见内存函数的使用方法及注意事项并学会模拟实现; 如果您觉得文章不错,期待你的一键三连哦,你的鼓励是我创作的动力…...

低代码平台介绍(国内常见的)
文章目录 前言1、阿里云宜搭2、腾讯云微搭3、百度爱速搭4、华为云Astro轻应用 Astro Zero(AppCube)5、字节飞书多维表格6、云程低代码平台7、ClickPaaS8、网易轻舟9、用友YonBuilder10、金蝶苍穹云平台11、泛微平台12、蓝凌低代码平台13、简道云14、轻流…...
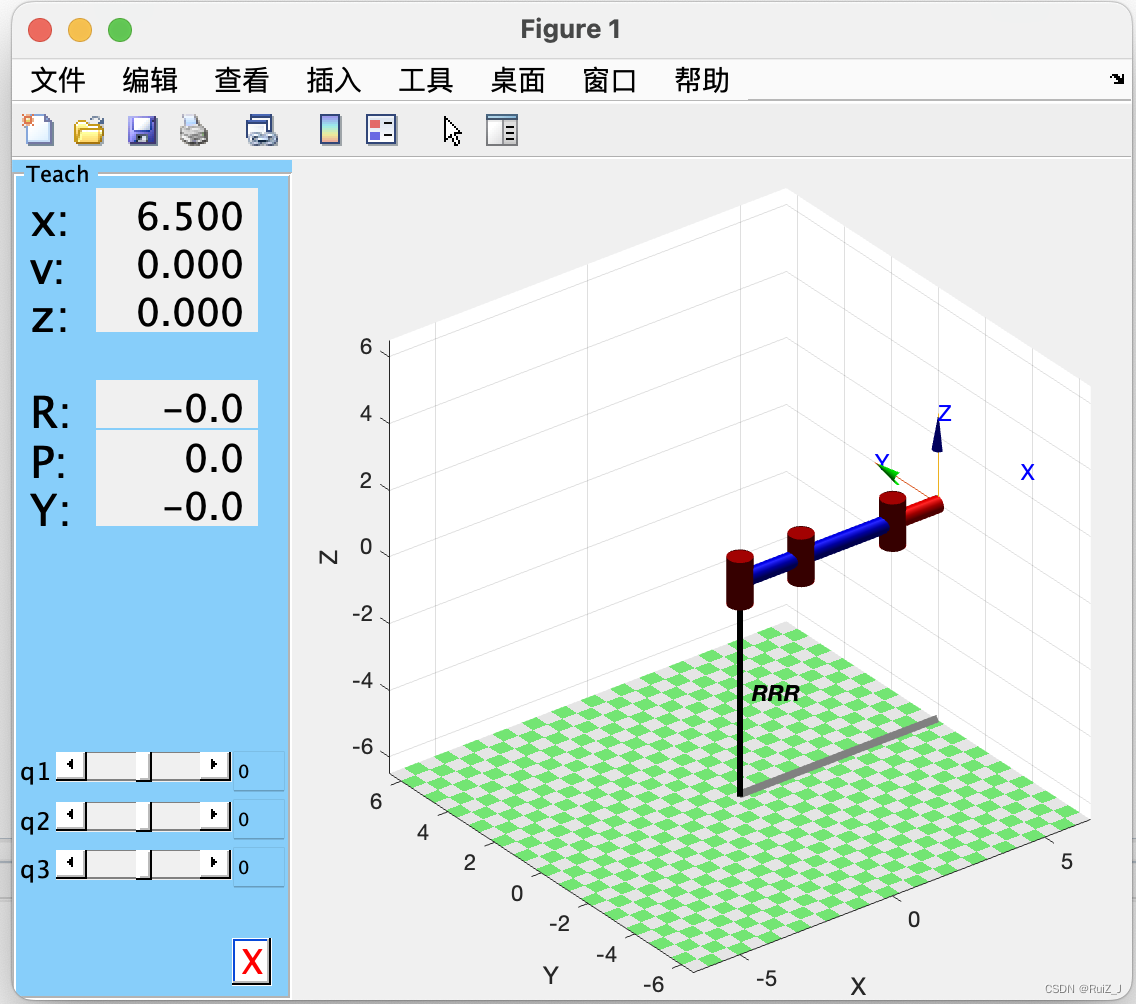
matlab RRR机械臂 简略代码
RRR机器人!启动! gazebo在arm mac上似乎难以运行,退而选择Matlab,完成老师第一个作业,现学现卖,权当记录作业过程,有不足之处,多多指教。 作业!启动! RRR机…...

集成测试,单元测试隔离 maven-surefire-plugin
详见 集成测试,单元测试隔离 maven-surefire-plugin maven的goal生命周期 Maven生存周期 - 含 integration-test Maven本身支持的命令(Goals)是有顺序的,越后面执行的命令,会将其前面的命令和其本身按顺序执行一遍,…...
渗透测试基础知识(1)
渗透基础知识一 一、Web架构1、了解Web2、Web技术架构3、Web客户端技术4、Web服务端组成5、动态网站工作过程6、后端存储 二、HTTP协议1、HTTP协议解析2、HTTP协议3、http1.1与http2.0的区别4、HTTP协议 三、HTTP请求1、发起HTTP请求2、HTTP响应与请求-HTTP请求3、HTTP响应与请…...

Android NDK开发
工程目录图 NDK中文官网 请点击下面工程名称,跳转到代码的仓库页面,将工程 下载下来 Demo Code 里有详细的注释 代码:TestNDK 参考文献 Android NDK 从入门到精通(汇总篇)Android JNI(一)——NDK与JNI基础Android之…...

使用python爬取淘宝商品信息
要使用Python爬取淘宝商品信息,您可以按照以下步骤: 安装必要的库 您需要安装Python的requests库和BeautifulSoup库。 要使用Python爬取淘宝商品信息,您可以按照以下步骤:安装必要的库 您需要安装Python的requests库和Beautifu…...

2026年最佳手机阅读器推荐:付费也值得的精品选择
在数字时代,阅读方式正在发生深刻变革。随着电子书、在线文章和多媒体内容的兴起,人们越来越倾向于通过智能手机进行阅读。然而,并非所有的阅读器都能提供优质的阅读体验。今天,我们将聚焦于一款即便付费也绝对物超所值的手机阅读…...

vue3+python基于Django的校园二手物品交易系统设计与实现49895951
目录同行可拿货,招校园代理 ,本人源头供货商项目背景技术栈核心功能模块关键实现细节扩展性设计参考开源项目项目技术支持源码获取详细视频演示 :同行可合作点击我获取源码->->进我个人主页-->获取博主联系方式同行可拿货,招校园代理 ,本人源头供货商 项目…...

Real-ESRGAN图像增强:3步掌握AI超分辨率魔法
Real-ESRGAN图像增强:3步掌握AI超分辨率魔法 【免费下载链接】Real-ESRGAN Real-ESRGAN aims at developing Practical Algorithms for General Image/Video Restoration. 项目地址: https://gitcode.com/gh_mirrors/re/Real-ESRGAN 你是否曾为模糊的老照片、…...
:用语义带宽、时序保真度与概念熵减重构AI训练评估)
认知通量(CT):用语义带宽、时序保真度与概念熵减重构AI训练评估
1. 项目概述:这不是又一个“大模型参数秀”,而是一次对AI认知边界的重新测绘“From 1T Tokens to Total Cognition: The Numbers Behind the New AI Brain…”——这个标题里没有一个生僻词,但组合在一起,却像一把钥匙,…...

GanttProject免费开源项目管理工具:简单高效的甘特图软件完全指南
GanttProject免费开源项目管理工具:简单高效的甘特图软件完全指南 【免费下载链接】ganttproject Official GanttProject repository. 项目地址: https://gitcode.com/gh_mirrors/ga/ganttproject GanttProject是一款功能强大的免费开源项目管理工具…...

网页端嵌入 Agent 对接前端方案
本文将深入探讨「网页端嵌入AI」的核心概念与实战技巧,帮助你快速掌握关键要点。让我们开始吧! 网页端嵌入 Agent 对接前端方案 1. 引言 当前前端项目正从被动展示走向主动交互,AI Agent 嵌入网页端可自动化 UI 操作、优化布局并辅助编码。…...

2026网盘横评:国民级云盘领衔,这几款备选也值得一看
前言作为长期接触AI资源、代码项目、大文件存储的从业者,日常高频使用各类网盘。很多朋友都会纠结主流网盘该如何选择,不同产品的存储能力、传输表现、功能适配差距明显。本文摒弃夸张测评,以客观分享的视角,从传输、存储、功能、…...

ElevenLabs支持闽南语吗?福建话语音合成实测:从API调用到音色克隆的7步通关手册
更多请点击: https://intelliparadigm.com 第一章:ElevenLabs福建话语音支持现状与能力边界 ElevenLabs 目前尚未在官方语音模型库中提供对福建话(含闽南语、闽东语等分支)的原生支持。其公开文档与 API 文档均未列出任何以“Fuj…...

PS 图片模糊修复教程:4 种方法,一键变高清
在日常设计、摄影后期、电商运营等场景中,模糊图片往往会严重影响观感与使用效果——无论是拍摄时的对焦失误、低分辨率素材的压缩失真,还是老照片的模糊褪色,都需要快速恢复清晰度。本文整理4种超实用的图片清晰化方法,涵盖PS原生…...

《CVPR2025-DEIM创新改进项目实战:从原理到部署的深度学习优化全攻略》018、DeepLab-DEIM与SegFormer-DEIM语义分割优化全记录
CVPR2025-DEIM创新改进项目实战:DeepLab-DEIM与SegFormer-DEIM语义分割优化全记录 一、从一次令人崩溃的显存溢出说起 上周三凌晨两点,我盯着屏幕上那个“CUDA out of memory”的红色报错,差点把咖啡泼到键盘上。当时正在跑一个DeepLabV3+的语义分割实验,输入尺寸不过是1…...