【NLP】一个使用PyTorch实现图像分类的迁移学习实例
一个使用PyTorch实现图像分类的迁移学习实例
- 1. 导入模块
- 2. 加载数据
- 3. 模型处理
- 4. 训练及验证模型
- 5. 微调
- 6. 其他代码
在特征提取中,可以在预先训练好的网络结构后修改或添加一个简单的分类器,然后将源任务上预先训练好的网络作为另一个目标任务的特征提取器,只对最后增加的分类器参数重新学习,而预先训练好的网络参数不被修改或冻结。
在完成新任务的特征提取时使用的是源任务中学习到的参数,而不用重新学习所有参数。下面的示例用一个实例具体说明如何通过特征提取的方法进行图像分类。
1. 导入模块
from datetime import datetimeimport matplotlib.pyplot as plt
import numpy as np
import torch
import torchvision
import torchvision.transforms as transforms
from torch import nn
from torchvision import models
2. 加载数据
这里需要事先将CIFAR10数据下载到本地,因为比较耗时,因此,将download=False。除此之外,还增加了一些预处理功能,比如数据标准化、对图片进行裁剪等。
def load_data(data, batch_size=64, num_workers=2, mean=None, std=None):if std is None:std = [0.229, 0.224, 0.225]if mean is None:mean = [0.485, 0.456, 0.406]trans_train = transforms.Compose([transforms.RandomResizedCrop(224), transforms.RandomHorizontalFlip(),transforms.ToTensor(), transforms.Normalize(mean=mean, std=std)])trans_valid = transforms.Compose([transforms.Resize(256), transforms.CenterCrop(224), transforms.ToTensor(),transforms.Normalize(mean=mean, std=std)])train_set = torchvision.datasets.CIFAR10(root=data, train=True, download=True, transform=trans_train)trainloader = torch.utils.data.DataLoader(train_set, batch_size=batch_size, shuffle=True, num_workers=num_workers)test_set = torchvision.datasets.CIFAR10(root=data, train=False, download=True, transform=trans_valid)testloader = torch.utils.data.DataLoader(test_set, batch_size=batch_size, shuffle=False, num_workers=num_workers)return trainloader, testloader
3. 模型处理
这个部分包含三个操作:
- 下载预训练模型:使用的预训练模型为resnet18,且已经在ImageNet大数据集上训练好了
- 冻结模型参数:使其在反向传播时,不会更新
- 修改最后一层的输出类别数:该数据集中有1000个类别,即原始输出为512×1000,现将其修改为512×10,因为这里使用的新数据集有10个类别
def freeze_net(num_class=10):# 下载预训练模型net = models.resnet18(pretrained=True)# 冻结模型参数for params in net.parameters():params.requires_grad = False# 修改最后一层的输出类别数net.fc = nn.Linear(512, num_class)# 查看冻结前后的参数情况total_params = sum(p.numel() for p in net.parameters())print(f'原总参数个数:{total_params}')total_trainable_params = sum(p.numel() for p in net.parameters() if p.requires_grad)print(f'需训练参数个数:{total_trainable_params}')return net
原总参数个数:11181642
需训练参数个数:5130
从输出上可知,如果不冻结,需要更新的参数太多了,冻结之后只需要更新全连接层的参数即可。
4. 训练及验证模型
这里选用交叉熵作为损失函数,使用SGD作为优化器,学习率为1e-3,权重衰减设为1e-3,代码如下:
# 训练及验证模型
def train(net, train_data, valid_data, num_epochs, optimizer, criterion):prev_time = datetime.now()for epoch in range(num_epochs):train_loss = 0train_acc = 0net = net.train()for im, label in train_data:im = im.to(device) # (bs, 3, h, w)label = label.to(device) # (bs, h, w)# forwardoutput = net(im)loss = criterion(output, label)# backwardoptimizer.zero_grad()loss.backward()optimizer.step()train_loss += loss.item()train_acc += get_acc(output, label)cur_time = datetime.now()h, remainder = divmod((cur_time - prev_time).seconds, 3600)m, s = divmod(remainder, 60)time_str = "Time %02d:%02d:%02d" % (h, m, s)if valid_data is not None:valid_loss = 0valid_acc = 0net = net.eval()for im, label in valid_data:im = im.to(device) # (bs, 3, h, w)label = label.to(device) # (bs, h, w)output = net(im)loss = criterion(output, label)valid_loss += loss.item()valid_acc += get_acc(output, label)epoch_str = ("Epoch %d. Train Loss: %f, Train Acc: %f, Valid Loss: %f, Valid Acc: %f, "% (epoch, train_loss / len(train_data),train_acc / len(train_data), valid_loss / len(valid_data),valid_acc / len(valid_data)))else:epoch_str = ("Epoch %d. Train Loss: %f, Train Acc: %f, " %(epoch, train_loss / len(train_data),train_acc / len(train_data)))prev_time = cur_timeprint(epoch_str + time_str)
运行结果:
Epoch 0. Train Loss: 1.474121, Train Acc: 0.498322, Valid Loss: 0.901339, Valid Acc: 0.713177, Time 00:03:26
Epoch 1. Train Loss: 1.222752, Train Acc: 0.576946, Valid Loss: 0.818926, Valid Acc: 0.730494, Time 00:04:35
Epoch 2. Train Loss: 1.172832, Train Acc: 0.592651, Valid Loss: 0.777265, Valid Acc: 0.737759, Time 00:04:23
Epoch 3. Train Loss: 1.158157, Train Acc: 0.596228, Valid Loss: 0.761969, Valid Acc: 0.746517, Time 00:04:28
Epoch 4. Train Loss: 1.143113, Train Acc: 0.600643, Valid Loss: 0.757134, Valid Acc: 0.742138, Time 00:04:24
Epoch 5. Train Loss: 1.128991, Train Acc: 0.607797, Valid Loss: 0.745840, Valid Acc: 0.747014, Time 00:04:24
Epoch 6. Train Loss: 1.131602, Train Acc: 0.603561, Valid Loss: 0.740176, Valid Acc: 0.748109, Time 00:04:21
Epoch 7. Train Loss: 1.127840, Train Acc: 0.608336, Valid Loss: 0.738235, Valid Acc: 0.751990, Time 00:04:19
Epoch 8. Train Loss: 1.122831, Train Acc: 0.609275, Valid Loss: 0.730571, Valid Acc: 0.751692, Time 00:04:18
Epoch 9. Train Loss: 1.118955, Train Acc: 0.609715, Valid Loss: 0.731084, Valid Acc: 0.751692, Time 00:04:13
Epoch 10. Train Loss: 1.111291, Train Acc: 0.612052, Valid Loss: 0.728281, Valid Acc: 0.749602, Time 00:04:09
Epoch 11. Train Loss: 1.108454, Train Acc: 0.612712, Valid Loss: 0.719465, Valid Acc: 0.752787, Time 00:04:15
Epoch 12. Train Loss: 1.111189, Train Acc: 0.612012, Valid Loss: 0.726525, Valid Acc: 0.751294, Time 00:04:09
Epoch 13. Train Loss: 1.114475, Train Acc: 0.610594, Valid Loss: 0.717852, Valid Acc: 0.754080, Time 00:04:06
Epoch 14. Train Loss: 1.112658, Train Acc: 0.608596, Valid Loss: 0.723336, Valid Acc: 0.751393, Time 00:04:14
Epoch 15. Train Loss: 1.109367, Train Acc: 0.614950, Valid Loss: 0.721230, Valid Acc: 0.752588, Time 00:04:06
Epoch 16. Train Loss: 1.107644, Train Acc: 0.614230, Valid Loss: 0.711586, Valid Acc: 0.755275, Time 00:04:08
Epoch 17. Train Loss: 1.100239, Train Acc: 0.613411, Valid Loss: 0.722191, Valid Acc: 0.749303, Time 00:04:11
Epoch 18. Train Loss: 1.108576, Train Acc: 0.611013, Valid Loss: 0.721263, Valid Acc: 0.753483, Time 00:04:08
Epoch 19. Train Loss: 1.098069, Train Acc: 0.618027, Valid Loss: 0.705413, Valid Acc: 0.757962, Time 00:04:06
从结果上看,验证集的准确率达到75%左右。下面采用微调+数据增强的方法继续提升准确率。
5. 微调
微调允许修改预训练好的网络参数来学习目标任务,所以训练时间要比特征抽取方法长,但精度更高。微调的大致过程是再预训练的网络上添加新的随机初始化层,此外预训练的网络参数也会被更新,但会使用较小的学习率以防止预训练好的参数发生较大改变。
常用的方法是固定底层的参数,调整一些顶层或具体层的参数。这样可以减少训练参数的数量,也可以避免过拟合的发生。尤其是针对目标任务的数据量不够大的时候,该方法会很有效。
实际上,微调优于特征提取,因为它能对迁移过来的预训练网络参数进行优化,使其更加适合新的任务。
(1)数据预处理
对训练数据添加了几种数据增强方法,比如图片裁剪、旋转、颜色改变等方法。测试数据与特征提取的方法一样。
if fine_tuning is False:trans_train = transforms.Compose([transforms.RandomResizedCrop(224),transforms.RandomHorizontalFlip(),transforms.ToTensor(),transforms.Normalize(mean=mean, std=std)])else:trans_train = transforms.Compose([transforms.RandomResizedCrop(size=256, scale=(0.8, 1.0)),transforms.RandomRotation(degrees=15),transforms.ColorJitter(),transforms.RandomResizedCrop(224),transforms.RandomHorizontalFlip(),transforms.ToTensor(),transforms.Normalize(mean=mean, std=std)])
(2)修改模型的分类器层
修改最后全连接层,把类别数由原来的1000改为10。
def freeze_net(num_class=10, fine_tuning=False):# 下载预训练模型net = models.resnet18(pretrained=True)print(net)if fine_tuning is False:# 冻结模型参数for params in net.parameters():params.requires_grad = False# 修改最后一层的输出类别数net.fc = nn.Linear(512, num_class)# 查看冻结前后的参数情况total_params = sum(p.numel() for p in net.parameters())print(f'原总参数个数:{total_params}')total_trainable_params = sum(p.numel() for p in net.parameters() if p.requires_grad)print(f'需训练参数个数:{total_trainable_params}')# 打印出第一层的权重print(f'第一层的权重:{net.conv1.weight.type()}')return net
训练结果:
Epoch 0. Train Loss: 1.455535, Train Acc: 0.488460, Valid Loss: 0.832547, Valid Acc: 0.721400, Time 00:14:48
Epoch 1. Train Loss: 1.342625, Train Acc: 0.530280, Valid Loss: 0.815430, Valid Acc: 0.723500, Time 10:31:48
Epoch 2. Train Loss: 1.319122, Train Acc: 0.535680, Valid Loss: 0.866512, Valid Acc: 0.699000, Time 00:12:02
Epoch 3. Train Loss: 1.310949, Train Acc: 0.541700, Valid Loss: 0.789511, Valid Acc: 0.728000, Time 00:12:03
Epoch 4. Train Loss: 1.313486, Train Acc: 0.538500, Valid Loss: 0.762553, Valid Acc: 0.741300, Time 00:12:19
Epoch 5. Train Loss: 1.309776, Train Acc: 0.540680, Valid Loss: 0.777906, Valid Acc: 0.736100, Time 00:11:43
Epoch 6. Train Loss: 1.302117, Train Acc: 0.541780, Valid Loss: 0.779318, Valid Acc: 0.737200, Time 00:12:00
Epoch 7. Train Loss: 1.304539, Train Acc: 0.544320, Valid Loss: 0.795917, Valid Acc: 0.726500, Time 00:13:16
Epoch 8. Train Loss: 1.311748, Train Acc: 0.542400, Valid Loss: 0.785983, Valid Acc: 0.728000, Time 00:14:48
Epoch 9. Train Loss: 1.302069, Train Acc: 0.544820, Valid Loss: 0.781665, Valid Acc: 0.734700, Time 00:14:15
Epoch 10. Train Loss: 1.298019, Train Acc: 0.547040, Valid Loss: 0.771555, Valid Acc: 0.742200, Time 00:16:11
Epoch 11. Train Loss: 1.310127, Train Acc: 0.538700, Valid Loss: 0.764313, Valid Acc: 0.739300, Time 00:17:33
Epoch 12. Train Loss: 1.300172, Train Acc: 0.544720, Valid Loss: 0.765881, Valid Acc: 0.734200, Time 00:12:04
Epoch 13. Train Loss: 1.289607, Train Acc: 0.546980, Valid Loss: 0.753371, Valid Acc: 0.742500, Time 00:11:49
Epoch 14. Train Loss: 1.295938, Train Acc: 0.546280, Valid Loss: 0.821099, Valid Acc: 0.721900, Time 00:11:43
…
使用微调训练方式的时间明显大于使用特征提取方式的时间,但是验证集上的准确率并没有提高,这是因为由于GPU内存限制,这里将batch_size设为了16。
6. 其他代码
if __name__ == '__main__':data_path = './data'classes = ('plane', 'car', 'bird', 'cat', 'deer', 'dog', 'forg', 'horse', 'ship', 'truck')if torch.cuda.is_available():device = torch.device('cuda:0')torch.cuda.empty_cache()else:device = torch.device('cpu')# 加载数据train_loader, test_loader = load_data(data=data_path, fine_tuning=True)# 随机获取部分训练数据data_iter = iter(train_loader)images, labels = data_iter.next()# 显示图像imshow(torchvision.utils.make_grid(images[:4]))# 打印标签print(' '.join('%5s' % classes[labels[j]] for j in range(4)))# 加载模型net = freeze_net(num_class=len(classes), fine_tuning=True)net = net.to(device)# 定义损失函数及优化器criterion = nn.CrossEntropyLoss()# 只需要优化最后一层参数optimizer = torch.optim.SGD(net.fc.parameters(), lr=1e-3, weight_decay=1e-3, momentum=0.9)# 训练及验证模型train(net, train_loader, test_loader, 20, optimizer, criterion)
相关文章:

【NLP】一个使用PyTorch实现图像分类的迁移学习实例
一个使用PyTorch实现图像分类的迁移学习实例 1. 导入模块2. 加载数据3. 模型处理4. 训练及验证模型5. 微调6. 其他代码 在特征提取中,可以在预先训练好的网络结构后修改或添加一个简单的分类器,然后将源任务上预先训练好的网络作为另一个目标任务的特征提…...
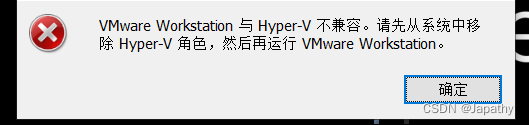
【wsl-windows子系统】安装、启用、禁用以及同时支持docker-desktop和vmware方案
如果你要用docker桌面版,很可能会用到wsl,如果没配置好,很可能wsl镜像会占用C盘很多空间。 前提用管理员身份执行 wsl-windows子系统安装和启用 pushd "%~dp0" dir /b %SystemRoot%\servicing\Packages\*Hyper-V*.mum >hyper…...

使用docker部署springboot微服务项目
文章目录 1. 环境准备1. 准备好所用jar包项目2.编写相应的Dockerfile文件3.构建镜像4. 运行镜像5. 测试服务是否OK6.端口说明7.进入容器内8. 操作容器的常用命令 1. 环境准备 检查docker是否已安装 [rootlocalhost /]# docker -v Docker version 1.13.1, build 7d71120/1.13.…...
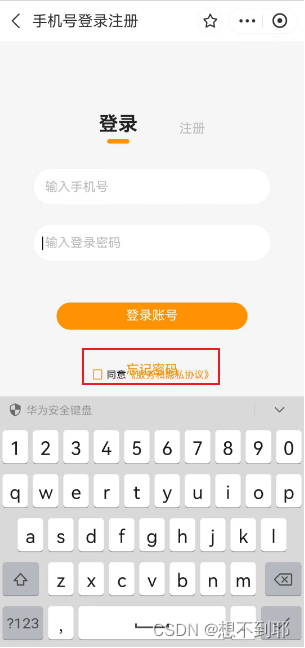
uniapp兼容微信小程序和支付宝小程序遇到的坑
1、支付宝不支持v-show 改为v-if。 2、v-html App端和H5端支持 v-html ,微信小程序会被转为 rich-text,其他端不支持 v-html。 解决方法:去插件市场找一个支持跨端的富文本组件。 3、导航栏处有背景色延伸至导航栏外 兼容微信小程序和支…...
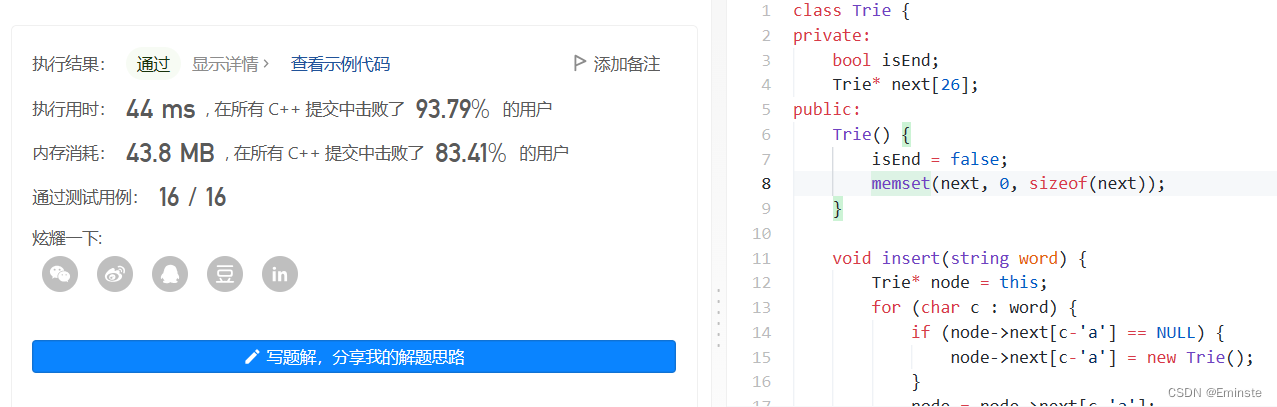
LeetCode208.Implement-Trie-Prefix-Tree<实现 Trie (前缀树)>
题目: 思路: tire树,学过,模板题。一种数据结构与算法的结合吧。 代码是: //codeclass Trie { private:bool isEnd;Trie* next[26]; public:Trie() {isEnd false;memset(next, 0, sizeof(next));}void insert(strin…...

第1章 JavaScript简史
JavaScript的起源 JavaScript是Netscape公司与Sun公司合作开发的在JavaScript诞生之前游览器就是显示超文本文档的简单的软件,JavaScript为此增加了交互行为ECMAScript是JavaScript的标准化,本质上是同一个语言JavaScript是一门脚本语言通常只能运行在游…...

DevOps-GitHub/GitLab
DevOps-GitHub/GitLab GitHub是一个开源代码托管平台。基于web的Git仓库,提供共有仓库和私有仓库(私有仓库收费)。 GitLab可以创建免费私有仓库。 GitHub 为了快速操作,这里对创建仓库以及注册不做说明。 首先再GitHub上创建一…...
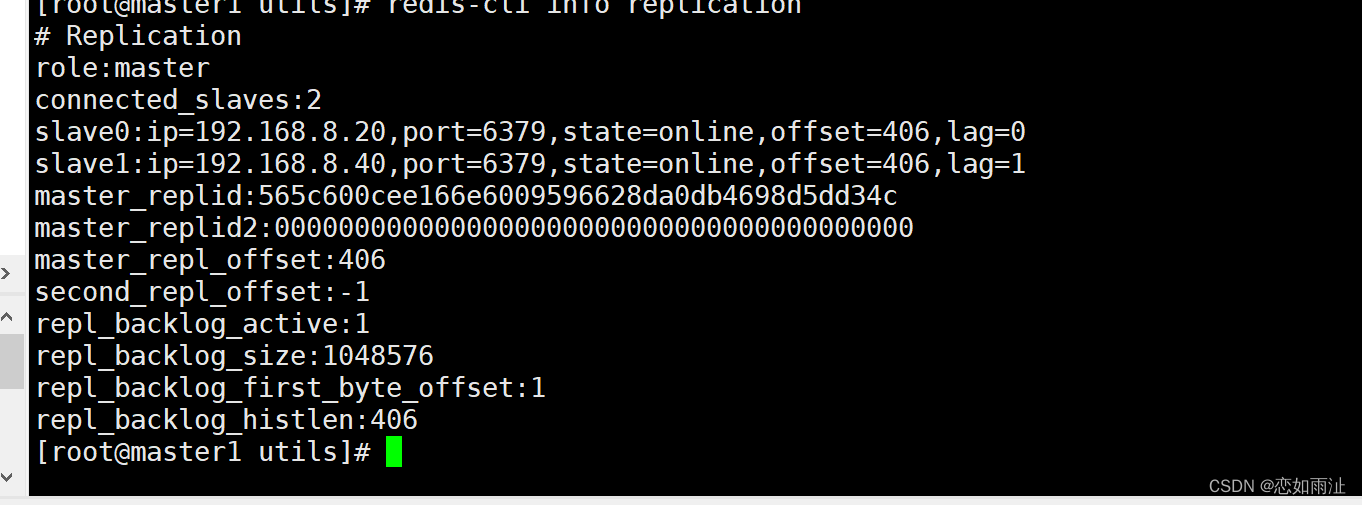
redis群集(主从复制)
---------------------- Redis 主从复制 ---------------------------------------- 主从复制,是指将一台Redis服务器的数据,复制到其他的Redis服务器。前者称为主节点(Master),后者称为从节点(Slave);数据的复制是单向的…...
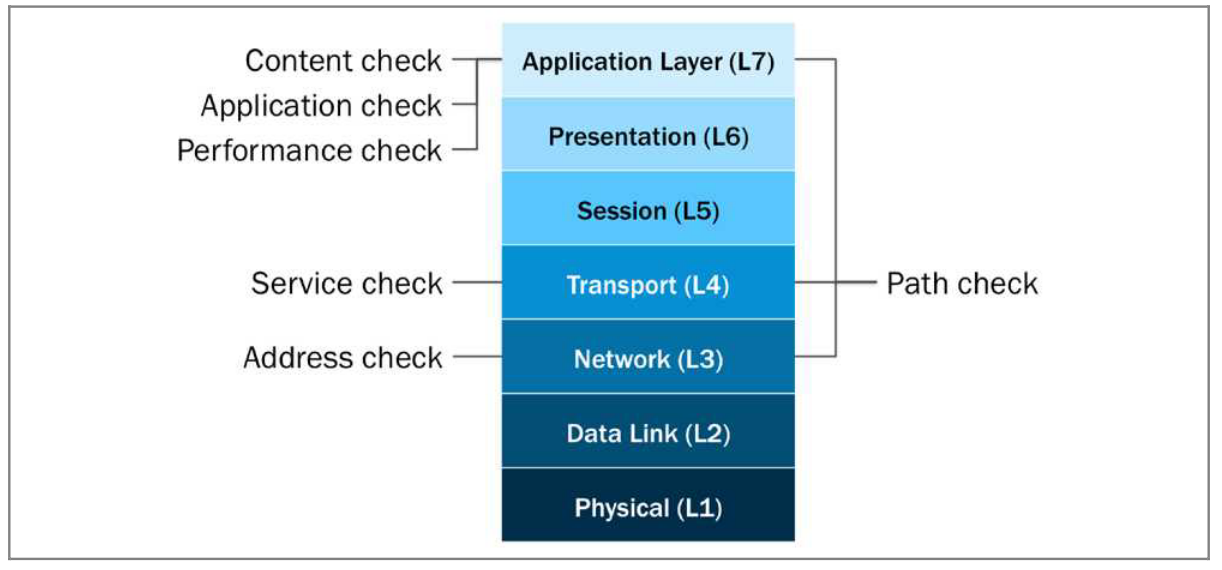
F5 LTM 知识点和实验 5-健康检测
第五章:健康检测 监控的分类: 地址监控(3层)服务监控(4层)内容监控(7层)应用监控(7层)性能监控(7层)路径监控(3、4、7层)三层监控: 三层监控可以帮助bipip系统通过检查网络是否可达监视资源。比如使用icmp echo,向监控节点发送icmp_echo报文,如果接收到响应…...

❤️创意网页:能量棒页面 - 可爱版(加载进度条)
✨博主:命运之光 🌸专栏:Python星辰秘典 🐳专栏:web开发(简单好用又好看) ❤️专栏:Java经典程序设计 ☀️博主的其他文章:点击进入博主的主页 前言:欢迎踏入…...
)
C语言中的操作符(万字详解)
C语言中的操作符(万字详解) 一、算术操作符()1.除号 /2.取余 %二、移位操作符1.原码2.反码3.补码4.左移操作符5.右移操作符三、位操作符1.按位与操作符:&2.按位或操作符:|3.按位异或操作符:…...
Panda 编译时原子化 CSS-in-JS 框架的跨平台方案
Panda 编译时原子化 CSS-in-JS 框架的跨平台方案 Panda 编译时原子化 CSS-in-JS 框架的跨平台方案 对编译时原子化CSS框架的思考编译时 CSS-in-JS 方案对比 LinariaPandacss总结 weapp-pandacss 介绍快速开始 pandacss 安装和配置 0. 安装和初始化 pandacss1. 配置 postcss2. …...

【图论】BFS中的最短路模型
算法提高课笔记 目录 迷宫问题题意思路代码 武士风度的牛题意思路代码 抓住那头牛题意思路代码 BFS可以解决边权为1的最短路问题,下面是三道相关例题 迷宫问题 原题链接 给定一个 nn 的二维数组,如下所示: int maze[5][5] {0, 1, 0, 0, …...
Linux Mint 21.2 ISO 镜像开放下载
导读Linux Mint 21.2 ISO 镜像于 2023 年 6 月 21 日公测,开发者在这段时间内收集并修复了用户反馈的诸多问题。 代号为“Victoria”的 Linux Mint 21.2 ISO 镜像于今天正式开放下载,新版本基于 Ubuntu 22.04 LTS,提供 Cinnamon 5.8、Xfce 4.…...
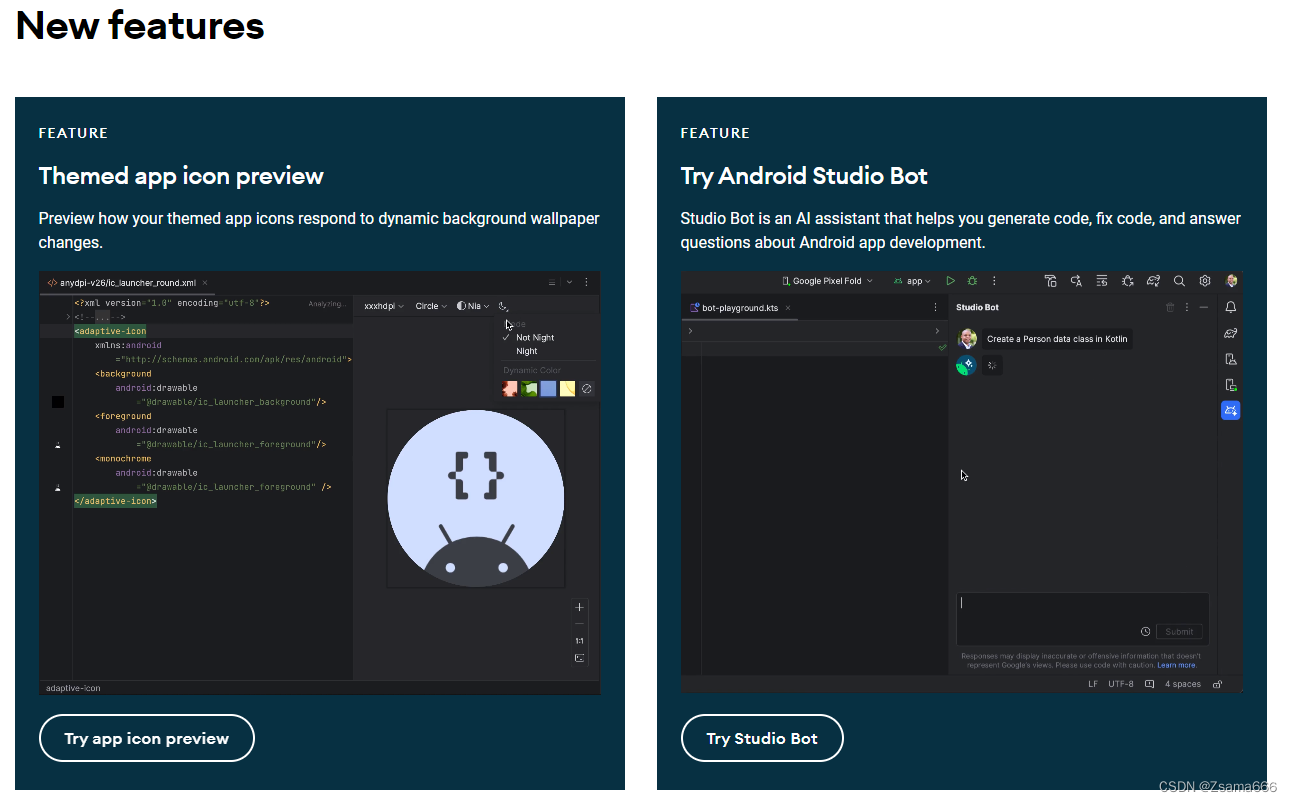
版本适配好帮手 Android SDK Upgrade Assistant / Android Studio Giraffe新功能
首先是新版本一顿下载↓: Download Android Studio & App Tools - Android Developers 在Tools中找到Android SDK Upgrade Assistant 可以在此直接查看SDK升级相关信息,不用跑到WEB端去查看了。 例如看一下之前经常要对老项目维护的android 12蓝牙…...
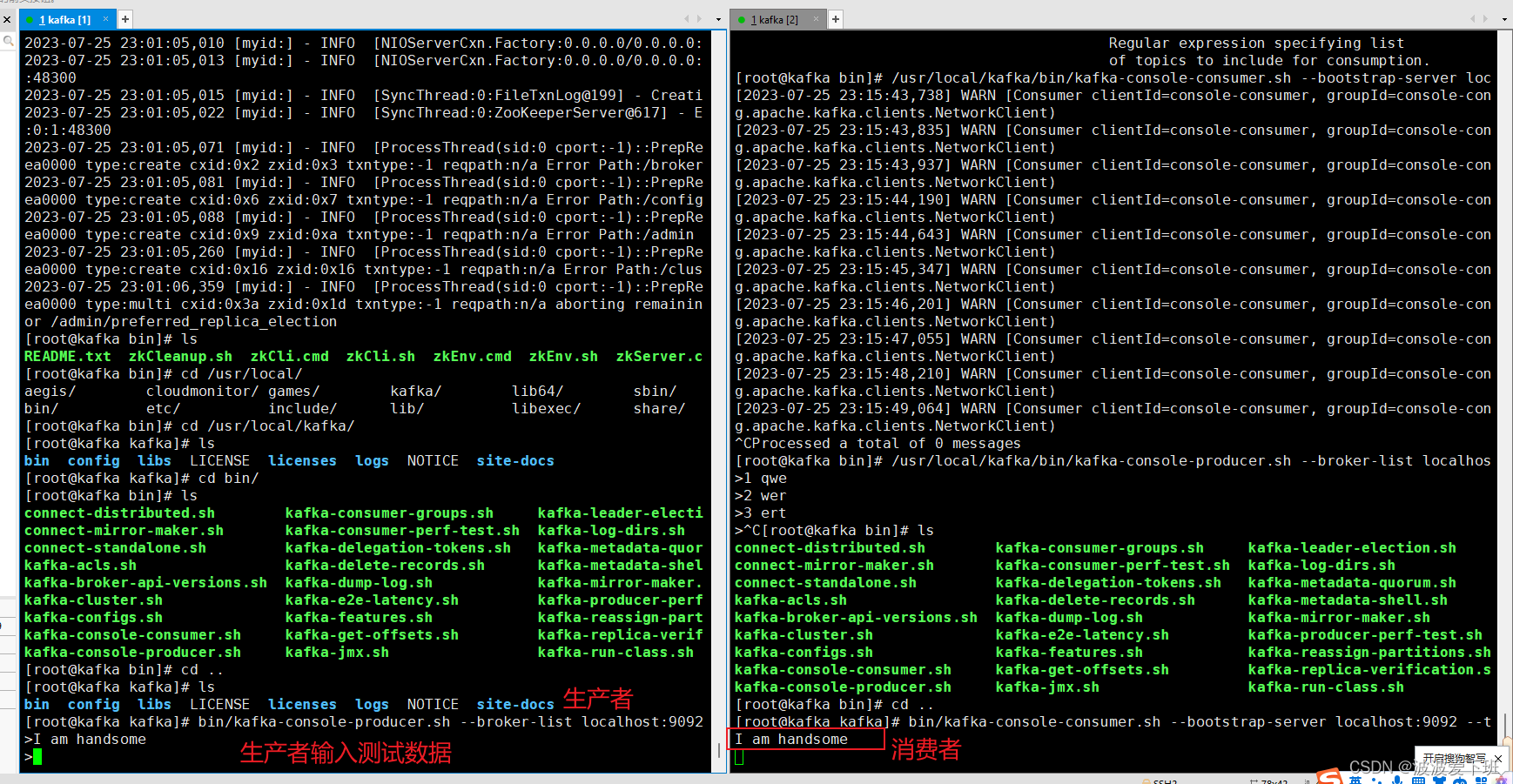
kafka权威指南学习以及kafka生产配置
0、kafka常用命令 Kafka是一个分布式流处理平台,它具有高度可扩展性和容错性。以下是Kafka最新版本中常用的一些命令: 创建一个主题(topic): bin/kafka-topics.sh --create --topic my-topic --partitions 3 --replic…...

自由行的一些小tips
很多很多年前,写过一些关于自由行的小攻略,关于互联网时代的自助旅游,说起来八年了,很多信息可能过期了。 前几天准备回坡,因为自己比较抠门,发现目前大陆回新加坡的机票比较贵(接近4000人民币&…...

uiautomatorViewer无法获取Android8.0手机屏幕截图的解决方案
问题描述: 做APP UI自动化的时候,会碰到用uiautomatorViewer在Android 8.0及以上版本的手机上,无法获取到手机屏幕截图,无法获取元素定位信息的问题,会有以下的报 在低版本的Android手机上,则没有这个问题…...
)
使用LangChain构建问答聊天机器人案例实战(三)
使用LangChain构建问答聊天机器人案例实战 LangChain开发全流程剖析 接下来,我们再回到“get_prompt()”方法。在这个方法中,有系统提示词(system prompts)和用户提示词(user prompts),这是从相应的文件中读取的,从“system.prompt”文件中读取系统提示词(system_tem…...
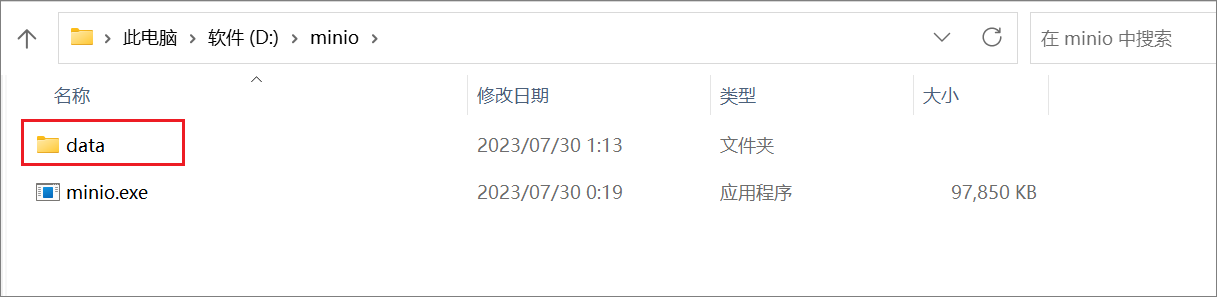
在windows上安装minio
1、下载windows版的minio: https://dl.min.io/server/minio/release/windows-amd64/minio.exe 2、在指定位置创建一个名为minio文件夹,然后再把下载好的文件丢进去: 3、右键打开命令行窗口,然后执行如下命令:(在minio.…...

JWT密钥轮换缺陷与零停机热修复实战指南
1. 这不是一次普通升级,而是一次密钥信任体系的临界点崩塌Seedance2.0 v2.0.3发布不到72小时,我在给客户做例行安全巡检时,发现一个反直觉的现象:所有新签发的JWT令牌在旧版本客户端(v2.0.2)上验证失败&…...

C++的内存管理详细解释
一、C/C内存分布栈又叫堆栈,非静态局部变量/函数参数/返回值等等,栈是向下增长的。内存映射段是高效的I/O映射方式,用于装载一个共享的动态内存库。用户可使用系统接口创建共享共享内存,做进程间通信。堆用于程序运行时动态内存分…...

ESXi 7.0升8.0后VM启动失败?硬件版本降级就搞定
很多运维人员将ESXi 7.0成功升级到8.0后,会遇到一个棘手问题:原有虚拟机(VM)无法启动,弹出错误提示“incompatible hardware version”(不兼容的硬件版本)。其实故障核心原因很明确:…...

终极指南:WinDiskWriter - 简单快速制作Windows启动盘的Mac神器
终极指南:WinDiskWriter - 简单快速制作Windows启动盘的Mac神器 【免费下载链接】windiskwriter 🖥 Windows Bootable USB creator for macOS. 🛠 Patches Windows 11 to bypass TPM and Secure Boot requirements. 👾 UEFI &…...

TV Bro:解锁智能电视上网的终极遥控器浏览器方案
TV Bro:解锁智能电视上网的终极遥控器浏览器方案 【免费下载链接】tv-bro Simple web browser for android optimized to use with TV remote 项目地址: https://gitcode.com/gh_mirrors/tv/tv-bro 想象一下,坐在舒适的沙发上,手握电视…...

PeaZip:完全免费的跨平台压缩软件,支持200+格式的终极解决方案
PeaZip:完全免费的跨平台压缩软件,支持200格式的终极解决方案 【免费下载链接】PeaZip Free Zip / Unzip software and Rar file extractor. Cross-platform file and archive manager. Features volume spanning, compression, authenticated encryptio…...

如何在Linux上安装Realtek R8125 2.5GbE网卡驱动:完整指南
如何在Linux上安装Realtek R8125 2.5GbE网卡驱动:完整指南 【免费下载链接】realtek-r8125-dkms A DKMS package for easy use of Realtek r8125 driver, which supports 2.5 GbE. 项目地址: https://gitcode.com/gh_mirrors/re/realtek-r8125-dkms 你是否正…...

UWB传统厘米级定位 VS 镜像视界AI无感定位|大模型融合视频孪生全面重塑全域空间感知
UWB传统厘米级定位 VS 镜像视界AI无感定位|大模型融合视频孪生全面重塑全域空间感知在全域空间高精度感知产业高速迭代进程中,室内外人员与目标定位技术逐步分化为两大主流发展路径,其一为深耕多年、依托硬件组网实现测距定位的传统UWB厘米级…...

LiveSplit终极指南:为速度跑者量身定制的精准计时神器
LiveSplit终极指南:为速度跑者量身定制的精准计时神器 【免费下载链接】LiveSplit A sleek, highly customizable timer for speedrunners. 项目地址: https://gitcode.com/gh_mirrors/li/LiveSplit LiveSplit是一款专为速度跑者打造的轻量级、高度可定制的计…...

Steam Deck Tools 终极指南:Windows 掌机的完美伴侣
Steam Deck Tools 终极指南:Windows 掌机的完美伴侣 【免费下载链接】steam-deck-tools (Windows) Steam Deck Tools - Fan, Overlay, Power Control and Steam Controller for Windows 项目地址: https://gitcode.com/gh_mirrors/st/steam-deck-tools 还在为…...