kafka权威指南学习以及kafka生产配置
0、kafka常用命令
Kafka是一个分布式流处理平台,它具有高度可扩展性和容错性。以下是Kafka最新版本中常用的一些命令:
-
创建一个主题(topic):
bin/kafka-topics.sh --create --topic my-topic --partitions 3 --replication-factor 3 --bootstrap-server localhost:9092 -
查看主题列表:
bin/kafka-topics.sh --list --bootstrap-server localhost:9092 -
查看主题的详细信息:
bin/kafka-topics.sh --describe --topic my-topic --bootstrap-server localhost:9092 -
发送消息到主题:
bin/kafka-console-producer.sh --topic my-topic --bootstrap-server localhost:9092 -
从主题消费消息:
bin/kafka-console-consumer.sh --topic my-topic --from-beginning --bootstrap-server localhost:9092 -
查看消费者组的偏移量(offset):
bin/kafka-consumer-groups.sh --describe --group my-group --bootstrap-server localhost:9092 -
启动Kafka服务:
bin/kafka-server-start.sh config/server.properties
1.kafka最佳配置
有几个节点写几个节点
vim /srv/app/kafka/config/server.properties
记得改broker.id
broker.id=0
listeners=PLAINTEXT://10.53.32.126:9092
advertised.listeners=PLAINTEXT://10.53.32.126:9092
num.network.threads=3
num.io.threads=8
socket.send.buffer.bytes=102400
socket.receive.buffer.bytes=102400
socket.request.max.bytes=104857600
log.dirs=/srv/data/kafka-data
num.partitions=3
num.recovery.threads.per.data.dir=3
offsets.topic.replication.factor=3
transaction.state.log.replication.factor=3
transaction.state.log.min.isr=3
log.retention.hours=4
log.segment.bytes=1073741824
log.retention.check.interval.ms=300000
zookeeper.connection.timeout.ms=6000
zookeeper.connect=10.53.32.126:2181,10.53.32.153:2181,10.53.32.134:2181
group.initial.rebalance.delay.ms=0
default.replication.factor=22zookeeper最佳配置
有几个节点写几个节点
vim conf/zoo.cfg
tickTime=2000
initLimit=10
syncLimit=5
dataDir=/srv/data/zookeeper-data
dataLogDir=/srv/data/zookeeper-datalog
clientPort=2181
autopurge.snapRetainCount=10
autopurge.purgeInterval=1
maxClientCnxns=1200
leaderServes=yes
minSessionTimeout=4000
maxSessionTimeout=40000
server.1=10.53.32.126:2888:3888
server.2=10.53.32.153:2888:3888
server.3=10.53.32.134:2888:3888
## Metrics Providers
# https://prometheus.io Metrics Exporter
metricsProvider.className=org.apache.zookeeper.metrics.prometheus.PrometheusMetricsProvider
metricsProvider.httpPort=7000
metricsProvider.exportJvmInfo=true一、如果是zk单节点
- 下载并启动zk http://bit.ly/2sDWSgJ。 单机服务 下⾯的例⼦演⽰了如何使⽤基本的配置安装 Zookeeper,安装⽬录为 /usr/local/zookeeper, 数据⽬录为 /var/lib/zookeeper。
- 启动zk
-
# tar -zxf zookeeper-3.4.6.tar.gz # mv zookeeper-3.4.6 /usr/local/zookeeper # mkdir -p /var/lib/zookeeper # cat > /usr/local/zookeeper/conf/zoo.cfg << EOF tickTime=2000 dataDir=/var/lib/zookeeper clientPort=2181 > EOF # export JAVA_HOME=/usr/java/jdk1.8.0_51 # /usr/local/zookeeper/bin/zkServer.sh start JMX enabled by default Using config: /usr/local/zookeeper/bin/../conf/zoo.cfg Starting zookeeper ... STARTED - 确认2181端口开启
telnet localhost 2181ss -luntp|grep 2181二、如果是zk集群
一般选择3或者5个基数节点
修改群组配置文件,增加my.id文件和配置项
vim /usr/local/zookeeper/conf/zoo.cfgmyid=1
tickTime=2000
dataDir=/var/lib/zookeeper
clientPort=2181
initLimit=20
syncLimit=5
server.1=zoo1.example.com:2888:3888
server.2=zoo2.example.com:2888:3888
server.3=zoo3.example.com:2888:3888其中initLimit 表⽰⽤于在从节点与主节点之间建⽴初始化连接的时间上限, syncLimit 表⽰允许从节点与主节点处于不同步状态的时间上限,这两个值都是 tickTime 的 倍数,所以 initLimit 是 20*2000ms,也就是 40s
配置⾥还列出了群组中所有服务器的地 址。服务器地址遵循 server.X=hostname:peerPort:leaderPort
除了公共的配置⽂件外,每个服务器都必须在 data Dir ⽬录中创建⼀个叫作 myid 的⽂件,⽂ 件⾥要包含服务器 ID,这个 ID 要与配置⽂件⾥配置的 ID 保持⼀致。完成这些步骤后,就可以 启动服务器,让它们彼此间进⾏通信了。
三、安装kafka
下载kafkaApache Kafka下载最新版本的 Kafkahttps://downloads.apache.org/kafka/3.5.1/kafka_2.12-3.5.1.tgz
# tar -zxvf kafka_2.12-3.5.1.tgzmv kafka_2.12-3.5.1 /usr/local/kafkamkdir /tmp/kafka-logs
# export JAVA_HOME=/usr/java/jdk1.8.0_51
/usr/local/kafka/bin/kafka-server-start.sh -daemon /usr/local/kafka/config/server.properties
查看kafka是否启动
查看kafka是否报错
ps -ef|grep kafka测试是否正常安装,备注新版本不需要以来zook
kafka版本过高所致,2.2+=的版本,已经不需要依赖zookeeper来查看/创建topic,新版本使用 --bootstrap-server替换老版本的 --zookeeper-server。
创建topic
老版本kafka
/usr/local/kafka/bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic test新版本kafka
[root@kafka bin]# /usr/local/kafka/bin/kafka-topics.sh --bootstrap-server 172.18.207.104:9092 --create --replication-factor 1 --partitions 1 --topic test
Created topic test.列出topic
[root@kafka bin]# /usr/local/kafka/bin/kafka-topics.sh --list --bootstrap-server 172.18.207.104:9092
test
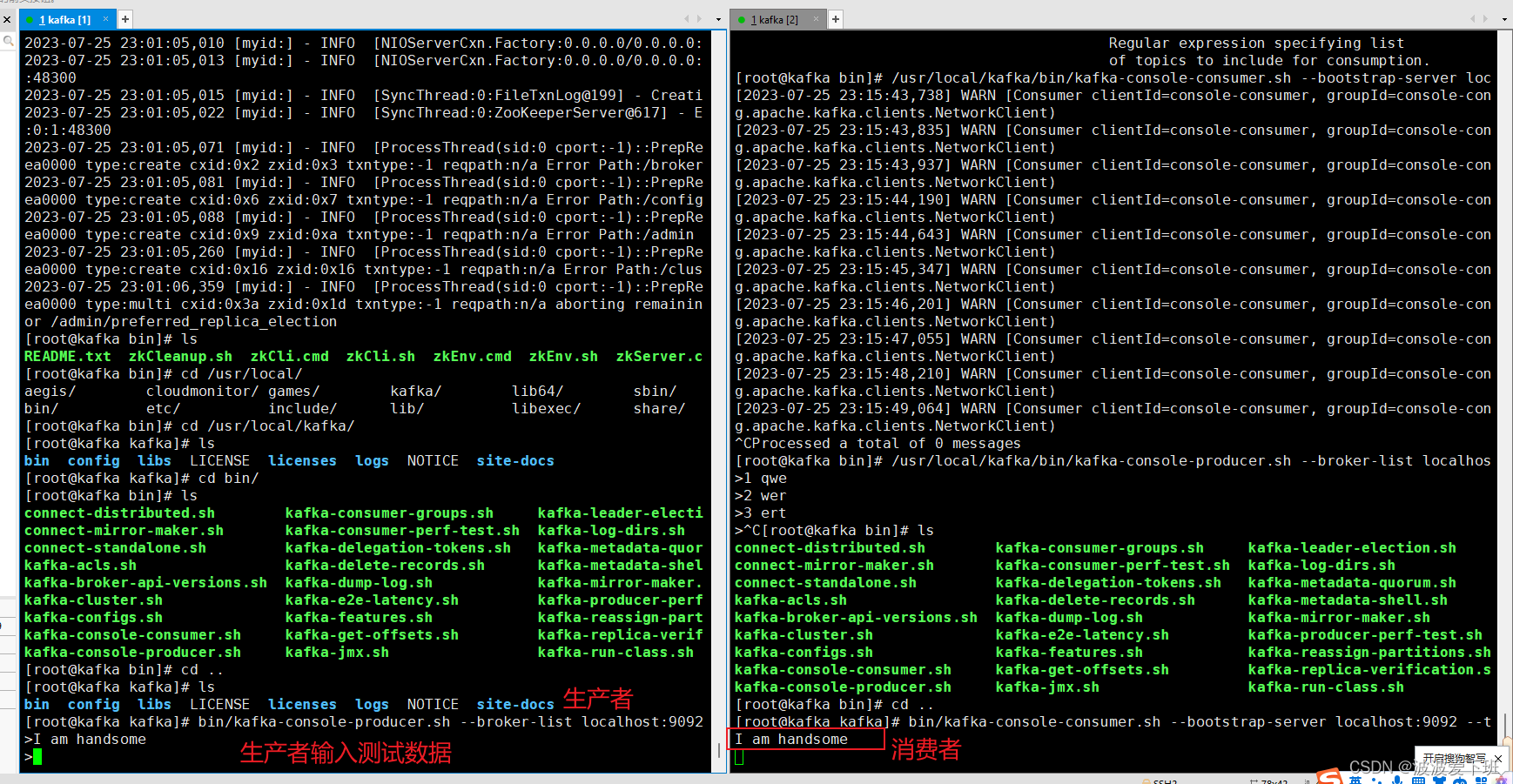
4 启动消费端接收消息
命令:
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test执行上述命令红不要关闭窗口,继续并执行下面的生产端命令
5 生产端发送消息
命令:
bin/kafka-console-producer.sh --broker-list localhost:9092 --topic test在生产端输入消息:I am handsome 然后回车,在消费端4查看会发现实施消费,前提是在同一个topic下
三、kafka集群配置
3.1 broker配置(好好看一遍)
3.1.1 broker.id
每个 broker 都需要有⼀个标识符,使⽤ broker.id 来表⽰。它的默认值是 0,也可以被设置成 其他任意整数。这个值在整个 Kafka 集群⾥必须是唯⼀的。这个值可以任意选定,如果出于维护 的需要,可以在服务器节点间交换使⽤这些 ID。建议把它们设置成与机器名具有相关性的整数, 这样在进⾏维护时,将 ID 号映射到机器名就没那么⿇烦了。例如,如果机器名包含唯⼀性的数 字(⽐如 host1.example.com、host2.example.com),那么⽤这些数字来设置 broker.id 就 再好不过了。
02. port 如果使⽤配置样本来启动 Kafka,它会监听 9092 端⼝。修改 port 配置参数可以把它设置成其 他任意可⽤的端⼝。要注意,如果使⽤ 1024 以下的端⼝,需要使⽤ root 权限启动 Kafka,不 过不建议这么做。
03 zookeeper.connect ⽤于保存 broker 元数据的 Zookeeper 地址是通过 zookeeper.connect 来指定的。 localhost:2181 表⽰这个 Zookeeper 是运⾏在本地的 2181 端⼝上。该配置参数是⽤冒号 分隔的⼀组 hostname:port/path 列表,每⼀部分的含义如下: hostname 是 Zookeeper 服务器的机器名或 IP 地址; port 是 Zookeeper 的客户端连接端⼝; /path 是可选的 Zookeeper 路径,作为 Kafka 集群的 chroot 环境。如果不指定,默认使 ⽤根路径。 如果指定的 chroot 路径不存在,broker 会在启动的时候创建它。
在 Kafka 集群⾥使⽤ chroot 路径是⼀种最佳实践。Zookeeper 群组可以共享给其他应⽤ 程序,即使还有其他 Kafka 集群存在,也不会产⽣冲突。最好是在配置⽂件⾥指定⼀组 Zookeeper 服务器,⽤分号把它们隔开。⼀旦有⼀个 Zookeeper 服务器宕机,broker 可 以连接到 Zookeeper 群组的另⼀个节点上。
04. log.dirs Kafka 把所有消息都保存在磁盘上,存放这些⽇志⽚段的⽬录是通过 log.dirs 指定的。它是⼀组 ⽤逗号分隔的本地⽂件系统路径。如果指定了多个路径,那么 broker 会根据“最少使⽤”原则, 把同⼀个分区的⽇志⽚段保存到同⼀个路径下。要注意,broker 会往拥有最少数⽬分区的路径新 增分区,⽽不是往拥有最⼩磁盘空间的路径新增分区。
05. num.recovery.threads.per.data.dir 对于如下 3 种情况,Kafka 会使⽤可配置的线程池来处理⽇志⽚段: 服务器正常启动,⽤于打开每个分区的⽇志⽚段; 服务器崩溃后重启,⽤于检查和截短每个分区的⽇志⽚段; 服务器正常关闭,⽤于关闭⽇志⽚段。 默认情况下,每个⽇志⽬录只使⽤⼀个线程。因为这些线程只是在服务器启动和关闭时会⽤到, 所以完全可以设置⼤量的线程来达到并⾏操作的⽬的。特别是对于包含⼤量分区的服务器来说, ⼀旦发⽣崩溃,在进⾏恢复时使⽤并⾏操作可能会省下数⼩时的时间。设置此参数时需要注意, 所配置的数字对应的是 log.dirs 指定的单个⽇志⽬录。也就是说,如果 num.recovery.threads.per.data.dir 被设为 8,并且 log.dir 指定了 3 个路径,那么 总共需要 24 个线程。
06. auto.create.topics.enable 默认情况下,Kafka 会在如下⼏种情形下⾃动创建主题: 当⼀个⽣产者开始往主题写⼊消息时; 当⼀个消费者开始从主题读取消息时; 当任意⼀个客户端向主题发送元数据请求时。 很多时候,这些⾏为都是⾮预期的。⽽且,根据 Kafka 协议,如果⼀个主题不先被创建,根本⽆ 法知道它是否已经存在。如果显式地创建主题,不管是⼿动创建还是通过其他配置系统来创建, 都可以把 auto.create.topics.enable 设为 false。
3.1.2 主题的默认配置(了解)
01. num.partitions
num.partitions 参数指定了新创建的主题将包含多少个分区,该参数的默认值是 1。要注意, 我们可以增加主题分区的个数,但不能减少分区的个数。所以,如果要让⼀个主题的分区个数少 于 num.partitions 指定的值,需要⼿动创建该主题
如何选定分区数量
为主题选定分区数量并不是⼀件可有可⽆的事情,在进⾏数量选择时,需要考虑如下⼏个因 素。
如果不知道这些信息,那么根据经验,把分区的⼤⼩限制在 25GB 以内可以得到⽐较理想的效 果。
02. log.retention.ms
Kafka 通常根据时间来决定数据可以被保留多久。默认使⽤ log.retention.hours 参数来配 置时间,默认值为 168 ⼩时,也就是⼀周。除此以外,还有其他两个参数 log.retention.minutes 和 log.retention.ms。这 3 个参数的作⽤是⼀样的,都是决定 消息多久以后会被删除,不过还是推荐使⽤ log.retention.ms。如果指定了不⽌⼀个参数, Kafka 会优先使⽤具有最⼩值的那个参数
03. log.retention.bytes 另⼀种⽅式是通过保留的消息字节数来判断消息是否过期。它的值通过参数 log.retention.bytes 来指定,作⽤在每⼀个分区上。也就是说,如果有⼀个包含 8 个分区 的主题,并且 log.retention.bytes 被设为 1GB,那么这个主题最多可以保留 8GB 的数 据。所以,当主题的分区个数增加时,整个主题可以保留的数据也随之增加。
如果同时指定了 log.retention.bytes 和 log.retention.ms(或者另⼀个时间参 数),只要任意⼀个条件得到满⾜,消息就会被删除
04. log.segment.bytes 以上的设置都作⽤在⽇志⽚段上,⽽不是作⽤在单个消息上。当消息到达 broker 时,它们被追 加到分区的当前⽇志⽚段上。当⽇志⽚段⼤⼩达到 log.segment.bytes 指定的上限(默认是 1GB)时,当前⽇志⽚段就会被关闭,⼀个新的⽇志⽚段被打开。如果⼀个⽇志⽚段被关闭,就 开始等待过期。这个参数的值越⼩,就会越频繁地关闭和分配新⽂件,从⽽降低磁盘写⼊的整体 效率。
⽇志⽚段的⼤⼩会影响使⽤时间戳获取偏移量。在使⽤时间戳获取⽇志偏移量时,Kafka 会 检查分区⾥最后修改时间⼤于指定时间戳的⽇志⽚段(已经被关闭的),该⽇志⽚段的前⼀ 个⽂件的最后修改时间⼩于指定时间戳。然后,Kafka 返回该⽇志⽚段(也就是⽂件名)开 头的偏移量。对于使⽤时间戳获取偏移量的操作来说,⽇志⽚段越⼩,结果越准确。
3.2需要多少个broker
⼀个 Kafka 集群需要多少个 broker 取决于以下⼏个因素。⾸先,需要多少磁盘空间来保留数据,以 及单个 broker 有多少空间可⽤。如果整个集群需要保留 10TB 的数据,每个 broker 可以存储 2TB,那么⾄少需要 5 个 broker。如果启⽤了数据复制,那么⾄少还需要⼀倍的空间,不过这要取决 于配置的复制系数是多少(将在第 6 章介绍)。也就是说,如果启⽤了数据复制,那么这个集群⾄少 需要 10 个 broker。
第⼆个要考虑的因素是集群处理请求的能⼒。这通常与⽹络接⼝处理客户端流量的能⼒有关,特别是 当有多个消费者存在或者在数据保留期间流量发⽣波动(⽐如⾼峰时段的流量爆发)时。如果单个 broker 的⽹络接⼝在⾼峰时段可以达到 80% 的使⽤量,并且有两个消费者,那么消费者就⽆法保持 峰值,除⾮有两个 broker。如果集群启⽤了复制功能,则要把这个额外的消费者考虑在内。因磁盘吞 吐量低和系统内存不⾜造成的性能问题,也可以通过扩展多个 broker 来解决。
3.2.1 broker配置
要把⼀个 broker 加⼊到集群⾥,只需要修改两个配置参数。⾸先,所有 broker 都必须配置相同的 zookeeper.connect,该参数指定了⽤于保存元数据的 Zookeeper 群组和路径。
其次,每个 broker 都必须为 broker.id 参数设置唯⼀的值。
3.2.2为什么不把 vm.swappiness 设为零?
先前,⼈们建议尽量把 vm.swapiness 设为 0,它意味着“除⾮发⽣内存溢出,否则不要进 ⾏内存交换”。直到 Linux 内核 3.5-rc1 版本发布,这个值的意义才发⽣了变化。这个变化被 移植到其他的发⾏版上,包括 Red Hat 企业版内核 2.6.32-303。在发⽣变化之后,0 意味 着“在任何情况下都不要发⽣交换”。所以现在建议把这个值设为 1。
3.2.3脏页
脏⻚会被冲刷到磁盘上,调整内核对脏⻚的处理⽅式可以让我们从中获益。Kafka 依赖 I/O 性能 为⽣产者提供快速的响应。这就是为什么⽇志⽚段⼀般要保存在快速磁盘上,不管是单个快速磁 盘(如 SSD)还是具有 NVRAM 缓存的磁盘⼦系统(如 RAID)。这样⼀来,在后台刷新进程将 脏⻚写⼊磁盘之前,可以减少脏⻚的数量,这个可以通过将 vm.dirty_background_ratio 设为⼩于 10 的值来实现。该值指的是系统内存的百分⽐,⼤部分情况下设为 5 就可以了。它不 应该被设为 0,因为那样会促使内核频繁地刷新⻚⾯,从⽽降低内核为底层设备的磁盘写⼊提供 缓冲的能⼒。
通过设置 vm.dirty_ratio 参数可以增加被内核进程刷新到磁盘之前的脏⻚数量,可以将它设 为⼤于 20 的值(这也是系统内存的百分⽐)。这个值可设置的范围很⼴,60~80 是个⽐较合理 的区间。不过调整这个参数会带来⼀些⻛险,包括未刷新磁盘操作的数量和同步刷新引起的⻓时 间 I/O 等待。如果该参数设置了较⾼的值,建议启⽤ Kafka 的复制功能,避免因系统崩溃造成数 据丢失。 为了给这些参数设置合适的值,最好是在 Kafka 集群运⾏期间检查脏⻚的数量,不管是在⽣存环 境还是模拟环境。可以在 /proc/vmstat ⽂件⾥查看当前脏⻚数量
cat /proc/vmstat | egrep "dirty|writeback"3.2.4文件系统
不管使⽤哪⼀种⽂件系统来存储⽇志⽚段,最好要对挂载点的 noatime 参数进⾏合理的设置。 ⽂件元数据包含 3 个时间戳:创建时间(ctime)、最后修改时间(mtime)以及最后访问时间 (atime)。默认情况下,每次⽂件被读取后都会更新 atime,这会导致⼤量的磁盘写操作,⽽ 且 atime 属性的⽤处不⼤,除⾮某些应⽤程序想要知道某个⽂件在最近⼀次修改后有没有被访问 过(这种情况可以使⽤ realtime)。Kafka ⽤不到该属性,所以完全可以把它禁⽤掉。为挂载 点设置 noatime 参数可以防⽌更新 atime,但不会影响 ctime 和 mtime
3.2.5网络,用到了查哈怎么该
⽹络 默认情况下,系统内核没有针对快速的⼤流量⽹络传输进⾏优化,所以对于应⽤程序来说,⼀般 需要对 Linux 系统的⽹络栈进⾏调优,以实现对⼤流量的⽀持。实际上,调整 Kafka 的⽹络配 置与调整其他⼤部分 Web 服务器和⽹络应⽤程序的⽹络配置是⼀样的。⾸先可以对分配给 socket 读写缓冲区的内存⼤⼩作出调整,这样可以显著提升⽹络的传输性能。socket 读写缓冲 区对应的参数分别是 net.core.wmem_default 和 net.core.rmem_default,合理的值是 131 072(也就是 128KB)。读写缓冲区最⼤值对应的参数分别是 net.core.wmem_max 和 net.core.rmem_max,合理的值是 2 097 152(也就是 2MB)。要注意,最⼤值并不意味着 每个 socket ⼀定要有这么⼤的缓冲空间,只是说在必要的情况下才会达到这个值。 除了设置 socket 外,还需要设置 TCP socket 的读写缓冲区,它们的参数分别是 net.ipv4.tcp_wmem 和 net.ipv4.tcp_rmem。这些参数的值由 3 个整数组成,它们使⽤空 格分隔,分别表⽰最⼩值、默认值和最⼤值。最⼤值不能⼤于 net.core.wmem_max 和 net.core.rmem_max 指定的⼤⼩。例如,“4096 65536 2048000”表⽰最⼩值是 4KB、默认 值是 64KB、最⼤值是 2MB。根据 Kafka 服务器接收流量的实际情况,可能需要设置更⾼的最⼤ 值,为⽹络连接提供更⼤的缓冲空间。 还有其他⼀些有⽤的⽹络参数。例如,把 net.ipv4.tcp_window_scaling 设为 1,启⽤ TCP 时间窗扩展,可以提升客户端传输数据的效率,传输的数据可以在服务器端进⾏缓冲。把 net.ipv4.tcp_max_syn_backlog 设为⽐默认值 1024 更⼤的值,可以接受更多的并发连 接。把 net.core.netdev_max_backlog 设为⽐默认值 1000 更⼤的值,有助于应对⽹络流 量的爆发,特别是在使⽤千兆⽹络的情况下,允许更多的数据包排队等待内核处理。
还是建议使⽤最新版本的 Kafka,让消费者把偏移量提交到 Kafka 服务器上,消除对 Zookeeper 的依赖。
虽然多个 Kafka 集群可以共享⼀个 Zookeeper 群组,但如果有可能的话,不建议把 Zookeeper 共 享给其他应⽤程序。Kafka 对 Zookeeper 的延迟和超时⽐较敏感,与 Zookeeper 群组之间的⼀个 通信异常就可能导致 Kafka 服务器出现⽆法预测的⾏为。这样很容易让多个 broker 同时离线,如果 它们与 Zookeeper 之间断开连接,也会导致分区离线
四、Kafka ⽣产者——向 Kafka 写⼊数据
在⼀个信⽤卡事务处理系统⾥,有⼀个客户端应⽤程序,它可能是⼀个在线商店,每当有⽀付 ⾏为发⽣时,它负责把事务发送到 Kafka 上。另⼀个应⽤程序根据规则引擎检查这个事务,决定是批 准还是拒绝。批准或拒绝的响应消息被写回 Kafka,然后发送给发起事务的在线商店。第三个应⽤程 序从 Kafka 上读取事务和审核状态,把它们保存到数据库,随后分析师可以对这些结果进⾏分析,或 许还能借此改进规则引擎。
在这⼀章,我们将从 Kafka ⽣产者的设计和组件讲起,学习如何使⽤ Kafka ⽣产者。我们将演⽰如 何创建 KafkaProducer 和 ProducerRecords 对象、如何将记录发送给 Kafka,以及如何处理从 Kafka 返回的错误,然后介绍⽤于控制⽣产者⾏为的重要配置选项,最后深⼊探讨如何使⽤不同的分 区⽅法和序列化器,以及如何⾃定义序列化器和分区器。
第三⽅客户端 除了内置的客户端外,Kafka 还提供了⼆进制连接协议,也就是说,我们直接向 Kafka ⽹络端⼝ 发送适当的字节序列,就可以实现从 Kafka 读取消息或往 Kafka 写⼊消息。还有很多⽤其他语 ⾔实现的 Kafka 客户端,⽐如 C++、 Python、Go 语⾔等,它们都实现了 Kafka 的连接协议, 使得 Kafka 不仅仅局限于在 Java ⾥使⽤。这些客户端不属于 Kafka 项⽬,不过 Kafka 项⽬ wiki 上提供了⼀个清单,列出了所有可⽤的客户端。
4.1生产者概览
使用场景区分需求
⼀个应⽤程序在很多情况下需要往 Kafka 写⼊消息:记录⽤户的活动(⽤于审计和分析)、记录度量 指标、保存⽇志消息、记录智能家电的信息、与其他应⽤程序进⾏异步通信、缓冲即将写⼊到数据库 的数据,等等。 多样的使⽤场景意味着多样的需求:是否每个消息都很重要?是否允许丢失⼀⼩部分消息?偶尔出现 重复消息是否可以接受?是否有严格的延迟和吞吐量要求? 在之前提到的信⽤卡事务处理系统⾥,消息丢失或消息重复是不允许的,可以接受的延迟最⼤为 500ms,对吞吐量要求较⾼——我们希望每秒钟可以处理⼀百万个消息。
保存⽹站的点击信息是另⼀种使⽤场景。在这个场景⾥,允许丢失少量的消息或出现少量的消息重 复,延迟可以⾼⼀些,只要不影响⽤户体验就⾏。换句话说,只要⽤户点击链接后可以⻢上加载⻚ ⾯,那么我们并不介意消息要在⼏秒钟之后才能到达 Kafka 服务器。吞吐量则取决于⽹站⽤户使⽤⽹ 站的频度。 不同的使⽤场景对⽣产者 API 的使⽤和配置会有直接的影响。
流程
在发送 ProducerRecord 对象------序列化------>>分区器--->>发动到主题-->>
如果消息成功写⼊ Kafka,就返回⼀个 RecordMetaData 对象,它包含了主题和分区信息,以及记录在分区⾥的偏移量。如果写⼊失败, 则会返回⼀个错误。⽣产者在收到错误之后会尝试重新发送消息,⼏次之后如果还是失败,就返回错 误信息
相关文章:
kafka权威指南学习以及kafka生产配置
0、kafka常用命令 Kafka是一个分布式流处理平台,它具有高度可扩展性和容错性。以下是Kafka最新版本中常用的一些命令: 创建一个主题(topic): bin/kafka-topics.sh --create --topic my-topic --partitions 3 --replic…...

自由行的一些小tips
很多很多年前,写过一些关于自由行的小攻略,关于互联网时代的自助旅游,说起来八年了,很多信息可能过期了。 前几天准备回坡,因为自己比较抠门,发现目前大陆回新加坡的机票比较贵(接近4000人民币&…...

uiautomatorViewer无法获取Android8.0手机屏幕截图的解决方案
问题描述: 做APP UI自动化的时候,会碰到用uiautomatorViewer在Android 8.0及以上版本的手机上,无法获取到手机屏幕截图,无法获取元素定位信息的问题,会有以下的报 在低版本的Android手机上,则没有这个问题…...
)
使用LangChain构建问答聊天机器人案例实战(三)
使用LangChain构建问答聊天机器人案例实战 LangChain开发全流程剖析 接下来,我们再回到“get_prompt()”方法。在这个方法中,有系统提示词(system prompts)和用户提示词(user prompts),这是从相应的文件中读取的,从“system.prompt”文件中读取系统提示词(system_tem…...
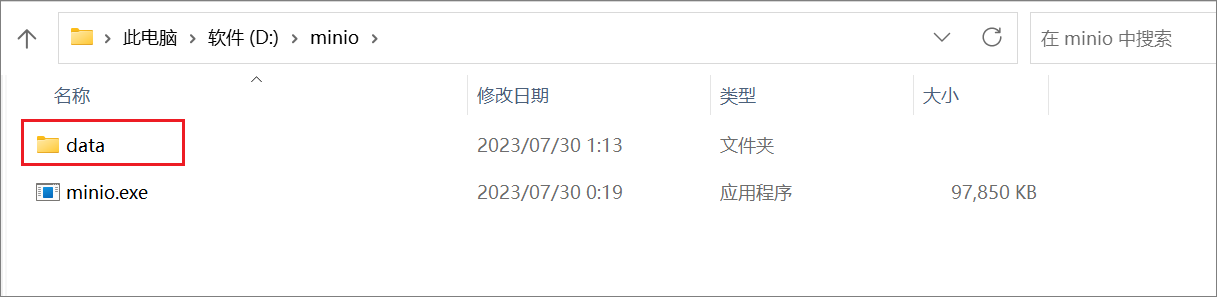
在windows上安装minio
1、下载windows版的minio: https://dl.min.io/server/minio/release/windows-amd64/minio.exe 2、在指定位置创建一个名为minio文件夹,然后再把下载好的文件丢进去: 3、右键打开命令行窗口,然后执行如下命令:(在minio.…...

22. 数据库的隔离级别和锁机制
文章目录 数据库的隔离级别和锁机制一、数据库隔离级别1. 隔离级别说明2. 如何选择隔离级别3. 查询当前客户端隔离级别的命令.4. 修改隔离的命令 二、数据库中的锁1. 共享锁、排他锁2. 死锁3. 行级锁、表级锁 三、解决更新丢失问题1. 解决方案2. 乐观锁、悲观锁3. 乐观锁、悲观…...
)
【题解】[ABC312E] Tangency of Cuboids(adhoc)
【题解】[ABC312E] Tangency of Cuboids 少见的 at 评分 \(2000\) 的 ABC E 题,非常巧妙的一道题。 特别鸣谢:dbxxx 给我讲解了他的完整思路。 题目链接 ABC312E - Tangency of Cuboids 题意概述 给定三维空间中的 \(n\) 个长方体,每个长方体…...

k8s服务发现之使用 HostAliases 向 Pod /etc/hosts 文件添加条目
某些情况下,DNS 或者其他的域名解析方法可能不太适用,您需要配置 /etc/hosts 文件,在Linux下是比较容易做到的,在 Kubernetes 中,可以通过 Pod 定义中的 hostAliases 字段向 Pod 的 /etc/hosts 添加条目。 适用其他方…...

python中有哪些比较运算符
目录 python中有哪些比较运算符 使用比较运算符需要注意什么 总结 python中有哪些比较运算符 在Python中,有以下比较运算符可以用于比较两个值之间的关系: 1. 等于 ():检查两个值是否相等。 x y 2. 不等于 (!):检查两个…...

Python网络编程详解:Socket套接字的使用与开发
Python网络编程详解:Socket套接字的使用与开发 1. 引言 网络编程是现代应用开发中不可或缺的一部分。通过网络编程,我们可以实现不同设备之间的通信和数据交换,为用户提供更加丰富的服务和体验。Python作为一种简洁而强大的编程语言&#x…...

Appium+python自动化(二十六)- Toast提示(超详解)简介
开始今天的主题 - 获取toast提示 在日常使用App过程中,经常会看到App界面有一些弹窗提示(如下图所示)这些提示元素出现后等待3秒左右就会自动消失,这个和我日常生活中看到的烟花和昙花是多么的相似,那么我们该如何获取…...

SpringBoot自动装配介绍
SpringBoot是对Spring的一种扩展,其中比较重要的扩展功能就是自动装配:通过注解对常用的配置做默认配置,简化xml配置内容。本文会对Spring的自动配置的原理和部分源码进行解析,本文主要参考了Spring的官方文档。 自动装配的组件 …...

1400*D. Candy Box (easy version)(贪心)
3 10 9 Example input 3 8 1 4 8 4 5 6 3 8 16 2 1 3 3 4 3 4 4 1 3 2 2 2 4 1 1 9 2 2 4 4 4 7 7 7 7 output 题意: n个糖果,分为多个种类,要求尽可能的多选,并且使得不同种类的数量不能相同。 解析: 记录每种糖…...

设计模式-备忘录模式在Java中使用示例-象棋悔棋
场景 备忘录模式 备忘录模式提供了一种状态恢复的实现机制,使得用户可以方便地回到一个特定的历史步骤,当新的状态无效 或者存在问题时,可以使用暂时存储起来的备忘录将状态复原,当前很多软件都提供了撤销(Undo)操作࿰…...

用合成数据训练托盘检测模型【机器学习】
想象一下,你是一名机器人或机器学习 (ML) 工程师,负责开发一个模型来检测托盘,以便叉车可以操纵它们。 你熟悉传统的深度学习流程,已经整理了手动标注的数据集,并且已经训练了成功的模型。 推荐:用 NSDT设…...

人性-基本归因错误
定义 基本归因谬误指出,你评价别人的一个行为时,你会高估他的内部因素——比如性格的影响,低估外在的情景之类各种复杂因素的影响。 具体表现是对自己,我们很愿意分析复杂的原因;对别人,如果他一句话说的…...

游戏引擎:打造梦幻游戏世界的秘密武器
介绍 游戏引擎是游戏开发中不可或缺的工具,它为开发者提供了构建游戏世界所需的各种功能和工具。本文将介绍游戏引擎的概念、使用方法以及一个完整的游戏项目示例。 游戏引擎的概念 游戏引擎是一种软件框架,它提供了游戏开发所需的各种功能和工具&…...
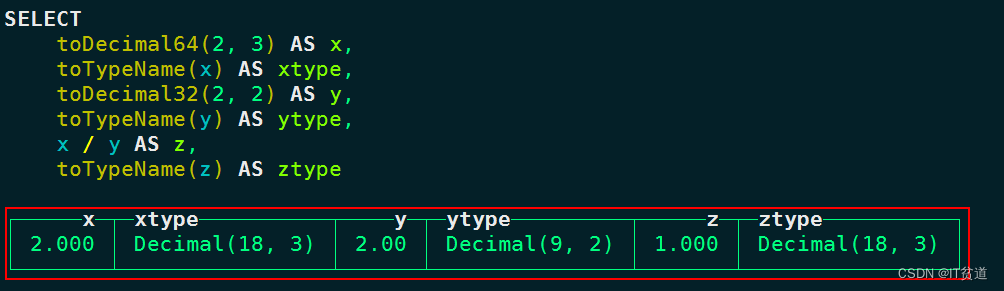
ClickHouse(六):Clickhouse数据类型-1
进入正文前,感谢宝子们订阅专题、点赞、评论、收藏!关注IT贫道,获取高质量博客内容! 🏡个人主页:含各种IT体系技术,IT贫道_Apache Doris,Kerberos安全认证,大数据OLAP体系技术栈-CSDN博客 &…...
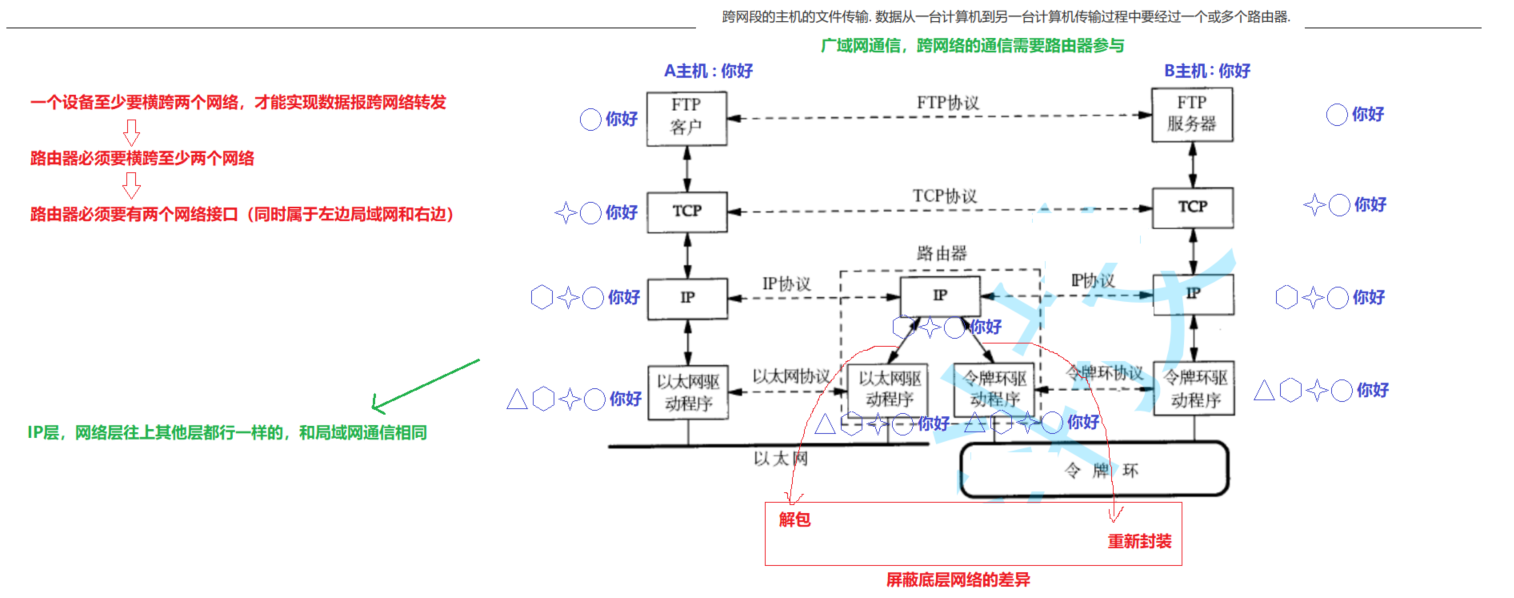
【Linux】网络基础
🍎作者:阿润菜菜 📖专栏:Linux系统网络编程 文章目录 一、协议初识和网络协议分层(TCP/IP四层模型)认识协议TCP/IP五层(或四层)模型 二、认识MAC地址和IP地址认识MAC地址认识IP地址认…...

小程序-接口概率性接收不到参数
在小程序上调用一个接口,传入筛选条件,但返回结果却没有进行筛选,概率性出现这种情况,频率较低。 然后在postman调用该接口,调用很多很多次,发现也出现这种问题,看了代码,接口的传参…...

3C产品功能太多15秒讲不完?用爆款复刻Agent做2分钟完整演示,用户看完直接下单
3C数码产品做千川素材,最容易遇到一个问题:功能很多,15秒根本讲不清。蓝牙耳机要讲降噪、音质、续航、佩戴舒适度;智能手表要讲运动监测、健康功能、续航、防水和系统兼容;小家电要讲使用场景、操作步骤、参数差异和售…...
第1小节:光学物镜核心原理)
0601光刻机 第六篇:EUV超精密光学系统(S级 长期死磕突破)第1小节:光学物镜核心原理
第六篇:EUV超精密光学系统(S级 长期死磕突破) 第1小节:光学物镜核心原理(硬核无水分,从物理本质到工程实现) 前置硬核声明 EUV物镜是光刻机的“原子级眼睛”,13.5nm波长决定透射方案…...

免费开源AMD Ryzen调试工具SMUDebugTool:释放处理器性能的终极指南
免费开源AMD Ryzen调试工具SMUDebugTool:释放处理器性能的终极指南 【免费下载链接】SMUDebugTool A dedicated tool to help write/read various parameters of Ryzen-based systems, such as manual overclock, SMU, PCI, CPUID, MSR and Power Table. 项目地址…...

qb-web测试策略:Jest单元测试与Vue组件测试最佳实践
qb-web测试策略:Jest单元测试与Vue组件测试最佳实践 【免费下载链接】qb-web A qBittorrent Web UI, write in TypeScriptVue. 项目地址: https://gitcode.com/gh_mirrors/qb/qb-web qb-web作为基于TypeScriptVue开发的qBittorrent Web UI,采用Je…...

树突状细胞相关细胞因子的功能及疾病关联
树突状细胞作为免疫系统中核心的抗原呈递细胞,其分泌的多种细胞因子(IL-1α、IL-1β、IL-6、TNFα、IL-10)在免疫反应的启动、调控及稳态维持中发挥着核心作用。这些细胞因子具有双重调控特性,既是机体抵御病原体入侵的重要屏障&a…...

零经验应届生简历怎么写?3分钟AI生成直接拿面试
毕业季到了,你是不是也跟我一样,简历投了几十份,结果石沉大海,连个面试机会都没有?尤其看到那些社招大佬,简历上项目经验、数据成果写得一套一套的,再看看自己的,除了实习经历就是课…...

对比按需计费与 Token Plan 套餐哪种方式更适合长期项目
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 对比按需计费与 Token Plan 套餐哪种方式更适合长期项目 在长期且用量稳定的开发项目中,如何选择成本模型是技术决策的…...

创业公司如何借助 Taotoken 的多模型聚合能力快速验证产品 AI 功能
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 创业公司如何借助 Taotoken 的多模型聚合能力快速验证产品 AI 功能 对于资源有限的创业团队而言,在产品早期快速验证核…...

论完善代码版本信息构建AI在精工产业与智能设备短板—东方仙盟
出众的现代 AI时至今日,人工智能发展日新月异。在 UI 设计、网页开发、纯软件系统搭建等不依托实体硬件的领域,AI 表现已然成熟。常规信息化工作,AI 皆可独立完成,效率出众,为日常开发与设计减负良多。精工硬件领域 AI…...

3个关键步骤:在macOS上制作Windows启动盘的完整指南
3个关键步骤:在macOS上制作Windows启动盘的完整指南 【免费下载链接】windiskwriter 🖥 Windows Bootable USB creator for macOS. 🛠 Patches Windows 11 to bypass TPM and Secure Boot requirements. 👾 UEFI & Legacy Sup…...