elasticsearch 官方优化建议
.一般建议
a.不要返回过大的结果集。这个建议对一般数据库都是适用的,如果要获取大量结果,可以使用search_after api,或者scroll (新版本中已经不推荐)。
b.避免大的文档。
2. 如何提高索引速度
a.使用批量请求。为了达到最好的效果,可以进行测试,递增地提高bulk的数量,比如从100,到200,再到400,达到一个吞吐量和响应时间的平衡。
b.使用多线程发送数据。
c.关闭或者减小refresh_interval。从内存缓存写入磁盘缓存(memorybuffer -> filesystem cache),这个过程叫做refresh。在这个过程之前内存缓存里面的文档是不可被搜索的,这也是为什么es被称为近实时索引的原因。
在索引初始化(大量导入文档)的时候,可以关闭refresh_interval。当产品允许较大的不可搜索时间,可以将index.refresh_interval设置为30s,提高索引速度。
d.初始化时关闭复制分片。索引时设置index.number_of_replicas为0,避免主分片复制数据,索引完毕后再调整到正常的复制分片数。
e.关闭swapping。swap会极大地降低es的索引速度。
Swap分区(即交换区)在系统的物理内存不够用的时候,把硬盘空间中的一部分空间释放出来,以供当前运行的程序使用。
那些被释放的空间可能来自一些很长时间没有什么操作的程序,这些被释放的空间被临时保存到Swap分区中,等到那些程序要运行时,再从Swap分区中恢复保存的数据到内存中。f.给文件系统缓存分配足够多的内存。文件系统换行用来处理io操作,至少要将物理机一半的内存分配给文件系统缓存。比如物理机内存64g,那么至少分配32g给文件系统缓存,剩下的内存才考虑分配给es。
g.使用自动生成的id。如果使用指定的id,es会检查这个id是否已经存在,而且随着文档数越多,这个判重操作越耗时。索引的时候,如果没有指定id,es会自动生成id。
{"_index": "sales","_type": "_doc","_id": "xb7IY4cB6Rdc8HbDycuE", // auto-generated id"_version": 1,"result": "created","_shards": {"total": 2,"successful": 1,"failed": 0},"_seq_no": 10,"_primary_term": 1
}h.使用更好的硬件。比如SSD,或者Amazon的Elastic Block Storage。
i.调整索引缓存大小。确保每个索引分片能获得512M的缓存,即 indices.memory.index_buffer_size = 512M,大于512M没有更多提升效果。
j.使用cross-cluster replication 来实现读写分离,这样让索引集群压力更小。这和mysql中的读写分离很类似。
3.如何提到搜索速度
a.给文件系统缓存分配足够多的内存。
b.在linux环境中设置合适的readahead。但是es中的查询更多的是随机io,过大的readahead反而使文件系统的页缓存严重抖动,从而使查询性能下降。
Linux的文件预读readahead,指Linux系统内核将指定文件的某区域预读进页缓存起来,便于接下来对该区域进行读取时,不会因缺页(page fault)而阻塞。因为从内存读取比从磁盘读取要快很多。
预读可以有效的减少磁盘的寻道次数和应用程序的I/O等待时间,是改进磁盘读I/O性能的重要优化手段之一。使用命令lsblk查看readahead值。c.使用更好的硬件。
d.好的文档模型。酌情使用nested query, parent query, 避免使用join query。
| 文档模型 | 对比普通查询 |
| nested query | 慢几倍 |
| parent query | 慢几百倍 |
| join query | 应当避免 |
e.尽可能少的查询字段。在越多的字段上匹配,查询速度就越慢。在索引的时候可以将需要查询的多个字段聚合到一个字段中。使用copy_to 可以自动实现这一功能,以下示例将name和plot字段聚合到name_and_plot字段中。
PUT movies
{"mappings": {"properties": {"name_and_plot": {"type": "text"},"name": {"type": "text","copy_to": "name_and_plot"},"plot": {"type": "text","copy_to": "name_and_plot"}}}
}f.预先索引数据。比如如果想对price字段做range聚合,那么预先计算出单个文档的price范围,那么就能将range聚合转化成terms聚合。这样确实能提高效率,但是不太灵活。
插入文档:
PUT index/_doc/1
{"designation": "spoon","price": 13
}range聚合查询:
GET index/_search
{"aggs": {"price_ranges": {"range": {"field": "price","ranges": [{ "to": 10 },{ "from": 10, "to": 100 },{ "from": 100 }]}}}
}另一种做法,预先计算price_range:
PUT index
{"mappings": {"properties": {"price_range": {"type": "keyword"}}}
}PUT index/_doc/1
{"designation": "spoon","price": 13,"price_range": "10-100"
}使用terms聚合:
GET index/_search
{"aggs": {"price_ranges": {"terms": {"field": "price_range"}}}
}g.尽可能将字段自定义为keyword。对于数字类型的字段,es对其range查询做了优化。在term层级的查询下,keyword字段比数字类型要好。
在以下两种情况下可以考虑将数字类型定义为keyword:
1.不需要对这些数据进行range查询
2.有很高的查询速度要求。
如果实在不清楚哪个好,可以用 multi-field为数字类型的字段同时定义数字类型和keyword类型。
h.避免使用脚本。如果可能,避免使用脚本排序,使用脚本聚合,以及script_scorequery。
i.使用四舍五入的日期。这样有助于es进行缓存,精确到秒级别的查询有时候并无必要。
实时查询(秒级):
PUT index/_doc/1
{"my_date": "2016-05-11T16:30:55.328Z"
}GET index/_search
{"query": {"constant_score": {"filter": {"range": {"my_date": {"gte": "now-1h","lte": "now"}}}}}
}分钟级查询:
GET index/_search
{"query": {"constant_score": {"filter": {"range": {"my_date": {"gte": "now-1h/m","lte": "now/m"}}}}}
}j.对只读索引进行force-merge。在时序索引中,过期的索引都是只读的,将其合并成一个段能加快查询速度。
k.预热global ordinals。ordinals 是doc values的具体存储形式。一般情况下一个字段的global ordinals是懒加载的。如果某个字段在聚合上用到很多,我们可以先将其预热(加载到heap),当做field data cache.的一部分。
PUT index
{"mappings": {"properties": {"foo": {"type": "keyword","eager_global_ordinals": true}}}
}l.预热文件系统缓存。设置index.store.preload参数即可。注意,必须确保文件系统缓存足够大,否则会让查询变得更慢。
m.使用索引排序来加速连接查询。比如我们要进行过滤 a AND b AND …,然后a是low-cardinality(低区分度)。那么我们可以先对a进行排序,那么一旦a的某个值不匹配这个表达式,那么有相同的值的文档都可以跳过。
n.使用preference进行缓存使用优化。es中有非常多的缓存,比如文件系统缓存(最重要),请求缓存,查询缓存,但是这些缓存都是在节点层面。默认情况下es会使用round-robin算法分配查询到不同的分片上去,这样缓存就失效了。
如果可以,使用preference参数将用户的请求和对应的分片或者节点绑定起来,这样缓存就不会失效。例如:
GET /_search?preference=_shards:2,3
{"query": {"match": {"title": "elasticsearch"}}
}o.更多的复制分片会提升吞吐量(但并不一定)。在系统资源充足的情况下,复制分片越多吞吐量会越高。但是过多的分片会让故障恢复变得更慢。
p.使用profile api优化查询语句。和mysql中的explain类似,例如:
GET /my-index-000001/_search
{"profile": true,"query" : {"match" : { "message" : "GET /search" }}
}{"took": 25,"timed_out": false,"_shards": {"total": 1,"successful": 1,"skipped": 0,"failed": 0},"hits": {"total": {"value": 5,"relation": "eq"},"max_score": 0.17402273,"hits": [...] },"profile": {"shards": [{"id": "[2aE02wS1R8q_QFnYu6vDVQ][my-index-000001][0]","searches": [{"query": [{"type": "BooleanQuery","description": "message:get message:search","time_in_nanos" : 11972972,"breakdown" : {"set_min_competitive_score_count": 0,"match_count": 5,"shallow_advance_count": 0,"set_min_competitive_score": 0,"next_doc": 39022,"match": 4456,"next_doc_count": 5,"score_count": 5,"compute_max_score_count": 0,"compute_max_score": 0,"advance": 84525,"advance_count": 1,"score": 37779,"build_scorer_count": 2,"create_weight": 4694895,"shallow_advance": 0,"create_weight_count": 1,"build_scorer": 7112295},...q.使用 index_phrases 加速phrase query。index_phrases,会将两个单词的组合单独索引,这样可以加速phrase query。
r.使用 index_phrases 加速prefix query。同上。
s.使用constant_keyword加速过滤。如果某个字段的大多数情况下的值是个常量,但是我们又经常要对其进行过滤,我们可以将其拆分成两个索引,一个使用constant_keyword,一个不使用。
mapping如下:
UT bicycles
{"mappings": {"properties": {"cycle_type": {"type": "constant_keyword","value": "bicycle"},"name": {"type": "text"}}}
}PUT other_cycles
{"mappings": {"properties": {"cycle_type": {"type": "keyword"},"name": {"type": "text"}}}
}查询语句:
GET bicycles,other_cycles/_search
{"query": {"bool": {"must": {"match": {"description": "dutch"}},"filter": {"term": {"cycle_type": "bicycle"}}}}
}在查询bicycles索引时,es会将查询语句自动转换为:
GET bicycles,other_cycles/_search
{"query": {"match": {"description": "dutch"}}
}4.磁盘优化
a.禁用不需要的特性。
比如数字类型的字段如果不需要进行过滤,可以不对其进行索引。
PUT index
{"mappings": {"properties": {"foo": {"type": "integer","index": false}}}
}es会对text类型的字段存储一些打分信息,如果不需要对这些字段进行打分,可以将其设置为match_only_text类型
b.不要使用默认动态字符串映射。默认动态字符串映射会将字符串类型映射为text和keyword类型,这样很浪费空间。可以预先配置所有字符串映射类型为keyword。
PUT index
{"mappings": {"dynamic_templates": [{"strings": {"match_mapping_type": "string","mapping": {"type": "keyword"}}}]}
}c.监控分片大小。越大的分片能更有效地存储数据。但是分片越大,故障恢复也会越慢。
d.禁用_source字段。_source会存储原始的json数据,如果不需要,就将其禁用。
e.使用best_compression进行压缩。es默认使用 LZ4 进行压缩,使用best_compression可以提升压缩比率,但是会影响数据存取性能。
f.force-merge.强制合并段能提升存储效率。注意,force-merge应当在没有文件写入后进行, 比如在过期的时序索引节点上。
g.shrink 索引。即收缩索引,将当前索引重新索引成分片数更少的索引。分片越大,存储效率越高。
shrink索引有如下条件。
1.索引必须只读。
2.节点必须包含索引的所有分片(主分片,或者复制分片都可以)
3.索引状态必须是健康的。
h.使用能满足需求的最小的数字类型。比如能用byte, 不用short。这个在其他db比如mysql中也适用。
i.使用索引排序来提升文档的压缩性能。排序后相似的文档会放在一起,es能根据他们的特性有效地进行压缩。
设定索引排序:
PUT my-index-000001
{"settings": {"index": {"sort.field": "date", "sort.order": "desc" }},"mappings": {"properties": {"date": {"type": "date"}}}
}j.索引文档时保证json字段顺序一致。es在存储的时候将多个文档压缩成一成block,如果json文档顺序一致,es能更好的对更长的相同的字符串进行压缩。
k.roll-up历史数据。使用roll up api来归档历史数据,他们依然可以访问,但是有着更高的存储效率。
5.分片大小
1.将索引分片大小保持在10G~50G之间
2.平均下来每G堆内存下不要超过20个分片。
相关文章:
elasticsearch 官方优化建议
.一般建议 a.不要返回过大的结果集。这个建议对一般数据库都是适用的,如果要获取大量结果,可以使用search_after api,或者scroll (新版本中已经不推荐)。 b.避免大的文档。 2. 如何提高索引速度 a.使用批量请求。为了…...
从入门到精通系列之五:K8s的基本概念和术语之应用类)
Kubernetes(K8s)从入门到精通系列之五:K8s的基本概念和术语之应用类
Kubernetes K8s从入门到精通系列之五:K8s的基本概念和术语之应用类 一、Service与Pod二、Label与标签选择器三、Pod与Deployment四、Service的ClusterIP地址五、Service的外网访问问题六、有状态的应用集群七、批处理应用八、应用配置问题九、应用的运维一、Service与Pod Ser…...
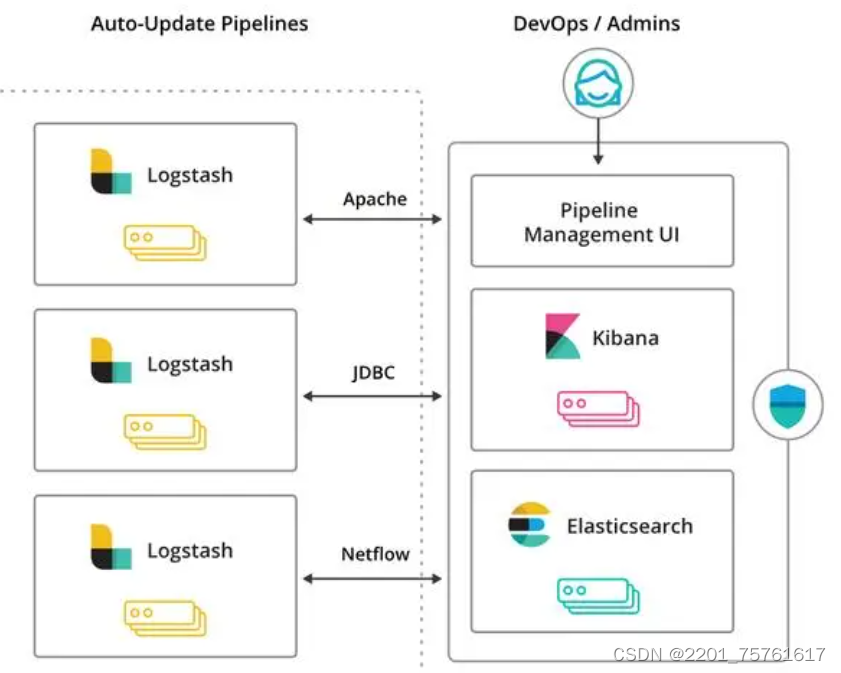
DevOps(四)
CD(二) 1. CDStep 1 - 上传代码Step 2 - 下载代码Step 3 - 检查代码Step 4 - 编译代码Step 5 - 上传仓库Step 6 - 下载软件Step 7 - 制作镜像Step 8 - 上传镜像Step 9 - 部署服务2. 整体预览2.1 预览1. 修改代码2. 查看sonarqube检查结果3. 查看nexus仓库4. 查看harbor仓库5.…...

Element-plus侧边栏踩坑
问题描述 el-menu直接嵌套el-menu-item菜单,折叠时不会出现文字显示和小箭头无法隐藏的问题,但是实际开发需求中难免需要把el-menu-item封装为组件 解决 vue3项目中嵌套两层template <template><template v-for"item in list" :k…...
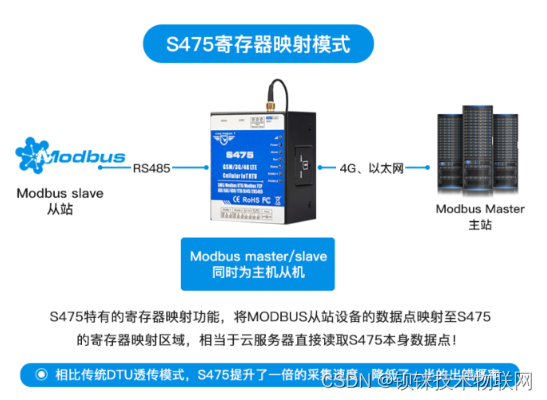
支持多种通信方式和协议方便接入第三方服务器或云平台
2路RS485串口是一种常用的通信接口,可以支持Modbus Slave协议,并可接入SCADA、HMI、DSC、PLC等上位机。它还支持Modbus RTU Master协议,可用于扩展多达48个Modbus Slave设备,如Modbus RTU远程数据采集模块、电表、水表、柴油发电机…...
使用 OpenCV 进行图像模糊度检测(拉普拉斯方差方法)
写在前面 工作中遇到,简单整理人脸识别中,对于模糊程度较高的图像数据,识别率低,错误率高。虽然使用 AdaFace 模型,对低质量人脸表现尤为突出。但是还是需要对 模糊程度高的图像进行丢弃处理当前通过阈值分类ÿ…...

神经网络简单介绍
人工神经网络(artififial neural network) 简称神经网络,它是一种模仿生物神经网络结构和功能的非线性数学模型。 神经网络通过输入层接受原始特征信息,再通过隐藏层进行特征信息的加工和提取,最后通过输出层输出结果。 根据需要神经网络可以…...
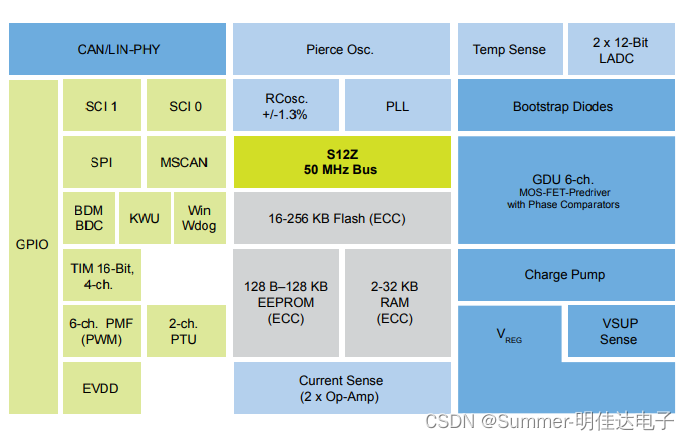
16位S912ZVML32F3MKH、S912ZVML31F1WKF、S912ZVML31F1MKH混合信号MCU,适用于汽车和工业电机控制应用。
S12 MagniV微控制器是易于使用且高度集成的混合信号MCU,非常适合用于汽车和工业应用。S12 MagniV MCU提供单芯片解决方案,是基于成熟的S12技术的完整系统级封装 (SiP) 解决方案,在整个产品组合内软件和工具都兼容。 S12 MagniV系统级封装 (S…...

力扣 509. 斐波那契数
题目来源:https://leetcode.cn/problems/fibonacci-number/description/ C题解1:根据题意,直接用递归函数。 class Solution { public:int fib(int n) {if(n 0) return 0;else if(n 1) return 1;else return(fib(n-1) fib(n-2));} }; C题…...

使用 DolphinDB TopN 函数探索高效的Alpha因子
DolphinDB 已经有非常多的窗口计算函数,例如 m 系列的滑动窗口计算,cum 系列累计窗口计算,tm 系列的的时间窗口滑动计算。但是所有这类函数都是对窗口内的所有记录进行指标计算,难免包含很多噪音。 DolphinDB 的金融领域用户反馈…...

超聚变和厦门大学助力兴业银行构建智慧金融隐私计算平台,助力信用卡业务精准营销...
兴业银行与超聚变数字技术有限公司、厦门大学携手,发挥产学研用一体化整体优势联合建设,厦门大学提供先进的算法模型及科研能力,超聚变提供产品解决方案及工程能力,兴业银行提供金融实践能力,三方发挥各自领域优势&…...

docker 的compose安装
1. Docker Compose 环境安装 Docker Compose 是 Docker 的独立产品,因此需要安装 Docker 之后在单独安装 Docker Compose docker compose 实现单机容器集群编排管理(使用一个模板文件定义多个应用容器的启动参数和依赖关系,并使用docker co…...

JavaScript---事件对象event
获取事件对象: 事件对象:是个对象,这个对象里有事件触发时的相关信息,在事件绑定的回调函数的第一个参数就是事件对象,一般命名为event、ev、e eg: 元素.addEventListener(click,function (e){}) 部分常用属性&…...

Day 15 C++对象模型和this指针
目录 C对象模型 类内的成员变量和成员函数分开存储 总结 this指针 概念 示例 用途 当形参和成员变量同名时 在非静态成员函数中,如果希望返回对象本身 例子 空指针访问成员函数 示例 const修饰成员函数 常函数(const member function&…...

HarmonyOS/OpenHarmony元服务开发-卡片生命周期管理
创建ArkTS卡片,需实现FormExtensionAbility生命周期接口。 1.在EntryFormAbility.ts中,导入相关模块。 import formInfo from ohos.app.form.formInfo; import formBindingData from ohos.app.form.formBindingData; import FormExtensionAbility from …...

软件工程01
软件工程原则: 开闭原则: open closed principle : 对扩展开放,对修改关闭,,,只让扩展,不让修改,用新增的类去替代修改的类 扩展之后,代码不用改变ÿ…...
UML/SysML建模工具更新(2023.7)(1-5)有国产工具
DDD领域驱动设计批评文集 欢迎加入“软件方法建模师”群 《软件方法》各章合集 最近一段时间更新的工具有: 工具最新版本:Visual Paradigm 17.1 更新时间:2023年7月11日 工具简介 很用心的建模工具。支持编写用例规约。支持文本分析和C…...

Mac plist文件
macOS、iOS、iPadOS的应用程序都可能会有plist配置文件,他是苹果系列操作系统特有的配置文件。 plist的本质是个xml格式的文本文件,英文全称是property list,文件后缀使用.plist。 对于普通用户来说,基本不用管plist文件是什么&…...
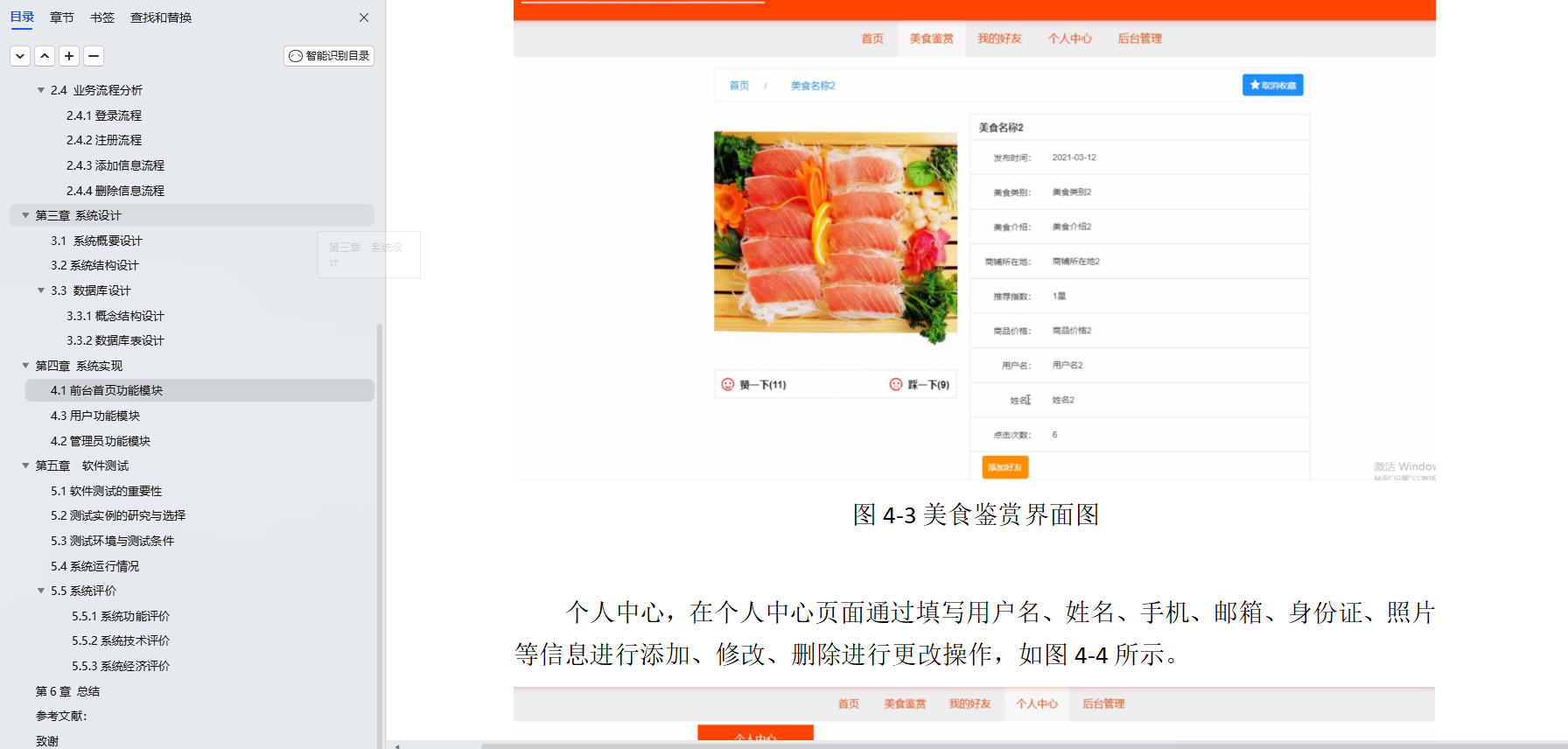
基于Java+SpringBoot+vue前后端分离校园周边美食探索分享平台设计实现
博主介绍:✌全网粉丝30W,csdn特邀作者、博客专家、CSDN新星计划导师、Java领域优质创作者,博客之星、掘金/华为云/阿里云/InfoQ等平台优质作者、专注于Java技术领域和毕业项目实战✌ 🍅文末获取源码联系🍅 👇🏻 精彩专…...

【openwrt】package介绍
openwrt package介绍 OpenWrt 构建系统主要围绕package的概念展开。不管是什么软件,几乎都对应一个package。 这几乎适用于系统中的所有内容:HOST工具、交叉编译工具链、Linux 内核、内核mod、根文件系统和上层的应用软件。 一个 OpenWrt package本质上…...

知识竞赛电子计分板 vs 手工计分板:差距有多大
知识竞赛电子计分板 vs 手工计分板:差距有多大 无论是学校班级的趣味问答,还是企业年会、电视直播的知识竞赛,计分板都是整场活动的核心视觉焦点。传统的手工计分板(如白板、翻牌、纸质表格)曾陪伴我们多年,…...

番茄小说下载器终极指南:三步打造你的私人数字图书馆
番茄小说下载器终极指南:三步打造你的私人数字图书馆 【免费下载链接】fanqienovel-downloader 下载番茄小说 项目地址: https://gitcode.com/gh_mirrors/fa/fanqienovel-downloader 你是否曾在深夜追更小说时突然断网?或者想在地铁上继续阅读却发…...

Taotoken平台Token Plan套餐如何帮助控制每日大赛项目成本
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken平台Token Plan套餐如何帮助控制每日大赛项目成本 1. 项目背景与成本挑战 在AI应用开发中,尤其是像“每日大赛…...

从BMP文件头到像素遍历:手把手教你用C语言和VS2022读取图片的RGB数据
从BMP文件头到像素遍历:手把手教你用C语言和VS2022读取图片的RGB数据 在数字图像处理领域,理解图像数据的底层存储结构是开发者必须掌握的核心技能。BMP作为Windows系统中最基础的位图格式,其简单的文件结构使其成为学习图像处理的理想起点。…...

Steam创意工坊下载终极指南:无需Steam账号也能畅玩海量模组
Steam创意工坊下载终极指南:无需Steam账号也能畅玩海量模组 【免费下载链接】WorkshopDL WorkshopDL - The Best Steam Workshop Downloader 项目地址: https://gitcode.com/gh_mirrors/wo/WorkshopDL WorkshopDL是一款跨平台Steam创意工坊下载工具ÿ…...

Linux查看文件内容
🏷️ 标签:Linux 查看文件 文件类型 Linux命令 运维 后端开发 📝 适用人群:Linux 新手、运维、后端、学生、实训使用 💡 亮点:包含 查看文件类型 查看整个文件 查看部分文件,结构清晰、示例可…...

Python PCB工具终极指南:5分钟学会解析Gerber和Excellon文件
Python PCB工具终极指南:5分钟学会解析Gerber和Excellon文件 【免费下载链接】pcb-tools Tools to work with PCB data (Gerber, Excellon, NC files) using Python. 项目地址: https://gitcode.com/gh_mirrors/pc/pcb-tools 你是否曾面对一堆Gerber和Excell…...

数环通iPaaS流程引擎中断恢复机制设计:快照 + 消息驱动实现无缝续跑
一个无法回避的问题 做iPaaS自动化引擎开发的同学迟早会遇到这个问题:流程跑到一半断了,怎么办? 不是那种代码bug导致的异常退出——那种靠异常处理就行。我说的是更真实、更棘手的场景: 服务发版需要滚动重启,机器上还…...

从欧氏距离到余弦相似度:5种距离度量如何影响你的KNN模型?用Scikit-learn实战对比
从欧氏距离到余弦相似度:5种距离度量如何影响你的KNN模型?用Scikit-learn实战对比 在机器学习的世界里,K近邻算法(KNN)因其简单直观而广受欢迎。但很多实践者往往只关注k值的选择,却忽略了另一个同等重要的超参数——距离度量。就…...

环保设备系统控制柜制造:从工艺联动到稳定达标的完整解析
一、什么是环保设备系统控制柜制造?环保设备系统控制柜制造,是指根据废气治理、污水处理、粉尘治理、喷淋塔、活性炭吸附、催化燃烧、RTO/RCO、除尘器、风机水泵、加药系统、污泥处理、在线监测和环保设备联动控制等实际需求,对PLC、变频器、…...