【多模态】21、BARON | 通过引入大量 regions 来提升模型开放词汇目标检测能力(CVPR2021)

文章目录
- 一、背景
- 二、方法
- 2.1 主要过程
- 2.2 Forming Bag of Regions
- 2.3 Representing Bag of Regions
- 2.4 Aligning bag of regions
- 三、效果
论文:Aligning Bag of Regions for Open-Vocabulary Object Detection
代码:https://github.com/wusize/ovdet
出处:CVPR2023
一、背景
传统目标检测器只能识别特定的类别,开放词汇目标检测由于不受预训练类别的限制,能够检测任意类别的目标,而受到了很多关注
针对 OVD 问题的一个典型解决方案就是基于蒸馏的方法,也就是从预训练的 vision-language 模型中蒸馏出丰富的特征来识别丰富的类别
VLM 是通过大量的 image-text pairs 来学习将两者对齐,如图 1a 所示
之前也有很多蒸馏的方法通过将每个 region embedding 和对应的从 VLM 中输出的特征进行对齐
本文作者提出【align the embedding of BAg of RegiONs】,来让模型不仅仅理解单个的目标,而是理解场景
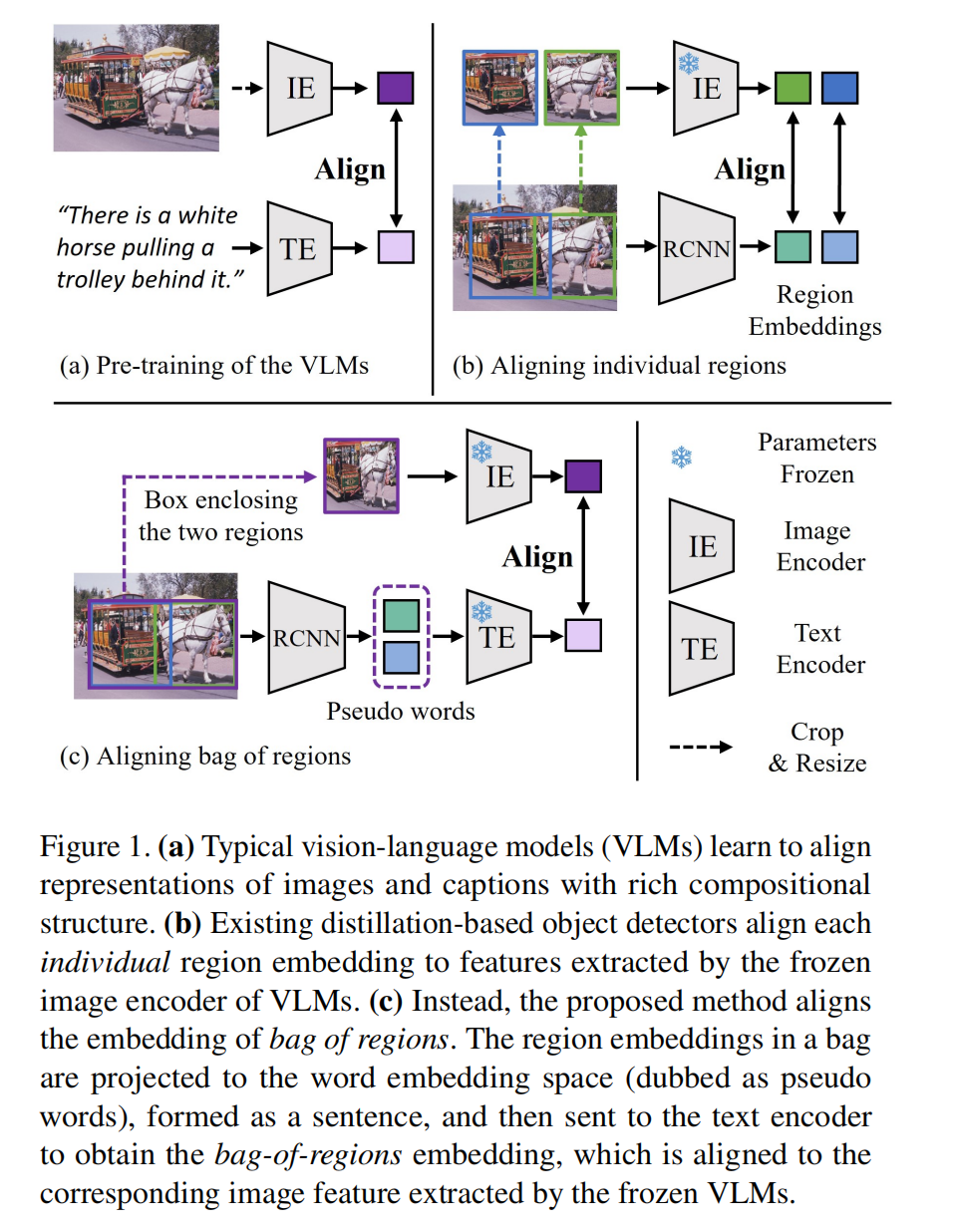
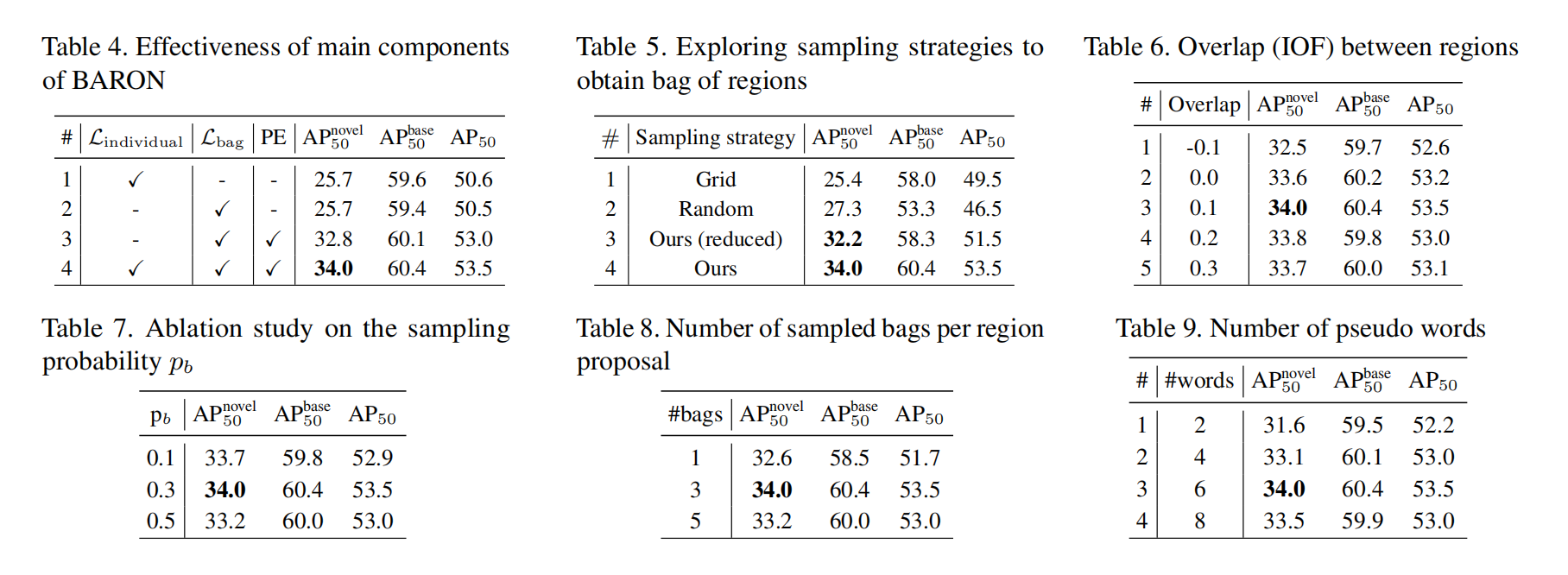
BARON 结构如图 1c 所示:
- 首先,从 bag 中抽取出和上下文相关的 region,由于 RPN 是需要能够提取出潜在的新类的,所以作者提出了 “neighborhood sampling strategy” 来抽取 region proposal 周围的框来帮助建模出共现的语义 concept
- 接着,BARON 通过将 region feature 投影到 word embedding space 得到 pseudo words,并且使用预训练好的 text encoder 来对这些 pseudo words 进行编码,得到一系列的 region embedding
- 投影到 word 空间的 pseudo words,就能够让 Text encoder 很好的抽取出共现的语义概念,并且理解整个场景
- 在送入 Text encoder 之前,为了保留 region box 的空间信息,会将 box shape 和 box center position 也投影到 embedding 中,驾到 pseudo word 上,然后再将 pseudo word 送入 Text encoder
- 训练 BARON 时,目标是将 bag-of-regions 的 embedding 和从教师 image encoder (IE)那里获得的 image crop 的 embedding 对齐,作者使用对比学习机制来学习 pseudo words 和 bag-of-regions embeddings,对比学习 loss 能够拉近成对儿的 pairs 的 student(detector)和 teacher(IE)embedding ,推远不成对儿的 pairs
二、方法
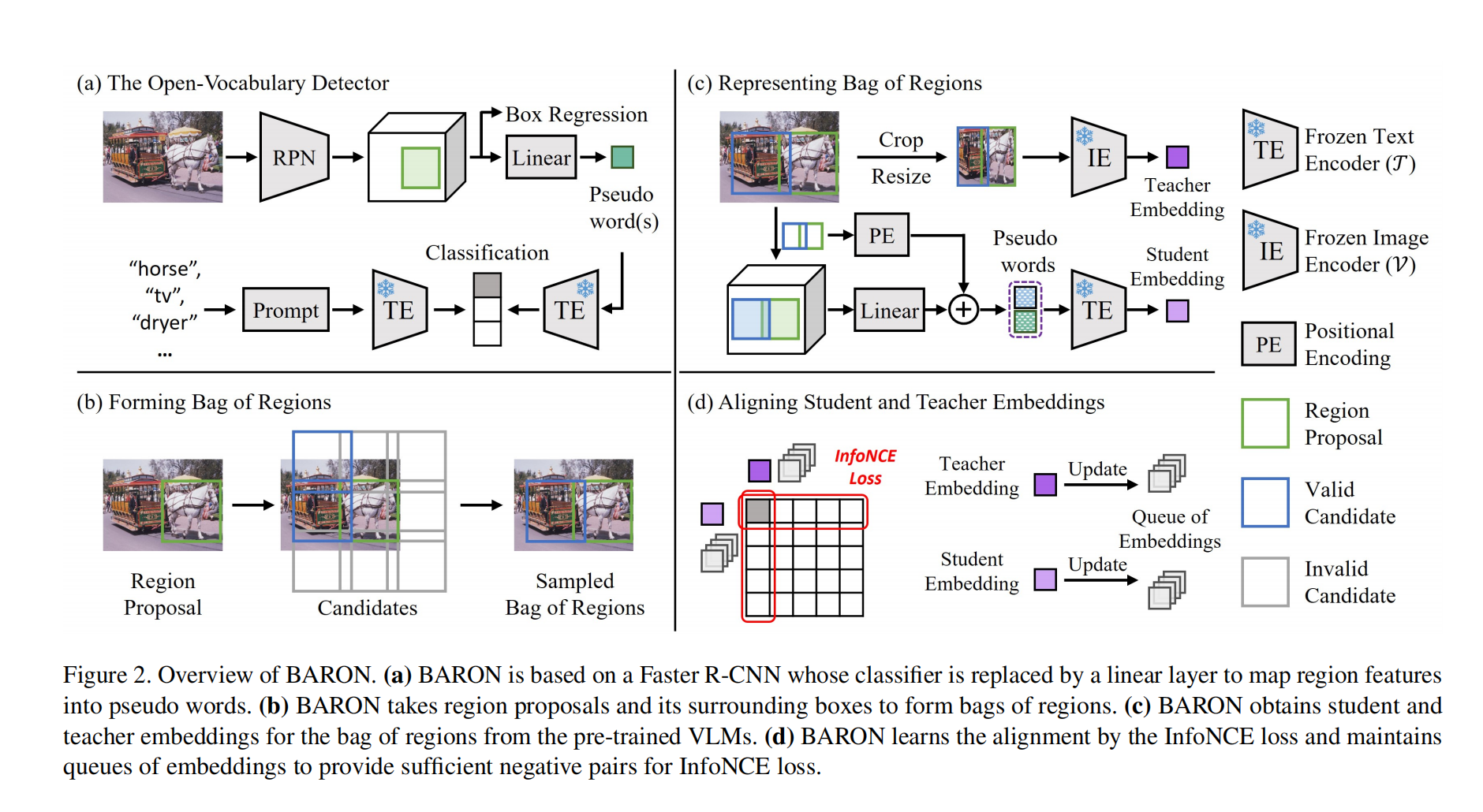
本文方法首次提出了对齐 bag of regions 的 embedding,之前的方法都是对齐单个 region 的 embedding
2.1 主要过程
本文方法主要基于 Faster R-CNN,为了让 Faster RNN 能够检测出任意词汇概念的目标,作者使用了一个线下映射层将原本的分类器代替了
线性映射层能够将 region features 映射到 word embedding space(即 pseudo words,如图 2a),这些 pseudo words 包含了每个目标更丰富的语义信息,类似于每个类别的名字包含了更多的单词(如 horse-driven trolley)
之后,将这些 pseudo words 输入 text encoder,计算和每个类别编码的相似性,然后得到类别结果
如图 2a 所示,给定 C 个目标类别,通过将类别名称转变为 prompt 模版 ‘a photo of {} in the scene’,并输入到 text encoder T 中来获得 embedding f c f_c fc
假设有 region 和其对应的 pseudo words w w w,该 region 是类别 c 的概率如下, < , > <,> <,> 表示 cosine 相似度, τ \tau τ 是温度系数
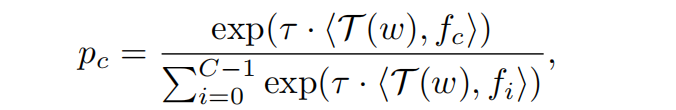
训练期间,只标注了基础类别,且也是使用基础类别来训练 Faster R-CNN 的回归和分类 loss 的
为了学习检测新类别(且没有 box 标注信息),之前的蒸馏方法都是只对齐单个的 region embedding 和其对应的从 VLMs 得到的特征
本文的方法为了捕捉更多的信息,将单个的 region 扩展到了 bag of regions
2.2 Forming Bag of Regions
本文中,也和其他方法一样使用 VLM 中的 image encoder 作者 teacher,来指导检测器的学习
不同的是,作者希望检测器能学习多个 concepts 的共现管辖,尤其是新目标的潜在出现的概率
为了效果和效率共存,作者将有如下两个属性的 regions 归到一个 bag 中去:
- 不同的 region 需要彼此距离接近
- 不同的 region 大小要相同
基于上面两个条件,作者使用 simple neighborhood sampling strategy,基于 RPN 预测得到的 region proposal,来构建 bag of regions
对每个 region proposal,作者都选取了其周围的 8 个相邻的 box 来作为候选,如图 2b 所示,此外,作者也会允许这些候选框之间有重叠,即 specific Intersection over Foreground (IOF) 来提高区域表达的连续性
为了平衡 bag 中 region 的 size,作者让着 8 个候选框的形状完全相同,且和该 region proposal 的大小也相同
2.3 Representing Bag of Regions
收集到 bag of regions 后, BARON 会从 student 和 teacher 中分别得到 bag-of-regions embeddings
假设第 i 个 groups 的第 j 个 region 为 b j i b_j^i bji,且 pseudo words 为 w j i w_j^i wji,用 T 表示预训练 VLM 的 文本编码器,V 表示图像编码器
1、student bag-of-regions embedding
由于region features 被投影到 word embedding space 且要和 text embedding 对齐,一个很直接的方法就是将这一系列的 pseudo words 进行 concat,然后输入 text encoder T 中,但是这样的话 region 的空间信息就会丢失,所以,作者将 bag 中的 regions 的中心位置、形状 都被编码了
位置编码会被夹到 pseudo word 上,然后再 concat
最终表达如下:
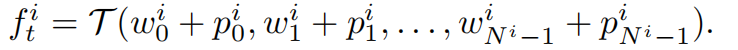
2、Teacher bag-of-regions embedding
使用 image encoder V 可以得到教师网络的编码,image feature 如下:
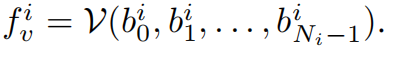
2.4 Aligning bag of regions
BARON 会将 teacher 的预测和 student 的学习结果进行对齐
给定 G 个 bag-of-regions,alignment InfoNCE loss 如下:
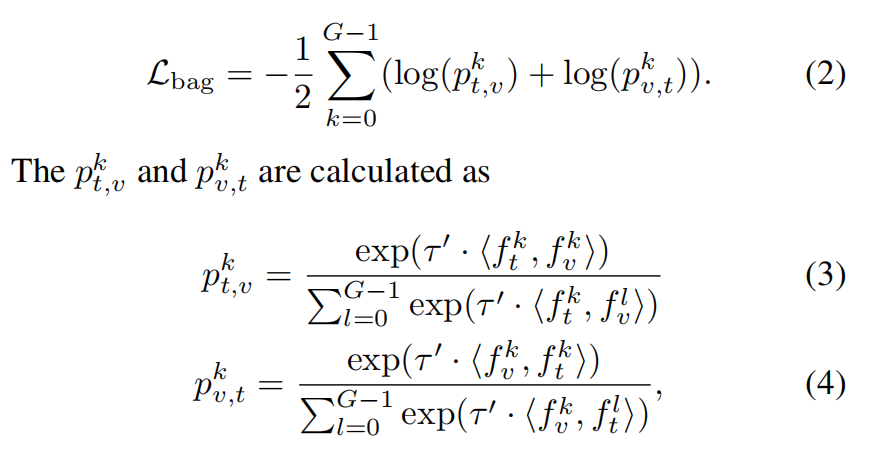
对齐单个 region:
单个 region 的 student 和 teacher embedding 的对齐对整个 bag-of-regions 的对齐很重要
所以,作者使用 individual-level distillation:
- teacher embedding:从 image encoder 的最后一个 attention 层使用 RoIAlign 获得
- 从 text encoder 的最后一个 attention layer 获得,对同一个 region 的所有 pseudo-word embedding 进行平均
- loss:使用 InfoNCE loss
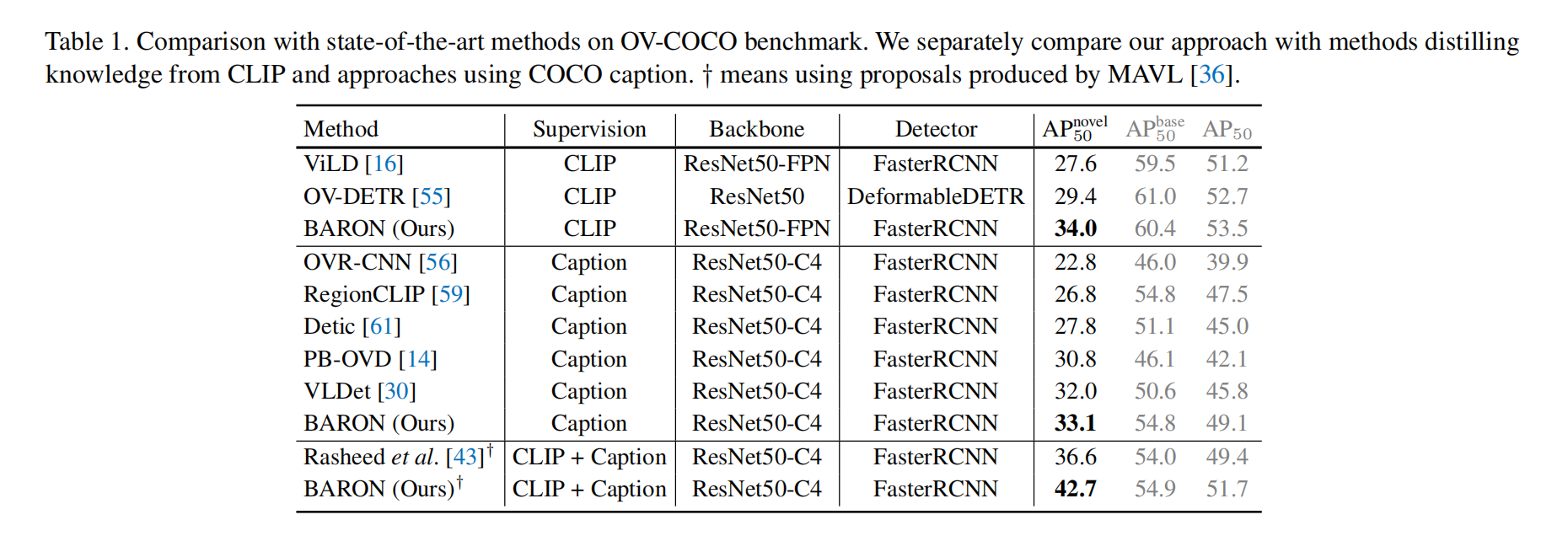
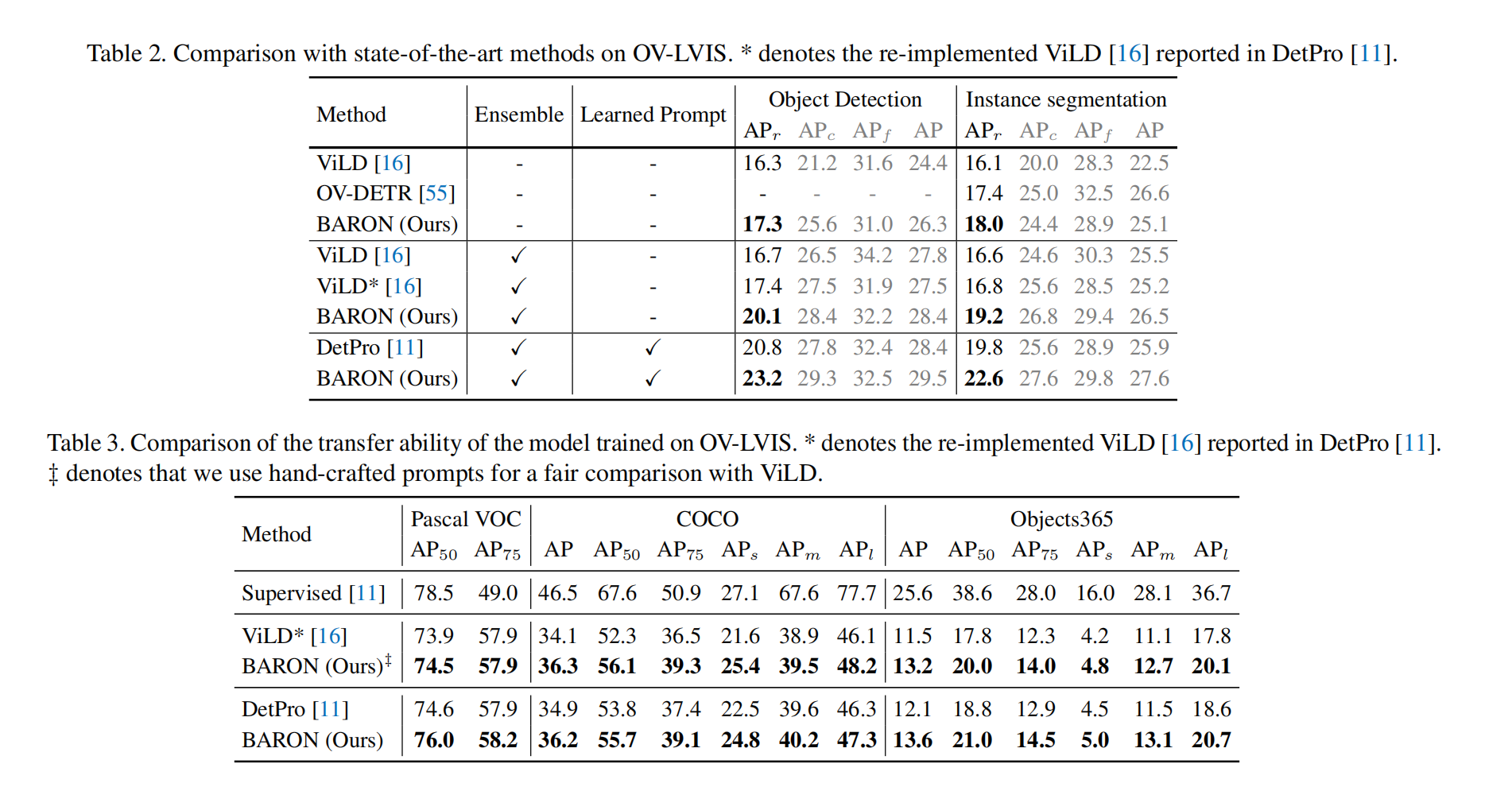
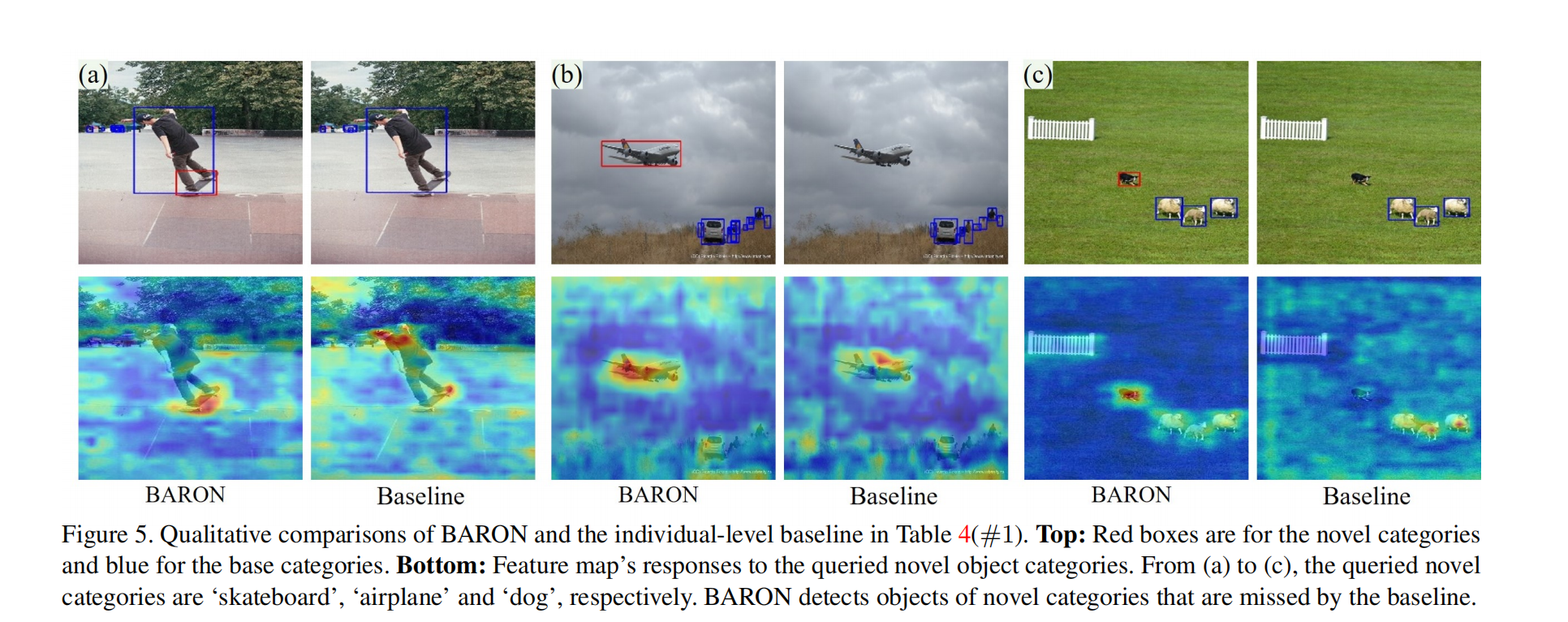
三、效果





相关文章:
【多模态】21、BARON | 通过引入大量 regions 来提升模型开放词汇目标检测能力(CVPR2021)
文章目录 一、背景二、方法2.1 主要过程2.2 Forming Bag of Regions2.3 Representing Bag of Regions2.4 Aligning bag of regions 三、效果 论文:Aligning Bag of Regions for Open-Vocabulary Object Detection 代码:https://github.com/wusize/ovdet…...

Ansible 自动化运维
目录 ansible 环境安装部署ansible 命令行模块inventory 主机清单 Ansible是一个基于Python开发的配置管理和应用部署工具,现在也在自动化管理领域大放异彩。它融合了众多老牌运维工具的优点,Pubbet和Saltstack能实现的功能,Ansible基本上都可…...

指纹浏览器能为TikTok运营提供哪些便利?
TikTok是一个非常垂直的平台,每个账号的内容都应尽可能保持垂直,这样平台才会给予更多的流量。有运营经验的TikTok用户一般会经营多个账号,从而获取更多的收益。指纹浏览器作为一种新型浏览器,它的优势不可否认。那么指纹浏览器能…...
关于远程直接内存访问技术 RDMA 的高性能架构设计介绍 | 龙蜥技术
编者按:传统以太网方案存在系统调用消耗大量时间、增加数据传输延时、对 CPU 造成很重的负担三个缺点,而 RDMA 技术可以解决以上三个缺点。那 RDMA 究竟是什么?它的方案的设计思路是什么?今天,浪潮信息驱动工程师刘伟带…...
【Boost搜索引擎项目】
文章目录 一、项目流程二、项目展示 一、项目流程 1.编写数据去标签模块–parser.cc 将去标签之后干净文档以title\3content\3url\ntitle\3content\3url\n格式放入同一文件中。 2.建立索引模块–index.hpp 读取处理好的行文本文件进行分词、权重计算等操作,在内存中…...
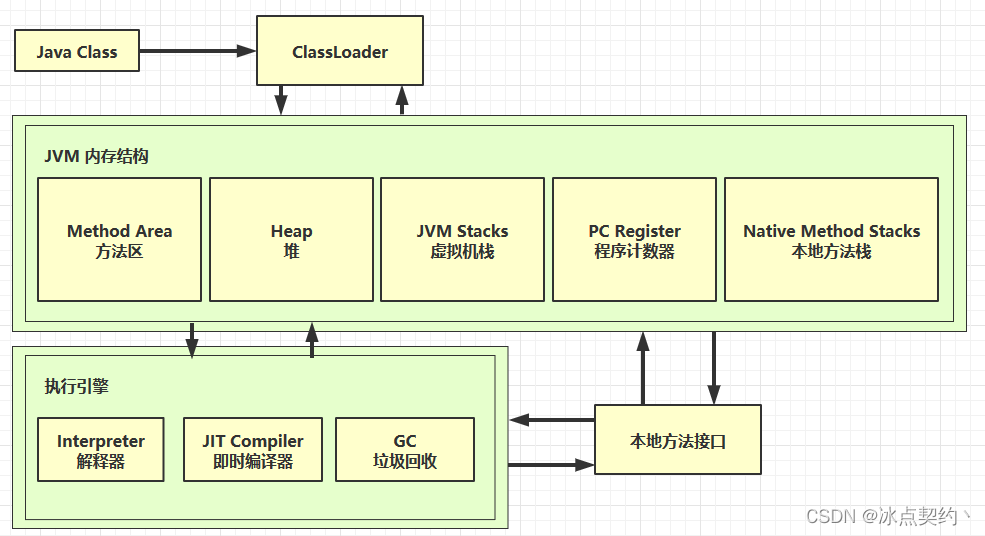
JVM入门篇-JVM的概念与学习路线
JVM入门篇-JVM的概念与学习路线 什么是 JVM 定义 Java Virtual Machine - java 程序的运行环境(java 二进制字节码的运行环境) 好处 一次编写,到处运行自动内存管理,垃圾回收功能数组下标越界检查多态 比较 jvm jre jdk 常…...

“程序员求职攻略:IT技术岗面试的必备技巧“
文章目录 每日一句正能量前言分享面试IT公司的小技巧IT技术面试有哪些常见的问题?分享总结遇到过的面试题后记 每日一句正能量 人活一世,不在乎朋友多少,不问财富几车,关键看在你最困难的时候,是否有一个伸出援手的人&…...

回归预测 | MATLAB实现WOA-ELM鲸鱼算法优化极限学习机多输入单输出回归预测
回归预测 | MATLAB实现WOA-ELM鲸鱼算法优化极限学习机多输入单输出回归预测 目录 回归预测 | MATLAB实现WOA-ELM鲸鱼算法优化极限学习机多输入单输出回归预测效果一览基本介绍程序设计参考资料 效果一览 基本介绍 Matlab实现WOA-ELM鲸鱼算法优化极限学习机多输入回归预测&#…...

方法的定义和格式
方法 什么是方法? 方法是程序中最小的执行单元 定义:把一些代码打包在一起,该过程称为方法 实际开发过程中,什么时候用到方法: 重复的代码,具有独立功能的代码可以抽取到方法中 实际开发中,方…...
:简易 shell 的实现(进程深刻理解、内建命令的使用))
【Linux】进程篇(补):简易 shell 的实现(进程深刻理解、内建命令的使用)
文章目录 makefilemybash.c 代码逻辑框架(重要的是,边写边查!) 命令行提示符,fflush 刷新显示获取 输入的 有效字符串,定义一个字符数组,用 fgets 从键盘上获取(注意处理命令行输入…...

django Ajax--前后端数据交互
一.Django的Ajax和JavaScript的Ajax Django的Ajax和JavaScript的Ajax实质上是指同一种技术,即异步JavaScript和XML(Asynchronous JavaScript and XML)。它允许在不刷新整个页面的情况下,通过前后端之间的异步交互来获取或发送数据…...

【嵌入式学习笔记】嵌入式入门1——GPIO
1.什么是GPIO General Purpose Input Output,即通用输入输出端口,简称GPIO,作用是负责采集外部器件的信息或者控制外部器件工作,即输入输出。 2.STM32 GPIO简介 2.1.GPIO特点 不同型号,IO口数量可能不一样&#x…...

[SQL挖掘机] - 多表连接: union
介绍: sql中的union是用于合并两个或多个select语句的结果集的操作符。它将多个查询的结果合并成一个结果集,并自动去除重复的行。请注意,union操作要求被合并的查询返回相同数量和类型的列。 用法: union的基本语法如下: select_stateme…...
)
AI面试官:SQL Server数据库(三)
AI面试官:SQL Server数据库(三) 当涉及到.NET工程师中关于SQL Server数据库的面试题时,主要考察候选人的数据库知识、SQL查询能力、数据库设计和优化等方面。 文章目录 AI面试官:SQL Server数据库(三)31. 数据库并发控制是什么?数据库有哪些常见的并发控制机制?32. 什…...

python刑事案卷图片转pdf
分两步,第一步是转图片,第二步是合并。 # -*- coding: utf-8 -*- import glob,os from PIL import Imagedef convert_to_pdf(path):# 打开图片文件img Image.open(path)# 将图片转换为 PDF,并保存到同名文件pdf_path os.path.splitext(path…...

vue使用driver.js完成页面引导的功能
需求:给客户做一个页面引导,教客户怎么做 效果: driverjs官方文档 一.安装driver.js # Using npm npm install driver.js# Using pnpm pnpm install driver.js# Using yarn yarn add driver.js 二.在自己需要引导的页面上引入driver.js i…...

学习中遇到的好博客
c日志工具之——log4cpp ECU唤醒的本质就是给ECU供电。 小文件:零拷贝技术 传输大文件:异步 IO 、直接 IO:如何高效实现文件传输:小文件采用零拷贝、大文件采用异步io直接io (123条消息) Linux网络编程 | 彻底搞懂…...
)
在CSDN学Golang云原生(Kubernetes集群安全)
一,ABAC授权模式 Kubernetes ABAC(Attribute-Based Access Control)授权模式是一种基于属性的访问控制模型,它可以根据用户或组的属性决定是否允许他们访问 Kubernetes 集群中的资源。 在使用 ABAC 授权模式时,管理员…...

浅谈深度神经网络
Deep neural networks are completely flexible by design, and there really are no fixed rules when it comes to model architecture. -- David Foster 前言 神经网络 (neural network) 受到人脑的启发,可模仿生物神经元相互传递信号。神经网络就是由神经元组成…...
『C语言初阶』第六章-操作符详解
前言 今天小羊又来为铁汁们更新C语言初阶的操作符详解,我们在平时写代码时总会写到一些算术操作符和赋值操作符,可是当铁汁们遇到其他的操作符时,就会望而却步,甚至写出一些bug,所以这期我给铁汁们带来新鲜出炉的操作…...

PowerToys汉化指南:3步让英文效率工具变成你的中文助手
PowerToys汉化指南:3步让英文效率工具变成你的中文助手 【免费下载链接】PowerToys-CN PowerToys Simplified Chinese Translation 微软增强工具箱 自制汉化 项目地址: https://gitcode.com/gh_mirrors/po/PowerToys-CN 你是不是曾经因为PowerToys的英文界面…...

免费一键去图片水印的app有哪些?2026年免费去水印app推荐与测评
在社交媒体时代,我们经常会遇到需要去除图片水印的情况——无论是处理自己的作品,还是优化电商产品图,亦或是整理素材库。但去水印听起来复杂,实际上现在已经有很多免费工具可以一键搞定。本文为你盘点2026年最实用的去水印解决方…...

CANN-opbase-昇腾NPU算子开发的基础设施为什么这么重要
CANN-opbase-昇腾NPU算子开发的基础设施为什么这么重要 所有 CANN AOL 算子仓库的底层都依赖 opbase。它不提供任何算子实现,提供的是算子注册、编译、调度的基础设施。如果你要写自定义 Ascend C 算子,opbase 是绕不过去的第一步。 opbase 提供了什么组…...

ContentBranch+CFBranch混合电影推荐模型|全网独家复现,深度学习实战篇 引入双分支融合架构,兼顾内容特征与协同信号、助力冷启动缓解、数据稀疏性优化、推荐精度有效涨点
目录 一、前言:混合推荐模型的核心价值与行业痛点 二、模型核心原理(全网独家拆解,通俗易懂) 2.1 整体架构逻辑 2.2 ContentBranch(内容分支)原理详解 2.3 CFBranch(协同过滤分支)原理详解 2.4 特征融合与预测层原理 2.5 模型优势总结 三、环境搭建(全平台适配…...

图表数据提取神器:3个步骤让WebPlotDigitizer帮你从图片中“挖“出宝贵数据
图表数据提取神器:3个步骤让WebPlotDigitizer帮你从图片中"挖"出宝贵数据 【免费下载链接】WebPlotDigitizer Computer vision assisted tool to extract numerical data from plot images. 项目地址: https://gitcode.com/gh_mirrors/we/WebPlotDigiti…...

TPU加速GAN训练实战:从设备配置到FID达标完整指南
1. 项目概述:为什么用TPU跑GAN不是“炫技”,而是解决实际瓶颈的刚需你有没有在Kaggle或Colab上训练过DCGAN、StyleGAN2或者哪怕一个简化版的WGAN?我试过——在单块P100 GPU上跑一个6464分辨率的生成器,50个epoch要花3小时17分钟&a…...

阿里云防火墙三层体系:安全组、iptables与云防火墙协同实战
1. 阿里云服务器防火墙不是“一个开关”,而是三层防御体系的协同控制点很多人第一次登录阿里云ECS控制台,看到“安全组”三个字,下意识就去翻“防火墙设置”菜单——结果找半天没找到。我带过十几期运维新人培训,90%的人第一反应都…...

Tomcat DefaultServlet MIME类型处理缺陷导致信息泄露
1. 这个漏洞不是“能读文件”那么简单,而是Tomcat在特定配置下主动把不该暴露的内部状态当HTTP响应发出去了CVE-2024-21733这个编号刚出来时,我第一反应是又一个“目录遍历”或“文件读取”类的老套路。但真正花半天时间搭环境复现、抓包分析、翻Tomcat源…...
)
告别操作割裂感:保存你的专属Blender配置文件(含Unity键位预设)
告别操作割裂感:保存你的专属Blender配置文件(含Unity键位预设) 在三维创作流程中,Blender与Unity的组合堪称黄金搭档。但当你在两个软件间频繁切换时,截然不同的操作方式就像开车时突然换挡——明明想左转却按了雨刷器…...

通过用量看板分析不同模型在taotoken上的实际token消耗差异
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 通过用量看板分析不同模型在taotoken上的实际token消耗差异 效果展示类,分享一名开发者在完成一个多轮对话项目后&…...