Spark Catalyst 查询优化器原理
这里我们讲解一下SparkSQL的优化器系统Catalyst,Catalyst本质就是一个SQL查询的优化器,而且和 大多数当前的大数据SQL处理引擎设计基本相同(Impala、Presto、Hive(Calcite)等)。了解Catalyst的SQL优化流程,也就基本了解了所有其他SQL处理引擎的工作原理。
*SQL优化器核心执行策略主要分为两个大的方向:基于规则优化(RBO)以及基于代价优化(CBO),基于规则
优化是一种经验式、启发式地优化思路,更多地依靠前辈总结出来的优化规则,简单易行且能够覆盖到大部分优
化逻辑,但是对于核心优化算子Join却显得有点力不从心。举个简单的例子,两个表执行Join到底应该使用
BroadcastHashJoin 还是SortMergeJoin?当前SparkSQL的方式是通过手工设定参数来确定,如果一个
表的数据量小于这个值就使用BroadcastHashJoin,但是这种方案显得很不优雅,很不灵活。基于代价优化
就是为了解决这类问题,它会针对每个Join评估当前两张表使用每种Join策略的代价,根据代价估算确定一种
代价最小的方案
*我们这里主要说明基于规则的优化,略提一下CBO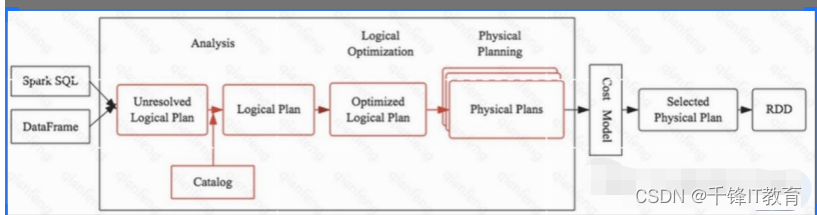
如上图是一个SQL经过优化器的最终生成物理查询计划的留存,红色部分是我们要重点说明的内容。大 家思考我们写的一个SQL最终如何在Spark引擎中转换成具体的代码执行的。任何一个优化器工作原理都大同小异:SQL语句首先通过Parser模块被解析为语法树,此棵树称为Unresolved Logical Plan; Unresolved Logical Plan通过Analyzer模块借助于数据元数据解析为Logical Plan;此时再通过各种基于规则的优化策略进行深入优化,得到Optimized Logical Plan;优化后的逻辑执行计划依然是逻辑的,并不能被Spark系统理解,此时需要将此逻辑执行计划转换为Physical Plan;为了更好的对整个过程进行理解,下文通过一个简单示例进行解释。
Parser
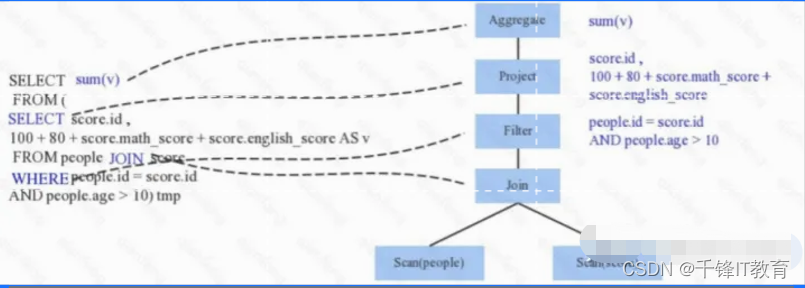
Parser简单来说是将SQL字符串切分成一个一个Token,再根据一定语义规则解析为一棵语法树。Parser模块目前基本都使用第三方类库 ANTLR 进行实现,比如Hive、 Presto、SparkSQL等。下图是一个示例性的SQL语句(有两张表,其中people表主要存储用户基本信息,score表存储用户 的各种成绩),通过Parser解析后的AST语法树如下图所示:
Analyzer
通过解析后的逻辑执行计划基本有了⻣架,但是系统并不知道score、sum这些都是些什么⻤,此 时需要基本的元数据信息来表达这些词素,最重要的元数据信息主要包括两部分:表的Scheme和 基本函数信息,表的scheme主要包括表的基本定义(列名、数据类型)、表的数据格式(Json、Text)、表的物理位置等,基本函数信息主要指类信息。
Analyzer会再次遍历整个语法树,对树上的每个节点进行数据类型绑定以及函数绑定,比如people 词素会根据元数据表信息解析为包含age、id以及name三列的表,people.age会被解析为数据类型 为int的变量,sum会被解析为特定的聚合函数,如下图所示:

Optimizer
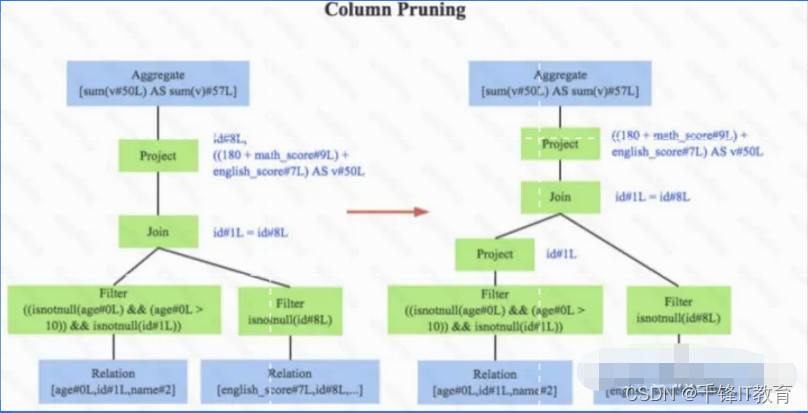
优化器是整个Catalyst的核心,上文提到优化器分为基于规则优化和基于代价优化两种,此处只介 绍基于规则的优化策略,基于规则的优化策略实际上就是对语法树进行一次遍历,模式匹配能够满 足特定规则的节点,再进行相应的等价转换。因此,基于规则优化说到底就是一棵树等价地转换为 另一棵树。SQL中经典的优化规则有很多,下文结合示例介绍三种比较常⻅的规则:谓词下推(Predicate Pushdown)、常量累加(Constant Folding)和列值裁剪(Column Pruning)
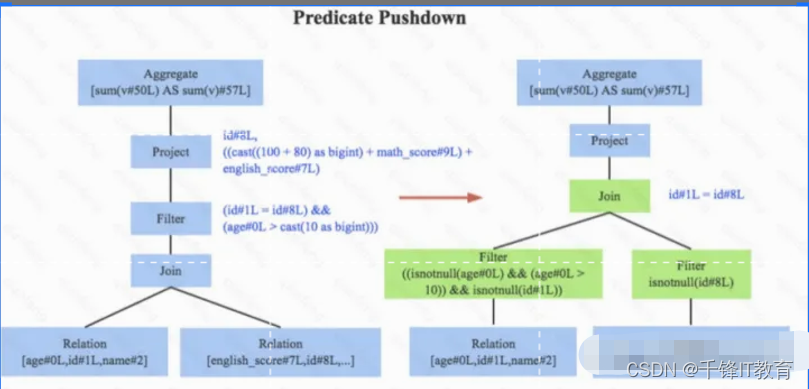
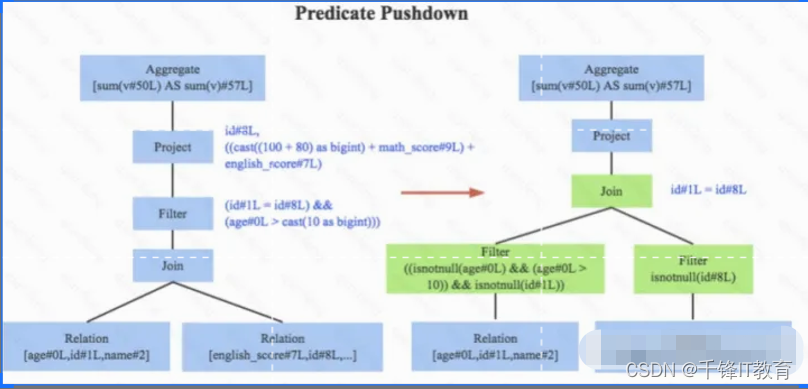
1.谓词下推, 下图左边是经过Analyzer解析后的语法树,语法树中两个表先做join,之后再使用age>10对结果进行过滤。大家知道join算子通常是一个非常耗时的算子,耗时多少一般取决于参与join的两个表的大小,如果能够减少参与join两表的大小,就可以大大降低join算子所需 时间。谓词下推就是这样一种功能,它会将过滤操作下推到join之前进行,下图中过滤条件age>0以及id!=null两个条件就分别下推到了join之前。这样,系统在扫描数据的时候就对数据 进行了过滤,参与join的数据量将会得到显著的减少,join耗时必然也会降低。
2.常量累加,如下图。 常量累加其实很简单,就是 x+(1+2) -> x+3 这样的规则,虽然是一个很小的改动,但是意义巨大。示例如果没有进行优化的话,每一条结果都需要执行一次100+80的操作,然后再与变量math_score以及english_score相加,而优化后就不需要再执行100+80操作。
3.列值裁剪,如下图。这是一个经典的规则,示例中对于people表来说,并不需要扫描它的所有列值,而只需要列值id,所以在扫描people之后需要将其他列进行裁剪,只留下列id。这个 优化一方面大幅度减少了网络、内存数据量消耗,另一方面对于列存数据库(Parquet)来说 大大提高了扫描效率
物理计划
经过上述步骤,逻辑执行计划已经得到了比较完善的优化,然而,逻辑执行计划依然没办法真正执行,他们只是逻辑上可行,实际上Spark并不知道如何去执行这个东⻄。比如Join只是一个抽象概 念,代表两个表根据相同的id进行合并,然而具体怎么实现这个合并,逻辑执行计划并没有说明。
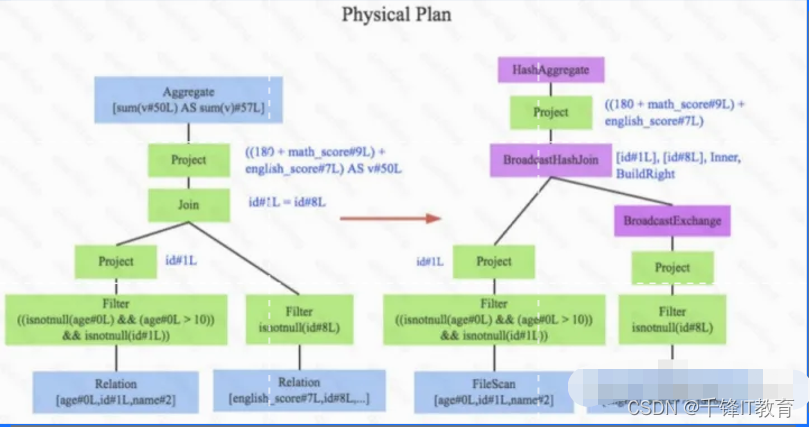
此时就需要将逻辑执行计划转换为物理执行计划,将逻辑上可行的执行计划变为Spark可以真正执 行的计划。比如Join算子,Spark根据不同场景为该算子制定了不同的算法策略,有BroadcastHashJoin、ShuffleHashJoin以及SortMergeJoin等(可以将Join理解为一个接口, BroadcastHashJoin是其中一个具体实现),物理执行计划实际上就是在这些具体实现中挑选一个耗时最小的算法实现,这个过程涉及到基于代价优化(CBO)策略,所谓基于代价 , 是因为物理执行计划的每一个节点都是有执行代价的,这个代价主要分为两部分
第一部分:该执行节点对数据集的影响,或者说该节点输出数据集的大小与分布(需要去采集)
第二部分:该执行节点操作算子的代价(相对固定,可用规则来描述)
在SQL 执行之前会根据代价估算确定一种代价最小的方案来执行。我们这里以Join为例子做个简单说明
*在SparkSQL中,Join可分为ShufflebasedJoin和BroadcastJoin。ShufflebasedJoin需要引入Shuffle,代价相对较高。BroadcastJoin无须Join,但要求至少有一张表足够小,能通过Spark的Broadcast机制广播到每个Executor中。*在不开启CBO中,SparkSQL通过spark.sql.autoBroadcastJoinThreshold判断是否启用BroadcastJoin。其默认值为10485760即10MB。并且该判断基于参与Join的表的原始大小。*在下图示例中,Table1大小为1TB,Table2大小为20GB,因此在对二者进行join时,由于二者都远大于自动BroatcastJoin的阈值,因此SparkSQL在未开启CBO时选用SortMergeJoin对二者进行Join。*而开启CBO后,由于Table1经过Filter1后结果集大小为500GB,Table2经过Filter2后结果集大小为10MB低于自动BroatcastJoin阈值,因此SparkSQL选用BroadcastJoin。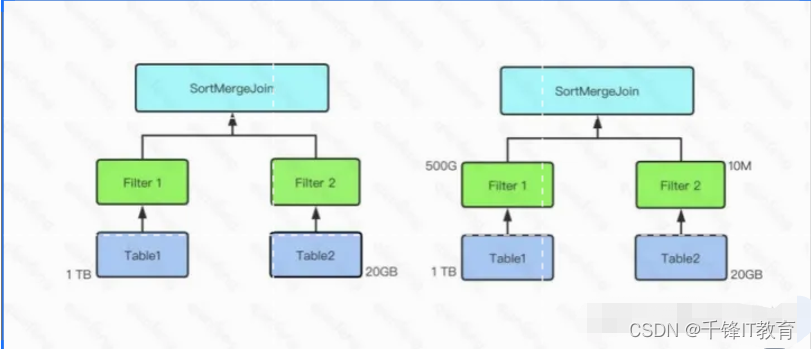
相关文章:
Spark Catalyst 查询优化器原理
这里我们讲解一下SparkSQL的优化器系统Catalyst,Catalyst本质就是一个SQL查询的优化器,而且和 大多数当前的大数据SQL处理引擎设计基本相同(Impala、Presto、Hive(Calcite)等)。了解Catalyst的SQL优化流程&…...
贝叶斯分析法在市场调研中的应用
一、市场调研的需求场景 在营销活动的用研调研时,我们经常会去问用户在不同平台的品类付费情况,以对比大促期间本品和竞品分别在哪些品类上具有市场优势,他们之间的差距具体在哪里、差距有多大。假如根据调研问卷结果,我们知道拼多多用户有30%的人在大促购买生鲜类,而淘宝…...
JavaEE——MyBatis将查询结果集封装进POJO实体类
简单介绍 在之前的我们比较详细的介绍过MyBatis的配置信息的时候,在SQL映射文件中说过我们可以直接将结果集映射到我们的POJO实体类中,省去了我们自己处理查询结果集的时间和代码,接下来我们就来演示将单条数据和多条数据映射到我们POJO实体…...

C++11 包装器function
文章首发公众号:iDoitnow C提供了多个包装器,它们主要是为了给其他编程接口提供更一致或更合适的接口。C11提供了多个包装器,这里我们重点了解一下包装器function。 对于function, C 参考手册给出的定义为: 类模板 std::function…...

XCP实战系列介绍14-基于Vector_Davinci工具的XCP配置介绍(三)
本文框架 1.概述2. 其他模块配置2.1 XCP初始化3. 手工代码部分3.1 周期函数添加3.2 DAQ Event调用3.3 XCP模块本身代码3.4 标定量的添加1.概述 在对XCP的配置部分介绍中我们计划分别对通讯部分配置、XCP模块本身配置及其他相关模块配置三篇进行介绍,在前两篇我们介绍了XCP配置…...

计算机图形学:中点BH算法对任意斜率的直线扫描转换方法
作者:非妃是公主 专栏:《计算机图形学》 博客地址:https://blog.csdn.net/myf_666 个性签:顺境不惰,逆境不馁,以心制境,万事可成。——曾国藩 文章目录专栏推荐专栏系列文章序一、问题提出二、…...
(十一)、用户中心页面【uniapp+uinicloud多用户社区博客实战项目(完整开发文档-从零到完整项目)】
1,个人中心页面 1.1 新建个人中心页面 1.2 纯净版个人中心页面代码: <template><view class"user"><view class"top"><view class"group"><view class"userinfo"><!-- 顶部 左侧 头像 …...

LA@复数和复矩阵@实对称阵相关定理
文章目录复数🎈复矩阵和复向量共轭矩阵性质定理实对称阵的相关定理复数🎈 复数 (数学) (wikipedia.org) 加法:(abi)(cdi)(ac)(bd)i)减法:(abi)−(cdi)(a−c)(b−d)i)乘法:(abi)(cdi)acbciadibdi2(ac−bd)(bcad)i除法&…...

cmd set命令笔记
使用 set是cmd最基础的命令,每个人都会用,但其实它还是有些知识的。 set 用来接收入参 set /p var请选择(1或2或3): echo %var%可以接收输入的参数。 set /p var请选择(1或2或3): echo %var% 语法 he…...
IB学校获得IBO授权究竟有多难?
IB 学校认证之路,道阻且长 The road to IB school accreditation is long and difficult一所学校能获得IB授权必须经过IBO非常严格的审核,在办学使命&教育理念、组织架构、师资力量&授课技能、学校硬件设施和课程体系上完全符合标准才可获得授权…...
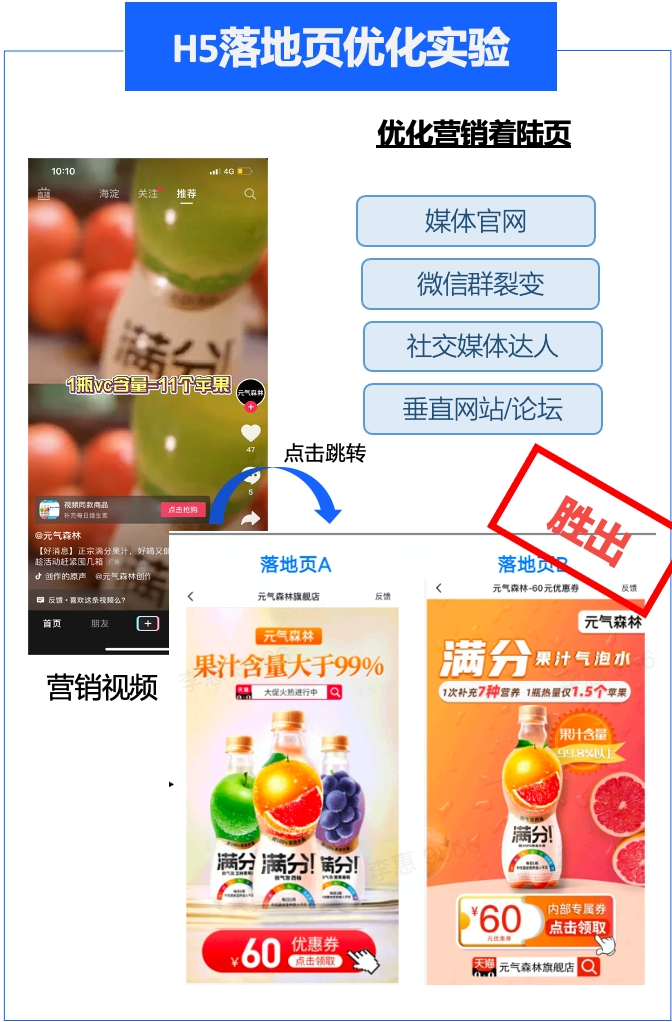
火山引擎 DataTester:A/B 测试,让企业摆脱广告投放“乱烧钱”
更多技术交流、求职机会,欢迎关注字节跳动数据平台微信公众号,回复【1】进入官方交流群 在广告投放的场景下,一线广告优化师通常会创建多个计划,去测试不同的广告素材效果。这套方法看似科学,实际上却存在诸多问题&…...
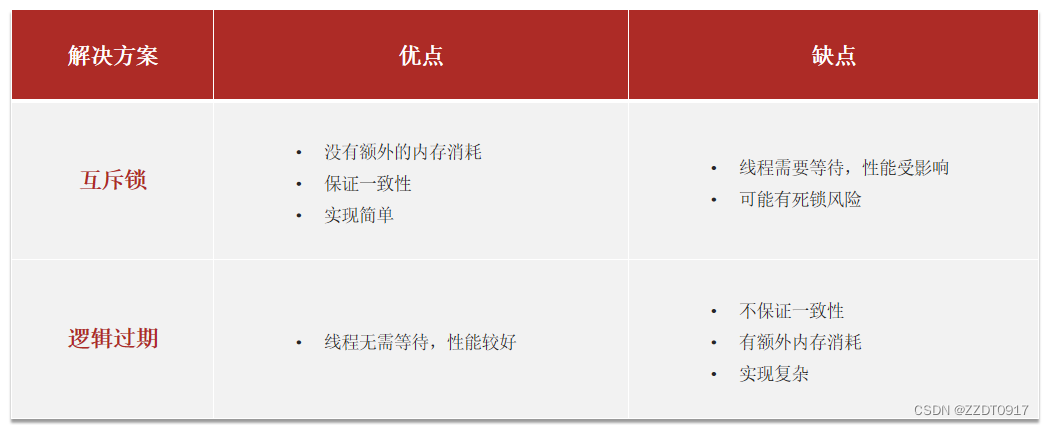
黑马redis学习记录:缓存
一、介绍 什么是缓存? 缓存(Cache),就是数据交换的缓冲区,俗称的缓存就是缓冲区内的数据,一般从数据库中获取,存储于本地代码 缓存无处不在 为什么要使用缓存? 因为速度快,好用缓存数据存储于代码中,而…...
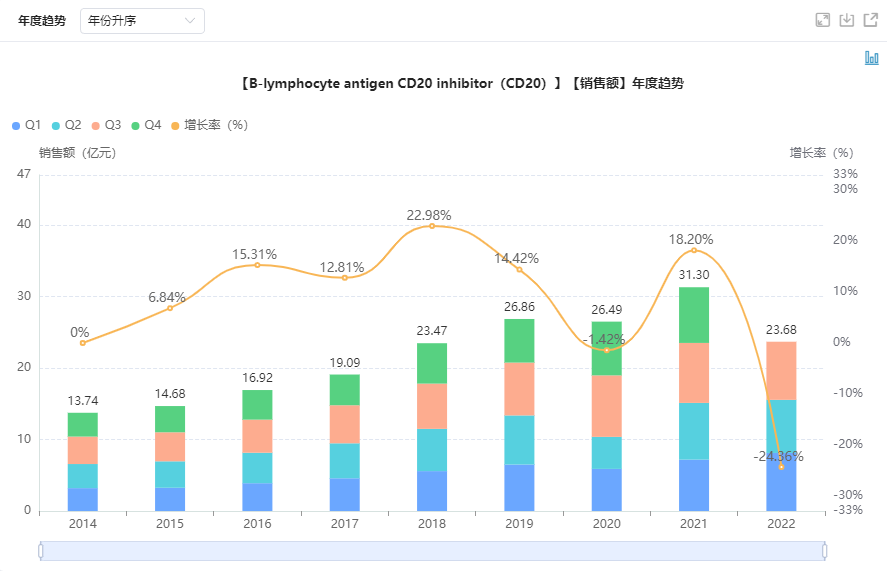
CD20靶向药物|适应症|市场销售-上市药品前景分析
CD20是靶向治疗的第一个靶点,是B细胞淋巴瘤的现代治疗药物。CD20作为治疗剂的使用被认为是方便的,原因有二。首先,在 CD20 阳性肿瘤的情况下,这种受体大量存在于 B 淋巴细胞表面——每个细胞大约有十万个分子。其次,干…...

多源 复制
使复制从属服务器能够同时从多个主服务器接收事务至少需要两个主服务器和一个从属服务器设备从属服务器为每个主服务器创建一个 复制通道从属服务器必须使用基于表的资料档案库多源复制与基于文件的资料档案库不兼容不尝试检测或解决冲突如果需要此功能,则由应用程序…...
微服务项目【消息推送(RabbitMQ)】
创建消费者 第1步:基于Spring Initialzr方式创建zmall-rabbitmq消费者模块 第2步:在公共模块中添加rabbitmq相关依赖 <!--rabbitmq--> <dependency><groupId>org.springframework.boot</groupId><artifactId>spring-bo…...

vr电力刀闸事故应急演练实训系统开发
电力事故是在电力生产和输电过程中可能发生的意外事件,它们可能会对人们的生命财产安全造成严重的威胁。因此,电力事故应急演练显得尤为重要。而VR技术则可以为电力事故应急演练提供一种全新的解决方案。 在虚拟环境中,元宇宙VR会模拟各种触电…...
C++类和对象补充
目录 前言: 1. 构造函数->初始化列表 1.1 初始化列表出现原因 1.2 初始化列表写法 2. explicit关键字 2.1 explict的出现 2.2 explict的写法 3. static成员 4. 友元 4.1 友元函数 4.2 友元类 5. 内部类和匿名对象 5.1 内部类 5.2 匿名对象 前言&a…...
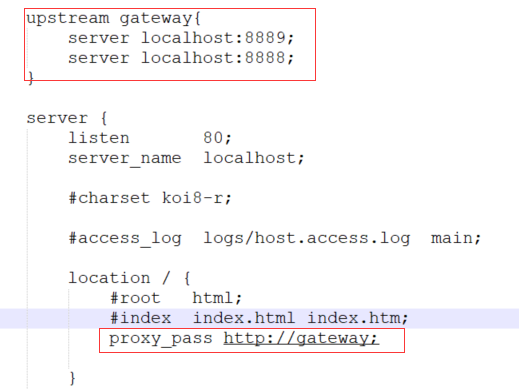
08 SpringCloud 微服务网关Gateway组件
网关简介 大家都都知道在微服务架构中,一个系统会被拆分为很多个微服务。那么作为客户端要如何去调用这么多的微服务呢? 如果没有网关的存在,我们只能在客户端记录每个微服务的地址,然后分别去用。 这样的架构,会存…...
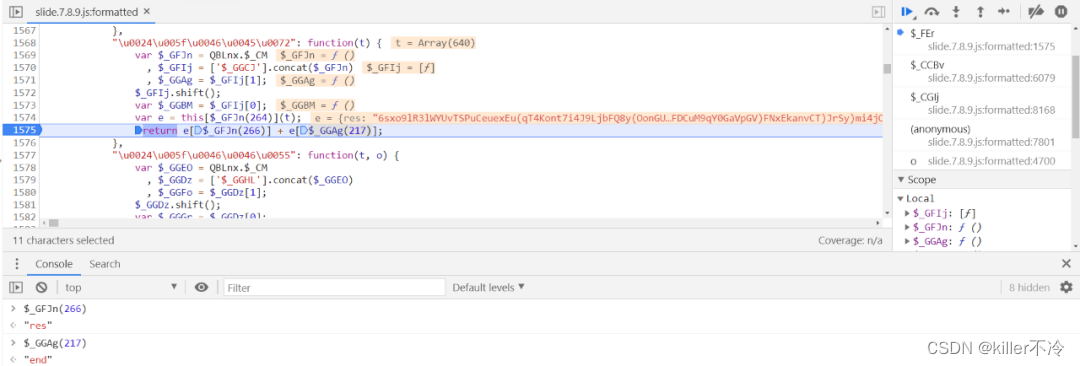
极验3代 加密分析
目标链接 aHR0cHM6Ly93d3cuZ2VldGVzdC5jb20vZGVtby9zbGlkZS1mbG9hdC5odG1s接口分析 极验参数重要信息 gt和challenge;gt是固定的,但是challenge每次请求会产生不同的,这里的请求的并没有什么加密参数。 下一个请求 gettype.php,…...

python 数据分析可视化实战 超全 附完整代码数据
代码数据:https://download.csdn.net/download/qq_38735017/873799141.1 数据预处理1.1.1 异常值检测①将支付时间转为标准时间的过程中发生错误,经排查错误数据为‘2017/2/29’,后将其修改为‘2017/2/27’。②经检测发现部分订单应付金额与实付金额都为…...

SEAforth多核芯片在工业控制中的并行处理优势
1. SEAforth芯片架构解析:工业控制的并行革命在工业自动化领域,传统单核MCU正面临越来越严峻的性能瓶颈。我曾参与过一个大型石化厂的温度监测系统改造项目,原系统采用常规ARM处理器,当需要同时处理32路热电偶信号、4路压力传感器…...

InjectFix实战解析:在Unity IL2CPP环境下实现C#热修复的权衡与策略
1. InjectFix在IL2CPP环境下的核心价值 当你的Unity手游在应用商店上线后突然出现致命Bug,传统解决方案往往需要重新打包、提交审核、等待上架,这个过程可能耗时数天。而InjectFix提供的C#热修复能力,可以在不更新客户端的情况下快速修复线上…...

优化ESP32 ADF 音频问题
可以,现在已经进入音质调试阶段了,不是“能不能播放”的阶段。 你现在的问题大概率不是一个单点问题,而是下面几类之一: 1. 音量 / 增益太大,导致 ES8388 或 MD8002A 功放削顶失真 2. I2S 时钟不准,导致声音…...

4sapi 企业级实战:统一模型网关与全生命周期管理解决方案
引言随着大模型技术在企业中的广泛应用,越来越多的企业开始面临 "模型碎片化" 的挑战。不同部门、不同业务线各自对接不同的大模型厂商,使用不同的 API 接口,导致企业内部出现了多个独立的 AI 孤岛,带来了一系列严重的问…...
)
AI原生图计算不是“加个GNN层”那么简单:SITS 2026定义的5层工程化成熟度模型(附自测清单+迁移路线图)
更多请点击: https://intelliparadigm.com 第一章:AI原生图计算应用:SITS 2026图神经网络工程化方案 SITS 2026 是面向大规模动态图场景的AI原生图计算框架,深度融合GNN训练、图拓扑实时更新与边缘-云协同推理能力。其核心设计摒…...

41《CAN总线报文周期、抖动与实时性分析》
CAN总线基础:从物理层到数据链路层的核心概念 一、一个让我熬夜的CAN问题 去年调试某款车载ECU时遇到个诡异现象:同一批次的控制器,有的在-20℃低温下CAN通信完全正常,有的却频繁丢帧。示波器挂上去一看,显性电平的下降沿斜率明显变缓,从正常的15ns拖到了40ns。查了三天…...

面试被问烂的20道编程基础题,你必须全会,不然别去面试
文章目录前言一、Python基础篇(6道)1. Python中list和tuple有什么区别?2. Python 3.7之后普通dict已经有序了,那OrderedDict还有存在的必要吗?3. Python中的深拷贝和浅拷贝有什么区别?4. Python中的*args和…...

信息安全工程师-主动防御体系核心技术:从监测溯源到隐私保护全解析
一、引言(一)技术定义与软考定位主动防御是相对于被动防御的安全理念,核心是通过主动诱捕、溯源标记、容忍恢复等技术,突破传统 “边界防护 事后补救” 的局限,实现攻击全生命周期的管控。本文涉及的数字水印、网络攻…...
 - Android 反编译器和调试器)
JEB Pro 5.40 (macOS, Linux, Windows) - Android 反编译器和调试器
JEB Pro 5.40 (macOS, Linux, Windows) - 逆向工程平台 Reverse Engineering for Professionals. 请访问原文链接:https://sysin.org/blog/jeb/ 查看最新版。原创作品,转载请保留出处。 作者主页:sysin.org JEB Decompiler JEB 是逆向工程…...

python算法毕设课题100例
文章目录🚩 1 前言1.1 选题注意事项1.1.1 难度怎么把控?1.1.2 题目名称怎么取?1.2 开题选题推荐1.2.1 起因1.2.2 核心- 如何避坑(重中之重)1.2.3 怎么办呢?🚩2 选题概览🚩 3 项目概览题目1 : 基于协同过滤的…...