基于深度学习的高精度狗狗检测识别系统(PyTorch+Pyside6+YOLOv5模型)
摘要:基于深度学习的高精度狗狗检测识别系统可用于日常生活中检测与定位120类狗狗目标,利用深度学习算法可实现图片、视频、摄像头等方式的狗狗目标检测识别,另外支持结果可视化与图片或视频检测结果的导出。本系统采用YOLOv5目标检测模型训练数据集,使用Pysdie6库来搭建页面展示系统,同时支持ONNX、PT等模型作为权重模型的输出。本系统支持的功能包括训练模型的导入、初始化;置信分与IOU阈值的调节、图像上传、检测、可视化结果展示、结果导出与结束检测;视频的上传、检测、可视化结果展示、结果导出与结束检测;摄像头的上传、检测、可视化结果展示与结束检测;已检测目标列表、位置信息;前向推理用时。另外本狗狗检测系统同时支持原始图像与检测结果图像的同时展示,原始视频与检测结果视频的同时展示。本博文提供了完整的Python代码和使用教程,适合新入门的朋友参考,完整代码资源文件请转至文末的下载链接。

基本介绍
近年来,机器学习和深度学习取得了较大的发展,深度学习方法在检测精度和速度方面与传统方法相比表现出更良好的性能。YOLOv5是单阶段目标检测算法YOLO的第五代,根据实验得出结论,其在速度与准确性能方面都有了明显提升,开源的代码可见https://github.com/ultralytics/yolov5。因此本博文利用YOLOv5检测算法实现一种高精度狗狗检测模型,再搭配上Pyside6库写出界面系统,完成目标检测识别页面的开发。注意到YOLO系列算法的最新进展已有YOLOv6、YOLOv7、YOLOv8等算法,将本系统中检测算法替换为最新算法的代码也将在后面发布,欢迎关注收藏。
环境搭建
(1)下载完整文件到自己电脑上,然后使用cmd打开到文件目录
(2)利用Conda创建环境(Anacodna),conda create -n yolo5 python=3.8 然后安装torch和torchvision(pip install torch1.10.0+cu113 torchvision0.11.0+cu113 -f https://download.pytorch.org/whl/torch_stable.html -i https://pypi.tuna.tsinghua.edu.cn/simple)其中-i https://pypi.tuna.tsinghua.edu.cn/simple代表使用清华源,这行命令要求nvidia-smi显示的CUDA版本>=11.3,最后安装剩余依赖包使用:pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple


(3)安装Pyside6库 pip install pyside6==6.3 -i https://pypi.tuna.tsinghua.edu.cn/simple

(4)对于windows系统下的pycocotools库的安装:pip install pycocotools-windows -i https://pypi.tuna.tsinghua.edu.cn/simple
界面及功能展示
下面给出本博文设计的软件界面,整体界面简洁大方,大体功能包括训练模型的导入、初始化;置信分与IOU阈值的调节、图像上传、检测、可视化结果展示、结果导出与结束检测;视频的上传、检测、可视化结果展示、结果导出与结束检测;已检测目标列表、位置信息;前向推理用时。希望大家可以喜欢,初始界面如下图:

模型选择与初始化
用户可以点击模型权重选择按钮上传训练好的模型权重,训练权重格式可为.pt、.onnx以及。engine等,之后再点击模型权重初始化按钮可实现已选择模型初始化信息的设置。


置信分与IOU的改变
在Confidence或IOU下方的输入框中改变值即可同步改变滑动条的进度,同时改变滑动条的进度值也可同步改变输入框的值;Confidence或IOU值的改变将同步到模型里的配置,将改变检测置信度阈值与IOU阈值。
图像选择、检测与导出
用户可以点击选择图像按钮上传单张图片进行检测与识别。

再点击图像检测按钮可完成输入图像的目标检测功能,之后系统会在用时一栏输出检测用时,在目标数量一栏输出已检测到的目标数量,在下拉框可选择已检测目标,对应于目标位置(即xmin、ymin、xmax以及ymax)标签值的改变。

再点击检测结果展示按钮可在系统左下方显示输入图像检测的结果,系统将显示识别出图片中的目标的类别、位置和置信度信息。

点击图像检测结果导出按钮即可导出检测后的图像,在保存栏里输入保存的图片名称及后缀即可实现检测结果图像的保存。

点击结束图像检测按钮即可完成系统界面的刷新,将所有输出信息清空,之后再点击选择图像或选择视频按钮来上传图像或视频。
视频选择、检测与导出
用户可以点击选择视频按钮上传视频进行检测与识别,之后系统会将视频的第一帧输入到系统界面的左上方显示。

再点击视频检测按钮可完成输入视频的目标检测功能,之后系统会在用时一栏输出检测用时,在目标数量一栏输出已检测到的目标数量,在下拉框可选择已检测目标,对应于目标位置(即xmin、ymin、xmax以及ymax)标签值的改变。

点击暂停视频检测按钮即可实现输入视频的暂停,此时按钮变为继续视频检测,输入视频帧与帧检测结果会保留在系统界面,可点击下拉目标框选择已检测目标的坐标位置信息,再点击继续视频检测按钮即可实现输入视频的检测。
点击视频检测结果导出按钮即可导出检测后的视频,在保存栏里输入保存的图片名称及后缀即可实现检测结果视频的保存。

点击结束视频检测按钮即可完成系统界面的刷新,将所有输出信息清空,之后再点击选择图像或选择视频按钮来上传图像或视频。
摄像头打开、检测与结束
用户可以点击打开摄像头按钮来打开摄像头设备进行检测与识别,之后系统会将摄像头图像输入到系统界面的左上方显示。

再点击摄像头检测按钮可完成输入摄像头的目标检测功能,之后系统会在用时一栏输出检测用时,在目标数量一栏输出已检测到的目标数量,在下拉框可选择已检测目标,对应于目标位置(即xmin、ymin、xmax以及ymax)标签值的改变。

点击结束视频检测按钮即可完成系统界面的刷新,将所有输出信息清空,之后再点击选择图像或选择视频或打开摄像按钮来上传图像、视频或打开摄像头。
算法原理介绍
本系统采用了基于深度学习的单阶段目标检测算法YOLOv5,相比于YOLOv3和YOLOv4,YOLOv5在检测精度和速度上都有很大的提升。YOLOv5算法的核心思想是将目标检测问题转化为一个回归问题,通过直接预测物体中心点的坐标来代替Anchor框。此外,YOLOv5使用SPP(Spatial Pyramid Pooling)的特征提取方法,这种方法可以在不增加计算量的情况下,有效地提取多尺度特征,提高检测性能。YOLOv5s模型的整体结构如下图所示。

YOLOv5网络结构是由Input、Backbone、Neck、Prediction组成。YOLOv5的Input部分是网络的输入端,采用Mosaic数据增强方式,对输入数据随机裁剪,然后进行拼接。Backbone是YOLOv5提取特征的网络部分,特征提取能力直接影响整个网络性能。在特征提取阶段,YOLOv5使用CSPNet(Cross Stage Partial Network)结构,它将输入特征图分为两部分,一部分通过一系列卷积层进行处理,另一部分直接进行下采样,最后将这两部分特征图进行融合。这种设计使得网络具有更强的非线性表达能力,可以更好地处理目标检测任务中的复杂背景和多样化物体。在Neck阶段使用连续的卷积核C3结构块融合特征图。在Prediction阶段,模型使用结果特征图预测目标的中心坐标与尺寸信息。博主觉得YOLOv5不失为一种目标检测的高性能解决方案,能够以较高的准确率对目标进行分类与定位。当然现在YOLOv6、YOLOv7、YOLOv8等算法也在不断提出和改进,后续博主也会将这些算法融入到本系统中,敬请期待。
数据集介绍
本系统使用的120类狗狗数据集标注了狗狗的120类品种,数据集总计20580张图片。该数据集中类别都有大量的旋转和不同的光照条件,有助于训练出更加鲁棒的检测模型。本文实验的狗狗检测识别数据集包含训练集16745张图片,验证集3835张图片,选取部分数据部分样本数据集如下图所示。由于YOLOv5算法对输入图片大小有限制,需要将所有图片调整为相同的大小。为了在不影响检测精度的情况下尽可能减小图片的失真,我们将所有图片调整为640x640的大小,并保持原有的宽高比例。此外,为了增强模型的泛化能力和鲁棒性,我们还使用了数据增强技术,包括随机旋转、缩放、裁剪和颜色变换等,以扩充数据集并减少过拟合风险。

关键代码解析
本系统的深度学习模型使用PyTorch实现,基于YOLOv5算法进行目标检测。在训练阶段,我们使用了预训练模型作为初始模型进行训练,然后通过多次迭代优化网络参数,以达到更好的检测性能。在训练过程中,我们采用了学习率衰减和数据增强等技术,以增强模型的泛化能力和鲁棒性。
在测试阶段,我们使用了训练好的模型来对新的图片和视频进行检测。通过设置阈值,将置信度低于阈值的检测框过滤掉,最终得到检测结果。同时,我们还可以将检测结果保存为图片或视频格式,以便进行后续分析和应用。本系统基于YOLOv5算法,使用PyTorch实现。代码中用到的主要库包括PyTorch、NumPy、OpenCV、PyQt等。


Pyside6界面设计
Pyside6是Python语言的GUI编程解决方案之一,可以快速地为Python程序创建GUI应用。在本博文中,我们使用Pyside6库创建一个图形化界面,为用户提供简单易用的交互界面,实现用户选择图片、视频进行目标检测。
我们使用Qt Designer设计图形界面,然后使用Pyside6将设计好的UI文件转换为Python代码。图形界面中包含多个UI控件,例如:标签、按钮、文本框、多选框等。通过Pyside6中的信号槽机制,可以使得UI控件与程序逻辑代码相互连接。
实验结果与分析
在实验结果与分析部分,我们使用精度和召回率等指标来评估模型的性能,还通过损失曲线和PR曲线来分析训练过程。在训练阶段,我们使用了前面介绍的狗狗数据集进行训练,使用了YOLOv5算法对数据集训练,总计训练了300个epochs。在训练过程中,我们使用tensorboard记录了模型在训练集和验证集上的损失曲线。从下图可以看出,随着训练次数的增加,模型的训练损失和验证损失都逐渐降低,说明模型不断地学习到更加精准的特征。在训练结束后,我们使用模型在数据集的验证集上进行了评估,得到了以下结果。

下图展示了我们训练的YOLOv5模型在验证集上的PR曲线,从图中可以看出,模型取得了较高的召回率和精确率,整体表现良好。

下图展示了本博文在使用YOLOv5模型对狗狗数据集进行训练时候的Mosaic数据增强图像。


综上,本博文训练得到的YOLOv5模型在数据集上表现良好,具有较高的检测精度和鲁棒性,可以在实际场景中应用。另外本博主对整个系统进行了详细测试,最终开发出一版流畅的高精度目标检测系统界面,就是本博文演示部分的展示,完整的UI界面、测试图片视频、代码文件等均已打包上传,感兴趣的朋友可以关注我私信获取。
其他基于深度学习的目标检测系统如西红柿、猫狗、山羊、野生目标、烟头、二维码、头盔、交警、野生动物、野外烟雾、人体摔倒识别、红外行人、家禽猪、苹果、推土机、蜜蜂、打电话、鸽子、足球、奶牛、人脸口罩、安全背心、烟雾检测系统等有需要的朋友关注我,从博主其他视频中获取下载链接。
完整项目目录如下所示:
相关文章:
基于深度学习的高精度狗狗检测识别系统(PyTorch+Pyside6+YOLOv5模型)
摘要:基于深度学习的高精度狗狗检测识别系统可用于日常生活中检测与定位120类狗狗目标,利用深度学习算法可实现图片、视频、摄像头等方式的狗狗目标检测识别,另外支持结果可视化与图片或视频检测结果的导出。本系统采用YOLOv5目标检测模型训练…...
从互联网到云时代,Apache RocketMQ 是如何演进的?
作者:隆基 2022 年,RocketMQ 5.0 的正式版发布。相对于 4.0 版本而言,架构走向云原生化,并且覆盖了更多业务场景。 消息队列演进史 操作系统、数据库、中间件是基础软件的三驾马车,而消息队列属于最经典的中间件之一…...
)
XML (可扩展标记语言)
目录 一、概念 二. 使用: 1. 基本语法: 2. 组成部分: (1)文档声明 (2) 指令(了解):结合css (3) 标签:标签名称自定义 (4)…...
、bind()、listen()、htons())
socket()、bind()、listen()、htons()
socket() socket() 是一个系统调用函数,用于创建一个套接字(socket),通过该套接字进行网络通信。在这段代码中,socket() 函数被用于创建一个本地套接字。 具体来说,这是 socket() 在代码中的使用方式&…...
提升开发效率,Lombok的链式编程和构建模式
目录 链式编程 定义 代码示例 编辑 Accessors(chaintrue) 开启链式编程 编辑 Accessors(chain true,fluent true) 去除set和get 构建模式 定义 代码示例 编辑 踩坑 Singular 定义 代码示例 踩坑默认值情况 编辑 With 定义 代码示例 链式编程 定义 链…...

DuDuTalk:AI语音工牌如何帮助教培公司高效管理课程顾问团队
近年来,随着人工智能的快速发展,越来越多的公司开始利用AI技术来提高工作效率和管理效果。在教育培训行业中,课程顾问团队的管理对于公司的运营和发展至关重要。 而在实际管理中,受教培人员素质参差不齐,能力差异大&a…...

C语言——静态库和动态库的创建和使用
使用库函数是源码的一种保护 库函数其实不是新鲜的东西,我们一直都在用,比如C库。我们执行pringf() 这个函数的时候,就是调用C库的函数. 下面记录静态库和动态库的生成和使用. 静态库:libxxx.a 动态库:libxxx.so 静态库: 在程序编译的时候,将库编译进可执行程序中, 运行的…...
数学学习——最优化问题引入、凸集、凸函数、凸优化、梯度、Jacobi矩阵、Hessian矩阵
文章目录 最优化问题引入凸集凸函数凸优化梯度Jacobi矩阵Hessian矩阵 最优化问题引入 例如:有一根绳子,长度一定的情况下,需要如何围成一个面积最大的图像?这就是一个最优化的问题。就是我们高中数学中最常见的最值问题。 最优化…...
HCIP期中实验
考试需求 1 、该拓扑为公司网络,其中包括公司总部、公司分部以及公司骨干网,不包含运营商公网部分。 2 、设备名称均使用拓扑上名称改名,并且区分大小写。 3 、整张拓扑均使用私网地址进行配置。 4 、整张网络中,运行 OSPF 协议…...

【Git系列】IDEA集成Git
🐳IDEA集成Git 🧊1. idea配置git🧊2. idea添加暂存区和提交🪟创建文件🪟将整个项目添加到暂存区🪟提交到本地仓库🪟查看控制台,显示提交的信息🪟修改文件,再次…...
短视频矩阵源码开发搭建分享--多账号授权管理
目录 文章目录 前言 一、矩阵号系统是什么? 二、使用步骤 1.创建推广项目 2.多账号授权 3.企业号智能客服系统 总结 前言 短视频多账号矩阵系统,通过多账号一键授权管理的方式,为运营人员打造功能强大及全面的“矩阵式“管理平台。…...
数据中台系列2:rabbitMQ 安装使用之 window 篇
RabbitMQ 是一个开源的消息队列系统,是高级消息队列协议(AMQP)的标准实现,用 erlang 语言开发。 因此安装 RabbitMQ 之前要先安装好 erlang。 1、安装 erlang 到 这里 下载本机能运行的最新版 erlang 安装包。如果本机没有装过 …...
Windows驱动开发
开发Windows驱动程序时,debug比较困难,并且程序容易导致系统崩溃,这时可以使用Virtual Box进行程序调试,用WinDbg在主机上进行调试。 需要使用的工具: Virtual Box:用于安装虚拟机系统,用于运…...

汽车分析,随时间变化的燃油效率
简述 今天我们来分析一个汽车数据。 数据集由以下列组成: 名称:每辆汽车的唯一标识符。MPG:燃油效率,以英里/加仑为单位。气缸数:发动机中的气缸数。排量:发动机排量,表示其大小或容量。马力&…...

大数据面试题之Elasticsearch:每日三题(六)
大数据面试题之Elasticsearch:每日三题 1. 为什么要使用Elasticsearch?2.Elasticsearch的master选举流程?3.Elasticsearch集群脑裂问题? 1. 为什么要使用Elasticsearch? 系统中的数据,随着业务的发展,时间…...
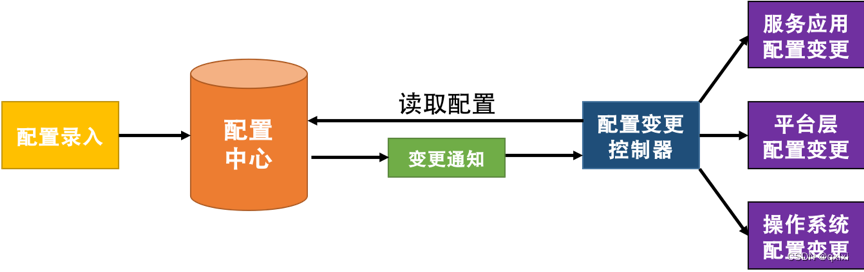
【管理设计篇】聊聊分布式配置中心
为什么需要配置中心 对于一个软件系统来说,除了数据、代码,还有就是软件配置,比如操作系统、数据库配置、服务配置 端口 ip 、邮箱配置、中间件软件配置、启动参数配置等。如果说是一个小型项目的话,可以使用Spring Boot yml文件…...

远程控制平台简介
写在前面 之所以想自己动手实现一个远程控制平台,很大一部分原因是因为我那糟糕的记性,虽然经常加班到很晚,拖着疲惫的步伐回到家,才想起忘记打卡了,如果我能在家控制在办公室的手机打一下卡就好了… 有人说,市场上有TeamViewer,向日葵,AnyDesk,ToDesk,等等这些老大…...
韦东山Linux驱动入门实验班(5)LED驱动---驱动分层和分离,平台总线模型
前言 (1)前面已经已经详细介绍了LED驱动如何进行编写的代码。如果韦东山Linux驱动入门实验班(4)LED驱动已经看懂了,驱动入门实验班后面的那些模块实验,其实和单片机操作差不太多了。我就不再浪费时间进行讲…...

【雕爷学编程】MicroPython动手做(02)——尝试搭建K210开发板的IDE环境
知识点:简单了解K210芯片 2018年9月6日,嘉楠科技推出自主设计研发的全球首款基于RISC-V的量产商用边缘智能计算芯片勘智K210。该芯片依托于完全自主研发的AI神经网络加速器KPU,具备自主IP、视听兼具与可编程能力三大特点,能够充分适配多个业务场景的需求。作为嘉楠科…...

C#——Thread与Task的差异比较及使用环境
C#——Thread与Task的差异比较及使用环境 前言一、差异1. 创建和管理:2. 异步编程:3. 返回值:4. 异常处理:5. 线程复用: 总结 前言 前面两篇文章,分别通过各自的实例讲了关于Task以及Thread的相关的使用特…...
)
从测速到配置:一套完整的cFosSpeed网络加速保姆级教程(适用于小白)
从零开始掌握cFosSpeed:网络加速全流程实战指南对于经常进行在线游戏、视频会议或大文件传输的用户来说,网络延迟和带宽利用率低下往往是影响体验的关键痛点。cFosSpeed作为一款专业的网络流量优化工具,能够显著改善这些问题,但许…...

基于LM22678的树莓派硬盘专用电源设计:解决供电不稳与电流冲击
1. 项目概述:为什么我们需要一个“专用”电源?如果你正在用树莓派搭配一块机械硬盘搭建一个家庭服务器或者个人云存储,可能已经遇到了一个不大不小的麻烦:供电不稳。树莓派官方推荐的5V/3A电源,单独带树莓派4B跑满负载…...

Redis分布式锁进阶第二十篇
一、本篇前置衔接 第二十篇我们完成了全系列终局复盘,整理了故障排查SOP与企业级落地铁律。常规单资源锁、热点分片锁、隔离锁全部讲透,但真实复杂业务永远不是单一资源:下单要扣库存、扣优惠券、扣积分、冻结余额,多资源并行争抢…...

WPF虚拟桌宠组件:可嵌入、高性能、工程化UI生命体
1. 这不是“桌面宠物”,而是一个可嵌入的WPF UI组件化生命体你可能在Windows XP时代见过那只晃着尾巴、偶尔打哈欠的3D小猫,也可能在Win10系统托盘里点开过一个会眨眼的像素狐狸——但那些是独立进程、是系统级小工具、是“看一眼就关掉”的轻量娱乐。而…...

孤舟笔记 互联网常用框架篇三 Dubbo是如何动态感知服务下线的?注册中心和服务端双保险
文章目录先说结论机制一:注册中心通知机制二:心跳检测机制三:连接事件感知机制四:定时拉取四种机制的协作回答技巧与点评加分回答面试官点评个人网站微服务环境下,服务实例随时可能上下线——重启、扩容、宕机……调用…...

Airtest Poco实战:5分钟搞定微信小程序自动化测试环境搭建与元素抓取
Airtest Poco实战:5分钟搞定微信小程序自动化测试环境搭建与元素抓取微信小程序作为轻量级应用的代表,已经渗透到电商、社交、工具等各个领域。随着小程序功能的日益复杂,自动化测试成为保障产品质量的重要手段。本文将带你快速搭建微信小程序…...

基于MAX78000的医疗紧急呼叫系统:边缘AI与低功耗设计实战
1. 项目概述与核心价值大家好,我是Victor Hugo,一名电子工程师。今天我想和大家分享一个我最近完成并参与设计竞赛的项目:一个基于MAX78000 FTHR开发板的医疗紧急呼叫辅助系统。这个项目的核心,不是从零开始造一个新轮子ÿ…...

论文润色深度测评:GPT-5.5 + Gemini 3.1 Pro:教你学会1+1>2的论文润色方法
各位同仁好,我是七哥。一个在高校里从事人工智能相关领域研究,钻研用大模型AI实操的学术人。可以和七哥交流学术写作或Gemini、GPT、Claude等大模型学术实操相关问题,多多交流,相互成就,共同进步。 2026年的科研圈,AI工具的选择已经从有没有变成了强不强,七哥评测了GPT…...
)
告别SVN恐惧症:美术策划也能轻松上手的Unity PlasticSCM极简入门(附团队项目拉取实战)
告别SVN恐惧症:美术策划也能轻松上手的Unity PlasticSCM极简入门(附团队项目拉取实战) 在游戏开发团队中,版本控制系统是协作的基石,但传统工具如SVN往往让非技术成员望而生畏。当美术资源频繁更新、策划案不断迭代时&…...

ComfyUI-Manager完整指南:如何轻松管理你的AI工作流扩展库
ComfyUI-Manager完整指南:如何轻松管理你的AI工作流扩展库 【免费下载链接】ComfyUI-Manager ComfyUI-Manager is an extension designed to enhance the usability of ComfyUI. It offers management functions to install, remove, disable, and enable various c…...