计算机论文中名词翻译和解释笔记
看论文中一些英文的简写不知道中文啥意思,或者一个名词不知道啥意思。
于是自己做了一个个人总结。
持续更新
目录
- Softmax
- Deep Learning(深度学习)
- 循环神经网络(Recurrent Neural Network简称 RNN)
- 损失函数/代价函数(Loss Function)
- 基于手绘草图的三维模型检索(Sketch based shape retrieval,SBSR)
- 卷积神经网络(Convolutional Neural Networks, CNN)
- 多视图卷积神经网络(Multi-view Convolutional Neural Networks,MVCNN)
- BN(Batch Normalization 翻译成中文:批归一化)
- 自然语言处理(NLP,Natural Language Processing)
- 计算机视觉(Computer Vision 简称CV)
- 注意力机制(Attention Mechanism)
- 自注意力机制(Self-attention)
- CBAM注意力机制模块
- MLP((Multi-Layer Perceptron)
- RPN(region proposal network)区域候选网络
- 元类别
- 交叉熵
- 卷积(conv)
- 多尺度特征
- 多层特征融合 (dense multi-layers aggregation, Dense-MLA)
- 偏置注意力机制(offset-attention, OSA)
- 最大池化
- 单层感知机(single-layer perceptron, SLP)
- 残差连接
- 类别
- 总体准确率(overall accuracy, OA)
- 消融实验
- 卷积核
- 注意力矩阵
- 动态图卷积网络(dynamic graph CNN, DGCNN)
- 递归注意卷积神经网络(recurrent attention convolutional neural network, RA-CNN)
- 球邻域查询
- 压缩感知机预测类标签
- 上下文特征
- 分辨率
- 区域建议网络(region proposal network, RPN)
- 弱监督细分类方法
- 双线性卷积神经网络模型(Bilinear CNN)
- 泛化能力
- 感受野
- 残差块(Residual Block)
- FC 层
- 扁平化处理
- 空间感知胶囊块
- 显著特征检测(Salient feature detection,SFD)
- 完全特征融合(Complete feature fusion,CFF)
- 过拟合
- 特征描述符
- 鲁棒性
- 激活函数
- 梯度下降算法
- ResNet50
- resnet中的bottleneck block
- 门向量
- 分数排序正则化
- 归一化
- sigmoid
- chatgpt
- Resnet
- concat
- ⊙ / 通道积(channel-wise)
Softmax
Softmax是一种数学函数,通常用于将一组任意实数转换为表示概率分布的实数。其本质上是一种归一化函数,可以将一组任意的实数值转化为在[0, 1]之间的概率值,因为softmax将它们转换为0到1之间的值,所以它们可以被解释为概率。如果其中一个输入很小或为负,softmax将其变为小概率,如果输入很大,则将其变为大概率,但它将始终保持在0到1之间。
Softmax是逻辑回归的一种推广,可以用于多分类任务,其公式与逻辑回归的sigmoid函数非常相似。只有当分类是互斥的,才可以在分类器中使用softmax函数,也就是说只能是多元分类(即数据只有一个标签),而不能是多标签分类(即一条数据可能有多个标签)。
许多多层神经网络输出层的最后一层是一个全连接层,输出是一个实数向量,这个向量通常代表了每个类别的得分或置信度。为了将这些得分转换为概率分布,通常会使用softmax函数。因为它将分数转换为规范化的概率分布,可以显示给用户或用作其他系统的输入。所以通常附加一个softmax函数在神经网络的最后一层之后。

https://zhuanlan.zhihu.com/p/628492966
Deep Learning(深度学习)
循环神经网络(Recurrent Neural Network简称 RNN)
特指将当前的状态信息循环传递给自身的网络模型。
损失函数/代价函数(Loss Function)
损失函数是用来衡量机器学习模型预测结果与真实结果之间的差异程度的函数。在机器学习中,我们通常会使用训练数据来训练模型,然后使用测试数据来评估模型的性能。损失函数可以作为模型训练过程中的优化目标,帮助模型找到最优的参数值,使得预测结果与真实结果之间的差异最小化。
具体来说,损失函数可以根据不同的任务和应用场景而有所不同。例如,在分类任务中,我们通常会使用交叉熵损失函数来衡量模型预测结果与真实标签之间的差异。在回归任务中,我们可以使用均方误差(MSE)或平均绝对误差(MAE)等损失函数来衡量模型预测结果与真实值之间的差异。通过优化损失函数,我们可以训练出更加准确和可靠的机器学习模型,从而提高模型的性能和泛化能力。
基于手绘草图的三维模型检索(Sketch based shape retrieval,SBSR)
卷积神经网络(Convolutional Neural Networks, CNN)
多视图卷积神经网络(Multi-view Convolutional Neural Networks,MVCNN)
BN(Batch Normalization 翻译成中文:批归一化)
https://blog.csdn.net/hjimce/article/details/50866313
自然语言处理(NLP,Natural Language Processing)
是研究人与计算机交互的语言问题的一门学科。
计算机视觉(Computer Vision 简称CV)
注意力机制(Attention Mechanism)
注意力机制:当面对大量的数据时,我们的大脑会把注意力放在主要的信息上,这就是大脑的注意力机制。
https://blog.csdn.net/Aaaa_ZZZ/article/details/126749836
自注意力机制(Self-attention)
CBAM注意力机制模块
一般而言,注意力机制可以分为:通道注意力机制、空间注意力机制、二者的结合。
- 空间注意力机制(关注每个通道的比重):
- 通道注意力机制(关注每个像素点的比重):SENet
- 二者的结合:CBAM
MLP((Multi-Layer Perceptron)
即多层感知器,是一种趋向结构的人工神经网络,映射一组输入向量到一组输出向量。MLP可以被看做是一个有向图,由多个节点层组成,每一层全连接到下一层。除了输入节点,每个节点都是一个带有非线性激活函数的神经元(或称处理单元)。一种被称为反向传播算法的监督学习方法常被用来训练MLP。MLP是感知器的推广,克服了感知器无法实现对线性不可分数据识别的缺点。)
RPN(region proposal network)区域候选网络
文章
元类别
"元类别"是一个比较抽象的概念,主要用于编程和数据分析领域。
- 在面向对象编程中,元类别(Meta Class)是一种用于生成类的类。换句话说,就像常规类定义了对象的结构和行为,元类别则定义了类的结构和行为。Python中有元类的概念,通过元类我们可以控制和修改类的创建。
- 在数据分析中,元类别可能指的是数据的一个高级分类。比如,我们有一堆数据关于不同类型的动物,这些动物可以被分为“哺乳动物”,“鸟类”,“鱼类”等。然后,“哺乳动物”、“鸟类”、和“鱼类”这些可以被进一步归纳为一个元类别,比如“动物”。
这个词的具体含义可能会根据上下文而变化。
交叉熵
交叉熵是一种用于衡量两个概率分布之间差异的指标。在机器学习中,我们通常使用交叉熵来比较模型输出的概率分布与真实标签的概率分布之间的差异。交叉熵越小,表示模型输出的概率分布越接近真实标签的概率分布,模型的性能也就越好。
卷积(conv)
在计算机中,卷积是一种数学运算,通常用于图像处理和信号处理中。卷积可以将两个函数合并成一个新的函数,其中一个函数通常是输入数据,另一个函数通常是权重或滤波器。在图像处理中,卷积可以用于提取图像中的特征,例如边缘、纹理等。在深度学习中,卷积神经网络(Convolutional Neural Network, CNN)使用卷积层来提取输入数据中的特征,并将这些特征用于下游任务,例如分类、检测等。
多尺度特征
多尺度特征是指在图像或视频中提取的具有不同尺度的特征。这些特征可以包括颜色、纹理、形状等信息,它们可以在不同的尺度下被提取,从而使算法能够更好地理解图像或视频中的内容。多尺度特征在计算机视觉和图像处理中非常常见,它们被广泛应用于目标检测、图像分类、人脸识别等任务中。
多层特征融合 (dense multi-layers aggregation, Dense-MLA)
偏置注意力机制(offset-attention, OSA)
最大池化
最大池化是一种常用的池化操作,它通常用于卷积神经网络中。在最大池化操作中,池化层将输入张量分割成若干个子区域,然后对每个子区域取最大值作为输出。这样做的效果是可以保留输入张量中最显著的特征,同时减少了输出张量的尺寸,从而减少了计算量和参数数量。最大池化被广泛应用于图像分类、目标检测等深度学习任务中。
单层感知机(single-layer perceptron, SLP)
单层感知机(Single-layer Perceptron,SLP)是一种最简单的神经网络模型,它是由一个输入层和一个输出层组成,其中每个输入对应一个权重,输出层根据输入和权重的线性组合再加上一个阈值进行二分类或多分类。SLP模型的输入可以是实数或者二元值,输出是一个实数或者一组实数,通常用于二分类或者多分类任务。SLP模型的训练过程使用的是感知机算法,它是一种基于梯度下降的优化算法,可以用于更新权重和阈值,使得模型能够更好地拟合训练数据。虽然SLP模型非常简单,但在一些简单的分类任务中已经能够取得不错的效果。
残差连接
残差连接(Residual Connection)是指在神经网络中将某一层的输入直接与该层的输出相加的操作。这种操作可以帮助神经网络更好地学习恒等映射,即将输入直接传递到输出,从而避免了梯度消失和梯度爆炸的问题,加速了模型的训练,并提高了模型的准确性。
具体来说,残差连接是在某一层的输出和输入之间建立一条直接的连接,将二者相加。这样做的好处是可以使得模型在学习某些复杂函数时更加容易,因为它可以通过残差连接来跳过某些层,从而更快地学习到恒等映射。此外,残差连接还可以帮助解决梯度消失和梯度爆炸的问题,因为它可以使得梯度能够更快地传播到较浅的层,从而加速了模型的训练,并提高了模型的准确性。
类别
类别是指在分类问题中待分类的对象所属的类别或类标签。在机器学习和深度学习中,分类问题是指将输入数据分为不同的类别,例如将图像分为不同的物体类别、将文本分为不同的主题类别等。每个类别通常由一个标签或者一个数字来表示,例如在图像分类任务中,可以将不同的物体类别分别用数字0、1、2等来表示。类别是分类问题中非常重要的概念,它决定了模型的输出和评估标准,并且是训练和测试数据集划分的基础。
总体准确率(overall accuracy, OA)
消融实验
消融实验是指在机器学习或深度学习中,通过逐步去除模型中的某些组件或功能,来探究这些组件或功能对模型性能的影响。消融实验通常用于研究模型的鲁棒性、泛化能力、可解释性等方面,以及验证某些假设或理论。在消融实验中,可以通过去除某些层、模块、特征或其他组件,来比较模型在有无这些组件的情况下的性能差异,从而得出结论。消融实验是一种常用的研究方法,可以帮助研究人员更好地理解模型的工作原理,从而指导模型的设计和优化。
卷积核
卷积核是卷积神经网络中的一种重要组件,也称为滤波器或过滤器。卷积核是一个小的矩阵,通常大小为1x1或3x3或5x5,它包含了一组权重,用于对输入的图像或特征图进行卷积操作。在卷积操作中,卷积核在输入图像或特征图上滑动,对每个位置进行卷积计算,从而得到一个输出特征图。卷积核的大小、数量和权重是卷积神经网络的关键设计参数之一,不同的卷积核可以提取不同的特征,例如边缘、纹理、颜色等。通过堆叠多个卷积层和激活函数,卷积神经网络可以逐渐提取更加高级的特征,从而实现图像分类、目标检测、语音识别等任务。
注意力矩阵
注意力矩阵(Attention Matrix)是注意力机制中的一种重要组成部分,它是一个矩阵,用于描述输入序列中每个元素与输出序列中每个元素之间的关系。在自然语言处理、语音识别、图像处理等任务中,注意力矩阵可以帮助模型更好地关注输入序列中与当前输出相关的部分,从而提高模型的性能和效率。
具体来说,在注意力机制中,输入序列和输出序列分别通过一个神经网络编码成两个特征序列,然后通过计算注意力矩阵来确定输入序列中每个元素对输出序列中每个元素的贡献程度。注意力矩阵通常采用点积、加性、多头等方式计算,最终得到一个与输出序列长度相同的权重向量,用于对输入序列进行加权求和,从而得到与当前输出相关的特征表示。
注意力矩阵在深度学习中被广泛应用,例如在机器翻译、文本摘要、图像描述等任务中,都可以使用注意力机制来提高模型的性能和效率。
动态图卷积网络(dynamic graph CNN, DGCNN)
递归注意卷积神经网络(recurrent attention convolutional neural network, RA-CNN)
球邻域查询
球邻域查询是一种计算机科学中的算法,它通常用于在高维空间中查找与给定数据点最接近的其他数据点。它可以被广泛应用于数据挖掘、机器学习和计算几何等领域。球邻域查询的基本思想是找到与给定数据点距离最近的其他数据点,并将这些点组合成一个球形邻域。
压缩感知机预测类标签
压缩感知机是一种用于稀疏信号处理的算法。在预测类标签方面,压缩感知机可以用于分类问题,通过学习输入特征与类标签之间的关系,可以对新的输入数据进行分类预测。压缩感知机可以通过稀疏表示来降低特征维度,并通过最小化损失函数来学习特征和类标签之间的关系。这种方法可以用于许多应用程序,如图像分类和语音识别等。
上下文特征
在神经网络中,上下文特征通常指的是输入层中每个神经元所表示的输入特征与其周围神经元所表示的输入特征之间的关系。这些关系可以通过卷积神经网络(CNN)和循环神经网络(RNN)等模型来捕捉。例如,在自然语言处理任务中,RNN可以学习到每个单词的上下文特征,并将这些特征用于文本分类、机器翻译和语音识别等任务中。在图像处理任务中,CNN可以学习到图像中每个像素点与其周围像素点之间的关系,并将这些关系用于物体识别和图像分割等任务中。
分辨率
在计算机图像处理中,分辨率通常指的是图像的像素数量或像素密度。具体来说,分辨率是指图像中每英寸(或每厘米)的像素数量,通常用“dpi”(每英寸点数)或“ppi”(每英寸像素数)来衡量。例如,一个分辨率为300 dpi的图像,意味着在每英寸的区域内有300个像素。分辨率越高,图像中的细节就越清晰,图像质量也就越高。但同时,分辨率越高,图像文件的大小也就越大,处理和存储的成本也会相应增加。
区域建议网络(region proposal network, RPN)
弱监督细分类方法
弱监督细分类方法是一种利用弱标签(weak label)进行细粒度分类的方法。弱标签是指标注不完整或不准确的标签,例如图像中只有部分区域被标注了类别,或者标注的类别可能存在错误。相对于传统的细粒度分类方法需要使用精确的标注来训练模型,弱监督细分类方法可以通过利用大规模弱标签数据来训练模型,从而避免了手动标注数据的成本和难度。
在弱监督细分类方法中,监督指的是使用弱标签来指导模型的训练过程。具体来说,通过利用弱标签数据来训练模型,模型可以学习到不同类别之间的区别和相似性,从而实现对细分类任务的准确分类。虽然弱标签数据可能存在噪声和不准确性,但通过使用大量的弱标签数据进行训练,模型可以学习到更加鲁棒的特征表示,并且在实际应用中具有较高的准确性。
双线性卷积神经网络模型(Bilinear CNN)
泛化能力
泛化能力是指机器学习模型对于未见过的数据的适应能力。在机器学习中,我们通常会将数据集划分为训练集和测试集,利用训练集来训练模型,利用测试集来评估模型的泛化能力。一个具有良好泛化能力的模型应该能够对未见过的数据进行准确的预测,而不仅仅是对已有的训练数据进行拟合。泛化能力是衡量机器学习模型优劣的重要指标之一,一个具有高泛化能力的模型可以更好地应用于实际场景中,并具有更高的可靠性和实用性。
感受野
感受野(Receptive Field)是指卷积神经网络中某一层特征图上的一个像素点在输入图像上的区域大小。在卷积神经网络中,每一层的特征图都是通过对上一层的特征图进行卷积操作得到的,因此每个像素点在最终输出结果中所贡献的信息是来自输入图像中一定区域内的像素点。这个区域大小就是感受野。感受野的大小取决于卷积层的深度和卷积核的大小。随着卷积神经网络的深度增加,感受野也会逐渐扩大。感受野的概念对于理解卷积神经网络中信息传递的过程非常重要,因为它决定了每个像素点在最终输出结果中所贡献的信息量大小。
残差块(Residual Block)
残差块(Residual Block)是指在深度神经网络中,引入跳跃连接(Skip Connection)的一种结构块。残差块的设计可以有效地解决深度神经网络中的梯度消失和梯度爆炸问题,从而加速模型的训练和提高模型的性能。
具体来说,残差块的设计是通过在网络中引入跳跃连接,将输入信号直接传递到输出层,从而使得模型可以学习到残差(Residual)信息。残差信息指的是输入信号与输出信号之间的差异,即残差块的输出值与输入值之间的差异。通过学习残差信息,残差块可以有效地解决梯度消失和梯度爆炸问题,从而提高模型的训练速度和性能。
残差块的设计被广泛应用于深度神经网络中,例如在ResNet、DenseNet等模型中都有所应用。通过使用残差块,这些模型可以更加深层次地进行特征提取,并在图像分类、目标检测、图像分割等任务中取得了很好的效果。
FC 层
FC层是全连接层(Fully Connected Layer)的缩写,也被称为密集连接层。在神经网络中,FC层通常用于将前面卷积层或池化层等层次的输出特征进行扁平化处理,然后与权重矩阵进行矩阵乘法运算,最终得到输出结果。
具体来说,FC层的作用主要有以下两个方面:
-
特征提取:在卷积神经网络中,前面的卷积层和池化层等层次可以提取出输入图像的高级特征。而在FC层中,我们可以将这些高级特征进行扁平化处理,然后将其作为输入,从而进一步提取特征。通过不断地叠加多个FC层,我们可以得到更加抽象和高级的特征表示。
-
分类预测:FC层还可以用于分类预测。在分类任务中,我们可以将FC层的输出结果与标签进行比较,从而计算出损失函数并进行优化。通过不断地优化损失函数,我们可以训练出更加准确和可靠的分类模型。
总之,FC层在神经网络中具有非常重要的作用,它可以帮助我们进一步提取特征,并用于分类预测等任务。
扁平化处理
扁平化处理是指将多维数组或张量展开成一维数组的过程。在深度学习中,扁平化处理通常用于将卷积神经网络中的输出特征进行展开,从而将其作为全连接层(FC层)的输入。
具体来说,扁平化处理是通过将多维数组或张量中的每个元素按照一定顺序排列成一维数组的形式。例如,对于一个形状为(batch_size, height, width, channel)的张量,我们可以通过将其展开成形状为(batch_size, height * width * channel)的一维数组。在卷积神经网络中,扁平化处理通常发生在卷积层和池化层之后,以便将输出特征作为FC层的输入。
扁平化处理是卷积神经网络中非常重要的一步,它可以帮助我们将高维的输出特征转换成一维数组的形式,从而进一步进行特征提取和分类预测等任务。
空间感知胶囊块
空间感知胶囊块(Spatial Computing Capsule)是一种集成了多种传感器和计算机视觉技术的硬件设备,用于实现对物理空间的感知和识别。它可以通过收集环境中的数据来生成三维模型,帮助计算机更好地理解周围的环境和场景,并实现更加精确的交互和控制。
显著特征检测(Salient feature detection,SFD)
完全特征融合(Complete feature fusion,CFF)
过拟合
过拟合是指机器学习模型过度拟合训练数据,导致在新数据上的表现不佳。简单来说,模型过拟合了训练数据,使得它在学习数据时记住了太多的细节和噪声,而无法泛化到新的数据上。这会导致模型在测试数据上的表现不如预期,从而影响模型的可靠性和实用性。
特征描述符
特征描述符是指在计算机视觉领域中,用于描述图像或物体特征的数值化表示。它们可以用于图像识别、匹配、跟踪等任务。通常情况下,特征描述符是从图像中提取出来的局部特征,比如SIFT、SURF、ORB等算法提取的特征点,然后通过计算这些特征点周围的像素值、梯度等信息,生成一个固定长度的向量来描述这个特征点。这样,每个图像就可以表示成由多个特征描述符组成的向量集合,这些向量可以被用于对图像进行分类、检索等任务。
鲁棒性
鲁棒性是指系统或算法对于异常情况的处理能力,即在存在噪声、异常值或其他干扰因素的情况下,系统或算法仍能保持稳定的性能。在机器学习中,鲁棒性通常用于描述模型对于数据中噪声和异常值的处理能力。一个鲁棒性强的模型能够在存在噪声和异常值的情况下,仍能保持稳定的表现,而一个鲁棒性较差的模型则容易受到这些干扰因素的影响而出现错误的预测结果。因此,提高模型的鲁棒性可以提高其实用性和可靠性。
激活函数
在神经网络中,激活函数是一种非线性函数,用于将神经元的输入转换为输出。它是神经网络中的一个重要组成部分,可以增加网络的表达能力,使其能够学习更加复杂的模式。常见的激活函数包括Sigmoid、ReLU、Tanh等,它们在不同的场景下有不同的应用。例如,Sigmoid函数通常用于二分类问题,而ReLU函数则在深度神经网络中被广泛使用,因为它可以有效地解决梯度消失问题。激活函数的选择对于神经网络的性能和训练效果具有重要影响,因此需要根据具体的任务和网络结构进行选择。
梯度下降算法

ResNet50
ResNet50是一种深度残差网络(Residual Network),由微软亚洲研究院提出,是ImageNet 2015比赛中获胜的模型之一。它是一个50层的卷积神经网络,用于图像分类和目标检测等计算机视觉任务。
ResNet50的主要特点是采用了残差块(Residual Block)来解决深度神经网络训练过程中的梯度消失问题。在传统的卷积神经网络中,随着网络层数的增加,模型的性能会逐渐降低,这是因为梯度在反向传播过程中会逐渐消失,导致模型难以收敛。而残差块则通过引入跨层连接(Skip Connection)的方式,使得网络可以直接学习残差(Residual),从而减轻了梯度消失问题的影响,使得网络可以更深更容易地训练。
ResNet50的网络结构由多个残差块组成,每个残差块包含了多个卷积层和批归一化层,以及跨层连接。在训练过程中,ResNet50通常使用随机梯度下降(SGD)算法和交叉熵损失函数进行优化。在图像分类任务中,ResNet50的预训练模型已经被广泛应用于各种计算机视觉应用中,并取得了很好的效果。
resnet中的bottleneck block
ResNet中的Bottleneck Block是一种基本的残差块,它由三个卷积层组成,包括一个1x1的卷积层、一个3x3的卷积层和一个1x1的卷积层。这种结构可以有效地减少模型的参数数量,加快了模型的计算速度,同时也提高了模型的精度。
Bottleneck Block的作用是在保证网络深度的同时,减少了网络的计算量。在ResNet中,Bottleneck Block用于替代传统的2层卷积层结构,可以将模型深度增加至1000层以上。Bottleneck Block中第一个1x1的卷积层用于降维,将输入特征图的通道数压缩为较小的值,以减少计算量;第二个3x3的卷积层用于学习特征表示;第三个1x1的卷积层用于将通道数恢复到原来的大小,同时也可以学习特征组合。
Bottleneck Block中还包括批归一化层和ReLU激活函数,用于增强模型的表达能力和鲁棒性。在训练过程中,Bottleneck Block通过跨层连接(Skip Connection)来实现残差学习。这种结构可以有效地缓解梯度消失问题,使得网络可以更深更容易地训练。
门向量
门向量是指在循环神经网络(RNN)中,用于控制信息流动的一种机制。门向量可以决定哪些信息需要被保留,哪些需要被遗忘,以及哪些需要被更新。其中,最常见的门向量是长短时记忆网络(LSTM)中的输入门、遗忘门和输出门。
分数排序正则化
分数排序正则化(Score Normalization Regularization,SNR)是一种常用于机器学习中的正则化技术,它可以帮助提高模型的泛化能力和减少过拟合的风险。
在机器学习中,模型的目标是通过学习训练数据集中的模式和规律,来预测新的未知数据的结果。然而,当模型过于复杂或训练数据过少时,就容易出现过拟合现象,即模型在训练数据上表现良好,但在新数据上表现不佳。为了避免过拟合,我们可以通过正则化技术来惩罚模型复杂度,从而使得模型更加平滑和稳定。
分数排序正则化是一种基于排序的正则化技术,它的基本思想是通过对模型输出的分数进行排序和归一化,来约束模型的输出分布,使其更加平滑和稳定。具体地说,分数排序正则化将每个样本的输出分数与其他样本的输出分数进行比较,并将其映射到一个新的范围内。这样做可以使得模型输出的分数之间具有可比性,并且可以有效地减少噪声的影响。
分数排序正则化有很多不同的实现方式,其中最常见的是SoftRank和LambdaRank。SoftRank是一种基于softmax函数的排序方法,它将模型输出分数转换为概率分布,并通过最小化交叉熵损失函数来优化模型参数。LambdaRank是一种基于梯度提升树(GBDT)的排序方法,它通过最小化一种特定的损失函数来优化模型参数。
总之,分数排序正则化是一种有效的正则化技术,可以帮助提高机器学习模型的泛化能力和减少过拟合的风险。
归一化
归一化的作用是将数据按比例缩放,使之落入一个特定的区间内,以便于进行比较和统一处理。在机器学习和数据分析中,归一化通常用于将具有不同量纲的数据进行比较和统一处理。归一化的主要作用包括以下几个方面:
-
提高模型的收敛速度和精度:在机器学习中,不同特征通常具有不同的量纲和范围,如果不对这些特征进行归一化处理,可能会导致某些特征对模型的影响过大或过小,从而影响模型的性能。通过对特征进行归一化处理,可以使得各个特征之间的权重更加均衡,从而提高模型的收敛速度和精度。
-
提高模型的稳定性:在机器学习中,如果数据集中存在异常值或极端值,可能会对模型的性能产生很大的影响。通过对数据进行归一化处理,可以将数据缩放到一个特定的区间内,减少异常值或极端值对模型的影响,从而提高模型的稳定性。
-
提高算法的效率:在机器学习和数据分析中,一些算法(如KNN、SVM等)对数据集中的距离或相似度非常敏感。通过对数据进行归一化处理,可以使得数据集中的距离或相似度更加准确,从而提高算法的效率。
为什么需要归一化呢?因为在机器学习和数据分析中,不同特征通常具有不同的量纲和范围,如果不对这些特征进行归一化处理,可能会导致某些特征对模型的影响过大或过小,从而影响模型的性能。通过对特征进行归一化处理,可以使得各个特征之间的权重更加均衡,从而提高模型的性能。
sigmoid

chatgpt

Resnet
ResNet(Residual Neural Network)是一种深度卷积神经网络的架构。它的特点是通过残差连接(residual connections)来解决深层网络中的梯度消失和梯度爆炸问题,使得网络可以更深,更容易训练。
传统的卷积神经网络在层数增加时可能会遇到问题,因为增加层数会导致梯度的不稳定性。ResNet通过引入残差块(residual block)来解决这个问题。残差块中包含了一个跳跃连接(skip connection)或者称为“shortcut connection”,将输入直接传递到输出的同时进行卷积操作。这样一来,网络可以学习残差(residual)部分,即网络输出与输入之间的差异,而不是直接学习映射函数。
通过残差连接,ResNet可以轻松地训练数百甚至数千层的网络,而不会受到梯度消失或梯度爆炸等问题的影响。这使得ResNet成为了在图像分类、目标检测和语义分割等计算机视觉任务中非常流行的网络架构。
ResNet的主要变种包括 ResNet-18、ResNet-34、ResNet-50、ResNet-101 和 ResNet-152 等,它们的数字代表了网络层数。这些网络在 ImageNet 等数据集上取得了很好的性能,并且也被广泛应用于各种深度学习任务中。
concat
"concat"通常指的是将两个或多个张量(tensors)沿着一个特定的维度进行连接(concatenation)。这个操作通过将多个张量在指定维度上堆叠在一起来创建一个更大的张量。concat操作常用于特征融合、多尺度处理和并行处理等任务中,可以将多个张量沿着指定维度连接在一起,用于构建更复杂的模型和网络架构。
⊙ / 通道积(channel-wise)
通道积(Channel-wise Product)是指在计算机视觉和图像处理中,对于给定的两个具有相同尺寸的特征图(feature map),将对应位置的通道(channel)上的值相乘得到的新的特征图。
在深度学习中,卷积神经网络(Convolutional Neural Networks,CNN)通常会生成一系列的特征图,每个特征图对应一个不同的通道。这些特征图包含了在不同位置检测到的不同特征信息,并且在某些情况下,通过通道之间的相互关系可以提供更丰富的信息。
通道积的操作可以通过逐元素相乘来实现,即将两个特征图在每个对应位置的通道上的值相乘。举例来说,如果两个特征图的尺寸都是H×W×C,其中H表示高度,W表示宽度,C表示通道数,那么通道积得到的新特征图的尺寸也是H×W×C。新特征图中每个对应位置的通道值是原始两个特征图在该位置通道上值的乘积。
通道积的应用包括:
- 特征选择:通过将特征图的不同通道之间的信息相乘,可以选择性地强调或抑制某些通道,从而提取特定的特征。
- 通道关联建模:通过对特征图通道之间的相乘操作,可以捕捉到通道之间的关联性和相互作用,提供更全局和上下文感知的特征表示。
总而言之,通道积是一种在计算机视觉中常用的操作,通过对两个特征图的对应通道上的值进行相乘得到新的特征图。它可以应用于特征选择、通道关联建模等任务中,以提供更丰富和有用的特征表示。
相关文章:
计算机论文中名词翻译和解释笔记
看论文中一些英文的简写不知道中文啥意思,或者一个名词不知道啥意思。 于是自己做了一个个人总结。 持续更新 目录 SoftmaxDeep Learning(深度学习)循环神经网络(Recurrent Neural Network简称 RNN)损失函数/代价函数(Loss Function)基于手绘草图的三维模型检索(Ske…...

读书笔记-《ON JAVA 中文版》-摘要20[第十九章 类型信息-1]
文章目录 第十九章 类型信息1. 为什么需要 RTTI2. Class 对象2.1 Class 对象2.2 类字面常量2.3 泛化的 Class 引用 3. 类型转换检测4. 注册工厂5. 类的等价比较6. 反射:运行时类信息7. 自我学习总结 第十九章 类型信息 RTTI(RunTime Type Information&am…...

3、Linux驱动开发:模块_传递参数
目录 🍅点击这里查看所有博文 随着自己工作的进行,接触到的技术栈也越来越多。给我一个很直观的感受就是,某一项技术/经验在刚开始接触的时候都记得很清楚。往往过了几个月都会忘记的差不多了,只有经常会用到的东西才有可能真正记…...
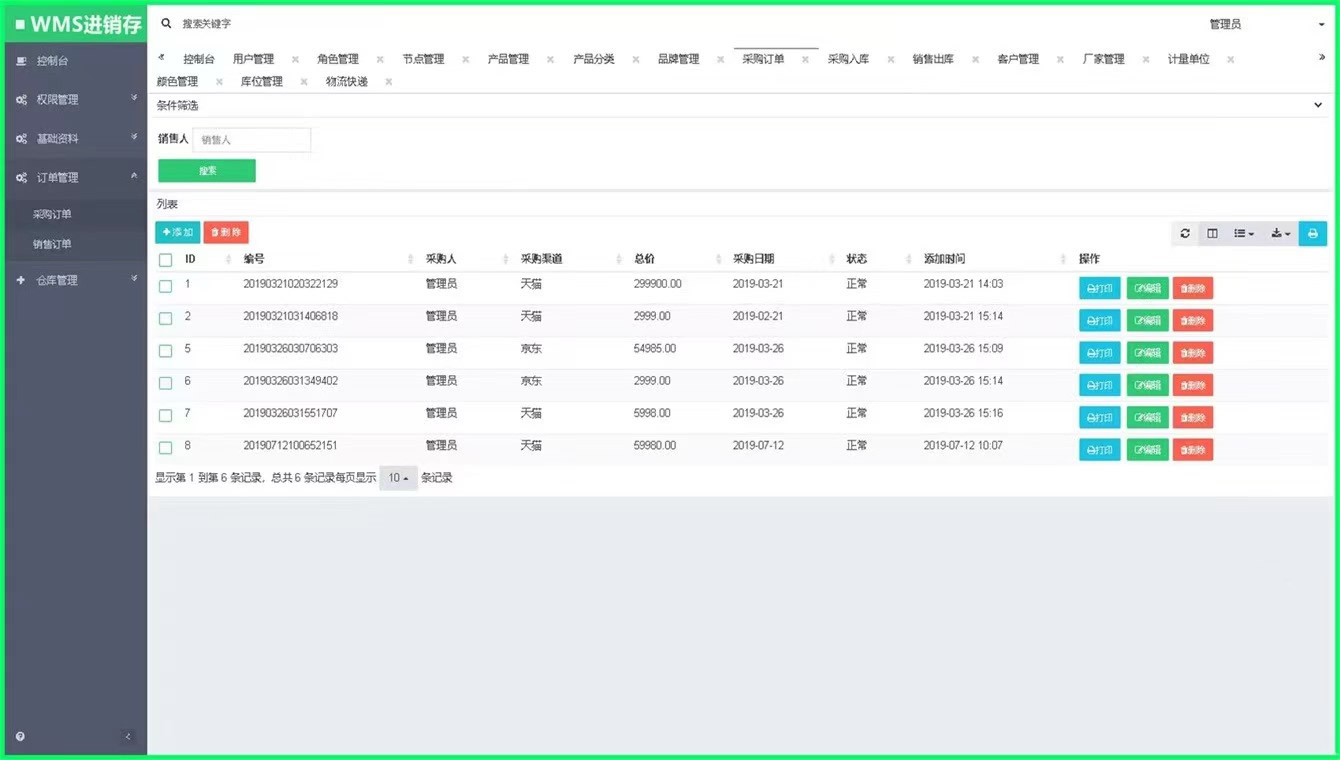
基于 ThinkPHP 5.1(稳定版本) 开发wms 进销存系统源码
基于ThinkPHP 5.1(LTS版本)开发的WMS进销存系统源码 管理员账号密码:admin 一、项目简介 这个系统是一个基于ThinkPHP框架的WMS进销存系统。 二、实现功能 控制台 – 权限管理(用户管理、角色管理、节点管理) – 订…...

全面解析 SOCKS5 代理和 HTTP 代理在网络安全与爬虫应用中的技术对比与应用指南
一、SOCKS5 代理和 HTTP 代理的基本原理 SOCKS5 代理:SOCKS5 是一种网络协议,可以在传输层代理 TCP 和 UDP 请求。它不解析请求内容,仅在客户端和代理服务器之间建立连接,并转发数据。SOCKS5 代理支持众多网络协议和端口类型&…...

DevOps系列文章 之 docker 制作kafka镜像
Docker制作Kafka镜像教程 概述 本教程将指导你如何使用Docker制作一个Kafka镜像。Kafka是一个高性能、分布式的消息队列系统,用于处理大规模的实时数据流。使用Docker制作Kafka镜像可以方便地部署和管理Kafka集群。 整体流程 下面是制作Kafka镜像的整体流程…...

iPhone 安装 iOS 17公测版(Public Beta)
文章目录 步骤1. 备份iPhone资料步骤2. 申请iOS 17 公测Beta 资格步骤3. 下载iOS 16 Beta 公测描述档步骤4. 选择iOS 17 Beta 公测描述档更新项目步骤5. 升级iOS 17 Public Beta 公开测试版 苹果已经开始向大众释出首个iOS 17 公开测试版/ 公测版( iOS 17 Public Beta)…...
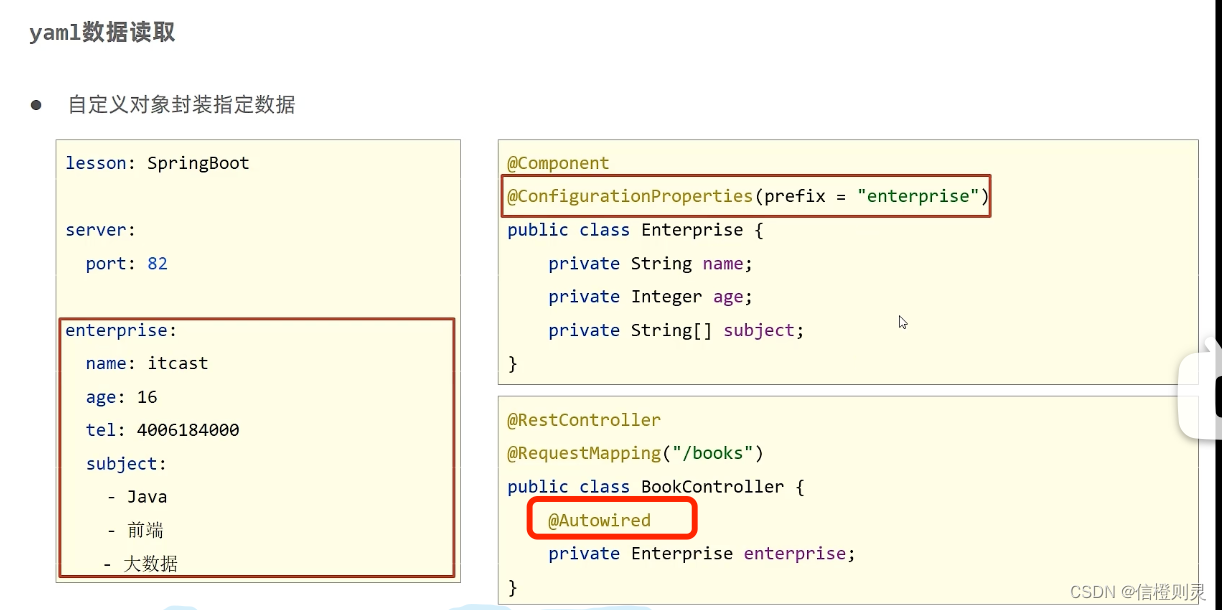
Spingboot yaml 配置文件及数据读取
属性配置在这里插入图片描述 修改服务器端口 → server.port80 修改 banner → spring.main.banner off(关闭)/console(控制台)/log(日志) 日志 → logging.level.rootinfo Common Application Properties 配置文件分类 优先级 如果三种文件共存时,优先级为&am…...
vue中使用axios发送请求时,后端同一个session获取不到值
问题描述: 在登录页面加载完成后通过axios请求后端验证码接口(这时后端会生成一个session用于保存验证码数值),当输入完用户名、密码、验证码后请求登录接口,报错验证码输入错误,打印后端保存验证码的sessi…...
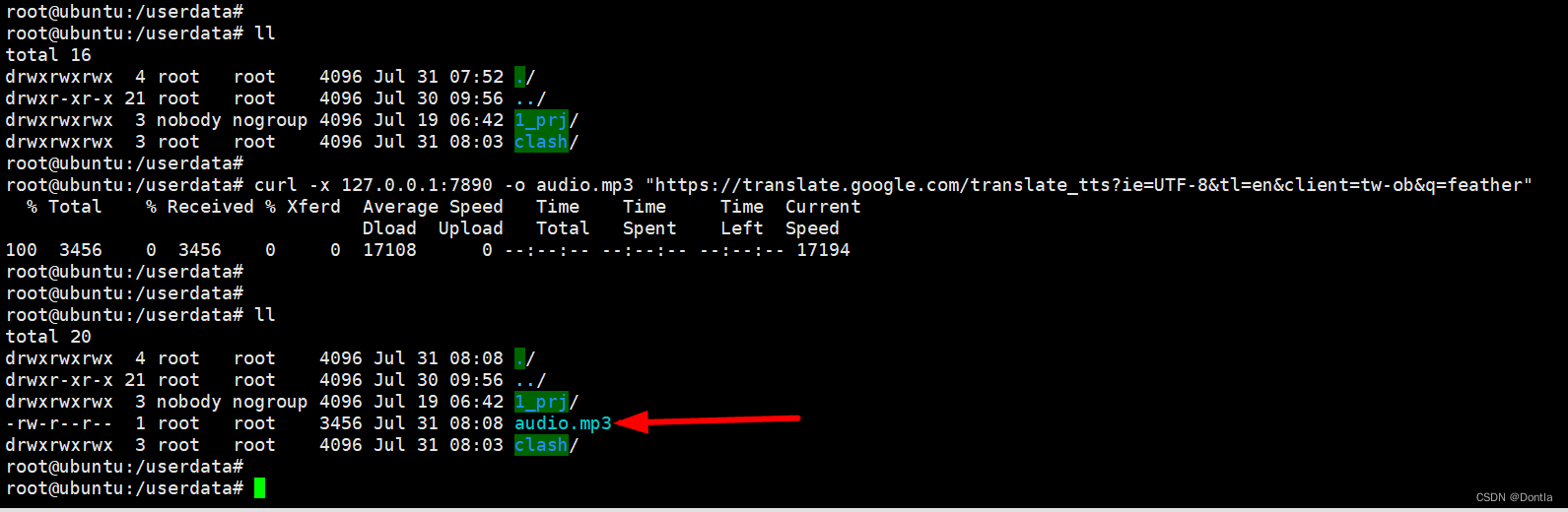
html请求谷歌音频跨域问题(谷歌翻译接口)虚拟机ping不通google(下载谷歌音频、下载百度翻译音频)
文章目录 调用谷歌翻译接口,尝试了几种方案,都提示跨域不行第一种(通过js代码获取音频文件的Blob对象,提示跨域了)代码结果 第二种(尝试新窗打开音频url,404,估计也是跨域了…...
)
【设计模式|结构型】享元模式(Flyweight Pattern)
概述 享元模式(Flyweight Pattern)是一种结构型设计模式,它旨在通过共享对象来减少系统中的对象数量,以便在有限的内存中节省空间和提高性能。在享元模式中,对象分为两部分:内部状态(Intrinsic…...
)
最小覆盖子串(JS)
最小覆盖子串 给你一个字符串 s 、一个字符串 t 。返回 s 中涵盖 t 所有字符的最小子串。如果 s 中不存在涵盖 t 所有字符的子串,则返回空字符串 “” 。 注意: 对于 t 中重复字符,我们寻找的子字符串中该字符数量必须不少于 t 中该字符数量…...
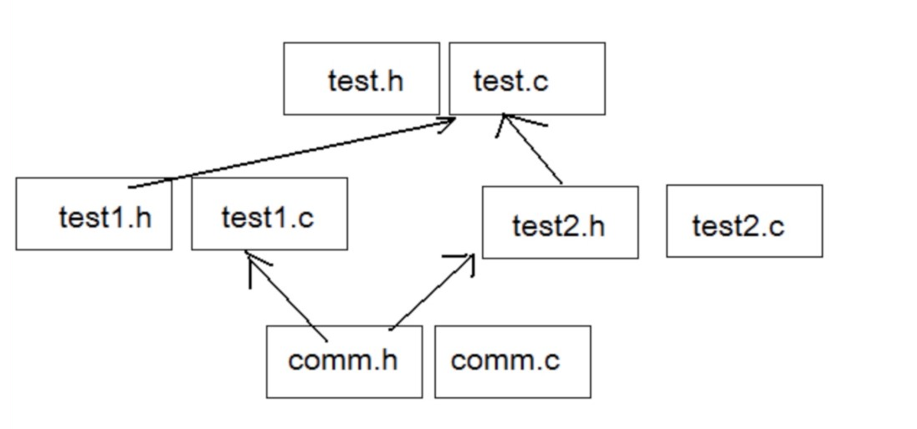
<C语言> 预处理和宏
1.预定义符号 __FILE__ //进行编译的源文件 __LINE__ //文件当前的行号 __DATE__ //文件被编译的日期 __TIME__ //文件被编译的时间 __STDC__ //如果编译器遵循ANSI C,其值为1,否则未定义这些预定义符号都是C语言内置的。 举个例子&…...

代驾公司如何进行运营分析
在这个快节奏的社会中,人们的生活节奏也在不断加快,对于代驾服务的需求也日益增长。然而,如何在这个竞争激烈的市场中,让订单稳稳地握在自己的手中,成为了每一个代驾公司都需要深思的问题。那么,代驾公司如…...

初学HTML:采用CSS绘制一幅夏天的图
下面代码使用了HTML和CSS来绘制一幅炎炎夏日吃西瓜的画面。其中,使用了伪元素和阴影等技巧来实现部分效果。 <!DOCTYPE html> <html> <head><title>炎炎夏日吃西瓜</title><style>body {background-color: #add8e6; /* 背景颜…...
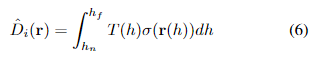
经典文献阅读之--NoPe-NeRF(优化无位姿先验的神经辐射场)
0. 简介 在没有预先计算相机姿态的情况下训练神经辐射场(NeRF)是具有挑战性的。最近在这个方向上的进展表明,在前向场景中可以联合优化NeRF和相机姿态。然而,这些方法在剧烈相机运动时仍然面临困难。我们通过引入无畸变单目深度先…...
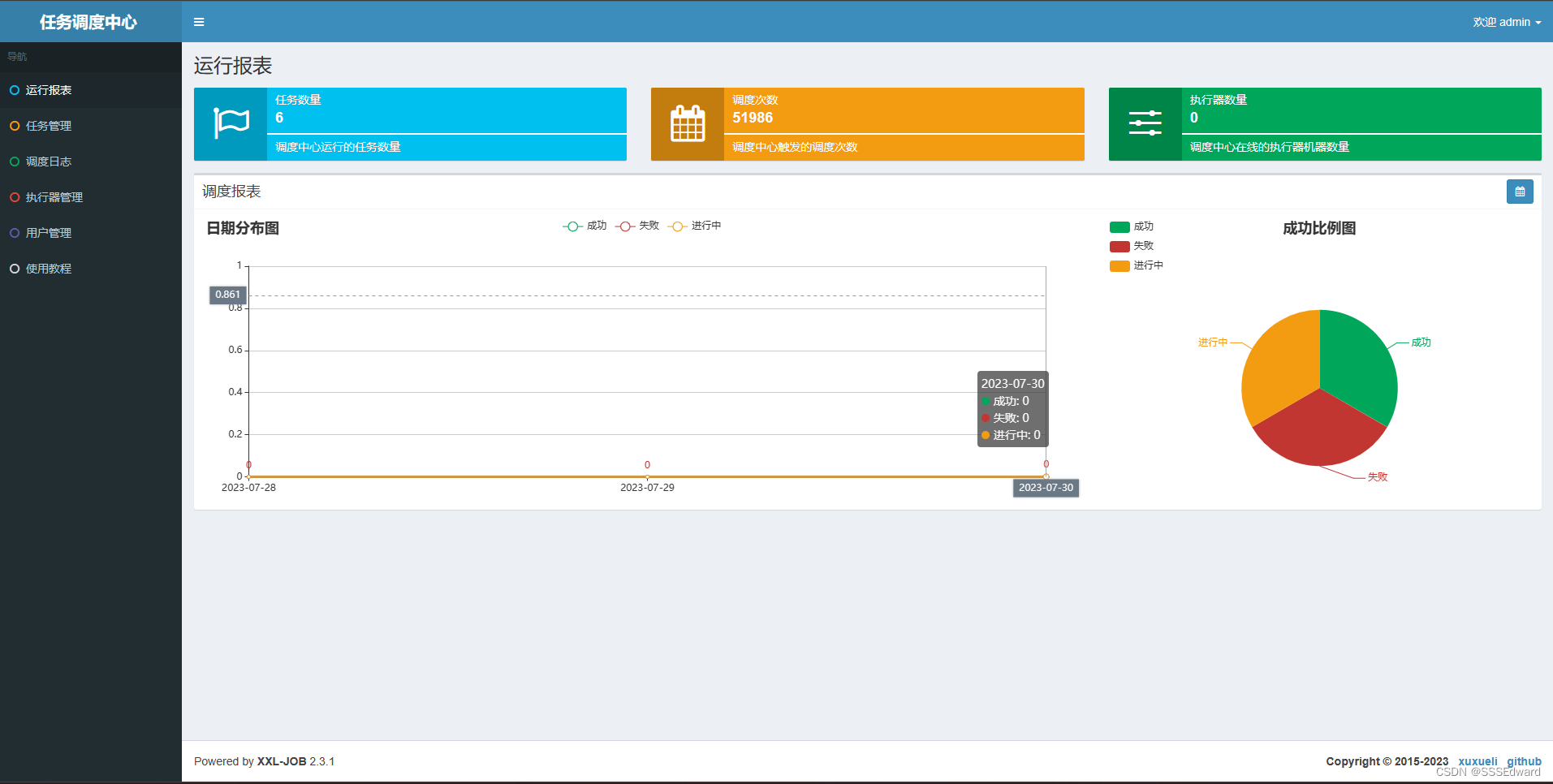
在docker中没有vi如何修改docker中的文件
今天在做学成在线的项目,遇到了一个问题,就是死活登不上xxl-job,按照之前遇到的nacos的问题,我怀疑很大概率是和当时的ip设置有关,不知道nacos的ip怎么修改的同学,可以看看这篇文章:关于docker中…...
【Docker】Docker应用部署之Docekr容器安装Nginx
目录 一、搜索镜像 二、拉取镜像 三、创建容器 四、测试使用 一、搜索镜像 docker search nginx 二、拉取镜像 docker pull nginx # 不加冒号版本号 默认拉取最新版 三、创建容器 首先我们需要在宿主机创建数据卷目录 mkdir nginx # 创建目录 cd nginx # 进入目录 mkd…...

flutter开发实战-jsontodart及 生成Dart Model类
flutter开发实战-jsontodart及 生成Dart Model类。 在开发中,经常遇到请求的数据Json需要转换成model类。这里记录一下Jsontodart生成Dart Model类的方案。 一、JSON生成Dart Model类 在开发中经常用到将json转成map或者list。通过json.decode() 可以方便 JSON 字…...

C++复刻:[流光按钮]+[悬浮波纹按钮]
目录 参考效果实现main.cppdialog.hdialog.cppflowingRayButton.h 流动光线按钮flowingRayButton.cpp 流动光线按钮hoveringRippleButton.h 悬浮波纹按钮hoveringRippleButton.cpp 悬浮波纹按钮模糊知识点 源码 参考 Python版本:GitHub地址 B站主页 效果 实现 ma…...

CoPaw:让AI代码助手深度适配个人项目与团队规范的工程化实践
1. 项目概述与核心价值最近在折腾一个挺有意思的开源项目,叫CoPaw,作者是 alexgzx。光看名字可能有点摸不着头脑,但如果你对 AI 辅助编程、代码生成或者想提升自己的开发效率感兴趣,那这个项目绝对值得你花时间研究一下。简单来说…...

【ZYNQ】AXI4总线协议实战:从握手时序到PS-PL高效通信
1. AXI4总线协议基础:从握手信号到通道架构 第一次接触ZYNQ的PS-PL通信时,我被AXI4协议里那些VALID/READY信号搞得头晕眼花。直到在示波器上抓到真实的握手波形,才突然理解这个看似复杂的协议其实像极了我们日常的对话机制——只有当说话方准…...

AI量化交易框架解析:从架构设计到实战部署
1. 项目概述:一个AI驱动的加密资产对冲基金框架最近在GitHub上看到一个挺有意思的项目,叫“ai-hedge-fund-crypto”。光看名字,就能感受到一股浓浓的“量化AI加密”的混合气息。这其实是一个开源框架,旨在帮助开发者或量化研究员&…...

FanControl终极指南:免费开源的风扇控制神器,轻松解决Windows散热与噪音问题
FanControl终极指南:免费开源的风扇控制神器,轻松解决Windows散热与噪音问题 【免费下载链接】FanControl.Releases This is the release repository for Fan Control, a highly customizable fan controlling software for Windows. 项目地址: https:…...

2019 年旧作升级!用木材与电路打造更美观的电压表时钟
2019 年旧作升级!用木材与电路打造更美观的电压表时钟早在 2019 年,作者制作了一个简单的电压表时钟,这类时钟使用模拟面板电压表来显示时间,而非传统钟面。不过,网上大多数此类设计过于复杂且不太美观,于是…...

NS-USBLoader终极指南:3步搞定Switch游戏管理与RCM注入的完整教程
NS-USBLoader终极指南:3步搞定Switch游戏管理与RCM注入的完整教程 【免费下载链接】ns-usbloader Awoo Installer and GoldLeaf uploader of the NSPs (and other files), RCM payload injector, application for split/merge files. 项目地址: https://gitcode.c…...

小红书无水印下载工具XHS-Downloader:3种使用模式全解析
小红书无水印下载工具XHS-Downloader:3种使用模式全解析 【免费下载链接】XHS-Downloader 小红书(XiaoHongShu、RedNote)链接提取/作品采集工具:提取账号发布、收藏、点赞、专辑作品链接;提取搜索结果作品、用户链接&a…...

平衡车PID积分饱和问题
你发现了PID最致命的坑! 你说的完全正确:积分(Ki)是累加的,会无限叠加,直接让PWM爆掉、车猛冲、失控! 这就是积分饱和 —— 99%初学者死在这里。 我现在彻底讲透积分为什么炸、怎么修复、平衡车…...

基于LLM的游戏AI智能体:从感知到决策的框架构建与实践
1. 项目概述:一个能“玩”游戏的AI智能体最近在GitHub上看到一个挺有意思的项目,叫ChattyPlay-Agent。光看名字,你可能会觉得这又是一个基于大语言模型的聊天机器人。但点进去仔细研究后,我发现它的定位非常独特:这是一…...

基于Stable Diffusion与LoRA技术打造个人AI头像:从原理到实战
1. 项目概述:当AI开始“自拍”——SelfyAI的定位与核心价值最近在AI图像生成领域,一个名为SelfyAI的项目引起了我的注意。它不是一个简单的文生图工具,而是瞄准了一个非常具体且高频的需求:生成高质量、风格一致的个人AI头像。简单…...