Python3 数据结构
列表
Python中列表是可变的,这是它区别于字符串和元组的最重要的特点,一句话概括即:列表可以修改,而字符串和元组不能。
以下是 Python 中列表的方法:
方法 描述
list.append(x) 把一个元素添加到列表的结尾,相当于 a[len(a):] = [x]。
list.extend(L) 通过添加指定列表的所有元素来扩充列表,相当于 a[len(a):] = L。
list.insert(i, x) 在指定位置插入一个元素。第一个参数是准备插入到其前面的那个元素的索引,例如 a.insert(0, x) 会插入到整个列表之前,而 a.insert(len(a), x) 相当于 a.append(x) 。
list.remove(x) 删除列表中值为 x 的第一个元素。如果没有这样的元素,就会返回一个错误。
list.pop([i]) 从列表的指定位置移除元素,并将其返回。如果没有指定索引,a.pop()返回最后一个元素。元素随即从列表中被移除。(方法中 i 两边的方括号表示这个参数是可选的,而不是要求你输入一对方括号,你会经常在 Python 库参考手册中遇到这样的标记。)
list.clear() 移除列表中的所有项,等于del a[:]。
list.index(x) 返回列表中第一个值为 x 的元素的索引。如果没有匹配的元素就会返回一个错误。
list.count(x) 返回 x 在列表中出现的次数。
list.sort() 对列表中的元素进行排序。
list.reverse() 倒排列表中的元素。
list.copy() 返回列表的浅复制,等于a[:]。
下面示例演示了列表的大部分方法:
实例
a = [66.25, 333, 333, 1, 1234.5]
print(a.count(333), a.count(66.25), a.count(‘x’))
2 1 0
a.insert(2, -1)
a.append(333)
a
[66.25, 333, -1, 333, 1, 1234.5, 333]
a.index(333)
1
a.remove(333)
a
[66.25, -1, 333, 1, 1234.5, 333]
a.reverse()
a
[333, 1234.5, 1, 333, -1, 66.25]
a.sort()
a
[-1, 1, 66.25, 333, 333, 1234.5]
注意:类似 insert, remove 或 sort 等修改列表的方法没有返回值。
将列表当做堆栈使用
列表方法使得列表可以很方便的作为一个堆栈来使用,堆栈作为特定的数据结构,最先进入的元素最后一个被释放(后进先出)。用 append() 方法可以把一个元素添加到堆栈顶。用不指定索引的 pop() 方法可以把一个元素从堆栈顶释放出来。例如:
实例
stack = [3, 4, 5]
stack.append(6)
stack.append(7)
stack
[3, 4, 5, 6, 7]
stack.pop()
7
stack
[3, 4, 5, 6]
stack.pop()
6
stack.pop()
5
stack
[3, 4]
将列表当作队列使用
也可以把列表当做队列用,只是在队列里第一加入的元素,第一个取出来;但是拿列表用作这样的目的效率不高。在列表的最后添加或者弹出元素速度快,然而在列表里插入或者从头部弹出速度却不快(因为所有其他的元素都得一个一个地移动)。
实例
from collections import deque
queue = deque([“Eric”, “John”, “Michael”])
queue.append(“Terry”) # Terry arrives
queue.append(“Graham”) # Graham arrives
queue.popleft() # The first to arrive now leaves
‘Eric’
queue.popleft() # The second to arrive now leaves
‘John’
queue # Remaining queue in order of arrival
deque([‘Michael’, ‘Terry’, ‘Graham’])
列表推导式
列表推导式提供了从序列创建列表的简单途径。通常应用程序将一些操作应用于某个序列的每个元素,用其获得的结果作为生成新列表的元素,或者根据确定的判定条件创建子序列。
每个列表推导式都在 for 之后跟一个表达式,然后有零到多个 for 或 if 子句。返回结果是一个根据表达从其后的 for 和 if 上下文环境中生成出来的列表。如果希望表达式推导出一个元组,就必须使用括号。
这里我们将列表中每个数值乘三,获得一个新的列表:
vec = [2, 4, 6]
[3*x for x in vec]
[6, 12, 18]
现在我们玩一点小花样:
[[x, x**2] for x in vec]
[[2, 4], [4, 16], [6, 36]]
这里我们对序列里每一个元素逐个调用某方法:
实例
freshfruit = [’ banana’, ’ loganberry ', 'passion fruit ']
[weapon.strip() for weapon in freshfruit]
[‘banana’, ‘loganberry’, ‘passion fruit’]
我们可以用 if 子句作为过滤器:
[3x for x in vec if x > 3]
[12, 18]
[3x for x in vec if x < 2]
[]
以下是一些关于循环和其它技巧的演示:
vec1 = [2, 4, 6]
vec2 = [4, 3, -9]
[x*y for x in vec1 for y in vec2]
[8, 6, -18, 16, 12, -36, 24, 18, -54]
[x+y for x in vec1 for y in vec2]
[6, 5, -7, 8, 7, -5, 10, 9, -3]
[vec1[i]*vec2[i] for i in range(len(vec1))]
[8, 12, -54]
列表推导式可以使用复杂表达式或嵌套函数:
[str(round(355/113, i)) for i in range(1, 6)]
[‘3.1’, ‘3.14’, ‘3.142’, ‘3.1416’, ‘3.14159’]
嵌套列表解析
Python的列表还可以嵌套。
以下实例展示了3X4的矩阵列表:
matrix = [
… [1, 2, 3, 4],
… [5, 6, 7, 8],
… [9, 10, 11, 12],
… ]
以下实例将3X4的矩阵列表转换为4X3列表:
[[row[i] for row in matrix] for i in range(4)]
[[1, 5, 9], [2, 6, 10], [3, 7, 11], [4, 8, 12]]
以下实例也可以使用以下方法来实现:
transposed = []
for i in range(4):
… transposed.append([row[i] for row in matrix])
…
transposed
[[1, 5, 9], [2, 6, 10], [3, 7, 11], [4, 8, 12]]
另外一种实现方法:
transposed = []
for i in range(4):
… # the following 3 lines implement the nested listcomp
… transposed_row = []
… for row in matrix:
… transposed_row.append(row[i])
… transposed.append(transposed_row)
…
transposed
[[1, 5, 9], [2, 6, 10], [3, 7, 11], [4, 8, 12]]
del 语句
使用 del 语句可以从一个列表中根据索引来删除一个元素,而不是值来删除元素。这与使用 pop() 返回一个值不同。可以用 del 语句从列表中删除一个切割,或清空整个列表(我们以前介绍的方法是给该切割赋一个空列表)。例如:
a = [-1, 1, 66.25, 333, 333, 1234.5]
del a[0]
a
[1, 66.25, 333, 333, 1234.5]
del a[2:4]
a
[1, 66.25, 1234.5]
del a[:]
a
[]
也可以用 del 删除实体变量:
del a
元组和序列
元组由若干逗号分隔的值组成,例如:
t = 12345, 54321, ‘hello!’
t[0]
12345
t
(12345, 54321, ‘hello!’)Tuples may be nested:
… u = t, (1, 2, 3, 4, 5)
u
((12345, 54321, ‘hello!’), (1, 2, 3, 4, 5))
如你所见,元组在输出时总是有括号的,以便于正确表达嵌套结构。在输入时可能有或没有括号, 不过括号通常是必须的(如果元组是更大的表达式的一部分)。
集合
集合是一个无序不重复元素的集。基本功能包括关系测试和消除重复元素。
可以用大括号({})创建集合。注意:如果要创建一个空集合,你必须用 set() 而不是 {} ;后者创建一个空的字典,下一节我们会介绍这个数据结构。
以下是一个简单的演示:
basket = {‘apple’, ‘orange’, ‘apple’, ‘pear’, ‘orange’, ‘banana’}
print(basket) # 删除重复的
{‘orange’, ‘banana’, ‘pear’, ‘apple’}
‘orange’ in basket # 检测成员
True
‘crabgrass’ in basket
False
以下演示了两个集合的操作
…
a = set(‘abracadabra’)
b = set(‘alacazam’)
a # a 中唯一的字母
{‘a’, ‘r’, ‘b’, ‘c’, ‘d’}
a - b # 在 a 中的字母,但不在 b 中
{‘r’, ‘d’, ‘b’}
a | b # 在 a 或 b 中的字母
{‘a’, ‘c’, ‘r’, ‘d’, ‘b’, ‘m’, ‘z’, ‘l’}
a & b # 在 a 和 b 中都有的字母
{‘a’, ‘c’}
a ^ b # 在 a 或 b 中的字母,但不同时在 a 和 b 中
{‘r’, ‘d’, ‘b’, ‘m’, ‘z’, ‘l’}
集合也支持推导式:
a = {x for x in ‘abracadabra’ if x not in ‘abc’}
a
{‘r’, ‘d’}
字典
另一个非常有用的 Python 内建数据类型是字典。
序列是以连续的整数为索引,与此不同的是,字典以关键字为索引,关键字可以是任意不可变类型,通常用字符串或数值。
理解字典的最佳方式是把它看做无序的键=>值对集合。在同一个字典之内,关键字必须是互不相同。
一对大括号创建一个空的字典:{}。
这是一个字典运用的简单例子:
tel = {‘jack’: 4098, ‘sape’: 4139}
tel[‘guido’] = 4127
tel
{‘sape’: 4139, ‘guido’: 4127, ‘jack’: 4098}
tel[‘jack’]
4098
del tel[‘sape’]
tel[‘irv’] = 4127
tel
{‘guido’: 4127, ‘irv’: 4127, ‘jack’: 4098}
list(tel.keys())
[‘irv’, ‘guido’, ‘jack’]
sorted(tel.keys())
[‘guido’, ‘irv’, ‘jack’]
‘guido’ in tel
True
‘jack’ not in tel
False
构造函数 dict() 直接从键值对元组列表中构建字典。如果有固定的模式,列表推导式指定特定的键值对:
dict([(‘sape’, 4139), (‘guido’, 4127), (‘jack’, 4098)])
{‘sape’: 4139, ‘jack’: 4098, ‘guido’: 4127}
此外,字典推导可以用来创建任意键和值的表达式词典:
{x: x**2 for x in (2, 4, 6)}
{2: 4, 4: 16, 6: 36}
如果关键字只是简单的字符串,使用关键字参数指定键值对有时候更方便:
dict(sape=4139, guido=4127, jack=4098)
{‘sape’: 4139, ‘jack’: 4098, ‘guido’: 4127}
遍历技巧
在字典中遍历时,关键字和对应的值可以使用 items() 方法同时解读出来:
knights = {‘gallahad’: ‘the pure’, ‘robin’: ‘the brave’}
for k, v in knights.items():
… print(k, v)
…
gallahad the pure
robin the brave
在序列中遍历时,索引位置和对应值可以使用 enumerate() 函数同时得到:
for i, v in enumerate([‘tic’, ‘tac’, ‘toe’]):
… print(i, v)
…
0 tic
1 tac
2 toe
同时遍历两个或更多的序列,可以使用 zip() 组合:
questions = [‘name’, ‘quest’, ‘favorite color’]
answers = [‘lancelot’, ‘the holy grail’, ‘blue’]
for q, a in zip(questions, answers):
… print(‘What is your {0}? It is {1}.’.format(q, a))
…
What is your name? It is lancelot.
What is your quest? It is the holy grail.
What is your favorite color? It is blue.
要反向遍历一个序列,首先指定这个序列,然后调用 reversed() 函数:
for i in reversed(range(1, 10, 2)):
… print(i)
…
9
7
5
3
1
要按顺序遍历一个序列,使用 sorted() 函数返回一个已排序的序列,并不修改原值:
basket = [‘apple’, ‘orange’, ‘apple’, ‘pear’, ‘orange’, ‘banana’]
for f in sorted(set(basket)):
… print(f)
…
apple
banana
orange
pear
相关文章:

Python3 数据结构
列表 Python中列表是可变的,这是它区别于字符串和元组的最重要的特点,一句话概括即:列表可以修改,而字符串和元组不能。 以下是 Python 中列表的方法: 方法 描述 list.append(x) 把一个元素添加到列表的结尾…...

Compose-Navigation带参传递
带参传递 目前 compose 还不支持传入对象作为参数! 简单双参数 根目录下新建文件夹 entity,新建单例类 ContentType 作为数据类存储位置 新增数据类 DemoContent,这表示我们需要传入的两个参数,后面带问号判空 object ContentT…...
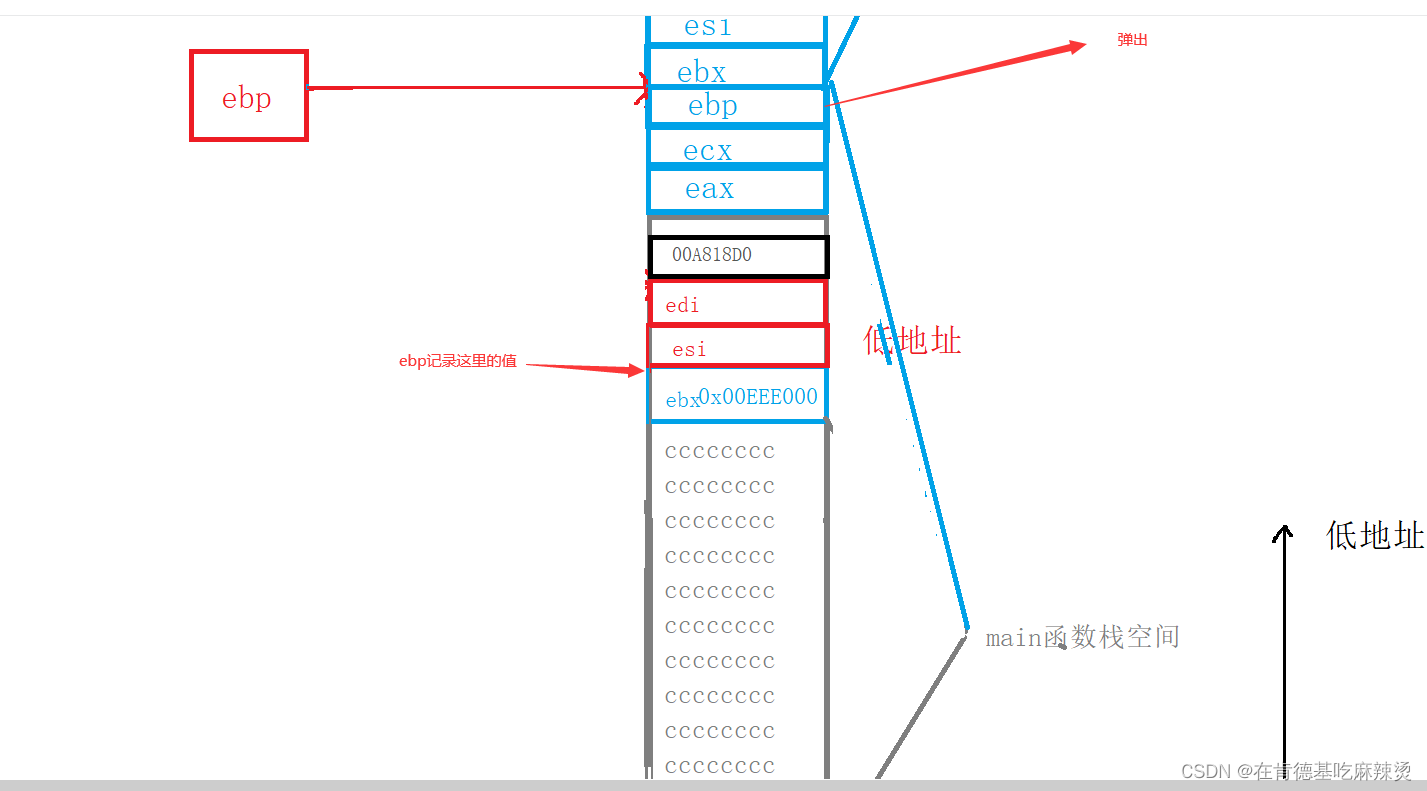
【函数栈帧的创建和销毁】 -- 神仙级别底层原理,你学会了吗?
文章目录1.函数的调用方式 2.函数在栈区上的动作 1.函数的调用方式 相信你对调用函数一点都不陌生,但是在调用函数的过程中,却存在着很多你无法见到的东西,这是底层信息,想要理解透彻,就得深入底层去观察。 本文以…...

Promise的使用及原理
此文章主要讲解核心思想和基本用法,想要了解更多细节全面的使用方式,请阅读官方API 这篇文章假定你具备最基本的异步编程知识,例如知道什么是回调,知道什么是链式调用,同时具备最基本的单词量,例如page、us…...
怎么拥有一个帅气的 CMD 命令窗口 ❓ - Windows
自从拥有这样一个炫酷的命令窗口,我都舍不得关掉它了 关于我为什么我要闲的去 “打扮” 一个命令窗口,这要从星期五下午的一场 摸鱼 🐠 开始,当时我要创建一个 vue ts vite 的项目练练手,为新项目开始做准备&#x…...
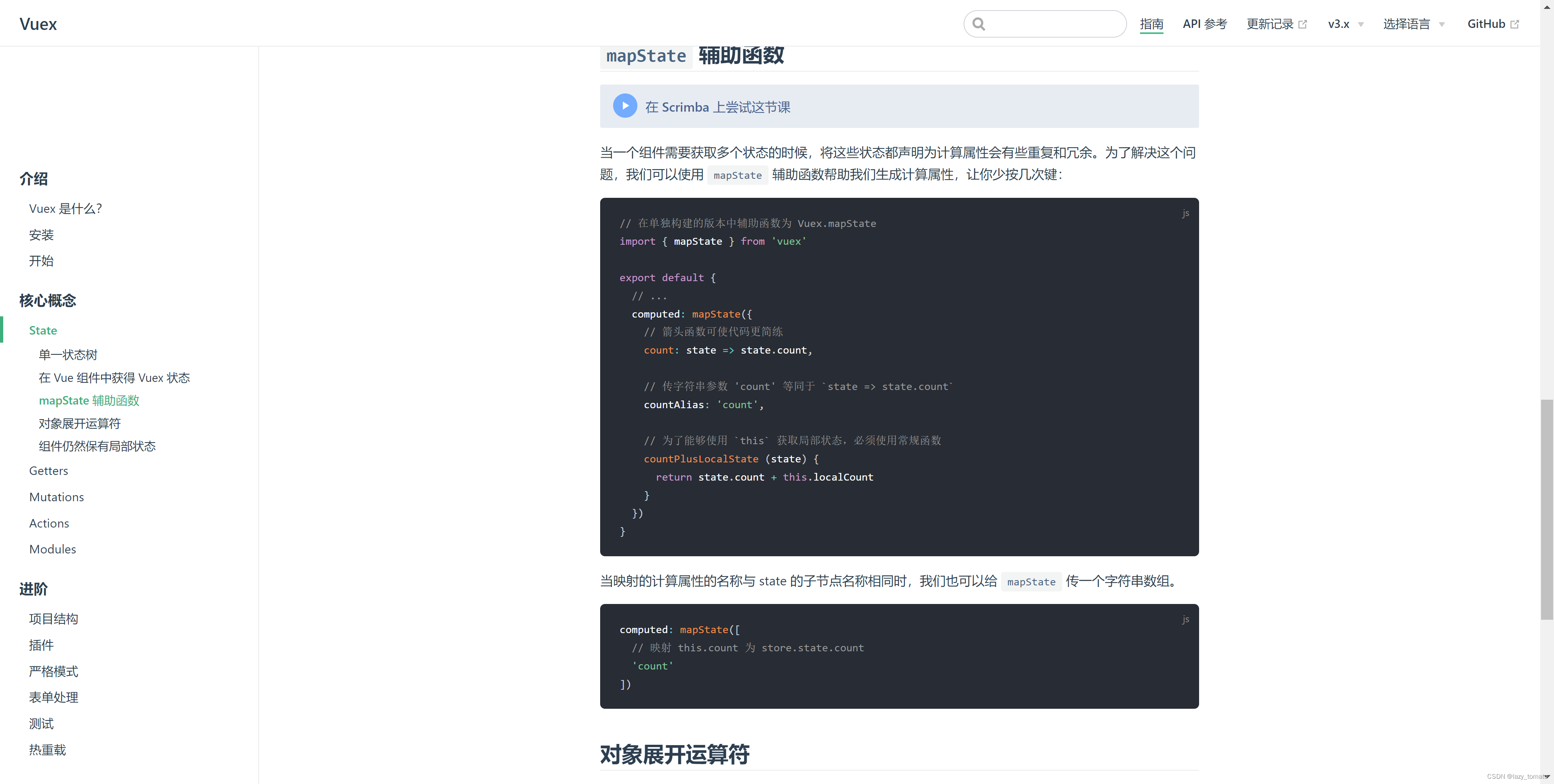
时隔多年再学习Vuex,什么?原来如此简单!
时隔多年再学习Vuex,什么?原来如此简单! start 写 Vue 写了好多年了,少不了和 Vuex 打交道。虽然使用它的次数非常频繁,但是潜意识里总觉得这东西很难,导致遇到与之相关的问题就容易慌张。时至今日,升级版…...

Linux笔记_gcc
Linux_gcc程序的翻译链接库make与makefile关于gcc的一些笔记。 程序的翻译 gcc/g是一个编译器。 预处理:头文件展开、条件编译、宏替换、去注释 编译:C语言汇编语言 汇编:汇编->可重定位目标二进制文件,不可以被执行࿰…...

2023美赛MCM A题 详细思路
2023美赛(MCM/ICM)如期开赛,为了尽早的帮大家确定选题。这里我们加急为大家编辑出A赛题详细思路,方便大家快速对A题目的难度有个大致的了解。同时,我们也给出了A题目简要的解题思路,以及该问题在实际解决中可能会遇到的难点。A题的…...
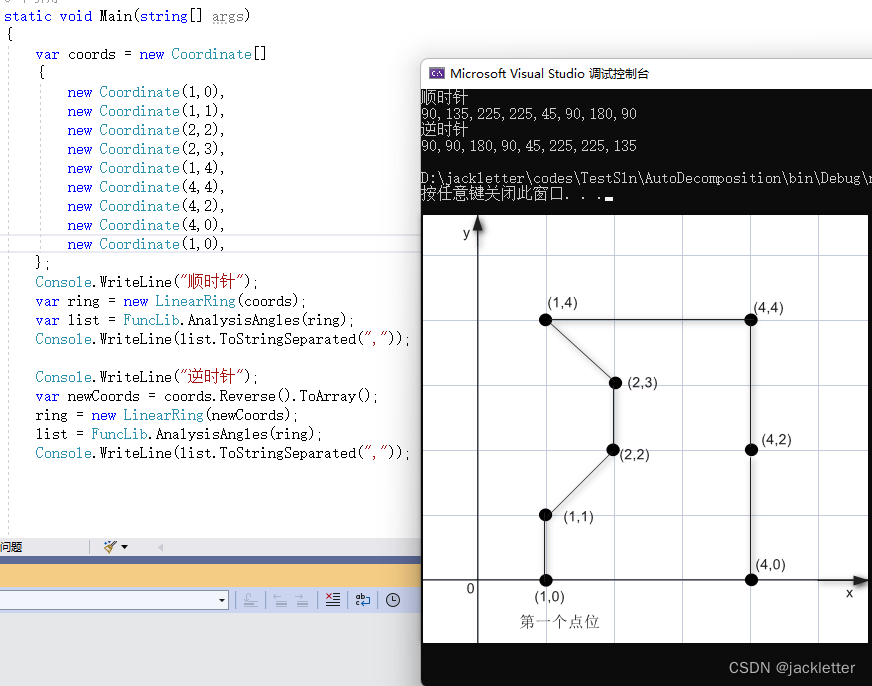
c#: NetTopologySuite凹凸多边形计算
环境: .net 6.0NetTopologySuite 2.5.0vs2022平面二维 一、夹角计算 1.1 计算向量与x轴正方向的夹角 方法: AngleUtility.Angle(Coordinate p) 下图上的t2即为p,之所以这么写是为了和AngleUtility.AngleBetweenOriented做比较 注意: 结果…...
NFT Insider #86:A16z 领投,YGG 获得 1380 万美元融资,The Sandbox与《北斗神拳》合作
引言:NFT Insider由NFT收藏组织WHALE Members、BeepCrypto联合出品,浓缩每周NFT新闻,为大家带来关于NFT最全面、最新鲜、最有价值的讯息。每期周报将从NFT市场数据,艺术新闻类,游戏新闻类,虚拟世界类&#…...

Sort_Algorithm
排序算法前言插入排序折半插入排序希尔排序冒泡排序快速排序选择排序堆排序归并排序前言 排序算法:将一堆数据元素按关键字递增或者递减的顺序,进行排序。 排序算法的评价指标:时间复杂度,空间复杂度,算法稳定性。 算…...
【初探人工智能】2、雏形开始长成
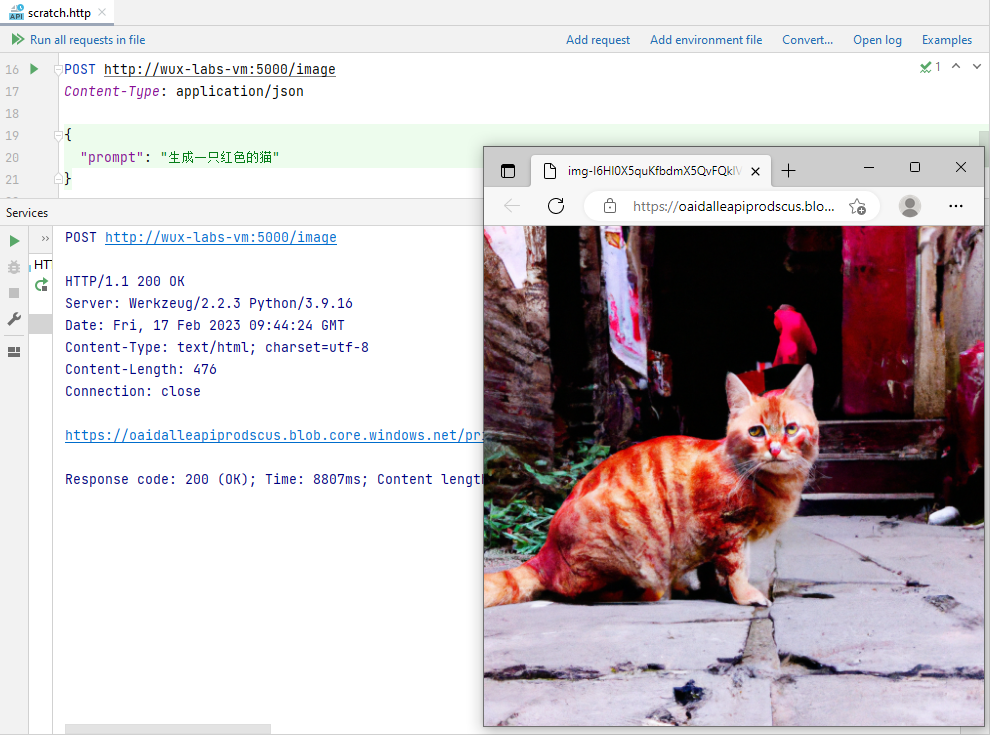
【初探人工智能】2、雏形开始长成【初探人工智能】2、雏形开始长成安装Flask封装Web接口雏形设置接收参数功能验证聊天写代码代码补全生成图片写在后面笔者初次接触人工智能领域,文章中错误的地方还望各位大佬指正! 【初探人工智能】2、雏形开始长成 在…...
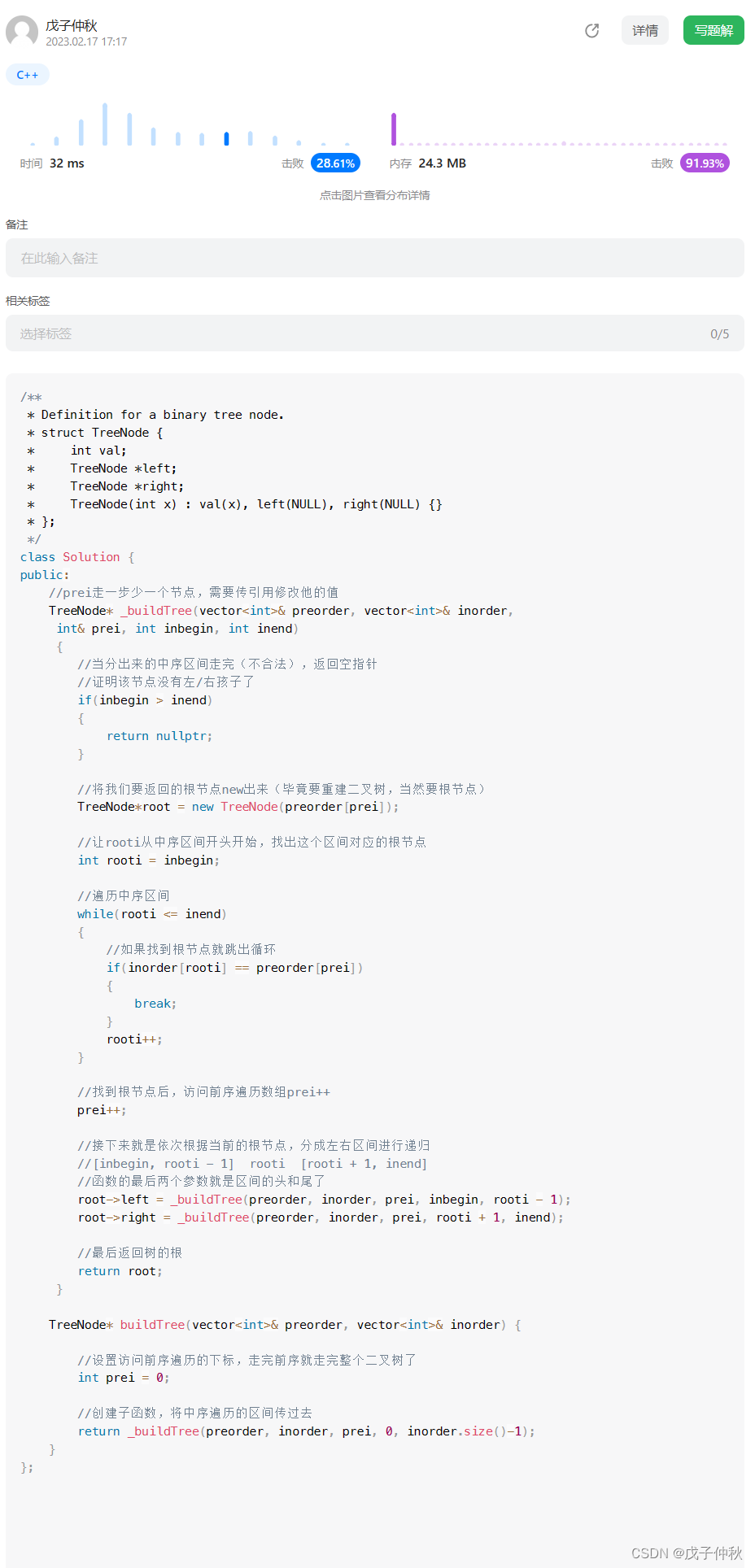
【LeetCode】剑指 Offer(2)
目录 写在前面: 题目: 题目的接口: 解题思路: 代码: 过啦!!! 写在最后: 写在前面: 今天的每日一题好难,我不会dp啊啊啊啊啊啊。 所以&am…...

【JavaSE】Lambda、Stream(659~686)
659.每天一考 1.写出获取Class实例的三种常见方式 Class clazz1 String.class; Class clazz2 person.getClass(); //sout(person); //xxx.yyy.zzz.Person... Class clazz3 Class.forName(String classPath);//体现反射的动态性2.谈谈你对Class类的理解 Class实例对应着加载…...
求梯度和Hessian Matrix(海森矩阵)的python实现)
有限差法(Finite Difference)求梯度和Hessian Matrix(海森矩阵)的python实现
数学参考 有限差方法求导,Finite Difference Approximations of Derivatives,是数值计算中常用的求导方法。数学上也比较简单易用。本文主要针对的是向量值函数,也就是f(x):Rn→Rf(x):\mathbb{R^n}\rightarrow \mathbb{R}f(x):Rn→R当然&…...

day33 贪心算法 | 1005、K次取反后最大化的数组和 134、加油站 135、分发糖果
题目 1005、K次取反后最大化的数组和 给定一个整数数组 A,我们只能用以下方法修改该数组:我们选择某个索引 i 并将 A[i] 替换为 -A[i],然后总共重复这个过程 K 次。(我们可以多次选择同一个索引 i。) 以这种方式修改…...

《蓝桥杯每日一题》递推·AcWing 3777. 砖块
1.题目描述n 个砖块排成一排,从左到右编号依次为 1∼n。每个砖块要么是黑色的,要么是白色的。现在你可以进行以下操作若干次(可以是 0 次):选择两个相邻的砖块,反转它们的颜色。(黑变白…...
)
mysql读写分离(maxscale)
1. 环境架构 需要三台服务器。192.168.2.10(master)192.168.2.20(slave)192.168.2.30(maxscale) 2. 部署mysql主从同步 mysql主从同步可以参考mysql主从同步 3. 部署maxscale服务 MaxScale中间件软件 …...
第八章 - 数据分组( group by , having , select语句顺序)
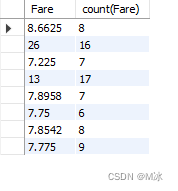
第八章 - 数据分组 group by数据分组过滤分组 having分组排序groub by语句的一些规定select语句顺序数据分组 在使用group by进行分组时,一般都会配合聚合函数一起使用,实现统计数据的功能。比如下面例子,需要按性别计算人数。按性别进行分组…...

Git(GitHub,Gitee 码云,GitLab)详细讲解
目录第一章 Git 概述1.1 何为版本控制1.2 为什么需要版本控制1.3 版本控制工具1.4 Git 简史1.5 Git 工作机制1.6 Git 和代码托管中心第二章 Git 安装第三章 Git 常用命令3.1 设置用户签名3.2 初始化本地库3.3 查看本地库状态3.3.1 首次查看(工作区没有任何文件&…...

OpenAccess十年:EDA互操作性标准如何重塑芯片设计流程
1. 从愿景到现实:OpenAccess十年之路的深度复盘十年前,也就是2002年的12月,当Si2(硅集成倡议组织)首次向联盟成员发布OpenAccess 2.0时,恐怕没有多少人能预料到,这个源于半导体巨头内部需求的“…...

终极指南:如何用FanControl实现Windows系统风扇智能温控与静音优化
终极指南:如何用FanControl实现Windows系统风扇智能温控与静音优化 【免费下载链接】FanControl.Releases This is the release repository for Fan Control, a highly customizable fan controlling software for Windows. 项目地址: https://gitcode.com/GitHub…...
)
Midjourney V6 acrylic paint提示词工程:从模糊描述到精准输出的12个专业级Prompt模板(含色彩层厚/笔触硬度/画布纹理三重控制)
更多请点击: https://intelliparadigm.com 第一章:Midjourney V6丙烯画风格的核心演进与底层渲染机制 Midjourney V6 对丙烯画(Acrylic Painting)风格的建模已脱离早期依赖纹理叠加与后处理滤镜的粗粒度模拟,转向基于…...

STM32F407上电后第一行代码:手把手带你读懂启动文件startup_stm32f407xx.s
STM32F407启动文件深度解析:从复位到main()的底层之旅 当你第一次打开STM32的MDK工程时,那个神秘的.s文件是否曾让你望而却步?作为连接硬件与C语言世界的桥梁,启动文件(startup_stm32f407xx.s)完成了从芯片…...

STM32F103C8T6驱动5V LCD1602,开漏输出+上拉电阻的硬件连接与代码避坑指南
STM32F103C8T6驱动5V LCD1602的硬件设计与代码实战指南 当3.3V的STM32遇到5V供电的LCD1602模块时,电平不匹配问题常常让初学者头疼不已。本文将深入解析开漏输出配合上拉电阻的解决方案,通过硬件原理分析、示波器实测对比和完整代码示例,带你…...

Windows风扇控制终极指南:5分钟学会FanControl智能调校
Windows风扇控制终极指南:5分钟学会FanControl智能调校 【免费下载链接】FanControl.Releases This is the release repository for Fan Control, a highly customizable fan controlling software for Windows. 项目地址: https://gitcode.com/GitHub_Trending/f…...

从玩具车到智能体:用STC89C52给小车装上‘眼睛’和‘触角’的传感器融合实战
从玩具车到智能体:STC89C52多传感器融合的决策系统设计 当一辆普通的玩具车被赋予环境感知能力,它便开始了向智能体的进化。在这个项目中,我们使用STC89C52单片机作为"大脑",通过超声波模块和漫反射光电传感器构建了一…...
)
别再乱接电阻了!手把手教你为DDR4/DDR5内存信号选对端接方案(附仿真对比)
别再乱接电阻了!手把手教你为DDR4/DDR5内存信号选对端接方案(附仿真对比) 第一次调试DDR5内存接口时,我盯着示波器上扭曲的信号波形整整三天没合眼。当我把串联端接电阻从22Ω换成39Ω的瞬间,眼图突然像被施了魔法一样…...

009、NPU、TPU与硬件加速器在TinyML中的作用
009、NPU、TPU与硬件加速器在TinyML中的作用 去年冬天调试一个智能门锁的唤醒词模型,模型在PC上跑得飞起,量化后只有48KB,自信满满地烧进STM32F4。结果呢?唤醒延迟从预期的200ms直接飙到1.2秒,电池续航从三个月缩水到两周。拆开示波器一看,CPU在跑模型的时候几乎被占满,…...

Efficient-KAN:突破传统神经网络瓶颈的Kolmogorov-Arnold网络实战指南
Efficient-KAN:突破传统神经网络瓶颈的Kolmogorov-Arnold网络实战指南 【免费下载链接】efficient-kan An efficient pure-PyTorch implementation of Kolmogorov-Arnold Network (KAN). 项目地址: https://gitcode.com/GitHub_Trending/ef/efficient-kan 深…...