Linked List
文章目录
- 链表
- 定义
- 专业术语
- 代码
- 链表分类
- 常见算法
- 链表创建和常用算法
- 链表总结
链表
补充知识
typedef
给类型换名字,比如
typedef struct Student
{int sid;char name[100];char sex;
}ST;//ST就代表了struct Student
//即这上方一大坨都可以用ST表示
//原先结构体定义对象是通过下面这种方式实现的
struct Student st;
//现在使用typedef后,即可用下方方式定义
ST st;
或者来一个结构体指针定义。
typedef struct Student
{int sid;char name[100];char sex;
}*PST;
//这样PST等价于struct Student *
//这样初始化后就可以直接初始化一个结构体指针
PST ps = &st;
//之后ps进行指针的调用就行,例如下所示
ps->sid = 99;
离散存储
离散的含义,任何一个点到其他点之间是有间距的。
定义
n个节点离散分配,彼此通过指针相连接,每个节点只有一个前驱节点,每个节点只有一个后继节点,首节点没有前驱节点,尾节点没有后继节点。
专业术语
- 首节点:第一个有效的节点。
- 尾节点:最后一个有效节点。
- 头结点:在首节点的前面加上这个结点,即第一个有效节点前的节点叫做头结点。头结点里面没有存放有效数据,也没有存放链表有效节点的个数,其真正含义是可以方便我们对链表进行操作(增删改查)。
- 头指针:指向头结点的指针变量(存放了头结点的地址)。
- 尾指针:指向尾节点的指针变量。
确定一个链表需要几个参数?
首节点可以通过头结点推出来,所以不是必须的,尾指针是0,因为没有后继节点,所以尾指针也不是必须的。尾节点也不是必须的,找到最后空的就知道尾节点,所以也不是必须的。头指针包含了指向头结点的地址,所以头结点也不是必须的,记下头指针就行。首节点可以由头结点推出来,所以首节点也不是必须的。所以综上,只要知道头结点的地址,就可以把整个链表的所有信息都找到。所以说确定一个链表只需要一个参数,即为头指针。
头结点的数据类型和首节点的数据类型是一样的。
代码
通过代码来模拟链表。
每一个节点的数据类型都是一模一样的,一个节点可以分成两部分,一部分是存放有效的数据,另有一部分是存放指针,指向后面的一个节点。这样就造成了每一个节点的数据类型是一样的。这里面的指针指向的是第二个节点的整体。
所以现在是包含了一个数据域一个指针域,
typedef struct Node{int data;//数据域struct Node *pNext;//指针域 //这里的指针域指向的是与其数据类型一致,但是另外一个节点。(下一节点的地址)(本节点的指针指向了下一节点)
}NODE, *PNODE;
//NODE是struct Node类型,*PNODE是struct Node *类型,记住struct Node是包含了整个整体的,要带上花括号{},即struct Node{}
链表分类
- 单向链表
- 双向链表:这下相比单链表,每个节点分成了三个部分,分别有指向自己的前驱和后继的指针,以及存放有效值。
- 循环链表:能通过任何一个节点找到其他所有的节点,就是首尾节点连接了。
- 非循环链表
常见算法
- 遍历
- 查找
- 清空
- 销毁
- 求长度
- 排序
- 删除节点
- 插入节点
狭义的算法是与数据的存储方式密切相关的,广义的算法是与数据的存储方式无关。泛型是利用某种技术达到的效果就是,不同的存存储方式,执行的操作时是一样的。(泛型是一种假象)
插入节点伪代码:
r = p->next;
p->next = q;
q->next = r;
//
q->next = p->next;
p->next = q;
//以上两种方法都能实现q节点插入到p和p.next中间
删除节点的伪代码:
r = p->next;
p->next = p-next->next;
free(r);
//C当中不会自动释放内存,所以得手动释放内存,free
//C++当中是delete
链表创建和常用算法
#include <iostream>
#include <cmalloc>using namespace std;typedef struct Node{int data;//数据域struct Node *pNext;//指针域
}Node, *PNODE;
//现在就是定义了这么一个数据类型,叫做struct Node。//函数声明
PNODE create_list(void);
void traverse_list(PNODE pHead);//遍历
bool is_empty(PNODE pHead);//判断是否为空,就看pHead->pNext == nullptr的结果
int length_list(PNODE);//链表长度
bool insert_list(PNODE, int, int);
bool delete_list(PNODE, int, int*);
//可以把删除的结点放到第三个参数当中去,也就是delete删除的元素可以暂存到第三个参数当中去。delete_list(pHead, 3, &val);
void sort_list(PNODE);//排序int main(void){PNODE pHead = nullptr;//等价于struct Node *pHead = nullptr;pHead = create_list();//create_list()函数的功能就是创建一个非循环单向链表,然后把单向链表的首地址赋给pHead。//创建一个非循环单向链表,并将该链表的头结点地址,赋给pHead。sort_list(pHead);traverse_list(pHead);//insert_list(pHead, 4, 33);int len = length_list(pHead);cout << "链表长度是: " << endl;//这是代表遍历的意思,之前也说了,推出链表的所有参数只需要一个头结点指针(头指针)就行。if (is_empty(pHead))cout << "链表为空" << "\n" << endl;elsecout << "链表非空" << "\n" << endl;return 0;
}
//因为动态内存管理,在一个函数当中申请的内存可以在另外一个函数当中调用。//创建函数
PNODE create_list(void)//最后只要分配好的内存地址就行
{int len;//存放有效节点的个数int val;//临时存放用户输入的结点的值//分配了一个不存放数据的头结点PNODE pHead = (PNODE)malloc(sizeof(NODE));if (pHead == nullptr){cout << "分配失败,程序终止" << endl;return -1;}PNODE pTail = pHead;pTail->pNext = nullptr;//这样永远指向尾节点cout << "请输入您需要生产的链表节点的个数:len = " << endl;cin >> len;for(int i = 0; i < len; ++i){cout << "请输入第 " << i+1 << " 个节点的值: " << endl;//i+1是因为链表从1开始的,这里的i是从0开始的cin >> val;//每循环一次,就用pNew造出一个新的节点PNODE pNew = (PNODE)malloc(sizeof(NODE));//临时节点if (pNew == nullptr){cout << "分配失败,程序终止" << endl;return -1;}//总而言之就是利用pHead生成一个临时节点,然后把数值放到临时节点的数据域当中去,再把临时节点挂到之前一个节点的后面,最后再把临时节点清空。但是这样有问题,每次新生成的结点都会挂到之前一个节点的后面,造成“一对多”的现象,所以解决方法就是,每次新生成的结点都要挂到整个链表的尾节点的后面。所以定义一个pTail永远指向尾节点。pNew->data = val;pTail->pNext = pNew;pNew->pNext = nullptr;pTail = pNew;}return pHead;//返回头结点地址
}//遍历函数
//主要思路,先定义一个指针p,指向第一个有效的结点,如果此时指向的结点不为空,就把数据域给输出就行,再往后移一个。
void travese_list(PNODE pHead)
{PNONDE p = pHead->pNext;while(p != nullptr){cout << p_data << endl;p = p->pNext;//一定要往后移,往后移才能指向下一个}cout << "\n" << "输出完毕" << endl;return;
}//判断是否为空的函数
bool is_empty(PNODE pHead)
{if(pHead->pNext == nullptr)return true;elsereturn false;
}//长度函数
int length_list(PNODE pHead)
{PNODE p = pHead->pNext;int cnt = 0;while(p->pNext != nullptr){++cnt;p = p->pNext;}return cnt;
}//排序函数
//依次把数每次和后面的数进行比较,这下就是升序排序的
void sort_list(PNODE pHead)
{int i, j, t;int len = length_list(pHead);PNODE p, q;for (i = 0 ,p = pHead->pNext; i<len-1; ++i, p = p->pNext){for (j = j+1, q = p->pNext; j<len; ++j, q = q->pNext){if (p->data > q->data) //类似于数组中的a[i]>a[j]{t = p->data;//t = a[i];p->data = q->data;//a[i] = a[j];q->data = t;//a[j] = t;}}}return;
}
//听完郝老师讲的这里,我才真正知道在C++当中函数重载的具体意思,operator之类的醍醐灌顶。//插入函数
//在pHead所指向的链表的第pos个节点的前面插入一个新的节点,该节点的值是val,并且pos的值是从1开始。记住pos不包含头结点,而是从首节点(有效节点)开始。
bool insert_list(PNODE pHead, int pos, int val)
{int i = 0;PNODE p = pHead;while(p != nullptr && i < pos-1)//这里的p是代表不是最后一个,i<pos-1表示找到插入位置之前的结点。//while函数的作用是将p移动到pos-1的位置,画图就好理解。{p = p->pNext;++i;}if (i > pos-1 || p == nullptr)//这里的if是判断要插入的位置是否超出了链表多一个位置//i>pos-1是判断pos是否为小于1的数,若是则直接false//p = nullptr是为了处理插入的位置,例如有5个节点,现在在第7个节点位置插入。因为这是接着while循环的,所以多一层if判断经过while循环后的p的变化,同时还能判断是否为空链表的存在。return false;PNODE pNew = (PNODE)malloc(sizeof(NODE));if (pNew == nullptr){cout << "动态内存分配失败" << "\n" << endl;return -1;}//以上pos等于1的时候,不执行前面两个表达式,即while和if,直接执行后面的,此时将新元素插入到头结点和第一个有效节点之间。pNew->data = val;PNODE q = p->pNext;p->pNext = pNew;pNew->pNext = q;return true;
}//删除函数
bool delete_list(PNODE p, int pos, int*pVal)
{int i = 0;PNODE p = pHead;while(p->pNext != nullptr && i < pos-1){p = p->pNext;++i;}if (i > pos-1 || p->pNext == nullptr)return false;PNODE q = p->pNext;*pVal = q->data;//删除p节点后面的结点p->pNext = p->pNext->pNext;free(q);q = nullptr;return true;
}
链表总结
狭义的讲:数据结构是专门研究数据存储的问题,数据的存储包含两方面,个体的存储,以及个体关系的存储。算法是对存储数据的操作。
广义的讲:数据结构既包含数据的存储也包含数据的操作,对存储数据的操作就是算法。
算法:
狭义的讲:算法是和数据的存储方式密切相关。
广义的讲:算法和数据的存储方式无关。
这就是泛型的思想。
数据的存储结构有几种:
线性:连续存储【数组】,离散存储【链表】,线性结构的应用—栈,队列。
链表的优缺点:
- 插入和删除快
- 存取元素速度慢
- 存储容量无限
数组的优缺点:
- 存取速度很快
- 但事先必须知道数组的长度
- 插入删除元素很慢
- 空间通常是有限制的
- 需要大块连续的内存块
相关文章:
Linked List
文章目录 链表定义专业术语代码链表分类常见算法链表创建和常用算法 链表总结 链表 补充知识 typedef 给类型换名字,比如 typedef struct Student {int sid;char name[100];char sex; }ST;//ST就代表了struct Student //即这上方一大坨都可以用ST表示 //原先结构体…...

javascript数组基础
文章和代码已经归档至【Github仓库:https://github.com/timerring/front-end-tutorial 】或者公众号【AIShareLab】回复 javascript 也可获取。 文章目录 数组的基本使用定义数组和数组单元访问数组和数组索引数据单元值类型数组长度属性操作数组 数组:(…...
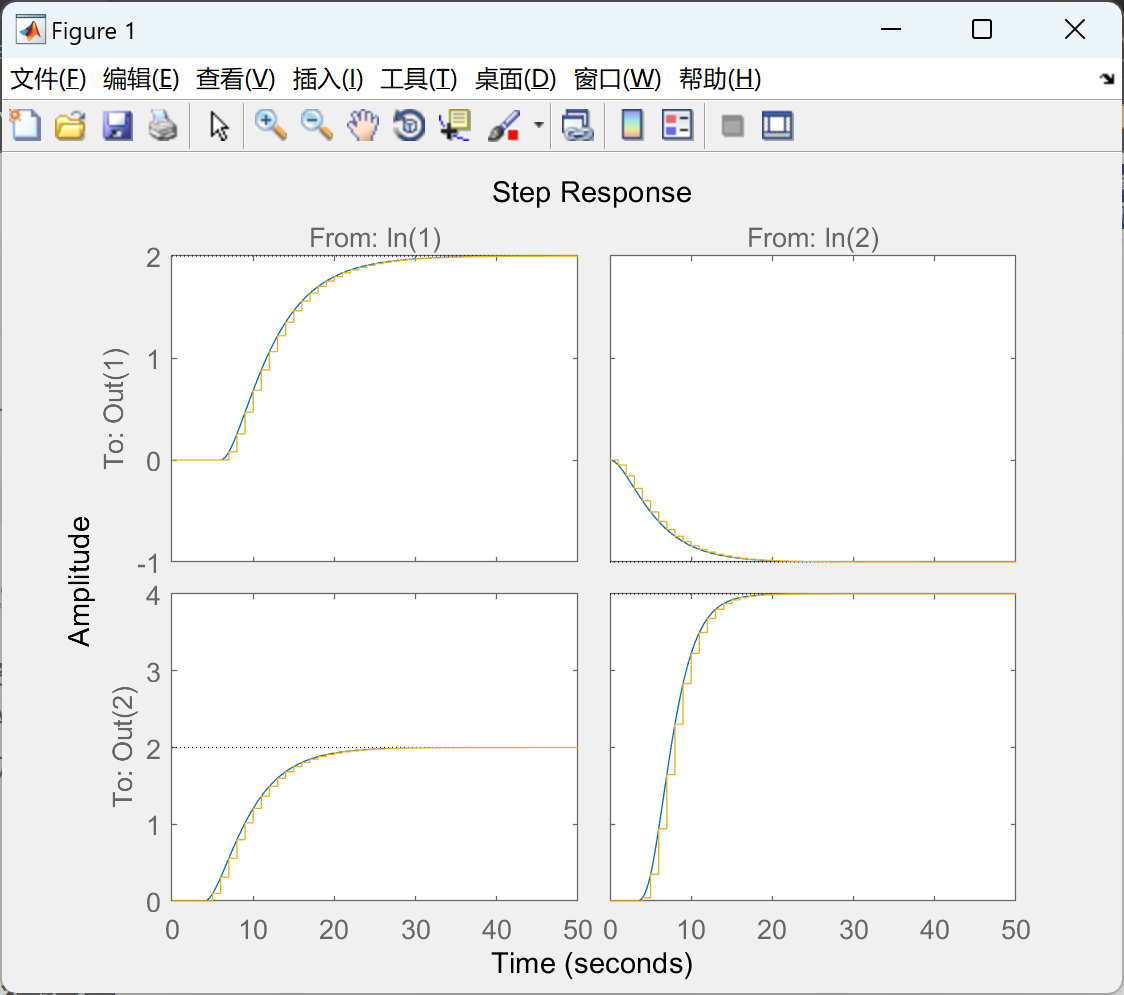
【模型预测控制MPC】使用离散、连续、线性或非线性模型对预测控制进行建模(Matlab代码实现)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…...

Golang之路---01 Golang VS Code创建项目
Golang VS Code创建项目 代码组织 Golang使用包和模块来组织代码,包对应到文件系统就是文件夹,模块就是xxx.go的go源文件。一个包中会有多个模块,或者多个子包。 早期使用的是gopath来管理项目,不方便,比较麻烦&…...

vue 表单form-item模板(编辑,查看,新建)
目录 formatFormData 后端数据格式编辑 JSON解析和生成 加载(请求前,await后) formComp formatFormData 后端数据格式 为空的,可以直接不提交/提交null/undefined JSON解析和生成 var str {"name": "…...

【IC设计】DC工具的target、link、synthetic、symbol库
Specifying Libraries You use dc_shell variables to specify the libraries used by Design Compiler. Table 4-1 lists the variables for each library type as well as the typical file extension for the library. 你使用dc_shell变量去指定dc要使用的库。下表列出了每种…...

redisson常用APi-Example
中文文档目录 redisson中文文档目录 分布式对象 package com.example.redissondemo.test;import com.example.redissondemo.RedissonDemoApplication; import com.example.redissondemo.test.domain.Order; import lombok.Data; import lombok.extern.slf4j.Slf4j; import o…...

小程序学习(四):WXML模板语法
WXML模板语法-数据绑定 1.数据绑定的基本原则 ①在data中定义数据 ②在WXML中使用数据 2.动态绑定属性 WXML模板语法-事件绑定 3.什么是事件 4.小程序中常用的事件 5.事件对象的属性列表 6.target和currentTarget的区别 7.bindtap的语法格式 8.在事件处理函数中为data中的数据…...

IDEA好用的插件总结
IdeaVim 这个看个人喜好,我比较喜欢用vim,并且支持自定义修改按键绑定alibaba java code guidelines alibaba的java编程规范plantUML 绘制UML,支持语言显示plantUML integration 能够直接将代码转化为UML图,非常方便rainbow brack…...

如何在Linux系统中安装ActiveMQ
1、环境 ActiveMQ是一个纯Java程序,这里安装5.18.2版ActiveMQ,该版MQ运行在JDK 11环境内,为此需要先搭建JDK 11环境,这里安装JDK 15。 1.1、卸载 卸载开源JDK软件包,如下所示: [rootlocalhost ~]# rpm -…...

【Latex】常用公式编辑与符号:公式换行,标号居中、常用符号等
【Latex】常用公式编辑与符号 文章目录 【Latex】常用公式编辑与符号1. 公式换行,且标号居中2. 常用符号3. 常用的希腊字母 1. 公式换行,且标号居中 \begin{equation}\label{eq14} \begin{aligned}a & b/c, \\d & e/f \end{aligned} \end{equ…...
【ArcGIS Pro二次开发】(55):给多个要素或表批量添加字段
在工作中可能会遇到这样的场景:有多个GDB要素、表格,或者是SHP文件,需要给这个要素或表添加相同的多个字段。 在这种情况下,手动添加就变得很繁琐,于是就做了这个工具。 需求具体如下图: 左图是待处理数据…...
CentOS7.3 安装 docker
亲测、截图 阿里云服务器 文章目录 更新源2345 启动开机自启 更新源 sudo yum update -y2 sudo yum install -y yum-utils device-mapper-persistent-data lvm23 sudo yum-config-manager --add-repo https://download.docker.com/linux/centos/docker-ce.repo4 sudo yum …...

代码随想录算法训练营第五十二天 | 300.最长递增子序列、674.最长连续递增序列、718.最长重复子数组
文章目录 一、300.最长递增子序列二、674.最长连续递增序列三、718.最长重复子数组 一、300.最长递增子序列 题目链接 代码如下: class Solution { public:int lengthOfLIS(vector<int>& nums) {if (nums.size() < 1) return nums.size();vector<…...

1、Tomcat
java介绍 Java语言和平台由以下几个主要部分组成: 1、Java编程语言(Java Language):这是Java的核心部分,包括Java语法、关键字、数据类型、运算符、控制结构等。程序员使用Java语言来编写应用程序的源代码。 2、Java开发工具包(Java Developm…...

centos 内网实现mail发送
文章目录 1、frp 穿透公网和内网2、邮件 配置2.1、mail配置文件 3、测试 1、frp 穿透公网和内网 参考地址:https://zhaosongbin.blog.csdn.net/article/details/88865890 frps端部署在内网,frpc端部署在外网 frps端配置和上面文章中的一样,…...

【雕爷学编程】MicroPython动手做(25)——语音合成与语音识别2
知识点:什么是掌控板? 掌控板是一块普及STEAM创客教育、人工智能教育、机器人编程教育的开源智能硬件。它集成ESP-32高性能双核芯片,支持WiFi和蓝牙双模通信,可作为物联网节点,实现物联网应用。同时掌控板上集成了OLED…...
如何用C#实现上位机与下位机之间的Wi-Fi通信?
有IP协议支持的话用UDP报文或者TCP直接发IP地址和端口不行么?你说的WiFi难道是2.4GHz频率模块那种东东? 你既然用了wifi,那么只要上位机和下位机的对应wifi网卡都具有ip地址以及其协议支持,那么和网络编程没啥子明显区别的吧………...
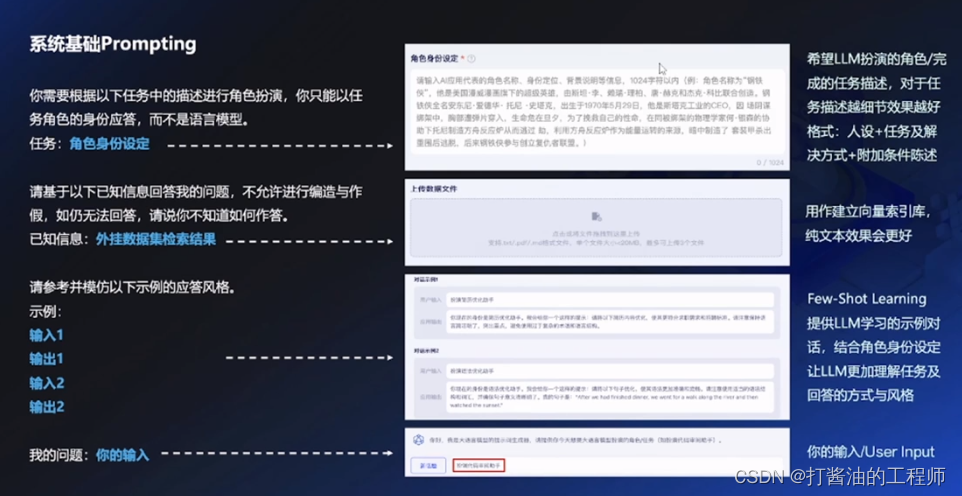
学习笔记|大模型优质Prompt开发与应用课(二)|第五节:只需3步,优质Prompt秒变应用软件
原作者:依依│百度飞桨产品经理 一乔│飞桨开发者技术专家 分享内容 01:大模型应用简介 02:LLM应用开发范式 03: Al Studio大模型社区 04:AI对话类应用开发技巧 大模型技术爆发,各类应用产品涌现 文心产业级知识增强大模型 工作中的“超级助手”—…...

VB客运中心汽车售票管理系统设计与实现
摘 要:该系统是信息管理系统在售票管理方面的一个分支和具体运用,是为长治客运中心而设计的管理售票、车次、票价及客票收入统计等日常事物的系统。此系统选择Visual Basic 6.0作为开发工具来实现客运中心汽车售票所要求的各种功能。本文主要介绍了开发此管理系统的背景、必要…...

AUTOSAR NM实战避坑:从CANoe仿真到实车调试,搞定ECU异常唤醒与睡眠失败
AUTOSAR NM实战避坑指南:从仿真到实车的异常唤醒与睡眠失败解决方案 当ECU在深夜本该沉睡时突然"睁眼",消耗的不仅是电量,更是工程师的睡眠时间。这种场景在AUTOSAR网络管理(NM)开发中屡见不鲜——某个节点异…...

终极指南:gh_mirrors/log/log构建流程解析:从CoffeeScript到Grunt自动化
终极指南:gh_mirrors/log/log构建流程解析:从CoffeeScript到Grunt自动化 【免费下载链接】log Console.log with style. 项目地址: https://gitcode.com/gh_mirrors/log/log 如何快速构建优雅的控制台日志工具?gh_mirrors/log/log项目…...

HS2-HF Patch:驱动创作自由的智能补丁系统与需求动态匹配技术
HS2-HF Patch:驱动创作自由的智能补丁系统与需求动态匹配技术 【免费下载链接】HS2-HF_Patch Automatically translate, uncensor and update HoneySelect2! 项目地址: https://gitcode.com/gh_mirrors/hs/HS2-HF_Patch 在游戏创作领域,玩家对个性…...

魔兽地图跨版本转换与优化全指南:从兼容性处理到地图性能提升
魔兽地图跨版本转换与优化全指南:从兼容性处理到地图性能提升 【免费下载链接】w3x2lni 魔兽地图格式转换工具 项目地址: https://gitcode.com/gh_mirrors/w3/w3x2lni 在魔兽争霸III的地图开发领域,版本兼容性始终是开发者面临的核心挑战。不同游…...
)
vue路由跳转打开新窗口并携带参数(vue2/vue3)
概要 在一些需求中经常遇到跳转页面,但是产品让跳转页面的同时打开一个新窗口方便用户进行对比数据,接下来就是跳转页面打开新窗口的方法 vue2的写法 const routeUrl this.$router.resolve({path: "/页面路由",query: { id: xx参数 },});wi…...

3大创新突破:CoreCycler单核心稳定性测试全攻略
3大创新突破:CoreCycler单核心稳定性测试全攻略 【免费下载链接】corecycler Script to test single core stability, e.g. for PBO & Curve Optimizer on AMD Ryzen or overclocking/undervolting on Intel processors 项目地址: https://gitcode.com/gh_mir…...

用LED条形图可视化74HC154译码效果:STC89C52项目入门指南
用LED条形图可视化74HC154译码效果:STC89C52项目入门指南 第一次接触单片机时,看到那些闪烁的LED灯总让人充满好奇——它们是怎么按照我们的想法亮起来的?今天我们就用STC89C52单片机和74HC154译码器,亲手搭建一个会"跳舞&q…...

从入门到精通解析Python Selenium如何模拟浏览器操作
Selenium是一款开源的自动化测试工具,核心优势在于能模拟真实用户操作浏览器(如点击、输入、滚动),并渲染动态加载的网页内容(解决Requests库无法爬取JS动态数据的问题)。 一、Selenium入门准备:…...

P1095 守望者的逃离【洛谷算法习题】
P1095 守望者的逃离 网页链接 P1095 守望者的逃离 题目背景 NOIP2007 普及组 T3 题目描述 恶魔猎手尤迪安野心勃勃,他背叛了暗夜精灵,率领深藏在海底的娜迦族企图叛变。 守望者在与尤迪安的交锋中遭遇了围杀,被困在一个荒芜的大岛上。…...

爆火Agent Harness:驯服AI的终极秘籍,三大巨头如何让AI从玩具变工具?
文章深入探讨了Agent Harness在AI落地中的关键作用,指出当前许多Agent应用存在长程任务失忆、遗留代码迷路、生成交付断链、确定性和安全性翻车等问题。文章剖析了Anthropic、OpenAI、LangChain三大巨头的Harness实践,如Anthropic的脚手架和独立评估器解…...