python-网络爬虫.Request
Request
python中requests库使用方法详解:
一简介:
Requests 是Python语言编写,基于urllib,
采用Apache2 Licensed开源协议的 HTTP 库。
与urllib相比,Requests更加方便,处理URL资源特别流畅。
可以节约我们大量的工作,建议爬虫使用Requests库。
二、安装Requests库 命令行方式:pip install requests
pycharm安装:
项目导入:import requests
requests库7个主要方法,13个关键字参数:
方法 说明
requsts.requst() 构造一个请求,最基本的方法,是下面方法的支撑
requsts.get() 获取网页,对应HTTP中的GET方法
requsts.post() 向网页提交信息,对应HTTP中的POST方法
requsts.head() 获取html网页的头信息,对应HTTP中的HEAD方 法
requsts.put() 向html提交put方法,对应HTTP中的PUT方法
requsts.patch() 向html网页提交局部请求修改的的请求,
对应HTTP中的PATCH方法
requsts.delete() 向html提交删除请求,对应HTTP中的DELETE方法
三、基本用法:
import requests
response = requests.get('http://www.baidu.com')
print(response.status_code) # 打印状态码
print(response.url) # 打印请求url
print(response.headers) # 打印头信息
print(response.cookies) # 打印cookie信息
print(response.text) #以文本形式打印网页源码 返回的类 型是str
print(response.content) #以字节流形式打印 返回的类型是bytes print(response.apparent_encoding) #网站的编码格式
GET请求:
GET是通过URL方式请求,可以直接看到,明文传输。
response = requests.get('http://www.baidu.com')
GET用于从服务器端获取数据,包括静态资源(HTML|JS|CSS|Image等等)、 动态数据展示(列表数据、详情数据等等)。
其中:利用返回值的 text 属性,可以得到请求的内容:
import requests
response = requests.get("http://www.baidu.com")
response.encoding = "utf-8" #中文显示
print(response.text)
我们终于将一个网页以程序方式自动获取到了。
偶尔我们还需要
带参数的 get() 方法1;
url = 'http://www.baidu.com/s?page=2' # 使用?携带参数
response = requests.get(url)
print(response.text)
带参数的 get() 方法2:
url = 'http://www.baidu.com/s' data= {'page': '2'} #将携带的参数传给params
response = requests.get(url, params=data)
print(response.text)
有些网站访问时必须带有浏览器等信息,如果不传入headers就会报错 如果想传递headers,可以利用headers参数: 只需要将一个dict传递给headers参数便可以定制headers import requests response = requests.get("https://www.zhihu.com/explore")
print(response.text)
POST请求
POST是通过header请求,可以开发者工具或者抓包可以看到,同样也是明 文的。
POST用于向服务器提交数据,比如增删改数据,提交一个表单新建一个用 户、 或修改一个用户等
典型的写法如下:
response=requests.post(url=url,headers=headers,data=data_search)
对于POST请求,当我们传递参数的时候,一般是利用data这个参数,
直接 上代码:
data = {
'name': 'zhangsan' ,
'age': 22, 'sex':
'男'
}
response = requests.post('http://httpbin.org/post' , data=data)
#print(response.text) #中文显示乱码
print(response.content.decode("unicode-escape"))
从输出结果中的“form”值来看传参数成功了,并由服务器返回给我们一个requests简单爬虫案例:
# 天气网西安地区爬虫案例
# -*- coding:utf-8 -*-
'''
@Author: 董咚咚
@contact: 2648633809@qq.com
@Time: 2023/7/31 14:59
@version: 1.0
'''
import requests
import lxml
from lxml import etreeclass WeatherSpider:def __init__(self):self.url = "http://www.weather.com.cn/weather/101110101.shtml"self.headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.119 Safari/537.36"}def get_url_content(self):return requests.get(self.url, headers=self.headers).content.decode()def get_weather_data(self, html):tmp_html = etree.HTML(html)tomorrow_doc = tmp_html.xpath("//div[contains(@class,'con') and contains(@class,'today')]//div[@class='c7d']/ul/li[2]")[0]weather_data = {}weather_data["date"] = tomorrow_doc.xpath("./h1/text()")[0]weather_data["weather"] = tomorrow_doc.xpath("./p[@class='wea']/@title")[0]weather_data["temperature_max"] = tomorrow_doc.xpath("./p[@class='tem']/span/text()")[0]weather_data["temperature_min"] = tomorrow_doc.xpath("./p[@class='tem']/i/text()")[0]weather_data["air_speed"] = tomorrow_doc.xpath("./p[@class='win']/i/text()")[0]return weather_datadef run(self):content_html = self.get_url_content()data = self.get_weather_data(content_html)print(data)if __name__ == '__main__':spider = WeatherSpider()spider.run()运行结果如下:
{'date': '18日(明天)' , 'weather': '多云转晴' , 'temperature_max': '24' , 'temperature_min': '10℃' , 'air_speed': '3-4级'}
相关文章:

python-网络爬虫.Request
Request python中requests库使用方法详解: 一简介: Requests 是Python语言编写,基于urllib, 采用Apache2 Licensed开源协议的 HTTP 库。 与urllib相比,Requests更加方便,处理URL资源特别流畅。 可以节约我…...
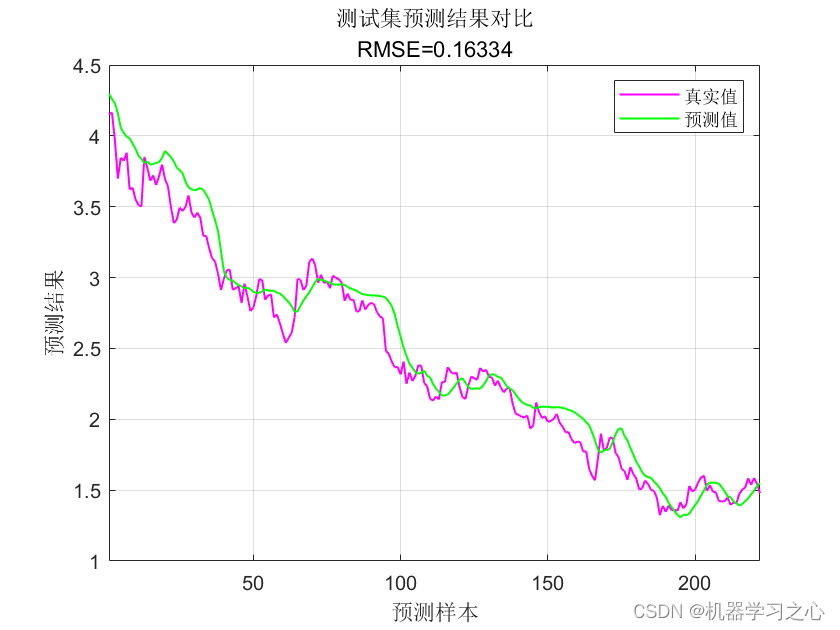
时序预测 | MATLAB实现GRNN广义回归神经网络时间序列预测(多指标,多图)
时序预测 | MATLAB实现GRNN广义回归神经网络时间序列预测(多指标,多图) 目录 时序预测 | MATLAB实现GRNN广义回归神经网络时间序列预测(多指标,多图)效果一览基本介绍程序设计参考资料效果一览 基本介绍 1.MATLAB实现GRNN广义回归神经网络时间序列预测(完整源码和数据) …...
如何看待低级爬虫与高级爬虫?
爬虫之所以分为高级和低级,主要是基于其功能、复杂性和灵活性的差异。根据我总结大概有下面几点原因: 功能和复杂性:高级爬虫通常提供更多功能和扩展性,包括处理复杂页面结构、模拟用户操作、解析和清洗数据等。它们解决了开发者…...

3.分支与循环
一、分支结构 1.概念 一个 CPP 程序默认是按照代码书写顺序,从上到下依次执行下来的。但是,有时我们需要选择性的执行某些语句,来实现更加复杂的逻辑,这时候就需要分支结构语句的功能来实现。选择合适的分支语句可以显著提高程序…...
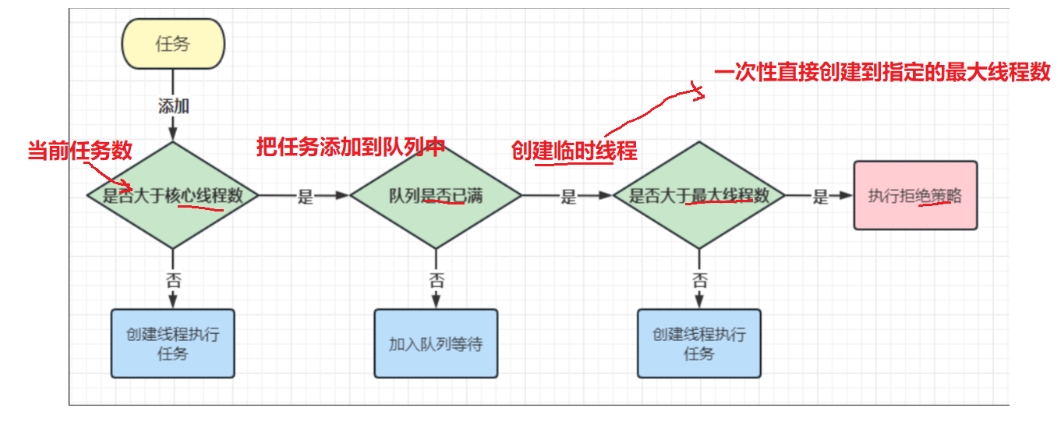
面试之多线程案例(四)
1.单例模式 单例模式是指在内存中只会创建且仅创建一次对象的设计模式。在程序中多次使用同一个对象且作用相同时,为了防止频繁地创建对象使得内存飙升,单例模式可以让程序仅在内存中创建一个对象,让所有需要调用的地方都共享这一单例对象。…...
抄写Linux源码(Day1:获取并运行 Linux0.11)
Day1:获取并运行 Linux0.11 参考资料:https://zhuanlan.zhihu.com/p/438577225 这是我参考的一个别人写的 Linux0.11 解读:https://github.com/dibingfa/flash-linux0.11-talk 我获取 Linux-0.11 源码的链接:https://github.com/…...
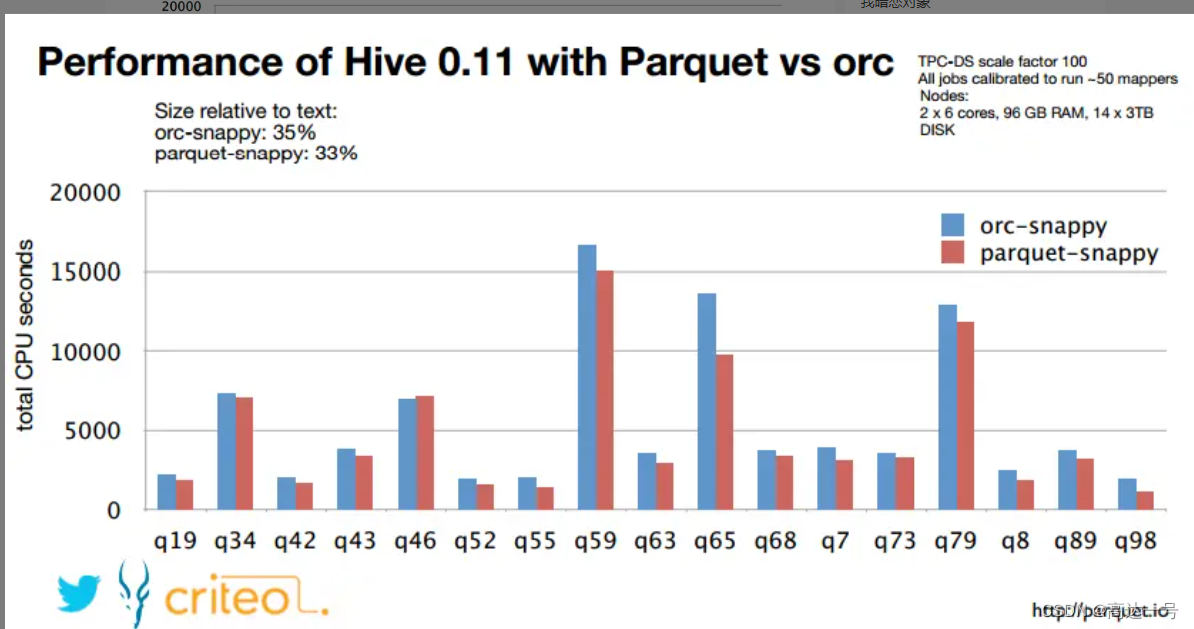
大数据_Hadoop_Parquet数据格式详解
之前有面试官问到了parquet的数据格式,下面对这种格式做一个详细的解读。 参考链接 : 列存储格式Parquet浅析 - 简书 Parquet 文件结构与优势_parquet文件_KK架构的博客-CSDN博客 Parquet文件格式解析_parquet.block.size_davidfantasy的博客-CSDN博…...

Docker的安装和部署
目录 一、Docker的安装部署 (1)关闭防火墙 (2)关闭selinux (3)安装docker引擎 (4)启动docker (5)设置docker自启动 (6)测试doc…...

FPGA项目实现:秒表设计
文章目录 项目要求项目设计 项目要求 设计一个时钟秒表,共六个数码管,前两位显示分钟,中间两位显示时间秒,后两位显示毫秒的高两位,可以通过按键来开始、暂停以及重新开始秒表的计数。 项目设计 为完成此项目共设计…...
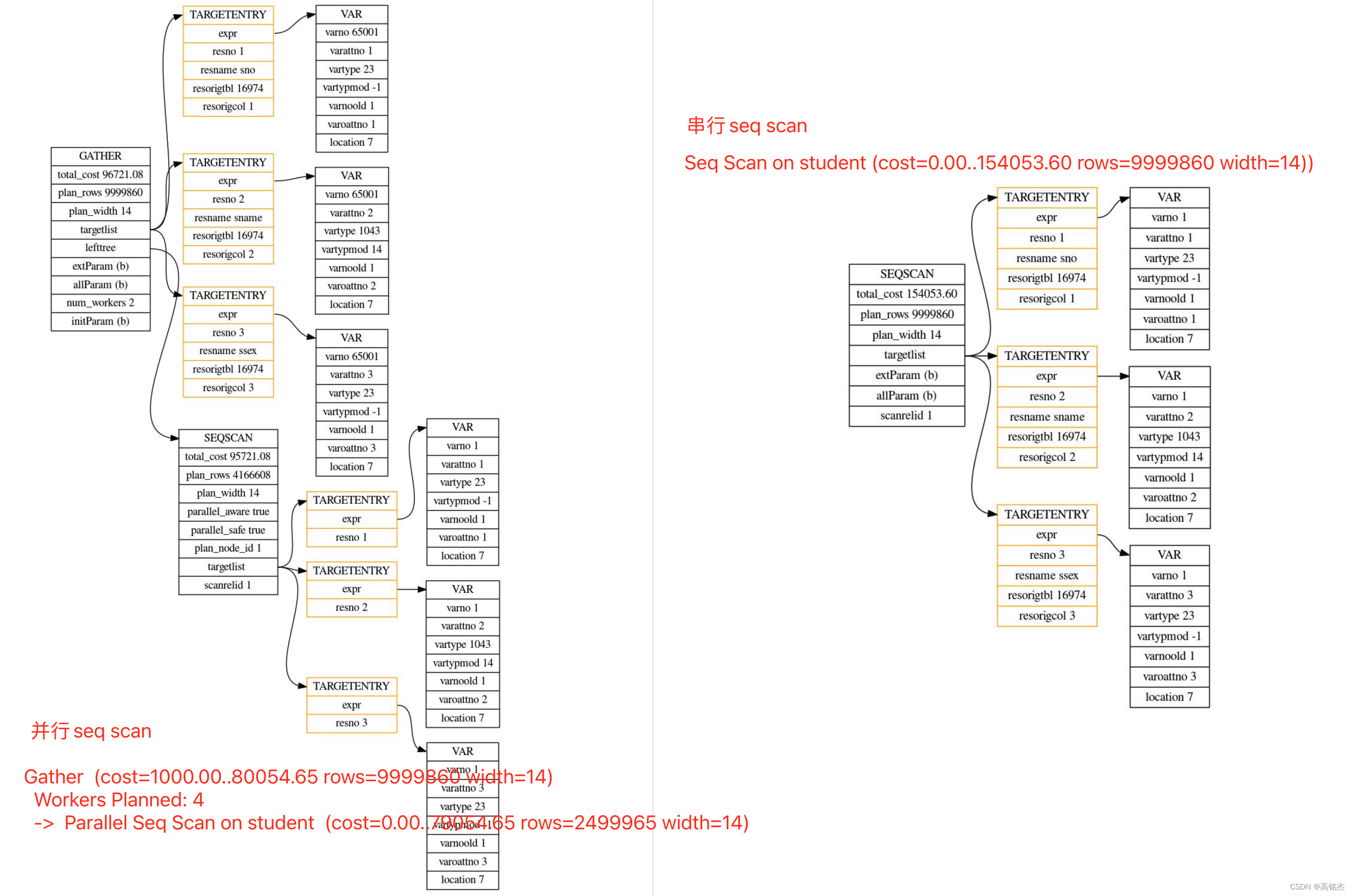
Postgresql源码(109)并行框架实例与分析
1 PostgreSQL并行参数 系统参数 系统总worker限制:max_worker_processes 默认8 系统总并发限制:max_parallel_workers 默认8 单Query限制:max_parallel_workers_per_gather 默认2 表参数限制:parallel_workers alter table tbl …...

ES派生类的prototype方法中,不能访问super的解决方案
1 下面的B.prototype.compile方法中,无法访问super class A {compile() {console.log(A)} }class B extends A {compile() {super.compile()console.log(B)} }B.prototype.compile function() {super.compile() // 报错,不可以在此处使用superconsole.…...

使用adb通过电脑给安卓设备安装apk文件
最近碰到要在开发板上安装软件的问题,由于是开发板上的安卓系统没有解析apk文件的工具,所以无法通过直接打开apk文件来安装软件。因此查询各种资料后发现可以使用adb工具,这样一来可以在电脑上给安卓设备安装软件。 ADB 就是连接 Android 手…...
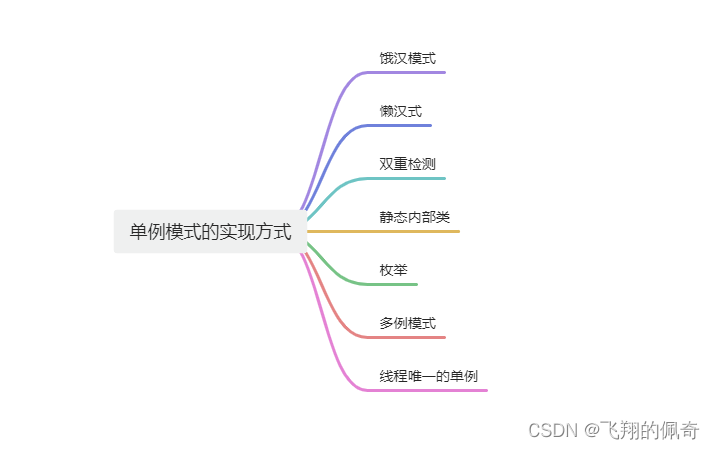
113、单例Bean是单例模式吗?
单例Bean是单例模式吗? 通常来说,单例模式是指在一个JVM中,一个类只能构造出来一个对象,有很多方法来实现单例模式,比如懒汉模式,但是我们通常讲的单例模式有一个前提条件就是规定在一个JVM中,那如果要在两个JVM中保证单例呢?那可能就要用分布式锁这些技术,这里的重点…...
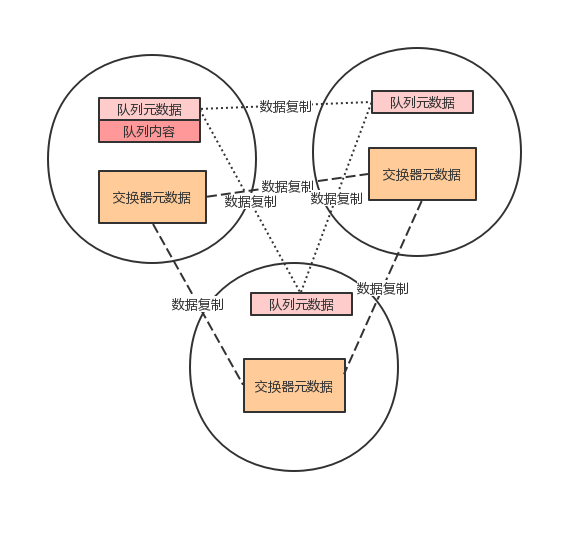
RabbitMQ 集群部署
RabbiMQ 是用 Erlang 开发的,集群非常方便,因为 Erlang 天生就是一门分布式语言,但其本身并不支持负载均衡。 RabbitMQ 的集群节点包括内存节点、磁盘节点。RabbitMQ 支持消息的持久化,也就是数据写在磁盘上,最合适的方案就是既有内存节点,又有磁盘节点。 RabbitMQ 模式大…...

2023年【零声教育】13代C/C++Linux服务器开发高级架构师课程体系分析
对于零声教育的C/CLinux服务器高级架构师的课程到2022目前已经迭代到13代了,像之前小编也总结过,但是课程每期都有做一定的更新,也是为了更好的完善课程跟上目前互联网大厂的岗位技术需求,之前课程里面也包含了一些小的分支&#…...

iOS开发-实现热门话题标签tag显示控件
iOS开发-实现热门话题标签tag显示控件 话题标签tag显示非常常见,如选择你的兴趣,选择关注的群,超话,话题等等。 一、效果图 二、实现代码 由于显示的是在列表中,这里整体控件是放在UITableViewCell中的。 2.1 标签…...

linux系统磁盘性能监视工具iostat
目录 一、iostat介绍 二、命令格式 三、命令参数 四、参考命令:iostat -c -x -k -d 1 (一)输出CPU 属性值 (二)CPU参数分析 (三)磁盘每一列的含义 (四)磁盘参数分…...

BT#蓝牙 - Link Policy Settings
对于Classic Bluetooth的Connection,有一个Link_Policy_Settings,是HCI configuration parameters中的一个。 Link_Policy_Settings 参数决定了本地链路管理器(Link Manager)在收到来自远程链路管理器的请求时的行为,还用来决定改变角色(rol…...

c++ | 动态链接库 | 小结
//环境 linux c //生成动态链接库 //然后调用动态链接库中的函数//出现的问题以及解决//注意在win和在linux中调用动态链接库的函数是不一样的//在要生成链接库的cpp文件中比如以后要调用本文件中的某个函数,需要extern "c" 把你定的函数“再封装”避免重…...

如何使用Flask-SQLAlchemy来管理数据库连接和操作数据?
首先,我们需要安装Flask-SQLAlchemy。你可以使用pip来安装它,就像这样: pip install Flask-SQLAlchemy好了,现在我们已经有了一个可以操作数据库的工具,接下来让我们来看看如何使用它吧! 首先,…...

2026届最火的AI论文助手解析与推荐
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 在人工智能生成内容(AIGC)技术迅猛发展之际,它一方面提升…...

实战-Spine动画与UI元素的层级穿插艺术
1. Spine动画与UI层级穿插的核心挑战 在2D游戏开发中,角色动画和UI元素的视觉层级管理是个高频痛点。我遇到过最典型的场景是:当角色装备武器时,武器需要插入到手臂和身体之间;释放技能时,特效又要在特定骨骼层级间动态…...

如何通过LizzieYzy围棋AI分析工具在30天内实现棋力突破:从入门到实战的完整指南
如何通过LizzieYzy围棋AI分析工具在30天内实现棋力突破:从入门到实战的完整指南 【免费下载链接】lizzieyzy LizzieYzy - GUI for Game of Go 项目地址: https://gitcode.com/gh_mirrors/li/lizzieyzy 在围棋AI技术飞速发展的今天,LizzieYzy作为一…...

强化学习在双摆控制中的应用与挑战
1. 双摆控制中的强化学习挑战双摆系统是控制理论中经典的欠驱动非线性系统,由两个通过关节连接的刚性杆组成,仅有一个关节可施加驱动力。这种系统表现出丰富的动力学特性,包括混沌行为和高度敏感性,使其成为测试控制算法的理想平台…...

保姆级教程:手把手教你将VisDrone数据集转成MOT格式,适配MOTR等模型训练
保姆级教程:手把手教你将VisDrone数据集转成MOT格式,适配MOTR等模型训练 在计算机视觉领域,多目标跟踪(MOT)一直是研究热点之一。而VisDrone作为无人机视角下的经典数据集,其丰富的场景和挑战性的标注使其成为MOT研究的理想选择。…...

告别Arduino IDE:在Visual Studio Code中搭建高效Arduino开发环境
1. 为什么选择VS Code开发Arduino项目 第一次接触Arduino开发时,大多数人都是从官方Arduino IDE开始的。这个简单的开发环境确实能快速上手,但随着项目复杂度增加,它的局限性就越来越明显:代码补全功能弱、项目管理混乱、调试工具…...

离开Meta后田渊栋官宣创业,估值达46.5亿美元;17个小时谈判破裂,三星电子5万名员工或将罢工;微软纳德拉官宣MDASH框架 | 极客头条
「极客头条」—— 技术人员的新闻圈!CSDN 的读者朋友们好,「极客头条」来啦,快来看今天都有哪些值得我们技术人关注的重要新闻吧。(投稿或寻求报道:zhanghycsdn.net)整理 | 郑丽媛出品 | CSDN(I…...
)
收藏!小白/程序员轻松入门大模型,抓住AI时代职业发展机遇(附学习路线)
收藏!小白/程序员轻松入门大模型,抓住AI时代职业发展机遇(附学习路线) 本文系统介绍了AI大模型的学习路径,涵盖Transformer结构、主流大模型、预训练与后训练过程、模型压缩量化、MoE专家模型、RAG与Agent技术、部署与…...
)
2026年小白程序员必看:5项吃香AI技能,助你薪资翻倍(建议收藏)
2026年小白程序员必看:5项吃香AI技能,助你薪资翻倍(建议收藏) 随着AI大模型重构职场规则,掌握相关技能将极大提升工作效率和薪资。本文为小白和程序员推荐了5项最吃香的AI技能:RAG、提示词工程、多模态大模…...

uni-app安卓云打包实战:三种证书方案详解与避坑指南
1. 为什么需要关注安卓打包证书? 第一次接触uni-app安卓云打包的开发者,往往会在证书选择环节卡壳。我自己刚入门时也踩过坑——用测试证书打了包,结果应用商店审核被拒,白白浪费两周时间。证书不仅是APK的"身份证"&…...