Docker啥是数据持久化?
文章目录
- 数据持久化
- 数据卷
- 相关命令
- 创建读写数据卷
- 创建只读数据卷
- 数据卷共享
- 数据卷容器
- 实现数据卷共享
- nginx实现数据卷共享
- nfs
- 总结
- Dockerfile持久化
- Dockerfile方式
- docker run
- 总结

数据持久化
在容器层的 UnionFS(联合文件系统)中对文件/目录的任何修改,无论是手工修改还是容器在运行过程中的修改,在该容器丢失或被删除后这些修改将全部丢失。即这些修改是无法保存下来的。若要保存下来这些修改,通常有两种方式:
定制镜像持久化:将这个修改过的容器生成一个新的镜像,让这些修改变为只读的镜像
数据卷持久化:将这些修改通过数据卷同步到宿主机
数据卷
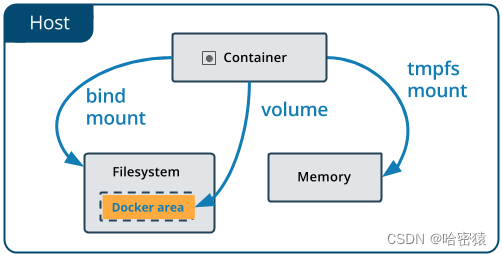
是什么
数据卷在Docker中的设计目的是为了实现数据的持久化和共享,它是宿主机中的一个特殊的文件或目录,与容器中的另一个文件或目录进行直接关联。数据卷使得容器可以在运行时与宿主机之间共享数据,并且数据卷是持久存在的,与容器的生命周期无关。
以下是数据卷的详细解释:
数据卷与挂载点:
数据卷实际上是宿主机中的一个文件或目录,它可以与容器中的一个文件或目录建立直接关联。在宿主机中的这个文件或目录就称为数据卷,而在容器中与数据卷关联的文件或目录则称为该数据卷在容器中的挂载点。当容器运行时,数据卷会被挂载到容器的挂载点上,使得容器可以访问宿主机中的数据。数据持久化:
数据卷是为了实现数据持久化而设计的。容器中的数据可以在数据卷中进行存储,而不会受到容器的生命周期影响。这意味着即使容器被删除,数据卷中的数据仍然保留在宿主机上,可以被其他容器或者宿主机访问和使用。数据卷与容器解耦:
数据卷的一个重要特性是它与容器解耦。这意味着数据卷可以被多个容器共享,并且容器可以独立于数据卷的创建和销毁。因此,即使容器被删除,数据卷仍然存在,可以在其他容器中继续使用。数据卷与UnionFS的区别:
Docker使用UnionFS(联合文件系统)将文件系统层进行组合,实现镜像分层和容器启动等功能。然而,数据卷是完全独立于UnionFS的,它是宿主机文件系统中的一个实体,不属于容器的文件系统层。这使得数据卷更适合用于持久化存储和数据共享。数据卷的创建和管理:
在Docker中,可以使用docker volume命令或者Docker Compose来创建和管理数据卷。数据卷可以通过名称进行标识,方便在不同容器之间进行共享和重用。总结来说,数据卷是Docker中用于实现数据持久化和共享的重要特性。它完全独立于容器的生命周期,使得容器可以方便地与宿主机之间共享数据,并且保证数据在容器被删除后仍然存在。数据卷的使用大大提高了容器应用的灵活性和可靠性。
靠硬连接实现
特性
数据卷(Data Volumes)是Docker中用于实现数据持久化和共享的特性,具有以下明显特性:
数据初始化:
数据卷在容器启动时进行初始化。如果数据卷在容器启动之前已经包含数据,那么容器启动后这些数据会直接在数据卷中可用。反之,如果容器中已有数据,启动后也会出现在数据卷中,确保数据的同步性。实时同步:
对数据卷或挂载点中的内容进行修改后,对方(容器或宿主机)立即可以看到这些修改。数据卷实现了数据在容器和宿主机之间的实时同步,保证数据的一致性。持久性:
数据卷是持久存在的,即使挂载数据卷的容器已经被删除。数据卷与容器的生命周期解耦,因此即使容器被删除,数据卷中的数据仍然保留,可以被其他容器或者宿主机继续访问和使用。共享和重用:
数据卷可以在容器之间共享和重用。这意味着多个容器可以使用同一个数据卷,从而实现容器之间的数据共享。数据卷的独立性和可移动性使得容器更具可扩展性和灵活性。容器间传递数据:
通过数据卷,容器之间可以传递数据,而无需依赖网络共享或复杂的通信机制。数据卷允许容器之间直接读写数据,方便实现数据交换。易于管理:
Docker提供了丰富的命令和工具来创建、查看和管理数据卷。使用docker volume命令可以创建和列出数据卷,使用Docker Compose可以在多个容器之间定义和共享数据卷。数据隔离:
数据卷提供了一种将数据从容器中分离出来的方法,从而实现数据隔离。容器之间的数据互不影响,保证了数据的安全性和独立性。综合来说,数据卷是Docker中用于实现数据持久化、共享和隔离的重要特性。它使得容器可以方便地访问宿主机中的数据,并且数据在容器的生命周期内保持持久化,提高了容器应用的可靠性和灵活性。
相关命令
Docker的数据卷是一种特殊的文件或目录,它可以在容器和宿主机之间进行共享和持久化存储。数据卷使得容器内的数据可以在容器销毁后仍然保留,并且可以被多个容器共享。下面是Docker中数据卷相关的常用命令及其详细信息:
-
创建一个数据卷:
使用命令docker volume create <VOLUME_NAME>可以创建一个新的数据卷。
例如:docker volume create my_volume -
查看所有数据卷:
使用命令docker volume ls可以列出所有当前存在的数据卷。
例如:docker volume ls -
查看数据卷详情:
使用命令docker volume inspect <VOLUME_NAME>可以查看特定数据卷的详细信息。
例如:docker volume inspect my_volume -
删除一个数据卷:
使用命令docker volume rm <VOLUME_NAME>可以删除不再需要的数据卷。
例如:docker volume rm my_volume -
使用数据卷创建容器:
使用命令docker run时,通过选项-v或--volume可以将一个数据卷挂载到容器中。这样容器内的数据就可以与宿主机共享,持久化存储。
例如:docker run -d -v my_volume:/app/data my_image -
使用匿名数据卷:
使用命令docker run时,可以使用选项-v或--volume来创建一个匿名数据卷,它没有指定名称,但可以在容器内使用。匿名数据卷通常用于临时存储容器内的数据。
例如:docker run -d -v /app/data my_image -
挂载宿主机目录作为数据卷:
使用命令docker run时,可以使用选项-v或--volume来将宿主机上的目录挂载为容器内的数据卷,实现容器与宿主机之间的数据共享。
例如:docker run -d -v /host/data:/container/data my_image -
挂载只读数据卷:
使用命令docker run时,通过选项--volume可以指定数据卷挂载为只读模式,容器内无法对该数据卷进行写操作。
例如:docker run -d --volume /app/data:ro my_image
数据卷是Docker中非常有用的功能,它允许容器内的数据持久化存储,并且容器之间可以共享数据。通过以上命令,您可以轻松地创建、管理和使用Docker数据卷。
创建读写数据卷
当使用docker run命令启动容器时,可以通过-v选项来指定数据卷的挂载。数据卷的语法格式为:
docker run -it -v /宿主机目录绝对路径:/容器内目录绝对路径 镜像
下面对该命令的各个部分进行详细解释:
-
-it: 这是两个选项的组合,用于以交互模式运行容器,并将终端连接到容器的标准输入输出。这使得在容器中可以交互式地执行命令。 -
-v: 这是用来指定数据卷挂载的选项。通过-v选项,可以将宿主机的目录或文件挂载到容器内的指定目录。 -
/宿主机目录绝对路径: 这是宿主机上的目录或文件的绝对路径,用来指定要挂载的数据卷。 -
/容器内目录绝对路径: 这是容器内部的目录的绝对路径,用来指定数据卷在容器中的挂载点。容器内的该路径将与宿主机上指定的路径建立直接关联。
例如,假设有一个宿主机目录/home/user/data,希望将它挂载到容器内的路径/app/data,可以使用以下命令:
docker run -it -v /home/user/data:/app/data image_name
如果宿主机中的/home/user/data目录不存在,Docker引擎会自动创建该目录。同样,如果容器内的/app/data目录不存在,也会被自动创建。
这样一来,在容器中对/app/data路径进行的任何读写操作都会实际上读写到宿主机上的/home/user/data目录,从而实现了数据在容器和宿主机之间的共享。同时,数据的持久性也得到了保障,即使容器被删除,/home/user/data目录中的数据也不会受到影响。
[root@docker ~]# docker run --name myutu -it -v /root/host_mount:/opt/uc_mount ubuntu:latest /bin/bash
root@c751f2dd8296:/# ls -l /opt
total 0
drwxr-xr-x 2 root root 6 Jul 21 11:58 uc_mount
在容器创建test文件,并写入数据
root@c751f2dd8296:/opt/uc_mount# echo "123456" >>test
root@c751f2dd8296:/opt/uc_mount# cat test
123456可以在宿主机上同样看到数据
[root@docker ~]# ls
anaconda-ks.cfg host_mount tom-export.tar
[root@docker ~]# cd host_mount/
[root@docker host_mount]# ls
test
[root@docker host_mount]# cat test
123456查看myutu的详细信息
"Mounts": [{"Type": "bind","Source": "/root/host_mount","Destination": "/opt/uc_mount","Mode": "","RW": true,"Propagation": "rprivate"}这里给出了数据卷 Source 与挂载点 Destination 的绑定关系,且容器对挂载点的默认操作权限是 RW 读写的。
也可以使用mount将进行挂载
docker run --name myutu -it -mount --source=<数据卷名>,target=/opt/uc_mount ubuntu:latest /bin/bash
该
docker service create命令不支持-vor--volume标志。将卷安装到服务的容器中时,必须使用该--mount标志。
创建只读数据卷
在Docker中,可以通过在数据卷挂载时添加:ro选项来创建只读数据卷。这样设置的数据卷在容器内部是只读的,容器无法对其中的内容进行写操作,只能读取其中的数据。以下是详细步骤:
-
创建只读数据卷:
首先,您需要有一个宿主机上的目录,作为数据卷的来源。假设我们要将宿主机的/host_data目录作为只读数据卷,将其挂载到容器内的/container_data目录。使用以下命令来创建只读数据卷:
docker run -it -v /host_data:/container_data:ro ubuntu这将以交互模式运行一个Ubuntu容器,并将宿主机的
/host_data目录挂载到容器内的/container_data目录,并且设置为只读(:ro)。 -
验证只读数据卷:
在容器内,您可以访问/container_data目录,并读取其中的内容,但是无法在容器内对该目录进行写操作。任何试图在容器内对该目录进行写入的尝试都会失败。 -
注意事项:
- 只读数据卷只能在数据卷的创建时设置,一旦容器启动,无法在运行中更改数据卷的读写属性。
- 如果需要在容器内写入数据,可以在创建容器时不添加
:ro选项,或者另外创建一个可写数据卷进行挂载。 - 只读数据卷对于共享配置文件、静态资源等情况非常有用,可以避免误操作导致数据损坏。
通过创建只读数据卷,您可以增加对数据的保护,确保容器中的数据不会被意外修改。同时,只读数据卷也有助于提高容器的安全性和稳定性。
创建只读数据卷,同时创建文件写数据,可以看到容器在这个目录不能进行写操作了。
[root@docker host_mount]# docker run --name myutro -it -v /root/host_ro:/opt/uc_ro:ro ubuntu:latest /bin/bash
root@e4111ebd1306:/# cd opt/
root@e4111ebd1306:/opt# ls
uc_ro
root@e4111ebd1306:/opt# cd uc_ro/
root@e4111ebd1306:/opt/uc_ro# echo "123456" >test
bash: test: Read-only file system需要注意的容器只是在挂载点无法进行有关写的操作了,但是还可以在其他目录下进行正常操作的。
在宿主机上进行写操作
[root@docker host_ro]# echo '123456' >test1
[root@docker host_ro]# ls
test1可以启动容器进行查看
[root@docker host_ro]# docker start myutro
myutro
[root@docker host_ro]# docker exec -it myutro /bin/bash
root@e4111ebd1306:/# cd opt/
root@e4111ebd1306:/opt# ls
uc_ro
root@e4111ebd1306:/opt# cd uc_ro/
root@e4111ebd1306:/opt/uc_ro# cat test1
123456看查看容器的详细信息
"Mounts": [{"Type": "bind","Source": "/root/host_ro","Destination": "/opt/uc_ro","Mode": "ro","RW": false,"Propagation": "rprivate"}], 只读数据卷,指的是容器对挂载点的操作权限是只读的。宿主机对数据卷的操作权限始终是读写的。
有些情况下,为了防止容器在运行过程中对文件产生修改,就需要创建只读数据卷
可以使用mount进行挂载
[root@docker host_mount]# docker run --name myutro -it --mount source=<数据卷名>,destination=/opt/uc_ro,readonly ubuntu:latest /bin/bash
数据卷共享
Docker的数据卷允许容器之间共享数据,这对于构建复杂的应用程序或微服务体系结构时非常有用。下面详细介绍Docker数据卷的共享特性:
-
多个容器之间共享数据:
使用数据卷,可以将宿主机上的目录(或文件)挂载到多个容器的不同位置,从而实现多个容器之间的数据共享。这些容器可以是同一镜像的多个实例,也可以是不同镜像的容器,只要它们挂载了相同的数据卷,就可以共享其中的数据。 -
数据卷的生命周期与容器解耦:
数据卷是独立于容器的,因此即使容器被删除,数据卷中的数据仍然保留。这使得多个容器可以独立地创建、启动、停止和删除,而数据卷仍然存在,并可以在其他容器中继续使用。 -
数据卷共享的灵活性:
容器之间的数据卷共享非常灵活。可以将数据卷挂载到多个容器的不同路径,使得不同容器可以在自己的文件系统中使用共享数据。这使得多个容器可以使用相同的配置文件、静态资源等数据,方便进行集中管理。 -
数据卷共享的应用场景:
- 数据库集群:多个数据库容器可以共享数据卷,确保数据在多个数据库节点之间的一致性和持久性。
- 负载均衡和反向代理:多个负载均衡或反向代理容器可以共享配置文件和SSL证书等数据,以保持一致的配置和安全性。
- 日志收集:多个日志收集容器可以共享数据卷,将日志数据保存到宿主机上,以便进行集中管理和分析。
-
共享数据卷的创建和管理:
共享数据卷需要在容器创建时进行挂载,可以使用docker run命令的-v选项来指定宿主机目录和容器内目录的挂载关系。也可以使用Docker Compose来定义和管理多个容器的数据卷共享。 -
数据卷共享的注意事项:
- 共享数据卷时,要确保多个容器使用相同的数据卷名称和挂载路径。
- 在多个容器之间共享敏感数据时要格外小心,确保数据的安全性和权限设置。
- 不要在共享数据卷中存储容器内部运行时生成的数据,因为容器删除后这些数据也会丢失。
通过数据卷共享,Docker提供了一种方便的方式来实现容器之间的数据共享和交换,使得多个容器可以更好地协同工作,构建复杂的应用程序和服务。同时,数据卷的持久性和独立性保证了共享数据的安全性和可靠性。
数据卷容器
Docker的数据卷容器(Volume Containers)是一种创建和管理数据卷的方法,它是一个专门用于共享数据的容器。数据卷容器与普通应用容器不同,它的主要目的是提供一个持久化存储的解决方案,使得多个应用容器可以方便地共享数据,并且数据的生命周期与容器解耦。以下是数据卷容器的详细介绍:
-
数据卷容器的创建:
创建数据卷容器的步骤如下:- 首先,使用
docker create命令创建一个数据卷容器,指定数据卷容器的名称或ID以及要挂载的数据卷目录。 - 然后,可以使用
docker run命令创建其他应用容器,并使用--volumes-from参数来指定刚创建的数据卷容器,从而将数据卷共享给其他容器。
- 首先,使用
-
数据卷容器的特性:
- 数据卷容器与数据卷的创建和管理解耦:数据卷容器独立于应用容器的创建和销毁,数据卷容器的生命周期可以比应用容器更长久,这使得数据卷中的数据可以持久存在。
- 数据卷容器可以包含多个数据卷:一个数据卷容器可以包含多个数据卷,通过将不同的数据卷目录挂载到不同的应用容器中,实现多个数据卷的共享和管理。
- 共享数据卷给多个应用容器:通过使用
--volumes-from参数,可以将一个数据卷容器中的数据卷共享给多个应用容器,实现容器之间的数据共享。 - 数据卷容器的数据卷具有持久性:即使所有应用容器都被删除,数据卷容器的数据卷仍然保留,可以在新的应用容器中继续使用。
-
数据卷容器的优势:
- 简化数据共享:通过数据卷容器,可以将数据卷从应用容器中解耦出来,使得多个应用容器可以方便地共享数据。
- 简化备份和迁移:数据卷容器中的数据卷可以在多个应用容器之间移动,这使得数据备份和容器迁移变得更加简单和高效。
- 增强数据隔离:数据卷容器提供了一层额外的隔离,将数据从应用容器中分离出来,提高了数据的安全性和独立性。
-
数据卷容器的注意事项:
- 当创建一个数据卷容器时,最好不要运行该容器,可以使用
docker create命令创建而不是docker run命令。 - 数据卷容器中的数据卷具有全局性,不会受到应用容器的限制,所以要小心不要在数据卷容器中修改或删除重要数据。
- 当创建一个数据卷容器时,最好不要运行该容器,可以使用
数据卷容器是Docker中非常有用的特性,它为数据的持久化存储和多个容器之间的数据共享提供了方便和灵活的解决方案。通过合理利用数据卷容器,可以更好地组织和管理数据,并提高容器化应用的可靠性和可扩展性。
实现数据卷共享
Docker提供了多种方法来实现数据卷共享,以下是两种常用的方法:
-
使用主机挂载卷(Host-mounted Volumes):
这种方法是将宿主机上的目录直接挂载到多个容器中,从而实现数据共享。在docker run命令中,使用-v选项来指定宿主机目录和容器内目录的挂载关系,然后可以在多个容器中使用相同的宿主机目录来共享数据。例如:docker run -d -v /host_data:/container_data container_image这样,
/host_data目录会被挂载到多个容器的/container_data目录,实现数据共享。创建myutu2和myutu的实现挂载路径一样
[root@docker host_ro]# docker run --name myutu2 -it -v /root/host_mount:/opt/uc_mount ubuntu:latest /bin/bash root@4f846003a316:~# cd /opt root@4f846003a316:/opt# ls uc_mount root@4f846003a316:/opt# cd uc_mount/ root@4f846003a316:/opt/uc_mount# ls test root@4f846003a316:/opt/uc_mount# cat test 123456 -
使用数据卷容器(Volume Containers):
数据卷容器是一个专门用于共享数据的容器,它可以包含多个数据卷,并将这些数据卷共享给其他容器。首先,使用docker create命令创建一个数据卷容器,并指定数据卷目录:docker create -v /container_data --name data_container busybox /bin/true然后,在多个应用容器中使用
--volumes-from参数指定刚创建的数据卷容器,以实现数据共享:docker run -d --volumes-from data_container app_image这样,
data_container容器中的数据卷将被共享给多个应用容器。
无论使用哪种方法,都能实现数据卷的共享,但数据卷容器的方法更加灵活和可扩展,特别适用于需要多个容器之间共享多个数据卷的情况。而主机挂载卷的方法则更适用于简单的数据共享需求或者单机环境下的数据持久化。根据具体场景和需求,选择合适的方法来实现数据卷的共享。
nginx实现数据卷共享
[root@localhost /]# docker volume create nginx-web
nginx-web
[root@localhost /]# docker volume inspect nginx-web
[{"CreatedAt": "2023-07-25T21:18:17+08:00","Driver": "local","Labels": null,"Mountpoint": "/var/lib/docker/volumes/nginx-web/_data","Name": "nginx-web","Options": null,"Scope": "local"}
]
进入宿主机共享数据卷的目录中,创建首页显示
[root@localhost /]# cd /var/lib/docker/volumes/nginx-web/_data
[root@localhost _data]# vim index.html
[root@localhost _data]# cat index.html
hello world
将建server服务机器
docker run -d --name nginx1 -p 8081:80 --mount source=nginx-web,target=/usr/share/nginx/html --cpu-shares 10 --cpus 1 --cpuset-cpus 0 -m 10000000 nginx:latestdocker run -d --name nginx2 -p 8082:80 --mount source=nginx-web,target=/usr/share/nginx/html --cpu-shares 10 --cpus 1 --cpuset-cpus 0 -m 10000000 nginx:latestdocker run -d --name nginx3 -p 8083:80 --mount source=nginx-web,target=/usr/share/nginx/html --cpu-shares 10 --cpus 1 --cpuset-cpus 0 -m 10000000 nginx:latestnfs
下载
yum install nfs-utils -y
启动
[root@localhost _data]# systemctl start nfs[root@localhost _data]# systemctl enable nfs
Created symlink from /etc/systemd/system/multi-user.target.wants/nfs-server.service to /usr/lib/systemd/system/nfs-server.service.
[root@localhost _data]# ps aux|grep nfs
root 3621 0.0 0.0 0 0 ? S< 21:32 0:00 [nfsd4_callbacks]
root 3627 0.0 0.0 0 0 ? S 21:32 0:00 [nfsd]
root 3628 0.0 0.0 0 0 ? S 21:32 0:00 [nfsd]
root 3629 0.0 0.0 0 0 ? S 21:32 0:00 [nfsd]
root 3630 0.0 0.0 0 0 ? S 21:32 0:00 [nfsd]
root 3631 0.0 0.0 0 0 ? S 21:32 0:00 [nfsd]
root 3632 0.0 0.0 0 0 ? S 21:32 0:00 [nfsd]
root 3633 0.0 0.0 0 0 ? S 21:32 0:00 [nfsd]
root 3634 0.0 0.0 0 0 ? S 21:32 0:00 [nfsd]
root 3644 0.0 0.0 112824 976 pts/1 S+ 21:32 0:00 grep --color=auto nfs-
创建目录以及共享数据
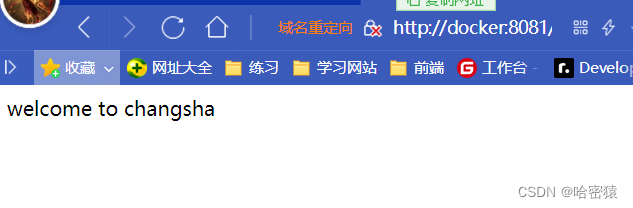
[root@localhost _data]# mkdir /web [root@localhost _data]# cd /web/[root@localhost web]# cat index.html welcome to changsha -
共享出来
[root@localhost web]# vim /etc/exports
[root@localhost web]# cat /etc/exports
/web 192.168.2.0/24(rw,sync,all_squash)
[root@localhost web]# exportfs -av
exporting 192.168.2.0/24:/web
查看文件权限,可以看到这个时候只有主机有写权限,即使上面写了是读写权利,但是文件如果只是读权利的话,最后访问机也只会有读权利,两者取轻的一方(如果不相等)
[root@localhost web]# ll -d /web
drwxr-xr-x 2 root root 24 7月 25 21:34 /web
给权限
[root@localhost web]# chmod 777 /web
创建卷
docker volume create --driver local --opt type=nfs --opt o=addr=192.168.2.99,nolock,soft,rw,sync --opt device=:/web nfs-web
[root@localhost web]# docker volume ls
DRIVER VOLUME NAME
...
local nfs-web
...[root@localhost web]# docker volume inspect nfs-web
[{"CreatedAt": "2023-07-25T22:12:56+08:00","Driver": "local","Labels": null,"Mountpoint": "/var/lib/docker/volumes/nfs-web/_data","Name": "nfs-web","Options": {"device": ":/web","o": "addr=192.168.2.99,nolock,soft,rw,sync","type": "nfs"},"Scope": "local"}
]docker run -d -p 8081:80 --name nginx1 -v nfs-web:/usr/share/nginx/html nginx:latest
总结
-
数据卷和宿主机文件系统:
- 数据卷是Docker中一种特殊的文件/目录,它完全独立于容器的生命周期,属于宿主机的文件系统,但不属于UnionFS(镜像分层文件系统)。数据卷在宿主机上创建,并在容器中挂载,形成宿主机和容器之间的挂载关系。
- 数据卷是宿主机上的文件/目录,但通过挂载,在容器中可以访问和操作它。容器内的挂载点与数据卷之间是硬链接关系,即对数据卷进行的修改在容器内可以实时反映,反之亦然。
-
容器的存在与数据卷无关:
- 数据卷的生命周期与容器解耦,数据卷的持久性不受容器的存在与否影响。即使容器被删除,数据卷仍然存在,可以在其他容器中继续使用。这使得数据卷成为在多个容器之间共享和重用数据的理想选择。
-
数据卷持久化和数据实时性持久化:
- 数据卷的持久化是指数据卷的数据不随容器的生命周期而变化或删除。因为数据卷属于宿主机文件系统,所以即使容器被删除,数据卷中的数据仍然保留。这确保了数据的持久性,不会出现容器销毁导致数据丢失的情况。
- 数据实时性持久化是指对容器内的数据卷所做的任何修改会实时地反映到宿主机文件系统上,并且对宿主机上的数据卷的修改也会实时反映到容器内。这是由于数据卷和容器内的挂载点之间是硬链接关系,所以对数据卷的任何修改都是即时生效的。
总结来说,数据卷是一种特殊的文件/目录,它独立于容器的生命周期,属于宿主机文件系统,并与容器内的挂载点形成硬链接关系。容器的存在与数据卷无关,数据卷的持久化保证了数据的持久性,而数据实时性持久化确保了容器内对数据卷的修改和宿主机上对数据卷的修改是实时反映的。这使得数据卷成为在容器化环境中进行数据持久化和共享的重要特性。
Dockerfile持久化
在Docker中,Dockerfile是用于定义Docker镜像构建过程的文本文件。它包含一系列的指令和参数,用于描述如何构建一个特定的Docker镜像。持久化指的是在构建Docker镜像的过程中,保留镜像的中间层,以便在后续构建中可以重复使用这些层,提高构建速度和效率。
以下是关于Dockerfile持久化的详细信息:
-
构建镜像的层级结构:
在Dockerfile中,每个指令都会生成一个新的层级。每个层级都包含了一个或多个文件系统的修改,这些修改是上一个层级的基础。构建镜像时,Docker会将这些层级叠加在一起,形成一个镜像的结构。持久化指的是在后续的构建中,可以重复使用这些层级,而不需要重新构建它们,从而节省时间和资源。 -
利用缓存:
Docker使用缓存机制来实现镜像构建的持久化。当构建Docker镜像时,如果某个指令在前一次构建中已经执行过,并且该指令的内容没有发生变化,Docker会从缓存中获取这个指令的结果,而不会重新执行它,从而加快构建速度。 -
有效使用 .dockerignore 文件:
在持久化构建时,可以使用.dockerignore文件来排除一些不需要的文件和目录,避免将不必要的文件添加到镜像中。这样可以减少层级的数量和镜像的大小,同时加快构建过程。 -
多阶段构建:
从Docker 17.05版本开始,引入了多阶段构建(Multi-stage Builds)功能,可以通过多个FROM指令在一个Dockerfile中定义多个构建阶段。每个阶段都可以使用不同的基础镜像,并且可以只保留特定阶段的层级,丢弃其他无关的层级。这样可以更加有效地持久化构建,减少最终镜像的大小。 -
清理无用的镜像和层级:
在构建Docker镜像时,可能会产生一些无用的中间镜像和层级。可以通过定期清理这些无用的镜像和层级,释放磁盘空间,避免存储浪费。
总结来说,Dockerfile持久化是通过缓存和优化构建过程,减少重复构建的次数,从而加快镜像构建速度和提高构建效率。合理利用缓存、多阶段构建和清理无用镜像都是持久化构建过程中的常用策略。
Dockerfile方式
创建一个Dockerfile
使用VOLUME,给出容器内数据卷所在位置
FROM centos:7
MAINTAINER ydh ydh@qq.com
LABEL version="1.0" description="this is a centos7 image made inydh " auth="ydh" email="ydh@qq.com"VOLUME /opt/test1 /opt/hello
ENV WORKPATH /opt
WORKDIR $WORKPATHRUN yum install -y wget vim net-tools
CMD /bin/bash
使用Dockerfile构建镜像mycentos:1.0
[root@docker cent]# docker build -f Dockerfile -t mycentos:1.0 .
[root@docker cent]# docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
mycentos 1.0 cb5016dfcd30 44 seconds ago 474MB启动镜像创建容器
[root@docker cent]# docker run -it --name mc mycentos:1.0
[root@a3ec93db84e9 opt]# cd /opt/
[root@a3ec93db84e9 opt]# ls
hello test1
查看容器mc的详细信息
同时查看对应的数据卷在宿主机的位置
"Mounts": [{"Type": "volume","Name": "1d0f4caaf86aab6acac46c26508c1580bd29d9be1573467191dba34d03f1986b","Source": "/var/lib/docker/volumes/1d0f4caaf86aab6acac46c26508c1580bd29d9be1573467191dba34d03f1986b/_data","Destination": "/opt/hello","Driver": "local","Mode": "","RW": true,"Propagation": ""},{"Type": "volume","Name": "a0e248f94700f7a39329f413f347c03e095fea9501591175e8ae575a94f22e23","Source": "/var/lib/docker/volumes/a0e248f94700f7a39329f413f347c03e095fea9501591175e8ae575a94f22e23/_data","Destination": "/opt/test1","Driver": "local","Mode": "","RW": true,"Propagation": ""}],docker run
在Dockerfile的基础上用docker run -v**:** **
[root@docker cent]# docker run --name mycentos123 -v/root/mycentos:/opt/uc_mycentos -it mycentos:1.0
[root@e249e8c21621 opt]# cd /opt/
[root@e249e8c21621 opt]# ls
hello test1 uc_mycentos可以看到uc_mycentos以及在容器中创建了
查看容器的详细信息,看什么变化
"Mounts": [{"Type": "bind","Source": "/root/mycentos","Destination": "/opt/uc_mycentos","Mode": "","RW": true,"Propagation": "rprivate"},{"Type": "volume","Name": "c21b9e506a63475204c416ce63f2330db28293ae9af5e9be8e6f5c82aede0837","Source": "/var/lib/docker/volumes/c21b9e506a63475204c416ce63f2330db28293ae9af5e9be8e6f5c82aede0837/_data","Destination": "/opt/test1","Driver": "local","Mode": "","RW": true,"Propagation": ""},{"Type": "volume","Name": "2addd2b3f5eae1c6c81dcb1b8a29fbb93e789dd9a7b38caefcb7d7b98e3d4dfa","Source": "/var/lib/docker/volumes/2addd2b3f5eae1c6c81dcb1b8a29fbb93e789dd9a7b38caefcb7d7b98e3d4dfa/_data","Destination": "/opt/hello","Driver": "local","Mode": "","RW": true,"Propagation": ""}],
可以看到在mount里面有增加了一条信息
总结
-
docker run -v方式:- 用法:
docker run -v /宿主机目录绝对路径:/容器内目录绝对路径 镜像 - 描述:这种方式是在启动容器时使用
-v选项来创建数据卷,并将宿主机中的目录挂载到容器内的指定目录。这种方式适用于已有的镜像,它允许用户根据需要灵活地指定数据卷的宿主机目录和容器内目录。
- 用法:
-
Dockerfile 中的
VOLUME指令方式:- 用法:在
Dockerfile中使用VOLUME指令来定义数据卷,格式为VOLUME ["/容器内目录绝对路径"]。 - 描述:
VOLUME指令在Dockerfile中用于声明容器内的数据卷,并告诉Docker,容器中的数据卷将在运行时可写入,并且与宿主机上的实际目录不同。Dockerfile中的VOLUME指令只能指定容器内目录,而不能直接指定宿主机中的目录。
- 用法:在
-
区别和优势:
docker run -v方式允许用户在启动容器时直接指定宿主机中的数据卷目录,这使得在启动容器时可以根据不同的使用场景指定不同的数据卷目录,更加灵活。Dockerfile中的VOLUME指令是在定义镜像时声明容器内的数据卷,它不能直接指定宿主机中的目录。这样的设计是为了将数据卷的定义和容器的运行逻辑解耦,使得镜像定义更为清晰和简洁。
总结来说,docker run -v 方式和 Dockerfile 中的 VOLUME 指令方式都可以用于创建数据卷。docker run -v 方式允许用户在启动容器时动态指定宿主机中的数据卷目录,更为灵活。而 Dockerfile 中的 VOLUME 指令方式用于在定义镜像时声明容器内的数据卷,将数据卷的定义与容器的运行逻辑解耦,使得镜像定义更为清晰。根据不同的使用场景和需求,选择合适的方式来创建数据卷。
相关文章:
Docker啥是数据持久化?
文章目录 数据持久化数据卷相关命令创建读写数据卷创建只读数据卷数据卷共享数据卷容器实现数据卷共享nginx实现数据卷共享nfs总结 Dockerfile持久化Dockerfile方式docker run总结 数据持久化 在容器层的 UnionFS(联合文件系统)中对文件/目录的任何修…...
)
CGAL 线段简化算法(2D)
文章目录 一、简介二、实现代码三、实现效果参考资料一、简介 线段简化是指:在减少一组折线中顶点数量的同时,尽可能保持整体形状的过程。CGAL中提供了一种迭代算法:通过从一条折线上移除顶点 q q q,迭代地将边 ( p , q...
在CentOS 7上挂载硬盘到系统的步骤及操作
目录 1:查询未挂载硬盘2:创建挂载目录3:检查磁盘是否被分区4:格式化硬盘5:挂载目录6:检查挂载状态7:设置开机自动挂载总结: 本文介绍了在CentOS 7上挂载硬盘到系统的详细步骤。通过确…...
螺旋矩阵(JS)
螺旋矩阵 题目 给你一个正整数 n ,生成一个包含 1 到 n2 所有元素,且元素按顺时针顺序螺旋排列的 n x n 正方形矩阵 matrix 。 示例 1: 输入:n 3 输出:[[1,2,3],[8,9,4],[7,6,5]]示例 2: 输入ÿ…...

C#常用数学插值法
目录 1、分段线性插值 2、三次样条插值 3、拉格朗日插值 (1)一元全区间不等距插值 (2)一元全区间等距插值 4、埃尔米特插值 (1)埃尔米特不等距插值 (2)埃尔米特等距插值 1、…...
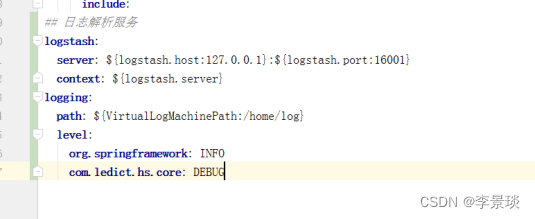
ELK日志管理平台架构和使用说明
一、部署架构 二、服务注册 2.1 日志解析服务 服务名:日志解析服务(Logstash) 服务默认端口:9600 2.2 日志查询服务 服务名:日志查询服务(Kibana) 服务默认端口:5601 三、对接…...

抖音短视频seo矩阵系统源码开发部署技术分享
抖音短视频的SEO矩阵系统是一个非常重要的部分,它可以帮助视频更好地被搜索引擎识别和推荐。以下是一些关于开发和部署抖音短视频SEO矩阵系统的技术分享: 一、 抖音短视频SEO矩阵系统的技术分享: 关键词研究:在开发抖音短视频SEO矩…...

docker 部署一个单节点的rocketmq
拉取镜像 sudo docker pull rocketmqinc/rocketmq创建数据挂载目录 mkdir -p /docker/rocketmq/data/namesrv/logs mkdir -p /docker/rocketmq/data/namesrv/store mkdir -p /docker/rocketmq/data/broker/logs mkdir -p /docker/rocketmq/data/broker/store /docker/…...

MySQL优化
目录 一. 优化 SQL 查询语句 1.1. 分析慢查询日志 1.2. 优化 SQL 查询语句的性能 1.2.1 优化查询中的索引 1.2.2 减少表的连接(join) 1.2.3 优化查询语句中的过滤条件 1.2.4 避免使用SELECT * 1.2.5 优化存储过程和函数 1.2.6 使用缓存 二. 优化表结构…...
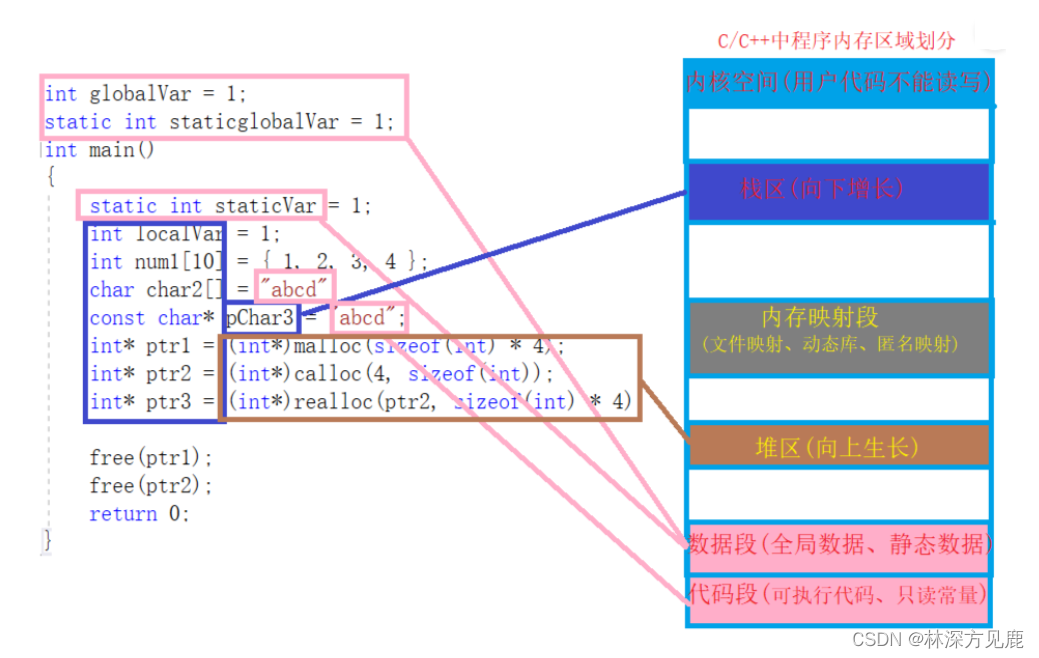
【C++】总结9
文章目录 C从源代码到可执行程序经过什么步骤静态链接和动态链接类的对象存储空间C的内存分区内存池在成员函数中调用delete this会出现什么问题?如果在类的析构函数中调用delete this,会发生什么? C从源代码到可执行程序经过什么步骤 预处理…...

C++报错 XX does not name a type;field `XX’ has incomplete type解决方案
C报错 XX does not name a type;field XX’ has incomplete type解决方案 两个C编译错误及解决办法–does not name a type和field XX’ has incomplete type 编译错误一:XX does not name a type 编译错误二:field XX’ has incomplete t…...

28.利用fminsearch、fminunc 求解最大利润问题(matlab程序)
1.简述 1.无约束(无条件)的最优化 fminunc函数 : - 可用于任意函数求最小值 - 统一求最小值问题 - 如求最大值问题: >对函数取相反数而变成求最小值问题,最后把函数值取反即为函数的最大值。 使用格式如下 1.必须预先把函数存…...

图像 检测 - FCOS: Fully Convolutional One-Stage Object Detection (ICCV 2019)
FCOS: Fully Convolutional One-Stage Object Detection - 全卷积一阶段目标检测(ICCV 2019) 摘要1. 引言2. 相关工作3. 我们的方法3.1 全卷积一阶目标检测器3.2 FCOS的FPN多级预测3.3 FCOS中心度 4. 实验4.1 消融研究4.1.1 FPN多级预测4.1.2 有无中心度…...
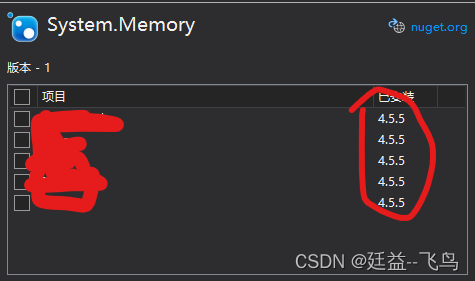
C# NDArray System.IO.FileLoadException报错原因分析
C# NDArray System.IO.FileLoadException 报错原因分析: 1.NuGet程序包版本有冲突 2.统一项目版本 1.打开解决方案NuGet程序包设置 2.查看是否有版本冲突 3.统一版本冲突...

快速响应,上门维修小程序让您享受无忧生活
随着科技的不断发展和智能手机的普及,上门维修小程序成为了现代人生活中越来越重要的一部分。上门维修小程序通过将维修服务与互联网相结合,为用户提供了更加便捷、高效的维修服务体验。下面将介绍上门维修小程序开发的优势。 提供便捷的预约方式&am…...
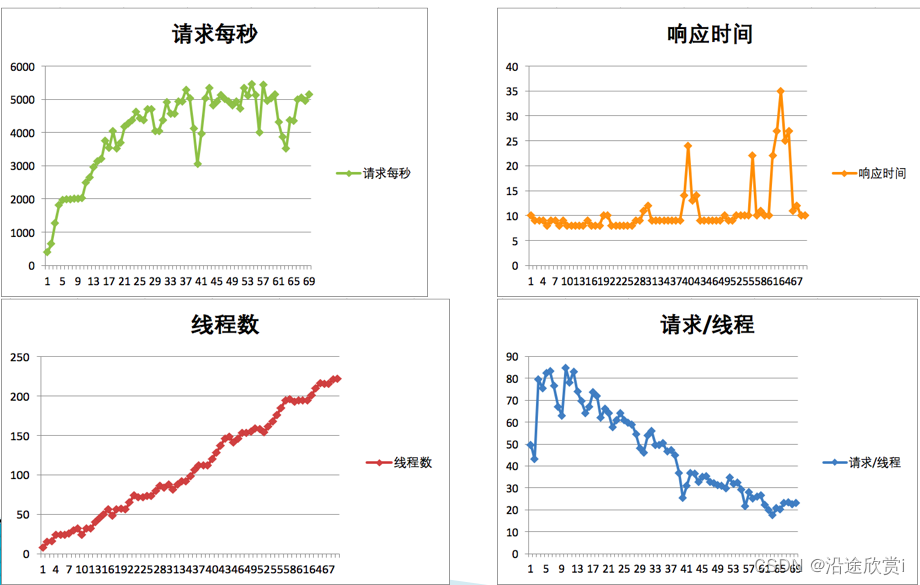
05、性能分析思路?
工具操作:包括压力工具、监控工具、剖析工具、调试工具。数值理解:包括上面工具中所有输出的数据。趋势分析、相关性分析、证据链分析:就是理解了工具产生的数值之后,还要把它们的逻辑关系想明白。这才是性能测试分析中最重要的一…...
【编程语言 · C语言 · calloc和realloc】
【编程语言 C语言 calloc和realloc】https://mp.weixin.qq.com/s?__bizMzg4NTE5MDAzOA&mid2247491544&idx1&sn72d8f9931cfa7ce7441a3248475ab619&chksmcfade321f8da6a374a5935bb46441a03a007c0589db6b8afa8c1991854d632a3201553e37b0b&payreadticketHGy…...

机器学习分布式框架ray运行pytorch实例
Ray是一个用于分布式计算的开源框架,它可以有效地实现并行化和分布式训练。下面是使用Ray来实现PyTorch的训练的概括性描述: 安装Ray:首先,需要在计算机上安装Ray。你可以通过pip或conda来安装Ray库。 准备数据:在使用…...
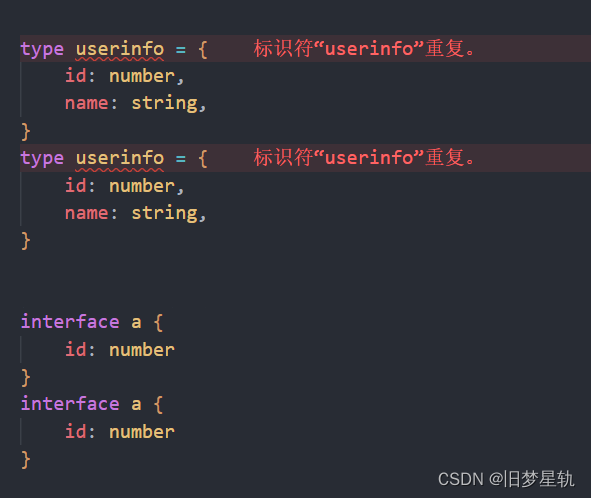
TypeScript 【type】关键字的进阶使用方式
导语: 在前面章节中,我们了解到 TS 中 type 这个关键字,常常被用作于,定义 类型别名,用来简化或复用复杂联合类型的时候使用。同时也了解到 为对象定义约束接口类型 的时候所使用的是 Interfaces。 其实对于前面&#…...
策略路由实现多ISP接入Internet
组网需求: 企业分别从ISP1和ISP2租用了一条链路 PC3用户上网访问Server1时走ISP1PC4用户上网访问Server1时走ISP2 拓扑图 一、ISP1 运营商 R1路由器 <Huawei>sys [Huawei]sys R1 [R1]un in en[R1]int g0/0/0 [R1-GigabitEthernet0/0/0]ip addr 2.2.2.2 2…...

数字家谱系统架构设计:从关系数据库到可视化交互的完整实现
1. 项目概述:从“家谱”到“数字家谱”的跨越最近在GitHub上看到一个挺有意思的项目,叫qiaoshouqing/familytree。光看名字,你可能会觉得,这不就是个家谱吗?没错,它的核心确实是家谱,但如果你把…...

DS4Windows完全指南:3步解决PlayStation手柄在Windows的兼容性问题
DS4Windows完全指南:3步解决PlayStation手柄在Windows的兼容性问题 【免费下载链接】DS4Windows Like those other ds4tools, but sexier 项目地址: https://gitcode.com/gh_mirrors/ds/DS4Windows 你是否曾经遇到过这样的问题:购买了心爱的PlayS…...

基于Wasp全栈框架的SaaS启动模板:快速构建多租户应用
1. 项目概述:一个为独立开发者量身定制的开源SaaS蓝图 如果你是一名独立开发者,或者是一个小团队的创始人,心里揣着一个SaaS产品的想法,却总在技术选型、架构设计和持续交付的迷宫里打转,那么 wasp-lang/open-saas …...

终极指南:如何使用Autoclick实现Mac自动点击900次/秒
终极指南:如何使用Autoclick实现Mac自动点击900次/秒 【免费下载链接】Autoclick A simple Mac app that simulates mouse clicks 项目地址: https://gitcode.com/gh_mirrors/au/Autoclick 你是否厌倦了重复性的鼠标点击工作?无论是游戏中的重复操…...

开源办公套件自动化部署与集成实战:基于OpenOffice的服务化解决方案
1. 项目概述:为什么我们需要一个“开源”的办公套件?如果你在GitHub上搜索过办公软件相关的仓库,大概率会看到过longyangxi/OpenOffice这个项目。乍一看,你可能会以为这是一个Apache OpenOffice的镜像或者某个分支。但点进去仔细研…...

人性最残忍的真相是:你越不把自己当回事,别人就越不把你当回事
那个总给别人买贵东西的人,最后都怎么样了? 目录 那个总给别人买贵东西的人,最后都怎么样了? 我们为什么会忍不住过度付出? 真正的爱,从来都不是单方面的牺牲 爱自己,是所有健康关系的前提 昨天刷到一句话,瞬间戳中了我:“永远不要拿自己辛苦钱,去给别人买自己都舍不…...

Arm Neoverse CMN-700互连架构与寄存器编程详解
1. Arm Neoverse CMN-700架构概览在现代高性能计算系统中,处理器核心数量的快速增长对互连架构提出了严峻挑战。作为Arm Neoverse平台的核心组件,CMN-700一致性互连网络采用创新的Mesh拓扑结构,解决了多核处理器间的通信瓶颈问题。我在实际芯…...

EL电致发光线与3D打印技术打造可穿戴发光骨架服
1. 项目概述:当发光骨架“活”过来每年万圣节,看着满大街的“幽灵”和“僵尸”,我总想搞点不一样的。直到去年,我决定不再满足于商店里千篇一律的服装,而是想自己动手,做一件真正能“发光”的、有科技感的骨…...

番茄小说下载器终极指南:3分钟打造你的私人数字图书馆
番茄小说下载器终极指南:3分钟打造你的私人数字图书馆 【免费下载链接】fanqienovel-downloader 下载番茄小说 项目地址: https://gitcode.com/gh_mirrors/fa/fanqienovel-downloader 你是否曾在深夜追更小说时,突然发现网络连接中断?…...
)
【限时解密】ElevenLabs未文档化的/v1/text-to-speech/{voice_id}/with-timing接口:获取逐词时间戳+音素级对齐数据(仅剩3个Beta白名单通道)
更多请点击: https://intelliparadigm.com 第一章:ElevenLabs英文语音生成的核心能力与技术定位 ElevenLabs 是当前业界领先的 AI 语音合成平台,其英文语音生成能力建立在自研的端到端神经声学模型(如 ElevenMultilingualV2&…...