hadoop与HDFS交互
一、利用Shell命令与HDFS进行交互
在进行HDFS编程实践前,需要首先启动Hadoop。可以执行如下命令启动Hadoop:
cd /usr/local/hadoop
./sbin/start-dfs.sh #启动hadoop
Hadoop支持很多Shell命令,其中fs是HDFS最常用的命令,利用fs可以查看HDFS文件系统的目录结构、上传和下载数据、创建文件等。
注意
本教程的命令是以”./bin/hadoop dfs”开头的Shell命令方式,实际上有三种shell命令方式。
1. hadoop fs
2. hadoop dfs
3. hdfs dfs
hadoop fs适用于任何不同的文件系统,比如本地文件系统和HDFS文件系统
hadoop dfs只能适用于HDFS文件系统
hdfs dfs跟hadoop dfs的命令作用一样,也只能适用于HDFS文件系统
我们可以在终端输入如下命令,查看fs总共支持了哪些命令
./bin/hadoop fs

在终端输入如下命令,可以查看具体某个命令的作用
例如:我们查看put命令如何使用,可以输入如下命令
./bin/hadoop fs -help put

1.目录操作
需要注意的是,Hadoop系统安装好以后,第一次使用HDFS时,需要首先在HDFS中创建用户目录。本教程全部采用hadoop用户登录Linux系统,因此,需要在HDFS中为hadoop用户创建一个用户目录,命令如下:
cd /usr/local/hadoop
./bin/hdfs dfs -mkdir -p /user/hadoop
该命令中表示在HDFS中创建一个“/user/hadoop”目录,“-mkdir”是创建目录的操作,“-p”表示如果是多级目录,则父目录和子目录一起创建,这里“/user/hadoop”就是一个多级目录,因此必须使用参数“-p”,否则会出错。
“/user/hadoop”目录就成为hadoop用户对应的用户目录,可以使用如下命令显示HDFS中与当前用户hadoop对应的用户目录下的内容:
./bin/hdfs dfs -ls .
该命令中,“-ls”表示列出HDFS某个目录下的所有内容,“.”表示HDFS中的当前用户目录,也就是“/user/hadoop”目录,因此,上面的命令和下面的命令是等价的:
./bin/hdfs dfs -ls /user/hadoop
如果要列出HDFS上的所有目录,可以使用如下命令:
./bin/hdfs dfs -ls
下面,可以使用如下命令创建一个input目录:
./bin/hdfs dfs -mkdir input
在创建个input目录时,采用了相对路径形式,实际上,这个input目录创建成功以后,它在HDFS中的完整路径是“/user/hadoop/input”。如果要在HDFS的根目录下创建一个名称为input的目录,则需要使用如下命令:
./bin/hdfs dfs -mkdir /input
可以使用rm命令删除一个目录,比如,可以使用如下命令删除刚才在HDFS中创建的“/input”目录(不是“/user/hadoop/input”目录):
./bin/hdfs dfs –rm –r /input
上面命令中,“-r”参数表示如果删除“/input”目录及其子目录下的所有内容,如果要删除的一个目录包含了子目录,则必须使用“-r”参数,否则会执行失败。
2.文件操作
在实际应用中,经常需要从本地文件系统向HDFS中上传文件,或者把HDFS中的文件下载到本地文件系统中。
首先,使用vim编辑器,在本地Linux文件系统的“/home/hadoop/”目录下创建一个文件myLocalFile.txt,里面可以随意输入一些单词,比如,输入如下三行:
Hadoop
Spark
XMU DBLAB
然后,可以使用如下命令把本地文件系统的“/home/hadoop/myLocalFile.txt”上传到HDFS中的当前用户目录的input目录下,也就是上传到HDFS的“/user/hadoop/input/”目录下:
./bin/hdfs dfs -put /home/hadoop/myLocalFile.txt input
可以使用ls命令查看一下文件是否成功上传到HDFS中,具体如下:
./bin/hdfs dfs -ls input
该命令执行后会显示类似如下的信息:
Found 1 items
-rw-r--r-- 1 hadoop supergroup 36 2017-01-02 23:55 input/ myLocalFile.txt
下面使用如下命令查看HDFS中的myLocalFile.txt这个文件的内容:
./bin/hdfs dfs –cat input/myLocalFile.txt
下面把HDFS中的myLocalFile.txt文件下载到本地文件系统中的“/home/hadoop/下载/”这个目录下,命令如下:
./bin/hdfs dfs -get input/myLocalFile.txt /home/hadoop/下载
可以使用如下命令,到本地文件系统查看下载下来的文件myLocalFile.txt:
cd ~
cd 下载
ls
cat myLocalFile.txt
最后,了解一下如何把文件从HDFS中的一个目录拷贝到HDFS中的另外一个目录。比如,如果要把HDFS的“/user/hadoop/input/myLocalFile.txt”文件,拷贝到HDFS的另外一个目录“/input”中(注意,这个input目录位于HDFS根目录下),可以使用如下命令:
./bin/hdfs dfs -cp input/myLocalFile.txt /input
二、利用Java API与HDFS进行交互
Hadoop不同的文件系统之间通过调用Java API进行交互,上面介绍的Shell命令,本质上就是Java API的应用。下面提供了Hadoop官方的Hadoop API文档,想要深入学习Hadoop,可以访问如下网站,查看各个API的功能。
Hadoop API文档:http://hadoop.apache.org/docs/stable/api/
利用Java API进行交互,需要利用软件Eclipse编写Java程序。
(一)在Ubuntu中安装Eclipse
Eclipse是常用的程序开发工具,很多程序代码都是使用Eclipse开发调试,因此,需要在Linux系统中安装Eclipse。可以在 ubuntu software 中直接下载 eclipse。

(二)使用Eclipse开发调试HDFS Java程序
Hadoop采用Java语言开发的,提供了Java API与HDFS进行交互。上面介绍的Shell命令,在执行时实际上会被系统转换成Java API调用。Hadoop官方网站提供了完整的Hadoop API文档(http://hadoop.apache.org/docs/stable/api/),想要深入学习Hadoop编程,可以访问Hadoop官网查看各个API的功能和用法。本教程只介绍基础的HDFS编程。
为了提高程序编写和调试效率,本教程采用Eclipse工具编写Java程序。
现在要执行的任务是:用Java编写程序检测HDFS中是否存在文件myLocalFile.txt,编译运行程序并显示检测结果。
1. 在Eclipse中创建项目
启动Eclipse。当Eclipse启动以后,会弹出如下图所示界面,提示设置工作空间(workspace)。
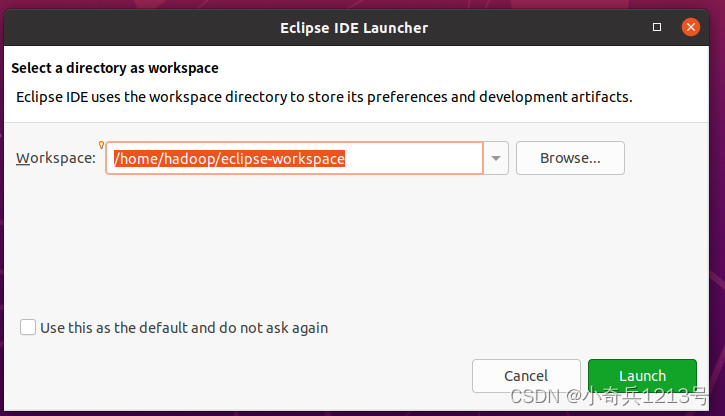
可以直接采用默认的设置“/home/hadoop/eclipse-workspace”,点击“Launch”按钮。可以看出,由于当前是采用hadoop用户登录了Linux系统,因此,默认的工作空间目录位于hadoop用户目录“/home/hadoop”下。
Eclipse启动以后,会呈现如下图所示的界面。
2. 为项目添加需要用到的JAR包
进入下一步的设置以后,会弹出如下图所示界面。
若没有,且找不到jdk,只有jre,可根据下面的文章进行操作。
https://blog.csdn.net/weixin_52308622/article/details/130688200?spm=1001.2014.3001.5501
需要在这个界面中加载该Java工程所需要用到的JAR包,这些JAR包中包含了可以访问HDFS的Java API。这些JAR包都位于Linux系统的Hadoop安装目录下,对于本教程而言,就是在“/usr/local/hadoop/share/hadoop”目录下。点击界面中的“Libraries”选项卡,然后,点击界面右侧的“Add External JARs…”按钮,会弹出如下图所示界面。
在该界面中,上面的一排目录按钮(即“usr”、“local”、“hadoop”、“share”、“hadoop”和“common”),当点击某个目录按钮时,就会在下面列出该目录的内容。
为了编写一个能够与HDFS交互的Java应用程序,一般需要向Java工程中添加以下JAR包:
(1)“/usr/local/hadoop/share/hadoop/common”目录下的所有JAR包,包括hadoop-common-3.3.2.jar、hadoop-common-3.3.2-tests.jar、hadoop-nfs-3.3.2.jar、hadoop-kms-3.3.2.jar和hadoop-registry-3.3.2.jar,注意,不包括目录jdiff、lib、sources和webapps;
(2)“/usr/local/hadoop/share/hadoop/common/lib”目录下的所有JAR包;
(3)“/usr/local/hadoop/share/hadoop/hdfs”目录下的所有JAR包,注意,不包括目录jdiff、lib、sources和webapps;
(4)“/usr/local/hadoop/share/hadoop/hdfs/lib”目录下的所有JAR包。
比如,如果要把“/usr/local/hadoop/share/hadoop/common”目录下的hadoop-common-3.3.2.jar、hadoop-common-3.3.2-tests.jar、hadoop-nfs-3.3.2.jar、hadoop-kms-3.3.2.jar和hadoop-registry-3.3.2.jar添加到当前的Java工程中,可以在界面中点击目录按钮,进入到common目录,然后,界面会显示出common目录下的所有内容。在界面中用鼠标点击选中hadoop-common-3.3.2.jar、hadoop-common-3.3.2-tests.jar、hadoop-nfs-3.3.2.jar、hadoop-kms-3.3.2.jar和hadoop-registry-3.3.2.jar(不要选中目录jdiff、lib、sources和webapps),然后点击界面右上角的“open”按钮,就可以把JAR包增加到当前Java工程中,出现的界面如下图所示。
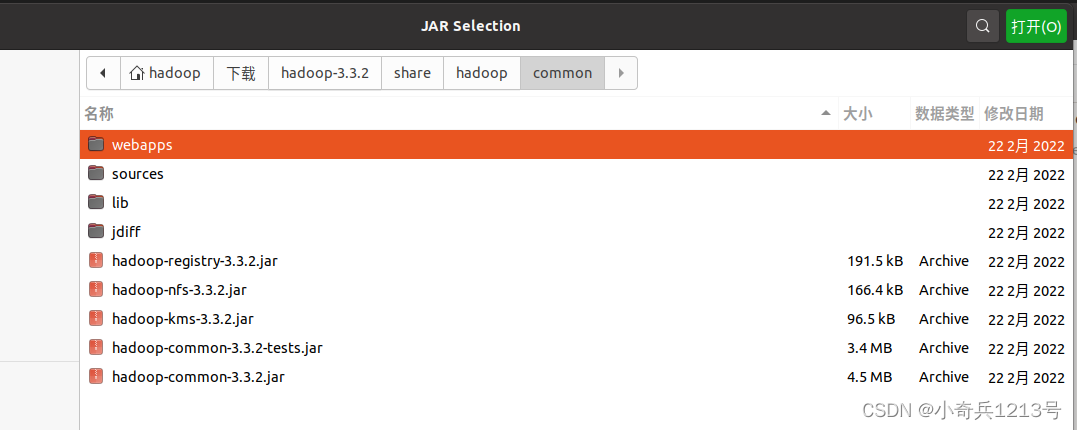
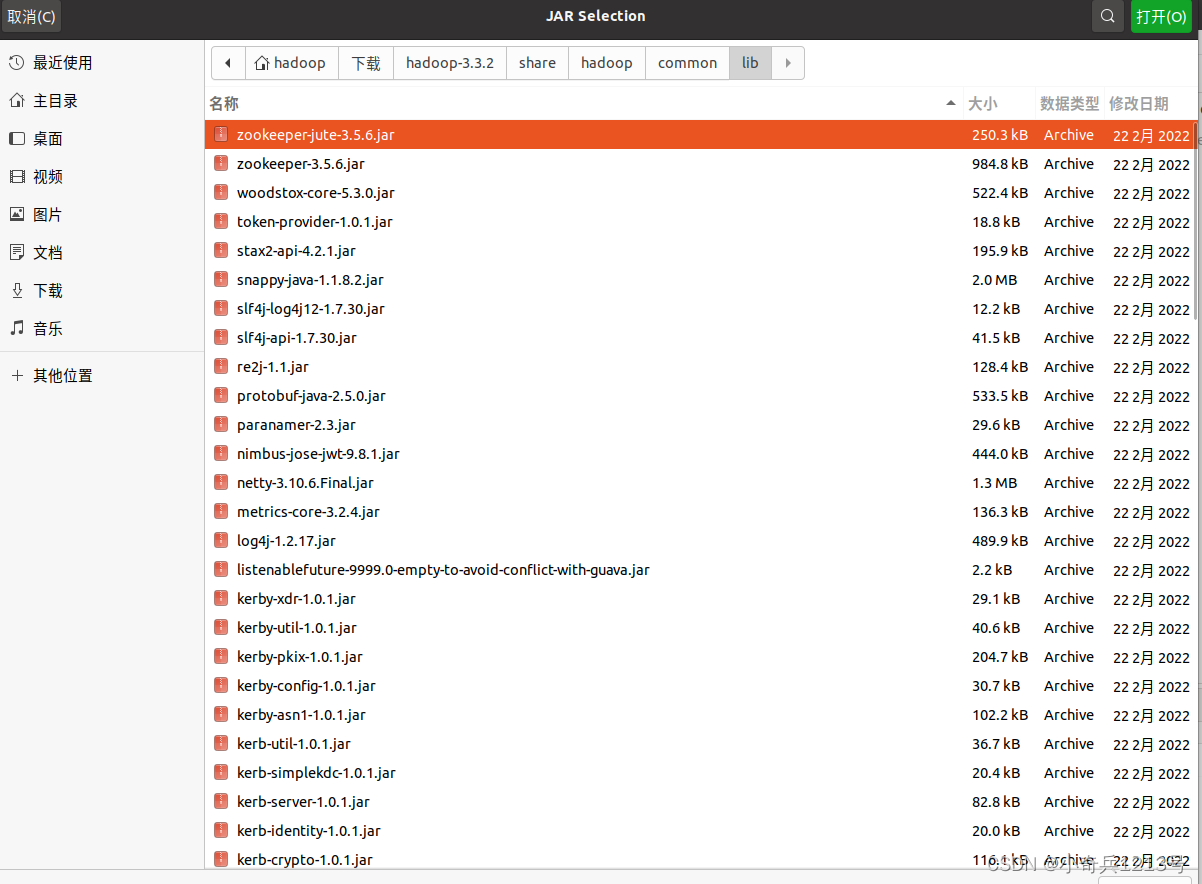
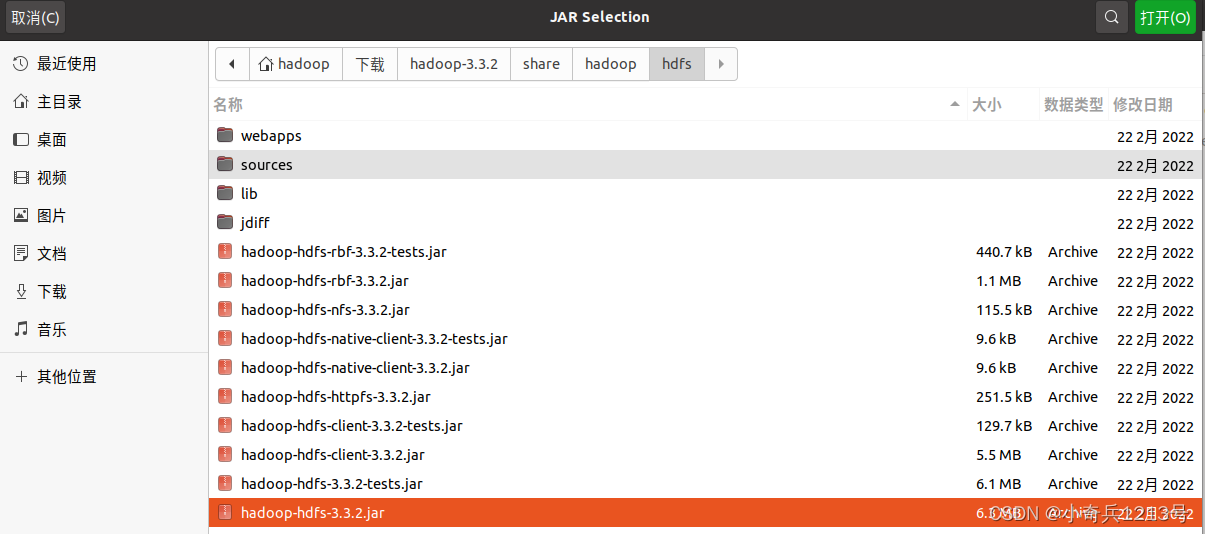
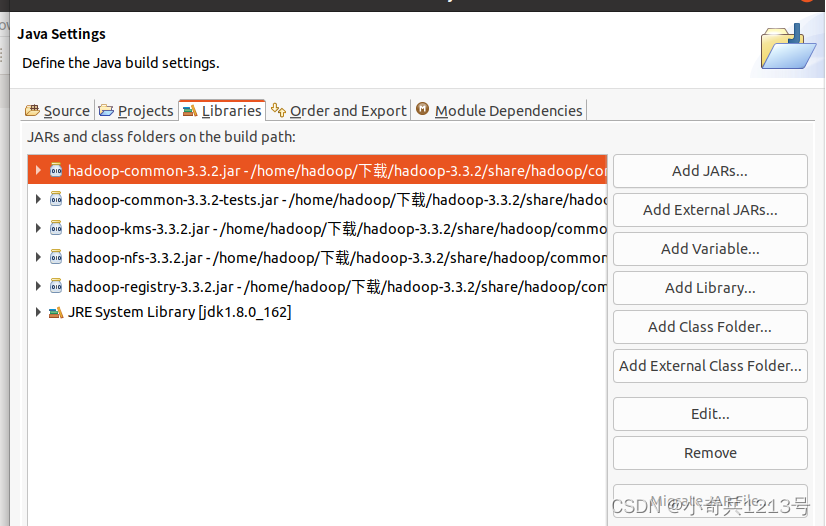
从这个界面中可以看出,hadoop-common-3.3.2.jar、hadoop-common-3.3.2-tests.jar、hadoop-nfs-3.3.2.jar、hadoop-kms-3.3.2.jar和hadoop-registry-3.3.2.jar已经被添加到当前Java工程中。然后,按照类似的操作方法,可以再次点击“Add External JARs…”按钮,把剩余的其他JAR包都添加进来。需要注意的是,当需要选中某个目录下的所有JAR包时,可以使用“Ctrl+A”组合键进行全选操作。全部添加完毕以后,就可以点击界面右下角的“Finish”按钮,完成Java工程HDFSExample的创建。
3. 编写Java应用程序
下面编写一个Java应用程序,用来检测HDFS中是否存在一个文件。
请在Eclipse工作界面左侧的“Package Explorer”面板中(如下图所示),找到刚才创建好的工程名称“HDFSExample”,然后在该工程名称上点击鼠标右键,在弹出的菜单中选择“New->Class”菜单。
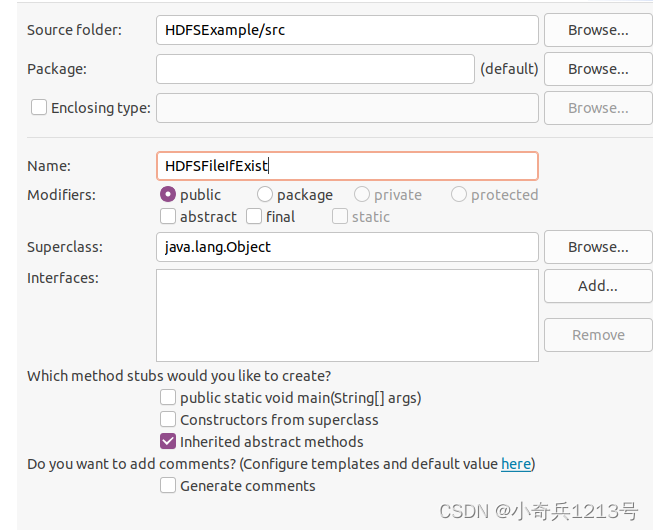
在该界面中,只需要在“Name”后面输入新建的Java类文件的名称,这里采用名称“HDFSFileIfExist”,其他都可以采用默认设置,然后,点击界面右下角“Finish”按钮,出现如下图所示界面。
可以看出,Eclipse自动创建了一个名为“HDFSFileIfExist.java”的源代码文件,请在该文件中输入以下代码:
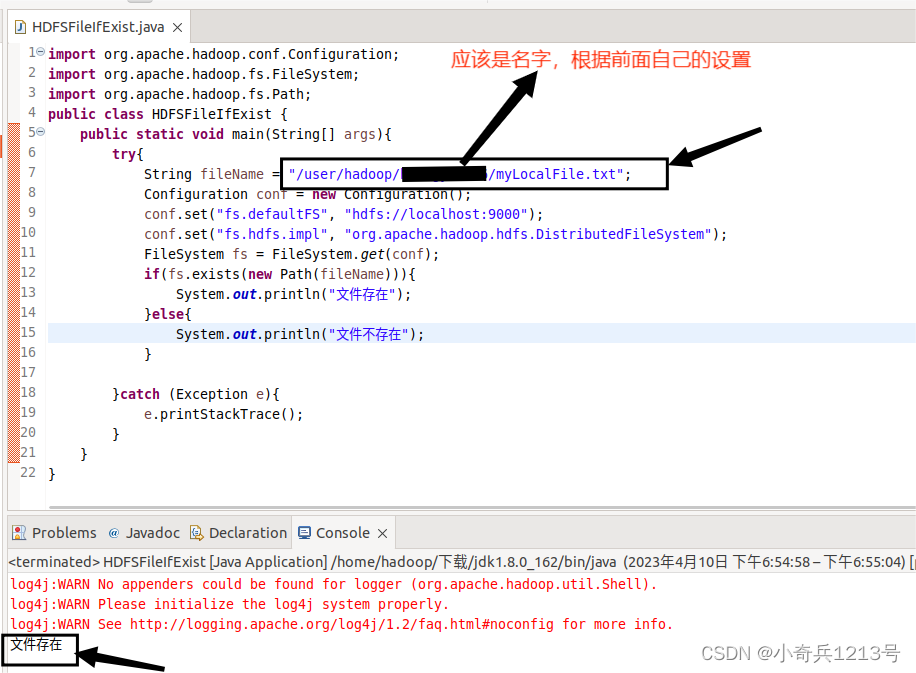
import org.apache.hadoop.conf.Configuration;import org.apache.hadoop.fs.FileSystem;import org.apache.hadoop.fs.Path;public class HDFSFileIfExist {public static void main(String[] args){try{String fileName = "test";Configuration conf = new Configuration();conf.set("fs.defaultFS", "hdfs://localhost:9000");conf.set("fs.hdfs.impl", "org.apache.hadoop.hdfs.DistributedFileSystem");FileSystem fs = FileSystem.get(conf);if(fs.exists(new Path(fileName))){System.out.println("文件存在");}else{System.out.println("文件不存在");}}catch (Exception e){e.printStackTrace();}}}该程序用来测试HDFS中是否存在一个文件,其中有一行代码:
String fileName = "test"
这行代码给出了需要被检测的文件名称是“test”,没有给出路径全称,表示是采用了相对路径,实际上就是测试当前登录Linux系统的用户hadoop,在HDFS中对应的用户目录下是否存在test文件,也就是测试HDFS中的“/user/hadoop/”目录下是否存在test文件。(根据前序实验内容,myLocalFile.txt的完整路径为/user/hadoop/(名字)/myLocalFile.txt)
4. 编译运行程序
在开始编译运行程序之前,请一定确保Hadoop已经启动运行,如果还没有启动,需要打开一个Linux终端,输入以下命令启动Hadoop:
cd /usr/local/hadoop
./sbin/start-dfs.sh
现在就可以编译运行上面编写的代码。可以直接点击Eclipse工作界面上部的运行程序的快捷按钮,当把鼠标移动到该按钮上时,在弹出的菜单中选择“Run As”,继续在弹出来的菜单中选择“Java Application”运行即可
相关文章:
hadoop与HDFS交互
一、利用Shell命令与HDFS进行交互 在进行HDFS编程实践前,需要首先启动Hadoop。可以执行如下命令启动Hadoop: cd /usr/local/hadoop ./sbin/start-dfs.sh #启动hadoop Hadoop支持很多Shell命令,其中fs是HDFS最常用的命令,利用fs…...
)
MYSQL 分区如何指定不同存储路径(多块磁盘)
理论 可以针对分区表的每个分区指定存储路径,对于innodb存储引擎的表只能指定数据路径,因为数据和索引是存储在一个文件当中,对于MYISAM存储引擎可以分别指定数据文件和索引文件,一般也只有RANGE、LIST分区、sub子分区才有可能需要…...
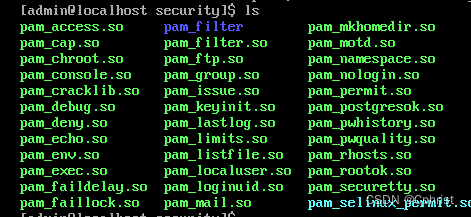
安全加固服务器
根据以下的内容来加固一台Linux服务器的安全。 首先是限制连续密码错误的登录次数,由于RHEL8之后都不再使用pam_tally.so和pam_tally2.so,而是pam_faillock.so 首先进入/usr/lib64/security/中查看有什么模块,确认有pam_faillock.so 因为只…...

Linux 命令学习:
1. PS命令 ps 的aux和-ef区别 1、输出风格不同,展示的格式略有不同 两者的输出结果差别不大,但展示风格不同。aux是BSD风格,-ef是System V风格。 2、aux会截断command列,而-ef不会,当结合grep时这种区别会影响到结果 …...
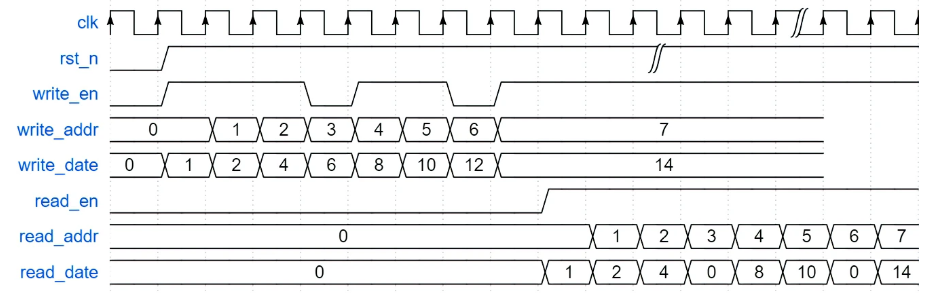
牛客网Verilog刷题——VL54
牛客网Verilog刷题——VL54 题目答案 题目 实现一个深度为8,位宽为4bit的双端口RAM,数据全部初始化为0000。具有两组端口,分别用于读数据和写数据,读写操作可以同时进行。当读数据指示信号read_en有效时,通过读地址信号…...
学习系统编程No.34【线程同步之信号量】
引言: 北京时间:2023/7/29/16:34,一切尽在不言中,前几天追了几部电视剧,看了几部电影,刷了n个视屏,在前天我们才终于从这快乐的日子里恢复过来,然后看了两节课,也就是上…...

SolidUI社区-Snakemq 通信源码分析
背景 随着文本生成图像的语言模型兴起,SolidUI想帮人们快速构建可视化工具,可视化内容包括2D,3D,3D场景,从而快速构三维数据演示场景。SolidUI 是一个创新的项目,旨在将自然语言处理(NLP)与计算机图形学相…...

【大数据之Flume】四、Flume进阶之复制和多路复用、负载均衡和故障转移、聚合案例
1 复制和多路复用 (1)需求:使用 Flume-1 监控文件变动(可以用Exec Source或Taildir Source),Flume-1 将变动内容传递给 Flume-2(用Avro Sink传),(用Avro Sou…...
前端学习--vue2--插槽
写在前面: 这个用法是在使用组件和创建组件中 文章目录 介绍简单使用多个插槽省写默认/后备内容作用域插槽常用实例Element-ui的el-table 废弃用法slot attributeslot-scope attribute 介绍 我们在定义一些组件的时候,由于组件内文字想要自定义&#…...
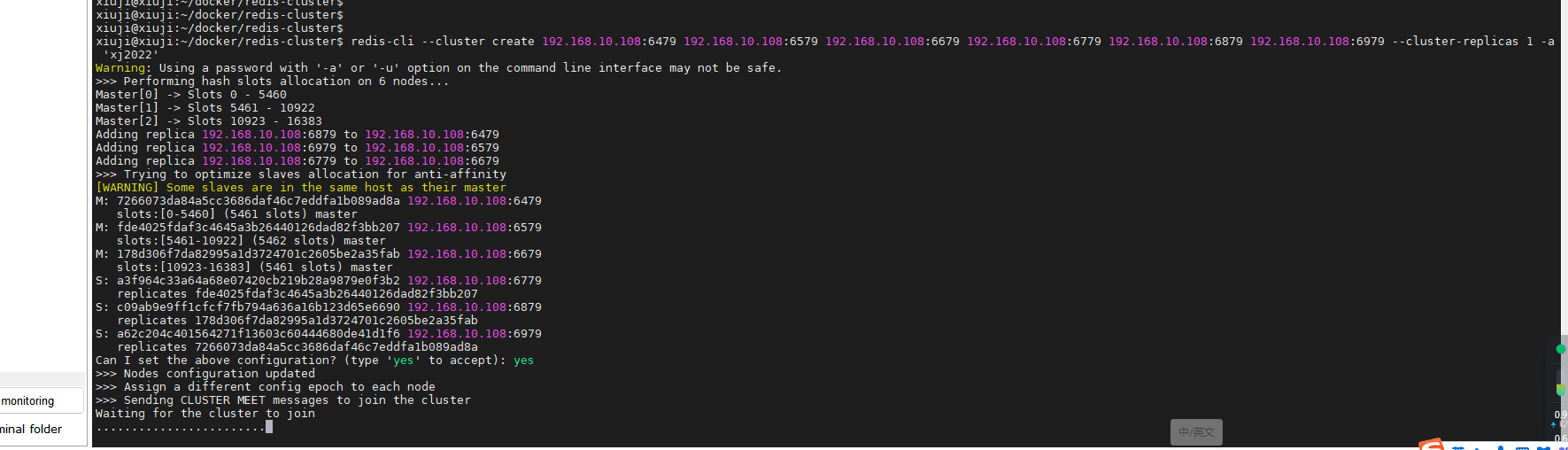
使用 Docker Compose 部署 Redis Cluster 集群,轻松搭建高可用分布式缓存
Redis Cluster(Redis 集群)是 Redis 分布式解决方案的一部分,它旨在提供高可用性、高性能和横向扩展的功能。Redis Cluster 能够将多个 Redis 节点组合成一个分布式集群,实现数据分片和负载均衡,从而确保在大规模应用场…...

在Spring Boot框架中集成 Spring Security
在Spring Boot框架中集成 Spring Security 目录 技术介绍SpringSecurity的核心功能:SpringSecurity特点:具体实现 1、集成依赖2、修改spring security实现service.impl.UserDetailsServiceImpl类 代码1具体解释代码2具体解释 实现config.SecurityConfi…...

登月再进一步:Apollo自动驾驶的里程碑
前言 「作者主页」:雪碧有白泡泡 「个人网站」:雪碧的个人网站 「推荐专栏」: ★java一站式服务 ★ ★前端炫酷代码分享 ★ ★ uniapp-从构建到提升★ ★ 从0到英雄,vue成神之路★ ★ 解决算法,一个专栏就够了★ ★ 架…...
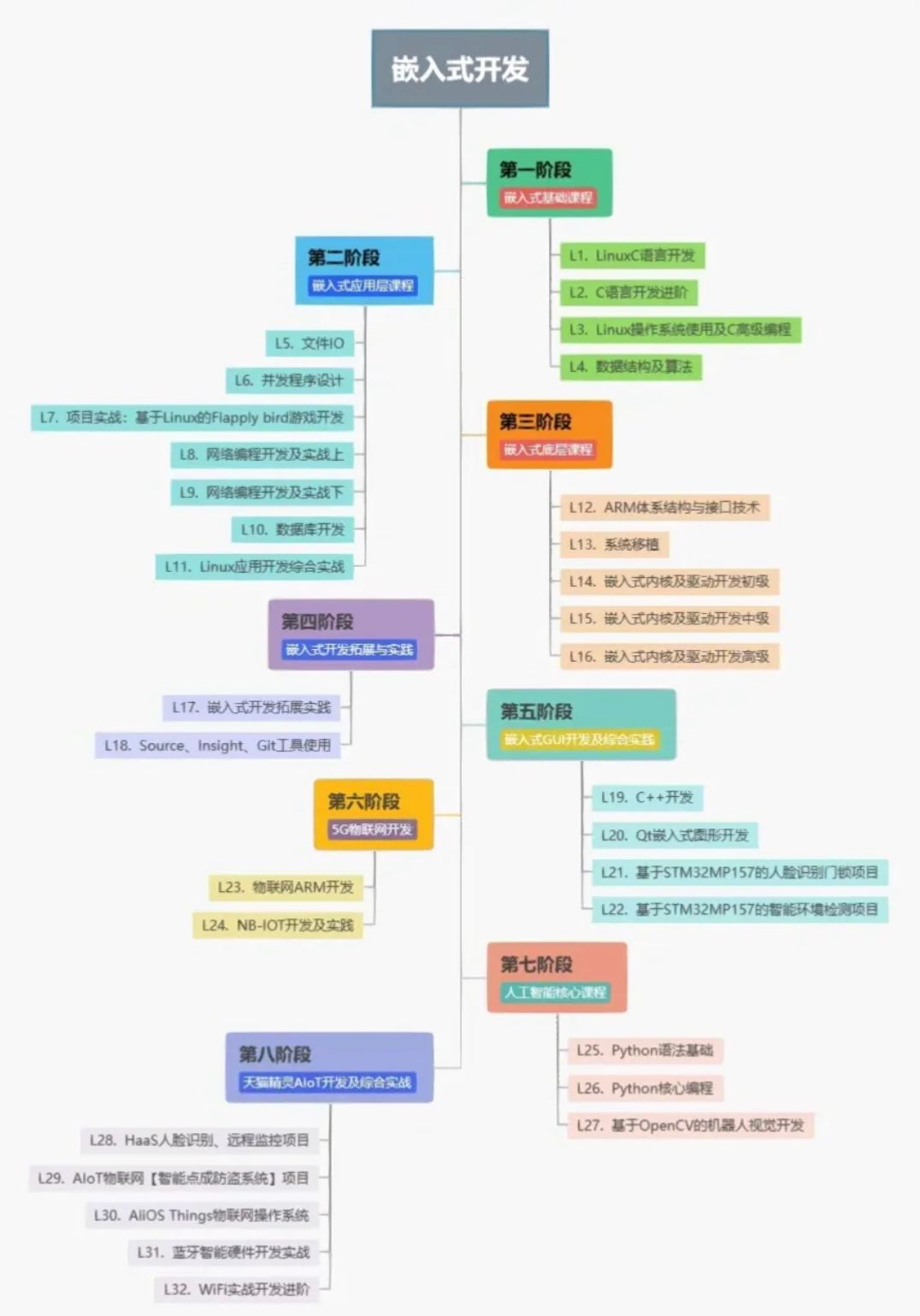
嵌入式一开始该怎么学?学习单片机
学习单片机: 模电数电肯定必须的,玩单片机大概率这两门课都学过,学过微机原理更好。 直接看野火的文档,芯片手册,外设手册。 学单片机不要纠结于某个型号,我认为stm32就OK,主要是原理和感觉。…...

Spring事件监听器ApplicationListener
目录 介绍 spirng启动后启动某方法 介绍 ApplicationEvent以及Listener是Spring为我们提供的一个事件监听、订阅的实现,内部实现原理是观察者设计模式,设计初衷也是为了系统业务逻辑之间的解耦,提高可扩展性以及可维护性。事件发布者并不需…...
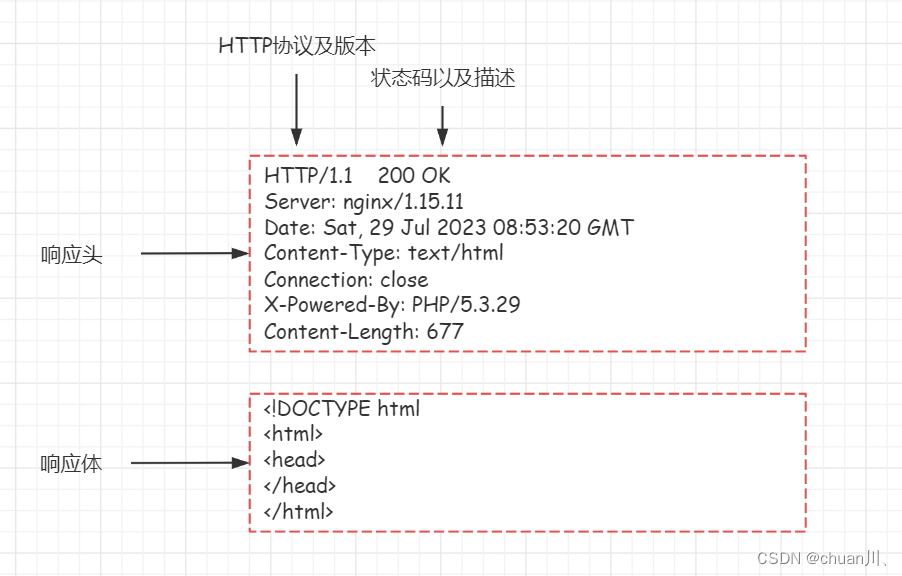
安全学习DAY10_HTTP数据包
HTTP数据包 文章目录 HTTP数据包小节导图Request请求数据包结构Request请求方法(方式)请求头(Header)Response响应数据包结构Response响应数据包状态码状态码作用:部分状态码详解判断网站文件是否存在的状态码…...

云原生落地实践的25个步骤
一、什么是云原生? 云原生从字面意思上来看可以分成云和原生两个部分。 云是和本地相对的,传统的应用必须跑在本地服务器上,现在流行的应用都跑在云端,云包含了IaaS,、PaaS和SaaS。 原生就是土生土长的意思,我们在开始…...

Stable diffusion 三大基础脚本 提示词矩阵,载入提示词,XYZ图表讲解
目录 0.本章讲解 1.提示词矩阵(prompt matrix) 1.2.提示词矩阵功能选项 1.2.1.把可变部分放在提示词文本的开头 1.2.2.为每张图片使用不同随机种子 1.2.3.选择提示词 1.2.4.选择分割符 1.2.5.宫格图边框(像素) 2.从文本框或文件载入提示词(Pro…...
uniapp uni-combox 下拉提示无匹配项(完美解决--附加源码解决方案及思路)
问题描述 匆匆忙忙又到了周一啦,一大早就来了一个头疼的问题,把我难得团团转,呜呜呜~ 下面我用代码的方式展示出来,看下你的代码是否与我的不同。 解决方案 <uni-forms-item label"名称" name"drugName&quo…...

10. Mybatis 项目的创建
目录 1. Mybatis 概念 2. 第一个 Mybits 查询 2.1 创建数据库和表 2.2 添加 Mybatis 框架支持 2.3 添加配置文件 2.4 配置 MyBatis 中的 XML 路径 2.5 添加业务代码 在学习 Mybatis 之前,我们需要知道 Mybatis 和 Spring 没有任何的关系。如果一定要强调二者…...
简介)
历年 Nobel prize in Physics (诺贝尔物理学奖)简介
历年 Fields Medal 与 Nobel prize in Physics 简介 Nobel prize in Physics 1901年12月10日 诺贝尔逝世5周年纪念日首次颁发诺贝尔奖。1916年 第一次世界大战 1914.7 至 1918.11诺贝尔物理学奖空缺1931年诺贝尔物理学奖空缺1934年诺贝尔物理学奖空缺1940年—1942年 第二次世界…...

量子机器学习噪声挑战与HPQS混合框架解析
1. 量子机器学习中的噪声挑战与HPQS解决方案量子机器学习(QML)作为量子计算与经典机器学习的交叉领域,正在重新定义我们处理复杂模式识别问题的方式。与传统机器学习不同,QML利用量子态的叠加和纠缠特性,理论上可以在某些特定任务上实现指数级…...

8051仿真器OMF转SIG格式的实战指南
1. Signum 8051 仿真器符号转换器使用指南在嵌入式开发领域,Signum Systems 的 8051 仿真器是一个常用的调试工具。很多开发者在使用 Vision 开发环境时,经常遇到需要将链接器生成的绝对目标模块(OMF)转换为仿真器专用格式的需求。本文将详细介绍这个转换…...

植入式网络广告效果影响因素及投放决策优化【附代码】
✨ 长期致力于植入式网络广告效果、产品植入形态、广告呈现方式、载具属性、品牌知名度研究工作,擅长数据搜集与处理、建模仿真、程序编写、仿真设计。 ✅ 专业定制毕设、代码 ✅ 如需沟通交流,点击《获取方式》 (1)多因素交互实验…...

hls::stream作为高层次设计中最总要的建模
template<typename __STREAM_T__> class stream{ protected://保护类型std::string _name;//hls::stream的命名,用于做标记使用std::deque<__STREAM_T__> _data;//队列public://对外接口stream(){//无参构造函数static unsigned _counter 1;std::strin…...

10M参数也能跑ARC与数独,Bengio团队押注「多轨迹推理」
10M 参数跑到数独 97%,GRAM 把递归推理改成多轨迹采样。 10M 参数,在大模型时代显得有些微不足道。 但 Yoshua Bengio 团队与 KAIST、Mila、NYU 研究人员提出的 GRAM,用这个量级的模型跑出了几组值得注意的结果。 在 Sudoku-Extreme 上准确率…...

【论文阅读】ManiFlow: A General Robot Manipulation Policy via Consistency Flow Training
快速了解部分 基础信息(英文): 1.题目: ManiFlow: A General Robot Manipulation Policy via Consistency Flow Training 2.时间: 2025.09 3.机构: University of Washington, UC San Diego, Nvidia, Allen Institute for AI 4.3个关键词: Fl…...

用 jose 正确实现 JWT 签发、验签与密钥轮换
1. 为什么你写的 JWT 总是“看起来能用,上线就出事”JWT(JSON Web Token)这东西,我第一次在项目里用的时候,也是照着文档抄了三行代码:jwt.sign(payload, secret)、jwt.verify(token, secret)、res.json({ …...

NotebookLM时间线创建全解析,手把手教你用AI自动生成可交互知识图谱
更多请点击: https://intelliparadigm.com 第一章:NotebookLM时间线创建的核心价值与适用场景 NotebookLM 的时间线(Timeline)功能并非简单的时间戳罗列,而是将文档片段、引用来源与用户思考按真实发生顺序动态编织成…...

给硬件新人的半导体测试扫盲:从晶圆到芯片,CP/FT/BI测试到底在测什么?
半导体测试全流程解析:从晶圆到芯片的质量守护 走进半导体制造的世界,就像观察一座精密运转的钟表工厂——每个齿轮都必须完美咬合才能确保最终产品走时准确。对于刚接触这个领域的新人来说,理解芯片从硅片到成品的测试流程,是掌握…...

G-Helper:华硕笔记本性能控制的终极轻量级替代方案
G-Helper:华硕笔记本性能控制的终极轻量级替代方案 【免费下载链接】g-helper Lightweight Armoury Crate alternative for Asus laptops with nearly the same functionality. Works with ROG Zephyrus, Flow, TUF, Strix, Scar, ProArt, Vivobook, Zenbook, Exper…...