Java中集合容器详解:简单使用与案例分析
目录
一、概览
1.1 Collection
1. Set
2. List
3. Queue
1.2 Map
二、容器中的设计模式
迭代器模式
适配器模式
三、源码分析
ArrayList
1. 概览
2. 扩容
3. 删除元素
4. 序列化
5. Fail-Fast
Vector
1. 同步
2. 扩容
3. 与 ArrayList 的比较
4. 替代方案
CopyOnWriteArrayList
1. 读写分离
2. 适用场景
LinkedList
1. 概览
2. 与 ArrayList 的比较
HashMap
1. 存储结构
2. 拉链法的工作原理
3. put 操作
4. 确定桶下标
5. 扩容-基本原理
6. 与 Hashtable 的比较
7. 对象作为key存储
ConcurrentHashMap
1. 存储结构
2. size 操作
3. JDK 1.8 的改动
LinkedHashMap
存储结构
afterNodeAccess()
afterNodeInsertion()
Java容器是一套工具,用于存储数据和对象。可以与C++的STL类比。Java容器也称为Java Collection Framework (JCF)。除了存储对象的容器之外,还提供了一套工具类,用于处理和操作容器中的对象。总体来说,这是一个框架,它包含了Java对象容器和工具类。
一、概览
容器主要包括 Collection 和 Map 两种,Collection 存储着对象的集合,而 Map 存储着键值对(两个对象)的映射表。
1.1 Collection
1. Set
- TreeSet:基于红黑树实现,支持有序性操作,例如根据一个范围查找元素的操作。但是查找效率不如 HashSet,HashSet 查找的时间复杂度为 O(1),TreeSet 则为 O(logN)。
- HashSet:基于哈希表实现,支持快速查找,但不支持有序性操作。并且失去了元素的插入顺序信息,也就是说使用 Iterator 遍历 HashSet 得到的结果是不确定的。
- LinkedHashSet:具有 HashSet 的查找效率,并且内部使用双向链表维护元素的插入顺序。
2. List
- ArrayList:基于动态数组实现,支持随机访问。
- Vector:和 ArrayList 类似,但它是线程安全的。
- LinkedList:基于双向链表实现,只能顺序访问,但是可以快速地在链表中间插入和删除元素。不仅如此,LinkedList 还可以用作栈、队列和双向队列。
3. Queue
- LinkedList:可以用它来实现双向队列。
- PriorityQueue:基于堆结构实现,可以用它来实现优先队列。
1.2 Map
- TreeMap:基于红黑树实现。
- HashMap:基于哈希表实现。
- HashTable:和 HashMap 类似,但它是线程安全的,这意味着同一时刻多个线程同时写入 HashTable 不会导致数据不一致。它是遗留类,不应该去使用它,而是使用 ConcurrentHashMap 来支持线程安全,ConcurrentHashMap 的效率会更高,因为 ConcurrentHashMap 引入了分段锁。
- LinkedHashMap:使用双向链表来维护元素的顺序,顺序为插入顺序或者最近最少使用(LRU)顺序。
二、容器中的设计模式
迭代器模式
Collection 继承了 Iterable 接口,其中的 iterator() 方法能够产生一个 Iterator 对象,通过这个对象就可以迭代遍历 Collection 中的元素。
从 JDK 1.5 之后可以使用 foreach 方法来遍历实现了 Iterable 接口的聚合对象。
List<String> list = new ArrayList<>();
list.add("a");
list.add("b");
for (String item : list) {System.out.println(item);
}适配器模式
java.util.Arrays#asList() 可以把数组类型转换为 List 类型。
@SafeVarargs
public static <T> List<T> asList(T... a)应该注意的是 asList() 的参数为泛型的变长参数,不能使用基本类型数组作为参数,只能使用相应的包装类型数组。
Integer[] arr = {1, 2, 3};
List list = Arrays.asList(arr);也可以使用以下方式调用 asList():
List list = Arrays.asList(1, 2, 3);三、源码分析
如果没有特别说明,以下源码分析基于 JDK 1.8。
在 IDEA 中 double shift 调出 Search EveryWhere,查找源码文件,找到之后就可以阅读源码。
ArrayList
1. 概览
因为 ArrayList 是基于数组实现的,所以支持快速随机访问。RandomAccess 接口标识着该类支持快速随机访问。
public class ArrayList<E> extends AbstractList<E>implements List<E>, RandomAccess, Cloneable, java.io.Serializable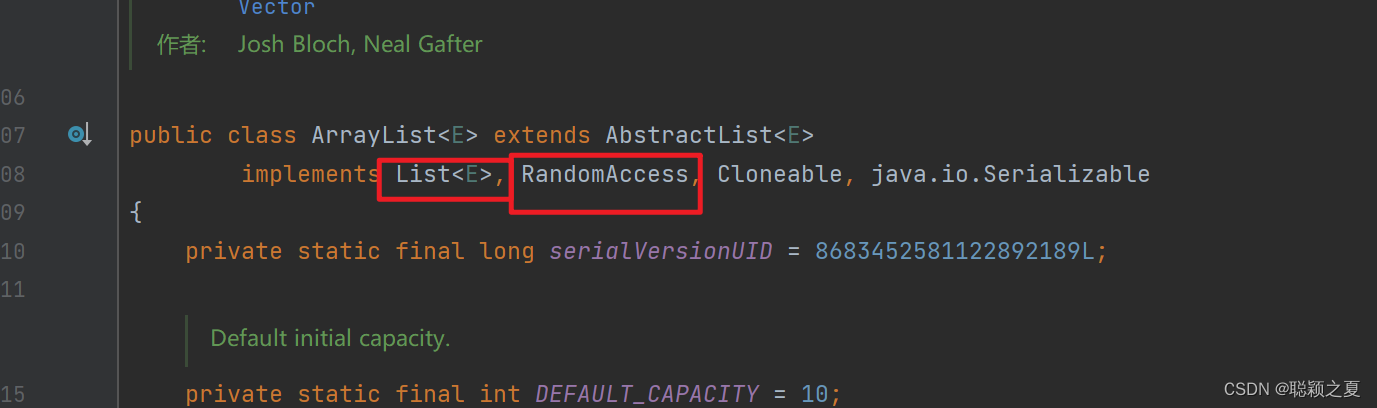
数组的默认大小为 10。
private static final int DEFAULT_CAPACITY = 10;2. 扩容
添加元素时使用 ensureCapacityInternal() 方法来保证容量足够,如果不够时,需要使用 grow() 方法进行扩容,新容量的大小为
oldCapacity + (oldCapacity >> 1),即 oldCapacity+oldCapacity/2。其中 oldCapacity >> 1 需要取整,所以新容量大约是旧容量的 1.5 倍左右。(oldCapacity 为偶数就是 1.5 倍,为奇数就是 1.5 倍-0.5)扩容操作需要调用
Arrays.copyOf()把原数组整个复制到新数组中,这个操作代价很高,因此最好在创建 ArrayList 对象时就指定大概的容量大小,减少扩容操作的次数。
public boolean add(E e) {ensureCapacityInternal(size + 1); elementData[size++] = e;return true;
}
private void ensureCapacityInternal(int minCapacity) {if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {minCapacity = Math.max(DEFAULT_CAPACITY, minCapacity);}ensureExplicitCapacity(minCapacity);
}
private void ensureExplicitCapacity(int minCapacity) {modCount++;if (minCapacity - elementData.length > 0)grow(minCapacity);
}
private void grow(int minCapacity) {int oldCapacity = elementData.length;int newCapacity = oldCapacity + (oldCapacity >> 1);if (newCapacity - minCapacity < 0)newCapacity = minCapacity;if (newCapacity - MAX_ARRAY_SIZE > 0)newCapacity = hugeCapacity(minCapacity);elementData = Arrays.copyOf(elementData, newCapacity);
}3. 删除元素
需要调用 System.arraycopy() 将 index+1 后面的元素都复制到 index 位置上,该操作的时间复杂度为 O(N),可以看到 ArrayList 删除元素的代价是非常高的。
public E remove(int index) {rangeCheck(index);modCount++;E oldValue = elementData(index);int numMoved = size - index - 1;if (numMoved > 0)System.arraycopy(elementData, index+1, elementData, index, numMoved);elementData[--size] = null; return oldValue;
}4. 序列化
ArrayList 基于数组实现,并且具有动态扩容特性,因此保存元素的数组不一定都会被使用,那么就没必要全部进行序列化。
保存元素的数组 elementData 使用 transient 修饰,该关键字声明数组默认不会被序列化。
transient Object[] elementData;ArrayList 实现了 writeObject() 和 readObject() 来控制只序列化数组中有元素填充那部分内容。
private void readObject(java.io.ObjectInputStream s)throws java.io.IOException, ClassNotFoundException {elementData = EMPTY_ELEMENTDATA;s.defaultReadObject();s.readInt(); if (size > 0) {ensureCapacityInternal(size);Object[] a = elementData;for (int i=0; i<size; i++) {a[i] = s.readObject();}}
}private void writeObject(java.io.ObjectOutputStream s)throws java.io.IOException{int expectedModCount = modCount;s.defaultWriteObject();s.writeInt(size);for (int i=0; i<size; i++) {s.writeObject(elementData[i]);}if (modCount != expectedModCount) {throw new ConcurrentModificationException();}
}序列化时需要使用 ObjectOutputStream 的 writeObject() 将对象转换为字节流并输出。而 writeObject() 方法在传入的对象存在 writeObject() 的时候会去反射调用该对象的 writeObject() 来实现序列化。反序列化使用的是 ObjectInputStream 的 readObject() 方法,原理类似。
ArrayList list = new ArrayList();
ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream(file));
oos.writeObject(list);5. Fail-Fast
Vector
1. 同步
它的实现与 ArrayList 类似,但是使用了 synchronized 进行同步。
public synchronized boolean add(E e) {modCount++;ensureCapacityHelper(elementCount + 1);elementData[elementCount++] = e;return true;
}
public synchronized E get(int index) {if (index >= elementCount)throw new ArrayIndexOutOfBoundsException(index);return elementData(index);
}2. 扩容
Vector 的构造函数可以传入 capacityIncrement 参数,它的作用是在扩容时使容量 capacity 增长 capacityIncrement。如果这个参数的值小于等于 0,扩容时每次都令 capacity 为原来的两倍。
public Vector(int initialCapacity, int capacityIncrement) {super();if (initialCapacity < 0)throw new IllegalArgumentException("Illegal Capacity: "+initialCapacity);this.elementData = new Object[initialCapacity];this.capacityIncrement = capacityIncrement;
}private void grow(int minCapacity) {int oldCapacity = elementData.length;int newCapacity = oldCapacity + ((capacityIncrement > 0) ?capacityIncrement : oldCapacity);if (newCapacity - minCapacity < 0)newCapacity = minCapacity;if (newCapacity - MAX_ARRAY_SIZE > 0)newCapacity = hugeCapacity(minCapacity);elementData = Arrays.copyOf(elementData, newCapacity);
}//调用没有 capacityIncrement 的构造函数时,
capacityIncrement 值被设置为 0,也就是说默认情况下 Vector 每次扩容时容量都会翻倍。public Vector(int initialCapacity) {this(initialCapacity, 0);
}
public Vector() {this(10);
}3. 与 ArrayList 的比较
- Vector 是同步的,因此开销就比 ArrayList 要大,访问速度更慢。最好使用 ArrayList 而不是 Vector,因为同步操作完全可以由程序员自己来控制;
- Vector 每次扩容请求其大小的 2 倍(也可以通过构造函数设置增长的容量),而 ArrayList 是 1.5 倍。
4. 替代方案
可以使用 Collections.synchronizedList(); 得到一个线程安全的 ArrayList。
List<String> list = new ArrayList<>();
List<String> synList = Collections.synchronizedList(list);也可以使用 concurrent 并发包下的 CopyOnWriteArrayList 类。
List<String> list = new CopyOnWriteArrayList<>();CopyOnWriteArrayList
1. 读写分离
写操作在一个复制的数组上进行,读操作还是在原始数组中进行,读写分离,互不影响。
写操作需要加锁,防止并发写入时导致写入数据丢失。
写操作结束之后需要把原始数组指向新的复制数组。
public boolean add(E e) {final ReentrantLock lock = this.lock;lock.lock();try {Object[] elements = getArray();int len = elements.length;Object[] newElements = Arrays.copyOf(elements, len + 1);newElements[len] = e;setArray(newElements);return true;} finally {lock.unlock();}
}
final void setArray(Object[] a) {array = a;
}2. 适用场景
CopyOnWriteArrayList 在写操作的同时允许读操作,大大提高了读操作的性能,因此很适合读多写少的应用场景。
但是 CopyOnWriteArrayList 有其缺陷:
- 内存占用:在写操作时需要复制一个新的数组,使得内存占用为原来的两倍左右;
- 数据不一致:读操作不能读取实时性的数据,因为部分写操作的数据还未同步到读数组中。
所以 CopyOnWriteArrayList 不适合内存敏感以及对实时性要求很高的场景。
LinkedList
1. 概览
基于双向链表实现,使用 Node 存储链表节点信息。
private static class Node<E> {E item;Node<E> next;Node<E> prev;
}每个链表存储了 first 和 last 指针:transient Node<E> first;
transient Node<E> last;2. 与 ArrayList 的比较
ArrayList 基于动态数组实现,LinkedList 基于双向链表实现。ArrayList 和 LinkedList 的区别可以归结为数组和链表的区别:
- 数组支持随机访问,但插入删除的代价很高,需要移动大量元素;
- 链表不支持随机访问,但插入删除只需要改变指针。
HashMap
为了便于理解,以下源码分析以 JDK 1.7 为主。
1. 存储结构
内部包含了一个 Entry 类型的数组 table。Entry 存储着键值对。它包含了四个字段,从 next 字段我们可以看出 Entry 是一个链表。即数组中的每个位置被当成一个桶,一个桶存放一个链表。HashMap 使用拉链法来解决冲突,同一个链表中存放哈希值和散列桶取模运算结果相同的 Entry。
transient Entry[] table;static class Entry<K,V> implements Map.Entry<K,V> {final K key;V value;Entry<K,V> next;int hash;Entry(int h, K k, V v, Entry<K,V> n) {value = v;next = n;key = k;hash = h;}public final K getKey() {return key;}public final V getValue() {return value;}public final V setValue(V newValue) {V oldValue = value;value = newValue;return oldValue;}public final boolean equals(Object o) {if (!(o instanceof Map.Entry))return false;Map.Entry e = (Map.Entry)o;Object k1 = getKey();Object k2 = e.getKey();if (k1 == k2 || (k1 != null && k1.equals(k2))) {Object v1 = getValue();Object v2 = e.getValue();if (v1 == v2 || (v1 != null && v1.equals(v2)))return true;}return false;}public final int hashCode() {return Objects.hashCode(getKey()) ^ Objects.hashCode(getValue());}public final String toString() {return getKey() + "=" + getValue();}
}2. 拉链法的工作原理
HashMap<String, String> map = new HashMap<>();
map.put("K1", "V1");
map.put("K2", "V2");
map.put("K3", "V3");- 新建一个 HashMap,默认大小为 16;
- 插入 <K1,V1> 键值对,先计算 K1 的 hashCode 为 115,使用除留余数法得到所在的桶下标 115%16=3。
- 插入 <K2,V2> 键值对,先计算 K2 的 hashCode 为 118,使用除留余数法得到所在的桶下标 118%16=6。
- 插入 <K3,V3> 键值对,先计算 K3 的 hashCode 为 118,使用除留余数法得到所在的桶下标 118%16=6,插在 <K2,V2> 前面。
应该注意到链表的插入是以头插法方式进行的,例如上面的 <K3,V3> 不是插在 <K2,V2> 后面,而是插入在链表头部。
查找需要分成两步进行:
- 计算键值对所在的桶;
- 在链表上顺序查找,时间复杂度显然和链表的长度成正比。
3. put 操作
public V put(K key, V value) {if (table == EMPTY_TABLE) {inflateTable(threshold);}// 键为 null 单独处理if (key == null)return putForNullKey(value);int hash = hash(key);// 确定桶下标int i = indexFor(hash, table.length);// 先找出是否已经存在键为 key 的键值对,如果存在的话就更新这个键值对的值为 valuefor (Entry<K,V> e = table[i]; e != null; e = e.next) {Object k;if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {V oldValue = e.value;e.value = value;e.recordAccess(this);return oldValue;}}modCount++;// 插入新键值对addEntry(hash, key, value, i);return null;
}HashMap 允许插入键为 null 的键值对。但是因为无法调用 null 的 hashCode() 方法,也就无法确定该键值对的桶下标,只能通过强制指定一个桶下标来存放。HashMap 使用第 0 个桶存放键为 null 的键值对。
private V putForNullKey(V value) {for (Entry<K,V> e = table[0]; e != null; e = e.next) {if (e.key == null) {V oldValue = e.value;e.value = value;e.recordAccess(this);return oldValue;}}modCount++;addEntry(0, null, value, 0);return null;
}使用链表的头插法,也就是新的键值对插在链表的头部,而不是链表的尾部。
void addEntry(int hash, K key, V value, int bucketIndex) {if ((size >= threshold) && (null != table[bucketIndex])) {resize(2 * table.length);hash = (null != key) ? hash(key) : 0;bucketIndex = indexFor(hash, table.length);}createEntry(hash, key, value, bucketIndex);
}
void createEntry(int hash, K key, V value, int bucketIndex) {Entry<K,V> e = table[bucketIndex];// 头插法,链表头部指向新的键值对table[bucketIndex] = new Entry<>(hash, key, value, e);size++;
}Entry(int h, K k, V v, Entry<K,V> n) {value = v;next = n;key = k;hash = h;
}4. 确定桶下标
很多操作都需要先确定一个键值对所在的桶下标。
int hash = hash(key);
int i = indexFor(hash, table.length);4.1 计算 hash 值
final int hash(Object k) {int h = hashSeed;if (0 != h && k instanceof String) {return sun.misc.Hashing.stringHash32((String) k);}h ^= k.hashCode();h ^= (h >>> 20) ^ (h >>> 12);return h ^ (h >>> 7) ^ (h >>> 4);
}public final int hashCode() {return Objects.hashCode(key) ^ Objects.hashCode(value);
}4.2 取模
令 x = 1<<4,即 x 为 2 的 4 次方,它具有以下性质:
x : 00010000
x-1 : 00001111令一个数 y 与 x-1 做与运算,可以去除 y 位级表示的第 4 位以上数:
y : 10110010
x-1 : 00001111
y&(x-1) : 00000010这个性质和 y 对 x 取模效果是一样的:y : 10110010
x : 00010000
y%x : 00000010我们知道,位运算的代价比求模运算小的多,因此在进行这种计算时用位运算的话能带来更高的性能。确定桶下标的最后一步是将 key 的 hash 值对桶个数取模:hash%capacity,如果能保证 capacity 为 2 的 n 次方,那么就可以将这个操作转换为位运static int indexFor(int h, int length) {return h & (length-1);
}5. 扩容-基本原理
设 HashMap 的 table 长度为 M,需要存储的键值对数量为 N,如果哈希函数满足均匀性的要求,那么每条链表的长度大约为 N/M,因此查找的复杂度为 O(N/M)。
为了让查找的成本降低,应该使 N/M 尽可能小,因此需要保证 M 尽可能大,也就是说 table 要尽可能大。HashMap 采用动态扩容来根据当前的 N 值来调整 M 值,使得空间效率和时间效率都能得到保证。
和扩容相关的参数主要有:capacity、size、threshold 和 load_factor。
| 参数 | 含义 |
|---|---|
| capacity | table 的容量大小,默认为 16。需要注意的是 capacity 必须保证为 2 的 n 次方。 |
| size | 键值对数量。 |
| threshold | size 的临界值,当 size 大于等于 threshold 就必须进行扩容操作。 |
| loadFactor | 装载因子,table 能够使用的比例,threshold = (int)(capacity* loadFactor)。 |
static final int DEFAULT_INITIAL_CAPACITY = 16;
static final int MAXIMUM_CAPACITY = 1 << 30;
static final float DEFAULT_LOAD_FACTOR = 0.75f;
transient Entry[] table;
transient int size;
int threshold;
final float loadFactor;
transient int modCount;从下面的添加元素代码中可以看出,当需要扩容时,令 capacity 为原来的两倍。
void addEntry(int hash, K key, V value, int bucketIndex) {Entry<K,V> e = table[bucketIndex];table[bucketIndex] = new Entry<>(hash, key, value, e);if (size++ >= threshold)resize(2 * table.length);
}扩容使用 resize() 实现,需要注意的是,扩容操作同样需要把 oldTable 的所有键值对重新插入 newTable 中,因此这一步是很费时的。
void resize(int newCapacity) {Entry[] oldTable = table;int oldCapacity = oldTable.length;if (oldCapacity == MAXIMUM_CAPACITY) {threshold = Integer.MAX_VALUE;return;}Entry[] newTable = new Entry[newCapacity];transfer(newTable);table = newTable;threshold = (int)(newCapacity * loadFactor);
}
void transfer(Entry[] newTable) {Entry[] src = table;int newCapacity = newTable.length;for (int j = 0; j < src.length; j++) {Entry<K,V> e = src[j];if (e != null) {src[j] = null;do {Entry<K,V> next = e.next;int i = indexFor(e.hash, newCapacity);e.next = newTable[i];newTable[i] = e;e = next;} while (e != null);}}
}6. 与 Hashtable 的比较
- Hashtable 使用 synchronized 来进行同步。
- HashMap 可以插入键为 null 的 Entry。
- HashMap 的迭代器是 fail-fast 迭代器。
- HashMap 不能保证随着时间的推移 Map 中的元素次序是不变的
7. 对象作为key存储
- 重写hashCode()和equals()方法,以确保Map能够正确地操作和检索对象。
- 确保对象的不可变性,以避免在对象作为键后修改对象的状态。
- 可选地实现Comparable接口,以支持对键的排序。
- 设计良好的hashCode()方法,以减少哈希冲突的可能性。
- 避免使用可变对象作为键,并在必要时及时更新Map中的键。
ConcurrentHashMap
1. 存储结构
static final class HashEntry<K,V> {final int hash;final K key;volatile V value;volatile HashEntry<K,V> next;
}ConcurrentHashMap 和 HashMap 实现上类似,最主要的差别是 ConcurrentHashMap 采用了分段锁(Segment),每个分段锁维护着几个桶(HashEntry),多个线程可以同时访问不同分段锁上的桶,从而使其并发度更高(并发度就是 Segment 的个数)。
Segment 继承自 ReentrantLock。
static final class Segment<K,V> extends ReentrantLock implements Serializable {private static final long serialVersionUID = 2249069246763182397L;static final int MAX_SCAN_RETRIES =Runtime.getRuntime().availableProcessors() > 1 ? 64 : 1;transient volatile HashEntry<K,V>[] table;transient int count;transient int modCount;transient int threshold;final float loadFactor;
}final Segment<K,V>[] segments;默认的并发级别为 16,也就是说默认创建 16 个 Segment。static final int DEFAULT_CONCURRENCY_LEVEL = 16;2. size 操作
每个 Segment 维护了一个 count 变量来统计该 Segment 中的键值对个数。
transient int count;在执行 size 操作时,需要遍历所有 Segment 然后把 count 累计起来。
ConcurrentHashMap 在执行 size 操作时先尝试不加锁,如果连续两次不加锁操作得到的结果一致,那么可以认为这个结果是正确的。
尝试次数使用 RETRIES_BEFORE_LOCK 定义,该值为 2,retries 初始值为 -1,因此尝试次数为 3。
如果尝试的次数超过 3 次,就需要对每个 Segment 加锁。
static final int RETRIES_BEFORE_LOCK = 2;
public int size() {final Segment<K,V>[] segments = this.segments;int size;boolean overflow; long sum; long last = 0L; int retries = -1;try {for (;;) {// 超过尝试次数,则对每个 Segment 加锁if (retries++ == RETRIES_BEFORE_LOCK) {for (int j = 0; j < segments.length; ++j)ensureSegment(j).lock(); }sum = 0L;size = 0;overflow = false;for (int j = 0; j < segments.length; ++j) {Segment<K,V> seg = segmentAt(segments, j);if (seg != null) {sum += seg.modCount;int c = seg.count;if (c < 0 || (size += c) < 0)overflow = true;}}// 连续两次得到的结果一致,则认为这个结果是正确的if (sum == last)break;last = sum;}} finally {if (retries > RETRIES_BEFORE_LOCK) {for (int j = 0; j < segments.length; ++j)segmentAt(segments, j).unlock();}}return overflow ? Integer.MAX_VALUE : size;
}3. JDK 1.8 的改动
JDK 1.7 使用分段锁机制来实现并发更新操作,核心类为 Segment,它继承自重入锁 ReentrantLock,并发度与 Segment 数量相等。
JDK 1.8 使用了 CAS 操作来支持更高的并发度,在 CAS 操作失败时使用内置锁 synchronized。
并且 JDK 1.8 的实现也在链表过长时会转换为红黑树。
LinkedHashMap
存储结构
继承自 HashMap,因此具有和 HashMap 一样的快速查找特性。
public class LinkedHashMap<K,V> extends HashMap<K,V> implements Map<K,V>内部维护了一个双向链表,用来维护插入顺序或者 LRU 顺序。
transient LinkedHashMap.Entry<K,V> head;
transient LinkedHashMap.Entry<K,V> tail;accessOrder 决定了顺序,默认为 false,此时维护的是插入顺序。
final boolean accessOrder;LinkedHashMap 最重要的是以下用于维护顺序的函数,它们会在 put、get 等方法中调用。
void afterNodeAccess(Node<K,V> p) { }
void afterNodeInsertion(boolean evict) { }afterNodeAccess()
当一个节点被访问时,如果 accessOrder 为 true,则会将该节点移到链表尾部。也就是说指定为 LRU 顺序之后,在每次访问一个节点时,会将这个节点移到链表尾部,保证链表尾部是最近访问的节点,那么链表首部就是最近最久未使用的节点。
void afterNodeAccess(Node<K,V> e) { LinkedHashMap.Entry<K,V> last;if (accessOrder && (last = tail) != e) {LinkedHashMap.Entry<K,V> p =(LinkedHashMap.Entry<K,V>)e, b = p.before, a = p.after;p.after = null;if (b == null)head = a;elseb.after = a;if (a != null)a.before = b;elselast = b;if (last == null)head = p;else {p.before = last;last.after = p;}tail = p;++modCount;}
}afterNodeInsertion()
在 put 等操作之后执行,当 removeEldestEntry() 方法返回 true 时会移除最晚的节点,也就是链表首部节点 first。
evict 只有在构建 Map 的时候才为 false,在这里为 true。
void afterNodeInsertion(boolean evict) { LinkedHashMap.Entry<K,V> first;if (evict && (first = head) != null && removeEldestEntry(first)) {K key = first.key;removeNode(hash(key), key, null, false, true);}
}removeEldestEntry() 默认为 false,如果需要让它为 true,需要继承 LinkedHashMap 并且覆盖这个方法的实现,这在实现 LRU 的缓存中特别有用,通过移除最近最久未使用的节点,从而保证缓存空间足够,并且缓存的数据都是热点数据。protected boolean removeEldestEntry(Map.Entry<K,V> eldest) {return false;
}相关文章:
Java中集合容器详解:简单使用与案例分析
目录 一、概览 1.1 Collection 1. Set 2. List 3. Queue 1.2 Map 二、容器中的设计模式 迭代器模式 适配器模式 三、源码分析 ArrayList 1. 概览 2. 扩容 3. 删除元素 4. 序列化 5. Fail-Fast Vector 1. 同步 2. 扩容 3. 与 ArrayList 的比较 4. 替代方案…...
机器学习04-数据理解之数据可视化-(基于Pima数据集)
什么是数据可视化? 数据可视化是指通过图表、图形、地图等视觉元素将数据呈现出来的过程。它是将抽象的、复杂的数据转化为直观、易于理解的视觉表达的一种方法。数据可视化的目的是帮助人们更好地理解数据,从中发现模式、趋势、关联和异常,从而作出更明…...

百度@全球开发者,见证中国科技超级“碗”!
潮汐涌动时,变化悄然发生。2023年全球AI浪潮迭起,大语言模型热度空前,生成式人工智能为千行百业高质量发展带来更多想象空间,一个蓬勃创新、重构万物的“大模型时代”正蓄势待发。 滴滴滴~百度全球开发者,…...
分库分表之基于Shardingjdbc+docker+mysql主从架构实现读写分离(一)
说明:请先自行安装好docker再来看本篇文章,本篇文章主要实现通过使用docker部署mysql实现读写分离,并连接数据库测试。第二篇将实现使用Shardingjdbc实现springboot的读写分离实现。 基于Docker去创建Mysql的主从架构 #创建主从数据库文件夹…...

Ajax跨域问题
什么是跨域问题? 跨域问题来源于JavaScript的"同源策略",即只有 协议主机名端口号 (如存在)相同,则允许相互访问。也就是说JavaScript只能访问和操作自己域下的资源,不能访问和操作其他域下的资源。跨域问题是针对JS和ajax的&…...

Vue + FormData + axios实现图片上传功能
当使用Vue FormData axios实现图片上传功能时,你可以按照以下步骤进行操作: 示例代码 首先,在Vue组件中,创建一个data属性来存储选择的文件和上传状态: data() {return {file: null,uploading: false}; }在模板中…...

设计模式系列:经典的单例模式
单例模式,是设计模式当中非常重要的一种,在面试中也常常被考察到。 正文如下: 一、什么时候使用单例模式? 单例模式可谓是23种设计模式中最简单、最常见的设计模式了,它可以保证一个类只有一个实例。我们平时网购时用的购物车,就是单例模式的一个例子。想一想,如果购物…...

macbook pro 散热解决办法
结论: 2017 macbook pro 13.3 寸 控制住温度, 不惧长时间满载、性能也飞起. 方案说明最低温度满载温度一、终极方案(成本 460元)120w半导体散热 导热垫31度71度二、推荐方案, 完全静音(成本 50元)828散热风扇 导热垫43度81度三、不拆机、低成本(20元)828散热风扇56度91度四、…...

高并发与性能优化的神奇之旅
作为公司的架构师或者程序员,你是否曾经为公司的系统在面对高并发和性能瓶颈时感到手足无措或者焦头烂额呢?笔者在出道那会为此是吃尽了苦头的,不过也得感谢这段苦,让笔者从头到尾去探索,找寻解决之法。 目录 第一站&…...
Django Rest_Framework(一)
1. Web应用模式 在开发Web应用中,有两种应用模式: 前后端不分离[客户端看到的内容和所有界面效果都是由服务端提供出来的。] 前后端分离【把前端的界面效果(html,css,js分离到另一个服务端或另一个目录下,python服务…...

VB+ACCESS智能公交考勤系统管理软件设计与实现
智能公交考勤系统管理软件设计 摘要:随着现代科学技术的发展,越来越多的企业对职工的考勤管理都实行了信息化管理,使用计算机系统代替繁琐冗余的手工方式来管理考勤事务。针对公交考勤的系统管理、人事管理、运营管理,提出了智能公交考勤管理系统。 智能公交考勤系统是典…...
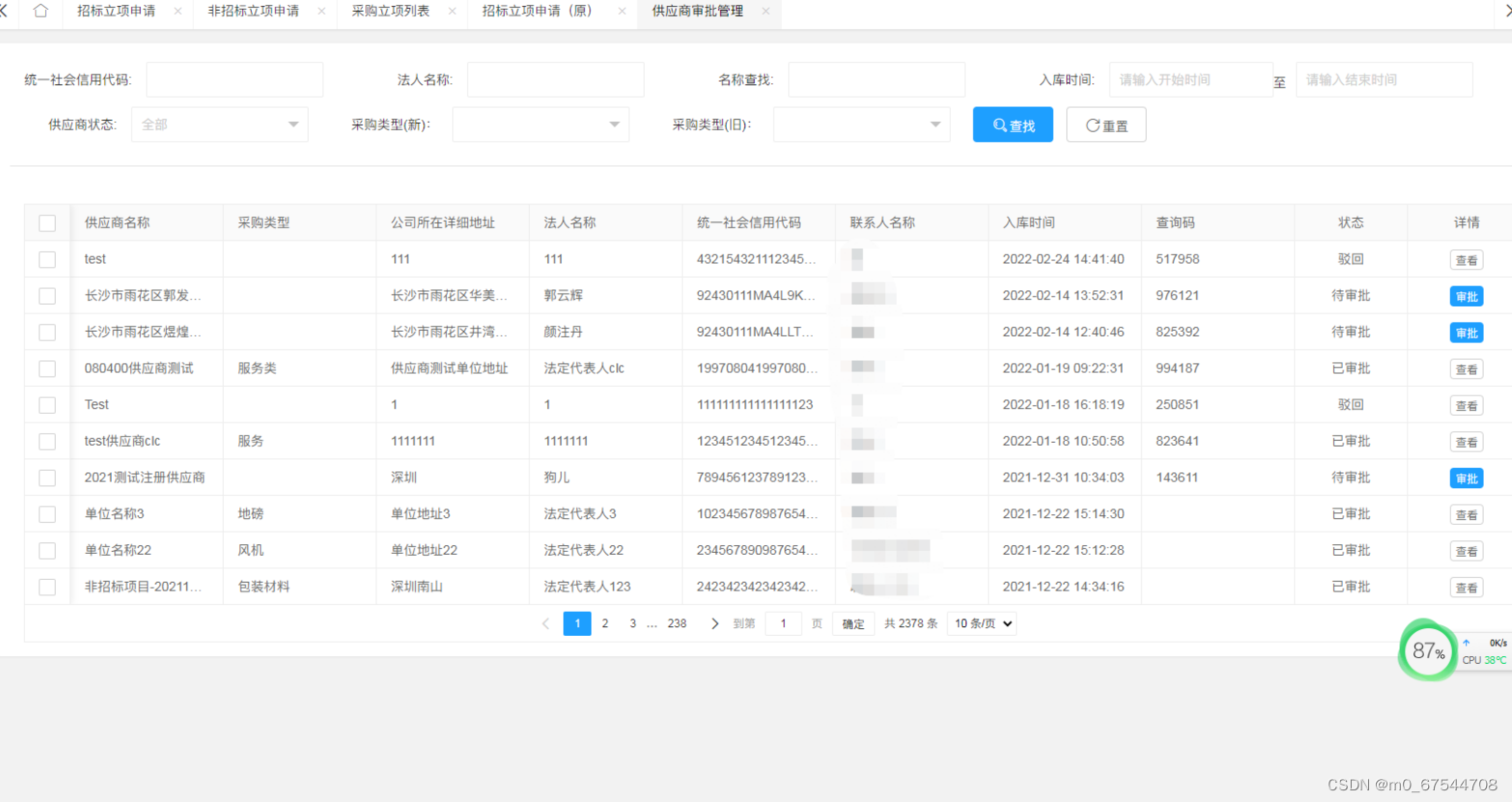
企业电子招标采购系统源码Spring Boot + Mybatis + Redis + Layui + 前后端分离 构建企业电子招采平台之立项流程图 tbms
 项目说明 随着公司的快速发展,企业人员和经营规模不断壮大,公司对内部招采管理的提升提出了更高的要求。在企业里建立一个公平、公开、公正的采购环境,最大限度控制采购成本至关重要。符合国家电子招投标法律法规及相关规范&am…...

【ES】笔记-ECMAScript 相关介绍
ECMASript 相关介绍 什么是ECMA ECMA(European Computer Manufacturers Association)中文名称为欧洲计算机制 造商协会,这个组织的目标是评估、开发和认可电信和计算机标准。1994 年后该 组织改名为 Ecma 国际。 什么是 ECMAScript ECMAS…...
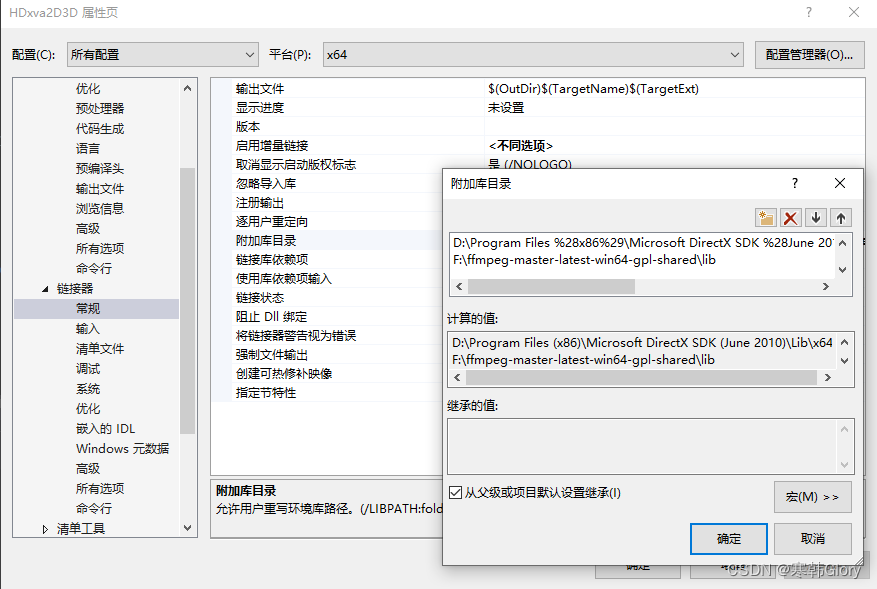
FFmpeg下载安装及Windows开发环境设置
1 FFmpeg简介 FFmpeg:FFmpeg是一套可以用来记录、转换数字音频、视频,并能将其转化为流的开源计算机程序。采用LGPL或GPL许可证。它提供了录制、转换以及流化音视频的完整解决方案。项目的名称来自MPEG视频编码标准,前面的"FF"代表…...
transformer面试常考题
1.位置编码有哪些?有什么区别? nn.embedding和正余弦编码两种用的多。nn.embedding是一种基于学习的嵌入方法, 通过神经网络的训练过程, 会自动学习数据中每个符号的嵌入向量表示。 而正余弦编码是一种手工设计的嵌入方式&…...

aws的EC2云服务器
亚马逊官网有免费试用1年的服务器 1. 启动生成实例 1.1 创建实例时需要生成 使用的默认的 Amazon Linux 和 一个.pem后缀的秘钥 1.2 网上下一个Mobaxterm ,实例名是公有 IPv4 DNS 地址 ,使用SSH连接,登录名是ec2-user...

hive函数大全
在hive内部有许多函数,如下: 内置运算符 关系运算符 算术运算符 逻辑运算符 复杂类型函数 内置函数内置聚合函数 数学函数 收集函数 类型转换函数 日期函数 条件函数 字符函数 内置聚合函数 内置表生成函数 1.1关系运算符 等值比较: 等值比较:<>…...

k8s概念-StatefulSet
StatefulSet 是用来管理有状态应用的控制器 StatefulSet 用来管理某Pod集合的部署和扩缩, 并为这些 Pod 提供持久存储和持久标识符StatefulSet | KubernetesStatefulSet 运行一组 Pod,并为每个 Pod 保留一个稳定的标识。 这可用于管理需要持久化存储或稳…...

HTMLCollection 和 NodeList 的详解,以及两者在开发情况下差异。
看结果直接看下文的举例子 HTMLCollection HTMLCollection 表示一个包含了元素(元素顺序为文档流中的接口)的集合(通用集合),还提供了从该集合中选择元素的属性和方法。 HTMLCollection 对象中的属性和方法: item(index) —— 返回 HTMLCollection 中指…...
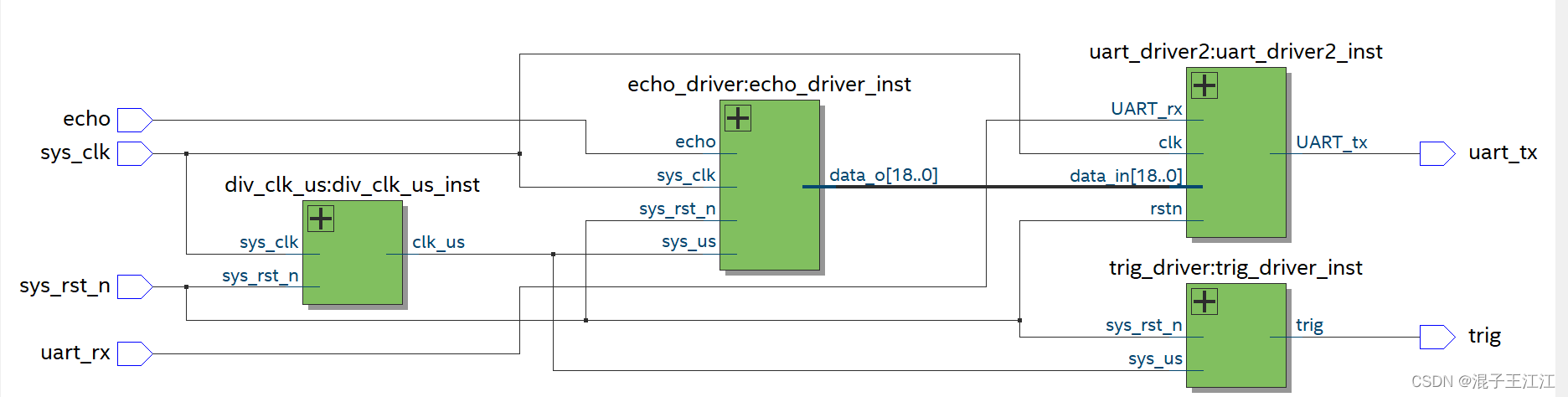
基于FPGA的超声波测距——UART串口输出
文章目录 前言一、超声波模块介绍1、产品特点2、超声波模块的时序图 二、系统设计1、系统模块框图2、RTL视图 三、源码1、div_clk_us(1us的分频)2、产生驱动超声波的信号3、串口发送模块4、HC_SR04_uart(顶层文件) 四、效果五、总结六、参考资料 前言 环境: 1、Quar…...

[智能体-7]:业务数据序列化为 JSON 字符串 完整示例
一、概念序列化:把程序里的对象 / 字典 / 实体数据 → 转换成JSON 格式字符串,用于网络传输、接口请求、存储。反序列化:JSON 字符串 → 还原成程序可直接使用的数据对象。二、Python 示例(最常用,对接 OpenAI / 大模型…...

中文Kodi媒体中心终极指南:4大本土化插件解决方案
中文Kodi媒体中心终极指南:4大本土化插件解决方案 【免费下载链接】xbmc-addons-chinese Addon scripts, plugins, and skins for XBMC Media Center. Special for chinese laguage. 项目地址: https://gitcode.com/gh_mirrors/xb/xbmc-addons-chinese 你是否…...

Java全栈工程师面试实录:从基础到微服务的深度技术对话
Java全栈工程师面试实录:从基础到微服务的深度技术对话 面试官与程序员的对话 面试官(李哥): 你好,欢迎来参加我们公司的面试。我是李哥,负责技术面试。先简单介绍一下你自己吧。 程序员(张浩&a…...

长期项目使用Taotoken聚合API的稳定性与容灾感受
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 长期项目使用Taotoken聚合API的稳定性与容灾感受 1. 项目背景与接入初衷 我们团队负责一个面向内部用户的中型知识问答系统&#…...
)
别再只会画矩形了!用Leaflet+L.geoJSON搞定复杂行政区遮罩(含飞地处理)
突破Leaflet遮罩技术瓶颈:复杂行政区与飞地处理的终极方案 当我们面对真实世界中的行政区划数据时,理想化的矩形遮罩显得力不从心。中国行政区划的复杂性——飞地、嵌套洞、不规则边界——要求开发者掌握更高级的地图遮罩技术。本文将带您深入Leaflet的L…...

BilibiliDown音频提取终极指南:3分钟学会从B站视频提取高质量音乐
BilibiliDown音频提取终极指南:3分钟学会从B站视频提取高质量音乐 【免费下载链接】BilibiliDown (GUI-多平台支持) B站 哔哩哔哩 视频下载器。支持稍后再看、收藏夹、UP主视频批量下载|Bilibili Video Downloader 😳 项目地址: https://gitcode.com/g…...

Windows硬件指纹保护终极教程:3步掌握EASY-HWID-SPOOFER安全使用
Windows硬件指纹保护终极教程:3步掌握EASY-HWID-SPOOFER安全使用 【免费下载链接】EASY-HWID-SPOOFER 基于内核模式的硬件信息欺骗工具 项目地址: https://gitcode.com/gh_mirrors/ea/EASY-HWID-SPOOFER 在数字时代,你的硬件信息正在被悄悄收集—…...
)
保姆级教程:用ENVI+SNAP搞定哨兵1号雷达数据预处理(附水稻监测实战)
从零掌握哨兵1号雷达数据处理:ENVI与SNAP双软件协同实战指南 当第一次接触哨兵1号雷达数据时,许多研究者都会被其独特的成像机制和处理流程所困扰。与光学遥感不同,雷达数据需要经过一系列专业预处理才能用于分析。本文将带你系统掌握ENVI和…...

OpenClaw Windows一键部署包简体中文版下载
OpenClaw(小龙虾)Windows 一键部署保姆级教程 | 10分钟养出你的数字员工(2026最新版) 前言:2026年爆火的开源AI智能体OpenClaw(昵称小龙虾),GitHub星标超28万,凭“本地运…...

7.1 DRAM Basics: Internals, Operation
这两段截图是《Memory Systems》一书中关于 DRAM 最基础定义的阐述。我为您提供翻译和深度解读: 1. 中文翻译 图1: 随机存取存储器(RAM)如果每一位使用一个单一的晶体管-电容器对,则被称为动态随机存取存储器(DRAM)。图 7.3 在右下角展示了 DRAM 存储单元的电路。这个电…...