通过案例实战详解elasticsearch自定义打分function_score的使用
前言
elasticsearch给我们提供了很强大的搜索功能,但是有时候仅仅只用相关度打分是不够的,所以elasticsearch给我们提供了自定义打分函数function_score,本文结合简单案例详解function_score的使用方法,关于function-score-query的文档最权威的莫过于官方文档:
function_score官方文档
基本数据准备
我们创建一张新闻表,包含如下字段:
| 字段 | 类型 | 说明 |
|---|---|---|
| id | Long | 新闻ID |
| title | string | 标题 |
| tags | string | 标签 |
| read_count | long | 阅读数 |
| like_count | long | 点赞数 |
| comment_count | long | 评论数 |
| rank | double | 自定义权重 |
| location | arrays | 文章发布经纬度 |
| pub_time | date | 发布时间 |
创建elasticsearch的 Mapping:
PUT /news
{"mappings": {"properties": {"id": {"type": "long"},"title": {"type": "text","analyzer": "standard"},"tags": {"type": "keyword"},"read_count": {"type": "long"},"like_count": {"type": "long"},"comment_count": {"type": "long"},"rank": {"type": "double"},"location": {"type": "geo_point"},"pub_time": {"type": "date","format": "yyyy-MM-dd HH:mm:ss||yyyy-MM-dd HH:mm||yyyy-MM-dd||epoch_millis"}}}
}
准备测试数据:
| id | title | tags | read_count | comment_count | like_count | rank | location | pub_time |
|---|---|---|---|---|---|---|---|---|
| 1 | 台风“杜苏芮”登陆福建晋江 多部门多地全力应对 | 台风;杜苏芮;福建 | 10000 | 2000 | 600 | 0 | 118.55199,24.78144 | 2023-07-29 09:47 |
| 2 | 受台风“杜苏芮”影响 北京7月29日至8月1日将有强降雨 | 台风;杜苏芮;北京 | 1000 | 200 | 60 | 0 | 116.23128,40.22077 | 2023-06-29 14:49:38 |
| 3 | 杭州解除台风蓝色预警信号 | 台风;杭州 | 10 | 2 | 6 | 0.9 | 120.21201,30.2084 | 2020-07-29 14:49:38 |
批量添加数据到elasticsearch中:
POST _bulk
{"create": {"_index": "news", "_id": 1}}
{"comment_count":600,"id":1,"like_count":2000,"location":[118.55199,24.78144],"pub_time":"2023-07-29 09:47","rank":0.0,"read_count":10000,"tags":["台风","杜苏芮","福建"],"title":"台风“杜苏芮”登陆福建晋江 多部门多地全力应对"}
{"create": {"_index": "news", "_id": 2}}
{"comment_count":60,"id":2,"like_count":200,"location":[116.23128,40.22077],"pub_time":"2023-06-29 14:49:38","rank":0.0,"read_count":1000,"tags":["台风","杜苏芮","北京"],"title":"受台风“杜苏芮”影响 北京7月29日至8月1日将有强降雨"}
{"create": {"_index": "news", "_id": 3}}
{"comment_count":6,"id":3,"like_count":20,"location":[120.21201,30.208],"pub_time":"2020-07-29 14:49:38","rank":0.99,"read_count":100,"tags":["台风","杭州"],"title":"杭州解除台风蓝色预警信号"}
random_score的使用
我们通过random_score理解一下weight、score_mode,boost_mode的作用分别是什么,先直接看Demo
GET /news/_search
{"query": {"function_score": {"query": {"match": {"title": "台风"}},"functions": [{"random_score": {}, "weight": 1},{"filter": { "match": { "title": "杭州" } },"weight":42}],"score_mode": "sum","boost_mode": "replace"}}
}
对应JAVA查询代码:
BoolQueryBuilder queryBuilder = QueryBuilders.boolQuery();queryBuilder.should(QueryBuilders.matchQuery("title","杭州"));FunctionScoreQueryBuilder.FilterFunctionBuilder[] filterFunctionBuilders = new FunctionScoreQueryBuilder.FilterFunctionBuilder[1];ScoreFunctionBuilder<RandomScoreFunctionBuilder> randomScoreFilter = new RandomScoreFunctionBuilder();((RandomScoreFunctionBuilder) randomScoreFilter).seed(2);filterFunctionBuilders[0] = new FunctionScoreQueryBuilder.FilterFunctionBuilder(randomScoreFilter);FunctionScoreQueryBuilder query = QueryBuilders.functionScoreQuery(queryBuilder, filterFunctionBuilders).scoreMode(FunctionScoreQuery.ScoreMode.SUM).boostMode(CombineFunction.SUM);SearchSourceBuilder searchSourceBuilder= new SearchSourceBuilder().query(query);SearchRequest searchRequest= new SearchRequest().searchType(SearchType.DFS_QUERY_THEN_FETCH).indices("news").source(searchSourceBuilder);SearchResponse response = restClient.search(searchRequest, RequestOptions.DEFAULT);SearchHits hits = response.getHits();String searchSource;for (SearchHit hit : hits){searchSource = hit.getSourceAsString();System.out.println(searchSource);}
查询结果:
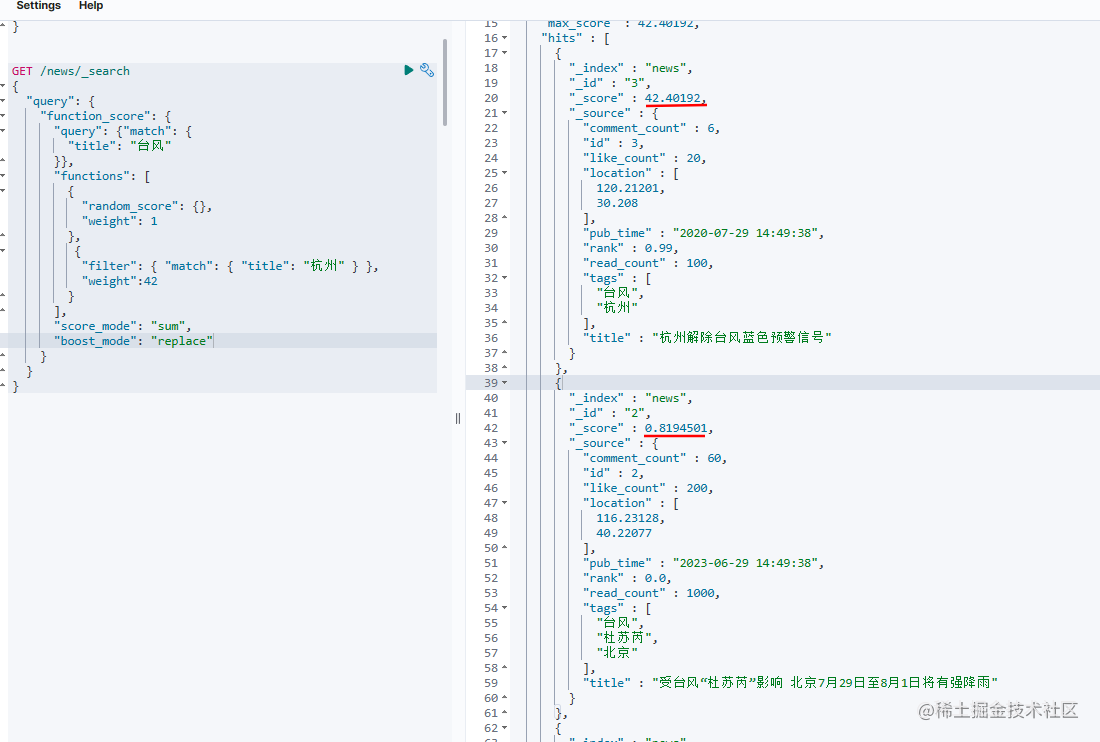
这个查询使用的function_score,query中通过title搜索“台风”,在functions我们增加了两个打分,一个是random_score,随机生成一个得分,得分的weight权重是1,第二个是如果标题中有“杭州”,得分权重为42,
-
random_score
顾名思义就是生成一个(0,1)之间的随机得分,我能想到的一个应用场景是,有一天产品要求:每个人看到新闻都不一样,要做到“千人千面”,而且只给你一天的时间,这样我们就可以使用random_score,每次拉取的数据都是随机的,每个人看到的新闻都是不一样的,这个随机查询比Mysql实现简单多了,0成本实现了“千人千面”。 -
weight
这个就是给生成的得分增加一个权重,在上面的Demo中,我们第一个weight=1,第二个weight=42,从搜索结果得分可以看出“杭州解除台风蓝色预警信号”这条得分是42.40192,而下面的只有0.8194501,因为增加了42倍的权重。 -
score_mode
score_mode的作用是对functions中计算出来的多个得分做汇总计算,比如我用了是sum,就是指将上面random_score得到的打分和filter中得到的42分相加,也就是说第一条42.40192得分是random_score生成了0.40192再加上filter中得到了42分。score_mode默认是采用multiply,总共有6种计算方式:
random_score函数 | 计算方式 |
|---|---|
multiply | scores are multiplied (default) |
sum | scores are summed |
avg | scores are averaged |
first | the first function that has a matching filter is applied |
max | maximum score is used |
min | minimum score is used |
boost_mode
boost_mode作用是将functions得到的总分数和我们query查询的得到的分数做计算,比如我们使用的是replace就是完全使用functions中的得分替代query中的得分,boost_mode总共有6种计算方式:
boost_mode函数 | 得分计算方式 |
|---|---|
multiply | query score and function score is multiplied (default) |
replace | only function score is used, the query score is ignored |
sum | query score and function score are added |
avg | average |
max | max of query score and function score |
min | min of query score and function score |
script_score的使用
script_score就是用记可以通过各种函数计算你文档中出现的字段,算出一个自己想要的得分,我们直接看Demo
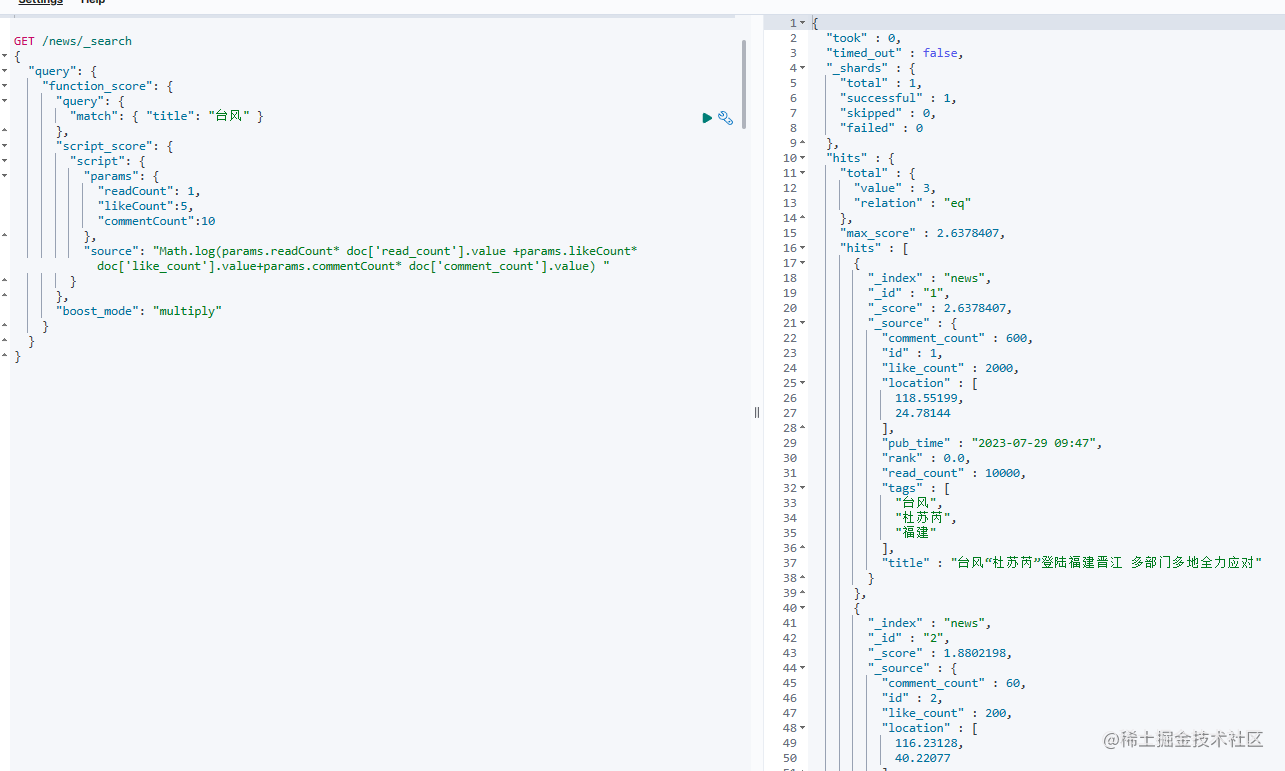
GET /news/_search
{"query": {"function_score": {"query": {"match": { "title": "台风" }},"script_score": {"script": {"params": {"readCount": 1,"likeCount":5,"commentCount":10},"source": "Math.log(params.readCount* doc['read_count'].value +params.likeCount* doc['like_count'].value+params.commentCount* doc['comment_count'].value) "}},"boost_mode": "multiply"}}
}
每篇新闻有阅读数、点赞数据、评论数,我们可以通过这三个指标算出一个分值来评价一篇文章的热度,然后将这个热度和query中的得分相乘,这样热度很高的文章可以排到更前面。在这个Demo中我使用了一个简单的加权来计算文章热度,一般来说阅读数是最大的,点赞数次之,评论数是最小的。
文章热度 = L o g ( 评论数 × 10 + 点赞数 × 5 + 阅读数 ) 文章热度=Log(评论数\times 10+点赞数\times5+阅读数) 文章热度=Log(评论数×10+点赞数×5+阅读数)
这里为了演示,简单算一下文章热度,真实的要比这个复杂的多,可能不同种类的文章重要性也是不一样的。
field_value_factor的使用
field_value_factor可以理解成elasticsearch给你一些内置的script_score,每次写script_score必定不是太方便,如果有一些内置的函数,开箱即用就方便多了,我们直接看Demo
GET /news/_search
{"query": {"function_score": {"query": {"match": {"title": "台风"}},"field_value_factor": {"field": "rank","factor": 10,"modifier": "sqrt","missing": 1},"boost_mode": "multiply"}}
}
这里的field_value_factor就对相当script_score的 sqrt(10 * doc['rank'].value),这里的factor是乘以多少倍,默认是1倍,missing是如果没有这个字段默认值为1,modifier是计算函数,field是要计算的字段。
modifier计算函数有以下类型可以选择
modifier函数 | 得分计算方式 |
|---|---|
none | Do not apply any multiplier to the field value |
log | Take the common logarithm of the field value. Because this function will return a negative value and cause an error if used on values between 0 and 1, it is recommended to use log1p instead. |
log1p | Add 1 to the field value and take the common logarithm |
log2p | Add 2 to the field value and take the common logarithm |
ln | Take the natural logarithm of the field value. Because this function will return a negative value and cause an error if used on values between 0 and 1, it is recommended to use ln1p instead. |
ln1p | Add 1 to the field value and take the natural logarithm |
ln2p | Add 2 to the field value and take the natural logarithm |
square | Square the field value (multiply it by itself) |
sqrt | Take the square root of the field value |
reciprocal | Reciprocate the field value, same as 1/x where x is the field’s value |
衰减函数Decay functions的使用
衰减函数可以理解成计算文档中某一个字段与给定值的距离,如果距离越近得分就越高,距离越远得分就越低,这个就比较适用于新闻发布时间的衰减了,越久前发布的新闻,得分应该越小,排序越往后。我们直接看Demo
GET /news/_search
{"query": {"function_score": {"query": {"match": {"title": "台风"}},"functions": [{"gauss": {"pub_time": {"origin": "now","offset": "7d","scale": "60d","decay": 0.9}}},{"exp": {"location": {"origin": {"lat": 120.21551,"lon": 30.25308},"offset": "50km","scale": "50km","decay": 0.1}}}],"score_mode": "sum", "boost_mode": "sum"}}
}
搜索结果:

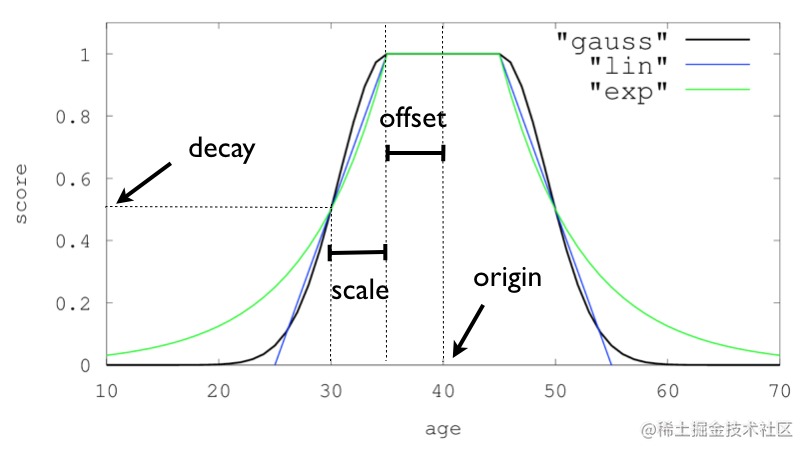
衰减函数有3种,分别为gauss高斯函数、lin线程函数、exp对数函数,具体的计算公式可以参考官方文档,这里我们主要理解衰减函数的4个参数作用是什么。
-
origin
可以理解成计算距离的原点,比如上面计算新闻发布时间的原点是当前时间,计算经纬度的原点是用户搜索位置,比如我在杭州,那么origin就是杭州的经纬度 -
offset
这个偏移量可以理解成不需要衰减的距离,比如在上面的Demo中,距离pub_time的offset为7d,意思是说近7天内发布的新闻都不需要衰减,得分直接为1。计算经纬度中的offset为50km意思是说距离用户50km里的新闻不需要衰减,50km内的基本都是杭州本地的新闻,就没必要衰减了。 -
scale和decay
这两个参数可以参考官方给的三种函数衰减图,scale和decay表示距离为scale后得分衰减到原来的scale倍。比如上面时间衰减offset=7d, scale=60d,decay= 0.9加起来的意思就是7天内的新闻不衰减,67天(7d+60d)前的新闻得分为0.9,在经纬度衰减中offset=50km, scale=50km,decay= 0.1的意思是50km内的距离不衰减,100km(50km+50km)外的数据得分为0.1。
总结
elasticsearch的function_score给我提供了好几种很灵活的自定义打分策略,在实际项目中需要根据自己的需求合理的组合这些打分策略并调整对应参数才能满足自己的搜索需求,本文主要介绍function_score的使用,接下来我会根据一个实际的搜索应用介绍一下如何组合、设置这些函数以达到比较理解的搜索效果。
相关文章:
通过案例实战详解elasticsearch自定义打分function_score的使用
前言 elasticsearch给我们提供了很强大的搜索功能,但是有时候仅仅只用相关度打分是不够的,所以elasticsearch给我们提供了自定义打分函数function_score,本文结合简单案例详解function_score的使用方法,关于function-score-query…...
SpringBoot第28讲:SpringBoot集成MySQL - MyBatis-Plus方式
SpringBoot第28讲:SpringBoot集成MySQL - MyBatis-Plus方式 本文是SpringBoot第28讲,MyBatis-Plus(简称 MP)是一个 MyBatis的增强工具,在 MyBatis 的基础上只做增强不做改变,为简化开发、提高效率而生。MyB…...

AI 绘画Stable Diffusion 研究(三)sd模型种类介绍及安装使用详解
本文使用工具,作者:秋葉aaaki 免责声明: 工具免费提供 无任何盈利目的 大家好,我是风雨无阻。 今天为大家带来的是 AI 绘画Stable Diffusion 研究(三)sd模型种类介绍及安装使用详解。 目前,AI 绘画Stable Diffusion的…...

Docker 命令没有提示信息
问题描述 提示:这里描述项目中遇到的问题: linux安装docker后发现使用docker命令没有提示功能,使用 Tab 键的时候只是提示已有的文件 解决方案: 提示:这里填写该问题的具体解决方案: Bash命令补全 Docke…...

springboot第33集:nacos图
./startup.sh -m standalone Nacos是一个内部微服务组件,需要在可信的内部网络中运行,不可暴露在公网环境,防止带来安全风险。Nacos提供简单的鉴权实现,为防止业务错用的弱鉴权体系,不是防止恶意攻击的强鉴权体系。 鉴…...
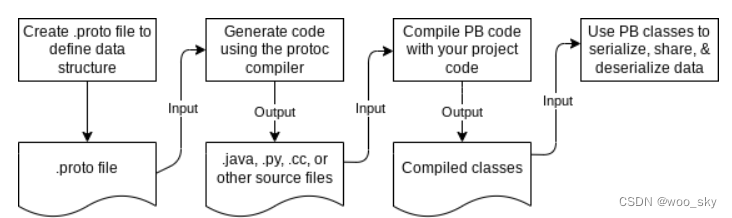
学习gRPC(一)
gRPC 简介 根据官网的介绍,gRPC 是开源高性能远程过程调用(RPC)框架,可以在任何环境中运行。它可以有效地连接数据中心内部和数据中心之间的服务,并为负载平衡、跟踪、运行状况检查和身份验证提供支持。同时由于其建立…...

【二进制安全】堆漏洞:Double Free原理
参考:https://www.anquanke.com/post/id/241598 次要参考:https://xz.aliyun.com/t/6342 malloc_chunk 的源码如下: struct malloc_chunk { INTERNAL_SIZE_T prev_size; /*前一个chunk的大小*/ INTERNAL_SIZE_T size; /*当前chunk的…...

python之open,打开文件时,遇到解码错误处理方式
在Python中,当我们打开一个文件时,我们可以指定文件的编码方式。如果文件的编码方式与我们指定的编码方式不同,那么就会出现解码错误。为了避免这种情况,我们可以使用errors参数来指定如何处理解码错误。 errors参数用于指定解码…...

STM32 CAN通信-CubeMX环境下CAN通信程序的编程与调试经验
文章目录 STM32 CAN通信-CubeMX环境下CAN通信程序的编程 STM32 CAN通信-CubeMX环境下CAN通信程序的编程 STM32F103ZE芯片 CAN通信测试代码: #include "main.h" #include "can.h"CAN_HandleTypeDef hcan1;void SystemClock_Config(void);int ma…...
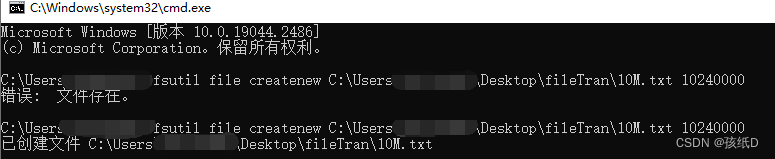
windows创建不同大小的文件命令
打开命令窗口(windowsR输入cmd打开) 输入:fsutil file createnew C:\Users\Desktop\fileTran\10M.txt 10240000,创建10M大小的文件。 文件若存在需要先删除。...

Attention Is All You Need
Attention Is All You Need 摘要1. 简介2. Background3. 模型架构3.1 编码器和解码器堆栈3.2 Attention3.2.1 缩放的点积注意力(Scaled Dot-Product Attention)3.2.2 Multi-Head Attention3.2.3 Attention 在我们模型中的应用 3.3 Position-wise前馈网络…...
手写线程池 - C++版 - 笔记总结
1.线程池原理 创建一个线程,实现很方便。 缺点:若并发的线程数量很多,并且每个线程都是执行一个时间较短的任务就结束了。 由于频繁的创建线程和销毁线程需要时间,这样的频繁创建线程会大大降低 系统的效率。 2.思考 …...

PHP 容器化引发线上 502 错误状态码的修复
最后更新时间 2023-01-24. 背景 笔者所在公司技术栈为 Golang PHP,目前部分项目已经逐步转 Go 语言重构,部分 PHP 业务短时间无法用 Go 重写。 相比 Go 语言,互联网公司常见的 Nginx PHP-FPM 模式,经常会出现性能问题—— 特…...

QT中UDP之UDPsocket通讯
目录 UDP: 举例: 服务器端: 客户端: 使用示例: 错误例子并且改正: UDP: (User Datagram Protocol即用户数据报协议)是一个轻量级的,不可靠的࿰…...

【C语言】10-三大结构之循环结构-1
1. 引言 在日常生活中经常会遇到需要重复处理的问题,例如 统计全班 50 个同学平均成绩的程序求 30 个整数之和检查一个班级的同学程序是否及格要处理以上问题,最原始的方法是分别编写若干个相同或相似的语句或者程序段进行处理 例如:处理 50 个同学的平均成绩可以先计算一个…...

Windows下RocketMQ的启动
下载地址:下载 | RocketMQ 解压后 一、修改runbroker.cmd 修改 bin目录下的runbroker.cmd set "JAVA_OPT%JAVA_OPT% -server -Xms2g -Xmx2g" set "JAVA_OPT%JAVA_OPT% -XX:MaxDirectMemorySize15g" set "JAVA_OPT%JAVA_OPT% -cp %CLASSP…...

linux内核升级 docker+k8s更新显卡驱动
官方驱动 | NVIDIA在此链接下载对应的显卡驱动 # 卸载可能存在的旧版本nvidia驱动(如果没有安装过可跳过,建议执行) sudo apt-get remove --purge nvidia* # 安装驱动需要的依赖 sudo apt-get install dkms build-essential linux-headers-generic sudo vim /etc/mo…...

express学习笔记2 - 三大件概念
中间件 中间件是一个函数,在请求和响应周期中被顺序调用(WARNING:提示:中间件需要在响应结束前被调用) 路由 应用如何响应请求的一种规则 响应 / 路径的 get 请求: app.get(/, function(req, res) {res…...

Steam搬砖蓝海项目
这个项目早在很久之前就已经存在,并且一直非常稳定。如果你玩过一些游戏,你一定知道Steam是什么平台。Steam平台是全球最大的综合性数字发行平台之一,玩家可以在该平台购买、下载、讨论、上传和分享游戏和软件。 今天我给大家解释一下什么是…...

就业并想要长期发展选数字后端还是ic验证?
“就业并想要长期发展选数字后端还是ic验证?” 这是知乎上的一个热点问题,浏览量达到了13,183。看来有不少同学对这个问题感到疑惑。之前更新了数字后端&数字验证的诸多文章,从学习到职业发展,都写过,唯一没有做过…...

X光安检目标识别分割数据集lableme格式2000张5类别
数据集格式:labelme格式(不包含mask文件,仅仅包含jpg图片和对应的json文件)图片数量(jpg文件个数):2000标注数量(json文件个数):2000标注类别数:5标注类别名称:["Electronic Items","Laptop",&quo…...

UWB硬件堆叠 vs 镜像视界无感原生:新质生产力下的定位革命
UWB硬件堆叠 vs 镜像视界无感原生:新质生产力下的定位革命在数字孪生与空间智能加速落地的当下,全域感知技术正经历一场从“物理外挂”到“数字原生”的底层范式变革。长期以来,以UWB(超宽带)为代表的传统定位方案&…...

Adobe-GenP:5分钟解锁Adobe全家桶的终极方案
Adobe-GenP:5分钟解锁Adobe全家桶的终极方案 【免费下载链接】Adobe-GenP Adobe CC 2019/2020/2021/2022/2023 GenP Universal Patch 3.0 项目地址: https://gitcode.com/gh_mirrors/ad/Adobe-GenP 还在为Adobe Creative Cloud的高昂订阅费用发愁吗ÿ…...

掌握3大核心架构:LiveSplit如何为速度跑者提供毫秒级精准计时
掌握3大核心架构:LiveSplit如何为速度跑者提供毫秒级精准计时 【免费下载链接】LiveSplit A sleek, highly customizable timer for speedrunners. 项目地址: https://gitcode.com/gh_mirrors/li/LiveSplit 如果你是一名速度跑者,面对复杂的游戏计…...

台州华声汽车音响改装店推荐,资深玩家都去这几家
在汽车音响改装领域,选择一家靠谱的门店,往往比挑选器材本身更考验车主的眼光。对于追求极致听感的资深玩家而言,改装的成败不仅取决于喇叭、功放等硬件的参数,更在于安装工艺、声学调校与项目统筹能力。近期,笔者深度…...

用USRP B200mini和GNU Radio抓取大疆无人机位置:一个极客的无线安全实验手记
极客实验室:用USRP B200mini破解无人机通信协议实战指南 从零开始的SDR探险 去年夏天的一个傍晚,我在阳台上调试天线时,突然注意到头顶频繁掠过的无人机。这些飞行器究竟在传输什么数据?这个偶然的观察引发了我长达三个月的技术…...

【APP分发系统二开版】app打包一键免IOS免签封包分发平台源码 带绿标
内容目录一、详细介绍二、效果展示1.部分代码2.效果图展示三、学习资料下载一、详细介绍 60gx版APP分发系统在线IOS免签封包分发平台源码免签封装带绿标已对接码支付 这个源码某站卖300,主要是因为他有几个功能比较好。 支持一键IOS在线免签封装。买源码可免费协助…...

yolo11红外光伏板图像识别 光伏板缺陷检测系统
YOLOv11光伏板热缺陷检测系统是一种利用先进的YOLOv11算法进行太阳能光伏板缺陷识别的解决方案。这种系统通常会包含以下几个关键部分: 安装教程 1.安装minconda 2.pycharm 3.安装cuda(11.0)(下载链接:https://develop…...

2026年获客成本飙升?GEO优化让线索成本降低60%
2026年获客成本飙升?GEO优化让线索成本降低60% 摘要 :传统获客方式成本越来越高,百度竞价按点击付费,展会一次花费数万,线索成本难以下降。本文介绍一种新的获客方式——GEO优化,通过AI搜索优化直接触达目标…...

B2B制造业如何利用GEO优化获得精准询盘:实战指南
B2B制造业如何利用GEO优化获得精准询盘:实战指南 摘要 :随着AI搜索渗透率超过85%,B2B制造业的获客逻辑正在被重塑。本文详细介绍GEO(Generative Engine Optimization)优化技术如何帮助工业品、机械配件企业获得精准询盘…...