pytorch学习——如何构建一个神经网络——以手写数字识别为例
目录
一.概念介绍
1.1神经网络核心组件
1.2神经网络结构示意图
1.3使用pytorch构建神经网络的主要工具
二、实现手写数字识别
2.1环境
2.2主要步骤
2.3神经网络结构
2.4准备数据
2.4.1导入模块
2.4.2定义一些超参数
2.4.3下载数据并对数据进行预处理
2.4.4可视化数据集中部分元素
2.4.5构建模型和实例化神经网络
2.4.6训练模型
2.4.7可视化损失函数
2.4.7.1 train loss
2.4.7.2 test loss
一.概念介绍
神经网络是一种计算模型,它模拟了人类神经系统的工作方式,由大量的神经元和它们之间的连接组成。每个神经元接收一些输入信息,并对这些信息进行处理,然后将结果传递给其他神经元。这些神经元之间的连接具有不同的权重,这些权重可以根据神经网络的训练数据进行调整。通过调整权重,神经网络可以对输入数据进行分类、回归、聚类等任务。
通俗来讲,神经网络就是设置一堆参数,初始化这堆参数,然后通过求导,知道这些参数对结果的影响,然后调整这些参数的大小。直到参数大小可以接近完美地拟合实际结果。神经网络有两个部分:正向传播和反向传播。正向传播是求值,反向传播是求出参数对结果的影响,从而调整参数。所以,神经网络:正向传播->反向传播->正向传播->反向传播……
比如我们要预测一个图像是不是猫。如果是猫,它的结果就是1,如果不是猫,它的结果就是0.我们现在有一堆图片,有的是猫,有的不是猫,所以它对应的标签(这个是y)是:0 1 1 0 1。而我们的预测结果可能是对的,也可能是错的,假设我们的预测结果是:0 0 1 1 0.我们有3个预测对了,有2个预测错了。那么我们的损失值是2/5。当然这么搞的话太“粗糙”了,实际上我们会有一个函数来定义损失值是什么。而且我们的预测结果也不是一个确凿的数字,而是一个概率:比如我们预测第3张图片是猫的概率是0.8,那么我们的预测结果是0.8.总之,定义了损失值(这个损失值记为J)以后,我们要让这个损失值尽可能地小。
参考:什么是神经网络? - 绯红之刃的回答 - 知乎
1.1神经网络核心组件
神经网络看上去挺复杂,节点多,层多,参数多,但其结构都是类似的,核心部分和组件都是相通的,确定完这些核心组件,这个神经网络也就基本确定了。
核心组件包括:
(1)层:神经网络的基础数据结构是层,层是一个数据处理模块,它接受一个或多个张量作为输入,并输出一个或多个张量,由一组可调整参数描述。
(2)模型:模型是由多个层组成的网络,用于对输入数据进行分类、回归、聚类等任务。
(3)损失函数:参数学习的目标函数,通过最小化损失函数来学习各种参数。损失函数是衡量模型输出结果与真实标签之间的差异的函数,目标是最小化损失函数,提高模型性能。
(4)优化器:使损失函数的值最小化。根据损失函数的梯度更新神经网络中的权重和偏置,以使损失函数的值最小化,提高模型性能和稳定性。
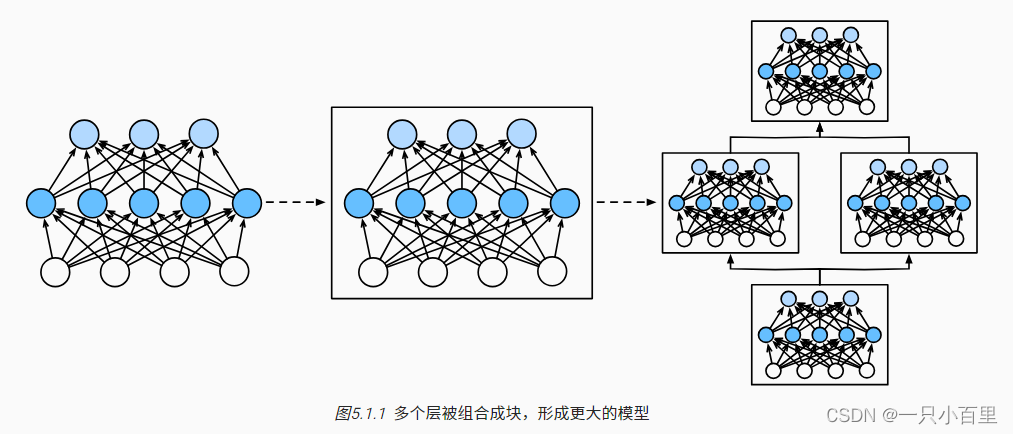
1.2神经网络结构示意图
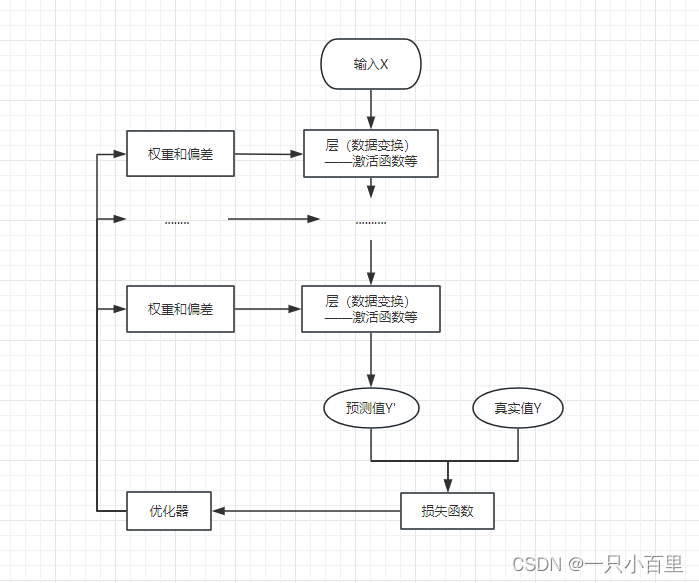
描述:多个层链接在一起构成一个模型或网络,输入数据通过这个模型转换为预测值,然后损失函数把预测值与真实值进行比较,得到损失值(损失值可以是距离、概率值等),该损失值用于衡量预测值与目标结果的匹配或相似程度,优化器利用损失值更新权重参数,从而使损失值越来越小。这是一个循环过程,损失值达到一个阀值或循环次数到达指定次数,循环结束。
1.3使用pytorch构建神经网络的主要工具

参考:第3章 Pytorch神经网络工具箱 | Python技术交流与分享
在PyTorch中,构建神经网络主要使用以下工具:
-
torch.nn模块:提供了构建神经网络所需的各种层和模块,如全连接层、卷积层、池化层、循环神经网络等。
-
torch.nn.functional模块:提供了一些常用的激活函数和损失函数,如ReLU、Sigmoid、CrossEntropyLoss等。
-
torch.optim模块:提供了各种优化器,如SGD、Adam、RMSprop等,用于更新神经网络中的权重和偏置。
-
torch.utils.data模块:提供了处理数据集的工具,如Dataset、DataLoader等,可以方便地处理数据集、进行批量训练等操作。
这些工具之间的相互关系如下:
-
使用torch.nn模块构建神经网络的各个层和模块。
-
使用torch.nn.functional模块中的激活函数和损失函数对神经网络进行非线性变换和优化。
-
使用torch.optim模块中的优化器对神经网络中的权重和偏置进行更新,以最小化损失函数。
-
使用torch.utils.data模块中的数据处理工具对数据集进行处理,方便地进行批量训练和数据预处理。
二、实现手写数字识别
2.1环境
实例环境使用Pytorch1.0+,GPU或CPU,源数据集为MNIST。
2.2主要步骤
(1)利用Pytorch内置函数mnist下载数据
(2)利用torchvision对数据进行预处理,调用torch.utils建立一个数据迭代器
(3)可视化源数据
(4)利用nn工具箱构建神经网络模型
(5)实例化模型,并定义损失函数及优化器
(6)训练模型
(7)可视化结果
2.3神经网络结构

实验中使用两个隐含层,每层激活函数为Relu,最后使用torch.max(out,1)找出张量out最大值对应索引作为预测值。
2.4准备数据
2.4.1导入模块
import numpy as np
import torch
# 导入 pytorch 内置的 mnist 数据
from torchvision.datasets import mnist
#导入预处理模块
import torchvision.transforms as transforms
from torch.utils.data import DataLoader
#导入nn及优化器
import torch.nn.functional as F
import torch.optim as optim
from torch import nn2.4.2定义一些超参数
# 定义训练和测试时的批处理大小
train_batch_size = 64
test_batch_size = 128# 定义学习率和迭代次数
learning_rate = 0.01
num_epoches = 20# 定义优化器的超参数
lr = 0.01
momentum = 0.5
#动量优化器通过引入动量参数(Momentum),在更新参数时考虑之前的梯度信息,可以使得参数更新方向更加稳定,同时加速梯度下降的收敛速度。动量参数通常设置在0.5到0.9之间,可以根据具体情况进行调整。2.4.3下载数据并对数据进行预处理
#定义预处理函数,这些预处理依次放在Compose函数中。
transform = transforms.Compose([transforms.ToTensor(),transforms.Normalize([0.5], [0.5])])
#下载数据,并对数据进行预处理
train_dataset = mnist.MNIST('./data', train=True, transform=transform, download=True)
test_dataset = mnist.MNIST('./data', train=False, transform=transform)
#dataloader是一个可迭代对象,可以使用迭代器一样使用。
train_loader = DataLoader(train_dataset, batch_size=train_batch_size, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=test_batch_size, shuffle=False)注:
①transforms.Compose可以把一些转换函数组合在一起;
②Normalize([0.5], [0.5])对张量进行归一化,这里两个0.5分别表示对张量进行归一化的全局平均值和方差。因图像是灰色的只有一个通道,如果有多个通道,需要有多个数字,如三个通道,应该是Normalize([m1,m2,m3], [n1,n2,n3])
③download参数控制是否需要下载,如果./data目录下已有MNIST,可选择False。
④用DataLoader得到生成器,这可节省内存。
2.4.4可视化数据集中部分元素
# 导入matplotlib.pyplot库,并设置inline模式
import matplotlib.pyplot as plt
%matplotlib inline# 枚举数据加载器中的一批数据
examples = enumerate(test_loader)
batch_idx, (example_data, example_targets) = next(examples)# 创建一个图像对象
fig = plt.figure()# 显示前6个图像和对应的标签
for i in range(6):plt.subplot(2,3,i+1) # 将图像分成2行3列,当前位置为第i+1个plt.tight_layout() # 自动调整子图之间的间距plt.imshow(example_data[i][0], cmap='gray', interpolation='none') # 显示图像plt.title("Ground Truth: {}".format(example_targets[i])) # 显示标签plt.xticks([]) # 隐藏x轴刻度plt.yticks([]) # 隐藏y轴刻度注:
-
导入matplotlib.pyplot库,并设置inline模式,以在Jupyter Notebook中显示图像。
-
枚举数据加载器中的一批数据,其中test_loader是一个测试数据集加载器。
-
创建一个图像对象,用于显示图像和标签。
-
显示前6个图像和对应的标签,其中plt.subplot()用于将图像分成2行3列,plt.tight_layout()用于自动调整子图之间的间距,plt.imshow()用于显示图像,plt.title()用于显示标签,plt.xticks()和plt.yticks()用于隐藏x轴和y轴的刻度。
2.4.5构建模型和实例化神经网络
class Net(nn.Module):"""使用sequential构建网络,Sequential()函数的功能是将网络的层组合到一起"""def __init__(self, in_dim, n_hidden_1, n_hidden_2, out_dim):super(Net, self).__init__()self.layer1 = nn.Sequential(nn.Linear(in_dim, n_hidden_1),nn.BatchNorm1d(n_hidden_1))self.layer2 = nn.Sequential(nn.Linear(n_hidden_1, n_hidden_2),nn.BatchNorm1d(n_hidden_2))self.layer3 = nn.Sequential(nn.Linear(n_hidden_2, out_dim))def forward(self, x):x = F.relu(self.layer1(x))x = F.relu(self.layer2(x))x = self.layer3(x)return x#检测是否有可用的GPU,有则使用,否则使用CPU
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
#实例化网络
model = Net(28 * 28, 300, 100, 10)
model.to(device)# 定义损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=lr, momentum=momentum)
2.4.6训练模型
# 开始训练
losses = []
acces = []
eval_losses = []
eval_acces = []for epoch in range(num_epoches):train_loss = 0train_acc = 0model.train()#动态修改参数学习率if epoch%5==0:optimizer.param_groups[0]['lr']*=0.1for img, label in train_loader:img=img.to(device)label = label.to(device)img = img.view(img.size(0), -1)# 前向传播out = model(img)loss = criterion(out, label)# 反向传播optimizer.zero_grad()loss.backward()optimizer.step()# 记录误差train_loss += loss.item()# 计算分类的准确率_, pred = out.max(1)num_correct = (pred == label).sum().item()acc = num_correct / img.shape[0]train_acc += acclosses.append(train_loss / len(train_loader))acces.append(train_acc / len(train_loader))# 在测试集上检验效果eval_loss = 0eval_acc = 0# 将模型改为预测模式model.eval()for img, label in test_loader:img=img.to(device)label = label.to(device)img = img.view(img.size(0), -1)out = model(img)loss = criterion(out, label)# 记录误差eval_loss += loss.item()# 记录准确率_, pred = out.max(1)num_correct = (pred == label).sum().item()acc = num_correct / img.shape[0]eval_acc += acceval_losses.append(eval_loss / len(test_loader))eval_acces.append(eval_acc / len(test_loader))print('epoch: {}, Train Loss: {:.4f}, Train Acc: {:.4f}, Test Loss: {:.4f}, Test Acc: {:.4f}'.format(epoch, train_loss / len(train_loader), train_acc / len(train_loader), eval_loss / len(test_loader), eval_acc / len(test_loader)))2.4.7可视化损失函数
2.4.7.1 train loss
plt.title('train loss')
plt.plot(np.arange(len(losses)), losses)
plt.legend(['Train Loss'], loc='upper right')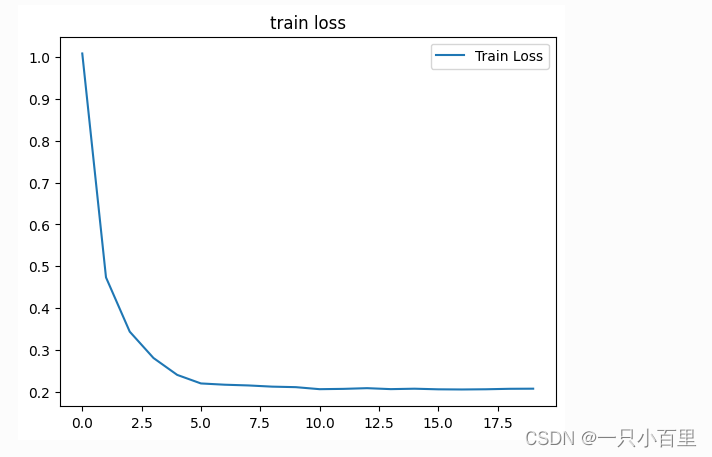
2.4.7.2 test loss
# 绘制测试集损失函数
plt.plot(eval_losses, label='Test Loss')
plt.title('Test Loss')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.legend()
plt.show()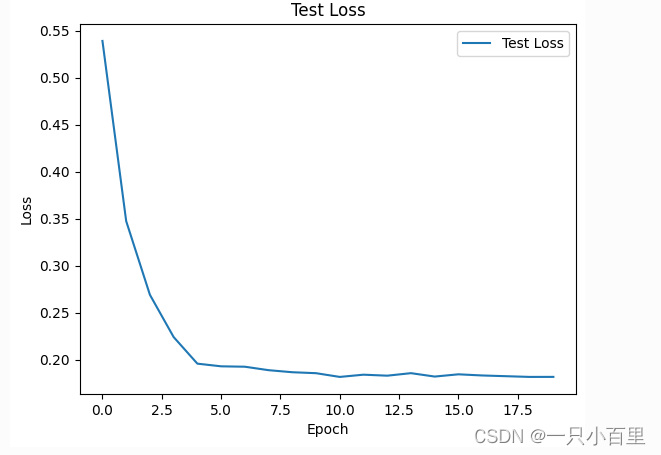
相关文章:
pytorch学习——如何构建一个神经网络——以手写数字识别为例
目录 一.概念介绍 1.1神经网络核心组件 1.2神经网络结构示意图 1.3使用pytorch构建神经网络的主要工具 二、实现手写数字识别 2.1环境 2.2主要步骤 2.3神经网络结构 2.4准备数据 2.4.1导入模块 2.4.2定义一些超参数 2.4.3下载数据并对数据进行预处理 2.4.4可视化数…...
PySpark 数据操作
数据输入 RDD对象 如图可见,PySpark支持多种数据的输入,在输入完成后,都会得到一个:RDD类的对象 RDD全称为:弹性分布式数据集(Resilient Distributed Datasets) PySpark针对数据的处理&…...

FPGA2-采集OV5640乒乓缓存后经USB3.0发送到上位机显示
1.场景 基于特权A7系列开发板,采用OV5640摄像头实时采集图像数据,并将其经过USB3.0传输到上位机显示。这是验证数据流能力的很好的项目。其中,用到的软件版本,如下表所示,基本的硬件情况如下。该项目对应FPGA工程源码…...

亚信科技AntDB数据库专家参加向量数据库首次技术标准研讨会
2023年7月19日下午,中国通信标准化协会大数据技术标准推进委员会数据库与存储工作组(CCSA TC601 WG4)联合中国信通院数据库应用创新实验室(CAICT DBL)在线上召开《向量数据库技术要求》标准首次研讨会。本次会议由中国…...

Windows中实现右键把电子书通过邮件发到kindle
不使用第三方软件,通过Windows自带的函数,可以实现右键将电子书通过电子邮件发送到kindle邮箱,从而实现kindle电子书传送功能。实现过程如下: 1. 使用bat添加右键功能 打开资源管理器,在地址中输入%APPDATA%\Microso…...

Three.js之创建3D场景
参考资料 【G】Three.js官方文档:https://threejs.org/docs/ Three.js是一个流行的WebGL库,官方文档提供了详细的API参考和示例,适合学习和参考。【G】Three.js GitHub链接:https://github.com/mrdoob/three.js 这是一个流行的基…...
一个3年Android的找工作记录
作者:Petterp 这是我最近 1个月 的找工作记录,希望这些经历对你会有所帮助。 有时机会就像一阵风,如果没有握住,那下一阵风什么时候吹来,往往是个运气问题。 写在开始 先说背景: 自考本,3年经验࿰…...

CAS原理解析
CAS是一种乐观锁机制,一种比较并交换的过程和理念,用来解决线程安全问题,具体来讲就是对共享变量值的安全更新机制。能够保证原子、可见、一致性。这种交换过程是在Unsafe类中实现。 从一段简单的代码开始来对源码做分析 public static void…...
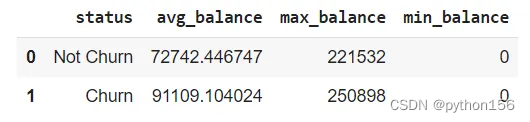
SQL项目实战:银行客户分析
大家好,本文将与大家分享一个SQL项目,即根据从数据集收集到的信息分析银行客户流失的可能性。这些洞察来自个人信息,如年龄、性别、收入和人口统计信息、银行卡类型、产品、客户信用评分以及客户在银行的服务时间长短等。对于银行而言&#x…...
)
【Redis深度专题】「核心技术提升」探究Redis服务启动的过程机制的技术原理和流程分析的指南(集群指令分析—实战篇)
探究Redis服务启动的过程机制的技术原理和流程分析的指南(集群指令分析—下篇) Cluster XX的集群指令(扩展)写入记录主节点和备节点切换-CLUSTER FAILOVER新加入master节点新加入slave节点为slave节点重新分配master分配哈希槽删除…...

ubuntu
安装 sudo apt-get update sudo apt-get install mysql-server mysql-client 设置root密码 cat /etc/mysql/debian.cnf 查看默认密码 mysql -u debian-sys-maint -p 连接输入密码 use mysql; select user,plugin from user; update user set pluginmysql_native_passwor…...
【芯片设计- RTL 数字逻辑设计入门 3- Verdi 常用使用命令】
文章目录 Verdi 全局显示Verdi 前导 0 的显示Verdi 数据笔数统计Verdi 波形数据dump Verdi 全局显示 bsubi -n 16 -J sam visualizer -tracedir ./veloce.wave/debug_waveform.stw 打开波形后,如果想要看到所有信号的数据,可以点击下图中红框中的按钮&a…...
python-pytorch基础之cifar10数据集使用图片分类
这里写目录标题 总体思路获取数据集下载cifar10数据解压包文件介绍加载图片数字化信息查看数据信息数据读取自定义dataset使用loader加载建模训练测试建测试数据的loader测试准确性测试一张图片读取一张图片加载模型预测图片类型创建一个预测函数随便来张马的图片结果其他打开一…...

华纳云:linux下磁盘管理与挂载硬盘方法是什么
在Linux下进行磁盘管理和挂载硬盘的方法如下: 磁盘管理: a. 查看已连接的磁盘:可以使用命令 fdisk -l 或 lsblk 查看系统中已连接的磁盘信息,包括硬盘和分区。 b. 创建分区:如果磁盘是全新的,需要使用 f…...

ChatGPT + Stable Diffusion + 百度AI + MoviePy 实现文字生成视频,小说转视频,自媒体神器!(一)
ChatGPT Stable Diffusion 百度AI MoviePy 实现文字生成视频,小说转视频,自媒体神器!(一) 前言 最近大模型频出,但是对于我们普通人来说,如何使用这些AI工具来辅助我们的工作呢,或者参与进入我们的生活…...

linux strcpy/strncpy/sprintf内存溢出问题
本文主要介绍strcpy/strncpy/sprintf都是不安全的,可能存在内存溢出的问题。下来进行实例分析。 strcpy代码: #include <stdio.h> #include <string.h> #include <stdlib.h> #include <stdbool.h>void test_func(char *str) {b…...
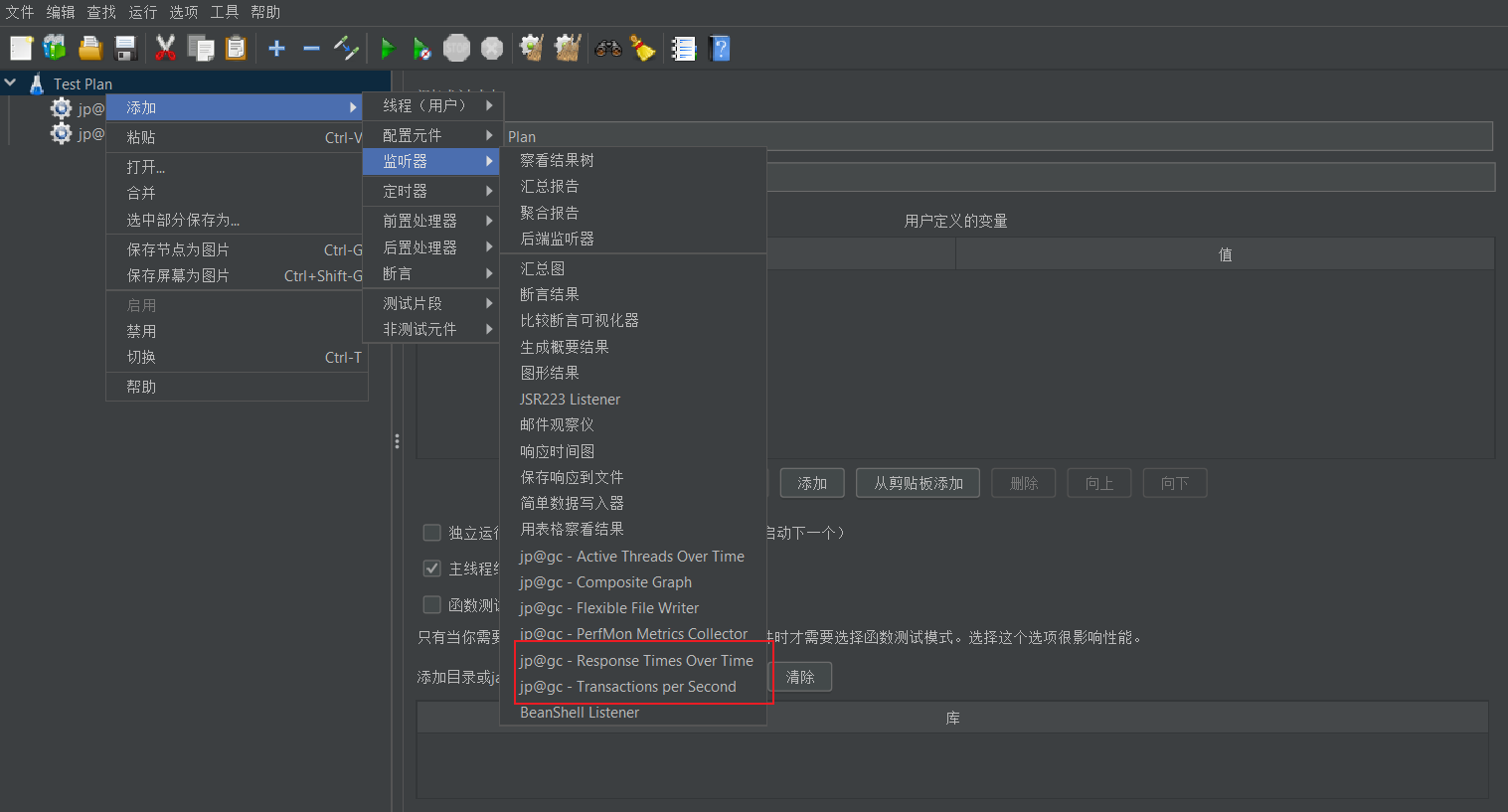
Jmeter如何添加插件
一、前言 在我们的工作中,我们可以利用一些插件来帮助我们更好的进行性能测试。今天我们来介绍下Jmeter怎么添加插件? 2023最新Jmeter接口测试从入门到精通(全套项目实战教程) 二、插件管理器 首先我们需要下载插件管理器j…...

flask---CBV使用和源码分析
1 cbv写法 -1 写个类,继承MethodView-2 在类中写跟请求方式同名的方法-3 注册路由:app.add_url_rule(/home, view_funcHome.as_view(home))#home是endpoint,就是路由别名#例子 class add(MethodView):def get(self):return holleapp.add_url…...

Qt 实现压缩文件、文件夹和解压缩操作zip
一、实现方式 通过Qt自带的库来实现,使用多线程方式,通过信号和槽来触发压缩与解压缩,并将压缩和解压缩结果回传过来。 使用的类: #include "QtGui/private/qzipreader_p.h" #include "QtGui/private/qzipwriter…...
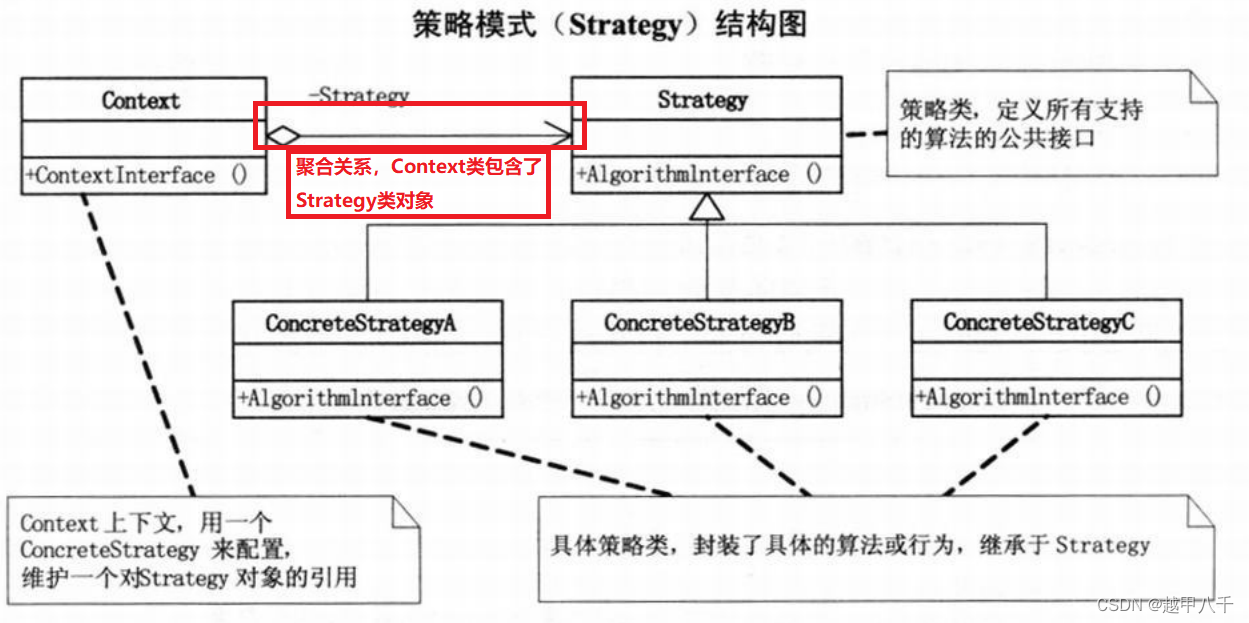
简单工厂模式VS策略模式
简单工厂模式VS策略模式 今天复习设计模式,由于简单工厂模式和策略模式太像了,重新整理梳理一下 简单工厂模式MUL图: 策略模式UML图: 1、简单工厂模式中只管创建实例,具体怎么使用工厂实例由调用方决定,…...

如何扩展Noisereduce:自定义降噪算法的开发指南
如何扩展Noisereduce:自定义降噪算法的开发指南 【免费下载链接】noisereduce Noise reduction in python using spectral gating (speech, bioacoustics, audio, time-domain signals) 项目地址: https://gitcode.com/gh_mirrors/no/noisereduce Noisereduc…...
)
Zabbix 7.0 在 Ubuntu 上启用中文界面语言(zh_CN)
Zabbix 7.0 配置中文选项(zh_CN) 适用于 Zabbix 7.0 系统默认情况下语言文件不包含中文的情况。环境说明 Zabbix 版本:7.0.15(LTS)问题现象 Language 下拉框中 Chinese (zh_CN) 是灰色不可选;原因是系统未安…...
深度解析TranslucentTB运行时依赖问题的创新解决方案
深度解析TranslucentTB运行时依赖问题的创新解决方案 【免费下载链接】TranslucentTB A lightweight utility that makes the Windows taskbar translucent/transparent. 项目地址: https://gitcode.com/gh_mirrors/tr/TranslucentTB TranslucentTB是一款广受欢迎的Wind…...

被AI冲击的App,反成了Agent的命门
2026年最流行的一个判断:AI Agent要吃掉一切图形界面,对话即服务,App即将消亡。 这个判断的依据并非没有道理。Agent确实在接管"发现"和"调度"——用户不再需要主动打开某个App,而是告诉Agent"帮我订一…...

昇腾CANN shmem:把多张 NPU 的 HBM 变成一块全局内存
hccl 的通信模型是消息传递——发送方调 send,接收方调 recv,两边同步。hixl 的模型是单边推送——发送方调 put,接收方不用参与。shmem 是第三种模型:PGAS(Partitioned Global Address Space),…...

不止于仿真:用MATLAB分析OFDM-QPSK系统抗噪声性能,这张误码率曲线图能告诉你什么?
从误码率曲线到系统优化:MATLAB深度解析OFDM-QPSK抗噪性能 在无线通信系统的设计与评估中,仿真分析是不可或缺的一环。当我们完成基础OFDM-QPSK系统的搭建后,如何从仿真结果中提取有价值的信息,进而指导系统优化?本文…...

有这5个迹象,说明你公司内斗很严重!
见字如面,我是军哥!昨天,一位读者小王给我留言。他在某大厂担任项目经理,最近工作推进得很艰难。同一件事开了好几次会,领导就是不拍板。跨部门协作费力不讨好,谁都不愿负责,项目卡在那里没有进…...
)
【Perplexity词组搭配查询权威基准测试】:覆盖医学/法律/工程三大垂直领域,17项指标碾压传统n-gram方法(数据已通过ACL评审)
更多请点击: https://intelliparadigm.com 第一章:Perplexity词组搭配查询权威基准测试概览 Perplexity(困惑度)作为衡量语言模型预测能力的核心指标,其在词组搭配(collocation)查询任务中的表…...

3个实战场景掌握Kafka-UI:高效管理Apache Kafka集群的实用指南
3个实战场景掌握Kafka-UI:高效管理Apache Kafka集群的实用指南 【免费下载链接】kafka-ui Open-Source Web UI for managing Apache Kafka clusters 项目地址: https://gitcode.com/gh_mirrors/kaf/kafka-ui Kafka-UI是一款专业的开源Web界面工具,…...

Taotoken控制台提供的API Key管理与访问控制功能详解
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken控制台提供的API Key管理与访问控制功能详解 对于团队管理者或项目负责人而言,如何安全、高效地分发和管理大模…...