PySpark 数据操作
数据输入
RDD对象
如图可见,PySpark支持多种数据的输入,在输入完成后,都会得到一个:RDD类的对象
RDD全称为:弹性分布式数据集(Resilient Distributed Datasets)
PySpark针对数据的处理,都是以RDD对象作为载体,即:
- 数据存储在RDD内
- 各类数据的计算方法,也都是RDD的成员方法
- RDD的数据计算方法,返回值依旧是RDD对象
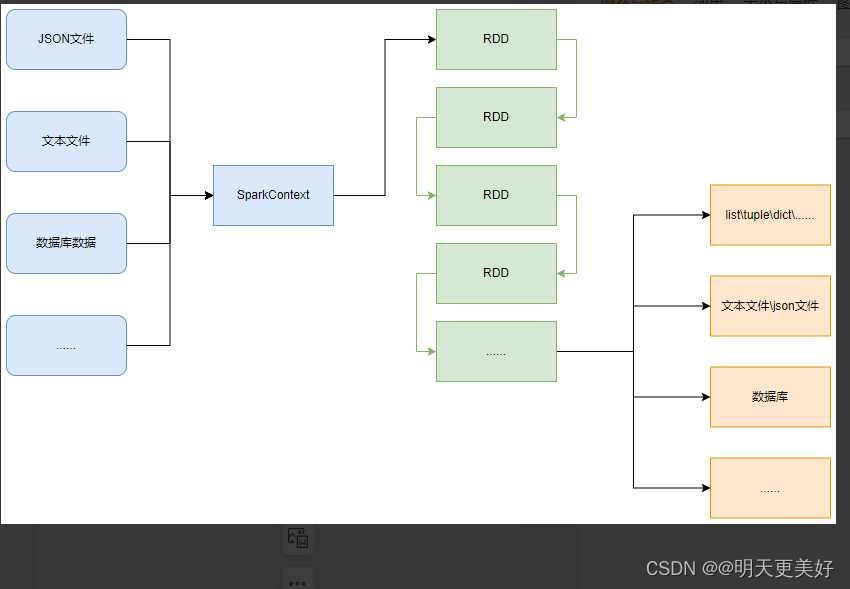
PySpark的编程模型(上图)可以归纳为:
- 准备数据到RDD -> RDD迭代计算 -> RDD导出为list、文本文件等
- 即:源数据 -> RDD -> 结果数据
Python数据容器转RDD对象
PySpark支持通过SparkContext对象的parallelize成员方法,将:
- list
- tuple
- set
- dict
- str
转换为PySpark的RDD对象
注意:
- 字符串会被拆分出1个个的字符,存入RDD对象
- 字典仅有key会被存入RDD对象
读取文件转RDD对象
PySpark也支持通过SparkContext入口对象,来读取文件,来构建出RDD对象。
总结:
1. RDD对象是什么?为什么要使用它?
RDD对象称之为分布式弹性数据集,是PySpark中数据计算的载体,它可以:
- 提供数据存储
- 提供数据计算的各类方法
- 数据计算的方法,返回值依旧是RDD(RDD迭代计算)
后续对数据进行各类计算,都是基于RDD对象进行
2. 如何输入数据到Spark(即得到RDD对象)
- 通过SparkContext的parallelize成员方法,将Python数据容器转换为RDD对象
- 通过SparkContext的textFile成员方法,读取文本文件得到RDD对象
数据计算
map方法
PySpark的数据计算,都是基于RDD对象来进行的,那么如何进行呢?
自然是依赖,RDD对象内置丰富的:成员方法(算子)

语法:

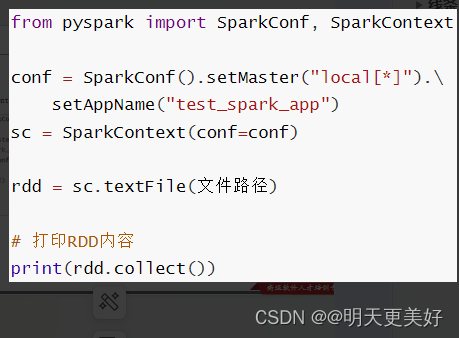
"""演示PySpark代码加载数据即数据输入
"""
from pyspark import SparkConf, SparkContextconf = SparkConf().setMaster("local[*]").setAppName("test_spark")
sc = SparkContext(conf=conf)# # 通过parallelize方法将Python对象加载到Spark内,成为RDD对象
rdd1 = sc.parallelize([1, 2, 3, 4, 5])
rdd2 = sc.parallelize((1, 2, 3, 4, 5))
rdd3 = sc.parallelize("abcdefg")
rdd4 = sc.parallelize({1, 2, 3, 4, 5})
rdd5 = sc.parallelize({"key1": "value1", "key2": "value2", "key3": "value3"})# # 如果要查看RDD里边有什么内容,需要用collect()方法
print(rdd1.collect())
print(rdd2.collect())
print(rdd3.collect())
print(rdd4.collect())
print(rdd5.collect())
# 用过textFile方法,读取文件数据加载到Spark内,成为RDD对象
rdd = sc.textFile("E:/百度网盘/1、Python快速入门(8天零基础入门到精通)/资料/第15章资料/资料/hello.txt")
print(rdd.collect())
sc.stop()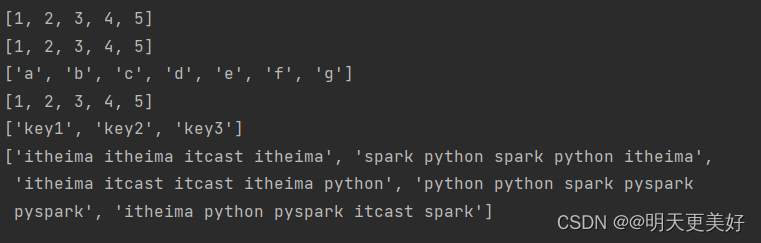
总结:
1. map算子(成员方法)
- 接受一个处理函数,可用lambda表达式快速编写
- 对RDD内的元素逐个处理,并返回一个新的RDD
2. 链式调用
- 对于返回值是新RDD的算子,可以通过链式调用的方式多次调用算子。
flatMap方法
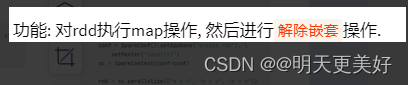

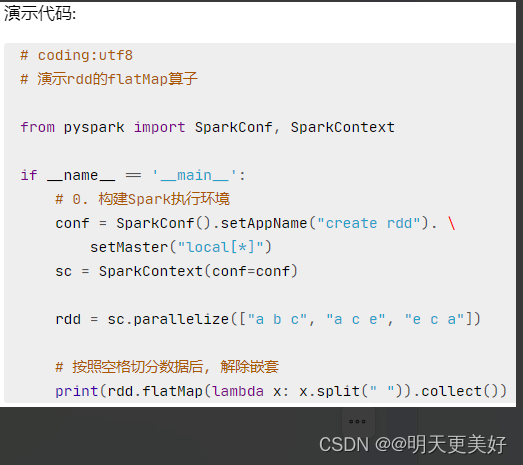

总结
flatMap算子
- 计算逻辑和map一样
- 可以比map多出,解除一层嵌套的功能
reduceByKey方法




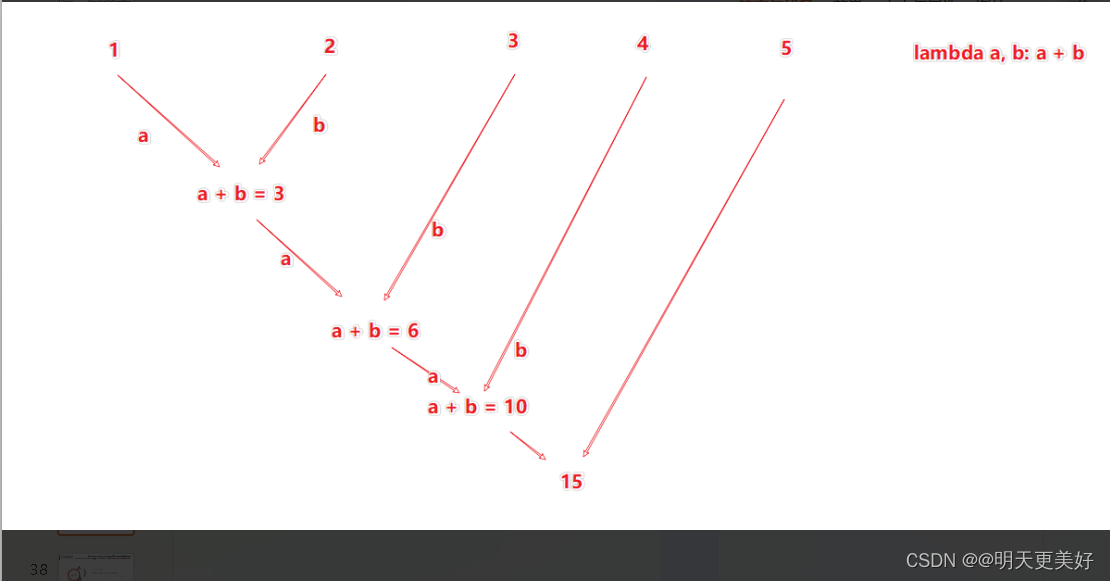
"""
PySpark代码加载数据reduceByKey方法
针对KV型 RDD
自动按照key分组,然后根据你提供的聚合逻辑完成组内数(value)的聚合操作.二元元祖
"""from pyspark import SparkConf, SparkContext
# 配置Python解释器
import os
os.environ['PYSPARK_PYTHON'] = "D:/Python/Python311/python.exe"conf = SparkConf().setMaster("local[*]").setAppName("test_spark")
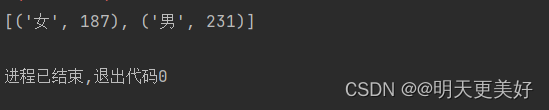
sc = SparkContext(conf=conf)rdd = sc.parallelize([('男', 99), ('女', 88),('女',99), ('男',77), ('男', 55)])
# 需求,求男生和女生俩个组的成绩之和
rdd2 = rdd.reduceByKey(lambda a, b: a + b)
print(rdd2.collect())
总结:
reduceByKey算子
- 接受一个处理函数,对数据进行两两计算

练习案例1
WordCount案例
使用学习到的内容,完成:
- 读取文件
- 统计文件内,单词的出现数量
hello.txt
itheima itheima itcast itheima
spark python spark python itheima
itheima itcast itcast itheima python
python python spark pyspark pyspark
itheima python pyspark itcast spark
"""
完成练习案例:单词计数统计
"""
# 1.构建执行环境入口对象
from pyspark import SparkConf, SparkContext
import os
os.environ['PYSPARK_PYTHON'] = "D:/Python/Python311/python.exe"
conf = SparkConf().setMaster("local[*]").setAppName("test_spark")
sc = SparkContext(conf=conf)
# 2.读取数据
rdd = sc.textFile("E:/百度网盘/1、Python快速入门(8天零基础入门到精通)/资料/第15章资料/资料/hello.txt")
# 3.取出全部单词
wor_rdd = rdd.flatMap(lambda a: a.split(" "))
# print(wor_rdd.collect())
# 4.将所有单词都转换成二元元组,单词为key,Value设置为1
word_with_one_rdd = wor_rdd.map(lambda word: (word, 1))
# print(word_with_one_rdd.collect())
# 5.分组并求和
result = word_with_one_rdd.reduceByKey(lambda a, b: a + b)
# 6.打印输出结果
print(result.collect())结果:
[('python', 6), ('itheima', 7), ('itcast', 4), ('spark', 4), ('pyspark', 3)]
filter方法
功能:过滤想要的数据进行保留

"""
PySpark代码加载数据Filter方法
"""
from pyspark import SparkConf, SparkContext
# 配置Python解释器
import osos.environ['PYSPARK_PYTHON'] = "D:/Python/Python311/python.exe"
conf = SparkConf().setMaster("local[*]").setAppName("test_spark")
sc = SparkContext(conf=conf)# 准备一个RDD
rdd = sc.parallelize([1, 2, 3, 4, 5, 6, 7])
# 对RDD的数据进行过滤
rdd2 = rdd.filter(lambda num: num % 2 == 0) # 整数返回true 奇数返回falseprint(rdd2.collect())结果:
[2, 4, 6]总结:
filter算子
- 接受一个处理函数,可用lambda快速编写
- 函数对RDD数据逐个处理,得到True的保留至返回值的RDD中
distinct方法
功能:对RDD数据进行去重,返回新的RDD
语法:
rdd.distinct() 无需传参
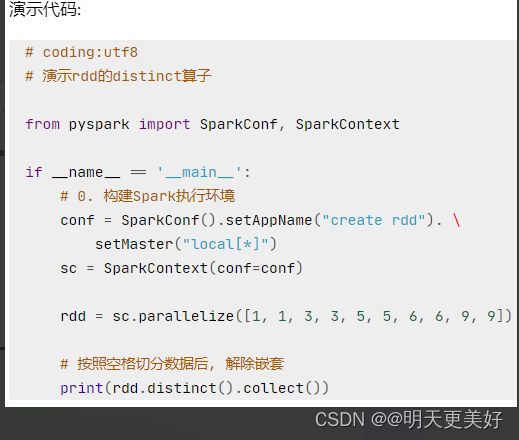
"""
PySpark代码加载数据distinct方法
去重 无需传参
"""
from pyspark import SparkConf, SparkContext
# 配置Python解释器
import osos.environ['PYSPARK_PYTHON'] = "D:/Python/Python311/python.exe"
conf = SparkConf().setMaster("local[*]").setAppName("test_spark")
sc = SparkContext(conf=conf)# 准备一个RDD
rdd = sc.parallelize([1, 1, 2, 3, 3, 3, 5, 6, 7, 7, 7, 7, 7])
# 对RDD的数据进行去重
rdd2 = rdd.distinct()
print(rdd2.collect())结果:
[1, 2, 3, 5, 6, 7]
总结:
distinct算子
- 完成对RDD内数据的去重操作
sortBy方法
功能:对RDD数据进行排序,基于你指定的排序依据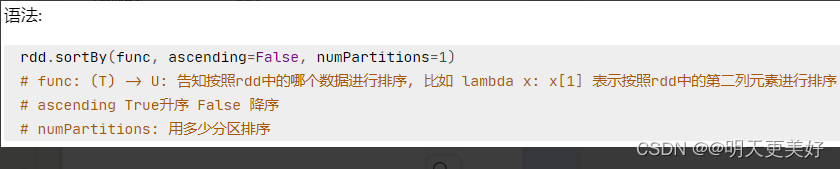
"""
PySpark代码加载数据sortBy方法
排序
语法:
rdd.sortBy(func,ascending=False, numPartitions=1)
# func:(T)U:告知按照rdd中的哪个数据进行排序,
比如lambda x:x[1]表示按照rdd中的第二列元素进行排序
# ascending True升序 False降序
# numPartitions:用多少分区排序
"""
# 1.构建执行环境入口对象
from pyspark import SparkConf, SparkContext
import os
os.environ['PYSPARK_PYTHON'] = "D:/Python/Python311/python.exe"
conf = SparkConf().setMaster("local[*]").setAppName("test_spark")
sc = SparkContext(conf=conf)
# 2.读取数据
rdd = sc.textFile("E:/百度网盘/1、Python快速入门(8天零基础入门到精通)/资料/第15章资料/资料/hello.txt")
# 3.取出全部单词
wor_rdd = rdd.flatMap(lambda a: a.split(" "))
# 4.将所有单词都转换成二元元组,单词为key,Value设置为1
word_with_one_rdd = wor_rdd.map(lambda word: (word, 1))
# 5.分组并求和
result = word_with_one_rdd.reduceByKey(lambda a, b: a + b)
# 6.打印输出结果
print(result.collect())
# 7.对结果进行排序
a = result.sortBy(lambda x: x[1], ascending=False, numPartitions=1) # 降序
print(a.collect())b = result.sortBy(lambda x: x[1], ascending=True, numPartitions=1) # 升序
print(b.collect())结果:
[('python', 6), ('itheima', 7), ('itcast', 4), ('spark', 4), ('pyspark', 3)]
[('itheima', 7), ('python', 6), ('itcast', 4), ('spark', 4), ('pyspark', 3)]
[('pyspark', 3), ('itcast', 4), ('spark', 4), ('python', 6), ('itheima', 7)]
总结:
sortBy算子
- 接收一个处理函数,可用lambda快速编写
- 函数表示用来决定排序的依据
- 可以控制升序或降序
- 全局排序需要设置分区数为1
练习案例2
案例
{"id":1,"timestamp":"2019-05-08T01:03.00Z","category":"平板电脑","areaName":"北京","money":"1450"}|{"id":2,"timestamp":"2019-05-08T01:01.00Z","category":"手机","areaName":"北京","money":"1450"}|{"id":3,"timestamp":"2019-05-08T01:03.00Z","category":"手机","areaName":"北京","money":"8412"} {"id":4,"timestamp":"2019-05-08T05:01.00Z","category":"电脑","areaName":"上海","money":"1513"}|{"id":5,"timestamp":"2019-05-08T01:03.00Z","category":"家电","areaName":"北京","money":"1550"}|{"id":6,"timestamp":"2019-05-08T01:01.00Z","category":"电脑","areaName":"杭州","money":"1550"} {"id":7,"timestamp":"2019-05-08T01:03.00Z","category":"电脑","areaName":"北京","money":"5611"}|{"id":8,"timestamp":"2019-05-08T03:01.00Z","category":"家电","areaName":"北京","money":"4410"}|{"id":9,"timestamp":"2019-05-08T01:03.00Z","category":"家具","areaName":"郑州","money":"1120"} {"id":10,"timestamp":"2019-05-08T01:01.00Z","category":"家具","areaName":"北京","money":"6661"}|{"id":11,"timestamp":"2019-05-08T05:03.00Z","category":"家具","areaName":"杭州","money":"1230"}|{"id":12,"timestamp":"2019-05-08T01:01.00Z","category":"书籍","areaName":"北京","money":"5550"} {"id":13,"timestamp":"2019-05-08T01:03.00Z","category":"书籍","areaName":"北京","money":"5550"}|{"id":14,"timestamp":"2019-05-08T01:01.00Z","category":"电脑","areaName":"北京","money":"1261"}|{"id":15,"timestamp":"2019-05-08T03:03.00Z","category":"电脑","areaName":"杭州","money":"6660"} {"id":16,"timestamp":"2019-05-08T01:01.00Z","category":"电脑","areaName":"天津","money":"6660"}|{"id":17,"timestamp":"2019-05-08T01:03.00Z","category":"书籍","areaName":"北京","money":"9000"}|{"id":18,"timestamp":"2019-05-08T05:01.00Z","category":"书籍","areaName":"北京","money":"1230"} {"id":19,"timestamp":"2019-05-08T01:03.00Z","category":"电脑","areaName":"杭州","money":"5551"}|{"id":20,"timestamp":"2019-05-08T01:01.00Z","category":"电脑","areaName":"北京","money":"2450"} {"id":21,"timestamp":"2019-05-08T01:03.00Z","category":"食品","areaName":"北京","money":"5520"}|{"id":22,"timestamp":"2019-05-08T01:01.00Z","category":"食品","areaName":"北京","money":"6650"} {"id":23,"timestamp":"2019-05-08T01:03.00Z","category":"服饰","areaName":"杭州","money":"1240"}|{"id":24,"timestamp":"2019-05-08T01:01.00Z","category":"食品","areaName":"天津","money":"5600"} {"id":25,"timestamp":"2019-05-08T01:03.00Z","category":"食品","areaName":"北京","money":"7801"}|{"id":26,"timestamp":"2019-05-08T01:01.00Z","category":"服饰","areaName":"北京","money":"9000"} {"id":27,"timestamp":"2019-05-08T01:03.00Z","category":"服饰","areaName":"杭州","money":"5600"}|{"id":28,"timestamp":"2019-05-08T01:01.00Z","category":"食品","areaName":"北京","money":"8000"}|{"id":29,"timestamp":"2019-05-08T02:03.00Z","category":"服饰","areaName":"杭州","money":"7000"}
需求,复制以上内容到文件中,使用Spark读取文件进行计算:
- 各个城市销售额排名,从大到小
- 全部城市,有哪些商品类别在售卖
- 北京市有哪些商品类别在售卖
"""
使用Spark读取文件进行计算:
各个城市销售额排名,从大到小
全部城市,有哪些商品类别在售卖
北京市有哪些商品类别在售卖
"""
import json
from pyspark import SparkConf, SparkContext
import os
os.environ['PYSPARK_PYTHON'] = "D:/Python/Python311/python.exe"
conf = SparkConf().setMaster("local[*]").setAppName("test_spark")
sc = SparkContext(conf=conf)# TOD0 需求1:城市销售额排名
# 1.1 读取文件得到RDD
rdd = sc.textFile("E:/百度网盘/1、Python快速入门(8天零基础入门到精通)/资料/第15章资料/资料/orders.txt")
# print(rdd.collect())# 1.2取出一个个JSON字符串
json_str = rdd.flatMap(lambda a: a.split("|"))
# print(json_str.collect())# 1.3将一个个JSON字符串转换为字典
my_dict = json_str.map(lambda x: json.loads(x))
# print(my_dict.collect())# 1.4 取出城市和销售额数据
# (城市,销售额)
city_with_money_rdd = my_dict.map(lambda x: (x["areaName"], int(x['money'])))
# print(city_with_money_rdd.collect())# 1.5 按城市分组按销售额聚合
city_result = city_with_money_rdd.reduceByKey(lambda a, b: a + b)
# print(city_result.collect())# 1.6 按销售额聚合结果进行排序
sorting = city_result.sortBy(lambda a: a[1], ascending=False, numPartitions=1)
print(f"需求1的结果是:{sorting.collect()}")# TODD 需求2:全部城市,有哪些商品类别在售卖
city_with_category_rdd = my_dict.map(lambda x: (x['category'])).distinct()
print(f"需求2的结果是:{city_with_category_rdd.collect()}")# TODD 需求3:北京市有哪些商品类别在售卖
# 3.1 过滤北京是市的数据
bj_dict = my_dict.filter(lambda a: a["areaName"] == "北京")
# print(bj_dict.collect())# # 3.2 取出全部商品列表
# bj_category = bj_dict.map(lambda a: a["category"])
# print(bj_category.collect())# # 3.3 进行商品类别去重
# bj_category_distinct = bj_category.distinct()
# print(f"北京市售卖的商品有{bj_category_distinct.collect()}")# 3.2 取出全部商品列表 进行商品类别去重
bj_category = bj_dict.map(lambda a: a["category"]).distinct()
print(f"北京市售卖的商品有{bj_category.collect()}")结果:
需求1的结果是:[('北京', 91556), ('杭州', 28831), ('天津', 12260), ('上海', 1513), ('郑州', 1120)]需求2的结果是:['电脑', '家电', '食品', '平板电脑', '手机', '家具', '书籍', '服饰']北京市售卖的商品有['家电', '电脑', '食品', '平板电脑', '手机', '家具', '书籍', '服饰']数据输出
输出为Python对象
数据输入:
- sc.parallelize
- sc.textFile
数据计算:
- rdd.map
- rdd.flatMap
- rdd.reduceByKey
- ...

collect算子
功能:将rdd各个分区内的数据,统一收集到Driver中,形成一个List对象
用法:
rdd.collect()
返回一个List
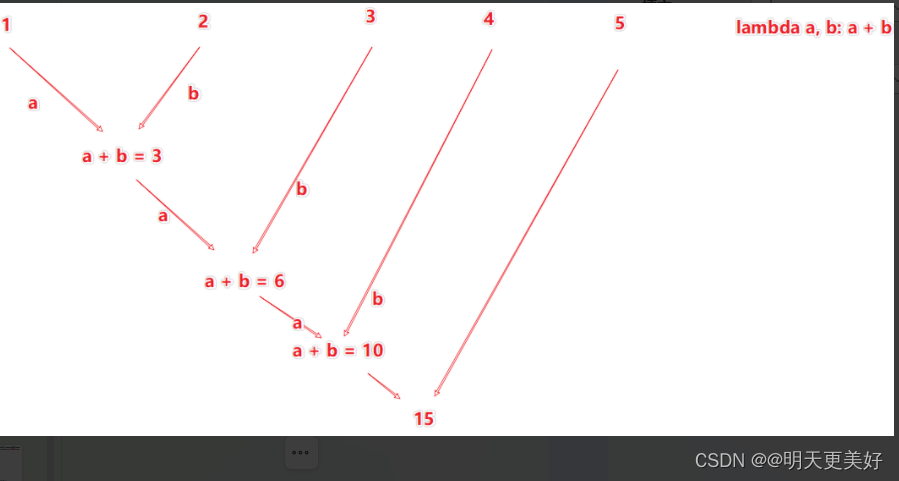
reduce算子
功能:对RDD数据集按照你传入的逻辑进行聚合
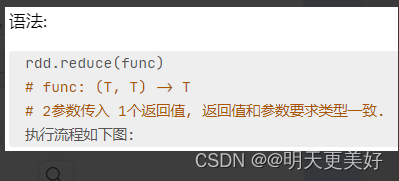

返回值等同于计算函数的返回值
take算子
功能:取RDD的前N个元素,组合成List返回给你
用法:
sc.parallelize([1, 2, 65, 5, 8, 841, 2, 48, 12, 21, 48]).take(6)结果:
[1, 2, 65, 5, 8, 841]count算子
功能:计算RDD有多少条数据,返回值是一个数字
总结:
1. Spark的编程流程就是:
- 将数据加载为RDD(数据输入)
- 对RDD进行计算(数据计算)
- 将RDD转换为Python对象(数据输出)
2. 数据输出的方法
- collect:将RDD内容转换为list
- reduce:对RDD内容进行自定义聚合
- take:取出RDD的前N个元素组成list
- count:统计RDD元素个数
数据输出可用的方法是很多的,简单的介绍了4个。
输出到文件中
saveAsTextFile算子
功能:将RDD的数据写入文本文件中
支持 本地写成,hdfs等文件系统
代码:
rdd = sc.parallelize([1, 2, 3, 4, 5, 6])rdd.saveAsTextFile("D:/output")
注意事项
调用保存文件的算子,需要配置Hadoop依赖
下载Hadoop安装包
- 解压到电脑任意位置
- 在Python代码中使用os模块配置:os.environ[‘HADOOP_HOME’] = ‘HADOOP解压文件夹路径’
- 下载winutils.exe,并放入Hadoop解压文件夹的bin目录内
- 下载hadoop.dll,并放入:C:/Windows/System32 文件夹内
修改rdd分区为1个
方式1,SparkConf对象设置属性全局并行度为1:
conf = SparkConf().setMaster("local[*]").setAppName("test_spark")
# 设置spark全局并行度为1
conf.set('spark.default.parallelism', '1')sc = SparkContext(conf=conf)方式2,创建RDD的时候设置(parallelize方法传入numSlices参数为1):
rdd1 = sc.parallelize([1, 2, 3, 4, 5, 6], numSlices=1) # 设置分区为1rdd1 = sc.parallelize([1, 2, 3, 4, 5, 6], 1) # 设置分区为1总结:
1. RDD输出到文件的方法
- rdd.saveAsTextFile(路径)
- 输出的结果是一个文件夹
- 有几个分区就输出多少个结果文件
2. 如何修改RDD分区
- SparkConf对象设置conf.set("spark.default.parallelism", "1")
- 创建RDD的时候,sc.parallelize方法传入numSlices参数为1
相关文章:
PySpark 数据操作
数据输入 RDD对象 如图可见,PySpark支持多种数据的输入,在输入完成后,都会得到一个:RDD类的对象 RDD全称为:弹性分布式数据集(Resilient Distributed Datasets) PySpark针对数据的处理&…...

FPGA2-采集OV5640乒乓缓存后经USB3.0发送到上位机显示
1.场景 基于特权A7系列开发板,采用OV5640摄像头实时采集图像数据,并将其经过USB3.0传输到上位机显示。这是验证数据流能力的很好的项目。其中,用到的软件版本,如下表所示,基本的硬件情况如下。该项目对应FPGA工程源码…...

亚信科技AntDB数据库专家参加向量数据库首次技术标准研讨会
2023年7月19日下午,中国通信标准化协会大数据技术标准推进委员会数据库与存储工作组(CCSA TC601 WG4)联合中国信通院数据库应用创新实验室(CAICT DBL)在线上召开《向量数据库技术要求》标准首次研讨会。本次会议由中国…...

Windows中实现右键把电子书通过邮件发到kindle
不使用第三方软件,通过Windows自带的函数,可以实现右键将电子书通过电子邮件发送到kindle邮箱,从而实现kindle电子书传送功能。实现过程如下: 1. 使用bat添加右键功能 打开资源管理器,在地址中输入%APPDATA%\Microso…...

Three.js之创建3D场景
参考资料 【G】Three.js官方文档:https://threejs.org/docs/ Three.js是一个流行的WebGL库,官方文档提供了详细的API参考和示例,适合学习和参考。【G】Three.js GitHub链接:https://github.com/mrdoob/three.js 这是一个流行的基…...
一个3年Android的找工作记录
作者:Petterp 这是我最近 1个月 的找工作记录,希望这些经历对你会有所帮助。 有时机会就像一阵风,如果没有握住,那下一阵风什么时候吹来,往往是个运气问题。 写在开始 先说背景: 自考本,3年经验࿰…...

CAS原理解析
CAS是一种乐观锁机制,一种比较并交换的过程和理念,用来解决线程安全问题,具体来讲就是对共享变量值的安全更新机制。能够保证原子、可见、一致性。这种交换过程是在Unsafe类中实现。 从一段简单的代码开始来对源码做分析 public static void…...
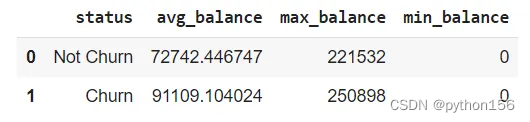
SQL项目实战:银行客户分析
大家好,本文将与大家分享一个SQL项目,即根据从数据集收集到的信息分析银行客户流失的可能性。这些洞察来自个人信息,如年龄、性别、收入和人口统计信息、银行卡类型、产品、客户信用评分以及客户在银行的服务时间长短等。对于银行而言&#x…...
)
【Redis深度专题】「核心技术提升」探究Redis服务启动的过程机制的技术原理和流程分析的指南(集群指令分析—实战篇)
探究Redis服务启动的过程机制的技术原理和流程分析的指南(集群指令分析—下篇) Cluster XX的集群指令(扩展)写入记录主节点和备节点切换-CLUSTER FAILOVER新加入master节点新加入slave节点为slave节点重新分配master分配哈希槽删除…...

ubuntu
安装 sudo apt-get update sudo apt-get install mysql-server mysql-client 设置root密码 cat /etc/mysql/debian.cnf 查看默认密码 mysql -u debian-sys-maint -p 连接输入密码 use mysql; select user,plugin from user; update user set pluginmysql_native_passwor…...
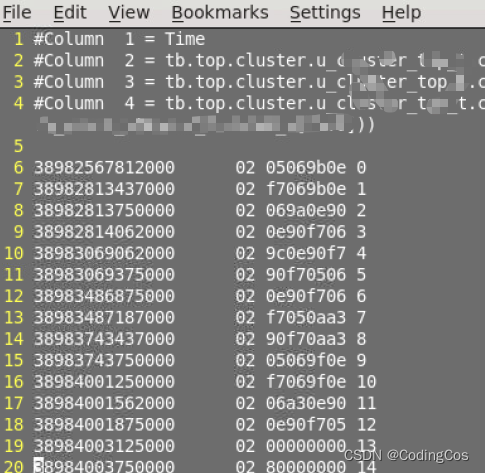
【芯片设计- RTL 数字逻辑设计入门 3- Verdi 常用使用命令】
文章目录 Verdi 全局显示Verdi 前导 0 的显示Verdi 数据笔数统计Verdi 波形数据dump Verdi 全局显示 bsubi -n 16 -J sam visualizer -tracedir ./veloce.wave/debug_waveform.stw 打开波形后,如果想要看到所有信号的数据,可以点击下图中红框中的按钮&a…...
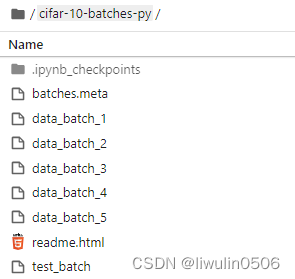
python-pytorch基础之cifar10数据集使用图片分类
这里写目录标题 总体思路获取数据集下载cifar10数据解压包文件介绍加载图片数字化信息查看数据信息数据读取自定义dataset使用loader加载建模训练测试建测试数据的loader测试准确性测试一张图片读取一张图片加载模型预测图片类型创建一个预测函数随便来张马的图片结果其他打开一…...

华纳云:linux下磁盘管理与挂载硬盘方法是什么
在Linux下进行磁盘管理和挂载硬盘的方法如下: 磁盘管理: a. 查看已连接的磁盘:可以使用命令 fdisk -l 或 lsblk 查看系统中已连接的磁盘信息,包括硬盘和分区。 b. 创建分区:如果磁盘是全新的,需要使用 f…...

ChatGPT + Stable Diffusion + 百度AI + MoviePy 实现文字生成视频,小说转视频,自媒体神器!(一)
ChatGPT Stable Diffusion 百度AI MoviePy 实现文字生成视频,小说转视频,自媒体神器!(一) 前言 最近大模型频出,但是对于我们普通人来说,如何使用这些AI工具来辅助我们的工作呢,或者参与进入我们的生活…...

linux strcpy/strncpy/sprintf内存溢出问题
本文主要介绍strcpy/strncpy/sprintf都是不安全的,可能存在内存溢出的问题。下来进行实例分析。 strcpy代码: #include <stdio.h> #include <string.h> #include <stdlib.h> #include <stdbool.h>void test_func(char *str) {b…...
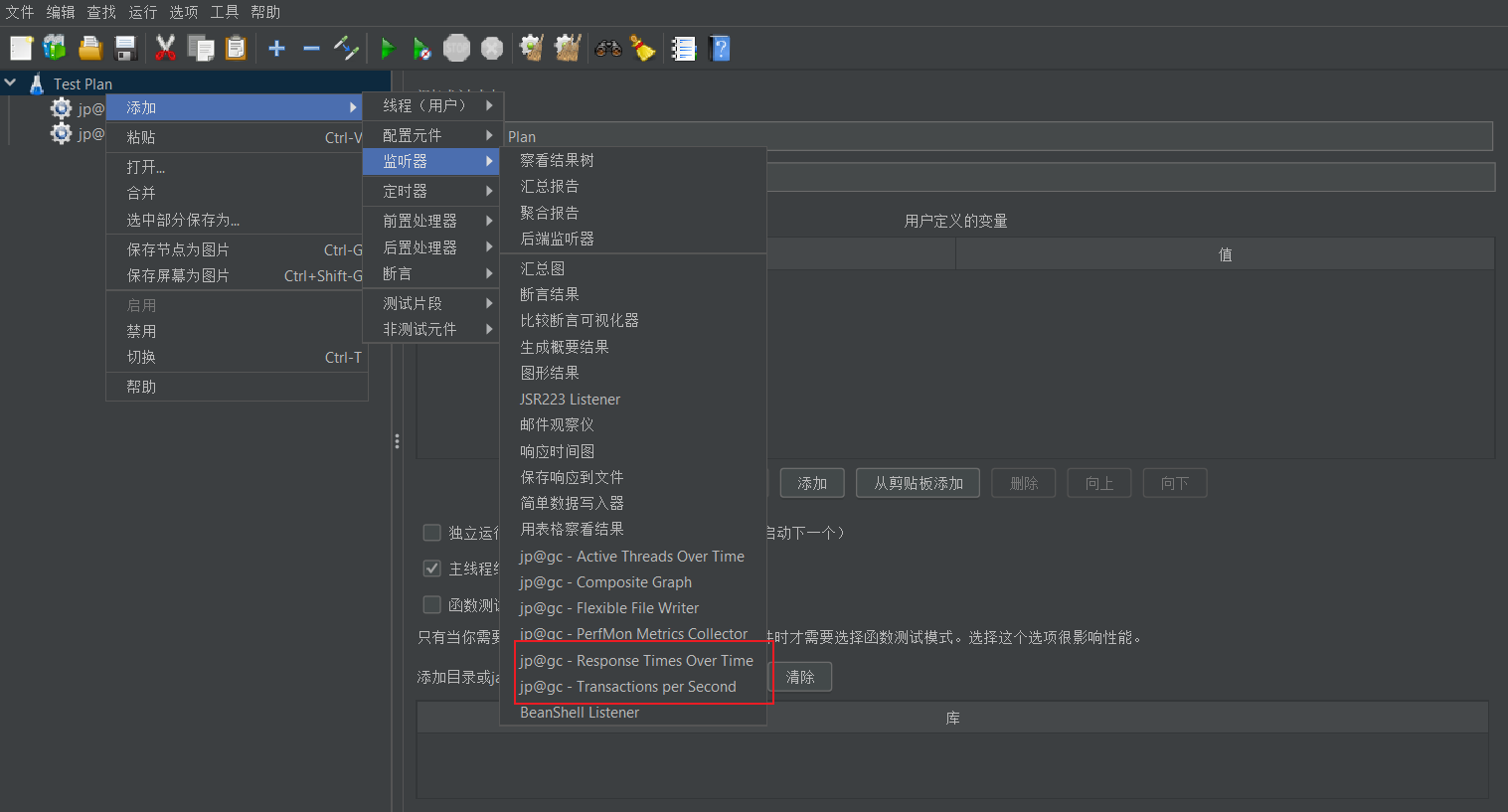
Jmeter如何添加插件
一、前言 在我们的工作中,我们可以利用一些插件来帮助我们更好的进行性能测试。今天我们来介绍下Jmeter怎么添加插件? 2023最新Jmeter接口测试从入门到精通(全套项目实战教程) 二、插件管理器 首先我们需要下载插件管理器j…...

flask---CBV使用和源码分析
1 cbv写法 -1 写个类,继承MethodView-2 在类中写跟请求方式同名的方法-3 注册路由:app.add_url_rule(/home, view_funcHome.as_view(home))#home是endpoint,就是路由别名#例子 class add(MethodView):def get(self):return holleapp.add_url…...

Qt 实现压缩文件、文件夹和解压缩操作zip
一、实现方式 通过Qt自带的库来实现,使用多线程方式,通过信号和槽来触发压缩与解压缩,并将压缩和解压缩结果回传过来。 使用的类: #include "QtGui/private/qzipreader_p.h" #include "QtGui/private/qzipwriter…...
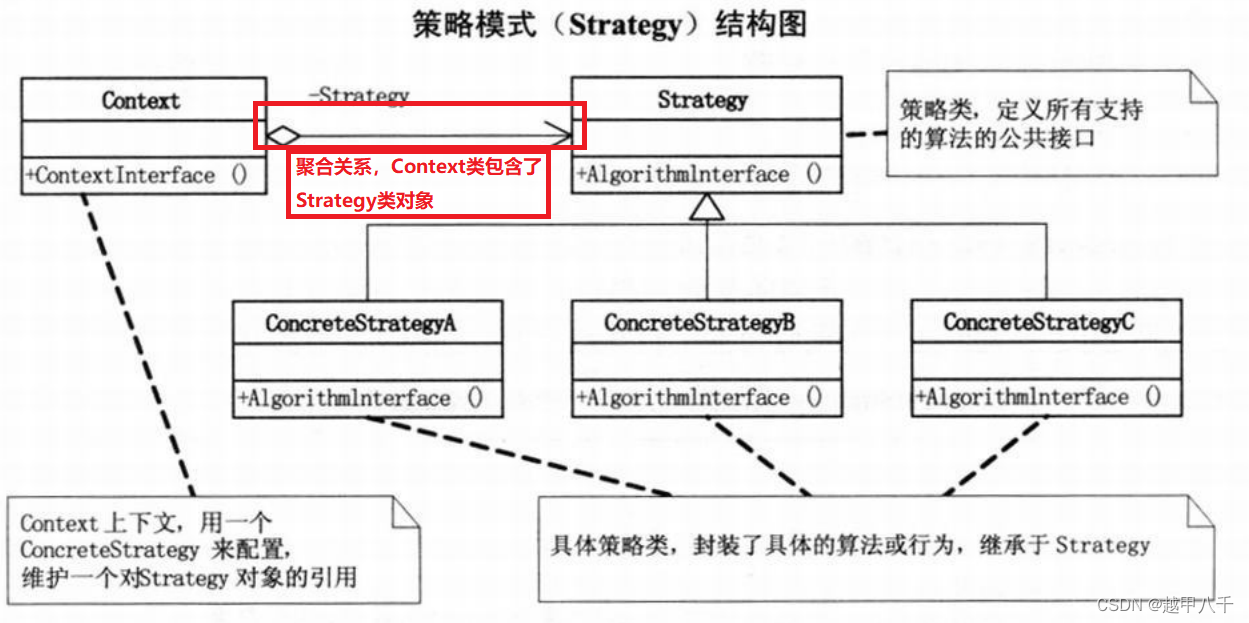
简单工厂模式VS策略模式
简单工厂模式VS策略模式 今天复习设计模式,由于简单工厂模式和策略模式太像了,重新整理梳理一下 简单工厂模式MUL图: 策略模式UML图: 1、简单工厂模式中只管创建实例,具体怎么使用工厂实例由调用方决定,…...
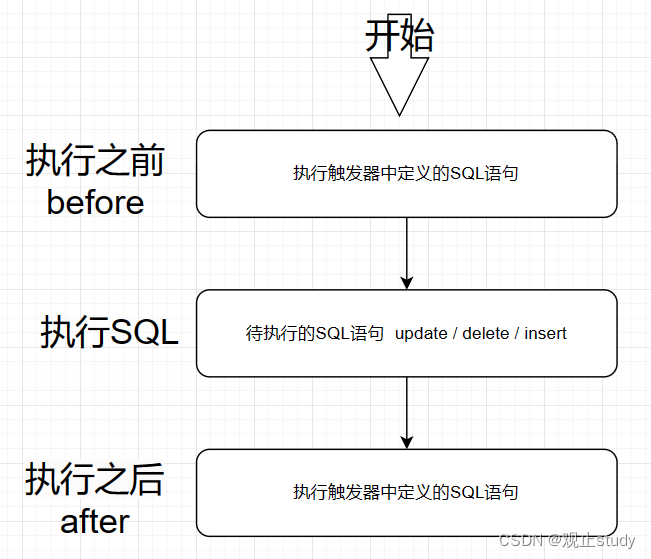
【MySQL】触发器 (十二)
🚗MySQL学习第十二站~ 🚩本文已收录至专栏:MySQL通关路 ❤️文末附全文思维导图,感谢各位点赞收藏支持~ 一.引入 触发器是与表有关的数据库对象,作用在insert/update/delete语句执行之前(BEFORE)或之后(AFTER),自动触发并执行触发器中定义的SQL语句集合。它可以协助应…...

OpenHarmony芯片解决方案:从硬件抽象到编译配置实战指南
1. 项目概述:从零理解OpenHarmony芯片解决方案如果你正在或准备踏入OpenHarmony的硬件开发领域,那么“芯片解决方案”这个概念,就是你绕不开的第一道门槛。它不像写一个纯应用层的“Hello World”程序那么简单,而是连接你手中那块…...

B2B制造业如何利用GEO优化获得精准询盘:实战指南
B2B制造业如何利用GEO优化获得精准询盘:实战指南 摘要 :随着AI搜索渗透率超过85%,B2B制造业的获客逻辑正在被重塑。本文详细介绍GEO(Generative Engine Optimization)优化技术如何帮助工业品、机械配件企业获得精准询盘…...

STM32G474的HRTIM驱动DAC:你的锯齿波‘毛刺’和失真,可能是这两个寄存器配置反了
STM32G474的HRTIM驱动DAC:锯齿波失真问题深度解析与优化方案 在精密模拟电路设计中,STM32G474系列微控制器凭借其高性能HRTIM(高分辨率定时器)和DAC(数模转换器)的组合,成为生成高精度波形的重要…...

如何5分钟掌握LDDC歌词工具:面向音乐爱好者的终极歌词管理指南
如何5分钟掌握LDDC歌词工具:面向音乐爱好者的终极歌词管理指南 【免费下载链接】LDDC 简单易用的精准歌词(逐字歌词/卡拉OK歌词)下载匹配工具|A simple and user-friendly tool for downloading and matching precise lyrics (word-by-word lyrics/Karaoke lyrics) …...

蓝牙、Wi-Fi、5G、NB-IoT四大无线技术核心差异与选型指南
1. 无线通信技术全景概览:从身边到万物每天一睁眼,我们就被各种看不见的“波”包围着。手机自动连上家里的Wi-Fi,耳机里传来蓝牙音箱的音乐,出门后手机信号满格,甚至街边的智能路灯、家里的智能电表,都在悄…...

KVM网络配置踩坑记:从virt-install的`--network`参数到virsh管理虚拟网桥
KVM网络配置实战:从virt-install到virsh的深度解析 当你在本地环境搭建KVM虚拟机时,网络配置往往是第一个拦路虎。不同于物理机插上网线就能用的简单体验,虚拟化环境中的网络需要经过多层抽象和配置才能正常工作。本文将带你深入KVM网络配置的…...

【GEO实战密码】GEO 的真正护城河,是 RAG
《GEO实战密码》节选:GEO 的真正护城河,是 RAG企业做生成式搜索优化,别只盯着外部曝光。AI 愿不愿意引用你,首先取决于你的内容值不值得被信任。最近和不少企业聊 GEO,也就是生成式搜索优化,发现一个非常典…...

从Java到AI大模型:小白程序员必备转型指南,收藏学习不迷路!
本文为传统Java开发者提供了从入门到精通AI大模型的四步转型路径。首先利用成熟AI接口,其次掌握Langchain和LlamaIndex开发工具,再次深入Agent机制设计自动化流程,最后搭建本地专属模型。作者结合自身经验,分享了实战项目和避坑指…...

音视频开发避坑:YUV420P图像处理时Stride不对齐,你的内存拷贝为啥总出错?
音视频开发避坑:YUV420P图像处理时Stride不对齐,你的内存拷贝为啥总出错? 在音视频开发中,YUV420P格式因其高效的存储方式被广泛使用,但许多开发者在处理这类图像时,常常会遇到内存拷贝错误、程序崩溃或画面…...

告别邮件测试烦恼:MailHog一站式解决方案让开发调试更高效
告别邮件测试烦恼:MailHog一站式解决方案让开发调试更高效 【免费下载链接】MailHog Web and API based SMTP testing 项目地址: https://gitcode.com/gh_mirrors/ma/MailHog 还在为测试邮件功能而烦恼吗?每次开发邮件发送模块时,你是…...