HDFS 分布式存储 spark storm HBase
HDFS 分布式存储 spark storm HBase
分布式结构 master slave
name node client 负责文件的拆分 128MB 3份
data node
MapReduce 分布式计算 离线计算 2.X之前 速度比较慢 对比spark
编程思想 Map 分 Reduce 合
hadoop streaming Mrjob
Yarn 资源管理 cpu 内存 MapReduce spark 分布式计算
RM NM AM
社区版 CDH
什么是Hive
-
基于Hadoop 数据保存到HDFS
-
数据仓库工具
-
结构化的数据 映射为一张数据库表
01,张三,89
02,李四,91
03,赵武,92
-
HQL查询功能 (Hive SQL)
-
本质 把HQL翻译成MapReduce 降低使用hadoop计算的门槛
-
离线数据分析开发效率比直接用MapReduce 高
Hive架构
- 用户接口:shell命令行
- 元数据存储
- 数据库 表 都保存到那些位置上
- 表中的字段名字 类型
- mysql derby(自带)
- Drive
- 负责把HQL翻译成mapreduce
- 或者翻译成 shell 命令
Hive和Hadoop关系
- 利用hdfs存数据 利用mr算
- Hive只需要跟 Master节点打交道 不需要集群
Hive和关系型数据库区别
- hive 离线计算 海量查询
- hive最主要做查询 不涉及删除修改 默认不支持删除修改,默认不支持事务,并不完全支持标准sql
- sql CRUD全部支持, 支撑在线业务,索引完整 支持事务
Hive 基本使用
- 创建表
CREATE TABLE student(classNo string, stuNo string, score int) row format delimited fields terminated by ',';
-
字段不需要指定占多少字节
-
需要通过row format delimited fields terminated by ','指定列的分隔符
-
加载表数据的时候尽量使用 load data方式 把整个文件put上去
load data local inpath '/home/hadoop/tmp/student.txt'overwrite into table student; -
内部表和外部表
-
managed table
-
创建表的时候
CREATE TABLE 表名(字段名 字段类型,)row format delimited fields terminated by ',' -
删除表
元数据和数据一起删除
-
数据位置
- 默认是/user/hive/warehouse
-
-
external table
-
建表语句
CREATE External TABLE 表名(字段名 字段类型,)row format delimited fields terminated by ',' location '数据在hdfs上的路径'; -
删除表
- 只删除元数据 数据会保留
-
数据可以在hdfs上的任意位置
-
-
-
分区表
-
当数据量比较大的时候,使用分区表可以缩小查询的数据范围
-
分区表实际上就是在表的目录下创建的子目录
-
如果有分区表的话查询的时候,尽量要使用分区字段
-
创建分区表的语句
create table 表名 (字段名,字段类型....) partitioned by (分区字段名 分区字段类型) row format delimited fields terminated by ',' lines terminated by '\n' stored as textfile; -
向分区表中插入数据
load data local inpath '/home/hadoop/tmp/employee.txt' into table 表名 partition(分区字段名字='分区的具体值'); -
添加分区
alter table 表名 add if not exists partition(分区字段名字='分区的具体值'); -
动态分区
-
插入数据的时候指定分区的字段,会自动帮助创建分区所对应的文件夹
-
需要关掉默认设置
set hive.exec.dynamic.partition.mode=nonstrict;
-
-
UDF自定义函数
-
hive提供的函数不能满足需求的时候就可以使用自定函数
-
使用别人已经编译好的.jar
-
jar加到 hive环境中
-
jar 可以在hdfs上 也可是在centos 上
-
创建一个临时函数
CREATE TEMPORARY FUNCTION 自定义函数名字 as '自定义函数在jar包中的包名' -
创建一个永久函数
CREATE FUNCTION 自定义函数名字 as '自定义函数在jar包中的包名' using jar 'jar位置';
-
-
自己写python脚本实现udf、udaf
-
add file python文件的位置
-
SELECT TRANSFORM(fname, lname) USING 'python udf1.py' AS (fname, l_name) FROM u;
-
-
综合案例
-
collect_set/collect_list
- group by之后 针对某一列聚合 结果放到[]
- 区别 一个去重 一个不去重
-
lateral view explode
-
explode函数 把复杂数据类型 array map 拆开 一行变多行
-
lateral view 和explode函数 配合使用 创建虚拟视图 可以把explode的结果和其它列一起查询
-
select article_id,kw from articles lateral view outer explode(key_words) t as kw
-
-
CONCAT, CONCAT_WS
- 不同列的字符串拼接到一起
- concat_ws 可以把array中的元素拼接到同一个字符串中 指定分割符
-
str_to_map 把具有key:value形式的字符串转换成map
sqoop 介绍
-
作用 数据交换工具 可以实现 数据在mysql oracle<==> hdfs之间互相传递
-
原理 通过写sqoop 命令 把sqoop命令翻译成mapreduce 通过mapreduce连接各种数据源 实现数据的传递
-
通过sqoop 把数据从mysql导入到hdfs
- sqoop import --connect jdbc:mysql://mysql数据库地址:3306/数据库名字 --username root --password password --table 要导出数据的表名 -m mrjob的数量
- 默认会把文件导入到 hdfs上 /user/linux用户名 文件夹下
- 通过 --target-dir指定其它位置
HBase介绍
-
分布式开源数据库
-
面向列
-
Big Table开源实现
-
适合非结构化数据的存储
-
PB级别数据
-
可以支撑在线业务
-
分布式系统特点 :易于扩展,支持动态伸缩,并发数据处理
面向列数据库
-
关系型数据库:行式存储 每一行数据都是连续的 所有的记录都放到一个连续的存储空间中
-
列数据库: 列式存储 每一列对应一个文件 不同列并不对应连续的存储空间
-
结构化数据 V.S. 非结构化数据
- 结构化数据
- 预定义的数据模型 模型一旦确定不会经常变化(表结构不会频繁调整)
- 非结构化数据
- 没有预定义数据模型
- 模型不规则 不完整
- 文本 图片 视频 音频
- 结构化数据
-
Hive 和 Hbase区别
- hive hbase 共同点
- 都可以处理海量数据
- 文件都是保存到hdfs上
- hive 和 hbase不同
- 计算不是通过mapreduce实现的 自己实现的CRUD功能
- hive 通过mapreduce实现 数据查询的
- hbase 可以有集群 集群的管理是通过zookeeper实现
- hive 只能做离线计算
- hbase 提供对数据的随机实时读/写访问功能
- hive hbase 共同点
-
HBase 对事务的支持 只支持行级别的事务
-
CAP定理
- 分区容错性 分布式系统都要有的特性,任何时候都要能提供服务 P保证
- HBase CP系统 强一致性
Hbase 数据模型
- NameSpace 对应 关系型数据库 database
- 表(table):用于存储管理数据,具有稀疏的、面向列的特点。
- 行 (row): 每一行都对应一个row key 行键 Hbase有索引但是只是在行键 rowkey有索引
- 列 Column family 和 Column qualifier 组成
- 列族(ColumnFamily)保存的就是 键值对集合 key:value
- 时间戳(TimeStamp):是列的一个属性
Hbase 和 传统关系型数据库区别
-
创建HBase表的时候只需要指定表名 和 列族
-
每一个行当中 只需要列族相同就可以了 至于每个列族中的 key:value对 key可以完全不同
HBase基础架构
-
Client
-
Zookeeper
- 保证HMaster有一个活着
- HRegionServer HMaster地址存储
- 监控Region Server状态 将Region Server信息通知HMaster
- 元数据存储
-
HMaster
-
HRegionServer
-
HStore
- 每一个column family 对应了一个HStore
-
HRegion
-
HLog
面向列数据库 列式存储
适合存非关系型数据
hbase 创建表的过程很简单 只需要指定表名和列族的名字就可以了
create ‘表名’,‘列族名字’
NameSpace -》数据库
table
row-key 行键 hbase的索引只在 row-key才有
column family 列族 key:value 这里面key 又叫 column quanlifier
不同行的 相同的column family 中 column quanlifier可以完全不同
组件
-
HMaster
-
HRegionServer
- HRegion
- Hstore (一个列族对应)
- memstore
- storefile
- Hstore (一个列族对应)
- HRegion
如果遇到 hdfs safe mode
通过 hdfs dfsadmin -safemode leave
hive 一定要先启动元数据服务
- hive --service metastore&
相关文章:

HDFS 分布式存储 spark storm HBase
HDFS 分布式存储 spark storm HBase 分布式结构 master slave name node client 负责文件的拆分 128MB 3份 data node MapReduce 分布式计算 离线计算 2.X之前 速度比较慢 对比spark 编程思想 Map 分 Reduce 合 hadoop streaming Mrjob Yarn 资源管理 cpu 内存 MapReduc…...

Vue3文字实现左右和上下滚动
可自定义设置以下属性: 滚动文字数组(sliderText),类型:Array<{title: string, link?: string}>,必传,默认[] 滚动区域宽度(width),类型:…...

Docker Sybase修改中文编码
镜像:datagrip/sybase 镜像默认用户名sa,密码myPassword,服务名MYSYBASE 1.进入容器 docker exec -it <container_name> /bin/bash2.加载Sybase环境变量 source /opt/sybase/SYBASE.sh3.查看是否安装了中文字符集 isql -Usa -PmyP…...
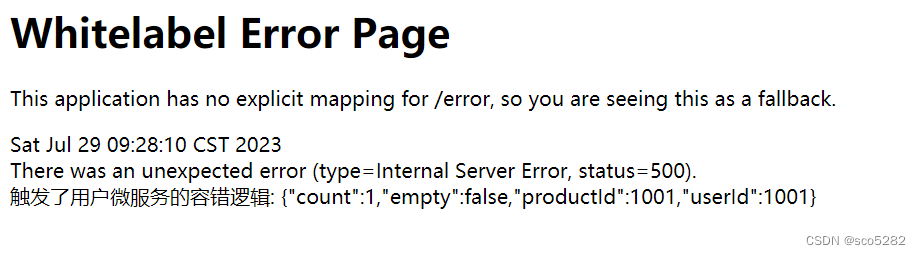
【SpringCloud Alibaba】(六)使用 Sentinel 实现服务限流与容错
今天,我们就使用 Sentinel 实现接口的限流,并使用 Feign 整合 Sentinel 实现服务容错的功能,让我们体验下微服务使用了服务容错功能的效果。 因为内容仅仅围绕着 SpringCloud Alibaba技术栈展开,所以,这里我们使用的服…...
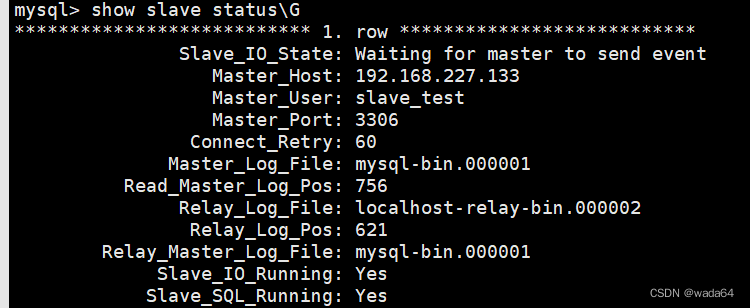
mysql的主从复制
1.主从复制的原理 主从复制的原理是通过基于日志的复制方式实现数据的同步。当主服务器上发生数据变更时,会将这些变更写入二进制日志(Binary Log)中。从服务器通过连接到主服务器,请求从主服务器获取二进制日志,并将…...

【Golang 接口自动化03】 解析接口返回XML
目录 解析接口返回数据 定义结构体 解析函数: 测试 优化 资料获取方法 上一篇我们学习了怎么发送各种数据类型的http请求,这一篇我们来介绍怎么来解析接口返回的XML的数据。 解析接口返回数据 定义结构体 假设我们现在有一个接口返回的数据resp如…...
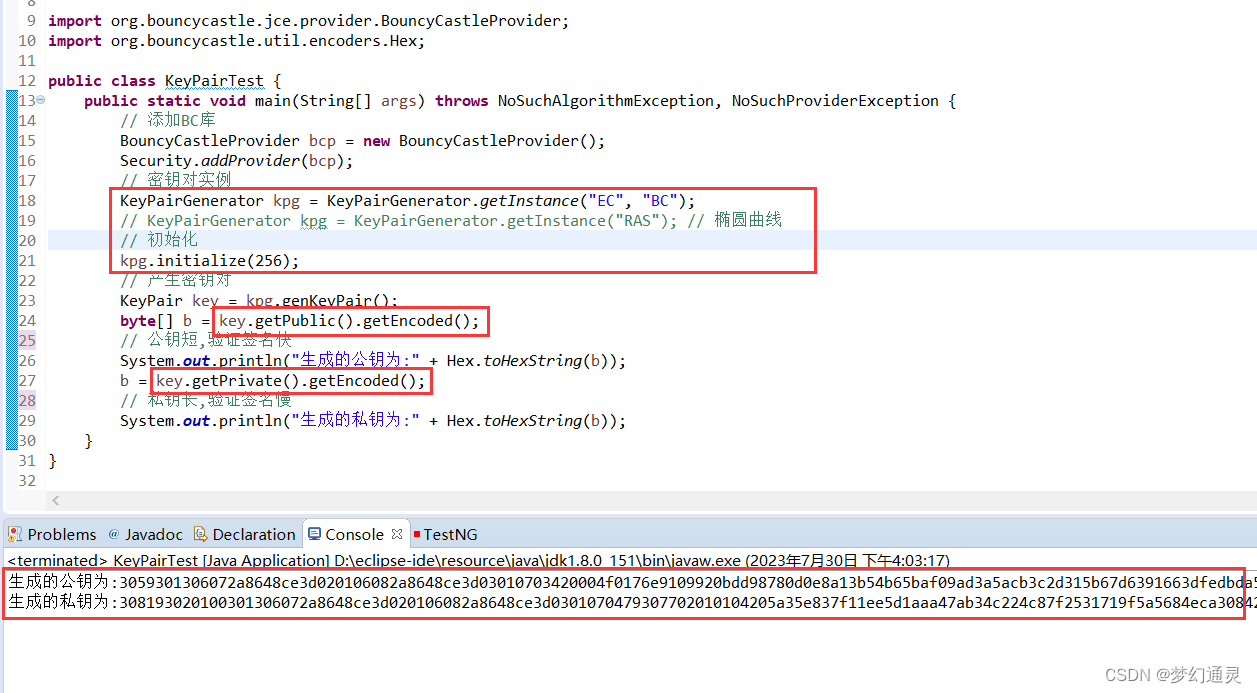
Java+bcprov库实现对称和非对称加密算法
BouncyCastle,即BC,其是一款开源的密码包,包含了大量的密码算法。 本篇主要演示BC库引入,对称加密算法AES、SM4和 非对称加密EC算法的简单实现,以下是实现过程。 一、将BC添加到JRE环境 前提:已安装JRE环…...

国内最大Llama开源社区发布首个预训练中文版Llama2
"7月31日,Llama中文社区率先完成了国内首个真正意义上的中文版Llama2-13B大模型,从模型底层实现了Llama2中文能力的大幅优化和提升。毋庸置疑,中文版Llama2一经发布将开启国内大模型新时代! | 全球最强,但中文短板…...
Qt应用开发(基础篇)——滑块类 QSlider、QScrollBar、QDial
目录 一、前言 二、QAbstractSlider类 1、invertedAppearance 2、invertedControls 3、maximum 4、minimum 5、orientation 6、pageStep 7、singleStep 8、sliderDown 9、tracking 10、sliderPosition 11、value 12、信号 三、QDial类 1、notchSize 2、notchTa…...
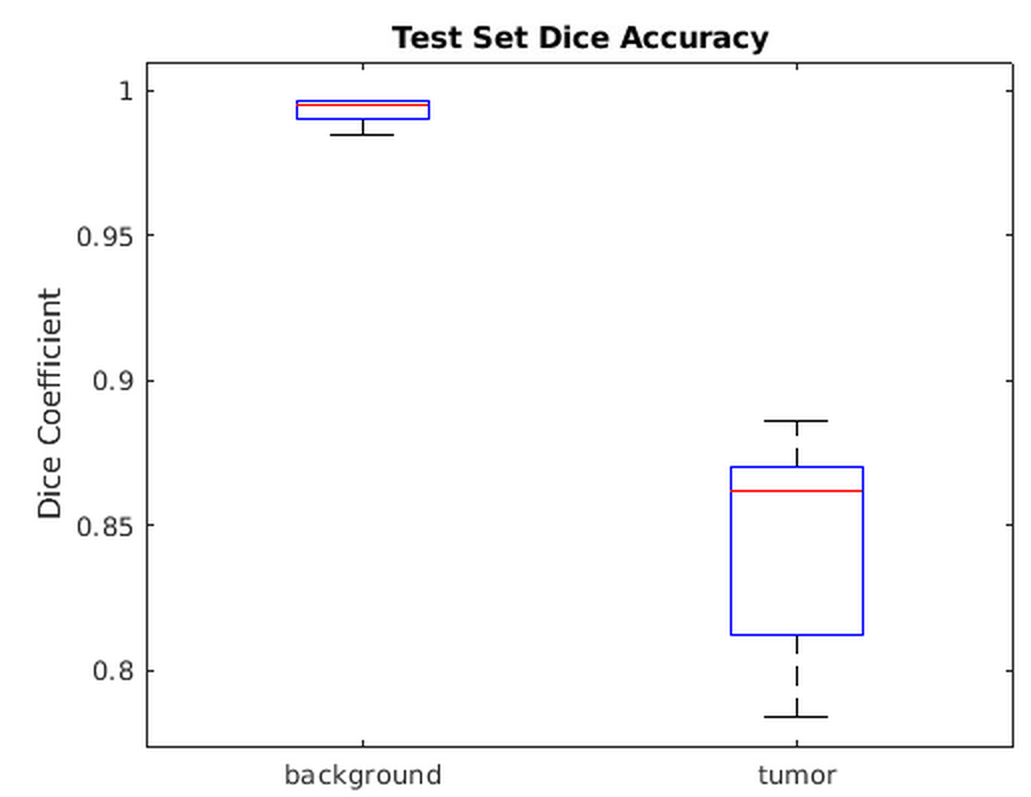
【3-D深度学习:肺肿瘤分割】创建和训练 V-Net 神经网络,并从 3D 医学图像中对肺肿瘤进行语义分割研究(Matlab代码实现)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…...

MongoDB文档--架构体系
阿丹: 在开始学习先了解以及目标知识的架构体系。就能事半功倍。 架构体系 MongoDB的架构体系由以下几部分组成: 存储结构:MongoDB采用文档型存储结构,一个数据库包含多个集合,一个集合包含多个文档。存储形式&#…...
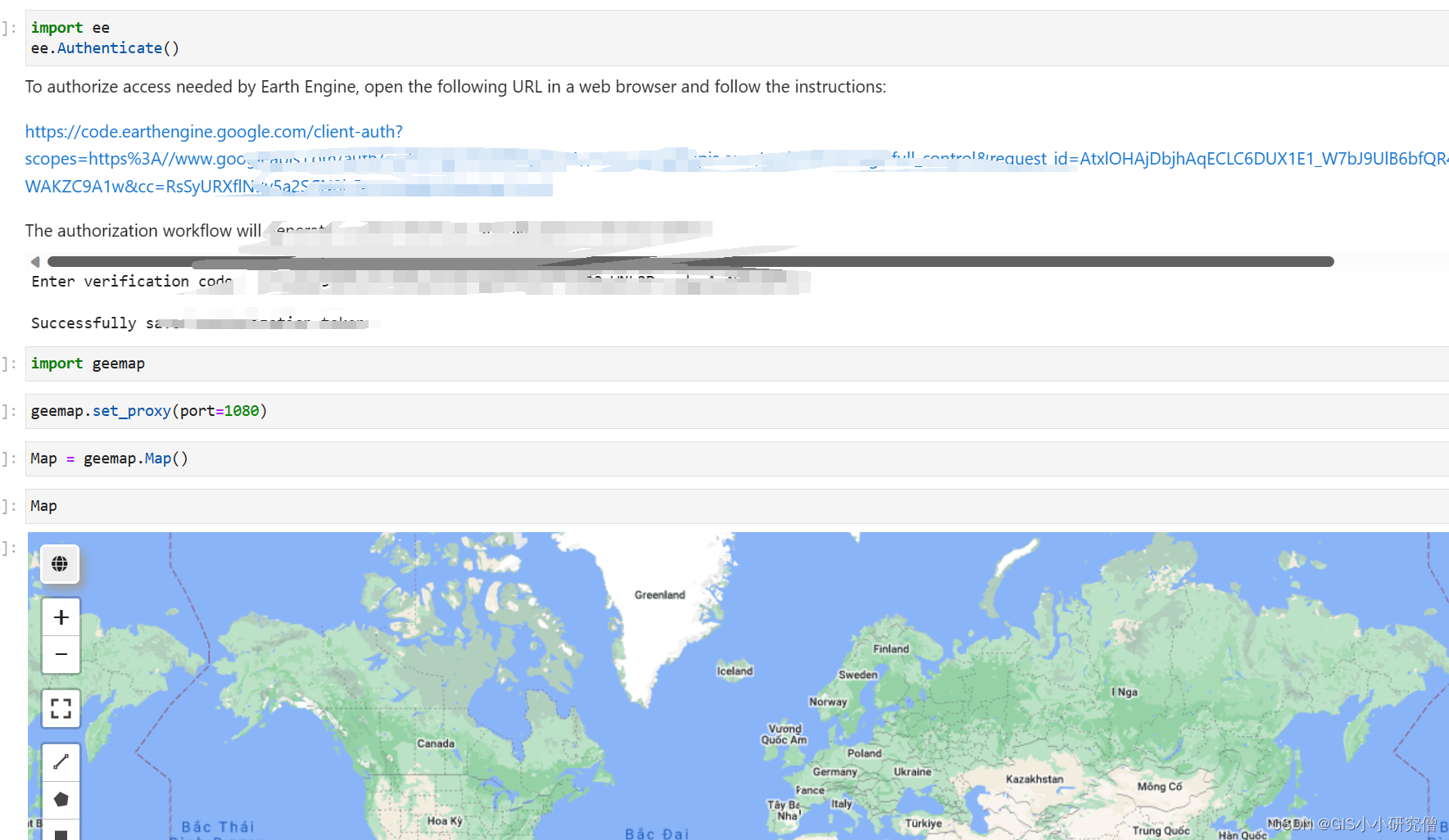
GEE学习03-Geemap配置与安装,arcgis pro自带命令提示符位置等
跟着吴秋生老师的视频开展的学习,首先购买了云,用来设置全局。 1、尝试使用arcgis pro自带的conda conda env list查看电脑上环境,我自己电脑上有三个环境,使用的arcgis pro python克隆的环境作为的默认的环境 但是这样的前提…...

软件测试面试总结——http协议相关面试题
前言 在PC浏览器的地址栏输入一串URL,然后按Enter键这个页面渲染出来,这个过程中都发生了什么事?这个是很多面试官喜欢问的一个问题 如果测试只是停留在表面上点点点,不知道背后的逻辑,是无法发现隐藏的bug,只能找一…...

大数据与okcc呼叫中心融合的几种方式
在实际的生产实践中,为提高营销效率,避免骚扰大众,很多呼叫中心业务会与大数据平台进行合作,进行精准营销。 买卖数据是非法的,大数据平台方并不会提供直接的数据,一般情况下,提供的数据都是脱…...

WAF绕过-工具特征-菜刀+冰蝎+哥斯拉
WAF绕过主要集中在信息收集,漏洞发现,漏洞利用,权限控制四个阶段。 1、什么是WAF? Web Application Firewall(web应用防火墙),一种公认的说法是“web应用防火墙通过执行一系列针对HTTP/HTTPS的安…...

使代码减半的5个Python装饰器
大家好,到目前为止,Python编程语言由于其语法简单,在机器学习和网络开发等各个领域的应用功能强大。除非绝对必要,装饰器一般很少出现在视野中,比如使用staticmethod装饰器来表示类中的静态方法。装饰器能提供的大量强…...

线程池的线程回收问题
首先,线程池里面分为核心线程和非核心线程。 核心线程是常驻在线程池里面的工作线程,它有两种方式初始化。 向线程池里面添加任务的时候,被动初始化主动调用prestartAllCoreThreads方法 当线程池里面的队列满了的情况下,为了增加…...

盘点那些不想骑车的原因和借口。
在自行车骑行的热潮中,我们都会找到各种千奇百怪的借口来解释我们为什么不想骑。本文将结合当前热点话题和趋势,从心理学、文化等多个角度,深入探讨这些借口背后的原因。 首先,我们不能忽视的是,骑行是一项需要耐力和毅…...
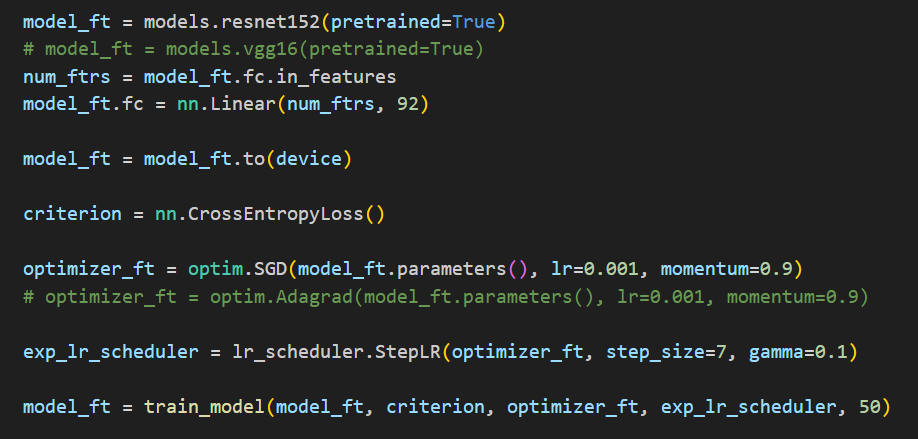
【深度学习Week3】ResNet+ResNeXt
ResNetResNeXt 一、ResNetⅠ.视频学习Ⅱ.论文阅读 二、ResNeXtⅠ.视频学习Ⅱ.论文阅读 三、猫狗大战Lenet网络Resnet网络 四、思考题 一、ResNet Ⅰ.视频学习 ResNet在2015年由微软实验室提出,该网络的亮点: 1.超深的网络结构(突破1000层&…...

Visual Studio 2022的MFC框架全面理解
我是荔园微风,作为一名在IT界整整25年的老兵,今天我们来重新审视一下Visual Studio 2022开发工具下的MFC框架知识。 MFC(Microsoft Foundation Class,微软基础类库)是微软为了简化程序员的开发工作所开发的一套C类的集合…...

graph-autofusion:CANN 的自动算子融合引擎
GE 的图优化 pass 里,算子融合是对推理性能影响最大的一个。但 GE 的融合规则是硬编码的——ConvBNReLU 写一条规则,BMMSoftmaxBMM 写一条规则。规则多了维护成本直线上升,总有覆盖不到的融合场景。 graph-autofusion 解决了这个问题。它是一…...

青铜器RDM:CBB 模块全周期管控,赋能研发高效复用
阶段 1、痛点与定位在研发项目中,CBB 通用基础模块是提升研发效率、降低研发成本、保障产品可靠性的核心关键。如何高效管理、复用、评价 CBB?青铜器 RDM 系统给出一站式解决方案。阶段 2、资源库搭建与全周期管控系统内置标准化 CBB 资源库,…...
)
别再硬编码了!ABAP Text Elements 三分钟搞定报表字段中文显示(附图标添加技巧)
ABAP文本元素实战:告别硬编码的报表开发艺术 每次看到报表界面上那些冷冰冰的字段名——MATNR、WERKS、VBELN——你是不是也感到一丝尴尬?业务用户可不懂这些技术缩写,他们需要的是直观的"物料编号"、"工厂"和"销售…...

从环境变量到Git Bash:给Plink找个‘家’,让你的遗传数据分析命令随处可跑
从环境变量到Git Bash:打造遗传数据分析的高效工作流 在遗传数据分析的日常工作中,Plink作为核心工具几乎出现在每个分析流程中。但许多研究者都会遇到这样的困扰:每次打开新的终端窗口,要么需要反复输入冗长的路径,要…...

华为云API调用实战:如何用Python脚本自动获取并刷新IAM用户Token?
华为云API自动化鉴权实战:Python实现Token动态管理与高可用方案 在云原生应用开发中,服务间API调用已成为现代系统架构的基石。华为云作为国内领先的云服务提供商,其API网关的鉴权机制直接关系到业务系统的稳定性和安全性。对于中高级开发者而…...

CacheTool配置指南:如何通过YAML文件简化操作流程
CacheTool配置指南:如何通过YAML文件简化操作流程 【免费下载链接】cachetool CLI App and library to manage apc & opcache. 项目地址: https://gitcode.com/gh_mirrors/ca/cachetool CacheTool是一款强大的PHP缓存管理工具,能够通过命令行…...

高级音频解密技术实现:ncmdump模块化架构解析与自动化工作流
高级音频解密技术实现:ncmdump模块化架构解析与自动化工作流 【免费下载链接】ncmdump 项目地址: https://gitcode.com/gh_mirrors/ncmd/ncmdump 在数字音乐版权保护日益严格的今天,网易云音乐的NCM加密格式为用户带来了设备兼容性的技术挑战。n…...

HTTPS握手失败?别慌!手把手教你用OpenSSL和Wireshark排查TLS与Cipher Suites问题
HTTPS握手失败?别慌!手把手教你用OpenSSL和Wireshark排查TLS与Cipher Suites问题 当你面对浏览器中那个刺眼的"SSL Handshake Failed"错误时,是否感到无从下手?作为经历过数百次HTTPS故障排查的老兵,我深知这…...

考前终极口诀合集,30秒过一遍
考前最后冲刺,别再翻教材了!把所有核心口诀集中在一起,科科过软考培训对系统集成项目管理工程师考前冲刺从头到尾过一遍,30秒搞定,能掌握不少必会知识点。一、挣值与关键路径——计算题的铁口诀挣值分析口诀࿱…...

香橙派Lite全解析:从硬件到应用,玩转ARM开发板与物联网项目
1. 香橙派Lite:一张能装进口袋的“万能主板”如果你对树莓派(Raspberry Pi)这类单板电脑有所耳闻,但又觉得它价格偏高或者想尝试更多选择,那么来自中国的香橙派(Orange Pi)系列绝对值得你深入了…...