生成对抗网络DCGAN学习
在AI内容生成领域,有三种常见的AI模型技术:GAN、VAE、Diffusion。其中,Diffusion是较新的技术,相关资料较为稀缺。VAE通常更多用于压缩任务,而GAN由于其问世较早,相关的开源项目和科普文章也更加全面,适合入门学习。
博主从入门和学习角度用Tensorflow跑通了DCGAN,本文对其进行记录以及分享。
1.简介
GAN(Generative Adversarial Network)是一种用于生成模型的机器学习框架。其原理基于两个主要组件:生成器(Generator)和判别器(Discriminator),二者通过对抗学习的方式相互竞争和提升。
从2014年左右发展至今,GAN目前有很多分支:
- GAN 朴素GAN,最原始版本
- DCGAN 卷积神经网络GAN
- CGAN 条件GAN,训练时传入额外条件,例如通过不同的mask区域生成不同内容,可控制的生成
- SeqGAN 使用GAN生成某些风格的句子,但不能进行对答
- Cycle GAN 可实现图像风格迁移,其实现略复杂
- 省略
2.原理介绍
先来看图
生成器(Generator)和判别器(Discriminator)是GAN的两个主要模型,生成器在上图中用缩写G表示,判别器用缩写D表示。
生成器G输入[N]的一维噪声,即InputNoise。输出[W * H * RGB](大致类似)的张量
判别器D输入一张图像,输出[1]的张量,即一个浮点数,通过0-1的值得到图像是真还是假
判别器需要尽可能的认出造假图片,生成器需要尽可能的骗过判别器,两者会在这2个目标上不断的通过反向传播进行学习,从而达到生成器和判别器的纳什均衡,最终输出质量很高的生成图像。
2.2 重点1
在训练中,判别器返回一个0-1区间的浮点数(如[0]=0.63,[0]=0.21)作为判断结果,值越高也越认为是真实图片。由于判别器也是一个神经网络模型,因此可以将输出层的梯度一直传递回输入层,然后将输入层的梯度作为生成器的梯度继续反向传播,从而完成一次训练。
然而,很多文章并没有提到这一点。如果没有接触过这种多模型梯度传递训练方法,可能会认为使用一个数学方法或者计算机视觉方法来构建判别器也可以让整个模型正常运行。但事实上,这种方法是不可行的(通常情况下)。
2.3 重点2
使用更多的层可以增强模型的推理能力。例如,在训练过程中,如果模型生成出眉毛 A 的特征,则有鼻子 B、C 和 D 相关的备选项;而如果生成出眉毛 E 的特征,则有鼻子 F 和 G 相关的备选项。
这也是为什么生成器需要使用三个隐层的原因(博主的观点)。通过增加隐层的数量,模型可以捕捉到更多的特征和抽象概念,从而提高生成器的表现能力和推理能力。更深层次的网络结构能够帮助模型学习更复杂的模式和关联,使其在生成结果时更加准确和多样化。
上图生成器部分的激活函数用的是LeakyReLU,实际上就单隐层神经网络来说,ReLU要比Sigmoid能多解决很多类型问题,Sigmoid更适合分类问题,遇到一些奇怪的问题不容易收敛,而LeakyReLU激活函数即和ReLU逻辑一样也可以返回负数信息,这是博主觉得采用这个激活函数的原因。
而至于tanH和Sigmoid的比较,它们在某种程度上相似。一般来说,网上普遍认为tanH比Sigmoid更好,主要原因是它具有较窄的数值边界范围。
2.4 重点3
对于2套样本比较损失这类问题,一般使用二分类交叉熵,这不同于分类问题。
而二分类交叉熵又是在只有2种结果(r和1-r),的情况下对公式进行的简化:
https://blog.csdn.net/grayrail/article/details/131619144
2.5 模式崩溃
训练时还会出现一种情况,即生成器始终卡在一个生成结果上,比如生成0-9数字,结果训练几轮后始终在生成数字3。
这种情况称为模式崩溃,一般增加训练样本数量并调节参数,没有比较好的办法。
3.实践准备
python库下载使用国内镜像源:
https://zhuanlan.zhihu.com/p/477179822
使用方式:
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple pyspider
github库下载耽误时间,可以缓存到gitee:

而gitee也有自己缓存好的镜像库,可以先去这里查:
https://gitcode.net/mirrors
python库查找:
https://pypi.org/
在pip中查找python库:
先 pip install pip-search 再使用命令 pip_search 搜索
4.实践
全连接神经网络版本的朴素GAN效果相对较差,而DCGAN(Deep Convolutional GAN)是卷积神经网络版本的GAN,下面以DCGAN为例使用Tensorflow进行实现:
import tensorflow as tf
import matplotlib.pyplot as plt
from tensorflow.keras import layers# 定义生成器模型
def build_generator():model = tf.keras.Sequential()model.add(layers.Dense(7*7*256, use_bias=False, input_shape=(100,)))model.add(layers.BatchNormalization())model.add(layers.LeakyReLU())model.add(layers.Reshape((7, 7, 256)))assert model.output_shape == (None, 7, 7, 256) # 注意:batch size 没有限制model.add(layers.Conv2DTranspose(128, (5, 5), strides=(1, 1), padding='same', use_bias=False))assert model.output_shape == (None, 7, 7, 128)model.add(layers.BatchNormalization())model.add(layers.LeakyReLU())model.add(layers.Conv2DTranspose(64, (5, 5), strides=(2, 2), padding='same', use_bias=False))assert model.output_shape == (None, 14, 14, 64)model.add(layers.BatchNormalization())model.add(layers.LeakyReLU())model.add(layers.Conv2DTranspose(1, (5, 5), strides=(2, 2), padding='same', use_bias=False, activation='tanh'))assert model.output_shape == (None, 28, 28, 1)return model# 定义判别器模型
def build_discriminator():model = tf.keras.Sequential()model.add(layers.Conv2D(64, (5, 5), strides=(2, 2), padding='same',input_shape=[28, 28, 1]))model.add(layers.LeakyReLU())model.add(layers.Dropout(0.3))model.add(layers.Conv2D(128, (5, 5), strides=(2, 2), padding='same'))model.add(layers.LeakyReLU())model.add(layers.Dropout(0.3))model.add(layers.Flatten())model.add(layers.Dense(1))return model# 定义生成器和判别器
generator = build_generator()
discriminator = build_discriminator()# 定义损失函数
loss_fn = tf.keras.losses.BinaryCrossentropy(from_logits=True)# 定义生成器和判别器的优化器
generator_optimizer = tf.keras.optimizers.Adam(1e-4)
discriminator_optimizer = tf.keras.optimizers.Adam(1e-4)def generator_loss(fake_output):return loss_fn(tf.ones_like(fake_output), fake_output)def discriminator_loss(real_output, fake_output):real_loss = loss_fn(tf.ones_like(real_output), real_output)fake_loss = loss_fn(tf.zeros_like(fake_output), fake_output)total_loss = real_loss + fake_lossreturn total_loss# 定义训练循环
@tf.function #这个是tensorflow的装饰器,标记后可提升性能,不加此标记也可
def train_step(images):# 生成噪声向量noise = tf.random.normal([BATCH_SIZE, 100])with tf.GradientTape() as gen_tape, tf.GradientTape() as disc_tape:# 使用生成器生成假图片generated_images = generator(noise, training=True)# 使用判别器判断真假图片real_output = discriminator(images, training=True)fake_output = discriminator(generated_images, training=True)# 计算损失函数gen_loss = generator_loss(fake_output)disc_loss = discriminator_loss(real_output, fake_output)# 计算梯度并更新生成器和判别器的参数gradients_of_generator = gen_tape.gradient(gen_loss, generator.trainable_variables)gradients_of_discriminator = disc_tape.gradient(disc_loss, discriminator.trainable_variables)generator_optimizer.apply_gradients(zip(gradients_of_generator, generator.trainable_variables))discriminator_optimizer.apply_gradients(zip(gradients_of_discriminator, discriminator.trainable_variables))def generate_and_save_images(model, epoch, test_input):predictions = model(test_input, training=False)print("predictions.shape:", predictions.shape)num_images = predictions.shape[0]rows = int(num_images ** 0.5) # 计算行数cols = num_images // rows # 计算列数fig = plt.figure(figsize=(8, 8))for i in range(num_images):plt.subplot(rows, cols, i+1)plt.imshow(predictions[i, :, :, 0] * 127.5 + 127.5, cmap='gray')plt.axis('off')plt.savefig('image_at_epoch_{:04d}.png'.format(epoch))#plt.show()# 加载MNIST数据集
(train_images, train_labels), (_, _) = tf.keras.datasets.mnist.load_data()# 标准化数据
train_images = train_images.reshape(train_images.shape[0], 28, 28, 1).astype('float32')
train_images = (train_images - 127.5) / 127.5# 批量大小与训练次数
BATCH_SIZE = 256
EPOCHS = 50# 数据集切分为批次并进行训练
dataset = tf.data.Dataset.from_tensor_slices(train_images).shuffle(60000).batch(BATCH_SIZE)for epoch in range(EPOCHS):for i,image_batch in enumerate(dataset):print("sub i",i)train_step(image_batch)print("------------------------------------------------------epoch:", epoch)# 每个 epoch 结束后生成并保存一组图像if (epoch + 1) % 5 == 0:seed = tf.random.normal([BATCH_SIZE, 100])generate_and_save_images(generator, epoch + 1, seed)
跑一阵子MNIST数据集后,结果如下:
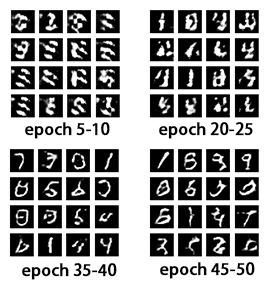
参考:
论文精读: https://www.bilibili.com/video/BV1rb4y187vD
同济子豪兄精读版本: https://www.bilibili.com/video/BV1oi4y1m7np
相关文章:
生成对抗网络DCGAN学习
在AI内容生成领域,有三种常见的AI模型技术:GAN、VAE、Diffusion。其中,Diffusion是较新的技术,相关资料较为稀缺。VAE通常更多用于压缩任务,而GAN由于其问世较早,相关的开源项目和科普文章也更加全面&#…...
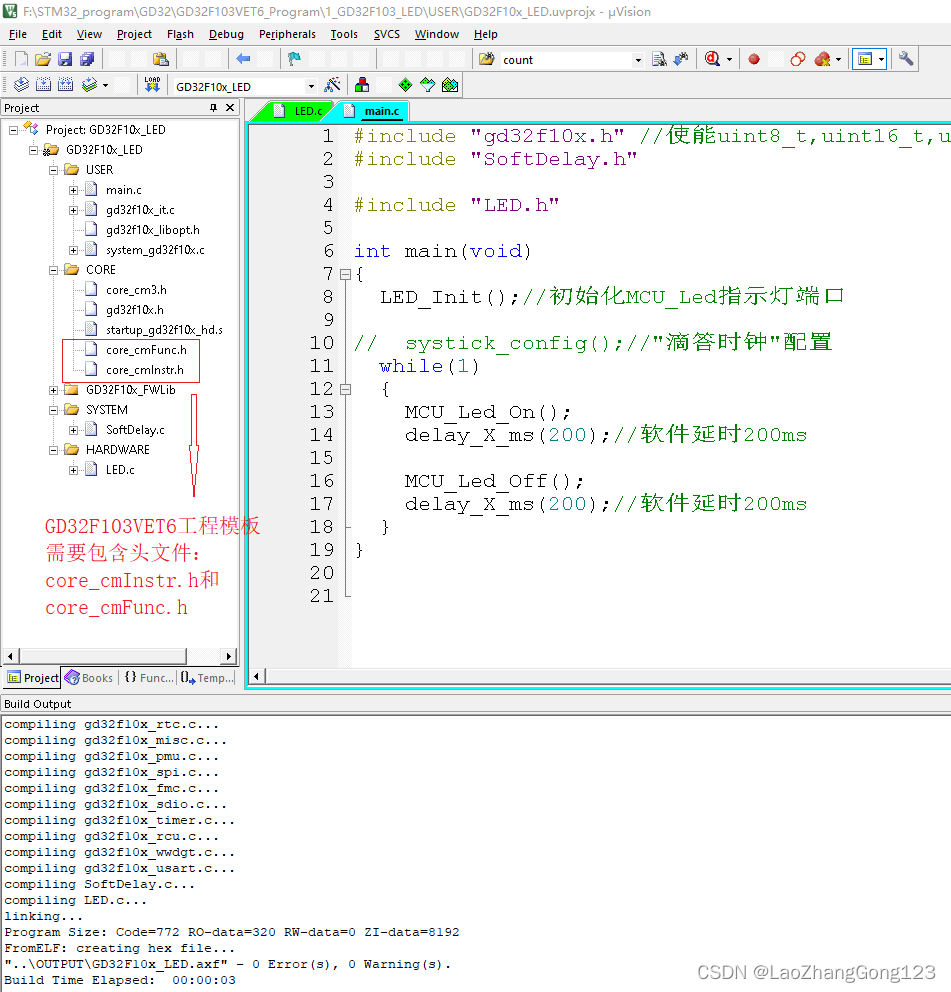
error: #5: cannot open source input file “core_cmInstr.h“
GD32F103VET6和STM32F103VET6引脚兼容。 GD32F103VET6工程模板需要包含头文件:core_cmInstr.h和core_cmFunc.h,这个和STM32F103还是有区别的,否则会报错,如下: error: #5: cannot open source input file "core…...

FastAPI 教程、结合vue实现前后端分离
英文版文档:https://fastapi.tiangolo.com/ 中文版文档:https://fastapi.tiangolo.com/zh/ 1、FastAPI 教程 简 介 FastAPI 和 Sanic 类似,都是 Python 中的异步 web 框架。相比 Sanic,FastAPI 更加的成熟、社区也更加的活跃。 …...
算法通关村第四关——如何基于数组(链表)实现栈
栈的基础知识 栈的特征 特征1 栈和队列是比较特殊的线性表,又被称为 访问受限的线性表。栈是很多表达式、符号等运算的基础,也是递归的底层实现(递归就是方法自己调用自己,在JVM的虚拟机栈中,一个线程中的栈帧就是…...

Postgresql警告日志的配置
文章目录 1.postgresql与日志有关的参数2.开启日志3.指定日志目录4.設置文件名format5.設置日志文件產出模式6.設置日志记录格式7.日誌輪換7.1非截斷式輪換7.2 截斷式輪換 8.日誌記錄內容8.1 log_statement8.2 log_min_duration_statement 9 輸出範本 1.postgresql与日志有关的…...

Java、JSAPI、 ssm架构 微信支付demo
1.前端 index.html <%page import"com.tenpay.configure.WxPayConfig"%> <% page language"java" contentType"text/html; charsetUTF-8" pageEncoding"UTF-8"%> <html><style>#fukuan{font-size: 50px;marg…...
MongoDB文档--基本安装-linux安装(mongodb环境搭建)-docker安装(挂载数据卷)-以及详细版本对比
阿丹: 前面了解了mongodb的一些基本概念。本节文章对安装mongodb进行讲解以及汇总。 官网教程如下: 安装 MongoDB - MongoDB-CN-Manual 版本特性 下面是各个版本的选择请在安装以及选择版本的时候参考一下: MongoDB 2.x 版本:…...

tomcat限制IP访问
tomcat可以通过增加配置,来对来源ip进行限制,即只允许某些ip访问或禁止某些来源ip访问。 配置路径:server.xml 文件下 标签下。与同级 <Valve className"org.apache.catalina.valves.RemoteAddrValve" allow"192.168.x.x&…...

互联网宠物医院系统开发:数字化时代下宠物医疗的革新之路
随着人们对宠物关爱意识的提高,宠物医疗服务的需求也日益增加。传统的宠物医院存在排队等待、预约难、信息不透明等问题,给宠物主人带来了诸多不便。而互联网宠物医院系统的开发,则可以带来许多便利和好处。下面将介绍互联网宠物医院系统开发…...

docker镜像批量导出导入
docker镜像批量导出导入 image_tar为存储镜像目录 删除所有容器 一、首先需要停止所有运行中的容器 docker stopdocker ps -a -q docker ps -a -q 意思是列出所有容器(包括未运行的),只显示容器编号,其中 -a : 显示所有的容器&…...
宇凡微2.4g遥控船开发方案,采用合封芯片
2.4GHz遥控船的开发方案是一个有趣且具有挑战性的项目。这样的遥控船可以通过无线2.4GHz频率进行远程控制,让用户在池塘或湖泊上畅游。以下是一个简要的2.4GHz遥控船开发方案: 基本构想如下 mcu驱动两个小电机,小电机上安装两个螺旋桨&#…...
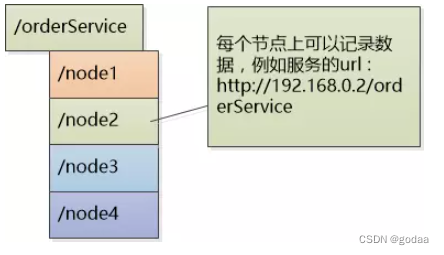
RPC框架引入zookeeper服务注册与服务发现
Zookeeper概念及其作用 ZooKeeper是一个分布式的,开放源码的分布式应用程序协调服务,是Google的Chubby一个开源的实现,是大数据生态中的重要组件。它是集群的管理者,监视着集群中各个节点的状态根据节点提交的反馈进行下一步合理…...
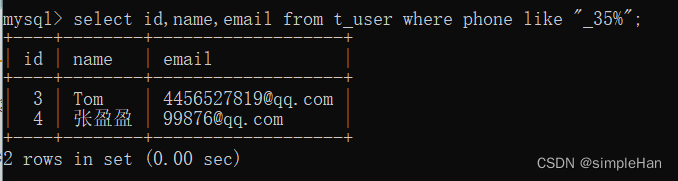
MySQL用通配符过滤数据
简单的不使用通配符过滤数据的方式使用的值都是已知的,但是当搜索产品名中包含ashui的所有产品时,用简单的比较操作符肯定不行,必须使用通配符。利用通配符可以创建比较特定数据的搜索模式。 通配符:用来匹配值的一部分的特殊字符…...

低通、高通、带通、阻通滤波器
目录 低通、高通、带通、阻通滤波器 低通、高通、带通、带阻滤波器的区别 通俗理解: 1、低通滤波器 2、高通滤波器 3、带通滤波器 4、带阻滤波器 5、全通滤波器 低通、高通、带通、阻通滤波器 低通、高通、带通、带阻滤波器的区别 低通滤波器:只…...

IDEA SpringBoot Maven profiles 配置
IDEA SpringBoot Maven profiles 配置 IDEA版本: IntelliJ IDEA 2022.2.3 注意:切换环境之后务必点击一下刷新,推荐点击耗时更短。 application.yaml spring:profiles:active: env多环境文件名: application-dev.yaml、 applicat…...

微信小程序 背景图片如何占满整个屏幕
1. 在页面的wxss文件中,设置背景图片的样式: page{background-image: url(图片路径);background-size: 100% 100%;background-repeat: no-repeat; } 2. 在页面的json文件中,设置背景图片的样式: {"backgroundTextStyle&qu…...

邪恶版ChatGPT来了!
「邪恶版」ChatGPT 出现:每月 60 欧元,毫无道德限制,专为“网络罪犯”而生。 WormGPT 并不是一个人工智能聊天机器人,它的开发目的不是为了有趣地提供无脊椎动物的人工智能帮助,就像专注于猫科动物的CatGPT一样。相反&…...
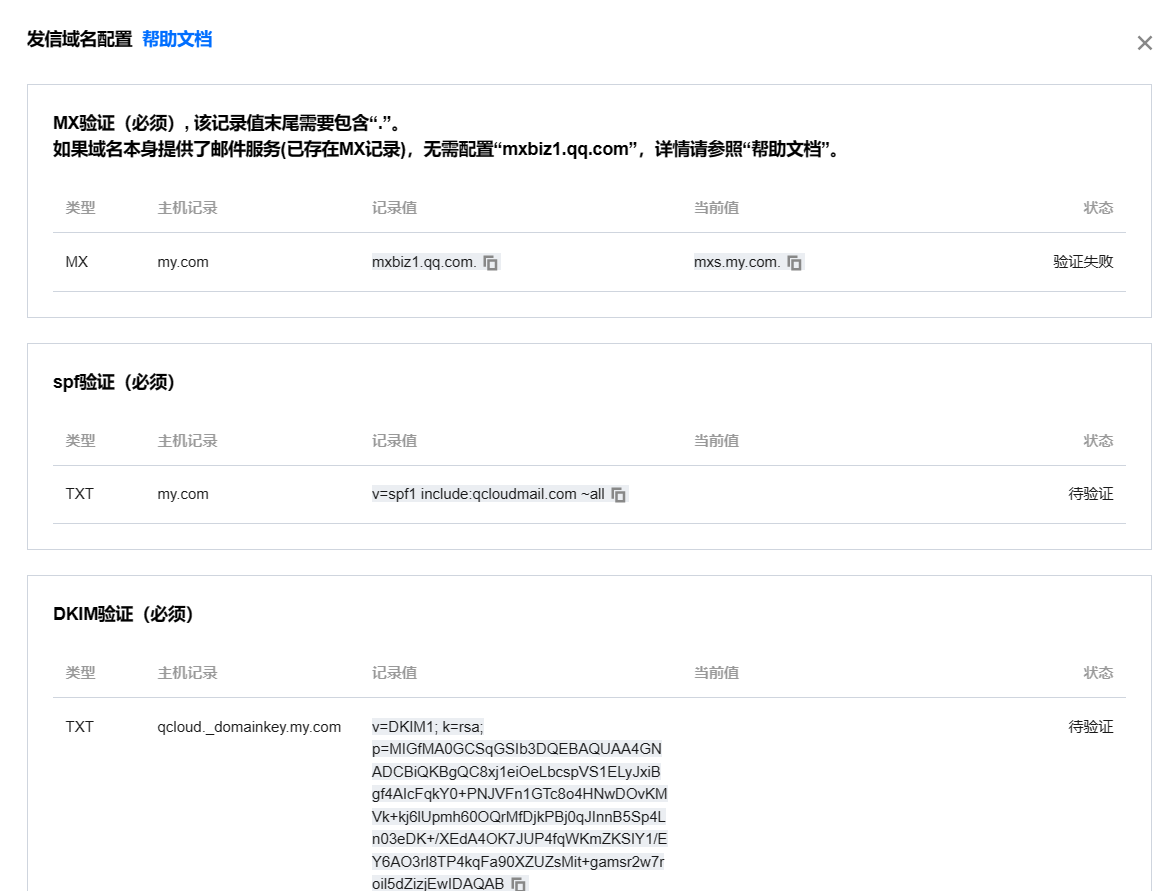
一、Postfix[安装与配置、smtp认证、Python发送邮件以及防垃圾邮件方法、使用腾讯云邮件服务]
Debian 11 一、安装 apt install postfix 二、配置 1.dns配置 解释:搭建真实的邮件服务器需要在DNS提供商那里配置下面的dns 配置A记录mail.www.com-1.x.x.x配置MX记录www.com-mail.www.com 解释:按照上面的配置通常邮件格式就是adminwww.com其通过…...

React哲学——官方示例
在本篇技术博客中,我们将介绍React官方示例:React哲学。我们将深入探讨这个示例中使用的组件化、状态管理和数据流等核心概念。让我们一起开始吧! 项目概览 React是一个流行的JavaScript库,用于构建用户界面。React的设计理念是…...
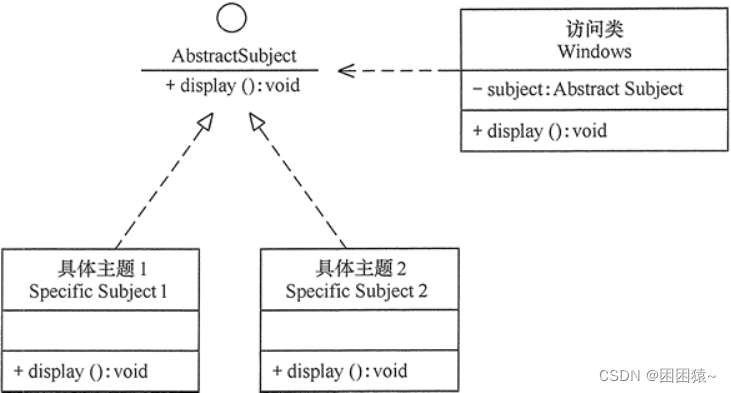
设计模式之开闭原则
什么是开闭原则? 开放封闭原则称为OCP原则(Open Closed Principle)是所有面向对象原则的核心。 “开闭原则”是面向对象编程中最基础和最重要的设计原则之一。 软件设计本身所追求的目标就是封装变化、降低耦合,而开放封闭原则正是对这一…...

64_《智能体微服务架构企业级实战教程》授权与认证之授权认证集成测试
前言 配套视频教程: 在 Bilibili课堂、CSDN课程、51CTO学堂 同步发售,提供:源码+部署脚本+文档。 bilibili课堂视频教程:智能体微服务架构企业级实战教程_哔哩哔哩_bilibili CSDN课程视频教程:智能体微服务架构企业级实战教程_在线视频教程-CSDN程序员研修院 51CTO学堂…...

量子计算中Loschmidt回声相位测量的创新方法
1. 量子计算中的Loschmidt回声相位测量方法概述Loschmidt回声是量子动力学中一个重要的概念,它描述了量子系统在时间反演演化后与初始状态的相似程度。在量子计算领域,精确测量Loschmidt回声的相位信息对于理解量子系统的非平衡态行为、计算能量本征值以…...

如何用SMUDebugTool彻底掌控你的AMD Ryzen处理器性能调优
如何用SMUDebugTool彻底掌控你的AMD Ryzen处理器性能调优 【免费下载链接】SMUDebugTool A dedicated tool to help write/read various parameters of Ryzen-based systems, such as manual overclock, SMU, PCI, CPUID, MSR and Power Table. 项目地址: https://gitcode.co…...

Python 3.7 + XGBoost 多分类实战:从数据清洗到SHAP模型解释的保姆级教程
Python 3.7 XGBoost 多分类实战:从数据清洗到SHAP模型解释的保姆级教程在机器学习领域,XGBoost因其出色的性能和可解释性成为众多数据科学家的首选工具。本文将带您完整走过多分类任务的全流程,从原始数据到可解释的预测模型,每个…...

物联网与云技术赋能咖啡后处理:CeriTech 的实时监控系统实践
1. 项目概述:用物联网与云技术重塑咖啡后处理在印尼的咖啡农场里,传统的发酵与干燥过程很大程度上依赖“感觉”和“经验”。一位有经验的农人可能会用手触摸、用鼻子闻,或者根据天气和日照时间来估算发酵是否完成、干燥是否均匀。这种方法固然…...

Java数组工具类实战:设计不可实例化的静态工具类
实现一个工具类 MathUtils,满足以下要求: 1. 所有方法均为静态,且该类不能从外部实例化(提示:使用私有构造器)。 2. 提供三个静态方法:- maxArray(int[] arr):返回较大值;…...

SSH工具对比:新手用户和熟练运维,选型逻辑有什么不同
结论 新手用户和熟练运维在选择 SSH 工具时,关注点往往完全不同。 新手更在意的是:能不能顺利连接、界面是否直观、文件和配置是否容易找到、网站出问题时能不能快速定位。 而熟练运维更在意的是:连接效率、命令自由度、多服务器管理能力、原…...

PCB的常规机械通孔与HDI工艺钻孔差异
结合常规 4 层通孔 PCB(非 HDI) 标准制程,分步骤讲清钻孔时机、先后顺序,区分机械通孔与板件结构,专业且贴合工厂实际流程。一、先明确 4 层通孔板基础结构4 层板结构:L1 → PP 半固化片 → L2/L3ÿ…...

Graphin高级应用:结合GISDK构建配置化图分析模块的完整指南
Graphin高级应用:结合GISDK构建配置化图分析模块的完整指南 【免费下载链接】Graphin 🌌 A React toolkit for graph visualization based on G6. 项目地址: https://gitcode.com/gh_mirrors/gr/Graphin 在当今数据驱动的时代,图可视化…...

通过Taotoken实现Hermes Agent自定义模型供应商接入
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 通过Taotoken实现Hermes Agent自定义模型供应商接入 Hermes Agent是一个流行的AI智能体开发框架,它支持通过配置自定义…...