Hive 安装介绍
介绍
Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供类SQL查询功能。
其本质是将SQL转换为MapReduce的任务进行运算,底层由HDFS来提供数据的存储,说白了hive可以理解为一个将SQL转换为MapReduce的任务的工具,甚至更进一步可以说hive就是一个MapReduce的客户端。
官网
### 官网
https://hive.apache.org/## 中文参考
https://www.docs4dev.com/docs/zh/apache-hive/3.1.1/reference/LanguageManual_DML.htmlHive的安装模式
内嵌模式: 内嵌式是内嵌在derby数据库俩存储元数据,也不需要额外起Metastore服务。数据库和Metastore服务都嵌入在主Hive Server进程中。这个是默认的,配置简单,但是一次只能一个客户端连接, 比较适合实验,不能用于生产环境。
本地模式: 本地模式采用外部数据库来存储元数据,目前支持的数据库有:mysql、postgre。本地模式不需要单独起metastore服务,用的是跟hive在同一个进程里的metastore服务。也就是说当你启动一个hive服务,里面默认会帮我们启动一个metastore服务。
远程模式: 远程模式下,需要单独起metastore服务,然后每个客户端都在配置文件里配置连接到该metastore服务。远程模式的metastore服务和hive运行在不同的进程中。在生产环境中,建议用远程模式来配置Hive metastore。在这种情况下,其他依赖hive的软件都可以通过访问metastore 访问hive
安装
##
cd /opt/software
tar -zxvf apache-hive-3.1.1-bin.tar.gz -C /opt/module/##
vi /etc/profile##
export HIVE_HOME=/opt/module/apache-hive-3.1.1-bin
export PATH=$PATH:$HADOOP_HOME/sbin:$HIVE_HOME/bin##
source /etc/profile## 修改hive的环境变量
cd /opt/module/apache-hive-3.1.1-bin/bin/ && vi hive-config.shexport JAVA_HOME=/opt/module/jdk1.8.0_11
export HIVE_HOME=/opt/module/apache-hive-3.1.1-bin
export HADOOP_HOME=/opt/module/hadoop-3.2.0
export HIVE_CONF_DIR=/opt/module/apache-hive-3.1.1-bin/conf## 拷贝hive的配置文件
cd /opt/module/apache-hive-3.1.1-bin/conf/
cp hive-default.xml.template hive-site.xml- 修改Hive配置文件,找到对应的位置进行修改: 主要是修改连接Mysql
<property><name>javax.jdo.option.ConnectionDriverName</name><value>com.mysql.cj.jdbc.Driver</value><description>Driver class name for a JDBC metastore</description></property>
<property><name>javax.jdo.option.ConnectionUserName</name><value>root</value><description>Username to use against metastore database</description></property>
<property><name>javax.jdo.option.ConnectionPassword</name><value>root123</value><description>password to use against metastore database</description></property>
<property><name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://192.168.202.131:3306/hive?useUnicode=true&characterEncoding=utf8&useSSL=false&serverTimezone=GMT</value><description>JDBC connect string for a JDBC metastore.To use SSL to encrypt/authenticate the connection, provide database-specific SSL flag in the connection URL.For example, jdbc:postgresql://myhost/db?ssl=true for postgres database.</description></property><property><name>datanucleus.schema.autoCreateAll</name><value>true</value><description>Auto creates necessary schema on a startup if one doesn't exist. Set this to false, after creating it once.To enable auto create also set hive.metastore.schema.verification=false. Auto creation is not recommended for production use cases, run schematool command instead.</description></property>
<property><name>hive.metastore.schema.verification</name><value>false</value><description>Enforce metastore schema version consistency.True: Verify that version information stored in is compatible with one from Hive jars. Also disable automaticschema migration attempt. Users are required to manually migrate schema after Hive upgrade which ensuresproper metastore schema migration. (Default)False: Warn if the version information stored in metastore doesn't match with one from in Hive jars.</description></property>
<property><name>hive.exec.local.scratchdir</name><value>/opt/module/apache-hive-3.1.1-bin/tmp/${user.name}</value><description>Local scratch space for Hive jobs</description></property><property>
<name>system:java.io.tmpdir</name>
<value>/opt/module/apache-hive-3.1.1-bin/iotmp</value>
<description/>
</property><property><name>hive.downloaded.resources.dir</name>
<value>/opt/module/apache-hive-3.1.1-bin/tmp/${hive.session.id}_resources</value><description>Temporary local directory for added resources in the remote file system.</description></property>
<property><name>hive.querylog.location</name><value>/opt/module/apache-hive-3.1.1-bin/tmp/${system:user.name}</value><description>Location of Hive run time structured log file</description></property><property><name>hive.server2.logging.operation.log.location</name>
<value>/opt/module/apache-hive-3.1.1-bin/tmp/${system:user.name}/operation_logs</value><description>Top level directory where operation logs are stored if logging functionality is enabled</description></property><property><name>hive.metastore.db.type</name><value>mysql</value><description>Expects one of [derby, oracle, mysql, mssql, postgres].Type of database used by the metastore. Information schema & JDBCStorageHandler depend on it.</description></property><property><name>hive.cli.print.current.db</name><value>true</value><description>Whether to include the current database in the Hive prompt.</description></property><property><name>hive.cli.print.header</name><value>true</value><description>Whether to print the names of the columns in query output.</description></property><property><name>hive.metastore.warehouse.dir</name><value>/user/hive/warehouse</value><description>location of default database for the warehouse</description></property>
上传mysql驱动包到/usr/local/soft/apache-hive-3.1.1-bin/lib/文件夹下,驱动包:mysql-connector-java-8.0.15.zip,解压后从里面获取jar包。
- 确保 mysql数据库中有名称为hive的数据库
- 初始化初始化元数据库
schematool -dbType mysql -initSchema
- 确保Hadoop启动
- 启动hive
# 启动
hive## 检测是否启动成功
show databases;
hive常用命令
## 启动hive
[linux01 hive]$ bin/hive## 显示数据库
hive>show databases;## 使用default数据库
hive>use default;
## 显示default数据库中的表
hive>show tables;## 创建student表, 并声明文件分隔符’\t’
hive> create table student(id int, name string) ROW FORMAT DELIMITED FIELDS TERMINATED BY ‘\t’;
相关文章:

Hive 安装介绍
介绍 Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供类SQL查询功能。 其本质是将SQL转换为MapReduce的任务进行运算,底层由HDFS来提供数据的存储,说白了hive可以理解为一个将SQL转换为Ma…...

npm ERR! code EPERM npm ERR! syscall unlink npm ERR!错误解决方法
npm ERR! code EPERM npm ERR! syscall unlink npm ERR!错误解决方法 1、问题描述2、解决方法 1、问题描述 由于之前电脑系统的原因,电脑重置了一下,之前安装的环境都没了,然后在重新安装node.js后在使用npm安装时总是报如下错误:…...
redis 高级篇4 分布式锁
一 redis架构图 1.1 redis的架构图 1.2 分布式锁满足条件 1.独占性;2.高可用;3.防死锁;4.不乱抢;5.重入性 二 分布式锁的案例情况 2.1 分布式锁1:单机分布式部署 描述: 使用lock锁和synchronized,单机…...

TPU-NNTC 编译部署LPRNet 车牌识别算法
TPU-NNTC 编译部署LPRNet 车牌识别算法 注意: 由于SOPHGO SE5微服务器的CPU是基于ARM架构,以下步骤将在基于x86架构CPU的开发环境中完成 初始化开发环境(基于x86架构CPU的开发环境中完成)模型转换 (基于x86架构CPU的开发环境中完成) 处理后的LPRNet 项…...
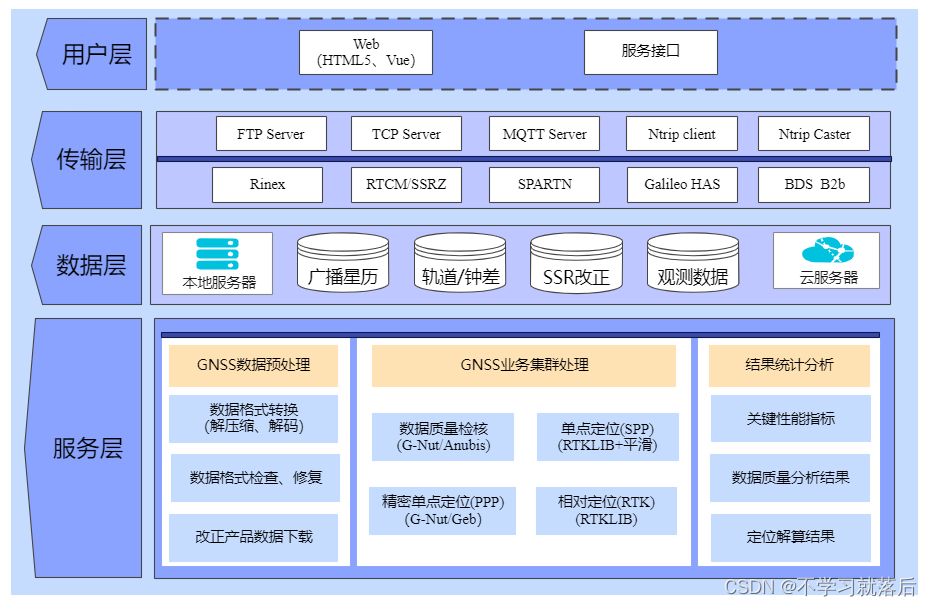
在线/开源GNSS处理软件/平台介绍
当前,存在较多的GNSS开源/免费软件,可用于质量检核、RTK解算和PPP解算等,本文总结了部分常用的处理软件,其详细信息如表1和表2所示。 表1 常用GNSS预处理(格式转换、质量检核)软件: 软件名称 …...

SpringBoot集成企业微信群聊机器人消息
目录 参考文档概述一、功能作用二、应用场景三、 群机器人发送限制四、创建机器人1、添加2、群机器人Webhook地址 五、发送消息1、文本 text请求体 图文连接 news 参考文档 官方文档 企业微信群机器人应用 概述 现在很多企业都在使用企业微信进行工作交流,自从企…...

五、驱动 - 音频系统硬件电路
文章目录 1. 音频系统硬件电路结构2. 蓝牙音频2.1 音乐播放2.2 VoIP通话2.3 4G通话3. 其他3.1 什么是S/PDIF1. 音频系统硬件电路结构 录音放音设备:mic、speaker、耳机、听筒这些带有录音放音功能的设备(因为录放设备可能是模拟设备也可能是数字设备,所以接口可能是模拟接口…...
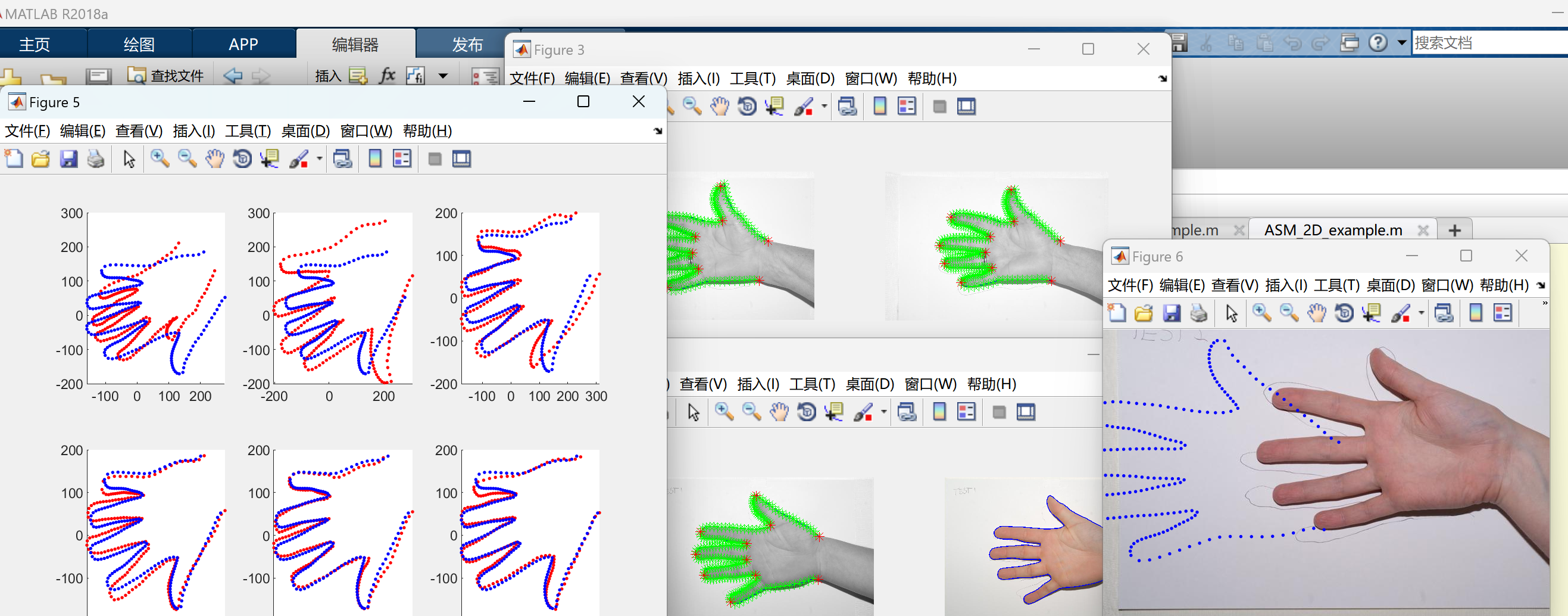
【图像分割和识别】活动形状模型 (ASM) 和活动外观模型 (AAM)(Matlab代码实现)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…...

HTML基础介绍2
表单格式化 ctrld:复制选中行数的所有代码 ctrlx:删除代码 <!DOCTYPE html> <html lang"en"> <head><meta charset"UTF-8"><title>表单综合案例</title> </head> <body> <!--…...
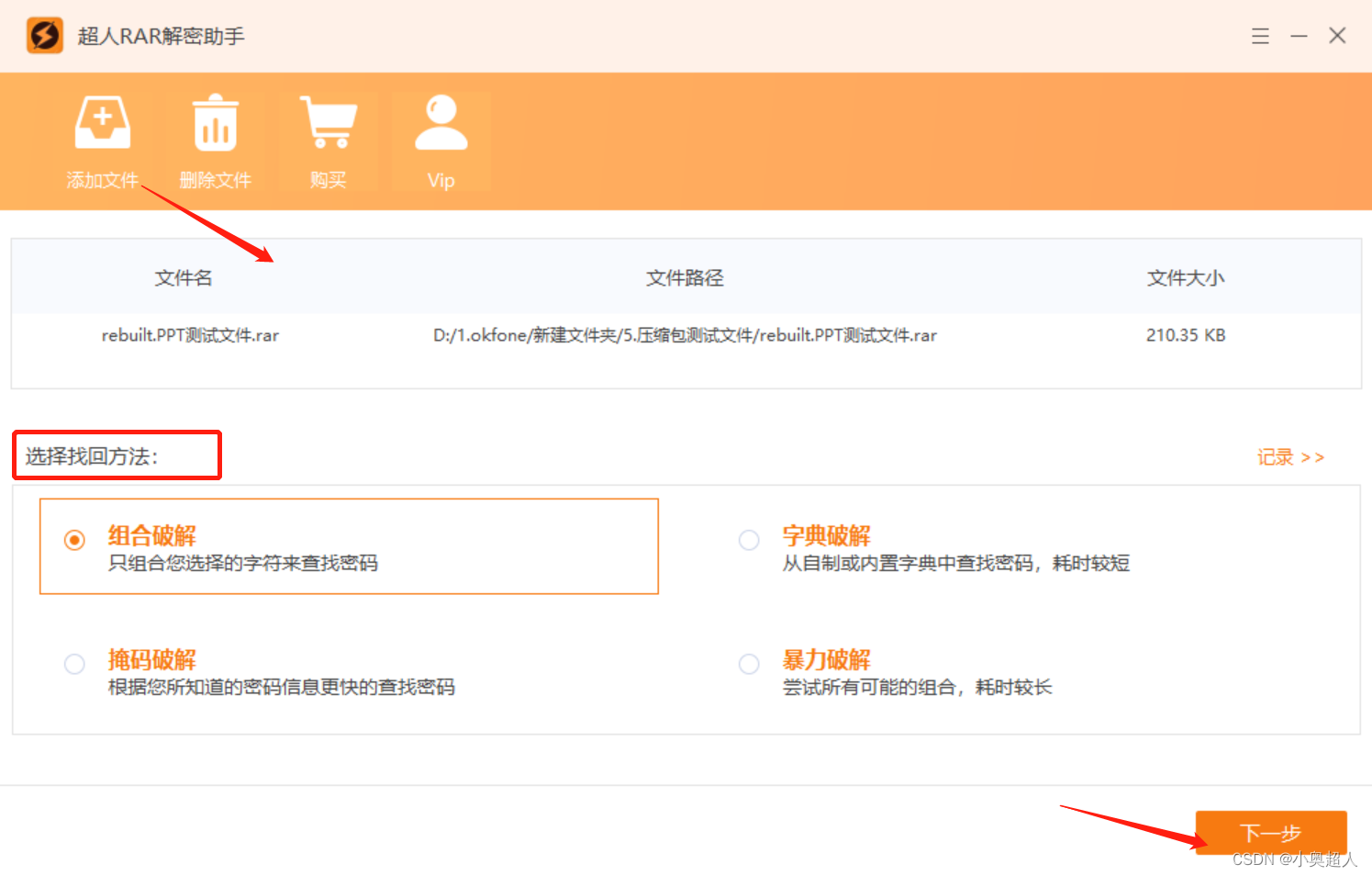
rar压缩包怎么改成zip格式
不知道大家有没有遇到需要转换压缩包格式的问题,今天想和大家分享rar压缩包改成zip格式的方法。 方法一: 直接修改rar压缩包的后缀名变为zip,就可以修改压缩包文件格式了 方法二: 先将rar压缩包解压出来,然后再将解…...

Mac 补丁管理
Mac 补丁管理涉及通过扫描收集所有缺失补丁的完整列表、下载缺失的补丁、在非生产计算机上测试它们,最后将它们推广到生产环境中进行部署来管理 macOS 端点,修补 Mac 设备(又称 Mac 修补)可增强 macOS 环境的安全级别。 什么是 m…...
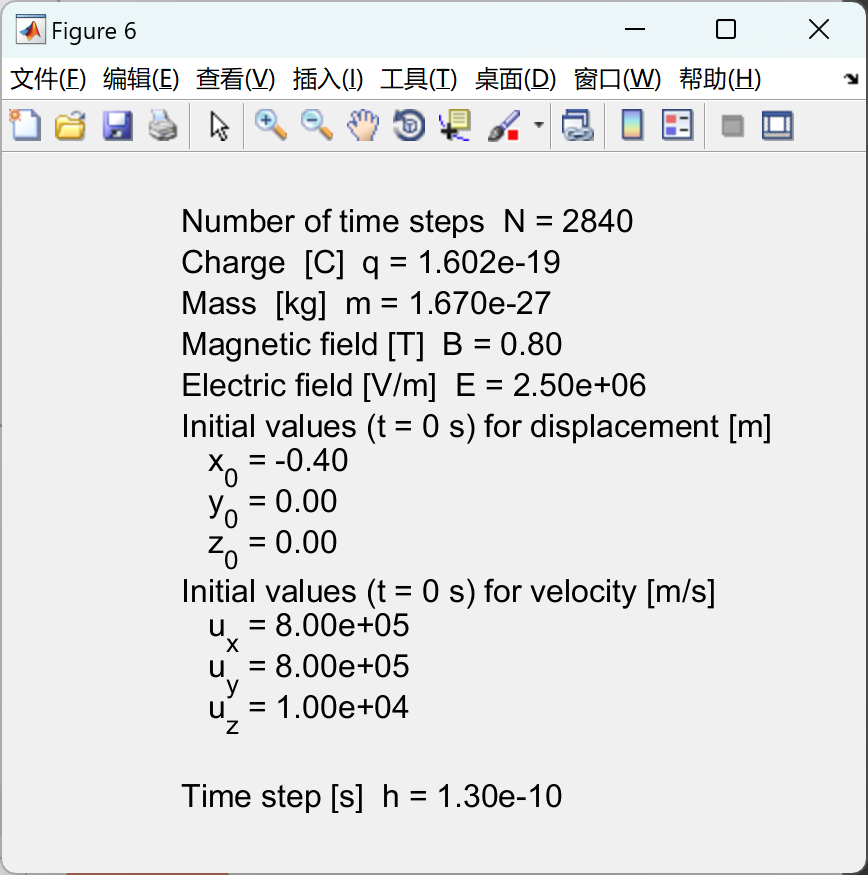
【物理】带电粒子在磁场和电场中移动的 3D 轨迹研究(Matlab代码实现)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…...

【云原生】K8S二进制搭建上篇
目录 一、环境部署1.1操作系统初始化 二、部署etcd集群2.1 准备签发证书环境在 master01 节点上操作在 node01与02 节点上操作 三、部署docker引擎四、部署 Master 组件4.1在 master01 节点上操 五、部署Worker Node组件 一、环境部署 集群IP组件k8s集群master01192.168.243.1…...
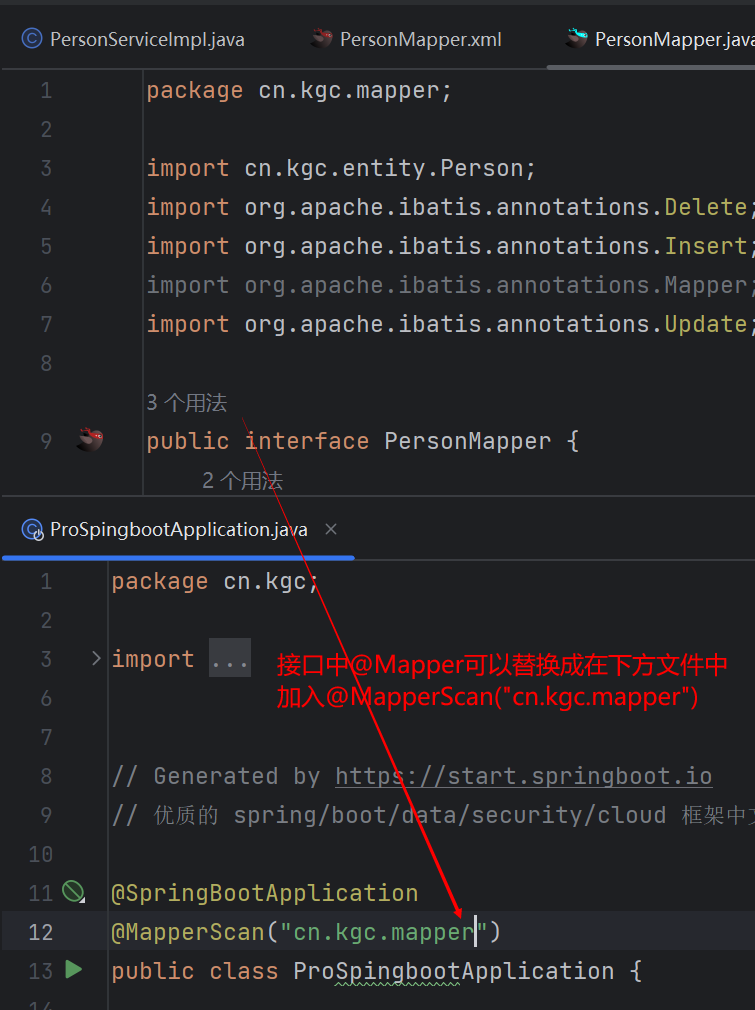
day49-Springboot
Springboot 1. Springboot简介 1.1 简介:Springboot来简化Spring应用开发的一个框架,约定大于配置 1.2 优点: 可以快速的构建独立运行的Spring项目; 框架内有Servlet容器,无需依赖外部,所以不需要达成w…...

Day 9 字符串
慢慢补。 Prefixes and Suffixes 水个代码先。 代码...

Promise用法
学习了promise之后,有点懂但让我说又说不出来,参考别人的记录一下。 1.什么是promise? 2.promise解决了什么问题 3.es6 promise语法 (1)then链式操作语法 (2)catch的语法 (3…...

JSP教程_编程入门自学教程_菜鸟教程-免费教程分享
教程简介 JSP(全称Java Server Pages)是由Sun Microsystems公司主导创建的一种动态网页技术标准。JSP部署于网络服务器上,可以响应客户端发送的请求,并根据请求内容动态地生成HTML、XML或其他格式文档的Web网页,然后返…...
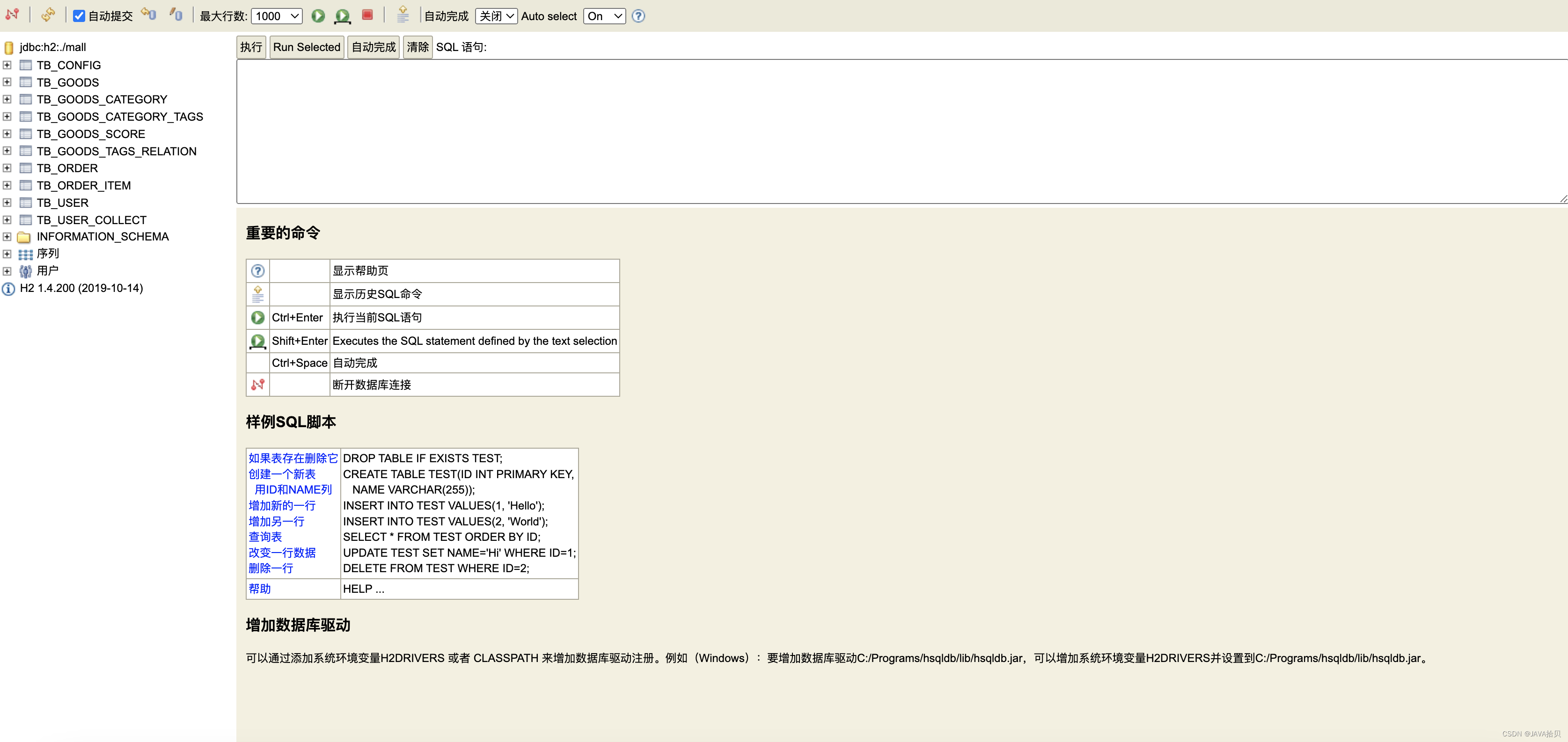
极简在线商城系统,支持docker一键部署
Hmart 给大家推荐一个简约自适应电子商城系统,针对虚拟商品在线发货,支持企业微信通知,支持docker一键部署,个人资质也可搭建。 前端 后端 H2 console 运行命令 docker run -d --name mall --restartalways -p 8080:8080 -e co…...
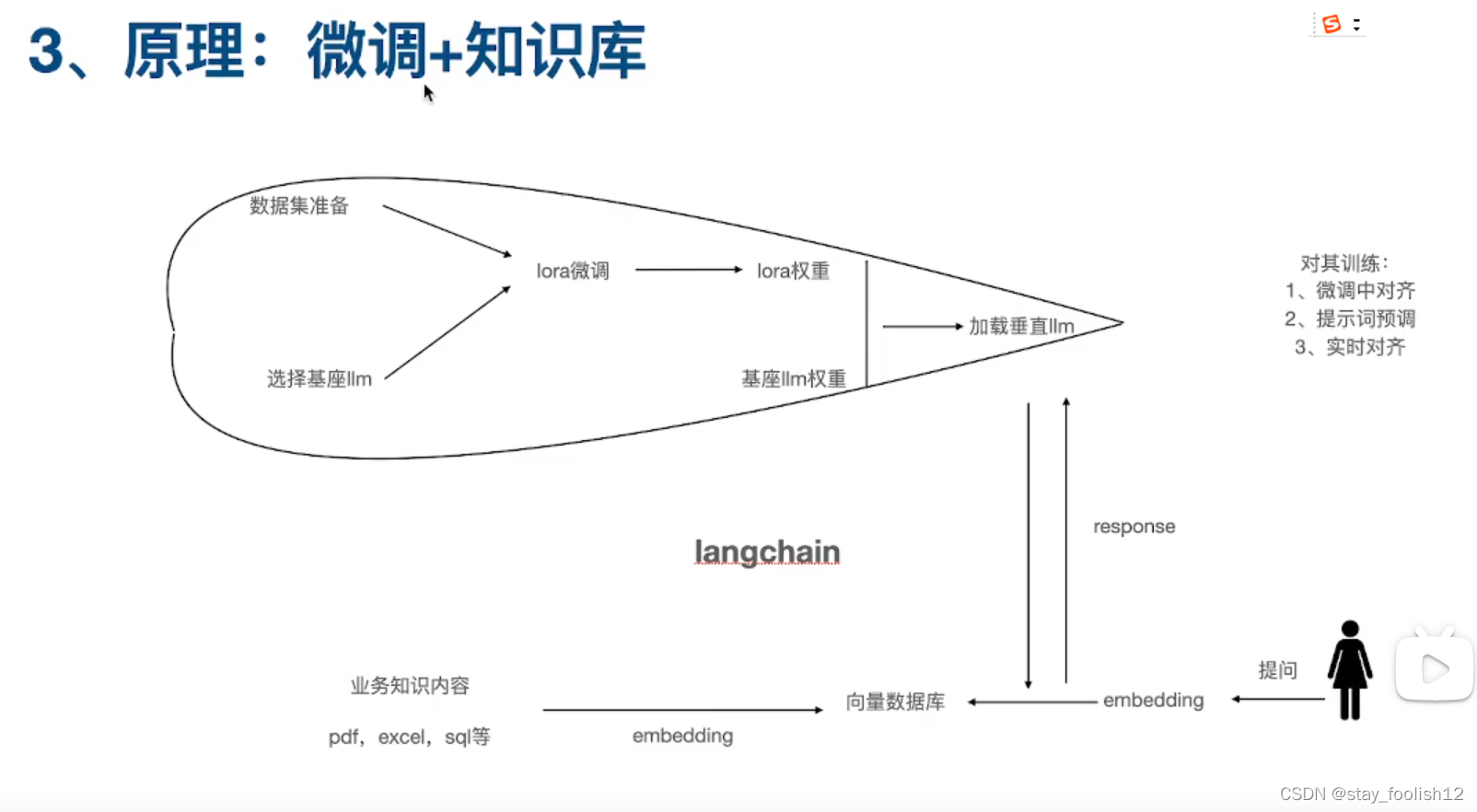
如何微调医疗大模型llm:llama2学习笔记
三个微调方向:简单医疗问答 临床问答 影像学 一般流程: 1 数据集准备 2 模型基座选择 3 微调 4 案例拆解 1 数据集准备:两种类型,一种文本一种影像 扩展,多模态 2 模型基座选择 多模态处理所有视频,文本…...
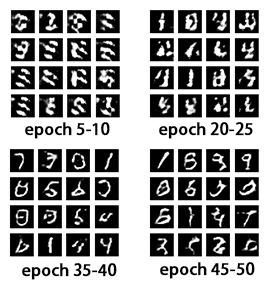
生成对抗网络DCGAN学习
在AI内容生成领域,有三种常见的AI模型技术:GAN、VAE、Diffusion。其中,Diffusion是较新的技术,相关资料较为稀缺。VAE通常更多用于压缩任务,而GAN由于其问世较早,相关的开源项目和科普文章也更加全面&#…...

Visual Studio 项目属性页开发完全教程:从基础到高级
Visual Studio 项目属性页开发完全教程:从基础到高级 【免费下载链接】project-system The .NET Project System for Visual Studio 项目地址: https://gitcode.com/gh_mirrors/pr/project-system Visual Studio 项目属性页是开发者管理项目配置的核心界面&a…...

别再只用Service了!ROS1 Action通信保姆级教程:从导航进度条到任务取消,手把手教你实现带反馈的机器人任务
别再只用Service了!ROS1 Action通信保姆级教程:从导航进度条到任务取消,手把手教你实现带反馈的机器人任务当你的机器人正在执行一个长达10分钟的导航任务时,突然发现目标点设置错误,这时候如果只能干等着任务完成或者…...
)
别再乱用npm install了!手把手教你用npx only-allow为项目指定包管理器(支持pnpm/yarn/npm)
用only-allow统一团队包管理器:从配置到CI的全流程指南 你是否曾经在拉取一个新项目后,面对npm install、yarn还是pnpm i的抉择感到困惑?或者更糟的是,团队成员混用不同包管理器导致node_modules结构不一致,引发各种诡…...

用STM32CubeMX和HAL库快速上手WS2812B:告别手动计算延时,一键生成驱动框架
基于STM32CubeMX的WS2812B智能灯光控制:从零构建现代化驱动方案在智能硬件和物联网设备快速发展的今天,WS2812B可编程LED灯带因其丰富的色彩表现和简单的单线控制方式,成为创客和工程师们最喜爱的显示组件之一。然而,传统的寄存器…...

上线前最后一道防线,DeepSeek代码审查如何帮你拦截87%的CVE类缺陷?
更多请点击: https://intelliparadigm.com 第一章:上线前最后一道防线,DeepSeek代码审查如何帮你拦截87%的CVE类缺陷? 在软件交付生命周期末期,传统人工代码审计与通用SAST工具常因误报率高、上下文理解弱而漏检高危漏…...

Owl-Alpha 新手快速上手指南
在处理大规模数据或构建高性能应用时,我们常常会遇到一个棘手的问题:如何在不阻塞主线程的情况下,高效地执行耗时任务?无论是处理图像、解析大型文件,还是进行复杂的数学运算,传统的单线程模式往往会让界面…...

企业内统一API网关与Taotoken聚合平台对接方案
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 企业内统一API网关与Taotoken聚合平台对接方案 在推进AI应用落地的过程中,许多中大型企业面临一个共同挑战:…...

Atomic Layout核心概念解析:Composition组件如何实现布局与间距分离的终极指南
Atomic Layout核心概念解析:Composition组件如何实现布局与间距分离的终极指南 【免费下载链接】atomic-layout Build declarative, responsive layouts in React using CSS Grid. 项目地址: https://gitcode.com/gh_mirrors/at/atomic-layout Atomic Layout…...

如何用WaveTools终极优化《鸣潮》游戏性能:从卡顿到丝滑的完整指南
如何用WaveTools终极优化《鸣潮》游戏性能:从卡顿到丝滑的完整指南 【免费下载链接】WaveTools 🧰鸣潮工具箱 项目地址: https://gitcode.com/gh_mirrors/wa/WaveTools 如果你正在玩《鸣潮》却频繁遭遇帧率波动、画面卡顿或操作延迟,那…...

用图神经网络做缺陷定位,准确率比传统方法高出30%
在现代软件工程的复杂迷宫中,缺陷定位始终是测试团队面临的核心挑战。想象这样一个场景:一个电商系统在特定压力条件下偶发订单丢失,日志中只留下泛泛的超时错误,问题可能深藏在上百个微服务的调用链、分布式事务的竞态条件或某个…...