ftrace 原理详细分析
===============================》内核新视界文章汇总《===============================
文章目录
- ftrace 原理分析
- 1 简介
- 2 ftrace 的编译器支持
- 2.1 HAVE_FUNCTION_TRACER 选项对 ftrace 的支持
- 2.2 HAVE_DYNAMIC_FTRACE 选项对动态 ftrace 的支持
- 3 ftrace 的初始化
- 4 function trace 流程
- 5 总结
ftrace 原理分析
1 简介
ftrace 是一个内核内部跟踪程序,用于帮助系统开发者和设计者观察内核内部正在发生的事情。它可以用于调试和分析用户空间之外的延迟和性能问题。
ftrace 的本意是指function tracer,这是因为它最开始主要是为了跟踪与采集内核运行时,函数的调用与执行情况。经过不断发展,ftrace逐渐提供了各类跟踪功能。例如,查看进程上下文切换的相关信息、系统中断被禁用的时间以及高优先级进程从被唤醒到被系统调度执行期间的最大延迟时间等等。这些功能可以很好的辅助内核开发和研究人员对内核进行调试, 并及时发现内核中的各类问题。另外,ftrace也具有很好的拓展性, 它提供了一些简洁易用的接口来允许开发者以插件的形式添加和使用更多种类的跟踪器(tracer) , 正因如此, 其逐渐发展成为了一个内核跟踪框架。一些常见的ftrace跟踪器如下:
| 跟踪器 | 相关功能描述 |
|---|---|
| function | 函数调用跟踪程序来跟踪所有内核函数。 |
| function_graph | 与函数跟踪程序相似,不同之处在于函数跟踪程序在函数的入口探测函数,而函数图跟踪程序在函数的入口和出口都进行跟踪。然后,它提供了绘制函数调用图的能力,类似于C源代码。 |
| blk | 阻塞式输入输出跟踪器, 跟踪记录Block I/O 相关信息 |
| irqsoff | 跟踪禁用中断的区域,并以最长的最大延迟保存跟踪。看tracing_max_latency文件。当记录新的max时,它将替换旧的跟踪值。最好在启用"latency-format"选项的情况下查看此跟踪,这在选择跟踪程序时自动设置。 |
| preemptoff | 类似于irqsoff,但是跟踪和记录抢占被禁用的时间量 |
| preemptirqsoff | 类似于irqsoff和preemptoff,但是跟踪和记录irqs和/或抢占被禁用的最大时间。 |
| wakeup | 跟踪和记录在最高优先级任务被唤醒后实际调度它所需要的最大延迟。按照一般开发人员的预期跟踪所有任务。 |
| wakeup_rt | 跟踪和记录RT任务所需要的最大延迟。这对于那些对RT任务的唤醒时间感兴趣的人很有用。 |
| wakeup_dl | 跟踪和记录唤醒SCHED_DEADLINE任务所需的最大延迟(与“wakeup”和“wakeup_rt”一样)。 |
| mmiotrace | 一种用于跟踪二进制模块的特殊跟踪程序。它将跟踪一个模块对硬件的所有调用。它也从I/O中写入和读取所有内容。 |
| branch | 这个跟踪程序可以在跟踪内核中可likely/unlikley的调用时配置。它将跟踪何时命中可能和不可能的分支,以及它的预测是否正确。 |
同样的,Ftrace还有个最常见的用途是 event 跟踪。内核有数百个静态事件点,可以通过tracefs启用这些事件点,以便查看内核的某些部分正在发生什么。
由于 ftrace 是一个大的框架,这里基于 function trace 进行分析。
2 ftrace 的编译器支持
2.1 HAVE_FUNCTION_TRACER 选项对 ftrace 的支持
首先对应 arch 要使用 ftrace 需要满足下面两个基础特性:
- STACKTRACE_SUPPORT - 实现
save_stack_trace() - TRACE_IRQFLAGS_SUPPORT - 实现
include/asm/irqflags.h
当 arch 支持 ftrace 时,需要在 Kconfig 中选中 HAVE_FUNCTION_TRACER 选项,该选项将会激活 ftrace 功能。
该功能将会在编译阶段为代码添加 -pg选项,该选项将会为每个函数开头生成mcount/__mcount函数,这对于用户空间不是难事,libc 库定义了 mcount函数来完成相关工作。而对于内核则需要架构代码去实现mcount和ftrace_stub函数。不同架构可能生成的函数名不是 mcount而是_mcount/__mcount,这取决于具体架构。
如下:
// x86,有 -pg
// echo 'main(){}' | gcc -x c -S -o - - -pg.text.globl main.type main, @function
main:
.LFB0:.cfi_startprocendbr64pushq %rbp.cfi_def_cfa_offset 16.cfi_offset 6, -16movq %rsp, %rbp.cfi_def_cfa_register 6
1: call *mcount@GOTPCREL(%rip) // 调用 mcountmovl $0, %eaxpopq %rbp.cfi_def_cfa 7, 8ret.cfi_endproc
...
// x86,没有 -pg
// echo 'main(){}' | gcc -x c -S -o - -.text.globl main.type main, @function
main:
.LFB0:.cfi_startprocendbr64pushq %rbp.cfi_def_cfa_offset 16.cfi_offset 6, -16movq %rsp, %rbp.cfi_def_cfa_register 6 // 没有 mcount 相关函数生成调用movl $0, %eaxpopq %rbp.cfi_def_cfa 7, 8ret.cfi_endproc
.LFE0:
...// aarch64,有 -pg
// echo 'main(){}' | aarch64-linux-gnu-gcc -x c -S -o - - -pg.text.global _mcount.align 2.global main.type main, %function
main:
.LFB0:.cfi_startprocstp x29, x30, [sp, -16]!.cfi_def_cfa_offset 16.cfi_offset 29, -16.cfi_offset 30, -8mov x29, spmov x0, x30mov x30, x0hint 7 // xpaclrimov x0, x30bl _mcount // 生成了 _mcountmov w0, 0ldp x29, x30, [sp], 16.cfi_restore 30.cfi_restore 29.cfi_def_cfa_offset 0ret.cfi_endproc
.LFE0:
ftrace 对于 mcount 的内部调用进行了,以便满足 ftrace 的要求。下面描述的是一个正确的mcount 应该做的事:
mcount应该检查函数指针ftrace_trace_function,看看它是否被设置为 ftrace_stub,如果是,那么无事可做,直接返回,如果不是,则进行调用ftrace_trace_function,第一个参数是 frompc,第二个参数时 selfpc。例如:foo() 调用 bar(),当 bar() 调用 mcount() 时:
frompc- 地址bar()将被用来返回到foo()selfpc- 地址bar()(mcount()大小校正)
// 理论流程
void ftrace_stub(void)
{return;
}void mcount(void)
{/* save any bare state needed in order to do initial checking */extern void (*ftrace_trace_function)(unsigned long, unsigned long);if (ftrace_trace_function != ftrace_stub)goto do_trace;/* restore any bare state */return;do_trace:/* save all state needed by the ABI (see paragraph above) */unsigned long frompc = ...;unsigned long selfpc = <return address> - MCOUNT_INSN_SIZE;ftrace_trace_function(frompc, selfpc);/* restore all state needed by the ABI */
}// arm64 实现
ENTRY(_mcount)mcount_enterldr_l x2, ftrace_trace_functionadr x0, ftrace_stubcmp x0, x2 // if (ftrace_trace_functionb.eq skip_ftrace_call // != ftrace_stub) {mcount_get_pc x0 // function's pcmcount_get_lr x1 // function's lr (= parent's pc)blr x2 // (*ftrace_trace_function)(pc, lr);skip_ftrace_call: // }
#ifdef CONFIG_FUNCTION_GRAPH_TRACERldr_l x2, ftrace_graph_returncmp x0, x2 // if ((ftrace_graph_returnb.ne ftrace_graph_caller // != ftrace_stub)ldr_l x2, ftrace_graph_entry // || (ftrace_graph_entryadr_l x0, ftrace_graph_entry_stub // != ftrace_graph_entry_stub))cmp x0, x2b.ne ftrace_graph_caller // ftrace_graph_caller();
#endif /* CONFIG_FUNCTION_GRAPH_TRACER */mcount_exit
ENDPROC(_mcount)
EXPORT_SYMBOL(_mcount)
NOKPROBE(_mcount)
基于HAVE_FUNCTION_TRACER我们还可以选择HAVE_FUNCTION_GRAPH_TRACER它会开启上述的CONFIG_FUNCTION_GRAPH_TRACER选项,以便于可以根据栈绘制调用表关系图(未仔细研究该部分)。
同样的,在 CONFIG_FUNCTION_GRAPH_TRACER下检查 ftrace_graph_return函数指针如果没有设置特定于ftrace_graph_entry和ftrace_graph_entry_stub函数,则调用特定于架构的ftrace_graph_caller,该函数反过来调用特定于架构的 prepare_ftrace_return,prepare_ftrace_return参数与 ftrace_trace_function 略有不同,第二个参数selfpc是相同的,但第一个参数应该是指向frompc的指针。
通常它位于堆栈上。这允许函数暂时劫持返回地址,使其指向特定于 arch 的函数return_to_handler。
下面是更新后的 mcount 伪代码:void mcount(void){...if (ftrace_trace_function != ftrace_stub)goto do_trace;+#ifdef CONFIG_FUNCTION_GRAPH_TRACER+ extern void (*ftrace_graph_return)(...);+ extern void (*ftrace_graph_entry)(...);+ if (ftrace_graph_return != ftrace_stub ||+ ftrace_graph_entry != ftrace_graph_entry_stub)+ ftrace_graph_caller();+#endif/* restore any bare state */...下面是新的 ftrace_graph_caller 汇编函数的伪代码:#ifdef CONFIG_FUNCTION_GRAPH_TRACERvoid ftrace_graph_caller(void){/* save all state needed by the ABI */unsigned long *frompc = &...;unsigned long selfpc = <return address> - MCOUNT_INSN_SIZE;/* passing frame pointer up is optional -- see below */prepare_ftrace_return(frompc, selfpc, frame_pointer);/* restore all state needed by the ABI */}#endif下面是新的 return_to_handler 汇编函数的伪代码。#ifdef CONFIG_FUNCTION_GRAPH_TRACERvoid return_to_handler(void){/* save all state needed by the ABI (see paragraph above) */void (*original_return_point)(void) = ftrace_return_to_handler();/* restore all state needed by the ABI *//* this is usually either a return or a jump */original_return_point();}#endif
2.2 HAVE_DYNAMIC_FTRACE 选项对动态 ftrace 的支持
针对上实现,后续即可由调用函数指针实现函数的记录等操作,最终展示在 ftrace 中。然而实际上上述实现是对性能损耗有影响的,因为每个函数都会调用mcount。
针对这个问题,内核设计实现了HAVE_DYNAMIC_FTRACE动态 ftrace 机制,该机制可以在没有激活 ftrace 的情况下,将所有 mcount 调用替换为 nop 操作,这样在没有激活 ftrace 时,对系统性能的影响几乎可以忽略不计。
在了解 HAVE_DYNAMIC_FTRACE 之前,还需要HAVE_FTRACE_MCOUNT_RECORD支持,HAVE_FTRACE_MCOUNT_RECORD会在编译阶段收集 mcount 信息,并生成__mcount_loc,以便于收集所有mcount信息,并进行处理。
在内核中有一个 recordmcount.pl脚本,当我们选中HAVE_FTRACE_MCOUNT_RECORD时,则会在编译每个 C 文件生成 Object 文件时调用该脚本,该脚本会为每个 object 文件创建一个名为__mcount_loc的段,其中保存了对 mcount 调用的所有偏移。
每个文件 obj 保存了__mcount_loc段,该段的每个部分保存了指向 mcount调用者的指针列表,并在最终链接 vmlinux 中,在 .init中使用 __start_mcount_loc和__end_mcount_loc之间保存了所有 mcount 调用者列表,后续启动内核时,内核读取该表,保存初始化相关数据并将其对应调用处转换为nops指令。
当以后启动跟踪或分析时,这些位置将被替换回指向某个函数的指针。
__mcount_loc中保存的偏移是基于段开头开始的,而不是每个函数的开头。
但是这个部分最终在 vmlinux 中的位置目前还不能确定。所以还不能用这种偏移量来记录这个点的最终地址。
recordmcount.pl中使用了一个诀窍,是将引用节开头的调用偏移量更改为引用该节中的函数符号。在链接步骤中,ld将根据我们记录的信息计算最终地址。
# e.g.
#
# .section ".sched.text", "ax"
# [...]
# func1:
# [...]
# call mcount (offset: 0x10)
# [...]
# ret
# .globl fun2
# func2: (offset: 0x20)
# [...]
# [...]
# ret
# func3:
# [...]
# call mcount (offset: 0x30)
# [...]#在上面的例子中,两个重定位的偏移量都将从.schedule .text中偏移。如果我们选择全局符号func2作为引用,并创建另一个文件tmp.S与新的偏移量:# .section __mcount_loc
# .quad func2 - 0x10
# .quad func2 + 0x10然后我们可以编译这个tmp.S写入tmp.O,并将其链接回原始对象。
在我们的算法中,我们将选择在本节中遇到的第一个全局函数作为引用。
但如果本节中没有全局函数,这就很难了。
在这种情况下,我们必须选择一个本地的。
例如func1:
# .section ".sched.text", "ax"
# func1:
# [...]
# call mcount (offset: 0x10)
# [...]
# ret
# func2:
# [...]
# call mcount (offset: 0x20)
# [...]
# .section "other.section"
如果我们创建tmp,与上面一样,当我们与原始对象链接在一起时,
我们将得到func1的两个符号:一个局部符号,一个全局符号。
在最终编译之后,最终会得到对func1的未定义引用,或者对其他文件中的另一个全局func1的错误引用。
由于局部对象可以引用局部变量,我们需要找到一种方法来创建tmp。
在将原始对象文件链接在一起后,不引用其本地对象。
为此,我们在链接tmp.o之前将func1转换为全局符号。
然后我们链接tmp。对于func1,我们将只有一个全局符号。我们可以将func1转换回局部符号,这样就完成了。
所以生成__mcount_loc有如下步骤:
1. 用“nm”记录所有的局部和弱符号。
2. 使用objdump查找所有调用站点偏移量和mcount的部分。
3. 将列表编译成它自己的对象。
4. 我们必须处理局部函数吗?否,执行步骤8。
5. 用objcopy创建一个对象,将这些局部函数转换为全局符号。
6. 将这个新对象与列表对象链接在一起。
7. 将局部函数转换回局部符号,并将结果重命名为原始对象。
8. 将该对象与列表对象链接。
9. 将结果移回原始对象。
至此,就可以在 vmlinux 中生成__mcount_loc并且动态的替换。
当我们支持 HAVE_DYNAMIC_FTRACE时默认会选中HAVE_FTRACE_MCOUNT_RECORD。
接下来当要去实现动态 mcount时,arch 需要如下的实现:
- asm/ftrace.h:- MCOUNT_ADDR- ftrace_call_adjust()- struct dyn_arch_ftrace{}- asm code:- mcount() (new stub)- ftrace_caller()- ftrace_call()- ftrace_stub()- C code:- ftrace_dyn_arch_init()- ftrace_make_nop()- ftrace_make_call()- ftrace_update_ftrace_func()
针对动态 ftrace 则不再需要 arch 去实现 mcount 了,arm64 如下,所有功能在 ftrace 中实现:
#else /* CONFIG_DYNAMIC_FTRACE */
/** _mcount() is used to build the kernel with -pg option, but all the branch* instructions to _mcount() are replaced to NOP initially at kernel start up,* and later on, NOP to branch to ftrace_caller() when enabled or branch to* NOP when disabled per-function base.*/
ENTRY(_mcount)ret
ENDPROC(_mcount)
EXPORT_SYMBOL(_mcount)
NOKPROBE(_mcount)
...
当然,针对上述手动生成__mcount_loc的方式,有些 gcc 支持直接生成__mcount_loc表,而不需要调用recordmcount.pl脚本来手动生成。
所以 Makefile 有对-mrecord-mcount选项的测试,一旦测试通过,说明支持自动生成 __mcount_loc此时为编译添加-mrecord-mcount选项。
另外在 GCC 4.6(2010) 引入了 -mfentry选项,把每个函数的prologue后面的 call mcount改成了在prologue前的
call __fentry__。原因是mcount有一个弊端是stack frame size难以确定,ftrace不能访问trace的参数。2011年,d57c5d51a30添加了x86-64的-mfentry支持。
GCC r215629 (2014)引入-mrecord-mcount、-mnop-mcount:
-mrecord-mcount 用于代替 linux/scripts/record_mcount.{pl,c}。
-mnop-mcount 不可用于 PIC,把__fentry__替换成 NOP。
截至今天,-mnop-mcount只有x86和SystemZ支持。
ifdef CONFIG_FUNCTION_TRACER
ifdef CONFIG_FTRACE_MCOUNT_RECORD# gcc 5 supports generating the mcount tables directlyifeq ($(call cc-option-yn,-mrecord-mcount),y)CC_FLAGS_FTRACE += -mrecord-mcountexport CC_USING_RECORD_MCOUNT := 1endififdef CONFIG_HAVE_NOP_MCOUNTifeq ($(call cc-option-yn, -mnop-mcount),y)CC_FLAGS_FTRACE += -mnop-mcountCC_FLAGS_USING += -DCC_USING_NOP_MCOUNTendifendif
endif
ifdef CONFIG_HAVE_FENTRYifeq ($(call cc-option-yn, -mfentry),y)CC_FLAGS_FTRACE += -mfentryCC_FLAGS_USING += -DCC_USING_FENTRYendif
endif
3 ftrace 的初始化
通过前面可以看到,当不支持动态 ftrace 时,我们直接根据 ftrace_trace_function函数指针调用,没有额外的初始化过程,而对于动态 ftrace 将会调用 ftrace_init对__mcount_loc进行初始化:
ftrace_init-> ftrace_process_locs最后生成的样子如下面的示意图:ftrace_pages_start|vftrace_page+-----------------------------+|index ||size || (int) | array of dyn_ftrace|records | +----------+----------+ +----------+----------+| (struct dyn_ftrace*) |---->|ip | | ... | | || | |flags | | | | || | |arch | | | | ||next | +----------+----------+ +----------+----------+| (struct ftrace_page*) |+-----------------------------+||vftrace_page+-----------------------------+|index ||size || (int) | array of dyn_ftrace|records | +----------+----------+ +----------+----------+| (struct dyn_ftrace*) |---->|ip | | ... | | || | |flags | | | | ||next | |arch | | | | || (struct ftrace_page*) | +----------+----------+ +----------+----------++-----------------------------+||vftrace_page+-----------------------------+|index ||size || (int) | array of dyn_ftrace|records | +----------+----------+ +----------+----------+| (struct dyn_ftrace*) |---->|ip | | ... | | || | |flags | | | | ||next | |arch | | | | || (struct ftrace_page*) | +----------+----------+ +----------+----------++-----------------------------+
后续探针就以ftrace_pages_start为起始的一张表中。为了遍历这张特殊的表,访问到其中的每一个dyn_ftrace *entry,就引入了这么一个宏定义,遍历整张表:
/** This is a double for. Do not use 'break' to break out of the loop,* you must use a goto.*/
#define do_for_each_ftrace_rec(pg, rec) \for (pg = ftrace_pages_start; pg; pg = pg->next) { \int _____i; \for (_____i = 0; _____i < pg->index; _____i++) { \rec = &pg->records[_____i];
接着在调用 ftrace_update_code将所有探针地址替换为 nop 指令:
ftrace_init-> ftrace_process_locs-> ftrace_update_codestatic int ftrace_update_code(struct module *mod, struct ftrace_page *new_pgs)
{
...for (pg = new_pgs; pg; pg = pg->next) {for (i = 0; i < pg->index; i++) {/* If something went wrong, bail without enabling anything */if (unlikely(ftrace_disabled))return -1;p = &pg->records[i];p->flags = rec_flags;// 如果编译没有替换为我们替换为 nop,则我们手动调用 ftrace_code_disable 来替换
#ifndef CC_USING_NOP_MCOUNT/** Do the initial record conversion from mcount jump* to the NOP instructions.*/if (!ftrace_code_disable(mod, p))break;
#endifupdate_cnt++;}}
...
}ftrace_code_disable-> ftrace_make_nop// arm64 架构
int ftrace_make_nop(struct module *mod, struct dyn_ftrace *rec,unsigned long addr)
{unsigned long pc = rec->ip;u32 old = 0, new;long offset = (long)pc - (long)addr;
...// 找到原来的指令 insnold = aarch64_insn_gen_branch_imm(pc, addr,AARCH64_INSN_BRANCH_LINK); // 生成一个 nop 指令的 insnnew = aarch64_insn_gen_nop();// 用新 insn 替换原来的 insnreturn ftrace_modify_code(pc, old, new, validate);
}
到这里 ftrace 的基本初始化完成,后续可以在 tracefs 中设置各类 tracer(current_tracer)来填充 ftrace_trace_function函数指针,即可调用对应 tracer 的回调,并进行相应处理。
4 function trace 流程
目前所有的 function trace 处于关闭状态,当我们使用 echo "function" > current_tracer时会配置 tracer 为 function trace,此时会根据set_ftrace_filter文件配置开启需要探测的函数,默认是全部,我们也可以通过写 set_ftrace_filter文件来开启我们想要探测的函数,这里以写set_ftrace_filter为例。
首先是 set_ftrace_filter回调定义:
trace_create_file("set_ftrace_filter", 0644, parent,ops, &ftrace_filter_fops);static const struct file_operations ftrace_filter_fops = {.open = ftrace_filter_open,.read = seq_read,.write = ftrace_filter_write,.llseek = tracing_lseek,.release = ftrace_regex_release,
};
当我们写时会调用ftrace_filter_write完成 trace 设置:
ftrace_filter_write-> ftrace_process_regex-> ftrace_match_records-> match_recordsstatic int
match_records(struct ftrace_hash *hash, char *func, int len, char *mod)
{
...do_for_each_ftrace_rec(pg, rec) {if (rec->flags & FTRACE_FL_DISABLED)continue;if (ftrace_match_record(rec, &func_g, mod_match, exclude_mod)) {ret = enter_record(hash, rec, clear_filter);if (ret < 0) {found = ret;goto out_unlock;}found = 1;}} while_for_each_ftrace_rec();
...
ftrace_match_record中会根据 function name 与 mcount_loc 中每条 rec->ip 然后按照kallsyms_lookup来匹配函数名,一旦匹配上,则调用enter_record 根据 rec->ip 计算 hash 并记录到全局 ftrace_hash 表中,后续根据ftrace_hash 来真正替换那些需要探测点。
实际替换发生在 set_ftrace_filter文件关闭阶段:
ftrace_regex_release-> ftrace_hash_move_and_update_ops-> ftrace_hash_move (1)-> ftrace_ops_update_code (2)
(1)第一步将本地记录的 record 表同步到全局变量 ftrace_ops 中。
(2)真正替换发生在第二步 ftrace_ops_update_code
ftrace_ops_update_code-> ftrace_run_modify_code-> ftrace_run_update_code-> ftrace_arch_code_modify_prepare-> arch_ftrace_update_code-> ftrace_modify_all_code-> ftrace_update_ftrace_func-> ftrace_replace_code-> ftrace_arch_code_modify_post_process
ftrace_update_ftrace_func首先会将原来 arch 中定义的 ftrace_call 替换为 ftrace_ops_list_func, 接着 ftrace_replace_code将会开始真正替换所有 mcount:
ftrace_replace_code-> do_for_each_ftrace_rec {__ftrace_replace_code// 在这里会根据配置等判断具体怎么替换,对于 function 这里替换为如下:-> ftrace_make_call}static int
__ftrace_replace_code(struct dyn_ftrace *rec, int enable)
{...ftrace_addr = ftrace_get_addr_new(rec);case FTRACE_UPDATE_MAKE_CALL:ftrace_bug_type = FTRACE_BUG_CALL;return ftrace_make_call(rec, ftrace_addr);
...
ftrace_get_addr_new在这里实际返回的就是 ftrace_caller
#ifndef FTRACE_ADDR
#define FTRACE_ADDR ((unsigned long)ftrace_caller)
#endif// arm64 动态 ftrace
ENTRY(ftrace_caller)mcount_entermcount_get_pc0 x0 // function's pcmcount_get_lr x1 // function's lrGLOBAL(ftrace_call) // tracer(pc, lr);nop // This will be replaced with "bl xxx"// where xxx can be any kind of tracer.#ifdef CONFIG_FUNCTION_GRAPH_TRACER
GLOBAL(ftrace_graph_call) // ftrace_graph_caller();nop // If enabled, this will be replaced// "b ftrace_graph_caller"
#endifmcount_exit
ENDPROC(ftrace_caller)
#endif /* CONFIG_DYNAMIC_FTRACE */ENTRY(ftrace_stub)ret
ENDPROC(ftrace_stub)
可以看到基于上述替换后,进入函数首先执行ftrace_caller,在 ftrace_caller中继续调用上面替换的"ftrace_call"而这里的 "ftrace_call"指向的则是ftrace_ops_list_func,也就是说,在 ftrace 开启下每个函数将会调用 ftrace_ops_list_func。
ftrace_ops_list_func-> __ftrace_ops_list_funcstatic inline void
__ftrace_ops_list_func(unsigned long ip, unsigned long parent_ip,struct ftrace_ops *ignored, struct pt_regs *regs)
{
...do_for_each_ftrace_op(op, ftrace_ops_list) {/** Check the following for each ops before calling their func:* if RCU flag is set, then rcu_is_watching() must be true* if PER_CPU is set, then ftrace_function_local_disable()* must be false* Otherwise test if the ip matches the ops filter** If any of the above fails then the op->func() is not executed.*/if ((!(op->flags & FTRACE_OPS_FL_RCU) || rcu_is_watching()) &&ftrace_ops_test(op, ip, regs)) {if (FTRACE_WARN_ON(!op->func)) {pr_warn("op=%p %pS\n", op, op);goto out;}op->func(ip, parent_ip, op, regs);}} while_for_each_ftrace_op(op);
...
从这里可以看到会去遍历ftrace_ops_list链表,并且使其与对应 ops 匹配,一旦匹配上则会调用 op->func
而这里的 op 实际则是对应我们在 current_tracer中设置的 tracer。
ftrace_ops_list链表保存了当前系统所有注册的tracer。tracer是一个struct ftrace_ops结构体,每一个 tracer都会去实现自己的 ftrace_ops。
struct ftrace_ops {ftrace_func_t func; // 对应 tracer 调用的 funcstruct ftrace_ops __rcu *next; // 下一个 tracerunsigned long flags;void *private;ftrace_func_t saved_func;// 当使用动态 ftrace 时,使用下面的数据与 current_tracer 匹配
#ifdef CONFIG_DYNAMIC_FTRACEstruct ftrace_ops_hash local_hash;struct ftrace_ops_hash *func_hash;struct ftrace_ops_hash old_hash;unsigned long trampoline;unsigned long trampoline_size;
#endif
};
那么这个结构体又怎么被写到全局链表中呢。这里涉及另一个结构体struct tracer,每个tracer真正实现的是这个数据结构,比如 irq,blk,function等。这里我们还是以function为例:
static struct tracer function_trace __tracer_data =
{.name = "function",.init = function_trace_init,.reset = function_trace_reset,.start = function_trace_start,.flags = &func_flags,.set_flag = func_set_flag,.allow_instances = true,
#ifdef CONFIG_FTRACE_SELFTEST.selftest = trace_selftest_startup_function,
#endif
};__init int init_function_trace(void)
{init_func_cmd_traceon();return register_tracer(&function_trace);
}
到这里一个 tracer 便被添加到了系统中。当我们 echo function > current_tracer 时,系统根据我们注册的 tracer->name 和
buf 比较,一旦比较成功有如下代码:
tracing_set_trace_write-> tracing_set_tracerstatic int tracing_set_tracer(struct trace_array *tr, const char *buf)
{
...if (tr->current_trace->reset)tr->current_trace->reset(tr);if (t->init) {ret = tracer_init(t, tr);if (ret)goto out;}
...int tracer_init(struct tracer *t, struct trace_array *tr)
{tracing_reset_online_cpus(&tr->trace_buffer);return t->init(tr);
}
也就是说会调用 function_trace 的 function_trace_init函数:
static int function_trace_init(struct trace_array *tr)
{ftrace_func_t func;/** Instance trace_arrays get their ops allocated* at instance creation. Unless it failed* the allocation.*/if (!tr->ops)return -ENOMEM;// 根据当前文件配置,选择对应调用的回调,这里是 function_trace_call/* Currently only the global instance can do stack tracing */if (tr->flags & TRACE_ARRAY_FL_GLOBAL &&func_flags.val & TRACE_FUNC_OPT_STACK)func = function_stack_trace_call;elsefunc = function_trace_call;// 将 func 绑定到 ftrace_ops 中。ftrace_init_array_ops(tr, func);tr->trace_buffer.cpu = get_cpu();put_cpu();tracing_start_cmdline_record();// 在这里还会对非动态 ftrace 更新 ftrace_trace_function 为 functracing_start_function_trace(tr);return 0;
}void ftrace_init_array_ops(struct trace_array *tr, ftrace_func_t func)
{/* If we filter on pids, update to use the pid function */if (tr->flags & TRACE_ARRAY_FL_GLOBAL) {if (WARN_ON(tr->ops->func != ftrace_stub))printk("ftrace ops had %pS for function\n",tr->ops->func);}tr->ops->func = func;tr->ops->private = tr;
}
至此 func 则与 ftrace_ops 绑定上,当我们在__ftrace_ops_list_func中遍历到匹配的 ftrace_ops->func 是则会直接调用,通过分析我们调用的是function_trace_call。
static void
function_trace_call(unsigned long ip, unsigned long parent_ip,struct ftrace_ops *op, struct pt_regs *pt_regs)
{struct trace_array *tr = op->private;struct trace_array_cpu *data;unsigned long flags;int bit;int cpu;int pc;if (unlikely(!tr->function_enabled))return;// 记录 preempt_countpc = preempt_count();preempt_disable_notrace();bit = trace_test_and_set_recursion(TRACE_FTRACE_START, TRACE_FTRACE_MAX);if (bit < 0)goto out;// 记录 cpuidcpu = smp_processor_id();data = per_cpu_ptr(tr->trace_buffer.data, cpu);if (!atomic_read(&data->disabled)) {// 记录 irqlocal_save_flags(flags);// 将记录数据写入 ring_buffertrace_function(tr, ip, parent_ip, flags, pc);}trace_clear_recursion(bit);out:preempt_enable_notrace();
}void
trace_function(struct trace_array *tr,unsigned long ip, unsigned long parent_ip, unsigned long flags,int pc)
{struct trace_event_call *call = &event_function;struct ring_buffer *buffer = tr->trace_buffer.buffer;struct ring_buffer_event *event;struct ftrace_entry *entry;// 和 tracepoint 类似,首先需要申请一个写入 ring_buffer 的记录数据空间event = __trace_buffer_lock_reserve(buffer, TRACE_FN, sizeof(*entry),flags, pc);if (!event)return;// 记录当前探测点的 ip 以及父亲 ip,以便于 trace 中的显示。entry = ring_buffer_event_data(event);entry->ip = ip;entry->parent_ip = parent_ip;// ok 数据过滤没有问题,直接将记录的 entry 提交的 ring_buffer 中。if (!call_filter_check_discard(call, entry, buffer, event)) {if (static_branch_unlikely(&ftrace_exports_enabled))ftrace_exports(event);__buffer_unlock_commit(buffer, event);}
}
直到这里 ftrace 的调用基本完成,后续即可通过 trace文件读取数据。同 tracepoint 一样,会有对应的格式化 function 被调用来处理记录的 function trace 数据,这里不再演示。
5 总结
通过 ftrace 分析可以看到,基于 function trace,内核拓展了 ftrace 框架,使其各自可以定义自己的 tracer 来跟踪调试内核,加上 trace evnet 机制,以及基于此设施的 perf 和 bpf ,使其形成了一个庞大内核调试框架。而这一切通过几个系统调用和 tracefs 文件系统接口完成在。
相关文章:

ftrace 原理详细分析
》内核新视界文章汇总《 文章目录 ftrace 原理分析1 简介2 ftrace 的编译器支持2.1 HAVE_FUNCTION_TRACER 选项对 ftrace 的支持2.2 HAVE_DYNAMIC_FTRACE 选项对动态 ftrace 的支持 3 ftrace 的初始化4 function trace 流程5 总结 ftrace 原理分析 1 简介 ftrace 是一个内核…...

UWB定位技术和蓝牙AOA有哪些不同?-高精度室内定位技术对比
UWB超宽带定位 UWB(Ultra Wide Band )即超宽带技术,它是一种无载波通信技术,利用纳秒级的非正弦波窄脉冲传输数据,因此其所占的频谱范围很宽。传统的定位技术是根据信号强弱来判别物体位置,信号强弱受外界…...
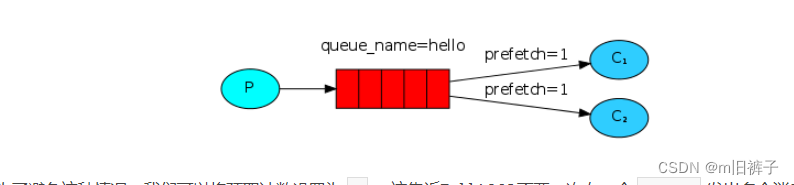
【RabbitMQ】golang客户端教程2——工作队列
任务队列/工作队列 在上一个教程中,我们编写程序从命名的队列发送和接收消息。在这一节中,我们将创建一个工作队列,该队列将用于在多个工人之间分配耗时的任务。 工作队列(又称任务队列)的主要思想是避免立即执行某些…...
芯旺微冲刺IPO,车规级MCU竞争白热化下的“隐忧”凸显
在汽车智能化和电动化发展带来的巨大蓝海市场下,产业链企业迎来了一波IPO小高潮。 日前,上海芯旺微电子技术股份有限公司(以下简称“芯旺微”)在科创板的上市申请已经被上交所受理,拟募资17亿元,用于投建车…...

HTML <s> 标签
例子 可以像这样标记删除线文本: 在 HTML 5 中,<s>仍然支持</s>已经不支持这个标签了。 浏览器支持 元素ChromeIEFirefoxSafariOpera<s>YesYesYesYesYes 所有浏览器都支持 <s> 标签。 定义和用法 <s> 标签可定义加…...

微信小程序 - scroll-view组件之上拉加载下拉刷新(解决上拉加载不触发)
前言 最近在做微信小程序项目中,有一个功能就是做一个商品列表分页限流然后实现上拉加载下拉刷新功能,遇到了一个使用scroll-viwe组件下拉刷新事件始终不触发问题,网上很多说给scroll-view设置一个高度啥的就可以解决,有些人设置了…...

rust usize与i64怎么比较大小?
在Rust中, usize 和 i64 是不同的整数类型,它们的位数和表示范围可能不同。因此,直接比较 usize 和 i64 是不允许的。如果需要比较它们的大小,可以将它们转换为相同的类型,然后进行比较。 要将 usize 转换为 i64 &…...
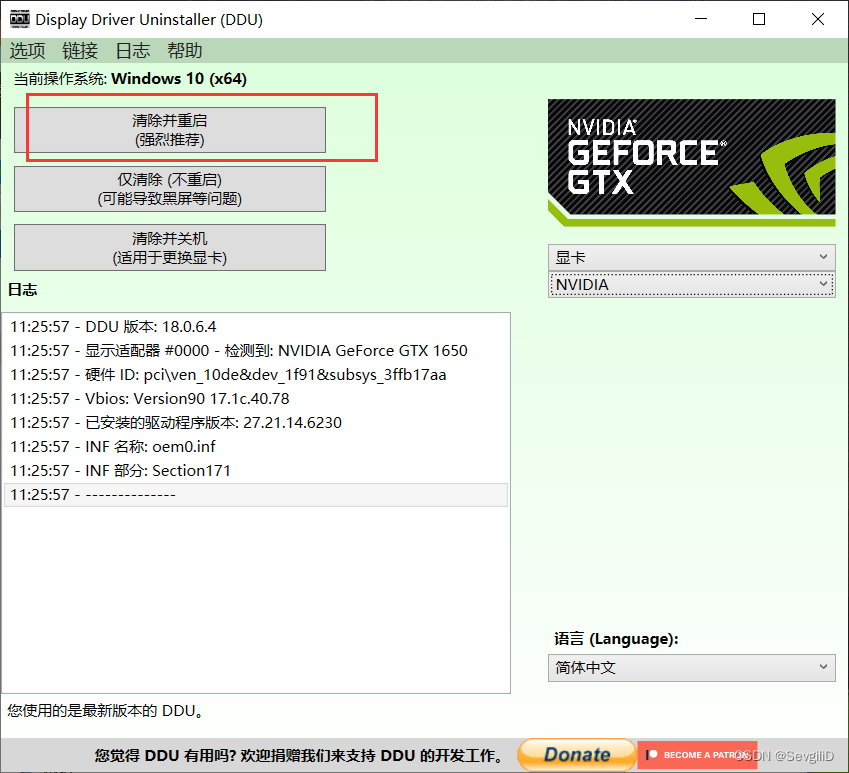
电脑更新win10黑屏解决方法
电脑更新win10黑屏解决方法 电脑黑屏出现原因解决步骤 彻底解决 电脑黑屏 出现原因 系统未更新成功就关机,导致系统出故障无法关机 解决步骤 首先长安电源键10s关机 按电源键开机,出现logo时按F8进入安全模式。 进入自动修复环境后,单击…...

STM32入门——外部中断
中断系统概述 中断:在主程序运行过程中,出现了特定的中断触发条件(中断源),使得CPU暂停当前正在运行的程序,转而去处理中断程序,处理完成后又返回原来被暂停的位置继续运行中断优先级ÿ…...
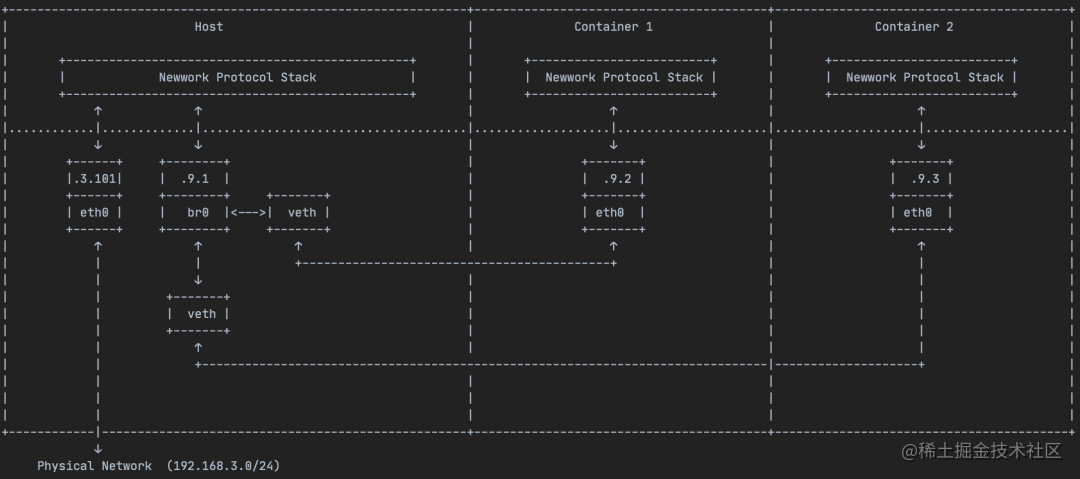
【计算机网络】NAT及Bridge介绍
OSI七层模型 七层模型介绍及举例 为通过网络将人类可读信息通过网络从一台设备传输到另一台设备,必须在发送设备沿 OSI 模型的七层结构向下传输数据,然后在接收端沿七层结构向上传输数据。 数据在 OSI 模型中如何流动 库珀先生想给帕尔梅女士发一封电…...
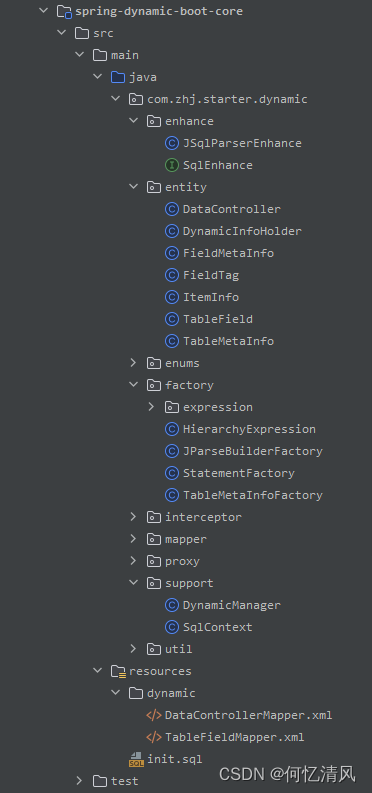
封装动态SQL的插件
最近根据公司的业务需要封装了一个简单的动态SQL的插件,要求是允许用户在页面添加SQL的where条件,然后开发者只需要给某个接口写查询对应的表,参数全部由插件进行拼接完成。下面是最终实现: 开发人员只需要在接口写上下面的查询SQ…...
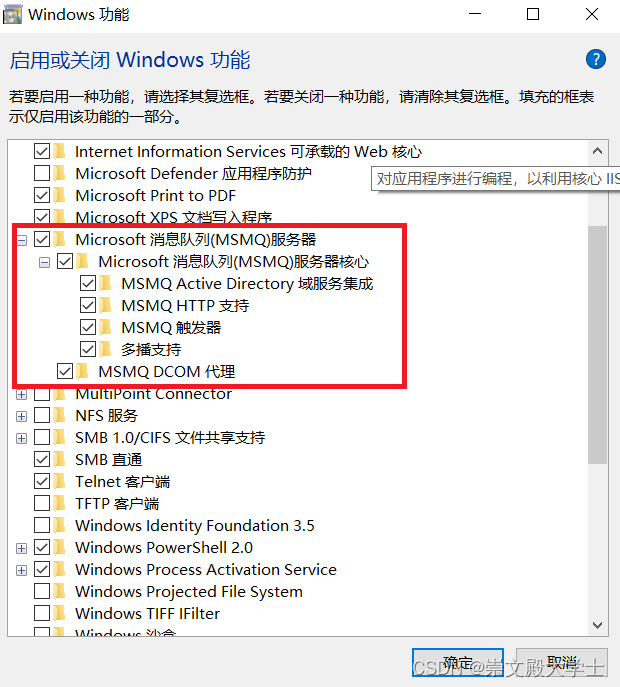
C# Microsoft消息队列服务器的使用 MSMQ
先安装消息队列服务器 private static readonly string path ".\\Private$\\myQueue";private void Create(){if (!MessageQueue.Exists(path)){MessageQueue.Create(path);}}private void Send(){Stopwatch stopwatch new Stopwatch();stopwatch.Start();Message…...

Kafka3.0.0版本——生产者如何提高吞吐量
目录 一、生产者提高吞吐量参数设置二、产者提高吞吐量代码示例 一、生产者提高吞吐量参数设置 batch.size:设置批次大小,默认16klinger.ms:设置等待时间,修改为5-100msbuffer.memory:设置缓冲区大小, 默认…...

js精度丢失的问题
1.js精度丢失的常见问题,从常见的浮点型进行计算,到位数很长的munber类型进行计算都会造成精度丢失的问题, 首先我们看一个问题: 0.1 0.2 ! 0.3 // truelet a 9007199254740992 a 1 a // true那么js为什么会出现精度丢失的问题&…...

C++ 编译预处理
在编译器对源程序进行编译时,首先要由处理器对程序文本进行预处理。预处理器提供了一组编译预处理指令和预处理操作符。预处理指令实际上不是C语言的一部分,它只是用来扩充C程序设计环境。所有的预处理指令在程序中都以“#”来引导,每一条预处…...
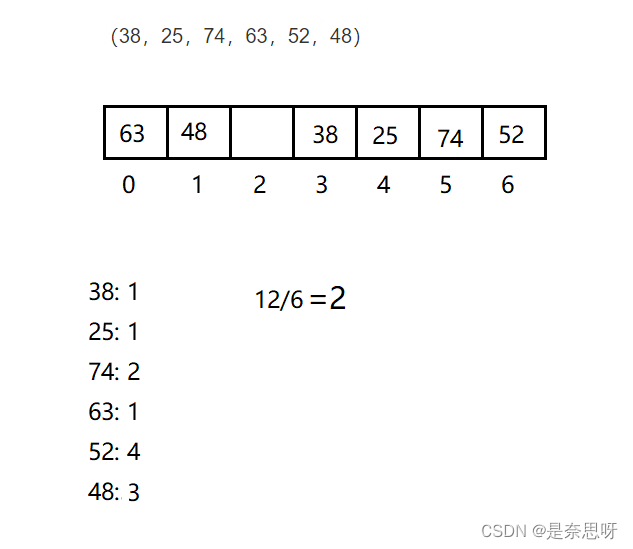
备战秋招 | 笔试强化22
目录 一、选择题 二、编程题 三、选择题题解 四、编程题题解 一、选择题 1、在有序双向链表中定位删除一个元素的平均时间复杂度为 A. O(1) B. O(N) C. O(logN) D. O(N*logN) 2、在一个以 h 为头指针的单循环链表中,p 指针指向链尾结点的条件是( ) A. p->ne…...
)
LeetCode ACM模式——哈希表篇(二)
刷题顺序及思路来源于代码随想录,网站地址:https://programmercarl.com 202. 快乐数 编写一个算法来判断一个数 n 是不是快乐数。 「快乐数」 定义为: 对于一个正整数,每一次将该数替换为它每个位置上的数字的平方和。然后重复…...

hadoop 3.1.3集群搭建 ubuntu20
相关 hyper-v安装ubuntu-20-server hyper-v建立快照 hyper-v快速创建虚拟机-导入导出虚拟机 准备 虚拟机设置 采用hyper-v方式安装ubuntu-20虚拟机和koolshare hostnameiph01192.168.66.20h02192.168.66.21h03192.168.66.22 静态IP 所有机器都需要按需设置 sudo vim /e…...
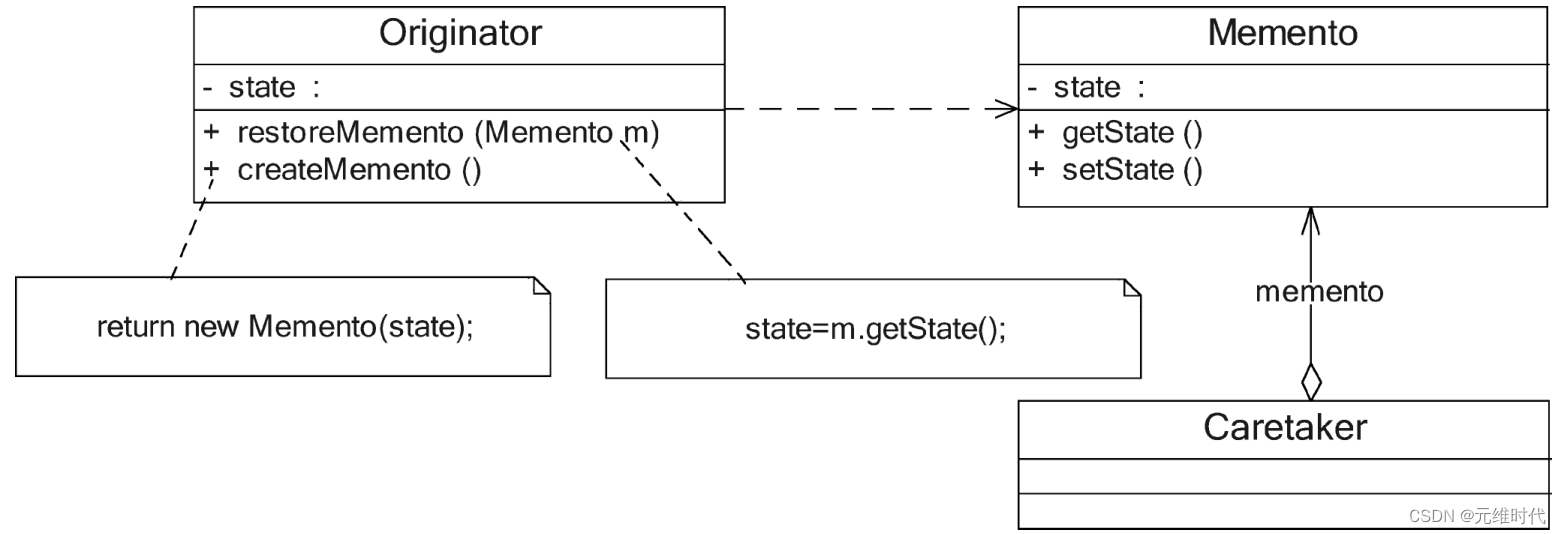
备忘录模式——撤销功能的实现
1、简介 1.1、概述 备忘录模式提供了一种状态恢复的实现机制,使得用户可以方便地回到一个特定的历史步骤。当新的状态无效或者存在问题时,可以使用暂时存储起来的备忘录将状态复原。当前很多软件都提供了撤销(Undo)操作…...

Golang 函数参数的传递方式 值传递,引用传递
基本介绍 我们在讲解函数注意事项和使用细节时,已经讲过值类型和引用类型了,这里我们再系统总结一下,因为这是重难点,值类型参数默认就是值传递,而引用类型参数默认就是引用传递。 两种传递方式(函数默认都…...

告别拍脑袋规划!用ArcGIS做绿道选线:如何科学量化坡度、水域、道路成本并加权计算
科学规划绿道的ArcGIS高阶技法:从成本栅格构建到最优路径生成绿道规划从来不是简单的"两点之间直线最短",而是需要综合考虑地形、生态、人文等多维因素的复杂决策过程。传统规划中常见的"拍脑袋"决策方式,往往导致建成后…...

BLE蓝牙扫描深度剖析:扫描原理、核心参数、前后台差异
一、前言BLE设备交互分为两大角色:广播端(外设Peripheral)与扫描端(中心Central)。上一篇博客详解了四大广播模式,本文聚焦配套核心能力——BLE扫描机制。绝大多数蓝牙开发疑难问题:前台能扫后台…...
)
第二周(第12周)
1.单电源供电的二阶低通滤波器2.功率放大电路...
)
别再用SonarQube凑数了!DeepSeek原生圈复杂度引擎的6大颠覆性能力(含GitHub私有部署密钥)
更多请点击: https://kaifayun.com 第一章:DeepSeek圈复杂度分析的底层原理与范式革命 DeepSeek圈复杂度分析并非传统McCabe度量的简单复刻,而是基于控制流图(CFG)动态重构与语义感知路径裁剪的双重机制构建的新范式。…...

武汉国电华美16875kVA串联谐振试验装置,这手活儿细
在超高压变电站和长距离电缆的现场,交流耐压试验是检验设备绝缘的“最后一关”。这位老师傅经手过不少大工程,他说,面对GIS、大型变压器这些“大块头”电容性试品,能不能顺利“过关”,往往就看串联谐振装置顶不顶得住。…...

通过curl命令快速测试Taotoken大模型API的连通性与返回格式
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 通过curl命令快速测试Taotoken大模型API的连通性与返回格式 在集成大模型能力到应用时,开发者通常需要一种快速、轻量的…...

UE5项目打包后RenderTarget导出图片全黑?手把手教你解决伽马校正与资产打包问题
UE5打包后RenderTarget导出图片全黑的终极解决方案当你花了整整三天时间调试RenderTarget导出功能,终于在编辑器里看到完美的截图效果,却在打包成可执行文件后发现所有导出的图片都变成了一片漆黑——这种从云端跌入谷底的感觉,每个UE开发者都…...

3步零基础掌握星露谷物语SMAPI模组加载器:高效管理你的模组世界
3步零基础掌握星露谷物语SMAPI模组加载器:高效管理你的模组世界 【免费下载链接】SMAPI The modding API for Stardew Valley. 项目地址: https://gitcode.com/gh_mirrors/smap/SMAPI SMAPI(Stardew Valley Modding API)是星露谷物语官…...

鸿蒙HarmonyOS 5与Unity跨运行时通信实战指南
1. 这不是“调个API”那么简单:为什么鸿蒙Unity通信总在临门一脚卡住我第一次把Unity打包的AR模块塞进HarmonyOS 5 App里时,信心满满——毕竟文档里写着“支持JS/ArkTS调用Native能力”,Unity也标榜“跨平台通用”。结果呢?App一启…...

深入解析NxDumpTool:Switch游戏文件系统提取的终极指南 [特殊字符]
深入解析NxDumpTool:Switch游戏文件系统提取的终极指南 🎮 【免费下载链接】nxdumptool Generates XCI/NSP/HFS0/ExeFS/RomFS/Certificate/Ticket dumps from Nintendo Switch gamecards and installed SD/eMMC titles. 项目地址: https://gitcode.com…...