基于埋点日志数据的网络流量统计 - PV、UV
水善利万物而不争,处众人之所恶,故几于道💦
文章目录
一、 网站总流量数统计 - PV
1. 需求分析
2. 代码实现
方式一
方式二
方式三:使用process算子实现
方式四:使用process算子实现
二、网站独立访客数统计 - UV
1. 需求分析
2. 代码实现
一、 网站总流量数统计 - PV
PV全称 Page View,也就是一个网站的页面浏览量。每当用户进入网站加载或者刷新某个页面时,就会给该网站带来PV量,它往往用来衡量一个网站的流量和用户活跃度。当然了,单个指标并不能全面的反映网站的实际情况,往往需要结合其他的指标进行分析。
1. 需求分析
埋点采集到的数据格式大概是这个样子(文件已上传资源) 第一个是userId、第二个是itemId、第三个是categoryId、第四个是behavior、第五个是timestamp
第一个是userId、第二个是itemId、第三个是categoryId、第四个是behavior、第五个是timestamp
所以我们要统计PV的话要先从第四列中筛选出PV,然后再进行累加,求出最终的PV
2. 代码实现
方式一:
先用readTextFile()读取文件,然后将读取到的每行数据封装成一个bean对象,再通过
filter过滤出我们需要的PV数据,这时得到的都是封装好的一个个对象没法直接sum,所以通过
map将数据映射为一个个的元组类型(PV,1)然后,使用
keyBy()将他们分到同一个并行度中进行
sum,得出最终的结果。
public class Flink01_Project_PV {public static void main(String[] args) {Configuration conf = new Configuration();conf.setInteger("rest.port",1000);StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(conf);env.setParallelism(2);env.readTextFile("input/UserBehavior.csv")// 将数据封装成 UserBehavior 对象.map(new MapFunction<String, UserBehavior>() {@Overridepublic UserBehavior map(String line) throws Exception {String[] data = line.split(",");return new UserBehavior(Long.valueOf(data[0]),Long.valueOf(data[1]),Integer.valueOf(data[2]),data[3],Long.valueOf(data[4]));}})// 过滤出行为为PV的数据.filter(new FilterFunction<UserBehavior>() {@Overridepublic boolean filter(UserBehavior value) throws Exception {return "pv".equals(value.getBehavior());}})// 因为直接求和的话没法求,所以做一次映射,映射成 (PV,1) 这样的结构.map(new MapFunction<UserBehavior, Tuple2<String,Long>>() {@Overridepublic Tuple2<String, Long> map(UserBehavior value) throws Exception {return Tuple2.of(value.getBehavior(),1L);}})// 然后 将他们通过key进行分组,进入同一个并行度里面 进行求和.keyBy(new KeySelector<Tuple2<String, Long>, String>() {@Overridepublic String getKey(Tuple2<String, Long> value) throws Exception {return value.f0;}})// 进行求和.sum(1).print();try {env.execute();} catch (Exception e) {e.printStackTrace();}}
}
运行结果:

方式二:
这种方式省去了方式一的封装对象,其他的思路都一样。
public class Flink01_Project_PV {public static void main(String[] args) {Configuration conf = new Configuration();conf.setInteger("rest.port",1000);StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(conf);env.setParallelism(2);env.readTextFile("input/UserBehavior.csv")// 直接过滤出我们想要的数据.filter(new FilterFunction<String>() {@Overridepublic boolean filter(String value) throws Exception {String[] data = value.split(",");return "pv".equals(data[3]);}})// 然后将结构转换为元组类型 (PV,1).map(new MapFunction<String, Tuple2<String,Long>>() {@Overridepublic Tuple2<String, Long> map(String value) throws Exception {String[] data = value.split(",");return Tuple2.of(data[3],1L);}})// 通过key分组.keyBy(new KeySelector<Tuple2<String, Long>, String>() {@Overridepublic String getKey(Tuple2<String, Long> value) throws Exception {return value.f0;}})// 求和.sum(1).print();try {env.execute();} catch (Exception e) {e.printStackTrace();}}
}
运行结果:

方式三:使用process算子实现
首先使用readTextFile读取数据,使用map将读取到的数据封装为对象,然后使用keyBy进行分组,最后使用process算子进行求解
- 为什么要使用keyBy():目的是让pv数据进入同一个并行度,如果不使用直接process的话,两个并行度里面都有一个sum,结果就不对了
- 为什么不使用filter过滤呢?因为我们的过滤逻辑是再process里面完成的,所以不用再额外过滤
public class Flink02_Project_PV_process {public static void main(String[] args) {Configuration conf = new Configuration();conf.setInteger("rest.port",1000);StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(conf);env.setParallelism(2);env.readTextFile("input/UserBehavior.csv")// 封装成 UserBehavior 对象.map(new MapFunction<String, UserBehavior>() {@Overridepublic UserBehavior map(String line) throws Exception {String[] data = line.split(",");return new UserBehavior(Long.valueOf(data[0]),Long.valueOf(data[1]),Integer.valueOf(data[2]),data[3],Long.valueOf(data[4]));}})// 通过key分组.keyBy(new KeySelector<UserBehavior, String>() {@Overridepublic String getKey(UserBehavior value) throws Exception {return value.getBehavior();}})// 使用proces算子实现 PV 的统计.process(new ProcessFunction<UserBehavior, String>() {// 定义累加变量long sum =0L ;@Overridepublic void processElement(UserBehavior value, Context ctx, Collector<String> out) throws Exception {// 判断用户行为是否是PVif ("pv".equals(value.getBehavior())){// 条件满足 sum+1sum++;// 将结果收集out.collect("pv = "+sum);}}}).print();try {env.execute();} catch (Exception e) {e.printStackTrace();}}
}
运行结果:

方式四:使用process算子实现
方式四相比于方式三省去了对象的封装,其他思路一样。
public class Flink02_Project_PV_process {public static void main(String[] args) {Configuration conf = new Configuration();conf.setInteger("rest.port",1000);StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(conf);env.setParallelism(2);env.readTextFile("input/UserBehavior.csv")// 通过key分组.keyBy(new KeySelector<String, String>() {@Overridepublic String getKey(String value) throws Exception {return value.split(",")[3];}})// 直接使用process求 PV.process(new ProcessFunction<String, String>() {// 定义累加变量long sum = 0L;@Overridepublic void processElement(String line, Context ctx, Collector<String> out) throws Exception {// 将过来的每行数据切割String[] datas = line.split(",");// 判断是否是我们想要的数据if("pv".equals(datas[3])){// 符合条件,将累加变量+1sum++;// 收集结果out.collect("pv = "+sum);}}}).print();try {env.execute();} catch (Exception e) {e.printStackTrace();}}
}
运行结果:

二、网站独立访客数统计 - UV
UV全称 Unique Visitor,也就是独立访客数。在PV中,我们统计的是所有用户对所有页面的浏览行为,也就是同一个用户的浏览行为会被重复统计。实际上我们关注的是在某一特定范围内(一天、一周或者一个月)内访问该网站的用户数,也就是每个访客只计算一次。它能从侧面反映出该网站的受欢迎程度和用户规模的大小。
1. 需求分析
要统计UV量的话,只需要对全量的PV,使用userId去重,然后就能得到独立访客数了。2. 代码实现
先filter过滤出PV数据,然后通过keyBy将PV分到同一组,然后使用process进行处理,处理方法是:用set集合存放userId,如果下一个userId可以加入该集合说明是一个新的独立访客,则收集当前集合的大小,若加入失败,说明集合中已经存在该userId,也就是不是一个新的独立访客,也就不做处理了。
public class Flink03_Project_UV {public static void main(String[] args) {Configuration conf = new Configuration();conf.setInteger("rest.port",1000);StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(conf);env.setParallelism(2);env.readTextFile("input/UserBehavior.csv")// 过滤出 PV 数据.filter(new FilterFunction<String>() {@Overridepublic boolean filter(String value) throws Exception {return "pv".equals(value.split(",")[3]);}})// 将PV的数据分到同一个组里面.keyBy(new KeySelector<String, String>() {@Overridepublic String getKey(String value) throws Exception {return value.split(",")[3];}})// 对同一组里面的数据进行处理.process(new ProcessFunction<String, String>() {// 存放 userId 的容器,回自动对数据进行去重,最后直接拿它的大小就知道UV了Set<Long> userIdSet = new HashSet<>();@Overridepublic void processElement(String value, Context ctx, Collector<String> out) throws Exception {Long userId = Long.valueOf(value.split(",")[0]);// 向set中添加userId,判断是否添加成功if (userIdSet.add(userId)) {// 添加成功的话,说明是一个新的独立访客,收集到此时容器大小out.collect("UV = "+ userIdSet.size());}}}).print();try {env.execute();} catch (Exception e) {e.printStackTrace();}}
}
运行结果:

相关文章:
基于埋点日志数据的网络流量统计 - PV、UV
水善利万物而不争,处众人之所恶,故几于道💦 文章目录 一、 网站总流量数统计 - PV 1. 需求分析 2. 代码实现 方式一 方式二 方式三:使用process算子实现 方式四:使用process算子实现 二、网站独立访客数统计 - UV 1. …...

cuda入门demo(2)——最基础的二方向sobel
⚠️主要是自己温习用,只保证代码正确性,不保证讲解的详细性。 今天继续总结cuda最基本的入门demo。很多教程会给你说conv怎么写,实际上sobel也是conv,并且conv本身已经用torch实现了。 之前在课题中尝试了sobel的变体࿰…...
软件外包开发的后台开发语言
在软件外包开发中,后台语言的选择通常取决于项目需求、客户偏好、团队技能和开发效率。今天和大家分享一些常用的后台语言及选择它们的原因,希望对大家有所帮助。北京木奇移动技术有限公司,专业的软件外包开发公司,欢迎交流合作。…...
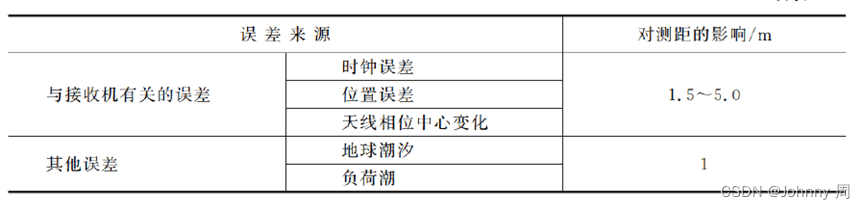
自动驾驶感知系统-全球卫星定位系统
卫星定位系统 车辆定位是让无人驾驶汽车获取自身确切位置的技术,在自动驾驶技术中定位担负着相当重要的职责。车辆自身定位信息获取的方式多样,涉及多种传感器类型与相关技术。自动驾驶汽车能够持续安全可靠运行的一个关键前提是车辆的定位系统必须实时…...
数据结构 | 基本数据结构——队列
目录 一、何谓队列 二、队列抽象数据类型 三、用Python实现队列 四、模拟:传土豆 五、模拟:打印任务 5.1 主要模拟步骤 5.2 Python实现 一、何谓队列 队列是有序集合,添加操作发生在“尾部”,移除操作则发生在“头部”。新…...
)
QT在label上透明绘图(二)
前面步骤参考前一篇文章 QT在label上透明绘图 一、给TransparentLabel类添加double transparency;变量, 二、ui添加doublespinbox,调整透明参数 void MainWindow::on_doubleSpinBox_valueChanged(double arg1) {transparentLabel->transparencyarg1;…...

微信小程序使用editor富文本编辑器 以及回显 全屏弹窗的模式
<!--富文本接收的位置--><view class"white-box"><view class"title"><view class"yellow-fence"></view><view class"v1">教研记录</view></view><view class"add-btn"…...
)
在CSDN学Golang场景化解决方案(基于gin框架的web开发脚手架)
一,中间件统一实现Oauth2身份验证 在Golang基于Gin框架开发Web应用程序时,可以使用gin-oauth2来实现Oauth2身份验证。下面是简单的步骤: 安装gin-oauth2包:go get github.com/appleboy/gin-oauth2导入依赖:import &q…...

关于Express 5
目录 1、概述 2、Express 5的变化 2.1 弃用或删除内容的列表: app.param(name,fn)名称中的前导冒号(:) app.del() app.param(fn) 复数方法名 res.json࿰…...

ftrace 原理详细分析
》内核新视界文章汇总《 文章目录 ftrace 原理分析1 简介2 ftrace 的编译器支持2.1 HAVE_FUNCTION_TRACER 选项对 ftrace 的支持2.2 HAVE_DYNAMIC_FTRACE 选项对动态 ftrace 的支持 3 ftrace 的初始化4 function trace 流程5 总结 ftrace 原理分析 1 简介 ftrace 是一个内核…...

UWB定位技术和蓝牙AOA有哪些不同?-高精度室内定位技术对比
UWB超宽带定位 UWB(Ultra Wide Band )即超宽带技术,它是一种无载波通信技术,利用纳秒级的非正弦波窄脉冲传输数据,因此其所占的频谱范围很宽。传统的定位技术是根据信号强弱来判别物体位置,信号强弱受外界…...
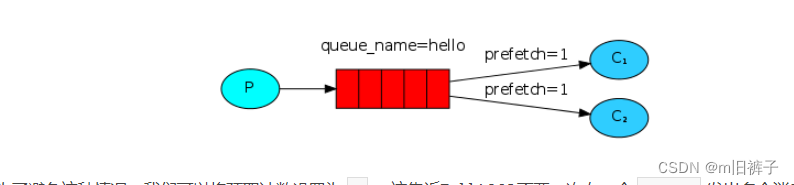
【RabbitMQ】golang客户端教程2——工作队列
任务队列/工作队列 在上一个教程中,我们编写程序从命名的队列发送和接收消息。在这一节中,我们将创建一个工作队列,该队列将用于在多个工人之间分配耗时的任务。 工作队列(又称任务队列)的主要思想是避免立即执行某些…...
芯旺微冲刺IPO,车规级MCU竞争白热化下的“隐忧”凸显
在汽车智能化和电动化发展带来的巨大蓝海市场下,产业链企业迎来了一波IPO小高潮。 日前,上海芯旺微电子技术股份有限公司(以下简称“芯旺微”)在科创板的上市申请已经被上交所受理,拟募资17亿元,用于投建车…...

HTML <s> 标签
例子 可以像这样标记删除线文本: 在 HTML 5 中,<s>仍然支持</s>已经不支持这个标签了。 浏览器支持 元素ChromeIEFirefoxSafariOpera<s>YesYesYesYesYes 所有浏览器都支持 <s> 标签。 定义和用法 <s> 标签可定义加…...

微信小程序 - scroll-view组件之上拉加载下拉刷新(解决上拉加载不触发)
前言 最近在做微信小程序项目中,有一个功能就是做一个商品列表分页限流然后实现上拉加载下拉刷新功能,遇到了一个使用scroll-viwe组件下拉刷新事件始终不触发问题,网上很多说给scroll-view设置一个高度啥的就可以解决,有些人设置了…...

rust usize与i64怎么比较大小?
在Rust中, usize 和 i64 是不同的整数类型,它们的位数和表示范围可能不同。因此,直接比较 usize 和 i64 是不允许的。如果需要比较它们的大小,可以将它们转换为相同的类型,然后进行比较。 要将 usize 转换为 i64 &…...
电脑更新win10黑屏解决方法
电脑更新win10黑屏解决方法 电脑黑屏出现原因解决步骤 彻底解决 电脑黑屏 出现原因 系统未更新成功就关机,导致系统出故障无法关机 解决步骤 首先长安电源键10s关机 按电源键开机,出现logo时按F8进入安全模式。 进入自动修复环境后,单击…...

STM32入门——外部中断
中断系统概述 中断:在主程序运行过程中,出现了特定的中断触发条件(中断源),使得CPU暂停当前正在运行的程序,转而去处理中断程序,处理完成后又返回原来被暂停的位置继续运行中断优先级ÿ…...
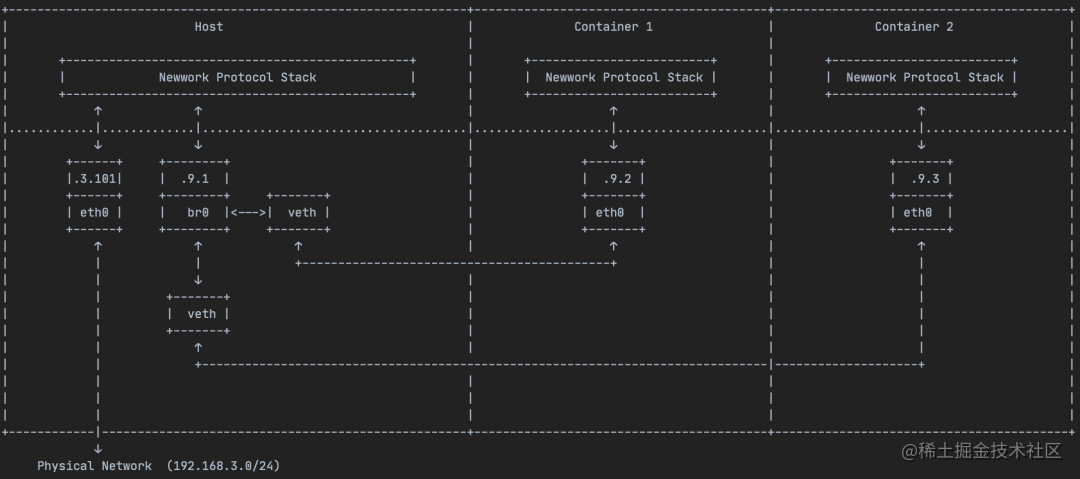
【计算机网络】NAT及Bridge介绍
OSI七层模型 七层模型介绍及举例 为通过网络将人类可读信息通过网络从一台设备传输到另一台设备,必须在发送设备沿 OSI 模型的七层结构向下传输数据,然后在接收端沿七层结构向上传输数据。 数据在 OSI 模型中如何流动 库珀先生想给帕尔梅女士发一封电…...
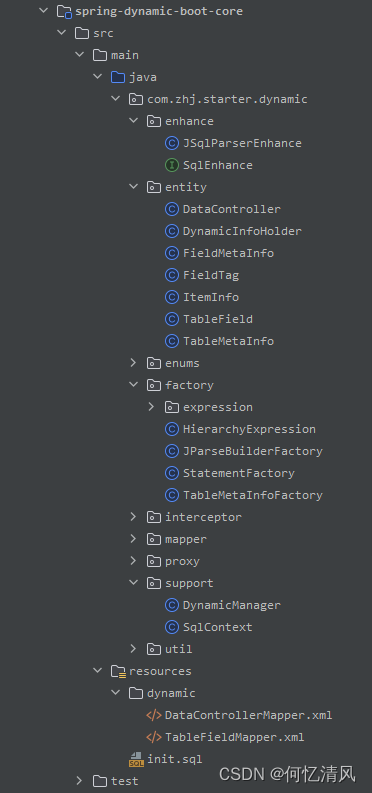
封装动态SQL的插件
最近根据公司的业务需要封装了一个简单的动态SQL的插件,要求是允许用户在页面添加SQL的where条件,然后开发者只需要给某个接口写查询对应的表,参数全部由插件进行拼接完成。下面是最终实现: 开发人员只需要在接口写上下面的查询SQ…...

BLE四大广播模式详解:可连接/不可连接/定向/周期广播
一、前言在低功耗蓝牙(BLE)开发中,广播(Advertising)是设备发现、连接建立、数据广播、设备重连的核心基石,所有BLE交互流程均始于广播报文的收发。不同于传统经典蓝牙,BLE所有广播行为标准化、…...

告别浪费!SolidWorks企业级共享方案,实现降本增效全攻略
还在为 SolidWorks 高昂的硬件投入和混乱的图纸管理头疼?告别“一人一机”的浪费模式,企业级共享方案才是降本增效的正解。这套攻略基于“1 台高性能服务器 云飞云共享云桌面”架构,帮你把硬件成本砍掉 60%,把软件利用率翻倍。一…...

Sangfor文件夹可以删除吗?【图文讲解】深信服文件夹残留清理?如何彻底删除深信服?Sangfor文件夹是什么?
(1)问题背景打开C盘,突然冒出个Sangfor 文件夹,占用好几个 GB 空间,想删又不敢删,怕删坏系统、断网崩溃;上网一查,说法五花八门,有人说是病毒,有人说是办公软…...

可解释AI新突破:基于局部帕累托最优的模型解释框架
1. 项目概述:当AI模型成为“黑箱”,我们如何撬开它?在机器学习项目里摸爬滚打十几年,我见过太多这样的场景:团队花大力气训练出一个准确率高达95%的复杂模型(比如深度神经网络),业务…...

第三卷第4章:原型模式设计思想
第三卷第4章:原型模式设计思想 目录介绍 01.案例引入与思考 1.1 痛点场景 1.2 它哪里不舒服 1.3 引出本篇主角 02.原型模式介绍 2.1 原型模式由来 2.2 原型模式定义...

taotoken如何帮助ubuntu开发者应对大模型api的频繁更新与版本迭代
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken如何帮助Ubuntu开发者应对大模型API的频繁更新与版本迭代 对于在Ubuntu环境下进行开发的工程师而言,大模型API…...
原理与ScalableHD架构优化实践)
超维计算(HDC)原理与ScalableHD架构优化实践
1. 超维计算(HDC)基础解析超维计算(Hyperdimensional Computing, HDC)是一种受大脑信息处理机制启发的计算范式,其核心思想是用高维随机向量(通常称为超向量或HV)来表示和处理信息。与传统神经网…...

论文润色深度测评:GPT-5.5 + Gemini 3.1 Pro:教你学会1+1>2的论文润色方法
各位同仁好,我是七哥。一个在高校里从事人工智能相关领域研究,钻研用大模型AI实操的学术人。可以和七哥交流学术写作或Gemini、GPT、Claude等大模型学术实操相关问题,多多交流,相互成就,共同进步。 2026年的科研圈,AI工具的选择已经从有没有变成了强不强,七哥评测了GPT…...

特定任务需求场景下的过约束并联机构构型设计与控制方法【附代码】
✨ 长期致力于曲面加工、构型综合、运动学和动力学建模、性能评价、多目标优化、滑模控制、鲁棒控制、视觉传感技术研究工作,擅长数据搜集与处理、建模仿真、程序编写、仿真设计。 ✅ 专业定制毕设、代码 ✅ 如需沟通交流,点击《获取方式》 (…...

告别手动复制!用这个自定义编辑器脚本一键备份/克隆Unity Terrain Data
告别手动复制!用这个自定义编辑器脚本一键备份/克隆Unity Terrain Data在Unity关卡设计和技术美术的工作流中,地形数据的灵活复用往往意味着反复的手动操作——导出高度图、备份材质参数、复制植被分布,每个环节都可能成为效率瓶颈。想象这样…...