双端冒泡排序
双端冒泡排序是对传统冒泡排序的改进,其主要改进在于同时从两端开始排序,相对于传统冒泡排序每次只从一端开始排序,这样可以减少排序的遍历次数。
传统冒泡排序从一端开始,每次将最大(或最小)的元素冒泡到序列的一端,然后再从剩余的元素中继续冒泡。这个过程需要进行 n-1 次遍历,每次遍历需要比较相邻的元素并进行交换。
而双端冒泡排序则从序列的两端同时开始,同时将最大和最小的元素冒泡到序列的两端,然后再缩小序列的范围,继续从两端开始冒泡。这样在一次遍历中可以确定两个边界的正确位置,从而减少了排序的遍历次数。
总体上来说,双端冒泡排序减少了比较和交换的次数,从而相对于传统冒泡排序有更好的性能。然而,双端冒泡排序的时间复杂度仍然是 O(n^2),因此对于大规模数据集,仍然不是最优选择。但在某些特定情况下,双端冒泡排序可能比传统冒泡排序略快一些。
class Solution {
public:void swap(int &a, int &b) {int tmp = a;a = b;b = tmp;}vector<int> sortArray(vector<int>& nums) {int left = 0;int right = nums.size() - 1;bool flag = true;while(left < right && flag) {for (int i = left; i < right - 1; i++) {if (nums[i] > nums[i+1]) {swap(nums[i], nums[i+1]);flag = true;}}left++;for (int i = right; i >= left; i--) { // 注意这个边界条件,这里不会越界if (nums[i-1] > nums[i]) {swap(nums[i-1], nums[i]);flag = true;}}right--;}return nums;}
};
相关文章:

双端冒泡排序
双端冒泡排序是对传统冒泡排序的改进,其主要改进在于同时从两端开始排序,相对于传统冒泡排序每次只从一端开始排序,这样可以减少排序的遍历次数。 传统冒泡排序从一端开始,每次将最大(或最小)的元素冒泡到…...

如何在Visual Studio Code中用Mocha对TypeScript进行测试
目录 使用TypeScript编写测试用例 在Visual Studio Code中使用调试器在线调试代码 首先,本文不是一篇介绍有关TypeScript、JavaScript或其它编程语言数据结构和算法的文章。如果你正在准备一场面试,或者学习某一个课程,互联网上可以找到许多…...

GO中Json的解析
一个json字串,想要拿到其中的数据,就需要解析出来 一、适用于json数据的结构已知的情况下 使用json.Unmarshal将json数据解析到结构体中 根据json字串数据的格式定义struct,用来保存解码后的值。这里首先定义了一个与要解析的数据结构一样的…...

chatgpt 提示词-关于数据科学的 75个词语
这里有 75 个 chatgpt 提示,可以立即将其用于数据科学或数据分析等。 1. 伪装成一个SQL终端 提示:假设您是示例数据库前的 SQL 终端。该数据库包含名为“用户”、“项目”、“订单”、“评级”的表。我将输入查询,您将用终端显示的内容进行…...

(自控原理)控制系统的数学模型
目录 一、时域数学模型 1、线性元件微分方程的建立 2、微分方程的求解方法编辑 3、非线性微分方程的线性化 二、复域数学模型 1、传递函数的定义 2、传递函数的标准形式 3、系统的典型环节的传递函数 4、传递函数的性质 5、控制系统数学模型的建立 6、由传递函数求…...

Webpack5 cacheGroups
文章目录 一、 cacheGroups是什么?二、怎么使用cacheGroups?三、cacheGroups实际应用之一? 一、 cacheGroups是什么? 在Webpack 5中,cacheGroups是用于配置代码拆分的规则,它可以帮助你更细粒度地控制生成…...
每篇10题)
前端面试的游览器部分(5)每篇10题
41.什么是浏览器的同步和异步加载脚本的区别?你更倾向于使用哪种方式,并解释原因。 浏览器的同步和异步加载脚本是两种不同的脚本加载方式,它们的主要区别在于加载脚本时是否阻塞页面的解析和渲染。 同步加载脚本: 同步加载脚本…...

数据挖掘七种常用的方法汇总
数据挖掘(Data Mining)就是从大量的、不完全的、有噪声的、模糊的、随机的实际应用数据中,提取隐含在其中的、人们事先不知道的、但又是潜在有用的信息和知识的过程。这个定义包括几层含义:数据源必须是真实的、大量的、含噪声的;发现的是用户…...
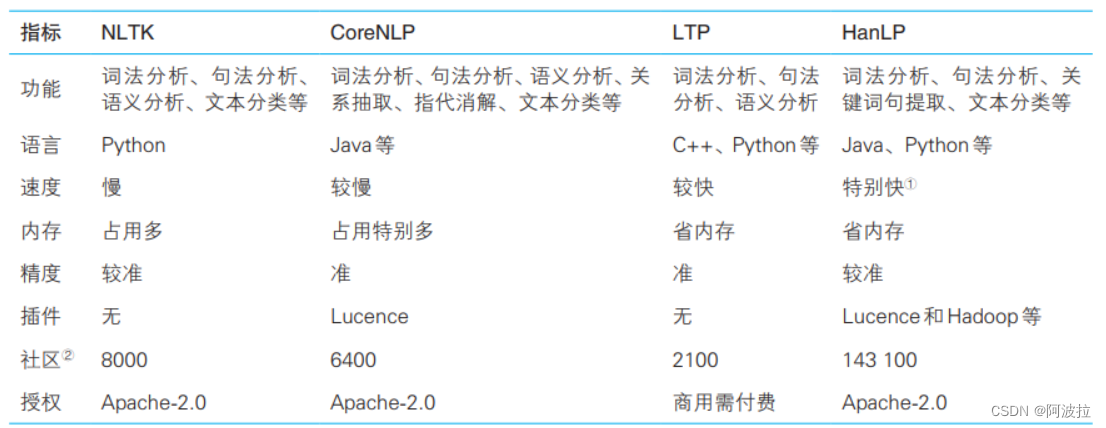
自然语言处理学习笔记(二)————语料库与开源工具
目录 1.语料库 2.语料库建设 (1)规范制定 (2)人员培训 (3)人工标注 3.中文处理中的常见语料库 (1)中文分词语料库 (2)词性标注语料库 (3…...

Rust dyn - 动态分发 trait 对象
dyn - 动态分发 trait 对象 dyn是关键字,用于指示一个类型是动态分发(dynamic dispatch),也就是说,它是通过trait object实现的。这意味着这个类型在编译期间不确定,只有在运行时才能确定。 practice tr…...

uniapp 中过滤获得数组中某个对象里id:1的数据
// 假设studentData是包含多个学生信息的数组 const studentData [{id: 1, name: 小明, age: 18},{id: 2, name: 小红, age: 20},{id: 3, name: 小刚, age: 19},{id: 4, name: 小李, age: 22}, ]; // 过滤获取id为1的学生信息 const result studentData.filter(item > ite…...

Django系列之Channels
1. Channels 介绍 Django 中的 HTTP 请求是建立在请求和响应的简单概念之上的。浏览器发出请求,Django服务调用相应的视图函数,并返回响应内容给浏览器渲染。但是没有办法做到 服务器主动推送消息给浏览器。 因此,WebSocket 就应运而生了。…...
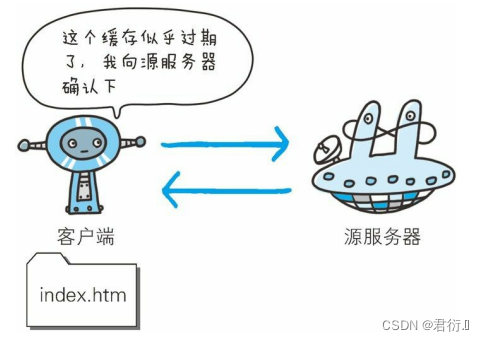
HTTP——五、与HTTP协作的Web服务器
HTTP 一、用单台虚拟主机实现多个域名二、通信数据转发程序 :代理、网关、隧道1、代理2、网关3、隧道 三、保存资源的缓存1、缓存的有效期限2、客户端的缓存 一台 Web 服务器可搭建多个独立域名的 Web 网站,也可作为通信路径上的中转服务器提升传输效率。…...

pyspark笔记 Timestamp 类型的比较
最近写pyspark遇到的一个小问题。 假设我们有一个pyspark DataFrame叫做dart 首先将dart里面timestamp这一列转化成Timestamp类型 dartdart.withColumn(timestamp,col(timestamp).cast(TimestampType()))查看timestamp的前5个元素 dart.select(timestamp).show(5,truncateFal…...
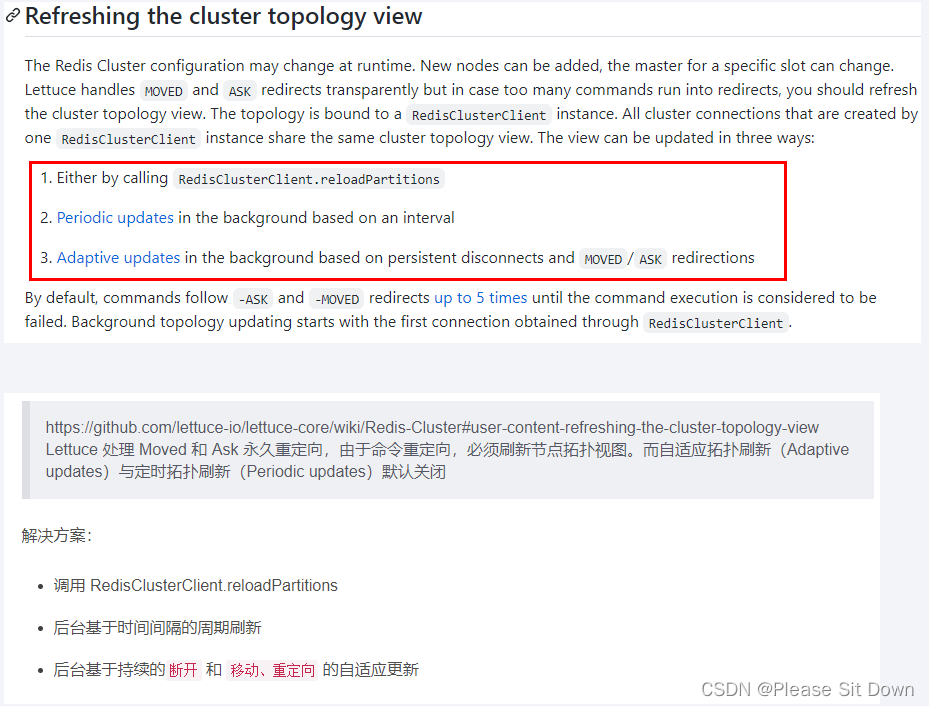
SpringBoot 集成 Redis
本地Java连接Redis常见问题: bind配置请注释掉保护模式设置为noLinux系统的防火墙设置redis服务器的IP地址和密码是否正确忘记写访问redis的服务端口号和auth密码 集成Jedis jedis是什么 Jedis Client是Redis官网推荐的一个面向java客户端,库文件实现…...
黑客学习笔记(网络安全)
一、首先,什么是黑客? 黑客泛指IT技术主攻渗透窃取攻击技术的电脑高手,现阶段黑客所需要掌握的远远不止这些。 以前是完全涉及黑灰产业的反派角色,现在大体指精通各种网络技术的程序人员 二、为什么要学习黑客技术?…...
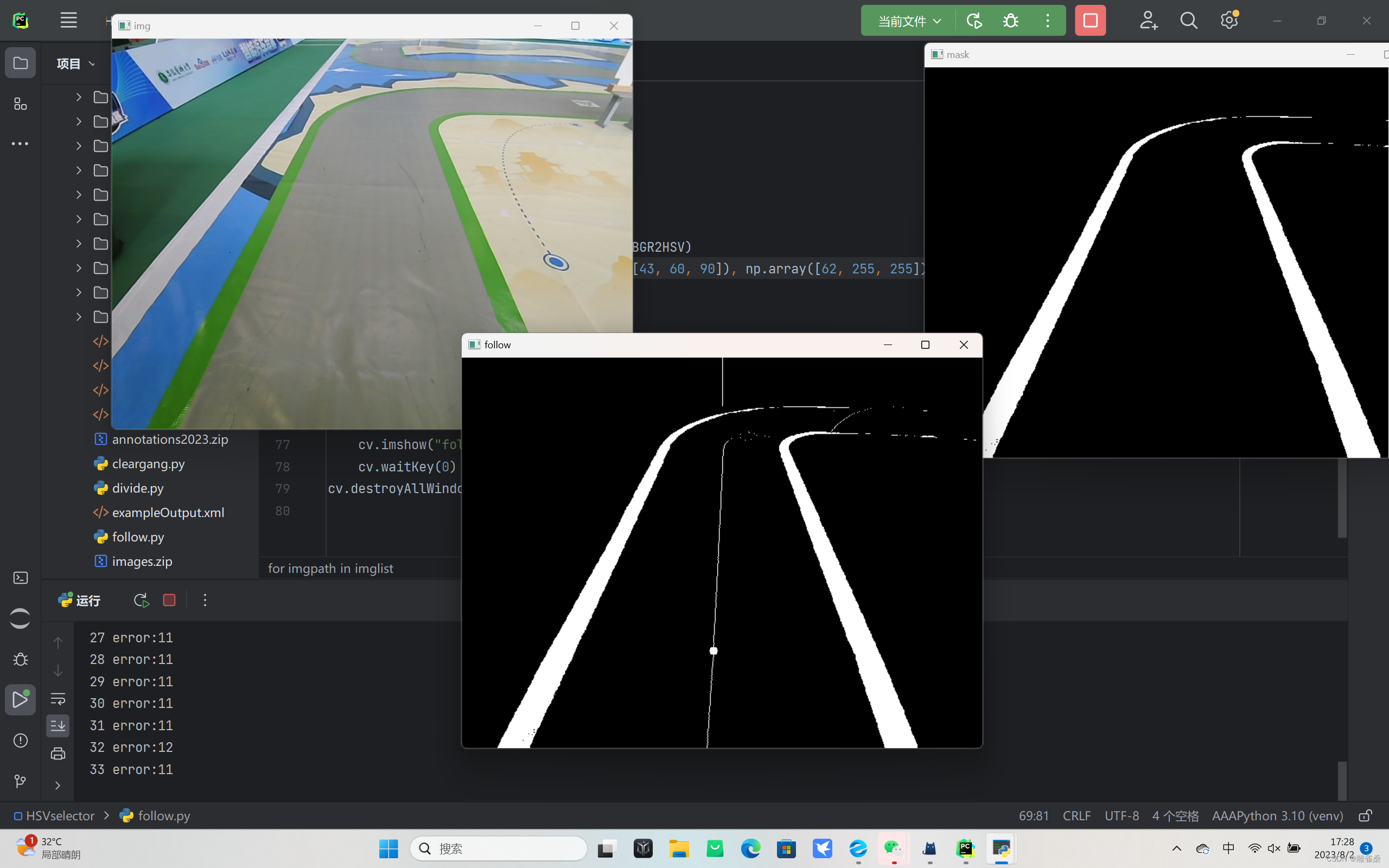
[openCV]基于拟合中线的智能车巡线方案V1
import cv2 as cv import os import numpy as np# 遍历文件夹函数 def getFileList(dir, Filelist, extNone):"""获取文件夹及其子文件夹中文件列表输入 dir:文件夹根目录输入 ext: 扩展名返回: 文件路径列表"""newDir d…...
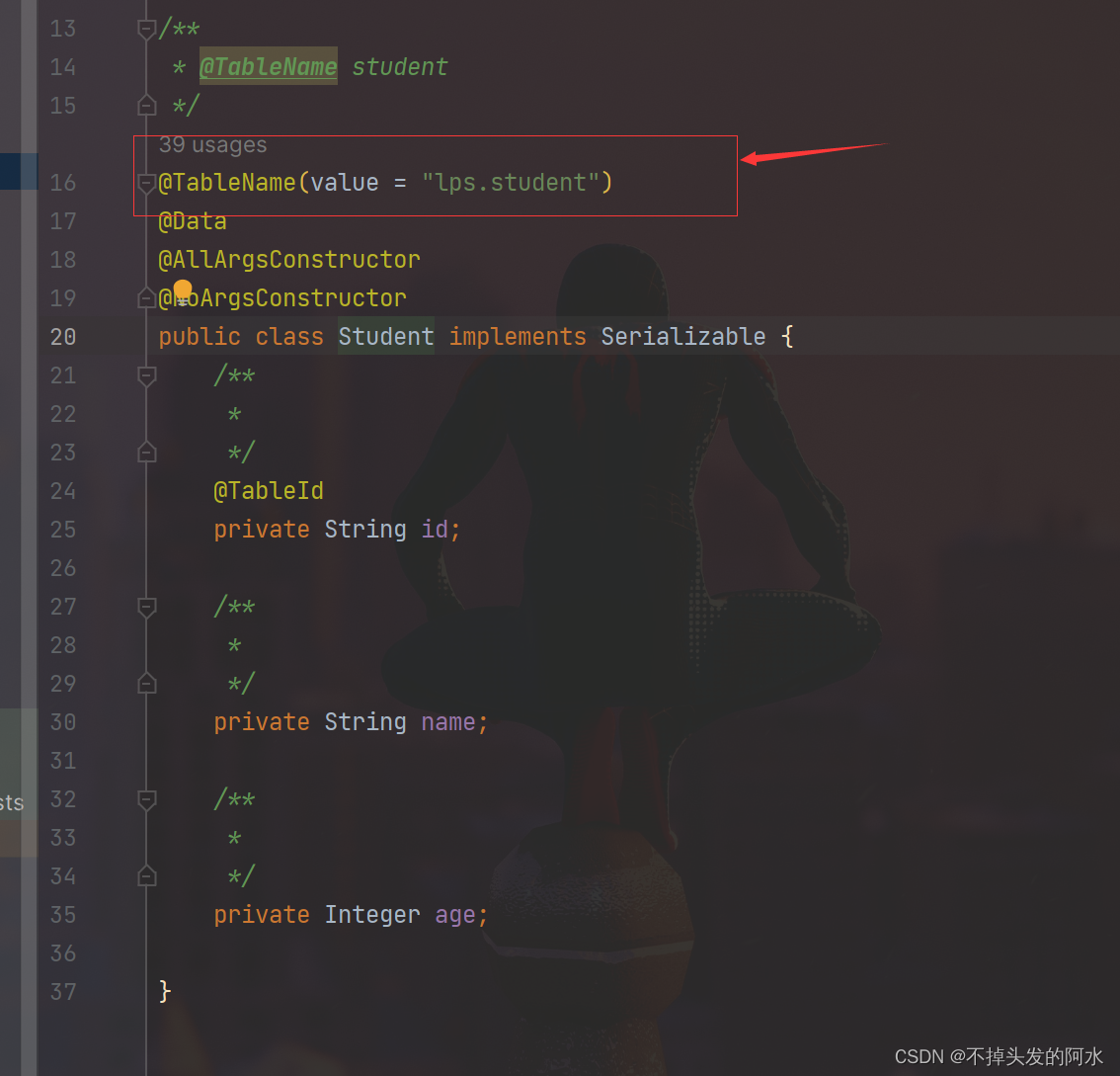
MyBatis-Plus 和达梦数据库实现高效数据持久化
一、添加依赖 首先,我们需要在项目的 pom.xml 文件中添加 MyBatis-Plus 和达梦数据库的依赖: <dependencies><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifac…...

已注销【888】
元神密码 - 飞书云文档 (feishu.cn)...

Ceph错误汇总
title: “Ceph错误汇总” date: “2020-05-14” categories: - “技术” tags: - “Ceph” - “错误汇总” toc: false original: true draft: true Ceph错误汇总 1、执行ceph-deploy报错 1.1、错误信息 ➜ ceph-deploy Traceback (most recent call last):File "/us…...

2026年如何搭建OpenClaw?阿里云2分钟新手步骤含大模型API与Skill配置
2026年如何搭建OpenClaw?阿里云2分钟新手步骤含大模型API与Skill配置。本文面向零基础用户,完整说明在轻量服务器与本地Windows11、macOS、Linux系统中部署OpenClaw(Clawdbot)的流程,包含环境配置、服务启动、Skills集…...

React 逻辑的可测试性:针对 React Hooks 的单体测试与渲染行为模拟的质量保障实践
React 逻辑的可测试性:针对 React Hooks 的单体测试与渲染行为模拟的质量保障实践 主讲人: 某资深前端架构师(也就是我) 受众: 想要逃离“闭包地狱”和“测试屎山”的前端开发者们 时长: 漫长的周一午后 第…...

鸿蒙游戏,会不会重演微信小游戏的爆发?
网罗开发(小红书、快手、视频号同名)大家好,我是 展菲,目前在上市企业从事人工智能项目研发管理工作,平时热衷于分享各种编程领域的软硬技能知识以及前沿技术,包括iOS、前端、Harmony OS、Java、Python等方…...

从Cortex-M3到M0的IAP移植踩坑记:中断向量表处理有何不同?
Cortex-M0 IAP开发实战:中断向量表重映射的底层逻辑与工程实践 第一次在Cortex-M0上部署IAP功能时,我习惯性地复制了M3/M4项目中的VTOR配置代码,结果所有中断都神秘消失了。这个看似简单的"寄存器配置"问题,背后隐藏着M…...

Python 匿名函数 lambda 基础语法与场景
文章目录前言一、先搞懂:lambda 到底是个啥?1.1 匿名函数,名字都懒得取的“临时工”1.2 lambda 和普通函数的核心区别二、lambda 基础语法全拆解2.1 无参数 lambda2.2 单个参数2.5 支持条件表达式三、lambda 为什么存在?核心使用场…...

别再只用翻转和裁剪了!PyTorch实战:用CutMix和Mixup让你的ResNet50在CIFAR-10上再涨几个点
突破传统数据增强瓶颈:PyTorch中CutMix与Mixup的实战调优指南 当你在CIFAR-10上反复调整学习率和权重衰减却始终无法突破准确率瓶颈时,是否想过问题可能出在数据层面?传统的数据增强方法如随机翻转、裁剪虽然能提供基本的正则化效果ÿ…...

基于STM32的平衡机器人PID控制系统设计
一、系统概述与核心原理 1. 系统定位 基于STM32的两轮自平衡机器人(Balance Bot)是自动控制理论的经典实践平台。系统通过MPU6050陀螺仪实时监测车身倾角,利用PID算法计算出电机补偿量,驱动直流电机保持车身直立不倒,并…...

【Python基础20讲】第01章:Python 环境搭建与第一个程序
博主智算菩萨,专注于人工智能、Python编程、音视频处理及UI窗体程序设计等方向。致力于以通俗易懂的方式拆解前沿技术,从零基础入门到高阶实战,陪伴开发者共同成长。目前已开设五大技术专栏,累计发布多篇原创技术文章,…...

从化学到计算机:如何根据你的专业,精准选择最对口的学术文献数据库?
从化学到计算机:如何根据你的专业,精准选择最对口的学术文献数据库? 刚踏入科研领域的研究者常面临一个共同困境:面对琳琅满目的学术数据库,如何快速锁定最适合自己学科的那一个?选择不当不仅浪费时间&…...

FastAPI后台任务完成,如何设计一个全局的、不掉线的SSE通知中心?
FastAPI全局SSE通知中心设计:构建高可靠异步任务通信架构 当用户点击"生成年度报表"按钮时,页面瞬间响应"任务已开始处理",而背后的数据聚合运算可能持续20分钟。如何让用户在这段时间自由浏览其他页面,并在…...