kubernetes 集群利用 efk 收集容器日志
文章目录
- @[toc]
- 前情提要
- 制作 centos 基础镜像
- 准备 efk 二进制文件
- 部署 efk 组件
- 配置 namespace
- 配置 gfs 的 endpoints
- 配置 pv 和 pvc
- 部署 elasticsearch
- efk-cm
- efk-svc
- efk-sts
- 部署 filebeat
- filebeat-cm
- filebeat-ds
- 部署 kibana
- kibana-cm
- kibana-svc
- kibana-dp
- 使用 nodeport 访问 kibana
- nodeport-kibana-svc
- 使用 ingress 的方式
- ingress yaml
文章目录
- @[toc]
- 前情提要
- 制作 centos 基础镜像
- 准备 efk 二进制文件
- 部署 efk 组件
- 配置 namespace
- 配置 gfs 的 endpoints
- 配置 pv 和 pvc
- 部署 elasticsearch
- efk-cm
- efk-svc
- efk-sts
- 部署 filebeat
- filebeat-cm
- filebeat-ds
- 部署 kibana
- kibana-cm
- kibana-svc
- kibana-dp
- 使用 nodeport 访问 kibana
- nodeport-kibana-svc
- 使用 ingress 的方式
- ingress yaml
前情提要
- 本实验环境信息如下:
- 本次实验使用的镜像非
efk自身的镜像,利用统一编译的centos镜像加上gfs持久化存储,将efk二进制文件挂载到容器内使用 - 本次实验依赖
gfs持久化,关于gfs的使用和部署,可以参考我之前的文档 Kubernetes 集群使用 GlusterFS 作为数据持久化存储 - k8s 版本:v1.23.17
- docker 版本:19.03.9
- efk 版本:7.9.2 (elasticsearch+filebeat+kibana)
- 本次实验使用的镜像非
制作 centos 基础镜像
- 为什么要使用统一的
centos镜像- 因为大部分镜像为了空间小,刨去了很多的工具,很大程度上影响了容器内的一些问题排查,尤其是网络层面,为了能安装更多自己需要的工具
- 如果需要针对一些组件升级,就可以只替换二进制文件,不需要修改镜像和维护镜像了
编写 dockerfile
FROM centos:7ENV LANG=C.UTF-8
ENV TZ "Asia/Shanghai"
ENV PS1 "\[\e[7;34m\]\u@\h\[\e[0m\]\[\e[0;35m\]:$(pwd) \[\e[0m\]\[\e[0;35m\]\t\[\e[0m\]\n\[\e[0;32m\]> \[\e[0m\]"# 让容器识别中文
RUN echo LANG='C.UTF-8' > /etc/locale.conf && \localedef -c -f UTF-8 -i zh_CN C.UTF-8# 将官方的源替换成清华源
## 安装一些可能用得到的调试工具
RUN sed -e 's|^mirrorlist=|#mirrorlist=|g' \-e 's|^#baseurl=http://mirror.centos.org/centos|baseurl=https://mirrors.tuna.tsinghua.edu.cn/centos|g' \-i.bak /etc/yum.repos.d/CentOS-*.repo && \yum install -y telnet \unzip \wget \curl \nmap-ncat \vim \net-tools \tree \bind-utils \jq \dig \less \more && yum clean all && \alias ll='ls -lh' && \alias tailf='tail -f'
构建镜像
docker build -t centos7:base_v1.0 .
准备 efk 二进制文件
Past Releases
- 打开上面的地址,在
Products里面分别输入elasticsearch,filebeat、kibana,在Version里面输入自己需要的版本号就可以下载了- 需要自己准备 java 8,去 oracle 官网就可以下载
# 这里选了一个官方不带 jdk 的 es,因为我这边要是用 java 8,不带 jdk 的 es 可以节省 150M 的空间
wget -c https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.9.2-no-jdk-linux-x86_64.tar.gz
wget -c https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-7.9.2-linux-x86_64.tar.gz
wget -c https://artifacts.elastic.co/downloads/kibana/kibana-7.9.2-linux-x86_64.tar.gz
# 这个是 kibana 的一个插件,可以实时查看容器的尾部日志
wget -c https://github.com/sivasamyk/logtrail/releases/download/v0.1.31/logtrail-7.9.2-0.1.31.zip
- 我是利用 gfs 做的持久化,所以,这些二进制文件下载好以后,都会提前先解压出来(
除了 kibana 和 logtrail 不需要解压,其他的都需要解压)
部署 efk 组件
以下只提供 yaml 文件,大家自己按照下面的顺序整理,然后依次 apply 即可
配置 namespace
---
apiVersion: v1
kind: Namespace
metadata:annotations:labels:name: journal
配置 gfs 的 endpoints
- 这块大家以自己实际的架构为准,这里是为了让 k8s 集群可以连接 gfs 开放的端点
- 如果和我一样用的 gfs,注意修改
addresses下面的 ip,以自己实际的为准
---
apiVersion: v1
kind: Endpoints
metadata:annotations:name: glusterfsnamespace: journal
subsets:
# gfs 服务端的地址,要修改成自己的
- addresses:- ip: 172.72.0.96- ip: 172.72.0.98ports:- port: 49152protocol: TCP
---
apiVersion: v1
kind: Service
metadata:annotations:name: glusterfsnamespace: journal
spec:ports:- port: 49152protocol: TCPtargetPort: 49152sessionAffinity: Nonetype: ClusterIP
配置 pv 和 pvc
pv
---
apiVersion: v1
kind: PersistentVolume
metadata:annotations:labels:package: journalname: journal-software-pv
spec:accessModes:- ReadOnlyManycapacity:storage: 10Giglusterfs:endpoints: glusterfspath: online-share/kubernetes_data/software/readOnly: falsepersistentVolumeReclaimPolicy: Retain
pvc
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:annotations:labels:package: journalname: journal-software-pvcnamespace: journal
spec:accessModes:- ReadOnlyManyresources:requests:storage: 10Giselector:matchLabels:package: journal
创建完 pvc 后,需要确认一下 pvc 是否为 Bound 状态
部署 elasticsearch
efk-cm
---
apiVersion: v1
data:elasticsearch.yml: |-cluster.name: efk-escluster.max_shards_per_node: 20000node.attr.rack: ${NODE_NAME}path.data: ${DATA_DIR}path.logs: ${LOG_DIR}network.host: 0.0.0.0http.port: 9200cluster.initial_master_nodes: ["es-0"]http.cors.enabled: truehttp.cors.allow-origin: "*"xpack.security.enabled: falsenode.name: ${POD_NAME}node.master: truenode.data: truetransport.tcp.port: 9300discovery.zen.minimum_master_nodes: 2discovery.zen.ping.unicast.hosts: ["es-0.es-svc.journal.svc.cluster.local:9300","es-1.es-svc.journal.svc.cluster.local:9300","es-2.es-svc.journal.svc.cluster.local:9300"]start.sh: |-#!/bin/bashset -xexport ES_JAVA_OPTS="-Xmx${JAVA_OPT_XMX} -Xms${JAVA_OPT_XMS} -Xss512k -XX:MaxGCPauseMillis=200 -XX:InitiatingHeapOccupancyPercent=45 -Djava.io.tmpdir=/tmp -Dsun.net.inetaddr.ttl=10 -Xloggc:${LOG_DIR}/gc.log"CONFIG_FILE=(jvm.options log4j2.properties role_mapping.yml)for FILENAME in ${CONFIG_FILE[@]}docat ${ES_HOME}/config/${FILENAME} > ${ES_PATH_CONF}/${FILENAME}donecp ${CONFIG_MAP_DIR}/elasticsearch.yml ${ES_PATH_CONF}/${ES_HOME}/bin/elasticsearchinit.sh: |-#!/bin/bashset -xmkdir -p ${LOG_DIR} ${DATA_DIR}chown 1000 -R ${LOG_DIR}chown 1000 -R ${DATA_DIR}
kind: ConfigMap
metadata:annotations:labels:name: es-cmnamespace: journal
efk-svc
---
apiVersion: v1
kind: Service
metadata:annotations:labels:app: esname: es-svcnamespace: journal
spec:clusterIP: Noneports:- name: tcpport: 9300targetPort: 9300- name: httpport: 9200targetPort: 9200selector:app: es
efk-sts
- 在 apply 之前记得先给节点打上 label,在 yaml 文件里面配置了亲和性,需要节点有 es= 这个 label 才会调度
---
apiVersion: apps/v1
kind: StatefulSet
metadata:annotations:labels:app: esname: esnamespace: journal
spec:replicas: 3selector:matchLabels:app: esserviceName: es-svctemplate:metadata:labels:app: esspec:# 因为用的是 hostpath 做 es 的数据持久化,这里做了一个亲和性## nodeAffinity 是为了把 pod 绑定到指定的节点上affinity:nodeAffinity:requiredDuringSchedulingIgnoredDuringExecution:nodeSelectorTerms:- matchExpressions:- key: esoperator: Exists## podAntiAffinity 是为了一个节点上只能出现一个副本podAntiAffinity:requiredDuringSchedulingIgnoredDuringExecution:- labelSelector:matchExpressions:- key: appoperator: Invalues:- estopologyKey: kubernetes.io/hostnamecontainers:- command:- /bin/bash- -c- sh $CONFIG_MAP_DIR/start.shenv:- name: APP_NAMEvalue: es- name: NODE_NAMEvalueFrom:fieldRef:fieldPath: spec.nodeName- name: POD_NAMEvalueFrom:fieldRef:fieldPath: metadata.name- name: NAMESPACEvalueFrom:fieldRef:fieldPath: metadata.namespace- name: DATA_DIRvalue: /efk/es/data- name: LOG_DIRvalue: /efk/es/logs- name: ES_PATH_CONFvalue: /efk/es/conf- name: CONFIG_MAP_DIRvalue: /efk/es/configmap- name: ES_HOMEvalue: /appdata/software/elasticsearch-7.9.2- name: JAVA_HOMEvalue: /appdata/software/jdk1.8.0_231- name: JAVA_OPT_XMSvalue: 256M- name: JAVA_OPT_XMXvalue: 256Mimage: centos7:base_v1.0imagePullPolicy: IfNotPresentlivenessProbe:failureThreshold: 60initialDelaySeconds: 5periodSeconds: 10successThreshold: 1tcpSocket:port: tcptimeoutSeconds: 1name: esports:- containerPort: 9300name: tcp- containerPort: 9200name: httpreadinessProbe:failureThreshold: 60initialDelaySeconds: 5periodSeconds: 10successThreshold: 1tcpSocket:port: tcptimeoutSeconds: 1securityContext:runAsUser: 1000volumeMounts:- mountPath: /efk/es/dataname: data- mountPath: /efk/es/logsname: logs- mountPath: /efk/es/configmapname: configmap- mountPath: /efk/es/confname: conf- mountPath: /appdata/softwarename: softwarereadOnly: trueinitContainers:- command:- /bin/sh- -c- . ${CONFIG_MAP_DIR}/init.shenv:- name: NODE_NAMEvalueFrom:fieldRef:fieldPath: spec.nodeName- name: POD_NAMEvalueFrom:fieldRef:fieldPath: metadata.name- name: DATA_DIRvalue: /efk/es/data- name: LOG_DIRvalue: /efk/es/log- name: ES_PATH_CONFvalue: /efk/es/conf- name: ES_HOMEvalue: /appdata/software/elasticsearch-7.9.2- name: CONFIG_MAP_DIRvalue: /efk/es/configmapimage: centos7:base_v1.0name: initvolumeMounts:- mountPath: /efk/es/dataname: data- mountPath: /efk/es/logsname: logs- mountPath: /efk/es/configmapname: configmapterminationGracePeriodSeconds: 0volumes:- hostPath:path: /data/k8s_data/estype: DirectoryOrCreatename: data- emptyDir: {}name: logs- emptyDir: {}name: conf- configMap:name: es-cmname: configmap- name: softwarepersistentVolumeClaim:claimName: journal-software-pvc
- 依次 apply 之后,可以通过下面的命令进行验证
kubectl get pod -n journal -o wide
这边是起了三个副本
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
es-0 1/1 Running 0 75s 172.30.1.78 172.72.0.96 <none> <none>
es-1 1/1 Running 0 54s 172.30.0.17 172.72.0.98 <none> <none>
es-2 1/1 Running 0 33s 172.30.2.16 172.72.0.95 <none> <none>
可以通过
pod ip来访问 es 集群
curl 172.30.1.78:9200/_cat/nodes
pod ip和pod 名字也是一一对应的
172.30.2.16 51 96 9 0.74 0.52 0.36 dilmrt - es-2
172.30.0.17 53 66 8 0.39 0.45 0.33 dilmrt - es-1
172.30.1.78 37 68 7 0.16 0.32 0.24 dilmrt * es-0
部署 filebeat
filebeat-cm
---
apiVersion: v1
data:filebeat.yaml: |-filebeat.inputs:- type: container# stream: stdoutencoding: utf-8paths:- /var/log/pods/*/*/*.logtail_files: true# 将error日志合并到一行multiline.pattern: '^([0-9]{4}|[0-9]{2})-[0-9]{2}'multiline.negate: truemultiline.match: aftermultiline.timeout: 10s# 设置条件logging.level: warninglogging.json: truelogging.metrics.enabled: falseoutput.elasticsearch:hosts: ["${ES_URL}"]indices:- index: "journal-center-%{+yyyy.MM.dd}"pipeline: k8s_pipelinek8s_pipeline.json: |-{"description": "解析k8s container日志","processors": [{"grok":{"field": "log.file.path","patterns": ["/var/log/pods/%{DATA:namespace}_%{DATA:pod_name}_.*/%{DATA:container_name}/.*"],"ignore_missing": true,"pattern_definitions":{"GREEDYMULTILINE": "(.|\n)*"}},"remove":{"field": "log.file.path"}}],"on_failure": [{"set":{"field": "error.message","value": "{{ _ingest.on_failure_message }}"}}]}startFilebeat.sh: |#!/bin/bashset -exDIR="$( cd "$( dirname "$0" )" && pwd )"LOG_DIR=/appdata/logs/${NAMESPACE}/${APP_NAME}DATA_DIR=/appdata/data/${NAMESPACE}/${APP_NAME}mkdir -p $LOG_DIR $DATA_DIRcurl -H 'Content-Type: application/json' -XPUT http://${ES_URL}/_ingest/pipeline/k8s_pipeline -d@${DIR}/k8s_pipeline.json$FILEBEAT_HOME/filebeat -e -c $DIR/filebeat.yaml --path.data $DATA_DIR --path.logs $LOG_DIR
kind: ConfigMap
metadata:annotations:labels:package: filebeatname: filebeat-cmnamespace: journal
filebeat-ds
---
apiVersion: apps/v1
kind: DaemonSet
metadata:annotations:labels:app: filebeatname: filebeatnamespace: journal
spec:selector:matchLabels:app: filebeattemplate:metadata:labels:app: filebeatspec:containers:- command:- /bin/bash- /appdata/init/filebeat/startFilebeat.shenv:- name: APP_NAMEvalue: filebeat-pod- name: NODE_NAMEvalueFrom:fieldRef:fieldPath: spec.nodeName- name: POD_NAMEvalueFrom:fieldRef:fieldPath: metadata.name- name: NAMESPACEvalueFrom:fieldRef:fieldPath: metadata.namespace- name: ES_URLvalue: es-0.es-svc.journal.svc.cluster.local:9200- name: FILEBEAT_HOMEvalue: /appdata/software/filebeat-7.9.2-linux-x86_64image: centos7:base_v1.0imagePullPolicy: IfNotPresentname: filebeatvolumeMounts:- mountPath: /appdata/init/filebeatname: init- mountPath: /appdata/softwarename: softwarereadOnly: true- mountPath: /var/log/podsname: pod-logsreadOnly: true- mountPath: /data/crt-data/containersname: container-logreadOnly: trueterminationGracePeriodSeconds: 0volumes:- name: softwarepersistentVolumeClaim:claimName: journal-software-pvc- configMap:name: filebeat-cmname: init- hostPath:path: /var/log/podsname: pod-logs- hostPath:path: /data/crt-data/containersname: container-log
- 验证索引的创建
- 这里的 ip 记得换成自己的 es ip
curl -s -XGET 172.30.1.78:9200/_cat/indices | grep 'journal-center'
返回类似如下的信息
不一定会立刻生成,具体要看实际的环境是否有 pod 产生日志,需要等一会再看看
green open journal-center-2023.08.03 J-Ylys9ES2CGovXrYwjCsg 1 1 7 0 129kb 70.8kb
部署 kibana
kibana-cm
---
apiVersion: v1
data:kibana.yml: |-server.port: 5601server.host: "0.0.0.0"elasticsearch.hosts: ["http://${ES_URL}"]pid.file: ${DATA_DIR}/kibana.pidi18n.locale: "zh-CN"path.data: ${DATA_DIR}xpack.infra.enabled: falsexpack.logstash.enabled: falselogging.quiet: truestartKibana.sh: |#!/bin/bashset -exDIR="$( cd "$( dirname "$0" )" && pwd )"mkdir -p $LOG_DIR $DATA_DIR ${APP_HOME}[[ -d "${KIBANA_HOME}" ]] || tar xf /appdata/software/kibana-7.9.2-linux-x86_64.tar.gz -C ${APP_HOME}${KIBANA_HOME}/bin/kibana-plugin install file:///appdata/software/logtrail-7.9.2-0.1.31.zip# 创建 logtrail 使用的索引curl -XPUT "${ES_URL}/.logtrail/config/1?pretty" -H 'Content-Type: application/json' -d '{"version" : 2,"index_patterns" : [{"es": {"default_index": "journal-center-*"},"tail_interval_in_seconds": 10,"es_index_time_offset_in_seconds": 0,"display_timezone": "local","display_timestamp_format": "MM-DD HH:mm:ss","max_buckets": 500,"default_time_range_in_days" : 0,"max_hosts": 100,"max_events_to_keep_in_viewer": 5000,"default_search": "","fields" : {"mapping" : {"timestamp" : "@timestamp","message": "message"},"message_format": "[{{{namespace}}}].[{{{pod_name}}}].[{{{container_name}}}] {{{message}}}","keyword_suffix" : "keyword"},"color_mapping" : {}}]}'# 配置索引生命周期,保留三天的日志curl -XPUT "${ES_URL}/_ilm/policy/journal-center_policy?pretty" -H 'Content-Type: application/json' -d '{"policy": {"phases": {"delete": {"min_age": "3d","actions": {"delete": {}}}}}}'# 配置索引的分片和副本数curl -XPUT "${ES_URL}/_template/journal-center_template?pretty" -H 'Content-Type: application/json' -d '{"index_patterns": ["journal-center-*"],"settings": {"number_of_shards": 1,"number_of_replicas": 1,"index.lifecycle.name": "journal-center_policy"}}'# 应用到现有的多个索引中curl -XPUT "${ES_URL}/journal-center-*/_settings?pretty" -H 'Content-Type: application/json' -d '{"index": {"lifecycle": {"name": "journal-center_policy"}}}'${KIBANA_HOME}/bin/kibana -c ${DIR}/kibana.yml
kind: ConfigMap
metadata:annotations:labels:app: kibananame: kibana-cmnamespace: journal
kibana-svc
---
apiVersion: v1
kind: Service
metadata:annotations:labels:app: kibananame: kibana-svcnamespace: journal
spec:ports:- name: kibanawebport: 5601protocol: TCPtargetPort: 5601selector:app: kibana
kibana-dp
---
apiVersion: apps/v1
kind: Deployment
metadata:annotations:labels:app: kibananame: kibananamespace: journal
spec:replicas: 1selector:matchLabels:app: kibanatemplate:metadata:labels:app: kibanaspec:containers:- command:- /bin/bash- /appdata/init/kibana/startKibana.shenv:- name: APP_NAMEvalue: kibana- name: NODE_NAMEvalueFrom:fieldRef:fieldPath: spec.nodeName- name: POD_NAMEvalueFrom:fieldRef:fieldPath: metadata.name- name: NAMESPACEvalueFrom:fieldRef:fieldPath: metadata.namespace- name: ES_URLvalue: es-0.es-svc.journal.svc.cluster.local:9200- name: KIBANA_HOMEvalue: /kibana/kibana-7.9.2-linux-x86_64- name: APP_HOMEvalue: /kibana- name: LOG_DIRvalue: /appdata/kibana/logs- name: DATA_DIRvalue: /appdata/kibana/dataimage: centos7:base_v1.0livenessProbe:failureThreshold: 60initialDelaySeconds: 5periodSeconds: 20successThreshold: 1tcpSocket:port: kibanawebtimeoutSeconds: 1name: kibanaports:- containerPort: 5601name: kibanawebprotocol: TCPreadinessProbe:failureThreshold: 60initialDelaySeconds: 5periodSeconds: 20successThreshold: 1tcpSocket:port: kibanawebtimeoutSeconds: 1securityContext:runAsUser: 1000volumeMounts:- mountPath: /appdata/init/kibananame: init- mountPath: /appdata/softwarename: softwarereadOnly: true- mountPath: /appdata/kibananame: kibanas- mountPath: /kibananame: kibanainstallterminationGracePeriodSeconds: 0volumes:- name: softwarepersistentVolumeClaim:claimName: journal-software-pvc- configMap:name: kibana-cmname: init- emptyDir: {}name: kibanas- emptyDir: {}name: kibanainstall
- 关于 kibana 的访问,这边提供两种方式供大家选择
使用 nodeport 访问 kibana
nodeport-kibana-svc
---
apiVersion: v1
kind: Service
metadata:annotations:labels:app: kibananame: kibana-nodeport-svcnamespace: journal
spec:type: NodePortports:- name: kibanawebport: 5601protocol: TCPtargetPort: 5601nodePort: 30007selector:app: kibana
apply 之后,就可以使用任一节点的 ip 加上 30007 去访问 kibana 的界面
使用 ingress 的方式
- 使用 ingress 需要先部署 ingress-controller ,我这边使用的是 nginx-ingress-controller,具体部署可以参考我另一篇博客:
- kubernetes 部署 nginx-ingress-controller
ingress yaml
---
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:annotations:kubernetes.io/ingress.class: nginxname: ingress-journalnamespace: journal
spec:rules:# host 字段不写,表示使用 ip 访问## host 字段可以写域名,如果没有 dns 解析,可以本地做 hosts 来验证- host: logs.study.comhttp:paths:- backend:service:name: kibana-svcport:number: 5601path: /pathType: Prefix
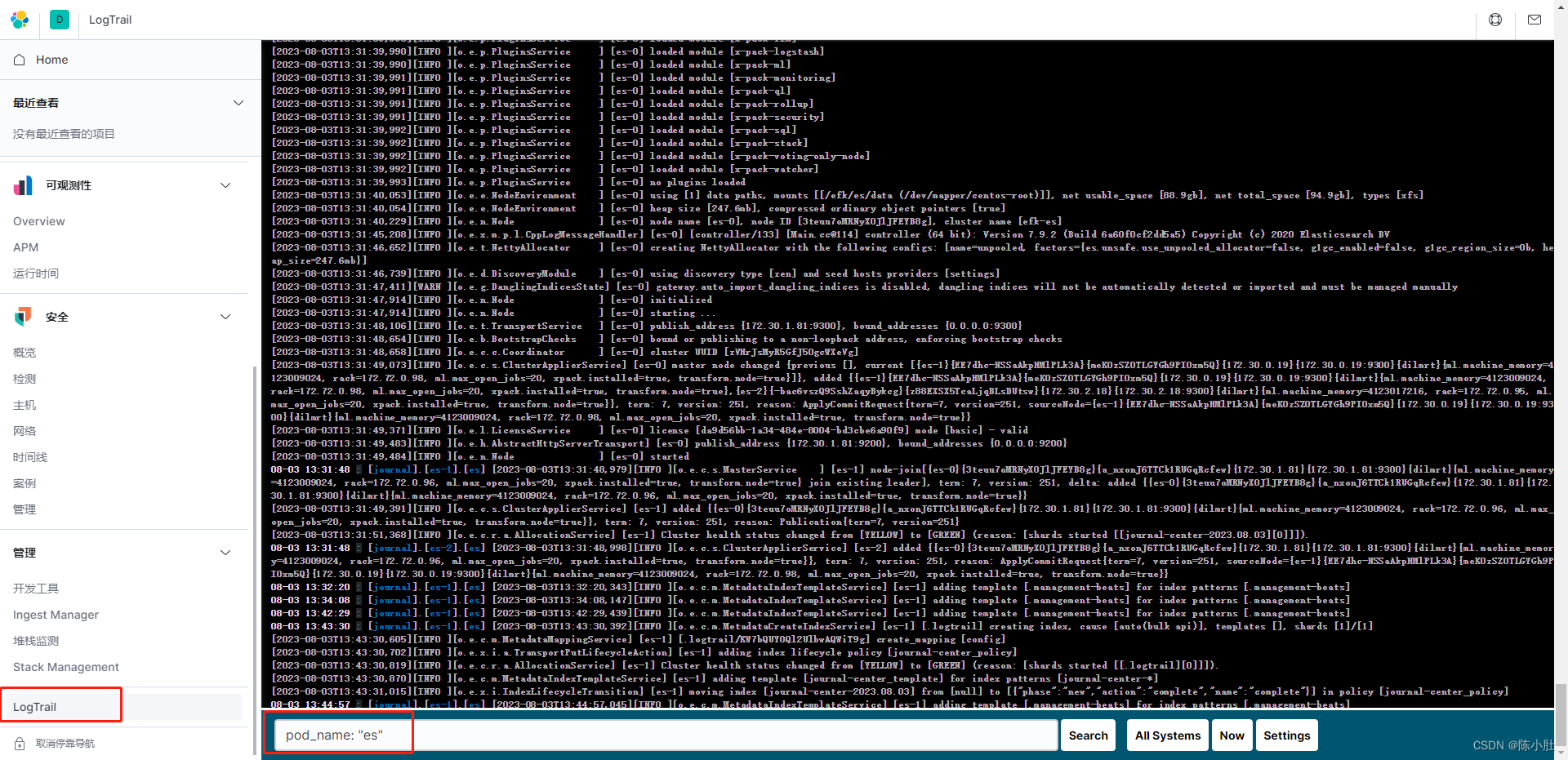
找到导航栏的 logtrail,然后在输入框输入 pod_name: “<pod名字>” 来看指定容器的日志
相关文章:
kubernetes 集群利用 efk 收集容器日志
文章目录 [toc]前情提要制作 centos 基础镜像准备 efk 二进制文件部署 efk 组件配置 namespace配置 gfs 的 endpoints配置 pv 和 pvc部署 elasticsearchefk-cmefk-svcefk-sts 部署 filebeatfilebeat-cmfilebeat-ds 部署 kibanakibana-cmkibana-svckibana-dp使用 nodeport 访问 …...

安防视频监控汇聚平台EasyCVR在移动端火狐浏览器中云台显示的优化
安防监控视频EasyCVR视频融合平台基于云边端一体化架构,具有强大的数据接入、视频监控汇聚、处理及分发能力,平台能对前端接入设备进行统一集中管理,支持采用设备树对设备进行分组、分级管理,支持设备状态监测、云端运维等功能&am…...
)
selenium官文文档阅读总结(day 3)
1.关联型xpath的用法 driver.find_element(By.XPATH,//a[text()"xxx"]/ancestor::祖先元素的标签名//……) 2.selenium等待 等待的作用 :在系统运行的过程中,等待网页内容的加载显示。需要耗费的时间,与网络速度、接口的复杂程度…...

【pandas百炼成钢】数据预览与预处理
知识目录 前言一、数据查看1 - 查看数据维度2 - 随机查看5条数据3 - 查看数据前后5行4 - 查看数据基本信息5 - 查看数据统计信息|数值6 - 查看数据统计信息|非数值7 - 查看数据统计信息|整体 二、缺失值处理8 - 计算缺失值|总计9 …...

怎么查到企业的供应商和客户?
企业的供应商和客户是什么? 其实不需要过多介绍,我们对供应商和客户都有自己的理解,供应商就是负责企业产品的供应,企业从供应商那里买材料进行加工得到的产品,卖给客户。 官方来说供应商是向企业和竞争对手提供各种…...

智能物流千人俱乐部---行业必备神器
千人俱乐部前两天正式推出了。 智能物流千人俱乐部详情 很多行业内的甲方和乙方的朋友过来问,这个千人俱乐部到底怎么玩?今天再来解释一下。 1、为什么搞这个千人俱乐部? 一个原因是:研习社天天都有甲方粉丝让推荐设备厂家&#x…...

uniapp uview文件上传的文件不是文件流,该如何处理?用了uni.chooseImage预览功能要如何做
在使用uniapp开发,运用的ui是用uview,这边需要做一个身份认证,如下图 使用的是uview的u-upload组件,可是这个组件传给后端的不是文件流 后端接口需要的是文件流格式,后面使用了uniapp的选择图片或者拍照的api&#x…...

pktgen-dpdk arm编译问题 “Platform must be built with RTE_FORCE_INTRINSICS“
编译报错 /usr/include/rte_atomic_32.h:9:4: error: #error Platform must be built with RTE_FORCE_INTRINSICS解决办法: 我是在 arm架构服务器上编译出现这个,要定义 RTE_FORCE_INTRINSICS 在meson.build中 增加gcc编译参数 add_project_arguments(…...

用html+javascript打造公文一键排版系统12:删除附件说明中“附件:”里的空格
如果我们在输入附件说明时在“附件:”之间加入空格,那么排版时就要删除这些空格。 因为string对象replace()支持正则表达式,于是考虑用replace()来完成。 写了一段只有一个多余空格的代码来测试: <!DOCTYPE HTML> <HT…...

容器技术:Docker搭建(通俗易懂)
目录 Docker搭建环境准备Docker安装1、查看服务器是否安装Docker2、卸载Docker3、安装Dokcer依赖环境4、配置Docker国内阿里云镜像5、安装Docker6、查看Docker信息7、配置阿里云镜像加速8、镜像安装10、运行实例11、查看实例状态12、测试 Docker命令集合 Docker搭建 环境准备 …...
)
Day 16 C++ 友元(friend)
目录 什么是友元(friend) 友元的三种实现 全局函数做友元 类做友元 成员函数做友元 什么是友元(friend) 友元是一种访问控制的机制,它允许一个类或函数访问另一个类的私有成员。通过友元关系,可以在需要…...

步进电机1
引脚说明: VCC:电源输入口 DC:9-42VDC:电源的取值范围 AB组:用于连接电机的四条线 STEP&PUL:脉冲信号接口,用于控制速度。无细分的情况下一个脉冲步进电机走一步。 DIR:方向信号接口&#x…...

PHP-简单项目引起的大麻烦--【白嫖项目】
强撸项目系列总目录在000集 PHP要怎么学–【思维导图知识范围】 文章目录 本系列校训本项目使用技术 首页小插曲小插曲完了么?必要的项目知识PHPThinkPHPThinkPHP的MVCThinkTemplateThinkPHP 6和ThinkPHP 5 phpStudy 设置导数据库展示页面数据库表结构项目目录如图…...
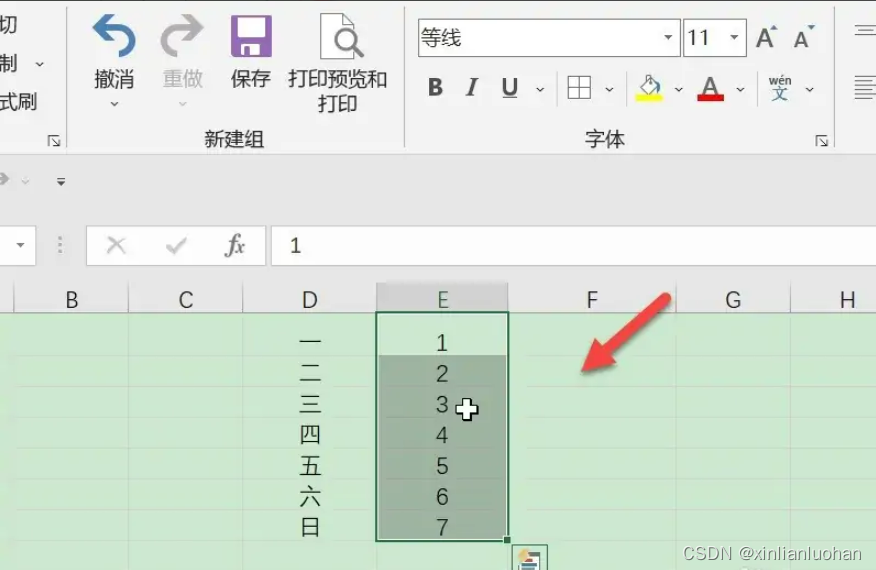
Excel如何把两列互换
第一步:选择一列 打开excel,选中一列后将鼠标放在列后,让箭头变成十字方向。 第二步:选择Shift键 按住键盘上的Shift键,将列往后移动变成图示样。 第三步:选择互换 完成上述操作后,松开鼠标两…...
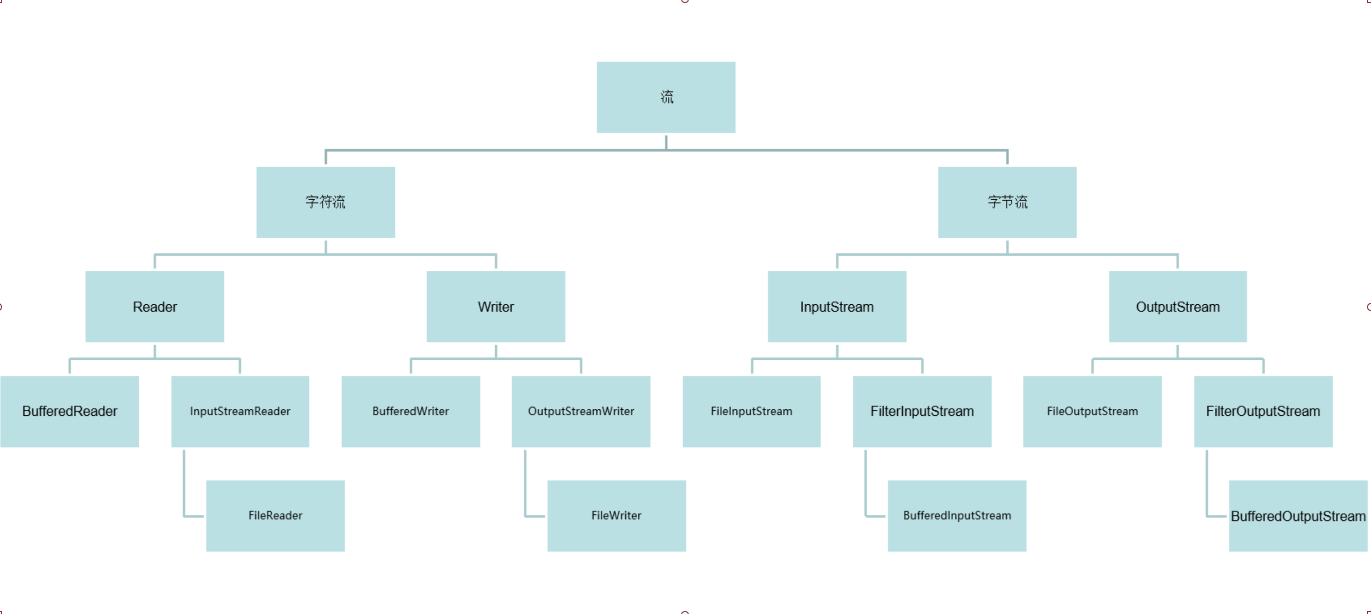
Java基础面试题2
Java基础面试题 一、IO和多线程专题 1.介绍下进程和线程的关系 进程:一个独立的正在执行的程序 线程:一个进程的最基本的执行单位,执行路径 多进程:在操作系统中,同时运行多个程序 多进程的好处:可以充…...
)
Typescript 第八章 异步编程,并行和并发(JavaScript事件循环,异步流,多线程类型安全)
Typescript第八章 异步编程,并发和并行 异步API,比如说回调,promise和流。 JavaScript引擎在一个线路中多路复用任务,而其他任务则处于空闲状态。这种事件循环是JavaScript引擎的标准线程模型。 多路复用是指在一个线程中同时处…...
)
c++ 打印当前时间(精确到毫秒)
打印时间精确到毫秒好实现,但是那种对用户可读性不好,更适合开头记一次结尾记一次,打印中间减出来的程序运行时间。 但是因为一些情况,我开多线程开的不方便打印结束时间,同事跟我说那你把开始时间打印一下࿰…...
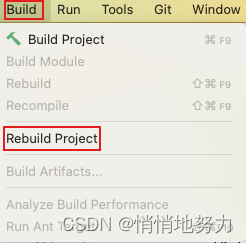
mapstruct 错误 java.lang.NoSuchMethodError: Ljava/lang/Double 错误
问题描述 在使用 mapstruct 的过程中遇到错误 java.lang.NoSuchMethodError: Ljava/lang/Double 错误 问题解决 maven clean, 然后 maven install Build -> Rebuild Project 执行 maven install 时, 如果报错 找不到 xxx 类, 但 ctrl鼠标左键 发现可以点进去这个类, 那…...
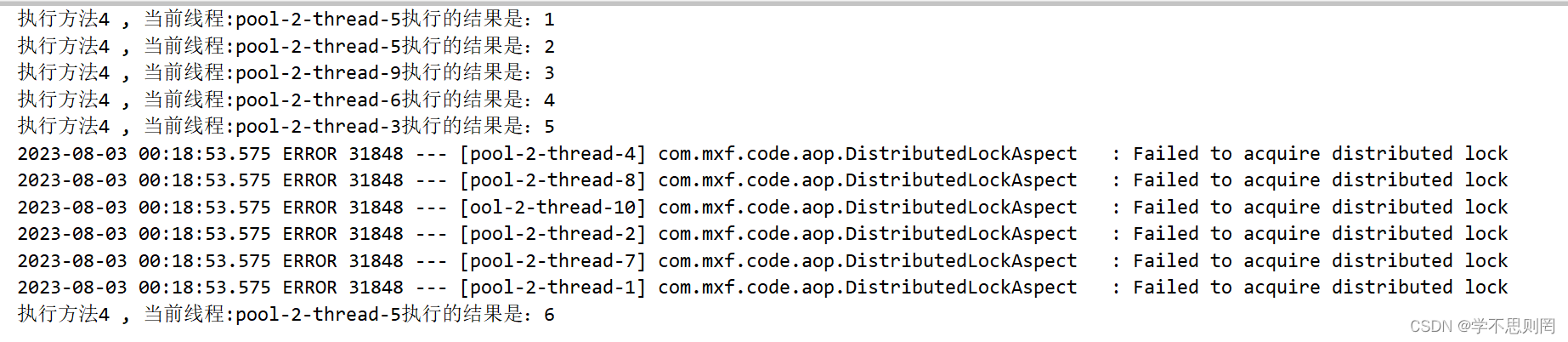
SpringBoot+AOP+Redission实战分布式锁
文章目录 前言一、Redission是什么?二、使用场景三、代码实战1.项目结构2.类图3.maven依赖4.yml5.config6.annotation7.aop8.model9.service 四、单元测试总结 前言 在集群环境下非单体应用存在的问题:JVM锁只能控制本地资源的访问,无法控制…...

Linux系统---进程概念
文章目录 冯诺依曼体系结构操作系统(OS)进程的理解 进程状态 进程优先级 环境变量 进程地址空间 Linux2.6内核进程调度队列 一、冯诺依曼体系结构 我们常见的计算机,如笔记本。我们不常见的计算机,如服务器,大部分都遵守冯诺依曼体系。 如图…...

Phi-3-mini-128k-instruct长文本处理效果实测:128K上下文极限测试
Phi-3-mini-128k-instruct长文本处理效果实测:128K上下文极限测试 最近,关于大模型处理长文本的能力讨论越来越热。很多朋友都在问,那些号称能处理几十万甚至上百万字上下文的模型,实际用起来到底怎么样?是不是真的能…...

ncmdump终极指南:三步解锁网易云音乐NCM加密格式,实现音乐自由播放
ncmdump终极指南:三步解锁网易云音乐NCM加密格式,实现音乐自由播放 【免费下载链接】ncmdump 项目地址: https://gitcode.com/gh_mirrors/ncmd/ncmdump 在数字音乐时代,你是否曾为网易云音乐下载的NCM格式文件无法在其他设备播放而烦…...

Vibe Coding导致技能退化?
AI辅助开发工具的快速发展已经引入了软件编写方式的明显转变。在开发者中,一个术语已经出现来描述这种转变——“Vibe Coding”。它指的是一种编程风格,开发者严重依赖直觉、AI生成的建议和迭代细化,而非深入推理系统的每个组件。 这种演变提…...
)
【奇点2026权威发布】:AIAgent任务调度必须绕开的7个LLM原生缺陷(附可验证的调度补偿算法伪代码)
第一章:【奇点2026权威发布】:AIAgent任务调度必须绕开的7个LLM原生缺陷(附可验证的调度补偿算法伪代码) 2026奇点智能技术大会(https://ml-summit.org) 大型语言模型在AIAgent任务调度中并非“即插即用”的可靠执行引擎——其底…...

Kandinsky-5.0-I2V-Lite-5s入门必看:PyCharm中调试模型调用代码详解
Kandinsky-5.0-I2V-Lite-5s入门必看:PyCharm中调试模型调用代码详解 1. 准备工作与环境配置 在开始调试Kandinsky-5.0-I2V-Lite-5s模型之前,我们需要确保开发环境已经正确设置。PyCharm作为一款强大的Python IDE,能够显著提升我们的开发效率…...

文墨共鸣模型自动化作业批改应用:针对编程与文本作业的智能评估
文墨共鸣模型自动化作业批改应用:针对编程与文本作业的智能评估 最近和几位当老师的朋友聊天,他们都在感慨,批改作业真是个体力活,尤其是编程作业和文科的问答题。编程题要一行行看逻辑、查错误,文科题要逐字逐句分析…...

40_终极落地Checklist:你的公司Agent是否真的会干活了
核心价值:可打印、可传播的检查表 更新频率:季度/半年重磅很多团队的 Agent 能跑起来、能演示、能交付,但真正到生产环境里能不能稳定地"干活",是两回事。这篇文章提供一个结构化的评估框架,帮你从五个维度判…...

AI 入门 30 天挑战 - Day 8 费曼学习法版 - 神经网络初探
🌟 完整项目和代码 本教程是 AI 入门 30 天挑战 系列的一部分! 💻 GitHub 仓库: https://github.com/Lee985-cmd/AI-30-Day-Challenge📖 CSDN 专栏: https://blog.csdn.net/m0_67081842?typeblog⭐ 欢迎 Star 支持!…...

HUNYUAN-MT 7B翻译终端与微信小程序开发结合:实现实时对话翻译工具
HUNYUAN-MT 7B翻译终端与微信小程序开发结合:实现实时对话翻译工具 你有没有遇到过这样的场景?在国外旅行,想和当地人交流却语言不通;或者工作中需要和外国同事沟通,但双方语言有障碍。这时候,一个能装在手…...

双重机器学习DML介绍
本文参考: [1]我在开始团做运筹_DML 一、核心原理与数学框架 双重机器学习(Double Machine Learning, DML)由Chernozhukov等学者于2018年提出,是一种结合机器学习与传统计量经济学的因果推断框架。其核心目标是在高维数据和非线…...