Flink DataStream API详解
DataStream API
参考:https://ci.apache.org/projects/flink/flink-docs-release-1.9/dev/datastream_api.html
Data Sources
Source是程序读取其输入的位置,您可以使用env.addSource(sourceFunction)将Source附加到程序中。Flink内置了许多预先实现的SourceFunction,但是您始终可以通过实现SourceFunction(non-parallel sources)来编写自定义Source,或者通过继承RichParallelSourceFunction或实现ParallelSourceFunction接口来实现并行Source.
File-based
readTextFile(path) - 逐行读取文本文件,底层使用TextInputFormat规范读取文件,并将其作为字符串返回
val env = StreamExecutionEnvironment.getExecutionEnvironment
val lines:DataStream[String]=env.readTextFile("file:///E:\\demo\\words")
lines.flatMap(_.split("\\s+"))
.map((_,1))
.keyBy(t=>t._1)
.sum(1)
.print()
env.execute("wordcount")
readFile(fileInputFormat, path) - 根据指定的文件输入格式读取文件(仅仅读取一次,类似批处理)
val env = StreamExecutionEnvironment.getExecutionEnvironment
val inputFormat=new TextInputFormat(null)
val lines:DataStream[String]=env.readFile(inputFormat,"file:///E:\\demo\\words")
lines.flatMap(_.split("\\s+"))
.map((_,1))
.keyBy(t=>t._1)
.sum(1)
.print()
env.execute("wordcount")
readFile(fileInputFormat, path, watchType, interval, pathFilter) - 这是前两个内部调用的方法。它根据给定的FileInputFormat读取指定路径下的文件,可以根据watchType定期检测指定路径下的文件,其中watchType的可选值为FileProcessingMode.PROCESS_CONTINUOUSLY或者FileProcessingMode.PROCESS_ONCE,检查的周期由interval参数决定。用户可以使用pathFilter参数排除该路径下需要排除的文件。如果指定watchType的值被设置为PROCESS_CONTINUOUSLY,表示一旦文件内容发生改变,整个文件内容会被重复处理。
val env = StreamExecutionEnvironment.getExecutionEnvironment
val inputFormat=new TextInputFormat(null)
val lines:DataStream[String]=env.readFile(inputFormat,"file:///E:\\demo\\words",FileProcessingMode.PROCESS_CONTINUOUSLY,5000,new FilePathFilter {override def filterPath(filePath: Path): Boolean = {filePath.getPath.endsWith(".txt")}})
lines.flatMap(_.split("\\s+"))
.map((_,1))
.keyBy(t=>t._1)
.sum(1)
.print()
env.execute("wordcount")
Socket-based
val env = StreamExecutionEnvironment.getExecutionEnvironment
val lines:DataStream[String]=env.socketTextStream("centos",9999)
lines.flatMap(_.split("\\s+"))
.map((_,1))
.keyBy(t=>t._1)
.sum(1)
.print()
env.execute("wordcount")
Collection-based(测试)
val env = StreamExecutionEnvironment.getExecutionEnvironment
val lines:DataStream[String]=env.fromCollection(List("this is a demo","good good"))
//val lines:DataStream[String]=env.fromElements("this is a demo","good good")
lines.flatMap(_.split("\\s+"))
.map((_,1))
.keyBy(t=>t._1)
.sum(1)
.print()
env.execute("wordcount")
Custom Source
import org.apache.flink.streaming.api.functions.source.{ParallelSourceFunction, SourceFunction}
import scala.util.Randomclass CustomSourceFunction extends ParallelSourceFunction[String]{@volatilevar isRunning:Boolean = trueval lines:Array[String] = Array("this is a demo","hello word","are you ok")override def run(ctx: SourceFunction.SourceContext[String]): Unit = {while(isRunning){Thread.sleep(1000)ctx.collect(lines(new Random().nextInt(lines.length)))//将数据输出给下游}}override def cancel(): Unit = {isRunning=false}
}
val env = StreamExecutionEnvironment.getExecutionEnvironment
val lines:DataStream[String]=env.addSource[String](new CustomSourceFunction)
lines.flatMap(_.split("\\s+"))
.map((_,1))
.keyBy(t=>t._1)
.sum(1)
.print()
env.execute("wordcount")
FlinkKafkaConsumer√
<dependency><groupId>org.apache.flink</groupId><artifactId>flink-connector-kafka_${scala.version}</artifactId><version>${flink.version}</version>
</dependency>
val env = StreamExecutionEnvironment.getExecutionEnvironment
val props = new Properties()
props.setProperty("bootstrap.servers", "centos:9092")
props.setProperty("group.id", "g1")
val lines=env.addSource(new FlinkKafkaConsumer("topic01",new SimpleStringSchema(),props))lines.flatMap(_.split("\\s+")).map((_,1)).keyBy(t=>t._1).sum(1).print()
env.execute("wordcount")
如果使用SimpleStringSchema,仅仅能获取value,如果用户希望获取更多信息,比如 key/value/partition/offset ,用户可以通过继承KafkaDeserializationSchema类自定义反序列化对象。
import org.apache.flink.api.common.typeinfo.TypeInformation
import org.apache.flink.streaming.connectors.kafka.KafkaDeserializationSchema
import org.apache.kafka.clients.consumer.ConsumerRecord
import org.apache.flink.streaming.api.scala._class UserKafkaDeserializationSchema extends KafkaDeserializationSchema[(String,String)] {//这个方法永远返回falseoverride def isEndOfStream(nextElement: (String, String)): Boolean = {false}override def deserialize(record: ConsumerRecord[Array[Byte], Array[Byte]]): (String, String) = {var key=""if(record.key()!=null && record.key().size!=0){key=new String(record.key())}val value=new String(record.value())(key,value)}//告诉Flink tuple元素类型override def getProducedType: TypeInformation[(String, String)] = {createTypeInformation[(String, String)]}
}
val env = StreamExecutionEnvironment.getExecutionEnvironment
val props = new Properties()
props.setProperty("bootstrap.servers", "centos:9092")
props.setProperty("group.id", "g1")
val lines:DataStream[(String,String)]=env.addSource(new FlinkKafkaConsumer("topic01",new UserKafkaDeserializationSchema(),props))
lines.map(t=>t._2).flatMap(_.split("\\s+"))
.map((_,1))
.keyBy(t=>t._1)
.sum(1)
.print()
env.execute("wordcount")
如果Kafka存储的都是json格式的字符串数据,用户可以使用系统自带的一些支持json的Schema,推荐使用:
- JsonNodeDeserializationSchema:要求value必须是json格式的字符串
- JSONKeyValueDeserializationSchema(meta):要求key、value都必须是josn格式数据,同时可以携带元数据(分区、 offset等)
val env = StreamExecutionEnvironment.getExecutionEnvironment
val props = new Properties()
props.setProperty("bootstrap.servers", "centos:9092")
props.setProperty("group.id", "g1")
val jsonData:DataStream[ObjectNode]=env.addSource(new FlinkKafkaConsumer("topic01",new JSONKeyValueDeserializationSchema(true),props))
jsonData.map(on=> (on.get("value").get("id").asInt(),on.get("value").get("name")))
.print()
env.execute("wordcount")
Data Sinks
Data Sinks接收DataStream数据,并将其转发到指定文件,socket,外部存储系统或者print它们,Flink预定义一些输出Sink。
File-based
write*:writeAsText|writeAsCsv(…)|writeUsingOutputFormat,请注意DataStream上的write*()方法主要用于调试目的。
val env = StreamExecutionEnvironment.getExecutionEnvironment
val props = new Properties()
props.setProperty("bootstrap.servers", "centos:9092")
props.setProperty("group.id", "g1")
env.addSource(new FlinkKafkaConsumer[String]("topic01",new SimpleStringSchema(),props))
.flatMap(_.split("\\s+"))
.map((_,1))
.keyBy(0)
.sum(1)
.writeAsText("file:///E:/results/text",WriteMode.OVERWRITE)
env.execute("wordcount")
以上写法只能保证at_least_once的语义处理,如果是在生产环境下,推荐使用flink-connector-filesystem将数据写到外围系统,可以保证exactly-once语义处理。
val env = StreamExecutionEnvironment.getExecutionEnvironment
val props = new Properties()
props.setProperty("bootstrap.servers", "centos:9092")
props.setProperty("group.id", "g1")
val bucketingSink = new BucketingSink[(String,Int)]("hdfs://centos:9000/BucketingSink")
bucketingSink.setBucketer(new DateTimeBucketer("yyyyMMddHH"))//文件目录
bucketingSink.setBatchSize(1024)
env.addSource(new FlinkKafkaConsumer[String]("topic01",new SimpleStringSchema(),props))
.flatMap(_.split("\\s+"))
.map((_,1))
.keyBy(0)
.sum(1)
.addSink(bucketingSink)
.setParallelism(6)
env.execute("wordcount")
print() | printToErr()
val env = StreamExecutionEnvironment.getExecutionEnvironment
val props = new Properties()
props.setProperty("bootstrap.servers", "centos:9092")
props.setProperty("group.id", "g1")
fsEnv.addSource(new FlinkKafkaConsumer[String]("topic01",new SimpleStringSchema(),props))
.flatMap(_.split("\\s+"))
.map((_,1))
.keyBy(0)
.sum(1)
.print("测试") //输出前缀 当有多个流输出到控制台时,可以添加前缀加以区分
.setParallelism(2)
env.execute("wordcount")
Custom Sink
class CustomSinkFunction extends RichSinkFunction[(String,Int)]{override def open(parameters: Configuration): Unit = {println("初始化连接")}override def invoke(value: (String, Int), context: SinkFunction.Context[_]): Unit = {println(value)}override def close(): Unit = {println("关闭连接")}
}
val env = StreamExecutionEnvironment.getExecutionEnvironment
val props = new Properties()
props.setProperty("bootstrap.servers", "centos:9092")
props.setProperty("group.id", "g1")
env.addSource(new FlinkKafkaConsumer[String]("topic01",new SimpleStringSchema(),props))
.flatMap(_.split("\\s+"))
.map((_,1))
.keyBy(0)
.sum(1)
.addSink(new CustomSinkFunction)
env.execute("wordcount")
RedisSink√
- 添加
<dependency><groupId>org.apache.bahir</groupId><artifactId>flink-connector-redis_2.11</artifactId><version>1.0</version>
</dependency>
class UserRedisMapper extends RedisMapper[(String,Int)]{// 设置数据类型override def getCommandDescription: RedisCommandDescription = {new RedisCommandDescription(RedisCommand.HSET,"wordcount")}override def getKeyFromData(data: (String, Int)): String = {data._1}override def getValueFromData(data: (String, Int)): String = {data._2.toString}
}
val env = StreamExecutionEnvironment.getExecutionEnvironment
val props = new Properties()
props.setProperty("bootstrap.servers", "centos:9092")
props.setProperty("group.id", "g1")
val jedisConfig=new FlinkJedisPoolConfig.Builder()
.setHost("centos")
.setPort(6379)
.build()
env.addSource(new FlinkKafkaConsumer[String]("topic01",new SimpleStringSchema(),props))
.flatMap(_.split("\\s+"))
.map((_,1))
.keyBy(0)
.sum(1)
.addSink(new RedisSink[(String, Int)](jedisConfig,new UserRedisMapper))
env.execute("wordcount")
FlinkKafkaProducer√
class UserKeyedSerializationSchema extends KeyedSerializationSchema[(String,Int)]{
Intoverride def serializeKey(element: (String, Int)): Array[Byte] = {element._1.getBytes()}override def serializeValue(element: (String, Int)): Array[Byte] = {element._2.toString.getBytes()}//可以覆盖 默认是topic,如果返回值为null,表示将数据写入到默认的topic中override def getTargetTopic(element: (String, Int)): String = {null}
}
val env = StreamExecutionEnvironment.getExecutionEnvironment
val props1 = new Properties()
props1.setProperty(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "centos:9092")
props1.setProperty(ConsumerConfig.GROUP_ID_CONFIG, "g1")
val props2 = new Properties()
props2.setProperty(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "centos:9092")
props2.setProperty(ProducerConfig.BATCH_SIZE_CONFIG,"100")
props2.setProperty(ProducerConfig.LINGER_MS_CONFIG,"500")
props2.setProperty(ProducerConfig.ACKS_CONFIG,"all")
props2.setProperty(ProducerConfig.RETRIES_CONFIG,"2")
env.addSource(new FlinkKafkaConsumer[String]("topic01",new SimpleStringSchema(),props1))
.flatMap(_.split("\\s+"))
.map((_,1))
.keyBy(0)
.sum(1)
.addSink(new FlinkKafkaProducer[(String, Int)]("topic02",new UserKeyedSerializationSchema,props2))
env.execute("wordcount")
DataStream Transformations
Map
Takes one element and produces one element.
dataStream.map { x => x * 2 }
FlatMap
Takes one element and produces zero, one, or more elements.
dataStream.flatMap { str => str.split(" ") }
Filter
Evaluates a boolean function for each element and retains those for which the function returns true.
dataStream.filter { _ != 0 }
Union
Union of two or more data streams creating a new stream containing all the elements from all the streams.
dataStream.union(otherStream1, otherStream2, ...)
Connect
“Connects” two data streams retaining their types, allowing for shared state between the two streams.
val stream1 = env.socketTextStream("centos",9999)
val stream2 = env.socketTextStream("centos",8888)
stream1.connect(stream2).flatMap(line=>line.split("\\s+"),line=>line.split("\\s+"))
.map(Word(_,1))
.keyBy("word")
.sum("count")
.print()
Split
Split the stream into two or more streams according to some criterion.
val split = someDataStream.split((num: Int) =>(num % 2) match {case 0 => List("even")case 1 => List("odd")}
)
Select
Select one or more streams from a split stream.
val even = split select "even"
val odd = split select "odd"
val all = split.select("even","odd")
val lines = env.socketTextStream("centos",9999)
val splitStream: SplitStream[String] = lines.split(line => {if (line.contains("error")) {List("error") //分支名称} else {List("info") //分支名称}
})
splitStream.select("error").print("error")
splitStream.select("info").print("info")
Side Out
val lines = env.socketTextStream("centos",9999)
//设置边输出标签
val outTag = new OutputTag[String]("error")
val results = lines.process(new ProcessFunction[String, String] {override def processElement(value: String, ctx: ProcessFunction[String, String]#Context, out: Collector[String]): Unit = {if (value.contains("error")) {ctx.output(outTag, value)} else {out.collect(value)}}
})
results.print("正常结果")
//获取边输出
results.getSideOutput(outTag)
.print("错误结果")
KeyBy
Logically partitions a stream into disjoint partitions, each partition containing elements of the same key. Internally, this is implemented with hash partitioning.
dataStream.keyBy("someKey") // Key by field "someKey"
dataStream.keyBy(0) // Key by the first element of a Tuple
Reduce
A “rolling” reduce on a keyed data stream. Combines the current element with the last reduced value and emits the new value.
env.socketTextStream("centos",9999)
.flatMap(_.split("\\s+"))
.map((_,1))
.keyBy(0)
.reduce((t1,t2)=>(t1._1,t1._2+t2._2))
.print()
Fold
A “rolling” fold on a keyed data stream with an initial value. Combines the current element with the last folded value and emits the new value.
env.socketTextStream("centos",9999)
.flatMap(_.split("\\s+"))
.map((_,1))
.keyBy(0)
.fold(("",0))((t1,t2)=>(t2._1,t1._2+t2._2))
.print()
Aggregations
Rolling aggregations on a keyed data stream. The difference between min and minBy is that min returns the minimum value, whereas minBy returns the element that has the minimum value in this field (same for max and maxBy).
zs 001 1200
ww 001 1500
zl 001 1000
env.socketTextStream("centos",9999)
.map(_.split("\\s+"))
.map(ts=>(ts(0),ts(1),ts(2).toDouble))
.keyBy(1)
.minBy(2)//输出含有最小值的记录
.print()
1> (zs,001,1200.0)
1> (zs,001,1200.0)
1> (zl,001,1000.0)
env.socketTextStream("centos",9999)
.map(_.split("\\s+"))
.map(ts=>(ts(0),ts(1),ts(2).toDouble))
.keyBy(1)
.min(2)
.print()
1> (zs,001,1200.0)
1> (zs,001,1200.0)
1> (zs,001,1000.0)
相关文章:

Flink DataStream API详解
DataStream API 参考:https://ci.apache.org/projects/flink/flink-docs-release-1.9/dev/datastream_api.html Data Sources Source是程序读取其输入的位置,您可以使用env.addSource(sourceFunction)将Source附加到程序中。Fl…...
函数对图像进行腐蚀操作】)
【如何使用cv::erode()函数对图像进行腐蚀操作】
文章目录 `cv::erode()`函数主要用途`cv::erode()`函数的参数卷积核cv::erode()函数主要用途 cv::erode()函数主要用于进行图像的腐蚀操作。这是一种图像处理技术,通常用于消除图像中的噪声、分离两个连接在一起的物体、或者使物体的边界变得更加明显。 腐蚀操作的基本思想是…...

C++数据结构之BST(二叉搜索树)的实现
目录 BST 的方法摘要查找节点四个引用,都有妙用递归版非递归版 插入节点利用search的返回值更新高度的注意事项插入算法的完整代码 删除节点框架单分支,直接替代双分支,化繁为简代码 code BST 预告:本文是后续实现各种各样平衡二叉…...
QT以管理员身份运行
以下配置后,QT在QT Creator调试时,或者生成的.exe程序,都将会默认以管理员身份运行。 一、MSVC编译器 1、在Pro文件中添加以下代码: QMAKE_LFLAGS /MANIFESTUAC:\"level\requireAdministrator\ uiAccess\false\\" …...

java中的缓冲流
Java.io.BufferedOutputStream 字节缓冲输出流,继承自OutputStream 构造方法: BufferedOutputStream (OutputStream out) 创建一个新的缓冲输出流,将数据写入指定的底层输出流BufferedOutputStream (OutputStream out, int size) 创建一个新…...
【小吉带你学Git】idea操作(1)_配置环境并进行基本操作
🎊专栏【Git】 🍔喜欢的诗句:更喜岷山千里雪 三军过后尽开颜。 🎆音乐分享【Counting Stars 】 欢迎并且感谢大家指出小吉的问题🥰 文章目录 🍔环境准备⭐配置Git忽略文件🎄方法🌺创…...
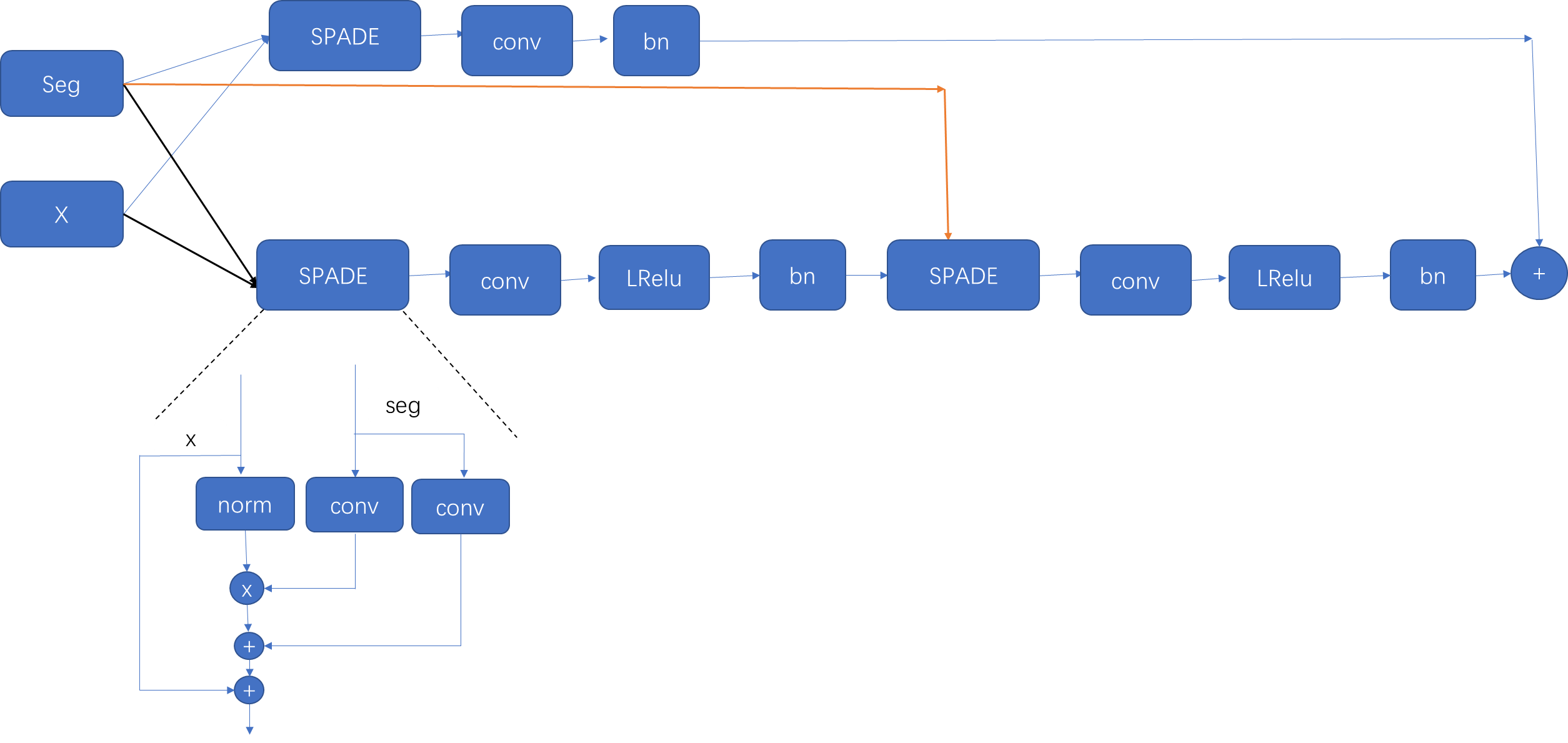
DP-GAN-生成器代码
首先看一下数据生成: 在预处理阶段会将label经过ont-hot编码转换为35个通道,即每个通道都是由(0,1)组成。 在train文件中,对生成器和判别器分别进行更新,根据loss的不同,分别计算对于的损失&a…...

2020-2023中国高等级自动驾驶产业发展趋势研究
1.1 概念界定 2020-2023中国高等级自动驾驶产业发展趋势研究Trends in China High-level Autonomous Driving from 2020 to 2023自动驾驶发展过程中,中国出现了诸多专注于研发L3级以上自动驾驶的公司,其在业界地位也越来越重要。本报告围绕“高等级自动…...
JDK19 - synchronized关键字导致的虚拟线程PINNED
JDK19 - synchronized关键字导致的虚拟线程PINNED 前言一. PINNED是什么意思1.1 synchronized 绑定测试1.2 synchronized 关键字的替代 二. -Djdk.tracePinnedThreads的作用和坑2.1 死锁案例测试2.2 发生原因的推测2.3 总结 前言 在 虚拟线程详解 这篇文章里面,我们…...
用msys2安装verilator并用spinal进行仿真
一 参考 SpinalHDL 开发环境搭建一步到位(图文版) - 极术社区 - 连接开发者与智能计算生态 (aijishu.com)https://aijishu.com/a/1060000000255643Setup and installation of Verilator — SpinalHDL documentation...
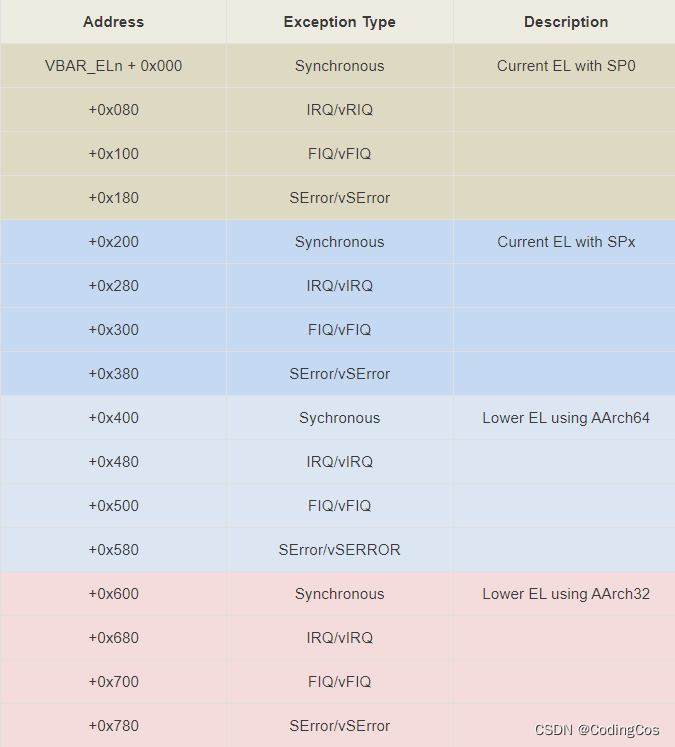
【ARM64 常见汇编指令学习 13 -- ARM 汇编 ORG 伪指令学习】
文章目录 ARM ORG 指令介绍UEFI 中对 ORG 指令的使用 ARM ORG 指令介绍 在ARM汇编中,"org"是一个汇编器伪指令,用于设置下一条指令的装入地址。"org"后面跟着的是一个表达式,这个表达式的值就是下一条指令的装入地址。如…...

Vue使用QuillEditor富文本编辑器问题记录
1.内容绑定的问题 绑定内容要使用 v-model:content"xxx" 的形式。 2.设置字体字号 字体以及字号大小的设置需要先注册。 <script> import { QuillEditor,Quill } from vueup/vue-quill import vueup/vue-quill/dist/vue-quill.snow.css; // 设置字体大小 c…...
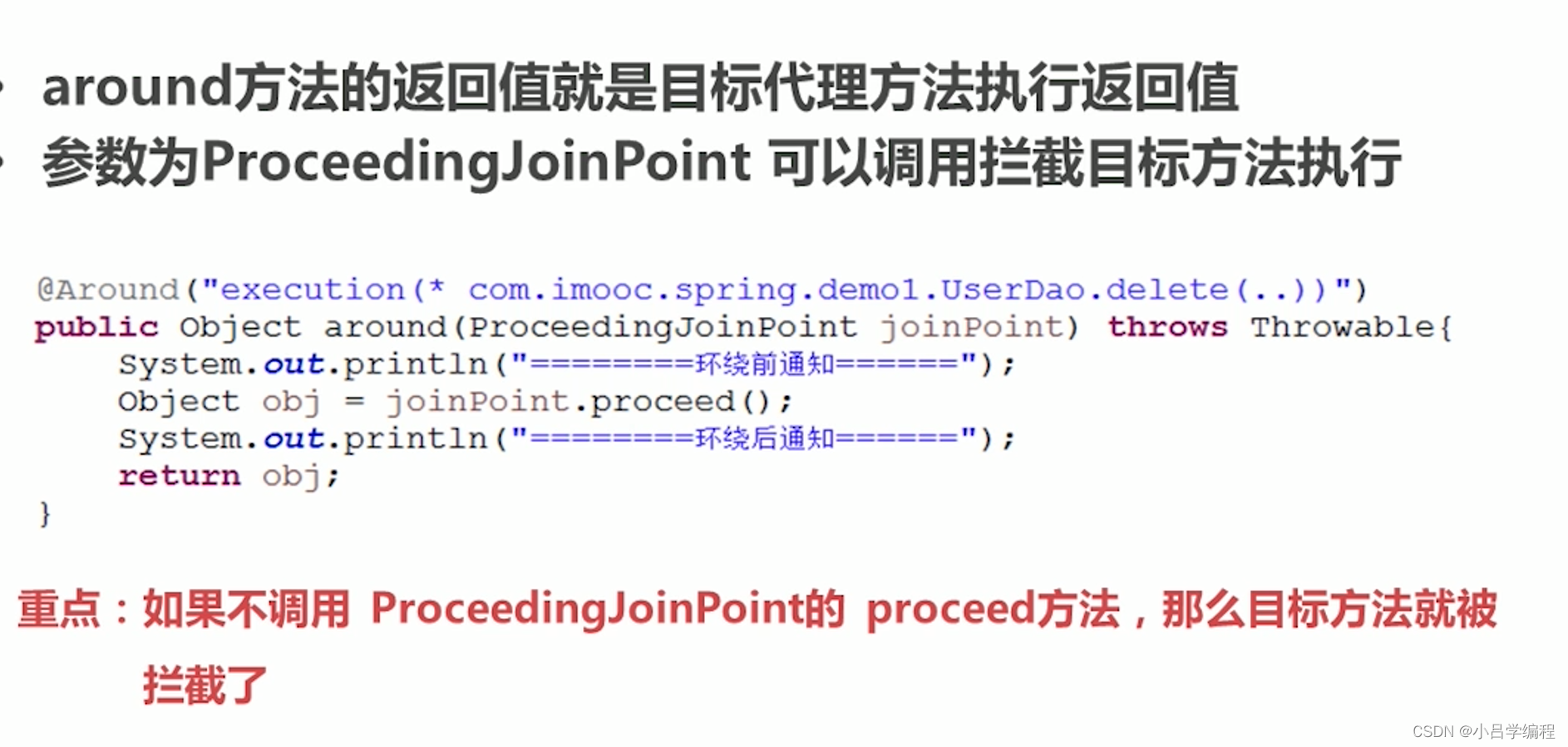
spring AOP学习
概念 面向切面编程横向扩展动态代理 相关术语 动态代理 spring在运行期,生成动态代理对象,不需要特殊的编译器 Spring AOP的底层就是通过JDK动态代理或者CGLIb动态代理技术为目标Bean执行横向织入 目标对象实现了接口,spring使用JDK的ja…...

16.M端事件和JS插件
16.1移动端 移动端也有自己独特的地方 ●触屏事件touch (也称触摸事件),Android 和I0S都有。 ●touch对象代表一个触摸点。触摸点可能是一根手指,也可能是一根触摸笔。触屏事件可响应用户手指(或触控笔)对屏幕或者触控板操作。 ●常见的触屏事件如下: …...

Zebec APP:构建全面、广泛的流支付应用体系
目前,流支付协议 Zebec Protocol 基本明确了生态的整体轮廓,它包括由其社区推动的模块化 Layer3 构架的公链 Nautilus Chain、流支付应用 Zebec APP 以及 流支付薪酬工具 Zebec payroll 。其中,Zebec APP 是原有 Zebec Protocol 的主要部分&a…...
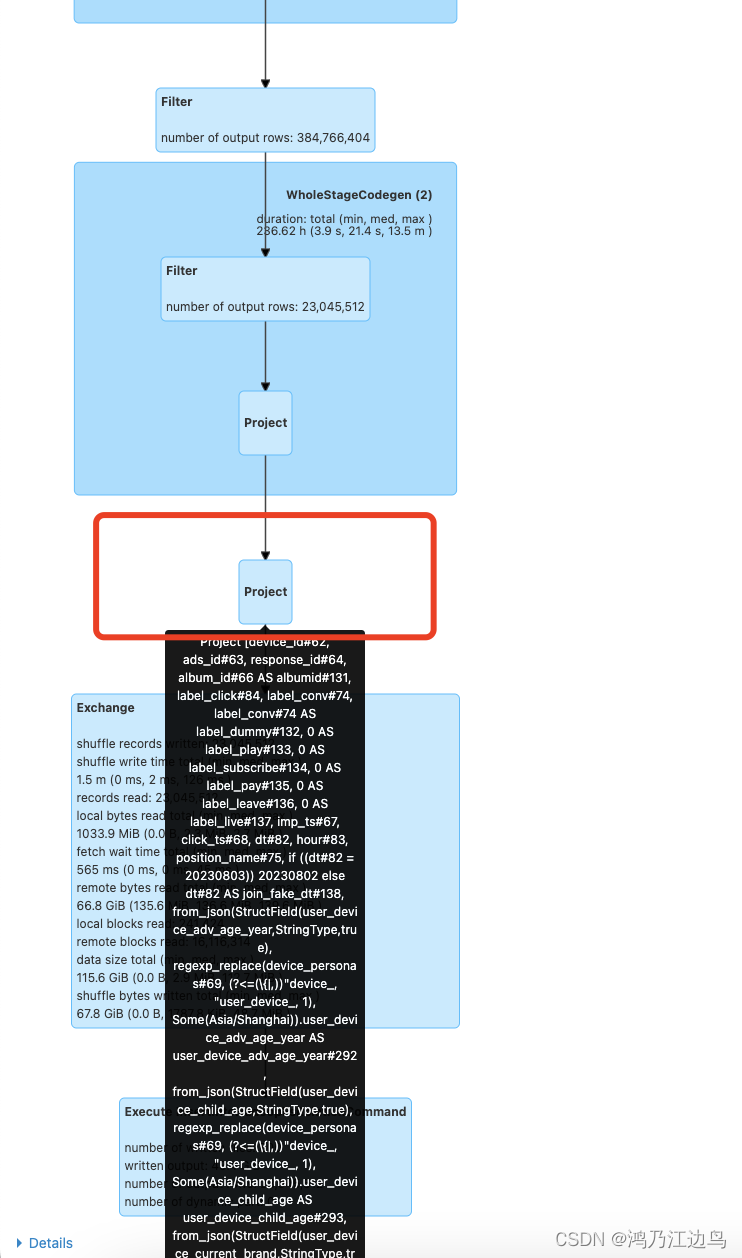
Spark 3.1.1 遇到的 from_json regexp_replace组合表达式慢问题的解决
背景 目前公司在从spark 2.4.x升级到3.1.1的时候,遇到了一类SQL极慢的情况,该SQL的如下(只列举了关键的): select device_personas.* from(selectdevice_id, ads_id, from_json(regexp_replace(device_personas, (?<(\\{|,))"devic…...

Docker 容器常用的命令和操作
1.容器操作 - 运行容器: docker run [OPTIONS] IMAGE [COMMAND] [ARG...] 示例: docker run -it --rm ubuntu /bin/bash - 查看正在运行的容器: docker ps [OPTIONS] 示例: docker ps -a - 停止容器: docker stop CONTAINER [CONTAINER...] 示…...
iTOP-RK3568开发板Windows 安装 RKTool 驱动
在烧写镜像之前首先需要安装 RKTool 驱动。 RKTool 驱动在网盘资料“iTOP-3568 开发板\01_【iTOP-RK3568 开发板】基础资料 \02_iTOP-RK3568 开发板烧写工具及驱动”路径下。 驱动如下图所示: 解压缩后,进入文件夹,如下图所示:…...

nginx rtmp http_flv直播推流
安装配置nginx yum install epel-release -y sudo rpm -Uvh http://li.nux.ro/download/nux/dextop/el7/x86_64/nux-dextop-release-0-5.el7.nux.noarch.rpm yum install ffmpeg ffmpeg-devel -y yum install gcc -y yum install pcre pcre-devel -y yum install openssl open…...

Day50 算法记录| 动态规划 17(子序列)
这里写目录标题 647. 回文子串516.最长回文子序列总结 647. 回文子串 1.动态规划和2.中心扩展 这个视频是基于上面的视频的代码 方法1:动态规划 布尔类型的dp[i][j]:表示区间范围[i,j] (注意是左闭右闭)的子串是否是回文子串,如…...

前端工程化配置完整指南
前端工程化配置完整指南:提升开发效率的利器 在当今快节奏的前端开发中,工程化配置已成为提升团队协作效率和项目质量的关键。无论是构建工具、代码规范,还是自动化部署,合理的前端工程化配置能够显著减少重复劳动,确…...

Kairoa v1.1.18 版本:AI聊天功能协议支持升级,助力开发者高效开发
AI聊天功能协议支持再升级Kairoa作为一款专为开发者打造的跨平台桌面工具箱,其v1.1.18版本在AI聊天功能上进行了重要完善。此前,AI聊天模块仅支持OpenAI格式的接口,而此次更新新增了Anthropic Messages API和Google Gemini原生协议的支持。这…...
 超详细实现(C 语言 + 逐行精讲))
链栈(链式栈) 超详细实现(C 语言 + 逐行精讲)
前言栈(Stack) 是一种后进先出(LIFO)的线性数据结构。前面我们学习了顺序栈(数组实现),今天我们学习它的兄弟 ——链栈(链式栈)。链栈 用单链表实现的栈它完美解决了顺序…...
)
效率神器!命令行终端优化(Zsh, iTerm2)
效率神器!命令行终端优化(Zsh, iTerm2) 对于开发者和技术爱好者来说,命令行终端是日常工作中不可或缺的工具。默认的终端配置往往功能有限,操作效率低下。通过优化终端环境,比如使用Zsh和iTerm2࿰…...
)
Q、K、V大揭秘:小白也能看懂的自注意力机制,助你入门大模型(收藏版)
本文用大白话解释了自注意力机制中的核心元素Q、K、V,通过图书馆找书的类比,说明了Q代表查询指令、K代表索引标签、V代表实际内容。文章阐述了Q、K、V如何协同工作,实现精准的信息匹配和加权整合,帮助读者理解大模型如何处理全局信…...

数据分析三件套:Numpy、Pandas、Matplotlib
目录 一、 环境准备与安装 1.1 确认Python环境 1.2 使用pip一键安装 1.3 验证安装是否成功 二、 NumPy:数组计算的基石 2.1 什么是NumPy? 2.2 创建数组的四种方式 2.3 数组的常用操作 2.3.1 形状操作 2.3.2 数学运算 2.3.3 索引与切片 2.4 Nu…...

OFA社区贡献指南:如何参与开源项目并成为核心开发者
OFA社区贡献指南:如何参与开源项目并成为核心开发者 【免费下载链接】OFA Official repository of OFA (ICML 2022). Paper: OFA: Unifying Architectures, Tasks, and Modalities Through a Simple Sequence-to-Sequence Learning Framework 项目地址: https://g…...

磁敏式传感器实战解析:从霍尔效应到工业测速应用
1. 磁敏式传感器入门:从霍尔效应说起 第一次接触磁敏式传感器是在五年前的一个工业自动化项目上,当时需要精确测量电机转速,传统的光电编码器在油污环境下频频失效。机械组的老师傅从工具箱里掏出个火柴盒大小的黑色元件说:"…...

双摄帧同步:从软同步到硬同步的工程实践与调试指南
1. 双摄帧同步技术概述 第一次接触双摄同步需求时,我也被各种专业术语搞得头晕眼花。简单来说,双摄帧同步就是要让手机的两个摄像头像双胞胎一样默契配合,确保它们拍摄的画面在时间上完全对齐。想象一下用双眼看世界时,如果左右眼…...

MATLAB GUI:打造你的专属图像美化工具箱
1. MATLAB GUI图像处理工具箱入门指南 第一次接触MATLAB GUI开发时,我也曾被那些专业术语吓到。但后来发现,用MATLAB做个图像处理工具箱其实比想象中简单得多。就像搭积木一样,把各种功能模块组合起来,就能做出一个实用的图像美化…...