机器学习05-数据准备(利用 scikit-learn基于Pima Indian数据集作数据预处理)
机器学习的数据准备是指在将数据用于机器学习算法之前,对原始数据进行预处理、清洗和转换的过程。数据准备是机器学习中非常重要的一步,它直接影响了模型的性能和预测结果的准确性
以下是机器学习数据准备的一些常见步骤:
数据收集:首先需要收集原始数据,可以是从数据库、文件、传感器等多种来源获取数据。数据的来源和质量直接影响了后续数据准备的难度和效果。
1. 数据清洗:数据清洗是指处理数据中的缺失值、异常值和重复值。缺失值是指数据中缺少某些属性值的情况,异常值是指与其他数据明显不同的值,而重复值是指数据中出现了重复的记录。清洗数据可以提高模型的鲁棒性和准确性。
2.特征选择:特征选择是从原始数据中选择最相关、最有用的特征作为模型的输入。选择合适的特征可以降低模型的复杂性,提高模型的泛化能力,并减少训练时间。
3.特征转换:特征转换是指对原始数据进行转换或缩放,以便更好地适应机器学习模型。例如,将类别型数据转换成数值型数据,对数值型数据进行标准化或归一化等操作。
4.数据划分:将数据集划分为训练集、验证集和测试集。训练集用于训练模型,验证集用于调整模型的超参数和验证模型的性能,测试集用于评估模型的泛化能力。
5.数据增强:对于数据量较少的情况,可以使用数据增强技术生成新的样本,以增加数据的多样性和数量,从而改善模型的泛化能力。
6.处理类别不平衡:在二分类或多分类问题中,数据中某些类别可能数量较少,导致类别不平衡。可以使用欠采样、过采样或集成学习等方法来处理类别不平衡问题。
7.数据编码:将类别型数据进行编码,例如使用独热编码(One-Hot Encoding)将类别转换成二进制向量。
8.数据标准化:对数值型数据进行标准化或归一化,使得不同特征具有相同的尺度,避免模型受到数据范围的影响。
以上步骤是机器学习数据准备的一部分,具体的数据准备步骤会因任务类型、数据类型和模型选择等因素而有所不同。数据准备是机器学习流程中的重要环节,它需要仔细考虑和实施,以保证数据的质量和模型的性能。
数据预处理
数据预处理需要根据数据本身的特性进行,有不同的格式和不同的要求,有缺失值的要填,有无效数据的要剔,有冗余维的要选,这些步骤都和数据本身的特性紧密相关。
数据预处理大致分为三个步骤:数据的准备、数据的转换、数据的输出。
为什么需要数据预处理?
数据处理是系统工程的基本环节,也是提高算法准确度的有效手段。
因此,为了提高算法模型的准确度,在机器学习中也要根据算法的特征和数据的特征对数据进行转换。
也就是说在开始机器学习的模型训练之前,需要对数据进行预处理,这是一个必需的过程。但是需要注意的是,不同的算法对数据有不同的假定,需要按照不同的方式转换数据。当然,如果按照算法的规则来准备数据,算法就可以产生一个准确度比较高的模型。
我们主要讲 利用scikitlearn 来转换数据,以便我们将处理后的数据应用到算法中,这样也可以提高算法模型的准确度。
什么是scikitlearn ?
scikit-learn(简称为sklearn)是一个流行的用于机器学习和数据挖掘的Python库。它提供了丰富的工具,用于构建和应用各种机器学习算法,并支持数据预处理、特征工程、模型评估等功能。scikit-learn
是开源的,易于使用,广泛应用于数据科学和机器学习领域。
scikit-learn 的主要特点包括:
简单易用:scikit-learn 提供了一致且易于使用的API,使得构建和应用机器学习模型变得非常简单。
大量算法:scikit-learn 支持众多的经典和先进的机器学习算法,包括回归、分类、聚类、降维等。它还提供了许多特征选择和特征转换的工具。
数据预处理:scikit-learn 提供了丰富的数据预处理功能,包括缺失值处理、数据标准化、数据归一化、数据编码等。
模型评估:scikit-learn 提供了评估机器学习模型性能的工具,包括交叉验证、网格搜索、学习曲线等。
整合性:scikit-learn 可以与其他Python库(如NumPy、Pandas)无缝整合,方便数据处理和模型应用。
文档齐全:scikit-learn 的官方文档非常详细,提供了丰富的示例和用法说明。
使用 scikit-learn 进行机器学习的一般流程包括数据准备、模型选择、模型训练、模型评估和预测。
接下来将介绍以下几种数据转换方法:
· 调整数据尺度(Rescale Data)。
· 正态化数据(Standardize Data)。
· 标准化数据(Normalize Data)。
· 二值数据(Binarize Data)。
四种不同的方法来格式化数据依然使用Pima Indian的数据
集作为例子。这四种方法都会按照统一的流程来处理数据:
· 导入数据。
· 按照算法的输入和输出整理数据。
· 格式化输入数据。
· 总结显示数据的变化。
scikit-learn 提供了两种标准的格式化数据的方法,每一种方法都有适
用的算法。利用这两种方法整理的数据,可以直接用来训练算法模型。在
scikit-learn 的说明文档中,也有对这两种方法的详细说明:
· 适合和多重变换(Fit and Multiple Transform)。
· 适合和变换组合(Combined Fit-and-Transform)。
推荐优先选择适合和多重变换(Fit and Multiple Transform)方法。
首先调用fit()函数来准备数据转换的参数,然后调用 transform()函数来做数据的预处理。适合和变换组合(Combined Fit-and-Transform)对绘图或汇总处理具有非常好的效果。
详细的数据预处理方法可以参考scikit-learn的API文档。
调整数据尺度
如果数据的各个属性按照不同的方式度量数据,那么通过调整数据的尺度让所有的属性按照相同的尺度来度量数据,就会给机器学习的算法模型训练带来极大的方便。
这个方法通常会将数据的所有属性标准化,并将数据转换成0和1之间的值,这对于梯度下降等算法是非常有用的,对于回归算法、神经网络算法和K近邻算法的准确度提高也起到很重要的作用。
在 scikit-learn 中,调整数据的尺度是数据预处理的重要步骤之一,它可以确保不同特征具有相同的尺度,避免模型受到数据范围的影响。通常有两种常见的尺度调整方法:
标准化(Standardization)和归一化(Normalization)
标准化(Standardization):
标准化是一种将特征数据转换为均值为0,标准差为1的过程。标准化后的数据符合标准正态分布,这对于一些模型(如线性回归、逻辑回归、支持向量机等)的训练过程有着较好的效果。在
scikit-learn 中,你可以使用 StandardScaler 来进行标准化。
示例:
import numpy as np
from sklearn.preprocessing import StandardScaler# 创建一个特征矩阵
X = np.array([[1, 2], [3, 4], [5, 6]])# 创建 StandardScaler 对象
scaler = StandardScaler()# 调整数据尺度(标准化)
X_scaled = scaler.fit_transform(X)
# 显示特征矩阵
print("X_scaled=\n", X_scaled)
运行结果:
X_scaled=[[-1.22474487 -1.22474487][ 0. 0. ][ 1.22474487 1.22474487]]
归一化(Normalization):
归一化是一种将特征数据缩放到一个指定的范围(通常是[0,
1])的过程。归一化后的数据在原始数据的分布上保持了相对的比例关系,适用于需要将特征放在同一量纲的算法(如KNN、神经网络等)。在
scikit-learn 中,你可以使用 MinMaxScaler 来进行归一化。
示例:
import numpy as np
from sklearn.preprocessing import MinMaxScaler# 创建一个特征矩阵
X = np.array([[1, 2], [3, 4], [5, 6]])# 创建 MinMaxScaler 对象
scaler = MinMaxScaler()# 调整数据尺度(归一化)
X_scaled = scaler.fit_transform(X)print(X_scaled)
运行结果:
[[0. 0. ][0.5 0.5][1. 1. ]]
这里的 fit_transform() 方法将用于对特征矩阵 X 进行尺度调整。首先,fit() 方法会计算每个特征的均值和标准差(对于标准化)或最大值和最小值(对于归一化)。然后,transform() 方法会根据计算得到的参数对特征矩阵 X 进行尺度调整。如果有测试集需要调整尺度,应该使用 fit() 方法计算训练集的参数,然后使用 transform() 方法分别对训练集和测试集进行尺度调整,确保使用相同的参数进行尺度调整,以避免信息泄漏。
实验:下面用Pima Indian 数据集将不同计量单位的数据统一成相同的尺度。
代码如下:
import pandas as pd
from matplotlib import pyplot as plt
from numpy import set_printoptions
from sklearn.preprocessing import MinMaxScaler#数据预处理
path = 'D:\down\\archive\\diabetes.csv'
data = pd.read_csv(path)
#将数据转成数组
array = data.values
#分割数据
X = array[:, 0:8]#创建MinMaxScaler对象
trans = MinMaxScaler(feature_range=(0, 1))
#数据归一化
newX = trans.fit_transform(X)
#设置数据打印格式
set_printoptions(precision=3)print(newX)运行结果:
[[0.353 0.744 0.59 ... 0.501 0.234 0.483][0.059 0.427 0.541 ... 0.396 0.117 0.167][0.471 0.92 0.525 ... 0.347 0.254 0.183]...[0.294 0.608 0.59 ... 0.39 0.071 0.15 ][0.059 0.633 0.492 ... 0.449 0.116 0.433][0.059 0.467 0.574 ... 0.453 0.101 0.033]]
正态化数据 -StandardScaler()
在机器学习中,将数据正态化是指将数据转换成符合正态分布(或高斯分布)的过程。正态化数据是一种常见的数据预处理步骤,它可以使得数据具有零均值和单位方差,有助于提高一些模型的性能,特别是需要数据满足正态分布假设的模型。
在 scikit-learn 中,你可以使用 StandardScaler来对数据进行正态化,这会将数据转换成均值为0,标准差为1的正态分布。
import pandas as pd
from numpy import set_printoptions
from sklearn.preprocessing import StandardScaler#数据预处理
path = 'D:\down\\archive\\diabetes.csv'
data = pd.read_csv(path)
#将数据转成数组
array = data.values
#分割数据
X = array[:, 0:8]#创建StandardScaler对象
trans = StandardScaler().fit(X)
#数据归一化
newX = trans.transform(X)
#设置数据打印格式
set_printoptions(precision=3)print(newX)运行结果:
[[ 0.64 0.848 0.15 ... 0.204 0.468 1.426][-0.845 -1.123 -0.161 ... -0.684 -0.365 -0.191][ 1.234 1.944 -0.264 ... -1.103 0.604 -0.106]...[ 0.343 0.003 0.15 ... -0.735 -0.685 -0.276][-0.845 0.16 -0.471 ... -0.24 -0.371 1.171][-0.845 -0.873 0.046 ... -0.202 -0.474 -0.871]]
标准化数据
标准化数据(Normalize Data)处理是将每一行的数据的距离处理成1(在线性代数中矢量距离为
1)的数据又叫作“归一元”处理,适合处理稀疏数据(具有很多为 0 的数据),归一元处理的数据对使用权重输入的神经网络和使用距离的 K近邻算法的准确度的提升有显著作用。
使用scikitlearn 中的 Normalizer 类实现。代码如下:
import pandas as pd
from numpy import set_printoptions
from sklearn.preprocessing import Normalizer#数据预处理
path = 'D:\down\\archive\\diabetes.csv'
data = pd.read_csv(path)
#将数据转成数组
array = data.values
#分割数据
X = array[:, 0:8]#创建StandardScaler对象
trans = Normalizer().fit(X)
#数据归一化
newX = trans.transform(X)
#设置数据打印格式
set_printoptions(precision=3)print(newX)运行结果:
[[0.034 0.828 0.403 ... 0.188 0.004 0.28 ][0.008 0.716 0.556 ... 0.224 0.003 0.261][0.04 0.924 0.323 ... 0.118 0.003 0.162]...[0.027 0.651 0.388 ... 0.141 0.001 0.161][0.007 0.838 0.399 ... 0.2 0.002 0.313][0.008 0.736 0.554 ... 0.241 0.002 0.182]]
二值数据
二值数据(Binarize Data)是使用值将数据转化为二值,大于阈值设置为1,小于阈值设置为0。这个过程被叫作二分数据或阈值转换。在生成明确值或特征工程增加属性的时候使用,使用scikit-learn中的Binarizer类实现。
代码如下:
import pandas as pd
from numpy import set_printoptions
from sklearn.preprocessing import Binarizer#数据预处理
path = 'D:\down\\archive\\diabetes.csv'
data = pd.read_csv(path)
#将数据转成数组
array = data.values
#分割数据
X = array[:, 0:8]#创建StandardScaler对象
trans = Binarizer(threshold=0.0).fit(X)
#数据归一化
newX = trans.transform(X)
#设置数据打印格式
set_printoptions(precision=3)print(newX)运行结果:
[[1. 1. 1. ... 1. 1. 1.][1. 1. 1. ... 1. 1. 1.][1. 1. 1. ... 1. 1. 1.]...[1. 1. 1. ... 1. 1. 1.][1. 1. 1. ... 1. 1. 1.][1. 1. 1. ... 1. 1. 1.]]
scikit-learn中对数据进行预处理的四种方法。这四种方法适用于不同的场景,可以在实践中根据不同的算法模型来选择不同的数据预处理方法.先看个大概,后续再度这些格式化数据做更深入的理解说明
相关文章:
)
机器学习05-数据准备(利用 scikit-learn基于Pima Indian数据集作数据预处理)
机器学习的数据准备是指在将数据用于机器学习算法之前,对原始数据进行预处理、清洗和转换的过程。数据准备是机器学习中非常重要的一步,它直接影响了模型的性能和预测结果的准确性 以下是机器学习数据准备的一些常见步骤: 数据收集ÿ…...
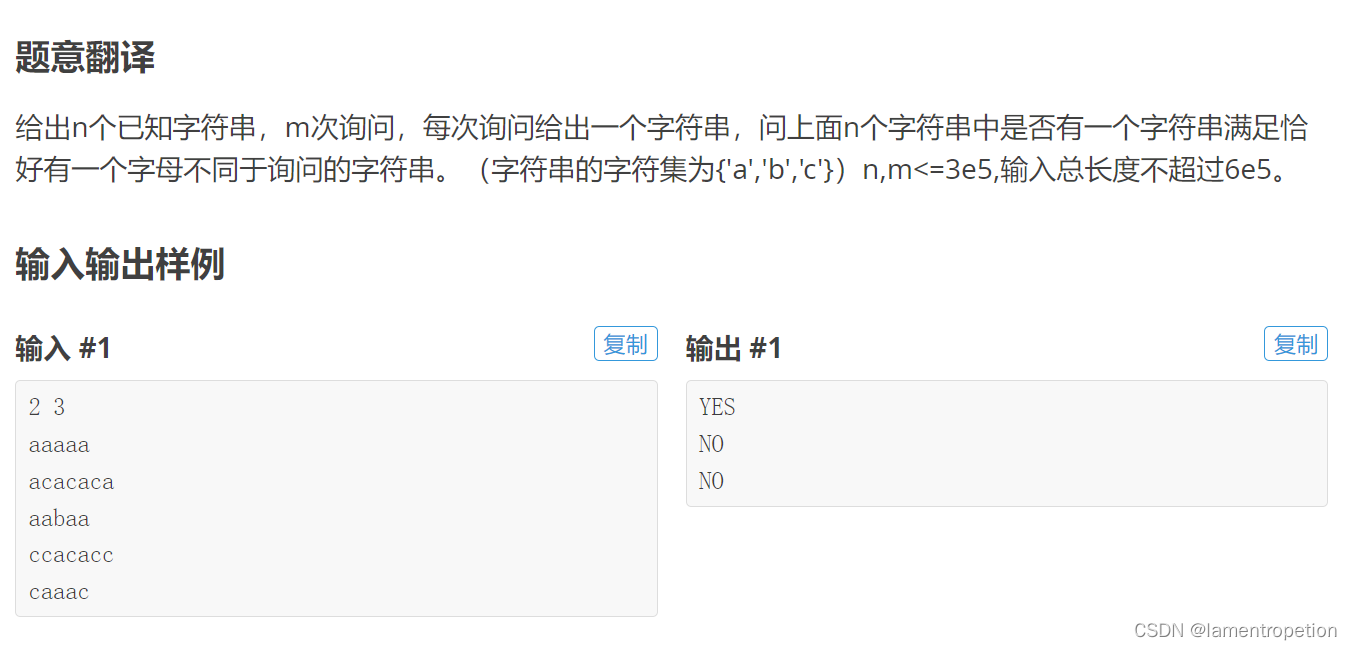
【枚举+trie+dfs】CF514 C
Problem - 514C - Codeforces 题意: 思路: 其实是trie上dfs的板题 先把字符串插入到字典树中 对于每次询问,都去字典树上dfs 注意到字符集只有3,因此如果发现有不同的字符,去枚举新的字符 Code: #in…...
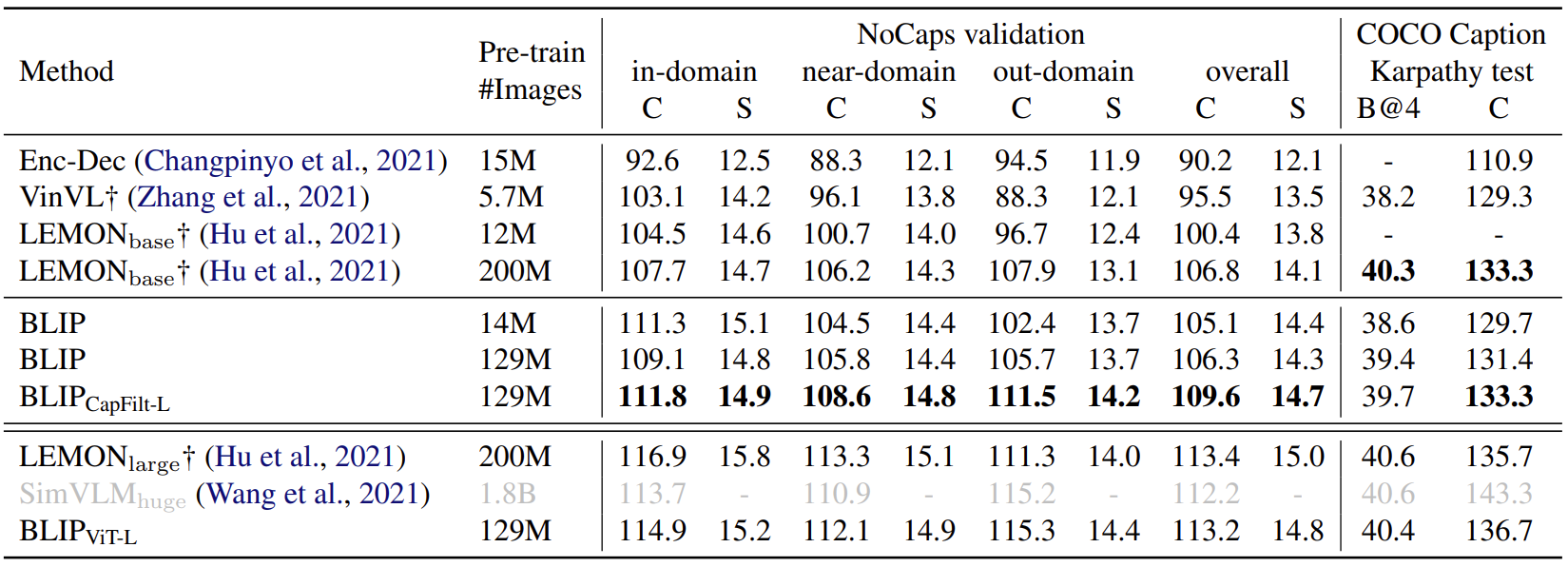
【计算机视觉】BLIP:统一理解和生成的自举多模态模型
文章目录 一、导读二、背景和动机三、方法3.1 模型架构3.2 预训练目标3.3 BLIP 高效率利用噪声网络数据的方法:CapFilt 四、实验4.1 实验结果4.2 各个下游任务 BLIP 与其他 VLP 模型的对比 一、导读 BLIP 是一种多模态 Transformer 模型,主要针对以往的…...
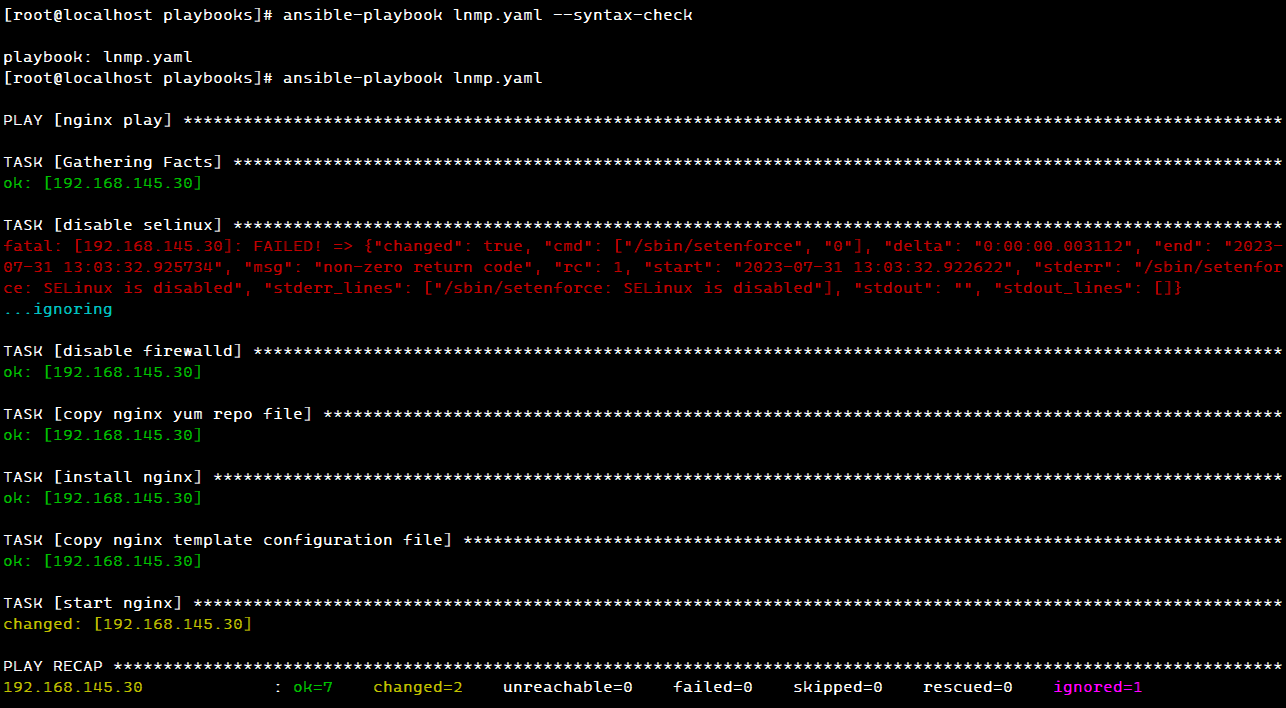
【Ansible】Ansible自动化运维工具之playbook剧本搭建LNMP架构
LNMP 一、playbooks 分布式部署 LNMP1. 环境配置2. 安装 ansble3. 安装 nginx3.1 准备 nginx 相关文件3.2 编写 lnmp.yaml 的 nginx 部分3.3 测试 nginx4. 安装 mysql4.1 准备 mysql 相关文件4.2 编写 lnmp.yaml 的 mysql 部分4.3 测试 mysql5. 安装 php5.1 编写 lnmp.yaml 的 …...

Spring中的事务
一、为什么需要事务? 事务定义 将一组操作封装成一个执行单元(封装到一起),要么全部成功,要么全部失败。 为什么要用事务? 比如转账分为两个操作: 第一步操作: A 账户 -100 元…...
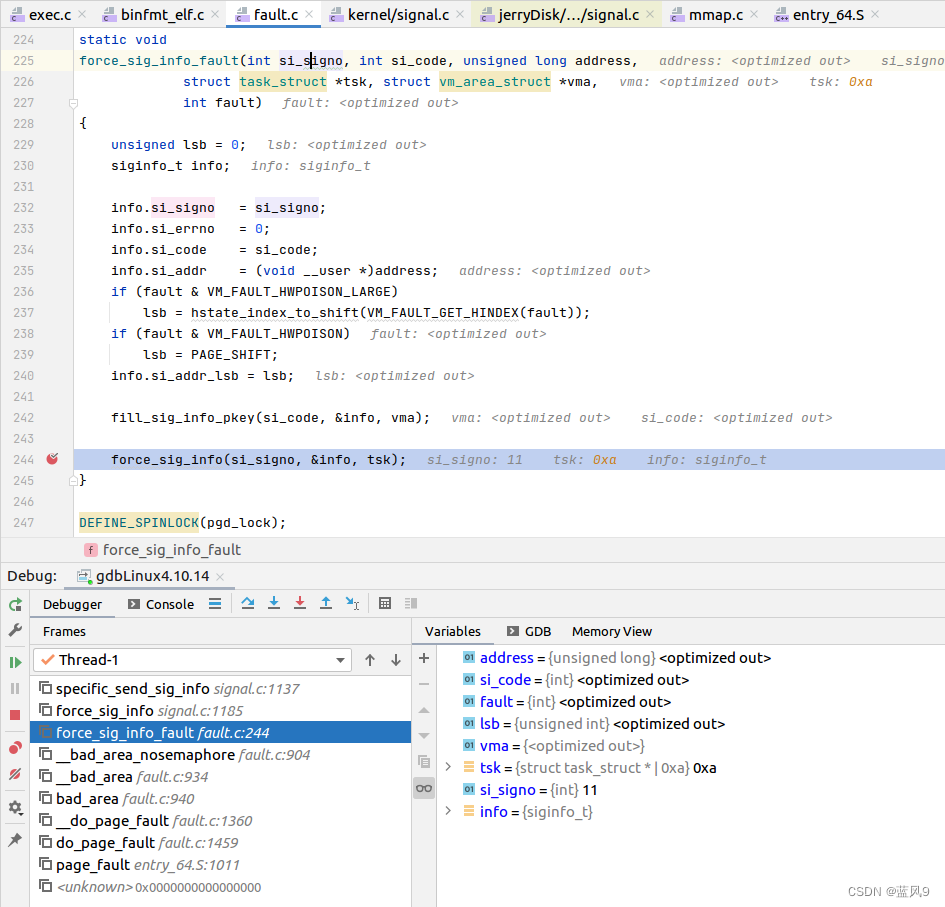
38 非法地址访问的 segment fault 的调试
前言 在前面一篇文章 coredump 的生成和使用 中, 我们看到 "测试用例2 - 非法地址访问" 产生了一个 segment fault 我们这里 就来调试一下 这个 segment fault 是怎么回事 测试用例 #include "stdio.h"int main(int argc, char** argv) {int x 2; i…...
的用法详解)
c++中c_str()的用法详解
c_str()就是将C的string转化为C的字符串数组!!! C中没有string,所以函数c_str()就是将C的string转化为C的字符串数组,c_str()生成一个const char *指针,指向字符串的首地址。 下文通过3段简单的代码比较分析…...

谈谈关于新能源汽车的话题
新能源汽车是指使用新型能源替代传统燃油的汽车,主要包括纯电动汽车、插电式混合动力汽车和燃料电池汽车等。随着环境污染和能源安全问题的日益突出,新能源汽车已经成为全球汽车行业的发展趋势。下面我们来谈谈关于新能源汽车的话题。 首先,新…...
)
EventBus 开源库学习(二)
整体流程阅读 EventBus在使用的时候基本分为以下几步: 1、注册订阅者 EventBus.getDefault().register(this);2、订阅者解注册,否者会导致内存泄漏 EventBus.getDefault().unregister(this);3、在订阅者中编写注解为Subscribe的事件处理函数 Subscri…...

4_Apollo4BlueLite电源管理
1.Cortex-M4 Power Modes Apollo4BlueLite支持以下4种功耗模式: ▪ High Performance Active (not a differentiated power mode for the Cortex-M4) ▪ Active ▪ Sleep ▪ Deep Sleep (1)High Performance Mode 高性能模式不是arm定…...

Pytorch入门学习——快速搭建神经网络、优化器、梯度计算
我的代码可以在我的Github找到 GIthub地址 https://github.com/QinghongShao-sqh/Pytorch_Study 因为最近有同学问我如何Nerf入门,这里就简单给出一些我的建议: (1)基本的pytorch,机器学习,深度学习知识&a…...

举例说明typescript的Exclude、Omit、Pick
一、提前知识说明:联合类型 typescript的联合类型是一种用于表示一个值可以是多种类型中的一种的类型。我们使用竖线(|)来分隔每个类型,所以number | string | boolean是一个可以是number,string或boolean的值的类型。…...

记录一次Linux环境下遇到“段错误核心已转储”然后利用core文件解决问题的过程
参考Linux 下Coredump分析与配置 在做项目的时候,很容易遇到“段错误(核心已转储)”的问题。如果是语法错误还可以很快排查出来问题,但是碰到coredump就没办法直接找到问题,可以通过设置core文件来查找问题࿰…...

WPF中自定义Loading图
纯前端方式,通过动画实现Loading样式,如图所示 <Grid Width"35" Height"35" HorizontalAlignment"Center" VerticalAlignment"Center" Name"Loading"><Grid.Resources><DrawingBrus…...
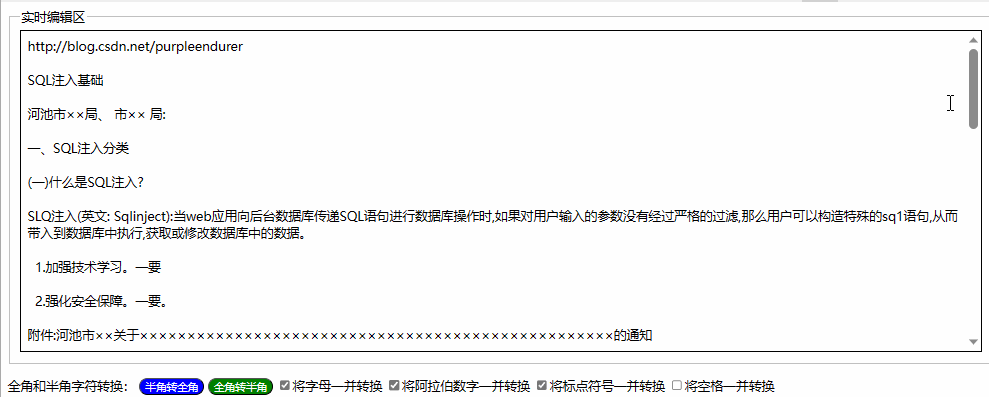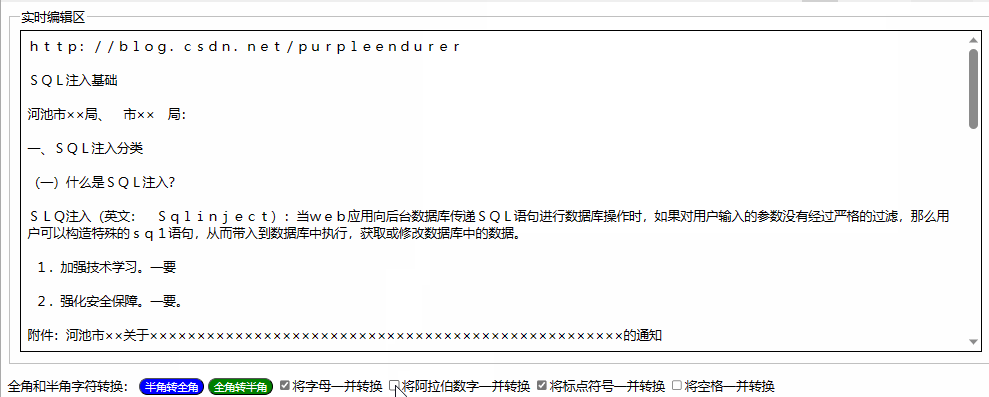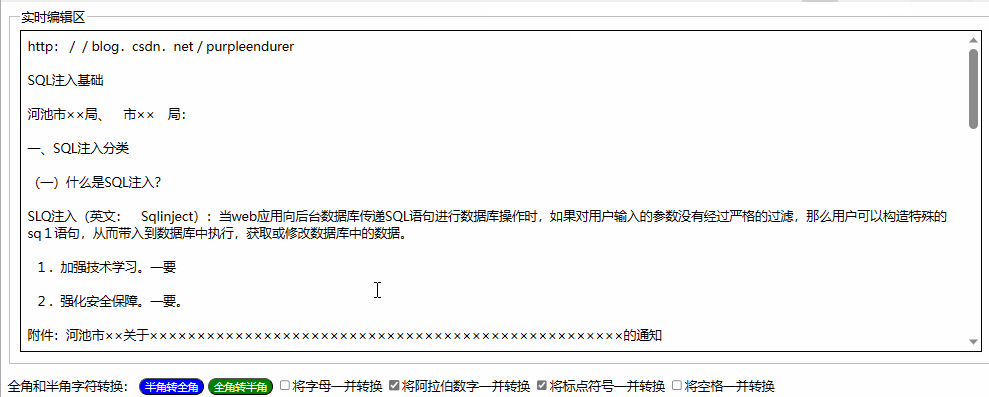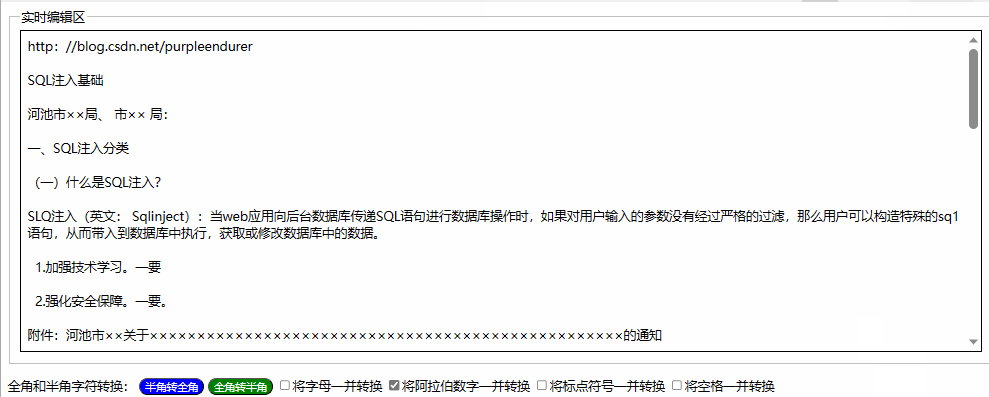
用html+javascript打造公文一键排版系统14:为半角和全角字符相互转换功能增加英文字母、阿拉伯数字、标点符号、空格选项
一、实际工作中需要对转换选项细化内容 在昨天我们实现了最简单的半角字符和全角字符相互转换功能,就是将英文字母、阿拉伯数字、标点符号、空格全部进行转换。 在实际工作中,我们有时只想英文字母、阿拉伯数字、标点符号、空格之中的一两类进行转换&a…...

叮咚买菜财报分析:叮咚买菜第二季度财报将低于市场预期
来源:猛兽财经 作者:猛兽财经 卖方分析师对叮咚买菜第二季度财报的预测 尽管叮咚买菜(DDL)尚未明确披露第二季度财报的具体日期,但根据其以往的业绩公告,猛兽财经认为叮咚买菜很有可能会在8月的第二周发布…...
设计模式行为型——中介者模式
目录 什么是中介者模式 中介者模式的实现 中介者模式角色 中介者模式类图 中介者模式代码实现 中介者模式的特点 优点 缺点 使用场景 注意事项 实际应用 什么是中介者模式 中介者模式(Mediator Pattern)属于行为型模式,是用来降低…...

Vue——formcreate表单设计器自定义组件实现(二)
前面我写过一个自定义电子签名的formcreate表单设计器组件,那时初识formcreate各种使用也颇为生疏,不过总算套出了一个组件不是。此次时隔半年又有机会接触formcreate,重新熟悉和领悟了一番各个方法和使用指南。趁热打铁将此次心得再次分享。…...
 和 人脸识别(Face recognition) 的区别)
人脸验证(Face verification) 和 人脸识别(Face recognition) 的区别
人脸验证(Face verification) 和 人脸识别(Face recognition) 的区别 Face verification 和 Face recognition 都是人脸识别的技术,但是它们的应用和目的不同。 Face verification(人脸验证)是指通过比对两张人脸图像,判断它们是…...

前端如何打开钉钉(如何唤起注册表中路径与软件路径不关联的软件)
在前端唤起本地应用时,我查询了资料,在注册表中找到腾讯视频会议的注册表情况,如下: 在前端代码中加入 window.location.href"wemeet:"; 就可以直接唤起腾讯视频会议,但是我无法唤起钉钉 之所以会这样&…...

视频剪辑效率翻倍:Qwen3-ForcedAligner-0.6B自动字幕生成实战体验
视频剪辑效率翻倍:Qwen3-ForcedAligner-0.6B自动字幕生成实战体验 1. 为什么你需要这个字幕生成工具 手动添加字幕可能是视频制作过程中最耗时的环节之一。传统方法需要反复听录音、手动打轴、调整时间码,一个10分钟的视频可能需要花费1-2小时。而Qwen…...

智能图像识别自动点击:解放双手的安卓自动化神器
智能图像识别自动点击:解放双手的安卓自动化神器 【免费下载链接】Smart-AutoClicker An open-source auto clicker on images for Android 项目地址: https://gitcode.com/gh_mirrors/smar/Smart-AutoClicker 你是否曾遇到这样的困境:游戏中需要…...

源码之家_最新建站源码_开源项目_成品源码一键部署
在互联网技术飞速发展的今天,网站建设已成为企业、个人展示形象、开展业务的重要窗口。然而,从零开始搭建一个功能完善、界面美观的网站,往往需要投入大量的时间和精力。对于开发者而言,寻找优质、可靠的源码资源,成为…...

PSSE与IEEE数据格式互转实战:解决变压器参数异常的避坑指南
PSSE与IEEE数据格式互转实战:变压器参数异常分析与精准修正 电力系统仿真工程师在日常工作中经常面临不同软件平台间数据迁移的挑战。当您手头的IEEE标准潮流数据需要导入PSSE进行分析时,数据格式转换过程中的参数映射问题可能成为影响仿真精度的隐形杀…...

如何通过EhViewer实现安卓画廊资源高效管理与无缝阅读体验?
如何通过EhViewer实现安卓画廊资源高效管理与无缝阅读体验? 【免费下载链接】EhViewer 🥥 A fork of EhViewer, feature requests are not accepted. Forked from https://gitlab.com/NekoInverter/EhViewer 项目地址: https://gitcode.com/GitHub_Tre…...

终极pix2pix训练指南:200个epoch完整流程与实战技巧
终极pix2pix训练指南:200个epoch完整流程与实战技巧 【免费下载链接】pix2pix-tensorflow Tensorflow port of Image-to-Image Translation with Conditional Adversarial Nets https://phillipi.github.io/pix2pix/ 项目地址: https://gitcode.com/gh_mirrors/pi…...

重构视频知识提取:Bili2text如何将B站内容转化为结构化文本
重构视频知识提取:Bili2text如何将B站内容转化为结构化文本 【免费下载链接】bili2text Bilibili视频转文字,一步到位,输入链接即可使用 项目地址: https://gitcode.com/gh_mirrors/bi/bili2text 在信息过载的时代,视频平台…...

SpringBoot单元测试实战:从Service到Controller的Mock技巧全解析
SpringBoot单元测试实战:从Service到Controller的Mock技巧全解析 单元测试是保障代码质量的重要防线,但在实际开发中,许多团队往往因为时间压力或技术复杂度而忽视这一环节。SpringBoot作为Java生态中最流行的框架之一,其单元测试…...

若依框架多级目录闪退问题解决:手把手教你添加router-view的正确姿势
若依框架多级目录闪退问题深度解析与实战修复指南 最近在若依框架的实际项目开发中,不少前端工程师反馈遇到一个棘手问题:当系统包含多级目录菜单时,点击后菜单会在页面中短暂闪现随即消失。这种现象不仅影响用户体验,也暴露出框架…...

中兴B860AV3.2-T芯片型号鉴别与刷机固件匹配全攻略
1. 中兴B860AV3.2-T芯片型号鉴别的重要性 最近在折腾中兴B860AV3.2-T盒子时,我发现一个特别容易踩坑的地方——这盒子居然有两种不同的处理器芯片!一种是S905L3B,另一种是S905L3SB。刚开始我也没太在意这个区别,结果刷机时直接翻车…...