mlr3verse vs KM曲线:谁能更精准地预测生存率?
一、引言
生存分析是统计学中一种重要的方法,用于分析个体在特定时间段内生存的概率或生存率。它在医学、流行病学、生物学等领域被广泛应用。通过生存分析,我们可以评估治疗方法的效果、预测疾病进展的风险以及评估特定因素对生存率的影响。
生存率的准确预测对于医学和研究领域至关重要。传统的生存分析方法中,「Kaplan-Meier(KM)」 生存曲线已被广泛使用来估计生存函数。然而,随着机器学习和深度学习等技术的发展,新的方法如 「mlr3verse」 也被引入生存分析领域。mlr3verse采用嵌入式方法,结合高维数据处理能力,提供了更加灵活和准确的生存分析。
在本文中,我们将比较mlr3verse和KM生存曲线在生存率预测方面的性能差异。我们将考虑两种方法的优势和局限性,并结合具体案例和实验研究结果来评估它们的预测精度。这将有助于研究人员和医学专业人员选择适合其研究目的的生存分析方法。
二、生存分析概述
2.1 生存分析的基本概念和用途
-
「生存分析的基本概念包括以下几个要素」:
-
生存时间(Survival Time):指个体从某个起始时间点到达特定事件(如死亡)之间的时间长度。 -
生存状态(Survival Status):表示个体是否已经经历了特定事件,通常用二元变量(生存或死亡)来表示。 -
生存函数(Survival Function):用于描述在给定时间点上个体仍然存活的概率。生存函数是一个递减的曲线,随着时间的推移,概率逐渐减少。 -
生存率(Survival Rate):表示在某个特定时间点上个体存活的概率。 -
风险因素(Risk Factors):指影响个体生存概率的因素,如年龄、性别、疾病状态等。
-
「生存分析原理」
生存函数通常用Kaplan-Meier方法来估计,其数学表达式如下: S(t) = S(t-1) * (1 - d(t)/n(t))其中:
-
S(t) 表示在时间点t上的生存函数值,即在t时刻存活的概率。 -
S(t-1) 表示在时间点t-1上的生存函数值。 -
d(t) 表示在时间点t上发生事件(比如死亡)的个体数量。 -
n(t) 表示在时间点t上处于观测状态(未发生事件或被失踪)的个体数量。
根据公式,生存函数的计算是通过递归的方式进行的。初始时,S(0) = 1,表示所有个体在起始时间点都是存活的。随着时间的推移和事件的发生,生存函数逐渐减少。
需要注意的是,当某个时间点上没有发生事件的个体时(d(t) = 0),则生存函数值不变,即S(t) = S(t-1)。而当事件发生时(d(t) > 0),生存函数值会相应地减少。
通过计算每个时间点上的生存函数值,可以得到整个生存函数曲线。这条曲线可以提供关于个体存活概率的估计和比较。当然还有其它的方法,我们接下来介绍!
-
「生存分析的应用非常广泛,主要用于以下几个方面」:
-
医学研究:生存分析可用于评估新药或治疗方法对患者生存率的影响,从而确定最佳治疗方案。 -
流行病学:生存分析可用于研究特定疾病的发病率和死亡率,并评估风险因素的作用。 -
生物学:生存分析可应用于动物或植物的寿命研究,以了解其存活和寿命的模式。 -
社会科学:生存分析可应用于人口学研究,探索个体的生命历程、结婚时间、就业时间等。
三、mlr3verse概述
3.1 mlr3verse简介
mlr3verse是一个新的生存分析工具集,它基于R语言中的mlr3框架开发而成。mlr3verse为研究人员和数据科学家提供了一套功能强大的工具,用于处理、建模和评估生存数据。
-
首先,mlr3verse提供了统一的框架,使用户可以在同一个环境下进行数据预处理、模型选择和模型评估等任务。这个框架整合了多个相关包,如mlr3、mlr3proba和mlr3learners,简化了工作流程,提高了效率。 -
其次,mlr3verse支持多种常用的生存分析模型,如Cox比例风险模型和加速失效时间模型等。此外,它还允许用户自定义模型,满足个性化的需求。用户可以根据实际研究需要选择合适的模型,并进行灵活的建模。 -
除此之外,mlr3verse还提供了自动超参数调优功能,帮助用户选择最佳的模型参数组合。通过交叉验证等技术,它能够自动搜索最合适的超参数,提高建模的准确性和稳定性。 -
另外,mlr3verse还集成了丰富的特征工程功能,包括特征选择和特征变换等。用户可以根据数据特点进行特征工程,提取更具预测能力的特征,改善模型性能。 -
最后,mlr3verse提供直观易用的结果可视化功能,用户可以绘制生存曲线、风险曲线等图形,对生存分析结果进行直观理解和评估。
3.2 mlr3verse的优势和创新之处
-
统一的框架:mlr3verse提供了一个统一的框架,将数据处理、建模和评估整合在一起。这样,用户可以在同一个环境中进行数据预处理、模型选择和模型评估,避免了不同工具之间的兼容性问题。 -
高度灵活的模型选择:mlr3verse支持多种常用的生存分析模型,如Cox比例风险模型、加速失效时间模型等,并且可以自定义模型。用户可以根据具体的研究需求选择合适的模型,进行灵活的建模。 -
自动化的超参数调优:mlr3verse提供了自动化的超参数调优功能,可以帮助用户选择最佳的模型超参数组合。通过交叉验证等技术,mlr3verse能够自动搜索模型的最佳超参数,提高建模的准确性和稳定性。 -
集成的特征工程:mlr3verse支持丰富的特征工程功能,包括特征选择、特征变换等。用户可以根据数据特点进行特征工程,提取更具有预测能力的特征,改善模型性能。 -
直观的结果可视化:mlr3verse提供了直观易用的结果可视化功能,可以帮助用户理解和解释生存分析的结果。用户可以绘制生存曲线、风险曲线等图形,以及进行模型的性能评估和比较。
总而言之,mlr3verse作为一种新的生存分析工具,具有统一的框架、支持多种模型选择、自动超参数调优、丰富的特征工程和直观的结果可视化等特点。它能够帮助研究人员和数据科学家更高效地进行生存分析任务,并得到准确可靠的结果和解释。
四、mlr3verse VS KM分析
4.1 KM曲线的优势和局限性
-
「KM曲线在生存分析中的常见应用和优点」:
-
生存函数估计:KM曲线是生存分析中最常用的工具之一,能够估计特定时间点上存活的概率。它可以根据样本数据的生存时间和观测状态,估计出不同时间点上的生存概率。 -
生存时间比较:KM曲线可以用于比较不同组别或处理间的生存时间差异。通过绘制不同组别的KM曲线,并使用统计方法(如log-rank检验),可以评估不同因素对生存时间的影响,识别高风险组和低风险组。 -
事件发生率:除了生存概率,KM曲线还提供了事件发生率(如死亡率)的估计。通过观察曲线的斜率变化,可以了解事件发生的速率和趋势。 -
可视化效果:KM曲线以图形方式展现了随时间变化的生存概率,直观地显示了不同组别或处理间的差异。这种可视化效果有助于研究人员和决策者更好地理解和传达生存分析的结果。
-
「KM曲线的限制和可能存在的问题」:
-
遗失数据偏倚:当样本中存在遗失数据时,KM曲线可能存在偏倚。如果遗失数据与生存时间有关,且未被正确处理,那么估计的生存概率可能是不准确的。 -
截断数据限制:KM曲线无法考虑截断数据的影响。当研究中存在截断数据(例如观察期结束时未发生事件),KM曲线可能低估生存概率。 -
假设限制:KM曲线基于一些假设,如事件发生是独立和随机的。如果假设不成立,比如存在相关事件或违反比例风险假设,那么KM曲线的解释和比较可能会出现问题。 -
组别比较局限性:KM曲线用于比较不同组别之间的生存时间差异,但它并不能提供具体的风险因素和效应大小。要深入了解这些因素,需要使用更复杂的统计模型。 -
时间分辨率限制:KM曲线对观测时间进行离散化处理,可能会导致时间分辨率不足。在研究中,可能有更精细的时间尺度,需要使用其他方法来处理。
4.2 mlr3verse的优势和功能
-
「mlr3verse新一代生存分析工具的优势」
-
统一框架:mlr3verse提供了一个统一的框架,整合了多个生存分析任务的包和工具。这意味着数据科学家和研究人员可以使用相同的接口来处理和分析不同的生存分析问题,从而简化了工作流程。 -
增强的功能:mlr3verse提供了许多强大的功能,包括数据预处理、特征选择、模型训练和评估等。它支持各种统计和机器学习模型,可以灵活地处理各种类型的数据,并提供丰富的性能评估指标和交叉验证方法。 -
可扩展性:mlr3verse具有良好的可扩展性,可以轻松地集成其他生存分析方法和外部包。用户可以根据自己的需求自定义和扩展分析流程,以适应不同领域和问题的要求。 -
高效和自动化:mlr3verse通过高效的计算和自动化功能提高了工作效率。它支持并行计算和分布式计算,可加快计算速度。此外,mlr3verse的结果和分析过程可追溯和复现,方便与他人共享和验证研究结果
-
「mlr3verse在预测生存率方面的潜力和创新功能」
-
高级模型选择:mlr3verse提供多种高级生存分析模型,包括传统的Cox比例风险模型、基于深度学习的模型和集成模型等。这些模型考虑到多个因素对生存时间的影响,能够更准确地预测生存率。 -
特征工程:mlr3verse提供灵活的特征选择和转换功能,有助于用户选择和构建与生存率相关的特征。这有助于改善模型的预测性能,并发现影响生存率的潜在因素。 -
不确定性估计:mlr3verse支持对生存率预测结果的不确定性进行估计。通过使用交叉验证和重采样技术,可以获得模型预测的置信区间和可靠性度量,提供更全面和可解释的预测结果。 -
结果可视化:mlr3verse提供了丰富的结果可视化功能,可以直观地展示预测的生存率和相关变量之间的关系。这有助于研究人员更好地理解和解释模型结果,并进行进一步的数据分析和解读。
综上所述,mlr3verse作为新一代的生存分析工具,具有统一框架、增强的功能、可扩展性和高效自动化等优势,并在预测生存率方面具有潜力和创新功能。这使得它成为研究生存分析的重要工具,并能够在预测生存率方面提供准确和可靠的结果。
4.3 mlr3verse和KM的异同
-
功能不同:mlr3verse是一个包含多个生存分析任务的综合框架,它提供了数据预处理、模型选择、模型训练和评估等功能。与此相反,KM方法是一种用于估计生存函数的非参数方法,主要用于直观地描述事件发生概率随时间的变化趋势。 -
数据要求不同:mlr3verse适用于各种类型的数据,包括连续、离散和分类变量。它可以处理缺失数据以及其他类型的特殊情况。KM方法通常适用于仅具有事件发生信息的数据集,例如生存时间和事件指示器。 -
模型选择与解释性:mlr3verse提供了多种生存分析模型选择的功能,包括传统的Cox比例风险模型、基于深度学习的模型和集成模型等。这些模型可以更准确地预测生存率,但可能较复杂,解释性较差。相比之下,KM方法不涉及具体的模型假设,更易于解释。 -
预测能力与应用场景:mlr3verse的模型通常具有更好的预测能力,适用于复杂的数据集和预测需求。它更适合进行个体化的生存率预测和风险评估。KM方法主要用于群体层面的生存分析,可以提供整体的生存曲线和中位生存时间等统计量。
综上所述,mlr3verse和KM在功能、数据要求、模型选择与解释性以及应用场景上存在显著的差异。mlr3verse作为一个综合的生存分析框架,具有更多的功能和预测能力,适用于复杂的数据分析和预测需求。而KM方法则更适合用于描述整体生存概率的变化趋势,并具有简单和直观的解释性。根据具体的分析目标和数据情况,选择适合的工具是非常重要的。
五、mlr3verse和KM比较
5.1 数据集载入
library(survival)
str(gbsg)
结果展示:
> str(gbsg)
'data.frame': 686 obs. of 10 variables:
$ age : int 49 55 56 45 65 48 48 37 67 45 ...
$ meno : int 0 1 1 0 1 0 0 0 1 0 ...
$ size : int 18 20 40 25 30 52 21 20 20 30 ...
$ grade : int 2 3 3 3 2 2 3 2 2 2 ...
$ nodes : int 2 16 3 1 5 11 8 9 1 1 ...
$ pgr : int 0 0 0 0 0 0 0 0 0 0 ...
$ er : int 0 0 0 4 36 0 0 0 0 0 ...
$ hormon : int 0 0 0 0 1 0 0 1 1 0 ...
$ rfstime: int 1838 403 1603 177 1855 842 293 42 564 1093 ...
$ status : Factor w/ 2 levels "0","1": 1 2 1 1 1 2 2 1 2 2 ...
age:患者年龄
meno:更年期状态(0表示未更年期,1表示已更年期)
size:肿瘤大小
grade:肿瘤分级
nodes:受累淋巴结数量
pgr:孕激素受体表达水平
er:雌激素受体表达水平
hormon:激素治疗(0表示否,1表示是)
rfstime:复发或死亡时间(以天为单位)
status:事件状态(0表示被截尾,1表示事件发生)
5.2 KM生存曲线
library(ggplot2)
library(survminer)
# 绘制生存曲线
fit <- survfit(Surv(survtime,censdead
) ~ hormone,data = gbcs)
ggsurvplot(fit, data = gbcs,risk.table = TRUE,
ggtheme = theme_bw(),
xlab = "days",break.x.by=200,
tables.y.text=FALSE,legend.title="",
fontsize=5,break.y.by=0.2,
font.x = 15,
font.y = 15,
font.tickslab = 15,
font.legend = 15,
ylab='Event-free survival probability',
legend = c(0.90,0.85),pval.coord = c(5,0.25),pval.size=5,
pval.family="Times New Roman",palette = c("red","green"))
5.3 mlr3verse生存分析
-
「设定任务」
options (repos = c (raphaels1 = "https://raphaels1.r-universe.dev", mlrorg = "https://mlr-org.r-universe.dev", CRAN = 'https://cloud.r-project.org'))
install.packages("dictionar6")
install.packages("param6")
install.packages("ranger")
install.packages("survivalmodels")
install.packages("mlr3")
install.packages("mlr3proba")
install.packages("mlr3verse")
install.packages("mlr3extralearners")
library("mlr3extralearners")
library(mlr3)
library(mlr3proba)
library(mlr3verse)
library(mlr3pipelines)
library(survex)
library(survival)
data(gbcs)
gbcs <- gbcs[,-c(1,2,3,4)]
gbcs$hormone <- as.factor(gbcs$hormone)
task = as_task_surv(gbcs,
time = "survtime",
event = "censdead",id="gbcs")
task$head()
#绘制KM曲线
autoplot(task,rhs="hormone")
结果展示:
> task$head()
survtime censdead age censrec estrg_recp grade hormone menopause nodes
1: 2282 0 38 1 105 3 1 1 5
2: 2006 0 52 1 14 1 1 1 1
3: 1456 1 47 1 89 2 1 1 1
4: 148 0 40 0 11 1 1 1 3
5: 1863 0 64 0 9 2 2 2 1
6: 1933 0 49 0 64 1 2 2 3
prog_recp rectime size
1: 141 1337 18
2: 78 1420 20
3: 422 1279 30
4: 25 148 24
5: 19 1863 19
6: 356 1933 56
-
「生存分析预测」
ranger_learner <- lrn("surv.ranger")
ranger_learner$train(task)
ranger_learner_explainer <- explain(ranger_learner,
data = gbcs,
y = Surv(gbcs$survtime, gbcs$censdead),
label = "Ranger model")
ranger_learner_explainer |> predict_profile(gbcs[1,]) |> plot(numerical_plot_type = "contours",variables = c("hormone", "age"),facet_ncol = 2,subtitle = NULL)
六、总结
综上所述,mlr3verse和KM在功能、数据要求、模型选择与解释性以及应用场景上存在显著的差异。mlr3verse作为一个综合的生存分析框架,具有更多的功能和预测能力,适用于复杂的数据分析和预测需求。而KM方法则更适合用于描述整体生存概率的变化趋势,并具有简单和直观的解释性。根据具体的分析目标和数据情况,选择适合的工具是非常重要的。如果想了解如何评估mlr3verse模型性能和特征重要性图,请关注和私信我,我们一起讨论学习。原创不易,如果觉得写的还行的话,请留下您的赞和再看,谢谢!
*「未经许可,不得以任何方式复制或抄袭本篇文章之部分或全部内容。版权所有,侵权必究。」
相关文章:
mlr3verse vs KM曲线:谁能更精准地预测生存率?
一、引言 生存分析是统计学中一种重要的方法,用于分析个体在特定时间段内生存的概率或生存率。它在医学、流行病学、生物学等领域被广泛应用。通过生存分析,我们可以评估治疗方法的效果、预测疾病进展的风险以及评估特定因素对生存率的影响。 生存率的准…...
TechTool Pro for mac(硬件监测和系统维护工具)
TechTool Pro 是为 Mac OS X 重新设计的全新工具程序,不但保留旧版原有的硬件侦测功能,还可检查系统上其他重要功能,如:网络连接,区域网络等。 TechTool Pro for mac随时监控和保护您的电脑,并可预设定期检…...
排序算法(九大)- C++实现
目录 基数排序 快速排序 Hoare版本(单趟) 快速排序优化 三数取中 小区间优化 挖坑法(单趟) 前后指针法(单趟) 非递归实现(快排) 归并排序 非递归实现(归并&am…...
)
lettuce连接池的源代码(link)
springboot研究九:lettuce连接池很香,撸撸它的源代码_lettuce springboot_君哥聊技术的博客-CSDN博客...

小白到运维工程师自学之路 第六十二集 (docker持久化与数据卷容器)
一、概述 Docker持久化是指将容器中的数据持久保存在主机上,以便在容器重新启动或迁移时不丢失数据。由于Docker容器是临时和可变的,它们的文件系统默认是易失的,这意味着容器中的任何更改或创建的文件都只存在于此容器的生命周期内。但是&a…...
37.利用linprog解 有约束条件多元变量函数最小值(matlab程序)
1.简述 linprog函数主要用来求线型规划中的最小值问题(最大值的镜像问题,求最大值只需要加个“-”) 2. 算法结构及使用方法 针对约束条件为Axb或Ax≤b的问题 2.1 linprog函数 xlinprog(f,A,b) xlinprog(f,A,b,Aeq,beq) xlinprog(f,A,b,Aeq,…...

分页Demo
目录 一、分页对象封装 分页数据对象 分页查询实体类 实体类用到的utils ServiceException StringUtils SqlUtil BaseMapperPlus,> BeanCopyUtils 二、示例 controller service dao 一、分页对象封装 分页数据对象 import cn.hutool.http.HttpStatus; import com.…...
)
ChatGPT超详细介绍与功能与免费网页版(超全面!)
ChatGPT ChatGPT前言ChatGPT介绍ChatGPT的优点关于ChatGPT的一些问题1.chatgpt是什么意思?2.chatgpt国内能用吗? 国内可用的ChatGPT网页版:1.ChatGPT prompts2.这个网站收集了5000多个ChatGPT 应用,可以在线运行3.ChatGPT Box4.飞书chatgpt5.AI-Produc…...
3.PyCharm安装
PyCharm是由JetBrains推出的Python开发IDE,是最受欢迎的Python IDE之一。PyCharm为Python开发者提供了许多高级功能如代码自动完成、调试等。它使用智能引擎来分析代码,能够自动识别代码中的错误并提供快速修复方案。PyCharm适用于各种规模的项目,包括小型Python脚本和大型P…...

【C语言进阶篇】关于指针的八个经典笔试题(图文详解)
🎬 鸽芷咕:个人主页 🔥 个人专栏:《C语言初阶篇》 《C语言进阶篇》 ⛺️生活的理想,就是为了理想的生活! 文章目录 📋 前言💬 指针笔试题💭 笔试题 1:✅ 代码解析⁉️ 检验结果&…...

用Rust实现23种设计模式之 策略模式
关注我,学习Rust不迷路!! 优点 灵活性:策略模式允许你在运行时动态地选择不同的算法或行为,而无需修改已有的代码。可扩展性:通过添加新的策略类,你可以轻松地扩展策略模式的功能。可维护性&a…...

面试题:说说JS的this指向问题?
1、this永远指向一个对象; 2、this的指向完全取决于函数调用的位置; 可以借鉴这篇文章,说的很详细(点击) 总结: 1、 以方法的形式调用时, this 是调用方法的对象; 2、绑定事件函…...

ansible——roles 角色
一、概述 1.roles角色简介 roles用于层次性、结构化地组织playbook。roles能够根据层次型结构自动装载变量文件、tasks以及handlers等。要使用roles只需要在playbook中使用include指令引入即可。 简单来讲,roles就是通过分别将变量、文件、任务、模板及处理器放置…...
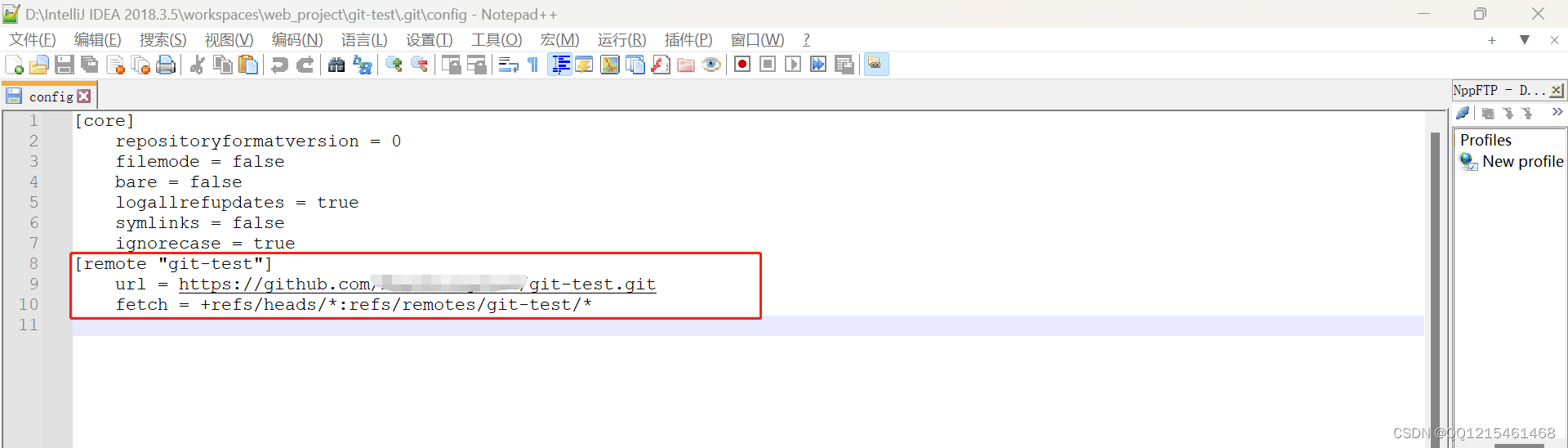
GitHub上删除项目后,IDEA分享项目到GitHub提示Remote is already on GitHub
文章目录 一、错误信息二、解决方法1.删除GitHub上的项目2.找到项目里的.git隐藏文件3.找到config文件4.打开config文件,删除[remote "git-test"]及下面两行内容5.继续使用IDEA分享项目到GitHub即可 一、错误信息 二、解决方法 1.删除GitHub上的项目 2.…...

【机器学习 | 决策树】利用数据的潜力:用决策树解锁洞察力
🤵♂️ 个人主页: AI_magician 📡主页地址: 作者简介:CSDN内容合伙人,全栈领域优质创作者。 👨💻景愿:旨在于能和更多的热爱计算机的伙伴一起成长!!&…...
postgis mvt矢量切片 django drf mapboxgl
postgis mvt矢量切片 django drf mapboxgl 目录 0.前提 1.sql代码 2.django drf后端服务代码 3.具体的应用(整体代码) 4.参考 0.前提 [1] 静态的矢量切片可以采用 tippecanoe 生成,nginx代理,这种数据是不更新的;…...

C语言编程工具软件推荐!
1、VS(Visual Studio) [VS是目前最受欢迎的适用于Windows平台应用程序的综合开发环境,由于大多数同学使用的都是Windows操作系统,因此VS非常适合大家。在日常课堂和考试中,我们使用的VS2010支持多种不同的编程语言,VS2010最初支持…...
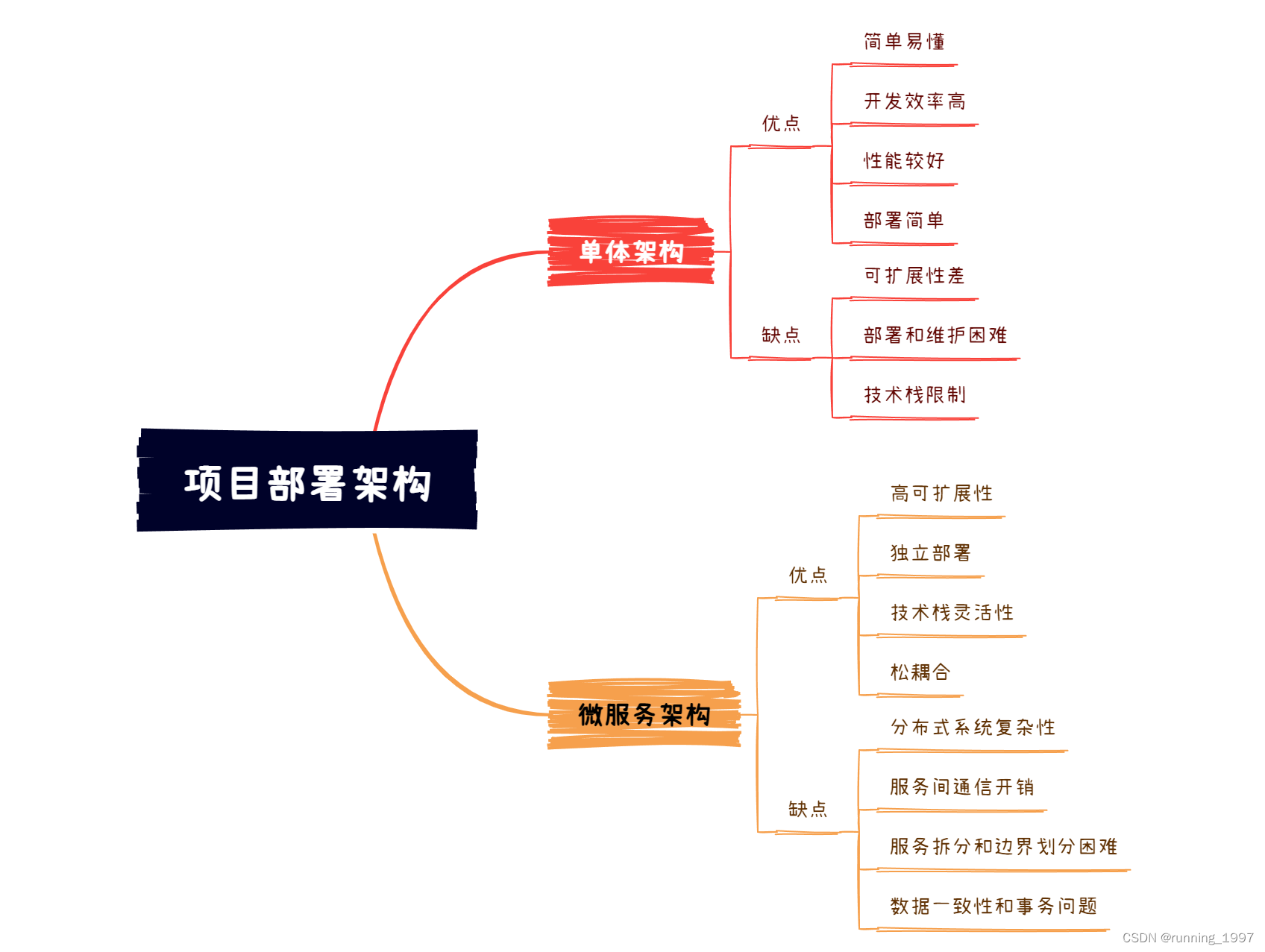
单体架构和微服务架构的区别
文章目录 一、单体架构的定义1. 单体架构的优点:2. 单体架构的缺点: 二、微服务架构的定义1. 微服务架构的优点:2. 微服务架构的缺点: 三、单体架构VS微服务架构1. 区别:1.1 架构规模:1.2 依赖关系…...

python--local对象、flask上下文源码分析
一、local对象 背景: 多线成并发操作一个变量,会导致数据错乱,可以使用互斥锁加锁处理数据不安全的情况 (临界区) 解决: 使用local对象处理,多个线程操作的变量是local对象,就不会…...

类文件一些内容
1、类加载 将类的字节码加载到JVM中,并转换为可以被JVM运行的数据结构的过程 类文件结构...

塞尔达传说旷野之息存档编辑器:轻松掌控海拉鲁大陆的终极工具
塞尔达传说旷野之息存档编辑器:轻松掌控海拉鲁大陆的终极工具 【免费下载链接】BOTW-Save-Editor-GUI A Work in Progress Save Editor for BOTW 项目地址: https://gitcode.com/gh_mirrors/bo/BOTW-Save-Editor-GUI 还在为《塞尔达传说:旷野之息…...

从“页面描述”到“AI事实层”——让机器读懂你的品牌
引言:为什么你的产品信息在AI答案中“丢失”了? 陆薇在数字营销领域摸爬滚打了九年。她做过技术、干过内容、搞过数据分析,算得上是这个行业里少有的“多面手”。她所在的智联优选,一家主营智能家居产品的跨境电商品牌,在过去一年里已经按照《答案之书》第八篇和第九篇的…...

如果没有 Tools,Agent 什么都做不了
一、什么是urllib3? urllib3 是一个用于处理 HTTP 请求和连接池的强大、用户友好的 Python 库。 它可以帮助你: 发送各种 HTTP 请求(GET, POST, PUT, DELETE等)。 管理连接池,提高网络请求效率。 处理重试和重定向。 支…...

零基础玩转AI上色:cv_unet_image-colorization保姆级部署教程
零基础玩转AI上色:cv_unet_image-colorization保姆级部署教程 1. 工具简介与核心价值 黑白照片上色技术让历史影像重获新生,而cv_unet_image-colorization正是这样一款开箱即用的AI工具。基于ModelScope的UNet架构模型,它能够智能分析黑白照…...

G-Helper华硕笔记本优化指南:告别臃肿控制软件,3步打造高效设备
G-Helper华硕笔记本优化指南:告别臃肿控制软件,3步打造高效设备 【免费下载链接】g-helper Lightweight, open-source control tool for ASUS laptops and ROG Ally. Manage performance modes, fans, GPU, battery, and RGB lighting across Zephyrus, …...

突破TIDAL音乐离线限制:tidal-dl-ng四象限应用指南
突破TIDAL音乐离线限制:tidal-dl-ng四象限应用指南 【免费下载链接】tidal-dl-ng TIDAL Media Downloader Next Generation! Up to HiRes / TIDAL MAX 24-bit, 192 kHz. 项目地址: https://gitcode.com/gh_mirrors/ti/tidal-dl-ng 场景痛点:当高品…...

Qwen3.5-9B量子计算辅助:算法描述理解+Qiskit代码生成+实验设计建议
Qwen3.5-9B量子计算辅助:算法描述理解Qiskit代码生成实验设计建议 1. 项目概述与核心能力 Qwen3.5-9B是一款拥有90亿参数的开源大语言模型,在量子计算领域展现出强大的辅助能力。该模型特别适合用于: 算法描述理解:解析复杂的量…...

[特殊字符] 第85课:戳气球
想系统提升编程能力、查看更完整的学习路线,欢迎访问 AI Compass:https://github.com/tingaicompass/AI-Compass 仓库持续更新刷题题解、Python 基础和 AI 实战内容,适合想高效进阶的你。📖 第85课:戳气球模块:动态规划 | 难度:Ha…...

颠覆式窗口控制:WindowResizer革命性尺寸调整技术全解析
颠覆式窗口控制:WindowResizer革命性尺寸调整技术全解析 【免费下载链接】WindowResizer 一个可以强制调整应用程序窗口大小的工具 项目地址: https://gitcode.com/gh_mirrors/wi/WindowResizer WindowResizer——这款开源窗口尺寸控制工具,正以革…...
扩展方案)
Hunyuan-MT Pro快速上手:添加语音输入/输出模块(Whisper+VITS)扩展方案
Hunyuan-MT Pro快速上手:添加语音输入/输出模块(WhisperVITS)扩展方案 1. 项目概述与扩展价值 Hunyuan-MT Pro是一个基于腾讯混元大模型的多语言翻译终端,原本专注于文本翻译。但实际使用中,我们经常遇到这样的场景&…...