【机器学习 | 决策树】利用数据的潜力:用决策树解锁洞察力

🤵♂️ 个人主页: @AI_magician
📡主页地址: 作者简介:CSDN内容合伙人,全栈领域优质创作者。
👨💻景愿:旨在于能和更多的热爱计算机的伙伴一起成长!!🐱🏍
🙋♂️声明:本人目前大学就读于大二,研究兴趣方向人工智能&硬件(虽然硬件还没开始玩,但一直很感兴趣!希望大佬带带)

该文章收录专栏
[✨— 《深入解析机器学习:从原理到应用的全面指南》 —✨]
决策树
1.1 分类
决策树是一种基于树形结构的分类模型,它通过对数据属性的逐步划分,将数据集分成多个小的决策单元。每个小的决策单元都对应着一个叶节点,在该节点上进行分类决策。决策树的核心是如何选择最优的分割属性。常见的决策树算法有ID3、C4.5和CART。
决策树的输入数据主要包括训练集和测试集。训练集是已知类别的样本集,测试集则是需要分类的未知样本集。
具体来说,构建决策树的过程可以分为如下几个步骤:
- 选择最优特征。在构建决策树时,需要从当前样本集合中选择一个最优的特征作为当前节点的划分属性。通常使用信息增益、信息增益比或基尼指数等指标来评估各个特征的划分能力,并选取最优特征。
- 划分子集。根据选取的最优特征,将当前样本集合划分成若干个子集。每个子集对应于一个子节点,且该节点所代表的样本集合与其父节点的样本集合不重复。
- 递归构建决策树。对于每个子节点,重复前两个步骤,直到所有的样本都被分配到叶子节点上,并且每个叶子节点对应着一个类别。
- 剪枝操作。由于决策树容易出现过拟合,因此需要进行剪枝操作。常用的剪枝方法包括预剪枝和后剪枝。
在进行分类时,对输入测试样本,按照各个属性的划分方式逐步匹配,最终到达某个叶子节点,并将该测试样本归为叶子节点所代表的类别。决策树的输出结果就是针对测试样本的分类结果,即该测试样本所属的类别。
决策树的优点在于易于理解和解释,能够处理不同类型的数据,且不需要对数据进行预处理。但是,决策树容易出现过拟合问题,因此在构建决策树时需要进行剪枝操作。常用的剪枝方法包括预剪枝和后剪枝。
1.1.1 案例
假设我们要构建一个决策树来预测一个人是否会购买某个产品。我们将使用以下特征来进行预测:
- 年龄:年龄范围在18岁到65岁之间。
- 性别:男性或女性。
- 收入:收入范围在0到100,000之间。
我们有一个包含以下数据的训练集:
| 编号 | 年龄 | 性别 | 收入 | 购买 |
|---|---|---|---|---|
| 1 | 25 | 男性 | 30,000 | 否 |
| 2 | 35 | 女性 | 40,000 | 否 |
| 3 | 45 | 女性 | 80,000 | 是 |
| 4 | 20 | 男性 | 10,000 | 否 |
| 5 | 55 | 男性 | 60,000 | 是 |
| 6 | 60 | 女性 | 90,000 | 是 |
| 7 | 30 | 男性 | 50,000 | 否 |
| 8 | 40 | 女性 | 75,000 | 是 |
现在,我们将使用这些数据来构建一个决策树模型。
首先,我们选择一个特征来作为根节点。我们可以使用信息增益或基尼不纯度等指标来选择最佳特征。在这个例子中,我们选择使用信息增益。
基尼指数和信息增益都是用于决策树中特征选择的指标,它们各有优劣。
基尼指数是一种衡量数据集纯度或不确定性的指标,常用于决策树算法中的特征选择。它基于基尼系数的概念,用于度量从数据集中随机选择两个样本,其类别标签不一致的概率。
基尼指数的计算公式如下:
G i n i ( D ) = 1 − Σ ( p i ) 2 Gini(D) = 1 - Σ (p_i)^2 Gini(D)=1−Σ(pi)2其中,Gini(D)表示数据集D的基尼指数,p_i表示数据集D中第i个类别的样本所占比例。
基尼指数的取值范围为0到1,数值越小表示数据集的纯度越高,即样本的类别越一致。当数据集D中只包含一种类别的样本时,基尼指数为0,表示数据集完全纯净。当数据集D中的样本类别均匀分布时,基尼指数最大(即值越小),为1,表示数据集的不确定性最高。
在决策树算法中,基尼指数被用于衡量选择某个特征进行划分后,数据集的纯度提升程度。通过计算每个特征的基尼指数,选择基尼指数最小的特征作为划分依据,以达到最大程度地减少数据集的不确定性。
计算每个特征的信息增益:
- 年龄的信息增益:0.029
- 性别的信息增益:0.152
- 收入的信息增益:0.048
根据信息增益,我们选择性别作为根节点。
信息增益是一种用于选择决策树节点的指标,它衡量了在选择某个特征作为节点后,数据集的纯度提高了多少。信息增益的计算基于信息熵的概念。
信息熵是用来衡量数据集的混乱程度或不确定性的度量。对于一个二分类问题(如购买与否),信息熵的计算公式如下 (多分类也一样,每个不题类别求和):
E n t r o p y ( S ) = − p ( Y e s ) ∗ l o g 2 ( p ( Y e s ) ) − p ( N o ) ∗ l o g 2 ( p ( N o ) ) Entropy(S) = -p(Yes) * log2(p(Yes)) - p(No) * log2(p(No)) Entropy(S)=−p(Yes)∗log2(p(Yes))−p(No)∗log2(p(No))
其中,S是数据集,p(Yes)和p(No)分别是购买为"是"和"否"的样本在数据集中的比例。(信息熵代表了分布越平均,样本信息含量越高,不确定性越大,信息熵越大,分布越不均匀,占比越大,信息熵会趋于0。所以以信息熵大小来确定分类,就是为了把一些小范围的集合分离出去)
信息增益的计算公式如下(不同类别信息熵相加):
G a i n ( S , A ) = E n t r o p y ( S ) − ∑ ( ∣ S v ∣ / ∣ S ∣ ) ∗ E n t r o p y ( S v ) Gain(S, A) = Entropy(S) - ∑(|Sv| / |S|) * Entropy(Sv) Gain(S,A)=Entropy(S)−∑(∣Sv∣/∣S∣)∗Entropy(Sv)
其中,S是数据集,A是要计算信息增益的特征,Sv是特征A的某个取值对应的子集,|Sv|是子集Sv的样本数量,|S|是数据集S的样本数量。 (通过这个子集数量控制其影响权重,然后确定信息增益最大的(即信息熵最小),白话就是选择一个分类中更主流的,特征更明显的)
信息增益越大,意味着使用特征A作为节点可以更好地分割数据集,提高纯度。
在我们的例子中,我们计算了每个特征的信息增益,并选择了具有最大信息增益的特征作为根节点。然后,我们根据根节点的取值将数据集分割成子集,并对每个子集计算信息增益,以选择下一个节点。这个过程一直持续到满足停止条件为止,例如子集中的样本都属于同一类别或达到了预定的树的深度。
总结以下是基尼指数和信息增益的优缺点
优点:
- 基尼指数:基尼指数是一种衡量不纯度的指标,它在计算上比信息增益更简单和高效。在处理大规模数据集时,基尼指数的计算速度通常比信息增益快。(单纯计算特征分类占比,占比平方)
- 信息增益:信息增益是一种衡量特征对于分类任务的贡献程度的指标。它基于信息论的概念,可以更好地处理多分类问题。信息增益在处理不平衡数据集时表现较好,能够更好地处理类别不均衡的情况。(除了计算特征分类占比,还添加了一个log函数,log比例乘上占比,使其贡献度分类占比大小情况得到增益)
缺点:
- 基尼指数:基尼指数只考虑了特征的不纯度,而没有考虑特征的取值个数。这意味着基尼指数可能会偏向具有更多取值的特征。在处理具有大量取值的特征时,基尼指数可能会导致决策树偏向这些特征。(基尼指数只要是要这个阈值,节点,能分出去的样本比例最大有多大,最大越大,越倾向于)
- 信息增益:信息增益对于具有较多取值的特征有一定的偏好,因为它倾向于选择具有更多分支的特征。这可能导致决策树过于复杂,容易过拟合训练数据(树的深度不要太深)。(信息增益根据一种信息学的信息熵,根据其性质,分类越平均越大,分类占比大越小的一个性质,来分节点。
综上所述,基尼指数和信息增益在不同的情况下有不同的优劣。在实际应用中,可以根据具体的问题和数据集的特点选择适合的指标。
接下来,我们根据性别的取值(男性或女性)将数据集分割成两个子集。
对于男性子集:
| 编号 | 年龄 | 收入 | 购买 |
|---|---|---|---|
| 1 | 25 | 30,000 | 否 |
| 4 | 20 | 10,000 | 否 |
| 5 | 55 | 60,000 | 是 |
| 7 | 30 | 50,000 | 否 |
对于女性子集:
| 编号 | 年龄 | 收入 | 购买 |
|---|---|---|---|
| 2 | 35 | 40,000 | 否 |
| 3 | 45 | 80,000 | 是 |
| 6 | 60 | 90,000 | 是 |
| 8 | 40 | 75,000 | 是 |
对于男性子集,我们可以看到购买的结果是"是"和"否"都有,所以我们需要进一步划分。我们选择年龄作为下一个节点。
对于年龄的取值(小于等于30岁和大于30岁):
对于小于等于30岁的子集:
| 编号 | 收入 | 购买 |
|---|---|---|
| 1 | 30,000 | 否 |
| 4 | 10,000 | 否 |
| 7 | 50,000 | 否 |
对于大于30岁的子集:
| 编号 | 收入 | 购买 |
|---|---|---|
| 5 | 60,000 | 是 |
对于小于等于30岁的子集,购买的结果都是"否",所以我们不需要再进行划分。
对于大于30岁的子集,购买的结果都是"是",所以我们不需要再进行划分。
对于女性子集,购买的结果都是"是",所以我们不需要再进行划分。
最终的决策树如下所示:
性别 = 男性:年龄 <= 30岁: 否年龄 > 30岁: 是
性别 = 女性: 是
这就是一个简单的决策树的例子。根据输入的特征,决策树可以根据特征的取值进行预测。请注意,这只是一个简单的示例,实际上,决策树可以有更多的特征和更复杂的结构。
首先,我们使用scikit-learn库来实现决策树:
from sklearn import tree
import numpy as np# 数据集
X = np.array([[25, 1, 30000],[35, 0, 40000],[45, 0, 80000],[20, 1, 10000],[55, 1, 60000],[60, 0, 90000],[30, 1, 50000],[40, 0, 75000]])Y = np.array([0, 0, 1, 0, 1, 1, 0, 1])# 创建决策树模型
clf = tree.DecisionTreeClassifier()# 训练模型
clf = clf.fit(X, Y)# 预测
print(clf.predict([[40, 0, 75000],[10, 0, 75000]])) # 输出:[1, 0]
然后,我们不使用任何机器学习库来实现决策树:
import numpy as npclass Node:def __init__(self, predicted_class):self.predicted_class = predicted_class # 预测的类别self.feature_index = 0 # 特征索引self.threshold = 0 # 阈值self.left = None # 左子树self.right = None # 右子树class DecisionTree:def __init__(self, max_depth=None):self.max_depth = max_depth # 决策树的最大深度def fit(self, X, y):self.n_classes_ = len(set(y)) # 类别的数量self.n_features_ = X.shape[1] # 特征的数量self.tree_ = self._grow_tree(X, y) # 构建决策树def predict(self, X):return [self._predict(inputs) for inputs in X] # 对输入数据进行预测def _best_gini_split(self, X, y):m = y.size # 样本的数量if m <= 1: # 如果样本数量小于等于1,无法进行分割return None, Nonenum_parent = [np.sum(y == c) for c in range(self.n_classes_)] # 每个类别在父节点中的样本数量best_gini = 1.0 - sum((n / m) ** 2 for n in num_parent) # 父节点的基尼指数best_idx, best_thr = None, None # 最佳分割特征索引和阈值for idx in range(self.n_features_): # 遍历每个特征thresholds, classes = zip(*sorted(zip(X[:, idx], y))) # 根据特征值对样本进行排序num_left = [0] * self.n_classes_ # 左子节点中每个类别的样本数量num_right = num_parent.copy() # 右子节点中每个类别的样本数量,初始值为父节点的样本数量for i in range(1, m): # 遍历每个样本c = classes[i - 1] # 样本的类别num_left[c] += 1 # 更新左子节点中对应类别的样本数量num_right[c] -= 1 # 更新右子节点中对应类别的样本数量gini_left = 1.0 - sum((num_left[x] / i) ** 2 for x in range(self.n_classes_)) # 左子节点的基尼指数gini_right = 1.0 - sum((num_right[x] / (m - i)) ** 2 for x in range(self.n_classes_)) # 右子节点的基尼指数gini = (i * gini_left + (m - i) * gini_right) / m # 加权平均的基尼指数if thresholds[i] == thresholds[i - 1]: # 如果特征值相同,则跳过(特征阈值)continueif gini < best_gini: # 如果基尼指数更小,则更新最佳分割特征索引和阈值 (循环每个特征,和每个阈值,以求解最优分类best_gini = ginibest_idx = idxbest_thr = (thresholds[i] + thresholds[i - 1]) / 2return best_idx, best_thr # 返回最佳分割特征索引和阈值def _best_gain_split(self, X, y):m = y.size # 样本的数量if m <= 1: # 如果样本数量小于等于1,无法进行分割return None, Nonenum_parent = [np.sum(y == c) for c in range(self.n_classes_)] # 计算每个类别的样本数量best_gain = -1 # 初始化最佳信息增益best_idx, best_thr = None, None # 初始化最佳特征索引和阈值for idx in range(self.n_features_): # 遍历每个特征thresholds, classes = zip(*sorted(zip(X[:, idx], y))) # 对每个特征值和类别标签进行排序num_left = [0] * self.n_classes_ # 初始化左子树的类别数量 (左边都是0,为0时自动计算为0) num_right = num_parent.copy() # 右子树的类别数量初始化为父节点的类别数量 (右边是全部)for i in range(1, m): # 遍历每个样本c = classes[i - 1] # 获取当前样本的类别num_left[c] += 1 # 左子树的类别数量增加num_right[c] -= 1 # 右子树的类别数量减少entropy_parent = -sum((num / m) * np.log2(num / m) for num in num_parent if num != 0) # 计算父节点的熵entropy_left = -sum((num / i) * np.log2(num / i) for num in num_left if num != 0) # 计算左子树的熵entropy_right = -sum((num / (m - i)) * np.log2(num / (m - i)) for num in num_right if num != 0) # 计算右子树的熵gain = entropy_parent - (i * entropy_left + (m - i) * entropy_right) / m # 计算信息增益(分类后左右的信息熵最小)if thresholds[i] == thresholds[i - 1]: # 如果当前样本的特征值和前一个样本的特征值相同,跳过(不一样才能分界)continueif gain > best_gain: # 如果当前的信息增益大于最佳信息增益best_gain = gain # 更新最佳信息增益best_idx = idx # 更新最佳特征索引best_thr = (thresholds[i] + thresholds[i - 1]) / 2 # 更新最佳阈值 (循环每个样本的值,根据两份数据均值确定阈值,一直循环)return best_idx, best_thr # 返回最佳特征索引和阈值def _grow_tree(self, X, y, depth=0):num_samples_per_class = [np.sum(y == i) for i in range(self.n_classes_)] # 计算每个类别的样本数量predicted_class = np.argmax(num_samples_per_class) # 预测的类别为样本数量最多的类别 (即确定分到该分支样本最多的记为该类)node = Node(predicted_class=predicted_class) # 创建节点if depth < self.max_depth: # 如果当前深度小于最大深度idx, thr = self._best_gain_split(X, y) # 计算最佳分割if idx is not None: # 如果存在最佳分割indices_left = X[:, idx] < thr # 左子树的样本索引 (第 idx特征中小于thr阈值的索引)X_left, y_left = X[indices_left], y[indices_left] # 左子树的样本X_right, y_right = X[~indices_left], y[~indices_left] # 右子树的样本node.feature_index = idx # 设置节点的特征索引node.threshold = thr # 设置节点的阈值node.left = self._grow_tree(X_left, y_left, depth + 1) # 构建左子树node.right = self._grow_tree(X_right, y_right, depth + 1) # 构建右子树return node # 返回节点def _predict(self, inputs):node = self.tree_ # 获取决策树的根节点while node.left: # 如果存在左子树if inputs[node.feature_index] < node.threshold: # 如果输入样本的特征值小于阈值node = node.left # 到左子树else:node = node.right # 到右子树return node.predicted_class # 返回预测的类别# 数据集
X = [[25, 1, 30000],[35, 0, 40000],[45, 0, 80000],[20, 1, 10000],[55, 1, 60000],[60, 0, 90000],[30, 1, 50000],[40, 0, 75000]]Y = [0, 0, 1, 0, 1, 1, 0, 1]# 创建决策树模型
clf = DecisionTree(max_depth=2)# 训练模型
clf.fit(np.array(X), np.array(Y))# 预测
print(clf.predict([[40, 0, 75000],[10, 0, 75000]])) # 输出:[1, 0]
请注意,这个不使用任何机器学习库的决策树实现是一个基本的版本,它可能无法处理所有的情况,例如缺失值、分类特征等。在实际应用中,我们通常使用成熟的机器学习库,如scikit-learn,因为它们提供了更多的功能和优化。
1.2 回归
当决策树用于回归任务时,它被称为决策树回归模型。与分类树不同,决策树回归模型的叶子节点不再表示类别标签,而是表示一段连续区间或者一个数值。它同样基于树形结构,通过对数据特征的逐步划分,将数据集分成多个小的决策单元,并在每个叶子节点上输出一个预测值。
以下是决策树回归模型的详细原理:
- 划分过程
与分类树相似,决策树回归模型也采用递归二分的方式进行划分。具体来说,从根节点开始,选择一个最优特征和该特征的最优划分点。然后将数据集按照该特征的取值分为两部分,分别构建左右子树。重复以上步骤,直到满足停止条件,比如达到最大深度、划分后样本数少于阈值等。
- 叶子节点的输出值
当到达某个叶子节点时,该叶子节点的输出值就是训练集中该叶子节点对应的所有样本的平均值(或中位数等)。
- 预测过程
对于一个测试样本,从根节点开始,按照各个特征的划分方式逐步匹配,最终到达某个叶子节点,并将该测试样本的预测值设为该叶子节点的输出值。
- 剪枝操作
与分类树一样,决策树回归模型也容易出现过拟合问题,因此需要进行剪枝操作。常用的剪枝方法包括预剪枝和后剪枝。
- 特点
决策树回归模型具有以下特点:
(1)易于解释:决策树回归模型能够直观地反映各个特征对目标变量的影响程度。
(2)非参数性:决策树回归模型不对数据分布做任何假设,适用于各种类型的数据。
(3)可处理多元特征:决策树回归模型可以同时处理多个输入特征。
(4)不需要数据正态化:决策树回归模型不需要对输入数据进行正态化等预处理。
🤞到这里,如果还有什么疑问🤞🎩欢迎私信博主问题哦,博主会尽自己能力为你解答疑惑的!🎩🥳如果对你有帮助,你的赞是对博主最大的支持!!🥳
相关文章:
【机器学习 | 决策树】利用数据的潜力:用决策树解锁洞察力
🤵♂️ 个人主页: AI_magician 📡主页地址: 作者简介:CSDN内容合伙人,全栈领域优质创作者。 👨💻景愿:旨在于能和更多的热爱计算机的伙伴一起成长!!&…...
postgis mvt矢量切片 django drf mapboxgl
postgis mvt矢量切片 django drf mapboxgl 目录 0.前提 1.sql代码 2.django drf后端服务代码 3.具体的应用(整体代码) 4.参考 0.前提 [1] 静态的矢量切片可以采用 tippecanoe 生成,nginx代理,这种数据是不更新的;…...

C语言编程工具软件推荐!
1、VS(Visual Studio) [VS是目前最受欢迎的适用于Windows平台应用程序的综合开发环境,由于大多数同学使用的都是Windows操作系统,因此VS非常适合大家。在日常课堂和考试中,我们使用的VS2010支持多种不同的编程语言,VS2010最初支持…...
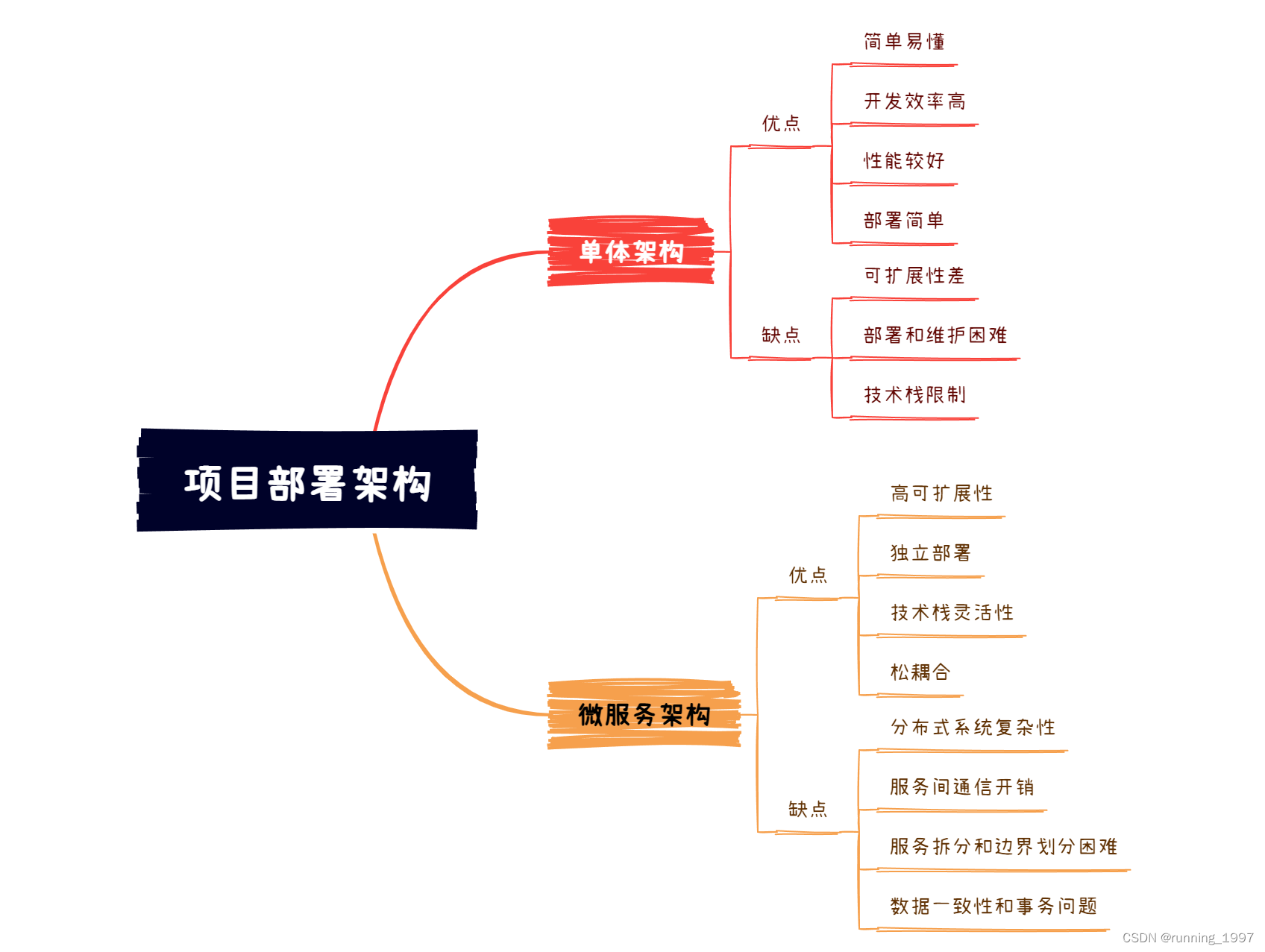
单体架构和微服务架构的区别
文章目录 一、单体架构的定义1. 单体架构的优点:2. 单体架构的缺点: 二、微服务架构的定义1. 微服务架构的优点:2. 微服务架构的缺点: 三、单体架构VS微服务架构1. 区别:1.1 架构规模:1.2 依赖关系…...

python--local对象、flask上下文源码分析
一、local对象 背景: 多线成并发操作一个变量,会导致数据错乱,可以使用互斥锁加锁处理数据不安全的情况 (临界区) 解决: 使用local对象处理,多个线程操作的变量是local对象,就不会…...

类文件一些内容
1、类加载 将类的字节码加载到JVM中,并转换为可以被JVM运行的数据结构的过程 类文件结构...

28 Java练习——实现两个集合的交集和并集
求并集的思路:假设传入的是一个ArrayList对象,求并集的时候直接调用其中一个List集合的addAll方法将另一个集合合并过来,而List的特性是有序,重复的。因此,使用Set接口的无序不可重复的特性,把Collection对…...

ES6学习-Promise
Promise 简单说就是一个容器,里面保存着某个未来才会结束的事件(通常是一个异步操作)的结果。 语法上: Promise 是一个对象,从它可以获取异步操作的消息。 特点 对象的状态不受外界影响。Promise 对象戴白哦一个异步操…...
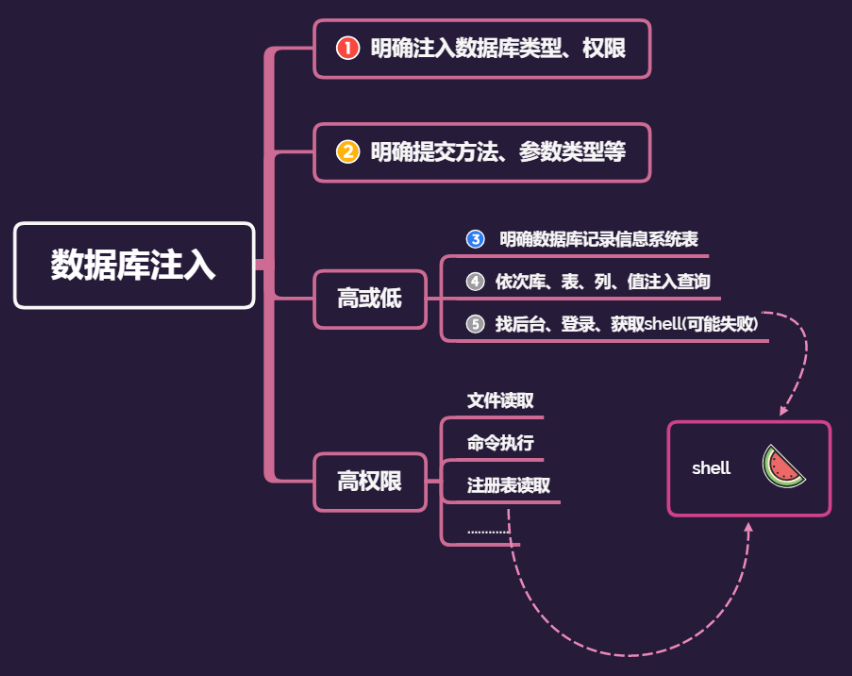
《Web安全基础》03. SQL 注入
web 1:简要 SQL 注入2:MySQL 注入2.1:信息获取2.2:跨库攻击2.3:文件读写2.4:常见防护 3:注入方法3.1:类型方法明确3.2:盲注3.3:编码3.4:二次注入3…...
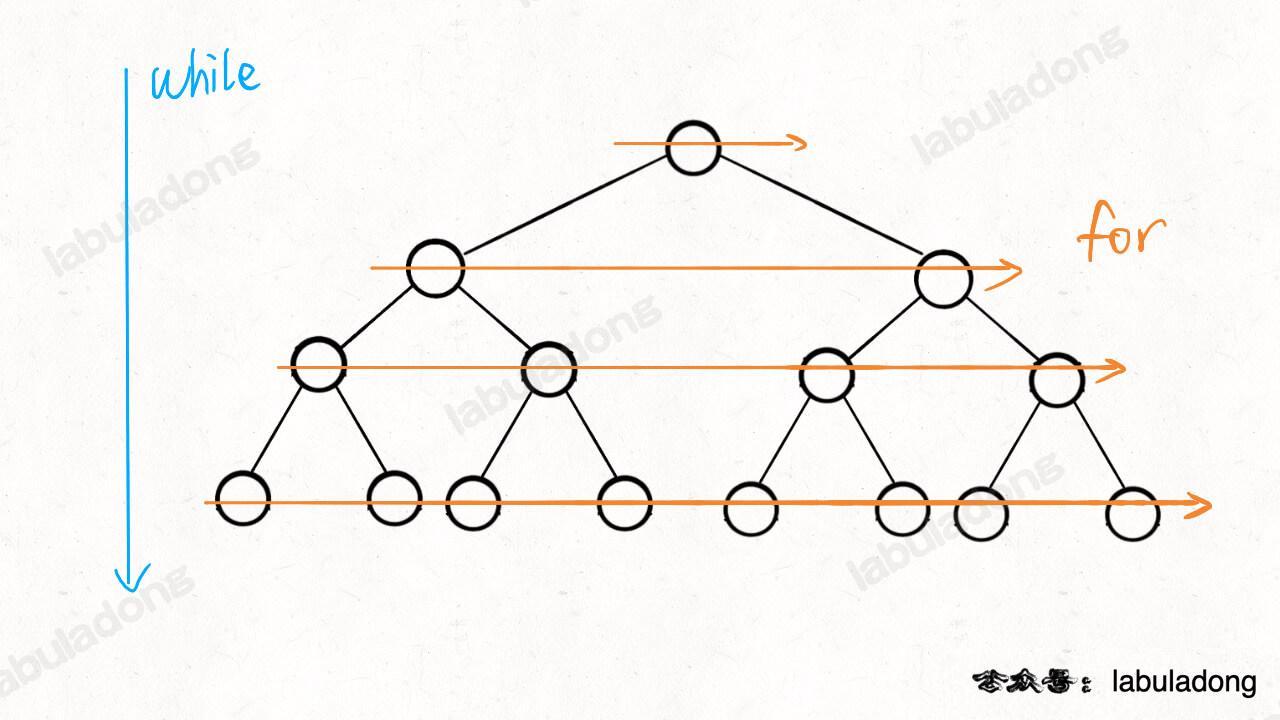
算法与数据结构(二十一)二叉树(纲领篇)
备注:本文旨在通过 labuladong 的二叉树(纲领篇)理解框架思维,用于个人笔记及交流学习,版权归原作者 labuladong 所有; 我刷了这么多年题,浓缩出二叉树算法的一个总纲放在这里,也许…...
visio,word添加缺少字体,仿宋_GB2312、楷体_GB2312、方正小标宋简体等字体下载
一. 内容简介 visio,word添加缺少字体,仿宋_GB2312、楷体_GB2312、方正小标宋简体等字体下载 二. 软件环境 2.1 visio 三.主要流程 3.1 下载字体 http://www.downza.cn/ 微软官方给的链接好多字体没有,其他好多字体网站,就是给你看个样式ÿ…...

Java爬虫
什么是爬虫? 通过请求,从而去获取互联网上的各种数据与资源,如文字,图片,视频。 本质上原理都一样,都是通过api请求,然后服务器就会发给你信息,然后你再根据这些信息去提取你想要的…...

海外应用商店优化实用指南之关键词
和SEO一样,关键词是ASO中的一个重要因素。就像应用程序标题一样,在Apple App Store和Google Play中处理应用程序关键字的方式也有所不同。 关键词研究。 对于Apple,我们的所有关键词只能获得100个字符,Google Play没有特定的关键…...
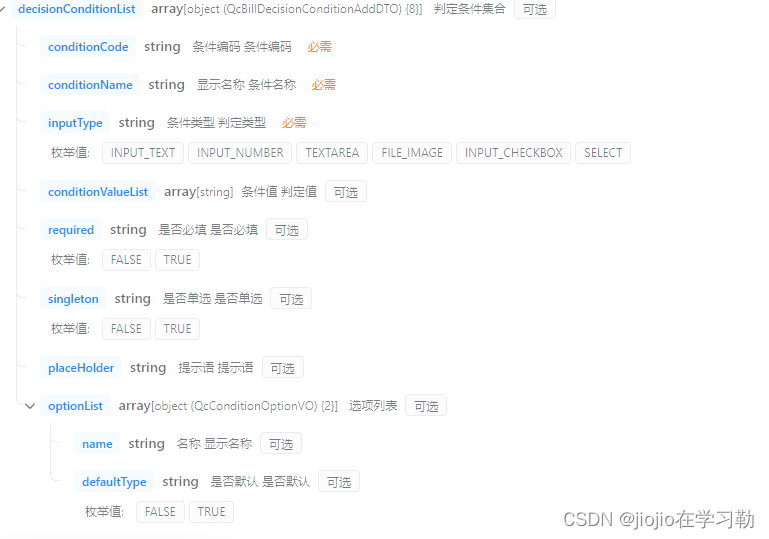
element+vue 之动态form
1.页面部分 <div v-for"(item,index) in formList" :key"index"><el-col :span"6" v-if"item.inputType0"><el-form-item :label"item.conditionName" :prop"item.conditionCode":rules"{req…...
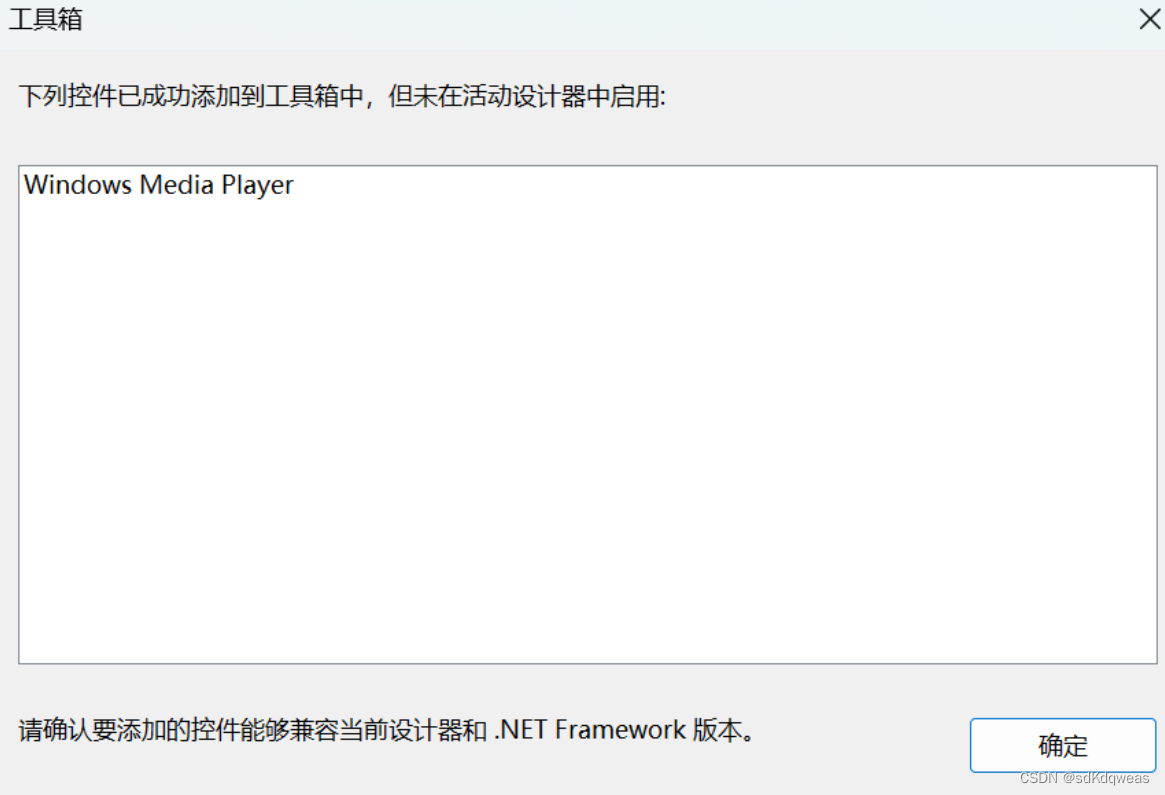
winform学习(3)-----Windows窗体应用和Windows窗体应用(.Net Framework)有啥区别?
1.模板选择 在学习winform的时候总是会对这两个应用不知道选择哪个?而且在学习的时候也没有具体的说明 首先说一下我是在添加控件的时候出现了以下问题 对于使用了Windows窗体应用这个模板的文件在工具箱中死活不见控件。 在转换使用了Windows窗体应用(.NET Fram…...

虚拟化中的中断机制:X86与PIC 8259A探索(上)
本系列深入探讨虚拟化中断技术,从X86架构和PIC 8259A的基础,到IOAPIC和MSI的编程,再到MSIX技术与Broiler设备的实战应用,全面剖析中断虚拟化的前沿进展。 X86 中断机制 在计算机架构中,CPU 运行的速度远远大于外设…...

软件外包开发语言排行榜
软件开发语言的排行榜是一个动态的话题,而在未来的几年中,新的技术和语言可能会不断涌现,影响排名。然而以下是一些在过去几年中一直受欢迎并有前途的软件开发语言,如果是新入门软件开发行业在学习语言做选择,希望下面…...
BI技巧丨利用OFFSET计算同环比
微软最近更新了很多开窗函数,其内部参数对比以往的DAX函数来说,多了很多,这就导致学习的时间成本直线上升。 而且对于新增函数的应用场景,很多小伙伴也是一知半解的,本期我们就来聊一聊关于最近新增的开窗函数——OFF…...

整理mongodb文档:collation
文章连接 整理mongodb文档:collation 看前提示 对于mongodb的collation。个人主要用的范围是在createcollection,以及find的时候用,所以本片介绍的时候也是这两个地方入手,对新手个人觉得理解概念就好。不要求强制性掌握,但是要…...

【LangChain】Prompts之Prompt templates
Prompts 编程模型的新方法是通过提示(prompts)。 prompts是指模型的输入。该输入通常由多个组件构成。 LangChain 提供了多个类和函数,使构建和使用prompts变得容易。 Prompt templates(提示模板): 参数化模型输入Example selectors(选择器示例): 动态选择要包含在…...

AI辅助开发新思路:让快马AI理解自然语言,自动生成分区数据智能查询系统
今天想和大家分享一个最近用AI辅助开发的实用工具——中科院分区智能查询系统。这个项目的核心思路是让AI理解科研人员的自然语言查询需求,自动转换成数据库操作,大大简化了科研数据检索的流程。 项目背景与需求分析 作为一名经常需要查阅期刊信息的科…...

LPDDR6的DVFS模式详解:如何用VDD2C/D和四种新策略优化手机续航与性能?
LPDDR6的DVFS模式详解:如何用VDD2C/D和四种新策略优化手机续航与性能? 当你在玩手机游戏时突然电量告急,或是观看高清视频时设备发烫降频,这背后其实是一场关于内存功耗的精密博弈。LPDDR6作为下一代移动设备内存标准,…...

探索Matlab在自动驾驶中的计算机视觉应用
Matlab自动驾驶,基于Matlab实现的计算机视觉代码。 计算机视觉是一门研究如何使机器“看”的科学,更进一步的说,就是是指用摄影机和电脑代替人眼对目标进行识别、跟踪和测量等机器视觉,并进一步做图形处理。 代码可正常运行在自动…...

如果没有 Tools,Agent 什么都做不了
一、什么是urllib3? urllib3 是一个用于处理 HTTP 请求和连接池的强大、用户友好的 Python 库。 它可以帮助你: 发送各种 HTTP 请求(GET, POST, PUT, DELETE等)。 管理连接池,提高网络请求效率。 处理重试和重定向。 支…...

STM32CubeMX配置SenseVoice-Small边缘计算模块
STM32CubeMX配置SenseVoice-Small边缘计算模块 1. 引言 在嵌入式设备上实现语音识别功能一直是物联网和智能设备开发的热点。SenseVoice-Small作为一款轻量级多语言语音识别模型,为边缘计算场景提供了理想的解决方案。本文将手把手教你如何使用STM32CubeMX工具配置…...

Ubuntu下MPI安装全攻略:从gcc到mpif90的完整配置流程
Ubuntu下MPI并行计算环境搭建实战指南 从零开始构建高性能计算基础环境 在科学计算和工程仿真领域,并行计算已经成为突破单机性能瓶颈的关键技术。作为最流行的消息传递接口标准,MPI(Message Passing Interface)让研究人员能够在集…...

Windows下OpenClaw安装指南:快速对接千问3.5-9B镜像
Windows下OpenClaw安装指南:快速对接千问3.5-9B镜像 1. 为什么选择OpenClaw千问3.5-9B组合 去年我在处理日常办公自动化时,发现很多重复性工作既耗时又容易出错。尝试过各种RPA工具后,最终被OpenClaw的"AI智能体本地化"特性吸引。…...

星图平台快速部署Qwen3-VL:30B:Ubuntu20.04环境配置全攻略
星图平台快速部署Qwen3-VL:30B:Ubuntu20.04环境配置全攻略 想在Ubuntu系统上快速部署强大的多模态AI模型?本文手把手教你从零开始配置星图GPU平台环境,30分钟搞定Qwen3-VL:30B部署! 1. 开篇:为什么选择这个部署方案 最…...

3分钟解锁QQ音乐加密文件:QMCDecode让你的音乐重获自由
3分钟解锁QQ音乐加密文件:QMCDecode让你的音乐重获自由 【免费下载链接】QMCDecode QQ音乐QMC格式转换为普通格式(qmcflac转flac,qmc0,qmc3转mp3, mflac,mflac0等转flac),仅支持macOS,可自动识别到QQ音乐下载目录,默认…...

三步解决华硕笔记本性能优化难题:G-Helper全方位调控指南
三步解决华硕笔记本性能优化难题:G-Helper全方位调控指南 【免费下载链接】g-helper Lightweight, open-source control tool for ASUS laptops and ROG Ally. Manage performance modes, fans, GPU, battery, and RGB lighting across Zephyrus, Flow, TUF, Strix,…...