深度学习(34)—— StarGAN(2)
深度学习(34)—— StarGAN(2)
完整项目在这里:欢迎造访
文章目录
- 深度学习(34)—— StarGAN(2)
- 1. build model
- (1)generator
- (2)mapping network
- (3)style encoder
- (4)discriminator
- 2. 加载数据dataloader
- 3. train
- 4. 训练 discriminator
- (1)real image loss
- (2)fake image loss
- 5. 训练generator
- (1) adversarial loss
- (2) style restruction loss
- (3) diversity sensitive loss
- (4)cycle-consistency loss
- 重点关注`!!!!!`
- debug processing
使用数据集结构:
- data
- train
- domian 1
- img 1
- img 2
- …
- domain 2
- img1
- img2
- …
- domain n
- domian 1
- val
- domian 1
- img 1
- img 2
- …
- domain 2
- img1
- img2
- …
- domain n
- domian 1
- train
1. build model
(1)generator

class Generator(nn.Module):def __init__(self, img_size=256, style_dim=64, max_conv_dim=512, w_hpf=1):super().__init__()dim_in = 2**14 // img_sizeself.img_size = img_sizeself.from_rgb = nn.Conv2d(3, dim_in, 3, 1, 1) #(in_channels,out_channels,kernel_size,stride,padding)self.encode = nn.ModuleList()self.decode = nn.ModuleList()self.to_rgb = nn.Sequential(nn.InstanceNorm2d(dim_in, affine=True),nn.LeakyReLU(0.2),nn.Conv2d(dim_in, 3, 1, 1, 0))# down/up-sampling blocksrepeat_num = int(np.log2(img_size)) - 4if w_hpf > 0:repeat_num += 1for _ in range(repeat_num):dim_out = min(dim_in*2, max_conv_dim)self.encode.append(ResBlk(dim_in, dim_out, normalize=True, downsample=True))self.decode.insert(0, AdainResBlk(dim_out, dim_in, style_dim,w_hpf=w_hpf, upsample=True)) # stack-likedim_in = dim_out# bottleneck blocksfor _ in range(2):self.encode.append(ResBlk(dim_out, dim_out, normalize=True))self.decode.insert(0, AdainResBlk(dim_out, dim_out, style_dim, w_hpf=w_hpf))if w_hpf > 0:device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')self.hpf = HighPass(w_hpf, device)def forward(self, x, s, masks=None):x = self.from_rgb(x)cache = {}for block in self.encode:if (masks is not None) and (x.size(2) in [32, 64, 128]):cache[x.size(2)] = xx = block(x)for block in self.decode:x = block(x, s)if (masks is not None) and (x.size(2) in [32, 64, 128]):mask = masks[0] if x.size(2) in [32] else masks[1]mask = F.interpolate(mask, size=x.size(2), mode='bilinear')x = x + self.hpf(mask * cache[x.size(2)])return self.to_rgb(x)


encoder 和decoder各6个ResBlk
(2)mapping network

class MappingNetwork(nn.Module):def __init__(self, latent_dim=16, style_dim=64, num_domains=2):super().__init__()layers = []layers += [nn.Linear(latent_dim, 512)]layers += [nn.ReLU()]for _ in range(3):layers += [nn.Linear(512, 512)]layers += [nn.ReLU()]self.shared = nn.Sequential(*layers)self.unshared = nn.ModuleList()for _ in range(num_domains):self.unshared += [nn.Sequential(nn.Linear(512, 512),nn.ReLU(),nn.Linear(512, 512),nn.ReLU(),nn.Linear(512, 512),nn.ReLU(),nn.Linear(512, style_dim))]def forward(self, z, y):h = self.shared(z)out = []for layer in self.unshared:out += [layer(h)]out = torch.stack(out, dim=1) # (batch, num_domains, style_dim)idx = torch.LongTensor(range(y.size(0))).to(y.device)s = out[idx, y] # (batch, style_dim)return s


unshared中有多个相同的分支,每个domain都有一个
(3)style encoder

class StyleEncoder(nn.Module):def __init__(self, img_size=256, style_dim=64, num_domains=2, max_conv_dim=512):super().__init__()dim_in = 2**14 // img_sizeblocks = []blocks += [nn.Conv2d(3, dim_in, 3, 1, 1)]repeat_num = int(np.log2(img_size)) - 2for _ in range(repeat_num):dim_out = min(dim_in*2, max_conv_dim)blocks += [ResBlk(dim_in, dim_out, downsample=True)]dim_in = dim_outblocks += [nn.LeakyReLU(0.2)]blocks += [nn.Conv2d(dim_out, dim_out, 4, 1, 0)]blocks += [nn.LeakyReLU(0.2)]self.shared = nn.Sequential(*blocks)self.unshared = nn.ModuleList()for _ in range(num_domains):self.unshared += [nn.Linear(dim_out, style_dim)]def forward(self, x, y):h = self.shared(x)h = h.view(h.size(0), -1)out = []for layer in self.unshared:out += [layer(h)]out = torch.stack(out, dim=1) # (batch, num_domains, style_dim)idx = torch.LongTensor(range(y.size(0))).to(y.device)s = out[idx, y] # (batch, style_dim)return s


unshared和上面的mapping network一样有两个domain所以有两个linear
(4)discriminator
class Discriminator(nn.Module):def __init__(self, img_size=256, num_domains=2, max_conv_dim=512):super().__init__()dim_in = 2**14 // img_sizeblocks = []blocks += [nn.Conv2d(3, dim_in, 3, 1, 1)]repeat_num = int(np.log2(img_size)) - 2for _ in range(repeat_num):dim_out = min(dim_in*2, max_conv_dim)blocks += [ResBlk(dim_in, dim_out, downsample=True)]dim_in = dim_outblocks += [nn.LeakyReLU(0.2)]blocks += [nn.Conv2d(dim_out, dim_out, 4, 1, 0)]blocks += [nn.LeakyReLU(0.2)]blocks += [nn.Conv2d(dim_out, num_domains, 1, 1, 0)]self.main = nn.Sequential(*blocks)def forward(self, x, y):out = self.main(x)out = out.view(out.size(0), -1) # (batch, num_domains)idx = torch.LongTensor(range(y.size(0))).to(y.device)out = out[idx, y] # (batch)return out

和style_encoder只有后面一点点不同
build完model之后就有权重加载权重,没有略过。下面打印了每个subnet的模型参数量
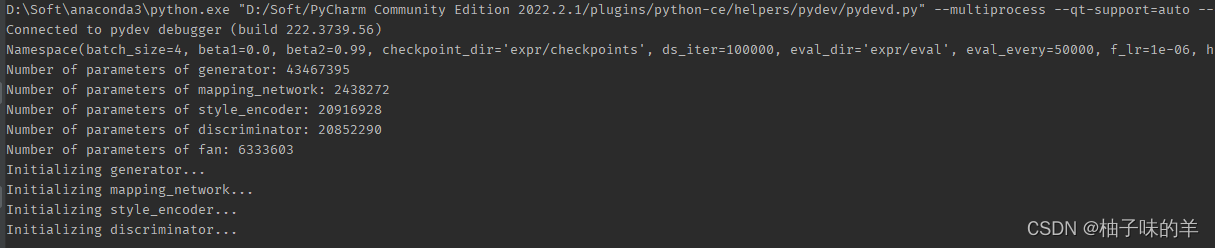
2. 加载数据dataloader
def get_train_loader(root, which='source', img_size=256,batch_size=8, prob=0.5, num_workers=4):print('Preparing DataLoader to fetch %s images ''during the training phase...' % which)crop = transforms.RandomResizedCrop(img_size, scale=[0.8, 1.0], ratio=[0.9, 1.1])rand_crop = transforms.Lambda(lambda x: crop(x) if random.random() < prob else x)transform = transforms.Compose([rand_crop,transforms.Resize([img_size, img_size]),transforms.RandomHorizontalFlip(),transforms.ToTensor(),transforms.Normalize(mean=[0.5, 0.5, 0.5],std=[0.5, 0.5, 0.5]),])if which == 'source':dataset = ImageFolder(root, transform)elif which == 'reference':dataset = ReferenceDataset(root, transform)else:raise NotImplementedErrorsampler = _make_balanced_sampler(dataset.targets)return data.DataLoader(dataset=dataset,batch_size=batch_size,sampler=sampler,num_workers=num_workers,pin_memory=True,drop_last=True)
如果图片是train直接用ImageFold,如果是reference使用自定义的ReferenceDatabase
class ReferenceDataset(data.Dataset):def __init__(self, root, transform=None):self.samples, self.targets = self._make_dataset(root)self.transform = transformdef _make_dataset(self, root):domains = os.listdir(root)fnames, fnames2, labels = [], [], []for idx, domain in enumerate(sorted(domains)):class_dir = os.path.join(root, domain)cls_fnames = listdir(class_dir)fnames += cls_fnamesfnames2 += random.sample(cls_fnames, len(cls_fnames))labels += [idx] * len(cls_fnames)return list(zip(fnames, fnames2)), labelsdef __getitem__(self, index):fname, fname2 = self.samples[index]label = self.targets[index]img = Image.open(fname).convert('RGB')img2 = Image.open(fname2).convert('RGB')if self.transform is not None:img = self.transform(img)img2 = self.transform(img2)return img, img2, labeldef __len__(self):return len(self.targets)
reference 是在每个domain中选择两张图片,这两张图片有相同的label。fnames用于记录其中一张图片,fnames2记录另一张,label记录两者的标签
def get_test_loader(root, img_size=256, batch_size=32,shuffle=True, num_workers=4):print('Preparing DataLoader for the generation phase...')transform = transforms.Compose([transforms.Resize([img_size, img_size]),transforms.ToTensor(),transforms.Normalize(mean=[0.5, 0.5, 0.5],std=[0.5, 0.5, 0.5]),])dataset = ImageFolder(root, transform)return data.DataLoader(dataset=dataset,batch_size=batch_size,shuffle=shuffle,num_workers=num_workers,pin_memory=True)3. train
def train(self, loaders):args = self.argsnets = self.netsnets_ema = self.nets_emaoptims = self.optims# fetch random validation images for debuggingfetcher = InputFetcher(loaders.src, loaders.ref, args.latent_dim, 'train')fetcher_val = InputFetcher(loaders.val, None, args.latent_dim, 'val')inputs_val = next(fetcher_val)# resume training if necessaryif args.resume_iter > 0:self._load_checkpoint(args.resume_iter)# remember the initial value of ds weightinitial_lambda_ds = args.lambda_dsprint('Start training...')start_time = time.time()for i in range(args.resume_iter, args.total_iters):# fetch images and labelsinputs = next(fetcher)x_real, y_org = inputs.x_src, inputs.y_srcx_ref, x_ref2, y_trg = inputs.x_ref, inputs.x_ref2, inputs.y_refz_trg, z_trg2 = inputs.z_trg, inputs.z_trg2masks = nets.fan.get_heatmap(x_real) if args.w_hpf > 0 else None# train the discriminatord_loss, d_losses_latent = compute_d_loss(nets, args, x_real, y_org, y_trg, z_trg=z_trg, masks=masks)self._reset_grad()d_loss.backward()optims.discriminator.step()d_loss, d_losses_ref = compute_d_loss(nets, args, x_real, y_org, y_trg, x_ref=x_ref, masks=masks)self._reset_grad()d_loss.backward()optims.discriminator.step()# train the generatorg_loss, g_losses_latent = compute_g_loss(nets, args, x_real, y_org, y_trg, z_trgs=[z_trg, z_trg2], masks=masks)self._reset_grad()g_loss.backward()optims.generator.step()optims.mapping_network.step()optims.style_encoder.step()g_loss, g_losses_ref = compute_g_loss(nets, args, x_real, y_org, y_trg, x_refs=[x_ref, x_ref2], masks=masks)self._reset_grad()g_loss.backward()optims.generator.step()# compute moving average of network parametersmoving_average(nets.generator, nets_ema.generator, beta=0.999)moving_average(nets.mapping_network, nets_ema.mapping_network, beta=0.999)moving_average(nets.style_encoder, nets_ema.style_encoder, beta=0.999)# decay weight for diversity sensitive lossif args.lambda_ds > 0:args.lambda_ds -= (initial_lambda_ds / args.ds_iter)# print out log infoif (i+1) % args.print_every == 0:elapsed = time.time() - start_timeelapsed = str(datetime.timedelta(seconds=elapsed))[:-7]log = "Elapsed time [%s], Iteration [%i/%i], " % (elapsed, i+1, args.total_iters)all_losses = dict()for loss, prefix in zip([d_losses_latent, d_losses_ref, g_losses_latent, g_losses_ref],['D/latent_', 'D/ref_', 'G/latent_', 'G/ref_']):for key, value in loss.items():all_losses[prefix + key] = valueall_losses['G/lambda_ds'] = args.lambda_dslog += ' '.join(['%s: [%.4f]' % (key, value) for key, value in all_losses.items()])print(log)# generate images for debuggingif (i+1) % args.sample_every == 0:os.makedirs(args.sample_dir, exist_ok=True)utils.debug_image(nets_ema, args, inputs=inputs_val, step=i+1)# save model checkpointsif (i+1) % args.save_every == 0:self._save_checkpoint(step=i+1)# compute FID and LPIPS if necessaryif (i+1) % args.eval_every == 0:calculate_metrics(nets_ema, args, i+1, mode='latent')calculate_metrics(nets_ema, args, i+1, mode='reference')
4. 训练 discriminator
def compute_d_loss(nets, args, x_real, y_org, y_trg, z_trg=None, x_ref=None, masks=None):assert (z_trg is None) != (x_ref is None) #X_real 为原图,y_org为原图的label。y_trg 为reference的label,z_trg 为reference随机生成的向量# with real imagesx_real.requires_grad_()out = nets.discriminator(x_real, y_org)loss_real = adv_loss(out, 1)loss_reg = r1_reg(out, x_real)# with fake imageswith torch.no_grad():if z_trg is not None:s_trg = nets.mapping_network(z_trg, y_trg)else: # x_ref is not Nones_trg = nets.style_encoder(x_ref, y_trg)x_fake = nets.generator(x_real, s_trg, masks=masks)out = nets.discriminator(x_fake, y_trg)loss_fake = adv_loss(out, 0)loss = loss_real + loss_fake + args.lambda_reg * loss_regreturn loss, Munch(real=loss_real.item(),fake=loss_fake.item(),reg=loss_reg.item())
latent 得到style 向量
(1)real image loss
- 需要先将real image输入discriminator得到结果out(batch*domain_num)
- 然后根据real image的label取真正label的结果(batch)
- 使用out计算与label的BCEloss
def adv_loss(logits, target):assert target in [1, 0]targets = torch.full_like(logits, fill_value=target)loss = F.binary_cross_entropy_with_logits(logits, targets)return loss
- 使用out计算与real image的回归loss (regression loss)
def r1_reg(d_out, x_in):# zero-centered gradient penalty for real imagesbatch_size = x_in.size(0)grad_dout = torch.autograd.grad(outputs=d_out.sum(), inputs=x_in,create_graph=True, retain_graph=True, only_inputs=True)[0] # 输入是image,属于这一类的pgrad_dout2 = grad_dout.pow(2)assert(grad_dout2.size() == x_in.size())reg = 0.5 * grad_dout2.view(batch_size, -1).sum(1).mean(0)return reg
(2)fake image loss
- 首先需要根据上面生成的随机向量经过mapping network生成每个风格风格向量
with torch.no_grad():if z_trg is not None:s_trg = nets.mapping_network(z_trg, y_trg)else: # x_ref is not Nones_trg = nets.style_encoder(x_ref, y_trg)
- mapping network 的输入是随机生成的latent 向量和label,因为mapping network是多分支的,所以有几个domain在network的结尾就有几个分支,之后根据label选择这个分支的结果作为最后的风格向量s_trg。
- 使用得到的风格向量s_trg和当前真实的图进入generator【希望real image转换为inference那样的风格】
- generator在decoder的过程中encoder得到的向量连同风格向量s_trg一起作为decoder的输入生成属于该风格的fake image
- 将fake image和其对应的label输入discriminator【为什么还要输入对应的label,又不是计算loss?——
因为discriminator也是多分支的,要根据真实的label取出预测的这个分支的value】 - 因为是fake image,所以是和0做loss
loss_fake = adv_loss(out, 0)
到这里我们已经计算了三个loss,分别是real image的loss, fake image 的loss 和real image得到的regeression loss,三者加权相加做为最后的discriminator的loss
loss = loss_real + loss_fake + args.lambda_reg * loss_reg
reference image 得到style 向量
latent向量:d_loss, d_losses_latent = compute_d_loss(nets, args, x_real, y_org, y_trg, z_trg=z_trg, masks=masks)
reference image:d_loss, d_losses_ref = compute_d_loss(nets, args, x_real, y_org, y_trg, x_ref=x_ref, masks=masks)
- 【有reference的时候相当于有图像了,不需要根据latent向量经过mapping network生成风格向量,而是使用reference image经过style encoder生成属于该style的风格向量】
- style encoder: reference image经过encoder生成一个向量,该向量再经过多分支得到style 向量,之后根据reference image的label得到最终的style 向量
- real image 根据reference image经过style encoder生成的style向量生成fake image
- 后面的过程和上面相同
5. 训练generator
def compute_g_loss(nets, args, x_real, y_org, y_trg, z_trgs=None, x_refs=None, masks=None):assert (z_trgs is None) != (x_refs is None)if z_trgs is not None:z_trg, z_trg2 = z_trgsif x_refs is not None:x_ref, x_ref2 = x_refs# adversarial lossif z_trgs is not None:s_trg = nets.mapping_network(z_trg, y_trg)else:s_trg = nets.style_encoder(x_ref, y_trg)x_fake = nets.generator(x_real, s_trg, masks=masks)out = nets.discriminator(x_fake, y_trg)loss_adv = adv_loss(out, 1)# style reconstruction losss_pred = nets.style_encoder(x_fake, y_trg)loss_sty = torch.mean(torch.abs(s_pred - s_trg))# diversity sensitive lossif z_trgs is not None:s_trg2 = nets.mapping_network(z_trg2, y_trg)else:s_trg2 = nets.style_encoder(x_ref2, y_trg)x_fake2 = nets.generator(x_real, s_trg2, masks=masks)x_fake2 = x_fake2.detach()loss_ds = torch.mean(torch.abs(x_fake - x_fake2))# cycle-consistency lossmasks = nets.fan.get_heatmap(x_fake) if args.w_hpf > 0 else Nones_org = nets.style_encoder(x_real, y_org)x_rec = nets.generator(x_fake, s_org, masks=masks)loss_cyc = torch.mean(torch.abs(x_rec - x_real))loss = loss_adv + args.lambda_sty * loss_sty \- args.lambda_ds * loss_ds + args.lambda_cyc * loss_cycreturn loss, Munch(adv=loss_adv.item(),sty=loss_sty.item(),ds=loss_ds.item(),cyc=loss_cyc.item())
latent 向量 生成style 向量
(1) adversarial loss
- 将real image和style向量输入generator生成fake image
- fake image 和 他的label经过discriminator辨别得到结果out
- 和上面一样计算BCEloss,但是这里虽然是生成的图,但是我们希望generator生成的fake image骗过discriminator,所以这里是和1做BCEloss:
loss_adv = adv_loss(out, 1)
(2) style restruction loss
- fake image 是我们根据real image 得到的希望的style的图片。
- 现在将fake image输入style encoder 得到这个image的style向量
- 这个向量和前面的真实style之间做loss
loss_sty = torch.mean(torch.abs(s_pred - s_trg))
(3) diversity sensitive loss
之前我们不是reference image都有两个嘛,现在排上用场了,前面我们处理的都是第一个reference,无论是latent 向量还是reference image
- 将第二个latent向量输入mapping network得到style 向量
- 将real image和这个style 向量输入generator生成第二个fake image
- 计算两个fake image之间的loss
loss_ds = torch.mean(torch.abs(x_fake - x_fake2))
我们希望同一张图片被转化为另一个风格都是不一样的,不是每次都是一样的,所以这个loss 我们希望是越大越好的
(4)cycle-consistency loss
- 我们希望real image生成的指定style的fake image经过指定real style 可以返回real image’,所以这里设置了cyclegan-consistency loss
- 根据fake image生成mask
- 使用style encoder得到real image的style向量
- generator根据fake image和real image的style向量生成rec_image
- 计算real image 和 recovery image之间做loss
loss_cyc = torch.mean(torch.abs(x_rec - x_real))
到这里generator的loss全部计算完,一共有四个,分别是对抗loss (loss_adv),风格loss(loss_sty),多样性loss(loss_ds),循环loss(loss_cyc),最终generator的loss为:loss = loss_adv + args.lambda_sty * loss_sty - args.lambda_ds * loss_ds + args.lambda_cyc * loss_cyc
reference image 生成style 向量
latent 向量:g_loss, g_losses_latent = compute_g_loss(nets, args, x_real, y_org, y_trg, z_trgs=[z_trg, z_trg2], masks=masks)
reference image:g_loss, g_losses_ref = compute_g_loss(nets, args, x_real, y_org, y_trg, x_refs=[x_ref, x_ref2], masks=masks)
重点关注!!!!!
-
无论是discriminator 还是generator都有两个过程:
- 使用latent向量经过mapping network生成的style 向量作为最终要转化的style
- 使用reference image经过style encoder生成的style向量作为最终要转化的style
-
无论latent向量还是reference image都是有两个的
debug processing
-
build_model
- generator
- mapping network
- style_encoder
- discriminator
-
data
-
train
okk,又是脑细胞死亡的一天,好饿好饿,886~
完整项目在这里:欢迎造访
相关文章:
深度学习(34)—— StarGAN(2)
深度学习(34)—— StarGAN(2) 完整项目在这里:欢迎造访 文章目录 深度学习(34)—— StarGAN(2)1. build model(1)generator(2&#…...

use lua
-- basic.lua print("hello ".."world") local a 1 --only this file can see b 2 -- global see -- not declare vaiable all asign to nil print(fuck) -- 字符串可以"" , ,[[]] -- 一些数值运算支持,进制数,科学数&a…...
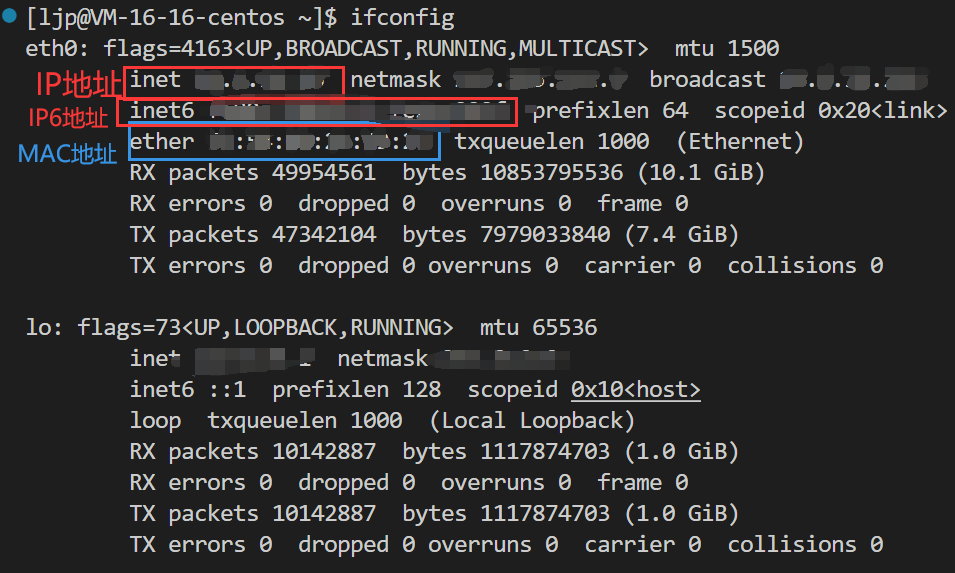
网络——初识网络
网络基础 文章目录 网络基础计算机网络产生的背景认识网络协议网络协议初识协议分层OSI七层模型TCP/IP四层模型网络传输基本流程协议报头 认识IP地址认识MAC地址ifconfig查看主机地址ifconfig查看主机地址 计算机网络产生的背景 独立模式:计算机之间相互独立 早期的…...

调试技巧(2)
6. 如何写出好(易于调试)的代码 6.1 优秀的代码: 代码运行正常bug很少效率高可读性高可维护性高注释清晰文档齐全 常见的coding技巧: 使用assert尽量使用const养成良好的编码风格添加必要的注释避免编码的陷阱。 这里讲一下assert…...

骨传导耳机真不伤耳吗?骨传导耳机有什么好处?
骨传导耳机真不伤耳吗?骨传导耳机有什么好处? 我先来说说骨传导耳机的工作原理吧,骨传导是一种传声方式,声波通过颅骨、颌骨等头部骨头的振动,将声音传到内耳。其实骨传导的现象我们很常见,就像我们平时嗑瓜…...

mac切换jdk版本
查询mac已有版本 1、打开终端,输入: /usr/libexec/java_home -V注意:输入命令参数区分大小写(必须是-V) 2.目前本地装有两个版本的jdk xxxxedydeMacBook-Pro-9 ~ % /usr/libexec/java_home -V Matching Java Virtual Machines (2):20.0.1 (…...
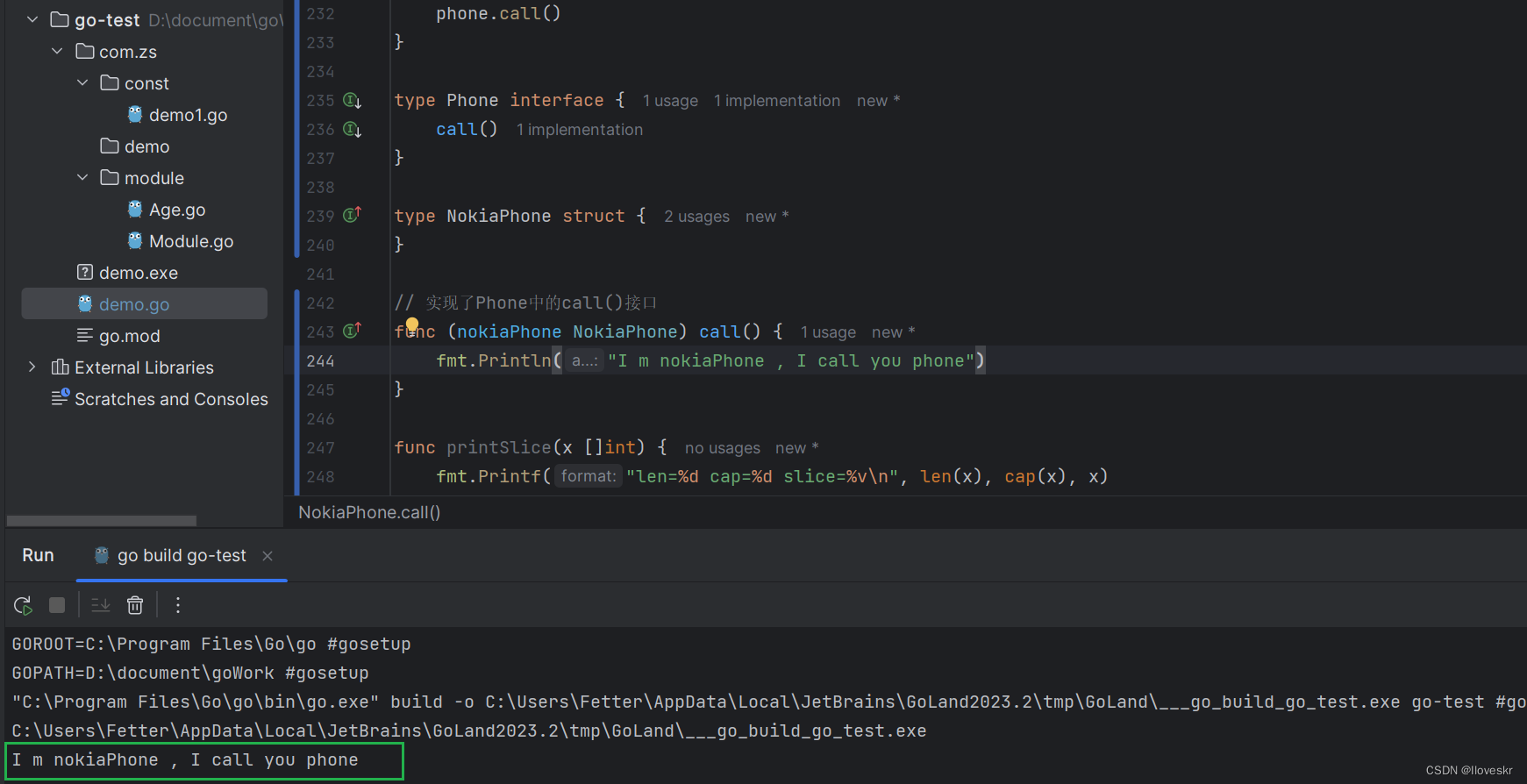
go 基本语法(简单案例)
!注: go中 对变量申明很是严格,申明了,在没有使用的情况下,也会产生编译错误 1.行分隔符 一行就是代码,无;分割,如果需要在一行展示,需要以;分割,…...
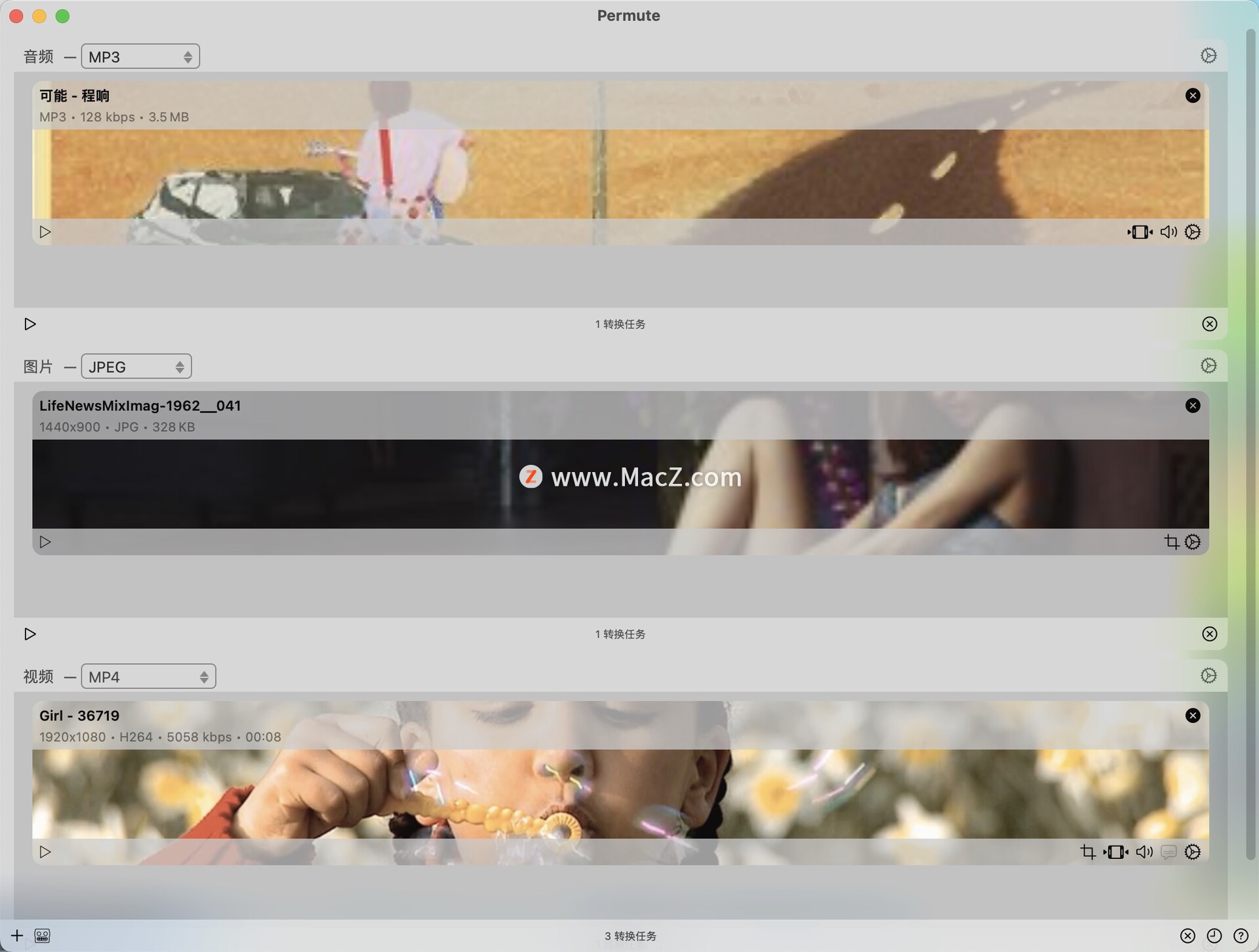
Permute 3 for mac音视频格式转换
Permute是一款Mac平台上的媒体格式转换软件,由Chaotic Software开发。它可以帮助用户快速地将各种音频、视频和图像文件转换成所需格式,并提供了一些常用工具以便于用户进行编辑和处理。 Permute的主要特点包括: - 支持大量格式:支…...

线程概念linux
何为线程: 线程是程序中负责执行的单位,它可以被看作是进程的一部分,是进程的子任务。线程与进程的区别在于,进程是一个资源单位,而线程是进程的一部分,它只有栈这个独立的资源,其他资源如代码…...
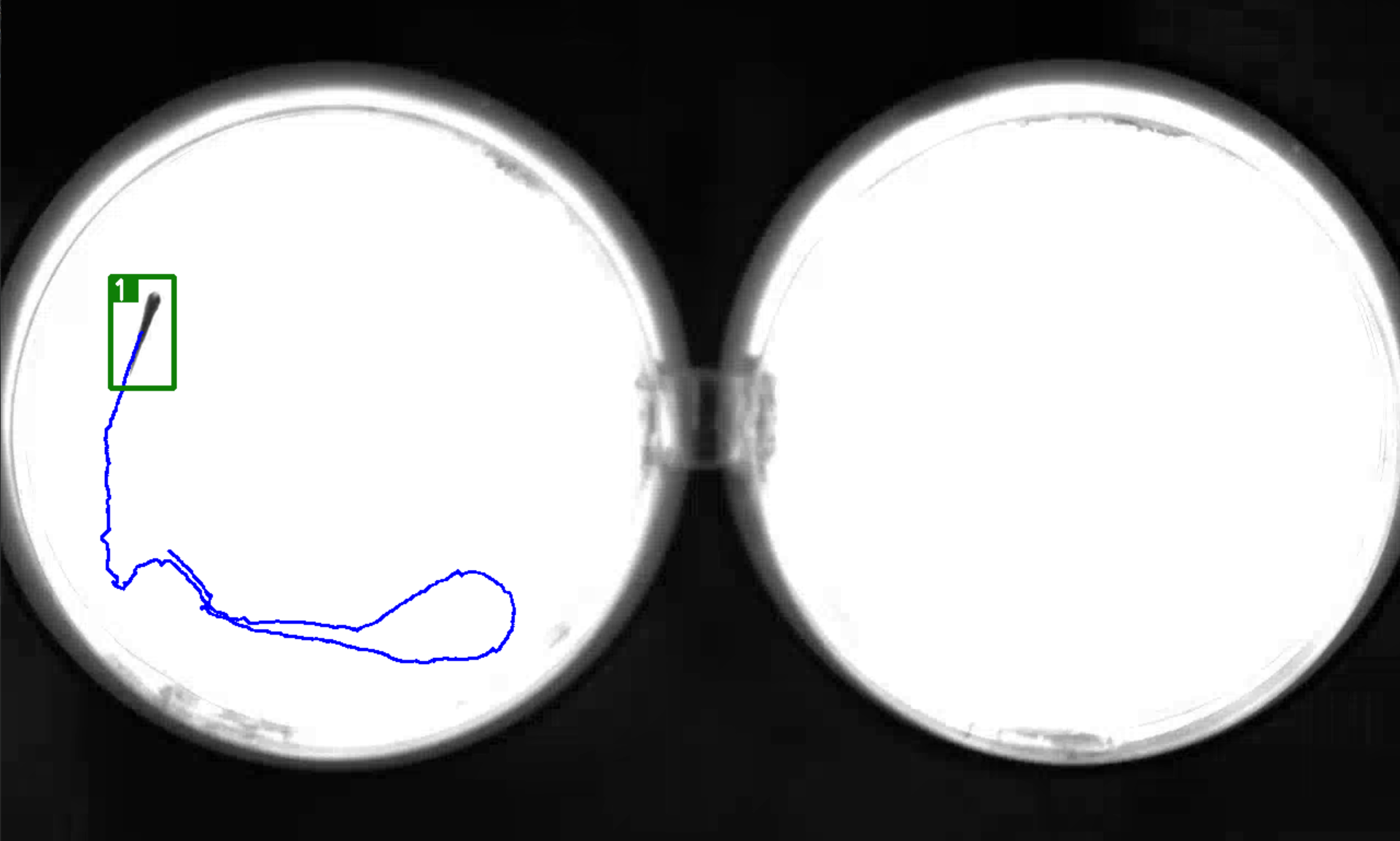
【Yolov5+Deepsort】训练自己的数据集(1)| 目标检测追踪 | 轨迹绘制
📢前言:本篇是关于如何使用YoloV5Deepsort训练自己的数据集,从而实现目标检测与目标追踪,并绘制出物体的运动轨迹。本章讲解的为第一个内容:简单介绍YoloV5Deepsort中所用到的目标检测,追踪及sort&Depp…...
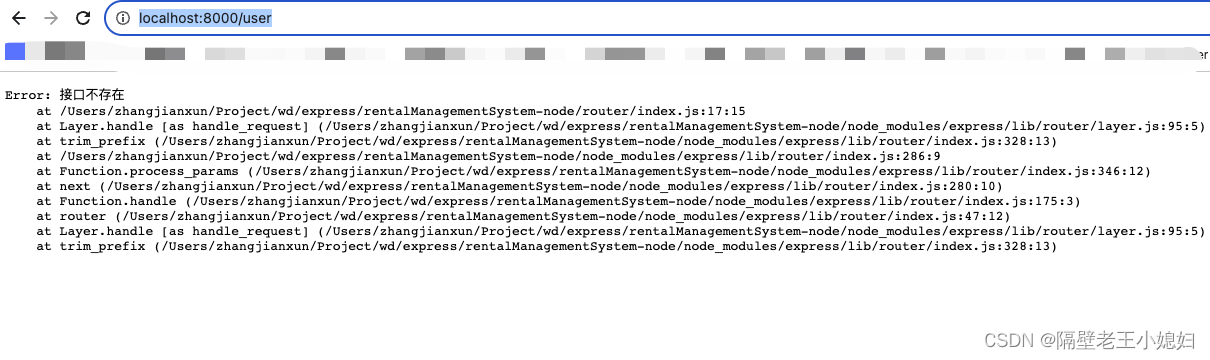
express学习笔记4 - 热更新以及express-boom
我们每次改动代码的时候都要重启项目,现在我们给项目添加一个热更新 npm install --save-dev nodemon # or using yarn: yarn add nodemon -D 在package.json添加一行代码 "dev": "nodemon ./bin/www" 重启项目 然后随便做改动ÿ…...
)
Ajax_02学习笔记(源码 + 图书管理业务 + 以及 个人信息修改功能)
Ajax_02 01_Bootstrap框架-控制弹框的使用 代码 <!-- 引入bootstrap.css --> <link href"https://cdn.jsdelivr.net/npm/bootstrap5.2.2/dist/css/bootstrap.min.css" rel"stylesheet"><button type"button" class"btn btn…...

Python-数据类型转换
当涉及数据类型转换时,Python提供了多种内置函数来执行不同类型之间的转换 以下是每个方法的详细说明和示例案例 整数和浮点数转换: int(x, base10): 将给定的参数x转换为整数。x可以是一个整数、浮点数或字符串。如果x是字符串,则可以提供…...
DASCTF 2023 0X401七月暑期挑战赛 Web方向 EzFlask ez_cms MyPicDisk 详细题解wp
EzFlask 源码直接给了 CtrlU查看带缩进的源码 import uuidfrom flask import Flask, request, session # 导入黑名单列表 from secret import black_list import jsonapp Flask(__name__) # 为 Flask 应用设置一个随机的 secret_key app.secret_key str(uuid.uuid4())# 检查…...
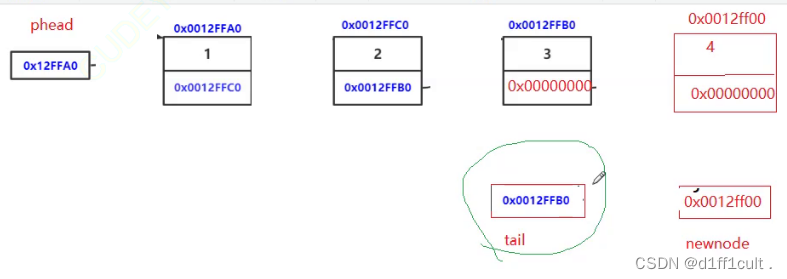
数据结构-链表
🗡CSDN主页:d1ff1cult.🗡 🗡代码云仓库:d1ff1cult.🗡 🗡文章栏目:数据结构专栏🗡 目录 目录 代码总览: 接口slist.h: slist.c: 1.什么是链表 1.1链…...

大数据Flink(五十五):Flink架构体系
文章目录 Flink架构体系 一、 Flink中的重要角色 二、Flink数据流编程模型 三、Libraries支持...

使用矢量数据库打造全新的搜索引擎
在技术层面上,矢量数据库采用了一种名为“矢量索引”的技术,这是一种组织和搜索矢量数据的方法,可以快速找到相似矢量。其中关键的一环是“距离函数”的概念,它可以衡量两个矢量的相似程度。 1.矢量数据库简介 矢量数据库是专门…...

算法提高-树状数组
算法提高-树状数组 241. 楼兰图腾(区间求和 单点修改)242. 一个简单的整数问题(差分推公式 实现 维护区间修改单点求和)243. 一个简单的整数问题2(区间修改和区间求和)AcWing 244. 谜一样的牛(…...

Django ORM详解:最全面的数据库处理指南
概要 深度探讨Django ORM的概念、基础使用、进阶操作以及详细解析在实际使用中如何处理数据库操作。这篇文章旨在帮助大家全面掌握Django ORM,理解其如何简化数据库操作,并透过表象理解其内部工作原理。 Django ORM简介 在深入讨论Django的ORMÿ…...

Istio 安全 授权管理AuthorizationPolicy
这个和cka考试里面的网络策略是类似的。它是可以实现更加细颗粒度限制的。 本质其实就是设置谁可以访问,谁不可以访问。默认命名空间是没有AuthorizationPolicy---允许所有的客户端访问。 这里是没有指定应用到谁上面去,有没有指定使用哪些客户端&#…...

2026黑科技对决:UWB硬件瓶颈 vs 镜像视界无感定位・跨镜追踪自由
2026黑科技对决:UWB硬件瓶颈 vs 镜像视界无感定位・跨镜追踪自由 一、UWB:厘米级精度,困在硬件里的“昂贵精准” UWB(超宽带)凭借短脉冲、宽频谱特性,在理想视距环境下可实现5–10厘米定位精度࿰…...

BS-RoFormer:音频分离技术的革命性突破,从混合音乐中提取纯净音轨的终极指南
BS-RoFormer:音频分离技术的革命性突破,从混合音乐中提取纯净音轨的终极指南 【免费下载链接】BS-RoFormer Implementation of Band Split Roformer, SOTA Attention network for music source separation out of ByteDance AI Labs 项目地址: https:/…...

终极指南:在Debian/Ubuntu系统上快速配置DisplayLink多屏扩展驱动
终极指南:在Debian/Ubuntu系统上快速配置DisplayLink多屏扩展驱动 【免费下载链接】displaylink-debian DisplayLink driver installer for Debian and Ubuntu based Linux distributions. 项目地址: https://gitcode.com/gh_mirrors/di/displaylink-debian …...

Markdown怎么转换成txt?5种方法+在线工具对比2026最全指南
在日常工作中,Markdown格式的文件越来越常见,但有时候我们需要将其转换为纯文本格式来适应不同的应用场景。本文将为你详细介绍md转txt的多种方法,包括本地转换、在线工具、编程方案等,帮助你快速找到最适合的解决方案。为什么需要…...
)
JS 异步 从零讲(大白话 + 真实场景 + 可运行案例)
按顺序:回调函数 → Promise → async/await,工作最常用,直接上手。1. 回调函数(最原始,缺点:回调地狱)2. Promise(解决回调地狱,链式调用)new Promise((reso…...

硬件选型干货|钡特电源DQ1-15D1709S与金升阳QA01-17属工业标准模块电源,避坑指南
在工业电子硬件研发中,工业DC-DC模块是板级隔离供电的核心器件,其标准化封装、性能稳定性及国产化水平,直接影响研发效率、系统可靠性与供应链安全。钡特电源DQ1-15D1709S与金升阳QA01-17作为国产直流电源模块领域的代表性型号,均…...

从零开始学大模型Agent:收藏这份反向学习路线,助你避开99%小白踩坑!
本文揭示当前大模型Agent学习路线普遍顺序错误,建议反向学习:先理解底层机制(动手写最小Agent),再掌握LangGraph流程建模(重点StateGraph、条件边、Checkpointer),深入核心模块工程&…...

拟态设计革命来了,你还在用老版MJ?2024Q2官方未披露的3类新拟态纹理权重算法首度解密
更多请点击: https://kaifayun.com 第一章:拟态设计革命的底层逻辑与时代必然性 拟态设计并非视觉层面的风格迁移,而是一场由安全范式迁移、计算环境异构化与攻击面指数级扩张共同驱动的系统性重构。其底层逻辑根植于“动态异构冗余”&…...

用USRP B200mini和GNU Radio抓取大疆无人机位置:一个极客的无线安全实验手记
极客实验室:用USRP B200mini破解无人机通信协议实战指南 从零开始的SDR探险 去年夏天的一个傍晚,我在阳台上调试天线时,突然注意到头顶频繁掠过的无人机。这些飞行器究竟在传输什么数据?这个偶然的观察引发了我长达三个月的技术…...

CW32F003与CW32F030国产MCU深度对比:从选型到项目实战全解析
1. 项目概述与核心价值最近在整理手头的开发板,翻出了两块来自武汉芯源的CW32F003和CW32F030。这两款芯片和对应的开发板,在国产MCU的入门级市场里,算得上是“老朋友”了,尤其是对于成本敏感、需要快速验证方案的工程师和学生来说…...