awk经典实战、正则表达式
目录
1.筛选给定时间范围内的日志
2.统计独立IP
案列
需求
代码
运行结果
3.根据某字段去重
案例
运行结果
4.正则表达式
1)认识正则
2)匹配字符
3)匹配次数
4)位置锚定:定位出现的位置
5)分组和后向引用
1.筛选给定时间范围内的日志
grep/sed/awk用正则去筛选日志时,如果要精确到小时、分钟、秒,则非常难以实现。
但是awk提供了mktime()函数,它可以将时间转换成epoch时间值。
root@Ubuntu:~# # 2019-11-10 03:42:40转换成epoch为1970-01-01 00:00:00
root@Ubuntu:~# awk 'BEGIN{print mktime("2023 08 05 08 44 40")}'
1691196280
借此,可以取得日志中的时间字符串部分,再将它们的年、月、日、时、分、秒都取出来,然后放入mktime()构建成对应的epoch值。因为epoch值是数值,所以可以比较大小,从而决定时间的大小。
下面strptime1()实现的是将2023-08-04-12-40-40 29T03:42:40+08:00格式的字符串转换成epoch值,然后和which_time比较大小即可筛选出精确到秒的日志。
可以利用patsplit来取时间中的数字
root@Ubuntu:~# vim demo.awk
root@Ubuntu:~# cat demo.awk
BEGIN{
#要筛选什么时间的日志,将其时间构建成epoch值
which_time = mktime("2023 08 04 22 40 29")
}
{
#取出日志的日期时间字符串部分
#match($0,"^.*\\[(.*)\\].*",arr)
#将日期时间字符串转换为epoch值
tmp_time = strptime1(arr[1])
#通过比较epoch值来比较时间大小
if(tmp_time > wgich_time){print}
}
#构建的时间字符串格式为:“2023-08-04T12:40:40+08:00"
function strptime1(str ,arr,Y,M,D,H,m,S){
patsplit(str,arr,"[0-9]{1,4}")
Y=arr[1]
M=arr[2]
D=arr[3]
H=arr[4]
m=arr[5]
S=srr[6]
return mktime(sprintf("%s %s %s %s %s %s",Y,M,D,H,m,S))
}
下面strptime2()实现的是将10/Nov/2023:23:53:44+08:00格式的字符串转换成epoch值,然后和which_time比较大小即可筛选出精确到秒的日志。
root@Ubuntu:~# vim dwmo.awk
root@Ubuntu:~# cat dwmo.awk
BEGIN{
# 要筛选什么时间的日志,将其时间构建成epoch值
which_time = mktime("2023 08 04 11 42 40")
}{
# 取出日志中的日期时间字符串部分
match($0,"^.*\\[(.*)\\].*",arr)
# 将日期时间字符串转换为epoch值
tmp_time = strptime2(arr[1])
# 通过比较epoch值来比较时间大小
if(tmp_time > which_time){
}
}# 构建的时间字符串格式为:"10/Nov/2023:23:53:44+08:00"
function strptime2(str,dt_str,arr,Y,M,D,H,m,S) {
dt_str = gensub("[/:+]"," ","g",str)
# dt_sr = "10 Nov 2023 23 53 44 08 00"
split(dt_str,arr," ")
Y=arr[3]
M=mon_map(arr[2])
D=arr[1]
H=arr[4]
m=arr[5]
S=arr[6]
return mktime(sprintf("%s %s %s %s %s %s",Y,M,D,H,m,S))
}function mon_map(str,mons){
mons["Jan"]=1
mons["Feb"]=2
mons["Mar"]=3
mons["Apr"]=4
mons["May"]=5
mons["Jun"]=6
mons["Jul"]=7
mons["Aug"]=8
mons["Sep"]=9
mons["Oct"]=10
mons["Nov"]=11
mons["Dec"]=12
return mons[str]
}
2.统计独立IP
? url 访问IP 访问时间 访问人
案列
a.com.cn|202.109.134.23|2015-11-20 20:34:43|guest
b.com.cn|202.109.134.23|2015-11-20 20:34:48|guest
c.com.cn|202.109.134.24|2015-11-20 20:34:48|guest
a.com.cn|202.109.134.23|2015-11-20 20:34:43|guest
a.com.cn|202.109.134.24|2015-11-20 20:34:43|guest
b.com.cn|202.109.134.25|2015-11-20 20:34:48|guest
需求
统计每个URL的独立访问IP有多少个(去重),并且要为每个URL保存一个对应的文件,得到的结果类似
代码
BEGIN{
FS="|"
}!arr[$1,$2]++{
arr1[$1]++
}END{
for(i in arr1) {
print i, arr1[i] >(i".txt")
}
}
root@Ubuntu:~# awk -f 1.awk demo3.txt
root@Ubuntu:~# ls -al
总计 92
drwx------ 6 root root 4096 8月 5 09:50 .
drwxr-xr-x 19 root root 4096 8月 3 17:32 ..
-rw-r--r-- 1 root root 109 8月 5 09:50 1.awk
-rw-r--r-- 1 root root 11 8月 5 09:50 a.com.cn.txt
-rw-r--r-- 1 root root 25 8月 4 10:19 awk
-rw------- 1 root root 973 8月 4 17:19 .bash_history
-rw-r--r-- 1 root root 3106 10月 17 2022 .bashrc
-rw-r--r-- 1 root root 11 8月 5 09:50 b.com.cn.txt
drwx------ 2 root root 4096 8月 3 18:13 .cache
-rw-r--r-- 1 root root 11 8月 5 09:50 c.com.cn.txt
drwxr-xr-x 2 root root 4096 8月 4 17:26 .cookiecutters
-rw-r--r-- 1 root root 566 8月 4 16:17 demo1.txt
-rw-r--r-- 1 root root 250 8月 5 09:24 demo2.txt
-rw-r--r-- 1 root root 300 8月 5 09:35 demo3.txt
-rw-r--r-- 1 root root 611 8月 5 09:08 demo.awk
-rw-r--r-- 1 root root 984 8月 5 08:50 dwmo.awk
-rw------- 1 root root 20 8月 4 10:37 .lesshst
-rw-r--r-- 1 root root 161 10月 17 2022 .profile
drwx------ 5 root root 4096 8月 3 17:39 snap
drwx------ 2 root root 4096 8月 3 17:39 .ssh
-rw------- 1 root root 8280 8月 5 09:50 .viminfo
运行结果
root@Ubuntu:~# cat a.com.cn.txt
a.com.cn 2
root@Ubuntu:~# cat b.com.cn.txt
b.com.cn 2
root@Ubuntu:~# cat c.com.cn.txt
c.com.cn 1
3.根据某字段去重
去掉uid=xxx重复的行
案例
2019-01-13_12:00_index?uid=123
2019-01-13_13:00_index?uid=123
2019-01-13_14:00_index?uid=333
2019-01-13_15:00_index?uid=9710
2019-01-14_12:00_index?uid=123
2019-01-14_13:00_index?uid=123
2019-01-15_14:00_index?uid=333
2019-01-16_15:00_index?uid=9710
首先利用uid去重,我们需要利用?进行划分,然后将uid=xxx保存在数组中,这是判断重复的依据
然后统计uid出现次数,第一次出现统计,第二次不统计
运行结果
root@Ubuntu:~# vim demo2.txt
root@Ubuntu:~# awk -F"?" '!arr[$2]++{print}' demo2.txt
2019-01-13_12:00_index?uid=123
2019-01-13_14:00_index?uid=333
2019-01-13_15:00_index?uid=9710
4.正则表达式
1)认识正则
(1)介绍
正则表达式应用广泛,在绝大多数的编程语言都可以完美应用,在Linux中,也有着极大的用处。
使用正则表达式,可以有效的筛选出需要的文本,然后结合相应的支持的工具或语言,完成任务需求。
在本篇博客中,我们使用grep/egrep来完成对正则表达式的调用
(2)正则表达式类型
正则表达式可以使用正则表达式引擎实现,正则表达式引擎是解释正则表达式模式并使用这些模式匹配文本的基础软件。
在Linux中,常用的正则表达式有:
POSIX 基本正则表达式(BRE)引擎
POSIX 扩展正则表达式(BRE)引擎
2)匹配字符
. 匹配任意单个字符,不能匹配空行
[] 匹配指定范围内的任意单个字符
[^] 取反
[:alnum:] 或 [0-9a-zA-Z]
[:alpha:] 或 [a-zA-Z]
[:upper:] 或 [A-Z]
[:lower:] 或 [a-z]
[:blank:] 空白字符(空格和制表符)
[:space:] 水平和垂直的空白字符(比[:blank:]包含的范围广)
[:cntrl:] 不可打印的控制字符(退格、删除、警铃...)
[:digit:] 十进制数字 或[0-9]
[:xdigit:]十六进制数字
[:graph:] 可打印的非空白字符
[:print:] 可打印字符
[:punct:] 标点符号
3)匹配次数
* 匹配前面的字符任意次,包括0次,贪婪模式:尽可能长的匹配
.* 任意前面长度的任意字符,不包括0次
\? 匹配其前面的字符0 或 1次
+ 匹配其前面的字符至少1次
{n} 匹配前面的字符n次
{m,n} 匹配前面的字符至少m 次,至多n次
{,n} 匹配前面的字符至多n次
{n,} 匹配前面的字符至少n次
4)位置锚定:定位出现的位置
^ 行首锚定,用于模式的最左侧
$ 行尾锚定,用于模式的最右侧
^PATTERN$,用于模式匹配整行
^$ 空行
^[[:space:]].*$ 空白行
< 或 \b 词首锚定,用于单词模式的左侧
> 或 \b 词尾锚定;用于单词模式的右侧
<PATTERN>
5)分组和后向引用
① 分组:() 将一个或多个字符捆绑在一起,当作一个整体进行处理
分组括号中的模式匹配到的内容会被正则表达式引擎记录于内部的变量中,这些变量的命名方式为: \1, \2, \3, ...
② 后向引用
引用前面的分组括号中的模式所匹配字符,而非模式本身
\1 表示从左侧起第一个左括号以及与之匹配右括号之间的模式所匹配到的字符
\2 表示从左侧起第2个左括号以及与之匹配右括号之间的模式所匹配到的字符,以此类推
& 表示前面的分组中所有字
相关文章:

awk经典实战、正则表达式
目录 1.筛选给定时间范围内的日志 2.统计独立IP 案列 需求 代码 运行结果 3.根据某字段去重 案例 运行结果 4.正则表达式 1)认识正则 2)匹配字符 3)匹配次数 4)位置锚定:定位出现的位置 5)分组…...

Python脚本-时间盲注
BlindBool_get import requests from optparse import OptionParser import threading#存放变量 DBName "" DBTables [] DBColumns [] DBData {} flag You are in #设置重连次数以及将连接改为短连接 #防止因为HTTP连接数过多导致的MAX retries exceeded with …...

面试总结-Redis篇章(十)——Redis哨兵模式、集群脑裂
Redis哨兵模式、集群脑裂 哨兵模式哨兵的作用服务状态监控 Redis集群(哨兵模式)脑裂解决办法 哨兵模式 为了保证Redis的高可用,Redis提供了哨兵模式 哨兵的作用 服务状态监控 Redis集群(哨兵模式)脑裂 假设由于网络原…...

el-table那些事
el-table那些事 获取el-table所有勾选的行数据 用于记录工作和日常学习遇到的坑,需求。 vue3element-plusts 获取el-table所有勾选的行数据 1、需要先声明一个ref变量,并赋值给el-table 2、通过el-table提供的getSelectionRows()函数获取选中的"行…...
)
kubernetes(一)
文章目录 1. k8s架构2. k8s集群搭建 1. k8s架构 2. k8s集群搭建...
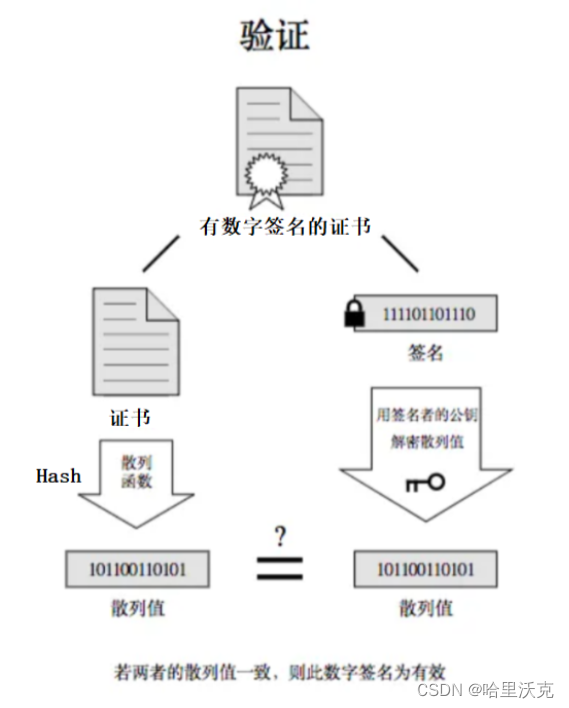
计算机网络(6) --- https协议
计算机网络(5) --- http协议_哈里沃克的博客-CSDN博客http协议https://blog.csdn.net/m0_63488627/article/details/132089130?spm1001.2014.3001.5501 目录 1.HTTPS的出现 1.HTTPS协议介绍 2.补充概念 1.加密 1.解释 2.原因 3.加密方式 对称加…...
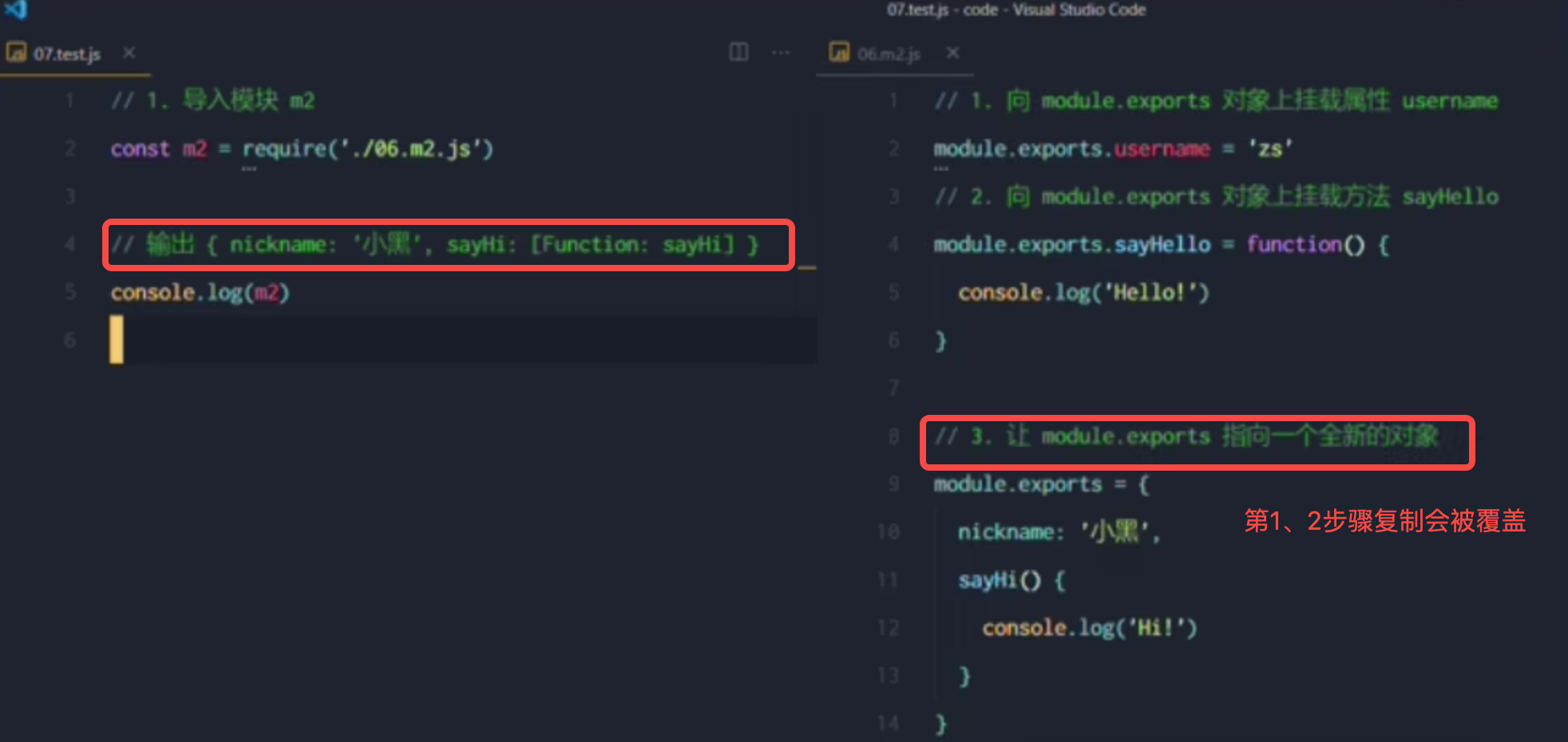
(三)Node.js - 模块化
1. Node.js中的模块化 Node.js中根据模块来源不同,将模块分为了3大类,分别是: 内置模块:内置模块由Node.js官方提供的,例如fs、path、http等自定义模块:用户创建的每个.js文件,都是自定义模块…...

502 bad gateway报错
代码在本地运行可以正常访问后端接口,部署服务器报错502。直接检查防火墙状态是否开启,先关闭防火墙试一下。如果是防火墙的原因在打开防火墙,开放需要的端口即可。 1、先查看防火墙状态: systemctl status firewalld2、停止防火…...

Flink学习教程
最近因为用到了Flink,所以博主开了《Flink教程》专栏来记录Flink的学习笔记。 【Apache Flink v1.16 中文文档】 【官网 - Apache Flink v1.3 中文文档】 一、基础 参考链接如下: Flink教程(01)- Flink知识图谱Flink教程&…...

flutter开发实战-实现音效soundpool播放音频及控制播放暂停停止设置音量
flutter开发实战-实现音效soundpool播放音频 最近开发过程中遇到低配置设备时候,在Media播放音频时候出现音轨限制问题。所以将部分音频采用音效sound来播放。 一、音效类似iOS中的Sound 在iOS中使用sound来播放mp3音频示例如下 // 通过通知的Sound设置为voip_c…...

Sequence 2023牛客暑期多校训练营6 E
登录—专业IT笔试面试备考平台_牛客网 题目大意:有一长度为n的数组a,有q次询问,每次要求将[l,r]的区间分成k个连续区间,满足每个区间和都是偶数,能满足要求就输出YES 1<n,q<1e5;0<ai<1e10;1<l<r&l…...

【ASP.NET MVC】使用动软(二)(10)
一、添加动软生成工程 按前文添加动态到工程 双击动软 完成新建数据库服务器后 ,需要关闭重新打开 选择简单三层,注意保存位置 注意切换数据库: 生成后拷贝五个文件夹到工程目录 注意目录结构: 添加四个项目到原来的工程&…...

STM32入门学习之独立看门狗(IWDG)
1.STM32的独立看门狗是一个具有独立时钟的片上外设。通常,为了防止程序卡死,可以设置看门狗定时复位。当看看门狗被使能之后,会按初始化时设置的计数值进行计数。当根据计数值计数的倒数时间为0时,便会自动复位程序,即…...

抖音seo矩阵系统源码搭建开发详解
抖音SEO矩阵系统是一个用于提高抖音视频在搜索引擎排名的工具。如果你想开发自己的抖音SEO矩阵系统,以下是详细的步骤: 开发步骤详解: 确定你需要的功能和算法 抖音SEO矩阵系统包含很多功能,比如关键词研究、内容优化、链接建设、…...
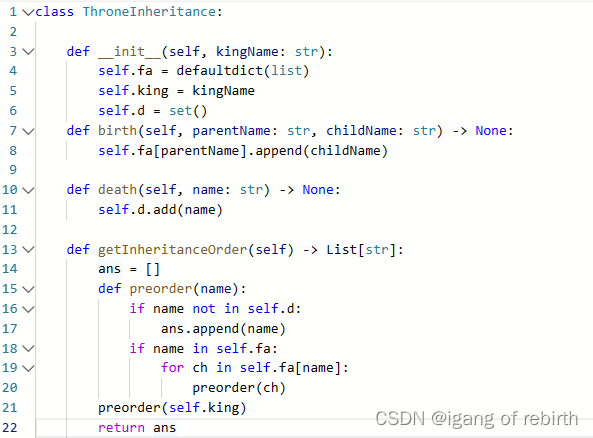
2685. 统计完全连通分量的数量;2718. 查询后矩阵的和;1600. 王位继承顺序
2685. 统计完全连通分量的数量 核心思想:枚举所有的连通分量,然后判断这些连通分量是不是完全连通分量,完全连通分量满足边数2e 点数v(v-1)。 2718. 查询后矩阵的和 核心思想:后面的改变更重要,所以我们直接逆向思维…...

SpringBoot统一功能处理(AOP思想实现)(统一用户登录权限验证 / 异常处理 / 数据格式返回)
主要是三个处理: 1、统一用户登录权限验证; 2、统一异常处理; 3、统一数据格式返回。 目录 一、用户登录权限校验 🍅 1、使用拦截器 🎈 1.1自定义拦截器 🎈 1.2 设置自定义拦截器 🎈创建cont…...

git stash 用法
起始 今天在看一个bug,之前一个分支的版本是正常的,在新的分支上上加了很多日志没找到原因,希望回溯到之前的版本,确定下从哪个提交引入的问题,但是还不想把现在的修改提交,也不希望在Git上看到当前修改的…...

生鲜蔬果小程序的完整教程
随着互联网的发展,线上商城成为了人们购物的重要渠道。其中,小程序商城在近年来的发展中,备受关注和青睐。本文将介绍如何使用乔拓云网后台搭建生鲜果蔬配送小程序,并快速上线。 首先,登录乔拓云网后台,进入…...

De Bruijin序列与魔术(二)——魔术《De Bruijin序列》
早点关注我,精彩不错过! 上一篇我们介绍了De Bruijin序列的基本数学内容以及其如何应用在魔术上的一些基本内容,今天我们就来学习一下这个经典的《De Bruijin序列》魔术。 De bruijin序列魔术 先看视频。 视频1 De Bruijin序列的魔术 魔术来源…...
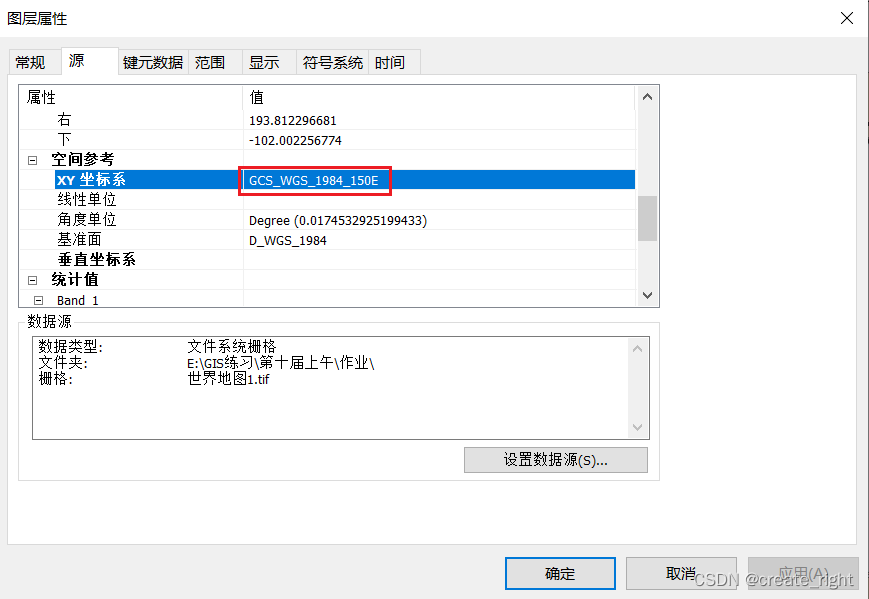
ARCGIS地理配准出现的问题
第一种。已有省级行政区矢量数据,在网上随便找一个相同省级行政区图片,利用地理配准工具给图片添加坐标信息。 依次添加省级行政区选择矢量数据、浙江省图片。 此时,图层默认的坐标系与第一个加载进来的省级行政区选择矢量数据的坐标系一致…...

hcxdumptool实战指南:5大高效技巧提升无线网络安全检测效率
hcxdumptool实战指南:5大高效技巧提升无线网络安全检测效率 【免费下载链接】hcxdumptool Small tool to capture packets from wlan devices. 项目地址: https://gitcode.com/gh_mirrors/hc/hcxdumptool hcxdumptool是一款专业的无线网络安全检测工具&#…...

【爱她就为她买龙虾】Open Claw 搭建使用全图文流程
❤️核心亮点❤️ 零代码门槛|全程可视化|无需手动配置环境|内置完整依赖|28 万 Tokens 额度 ༺♥༻下载地址 https://xiake.yun/api/download/package/16?promoCodeIV8E496E2F7A 🤍前言 2026 年热门的「数字员工…...

终极指南:如何用Prodigal在3分钟内完成原核生物基因预测
终极指南:如何用Prodigal在3分钟内完成原核生物基因预测 【免费下载链接】Prodigal Prodigal Gene Prediction Software 项目地址: https://gitcode.com/gh_mirrors/pr/Prodigal 还在为复杂的基因预测工具头疼吗?面对海量的微生物基因组数据&…...

LeetCode 数据流中第K大元素题解
LeetCode 数据流中第K大元素题解 题目描述 设计一个数据流,找到数据流中第 k 大的元素。 示例: 输入:k 3, arr [4,6,5]输出:5 解题思路 方法:堆 思路: 使用最小堆维护前 k 大的元素。遍历数据流ÿ…...

避坑指南:DolphinScheduler Docker部署后,MySQL数据源连不上的几种常见原因及排查
DolphinScheduler Docker部署MySQL数据源连接问题深度排查手册 当你兴冲冲地部署完DolphinScheduler的Docker版本,准备配置MySQL数据源时,突然遭遇"连接失败"的红色警告——这种挫败感我太熟悉了。去年我们团队迁移数据平台时就连续踩了三个坑…...

终极指南:3步快速掌握日语漫画OCR识别神器MangaOCR
终极指南:3步快速掌握日语漫画OCR识别神器MangaOCR 【免费下载链接】manga-ocr Optical character recognition for Japanese text, with the main focus being Japanese manga 项目地址: https://gitcode.com/gh_mirrors/ma/manga-ocr 你是否曾经面对日文漫…...

终极指南:10分钟将WinForms应用升级为现代化Material Design界面
终极指南:10分钟将WinForms应用升级为现代化Material Design界面 【免费下载链接】MaterialSkin Theming .NET WinForms, C# or VB.Net, to Googles Material Design Principles. 项目地址: https://gitcode.com/gh_mirrors/mat/MaterialSkin 你是否厌倦了传…...

Slide离线阅读功能详解:随时随地浏览Reddit内容的完整教程
Slide离线阅读功能详解:随时随地浏览Reddit内容的完整教程 【免费下载链接】Slide Slide is an open-source, ad-free Reddit browser for Android. 项目地址: https://gitcode.com/gh_mirrors/sl/Slide 你是否经常在地铁、飞机或网络信号不佳的地方想要浏览…...

3步解锁开源字体编辑器:从零基础到专业字体设计师的蜕变之路
3步解锁开源字体编辑器:从零基础到专业字体设计师的蜕变之路 【免费下载链接】fontforge Free (libre) font editor for Windows, Mac OS X and GNULinux 项目地址: https://gitcode.com/gh_mirrors/fo/fontforge FontForge是一款跨平台的开源字体编辑器&…...

2026 年我作为资深工程师如何使用 LLM Agent:从副驾到主驾的真实工作流转变
从副驾到主驾,2026 年资深工程师的 LLM Agent 实战工作流:哪些交给 Agent,哪些必须自己做。 原文链接:AI 小老六 一年之差:Agent 从「勉强能用」变成了「几乎离不开」 2025 年初,行业里最强的推理模型还是…...