Python网络爬虫在信息采集中的应用及教程
Python网络爬虫在信息采集中的应用与法律警告
摘要
随着互联网的发展,我们每天都面临着海量的信息。这些信息蕴含着无尽的价值,而要从中获取有用的数据,网络爬虫就成了我们的得力助手。Python作为一门简单而又强大的编程语言,被广泛应用于网络爬虫的开发。本文将介绍Python网络爬虫的原理和应用,并探讨与网络爬虫相关的法律问题,希望提醒各位开发者注意遵守法律法规,确保爬虫的合规性。
1. 引言
大数据时代已经来临,而数据的源泉就隐藏在无数网页背后。网络爬虫就像是一支探险队伍,能够帮助我们勘探这些无垠的信息世界。Python语言的简洁和易用,让它成为了网络爬虫领域的明星。但是,随着爬虫的普及,我们也需要警惕与之相关的法律问题,以免陷入法律漩涡。
2. Python网络爬虫的基本原理
在我们深入讨论爬虫的法律问题之前,先让我们简单了解一下Python网络爬虫的基本原理。
2.1 HTTP协议与网页请求
HTTP协议是网络爬虫的重要通信方式。我们的爬虫通过发送HTTP请求,从服务器获取网页数据。而服务器会回复我们的请求,并将网页数据传回,这样我们就可以得到所需的信息。
2.2 网页解析与数据提取
获取网页数据后,我们需要从中提取有用的信息。这就需要用到网页解析技术,如XPath或正则表达式。Python库中的BeautifulSoup和lxml等工具能够帮助我们解析网页,提取我们所需的数据。
2.3 数据存储与处理
获取的数据可以保存在本地文件中,也可以存储在数据库中。我们可以用Python处理这些数据,进行清洗、分析和可视化等操作,从而得到更有价值的信息。
3. Python网络爬虫的应用
网络爬虫可以在许多领域发挥作用。接下来,我们将看看它在一些应用方面的实际应用。
3.1 数据采集与分析
在市场调研、舆情监测等方面,爬虫可以帮助我们采集大量的数据,并通过数据分析来得出结论。比如,我们可以用爬虫从电商网站上采集商品价格信息,进而了解市场的价格波动情况。
3.2 网络搜索引擎
搜索引擎的核心就是爬虫。它们通过爬虫不断地收录互联网上的网页,然后通过索引和排序,为用户提供准确、丰富的搜索结果。
3.3 金融数据分析
金融行业对数据的需求非常庞大,而且时间敏感。爬虫可以帮助我们及时获取金融市场的数据,用于投资分析和决策。
3.4 社交媒体监测
社交媒体上的信息更新非常迅速,爬虫可以帮助企业及时掌握用户反馈和市场动态,从而做出更明智的营销策略。
4. 网络爬虫的法律问题
虽然网络爬虫有着诸多优势,但我们也要警惕与之相关的法律问题。以下是一些需要特别关注的问题:
4.1 隐私保护
在爬取网页数据时,我们可能会获取到用户的个人信息。因此,要特别注意隐私保护的问题。如果没有明确用户同意,我们不能擅自收集、使用或传播这些个人信息,否则将涉及隐私侵权问题。
4.2 版权问题
互联网上的信息是他人的智力成果,包括文字、图片、音视频等。在使用这些信息时,务必尊重原作者的版权,如果违反版权法律,将面临严重的法律责任。
4.3 合规性和规范性
爬虫在访问网站时,需要遵守网站的使用条款和Robots.txt协议。如果网站明确禁止爬虫访问,我们应该尊重这一规定,否则可能引发合规性问题。
4.4 争议案例分析
有些爬虫开发者因为不当使用而引发法律纠纷。我们可以从这些案例中吸取教训,明确自己的责任和义务,以免陷入类似的困境。
5. 法律警告与合规建议
了解了网络爬虫的法律问题后,我们应该采取一些措施来确保爬虫的合规性。
5.1 提供透明的爬虫目的和用户通知
我们应该在爬虫访问网站时,明确告知网站管理员我们的目的,并遵循网站的隐私政策。
5.2 尊重网站的Robots.txt协议
在
编写爬虫程序时,我们应该遵守网站的Robots.txt协议,不访问被禁止的页面。
5.3 遵守著作权法和数据采集规则
在使用他人作品或数据时,要确保遵守著作权法和数据采集规则,尊重原作者的权益。
5.4 避免给服务器带来过大压力
爬虫应该合理设置访问频率,避免对服务器造成过大的负担,否则可能会引发合规性问题。
6. 未来展望
随着技术的不断进步和法律法规的完善,网络爬虫将在更多领域发挥重要作用。我们期待着未来更智能、更合规的网络爬虫的出现。
7. 安装库
首先,确保你已经安装了Python,并具备基本的Python编程知识。然后,我们需要安装Requests和BeautifulSoup库。使用以下命令:
pip install requests
pip install beautifulsoup4
8. 发送HTTP请求
使用Requests库发送HTTP请求,从网页上获取数据。首先,导入Requests库:
import requests
然后,使用requests.get()函数发送GET请求:
url = 'https://example.com'
response = requests.get(url)
9. 解析网页数据
接下来,使用BeautifulSoup库解析网页数据。导入BeautifulSoup库:
from bs4 import BeautifulSoup
使用BeautifulSoup解析网页数据:
soup = BeautifulSoup(response.text, 'html.parser')
10. 提取数据
现在,我们可以从网页中提取我们需要的数据。使用BeautifulSoup的方法,如find()、find_all()等,来提取数据。
示例:提取网页中的所有标题:
titles = soup.find_all('h2')
for title in titles:print(title.text)
11. 完整示例
下面是一个完整的示例,将以上步骤结合在一起:
import requests
from bs4 import BeautifulSoupurl = 'https://example.com'
response = requests.get(url)soup = BeautifulSoup(response.text, 'html.parser')titles = soup.find_all('h2')
for title in titles:print(title.text)
7. 错误处理
在实际爬虫中,可能会遇到各种错误,比如网络连接错误、网页解析错误等。为了确保爬虫的稳定运行,我们需要进行错误处理。
示例:添加错误处理:
import requests
from bs4 import BeautifulSoupurl = 'https://example.com'try:response = requests.get(url)response.raise_for_status() # 检查是否有错误
except requests.exceptions.RequestException as e:print('网络连接错误:', e)exit(1)soup = BeautifulSoup(response.text, 'html.parser')titles = soup.find_all('h2')
for title in titles:print(title.text)
8. 总结
本教程介绍了如何使用Python中的Requests和BeautifulSoup库进行简单的网页数据采集。首先发送HTTP请求获取网页数据,然后使用BeautifulSoup解析和提取我们所需的信息。同时,我们添加了错误处理,确保爬虫的稳定运行。
9. 探索更多
这只是爬虫的基础,实际爬虫开发可能涉及更多复杂的情况。你可以继续学习更多的爬虫技术,探索更多的Python爬虫库,如Scrapy等,进一步拓展你的爬虫技能。
以上是一个简单的Python爬虫库教程,演示了如何使用Requests和BeautifulSoup进行网页数据采集。你可以根据需要进一步学习更多爬虫技术,优化爬虫性能,处理更复杂的网页结构,以及遵守法律规定和网站的使用协议。祝你在爬虫开发中取得成功!
法律警告:
本文所提供的信息仅供参考和学习交流,并不构成法律意见。网络爬虫的合规性问题因地区和法律法规的差异可能有所不同。在进行网络爬虫开发和使用时,务必遵守当地和国际法律法规,并尊重相关网站的规定和隐私权。如有法律疑问或纠纷,建议咨询合格的法律专业人士。
本文不对使用本文所提供的信息导致的任何违法行为或法律纠纷负责。读者在采用本文所述措施时,需自行承担相关风险和责任。
相关文章:

Python网络爬虫在信息采集中的应用及教程
Python网络爬虫在信息采集中的应用与法律警告 摘要 随着互联网的发展,我们每天都面临着海量的信息。这些信息蕴含着无尽的价值,而要从中获取有用的数据,网络爬虫就成了我们的得力助手。Python作为一门简单而又强大的编程语言,被…...

云主机测试Flink磁盘满问题解决
问题描述: 使用云主机测试Flink时,根目录满了。 经排查发现运行Flink任务后根目录空间一直在减少,最后定位持续增加的目录是/tmp目录 解决方法: 修改Flink配置使用一个相对较大的磁盘目录做为Flink运行时目录 # Override the…...

iOS开发-NSOperationQueue实现上传图片队列
iOS开发-NSOperationQueue实现上传图片队列 在开发中,遇到发帖需要上传图片,需要上传队列,这时候用到了NSOperationQueue 一、NSOperation与NSOperationQueue 什么NSOperation NSOperation为控制任务状态、优先级、依赖关系以及任务管理提…...

通过 CCIP 构建跨链应用(5 个案例)
Chainlink 的跨链互操作性协议(CCIP)是一种新的通用跨链通信协议,为智能合约开发人员提供了以最小化信任的方式在区块链网络之间传输数据和通证的能力。 目前,部署在多个区块链上的应用程序面临着资产、流动性和用户的碎片化问题…...

基于 yolov8 的人体姿态评估
写在前面 工作中遇到,简单整理博文内容为使用预训练模型的一个预测 Demo测试图片来源与网络,如有侵权请告知理解不足小伙伴帮忙指正 对每个人而言,真正的职责只有一个:找到自我。然后在心中坚守其一生,全心全意,永不停…...

计算机视觉(六)图像分类
文章目录 常见的CNNAlexnet1乘1的卷积 VGG网络Googlenet(Inception V1、V2、V3)全局平均池化总结 Resnet、ResnextResNet残差网络ResNeXt网络 应用案例VGGResnet 常见的CNN Alexnet DNN深度学习革命的开始 沿着窗口进行归一化。 1乘1的卷积 VGG网络…...

解决:vue通过params传参刷新页面参数丢失问题以及实现vue路由可选参数的解决办法
目录 🙋♂️ 实现params传参,刷新页面不丢参 🙋♂️ 实现vue配置可选路由参数 🙋♂️ 参考资料 解决vue 通过 name 和 params 进行页面传参时,刷新页面参数丢失问题以及vue路由实现可选参数 🙋♂…...

将postman接口导出的json转换为markdown
您可以使用 Postman 官方提供的工具或第三方工具将 Collection 文件转换为 Markdown 文件。 方式一 Postman 官方提供的工具是 Newman,它是一个命令行工具,可以帮助您运行和测试 Postman Collection,还可以将 Collection 转换为多种格式&am…...

教您一招解决找素材困难好的方法
创作视频内容时,找到合适的素材是至关重要的。然而,有时候寻找视频素材可能会变得困难。本文将分享一些实用的方法,帮助您轻松解决找视频素材困难的问题。 素材库和在线平台是寻找视频素材的首选方法。 利用专业的视频剪辑工具 在电脑上安…...

python_PyQt5开发验证K线视觉想法工具V1.2_批量验证
目录 运行情况: 编辑 结果json文件格式: 代码: 承接 【python_PyQt5开发验证K线视觉想法工具V1.1 _增加标记类型_线段】 博文 地址:python_PyQt5开发验证K线视觉想法工具V1.1 _增加标记类型_线段_程序猿与金融与科技的博客-…...
的排查思路)
应急响应-web后门(中间件)的排查思路
0x01 获取当前网络架构 语言,数据库,中间件,系统环境等 0x02 分析思路 1.利用时间节点筛选日志行为 2.利用已知的漏洞在日志进行特征搜索,快速定位到目标ip等信息 3.后门查杀,获取后门信息,进一步定位目…...
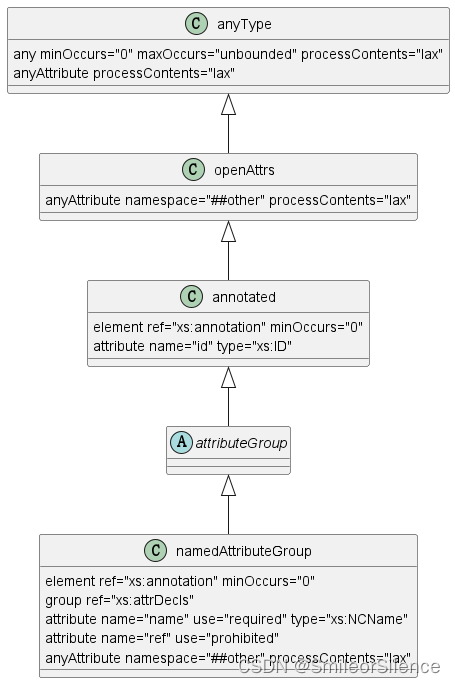
XML 学习笔记 7:XSD
本文章内容参考自: W3school XSD 教程 Extensible Markup Language (XML) 1.0 (Second Edition) XML Schema 2001 XML Schema Part 2: Datatypes Second Edition 文章目录 1、XSD 是什么2、XSD 内置数据类型 - built-in datatypes2.1、基本数据类型 19 种2.1.1、基本…...
)
neo4j图数据库基础操作命令(CQL语法)
天行健,君子以自强不息;地势坤,君子以厚德载物。 每个人都有惰性,但不断学习是好好生活的根本,共勉! 文章均为学习整理笔记,分享记录为主,如有错误请指正,共同学习进步。…...

vscode无法连接远程服务器的可能原因:远程服务器磁盘爆了
vscode输入密码后一直等待,无法进入远程服务器终端: 同时Remote-SSH输出包含以下内容 在日志中的以下几个部分: [17:15:05.529] > wget download failed 这表明VS Code尝试在远程服务器上下载VS Code服务器时失败了。> Cannot write…...
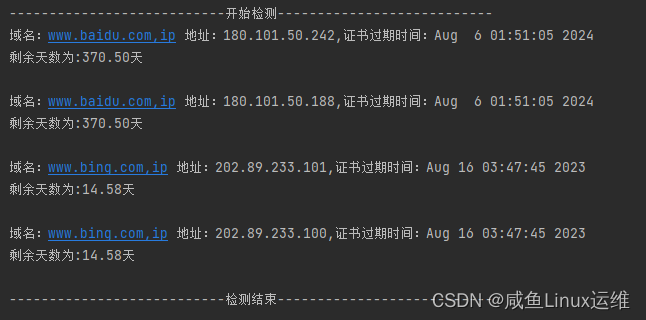
SSL 证书过期巡检脚本 (Python 版)
哈喽大家好,我是咸鱼 之前写了个 shell 版本的 SSL 证书过期巡检脚本 (文章:《SSL 证书过期巡检脚本》),后台反响还是很不错的 那么今天咸鱼给大家介绍一下 python 版本的 SSL 证书过期巡检脚本 (完整代码…...

从0到1自学网络安全(黑客)【附学习路线图+配套搭建资源】
前言 网络安全产业就像一个江湖,各色人等聚集。相对于欧美国家基础扎实(懂加密、会防护、能挖洞、擅工程)的众多名门正派,我国的人才更多的属于旁门左道(很多白帽子可能会不服气),因此在未来的…...

Michael.W基于Foundry精读Openzeppelin第20期——EnumerableMap.sol
0. 版本 [openzeppelin]:v4.8.3,[forge-std]:v1.5.6 0.1 EnumerableMap.sol Github: https://github.com/OpenZeppelin/openzeppelin-contracts/blob/v4.8.3/contracts/utils/structs/EnumerableMap.sol EnumerableMap库提供了Bytes32ToB…...

深入探索二叉树:应用、计算和遍历
当涉及到二叉树的计算问题时,我们可以进一步介绍如何计算叶子节点数、树的宽度和叶子的深度,并解释三种常见的二叉树遍历方式:先序遍历、中序遍历和后序遍历。 1. 计算叶子节点数 叶子节点是指没有子节点的节点,也就是树中的末端…...

关于 1 + 1 = 2 的证明
1 1 2 首先是皮亚诺的自然数公理 意大利数学家皮亚诺提出的关于自然数的 5 5 5 条公理如下(定义 S ( x ) S(x) S(x) 为自然数 x x x 的后继): 0 0 0 是自然数每一个自然数 n n n 都有一个自然数后继记为 S ( n ) S(n) S(n) 0 0 0 不是…...
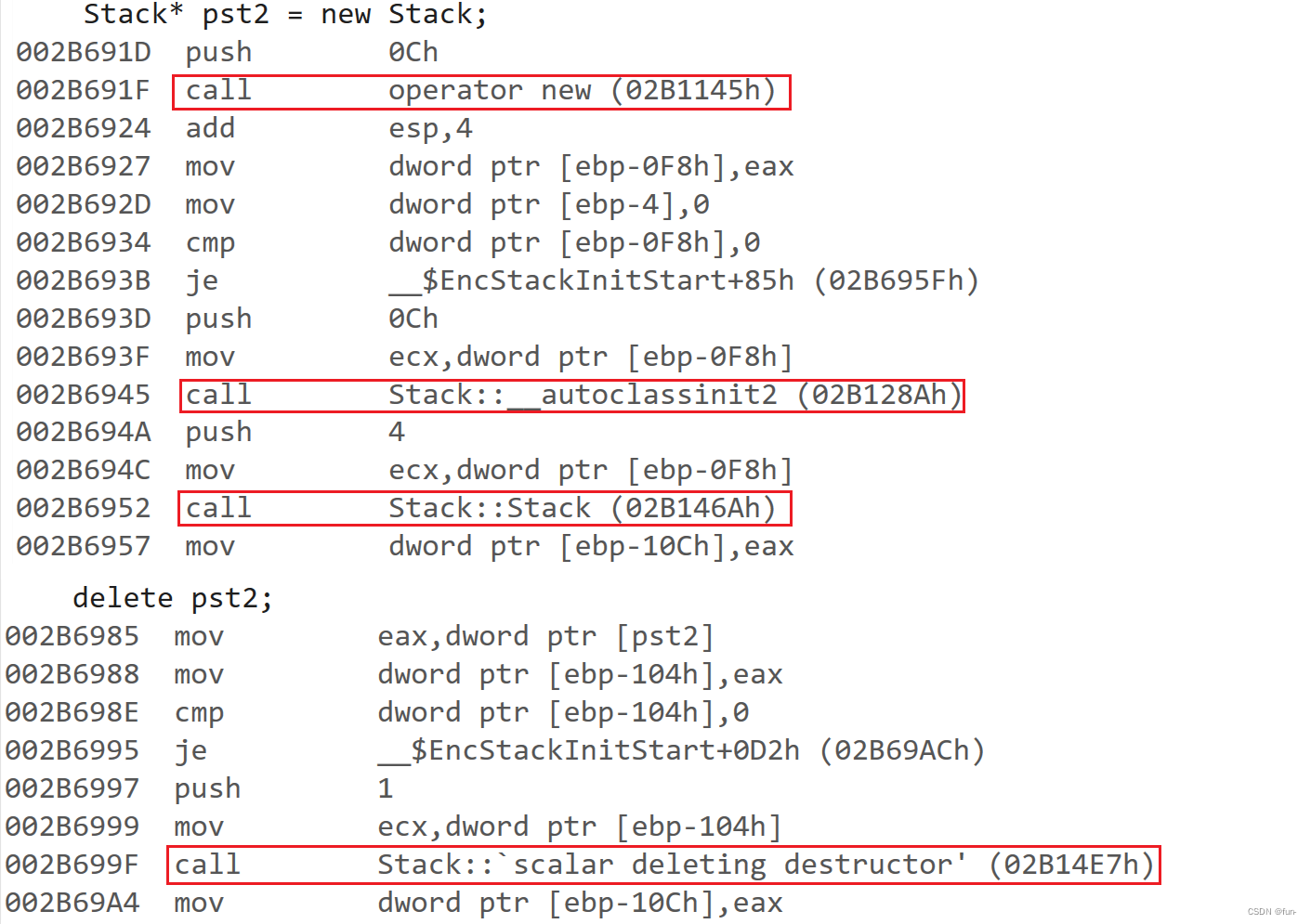
【C++】——内存管理
目录 回忆C语言内存管理C内存管理方式new deleteoperator new与operator delete函数new和delete的实现原理定位new表达式(placement-new)malloc/free和new/delete的区别 回忆C语言内存管理 void Test() {int* p1 (int*)malloc(sizeof(int));free(p1);int* p2 (int*)calloc(4…...

PlotSquared 终极指南:如何在 Minecraft 服务器上安装和配置强大的领地管理插件
PlotSquared 终极指南:如何在 Minecraft 服务器上安装和配置强大的领地管理插件 【免费下载链接】PlotSquared PlotSquared - Reinventing the plotworld 项目地址: https://gitcode.com/gh_mirrors/pl/PlotSquared PlotSquared 是一个功能强大的 Minecraft …...

统一去马赛克与降噪技术:ESUM模型解析与应用
1. 项目概述:统一去马赛克与降噪技术研究 在数字图像处理领域,去马赛克(Demosaicing)是图像信号处理(ISP)流水线中最关键的步骤之一。这项技术负责将传感器捕获的原始拜耳模式(Bayer Pattern&am…...

如何快速掌握哔哩下载姬Downkyi:面向新手的完整使用指南
如何快速掌握哔哩下载姬Downkyi:面向新手的完整使用指南 【免费下载链接】downkyi 哔哩下载姬downkyi,哔哩哔哩网站视频下载工具,支持批量下载,支持8K、HDR、杜比视界,提供工具箱(音视频提取、去水印等&…...

VMware Unlocker终极指南:如何在Windows/Linux上免费解锁macOS虚拟机支持
VMware Unlocker终极指南:如何在Windows/Linux上免费解锁macOS虚拟机支持 【免费下载链接】unlocker VMware Workstation macOS 项目地址: https://gitcode.com/gh_mirrors/unloc/unlocker 你是否曾经想在Windows或Linux电脑上运行macOS虚拟机,却…...

ESP32 Arduino核心开发终极指南:构建专业级物联网控制系统
ESP32 Arduino核心开发终极指南:构建专业级物联网控制系统 【免费下载链接】arduino-esp32 Arduino core for the ESP32 family of SoCs 项目地址: https://gitcode.com/GitHub_Trending/ar/arduino-esp32 还在为物联网项目开发中的硬件兼容性、开发环境复杂…...

硬件工程师转型软件设计:十大核心技巧与思维转换实战指南
1. 项目概述:一次思维模式的“跨界”升级作为一名在硬件领域摸爬滚打了十多年的老兵,我深知从示波器、烙铁和PCB布线软件转向代码编辑器、版本控制和软件架构图时,那种既兴奋又迷茫的感觉。硬件工程师转软件设计,这绝不仅仅是换个…...

i.MX6Q烧录翻车实录:从‘No Device Connected’到‘Push error’,我拔掉一个USB WiFi才搞定
i.MX6Q烧录实战:当USB设备冲突遇上OTG接口的排查指南 那天下午的阳光透过窗户斜射进实验室,我正对着i.MX6Q开发板进行例行固件更新。Mfgtools工具已经准备就绪,开发板电源接通,一切看起来都很完美——直到屏幕上跳出那个令人沮丧…...

STM32定时器中断配置详解:从时钟树到回调函数,一次搞懂ARR和PSC怎么算
STM32定时器中断配置详解:从时钟树到回调函数,一次搞懂ARR和PSC怎么算 在嵌入式开发中,定时器是最基础也最强大的外设之一。很多开发者虽然能够通过复制代码让定时器工作,但对于如何精确控制定时周期、理解时钟信号的传递路径以及…...

Python迭代器实战:构建高性能懒加载积分榜系统
1. 项目概述:从“可迭代”到“可控制”的数据流在Python的世界里,处理数据集合是家常便饭。无论是从数据库拉取用户列表,还是逐行读取一个巨大的日志文件,我们总在和各种序列打交道。但你是否想过,当你写下一个简单的f…...

无王无帝定乾坤,来自田间第一人 海棠山铁哥立标兴文脉
无王无帝定乾坤 ——来自田间第一人 一、破题:王权文脉之弊 旧序新局依附王权扎根民间权贵定义苍生共塑礼制浮华守心向善阶级垄断平等普惠文脉若随王朝而兴,必随王朝而竭; 唯有根植人心,方可生生不息。 二、田间崛起:…...