探讨|使用或不使用机器学习
动动发财的小手,点个赞吧!
机器学习擅长解决某些复杂问题,通常涉及特征和结果之间的困难关系,这些关系不能轻易地硬编码为启发式或 if-else 语句。然而,在决定 ML 是否是当前给定问题的良好解决方案时,有一些限制或需要注意的事项。在这篇文章[1]中,我们将深入探讨“使用或不使用 ML”这一主题,首先了解“传统”ML 模型,然后讨论随着生成式 AI 的进步,这种情况将如何变化。
为了澄清一些观点,我将使用以下举措作为示例:“作为一家公司,我想知道我的客户是否满意以及不满意的主要原因”。解决这个问题的“传统”基于机器学习的方法可能是:
-
获取客户对您的评论(应用程序或 Play 商店、Twitter 或其他社交网络、您的网站……) -
使用情感分析模型将评论分为正面/中性/负面。 -
对预测的“负面情绪”评论使用主题建模来了解它们的含义。

数据有足够的质量和数量吗?
在监督 ML 模型中,训练数据对于模型学习需要预测的任何内容(在本例中为评论中的情绪)是必要的。如果数据质量低(大量错别字、缺失数据、错误……),模型就很难表现良好。
❝这通常被称为“垃圾输入,垃圾输出”问题:如果您的数据是垃圾,那么您的模型和预测也将是垃圾。
❞
同样,您需要有足够的数据量供模型学习影响需要预测的不同因素。在此示例中,如果您只有负面评论标签,其中包含“无用”、“失望”或类似概念,则模型将无法了解到这些词通常在标签为“负面”时出现。
足够数量的训练数据还应该有助于确保您能够很好地表示执行预测所需的数据。例如,如果您的训练数据无法代表特定地理区域或特定人群,则模型更有可能在预测时无法很好地处理这些评论。
对于某些用例,拥有足够的历史数据也很重要,以确保我们能够计算相关的滞后特征或标签(例如“客户是否在明年支付信用额”)。
标签定义是否清晰且易于获取?
同样,对于传统的监督机器学习模型,您需要一个带标签的数据集:您知道想要预测的最终结果的示例,以便能够训练您的模型。
标签的定义是关键。在此示例中,我们的标签将是与评论相关的情绪。我们可能认为我们只能发表“正面”或“负面”评论,然后认为我们也可能发表“中立”评论。在这种情况下,根据给定的评论,通常会清楚标签是否需要是“正面”、“中立”或“负面”。但是想象一下,我们有“非常积极”、“积极”、“中立”、“消极”或“非常消极”的标签……对于给定的评论,是否很容易决定它是“积极”还是“非常积极” ”?需要避免标签缺乏明确的定义,因为使用嘈杂的标签进行训练将使模型更难学习。
现在标签的定义已经很清楚了,我们需要能够获得足够的、高质量的示例集的标签,这些示例将形成我们的训练数据。在我们的示例中,我们可以考虑手动标记一组评论,无论是在公司还是团队内部,还是将标记外部化给专业注释者(是的,有人全职为 ML 标记数据集!)。需要考虑与获得这些标签相关的成本和可行性。
解决方案的部署是否可行?
为了达到最终效果,机器学习模型的预测需要可用。根据用例,使用预测可能需要特定的基础设施(例如 ML 平台)和专家(例如 ML 工程师)。
在我们的示例中,由于我们希望将模型用于分析目的,因此我们可以离线运行它,并且利用预测将非常简单。然而,如果我们想在负面评论发布后 5 分钟内自动做出回应,那就另当别论了:需要部署和集成模型才能实现这一点。总的来说,重要的是要清楚地了解使用预测的要求是什么,以确保在可用的团队和工具的情况下它是可行的。
有什么利害关系?
机器学习模型的预测总会存在一定程度的误差。事实上,ML 中有一句经典的话:
❝如果模型没有错误,那么数据或模型肯定有问题
❞
理解这一点很重要,因为如果用例不允许这些错误发生,那么使用 ML 可能不是一个好主意。在我们的示例中,想象一下,我们使用该模型将客户的电子邮件分类为“是否提出指控”,而不是评论和情绪。拥有一个可以对对公司提出指控的电子邮件进行错误分类的模型并不是一个好主意,因为这可能会给公司带来可怕的后果。
使用机器学习在道德上是否正确?
已经有许多经过验证的预测模型基于性别、种族和其他敏感个人属性进行歧视的案例。因此,机器学习团队需要谨慎对待他们在项目中使用的数据和功能,同时也要质疑从道德角度来看,自动化某些类型的决策是否真的有意义。您可以查看我之前关于该主题的博客文章以了解更多详细信息。
我需要可解释性吗?
机器学习模型在某种程度上就像一个黑匣子:你输入一些信息,它们就会神奇地输出预测。模型背后的复杂性就是这个黑匣子背后的原因,特别是当我们与统计中的简单算法进行比较时。在我们的示例中,我们可能无法准确理解为什么评论被预测为“正面”或“负面”。
在其他用例中,可解释性可能是必须的。例如,在保险或银行等受到严格监管的行业。银行需要能够解释为什么向某人授予(或不授予)信贷,即使该决定是基于评分预测模型的。
这个话题与伦理道德有着密切的关系:如果我们不能完全理解模型的决策,就很难知道模型是否已经学会了歧视。
这一切会因为生成人工智能而改变吗?
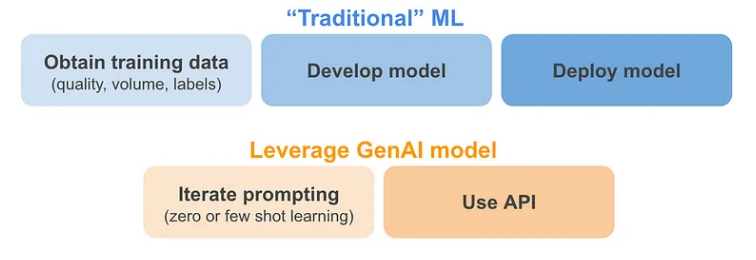
随着生成式人工智能的进步,许多公司正在提供网页和 API 来使用强大的模型。这如何改变我之前提到的有关 ML 的限制和考虑因素?
-
数据相关主题(质量、数量和标签):对于可以利用现有 GenAI 模型的用例,这肯定会发生变化。大量数据已用于训练 GenAI 模型。这些模型中的大多数都没有控制数据的质量,但这似乎弥补了它们使用的大量数据。由于这些模型,我们可能不再需要训练数据(同样,对于非常具体的用例)。这被称为零样本学习(例如“询问 ChatGPT 给定评论的情绪是什么”)和少样本学习(例如“向 ChatGPT 提供一些正面、中立和负面评论的示例,然后要求其提供对新评论的看法”)。关于这一点的一个很好的解释可以在 deeplearning.ai 时事通讯中找到。 -
部署可行性:对于可以利用现有 GenAI 模型的用例,部署变得更加容易,因为许多公司和工具正在为这些强大的模型提供易于使用的 API。如果出于隐私原因需要对这些模型进行微调或将其引入内部,那么部署当然会变得更加困难。
无论是否利用 GenAI,其他限制或考虑因素都不会改变:
-
高风险:这将继续成为一个问题,因为 GenAI 模型的预测也存在一定程度的错误。谁没有见过 GhatGPT 产生幻觉或提供毫无意义的答案?更糟糕的是,评估这些模型变得更加困难,因为无论其准确性如何,响应听起来总是充满信心,并且评估变得主观(例如“这个响应对我有意义吗?”)。 -
道德:仍然像以前一样重要。有证据表明 GenAI 模型可能会因用于训练的输入数据而产生偏差(链接)。随着越来越多的公司和功能开始使用这些类型的模型,明确这可能带来的风险非常重要。 -
可解释性:由于 GenAI 模型比“传统”机器学习更大、更复杂,其预测的可解释性变得更加困难。目前正在进行研究来了解如何实现这种可解释性,但它仍然非常不成熟(链接)。
总结
在这篇博文中,我们了解了在决定是否使用 ML 时需要考虑的主要事项,以及随着生成式 AI 模型的进展,情况会发生怎样的变化。讨论的主要主题是数据的质量和数量、标签获取、部署、风险、道德和可解释性。我希望这个总结在您考虑下一个 ML 计划(或不考虑)时有用!
Reference
Source: https://towardsdatascience.com/to-use-or-not-to-use-machine-learning-d28185382c14
本文由 mdnice 多平台发布
相关文章:
探讨|使用或不使用机器学习
动动发财的小手,点个赞吧! 机器学习擅长解决某些复杂问题,通常涉及特征和结果之间的困难关系,这些关系不能轻易地硬编码为启发式或 if-else 语句。然而,在决定 ML 是否是当前给定问题的良好解决方案时,有一…...
Git笔记--Ubuntu上传本地项目到github
目录 1--基本配置 2--本地上传 1--基本配置 ① 创建ssh-key cd ~/.sshssh-keygen -t rsa -C "邮箱地址"② 查看并关联ssh-key gedit id_rsa.pub 复制内容,在 GitHub 中依次点击 Settings -> SSH and GPG keys -> New SSH key,将 id…...

基于Go编写一个可视化Navicat本地密码解析器
前提 开发小组在测试环境基于docker构建和迁移一个MySQL8.x实例,过程中大意没有记录对应的用户密码,然后发现某开发同事本地Navicat记录了根用户,于是搜索是否能够反解析Navicat中的密码掩码(这里可以基本断定Navicat对密码是采用…...

Maven【入门笔记】
Maven 解决版本依赖的问题 https://www.liaoxuefeng.com/wiki/1252599548343744/1309301146648610 如果没有项目管理工具,在开发项目的时候,我们需要手动管理依赖包,需要管理依赖包的版本、去找到并下载依赖包、还有依赖包所依赖的包 等等。…...
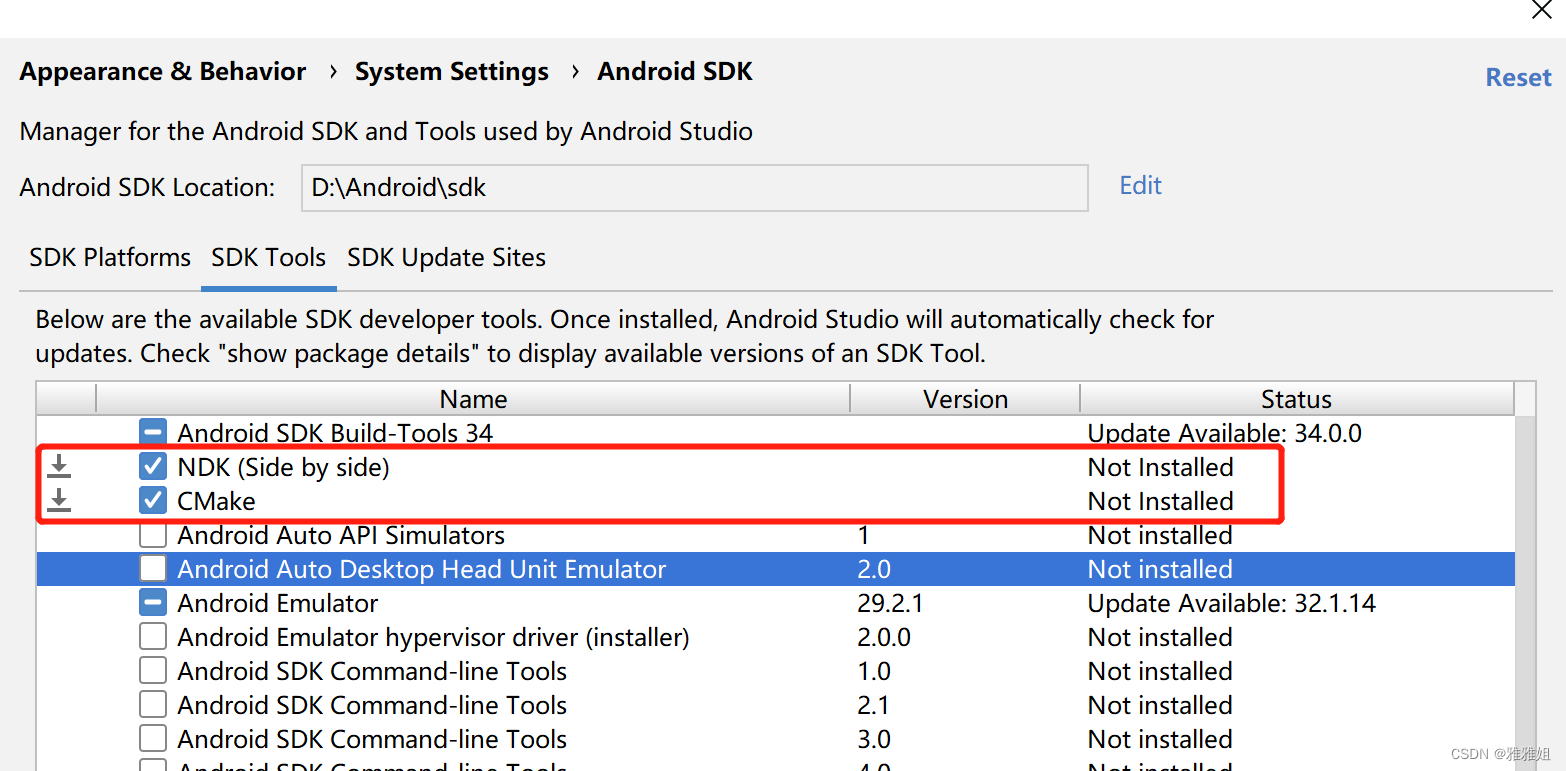
Android Studio中使用cmake开发JNI实战
JNI学习大纲 一、JNI编程入门 二、Android Studio中使用cmake开发JNI实战 第一章节我们介绍了JNI的开发步骤,那这一章节我们就开始在Android Studio中实战一下吧,Lets Start。 1. Android Studio中安装CMake插件 AS中菜单栏选择Tools>SDK Manager在…...
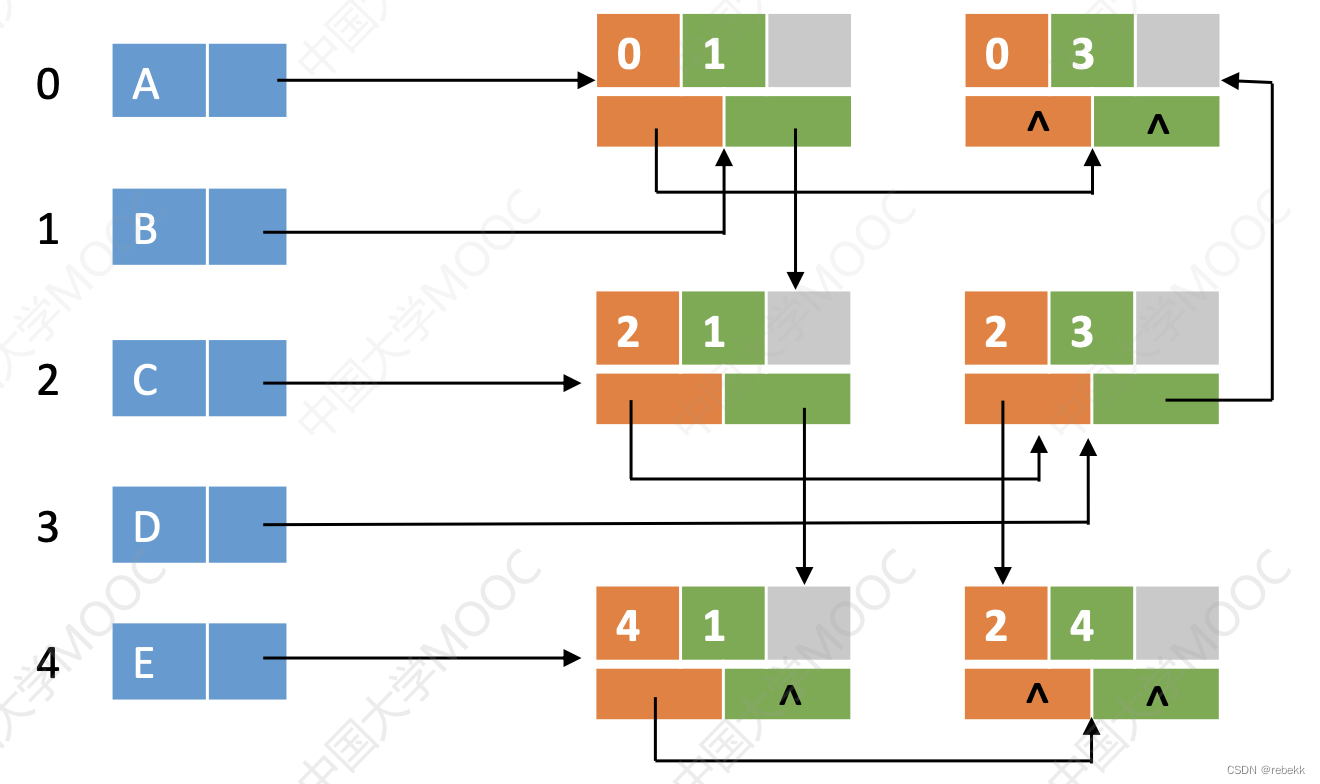
第七章 图论
第七章 图论 一、数据结构定义 图的邻接矩阵存储法#define MaxVertexNum 100 // 节点数目的最大值// 无边权,只用0或1表示边是否存在 bool graph[MaxVertexNum][MaxVertexNum];// 有边权 int graph[MaxVertexNum][MaxVertexNum];图的邻接表存储法 把所有节点存储为…...
)
IEEE SystemVerilog Chapter13 : Tasks and functions (subroutines)
13.2 Overview 任务和函数提供了从描述中的几个不同位置执行通用过程的能力。它们还提供了一种将大型过程分解为小型过程的方法,以便更容易地阅读和调试源代码描述。本小节讨论了任务和函数之间的区别,描述了如何定义和调用任务和函数,并给出…...
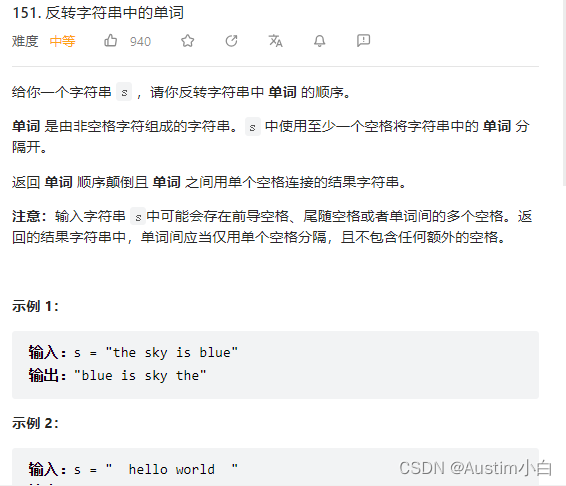
day39反转字符串总结
反转字符串原理其实就是交换位置,以中间为分隔点; 基本套路:遍历前一般字符,互换位置; for循环模板 void reverseString(char* s, int sSize){char temp;for (int i 0, j sSize - 1; i < sSize/2; i, j--) {temp…...
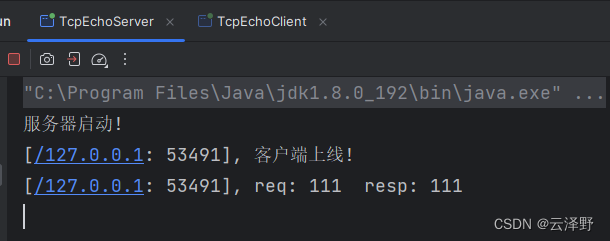
使用Socket实现TCP版的回显服务器
文章目录 1. Socket简介2. ServerSocket3. Socket4. 服务器端代码5. 客户端代码 1. Socket简介 Socket(Java套接字)是Java编程语言提供的一组类和接口,用于实现网络通信。它基于Socket编程接口,提供了一种简单而强大的方式来实现…...
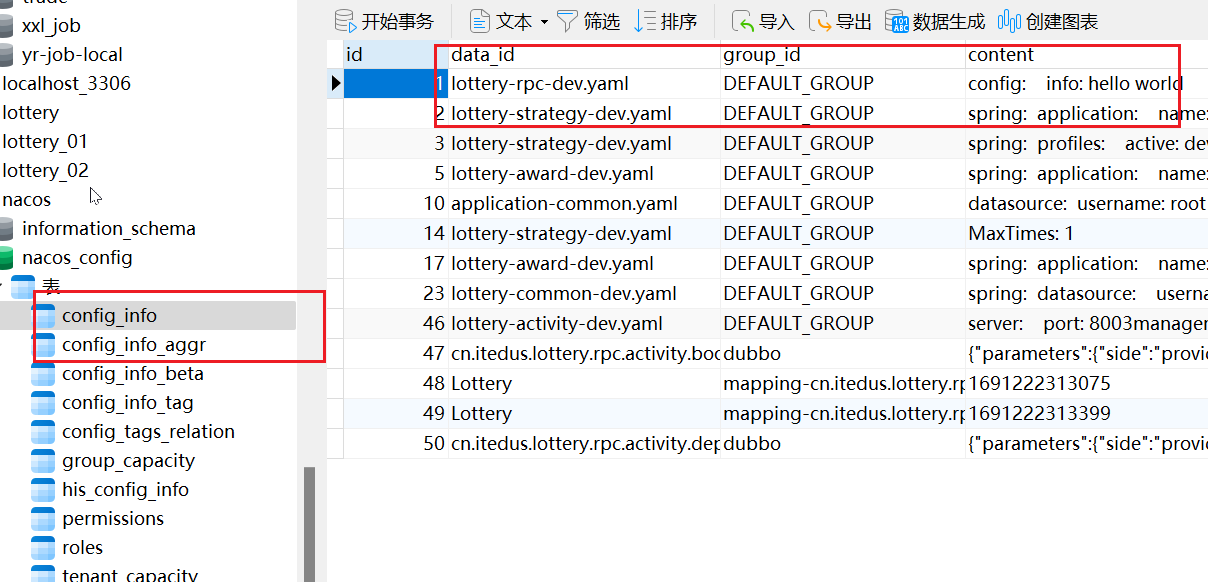
【Nacos篇】Nacos基本操作及配置
官方文档:https://nacos.io/zh-cn/docs/v2/ecology/use-nacos-with-spring-cloud.html 前置条件:SpringCloud脚手架 单机模式下的Nacos控制台: <dependencies><!-- Registry 注册中心相关 --><dependency><groupId>…...
Dockerfile构建Tomcat镜像
准备apache包和jdk并解压 [rootlocalhost tomcat]# ll 总用量 196728 -rw-r--r--. 1 root root 9690027 7月 17 2020 apache-tomcat-8.5.40.tar.gz -rw-r--r--. 1 root root 674 8月 2 20:19 Dockerfile -rw-r--r--. 1 root root 191753373 7月 17 2020 jdk-8u191-…...

k8s的介绍
简介 Kubernetes,简称K8s,是用8代替名字中间的8个字符“ubernete”而成的缩写。是一个开源的,用于管理云平台中多个主机上的容器化的应用, K8s的目标是让部署容器化的应用简单并且高效,K8s提供了应用部署,规划,更新,维护的一种机制。 K8s是Google开源的一个容器编排引…...

mysql sql语句 需要使用like 场景,解决方案
mysql 多重like 解决方案 方案一、使用like 方案二、使用REGEXP 正则匹配 方案三、使用group_concat多重模糊匹配 方案一、使用like 查询user包含小李并且小王的相关数据 SELECT * FROM user WHERE name LIKE %小王% or name like %小王% 方案二、使用REGEXP 正则匹配 查询use…...
通过C语言设计的贪吃蛇游戏(控制台终端)
一、项目介绍 当前通过控制台终端实现一个贪吃蛇小游戏,实现游戏的绘制、更新、控制等功能。 二、实现效果 三、完整代码 下面贴出的代码在Windows系统上编译运行,需要使用conio.h头文件中的getch()函数来获取键盘输入,用于控制蛇的移动。…...
c++实现Qt信号和槽机制
文章目录 简介信号槽信号与槽的连接 特点观察者模式定义观察者模式结构图 实现简单的信号和槽 简介 信号槽机制与Windows下消息机制类似,消息机制是基于回调函数,Qt中用信号与槽来代替函数指针,使程序更安全简洁。 信号和槽机制是 Qt 的核心…...
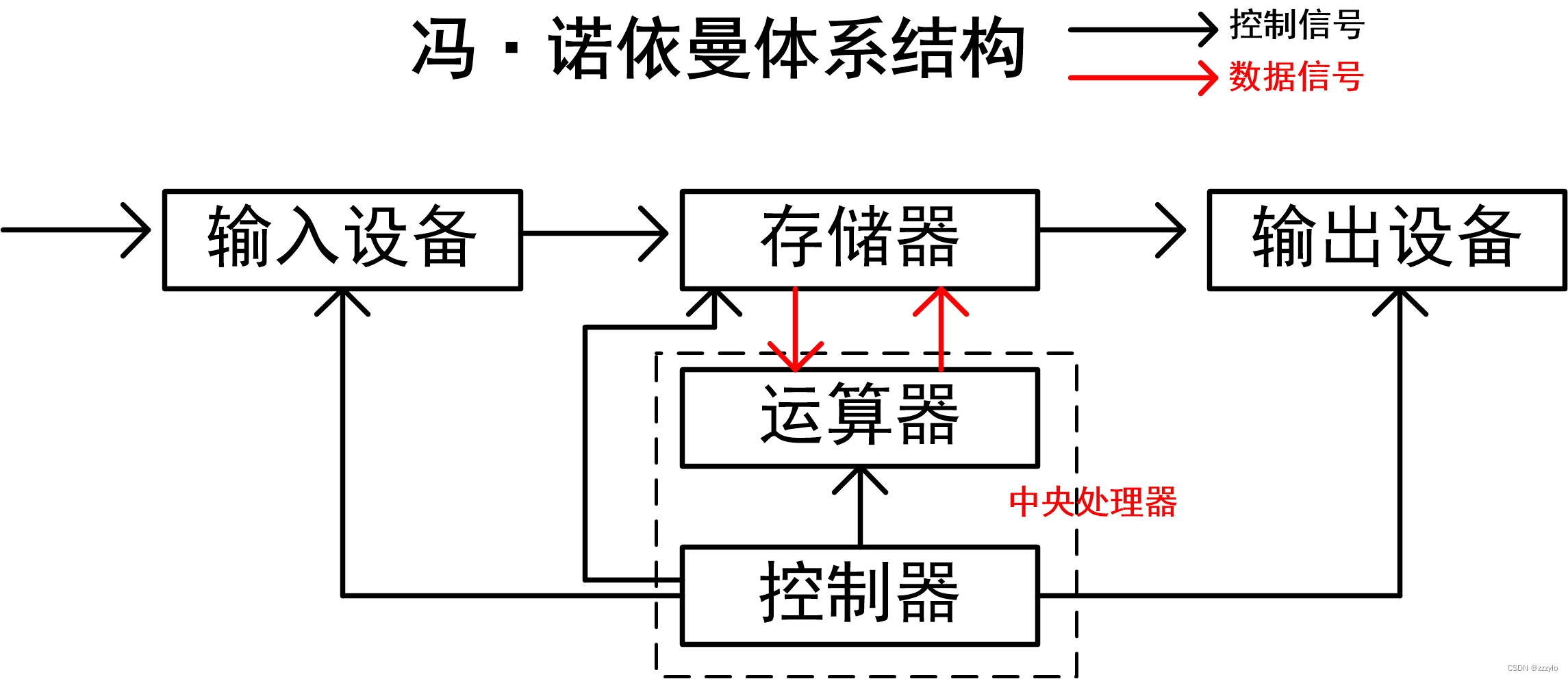
【Linux】五、进程
一、冯诺依曼体系结构 存储器:指的是内存; 输入设备:键盘、摄像头、话筒,磁盘,网卡; 输出设备:显示器、音响、磁盘、网卡; 中央处理器(CPU):运算器…...
使用 OpenCV 和 Python 卡通化图像-附源码
介绍 在本文中,我们将构建一个有趣的应用程序,它将卡通化提供给它的图像。为了构建这个卡通化器应用程序,我们将使用 python 和 OpenCV。这是机器学习令人兴奋的应用之一。在构建此应用程序时,我们还将了解如何使用 easygui、Tkinter 等库。在这里,您必须选择图像,然后应…...

GitLab不同角色对应的权限
Owner(拥有者): 拥有者是项目或组的创建者,拥有最高级别的权限。他们可以添加、删除项目成员,修改项目设置,管理访问权限,并进行项目转让。在组级别,他们还可以添加或删除子组和项目…...
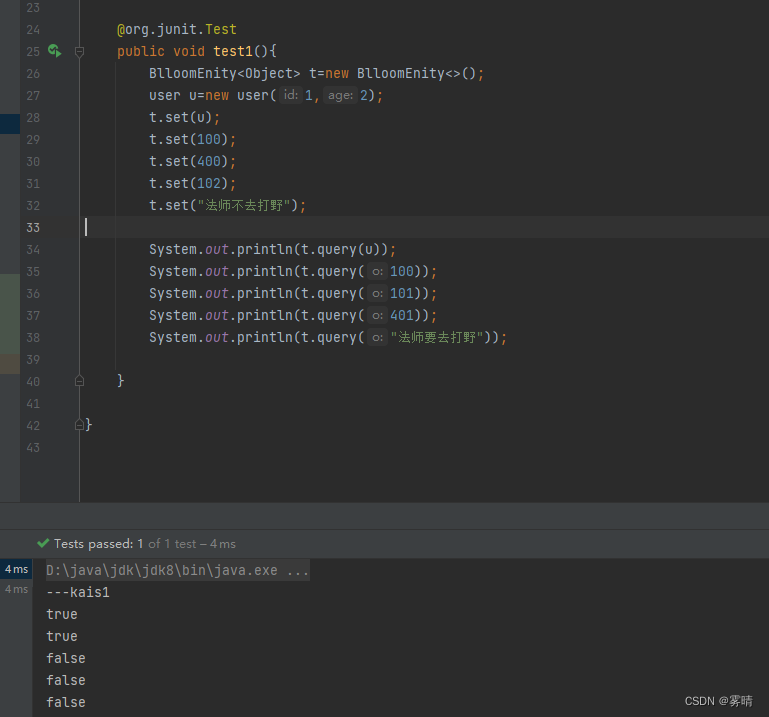
手写一个简易的布隆过滤器
1.什么是布隆过滤器 布隆过滤器(Bloom Filter)是1970年由布隆(人名)提出的。它实际上是一个很长的二进制向量和一系列随机映射函数。布隆过滤器可以用于检索一个元素是否在一个集合中。它的优点是空间效率和查询时间都比一般的算法要好的多,…...

阿里云快速部署开发环境 (Apache + Mysql8.0)
本文章的内容截取于云服务器管理控制台提供的安装步骤,再整合前人思路而成,文章末端会提供原文连接 ApacheMysql 8.0部署MySQL数据库(Linux)步骤一:安装MySQL步骤二:配置MySQL步骤三:远程访问My…...

如何快速掌握MTKClient:从零开始的联发科设备救砖与调试完整指南
如何快速掌握MTKClient:从零开始的联发科设备救砖与调试完整指南 【免费下载链接】mtkclient MTK reverse engineering and flash tool 项目地址: https://gitcode.com/gh_mirrors/mt/mtkclient 你是否曾经面对变砖的联发科手机束手无策?是否因为…...

如何通过DLSS版本管理工具提升30%游戏性能:实战指南
如何通过DLSS版本管理工具提升30%游戏性能:实战指南 【免费下载链接】dlss-swapper 项目地址: https://gitcode.com/GitHub_Trending/dl/dlss-swapper DLSS Swapper是一款开源游戏性能优化工具,专门用于管理DLSS、FSR和XeSS动态库版本。你是否曾…...

DownKyi完全指南:三步解锁B站8K视频下载的终极方案
DownKyi完全指南:三步解锁B站8K视频下载的终极方案 【免费下载链接】downkyi 哔哩下载姬downkyi,哔哩哔哩网站视频下载工具,支持批量下载,支持8K、HDR、杜比视界,提供工具箱(音视频提取、去水印等ÿ…...

如何用PCL2启动器打造完美的Minecraft模组体验:从零到精通的完整指南
如何用PCL2启动器打造完美的Minecraft模组体验:从零到精通的完整指南 【免费下载链接】PCL Minecraft 启动器 Plain Craft Launcher(PCL)。 项目地址: https://gitcode.com/gh_mirrors/pc/PCL 你是否厌倦了每次启动Minecraft都要手动配…...

3分钟高效恢复Windows 11 LTSC微软商店:完整解决方案指南
3分钟高效恢复Windows 11 LTSC微软商店:完整解决方案指南 【免费下载链接】LTSC-Add-MicrosoftStore Add Windows Store to Windows 11 24H2 LTSC 项目地址: https://gitcode.com/gh_mirrors/ltscad/LTSC-Add-MicrosoftStore 你是否在使用Windows 11 24H2 LT…...

【CH32V307实战】4P OLED屏I2C驱动移植与快速显示指南
1. CH32V307与4P OLED屏的硬件连接指南 第一次拿到CH32V307开发板和4P OLED屏时,最让我头疼的就是接线问题。这种4线制OLED(通常标注为4P或4PIN)相比传统的7线制简化了不少,但引脚定义各家厂商可能略有差异。经过多次实测…...

如何3步免费解锁WeMod专业版:2026年终极增强工具使用指南
如何3步免费解锁WeMod专业版:2026年终极增强工具使用指南 【免费下载链接】Wand-Enhancer Advanced UX and interoperability extension for Wand (WeMod) app 项目地址: https://gitcode.com/gh_mirrors/we/Wand-Enhancer 还在为WeMod专业版的订阅费用而犹豫…...

ncmdumpGUI:3分钟解锁网易云音乐ncm格式,让你的音乐无处不在
ncmdumpGUI:3分钟解锁网易云音乐ncm格式,让你的音乐无处不在 【免费下载链接】ncmdumpGUI C#版本网易云音乐ncm文件格式转换,Windows图形界面版本 项目地址: https://gitcode.com/gh_mirrors/nc/ncmdumpGUI 还在为网易云音乐下载的nc…...

技能工程化框架:从标准化定义到编排实战
1. 项目概述:从“技能”到“智能”的工程化桥梁在当今的软件开发领域,尤其是涉及复杂交互和自动化流程的场景,我们常常会听到“技能”这个词。它听起来很抽象,但如果你拆解过任何一款智能助手、自动化机器人或者一个大型的业务流程…...

从分布式到可分发:大规模软件制品分发架构设计与实践
1. 项目概述:从“分布式”到“可分发”的思维跃迁最近在梳理团队内部的基础设施时,又翻出了distr-sh/distr这个项目。说实话,第一次看到这个仓库名,我下意识地把它归类为又一个“分布式系统”框架。但当我真正点进去,花…...