计算机毕设 深度学习猫狗分类 - python opencv cnn
文章目录
- 0 前言
- 1 课题背景
- 2 使用CNN进行猫狗分类
- 3 数据集处理
- 4 神经网络的编写
- 5 Tensorflow计算图的构建
- 6 模型的训练和测试
- 7 预测效果
- 8 最后
0 前言
🔥 这两年开始毕业设计和毕业答辩的要求和难度不断提升,传统的毕设题目缺少创新和亮点,往往达不到毕业答辩的要求,这两年不断有学弟学妹告诉学长自己做的项目系统达不到老师的要求。
为了大家能够顺利以及最少的精力通过毕设,学长分享优质毕业设计项目,今天要分享的是
🚩 **基于深度学习猫狗分类 **
🥇学长这里给一个题目综合评分(每项满分5分)
- 难度系数:3分
- 工作量:3分
- 创新点:3分

1 课题背景
要说到深度学习图像分类的经典案例之一,那就是猫狗大战了。猫和狗在外观上的差别还是挺明显的,无论是体型、四肢、脸庞和毛发等等, 都是能通过肉眼很容易区分的。那么如何让机器来识别猫和狗呢?这就需要使用卷积神经网络来实现了。
本项目的主要目标是开发一个可以识别猫狗图像的系统。分析输入图像,然后预测输出。实现的模型可以根据需要扩展到网站或任何移动设备。我们的主要目标是让模型学习猫和狗的各种独特特征。一旦模型的训练完成,它将能够区分猫和狗的图像。
2 使用CNN进行猫狗分类
卷积神经网络 (CNN) 是一种算法,将图像作为输入,然后为图像的所有方面分配权重和偏差,从而区分彼此。神经网络可以通过使用成批的图像进行训练,每个图像都有一个标签来识别图像的真实性质(这里是猫或狗)。一个批次可以包含十分之几到数百个图像。
对于每张图像,将网络预测与相应的现有标签进行比较,并评估整个批次的网络预测与真实值之间的距离。然后,修改网络参数以最小化距离,从而增加网络的预测能力。类似地,每个批次的训练过程都是类似的。

3 数据集处理
猫狗照片的数据集直接从kaggle官网下载即可,下载后解压,这是我下载的数据:

相关代码
import os,shutiloriginal_data_dir = "G:/Data/Kaggle/dogcat/train"
base_dir = "G:/Data/Kaggle/dogcat/smallData"
if os.path.isdir(base_dir) == False:os.mkdir(base_dir)# 创建三个文件夹用来存放不同的数据:train,validation,test
train_dir = os.path.join(base_dir,'train')
if os.path.isdir(train_dir) == False:os.mkdir(train_dir)
validation_dir = os.path.join(base_dir,'validation')
if os.path.isdir(validation_dir) == False:os.mkdir(validation_dir)
test_dir = os.path.join(base_dir,'test')
if os.path.isdir(test_dir) == False:os.mkdir(test_dir)# 在文件中:train,validation,test分别创建cats,dogs文件夹用来存放对应的数据
train_cats_dir = os.path.join(train_dir,'cats')
if os.path.isdir(train_cats_dir) == False:os.mkdir(train_cats_dir)
train_dogs_dir = os.path.join(train_dir,'dogs')
if os.path.isdir(train_dogs_dir) == False:os.mkdir(train_dogs_dir)validation_cats_dir = os.path.join(validation_dir,'cats')
if os.path.isdir(validation_cats_dir) == False:os.mkdir(validation_cats_dir)
validation_dogs_dir = os.path.join(validation_dir,'dogs')
if os.path.isdir(validation_dogs_dir) == False:os.mkdir(validation_dogs_dir)test_cats_dir = os.path.join(test_dir,'cats')
if os.path.isdir(test_cats_dir) == False:os.mkdir(test_cats_dir)
test_dogs_dir = os.path.join(test_dir,'dogs')
if os.path.isdir(test_dogs_dir) == False:os.mkdir(test_dogs_dir)#将原始数据拷贝到对应的文件夹中 cat
fnames = ['cat.{}.jpg'.format(i) for i in range(1000)]
for fname in fnames:src = os.path.join(original_data_dir,fname)dst = os.path.join(train_cats_dir,fname)shutil.copyfile(src,dst)fnames = ['cat.{}.jpg'.format(i) for i in range(1000,1500)]
for fname in fnames:src = os.path.join(original_data_dir,fname)dst = os.path.join(validation_cats_dir,fname)shutil.copyfile(src,dst)fnames = ['cat.{}.jpg'.format(i) for i in range(1500,2000)]
for fname in fnames:src = os.path.join(original_data_dir,fname)dst = os.path.join(test_cats_dir,fname)shutil.copyfile(src,dst)#将原始数据拷贝到对应的文件夹中 dog
fnames = ['dog.{}.jpg'.format(i) for i in range(1000)]
for fname in fnames:src = os.path.join(original_data_dir,fname)dst = os.path.join(train_dogs_dir,fname)shutil.copyfile(src,dst)fnames = ['dog.{}.jpg'.format(i) for i in range(1000,1500)]
for fname in fnames:src = os.path.join(original_data_dir,fname)dst = os.path.join(validation_dogs_dir,fname)shutil.copyfile(src,dst)fnames = ['dog.{}.jpg'.format(i) for i in range(1500,2000)]
for fname in fnames:src = os.path.join(original_data_dir,fname)dst = os.path.join(test_dogs_dir,fname)shutil.copyfile(src,dst)
print('train cat images:', len(os.listdir(train_cats_dir)))
print('train dog images:', len(os.listdir(train_dogs_dir)))
print('validation cat images:', len(os.listdir(validation_cats_dir)))
print('validation dog images:', len(os.listdir(validation_dogs_dir)))
print('test cat images:', len(os.listdir(test_cats_dir)))
print('test dog images:', len(os.listdir(test_dogs_dir)))
train cat images: 1000
train dog images: 1000
validation cat images: 500
validation dog images: 500
test cat images: 500
test dog images: 500
4 神经网络的编写
cnn卷积神经网络的编写如下,编写卷积层、池化层和全连接层的代码
conv1_1 = tf.layers.conv2d(x, 16, (3, 3), padding='same', activation=tf.nn.relu, name='conv1_1')
conv1_2 = tf.layers.conv2d(conv1_1, 16, (3, 3), padding='same', activation=tf.nn.relu, name='conv1_2')
pool1 = tf.layers.max_pooling2d(conv1_2, (2, 2), (2, 2), name='pool1')
conv2_1 = tf.layers.conv2d(pool1, 32, (3, 3), padding='same', activation=tf.nn.relu, name='conv2_1')
conv2_2 = tf.layers.conv2d(conv2_1, 32, (3, 3), padding='same', activation=tf.nn.relu, name='conv2_2')
pool2 = tf.layers.max_pooling2d(conv2_2, (2, 2), (2, 2), name='pool2')
conv3_1 = tf.layers.conv2d(pool2, 64, (3, 3), padding='same', activation=tf.nn.relu, name='conv3_1')
conv3_2 = tf.layers.conv2d(conv3_1, 64, (3, 3), padding='same', activation=tf.nn.relu, name='conv3_2')
pool3 = tf.layers.max_pooling2d(conv3_2, (2, 2), (2, 2), name='pool3')
conv4_1 = tf.layers.conv2d(pool3, 128, (3, 3), padding='same', activation=tf.nn.relu, name='conv4_1')
conv4_2 = tf.layers.conv2d(conv4_1, 128, (3, 3), padding='same', activation=tf.nn.relu, name='conv4_2')
pool4 = tf.layers.max_pooling2d(conv4_2, (2, 2), (2, 2), name='pool4')flatten = tf.layers.flatten(pool4)
fc1 = tf.layers.dense(flatten, 512, tf.nn.relu)
fc1_dropout = tf.nn.dropout(fc1, keep_prob=keep_prob)
fc2 = tf.layers.dense(fc1, 256, tf.nn.relu)
fc2_dropout = tf.nn.dropout(fc2, keep_prob=keep_prob)
fc3 = tf.layers.dense(fc2, 2, None)
5 Tensorflow计算图的构建
然后,再搭建tensorflow的计算图,定义占位符,计算损失函数、预测值和准确率等等
self.x = tf.placeholder(tf.float32, [None, IMAGE_SIZE, IMAGE_SIZE, 3], 'input_data')
self.y = tf.placeholder(tf.int64, [None], 'output_data')
self.keep_prob = tf.placeholder(tf.float32)
# 图片输入网络中
fc = self.conv_net(self.x, self.keep_prob)
self.loss = tf.losses.sparse_softmax_cross_entropy(labels=self.y, logits=fc)
self.y_ = tf.nn.softmax(fc) # 计算每一类的概率
self.predict = tf.argmax(fc, 1)
self.acc = tf.reduce_mean(tf.cast(tf.equal(self.predict, self.y), tf.float32))
self.train_op = tf.train.AdamOptimizer(LEARNING_RATE).minimize(self.loss)
self.saver = tf.train.Saver(max_to_keep=1)
最后的saver是要将训练好的模型保存到本地。
6 模型的训练和测试
然后编写训练部分的代码,训练步骤为1万步
acc_list = []
with tf.Session() as sess:sess.run(tf.global_variables_initializer())for i in range(TRAIN_STEP):train_data, train_label, _ = self.batch_train_data.next_batch(TRAIN_SIZE)eval_ops = [self.loss, self.acc, self.train_op]eval_ops_results = sess.run(eval_ops, feed_dict={self.x:train_data,self.y:train_label,self.keep_prob:0.7})loss_val, train_acc = eval_ops_results[0:2]acc_list.append(train_acc)if (i+1) % 100 == 0:acc_mean = np.mean(acc_list)print('step:{0},loss:{1:.5},acc:{2:.5},acc_mean:{3:.5}'.format(i+1,loss_val,train_acc,acc_mean))if (i+1) % 1000 == 0:test_acc_list = []for j in range(TEST_STEP):test_data, test_label, _ = self.batch_test_data.next_batch(TRAIN_SIZE)acc_val = sess.run([self.acc],feed_dict={self.x:test_data,self.y:test_label,self.keep_prob:1.0})test_acc_list.append(acc_val)print('[Test ] step:{0}, mean_acc:{1:.5}'.format(i+1, np.mean(test_acc_list)))# 保存训练后的模型os.makedirs(SAVE_PATH, exist_ok=True)self.saver.save(sess, SAVE_PATH + 'my_model.ckpt')
训练结果如下:
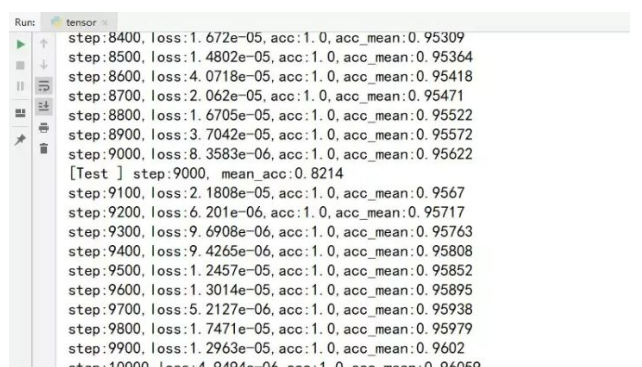
训练1万步后模型测试的平均准确率有0.82。
7 预测效果
选取三张图片测试
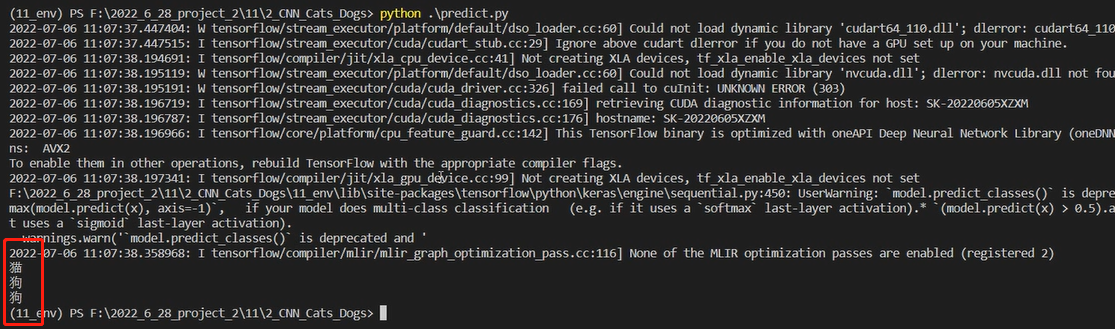
可见,模型准确率还是较高的。
8 最后
相关文章:
计算机毕设 深度学习猫狗分类 - python opencv cnn
文章目录 0 前言1 课题背景2 使用CNN进行猫狗分类3 数据集处理4 神经网络的编写5 Tensorflow计算图的构建6 模型的训练和测试7 预测效果8 最后 0 前言 🔥 这两年开始毕业设计和毕业答辩的要求和难度不断提升,传统的毕设题目缺少创新和亮点,往…...
60多行代码仿制B站首页一个好看的卡片效果
文章目录 1、为啥是这个?2、仿制效果3、实现思路4、代码5、查看B站如何实现 1、为啥是这个? 看到Bilibili首页的一个卡片,看着效果很不错,给人很舒适的感觉。一琢磨貌似也不难,甚至只需要一层 div 就可以实现主要框架…...

Redis内网主从节点搭建
Redis内网主从节点搭建 1、文件上传2、服务安装3、服务启动4、配置主从复制 1、文件上传 内网环境手动上传gcc-c、redis.tar文件 2、服务安装 # 解压 unzip gcc-c.zip unzip gcc_rpm.zip tar -zxvf redis-6.2.13.tar.gz# 安装 cd gcc_rpm/ rpm -ivh *.rpm --nodeps --force…...

ESP32-C2开发板 ESP8684芯片 兼容ESP32-C3开发
C2是一个芯片采用4毫米x 4毫米封装,与272 kB内存。它运行框架,例如ESP-Jumpstart和ESP造雨者,同时它也运行ESP-IDF。ESP-IDF是Espressif面向嵌入式物联网设备的开源实时操作系统,受到了全球用户的信赖。它由支持Espressif以及所有…...
Zebec 创始人 Sam 对话社区,“Zebec 生态发展”主题 AMA 回顾总结
近日,Zebec Protocol 创始人 Sam 作为嘉宾,与社区进行了以“Zebec 生态发展”为主题的 AMA 对话。Sam 在线上访谈上对 Zebec 路线图、Zebec 质押、NautChain通证进行了解读,并对 Zebec 的进展、生态建设的愿景进行了展望。本文将对本次 AMA 进…...
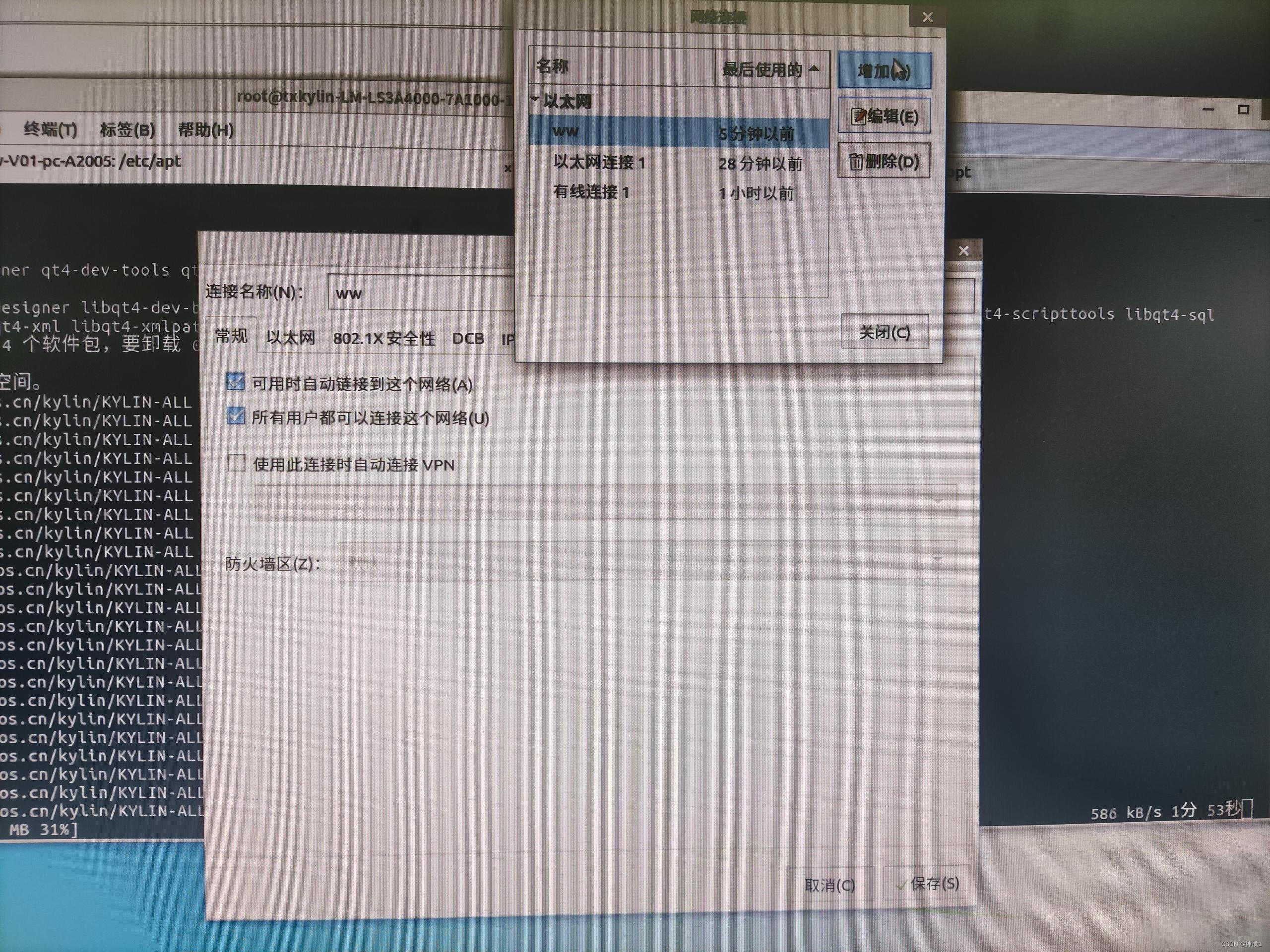
一台电脑给另外一台电脑共享网络
这里写自定义目录标题 有网的电脑上操作一根网线连接两台电脑没网的电脑上 有网的电脑上操作 右键->属性->共享 如同选择以太网,勾选。确认。 一根网线连接两台电脑 没网的电脑上 没网的电脑为mips&麒麟V10 新增个网络配置ww,设置如下。 …...
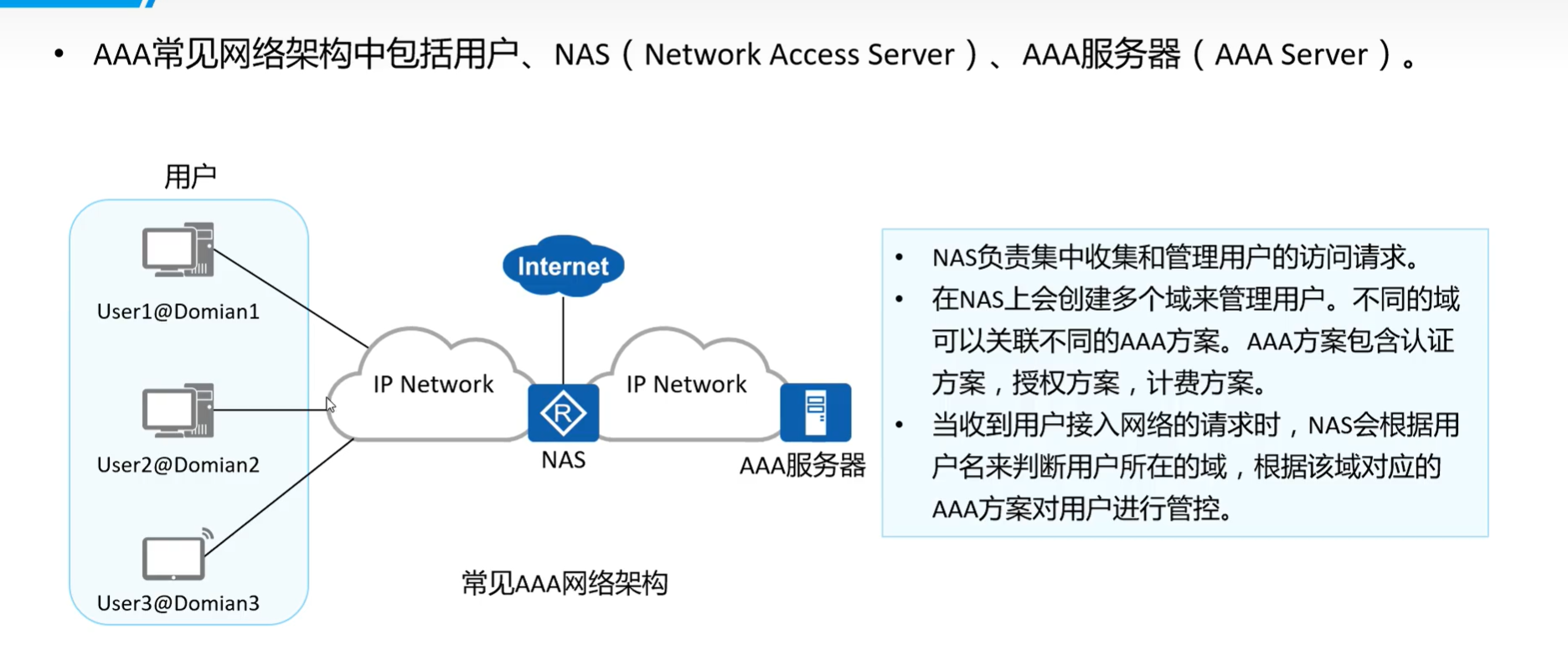
AAA 认证
概念 AAA是认证(Authentication)、授权(Authorization)和计费(Accounting)的简称,是网络安全中进行访问控制的一种安全管理机制,提供认证、授权和计费三种安全服务。 AAA 常见架构...
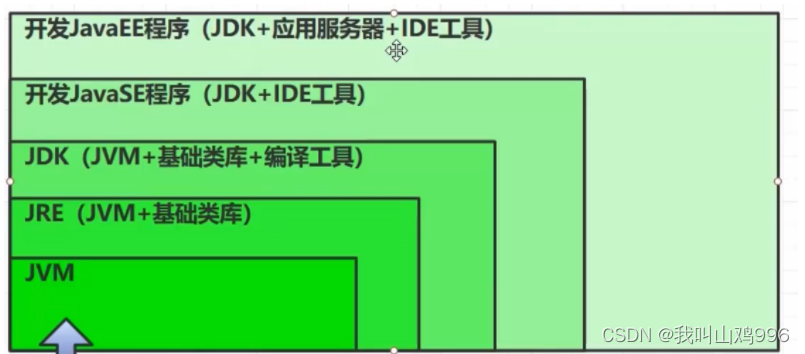
jvm-程序计数器
1、是什么 4 学习路线 类加载器 内存结构方法区 类堆 对象虚拟机栈程序计数器本地方法栈 执行引擎解释器编译器 热点代码 5 程序计数器–作用 java源代码编译蛏二进制字节码 jvm指令。 对所有平台保持一致性。记住下一条jvm指令的执行地址。寄存器,cpu中读取速度…...

NestJs Debug配置文件
(事缓则圆,人缓则安,语迟则贵,虎行似病,鹰立似睡。清俞万春《荡寇志》) {"version": "0.2.0","configurations": [{"type": "node","request": "launch","name": &quo…...

题解 | #C.idol!!# 2023牛客暑期多校6
C.idol!! 数学 题目大意 正整数 n n n 的双阶乘 n ! ! n!! n!! 表示不超过 n n n 且与 n n n 有相同奇偶性的所有正整数乘积 求对于给定 n n n , ∏ i 1 n i ! ! \prod\limits_{i1}^n i!! i1∏ni!! 的后缀 0 0 0 个数 解题思路 根据双阶乘的性质&…...

使用filebeat收集并解析springboot日志
序 本文主要研究一下如何使用filebeat收集并解析springboot日志 安装 在官网的下载页面filebeat/downloads提供了一些特定平台的安装包,不过对应linux最为省事的安装方式就是直接下载x86_64压缩包,然后解压即可 wget https://artifacts.elastic.co/d…...

P1993 小 K 的农场
小 K 的农场 题目描述 小 K 在 MC 里面建立很多很多的农场,总共 n n n 个,以至于他自己都忘记了每个农场中种植作物的具体数量了,他只记得一些含糊的信息(共 m m m 个),以下列三种形式描述:…...
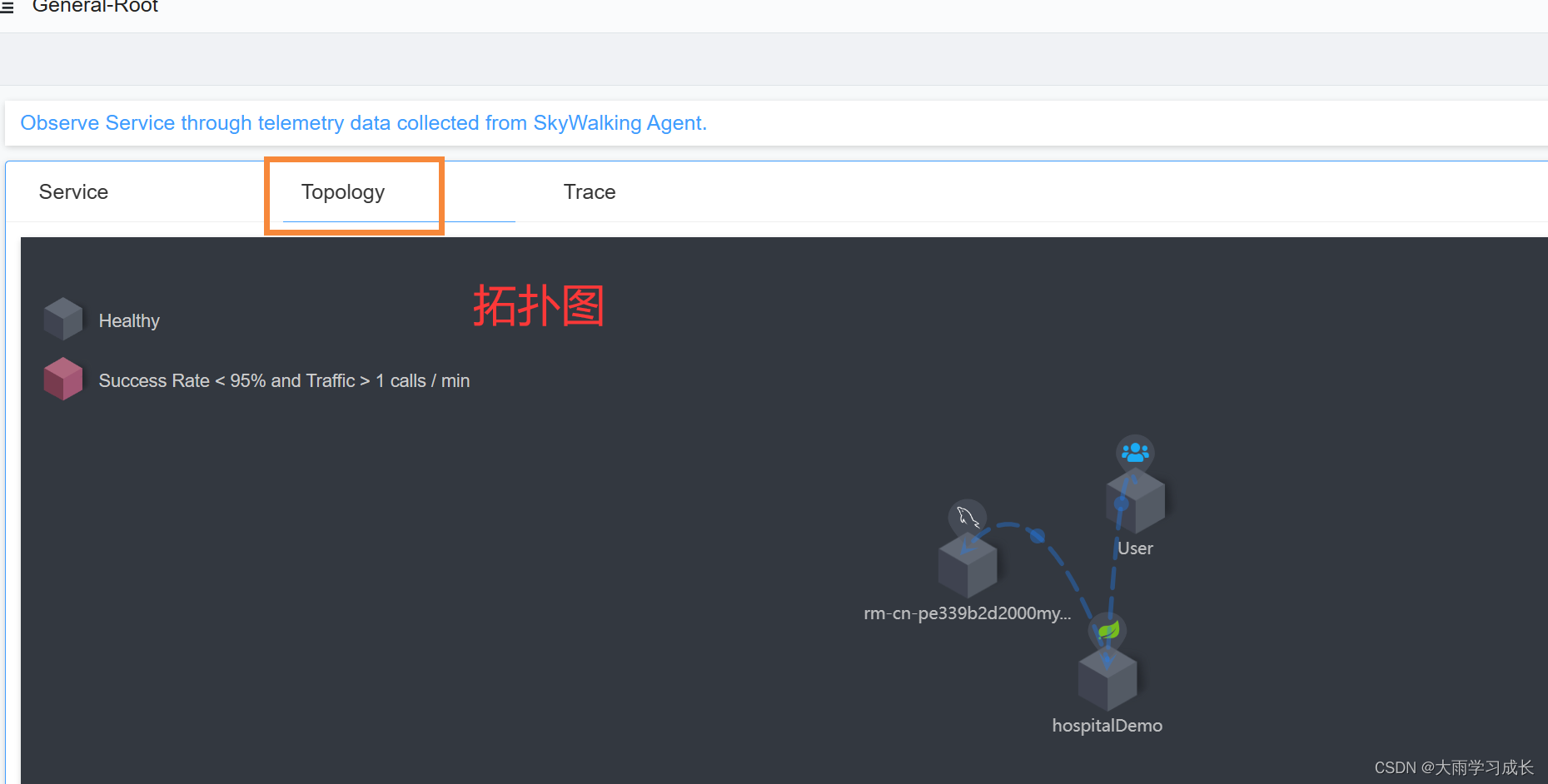
Spring boot 集成 Skywalking 配置 || Skywalking 打不开【已解决】
一、Skywalking官网 Apache SkyWalking 1.下载Skywalking APM (如果下载最新的,双击打开闪退,选老点的版本) 2. 下载 Skywalking Agents 如果下载太慢,建议复制下载链接,然后用下载器下载,比…...

手把手教你使用 ftrace 对 Linux 系统进行 debug
1、简介 strace:用来跟踪 Linux 进程执行时的系统调用和接收所接收的信号,可以跟踪到一个进程产生的系统调用,包括参数,返回值,执行消耗的时间。 ftrace:是一个 Linux 内核函数跟踪器,function tracer,旨在帮助开发人员和系统设计者可以找到内核内部发生的事情,从 L…...
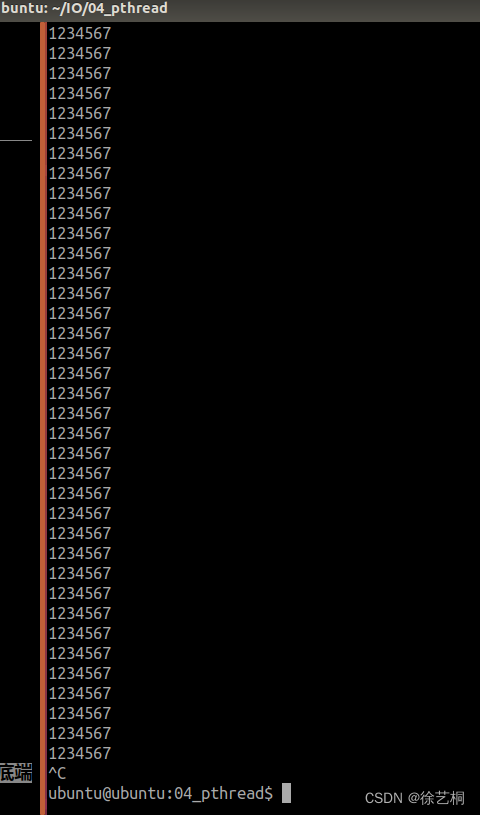
【练】要求定义一个全局变量 char buf[] = “1234567“,创建两个线程,不考虑退出条件,打印buf
要求定义一个全局变量 char buf[] "1234567",创建两个线程,不考虑退出条件,另: A线程循环打印buf字符串,B线程循环倒置buf字符串,即buf中本来存储1234567,倒置后buf中存储7654321. 不…...

iOS Viper架构(中文版)【看懂这篇就够了】
完整源码地址 一、iOS_Viper iOS的Viper架构,作为一个从业多年的iOS开发者,我个人认为应该要会一点viper 二、前言 viper的设计模式在iOS开发中不流行,甚至是Swift中,也没有用,我认为比较可惜。作为iOSer,当你掌握…...

深入理解缓存 TLB 原理
今天分享一篇TLB的好文章,希望大家夯实基本功,让我们一起深入理解计算机系统。 TLB 是 translation lookaside buffer 的简称。首先,我们知道 MMU 的作用是把虚拟地址转换成物理地址。 MMU工作原理 虚拟地址和物理地址的映射关系存储在页表…...

获取k8s scale资源对象的命令
kubectl get --raw /apis/<apiGroup>/<apiVersion>/namespaces/<namespaceName>/<resourceKind>/<resourceName>/scale 说明:scale资源对象用来水平扩展k8s资源对象的副本数,它是作为一种k8s资源对象的子资源存在…...

基于ChatYuan-large-v2 语言模型 Fine-tuning 微调训练 广告生成 任务
一、ChatYuan-large-v2 ChatYuan-large-v2是一个开源的支持中英双语的功能型对话语言大模型,与其他 LLM 不同的是模型十分轻量化,并且在轻量化的同时效果相对还不错,仅仅通过0.7B参数量就可以实现10B模型的基础效果,正是其如此的…...
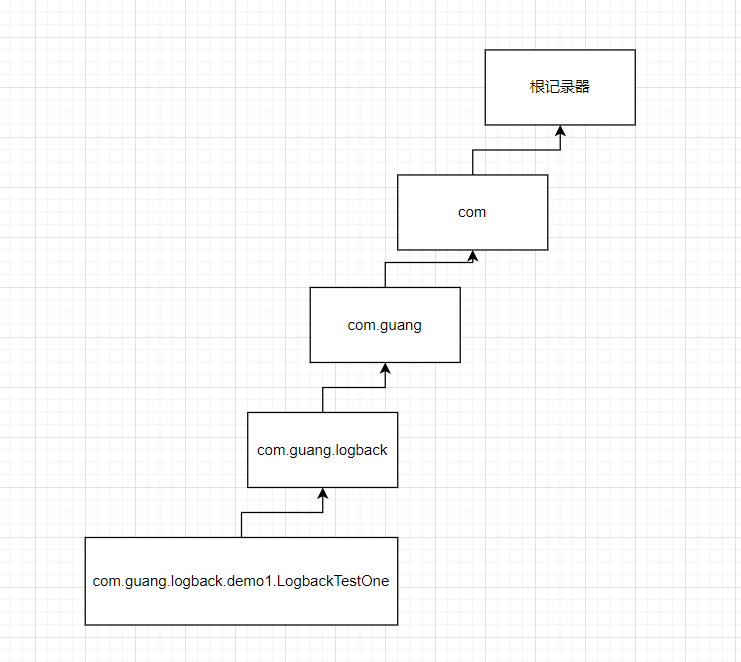
SpringBoot集成Logback日志
SpringBoot集成Logback日志 文章目录 SpringBoot集成Logback日志一、什么是日志二、Logback简单介绍三、SpringBoot项目中使用Logback四、概念介绍一、日志记录器Logger1.1、日志记录器对象生成1.2、记录器的层级结构1.3、过滤器1.4、logger设置日志级别1.5、java代码演示1.6、…...

从PUMA560到你的项目:手把手教你将经典DH建模流程迁移到自定义机械臂
从PUMA560到自定义机械臂:DH建模实战迁移指南 当机械臂从教科书案例走向真实项目时,最令人头疼的莫过于面对一个全新构型却不知如何下手。本文将以工业界经典的PUMA560为跳板,拆解一套可迁移的DH建模方法论,带您跨越从理论到实践的…...

HS2-HF_Patch终极指南:一键为Honey Select 2安装完整增强补丁
HS2-HF_Patch终极指南:一键为Honey Select 2安装完整增强补丁 【免费下载链接】HS2-HF_Patch Automatically translate, uncensor and update HoneySelect2! 项目地址: https://gitcode.com/gh_mirrors/hs/HS2-HF_Patch HS2-HF_Patch是专为《Honey Select 2》…...

STM32CubeIDE实战指南:从代码编译到一键下载的完整流程解析
1. STM32CubeIDE开发环境概述 对于刚接触STM32开发的工程师来说,选择一款合适的集成开发环境(IDE)至关重要。STM32CubeIDE是ST官方推出的免费开发工具,它集成了代码编辑、编译、调试和下载功能于一体,特别适合新手快速上手。我在实际项目中使…...
)
告别黑盒:5分钟为你的自定义CNN模型集成Grad-CAM可视化(附常见错误排查)
告别黑盒:5分钟为你的自定义CNN模型集成Grad-CAM可视化(附常见错误排查) 在深度学习项目中,我们常常陷入一个尴尬境地:模型准确率很高,但完全不知道它究竟"看"了图像的哪些部分做出决策。这种黑盒…...

5分钟快速上手:使用res-downloader实现视频号批量下载的终极指南
5分钟快速上手:使用res-downloader实现视频号批量下载的终极指南 【免费下载链接】res-downloader 视频号、小程序、抖音、快手、小红书、直播流、m3u8、酷狗、QQ音乐等常见网络资源下载! 项目地址: https://gitcode.com/GitHub_Trending/re/res-downloader …...

基于 Next.js 的无头电商架构实战:从 Vercel Commerce 看现代全栈开发
1. 项目概述:一个面向未来的全栈电商起点如果你最近在琢磨着用 Next.js 搞一个电商网站,或者想找一个现代、开箱即用的全栈电商模板来启动项目,那你大概率已经听说过vercel/commerce这个仓库了。它不是某个具体的电商平台,而是一个…...

防火墙和手动启动都试了?ArcGIS License Server无响应,可能是这两个核心文件在捣鬼
ArcGIS许可服务故障深度解析:当核心文件成为隐形杀手 当你面对ArcGIS License Server无响应的红色报错框,已经尝试了关闭防火墙、调整服务配置、甚至重启服务器等一系列标准操作后,那个令人沮丧的"cannot connect to license server sys…...
)
别再拷贝exe到NXBIN了!用批处理文件搞定NX二次开发外部exe的环境变量(附VS2015/NX12配置)
告别手动拷贝:用批处理智能管理NX二次开发环境变量 每次修改完NX二次开发的外部exe程序,都要手动拷贝到NXBIN目录?这种重复劳动不仅低效,还容易导致版本混乱。其实只需一个简单的批处理脚本,就能彻底解决环境变量配置问…...

终极ThinkPad风扇控制指南:告别噪音,拥抱静音高效
终极ThinkPad风扇控制指南:告别噪音,拥抱静音高效 【免费下载链接】TPFanCtrl2 ThinkPad Fan Control 2 (Dual Fan) for Windows 10 and 11 项目地址: https://gitcode.com/gh_mirrors/tp/TPFanCtrl2 你是否曾经因为ThinkPad风扇的"直升机起…...

gnamiblast-skill:基于技能化与管道化的智能文本处理工具解析
1. 项目概述与核心价值最近在GitHub上闲逛,又发现了一个挺有意思的项目,叫gabrivardqc123/gnamiblast-skill。光看这个名字,可能有点摸不着头脑,gnamiblast听起来像是个自造词,skill又指向了某种技能或功能。作为一名常…...