MySQL语句性能分析与优化
目录
SQL性能分析
SQL执行频率
SQL慢查询日志
Profile
Explain
SQL优化
插入数据的优化
主键优化
Order By优化
Group By优化
Limit 优化
Count 优化
Update 优化
多表连接查询优化
SQL性能分析
通过SQL性能分析来做SQL的优化,主要是优化SQL的查询语句(其中索引的优化占主要部分)
SQL执行频率
通过以下命令来查看INSERT、UPDATE、DELETE、SELECT的访问频次(查看不同语句所占的比例)
根据不同语句的执行频率来进行不同的优化
SHOW SESSION/GLOBAL STATUS; 查看当前会话/全局服务器的状态信息
SHOW SESSION/GLOBAL STATUS LIKE ‘Com_______’ #(7个下划线)查看当前会话/全局的SQL增删改查的执行频率(就是从服务器的状态信息中提取关于增删改查的信息)
show global status like 'Com_______'; #查看全局的SQL语句插入、更新、删除、查询的执行频率

SQL慢查询日志
查看MySQL的慢查询日志的开关是否打开
SHOW VARIABLES LIKE 'slow_query_log';
慢查询日志的作用
通过慢查询日志可以定位到哪些查询语句需要进行优化
慢查询日志是记录了所有执行时间超过指定参数(long-query-time,默认10s)的SQL语句的日志(即:当SQL语句的执行时间超过10s,我们就会认为此语句是慢查询)
慢查询日志的路径
Linux系统关于MySQL慢查询日志
Linux关于MySQL的配置文件在/etc/my.cnf中
Linux中默认MySQL的慢日志查询没有开启,需要配置MySQL的配置文件中配置如下信息:
#开启MySQL慢日志查询开关
slow_query_log = 1
#设置慢日志的时间为2s,SQL执行时间超过2s就会被视为慢查询
log_query_time = 2
#保存之后然后重启mysql服务
Linxu会自动生成相关的日志文件存放慢日志查询中记录的信息,存放的位置在/var/lib/mysql/localhost-slow.log中
Windows系统关于MySQL慢查询日志
Windows默认开启了慢查询日志的开关,可以在MySQL的配置问价查看慢查询日志信息
Windows关于MySQL的配置文件在C:\ProgramData\MySQL\MySQL Server 8.0\my.ini中(以下是关于慢查询日志的配置信息)
slow-query-log=1 #开启MySQL慢日志查询开关
slow_query_log_file="慢查询日志的存放位置" #指定慢查询日志文件的存放位置
long_query_time=10 #设置慢日志的时间为10s
如果还是找不到对应的慢查询日志的存储位置
可以通过show variables like 'slow_%'来查看
慢查询日志的格式
Time:执行SQL的时间
User@Host:通过哪个用户,在哪个主机上登录到此SQL的
Query_time:当前命令执行耗时的时间
Lock_time: 表锁的时间(InnoDB的行锁等待不会反应在这里)
Rows_sent: 返回多少行
Rows_examined:检查了多少行
USE:使用的哪个数据库
SET timestamp:执行SQL的时间戳
ApplicationName:此字段会注释掉,用于告知此用户是通过什么软件连接到数据库的(此处为DataGrip)
以及查询语句
如果Rows_examined很大,而Rows_sent很小,则说明此查询需要优化


Profile
通过Profile可以帮助我们了解SQL语句执行的时间都耗费到哪里去了(也会记录错误的语句)
查看当前MySQL是否支持profile操作以及是否启用了此操作
show variables like '%profil%';
在MySQL中开启Profile功能
set session/global profiling = True;
Window和Linux默认Profile是关闭的(不同的版本可能有区别)
Profile相关语句
SHOW PROFILES; #查看会话中每一条SQL的耗时基本情况(每条SQL语句都有唯一的query_id)
SHOW PROFILE FOR QUERY query_id; #查看此query_id对应的SQL语句各个阶段的耗时情况
SHOW PROFILE CPU FOR QUERY query_id; #查看此query_id对应的SQL语句的CPU使用情况




Explain
前面的分析语句都是通过时间粗略分析;explan可以看到Sql语句的执行计划(如何执行select语句信息,select语句执行过程中如何连接以及连接的顺序),经常通过此判断SQL语句的性能
MySQL索引3——Explain关键字和索引优化(SQL提示、索引失效、索引使用规则)_静下心来敲木鱼的博客-CSDN博客
SQL优化
插入数据的优化
Inster 优化
1、当插入多条数据时使用批量插入
INSTER INTO 表名 VALUES(值1.1 , 值2.1),(值1.2 , 值2.2)……;
2、当要插入的数据超过百条时,建议使用事务来进行优化(手动提交事务,通过事务来优化)
START TRANSCANTION;
INSERT INTO 表名 VALUES(值1.1 , 值2.1),(值1.2 , 值2.2)……;
INSERT INTO 表名 VALUES(值1.100, 值2.100),(值1. 101, 值2.101)……;
COMMIT;
3、当要大批量的插入数据时,使用INSTER语句插入性能低,可以使用MySQL提供的LOAD进行进行插入(将符合一定规则的文件直接导入到Mysql生成相应的表)
- 客户端连接MySQL时加上参数--local-infile;表示当前客户端连接服务端时,需要加载客户端本地文件
mysql --local-infile -u root -p
2、设置全局参数local_infile为1;表示开启从本地加载文件导入数据的开关
show variables like '%infile%'; #查看是否开启load开关
set global local_infile=1; #开启load开关
3、执行load指令将准备好的本地文件中的数据加载到表结构中
load data local infile ‘本地文件的路径’ into table 表名 fields terminated by ‘每个字段对应值的分隔符’ lines terminated by ‘每一行数据的分隔符’;
建议分隔符都使用英文符号
模拟load插入
员工信息.txt文件(路径为C:/Users/123/Desktop/员工信息.txt)
创建user123表
create table User123(
id int auto_increment primary key,
name varchar(10),
age int,
origo varchar(10)
);将.txt文件导入表中
load data local infile 'C:/Users/Tdemo/Desktop/员工信息.txt' into table user123 fields terminated by ',' lines terminated by ';';
此时查看表的数据
select * from user123;


主键优化
在对主键进行插入数据时,顺序插入性能高于乱序插入
InnoDB关于主键的数据组织方式
表数据都是根据主键顺序组织存放的,这种存储方式的表称为索引组织表(index organized table IOT),我们再进行主键存放时就是根据顺序存放的
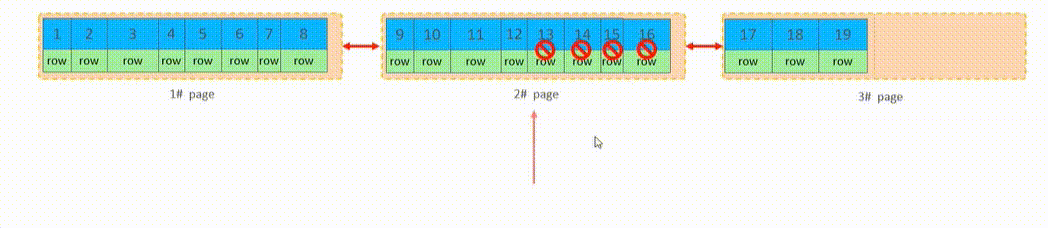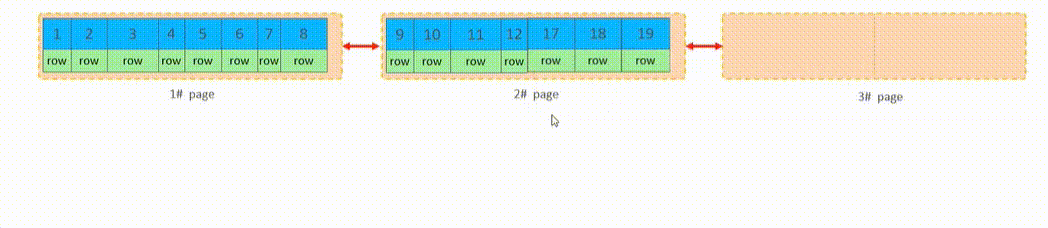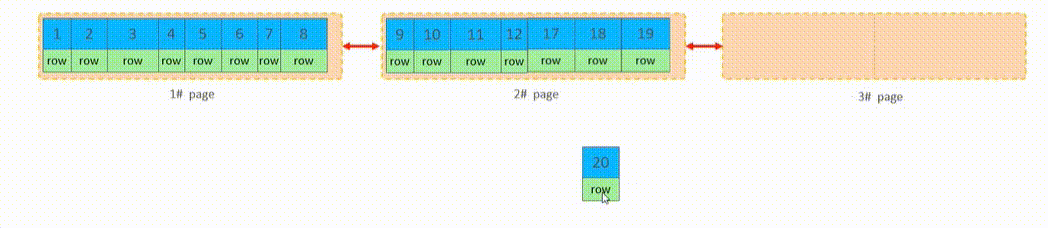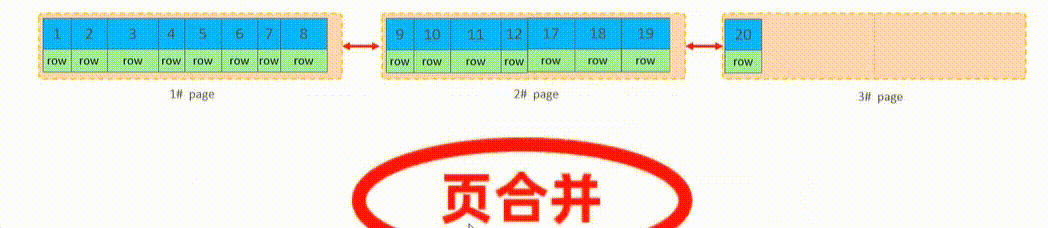
页分裂——乱序插入可能出现
页时InnoDB磁盘管理的最小单元,一个页的大小默认为16k,叶子节是有序的
每个页包含了2-N行数据(如果一行数据过大,就会行溢出)
页可以为空、也可以填充一半、也可以填充100%
主键顺序插入
主键乱序插入——可能会出现页分裂
50找到要插入的位置在第1个页的末尾;
发现此时第1页没有空间进行插入,此时会新建1个页;
然后找到第1个页的中间位置,将其右边的数据都迁移到新建的页中,然后再将50添加到新建的页中
此时再对三个页重新排序(需要消耗较多的性能)
页合并
当删除一行记录时,实际上记录并没有被物理删除,只是记录被标记(flaged)为删除;并且它的空间变得允许被其它记录声明使用
当页中删除的记录达到MERGE_THRESHOLD(默认为页的50%),InnoDB会开始寻找最靠近的页(前或后)看看是否可以将两个页合并以优化空间
Merge_threshold 合并页的阈值,可以自己设置(在创建表或索引时指定)
主键设计原则
1、满足业务需求的情况下,尽量降低主键的长度(此操作可以降低二级索引占用的空间)
2、插入数据时,建议主键进行顺序插入;可以使用AUTO_INCREMENT自增主键
3、尽量不要使用无序的值来作为主键,导致插入主键时可能乱序,在检索时也会耗费大量的IO
4、在进行业务操作时,尽量避免对主键的修改


Order By优化
进行排序时通过Explain显示的Extra字段的内容类型如果为Using Filsort,则需要进行优化,尽量将其优化为Using Index(通过满足覆盖索引实现)
Using Filesort和Index讲解
1、Using Filesort:通过表的索引或者全表扫描,读取满足条件的数据行,然后在排序缓冲区sort buffer中完成排序操作;所有不是通过索引直接返回排序结果的排序都叫FileSort排序
2、Using Index:查找使用了索引,并且通过索引可以接返回有序的数据,不需要额外排序,操作效率高
3、Backward index scan:反向扫描索引,进行降序排序时会出现;也是单独子啊排序缓冲区完成排序操作;需要进行优化
如何优化Backward index scan
在创建索引时,MySQL8之前的版本默认只是针对升序创建了索引;我们可以额外对字段创建关于降序的索引
格式如下(在字段后面跟上排序方式)
create index 索引名 on 表名(字段1 asc , 字段2 desc);
为字段1创建升序索引,为字段2创建倒序索引
总结
1、当创建联合索引后,在进行排序时如果一部分按照升序排序,一部分按照降序排序,则会产生using filesort;此时可以为此单独再创建索引
2、在使用索引时尽量实现覆盖索引
3、在使用是要避免索引失效
4、如果不可避免的出现filesort,在大数据排序时,可以适当增大排序缓冲区的大小sort_buffer_size(默认256k)
5、Show variables like ‘sort_buffer_size’; #查看排序缓冲区的大小;当排序缓冲区占满之后会占用磁盘进行排序
Group By优化
主要研究索引对分组查询的影响,思路和排序优化是一致的
进行分组时通过Explain显示的Extra字段的内容类型如果为Using Temporary,则需要进行优化,尽量将其优化为Using Index(通过满足覆盖索引实现)
Using Temporary讲解
Using temporary:查找使用到了临时表,性能比较低
总结
1、在分组操作时可以通过索引来提高效率
2、在分组操作时,索引的使用也是满足最左前缀法则的
3、在分组操作时,尽量实现覆盖索引,避免回表查询
4、在分组操作时,避免索引失效
Limit 优化
在大数据量情况下,越往后分页,耗时越长,可能也会造成资源浪费
当我们查询limit 10000,10时,我们需要排序MySQL前10010条记录,但是只范围10000-10010之间的10条记录,其它记录丢弃,此时查询的代价就很大(排序是为了保证每次通过limit查到的记录都一样)
可以通过覆盖索引+子查询的方式优化
通过子查询找到10000-10010对应数据的主键值,然后再通过主键值来查找对应的数据
需要注意有些版本Mysql不支持在in之后使用子查询的语法,所以以下的语句无法实现
Select * from 表名 where 主键值 in (select 主键值 from 表名 order by limit 10000,10);
方式二 我们可以将子查询的结果看作一张表,通过多表查询来实现
Select a.* from 表1 a, (select 主键值 from 表1 order by limit 10000,10) b where a.主键值=b.主键值;
Count 优化
不同存储引擎对于Count(*)的不同处理方式
MyISAM引擎中会把一个表的总行数存在磁盘上,因此执行count(*)的时候才会直接返回这个数,效率很高(前提是查询时没有where条件)
InnoDB引擎在执行count()*时,需要把遍历整张表,把数据一行一行地从引擎里面读出来,然后积累计数(如果为Null则不加1,如果为非Null值则计数加1),最后将积累的计数输出(无论是否有where条件,InnoDB都是这样操作的)
Count的不同用法以及性能差异
Count的主要用法有count(*)、count(主键)、count(字段)、count(X)
Count(主键) ——主键的总记录行数
会遍历整张表,把每一行的主键值提取出来返回给服务层,服务层拿到主键后直接按照行数进行累加(不进行判断是否为Null)
Count(字段) ——统计此字段有多少值不为Null,不一定是总记录数
分为加了Not Null约束和没有加Null约束两种情况
没有加Not Null约束:需要判断值是否为Null
把每一行的字段对应的值提取出来返回给服务层,服务层判断是否为Null,如果为Null则不加1,如果为非Null值则计数加1
加了Not Null约束:不需要判断是否为Null
把每一行的字段对应的值提取出来返回给服务层,服务层进行累加
Count(x) ——x为数字,查询表的总记录行数
InnoDB会遍历整张表,不过不会进行取值;服务层对于返回的每一行放一个数字x进去,直接按照行进行累加
Count(*) ——表当中的总记录行数
Mysql对InnoDB引擎做了优化,InnoDB引擎在执行count()*时,需要把遍历整张表,不过不会进行取值,直接按照行数进行累加,最后将积累的计数输出;底层count(*)=count(0)
性能比较
Count(*) ≈ Count(x) > Count(主键) > Count(字段)
尽量使用Count(*)
如何优化InnoDB引擎对Count关键字的处理
没有较好的优化策略,想要优化的话可以在插入数据或删除数据时自行计数,只不过比较繁琐
Update 优化
对于InnoDB引擎来说,默认事务隔离级别是通过行锁实现的;并且该行锁是针对索引加的锁,不是针对记录加的锁;如果该索引失效了,则会从行锁升级为表锁
即:对于建立了索引的字段使用的是行锁;没有建立索引的字段使用的是表锁;一旦锁表,就会降低并发操作
因此,优化建议为
1、使用Update时使用索引列作为更新条件,避免表锁
2、避免出现索引失效,将行锁升级为表锁
多表连接查询优化
内连接时,Mysql会自动把输出结果小的表选为驱动表,所以大表(输出结果多的表)的字段最好加上索引
左外连接时,左表会全表查询(不可避免地,因为要显示左表的全部数据),建议右边表的字段最好加上索引
右外连接时,右表会全表查询,建议左边表的字段最好加上索引
优化手段
1、在外连接时,尽量将小表作为驱动表,并保证被驱动表上的字段建立了索引
3、内连接时,尽量将大表的字段加上索引
相关文章:
MySQL语句性能分析与优化
目录 SQL性能分析 SQL执行频率 SQL慢查询日志 Profile Explain SQL优化 插入数据的优化 主键优化 Order By优化 Group By优化 Limit 优化 Count 优化 Update 优化 多表连接查询优化 SQL性能分析 通过SQL性能分析来做SQL的优化,主要是优化SQL的查询语…...

SpringBoot实现数据库读写分离
SpringBoot实现数据库读写分离 参考博客https://blog.csdn.net/qq_31708899/article/details/121577253 实现原理:翻看AbstractRoutingDataSource源码我们可以看到其中的targetDataSource可以维护一组目标数据源(采用map数据结构),并且做了路由key与目标…...
Linux(四)--包软件管理器与Linux上环境部署示例
一.包软件管理器【yum和apt】 1.先来学习使用yum命令。yum:RPM包软件管理器,用于自动化安装配置Linux软件,并可以自动解决依赖问题。通过yum命令我们可以轻松实现软件的下载,查找,卸载与更新等管理软件的操作。 最常用…...
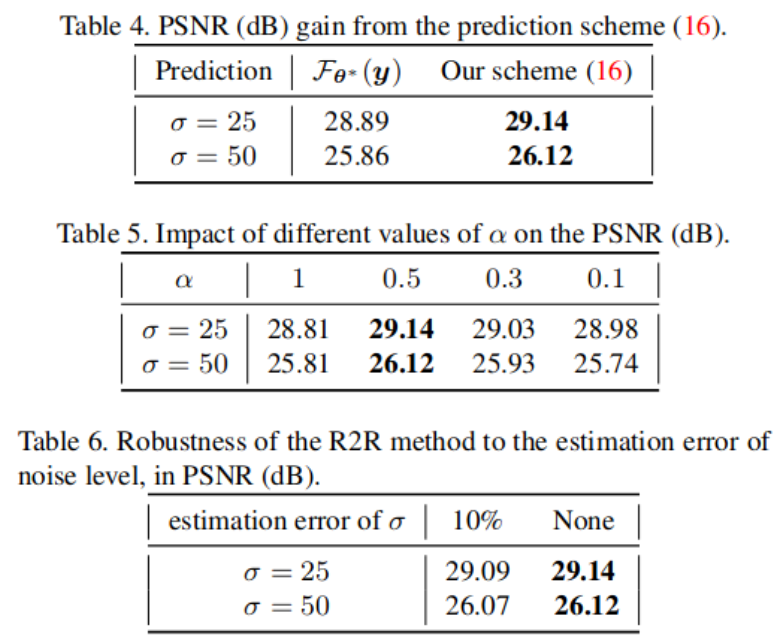
自监督去噪:Recorrupted-to-Recorrupted原理分析与总结
文章目录 1. 方法原理1.1 相关研究1.2 研究思路1.3 小结 2. 实验结果3. 总结 文章地址: https://ieeexplore.ieee.org/document/9577798/footnotes#footnotes 参考博客: https://github.com/PangTongyao/Recorrupted-to-Recorrupted-Unsupervised-Deep-Learning-for-Image-Den…...

【css】css实现水平和垂直居中
通过 justify-content 和 align-items设置水平和垂直居中, justify-content 设置水平方向,align-items设置垂直方向。 代码: <style> .center {display: flex;justify-content: center;align-items: center;height: 200px;border: 3px…...
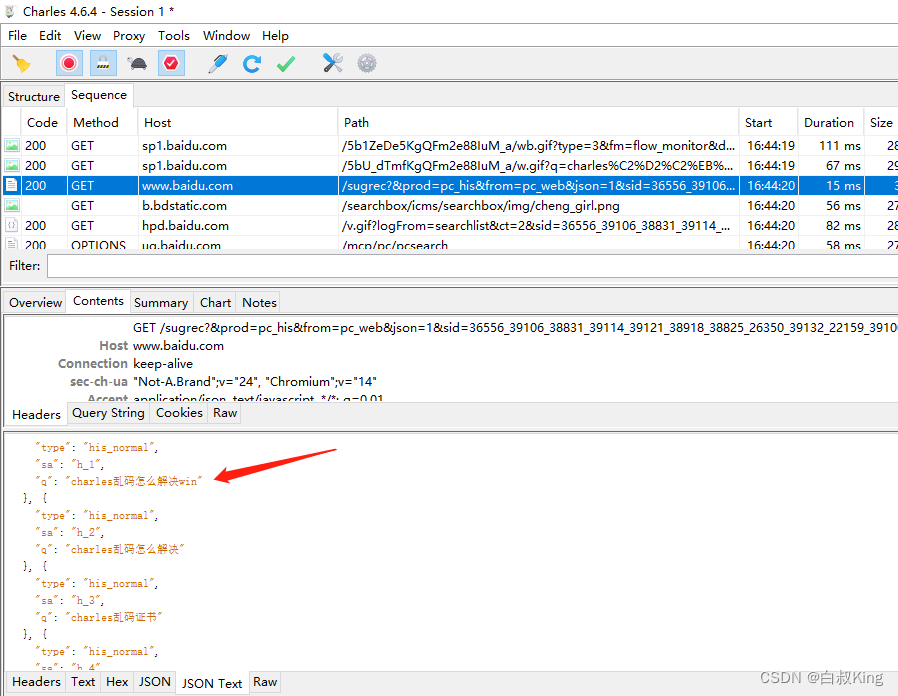
常见Charles在Windows10抓包乱码问题
废话不多说 直接开整 最近反复安装证书还是乱码 网上各种百度还是不行 首先计算机查看安装好的证书 certmgr.msc 找到并删除掉 重新安装证书 具体解决方法: 第一步:点击 【工具栏–>Proxy–>SSL Proxying Settings…】 第二步:配置…...

汽车维修保养记录查询API:实现车辆健康状况一手掌握
在当今的数字化世界中,汽车维修保养记录的查询和管理变得前所未有地简单和便捷。通过API,我们可以轻松地获取车辆的维修和保养记录,从而实现对手中车辆健康状况的实时掌握。 API(应用程序接口)是进行数据交换和通信的标…...
)
正则表达式学习记录(Python)
正则表达式学习记录(Python) 一、特殊符号和字符 多个正则表达式匹配 ( | ) 用来分隔不同的匹配模式,相当于逻辑或,可以符合其中任何一个正则表达式 at | home # 表示匹配at或者home bat | bet | bit # 表示匹配bat或…...

Ubuntu20.04操作系统安装Docker
1、添加Docker仓库 curl -fsSL https://mirrors.ustc.edu.cn/docker-ce/linux/ubuntu/gpg | sudo apt-key add -sudo add-apt-repository \"deb [archamd64] https://mirrors.ustc.edu.cn/docker-ce/linux/ubuntu/ \$(lsb_release -cs) \stable"2、安装Docker sudo…...
python制作小程序制作流程,用python编写一个小程序
这篇文章主要介绍了python制作小程序代码宠物运输,具有一定借鉴价值,需要的朋友可以参考下。希望大家阅读完这篇文章后大有收获,下面让小编带着大家一起了解一下。 1 importtkinter2 importtkinter.messagebox3 importmath4 classJSQ:5 6 7 d…...

Github 创建自己的博客网站
参考pku大佬视频制作,附上B站视频:【GitHub Pages 个人网站构建与发布】 同时还参考了:【Python版宝藏级静态站点生成器Material for MkDocs】 GitHub Pages 介绍 内容参考:GitHub Pages - 杨希杰的个人网站 (yang-xijie.githu…...
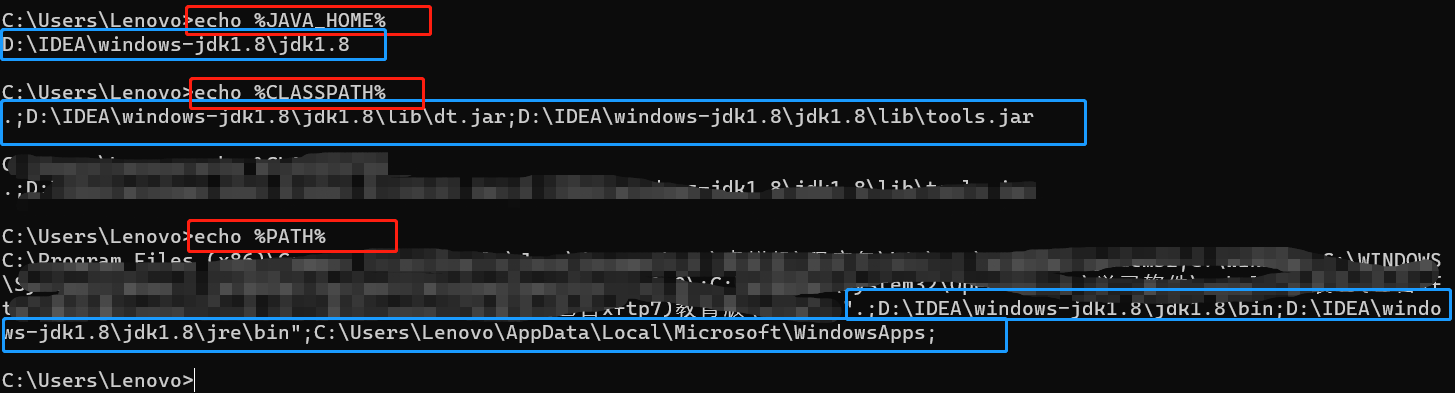
Windows上安装 jdk 环境并配置环境变量 (超详细教程)
👨🎓博主简介 🏅云计算领域优质创作者 🏅华为云开发者社区专家博主 🏅阿里云开发者社区专家博主 💊交流社区:运维交流社区 欢迎大家的加入! 🐋 希望大家多多支…...
高效构建 vivo 企业级网络流量分析系统
作者:vivo 互联网服务器团队- Ming Yujia 随着网络规模的快速发展,网络状况的良好与否已经直接关系到了企业的日常收益,故障中的每一秒都会导致大量的用户流失与经济亏损。因此,如何快速发现网络问题与定位异常流量已经成为大型企…...

认识awk
awk 认识awk awk是一种编程语言,用于在linux/unix下对文本和数据进行处理。数据可以来自标准输入(stdin)、一个或多个文件,或其它命令的输出。它支持用户自定义函数和动态正则表达式等先进功能,是linux/unix下的一个强大编程工具。它在命令行…...

【C#学习笔记】数组和索引器
文章目录 数组单维数组多维数组交错数组 索引器类上的索引器方法1方法2 接口中的索引器 数组 数组具有以下属性: 数组可以是一维、多维或交错的。创建数组实例时,将建立纬度数量和每个纬度的长度。 这些值在实例的生存期内无法更改。数值数组元素的默认…...

常见距离计算的Python实现
常见的距离有曼哈顿距离、欧式距离、切比雪夫距离、闵可夫斯基距离、汉明距离、余弦距离等,用Python实现计算的方式有多种,可以直接构造公式计算,也可以利用内置线性代数函数计算,还可以利用scipy库计算。 1.曼哈顿距离 也叫城市…...
开发运营监控
DevOps 监控使管理员能够实时了解生产环境中的元素,并有助于确保应用程序平稳运行,同时提供最高的业务价值,对于采用 DevOps 文化和方法的公司来说,这一点至关重要。 什么是开发运营监控 DevOps 通过持续开发、集成、测试、监控…...

食品小程序的制作教程
在今天的互联网时代,小程序已经成为了各行业推广和销售的重要途径。特别是对于食品行业来说,拥有一个专属的小程序商城可以带来更多的用户和销售机会。那么,如何制作一个完美的食品小程序呢?下面就跟随我来一步步教你,…...
从入门到精通系列之十三:软件负载平衡选项)
Kubernetes(K8s)从入门到精通系列之十三:软件负载平衡选项
Kubernetes K8s从入门到精通系列之十三:软件负载平衡选项 一、软件负载平衡选项二、keepalived and haproxy三、keepalived配置四、haproxy配置五、选项 1:在操作系统上运行服务六、选项 2:将服务作为静态 Pod 运行 一、软件负载平衡选项 当…...
数据特征选择 | Matlab实现具有深度度量学习的时频特征嵌入
文章目录 效果一览文章概述源码设计参考资料效果一览 文章概述 数据特征选择 | Matlab实现具有深度度量学习的时频特征嵌入。 深度度量学习尝试学习非线性特征嵌入或编码器,它可以减少来自同一类的示例之间的距离(度量)并增加来自不同类的示例之间的距离。 以这种方式工作的…...

AI Agent Harness Engineering 产品经理指南:如何定义智能体的“人设”与能力边界?
AI Agent Harness Engineering 产品经理指南:如何定义智能体的「人设」与能力边界 关键词:AI Agent、智能体管控工程(Harness Engineering)、产品经理、人设对齐、能力边界、智能体治理、生成式AI落地 摘要 随着生成式AI技术的成熟,AI Agent已经从概念验证阶段进入大规…...

从myplaces.shp到专题地图:手把手教你用QGIS C++ API实现点要素分级渲染
从myplaces.shp到专题地图:QGIS C API实现点要素分级渲染实战指南 当我们需要在桌面GIS应用中直观展示气象站降雨量、城市人口密度或商业网点销售额等连续型空间数据时,分级色彩渲染是最有效的可视化手段之一。本文将深入探讨如何利用QGIS强大的C API&am…...

从零构建个人知识库:Go+React全栈项目RocketNotes实战解析
1. 项目概述:从零到一构建个人知识管理工具最近在整理个人笔记和代码片段时,发现了一个挺有意思的开源项目fynnfluegge/rocketnotes。乍一看这个名字,可能会联想到火箭(Rocket)和笔记(Notes)的结…...

WandEnhancer技术解密:如何通过本地化增强重新定义游戏修改体验
WandEnhancer技术解密:如何通过本地化增强重新定义游戏修改体验 【免费下载链接】Wand-Enhancer Advanced UX and interoperability extension for Wand (WeMod) app 项目地址: https://gitcode.com/gh_mirrors/we/Wand-Enhancer 你是否曾经面对游戏修改工具…...

开源虚拟世界引擎Vircadia核心架构与部署实战指南
1. 项目概述:一个开源虚拟世界的核心引擎如果你对构建一个属于自己的、去中心化的虚拟世界感兴趣,那么你很可能已经听说过或者正在寻找一个合适的底层引擎。今天要聊的这个项目,就是这样一个领域的重量级选手:vircadia/vircadia-n…...

UEFITool终极指南:轻松解析和编辑UEFI固件的开源利器
UEFITool终极指南:轻松解析和编辑UEFI固件的开源利器 【免费下载链接】UEFITool UEFI firmware image viewer and editor 项目地址: https://gitcode.com/gh_mirrors/ue/UEFITool 你是否曾好奇计算机启动时底层发生了什么?想要深入了解UEFI固件的…...

Nestia:基于TypeScript编译时分析的NestJS端到端类型安全实践
1. 项目概述:当NestJS遇上TypeScript的极致类型安全如果你正在用NestJS开发后端API,并且对TypeScript的类型安全有近乎偏执的追求,那么你很可能已经听说过,或者正在寻找一个能让你“写一次,安全两次”的工具。我说的“…...

从零构建情感大语言模型:基于EmoLLM的实践指南
1. 项目概述:当大语言模型学会“察言观色”最近在折腾一个挺有意思的开源项目,叫SmartFlowAI/EmoLLM。光看名字你可能就猜到了,这玩意儿跟“情绪”和“大语言模型”有关。没错,它的核心目标就是让冷冰冰的LLM(Large La…...

紧急更新!Midjourney 6.2.1已悄然修复碳素印相的硫化银衰减模拟缺陷——但97%用户仍在用旧参数,立即校准你的工作流
更多请点击: https://intelliparadigm.com 第一章:碳素印相的视觉本质与Midjourney 6.2.1修复的底层动因 碳素印相的物质性光感逻辑 碳素印相并非数字渲染的模拟,而是一种基于明胶-碳黑颗粒物理沉积的连续调成像工艺。其高密度阴影区呈现哑…...

AI编程助手CodeBuddy:VS Code扩展的架构、部署与高效使用指南
1. 项目概述:CodeBuddy,你的AI编程伙伴最近在GitHub上看到一个挺有意思的项目,叫codebuddy,作者是olasunkanmi-SE。光看名字就能猜个大概——“代码伙伴”,这显然是一个旨在辅助编程的工具。作为一个在开发一线摸爬滚打…...