用队列实现栈——数据结构与算法


😶🌫️Take your time ! 😶🌫️
💥个人主页:🔥🔥🔥大魔王🔥🔥🔥
💥代码仓库:🔥🔥魔王修炼之路🔥🔥
💥所属专栏:🔥魔王的修炼之路–数据结构🔥
如果你觉得这篇文章对你有帮助,请在文章结尾处留下你的点赞👍和关注💖,支持一下博主。同时记得收藏✨这篇文章,方便以后重新阅读。
文章目录
- 一、题目
- 二、思路
- 三、代码
- 1、队列代码
- 2、创建两个队列模拟的栈
- 3、入栈
- 4、出栈
- 5、访问栈顶元素
- 6、判断栈是否为空
- 7、释放空间
- 8、总代码
- 四、总结
一、题目
力扣链接

二、思路
栈是后进先出,队列是先进先出.
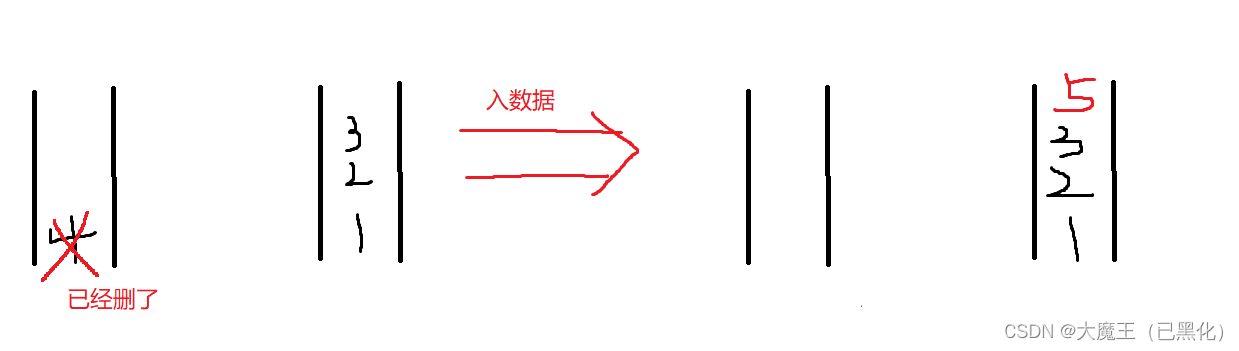
出队列:队列入了1,2,3,4后只能1,2,3,4出,栈入了1,2,3,4后只能4,3,2,1出,所以需要两个队列,当栈出元素时,先让前n-1个入到另一个队列并删除原队列中这n-1个数据,那么原来队列只剩下4了,然后把这个4删除就行。

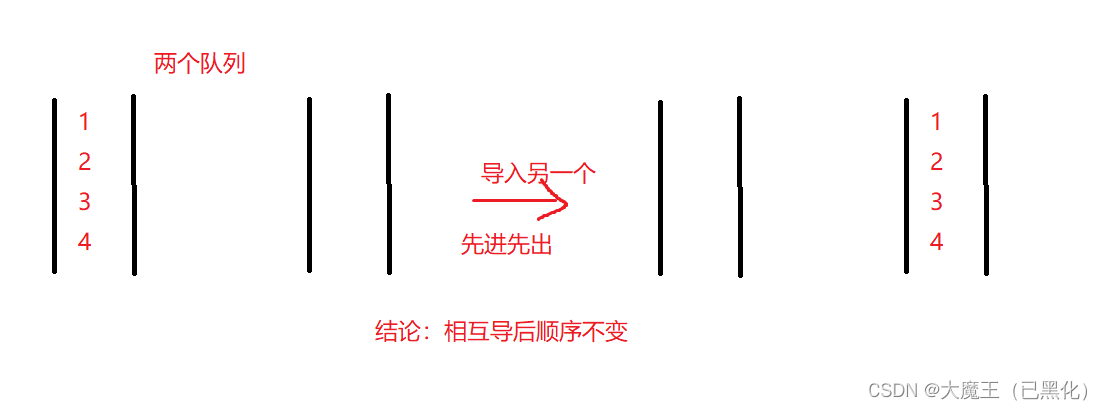
入队列:根据出队列发现,把一个队列数据放到另一个数据里面,原来的数据顺序不变,所以入队列时只需要入在那个不为空的队列里就行。
三、代码
1、队列代码
首先先把之前实现队列的代码粘贴上去,这样就不用再实现一遍队列了。
#include <stdlib.h>typedef int QDataType;typedef struct QueueNode
{struct QueueNode* next;QDataType data;
}QNode;typedef struct Queue
{QNode* head;QNode* tail;int size;
}Queue;void QInit(Queue* q)
{assert(q);q->head = q->tail = NULL;q->size = 0;
}void QDestroy(Queue* q)
{assert(q);while (q->head){QNode* next = q->head->next;free(q->head);q->head = next;}q->tail = NULL;q->size = 0;
}QNode* BuyNewnode(QDataType x)
{QNode* newnode = (QNode*)malloc(sizeof(QNode));if (newnode == NULL){perror("malloc error");assert(newnode);}newnode->data = x;newnode->next = NULL;return newnode;
}void QPush(Queue* q, QDataType x)
{assert(q);QNode* newnode = BuyNewnode(x);if (q->head == NULL){assert(q->head == q->tail);q->head = q->tail = newnode;}else{q->tail->next = newnode;q->tail = newnode;}q->size++;
}void QPop(Queue* q)
{assert(q);assert(q->head && q->tail);if (q->head->next == NULL){assert(q->head == q->tail);free(q->head);q->head = q->tail = NULL;}else{QNode* newhead = q->head->next;free(q->head);q->head = newhead;}q->size--;
}int QSize(Queue* q)
{assert(q);return q->size;
}bool QEmpty(Queue* q)
{assert(q);//-------------------------1------------------------------------------------//1这里的报错,但是其实根本没错,是在下面的2处错的,所以在哪个地方报错可以重点看那个地方,但并不一定就是这个部分错了。return q->size == 0;
}QDataType QFront(Queue* q)
{assert(q);assert(q->head);return q->head->data;
}QDataType QBack(Queue* q)
{assert(q);assert(!QEmpty(q));return q->tail->data;
}
2、创建两个队列模拟的栈
创建一个结构体,放两个队列作为成员,然后创建并初始化队列。
//匿名结构体,创建一个结构体是我的栈,因为我们使用队列模拟栈,所以里面放两个队列。
typedef struct {Queue q1;Queue q2;
} MyStack;//创建我的栈,前面我们的模拟栈的结构体已经创建好了,现在就是要创建一个指针指向我们开辟出的该结构体的空间,并使其初始化。因为这是创建好后用的返回值传给别的函数,所以不能直接创建变量,要malloc,否则除该作用域就销毁了。
MyStack* myStackCreate() {MyStack* creat = (MyStack*)malloc(sizeof(MyStack));if(creat == NULL){perror("malloc error");assert(creat);}QInit(&creat->q1);QInit(&creat->q2);return creat;
}
3、入栈
直接入到不为空的队列就行,因为两个相互导顺序还是原来的顺序。
void myStackPush(MyStack* obj, int x) {Queue* EmptyQ = &obj->q1;Queue* nonEmptyQ = &obj->q2;//if (QEmpty(&EmptyQ) == 0)-------------------------2(错的)----------------------------------if (QEmpty(EmptyQ) == 0){EmptyQ = &obj->q2;nonEmptyQ = &obj->q1;}QPush(nonEmptyQ, x);
}
4、出栈
让不为空的n-1个元素导到空队列中,原队列只剩最后一个,然后pop就行了。
int myStackPop(MyStack* obj) {Queue* EmptyQ = &obj->q1;Queue* nonEmptyQ = &obj->q2;if (!QEmpty(EmptyQ)){EmptyQ = &obj->q2;nonEmptyQ = &obj->q1;}while (QSize(nonEmptyQ) != 1){QPush(EmptyQ, QFront(nonEmptyQ));QPop(nonEmptyQ);}int ret = QFront(nonEmptyQ);QPop(nonEmptyQ);return ret;
}
5、访问栈顶元素
可以直接访问非空队列的最上面的元素即可。
//方法1.访问栈顶元素
int myStackTop(MyStack* obj) {if(!QEmpty(&obj->q1)){return QBack(&obj->q1);}elsereturn QBack(&obj->q2);
}
也可以再导一次,就像出栈一样,只不过不删除最后的元素,而是也导入另一个队列。
//方法2.访问栈顶元素
// 力扣检查比较严格,就算最后的那个return没用,但有返回值的函数结尾还是要加上return 的。
int myStackTop(MyStack* obj) {int ret = 0;Queue* EmptyQ = &obj->q1;Queue* nonEmptyQ = &obj->q2;if(!QEmpty(EmptyQ)){EmptyQ = &obj->q2;nonEmptyQ = &obj->q1;}while(QSize(nonEmptyQ)>0){if(QSize(nonEmptyQ) == 1){ret = QFront(nonEmptyQ);QPush(EmptyQ,QFront(nonEmptyQ));QPop(nonEmptyQ);return ret;}QPush(EmptyQ,QFront(nonEmptyQ));QPop(nonEmptyQ);}return ret;
}
6、判断栈是否为空
两个队列同时为空即为空。
bool myStackEmpty(MyStack* obj) {return QEmpty(&obj->q1) && QEmpty(&obj->q2);
}
7、释放空间
malloc了几次就释放几次。
void myStackFree(MyStack* obj) {QDestroy(&obj->q1);QDestroy(&obj->q2);free(obj);
}
8、总代码
#include <stdlib.h>typedef int QDataType;typedef struct QueueNode
{struct QueueNode* next;QDataType data;
}QNode;typedef struct Queue
{QNode* head;QNode* tail;int size;
}Queue;void QInit(Queue* q)
{assert(q);q->head = q->tail = NULL;q->size = 0;
}void QDestroy(Queue* q)
{assert(q);while (q->head){QNode* next = q->head->next;free(q->head);q->head = next;}q->tail = NULL;q->size = 0;
}QNode* BuyNewnode(QDataType x)
{QNode* newnode = (QNode*)malloc(sizeof(QNode));if (newnode == NULL){perror("malloc error");assert(newnode);}newnode->data = x;newnode->next = NULL;return newnode;
}void QPush(Queue* q, QDataType x)
{assert(q);QNode* newnode = BuyNewnode(x);if (q->head == NULL){assert(q->head == q->tail);q->head = q->tail = newnode;}else{q->tail->next = newnode;q->tail = newnode;}q->size++;
}void QPop(Queue* q)
{assert(q);assert(q->head && q->tail);if (q->head->next == NULL){assert(q->head == q->tail);free(q->head);q->head = q->tail = NULL;}else{QNode* newhead = q->head->next;free(q->head);q->head = newhead;}q->size--;
}int QSize(Queue* q)
{assert(q);return q->size;
}bool QEmpty(Queue* q)
{assert(q);//-------------------------1------------------------------------------------//1这里的报错,但是其实根本没错,是在下面的2处错的,所以在哪个地方报错可以重点看那个地方,但并不一定就是这个部分错了。return q->size == 0;
}QDataType QFront(Queue* q)
{assert(q);assert(q->head);return q->head->data;
}QDataType QBack(Queue* q)
{assert(q);assert(!QEmpty(q));return q->tail->data;
}//匿名结构体,创建一个结构体是我的栈,因为我们使用队列模拟栈,所以里面放两个队列。
typedef struct {Queue q1;Queue q2;
} MyStack;//创建我的栈,前面我们的模拟栈的结构体已经创建好了,现在就是要创建一个指针指向我们开辟出的该结构体的空间,并使其初始化。因为这是创建好后用的返回值传给别的函数,所以不能直接创建变量,要malloc,否则除该作用域就销毁了。
MyStack* myStackCreate() {MyStack* creat = (MyStack*)malloc(sizeof(MyStack));if(creat == NULL){perror("malloc error");assert(creat);}QInit(&creat->q1);QInit(&creat->q2);return creat;
}void myStackPush(MyStack* obj, int x) {Queue* EmptyQ = &obj->q1;Queue* nonEmptyQ = &obj->q2;//if (QEmpty(&EmptyQ) == 0)-------------------------2----------------------------------if (QEmpty(EmptyQ) == 0){EmptyQ = &obj->q2;nonEmptyQ = &obj->q1;}QPush(nonEmptyQ, x);
}int myStackPop(MyStack* obj) {Queue* EmptyQ = &obj->q1;Queue* nonEmptyQ = &obj->q2;if (!QEmpty(EmptyQ)){EmptyQ = &obj->q2;nonEmptyQ = &obj->q1;}while (QSize(nonEmptyQ) != 1){QPush(EmptyQ, QFront(nonEmptyQ));QPop(nonEmptyQ);}int ret = QFront(nonEmptyQ);QPop(nonEmptyQ);return ret;
}// //方法1.访问栈顶元素
// int myStackTop(MyStack* obj) {
// if(!QEmpty(&obj->q1))
// {
// return QBack(&obj->q1);
// }
// else
// return QBack(&obj->q2);
// }//方法2.访问栈顶元素
// 力扣检查比较严格,就算最后的那个return没用,但有返回值的函数结尾还是要加上return 的。
int myStackTop(MyStack* obj) {int ret = 0;Queue* EmptyQ = &obj->q1;Queue* nonEmptyQ = &obj->q2;if(!QEmpty(EmptyQ)){EmptyQ = &obj->q2;nonEmptyQ = &obj->q1;}while(QSize(nonEmptyQ)>0){if(QSize(nonEmptyQ) == 1){ret = QFront(nonEmptyQ);QPush(EmptyQ,QFront(nonEmptyQ));QPop(nonEmptyQ);return ret;}QPush(EmptyQ,QFront(nonEmptyQ));QPop(nonEmptyQ);}return ret;
}//方法3.访问栈顶元素
// int myStackTop(MyStack* obj) {
// Queue* EmptyQ = &obj->q1;
// Queue* nonEmptyQ = &obj->q2;
// if (!QEmpty(EmptyQ))
// {
// EmptyQ = &obj->q2;
// nonEmptyQ = &obj->q1;
// }
// while (QSize(nonEmptyQ) != 1)
// {
// QPush(EmptyQ, QFront(nonEmptyQ));
// QPop(nonEmptyQ);
// }
// int ret = QFront(nonEmptyQ);
// QPush(EmptyQ,QFront(nonEmptyQ));
// QPop(nonEmptyQ);
// return ret;
// }bool myStackEmpty(MyStack* obj) {return QEmpty(&obj->q1) && QEmpty(&obj->q2);
}void myStackFree(MyStack* obj) {QDestroy(&obj->q1);QDestroy(&obj->q2);free(obj);
}/*** Your MyStack struct will be instantiated and called as such:* MyStack* obj = myStackCreate();* myStackPush(obj, x);* int param_2 = myStackPop(obj);* int param_3 = myStackTop(obj);* bool param_4 = myStackEmpty(obj);* myStackFree(obj);
*/
四、总结
- -----1-----和-----2-----这两个地方是一个错误,因为在2多写了个取地址,然后在1处报错,结果检查了大半天也检查不出来,因为1处报错很难想出来是2处的问题。所以:报错的地方重点检查,如果真的没错误,可能是其他地方的问题。
- 分别指向空队列和非空队列时别弄混了,有点绕。
- 博主长期更新,博主的目标是不断提升阅读体验和内容质量,如果你喜欢博主的文章,请点个赞或者关注博主支持一波,我会更加努力的为你呈现精彩的内容。
🌈专栏推荐
😈魔王的修炼之路–C语言
😈魔王的修炼之路–数据结构初阶
😈魔王的修炼之路–C++
😈魔王的修炼之路–Linux
更新不易,希望得到友友的三连支持一波。收藏这篇文章,意味着你将永久拥有它,无论何时何地,都可以立即找到重新阅读;关注博主,意味着无论何时何地,博主将永久和你一起学习进步,为你带来有价值的内容。

相关文章:
用队列实现栈——数据结构与算法
😶🌫️Take your time ! 😶🌫️ 💥个人主页:🔥🔥🔥大魔王🔥🔥🔥 💥代码仓库:🔥🔥魔…...

Python“牵手”1688商品详情页数据采集方法,1688API接口申请指南
1688详情接口 API 是开放平台提供的一种 API 接口,它可以帮助开发者获取商品的详细信息,包括商品的标题、描述、图片等信息。在电商平台的开发中,详情接口API是非常常用的 API,因此本文将详细介绍详情接口 API 的使用。 一、1688…...
记录第一篇被”华为开发者联盟鸿蒙专区 “收录的文章
记录第一篇被”华为开发者联盟鸿蒙专区 “社区收录的文章。 坚持写作的动力是什么? 是记录、分享,以及更好的思考 。...
jenkins的cicd操作
cicd概念 持续集成( Continuous Integration) 持续频繁的(每天多次)将本地代码“集成”到主干分支,并保证主干分支可用 持续交付(Continuous Delivery) 是持续集成的下一步,持续…...
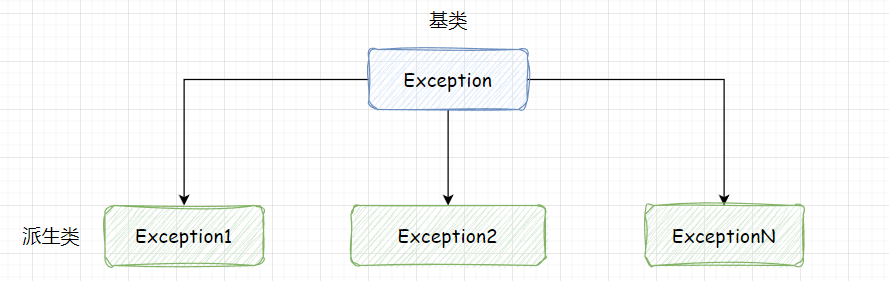
【C++】异常exception
文章目录 1. C语言中传统的处理错误方法2. C中的异常3. 异常的使用3.1 异常的抛出和捕获3.2 异常的重新抛出3.3 异常安全3.4 异常规范 4. 自定义异常体系5. 异常的优缺点 📝 个人主页 :超人不会飞)📑 本文收录专栏:《C的修行之路》…...

2023-08-06力扣今日三题
链接: 剑指 Offer 59 - I. 滑动窗口的最大值 题意: 一个lg长度的数组,一个长度k的滑动窗口,求所有滑动窗口中的最大值 解: 优先队列存储存储下标,数字大的优先,每次判断最大的值是否在范围…...

kubeasz在线安装K8S集群
一、介绍 Kubeasz 是一个基于 Ansible 自动化工具,用于快速部署和管理 Kubernetes 集群的工具。它支持快速部署高可用的 Kubernetes 集群,支持容器化部署,可以方便地扩展集群规模,支持多租户,提供了强大的监控和日志分…...

Vue中实现Web端鼠标横向滑动和触控板滑动效果
系列文章目录 文章目录 系列文章目录前言一、鼠标横向滑动效果二、触控板滑动效果总结 前言 在Web端,我们经常需要实现鼠标横向滑动和触控板滑动的效果,以便在页面中展示横向滑动的内容。本文将介绍如何使用Vue和JavaScript来实现这两种效果,…...
)
hdu5-Touhou Red Red Blue(贪心)
Problem - 7329 (hdu.edu.cn) 参考:题解 | #1006.Touhou Red Red Blue# 2023杭电暑期多校5 题解:(贪心) mp[R], mp[G], mp[P] 分别记录对应字母出现过多少次,没有AAA orABC 出现时不得分也不进行任何操作ÿ…...
【LeetCode 75】第二十三题(2352)相等行列对
目录 题目: 示例: 分析: 代码运行结果: 题目: 示例: 分析: 题目很简洁,就是要我们寻找行与列相同的对数。相同行与列不仅是要元素相同,还需要顺序也一样(…...
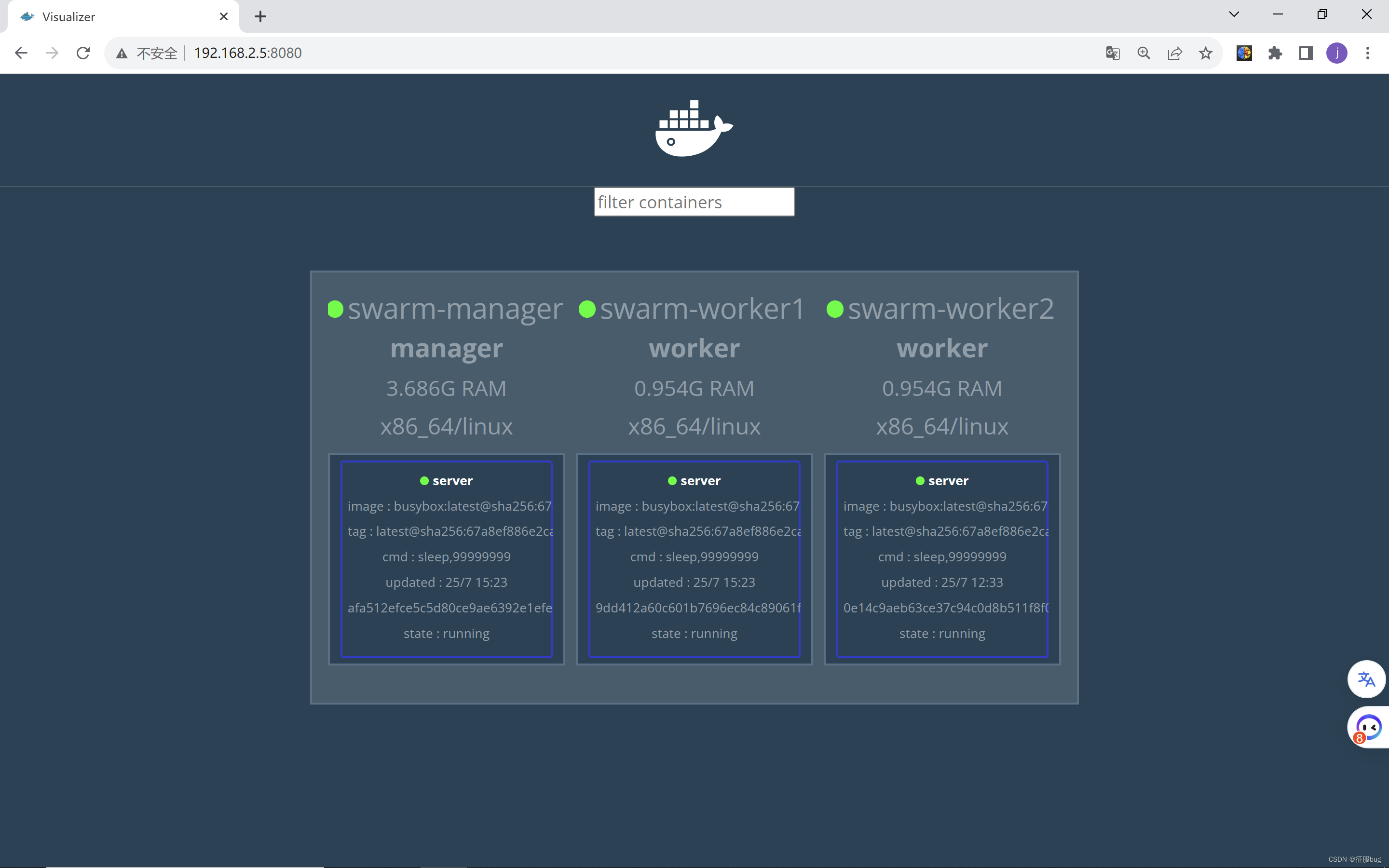
【云原生】详细学习Docker-Swarm部署搭建和基本使用
个人主页:征服bug-CSDN博客 kubernetes专栏:云原生_征服bug的博客-CSDN博客 目录 Docker-Swarm编排 1.概述 2.docker swarm优点 3.节点类型 4.服务和任务 5.路由网格 6.实践Docker swarm 1.概述 Docker Swarm 是 Docker 的集群管理工具。它将 Doc…...

awk相关知识点整理
1.awk的使用方法 1.1 语法 awk [options] script varvalue file(s) awk [options] -f scriptfile varvalue file1.2 命令常用选项 -F fs:fs指定输入分隔符,fs可以是字符串或正则表达式,如-F: -v varvalue:赋值一个用户定义变量…...
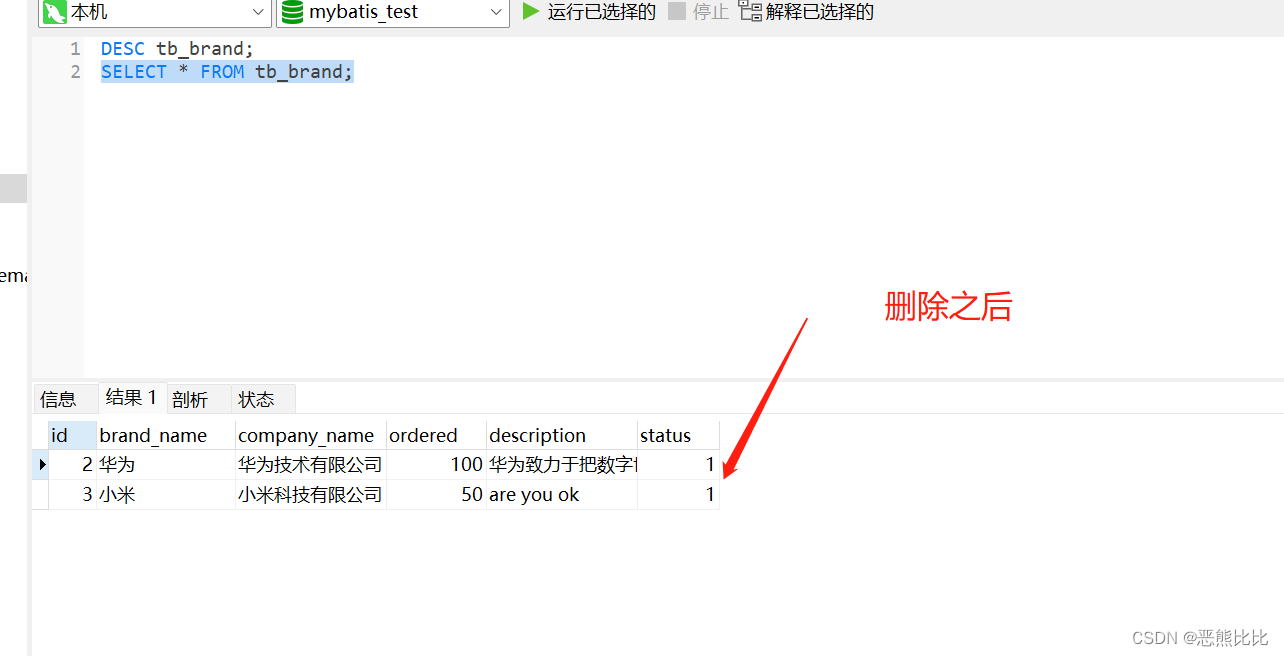
Mybatis案例-商品的增删改查
文章目录 1. aim2.环境准备3.查询3.1 查所有3.2 查看详情3.3 条件查询3.3.1 Mybatics如何接收参数?3.3.2 多条件查询3.3.3 动态条件查询3.3.4 单条件查询 4.添加主键返回 5.修改5.1 修改全部字段5.2 修改动态字段 6.删除6.1 删除1个6.2 批量删除 JDBC完成࿱…...

图像识别模型与训练策略
图像预处理 1.需要将图像Resize到相同大小输入到卷积网络中 2.翻转、裁剪、色彩偏移等操作 3.转化为Tensor数据格式 4.对RGB三种颜色通道进行标准化 data_transforms {train: transforms.Compose([transforms.Resize([96, 96]),transforms.RandomRotation(45),#随机旋转&…...
)
算法工程师-机器学习面试题总结(3)
FM模型 FM模型与逻辑回归相比有什么优缺点? FM(因子分解机)模型和逻辑回归是两种常见的预测建模方法,它们在一些方面有不同的优缺点。 FM模型的优点: 1. 能够捕获特征之间的交互作用:FM模型通过对特征向量…...
进程内topic高效通信)
ROS2学习(五)进程内topic高效通信
对ROS2有一定了解后,我们会发现ROS2中节点和ROS1中节点的概率有很大的区别。在ROS1中节点是最小的进程单元。在ROS2中节点与进程和线程的概念完全区分开了。具体区别可以参考 ROS2学习(四)进程,线程与节点的关系。 在ROS2中同一个进程中可能存在多个节点…...

算法-最大数
给定一组非负整数 nums,重新排列每个数的顺序(每个数不可拆分)使之组成一个最大的整数。 注意:输出结果可能非常大,所以你需要返回一个字符串而不是整数。 输入:nums [10,2] 输出:"210&…...

Spark中使用RDD算子GroupBy做词频统计的方法
测试文件及环境 测试文件在本地D://tmp/spark.txt,Spark采用Local模式运行,Spark版本3.2.0,Scala版本2.12,集成idea开发环境。 hello world java world java java实验代码 import org.apache.spark.rdd.RDD import org.apache.…...
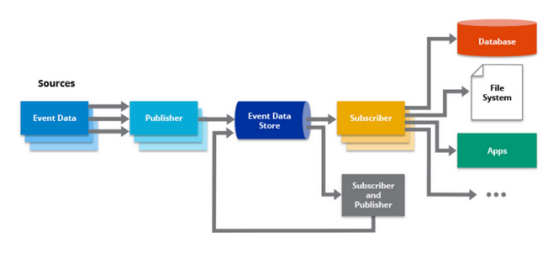
如何使用Kafka构建事件驱动的架构
事件驱动的架构(EDA)是一种软件设计模式,它关注事件的生成、检测和使用,以支持高效和可扩展的系统。在EDA中,事件是组件之间通信的主要手段,允许它们实时交互和响应更改。这种架构促进了松散耦合、可扩展性和响应性,使…...

ES6 解构赋值
解构赋值 解构赋值是一种在编程中常见且方便的语法特性,它可以让你从数组或对象中快速提取数据,并将数据赋值给变量。在许多编程语言中都有类似的特性。 在 JavaScript 中,解构赋值使得从数组或对象中提取数据变得简单。它可以用于数组和对…...

Unity游戏接入TapTap登录,从后台配置到打包上线的完整避坑指南
Unity游戏接入TapTap登录的全流程避坑指南:从配置到上线的实战经验 在独立游戏开发领域,TapTap平台凭借其庞大的用户基础和便捷的登录系统,已成为许多开发者的首选接入方案。然而,从后台配置到最终打包上线的完整流程中࿰…...

Wand-Enhancer终极指南:免费解锁WeMod专业功能的完整解决方案
Wand-Enhancer终极指南:免费解锁WeMod专业功能的完整解决方案 【免费下载链接】Wand-Enhancer Advanced UX and interoperability extension for Wand (WeMod) app 项目地址: https://gitcode.com/gh_mirrors/we/Wand-Enhancer 还在为WeMod专业版的高昂订阅费…...

Mantic.sh:Bash脚本实现的终端命令自动化与效率提升工具
1. 项目概述:一个为开发者打造的终端效率工具如果你和我一样,每天有超过一半的工作时间是在终端(Terminal)里度过的,那你肯定对效率工具有着近乎偏执的追求。从cd到ls,从grep到awk,我们依赖这些…...

怎么判断一家工厂还在不在正常生产?6 类活跃度信号,从纸面到现场
跑工厂的销售员都遇到过这种事:手机里存着一份名单,导航开两小时,到门口才发现卷帘门焊死、车间长草、保安说"厂子去年就搬了"。 问题出在哪?大多数人判断"这家工厂在不在",靠的是工商登记——执照…...

AI驱动全栈开发:Cursor集成模板与高效协作实践
1. 项目概述:当AI代码助手遇上全栈开发最近在GitHub上看到一个挺有意思的项目,叫“Cursor-FullStack-AI-App”。光看名字,你大概能猜到它和Cursor这个AI编程工具,以及全栈应用开发有关。作为一个在前后端都摸爬滚打过多年的开发者…...

初创团队如何通过Taotoken的Token Plan实现成本可控的AI应用开发
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 初创团队如何通过Taotoken的Token Plan实现成本可控的AI应用开发 对于预算敏感的初创团队和独立开发者而言,在开发AI应…...

【STC8H】GPIO模式深度解析:从准双向到推挽,如何精准控制外设
1. STC8H的GPIO模式全景解析 第一次接触STC8H的GPIO配置时,我被那个神秘的PxM0和PxM1寄存器搞得晕头转向。直到有一次调试I2C通讯失败,才发现是开漏模式配置错误。这次教训让我明白,理解GPIO的四种工作模式,就像掌握不同武器的使用…...
用户指引自助教学源码—东方仙盟)
未来之窗昭和仙君(九十四)用户指引自助教学源码—东方仙盟
软件教学引导功能说明书未来之窗昭和仙君 - cyberwin_fairyalliance_webquery一、功能概述软件教学引导功能主要用于为用户提供软件操作的引导,通过一系列步骤逐步引导用户完成软件的重要操作。该功能会创建遮罩层、高亮框和提示框,引导用户点击特定元素…...
)
多语种出海必备,ElevenLabs菲律宾文语音质量实测对比:Wavenet vs. Instant Voice vs. Custom Model(附MOS评分表)
更多请点击: https://intelliparadigm.com 第一章:多语种出海语音技术演进与菲律宾语本地化挑战 随着全球数字服务加速出海,语音交互系统正从单语种向多语种、低资源语言深度拓展。菲律宾语(Filipino/Tagalog)作为东…...

嵌入式动画优化:DMA驱动位图渲染在SAMD21上的实现
1. 项目概述与核心思路如果你玩过嵌入式开发,尤其是想在小小的微控制器屏幕上搞点流畅的动画,大概率会被“卡顿”和“闪屏”折磨过。传统的逐像素绘制,在需要全屏更新时,CPU时间几乎全耗在了等待屏幕刷新上,用户体验大…...