MongoDB文档-进阶使用-MongoDB索引-createindex()与dropindex()-在MongoDB中使用正则表达式来查找
阿丹:
之前研究了MongoDB的基础增删改查。在学会基础的数据库增删改查肯定是不够的。这个时候就涉及到了数据库搜索的时候的效率。需要提高数据的搜索效率。
MongoDB索引
在所以数据库中如果没有数据索引的时候。如果需要查找到一些数据。都会去主动扫描所有可能存在的集合。引入了索引概念就能很高效的使用索引来限制必须在集合中去搜索的文档数。
索引的概念:
索引是特殊数据集,用于存储集合数据的一部分。由于数据是部分数据。因此读取该数据变得更加容易。此部分集存储特定字段的值或按字段值排序的一组字段。
对索引的影响:
- 如何创建索引:createIndex()
- 如何查找索引:getindexes()
- 如何删除索引:dropindex()
索引的影响
从上面的介绍可以看到固然索引对于数据库很友好对于性能的提升也很友好,但是索引太多会减少其他操作。例如插入删除以及其他更新操作。反而得不偿失。
如果语句文档进行频繁的删除等更新操作,如果对于索引的这些字段也进行了影响。那么就需要对这些索引也进行更正改正。
也就是说本对于查询来说是很友好的,但是如果涉及到了索引字段的值修改就要修改MongoDB的两个内容阶段。
所以在索引的选择上要选择不经常更新的字段以及相对重要的字段来作为索引。

如上图所示;
id与code为不经常变更的数据字段所以将这两个字段可以设置为索引。方便我们进行搜索。
如何创建索引:createIndex()
在MongoDB中通过createindex的方法来创建
我先使用如下语句来进行创建了一个ExampleDB集合,然后将3个文档存放到了这个集合中去。
var Example = [{"_id":2,"adncode":1,"员工姓名":"帅丹"},{"_id":3,"adncode":2,"员工姓名":"大力丹"},{"_id":4,"adncode":1,"员工姓名":"库库丹"}
]
db.ExampleDB.insert(Example)在这个文档的格式中我们就可以使用“_id”和“adncode”作为索引。
那么我们接下来使用createindex方法创建索引
#创建索引
db.ExampleDB.createIndex({adncode:1})
代码解释:
这个语句是用于在ExampleDB数据库中创建一个索引,索引的名称是adncode,索引的列是第一列。
具体来说,db.ExampleDB.createIndex({adncode:1}) 是对名为ExampleDB的数据库中的adncode列创建索引,其中adncode是索引的名称,1表示该列是第一列。通过创建索引,可以提高查询adncode列的数据的效率。
参数“ 1”表示使用“ adncode”字段值创建索引时,应按升序对其进行排序。请注意,这与_id字段(ID字段用于唯一标识集合中的每个文档)不同,后者由MongoDB在集合中自动创建。现在,将按照adncode而不是_id字段对文档进行排序。
参数为1表示升序排序,而参数为-1表示倒序排序。在MongoDB中,索引的方向可以是单向(1或-1)或双向({-1,1}或{1,-1}),分别表示从左到右或从右到左的顺序。在创建索引时,可以根据实际需求选择适当的的方向和列来创建索引,以提供更快速的文件访问和查询性能。总之,索引的方向和参数可以根据具体的需求进行选择和调整,以实现最佳的性能和查询效果。
创建成功返回语句解释:
- numIndexesBefore:1表示运行命令之前索引中存在的字段值(集合中的实际字段)的数量。请记住,每个集合都有_id字段,该字段也算作索引的Field值。由于_id索引字段在最初创建时是集合的一部分,因此numIndexesBefore的值为1。
- numIndexesAfter:2表示运行命令后索引中存在的字段值的数目。
- 此处的“ ok:1”输出指定操作已成功,并且新索引已添加到集合中。
上面的代码显示了如何基于一个字段值创建索引,但是也可以基于多个字段值创建索引。
创建索引语句参数讲解
db.ExampleDB.createIndex(keys, options)是MongoDB中用于创建索引的语句。其中的keys参数指定要创建索引的键,可以是一个键文档(如{adncode: 1})或一个包含多个键的数组(如[adncode, code2])。options参数用于指定索引的选项和行为,它是一个包含多个选项的文档。
以下是一些常用的选项和它们的作用:
background:指定索引是否在后台创建,这样可以在创建索引时继续其他操作。默认情况下,索引是在前台创建的,这意味着其他操作会被阻塞。unique:指定索引是否是唯一的。如果设置为true,则在文档中不允许出现重复的索引键值。dropDups:在创建索引时是否删除重复的文档。如果设置为true,则在创建索引时将删除所有重复的文档。name:索引的名称,用于标识和引用该索引。expireAfterSeconds:指定文档过期的时间,以秒为单位。如果设置为一个正数,则在该时间后,文档将被删除。
在使用这个语句时,基本的语法是:
db.collection.createIndex(keys, options)
其中,keys参数可以根据需要设置为一个键文档或一个包含多个键的数组。options参数是可选的,可以根据需要设置为一个包含选项的文档。
需要注意的是,在创建索引时,应该根据实际需求和性能要求选择合适的类型和参数。索引的创建会增加存储空间和计算开销,并且在修改文档时也会受到影响。因此,应该仔细评估索引的需求和影响,并选择适当的的选择和参数。
一次性创建多个字段索引
db.Employee.createIndex({Employeeid:1, EmployeeName:1])代码解释:
现在,createIndex方法考虑多个字段值,这些值现在将导致根据“ Employeeid”和“ EmployeeName”创建索引。Employeeid:1和EmployeeName:1指示应在这2个字段值上创建索引,而:1则指示索引应按升序排列。
如何查找索引:使用getindexes()方法
#查找索引
db.ExampleDB.getIndexes()
代码解释:
- getIndexes方法用于查找集合中的所有索引。
- 输出返回一个文档,该文档仅显示集合中有2个索引,即_id字段,另一个是Employee id字段。:1表示索引中的字段值是按升序创建的。
如何删除索引:dropindex()
通过使用dropindex方法在MongoDB中删除索引
#删除索引
db.ExampleDB.dropIndex({adncode:1})
代码解释:
- dropIndex方法采用必需的字段值,该值需要从索引中删除。
- 返回结果值nIndexesWas:2表示在运行命令之前索引中存在的字段值的数目。请记住,每个集合都有_id字段,该字段也算作索引的Field值。
- ok:1输出指定该操作成功,并且从索引中删除了“ adncode”字段。
-
要一次删除集合中的所有索引,可以使用dropIndexes命令。
删除所有索引
db.ExampleDB.dropIndexes()代码解释
- dropIndexes方法将删除除_id索引以外的所有索引。
小总结:
- 定义索引对于快速高效地搜索集合中的文档非常重要。
- 可以使用createIndex方法创建索引。可以仅在一个字段或多个字段值上创建索引。
- 可以使用getIndexes方法找到索引。
- 可以通过将dropIndex用于单个索引或将dropIndex用于删除所有索引来删除索引。
在MongoDB中使用正则表达式(Regex)-爬虫可用
正则表达式基本概念:
正则表达式用于模式匹配,基本上用于在文档中发现和匹配字符串,以及一些校验规则。
通过正则表达式可以帮助我们在文档中快速的找到和定位到相应的字符串。
使用$regex运算符进行模式匹配
MongoDB中的regex运算符用于在集合中搜索特定的字符串。
比如在上面我们向目标集合中添加的文档们,我现在想要查询有“丹”字出现的文档。我就可以使用正则表达式类指定搜索条件。
#使用正则表达式来制定搜索条件
db.ExampleDB.find({员工姓名 : {$regex : "丹"}}
).forEach(printjson)

代码解释:
在这里,查找了所有带“丹”字符的员工姓名。因此使用$ regex运算符来定义“ 丹”的搜索条件,也能从结果看到返回了包含对应汉字的文档。
使用正则表达式中的语法对查询规则进行精准描述
规则“^”
比如我们可以使用在匹配规则字符串前添加“^”来保证匹配的时候前面是没有字符的。


可从结果看到“^”符号的作用就是规定在查找的时候关键字前面不能有其他字符。
规则“$”
还可以使用$符号规则来规定在匹配字符的后面不允许有其他字符


从两次的结果可以看到在加上$符号后,在关键字后面如果有字符就不在参与搜索了。
其他规则
字符匹配
元字符 . 可以匹配除换行符之外的任何字符。
例如:. " 可以匹配任何字符串,包括空字符串。
字符集合
用花括号 [] 表示一个字符集合,可以匹配其中任意一个字符。
例如:[abc] 可以匹配字符 a、b 或 c。
字符范围
用连字符 - 表示字符范围,可以匹配一定范围内的字符。
例如:[a-z] 可以匹配小写字母。
否定字符集合
用花括号 [^] 表示一个否定字符集合,可以匹配除了其中指定的字符之外的任何字符。
例如:[^abc] 可以匹配除了字符 a、b 或 c 之外的任何字符。
量词
量词用于匹配前面的元素出现的次数。常见的量词包括:
*表示前面的元素可以出现 0 次或多次。+表示前面的元素可以出现 1 次或多次。?表示前面的元素可以出现 0 次或 1 次。{n}表示前面的元素出现 n 次。{n,}表示前面的元素至少出现 n 次。{n,m}表示前面的元素至少出现 n 次,但不超过 m 次。
例如:a* 可以匹配 0 个或多个字母 a。
转义字符
在正则表达式中,一些特殊字符需要使用反斜杠 \ 进行转义,例如 \d 表示数字、\s 表示空白字符等。
例如:\d+ 可以匹配一个或多个数字。
与$ options进行模式匹配
使用正则表达式运算符时,还可以使用$ options关键字提供其他选项。假设我们想查找所有在目标集合中中带有英文字符的文档,而不管它是区分大小写还是不区分大小写。如果需要这样的结果,那么我们需要使用不区分大小写参数的$ options。
现在,我们运行与上一个相同的查询,我们将永远不会在结果中看到带有大写的英文的文档。为了确保将其包含在结果集中,我们需要添加$ options“ I”参数。
db.Employee.find({EmployeeName:{$regex: “Gu”,$options:’i’}}).forEach(printjson)代码解释:
1、带“ I”参数(表示不区分大小写)的$ options指定无论我们发现字母是小写还是大写,我们都希望执行搜索
2、结果表明,即使一个文档具有大写的目标字母,该文档仍会显示在结果集中
没有regex运算符的模式匹配

在这里没有使用regex运算符,也可以正常使用正则表达式匹配操作
#使用正则表达式来制定搜索条件
db.ExampleDB.find({员工姓名 : /库库丹/}
).forEach(printjson)
说明:
“//”在MongoDB中这个选项就说明在这些定界符中指定了搜索的条件。
具体正则表达式如何书写可以根据上面提供过的文档来书写。
相关文章:
MongoDB文档-进阶使用-MongoDB索引-createindex()与dropindex()-在MongoDB中使用正则表达式来查找
阿丹: 之前研究了MongoDB的基础增删改查。在学会基础的数据库增删改查肯定是不够的。这个时候就涉及到了数据库搜索的时候的效率。需要提高数据的搜索效率。 MongoDB索引 在所以数据库中如果没有数据索引的时候。如果需要查找到一些数据。都会去主动扫描所有可能存…...
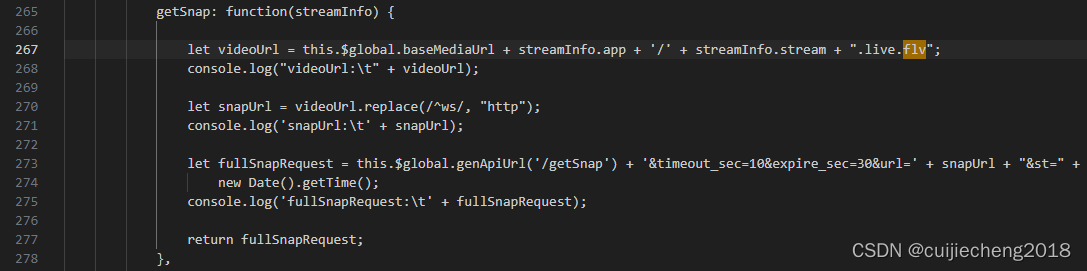
CentOS下ZLMediaKit的可视化管理网站MediaServerUI使用
一、简介 按照 ZLMediaKit快速开始 编译运行ZLMediaKit成功后,我们可以运行其合作开源项目MediaServerUI,来对ZLMediaKit进行可视化管理。通过MediaServerUI,我们可以实现在浏览器查看ZLMediaKit的延迟率、负载率、正在进行的推拉流、服务器…...

回归预测 | MATLAB实现POA-CNN-BiGRU鹈鹕算法优化卷积双向门控循环单元多输入单输出回归预测
回归预测 | MATLAB实现POA-CNN-BiGRU鹈鹕算法优化卷积双向门控循环单元多输入单输出回归预测 目录 回归预测 | MATLAB实现POA-CNN-BiGRU鹈鹕算法优化卷积双向门控循环单元多输入单输出回归预测预测效果基本介绍程序设计参考资料 预测效果 基本介绍 MATLAB实现POA-CNN-BiGRU鹈鹕…...
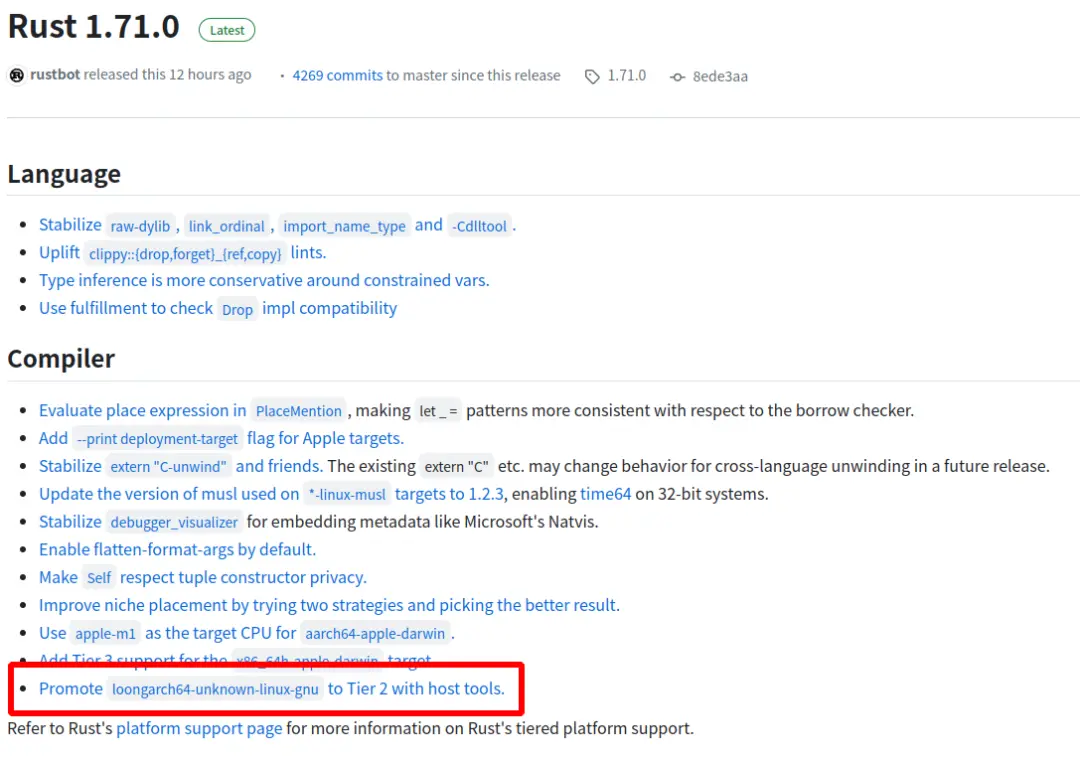
Rust 原生支持龙架构指令集
导读近日,Rust 开源社区发布 1.71.0 版本,实现对龙架构(LoongArch)指令集的原生支持。 龙架构操作系统发行版和开发者可基于上游社区源代码构建或直接下载 Rust 开源社区发布的龙架构二进制版本。Rust 开发者将在龙架构平台上获得…...

为生成式AI提速,亚马逊云科技Amazon EC2 P5满足GPU需求
生成式AI(Generative AI)已经成为全球范围内的一个重要趋势,得到越来越多企业和研究机构的关注和应用。纽约时间7月26日,亚马逊云科技数据库、数据分析和机器学习全球副总裁Swami Sivasubramanian在亚马逊云科技举办的纽约峰会上更…...

聊聊企业数据安全那些事~
保护企业数据安全的重要性与方法 随着信息技术的快速发展,企业数据的安全性变得越来越重要。在数字化时代,企业的核心业务和关键信息都存储在电脑系统中,一旦遭受到数据泄露、黑客攻击或恶意软件感染,将可能对企业造成严重的损害…...

日常随笔——如何把excel题库转换为word打印格式
将Excel题库转换为Word可以通过编程的方式实现。以下是一个使用Python的示例代码,该代码使用openpyxl库读取Excel文件,并使用python-docx库创建和保存Word文档。 首先,请确保已经安装了 openpyxl 和 python-docx 库。可以使用以下命令进行安…...

SpringCloud项目打包注意事项以及可能出错的几种情况
SpringCloud项目打包注意事项和可能出错的几种情况 1、检查子模块中的 parent的pom文件路径 \<relativePath/\>2、检查打包插件的位置3、检查module是否重复引用 欢迎访问我的个人博客:https://wk-blog.vip 1、检查子模块中的 parent的pom文件路径 <relat…...
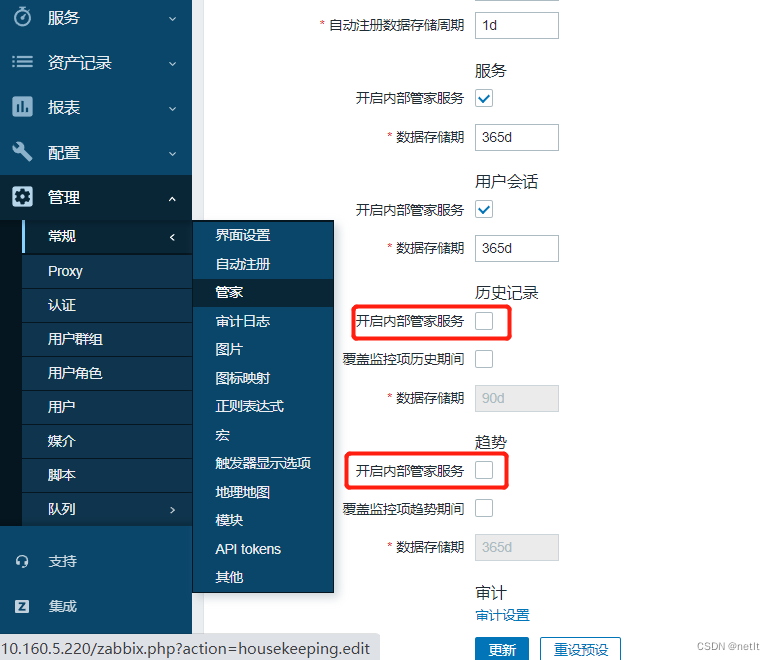
ZABBIX 6.4 Mysql数据库分表
ZABBIX监控设备较多的时候,Mysql数据库容易成为性能的瓶颈,可以通过数据库分表的方式来进行优化。步骤如下: 一、停用zabbix服务 # 避免修改分区表时,数据还有写入 systemctl stop zabbix 二、备份MySQL zabbix DB 避免修改分…...

多线程-Runable和Callable的区别
在Java中,多线程可以通过实现Runnable接口或使用Callable接口来实现。这两种方式有一些区别,如下所示: 返回值: Runnable接口的run()方法没有返回值,它表示一个没有返回结果的任务。Callable接口的call()方法有返回值…...
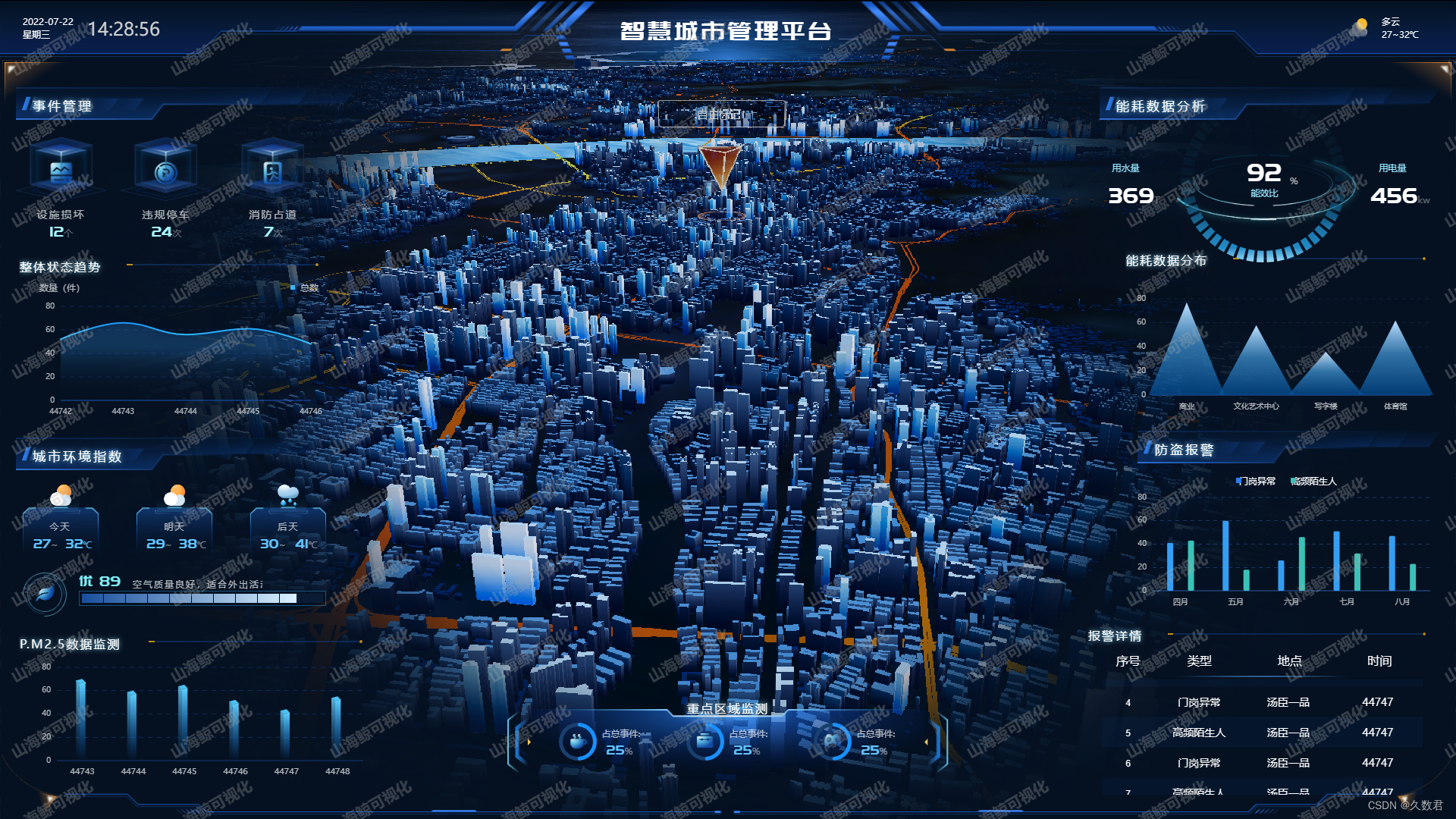
智慧城市规划新引擎:探秘数字孪生中的二维与三维GIS技术差异
智慧城市作为人类社会发展的新阶段,正日益引领着我们迈向数字化未来的时代。在智慧城市的建设过程中,地理信息系统(GIS)扮演着举足轻重的角色。而在GIS的发展中,二维和三维GIS作为两大核心技术,在城市规划与…...
Python入门自学进阶-Web框架——38、redis、rabbitmq、git
缓存数据库redis: NoSQL(Not only SQL)泛指非关系型的数据库。为了解决大规模数据集合多重数据类的挑战。 NoSQL数据库的四大分类: 键值(Key-Value)存储数据库列存储数据库文档型数据库图形(…...

论 SoC上的Linux如何拉动外部I/O
在MCU中(如classic autosr或其他RTOS),一般可以直接通过往对应的寄存器(地址转为指针)写值, 或者调用一些硬件抽象层或者驱动接口来拉动芯片提供的GPIO。 但是在Linux中,可能不会让应用层直接去…...
SpringBoot项目如何部署SSL证书 (JKS格式)
1、SpringBoot项目如何部署SSL证书 (JKS格式) 1. 获取 SSL 证书和私钥 首先,你需要获取有效的 SSL 证书和私钥。SSL 证书是一种用于加密通信的数字证书,它可以通过购买商业 SSL 证书或使用免费的 Let’s Encrypt 证书获得。请确保你拥有证书文件和与之…...

成功解决:ValueError Cannot assign non-leaf Tensor to parameter ‘weight‘
成功解决:ValueError Cannot assign non-leaf Tensor to parameter ‘weight‘ 欢迎大家来到安静到无声的《模式识别与人工智能(程序与算法)》,如果对所写内容感兴趣请看模式识别与人工智能(程序与算法)系列讲解 - 总目录,同时这也可以作为大家学习的参考。欢迎订阅,优…...

面试之快速学习SQL-基础增删改查语句
1. SELECT SELECT column1,column2,column3 FROM table_name;SELECT * FROM table_name;2. SQL SELECT DISTINCT 语句 在表中,可能会包含重复值。这并不成问题,不过,有时您也许希望仅仅列出不同(distinct)的值。 SE…...
nuxt脚手架创建项目
在初始化时遇到一个依赖找不到的问题,记录一下,如有遇到同样问题的小伙伴,希望能给你们一点指引。 从安装脚手架开始,首先 一:安装nuxt脚手架 1. C盘全局安装: npm i -g create-nuxt-app 安装后可creat…...
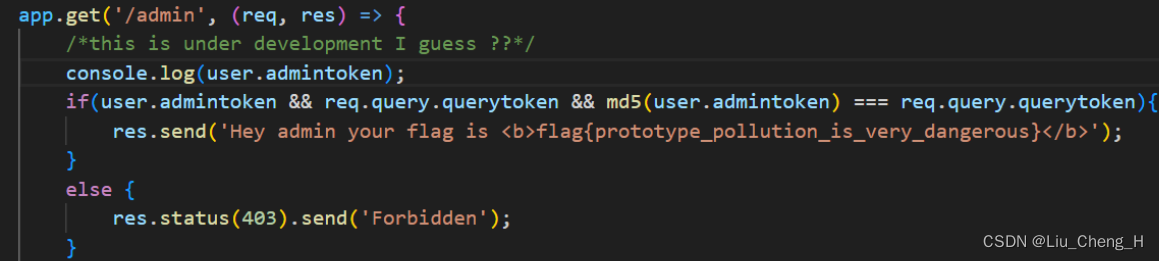
复现原型链污染漏洞
目录 一、复现原型链污染漏洞 hackit 2018 1、创建hackit_2018.js文件 2、运行hackit_2018.js文件 3、寻找原型链漏洞 4、污染原型链 hackit 2018 1、创建hackit_2018.js文件 const express require(express) var hbs require(hbs); var bodyParser require(body-par…...
.Net6 Web Core API 配置 Autofac 封装 --- 依赖注入
目录 一、NuGet 包导入 二、Autofac 封装类 三、Autofac 使用 四、案例测试 下列封装 采取程序集注入方法, 单个依赖注入, 也适用, 可<依赖注入>的地方配置 一、NuGet 包导入 Autofac Autofac.Extensions.DependencyInjection Autofac.Extras.DynamicProxy 二、Auto…...
鸿鹄工程项目管理系统em Spring Cloud+Spring Boot+前后端分离构建工程项目管理系统 em
Java版工程项目管理系统 Spring CloudSpring BootMybatisVueElementUI前后端分离 功能清单如下: 首页 工作台:待办工作、消息通知、预警信息,点击可进入相应的列表 项目进度图表:选择(总体或单个)项目…...

InsForge:基于Python的Instagram内容自动化创作与发布工具全解析
1. 项目概述与核心价值最近在折腾一个挺有意思的开源项目,叫InsForge。这名字听起来有点“工业锻造”的味道,实际上,它是一个专注于Instagram内容创作与自动化的工具集。简单来说,它试图帮你解决在Instagram上创作、发布、管理内容…...

SAP KO88结算时,如何用BADI_FINS_ACDOC_POSTING_EVENTS把成本中心塞进自定义字段?
SAP KO88结算实战:通过BADI_FINS_ACDOC_POSTING_EVENTS实现成本中心到自定义字段的精准映射 在SAP工单结算(KO88)的复杂业务场景中,财务凭证的标准化字段往往无法满足企业多维度的分析需求。特别是当需要将特定成本中心信息映射到…...

深度解析VS Code Live Server:高效前端开发实时预览配置秘籍
深度解析VS Code Live Server:高效前端开发实时预览配置秘籍 【免费下载链接】vscode-live-server Launch a development local Server with live reload feature for static & dynamic pages. 项目地址: https://gitcode.com/gh_mirrors/vs/vscode-live-serv…...

基于xclaude-plugin框架的Claude自定义插件开发实战指南
1. 项目概述:Claude插件生态的“瑞士军刀”如果你最近在深度使用Claude,尤其是Claude Desktop应用,那你大概率已经感受到了插件生态的潜力与混乱。官方插件商店虽然方便,但总有些特定需求找不到现成的解决方案,或者找到…...

基于MCP协议构建Reddit社区趋势分析工具:架构、部署与应用
1. 项目概述:一个实时洞察社区脉搏的利器最近在做一个社区运营相关的项目,需要实时追踪几个特定话题在Reddit上的讨论热度变化。手动刷帖、统计关键词频率这种笨办法效率太低,而且很难量化趋势。就在我琢磨着是不是要自己写个爬虫加分析脚本的…...

SQL学习指南——背景知识
关系型数据库中每个数据表都包含能够唯一标识某一行的信息(称为主键 primary key),以及完整描述实体所需的额外信息 一些数据表中还包含了导航到其他数据表的信息,这些列称为外键(foreign key) 术语术语定义实体数据库…...

NoC路由设计与缓存一致性协议的协同优化
1. 项目概述:缓存一致性对NoC路由设计的挑战与机遇在当今多核处理器架构中,片上网络(NoC)作为核心间通信的基础设施,其设计质量直接影响整体系统性能。我曾在一次芯片设计项目中深刻体会到,当核心数量增加到64个时,传统…...

量子优化基准测试库QOBLIB:原理与应用解析
1. 量子优化基准测试库QOBLIB概述量子计算在组合优化领域展现出突破经典计算极限的潜力,但如何系统评估量子算法的实际性能一直是研究难点。2025年发布的QOBLIB(Quantum Optimization Benchmarking Library)填补了这一空白,成为首…...

FastAPI快速入门:环境搭建+第一个接口
FastAPI快速入门:环境搭建第一个接口文章信息 标题:FastAPI快速入门:环境搭建第一个接口字数:4200字预估阅读时间:18分钟难度:⭐☆☆☆☆一、为什么选择FastAPI? 在2026年的Python Web框架生态中…...

基于Feather RP2040与CircuitPython的CNC旋钮宏键盘DIY指南
1. 项目概述:打造你的专属生产力旋钮如果你经常使用像Cura、Fusion 360或者Adobe系列这类专业软件,一定对频繁切换工具、调整参数时在键盘和鼠标间来回切换的繁琐深有体会。传统的键盘快捷键虽然快,但组合键太多容易忘记,而且缺乏…...