ZABBIX 6.4 Mysql数据库分表
ZABBIX监控设备较多的时候,Mysql数据库容易成为性能的瓶颈,可以通过数据库分表的方式来进行优化。步骤如下:
一、停用zabbix服务
# 避免修改分区表时,数据还有写入
systemctl stop zabbix
二、备份MySQL zabbix DB
避免修改分区表后各类异常,以便回滚
# 备份db:
mysqldump -h127.0.0.1 -P3306 -uroot -pP@ssw0rd1234 --single-transaction --default-character-set=utf8 -R -E zabbix --log-error=/usr/tmp/zabbix0323.log > /usr/tmp/zabbix0323.sql
三、进入mysql数据库输入脚本
mysql -uroot -p
以下为脚本内容
use zabbix;DELIMITER $$
CREATE PROCEDURE `partition_create`(SCHEMANAME varchar(64), TABLENAME varchar(64), PARTITIONNAME varchar(64), CLOCK int)
BEGIN /* SCHEMANAME = The DB schema in which to make changes TABLENAME = The table with partitions to potentially delete PARTITIONNAME = The name of the partition to create */ /* Verify that the partition does not already exist */DECLARE RETROWS INT; SELECT COUNT(1) INTO RETROWS FROM information_schema.partitions WHERE table_schema = SCHEMANAME AND table_name = TABLENAME AND partition_description >= CLOCK;IF RETROWS = 0 THEN /* 1. Print a message indicating that a partition was created. 2. Create the SQL to create the partition. 3. Execute the SQL from #2. */ SELECT CONCAT( "partition_create(", SCHEMANAME, ",", TABLENAME, ",", PARTITIONNAME, ",", CLOCK, ")" ) AS msg; SET @sql = CONCAT( 'ALTER TABLE ', SCHEMANAME, '.', TABLENAME, ' ADD PARTITION (PARTITION ', PARTITIONNAME, ' VALUES LESS THAN (', CLOCK, '));' ); PREPARE STMT FROM @sql; EXECUTE STMT; DEALLOCATE PREPARE STMT; END IF;
END$$
DELIMITER ;
DELIMITER $$
CREATE PROCEDURE `partition_drop`(SCHEMANAME VARCHAR(64), TABLENAME VARCHAR(64), DELETE_BELOW_PARTITION_DATE BIGINT)
BEGIN /* SCHEMANAME = The DB schema in which to make changes TABLENAME = The table with partitions to potentially delete DELETE_BELOW_PARTITION_DATE = Delete any partitions with names that are dates older than this one (yyyy-mm-dd) */ DECLARE done INT DEFAULT FALSE; DECLARE drop_part_name VARCHAR(16);/* Get a list of all the partitions that are older than the date in DELETE_BELOW_PARTITION_DATE. All partitions are prefixed with a "p", so use SUBSTRING TO get rid of that character. */ DECLARE myCursor CURSOR FOR SELECT partition_name FROM information_schema.partitions WHERE table_schema = SCHEMANAME AND table_name = TABLENAME AND CAST(SUBSTRING(partition_name FROM 2) AS UNSIGNED) < DELETE_BELOW_PARTITION_DATE; DECLARE CONTINUE HANDLER FOR NOT FOUND SET done = TRUE;/* Create the basics for when we need to drop the partition. Also, create @drop_partitions to hold a comma-delimited list of all partitions that should be deleted. */ SET @alter_header = CONCAT("ALTER TABLE ", SCHEMANAME, ".", TABLENAME, " DROP PARTITION "); SET @drop_partitions = "";/* Start looping through all the partitions that are too old. */ OPEN myCursor; read_loop: LOOP FETCH myCursor INTO drop_part_name; IF done THEN LEAVE read_loop; END IF; SET @drop_partitions = IF(@drop_partitions = "", drop_part_name, CONCAT(@drop_partitions, ",", drop_part_name)); END LOOP; IF @drop_partitions != "" THEN /* 1. Build the SQL to drop all the necessary partitions. 2. Run the SQL to drop the partitions. 3. Print out the table partitions that were deleted. */ SET @full_sql = CONCAT(@alter_header, @drop_partitions, ";"); PREPARE STMT FROM @full_sql; EXECUTE STMT; DEALLOCATE PREPARE STMT;SELECT CONCAT(SCHEMANAME, ".", TABLENAME) AS `table`, @drop_partitions AS `partitions_deleted`; ELSE /* No partitions are being deleted, so print out "N/A" (Not applicable) to indicate that no changes were made. */ SELECT CONCAT(SCHEMANAME, ".", TABLENAME) AS `table`, "N/A" AS `partitions_deleted`; END IF;
END$$
DELIMITER ;
DELIMITER $$
CREATE PROCEDURE `partition_maintenance`(SCHEMA_NAME VARCHAR(32), TABLE_NAME VARCHAR(32), KEEP_DATA_DAYS INT, HOURLY_INTERVAL INT, CREATE_NEXT_INTERVALS INT)
BEGIN DECLARE OLDER_THAN_PARTITION_DATE VARCHAR(16); DECLARE PARTITION_NAME VARCHAR(16); DECLARE OLD_PARTITION_NAME VARCHAR(16); DECLARE LESS_THAN_TIMESTAMP INT; DECLARE CUR_TIME INT;CALL partition_verify(SCHEMA_NAME, TABLE_NAME, HOURLY_INTERVAL); SET CUR_TIME = UNIX_TIMESTAMP(DATE_FORMAT(NOW(), '%Y-%m-%d 00:00:00'));SET @__interval = 1; create_loop: LOOP IF @__interval > CREATE_NEXT_INTERVALS THEN LEAVE create_loop; END IF;SET LESS_THAN_TIMESTAMP = CUR_TIME + (HOURLY_INTERVAL * @__interval * 3600); SET PARTITION_NAME = FROM_UNIXTIME(CUR_TIME + HOURLY_INTERVAL * (@__interval - 1) * 3600, 'p%Y%m%d%H00'); IF(PARTITION_NAME != OLD_PARTITION_NAME) THEN CALL partition_create(SCHEMA_NAME, TABLE_NAME, PARTITION_NAME, LESS_THAN_TIMESTAMP); END IF; SET @__interval=@__interval+1; SET OLD_PARTITION_NAME = PARTITION_NAME; END LOOP;SET OLDER_THAN_PARTITION_DATE=DATE_FORMAT(DATE_SUB(NOW(), INTERVAL KEEP_DATA_DAYS DAY), '%Y%m%d0000'); CALL partition_drop(SCHEMA_NAME, TABLE_NAME, OLDER_THAN_PARTITION_DATE);
END$$
DELIMITER ;
DELIMITER $$
CREATE PROCEDURE `partition_verify`(SCHEMANAME VARCHAR(64), TABLENAME VARCHAR(64), HOURLYINTERVAL INT(11))
BEGIN DECLARE PARTITION_NAME VARCHAR(16); DECLARE RETROWS INT(11); DECLARE FUTURE_TIMESTAMP TIMESTAMP;/* * Check if any partitions exist for the given SCHEMANAME.TABLENAME. */ SELECT COUNT(1) INTO RETROWS FROM information_schema.partitions WHERE table_schema = SCHEMANAME AND table_name = TABLENAME AND partition_name IS NULL;/* * If partitions do not exist, go ahead and partition the table */ IF RETROWS = 1 THEN /* * Take the current date at 00:00:00 and add HOURLYINTERVAL to it. This is the timestamp below which we will store values. * We begin partitioning based on the beginning of a day. This is because we don't want to generate a random partition * that won't necessarily fall in line with the desired partition naming (ie: if the hour interval is 24 hours, we could * end up creating a partition now named "p201403270600" when all other partitions will be like "p201403280000"). */ SET FUTURE_TIMESTAMP = TIMESTAMPADD(HOUR, HOURLYINTERVAL, CONCAT(CURDATE(), " ", '00:00:00')); SET PARTITION_NAME = DATE_FORMAT(CURDATE(), 'p%Y%m%d%H00');-- Create the partitioning query SET @__PARTITION_SQL = CONCAT("ALTER TABLE ", SCHEMANAME, ".", TABLENAME, " PARTITION BY RANGE(`clock`)"); SET @__PARTITION_SQL = CONCAT(@__PARTITION_SQL, "(PARTITION ", PARTITION_NAME, " VALUES LESS THAN (", UNIX_TIMESTAMP(FUTURE_TIMESTAMP), "));");-- Run the partitioning query PREPARE STMT FROM @__PARTITION_SQL; EXECUTE STMT; DEALLOCATE PREPARE STMT; END IF;
END$$
DELIMITER ;
DELIMITER $$
CREATE PROCEDURE `partition_maintenance_all`(SCHEMA_NAME VARCHAR(32))
BEGIN CALL partition_maintenance(SCHEMA_NAME, 'history', 90, 24, 7); CALL partition_maintenance(SCHEMA_NAME, 'history_log', 90, 24, 7); CALL partition_maintenance(SCHEMA_NAME, 'history_str', 90, 24, 7); CALL partition_maintenance(SCHEMA_NAME, 'history_text', 90, 24, 7); CALL partition_maintenance(SCHEMA_NAME, 'history_uint', 90, 24, 7); CALL partition_maintenance(SCHEMA_NAME, 'trends', 730, 24, 7); CALL partition_maintenance(SCHEMA_NAME, 'trends_uint', 730, 24, 7);
END$$
DELIMITER ;语法格式 说明 :
CALL partition_maintenance('', '', , , )
例, CALL partition_maintenance(SCHEMA_NAME, 'history', 90, 24, 7);
90: 意思是对history表未来保留90天分区的数据
24: 意思是 对history表 每24小时(1天)建立一个分区
7: 意思 是对history表每 次建立7个分区,如果每天执行存储话,比如今天3月23号第一次执行存储过程会创建3月23号到3月29号 7个分区,明天3月24号创建3月24号到3月30号 7个分区,但是因为24到29号的分区3月23号执行存储过程时已经建立,就只会创建3月30号的一个分区。以后每天依此类推
另外,因为我们zabbix已经有历史数据了,第一次执行存储时会把所有的历史数据全部放入第一个3月23号的分区中
四、执行分表并写入日志
nohup /usr/bin/mysql -h127.0.0.1 -u zabbix -pZabbix@123 -D zabbix -e "CALL partition_maintenance_all('zabbix');" >> /data/mysql/partition.log 2>&1 &
mysql -uroot -p
use zabbix
show create table history;

如果显示这样则为分表正常
五、设定每日维护分区排程
#每天凌晨1点执行存储过程,新建分区和删除历史分区
crontab -e
0 1 * * * /usr/bin/mysql -h127.0.0.1 -u zabbix -pZabbix@123 -D zabbix -e "CALL partition_maintenance_all('zabbix');" 1>/data/mysql/partition_job.log 2>/data/mysql/partition_job.bad
六、启用zabbix服务
# 避免修改分区表时,数据还有写入
systemctl start zabbix
七、 更改内部管家服务设定
#历史记录和趋势两个选项下的“开启内部管理服务”功能需要关闭
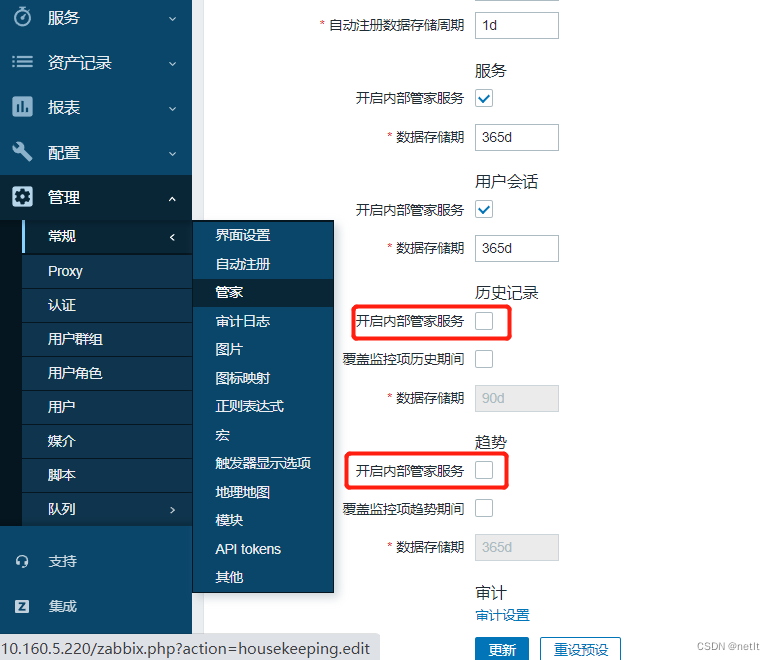
完成
相关文章:
ZABBIX 6.4 Mysql数据库分表
ZABBIX监控设备较多的时候,Mysql数据库容易成为性能的瓶颈,可以通过数据库分表的方式来进行优化。步骤如下: 一、停用zabbix服务 # 避免修改分区表时,数据还有写入 systemctl stop zabbix 二、备份MySQL zabbix DB 避免修改分…...

多线程-Runable和Callable的区别
在Java中,多线程可以通过实现Runnable接口或使用Callable接口来实现。这两种方式有一些区别,如下所示: 返回值: Runnable接口的run()方法没有返回值,它表示一个没有返回结果的任务。Callable接口的call()方法有返回值…...
智慧城市规划新引擎:探秘数字孪生中的二维与三维GIS技术差异
智慧城市作为人类社会发展的新阶段,正日益引领着我们迈向数字化未来的时代。在智慧城市的建设过程中,地理信息系统(GIS)扮演着举足轻重的角色。而在GIS的发展中,二维和三维GIS作为两大核心技术,在城市规划与…...
Python入门自学进阶-Web框架——38、redis、rabbitmq、git
缓存数据库redis: NoSQL(Not only SQL)泛指非关系型的数据库。为了解决大规模数据集合多重数据类的挑战。 NoSQL数据库的四大分类: 键值(Key-Value)存储数据库列存储数据库文档型数据库图形(…...

论 SoC上的Linux如何拉动外部I/O
在MCU中(如classic autosr或其他RTOS),一般可以直接通过往对应的寄存器(地址转为指针)写值, 或者调用一些硬件抽象层或者驱动接口来拉动芯片提供的GPIO。 但是在Linux中,可能不会让应用层直接去…...
SpringBoot项目如何部署SSL证书 (JKS格式)
1、SpringBoot项目如何部署SSL证书 (JKS格式) 1. 获取 SSL 证书和私钥 首先,你需要获取有效的 SSL 证书和私钥。SSL 证书是一种用于加密通信的数字证书,它可以通过购买商业 SSL 证书或使用免费的 Let’s Encrypt 证书获得。请确保你拥有证书文件和与之…...

成功解决:ValueError Cannot assign non-leaf Tensor to parameter ‘weight‘
成功解决:ValueError Cannot assign non-leaf Tensor to parameter ‘weight‘ 欢迎大家来到安静到无声的《模式识别与人工智能(程序与算法)》,如果对所写内容感兴趣请看模式识别与人工智能(程序与算法)系列讲解 - 总目录,同时这也可以作为大家学习的参考。欢迎订阅,优…...

面试之快速学习SQL-基础增删改查语句
1. SELECT SELECT column1,column2,column3 FROM table_name;SELECT * FROM table_name;2. SQL SELECT DISTINCT 语句 在表中,可能会包含重复值。这并不成问题,不过,有时您也许希望仅仅列出不同(distinct)的值。 SE…...
nuxt脚手架创建项目
在初始化时遇到一个依赖找不到的问题,记录一下,如有遇到同样问题的小伙伴,希望能给你们一点指引。 从安装脚手架开始,首先 一:安装nuxt脚手架 1. C盘全局安装: npm i -g create-nuxt-app 安装后可creat…...
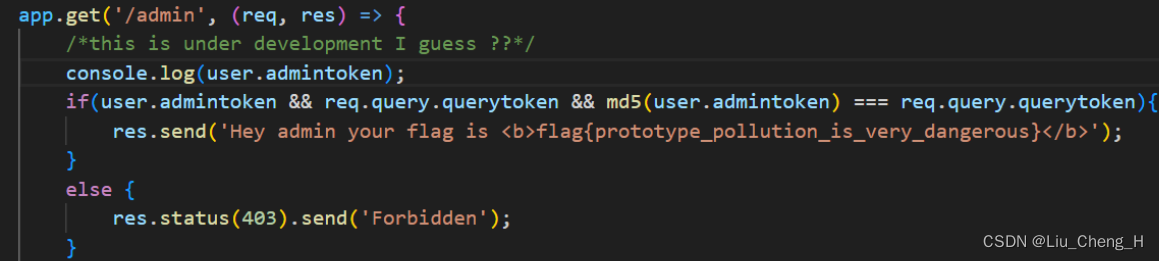
复现原型链污染漏洞
目录 一、复现原型链污染漏洞 hackit 2018 1、创建hackit_2018.js文件 2、运行hackit_2018.js文件 3、寻找原型链漏洞 4、污染原型链 hackit 2018 1、创建hackit_2018.js文件 const express require(express) var hbs require(hbs); var bodyParser require(body-par…...
.Net6 Web Core API 配置 Autofac 封装 --- 依赖注入
目录 一、NuGet 包导入 二、Autofac 封装类 三、Autofac 使用 四、案例测试 下列封装 采取程序集注入方法, 单个依赖注入, 也适用, 可<依赖注入>的地方配置 一、NuGet 包导入 Autofac Autofac.Extensions.DependencyInjection Autofac.Extras.DynamicProxy 二、Auto…...
鸿鹄工程项目管理系统em Spring Cloud+Spring Boot+前后端分离构建工程项目管理系统 em
Java版工程项目管理系统 Spring CloudSpring BootMybatisVueElementUI前后端分离 功能清单如下: 首页 工作台:待办工作、消息通知、预警信息,点击可进入相应的列表 项目进度图表:选择(总体或单个)项目…...
【搭建PyTorch神经网络进行气温预测】
import numpy as np import pandas as pd import matplotlib.pyplot as plt import torch import torch.optim as optim import warnings warnings.filterwarnings("ignore") %matplotlib inlinefeatures pd.read_csv(temps.csv)#看看数据长什么样子 features.head…...
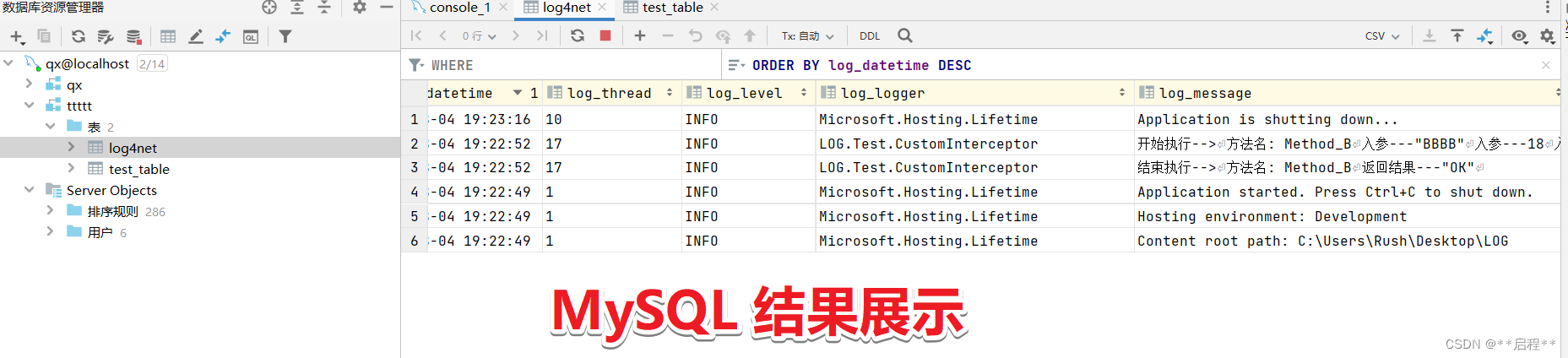
.Net6 Web Core API --- AOP -- log4net 封装 -- MySQL -- txt
目录 一、引入 NuGet 包 二、配置log4net.config 三、编写Log4net封装类 四、编写日志记录类 五、AOP -- 拦截器 -- 封装 六、案例编写 七、结果展示 一、引入 NuGet 包 log4net Microsoft.Extensions.Logging.Log4Net.AspNetCore MySql.Data ---- MySQL…...
【论文阅读】对抗溯源图主机入侵检测系统的模仿攻击(NDSS-2023)
作者:伊利诺伊大学芝加哥分校-Akul Goyal、Gang Wang、Adam Bates;维克森林大学-Xueyuan Han、 引用:Goyal A, Han X, Wang G, et al. Sometimes, You Aren’t What You Do: Mimicry Attacks against Provenance Graph Host Intrusion Detect…...

微信小程序多图片上传实用代码记录
微信小程序多图片上传实用代码记录 由于在小程序中,wx.uploadFile 只能一次上传一张图片,因此在一次需要上传多张图片的应用场景中例如商品图片上传、评论图片上传等场景下,不得不使用for等循环上传每一张图片,多次调用wx.upload…...

android实现获取系统全局对象实例
无需Context获取系统常用全局对象:Application,Activity,PackageManager等。 import android.app.Activity; import android.app.Application; import android.app.Service; import android.content.Context; import android.content.pm.Pac…...
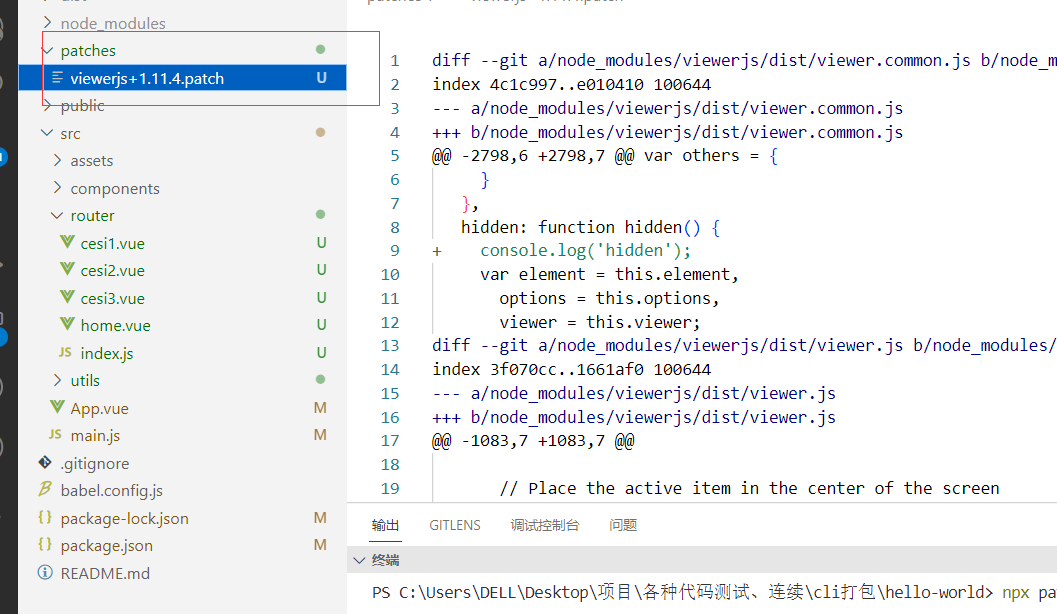
viewerjs 如何新增下载图片功能(npm包补丁)
文章目录 先实现正常的效果实现下载图片改变viewerjs的build函数源码改变之后,执行npm i 之后node_modules源码又变回了原样 1、viwerjs所有功能都很完善,但唯独缺少了图片的下载 2、需求:在用viwerjs旋转图片后,可以直接下载旋转…...
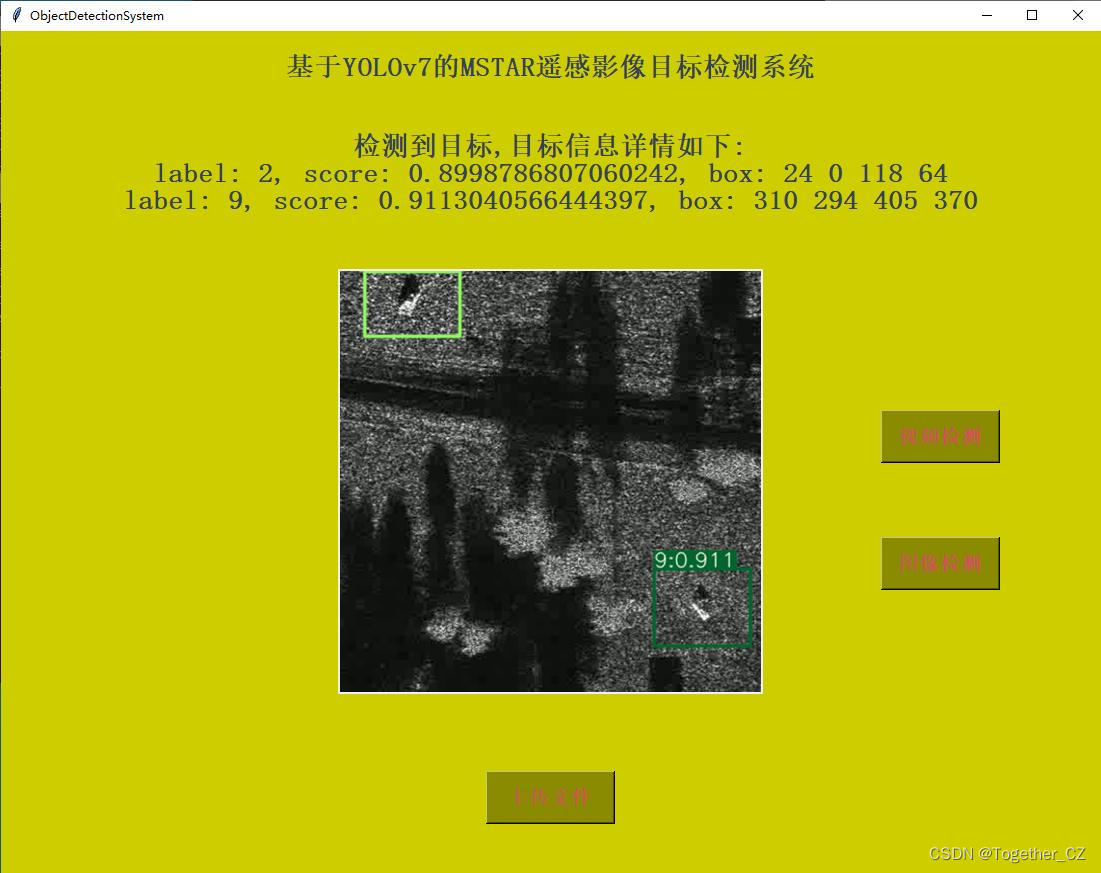
基于YOLOv7开发构建MSTAR雷达影像目标检测系统
MSTAR(Moving and Stationary Target Acquisition and Recognition)数据集是一个基于合成孔径雷达(Synthetic Aperture Radar,SAR)图像的目标检测和识别数据集。它是针对目标检测、机器学习和模式识别算法的研究和评估…...

关于c++中mutable、const、volatile这三个关键字及对应c++与汇编示例源码
这哥三之间的关系是有趣的,不妨看看这个: cv (const and volatile) type qualifiers - cppreference.com mutable permits modification of the class member declared mutable even if the containing object is declared const. 即便一个对象是con…...

第08章 FastAPI 与 SSE 流式 RAG 后端
第08章 FastAPI 与 SSE 流式 RAG 后端 到目前为止,知识库、检索工具、MCP 客户端都已经就绪,但仍缺少一个面向最终用户的入口。本章用 FastAPI 把整条 RAG 链路串起来:接收前端发来的自然语言问题,调用 MCP 工具检索相关工单&…...

终极指南:在Windows上直接安装安卓APK文件的5个简单步骤
终极指南:在Windows上直接安装安卓APK文件的5个简单步骤 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 想在Windows电脑上运行安卓应用,但又厌…...

LLM Notebooks:从零构建RAG问答系统的实践指南
1. 项目概述:一个面向大语言模型实践的“笔记本”仓库最近在GitHub上闲逛,发现了一个挺有意思的仓库,叫qianniuspace/llm_notebooks。光看名字,llm_notebooks,大语言模型笔记本,这指向性就非常明确了。这大…...

如何5分钟掌握N_m3u8DL-RE:流媒体下载终极解决方案
如何5分钟掌握N_m3u8DL-RE:流媒体下载终极解决方案 【免费下载链接】N_m3u8DL-RE Cross-Platform, modern and powerful stream downloader for MPD/M3U8/ISM. English/简体中文/繁體中文. 项目地址: https://gitcode.com/GitHub_Trending/nm3/N_m3u8DL-RE …...

Seraphine:英雄联盟智能BP助手与战绩查询工具完整指南
Seraphine:英雄联盟智能BP助手与战绩查询工具完整指南 【免费下载链接】Seraphine 英雄联盟战绩查询工具 项目地址: https://gitcode.com/gh_mirrors/se/Seraphine 在英雄联盟的对局中,BP(禁选英雄)阶段往往是决定胜负的关…...

3分钟完成30分钟任务:词达人自动化助手终极指南
3分钟完成30分钟任务:词达人自动化助手终极指南 【免费下载链接】cdr 微信词达人,高正确率,高效简洁。支持班级任务及自选任务 项目地址: https://gitcode.com/gh_mirrors/cd/cdr 你是否厌倦了每周在词达人平台上花费数小时完成枯燥的…...

避坑指南:Unity游戏在Linux上运行报错?OpenCV依赖和文件权限问题排查实录
Unity游戏Linux部署避坑指南:从权限修复到OpenCV依赖全解析 当你在Ubuntu上双击那个刚导出的Unity游戏.x86_64文件时,屏幕却弹出一行冰冷的错误信息——这种从云端跌入谷底的体验,每个跨平台开发者都经历过。不同于Windows的一键运行…...

基于PIR传感器与LIFX智能灯泡的物联网运动感应照明系统实战
1. 项目概述与核心价值如果你对智能家居自动化感兴趣,并且想亲手打造一个既实用又有趣的照明项目,那么这个基于Adafruit FunHouse和LIFX智能灯泡的运动感应照明系统,绝对是一个绝佳的起点。它不仅仅是一个“开灯关灯”的简单触发器࿰…...

LVGL在无显存TFT屏上的驱动适配:双缓冲与DMA优化实践
1. 项目概述:当TFT屏幕遇上LVGL最近在做一个嵌入式GUI项目,核心任务是把LVGL这个轻量级图形库,适配到一块分辨率不算高但接口比较“个性”的TFT屏幕上。这活儿听起来像是把标准插头插到非标插座上,得自己动手改改线序。LVGL这几年…...

开源AI应用开发平台TaskingAI:从RAG智能体到工作流编排实战
1. 项目概述:一个开源的AI应用开发平台最近在折腾AI应用开发的朋友,估计都绕不开一个核心痛点:想法很丰满,落地很骨感。你想做个智能客服、一个文档分析助手,或者一个个性化的内容生成工具,从模型调用、流程…...