Python入门自学进阶-Web框架——38、redis、rabbitmq、git
缓存数据库redis:
NoSQL(Not only SQL)泛指非关系型的数据库。为了解决大规模数据集合多重数据类的挑战。
NoSQL数据库的四大分类:
- 键值(Key-Value)存储数据库
- 列存储数据库
- 文档型数据库
- 图形(Graph)数据库
redis是业界主流的key-value nosql数据库之一。redis主要用在linux类系统。
要在 Ubuntu 上安装 Redis,打开终端,然后输入以下命令:
$sudo apt-get update $sudo apt-get install redis-server
在windows系统下,下载压缩包,解压缩后,就可以直接运行。
解压缩后的Redis-x64-5.0.14.1:

在此目录下运行cmd,在命令窗口运行命令redis-server redis.windows.conf,启动redis服务器

可以看到,服务的端口是6379。此启动方法表示临时服务安装成功。使用该指令创建的服务,不会再window service列表中出现redis服务名,此窗口关闭,临时服务会自动退出
后台服务安装启动指令:redis-server.exe --service-install redis.windows.conf --loglevel verbose(一定要先卸载已经安装的临时或者固定的服务,否则会出现错误)
卸载服务:redis-server --service-uninstall
启动服务指令:redis-server.exe --service-start
如果需要停止就执行 redis-server --service-stop // 停止服务
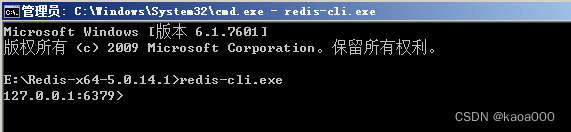
再打开一个cmd窗口,运行客户端:redis-cli.exe
redis-py 的API的使用可以分类为:
- 连接方式
- 连接池
- 操作
- String 操作
- Hash 操作
- List 操作
- Set 操作
- Sort Set 操作
- 管道
- 发布订阅
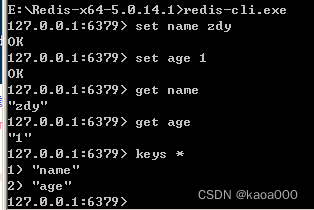
String操作:
使用:set 、get 、 keys *
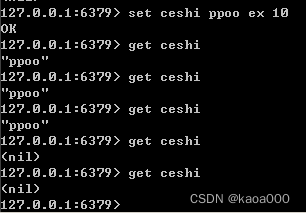
在使用set时,显示set语法:
![]()
set(name, value, ex=None, px=None, nx=False, xx=False)
| 1 2 3 4 5 6 |
|
其他一些命令:setnx(key,value) 、setex(key,value,time) 、psetex(key,time_ms,value) 、mset(*args,**kwargs) 、get(key) 、 mget(keys,*args)、 getset(key,value)、 getrange(key,start,end)、 setrange(key,offset,value)、setbit(key,offset,value) 、getbit(name,offset)、 bitcount(key,start=None,end=None)、 strlen(key)、 incr(self,key,amount=1)、 incrbyfloat(self,key,amount=1.0)、decr(self,key,amount=1) 、 append(key,value)
setbit/getbit/bitcount这一组命令来记录、统计用户登录信息。
Hash操作:
hset (key field value)、hget(key field)、 hmset(key,mapping)、 hmget(key field)、 hkeys(key)、 hgetall(key)、 hlen(key)、 hvals(key)、 hexists(key field)、 hincrby(key field)、 HSCAN key cursor [MATCH pattern] [COUNT count]、 hdel(key *field)、
list操作:
lpush、 llen、 lrange、 pushx、 lpushx、 linsert、lset、 lrem、 lpop、 lindex、 lrange、 ltrim、 rpoplpush、 blpop、 brpoplpush
set操作:
无序集合
sadd、scard 、 sdiff、 sdiffstore、 sinter、 sinterstore、 sismember、 smove、 spop、 srandmember、 srem、 sunion、 sunionstore、 sscan
有序集合
zadd、 zcard、 zrank、 zrem、 zrenrangebyrank、 zcount、 zincrby、 zrange、 zremrangebyscore、 zscore、 zinterstore、 zscan、
其他操作:
delete、exists、 keys 、 expire 、rename、 move、 randomkey、 type、 scan
python连接使用redis:
安装模块:pip install redis
使用:
import redisr = redis.Redis(host='127.0.0.1',port=6379)
r.set('foo','bar')
print(r.get('foo'))将host地址改为网卡的地址:
import redisr = redis.Redis(host='192.168.1.117',port=6379)
r.set('foo','bar')
print(r.get('foo'))结果是:ConnectionRefusedError: [WinError 10061] 由于目标计算机积极拒绝,无法连接。
需要修改redis.windows.conf文件中,将bind 127.0.0.1 改为bind 192.168.1.117
如果改为bind 0.0.0.0 则使用192.168.1.117或127.0.0.1都能访问到。
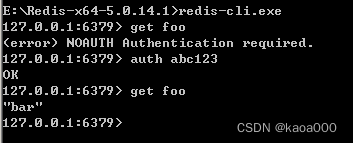
这时,是未经验证就直接访问了,可以使用密码进行验证。修改redis.windows.conf文件中的配置项:# requirepass foobared
可以看到,需要密码是注释掉的,即不需要密码验证,打开验证:requirepass abc123
重启后,再次运行上面的程序:提示:redis.exceptions.AuthenticationError: Authentication required.
现在需要验证了
import redisr = redis.Redis(host='127.0.0.1',port=6379,password='abc123')
r.set('foo','bar')
print(r.get('foo'))此时,连接成功。
在客户端使用时,也需要密码,还用auth password验证。
使用连接池:
import redispool =redis.ConnectionPool(host='192.168.1.117',port=6379,password='abc123')
r = redis.Redis(connection_pool=pool)
r.set('foo2','bar222')
print(r.get('foo2'))
r.set('ccc2',1234)管道:redis-py默认在执行每次请求都会创建(连接池申请连接)和断开(归还连接池)一次连接操作,如果想要在一次请求中指定多个命令,则可以使用pipline实现一次请求指定多个命令,并且默认情况下一次pipline 是原子性操作。
import redispool =redis.ConnectionPool(host='192.168.1.117',port=6379,password='abc123')
r = redis.Redis(connection_pool=pool)pipe = r.pipeline(transaction=True)
pipe.set('name','aaaaaaaa')
pipe.set('role','bbbbbbbbbbbb')
pipe.execute()消息队列RabbitMQ:
消息队列中间件——是分布式系统中重要的组件,主要解决应用耦合,异步消息,流量削锋等问题实现高性能,高可用,可伸缩和最终一致性。 使用较多的消息队列有 ActiveMQ(安全),RabbitMQ,ZeroMQ,Kafka(大数据),MetaMQ,RocketMQ
RabbitMQ ——一个由 Erlang 语言开发的 AMQP 的开源实现。
AMQP :Advanced Message Queue,高级消息队列协议。它是应用层协议的一个开放标准,为面向消息的中间件设计,基于此协议的客户端与消息中间件可传递消息,并不受产品、开发语言等条件的限制。
RabbitMQ 最初起源于金融系统,用于在分布式系统中存储转发消息,在易用性、扩展性、高可用性等方面表现不俗。具体特点包括:
1.可靠性(Reliability)
RabbitMQ 使用一些机制来保证可靠性,如持久化、传输确认、发布确认。
2.灵活的路由(Flexible Routing)
在消息进入队列之前,通过 Exchange 来路由消息的。对于典型的路由功能,RabbitMQ已经提供了一些内置的 Exchange 来实现。针对更复杂的路由功能,可以将多个Exchange 绑定在一起,也通过插件机制实现自己的 Exchange 。
3.消息集群(Clustering)
多个 RabbitMQ 服务器可以组成一个集群,形成一个逻辑 Broker
4.高可用(Highly Available Queues)
队列可以在集群中的机器上进行镜像,使得在部分节点出问题的情况下队列仍然可用。
5.多种协议(Multi-protocol)
RabbitMQ 支持多种消息队列协议,比如 STOMP、MQTT 等等。
6.多语言客户端(Many Clients)
RabbitMQ 几乎支持所有常用语言,比如 Java、.NET、Ruby 等等。
7.管理界面(Management UI)
RabbitMQ 提供了一个易用的用户界面,使得用户可以监控和管理消息 Broker 的许多方面。
8.跟踪机制(Tracing)
如果消息异常,RabbitMQ 提供了消息跟踪机制,使用者可以找出发生了什么。
9.插件机制(Plugin System)
RabbitMQ 提供了许多插件,来从多方面进行扩展,也可以编写自己的插件。
RabbitMQ的工作原理:

Broker:接收和分发消息的应用,RabbitMQ Server就是Message Broker
Connection: publisher / consumer(发布者/消费者)和 broker之间的TCP连接。(个人感觉用producer/consumer——生产者/消费者或publisher/subscriber——发布者/订阅者更合适) Channel:如果每一次访问RabbitMQ都建立一个Connection,在消息量大的时候建立TCP Connection的开销将是巨大的,效率也较低。Channel是在connection 内部建立的逻辑连接,如果应用程序支持多线程,通常每个thread创建单独的channel进行通讯,AMQP method包含了channel id 帮助客户端和message broker识别 channel,所以channel 之间是完全隔离的。Channel作为轻量级的Connection极大减少了操作系统建TCP connection的开销
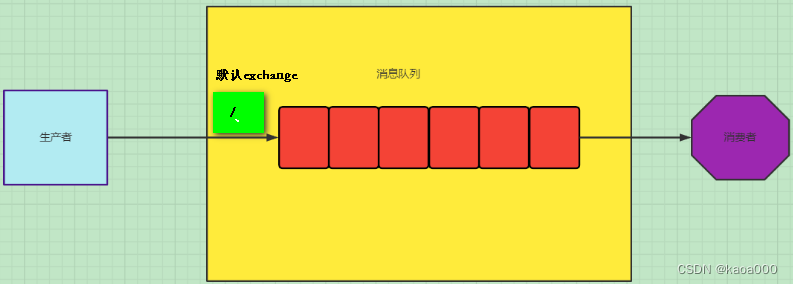
Exchange:message 到达 broker 的第一站,根据分发规则,匹配查询表中的 routing key,分发消息到queue 中去。常用的类型有: direct (point-to-point), topic(publish-subscribe) and fanout
(multicast)
Routing Key:生产者将消息发送到交换机时会携带一个key,来指定路由规则
binding Key:在绑定Exchange和Queue时,会指定一个BindingKey,生产者发送消息携带的RoutingKey会和bindingKey对比,若一致就将消息分发至这个队列
vHost 虚拟主机:每一个RabbitMQ服务器可以开设多个虚拟主机,每一个vhost本质上是一个mini版的RabbitMQ服务器,拥有自己的 "交换机exchange、绑定Binding、队列Queue",更重要的是每一个vhost拥有独立的权限机制,这样就能安全地使用一个RabbitMQ服务器来服务多个应用程序,其中每个vhost服务一个应用程序。
RabbitMQ的安装(windows版本):
RabbitMQ需要Erlang的支持,先安装这个支持包otp_win64_25.3.2.exe,OTP代表开放电信平台。 它是一个应用程序操作系统和一组用于构建大规模,容错,分布式应用程序的库和过程。核心概念是OTP行为,可以看作一个用回调函数作为参数的应用程序框架。



安装RabbitMQ:rabbitmq-server-3.12.1.exe

安装完成后,在服务列表中能可见:

安装管理界面(插件):
进入rabbitMQ安装目录的sbin目录,点击上方的路径框输入cmd,按下回车键

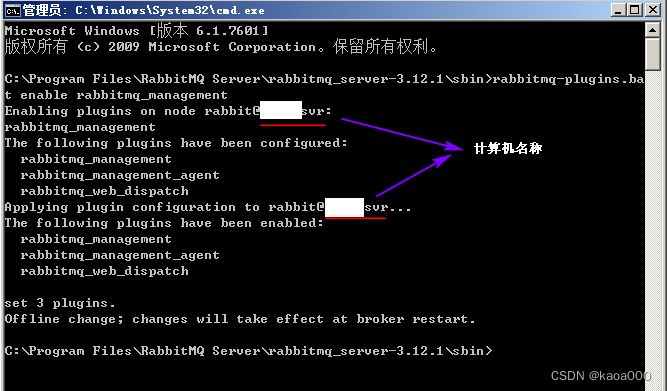
运行命令: rabbitmq-plugins enable rabbitmq_management
打开浏览器,输入http://127.0.0.1:15672/,登录
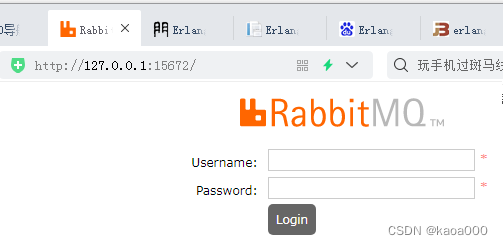
输入用户名和密码,初始都为guest
至此,安装完毕。
Python使用RabbitMQ,需要安装pika模块:pip install pika
RabbitMQ的使用:最简单的发布与接收
# File:sender.py 发送消息,即生产者
import pika # 链接mq需要pika模块connection = pika.BlockingConnection(pika.ConnectionParameters('localhost'))
channel = connection.channel()# 声明queue
channel.queue_declare(queue='hello')# 在RabbitMQ中一个消息不可能被直接发送到queue,即队列中,它总是需要通过exchange进行转发
channel.basic_publish(exchange='',routing_key='hello',body='消息体:hello world!'.encode('utf-8'),)
print("[x] sent 'hello word!'")
connection.close()
# File:recv.py 消费者,即接收者、订阅者
import pikaconnection = pika.BlockingConnection(pika.ConnectionParameters('localhost'))
channel = connection.channel()
channel.queue_declare(queue='hello')def callback(ch, method, properties, body):print("[x] Received %r" % body.decode("utf-8"))channel.basic_consume(queue='hello',on_message_callback=callback,auto_ack=True)print('[*] Waiting for message. To exit press CTRL+C')
channel.start_consuming()在消费者端,basic_consume方法中设置了auto_ack=True,即自动应答,即消费者接受消息后,自动应答RabbitMQ服务器,即Broker,然后在Broker中的队列中将此消息删除,否则,如果设置为False,则会在队列中一直存在,如下:

显示有2条未应答,消息还有2条。
可以设置手动应答:
# File:recv.py 消费者,即接收者、订阅者
import pikaconnection = pika.BlockingConnection(pika.ConnectionParameters('localhost'))
channel = connection.channel()
channel.queue_declare(queue='hello')def callback(ch, method, properties, body):print("[x] Received %r" % body.decode("utf-8"))# 如果basic_consume中auto_ack为False,则这里要手动进行应答channel.basic_ack(delivery_tag=method.delivery_tag) # 手动应答print('手动应答队列中消息')
channel.basic_consume(queue='hello',on_message_callback=callback,auto_ack=False)print('[*] Waiting for message. To exit press CTRL+C')
channel.start_consuming()
自带的用户、密码为guest的只能本机登录,可以增加用户:
rabbitmqctl add_user 用户名 密码
给指定用户添加管理员权限:
rabbitmqctl set_user_tags 用户名 administrator
给用户添加权限
rabbitmqctl set_permissions -p / 用户名 ".*" ".*" ".*"
以上是使用命令进行用户的添加,但是在测试时,出现问题:

查询网上的解决方法,也没成功,然后从web端增加了用户。
使用增加的用户进行消息操作:
生产者:
# File:sender.py 发送消息,即生产者
import pika # 链接mq需要pika模块
import time
user_info = pika.PlainCredentials('tester','test1234')
connection = pika.BlockingConnection(pika.ConnectionParameters('192.168.1.117',5672,'/',user_info))
channel = connection.channel()# 声明queue
# 如果指定的queue不存在,则会创建一个queue,如果已经存在 则不会做其他动作,官方推荐,每次使用时都可以加上这句
channel.queue_declare(queue='hello')# 在RabbitMQ中一个消息不可能被直接发送到queue,即队列中,它总是需要通过exchange进行转发
for i in range(0,20):channel.basic_publish(exchange='', # 简单模式,这里设置为空字符串就可以routing_key='hello', # 指定消息要发送到哪个queuebody='消息体{}:hello world!'.format(i).encode('utf-8'), ) # 指定要发送的消息print("[x] sent %s 'hello word!'" % i)time.sleep(1)
connection.close()#RabbitMQ中所有的消息都要先通过交换机,空字符串表示使用默认的交换机消费者:
# File:recv.py 消费者,即接收者、订阅者
import pikauser_info = pika.PlainCredentials('tester','test1234')
connection = pika.BlockingConnection(pika.ConnectionParameters('192.168.1.117',5672,'/',user_info))
channel = connection.channel()
channel.queue_declare(queue='hello')def callback(ch, method, properties, body):print("[x] Received %r" % body.decode("utf-8"))# 如果basic_consume中auto_ack为False,则这里要手动进行应答channel.basic_ack(delivery_tag=method.delivery_tag) # 手动应答print('手动应答队列中消息')# ch,即channel: 包含channel的一切属性和方法# method: 包含 consumer_tag, delivery_tag, exchange, redelivered, routing_key# properties: basic_publish 通过 properties 传入的参数# body: basic_publish发送的消息channel.basic_consume(queue='hello', # 接收指定queue的消息on_message_callback=callback, # 设置收到消息的回调函数auto_ack=False) # 指定为True,表示消息接收到后自动给消息发送方回复确认,已收到消息,False表示不自动确认,需要在callback中手工确认print('[*] Waiting for message. To exit press CTRL+C')# 一直处于等待接收消息的状态,如果没收到消息就一直处于阻塞状态,收到消息就调用上面的回调函数
channel.start_consuming()运行结果:
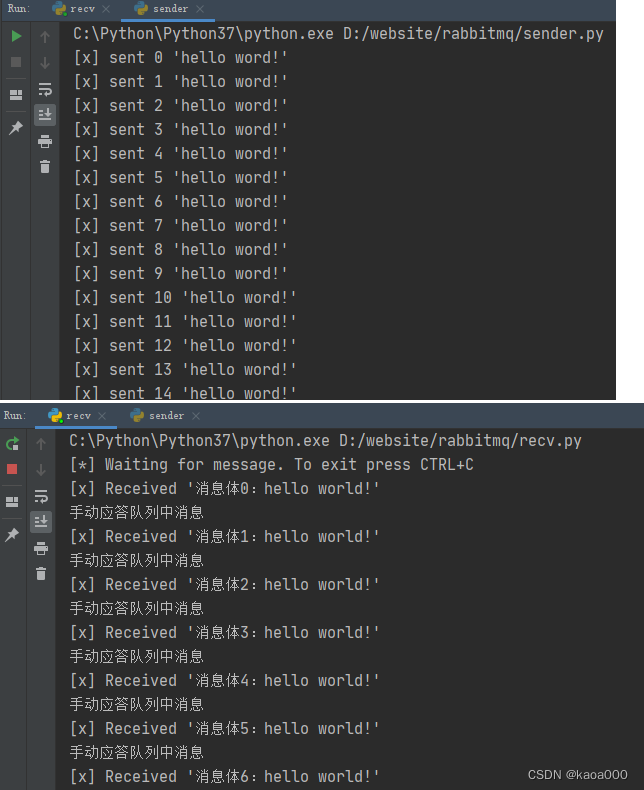
以上是RabbitMQ简单模式
上面的生产者存在一个问题,就是在我们的消费者还没开始消费完队列里的消息,如果这时rabbitmq服务挂了,那么消息队列里的消息将会全部丢失,解决方法是在声明队列时,声明队列为可持久化存储队列,并且在生产者在将消息插入到消息队列时,设置消息持久化存储,具体如下
# File:sender.py 发送消息,即生产者
import pika # 链接mq需要pika模块
import time
user_info = pika.PlainCredentials('tester','test1234')
connection = pika.BlockingConnection(pika.ConnectionParameters('192.168.1.117',5672,'/',user_info))
channel = connection.channel()# 声明queue
# 如果指定的queue不存在,则会创建一个queue,如果已经存在 则不会做其他动作,官方推荐,每次使用时都可以加上这句
channel.queue_declare(queue='durable_queue',durable=True)
#PS:这里不同种队列不允许名字相同,这个队列设置了持久化为True,即是一个持久化队列# 在RabbitMQ中一个消息不可能被直接发送到queue,即队列中,它总是需要通过exchange进行转发
for i in range(0,20):channel.basic_publish(exchange='', # 简单模式,这里设置为空字符串就可以routing_key='durable_queue', # 指定消息要发送到哪个queuebody='消息体{}:hello world!'.format(i).encode('utf-8'), # 指定要发送的消息properties=pika.BasicProperties(delivery_mode=2))# 设置当前消息持久化存储(properties=pika.BasicProperties(delivery_mode=2))print("[x] sent %s 'hello word!'" % i)time.sleep(1)
connection.close()#RabbitMQ中所有的消息都要先通过交换机,空字符串表示使用默认的交换机消费者,只需修改队列的声明与生产者一致即可,如channel.queue_declare(queue='durable_queue',durable=True)
同时开启多个消费者,会随机读取队列中的消息。
默认安装的RabbitMQ中,在运行了上面的程序后,在RabbitMQ中connections、channel、exchange、queues信息:
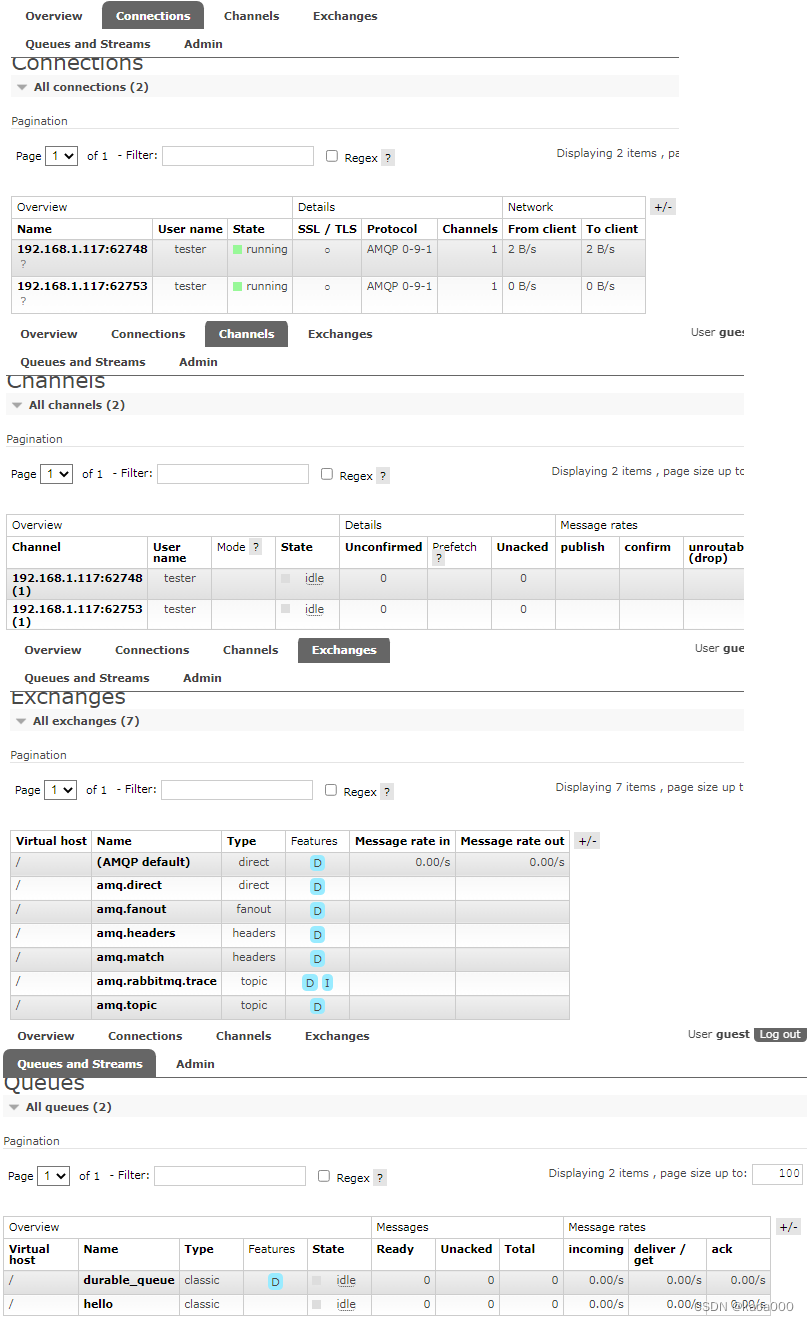
相关文章:
Python入门自学进阶-Web框架——38、redis、rabbitmq、git
缓存数据库redis: NoSQL(Not only SQL)泛指非关系型的数据库。为了解决大规模数据集合多重数据类的挑战。 NoSQL数据库的四大分类: 键值(Key-Value)存储数据库列存储数据库文档型数据库图形(…...

论 SoC上的Linux如何拉动外部I/O
在MCU中(如classic autosr或其他RTOS),一般可以直接通过往对应的寄存器(地址转为指针)写值, 或者调用一些硬件抽象层或者驱动接口来拉动芯片提供的GPIO。 但是在Linux中,可能不会让应用层直接去…...
SpringBoot项目如何部署SSL证书 (JKS格式)
1、SpringBoot项目如何部署SSL证书 (JKS格式) 1. 获取 SSL 证书和私钥 首先,你需要获取有效的 SSL 证书和私钥。SSL 证书是一种用于加密通信的数字证书,它可以通过购买商业 SSL 证书或使用免费的 Let’s Encrypt 证书获得。请确保你拥有证书文件和与之…...

成功解决:ValueError Cannot assign non-leaf Tensor to parameter ‘weight‘
成功解决:ValueError Cannot assign non-leaf Tensor to parameter ‘weight‘ 欢迎大家来到安静到无声的《模式识别与人工智能(程序与算法)》,如果对所写内容感兴趣请看模式识别与人工智能(程序与算法)系列讲解 - 总目录,同时这也可以作为大家学习的参考。欢迎订阅,优…...

面试之快速学习SQL-基础增删改查语句
1. SELECT SELECT column1,column2,column3 FROM table_name;SELECT * FROM table_name;2. SQL SELECT DISTINCT 语句 在表中,可能会包含重复值。这并不成问题,不过,有时您也许希望仅仅列出不同(distinct)的值。 SE…...
nuxt脚手架创建项目
在初始化时遇到一个依赖找不到的问题,记录一下,如有遇到同样问题的小伙伴,希望能给你们一点指引。 从安装脚手架开始,首先 一:安装nuxt脚手架 1. C盘全局安装: npm i -g create-nuxt-app 安装后可creat…...
复现原型链污染漏洞
目录 一、复现原型链污染漏洞 hackit 2018 1、创建hackit_2018.js文件 2、运行hackit_2018.js文件 3、寻找原型链漏洞 4、污染原型链 hackit 2018 1、创建hackit_2018.js文件 const express require(express) var hbs require(hbs); var bodyParser require(body-par…...
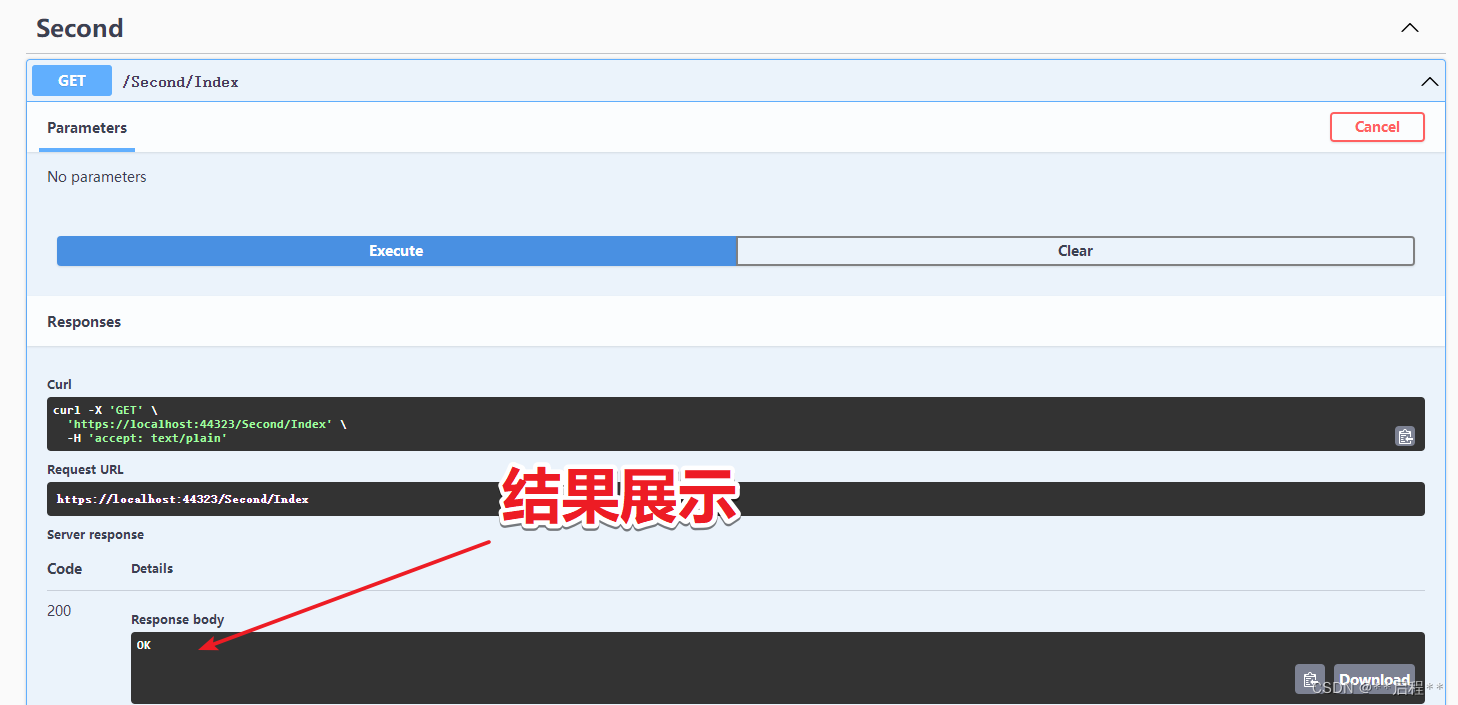
.Net6 Web Core API 配置 Autofac 封装 --- 依赖注入
目录 一、NuGet 包导入 二、Autofac 封装类 三、Autofac 使用 四、案例测试 下列封装 采取程序集注入方法, 单个依赖注入, 也适用, 可<依赖注入>的地方配置 一、NuGet 包导入 Autofac Autofac.Extensions.DependencyInjection Autofac.Extras.DynamicProxy 二、Auto…...
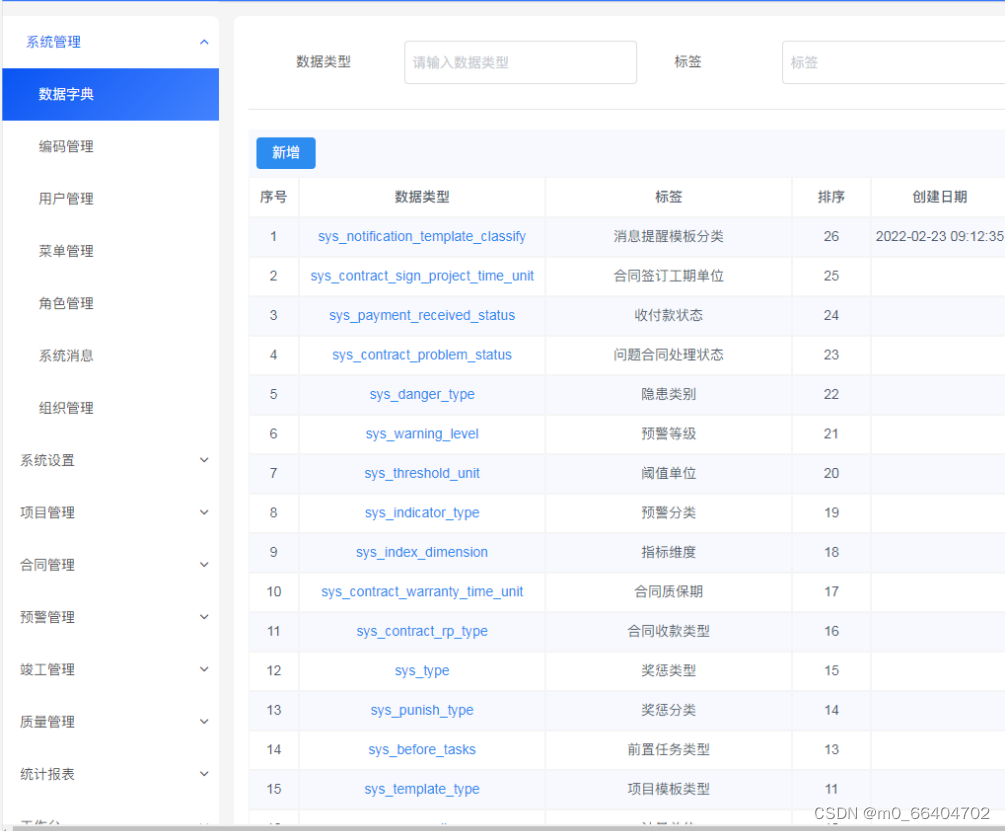
鸿鹄工程项目管理系统em Spring Cloud+Spring Boot+前后端分离构建工程项目管理系统 em
Java版工程项目管理系统 Spring CloudSpring BootMybatisVueElementUI前后端分离 功能清单如下: 首页 工作台:待办工作、消息通知、预警信息,点击可进入相应的列表 项目进度图表:选择(总体或单个)项目…...
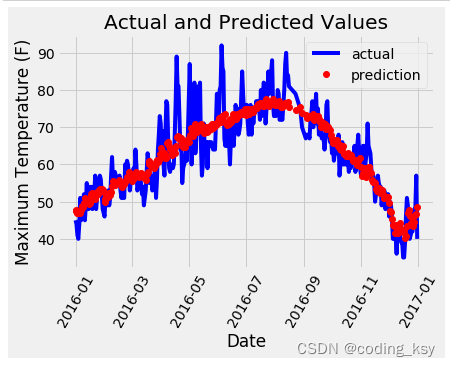
【搭建PyTorch神经网络进行气温预测】
import numpy as np import pandas as pd import matplotlib.pyplot as plt import torch import torch.optim as optim import warnings warnings.filterwarnings("ignore") %matplotlib inlinefeatures pd.read_csv(temps.csv)#看看数据长什么样子 features.head…...
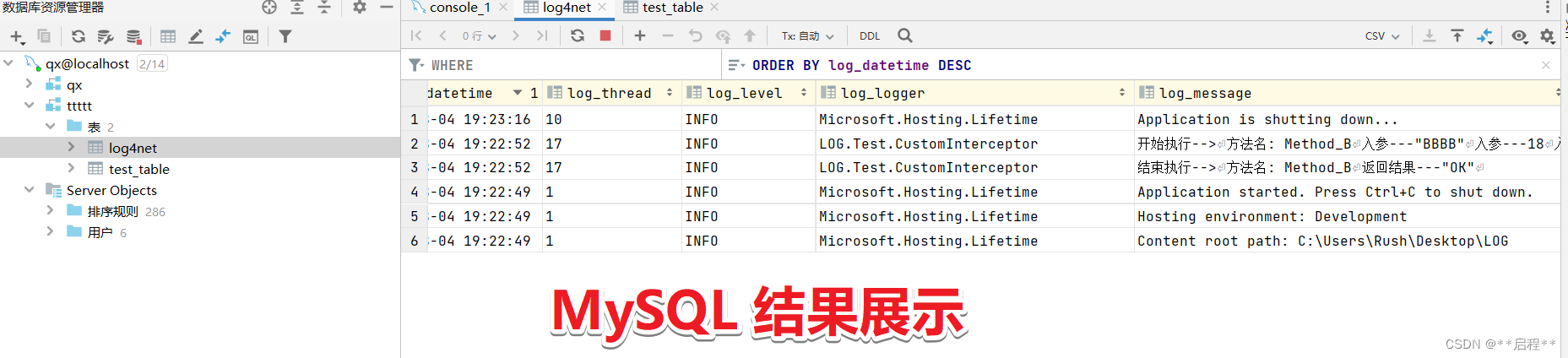
.Net6 Web Core API --- AOP -- log4net 封装 -- MySQL -- txt
目录 一、引入 NuGet 包 二、配置log4net.config 三、编写Log4net封装类 四、编写日志记录类 五、AOP -- 拦截器 -- 封装 六、案例编写 七、结果展示 一、引入 NuGet 包 log4net Microsoft.Extensions.Logging.Log4Net.AspNetCore MySql.Data ---- MySQL…...
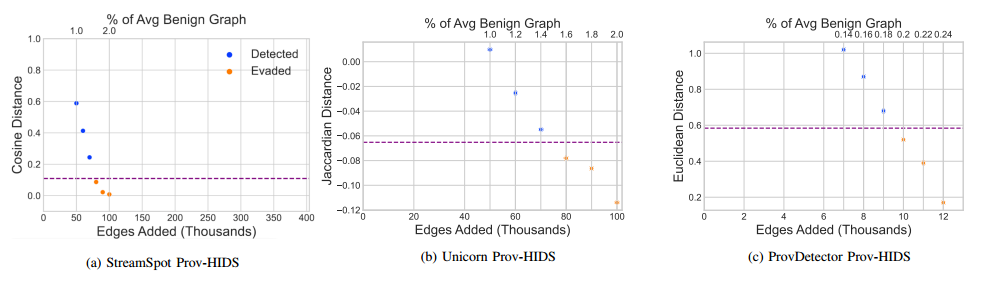
【论文阅读】对抗溯源图主机入侵检测系统的模仿攻击(NDSS-2023)
作者:伊利诺伊大学芝加哥分校-Akul Goyal、Gang Wang、Adam Bates;维克森林大学-Xueyuan Han、 引用:Goyal A, Han X, Wang G, et al. Sometimes, You Aren’t What You Do: Mimicry Attacks against Provenance Graph Host Intrusion Detect…...

微信小程序多图片上传实用代码记录
微信小程序多图片上传实用代码记录 由于在小程序中,wx.uploadFile 只能一次上传一张图片,因此在一次需要上传多张图片的应用场景中例如商品图片上传、评论图片上传等场景下,不得不使用for等循环上传每一张图片,多次调用wx.upload…...

android实现获取系统全局对象实例
无需Context获取系统常用全局对象:Application,Activity,PackageManager等。 import android.app.Activity; import android.app.Application; import android.app.Service; import android.content.Context; import android.content.pm.Pac…...
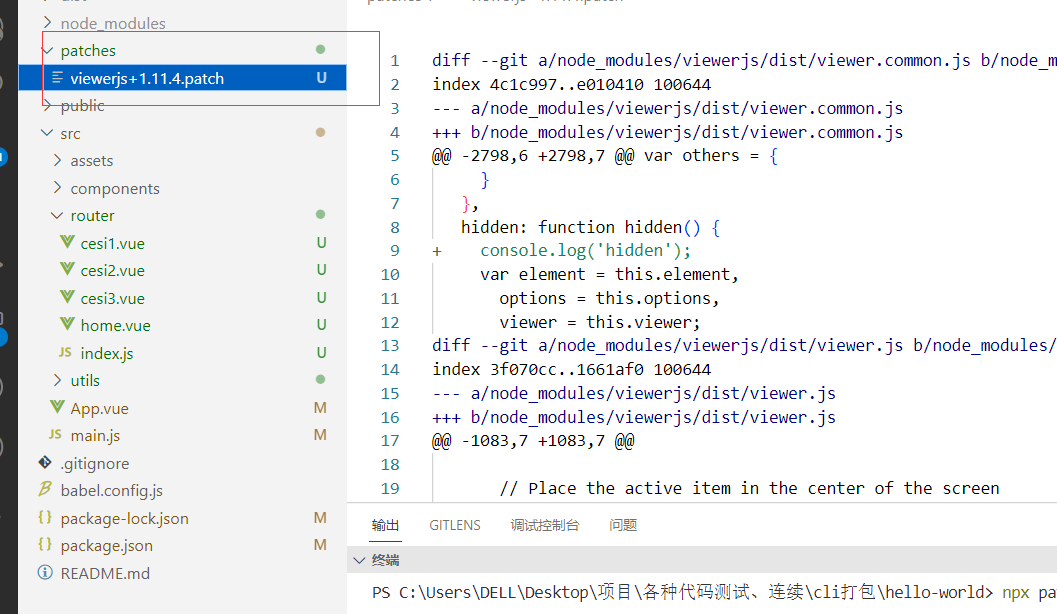
viewerjs 如何新增下载图片功能(npm包补丁)
文章目录 先实现正常的效果实现下载图片改变viewerjs的build函数源码改变之后,执行npm i 之后node_modules源码又变回了原样 1、viwerjs所有功能都很完善,但唯独缺少了图片的下载 2、需求:在用viwerjs旋转图片后,可以直接下载旋转…...
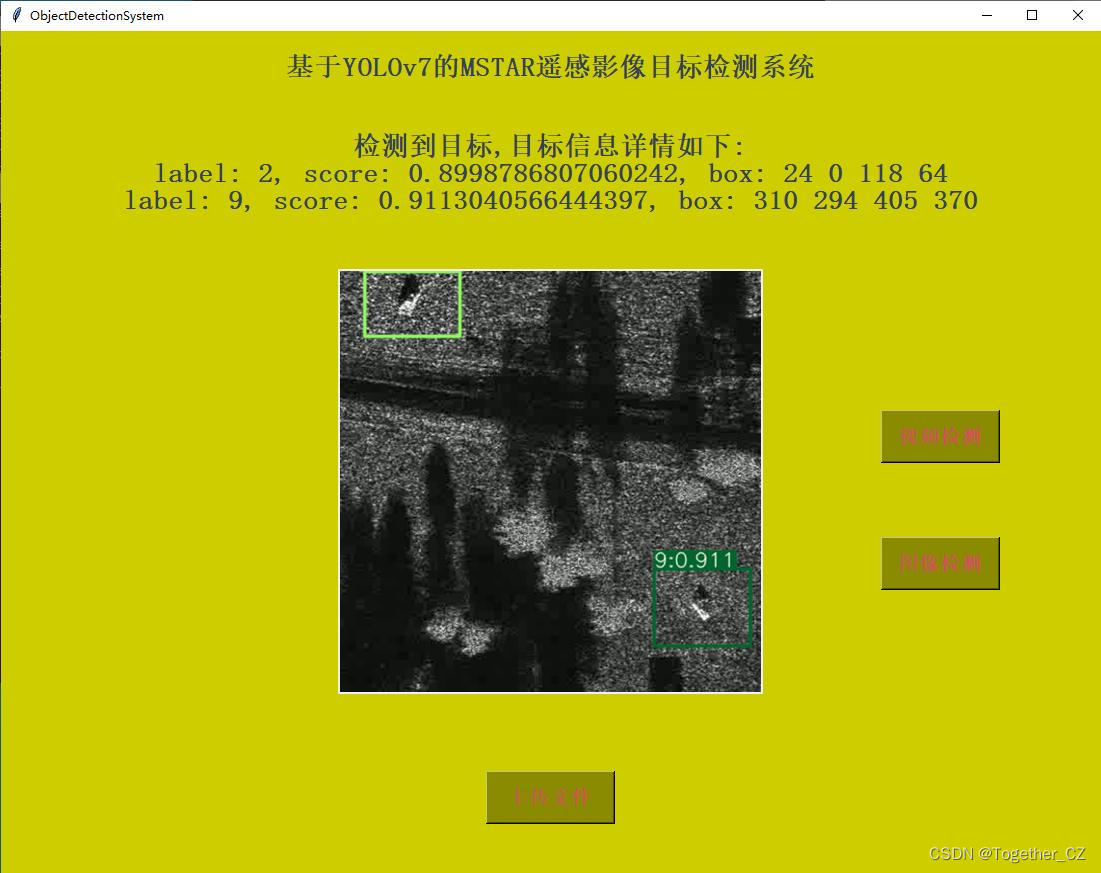
基于YOLOv7开发构建MSTAR雷达影像目标检测系统
MSTAR(Moving and Stationary Target Acquisition and Recognition)数据集是一个基于合成孔径雷达(Synthetic Aperture Radar,SAR)图像的目标检测和识别数据集。它是针对目标检测、机器学习和模式识别算法的研究和评估…...

关于c++中mutable、const、volatile这三个关键字及对应c++与汇编示例源码
这哥三之间的关系是有趣的,不妨看看这个: cv (const and volatile) type qualifiers - cppreference.com mutable permits modification of the class member declared mutable even if the containing object is declared const. 即便一个对象是con…...

把大模型装进手机,分几步?
点击关注 文 | 姚 悦 编 | 王一粟 大模型“跑”进手机,AI的战火已经从“云端”烧至“移动终端”。 “进入AI时代,华为盘古大模型将会来助力鸿蒙生态。”8月4日,华为常务董事、终端BG CEO、智能汽车解决方案BU CEO 余承东介绍,…...

c++游戏制作指南(三):c++剧情类文字游戏的制作
🍿*★,*:.☆( ̄▽ ̄)/$:*.★* 🍿 🍟欢迎来到静渊隐者的csdn博文,本文是c游戏制作指南的一部🍟 🍕更多文章请点击下方链接🍕 🍨 c游戏制作指南dz…...
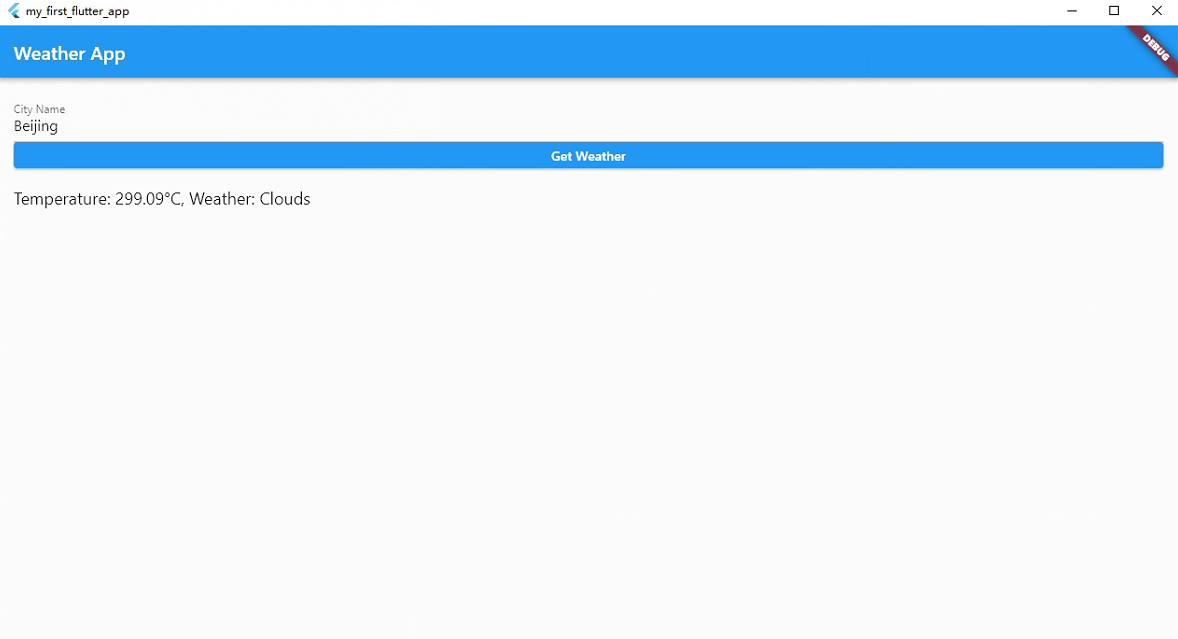
Flutter系列文章-实战项目
在本篇文章中,我们将通过一个实际的 Flutter 应用来综合运用最近学到的知识,包括保存到数据库、进行 HTTP 请求等。我们将开发一个简单的天气应用,可以根据用户输入的城市名获取该城市的天气信息,并将用户查询的城市列表保存到本地…...

Netgear路由器终极救援指南:用nmrpflash免费快速修复变砖设备
Netgear路由器终极救援指南:用nmrpflash免费快速修复变砖设备 【免费下载链接】nmrpflash Netgear Unbrick Utility 项目地址: https://gitcode.com/gh_mirrors/nmr/nmrpflash 当你的Netgear路由器在固件升级过程中意外断电,或者刷入错误固件导致…...

抖音批量下载神器:5分钟学会免费高效下载视频、音乐和直播
抖音批量下载神器:5分钟学会免费高效下载视频、音乐和直播 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallback s…...

3个步骤让Windows任务栏图标居中,打造macOS般的桌面体验
3个步骤让Windows任务栏图标居中,打造macOS般的桌面体验 【免费下载链接】TaskbarX Center Windows taskbar icons with a variety of animations and options. 项目地址: https://gitcode.com/gh_mirrors/ta/TaskbarX 你是否厌倦了Windows任务栏图标总是靠左…...

并行LLM推理技术:Hogwild! Inference原理与应用
1. 并行LLM推理的技术背景与挑战在传统Transformer架构中,语言模型的推理过程本质上是顺序执行的——每个新token的生成都严格依赖于之前所有token的注意力计算结果。这种串行特性导致两个显著瓶颈:首先,硬件计算资源利用率低下,特…...

3分钟掌握Seraphine:英雄联盟智能助手完全指南
3分钟掌握Seraphine:英雄联盟智能助手完全指南 【免费下载链接】Seraphine 英雄联盟战绩查询工具 项目地址: https://gitcode.com/gh_mirrors/se/Seraphine Seraphine是一款基于英雄联盟官方LCU API开发的智能游戏助手,通过自动BP系统和实时战绩查…...

开源银行API模拟器Bankr Buddy:金融科技开发的本地化测试解决方案
1. 项目概述:一个为开发者准备的银行API模拟器如果你正在开发一个需要与银行账户数据打交道的应用,无论是个人财务管理工具、预算分析软件,还是企业级的财务聚合服务,你肯定遇到过同一个难题:如何在不触碰真实用户敏感…...

GitClaw:基于Go的轻量级Git钩子服务器与集中式权限管理方案
1. 项目概述与核心价值如果你是一名开发者,尤其是经常在团队协作中处理Git仓库的工程师,那么你一定对“权限管理”这四个字又爱又恨。爱的是它能保障代码安全,恨的是它配置起来繁琐,尤其是在处理跨项目、跨团队的复杂权限矩阵时。…...

ARM Neoverse-V3架构解析与性能优化实战
1. ARM Neoverse-V3架构概览作为Arm公司面向基础设施领域的最新处理器IP,Neoverse-V3代表了当前服务器级处理器的顶尖设计水平。我在实际芯片开发中多次接触该架构,其设计哲学可概括为:通过精细化微架构控制实现性能与能效的完美平衡。1.1 指…...

AI编程助手安全规则实战:从SQL注入防御到团队安全基线构建
1. 项目概述:当AI编程助手遇上安全红线最近在GitHub上看到一个挺有意思的项目,叫“cursor-security-rules”。光看名字,你大概能猜到它和Cursor这个AI编程工具有关,而且重点是“安全规则”。没错,这个项目本质上是一个…...

Go语言实现Hermes引擎:高性能JavaScript字节码虚拟机解析与实践
1. 项目概述:一个Go语言实现的Hermes引擎最近在折腾一些需要高性能模板渲染的后端服务,偶然间在GitHub上发现了LAI-755/hermes-go这个项目。简单来说,这是一个用纯Go语言实现的Hermes引擎。如果你对前端生态熟悉,可能听说过Hermes…...